Embed Size (px)
Citation preview

Proceedings of the 59th Annual Meeting of the Association for Computational Linguisticsand the 11th International Joint Conference on Natural Language Processing, pages 3932–3945
August 1–6, 2021. ©2021 Association for Computational Linguistics
3932
Which Linguist Invented the Lightbulb?Presupposition Verification for Question-Answering
Najoung Kim†,∗, Ellie Pavlickφ,δ, Burcu Karagol Ayanδ, Deepak Ramachandranδ,∗†Johns Hopkins University φBrown University δGoogle Research
[email protected] {epavlick,burcuka,ramachandrand}@google.com
Abstract
Many Question-Answering (QA) datasetscontain unanswerable questions, but theirtreatment in QA systems remains primi-tive. Our analysis of the Natural Ques-tions (Kwiatkowski et al., 2019) dataset re-veals that a substantial portion of unanswer-able questions (∼21%) can be explained basedon the presence of unverifiable presupposi-tions. Through a user preference study, wedemonstrate that the oracle behavior of ourproposed system—which provides responsesbased on presupposition failure—is preferredover the oracle behavior of existing QA sys-tems. Then, we present a novel frameworkfor implementing such a system in three steps:presupposition generation, presupposition ver-ification, and explanation generation, report-ing progress on each. Finally, we show that asimple modification of adding presuppositionsand their verifiability to the input of a com-petitive end-to-end QA system yields modestgains in QA performance and unanswerabil-ity detection, demonstrating the promise of ourapproach.
1 Introduction
Many Question-Answering (QA) datasets includ-ing Natural Questions (NQ) (Kwiatkowski et al.,2019) and SQuAD 2.0 (Rajpurkar et al., 2018) con-tain questions that are unanswerable. While unan-swerable questions constitute a large part of exist-ing QA datasets (e.g., 51% of NQ, 36% of SQuAD2.0), their treatment remains primitive. That is,(closed-book) QA systems label these questions asUnanswerable without detailing why, as in (1):
(1) a. Answerable Q: Who is the currentmonarch of the UK?System: Elizabeth II.
∗Corresponding authors, †Work done at Google
b. Unanswerable Q: Who is the currentmonarch of France?System: Unanswerable.
Unanswerability in QA arises due to a multitude ofreasons including retrieval failure and malformedquestions (Kwiatkowski et al., 2019). We focuson a subset of unanswerable questions—namely,questions containing failed presuppositions (back-ground assumptions that need to be satisfied).
Questions containing failed presuppositions donot receive satisfactory treatment in current QA.Under a setup that allows for Unanswerable as ananswer (as in several closed-book QA systems; Fig-ure 1, left), the best case scenario is that the systemcorrectly identifies that a question is unanswerableand gives a generic, unsatisfactory response as in(1-b). Under a setup that does not allow for Unan-swerable (e.g., open-domain QA), a system’s at-tempt to answer these questions results in an inaccu-rate accommodation of false presuppositions. Forexample, Google answers the question Which lin-guist invented the lightbulb? with Thomas Edison,and Bing answers the question When did MarieCurie discover Uranium? with 1896 (retrieved Jan2021). These answers are clearly inappropriate,because answering these questions with any nameor year endorses the false presuppositions Some lin-guist invented the lightbulb and Marie Curie discov-ered Uranium. Failures of this kind are extremelynoticeable and have recently been highlighted bysocial media (Munroe, 2020), showing an outsizedimportance regardless of their effect on benchmarkmetrics.
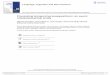
We propose a system that takes presuppositionsinto consideration through the following steps (Fig-ure 1, right):
1. Presupposition generation: Which linguistinvented the lightbulb? → Some linguist in-vented the lightbulb.

3933
QA Model
Knowledge source
UnanswerableQA Model
Q: Which linguist invented the lightbulb?
Knowledge sourceUnanswerable
Presupposition Generation (S5.1)
P: Some linguist invented the lightbulb
Q: Which linguist invented the lightbulb?
Verification (S5.2)
Explanation
Generator
Explanation Generation (S5.3)
End-to-End QA (S6)
User study (S4) because ...
Figure 1: A comparison of existing closed-book QA pipelines (left) and the proposed QA pipeline in this work(right). The gray part of the pipeline is only manually applied in this work to conduct headroom analysis.
2. Presupposition verification: Some linguistinvented the lightbulb. → Not verifiable
3. Explanation generation: (Some linguist in-vented the lightbulb, Not verifiable)→ Thisquestion is unanswerable because there is in-sufficient evidence that any linguist inventedthe lightbulb.
Our contribution can be summarized as follows:
• We identify a subset of unanswer-able questions—questions with failedpresuppositions—that are not handled well byexisting QA systems, and quantify their rolein naturally occurring questions through ananalysis of the NQ dataset (S2, S3).
• We outline how a better QA system couldhandle questions with failed presuppositions,and validate that the oracle behavior of thisproposed system is more satisfactory to usersthan the oracle behavior of existing systemsthrough a user preference study (S4).
• We propose a novel framework for handlingpresuppositions in QA, breaking down theproblem into three parts (see steps above), andevaluate progress on each (S5). We then inte-grate these steps end-to-end into a competitiveQA model and achieve modest gains (S6).
2 Presuppositions
Presuppositions are implicit assumptions of utter-ances that interlocutors take for granted. For exam-ple, if I uttered the sentence I love my hedgehog,
it is assumed that I, the speaker, do in fact owna hedgehog. If I do not own one (hence the pre-supposition fails), uttering this sentence would beinappropriate. Questions may also be inappropriatein the same way when they contain failed presuppo-sitions, as in the question Which linguist inventedthe lightbulb?.
Presuppositions are often associated with spe-cific words or syntactic constructions (‘triggers’).We compiled an initial list of presupposition trig-gers based on Levinson (1983: 181–184) andVan der Sandt (1992),1 and selected the followingtriggers based on their frequency in NQ (» means‘presupposes’):
• Question words (what, where, who...): Whodid Jane talk to? » Jane talked to someone.
• Definite article (the): I saw the cat » Thereexists some contextually salient, unique cat.
• Factive verbs (discover, find out, prove...): Ifound out that Emma lied. » Emma lied.
• Possessive ’s: She likes Fred’s sister. » Fredhas a sister.
• Temporal adjuncts (when, during, while...): Iwas walking when the murderer escaped fromprison. » The murderer escaped from prison.
• Counterfactuals (if + past): I would have beenhappier if I had a dog. » I don’t have a dog.
Our work focuses on presuppositions of ques-tions. We assume presuppositions project from
1We note that it is a simplifying view to treat all triggersunder the banner of presupposition; see Karttunen (2016).

3934
Cause of unanswerability % Example Q Comment
Unverifiable presupposition 30% what is the stock symbol for mars candy Presupposition ‘stock symbol for mars candy exists’ fails
Reference resolution failure 9% what kind of vw jetta do i have The system does not know who ‘i’ isRetrieval failure 6% when did the salvation army come to australia Page retrieved was Safe Schools Coalition AustraliaSubjectivity 3% what is the perfect height for a model Requires subjective judgmentCommonsensical 3% where does how to make an american quilt take place Document contains no evidence that the movie took place
somewhere, but it is commonsensical that it did
Actually answerable 8% when do other cultures celebrate the new year The question was actually answerable given the documentNot a question/Malformed question 3% where do you go my lovely full version Not an actual question
Table 1: Example causes of unanswerability in NQ. % denotes the percentage of questions that both annotatorsagreed to be in the respective cause categories.
wh-questions—that is, presuppositions (other thanthe presupposition introduced by the interrogativeform) remain constant under wh-questions as theydo under negation (e.g., I don’t like my sister hasthe same possessive presupposition as I like my sis-ter). However, the projection problem is complex;for instance, when embedded under other operators,presuppositions can be overtly denied (Levinson1983: 194). See also Schlenker (2008), Abrusán(2011), Schwarz and Simonenko (2018), Theiler(2020), i.a., for discussions regarding projectionpatterns under wh-questions. We adopt the view ofStrawson (1950) that definite descriptions presup-pose both existence and (contextual) uniqueness,but this view is under debate. See Coppock andBeaver (2012), for instance, for an analysis of thethat does not presuppose existence and presupposesa weaker version of uniqueness. Furthermore, wecurrently do not distinguish predicative and argu-mental definites.
Presuppositions and unanswerability. Ques-tions containing failed presuppositions are oftentreated as unanswerable in QA datasets. An ex-ample is the question What is the stock symbol forMars candy? from NQ. This question is not answer-able with any description of a stock symbol (thatis, an answer to the what question), because Marsis not a publicly traded company and thus does nothave a stock symbol. A better response would beto point out the presupposition failure, as in Thereis no stock symbol for Mars candy. However, state-ments about negative factuality are rarely explicitlystated, possibly due to reporting bias (Gordon andVan Durme, 2013). Therefore, under an extractiveQA setup as in NQ where the answers are spansfrom an answer source (e.g., a Wikipedia article), itis likely that such questions will be unanswerable.
Our proposal is based on the observation thatthe denial of a failed presupposition (¬P) can beused to explain the unanswerability of questions
(Q) containing failed presuppositions (P), as in (2).
(2) Q: Who is the current monarch of France?P: There is a current monarch of France.¬P: There is no such thing as a currentmonarch of France.
An answer that refers to the presupposition, such as¬P, would be more informative compared to bothUnanswerable (1-b) and an extractive answer fromdocuments that are topically relevant but do notmention the false presupposition.
3 Analysis of Unanswerable Questions
First, to quantify the role of presupposition failurein QA, two of the authors analyzed 100 randomlyselected unanswerable wh-questions in the NQ de-velopment set.2 The annotators labeled each ques-tion as presupposition failure or not presuppositionfailure, depending on whether its unanswerabilitycould be explained by the presence of an unverifi-able presupposition with respect to the associateddocument. If the unanswerability could not beexplained in terms of presupposition failure, theannotators provided a reasoning. The Cohen’s κfor inter-annotator agreement was 0.586.
We found that 30% of the analyzed questionscould be explained by the presence of an unver-ifiable presupposition in the question, consider-ing only the cases where both annotators werein agreement (see Table 1).3 After adjudicatingthe reasoning about unanswerability for the non-presupposition failure cases, another 21% fell intocases where presupposition failure could be par-tially informative (see Table 1 and Appendix Afor details). The unverifiable presuppositions were
2The NQ development set provides 5 answer annotationsper question—we only looked at questions with 5/5 Null an-swers here.
3wh-questions constitute ∼69% of the NQ developmentset, so we expect the actual portion of questions with presup-position failiure-based explanation to be ∼21%.

3935
Question: where can i buy a japanese dwarf flying squirrel
Simple unanswerable This question is unanswerable.
Presupposition failure-basedThis question is unanswerable because we could not verify that you canbuy a Japanese Dwarf Flying Squirrel anywhere.
Extractive explanationThis question is unanswerable because it grows to a length of 20 cm (8 in)and has a membrane connecting its wrists and ankles which enables it toglide from tree to tree.
DPR rewriteAfter it was returned for the second time, the original owner, referring toit as “the prodigal gnome", said she had decided to keep it and wouldnot sell it on Ebay again.
Table 2: Systems (answer types) compared in the user preference study and examples.
18%15%0%
65%
S1: ExtractiveS2: No Explanation
System 1 is Better System 2 is Better Both are Good Both are Bad
39%8%2%
49%
S1: Karpukhin (2020)S2: No Explanation
37%10%3%
49%
S1: Karpukhin (2020)S2: Extractive
74%
0%2%23%
S1: Presup.S2: No Explanation
57%
9%7% 24%
S1: Presup.S2: Extractive
41%
26%6% 24%
S1: Presup.S2: Karpukhin (2020)
Figure 2: Results of the user preference study. Chart labels denote the two systems being compared (S1 vs. S2).
triggered by question words (19/30), the definitearticle the (10/30), and a factive verb (1/30).
4 User Study with Oracle Explanation
Our hypothesis is that statements explicitly refer-ring to failed presuppositions can better4 speak tothe unanswerability of corresponding questions. Totest our hypothesis, we conducted a side-by-sidecomparison of the oracle output of our proposedsystem and the oracle output of existing (closed-book) QA systems for unanswerable questions. Weincluded two additional systems for comparison;the four system outputs compared are describedbelow (see Table 2 for examples):
• Simple unanswerable: A simple assertionthat the question is unanswerable (i.e., Thisquestion is unanswerable). This is the ora-cle behavior of closed-book QA systems thatallow Unanswerable as an answer.
• Presupposition failure-based explanation:A denial of the presupposition that is unveri-fiable from the answer source. This takes theform of either This question is unanswerablebecause we could not verify that... or ...be-cause it is unclear that... depending on the
4We define better as user preference in this study, but otherdimensions could also be considered such as trustworthiness.
type of the failed presupposition. See Sec-tion 5.3 for more details.
• Extractive explanation: A random sentencefrom a Wikipedia article that is topically re-lated to the question, prefixed by This questionis unanswerable because.... This system is in-troduced as a control to ensure that length biasis not in play in the main comparison (e.g.,users may a priori prefer longer, topically-related answers over short answers). Thatis, since our system, Presupposition failure-based explanation, yields strictly longer an-swers than Simple unanswerable, we want toensure that our system is not preferred merelydue to length rather than answer quality.
• Open-domain rewrite: A rewrite of the non-oracle output taken from the demo5 of DensePassage Retrieval (DPR; Karpukhin et al.2020), a competitive open-domain QA sys-tem. This system is introduced to test whetherpresupposition failure can be easily addressedby expanding the answer source, since a singleWikipedia article was used to determine pre-supposition failure. If presupposition failureis a problem particular only to closed-booksystems, a competitive open-domain systemwould suffice to address this issue. While theoutputs compared are not oracle, this system
5http://qa.cs.washington.edu:2020/

3936
Question (input) Template Presupposition (output)
which philosopher advocated the idea of return to nature some __ some philosopher advocated the idea of return to naturewhen was it discovered that the sun rotates __ the sun rotateswhen is the year of the cat in chinese zodiac __ exists ‘year of the cat in chinese zodiac’ existswhen is the year of the cat in chinese zodiac __ is contextually unique ‘year of the cat in chinese zodiac’ is contextually uniquewhat do the colors on ecuador’s flag mean __ has __ ‘ecuador’ has ‘flag’
Table 3: Example input-output pairs of our presupposition generator. Text in italics denotes the part taken from theoriginal question, and the plain text is the part from the generation template. All questions are taken from NQ.
has an advantage of being able to refer to allof Wikipedia. The raw output was rewrittento be well-formed, so that it was not unfairlydisadvantaged (see Appendix B.2).
Study. We conducted a side-by-side study with100 unanswerable questions. These questions wereunanswerable questions due to presupposition fail-ure, as judged independently and with high confi-dence by two authors.6 We presented an exhaustivebinary comparison of four different types of an-swers for each question (six binary comparisonsper question). We recruited five participants on aninternal crowdsourcing platform at Google, whowere presented with all binary comparisons forall questions. All comparisons were presented inrandom order, and the sides that the comparisonsappeared in were chosen at random. For each com-parison, the raters were provided with an unanswer-able question, and were asked to choose the systemthat yielded the answer they preferred (either Sys-tem 1 or 2). They were also given the options Bothanswers are good/bad. See Appendix B.1 for addi-tional details about the task setup.
Results. Figure 2 shows the user preferences forthe six binary comparisons, where blue and graydenote preferences for the two systems compared.We find that presupposition-based answers are pre-ferred against all three answer types with whichthey were compared, and prominently so whencompared to the oracle behavior of existing closed-book QA systems (4th chart, Presup. vs. No Ex-planation). This supports our hypothesis that pre-supposition failure-based answers would be moresatisfactory to the users, and suggests that buildinga QA system that approaches the oracle behaviorof our proposed system is a worthwhile pursuit.
6Hence, this set did not necessarily overlap with the ran-domly selected unanswerable questions from Section 3; wewanted to specifically find a set of questions that were repre-sentative of the phenomena we address in this work.
5 Model Components
Given that presupposition failure accounts for asubstantial proportion of unanswerable questions(Section 3) and our proposed form of explanationsis useful (Section 4), how can we build a QA sys-tem that offers such explanations? We decomposethis task into three smaller sub-tasks: presuppo-sition generation, presupposition verification, andexplanation generation. Then, we present progresstowards each subproblem using NQ.7 We use atemplatic approach for the first and last steps. Thesecond step involves verification of the generatedpresuppositions of the question against an answersource, for which we test four different strategies:zero-shot transfer from Natural Language Infer-ence (NLI), an NLI model finetuned on verification,zero-shot transfer from fact verification, and a rule-based/NLI hybrid model. Since we used NQ, ourmodels assume a closed-book setup with a singledocument as the source of verification.
5.1 Step 1: Presupposition Generation
Linguistic triggers. Using the linguistic triggersdiscussed in Section 2, we implemented a rule-based generator to templatically generate presuppo-sitions from questions. See Table 3 for examples,and Appendix C for a full list.
Generation. The generator takes as input a con-stituency parse tree of a question string from theBerkeley Parser (Petrov et al., 2006) and appliestrigger-specific transformations to generate the pre-supposition string (e.g., taking the sentential com-plement of a factive verb). If there are multipletriggers in a single question, all presuppositionscorresponding to the triggers are generated. Thus,a single question may have multiple presupposi-tions. See Table 3 for examples of input questionsand output presuppositions.
7Code and data will be available athttps://github.com/google-research/google-research/presup-qa

3937
How good is our generation? We analyzed 53questions and 162 generated presuppositions toestimate the quality of our generated presupposi-tions. This set of questions contained at least 10instances of presuppositions pertaining to each cat-egory. One of the authors manually validated thegenerated presuppositions. According to this anal-ysis, 82.7% (134/162) presuppositions were validpresuppositions of the question. The remainingcases fell into two broad categories of error: un-grammatical (11%, 18/162) or grammatical but notpresupposed by the question (6.2%, 10/162). Thelatter category of errors is a limitation of our rule-based generator that does not take semantics intoaccount, and suggests an avenue by which futurework can yield improvements. For instance, weuniformly apply the template ‘A’ has ‘B’8 for pre-suppositions triggered by ’s. While this templateworks well for cases such as Elsa’s sister » ‘Elsa’has ‘sister’, it generates invalid presuppositionssuch as Bachelor’s degree » #‘Bachelor’ has ‘de-gree’. Finally, the projection problem is anotherlimitation. For example, who does pip believe isestella’s mother has an embedded possessive undera nonfactive verb believe, but our generator wouldnevertheless generate ‘estella’ has ‘mother’.
5.2 Step 2: Presupposition Verification
The next step is to verify whether presuppositionsof a given question is verifiable from the answersource. The presuppositions were first generated us-ing the generator described in Section 5.1, and thenmanually repaired to create a verification datasetwith gold presuppositions. This was to ensure thatverification performance is estimated without apropagation of error from the previous step. Gen-erator outputs that were not presupposed by thequestions were excluded.
To obtain the verification labels, two of the au-thors annotated 462 presuppositions on their binaryverifiability (verifiable/not verifiable) based on theWikipedia page linked to each question (the linkswere provided in NQ). A presupposition was la-beled verifiable if the page contained any statementthat either asserted or implied the content of thepresupposition. The Cohen’s κ for inter-annotatoragreement was 0.658. The annotators reconciledthe disagreements based on a post-annotation dis-
8We used a template that puts possessor and possesseeNPs in quotes instead of using different templates dependingon posessor/possessee plurality (e.g., A __ has a __/A __ has__/__ have a __/__ have __).
cussion to finalize the labels to be used in the exper-iments. We divided the annotated presuppositionsinto development (n = 234) and test (n = 228)sets.9 We describe below four different strategieswe tested.
Zero-shot NLI. NLI is a classification task inwhich a model is given a premise-hypothesis pairand asked to infer whether the hypothesis is en-tailed by the premise. We formulate presuppositionverification as NLI by treating the document as thepremise and the presupposition to verify as the hy-pothesis. Since Wikipedia articles are often largerthan the maximum premise length that NLI modelscan handle, we split the article into sentences andcreated n premise-hypothesis pairs for an articlewith n sentences. Then, we aggregated these pre-dictions and labeled the hypothesis (the presuppo-sition) as verifiable if there are at least k sentencesfrom the document that supported the presuppo-sition. If we had a perfect verifier, k = 1 wouldsuffice to perform verification. We used k = 1 forour experiments, but k could be treated as a hyper-parameter. We used ALBERT-xxlarge (Lan et al.,2020) finetuned on MNLI (Williams et al., 2018)and QNLI (Wang et al., 2019) as our NLI model.
Finer-tuned NLI. Existing NLI datasets such asQNLI contain a broad distribution of entailmentpairs. We adapted the model further to the distri-bution of entailment pairs that are specific to ourgenerated presuppositions (e.g., Hypothesis: NPis contextually unique) through additional finetun-ing (i.e., finer-tuning). Through crowdsourcing onan internal platform, we collected entailment la-bels for 15,929 (presupposition, sentence) pairs,generated from 1000 questions in NQ and 5 sen-tences sampled randomly from the correspondingWikipedia pages. We continued training the modelfine-tuned on QNLI on this additional dataset toyield a finer-tuned NLI model. Finally, we aggre-gated per-sentence labels as before to get verifiabil-ity labels for (presupposition, document) pairs.
Zero-shot FEVER. FEVER is a fact verificationtask proposed by Thorne et al. (2018). We for-mulate presupposition verification as a fact veri-fication task by treating the Wikipedia article asthe evidence source and the presupposition as theclaim. While typical FEVER systems have a docu-
9The dev/test set sizes did not exactly match because wekept presuppositions of same question within the same split,and each question had varying numbers of presuppositions.

3938
Model Macro F1 Acc.
Majority class 0.44 0.78
Zero-shot NLI (ALBERT MNLI + Wiki sentences) 0.50 0.51Zero-shot NLI (ALBERT QNLI + Wiki sentences) 0.55 0.73Zero-shot FEVER (KGAT + Wiki sentences) 0.54 0.66Finer-tuned NLI (ALBERT QNLI + Wiki sentences) 0.58 0.76
Rule-based/NLI hybrid (ALBERT QNLI + Wiki presuppositions) 0.58 0.71Rule-based/NLI hybrid (ALBERT QNLI + Wiki sentences + Wiki presuppositions) 0.59 0.77Finer-tuned, rule-based/NLI hybrid (ALBERT QNLI + Wiki sentences + Wiki presuppositions) 0.60 0.79
Table 4: Performance of verification models tested. Models marked with ‘Wiki sentence’ use sentences fromWikipedia articles as premises, and ‘Wiki presuppositions’, generated presuppositions from Wikipedia sentences.
ment retrieval component, we bypass this step anddirectly perform evidence retrieval on the articlelinked to the question. We used the Graph NeuralNetwork-based model of Liu et al. (2020) (KGAT)that achieves competitive performance on FEVER.A key difference between KGAT and NLI mod-els is that KGAT can consider pieces of evidencejointly, whereas with NLI, the pieces of evidenceare verified independently and aggregated at theend. For presuppositions that require multihop rea-soning, KGAT may succeed in cases where aggre-gated NLI fails—e.g., for uniqueness. That is, ifthere is no sentence in the document that bears thesame uniqueness presupposition, one would needto reason over all sentences in the document.
Rule-based/NLI hybrid. We consider a rule-based approach where we apply the same genera-tion method described in Section 5 to the Wikipediadocuments to extract the presuppositions of theevidence sentences. The intended effect is to ex-tract content that is directly relevant to the taskat hand—that is, we are making the presupposi-tions of the documents explicit so that they canbe more easily compared to presuppositions beingverified. However, a naïve string match betweenpresuppositions of the document and the questionswould not work, due to stylistic differences (e.g.,definite descriptions in Wikipedia pages tend tohave more modifiers). Hence, we adopted a hybridapproach where the zero-shot QNLI model wasused to verify (document presupposition, questionpresupposition) pairs.
Results. Our results (Table 4) suggest that pre-supposition verification is challenging to existingmodels, partly due to class imbalance. Only themodel that combines finer-tuning and rule-baseddocument presuppositions make modest improve-
ment over the majority class baseline (78% →79%). Nevertheless, gains in F1 were substan-tial for all models (44% → 60% in best model),showing that these strategies do impact verifiability,albeit with headroom for improvement. QNLI pro-vided the most effective zero-shot transfer, possiblybecause of domain match between our task and theQNLI dataset—they are both based on Wikipedia.The FEVER model was unable to take advantageof multihop reasoning to improve over (Q)NLI,whereas using document presuppositions (Rule-based/NLI hybrid) led to gains over NLI alone.
5.3 Step 3: Explanation Generation
We used a template-based approach to explanationgeneration: we prepended the templates This ques-tion is unanswerable because we could not verifythat... or ...because it is unclear that... to the unver-ifiable presupposition (3). Note that we worded thetemplate in terms of unverifiability of the presuppo-sition, rather than asserting that it is false. Under aclosed-book setup like NQ, the only ground truthavailable to the model is a single document, whichleaves a possibility that the presupposition is veri-fiable outside of the document (except in the rareoccasion that it is refuted by the document). There-fore, we believe that unverifiability, rather thanfailure, is a phrasing that reduces false negatives.
(3) Q: when does back to the future part 4 comeoutUnverifiable presupposition: there issome point in time that back to the futurepart 4 comes outSimple prefixing: This question is unan-swerable because we could not verify thatthere is some point in time that back to thefuture part 4 comes out.

3939
Model Average F1 Long answer F1 Short answer F1 Unans. Acc Unans. F1
ETC (our replication) 0.645 0.742 0.548 0.695 0.694+ Presuppositions (flat) 0.641 0.735 0.547 0.702 0.700+ Verification labels (flat) 0.645 0.742 0.547 0.687 0.684+ Presups + labels (flat) 0.643 0.744 0.544 0.702 0.700+ Presups + labels (structured) 0.649 0.743 0.555 0.703 0.700
Table 5: Performance on NQ development set with ETC and ETC augmented with presupposition information. Wecompare our augmentation results against our own replication of Ainslie et al. (2020) (first row).
For the user study (Section 4), we used a manual,more fluent rewrite of the explanation generatedby simple prefixing. In future work, fluency is adimension that can be improved over templatic gen-eration. For example, for (3), a fluent model couldgenerate the response: This question is unanswer-able because we could not verify that Back to theFuture Part 4 will ever come out.
6 End-to-end QA Integration
While the 3-step pipeline is designed to generateexplanations for unanswerability, the generated pre-suppositions and their verifiability can also provideuseful guidance even for a standard extractive QAsystem. They may prove useful both to unanswer-able and answerable questions, for instance by indi-cating which tokens of a document a model shouldattend to. We test several approaches to augment-ing the input of a competitive extractive QA systemwith presuppositions and verification labels.
Model and augmentation. We used ExtendedTransformer Construction (ETC) (Ainslie et al.,2020), a model that achieves competitive perfor-mance on NQ, as our base model. We adoptedthe configuration that yielded the best reported NQperformance among ETC-base models.10 We ex-periment with two approaches to encoding the pre-supposition information. First, in the flat model,we simply augment the input question representa-tion (token IDs of the question) by concatenatingthe token IDs of the generated presuppositions andthe verification labels (0 or 1) from the ALBERTQNLI model. Second, in the structured model (Fig-ure 4), we take advantage of the global input layerof ETC that is used to encode the discourse unitsof large documents like paragraphs. Global tokensattend (via self-attention) to all tokens of their in-
10The reported results in Ainslie et al. (2020) are obtainedusing a custom modification to the inference procedure thatwe do not incorporate into our pipeline, since we are only in-terested in the relative gains from presupposition verification.
ternal text, but for other text in the document, theyonly attend to the corresponding global tokens. Weadd one global token for each presupposition, andallow the presupposition tokens to only attend toeach other and the global token. The value of theglobal token is set to the verification label (0 or 1).
Metrics. We evaluated our models on two sets ofmetrics: NQ performance (Long Answer, Short An-swer, and Average F1) and Unanswerability Clas-sification (Accuracy and F1).11 We included thelatter because our initial hypothesis was that sen-sitivity to presuppositions of questions would leadto better handling of unanswerable questions. TheETC NQ model has a built-in answer type classifi-cation step which is a 5-way classification between{Unanswerable, Long Answer, Short Answer, Yes,No}. We mapped the classifier outputs to binaryanswerability labels by treating the predicted labelas Unanswerable only if its logit was greater thanthe sum of all other options.
Results and Discussion Table 5 shows that aug-mentations that use only the presuppositions oronly the verification labels do not lead to gains inNQ performance over the baseline, but the presup-positions do lead to gains on Unanswerability Clas-sification. When both presuppositions and theirverifiability are provided, we see minor gains inAverage F1 and Unanswerability Classification.12
For Unanswerability Classification, the improvedaccuracy is different from the baseline at the 86%(flat) and 89% (structured) confidence level usingMcNemar’s test. The main bottleneck of our modelis the quality of the verification labels used for aug-mentation (Table 4)—noisy labels limit the capac-ity of the QA model to attend to the augmentations.
While the gain on Unanswerability Classifica-tion is modest, an error analysis suggests that
11Here, we treated ≥ 4 Null answers as unanswerable,following the definition in Kwiatkowski et al. (2019).
12To contextualize our results, a recently published NQmodel (Ainslie et al., 2020) achieved a gain of around ∼2%.

3940
the added presuppositions modulate the predictionchange in our best-performing model (structured)from the baseline ETC model. Looking at the caseswhere changes in model prediction (i.e., Unanswer-able (U) ↔ Answerable (A)) lead to correct an-swers, we observe an asymmetry in the two possi-ble directions of change. The number of correct A→ U cases account for 11.9% of the total numberof unanswerable questions, whereas correct U→A cases account for 6.7% of answerable questions.This asymmetry aligns with the expectation that thepresupposition-augmented model should achievegains through cases where unverified presupposi-tions render the question unanswerable. For exam-ple, given the question who played david brent’sgirlfriend in the office that contains a false presup-position David Brent has a girlfriend, the struc-tured model changed its prediction to Unanswer-able from the base model’s incorrect answer JuliaDavis (an actress, not David Brent’s girlfriend ac-cording to the document: . . . arrange a meetingwith the second woman (voiced by Julia Davis)).On the other hand, such an asymmetry is not ob-served in cases where changes in model predictionresults in incorrect answers: incorrect A→ U andU → A account for 9.1% and 9.2%, respectively.More examples are shown in Appendix F.
7 Related Work
While presuppositions are an active topic of re-search in theoretical and experimental linguistics(Beaver, 1997; Simons, 2013; Schwarz, 2016, i.a.,),comparatively less attention has been given to pre-suppositions in NLP (but see Clausen and Manning(2009) and Tremper and Frank (2011)). More re-cently, Cianflone et al. (2018) discuss automaticallydetecting presuppositions, focusing on adverbialtriggers (e.g., too, also...), which we excluded dueto their infrequency in NQ. Jeretic et al. (2020)investigate whether inferences triggered by presup-positions and implicatures are captured well byNLI models, finding mixed results.
Regarding unanswerable questions, their impor-tance in QA (and therefore their inclusion in bench-marks) has been argued by works such as Clark andGardner (2018) and Zhu et al. (2019). The analysisportion of our work is similar in motivation to unan-swerability analyses in Yatskar (2019) and Asai andChoi (2020)—to better understand the causes ofunanswerability in QA. Hu et al. (2019); Zhanget al. (2020); Back et al. (2020) consider answer-
ability detection as a core motivation of their mod-eling approaches and propose components such asindependent no-answer losses, answer verification,and answerability scores for answer spans.
Our work is most similar to Geva et al. (2021) inproposing to consider implicit assumptions of ques-tions. Furthermore, our work is complementary toQA explanation efforts like Lamm et al. (2020) thatonly consider answerable questions.
Finally, abstractive QA systems (e.g., Fan et al.2019) were not considered in this work, but their ap-plication to presupposition-based explanation gen-eration could be an avenue for future work.
8 Conclusion
Through an NQ dataset analysis and a user prefer-ence study, we demonstrated that a significant por-tion of unanswerable questions can be answeredmore effectively by calling out unverifiable pre-suppositions. To build models that provide suchan answer, we proposed a novel framework thatdecomposes the task into subtasks that can be con-nected to existing problems in NLP: presuppositionidentification (parsing and text generation), presup-position verification (textual inference and fact ver-ification), and explanation generation (text genera-tion). We observed that presupposition verification,especially, is a challenging problem. A combina-tion of a competitive NLI model, finer-tuning andrule-based hybrid inference gave substantial gainsover the baseline, but was still short of a fully satis-factory solution. As a by-product, we showed thatverified presuppositions can modestly improve theperformance of an end-to-end QA model.
In the future, we plan to build on this work byproposing QA systems that are more robust andcooperative. For instance, different types of presup-position failures could be addressed by more fluidanswer strategies—e.g., violation of uniquenesspresuppositions may be better handled by provid-ing all possible answers, rather than stating that theuniqueness presupposition was violated.
Acknowledgments
We thank Tom Kwiatkowski, Mike Collins,Tania Rojas-Esponda, Eunsol Choi, Annie Louis,Michael Tseng, Kyle Rawlins, Tania Bedrax-Weiss,and Elahe Rahimtoroghi for helpful discussionsabout this project. We also thank Lora Aroyo forhelp with user study design, and Manzil Zaheer forpointers about replicating the ETC experiments.

3941
ReferencesMárta Abrusán. 2011. Presuppositional and negative
islands: a semantic account. Natural Language Se-mantics, 19(3):257–321.
Joshua Ainslie, Santiago Ontanon, Chris Alberti, Va-clav Cvicek, Zachary Fisher, Philip Pham, AnirudhRavula, Sumit Sanghai, Qifan Wang, and Li Yang.2020. ETC: Encoding long and structured inputsin transformers. In Proceedings of the 2020 Con-ference on Empirical Methods in Natural LanguageProcessing (EMNLP), pages 268–284, Online. Asso-ciation for Computational Linguistics.
Akari Asai and Eunsol Choi. 2020. Challenges in in-formation seeking QA: Unanswerable questions andparagraph retrieval. arXiv:2010.11915.
Seohyun Back, Sai Chetan Chinthakindi, Akhil Kedia,Haejun Lee, and Jaegul Choo. 2020. NeurQuRI:Neural question requirement inspector for answer-ability prediction in machine reading comprehen-sion. In International Conference on Learning Rep-resentations.
David Beaver. 1997. Presupposition. In Handbook ofLogic and Language, pages 939–1008. Elsevier.
Andre Cianflone, Yulan Feng, Jad Kabbara, and JackieChi Kit Cheung. 2018. Let’s do it “again”: A firstcomputational approach to detecting adverbial pre-supposition triggers. In Proceedings of the 56th An-nual Meeting of the Association for ComputationalLinguistics (Volume 1: Long Papers), pages 2747–2755, Melbourne, Australia. Association for Com-putational Linguistics.
Christopher Clark and Matt Gardner. 2018. Simpleand effective multi-paragraph reading comprehen-sion. In Proceedings of the 56th Annual Meeting ofthe Association for Computational Linguistics (Vol-ume 1: Long Papers), pages 845–855, Melbourne,Australia. Association for Computational Linguis-tics.
David Clausen and Christopher D. Manning. 2009. Pre-supposed content and entailments in natural lan-guage inference. In Proceedings of the 2009 Work-shop on Applied Textual Inference (TextInfer), pages70–73, Suntec, Singapore. Association for Computa-tional Linguistics.
Elizabeth Coppock and David Beaver. 2012. Weakuniqueness: The only difference between definitesand indefinites. In Semantics and Linguistic Theory,volume 22, pages 527–544.
Angela Fan, Yacine Jernite, Ethan Perez, David Grang-ier, Jason Weston, and Michael Auli. 2019. ELI5:Long form question answering. In Proceedings ofthe 57th Annual Meeting of the Association for Com-putational Linguistics, pages 3558–3567, Florence,Italy. Association for Computational Linguistics.
Mor Geva, Daniel Khashabi, Elad Segal, Tushar Khot,Dan Roth, and Jonathan Berant. 2021. Did Aristotleuse a laptop? A question answering benchmark withimplicit reasoning strategies. arXiv:2101.02235.
Jonathan Gordon and Benjamin Van Durme. 2013. Re-porting bias and knowledge acquisition. In Proceed-ings of the 2013 Workshop on Automated KnowledgeBase Construction, AKBC ’13, page 25–30, NewYork, NY, USA. Association for Computing Machin-ery.
Minghao Hu, Furu Wei, Yuxing Peng, Zhen Huang,Nan Yang, and Dongsheng Li. 2019. Read+ verify:Machine reading comprehension with unanswerablequestions. In Proceedings of the AAAI Conferenceon Artificial Intelligence, volume 33, pages 6529–6537.
Paloma Jeretic, Alex Warstadt, Suvrat Bhooshan, andAdina Williams. 2020. Are natural language infer-ence models IMPPRESsive? Learning IMPlicatureand PRESupposition. In Proceedings of the 58th An-nual Meeting of the Association for ComputationalLinguistics, pages 8690–8705, Online. Associationfor Computational Linguistics.
Vladimir Karpukhin, Barlas Oguz, Sewon Min, PatrickLewis, Ledell Wu, Sergey Edunov, Danqi Chen, andWen-tau Yih. 2020. Dense passage retrieval foropen-domain question answering. In Proceedings ofthe 2020 Conference on Empirical Methods in Nat-ural Language Processing (EMNLP), pages 6769–6781, Online. Association for Computational Lin-guistics.
Lauri Karttunen. 2016. Presupposition: What wentwrong? In Semantics and Linguistic Theory, vol-ume 26, pages 705–731.
Tom Kwiatkowski, Jennimaria Palomaki, Olivia Red-field, Michael Collins, Ankur Parikh, Chris Al-berti, Danielle Epstein, Illia Polosukhin, Jacob De-vlin, Kenton Lee, Kristina Toutanova, Llion Jones,Matthew Kelcey, Ming-Wei Chang, Andrew M. Dai,Jakob Uszkoreit, Quoc Le, and Slav Petrov. 2019.Natural Questions: A benchmark for question an-swering research. Transactions of the Associationfor Computational Linguistics, 7:452–466.
Matthew Lamm, Jennimaria Palomaki, Chris Alberti,Daniel Andor, Eunsol Choi, Livio Baldini Soares,and Michael Collins. 2020. QED: A frameworkand dataset for explanations in question answering.arXiv:2009.06354.
Zhenzhong Lan, Mingda Chen, Sebastian Goodman,Kevin Gimpel, Piyush Sharma, and Radu Soricut.2020. ALBERT: A Lite BERT for self-supervisedlearning of language representations. In Interna-tional Conference on Learning Representations.
Stephen C. Levinson. 1983. Pragmatics, CambridgeTextbooks in Linguistics, pages 181–184, 194. Cam-bridge University Press.

3942
Zhenghao Liu, Chenyan Xiong, Maosong Sun, andZhiyuan Liu. 2020. Fine-grained fact verificationwith kernel graph attention network. In Proceedingsof the 58th Annual Meeting of the Association forComputational Linguistics, pages 7342–7351, On-line. Association for Computational Linguistics.
Randall Munroe. 2020. Learning new things fromGoogle. https://twitter.com/xkcd/status/1333529967079120896. Accessed: 2021-02-01.
Slav Petrov, Leon Barrett, Romain Thibaux, and DanKlein. 2006. Learning accurate, compact, and inter-pretable tree annotation. In Proceedings of the 21stInternational Conference on Computational Linguis-tics and 44th Annual Meeting of the Association forComputational Linguistics, pages 433–440, Sydney,Australia. Association for Computational Linguis-tics.
Pranav Rajpurkar, Robin Jia, and Percy Liang. 2018.Know what you don’t know: Unanswerable ques-tions for SQuAD. In Proceedings of the 56th An-nual Meeting of the Association for ComputationalLinguistics (Volume 2: Short Papers), pages 784–789, Melbourne, Australia. Association for Compu-tational Linguistics.
Rob A. Van der Sandt. 1992. Presupposition projec-tion as anaphora resolution. Journal of Semantics,9(4):333–377.
Philippe Schlenker. 2008. Presupposition projection:Explanatory strategies. Theoretical Linguistics,34(3):287–316.
Bernhard Schwarz and Alexandra Simonenko. 2018.Decomposing universal projection in questions. InSinn und Bedeutung 22, volume 22, pages 361–374.
Florian Schwarz. 2016. Experimental work in presup-position and presupposition projection. Annual Re-view of Linguistics, 2(1):273–292.
Mandy Simons. 2013. Presupposing. Pragmatics ofSpeech Actions, pages 143–172.
Peter F. Strawson. 1950. On referring. Mind,59(235):320–344.
Nadine Theiler. 2020. An epistemic bridge for presup-position projection in questions. In Semantics andLinguistic Theory, volume 30, pages 252–272.
James Thorne, Andreas Vlachos, ChristosChristodoulopoulos, and Arpit Mittal. 2018.FEVER: a large-scale dataset for fact extractionand VERification. In Proceedings of the 2018Conference of the North American Chapter ofthe Association for Computational Linguistics:Human Language Technologies, Volume 1 (LongPapers), pages 809–819, New Orleans, Louisiana.Association for Computational Linguistics.
Galina Tremper and Anette Frank. 2011. Extendingfine-grained semantic relation classification to pre-supposition relations between verbs. Bochumer Lin-guistische Arbeitsberichte.
Alex Wang, Amanpreet Singh, Julian Michael, FelixHill, Omer Levy, and Samuel R. Bowman. 2019.GLUE: A multi-task benchmark and analysis plat-form for natural language understanding. In Inter-national Conference on Learning Representations.
Adina Williams, Nikita Nangia, and Samuel Bowman.2018. A broad-coverage challenge corpus for sen-tence understanding through inference. In Proceed-ings of the 2018 Conference of the North AmericanChapter of the Association for Computational Lin-guistics: Human Language Technologies, Volume1 (Long Papers), pages 1112–1122, New Orleans,Louisiana. Association for Computational Linguis-tics.
Mark Yatskar. 2019. A qualitative comparison ofCoQA, SQuAD 2.0 and QuAC. In Proceedings ofthe 2019 Conference of the North American Chap-ter of the Association for Computational Linguistics:Human Language Technologies, Volume 1 (Longand Short Papers), pages 2318–2323, Minneapolis,Minnesota. Association for Computational Linguis-tics.
Zhuosheng Zhang, Junjie Yang, and Hai Zhao. 2020.Retrospective reader for machine reading compre-hension. arXiv:2001.09694.
Haichao Zhu, Li Dong, Furu Wei, Wenhui Wang, BingQin, and Ting Liu. 2019. Learning to ask unan-swerable questions for machine reading comprehen-sion. In Proceedings of the 57th Annual Meetingof the Association for Computational Linguistics,pages 4238–4248, Florence, Italy. Association forComputational Linguistics.
A Additional Causes of UnanswerableQuestions
Listed below are cases of unanswerable questionsfor which presupposition failure may be partiallyuseful:
• Document retrieval failure: The retrieveddocument is unrelated to the question, so thepresuppositions of the questions are unlikelyto be verifiable from the document.
• Failure of commonsensical presupposi-tions: The document does not directly sup-port the presupposition but the presuppositionis commonsensical.
• Presuppositions involving subjective judg-ments: verification of the presupposition re-quires subjective judgment, such as the exis-tence of the best song.

3943
Figure 3: The user interface for the user preference study.
• Reference resolution failure: the questioncontains an unresolved reference such as apro-form (I, here...) or a temporal expression(next year...). Therefore the presuppositionsalso fail due to unresolved reference.
B User Study
B.1 Task Design
Figure 3 shows the user interface (UI) for the study.The raters were given a guideline that instructedthem to select the answer that they preferred, imag-ining a situation in which they have entered thegiven question to two different QA systems. Toavoid biasing the participants towards any answertype, we used a completely unrelated, nonsensicalexample (Q: Are potatoes fruit? System 1: Yes,because they are not vegetables. System 2: Yes,because they are not tomatoes.) in our guidelinedocument.
B.2 DPR Rewrites
The DPR answers we used in the user study wererewrites of the original outputs. DPR by defaultreturns a paragraph-length Wikipedia passage thatcontains the short answer to the question. From thisdefault output, we manually extracted the sentence-level context that fully contains the short answer,and repaired the context into a full sentence if theextracted context was a sentence fragment. Thiswas to ensure that all answers compared in thestudy were well-formed sentences, so that userpreference was determined by the content of thesentences rather than their well-formedness.
C Presupposition Generation Templates
See Table 6 for a full list of presupposition triggersand templates used for presupposition generation.
D Data Collection
The user study (Section 4) and data collection of en-tailment pairs from presuppositions and Wikipediasentences (Section 5) have been performed bycrowdsourcing internally at Google. Details ofthe user study is in Appendix B. Entailment judge-ments were elicited from 3 raters for each pair, andmajority vote was used to assign a label. Becauseof class imbalance, all positive labels were kept inthe data and negative examples were down-sampledto 5 per document.
E Modeling Details
E.1 Zero-shot NLI
MNLI and QNLI were trained following instruc-tions for fine-tuning on top of ALBERT-xxlargeat https://github.com/google-research/
albert/blob/master/albert_glue_fine_
tuning_tutorial.ipynb with the default settingsand parameters.
E.2 KGAT
We used the off-the-shelf model from https://
github.com/thunlp/KernelGAT (BERT-base).
E.3 ETC models
For all ETC-based models, we used the same modelparameter settings as Ainslie et al. (2020) usedfor NQ, only adjusting the maximum global in-put length to 300 for the flat models to accommo-date the larger set of tokens from presuppositions.Model selection was done by choosing hyperparam-eter configurations yielding maximum Average F1.Weight lifting was done from BERT-base insteadof RoBERTa to keep the augmentation experimentssimple. All models had 109M parameters.
All model training was done using the Adamoptimizer with hyperparameter sweeps of learning

3944
Question (input) Template Presupposition (output)
who sings it’s a hard knock life there is someone that __ there is someone that sings it’s a hard knock lifewhich philosopher advocated the idea of return to nature some __ some philosopher advocated the idea of return to naturewhere do harry potter’s aunt and uncle live there is some place that __ there is some place that harry potter’s aunt and uncle livewhat did the treaty of paris do for the US there is something that __ there is something that the treaty of paris did for the USwhen was the jury system abolished in india there is some point in time that __ there is some point in time that the jury system was abolished in indiahow did orchestra change in the romantic period __ orchestra changed in the romantic periodhow did orchestra change in the romantic period there is some way that __ there is some way that orchestra changed in the romantic periodwhy did jean valjean take care of cosette __ jean valjean took care of cosettewhy did jean valjean take care of cosette there is some reason that __ there is some reason that jean valjean took care of cosettewhen is the year of the cat in chinese zodiac __ exists ‘year of the cat in chinese zodiac’ existswhen is the year of the cat in chinese zodiac __ is contextually unique ‘year of the cat in chinese zodiac’ is contextually uniquewhat do the colors on ecuador’s flag mean __ has __ ‘ecuador’ has ‘flag’when was it discovered that the sun rotates __ the sun rotateshow old was macbeth when he died in the play __ he died in the playwho would have been president if the south won the civil war it is not true that __ it is not true that the south won the civil war
Table 6: Example input-output pairs of our presupposition generator. Text in italics denotes the part taken from theoriginal question, and the plain text is the part from the generation template. All questions are taken from NQ.
Figure 4: The structured augmentation to the ETCmodel. Qk are question tokens, Pk are presuppositiontokens, Sl are sentence tokens, Pv are verification la-bels, Qid is the (constant) global question token andSid is the (constant) global sentence token.
rates in {3×10−5, 5×10−5} and number of epochsin {3, 5} (i.e., 4 settings). In cases of overfitting,an earlier checkpoint of the run with optimal vali-dation performance was picked. All training wasdone on servers utilizing a Tensor Processing Unit3.0 architecture. Average runtime of model trainingwith this architecture was 8 hours.
Figure 4 illustrates the structure augmented ETCmodel that separates question and presuppositiontokens that we discussed in Section 6.
F ETC Prediction Change Examples
We present selected examples of model predictionsfrom Section 6 that illustrate the difference in be-havior of the baseline ETC model and the struc-tured, presupposition-augmented model:
1. [Correct Answerable→ Unanswerable]NQ Question: who played david brent’s girl-friend in the officeRelevant presupposition: David Brent has agirlfriendWikipedia Article: The Office ChristmasspecialsGold Label: UnanswerableBaseline label: AnswerableStructured model label: Unanswerable
Explanation: The baseline model incorrectlypredicts arrange a meeting with the secondwoman (voiced by Julia Davis) as a long an-swer and Julia Davis as a short answer, in-ferring that the second woman met by DavidBrent was his girlfriend. The structured modelcorrectly flips the prediction to Unanswerable,possibly making use of the unverifiable pre-supposition David Brent has a girlfriend.
2. [Correct Unanswerable→ Answerable]NQ Question: when did cricket go to 6 balloversRelevant presupposition: Cricket went to 6balls per over at some pointWikipedia Article: Over (cricket)Gold Label: AnswerableBaseline label: UnanswerableStructured model label: AnswerableExplanation: The baseline model was likelyconfused because the long answer candidateonly mentions Test Cricket, but support forthe presupposition came from the sentenceAlthough six was the usual number of balls,it was not always the case, leading the struc-tured model to choose the correct long answercandidate.
3. [Incorrect Answerable→ Unanswerable]NQ Question: what is loihi and where doesit originate fromRelevant presupposition: there is someplace that it originates fromWikipedia Article: Loihi SeamountGold Label: AnswerableBaseline label: AnswerableStructured model label: UnanswerableExplanation: The baseline model finds thecorrect answer (Hawaii hotspot) but the struc-

3945
tured model incorrectly changes the predic-tion. This is likely due to verification error—although the presupposition there is someplace that it originates from is verifiable, itwas incorrectly labeled as unverifiable. Pos-sibly, the the unresolved it contributed to thisverification error, since our verifier currentlydoes not take the question itself into consider-ation.