Embed Size (px)
Citation preview

Why Mixed Effects Models?

Mixed Effects Models Recap/Intro
● Three issues with ANOVA– Multiple random effects– Categorical data– Focus on fixed effects
● What mixed effects models do– Random slopes– Link functions
● Iterative fitting

Problem One: Multiple Random EffectsProblem One: Multiple Random Effects
● Most studies sample both subjects and items
Subject 1Subject 1 Subject 2Subject 2
Knight Knight storystory
Monkey Monkey storystory

Problem One: Crossed Random EffectsProblem One: Crossed Random Effects
● Most studies sample both subjects and items
– Typically, subjects crossed with items● Each subject sees a
version of each item– May also be only
partially crossed● Each subject sees only
some of the items

...or Hierarchical Random Effects...or Hierarchical Random Effects
● Most studies sample both subjects and items
– Typically, subjects crossed with items
– May also have one nested within the other (hierarchical)● e.g. autobiographical
memory
● How to incorporate this into model?

Problem One: Multiple Random EffectsProblem One: Multiple Random Effects
● Why do we care about items, anyway?
● #1: Investigate robustness of effects across items– Concern is that effect could be driven by just 1 or 2
items – might not really be what we thought it was
– Psycholinguistics: View is that we studying language too, not just people● Other areas of psychology have not tended to care about this
– Note: Including items in a model doesn't really “confirm” that the effect is robust across items. It's still possible to get a reliable effect driven by a small number of items. But it allows you investigate how variable the effect is across items and why different items might be differentially influenced.

Problem One: Multiple Random EffectsProblem One: Multiple Random Effects
● Why do we care about items?
● #2: Violations of independence– A BIG ISSUE– Suppose Amélie and Zhenghan see
items A & B but Tuan sees items C & D– Likely that Amélie's results are more like
Zhenghan's than like Tuan's– But ANOVA assumes observations
independent– Even a small amount of dependency
can lead to spurious results (Quene & van
den Bergh, 2008)● Dependency you didn't account for makes the variance
look smaller than it actually is
AA BB
CC DD

What Constitutes an “Item”?What Constitutes an “Item”?
● Items assumed to be independently sampled sampled from population of relevantitems
● 2 related words / sentences not independently sampled
– “The coach knew you missed practice.”– “The coach knew that you missed practice.”– Not a coincidence both are in your
experiment!● Should be considered the same
item● But 2 unrelated things can be
different items
ALL POSSIBLEDISCOURSES

● ANOVA solution– Subjects analysis:
Average over multiple items for each subject
– Items analysis: Average over multiple subjects for each item
● Two sets of results– Sometime combined
with min F'– An approximation of
true min F
F1 = 18.31, p < .001
F2 = 22.10, p < .0001
Problem One: Crossed Random EffectsProblem One: Crossed Random Effects
Note: not real data or statistical tests

● Some debate on how accurate min F' is
– Scott will admit to not be fully read up on this since I came in after people started switching to mixed effects models
● Somewhat less relevant now that we can use mixed effects models instead
F1 = 18.31, p < .001
F2 = 22.10, p < .0001
Problem One: Crossed Random EffectsProblem One: Crossed Random Effects
Note: not real data or statistical tests

Mixed Effects Models Recap/Intro
● Three issues with ANOVA– Multiple random effects– Categorical data– Focus on fixed effects
● What mixed effects models do– Random slopes– Link functions
● Iterative fitting

Problem Two: Categorical Data
● ANOVA assumes our response is continuous
● But, we often want to look at categorical data
'Lightning hit the church.”
vs.“The church was hit by lightning.”
RT: 833 ms
Choice of syntactic structure
Item recalled or not
Region fixated in eye-tracking experiment

Problem One: Categorical Data
● Traditional solution:Analyze proportions
● Violates assumptions of ANOVA– Among other issues: ANOVA
assumes normal distribution, which has infinite tails
– But proportions are clearly bounded
– Model could predict impossible values like 110%
Problem Two: Categorical Data
But0 proportions 1
−

Problem One: Categorical Data
● Traditional solution:Analyze proportions
● Violates assumptions of ANOVA– Among other issues: ANOVA
assumes normal distribution, which has infinite tails
– But proportions are clearly bounded
– Model could predict impossible values like 110%
Problem Two: Categorical Data
But0 proportions 1
−

Problem One: Categorical Data
● Traditional solution: Analyze proportions
● Violates assumptions of ANOVA
● Can lead to:– Spurious effects (Type
I error)– Missing a true effects
(Type II error)
Problem Two: Categorical Data

Problem One: Categorical Data
● Transformations improve the situation but don't solve it
– Empirical logit is good (Jaeger, 2008)
– Arcsine less so
● Situation is worse for very high or very low proportions (Jaeger, 2008)
– .30 to .70 are OK
Problem Two: Categorical Data

Problem One: Categorical Data
● Why can't we just use logistic regression?– Predict if each trial's response is in category A or
category B
● This is essentially what we will end up doing
● But, if we are looking at things at a trial-by-trial basis...
– Need to control for the different items on each trial– Problem One again!
Problem Two: Categorical Data

Mixed Effects Models Recap/Intro
● Three issues with ANOVA– Multiple random effects– Categorical data– Focus on fixed effects
● What mixed effects models do– Random slopes– Link functions
● Iterative fitting

Problem Three: Focus on Fixed EffectsProblem Three: Focus on Fixed Effects
● ANOVA doesn't characterize differences between subjects or items
● The bird that they spotted was a ....
● We just have a mean effect● No info. about how much it varies
across participants or items
Predictable 283 ms
Unpredictable 309 ms
cardinalcardinal
pitohuipitohui
26 ms
MEAN READING TIME
EN
DIN
G

Problem Three: Focus on Fixed EffectsProblem Three: Focus on Fixed Effects
● Can try to account for some of this with an ANCOVA
– But not typically done– And would have to be done separately for
participants and items (Problem One again)
Predictable 283 ms
Unpredictable 309 ms
26 ms
MEAN

● Three issues with ANOVA– Multiple random effects– Categorical data– Focused on fixed effects
● What mixed effects models do– Random slopes– Link functions
● Iterative fitting
Mixed Effects Models Recap/IntroPower ofsubjectsanalysis!
Power ofitems
analysis!
Captain MLMto the rescue!
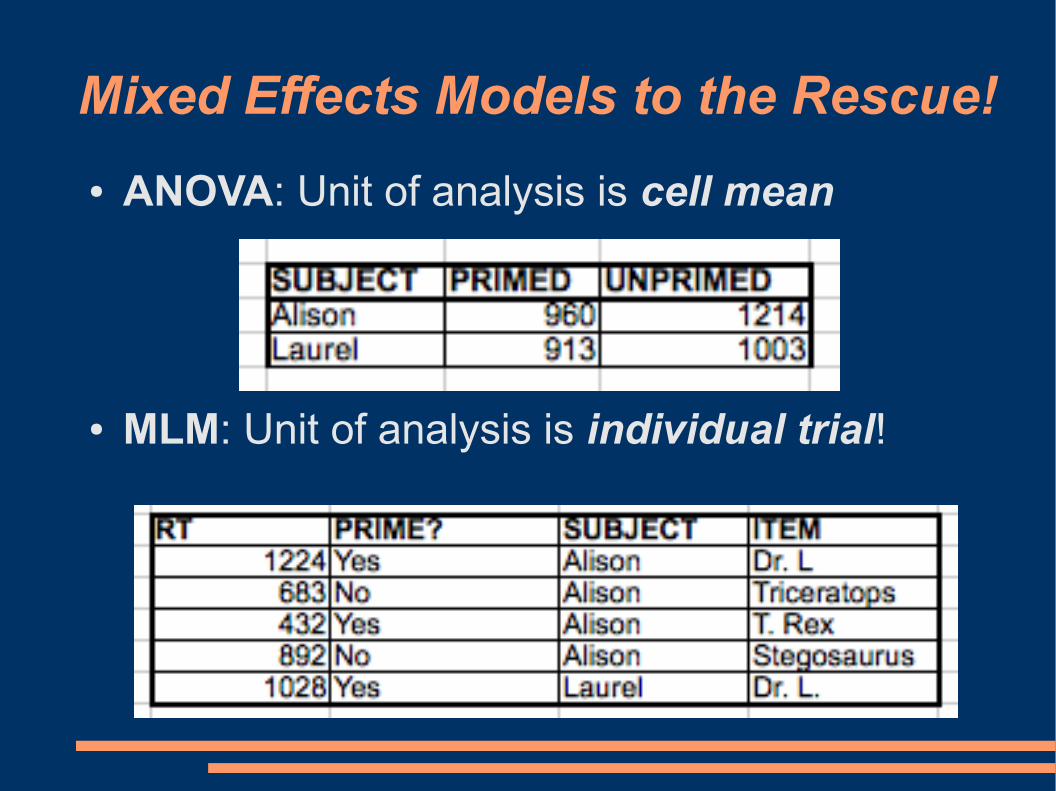
Mixed Effects Models to the Rescue!
● ANOVA: Unit of analysis is cell mean
● MLM: Unit of analysis is individual trial!

Mixed Models to the Rescue!
● Look at individual trials● Model outcome using regression
= ItemItem+ +RTRT
Prime?Prime?
SubjectSubject
Semantic categorization: Is it a dinosaur?
Problem One solved!Problem One solved!

Mixed Models to the Rescue!
● This means you will need your data formatted differently than you would for an ANOVA
– Each trial gets its own line

Mixed Models to the Rescue!
● Is this useful for what we care about?– Stereotypical view of regression is that it's about
predicting values– In experimental settings we more typically want to
know if Variable X matters● Yes! We can test individual effects: Do they
contribute to the model?– e.g. does priming predict something about RT?
=ItemItem
+ +RTRT
Prime?Prime? JasonJasonSubjectSubject

● Three issues with ANOVA– Multiple random effects– Categorical data– Focus on fixed effects
● What mixed effects models do– Random slopes– Link functions
● Iterative fitting
Mixed Effects Models Recap/Intro

Fixed vs. Random Slopes
● Fixed Slope: Same for all participants/items● Random Slope: Can vary by participants/items
= + +RTRT
Prime?Prime?
+
26 ms
88 ms
LaurelLaurel Stego.Stego.

Fixed vs. Random Slopes
● Fixed Slope: Same for all participants/items● Random Slope: Can vary by participants/items
= + +RTRT
Prime?Prime? LaurelLaurel
+
26 ms
315 ms
Dr. LDr. L
Example: Some items may show a larger priming effect than others

Fixed vs. Random Slopes
● Fixed Slope: Same for all participants/items● Random Slope: Can vary by participants/items● Can also test what explains variation
= + +RTRT
Prime?Prime? LaurelLaurel
+
26 ms
15 ms
Dr. LDr. L
+Lex.Freq.Lex.Freq.
300 ms
e.g. Adding lexical frequency to the model may account for variation in priming effect

Fixed vs. Random Slopes
● Fixed Slope: Same for all participants/items● Random Slope: Can vary by participants/items● Can also test what explains variation
= + +RTRT
Prime?Prime? LaurelLaurel
+
26 ms
15 ms
Dr. LDr. L
+Lex.Freq.Lex.Freq.
300 ms
Problem ThreeProblem ThreeSolved!Solved!

● Three issues with ANOVA– Multiple random effects– Categorical data– Focus on fixed effects
● What mixed effects models do– Random slopes– Link functions
● Iterative fitting
Mixed Effects Models Recap/Intro

Link Functions
● Specifies how to connect predictors to the outcome
● Every model has one....● ...sometimes, just the identity function– With Gaussian (normal) data
+ ++ ++ ++ +RTRT
ItemItemPrime?Prime? SubjectSubject
1300 ms

Link Functions
● Specifies how to connect predictors to the outcome
● For binomial (yes/no) outcomes: Model log odds to predict outcome
+ ++ ++ ++ +ItemItemPrime?Prime? SubjectSubjectYes/No
Problem Two solved!
AccuracyAccuracy

Link Functions● Default link function for binomial data is logit
(log odds)– Odds: p(yes)/p(no) or p(yes)/[1-p(yes)]
● No upper bound, but lower bound at 0
– Log Odds: ln(Odds)● Now unbounded at both ends
● Can also use probit– Based on cumulative distribution function of normal
distribution– Very highly correlated with logit; almost always give
you same results as logit● Probit assumes slightly fewer hits at low end of distribution
& slightly more hits at high end

● Three issues with ANOVA– Multiple random effects– Categorical data– Focus on fixed effects
● What mixed effects models do– Random slopes– Link functions
● Iterative fitting
Mixed Effects Models Recap/Intro

One Caveat...
Where do model results come from?
(Answer: When a design matrix and a data matrix really love each other...)

One Caveat...
● Fitting ANOVA / linearregression has easysolution
● A few matrix multiplications a computer can do easily– A “closed form solution”
● Like a “beta machine” … you put your data in and automatically get the One True Model out
b = (X'X)-1X'Y

One Caveat...
● MEMs requires iteration– Check various sets of
betas until you findthe best one
– R does this for you
● An estimation– Not mathematically guaranteed to be best fit
● Complicated models take longer to fit– If too many parameters relative to data, might completely fail
to converge (find the best set of betas)– Scott's only experience with this is with multiple random
slopes of interactions
The best model: The one thatsmiles with its eyes










![[ME] Multilevel Mixed Effects - Stata · Title me — Introduction to multilevel mixed-effects models DescriptionQuick startSyntaxRemarks and examples AcknowledgmentsReferencesAlso](https://img.pdfslide.net/doc/110x75/5fda116a20c50d3a9c01a419/me-multilevel-mixed-effects-stata-title-me-a-introduction-to-multilevel-mixed-effects.jpg)


















