Embed Size (px)
Citation preview


Wielowymiarowe metody segmentacjiWielowymiarowe metody segmentacjiCHAID ‐Metoda Automatycznej Detekcji Interakcji◦ CHAID ‐ Cele◦ CHAID – Dane◦ CHAID – Przebieg analizy◦ CHAID ‐ Parametry◦ CHAID ‐ Parametry◦ CHAID ‐WynikiMetody analizy skupień◦ Wprowadzenie◦ Charakterystyka obiektów◦ Metody grupowaniaMetody grupowania◦ Ocena poprawności grupowania

Segmentacja bez zmiennej wynikowej (grupowanie)Segmentacja bez zmiennej wynikowej (grupowanie)◦ Analiza skupień
Segmentacja ze zmienną wynikową (klasyfikacja)◦ Drzewa klasyfikacyjne (CHAID)Drzewa klasyfikacyjne (CHAID)◦ Analiza dyskryminacji◦ Regresja logistycznag j g y

Metoda ta pozwala wybrać z konkretnego, dużego zbioru zmiennych te z nich, które najsilniej wpływają na wskazaną zmienna (objaśniana) – zmienne porządkowane są według siłyzmienna (objaśniana) – zmienne porządkowane są według siły tego wpływu.
Pozwala też na dokładne wskazanie, które wartości zmiennychimplikują poszczególne wartości zmiennej zależnej.

Identyfikacja zmiennych najlepiej różnicujących wybrane zjawisko
St i ki i h l d ił i h łStworzenie rankingu zmiennych ze względu na siłę ich wpływu
Identyfikacja zestawów cech warunkujących występowanie danej wartości zmiennej zależnejdanej wartości zmiennej zależnej
Identyfikacja i opis segmentów respondentów

Zmienna Y
Lista predyktorów: X1,…, Xn

Próba losowa lub celowaWielkość próby musi odpowiadać ilości potencjalnych miennych objaśniających ( byt mała uniemożliwi dokonaniezmiennych objaśniających (zbyt mała uniemożliwi dokonanie wszystkich niezbędnych podziałów)Możliwe jest wykorzystanie zarówno zmiennych ciągłych jaki iMożliwe jest wykorzystanie zarówno zmiennych ciągłych, jaki i porządkowych czy nominalnychBraki danych mogą być traktowane jako odrębna kategoria lub y gą y j ę gbyć usunięte z analizy

Etapy analizy:Dla każdych dwu kategorii każdego predyktora liczony jest test Chi‐kwadrat (zmienne nominalne) lub test F (zmienne ciągłe) jakokwadrat (zmienne nominalne) lub test F (zmienne ciągłe) jako sprawdzian, czy różnicują one zmienna zależną.Jeśli tak nie jest, kategorie są ze sobą łączone – dzieje są tak aż do momentu wyczerpania możliwych kategorii dla danego predyktora.W przypadku zmiennych ciągłych tworzony jest początkowy podział na kategorie o zbliżonych liczebnościachna kategorie o zbliżonych liczebnościach

Dla każdego predyktora z uprzednio zdefiniowanymi kategoriami oblicza się wartość testu Chi‐kwadrat lub F ‐ dla tych wartości statystyk obliczane jest p‐valuestatystyk obliczane jest p valueWybierany jest predyktor z najmniejsza wartością p‐valueRespondenci dzieleni są według kategorii wybranej zmiennej ustalonych w pierwszym krokuW każdej z wyróżnionych podgrup cała procedura jest powtarzana ‐powstająw ten sposób kolejne podgrupypowstają w ten sposób kolejne podgrupy

Proces zatrzymuje się, gdy:◦ kolejnej wyróżnionej podgrupy nie da się już podzielić na różnicujące zmienną objaśnianą częścizmienną objaśnianą części
◦ liczebność podgrupy jest za mała dla przeprowadzenia testu niezależnościk l ł łb◦ kolejny podział doprowadziłby do powstania podgrupy o mniejszej niż zadana na początku liczebności
poprawka Bonferroniego – polecana ze względu na jednoczesnepoprawka Bonferroniego polecana ze względu na jednoczesne wykonywanie wielu testów (dotyczy to równie etapu łączenia kategorii).

k l ł b k ść d kmaksymalna głębokość drzewkamaksymalna liczba podziałówminimalna liczebność podgrupy która może zostać podzielonaminimalna liczebność podgrupy, która może zostać podzielonaminimalna liczebność podgrupy wynikowej podziałustosowanie poprawki Bonferroniegozezwolenie na dzielenie wcześniej połączonych kategoriikoszty błędnej klasyfikacji
l d dwalidacja drzewa

k k ś l f ść kl f kPodstawowym kryterium jakości analizy jest trafność klasyfikacji do poszczególnych kategorii zmiennej zależnej, jak i trafność klasyfikacji ogółem. g
Oblicza się je na podstawie tabeli krzyżowej rzeczywistych iprognozowanych wartości zmiennej zależnej.
Struktura podziałów prezentowana jest w formie drzewa któregoStruktura podziałów prezentowana jest w formie drzewa, którego korzeń to zmienna objaśniana, a kolejne rozgałęzienia obrazują kolejne podziały.

k ł b łNa każdej gałęzi widnieje nazwa zmiennej będącej podstawa podziału, oraz wartość statystyki Chi‐kwadrat (lub F), p‐value i liczba stopni swobody testu.yPo rozgałęzieniu zapisane są wartości danej zmiennej wyznaczające daną gałąź. Jeżeli kilka pierwotnych kategorii uległo połączeniu, na gałęzi zapisane są wszystkiegałęzi zapisane są wszystkie.Każdą podgrupę charakteryzują: liczba obserwacji, jaka do niej weszła i struktura zmiennej objaśnianej w danej podgrupie. Wyróżniona jest kategoria zmiennej objaśnianej o najwyższej frekwencji.

l ól h łó l lAnaliza poszczególnych podziałów pozwala na znalezienie iuporządkowanie zmiennych najsilniej różnicujących zmienną zależną.Struktura zmiennej objaśnianej w poszczególnych podgrupach pozwoliStruktura zmiennej objaśnianej w poszczególnych podgrupach pozwoli stwierdzić kierunek wpływu poszczególnych kategorii na zmienną zależną lub, jeśli ma ona charakter nominalny, współwystępowanie k ii i h i l ż h i i j l ż jkategorii zmiennych niezależnych i zmiennej zależnej.Ostatnie podgrupy (zwane liśćmi) w całym drzewie, lub powstające na skutek obcięcia drzewa na pewnym poziomie, można traktować jakoskutek obcięcia drzewa na pewnym poziomie, można traktować jako segmenty rynku.

CHAID
Zmienna Yspliting
Zmienna Xi(max zależność z Y)
merging
Zmienna X1 (max zależność z Y)
Zmienna X2 (max zależność z Y)


1,2
1,0
,8
,6
120
100
80
60
HOM12
,
,4
,2
0,0
‐,2 HOM32
40
20
0
‐20
HOM11
1,21,0,8,6,4,20,0
H ,2
HOM31
120100806040200‐20
H 20
,04
,03
,02
,01
6
5
4
02010 000102
HOM22
0,00
‐,01
‐,02
‐,03 6543210
V2
3
2
1
K
4,00
3,00
2,00
1,00
17
HOM21
,02,010,00‐,01‐,02
V1

ł ł h bnarzędzie służące do podziału heterogenicznego zbioru na homogeniczne segmenty
nie istnieją żadne warunki wstępne, na jakich musiałoby się opierać postępowanie segmentacyjne
postępowanie generuje hipotezy, a nie rozpatruje je.

k l hEksploracja danych◦ Kontrola danych◦ Poszukiwanie obiektów odstających◦ Wykrycie wewnętrznej struktury obiektów◦ Wykrywanie współzależności między zmiennymi
TypologiaTypologia◦ Weryfikacja istniejącej typologii◦ Propozycje klasyfikacji obiektów
R d k j d hRedukcja danych◦ Agregacja danych◦ Wybór reprezentantów grup

hHierarchiczne◦ tworzą drzewa binarne
Optymalizacyjno‐iteracyjnep y yj yj◦ poprawiają wstępny podział w kolejnych iteracjach na podstawie danej funkcji
kryterium
ObszaroweObszarowe◦ wykrywają obszary o dużej gęstości
Pozostałe◦ np. tworzą skupienia nierozłączne, niezupełne, rozmyte
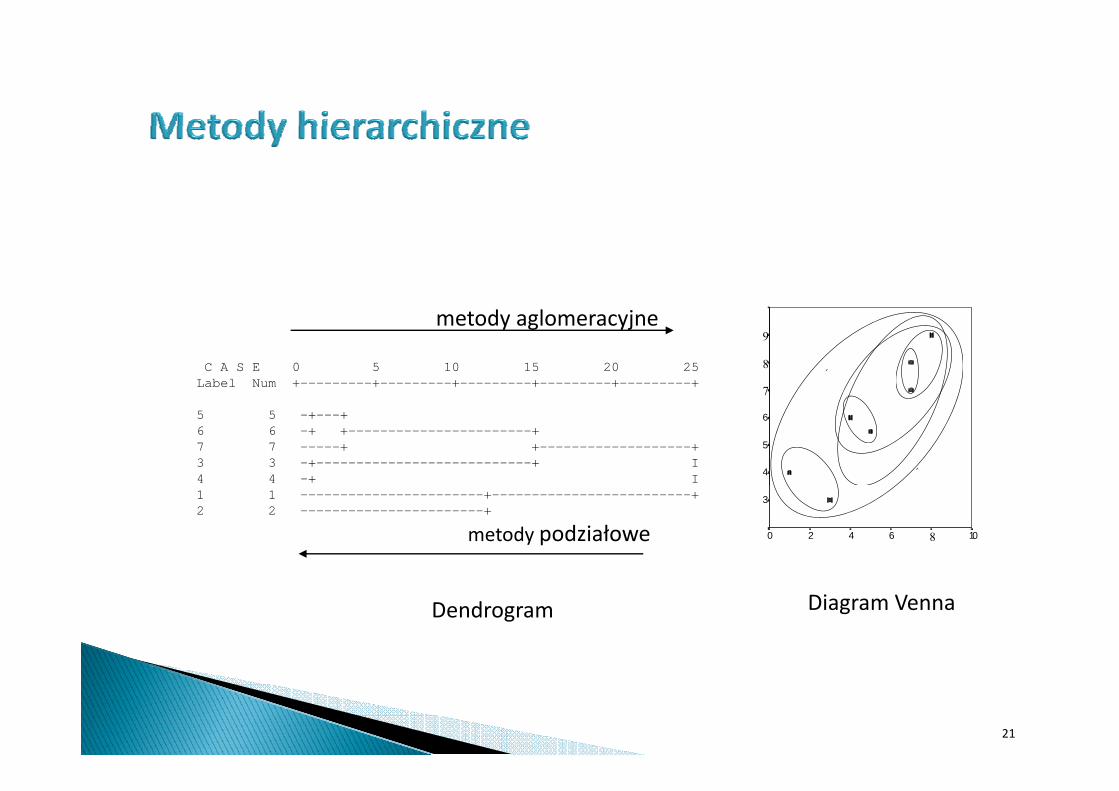
C A S E 0 5 10 15 20 25Label Num +---------+---------+---------+---------+---------+
metody aglomeracyjne9
8
7
5 5 -+---+6 6 -+ +-----------------------+7 7 -----+ +-------------------+3 3 -+---------------------------+ I4 4 -+ I
6
5
4
1 1 -----------------------+-------------------------+2 2 -----------------------+
metody podziałowe 1086420
3
Diagram VennaDendrogram
21

Technika hierarchicznej analizy skupień bierze się z metod mierzenia odległości między skupieniem jednoelementowym ( d b ) k k lk(pojedynczą obserwacją) a skupieniem zawierającym kilka obserwacji, lub między dwoma grupami wieloelementowymi.
22

1. Najbliższego sąsiedztwa (Single linkage, Nearest neighbor).
2. Najdalszego sąsiedztwa (Complete linkage, Furthest neighbor).
M di (M di l i )3. Mediany (Median clustering).
4. Środka ciężkości (Centroid clustering).
5 Średniej odległości wewnątrz skupień5. Średniej odległości wewnątrz skupień(Average linkage within groups).
6. Średniej odległości między skupieniami (A li k b )(Average linkage between groups).
7. Minimalnej wariancji Warda (Ward’s method).
23

metoda najbliższego sąsiedztwa metoda najdalszego sąsiedztwa metoda mediany
24metoda środka ciężkości metoda średniej grupowej metoda Warda

odległośćmiędzy dwoma klasterami to najmniejsza zodległość między dwoma klasterami to najmniejsza z odległości pomiędzy ich elementami; wadą metody jest tworzenie "łańcuchów", co w praktyce może prowadzić do uformowania grup dość heterogenicznych;pozwala na wykrycie obserwacji odstających, nie należącychpozwala na wykrycie obserwacji odstających, nie należących do żadnej z grup, i warto przeprowadzić klasyfikację za jej pomocą na samym początku, aby wyeliminować takie obserwacje i przejść bez nich do właściwej części analizyobserwacje i przejść bez nich do właściwej części analizy
25

dl ł ść d kodległość między utworzonym skupieniem a jednostką zewnętrzną to średnia arytmetyczna z dl ł ś d d k kodległości między jednostkami w skupieniu i
jednostką zewnętrzną
Odległość między dwoma skupieniami – średnia z odległości między jednostkami jednego i drugiego skupienia
26

Odległośćmiędzy utworzonym skupieniem aOdległość między utworzonym skupieniem a jednostką zewnętrzną to mediana odległości między jednostkami w skupieniu i jednostką zewnętrznąjednostkami w skupieniu i jednostką zewnętrzną
Odległość między dwoma skupieniami – mediana z dl ł ś i i d j d tk i j d i d iodległości między jednostkami jednego i drugiego
skupienia
27

W każdym kroku po utworzeniu skupienia i i dl ł ś iwyznacza się nową macierz odległości na
podstawie uśrednionych wartości cech( i h k i ji) h(stanowiących kryteria segmentacji) tych jednostek, które połączono w skupienia
Wartości średnie określa się mianem centroid
Natalia Nehrebecka 28

Kryterium grupowania jednostek: minimum zróżnicowania y g p jwartości cech, stanowiących kryteria segmentacji względem wartości średnich skupień tworzonych w kolejnych krokachGd i k j d kl t ó i jGdy powiększymy jeden z klasterów, wariancja wewnątrzgrupowa (liczona przez kwadraty odchyleń od średnich w klasterach) rośnie; metoda polega na takiej fuzji ) ; p g j jklasterów, która zapewnia najmniejszy przyrost tej wariancji dla danej iteracji
(empirycznie metoda daje bardzo dobre wyniki (grupy bardzo homogeniczne), jednak ma skłonność do tworzenia klasterów o podobnych rozmiarach;klasterów o podobnych rozmiarach;
nie jest też często w stanie zidentyfikować grup o szerokim zakresie zmienności poszczególnych cech oraz grup
29
zakresie zmienności poszczególnych cech oraz grup niewielkich
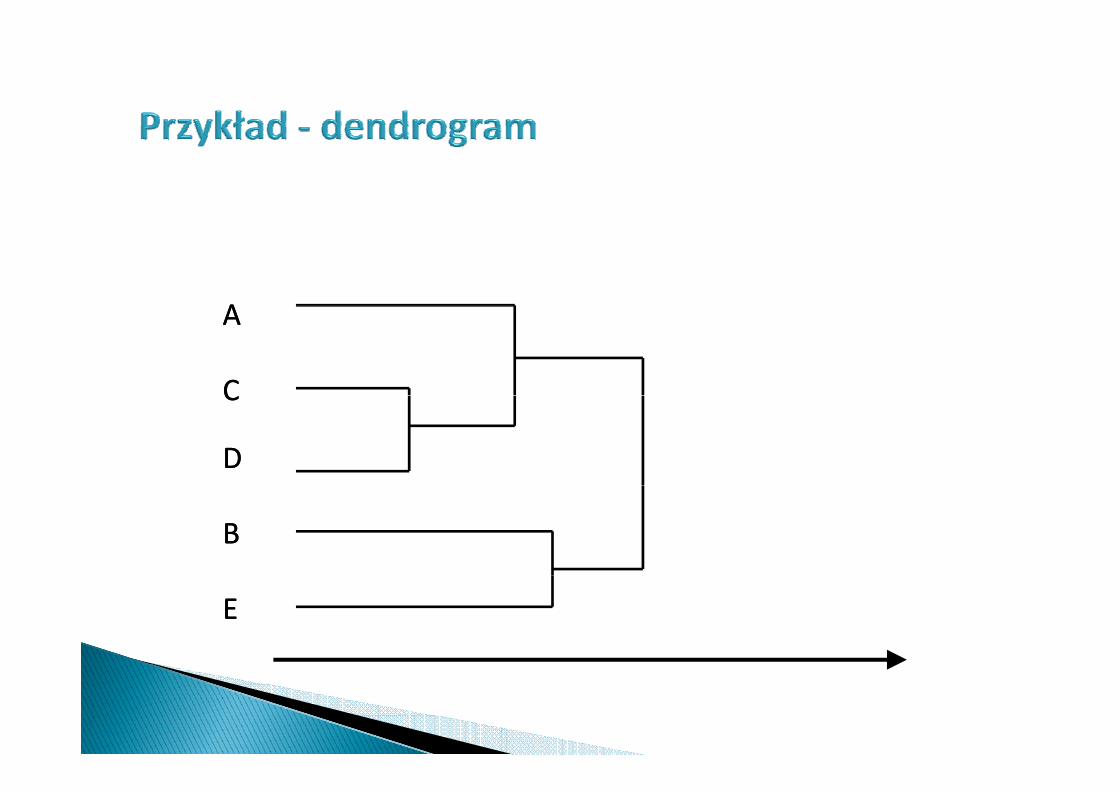
AA
CC
AA
DD
CC
BB
EE

Metod hierarchiczne nie określają liczby klasMetod hierarchiczne nie określają liczby klas.
Pozostaje więc problem, który podział jest
podziałem optymalnym.
Występuje kilka metod określających najlepszy y ęp j ją y j p ypodział.
Operują one najczęściej na poziomie połączeniaOperują one najczęściej na poziomie połączenia
klas i jego statystyk takich jak średnia i odchylenie standardowestandardowe.
Natalia Nehrebecka 31

dendrogram;dendrogram;
cubic clustering criterium Sarle’a;cubic clustering criterium Sarle a;
statystyka pseudo‐F;statystyka pseudo F;
test pseudo‐T2test pseudo T2
Natalia Nehrebecka 32

Cubic clustering criterion Sarla (CCC) testujenastępującą hipotezę:
H0 : dane pochodzą z rozkładu jednostajnego;H1 : dane pochodzą z mieszanych wielowymiarowychH1 : dane pochodzą z mieszanych wielowymiarowych rozkładów normalnych o równych wariancjach i prawdopodobieństwie wylosowania.
Dodatnie wartości CCC oznaczają, że uzyskana wartość R2 jest większa niż oczekiwana w przypadku rozkładu jednostajnego (wtedyoczekiwana w przypadku rozkładu jednostajnego (wtedyodrzucamy H0).
Natalia Nehrebecka 33

• Statystyka pseudo‐F statistic (lub PSF) mierzy rozdzielenie między grupami na bieżącym poziomie hierarchii;
• Wysokie wartości wskazują, że średnie wartości t h i h óż i i t t i i i d irozpatrywanych zmiennych różnią istotnie się między grupami;
• Nie ma rozkładu F Snedecora;Nie ma rozkładu F Snedecora;
Natalia Nehrebecka 34

• Statystyka pseudo‐T2 jest wariantem testu T2 Hotellinga.• jeśli wartość statystyki pseudo‐T2 jest duża, rozpatrywane w j y y p j , p ydanym kroku dwa skupienia nie powinny być połączone, ponieważ średnie wartości rozpatrywanych zmiennych różnią sięistotnie między nimi;• jeśli wartość statystyki jest mała, rozpatrywane w danym kroku dwa skupienia mogą być bezpiecznie połączonedwa skupienia mogą być bezpiecznie połączone.
Natalia Nehrebecka 35

Konieczne jest określenie a priori liczby segmentówKonieczne jest określenie a priori liczby segmentów
Dla ustalonej liczby segmentów dokonuje się rozdziałuDla ustalonej liczby segmentów dokonuje się rozdziału jednostek według wstępnie wybranych przedstawicieli każdego segmentug g
Zasada rozdziału: kryterium najmniejszej odległości względem wybranych przedstawicieli

1. Ustalamy liczbę grup (k)2 Wybieramy (w sposób losowy lub ustalony z góry) k punktów2. Wybieramy (w sposób losowy lub ustalony z góry) k punktów
przestrzeni, stanowiących tzw. zalążki środków ciężkości skupień(cluster seeds)K żd bi k ó (i 1 ) d i l d jbliż dl3. Każdy z obiektów (i=1,...,n) przydzielamy do grupy o najbliższym dlaniego środku ciężkości
4. Dla (j=1,...,k) obliczamy nowe środki ciężkości jako średnie(j ) y ę jarytmetyczne wszystkich obiektów należących do danej grupy
5. Powtarzamy kroki 3 i 4 aż do chwili, gdy nie następują przesunięciaobiektów między grupamiobiektów między grupami

Jednocześnie obliczana jest funkcja błędu podziału ‐ ogólna sumakwadratów odległości wewnątrzgrupowych liczonych od środkówi żk ś i tciężkości grup, tzn.
( )∑ ∑=k
ji MOdF 2,( )∑ ∑= ∈j SO
jiji1
,
gdzie d jest odległością euklidesową.gdzie d jest odległością euklidesową.

Mamy 8 elementów, które y ,chcemy podzielić na k=2 skupienia
Ustalamy zalążki środków ciężkości skupień, Arbitralnie (lub losowo) wybieramydwa elementy – punkty (1; 1) i (2; 1) Pozostałe elementy przyporządkowujemy
Iteracja 1
dwa elementy punkty (1; 1) i (2; 1). Pozostałe elementy przyporządkowujemydo najbliższych środków ciężkości skupień.

4
5
2
3
0
1
Iteracja 2
Skupienie 1 ma 3 elementy. Skupienie 2 ma 5 elementów. Wyznaczono środki
0 1 2 3 4 5 6Iteracja 2
Skupienie 1 ma 3 elementy. Skupienie 2 ma 5 elementów. Wyznaczono środkiciężkości skupień. Jeden obiekt leży bliżej środka ciężkości innego skupienia

3
4
5
1
2Iteracja 3
00 1 2 3 4 5 6
Obiekt przeszedł ze skupienia 2 do skupienia 1. Teraz oba skupienia mają po 4elementy. Wyznaczono nowe środki ciężkości skupień. Wszystkie punkty leżąnajbliżej środków ciężkości swoich skupień Algorytm kończy sięnajbliżej środków ciężkości swoich skupień. Algorytm kończy się



























