Embed Size (px)
Citation preview

BMI 871 2013 1 © Do not distribute
Why Normalizing v?
Why did we normalize v on the right side?
Because we want the length of the left side to be the eigenvalue

BMI 871 2013 2 © Do not distribute
CCI PCA Algorithm (1)

BMI 871 2013 3 © Do not distribute
CCI PCA Algorithm (2)

BMI 871 2013 4 © Do not distribute
PCA from the FERET Face Image Set
(a) Batch PCA; (b): One epoch; (c) 20 epochs

BMI 871 2013 5 © Do not distribute
Quiz: PCA Properties Quiz: What is NOT true? A. CCI PCA is an incremental learning
algorithm B. CCI PCA does not need the covariance
matrix of the input space to compute the first k principal component vectors
C. CCI PCA uses the properties that different eigenvectors are orthogonal when it computes the residual of the subspace spanned by the computed eigenvectors
D. The eigenvectors from CCI PCA are feature vectors that emerge from the sensory experience
E. The traditional batch PCA methods do not need to perform iterations

BMI 871 2013 6 © Do not distribute
Quiz: PCA Properties Quiz: What is NOT true? A. CCI PCA is an incremental learning
algorithm B. CCI PCA does not need the covariance
matrix of the input space to compute the first k principal component vectors
C. CCI PCA uses the properties that different eigenvectors are orthogonal when it computes the residual of the subspace spanned by the computed eigenvectors
D. The eigenvectors from CCI PCA are feature vectors that emerge from the sensory experience
E. The traditional batch PCA methods do not need to perform iterations
BMI 871 2013 7 © Do not distribute
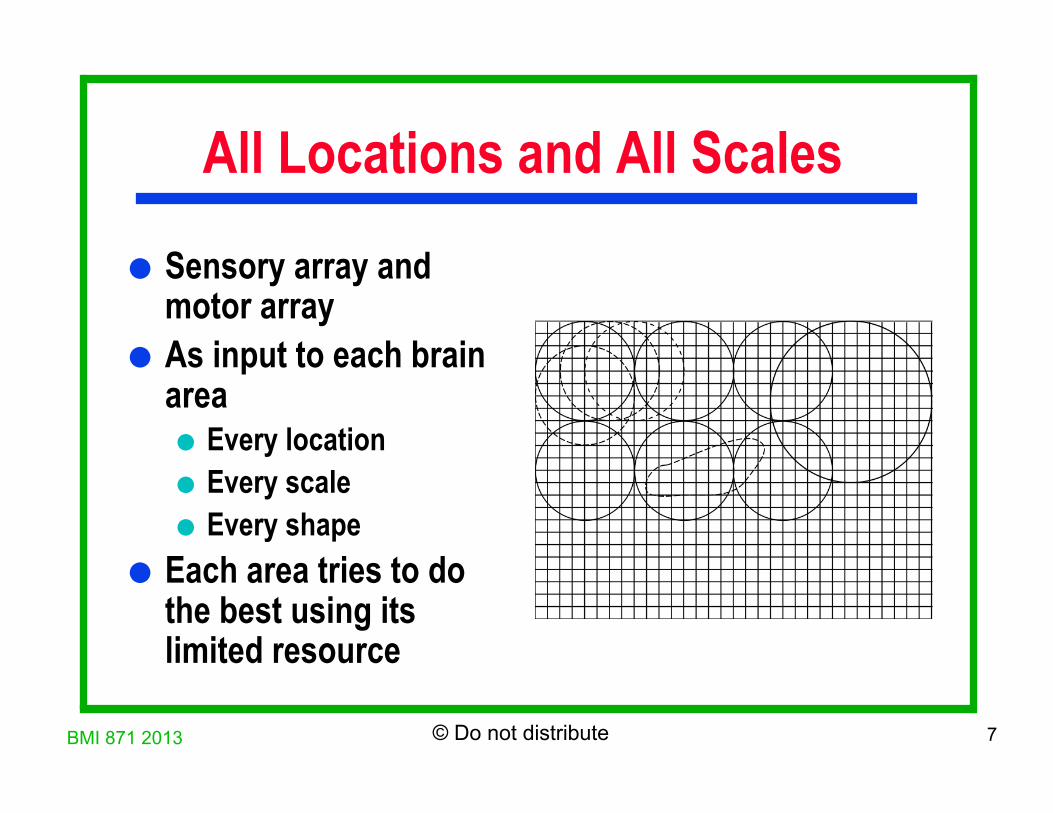
All Locations and All Scales
Sensory array and motor array
As input to each brain area Every location Every scale Every shape
Each area tries to do the best using its limited resource
BMI 871 2013 8 © Do not distribute
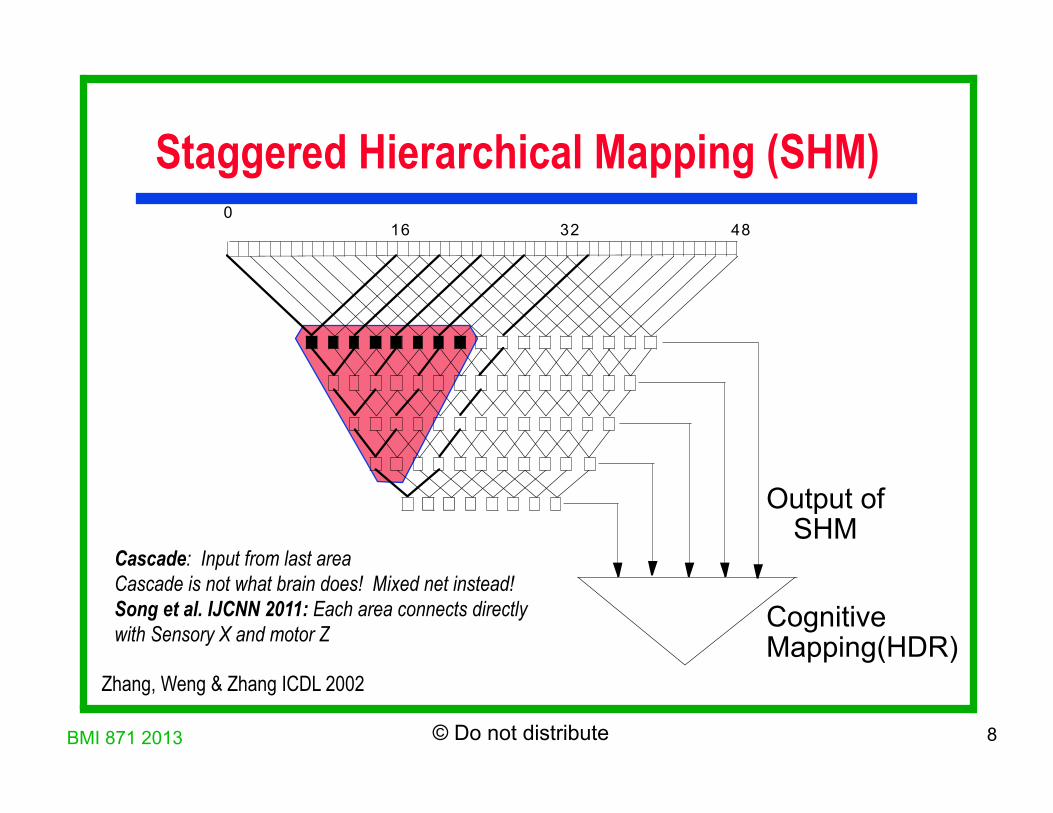
Staggered Hierarchical Mapping (SHM)
0
483216
Output ofSHM
CognitiveMapping(HDR)
Zhang, Weng & Zhang ICDL 2002
Cascade: Input from last area Cascade is not what brain does! Mixed net instead! Song et al. IJCNN 2011: Each area connects directly with Sensory X and motor Z

BMI 871 2013 9 © Do not distribute
PCA Net PCA Net:
Area 0: normalization: compute scatter vector Area 1: PCA Area 2: Nearest neighbor matching
Reconstruction Not neuromorphic: ordered PCA vectors
BMI 871 2013 10 © Do not distribute
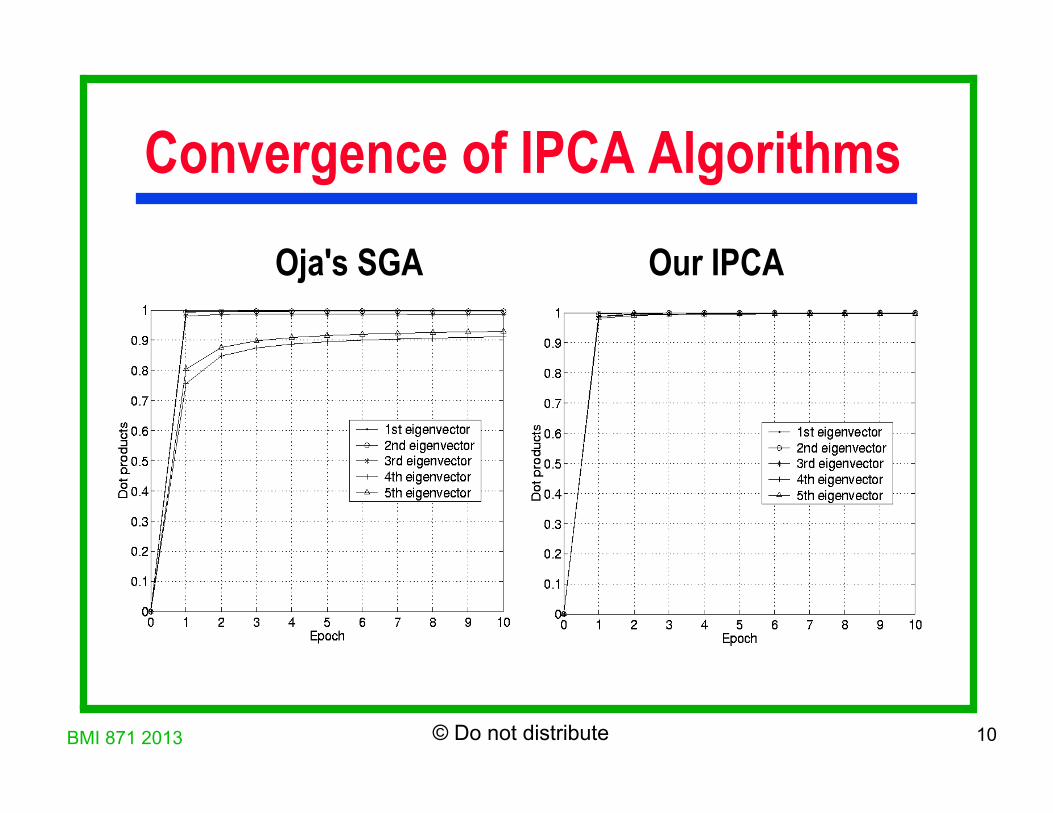
Convergence of IPCA Algorithms Oja's SGA Our IPCA
BMI 871 2013 11 © Do not distribute
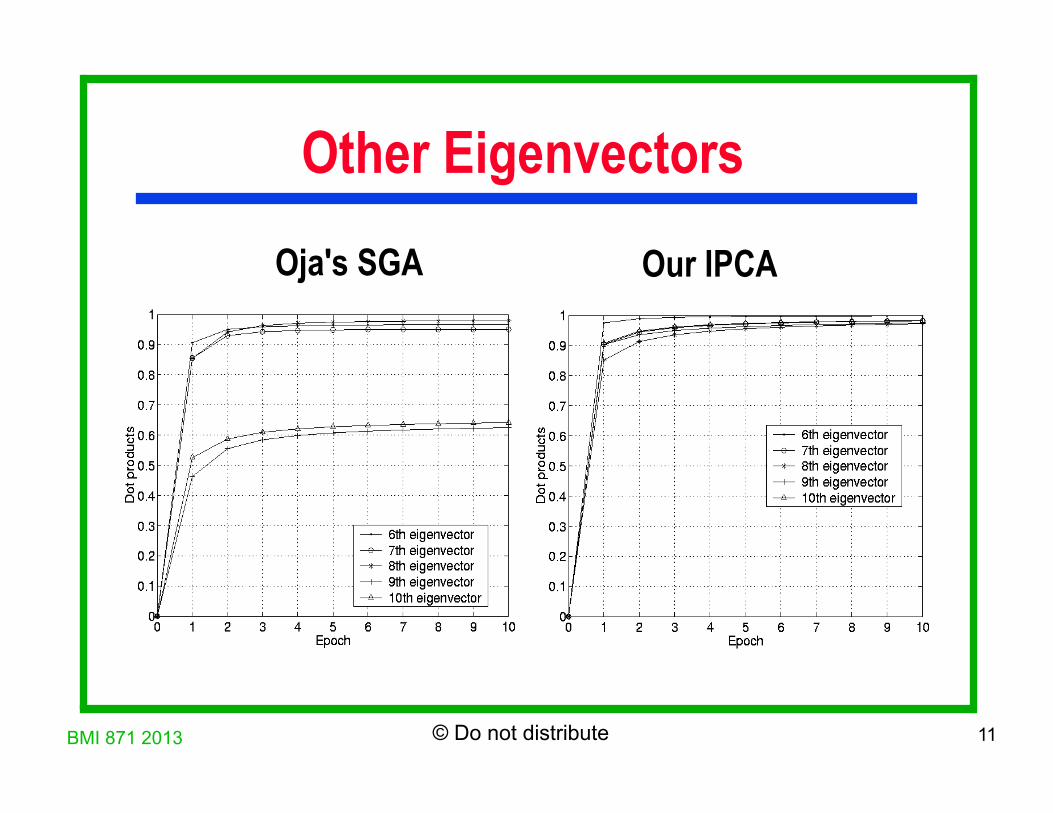
Other Eigenvectors Oja's SGA Our IPCA
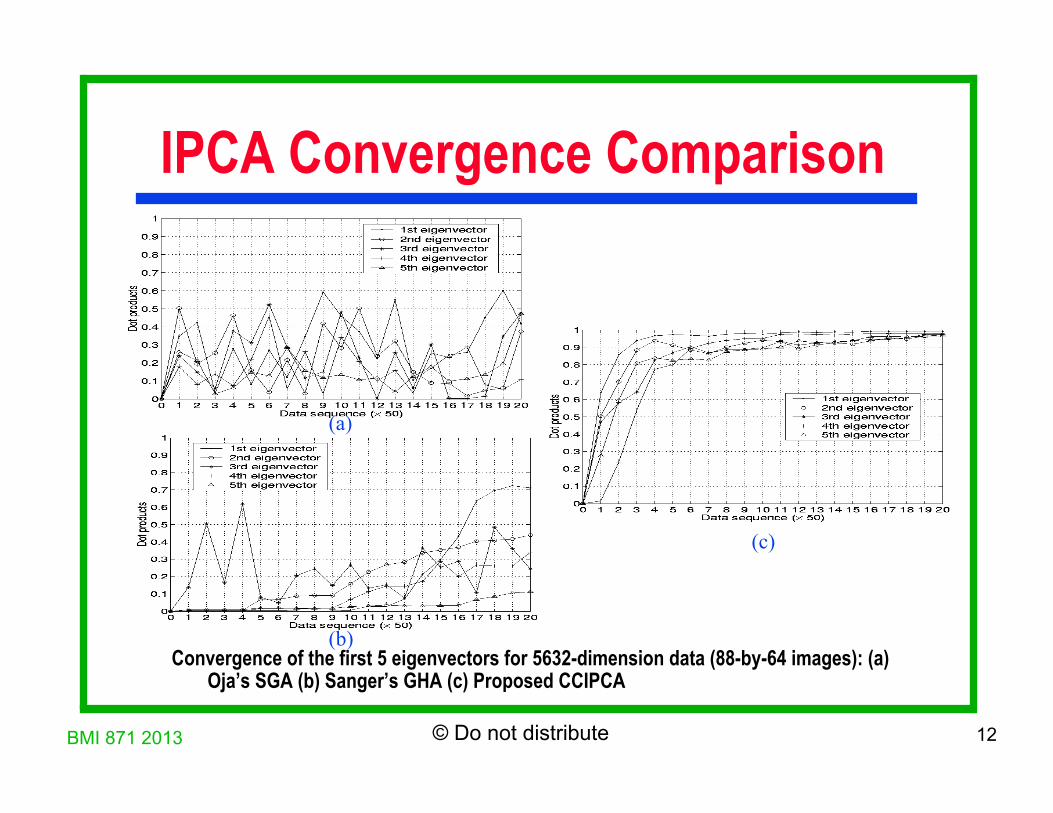
BMI 871 2013 12 © Do not distribute
IPCA Convergence Comparison
Convergence of the first 5 eigenvectors for 5632-dimension data (88-by-64 images): (a) Oja’s SGA (b) Sanger’s GHA (c) Proposed CCIPCA
(a)
(b)
(c)
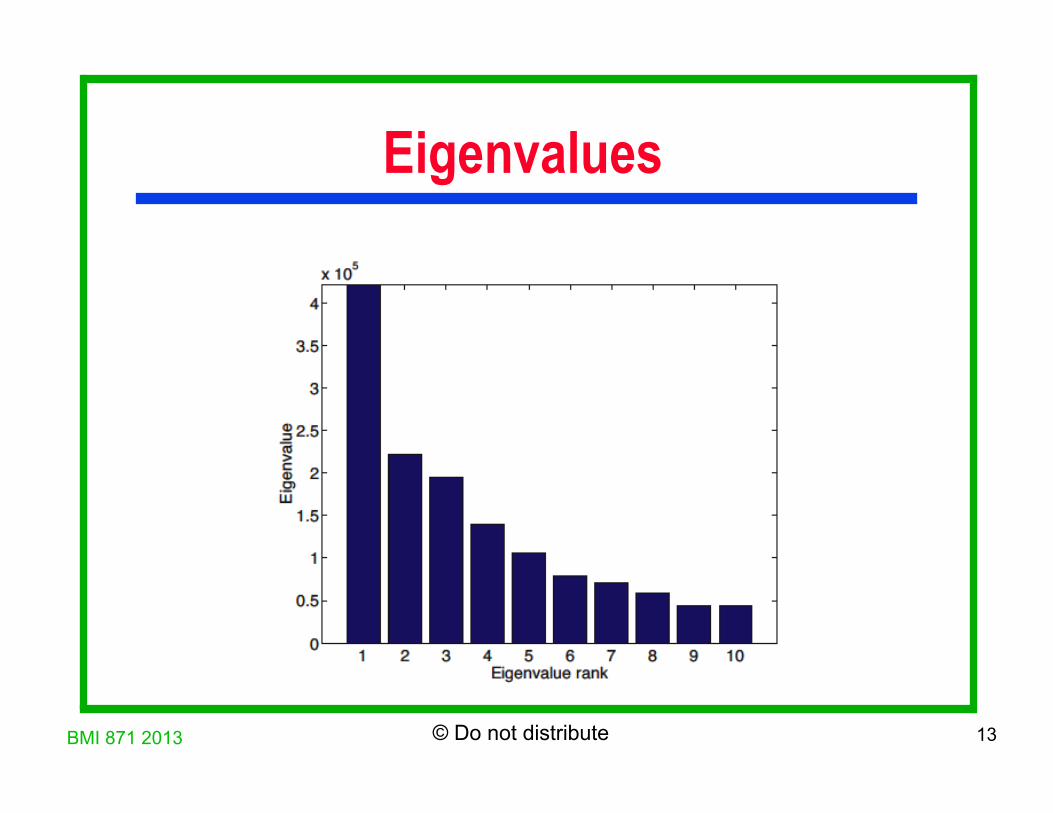
BMI 871 2013 13 © Do not distribute
Eigenvalues
BMI 871 2013 14 © Do not distribute
Questions?

BMI 871 2013 15 © Do not distribute
From CCI PCA to CCI LCA
LCA: Lobe Component Analysis Drop the orthogonality restriction Interaction between neurons:
lateral inhibition (biologically supported) Keep the CCI part
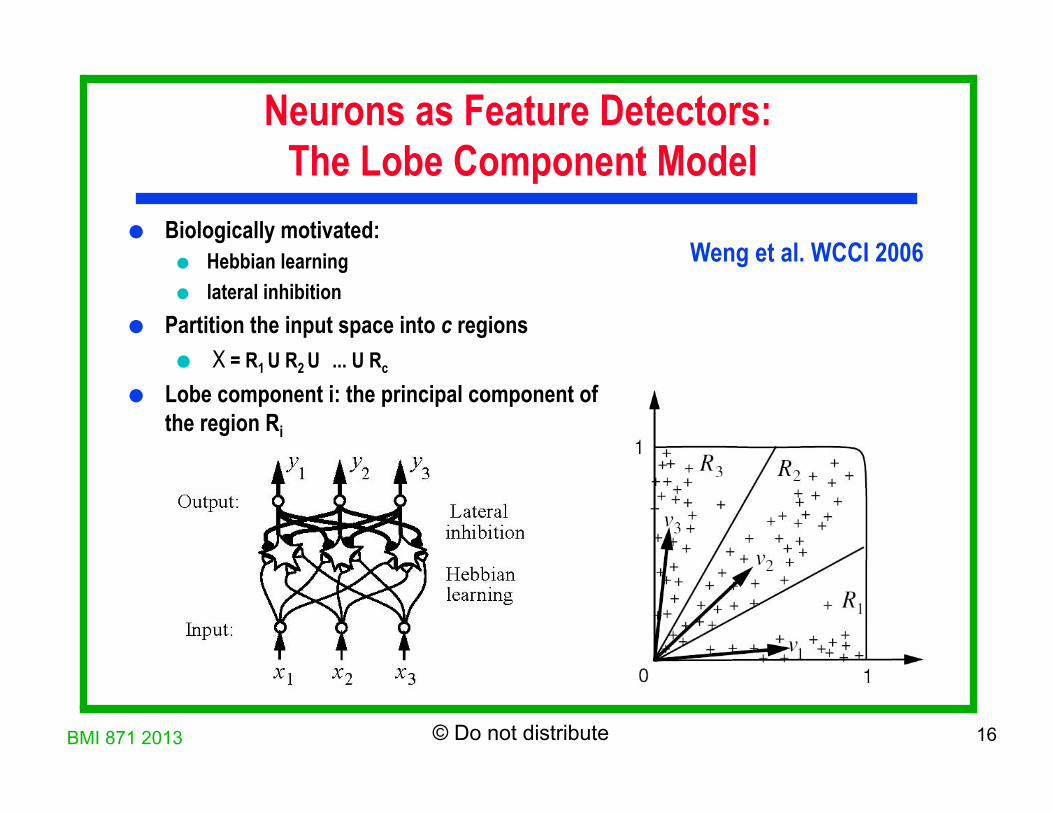
BMI 871 2013 16 © Do not distribute
Neurons as Feature Detectors: The Lobe Component Model
Biologically motivated: Hebbian learning lateral inhibition
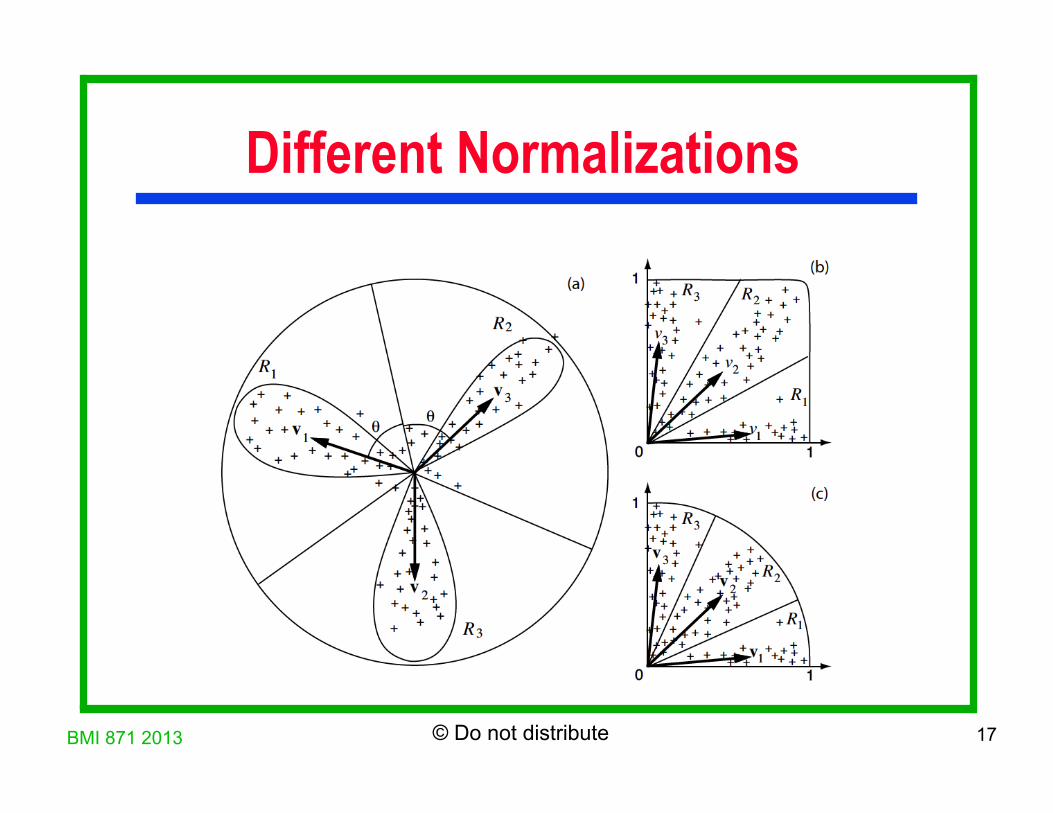
Partition the input space into c regions X = R1 U R2 U ... U Rc
Lobe component i: the principal component of the region Ri
Weng et al. WCCI 2006
BMI 871 2013 17 © Do not distribute
Different Normalizations

BMI 871 2013 18 © Do not distribute
Dual Optimality of CCI LCA Spatial optimality leads to the best target:
Given the number of neurons (limited resource), the target of the synaptic weight vectors minimizes the representation error based on “observation” x:
Temporal optimality leads to the best runner to the target: Given limited experience up to time t, find the best direction and step size for each t based on “observation” u = r x
Weng & Luciw TAMD vol. 1, no. 1, 2009

BMI 871 2013 19 © Do not distribute
CCI LCA Algorithm (1)

BMI 871 2013 20 © Do not distribute
CCI LCA Algorithm (2)
BMI 871 2013 21 © Do not distribute
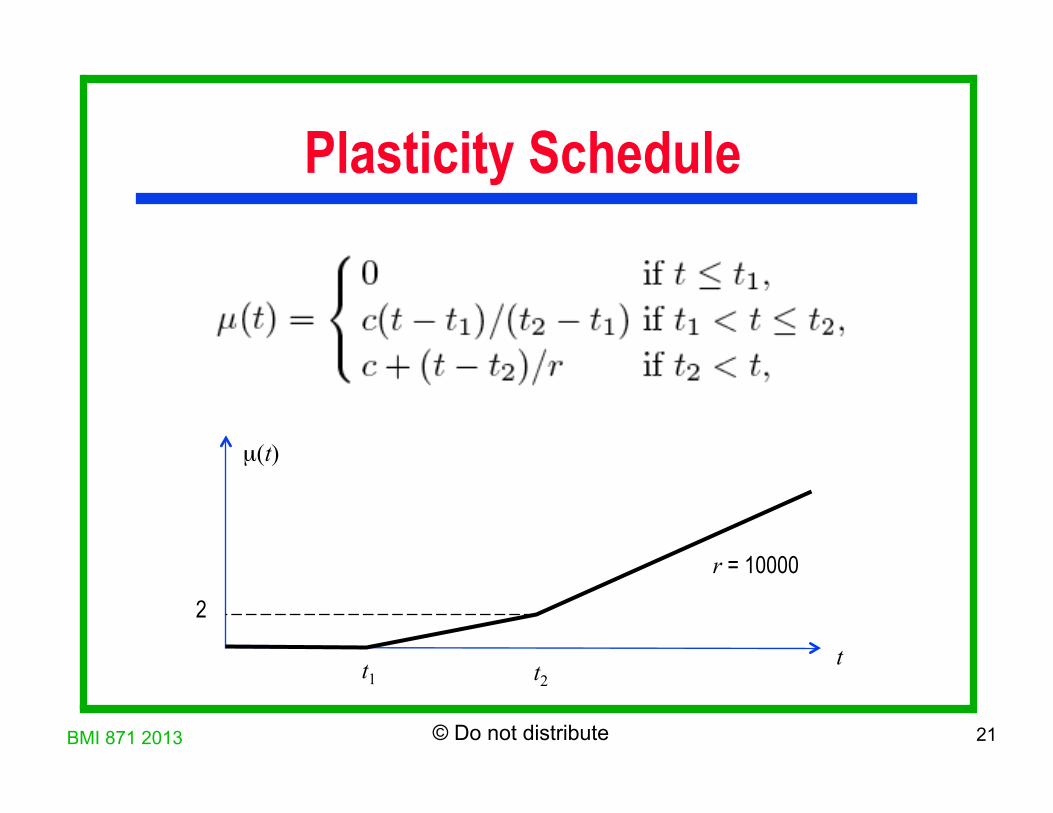
Plasticity Schedule
t1 t2 t
2
µ(t)
r = 10000
BMI 871 2013 22 © Do not distribute
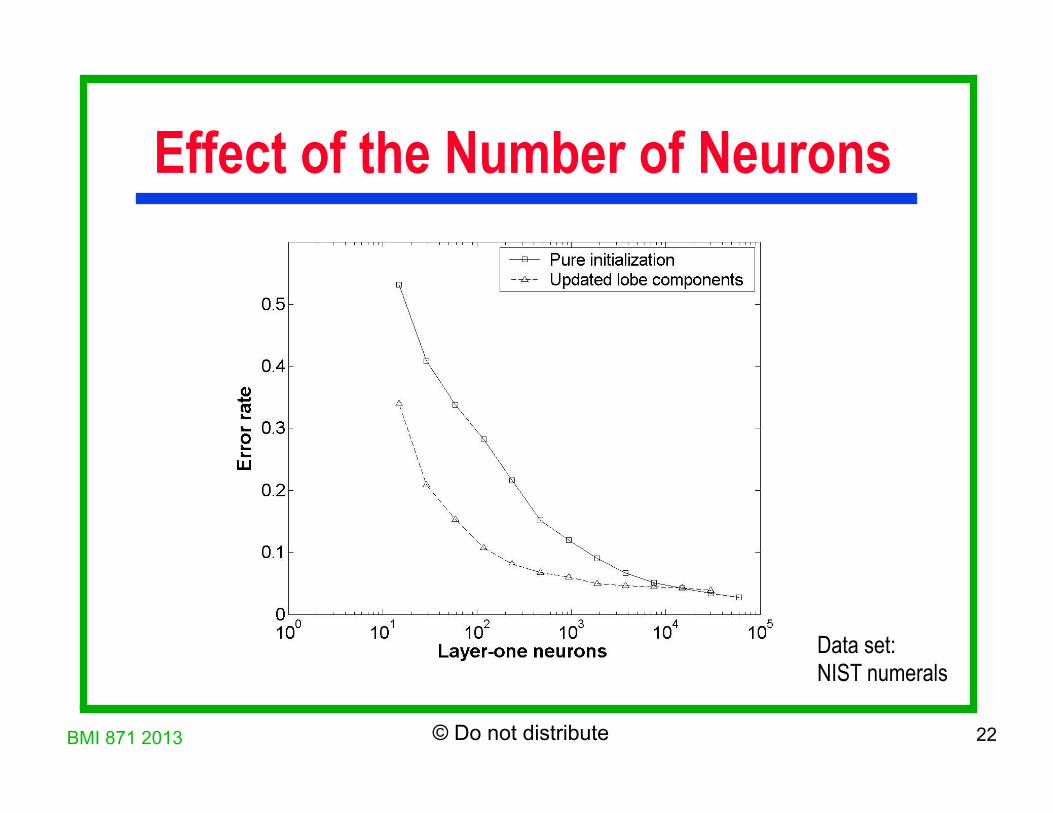
Effect of the Number of Neurons
Data set: NIST numerals

BMI 871 2013 23 © Do not distribute
Independent Component Analysis (ICA)
Formulation on chalk board: interactive

BMI 871 2013 24 © Do not distribute
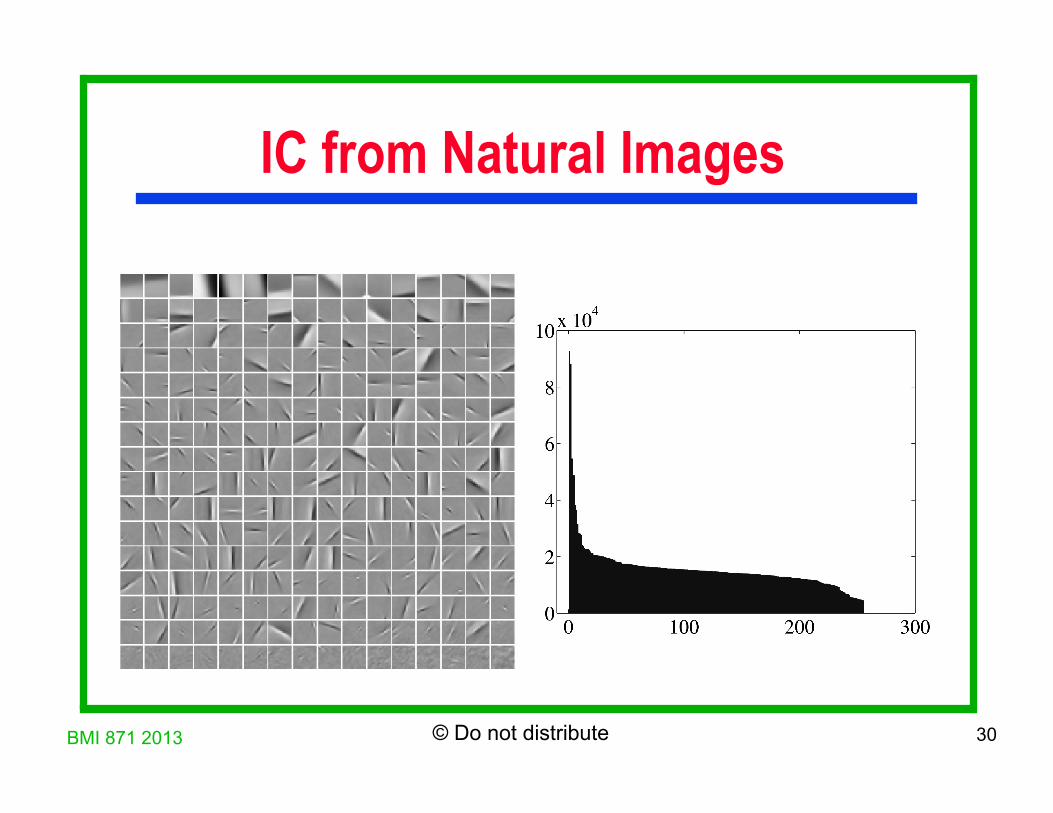
LCA is ICA for Super Gaussians
Super Gaussians: large concentration at mean (default firing level)
Natural images and cortical response are super Gaussians (Field 1994)
LCA is ICA for super Gaussians: provable from the nature of lobe components
BMI 871 2013 25 © Do not distribute
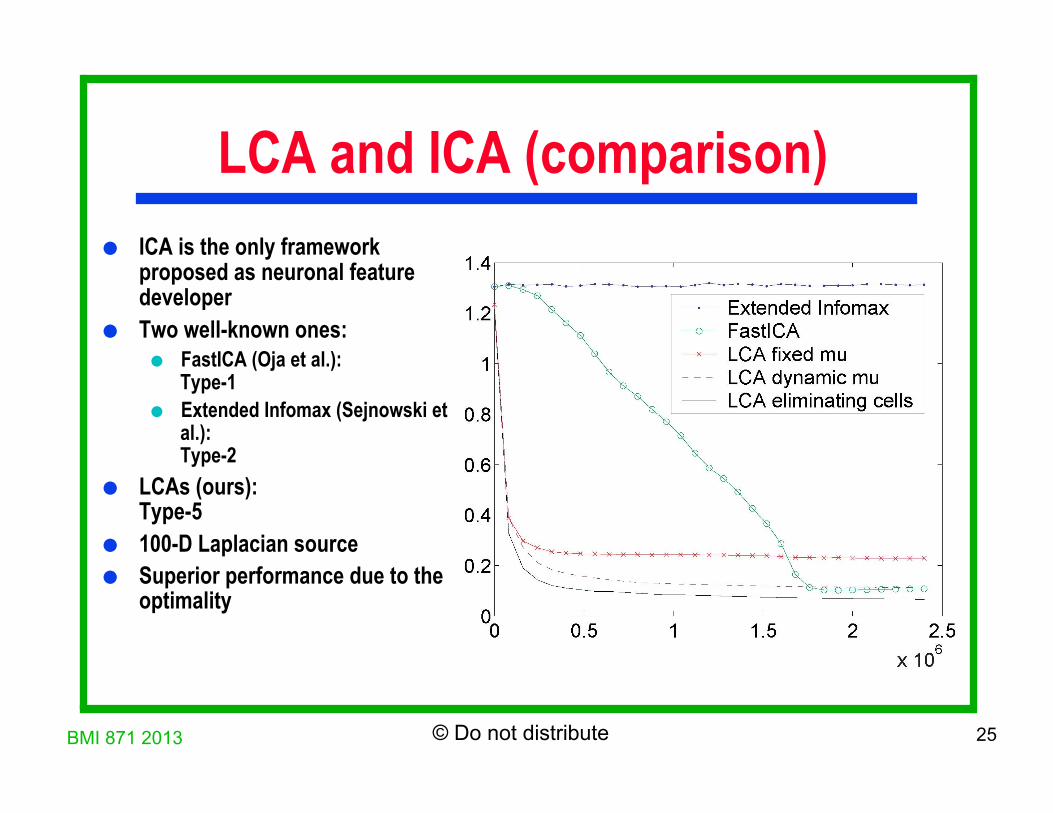
LCA and ICA (comparison) ICA is the only framework
proposed as neuronal feature developer
Two well-known ones: FastICA (Oja et al.):
Type-1 Extended Infomax (Sejnowski et
al.): Type-2
LCAs (ours): Type-5
100-D Laplacian source Superior performance due to the
optimality

BMI 871 2013 26 © Do not distribute
Quiz: LCA Quiz: What is NOT true with the CCI LCA
algorithm? A. It uses incremental learning algorithm B. It uses parallel competition to sort out
the top-k winners C. It uses the statistical efficiency
property so that it converges to the target quickly
D. It requires that lobe component vectors to be mutually orthogonal
E. It uses energy in the input in the sense that the retention rate and the learning rate always sum to 1

BMI 871 2013 27 © Do not distribute
Quiz: LCA Quiz: What is NOT true with the CCI LCA
algorithm? A. It uses incremental learning algorithm B. It uses parallel competition to sort out
the top-k winners C. It uses the statistical efficiency
property so that it converges to the target quickly
D. It requires that lobe component vectors to be mutually orthogonal
E. It uses energy in the input in the sense that the retention rate and the learning rate always sum to 1

BMI 871 2013 28 © Do not distribute
Natural Images
BMI 871 2013 29 © Do not distribute
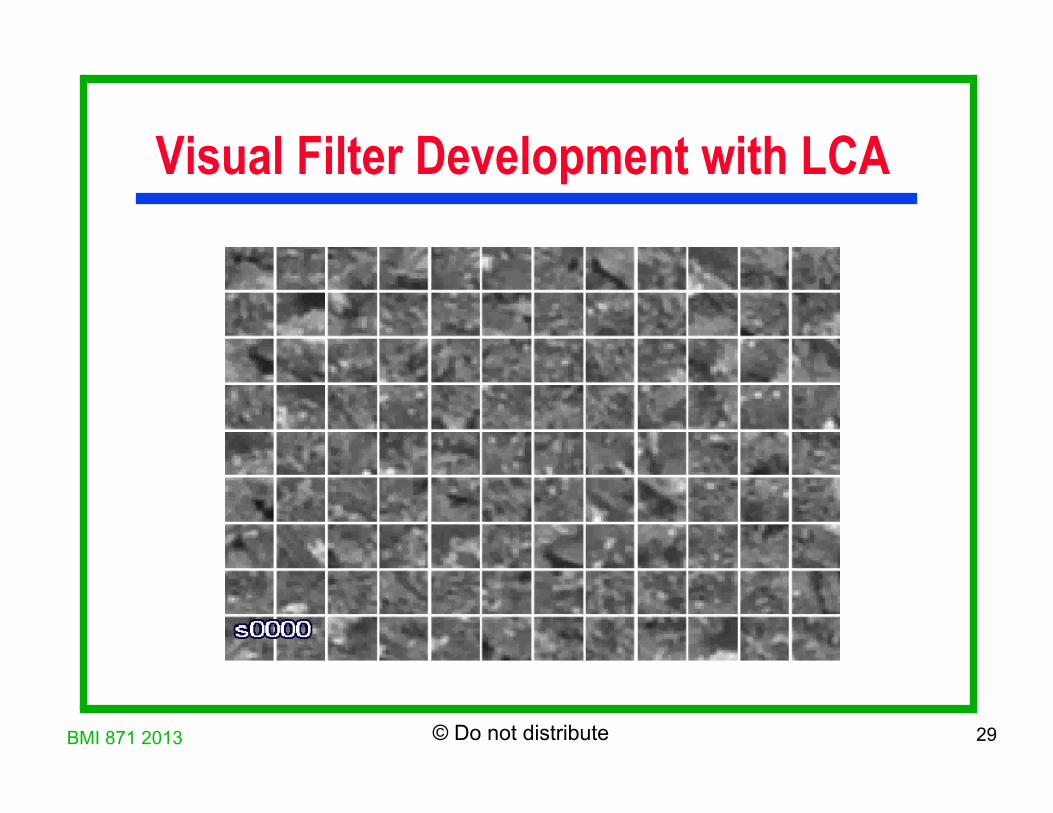
Visual Filter Development with LCA
BMI 871 2013 30 © Do not distribute
IC from Natural Images
BMI 871 2013 31 © Do not distribute
Questions?

BMI 871 2013 32 © Do not distribute
Ch 5 Properties of Representation

BMI 871 2013 33 © Do not distribute
Conventional Artif. Neural Networks Numeric representation Learning as a regression problem Feed forward network: state less Recurrent network: with state, but within hidden
area Supervised learning but few reinforcement learning Most algorithms have an incremental version System example: ALVINN by Dean Pomerleau

BMI 871 2013 34 © Do not distribute
Orientation-Invariant Feature Detectors?

BMI 871 2013 35 © Do not distribute
Not Really: You Missed Expression Details!
BMI 871 2013 36 © Do not distribute
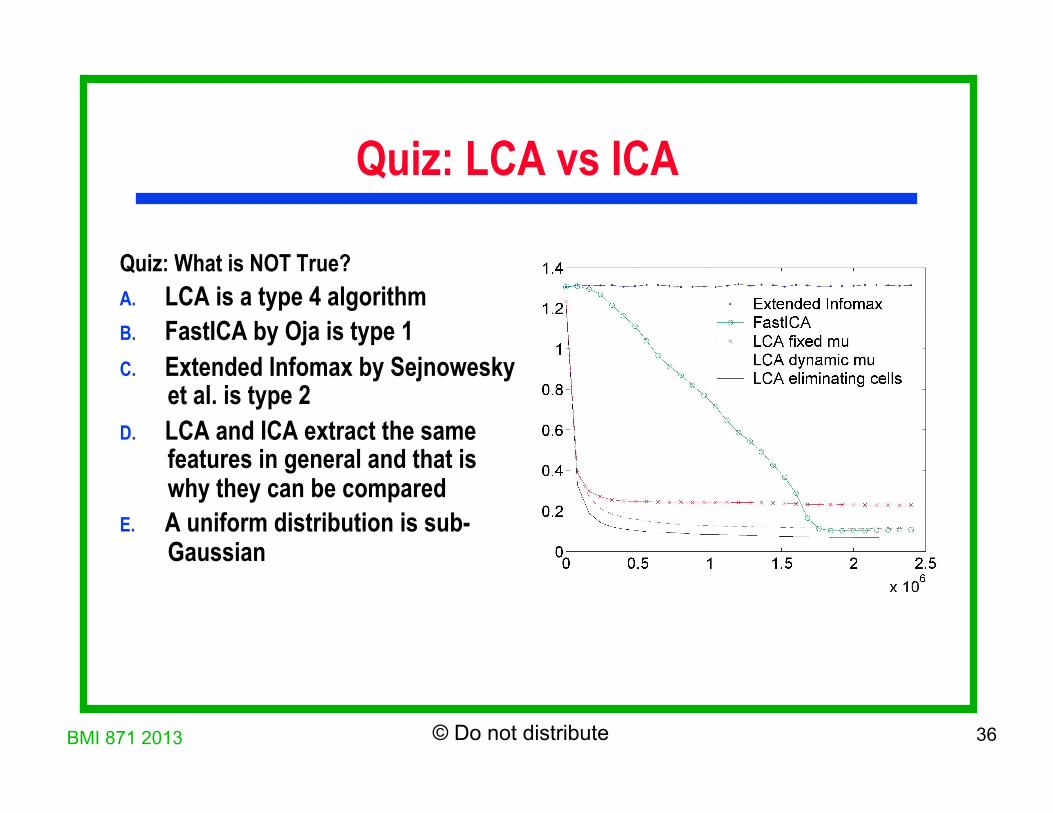
Quiz: LCA vs ICA Quiz: What is NOT True? A. LCA is a type 4 algorithm B. FastICA by Oja is type 1 C. Extended Infomax by Sejnowesky
et al. is type 2 D. LCA and ICA extract the same
features in general and that is why they can be compared
E. A uniform distribution is sub-Gaussian
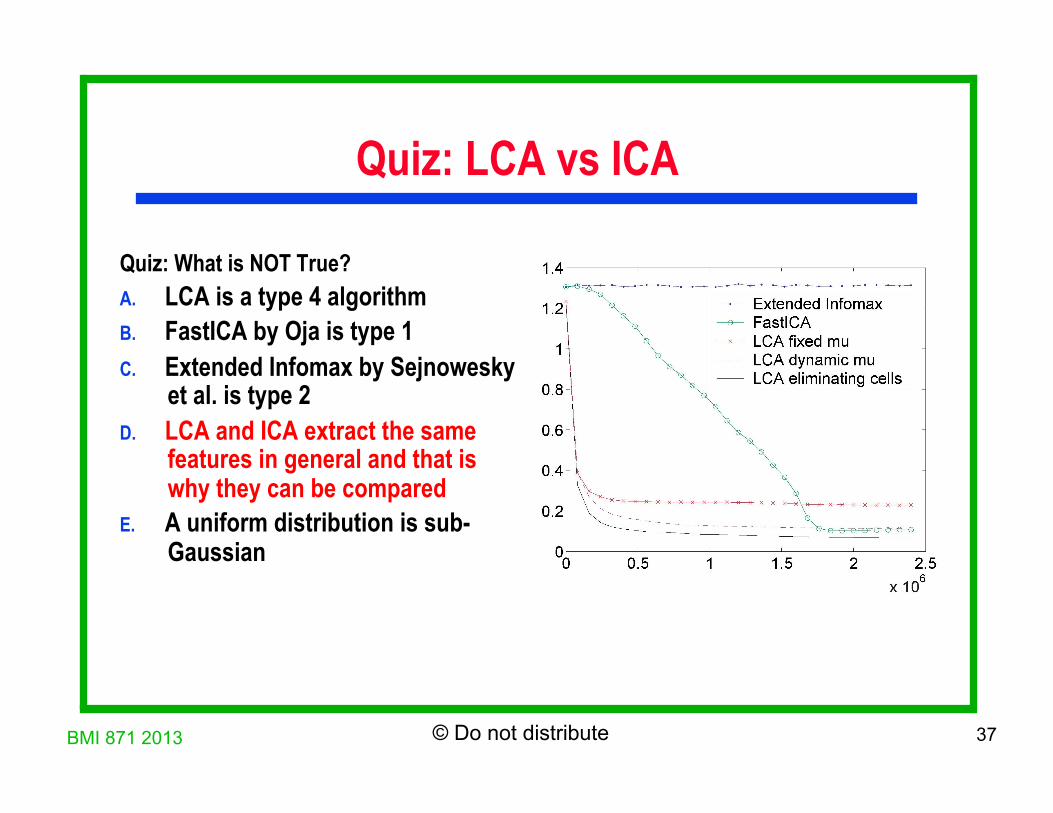
BMI 871 2013 37 © Do not distribute
Quiz: LCA vs ICA Quiz: What is NOT True? A. LCA is a type 4 algorithm B. FastICA by Oja is type 1 C. Extended Infomax by Sejnowesky
et al. is type 2 D. LCA and ICA extract the same
features in general and that is why they can be compared
E. A uniform distribution is sub-Gaussian

BMI 871 2013 38 © Do not distribute
Feature Extraction Methods Convolution Gabor Hopfield nets and Boltzmann machines ART Support Vector Machine (SVM) PCA Linear Discriminant Analysis (LDA) Independent Component Analysis (ICA) LCA
BMI 871 2013 39 © Do not distribute
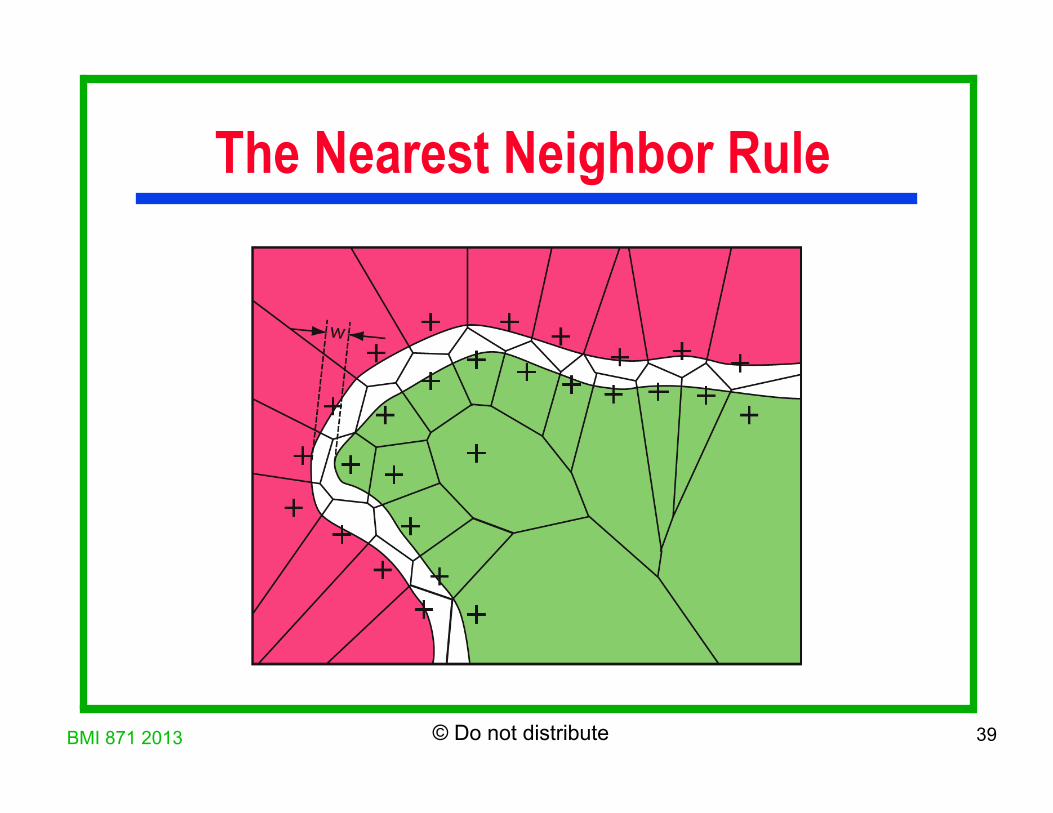
The Nearest Neighbor Rule

BMI 871 2013 40 © Do not distribute
LCA Net





























