Embed Size (px)
DESCRIPTION
Parallel Applications for Multi-core Processors Ana L u cia Vârbănescu T U Delft / Vrije Universiteit Amsterdam. with acknowledgements to: The Multicore Solutions Group @ IBM TJ Wantson, NY, USA Alexander van Amesfoort @ TUD Rob van Nieuwpoort @ VU/ASTRON. Outline. One introduction - PowerPoint PPT Presentation
Citation preview

with acknowledgements to: The Multicore Solutions Group @ IBM TJ Wantson, NY, USA
Alexander van Amesfoort @ TUDRob van Nieuwpoort @ VU/ASTRON
Parallel Applications for Multi-core Processors
Ana Lucia Vârbănescu TUDelft / Vrije Universiteit Amsterdam

2/79.95
Outline
►One introduction►Cell/B.E. case-studies
Sweep3D, Marvel, CellSortRadioastronomyAn Empirical Performance Checklist
►Alternatives GP-MC, GPUs
►Views on parallel applications… and multiple conclusions

3/79.95
One introduction

4/79.95
The history: STI Cell/B.E.
► Sony: main processor for PS3
► Toshiba: signal processing and video streaming
► IBM: high performance computing

5/79.95
The architecture
► 1 x PPE 64-bit PowerPC L1: 32 KB I$+32 KB
D$ L2: 512 KB
► 8 x SPE cores: Local store: 256 KB 128 x 128 bit vector
registers ► Hybrid memory
model: PPE: Rd/Wr SPEs: Async DMA

6/79.95
The Programming
►Thread-based model, with push/pull data flowThread scheduling by userMemory transfers are explicit
►Five layers of parallelism to be exploited: Task parallelism (MPMD) Data parallelism (SPMD)Data streaming parallelism (DMA double buffering) Vector parallelism (SIMD – up to 16-ways)Pipeline parallelism (dual-pipelined SPEs)

7/79.95
Sweep3D application
►Part of the ASCI benchmark►Solves a three-dimensional particle transport
problem►It is a 3D wavefront computation
IPDPS 2007: Fabrizio Petrini, Gordon Fossum, Juan Fernández, Ana Lucia Varbanescu, Michael Kistler, Michael Perrone: Multicore Surprises: Lessons Learned from Optimizing Sweep3D on the Cell Broadband Engine

8/79.95
Sweep3D computationSUBROUTINE sweep()
DO iq=1,8 ! Octant loop DO m=1,6/mmi ! Angle pipelining loop DO k=1,kt/mk! K-plane loop
RECV W/E ! Receive W/E I-inflows RECV N/S ! Receive N/S J-inflows
! JK-diagonals with MMI pipelining DO jkm=1,jt+mk-1+mmi-1! I-lines on this diagonal DO il=1,ndiag! Solve Sn equation IF .NOT. do_fixups DO i=1,it ENDDO! Solve Sn equation with fixups ELSE DO i=1,it ENDDO ENDIF
ENDDO ! I-lines on this diagonal ENDDO ! JK-diagonals with MMI
SEND W/E ! Send W/E I-outflows SEND N/S ! Send N/S J-outflows
ENDDO ! K-plane pipelining loop
ENDDO ! Angle pipelining loop
ENDDO ! Octant loop

9/79.95
Application parallelization► Process Level Parallelism
inherits wavefront parallelism implemented in MPI► Thread-level parallelism
Assign “chunks” of I-lines to SPEs ► Data streaming parallelism
Thread use double buffering, for both RD and WR► Vector parallelism
SIMD-ize the loops• E.g., 2-ways for double precision, 4-ways for single
precision► Pipeline parallelism
SPE dual-pipeline => multiple logical threads of vectorization

10/79.95
Experiments
►Run on SDK2.0, Q20 (prototype) blade2 Cell processors, 16 SPEs available 3.2GHz, 1GB RAM

11/79.95
Optimization techniques

12/79.95
Performance comparison

13/79.95
Sweep3D lessons:
►Essential SPE-level optimizations:Low-level parallelization
• Communication• SIMD-ization• Dual-pipelines
Address alignment DMA grouping
►Aggressive low-level optimizations = Algorithm tuning!!

14/79.95
Generic CellSort
► Based on bitonic merge/sort works on 2K array elements
► Sorts 8-byte patterns from an input string, ► Keeps track of the original position

15/79.95
►Memory limitations: SPE LS=256KB => 128KB data (16K-Keys) + 64KB indexes
Avoid branches (sorting is about if’s … ) SIMD-ization with (2Keys x 8B) per 16B vector
Data “compression”
KEYS
INDEXES
KEY
X X
INDEX
is replaced by

16/79.95
Re-implementing the if’s ► if (A>B)
Can be replaced with 6 SIMD instructions for comparing
inline int sKeyCompareGT16(SORT_TYPE A, SORT_TYPE B) { VECTORFORMS temp1, temp2, temp3, temp4; temp1.vui = spu_cmpeq( A.vect.vui, B.vect.vui ); temp2.vui = spu_cmpgt( A.vect.vui, B.vect.vui); temp3.vui = spu_slqwbyte( temp2.vui, 4); temp4.vui = spu_and(temp3.vui, temp1.vui); temp4.vui = spu_or(spu_or(temp4.vui, temp2.vui), temp1.vui);
return (spu_extract(spu_gather(temp4.vui),0) >= 8);}

17/79.95
The good results► input data: 256KB string► running on:
One PPE on Cell blade, The PPEon a PS3 PPE+16xSPEs on the same a Cell blade
► 16 SPEs => speed-up ~46
Sorting speed-up using 16SPEs for 256KB data
0.70 1.00
45.88
0.00
10.00
20.00
30.00
40.00
50.00
PPE @ Q20 PPE @ PS3 16 SPEs

18/79.95
The bad results
► Non-standard key types A lot of effort for implementing basic operations efficiently
► SPE-to-SPE communication wastes memory A larger local SPE sort was more efficient
► The limitation of 2k elements is killing performance Another basic algorithm may be required
► Cache-troubles PPE cache is “polluted” by SPEs accesses Flushing is not trivial

19/79.95
Lessons from CellSort
►Some algorithms do not fit the Cell/B.E.It pays off to look for different solutions at the
higher level (i.e., different algorithm)Hard to know in advance
►SPE-to-SPE communication may be expensive Not only time-wise, but memory-wise too!
►SPE memory is *very* limited Double buffering wastes memory too!
►Cell does show cache-effects

20/79.95
Multimedia Analysis & RetrievalMARVEL:► Machine tagging, searching and filtering of images &
video► Novel Approach:
Semantic models by analyzing visual, audio & speech modalities
Automatic classification of scenes, objects, events, people, sites, etc.
► http://www.research.ibm.com/marvel

21/79.95
MARVEL case-study
►Multimedia content retrieval and analysis
Extracts the values for 4 features of interest:
ColorHistogram, ColorCorrelogram,Texture, EdgeHistogram
Compares the image features with the model features and generates an overall confidence score

22/79.95
MarCell = MARVEL on Cell
►Identified 5 kernels to port on the SPEs:4 feature extraction algorithms
• ColorHistogram (CHExtract)• ColorCorrelogram(CCExtract)• Texture (TXExtract)• EdgeHistogram (EHExtract)
1 common concept detection, repeated for each feature
CH
CC
EH
TX
CD

23/79.95
MarCell – Porting
1
2
3
4
Detect & isolate kernels to be ported
Replace kernels with C++ stubs
Implement the data transfers and move kernels on SPEs
Iteratively optimize SPE code
ICPP 2007: A.L. Varbanescu, H.J. Sips, K.A. Ross, Q. Liu, A. Natsev, J.R. Smith, L.-K. Liu, An Effective Strategy for Porting C++ Applications on Cell.

24/79.95
Experiments
►Run on a PlayStation3 1Cell processor, 6 SPEs available 3.2GHz, 256MB RAM
►Double-checked with a Cell blade Q202 Cell processors, 16 SPEs available 3.2GHz, 1GB RAM
►SDK2.1

25/79.95
MarCell – kernels speed-up
Kernel SPE[ms]Speed-up vs. PPE
Speed-up vs.Desktop
Speed-up vs. Laptop
Overall contribution
AppStart 7.17 0.95 0.67 0.83 8 %
CHExtract 0.82 52.22 21.00 30.17 8 %
CCExtract 5.87 55.44 21.26 22.45 54 %
TXExtract 2.01 15.56 7.08 8.04 6 %
EHExtract 2.48 91.05 18.79 30.85 28 %
CDetect 0.41 7.15 3.75 4.88 2 %

26/79.95
Task parallelism – setup

27/79.95
Task parallelism – on Cell blade

28/79.95
Data parallelism – setup
►All SPEs execute the same kernel => SPMD
►Requires SPE reconfiguration:Thread re-creation Overlays
►Kernels scale, overall application doesn’t !!

29/79.95
Combined parallelism – setup
►Different kernels span over multiple SPEs►Load balancing
►CC and TX ideal candidates ►But we verify all
possible solutions

30/79.95
Combined parallelism - Cell blade [1/2]
Execution times for all possible scenarios using 16 SPEs
0.0075
0.0095
0.0115
0.0135
0.0155
0.0175
0.0195
0.0215
0.0235
Exe
cutio
n tim
e
4 9 10 11 12 13 14 15 16
CCPE 2008: A.L. Varbanescu, H.J. Sips, K.A. Ross, Q. Liu, A. Natsev, J.R. Smith, L.-K. Liu, Evaluating Application Mapping Scenarios on the Cell/B.E.

31/79.95
Best performance per number of used SPEs
0.008
0.009
0.01
0.011
0.012
0.013
1-1-1-1 1-2-1-1 1-3-1-1 2-3-1-1 2-3-2-1 1-4-2-2 2-4-2-2 2-4-3-2 3-5-2-2 4-4-3-2 3-4-3-4 2-6-3-4 3-5-3-5
SPEs/task (CH-CC-TX-EH)
Exe
cuti
on
tim
e
Tmin = 8.54 ms
Combined parallelism - Cell blade [2/2]

32/79.95
MarCell lessons:
►Mapping and scheduling:High-level parallelization
• Essential for “seeing” the influence of kernel optimizations
• Platform-oriented MPI-inheritance may not be good enough
Context switches are expensive Static scheduling can be replaced with dynamic
(PPE-based) scheduling

33/79.95
Radioastronomy
► Very large radiotelescopes LOFAR, ASKAP, SKA, etc.
► Radioastronomy features Very large data sets Off-line (files) and On-line processing (streaming) Simple computation kernels Time constraints
• Due to streaming• Due to storage capability
► Radioastronomy data processing is ongoing research Multi-core processors are a challenging solution

34/79.95
Getting the sky image
► The signal path from the antenna to the sky image We focus on imaging

35/79.95
Data imaging
► Two phases for building a sky image Imaging: gets measured visibilities and creates dirty image Deconvolution “cleans” the dirty image into a sky model.
► The more iterations, the better the model But more iterations = more measured visibilities
36/79.95
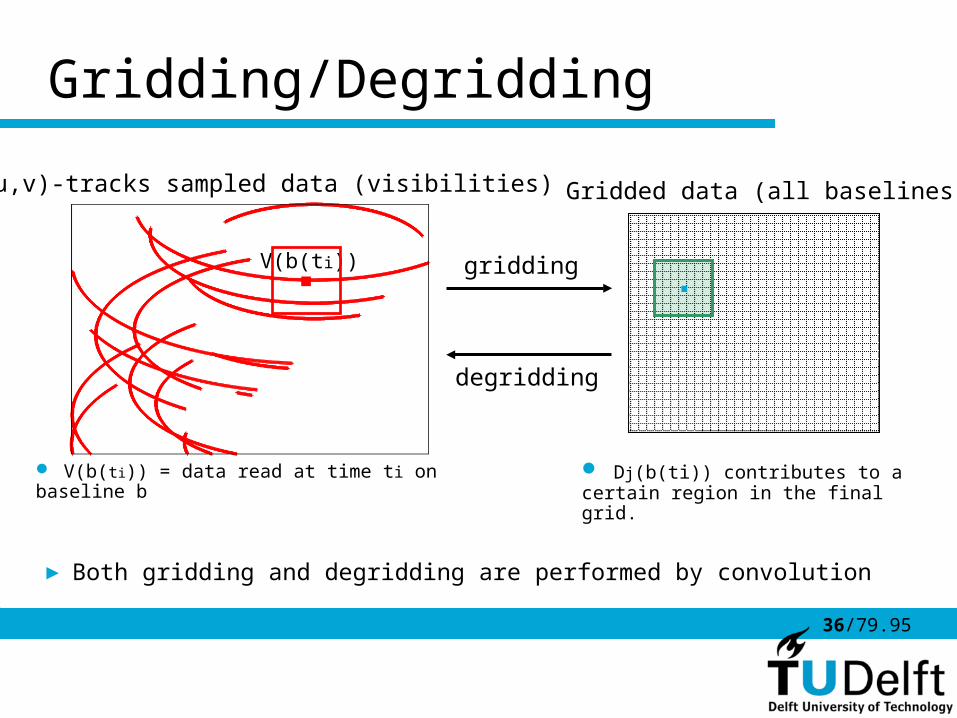
Gridding/Degridding
gridding
degridding
(u,v)-tracks sampled data (visibilities) Gridded data (all baselines)
V(b(ti))
V(b(ti)) = data read at time ti on baseline b Dj(b(ti)) contributes to a certain region in the final grid.
► Both gridding and degridding are performed by convolution

37/79.95
The code
forall (j =0..Nfreq;i=0..Nsamples−1) // for all samples
//the kernel position in C
compute cindex=C_Offset((u,v,w)[i],freq[j]);
//the grid region to fill
compute gindex=G_Offset((u,v,w)[i],freq[j]);
//for all points in the chosen region
for(x=0;x<M;x++) // sweep the convolution kernel
if (gridding) G[gindex+x]+=C[cindex+x]V[i,j]; if (degridding) V’[i,j]+=G[gindex+x]C[cindex+x];
► All operations are performed with complex numbers !

38/79.95
The computation
► Computation/iteration:M * (4ADD + 4MUL) = 8 * M
► Memory transfers/iteration: RD: 2* M * 8B ; WR: M * 8B
► Arithmetic intensity [FLOPs/byte]: 1/3 => memory intensive app!► Two consecutive data points “hit” different regions in C/G =>
dynamic!
Read (u,v,w)(t,b)V(t,b,f)
ComputeC_ind,G_ind
Read SC[k], SG[k]
ComputeSG[k]+D x SC[k]
WriteSG[k] to G
k = 1.. m x m
Samples x baselines x frequency_channels
HDD Memory

39/79.95
The data
► Memory footprint: C: 4MB ~ 100MB V: 3.5GB for 990 baselines x 1 sample/s x 16 fr.channels G: 4MB
► For each data point: Convolution kernel: from 15 x 15 up to 129 x 129

40/79.95
Data distribution
►“Round-robin”
►“Chunks”
►Queues
123456789101112
987654321 121110
63
12987
112
541

41/79.95
Parallelization
Read (u,v,w)(t,b)V(t,b,f)
ComputeC_ind,G_ind
Rd SC[k], SG[k]
ComputeSG[k]+D x SC[k]
Wr SG[k] to localG
k = 1.. m x m
Samples x baselines x frequency_channels
HDD Memory
DMA DMA
Add localGto finalG
►A master-worker model“Scheduling” decisions on the PPESPEs concerned only with computation

42/79.95
Optimizations
►Exploit data localityPPE: fill the queues in a “smart” way SPEs: avoid unnecessary DMA
►Tune queue sizes ►Increase queue filling speed
2 or 4 threads on the PPE
►Sort queuesBy g_ind and/or c_ind

43/79.95
Experiments set-up
► Collection of 990 baselines 1 baseline Multiple baselines
► Run gridding and degridding for: 5 different support sizes Different core/thread configurations
► Report: Execution time / operation (i.e., per gridding and per
degridding):Texec/op = Texec/(NSamples x NFreqChans x KernelSize x #Cores)

44/79.95
Results – overall evolution

45/79.95
Lessons from Gridding
►SPE kernels have to be as regular as possibleDynamic scheduling works on the PPE side
►Investigate data-dependent optimizationsTo spare memory accesses
►Arithmetic intensity is a very important metricAggressively optimizing the computation part only
pays off when communication-to-computation is small!!
►I/O can limit the Cell/B.E. performance

46/79.95
Performance checklist [1/2]
►Low-levelNo dynamics on the SPEsMemory alignment Cache behavior vs. SPE data contention Double-buffering Balance computation optimization with the
communicationExpect impact on the algorithmic level

47/79.95
Performance checklist [2/2]
►High-levelTask-level parallelization
• Symmetrical/asymmetricalStatic mapping if possible; dynamic only on the
PPEAddress data locality also on the PPEModerate impact on algorithm
►Data-dependent optimizationsEnhance data locality

48/79.95
Outline
►One introduction►Cell/B.E. case-studies
Sweep3D, Marvel, CellSortRadioastronomyAn Empirical Performance Checklist
►Alternatives GP-MC, GPUs
►Views on parallel applications… and multiple conclusions

49/79.95
Other platforms
► General Purpose MC Easier to program (SMP machines) Homogeneous Complex, traditional cores, multi-threaded
► GPU’s Hierarchical cores Harder to program (more parallelism) Complex memory architecture Less predictable

50/79.95
A Comparison
► Different strategies are required for each platform Core-specific optimization are the most important for GPP Dynamic job/data allocation are essential for Cell/B.E. Memory management for high data parallelism is critical for GPU

51/79.95
Efficiency (case-study) ► We have tried to the most “natural” programming model for each
platform ► The parallelization effort
GPP: 4 days • A Master-Worker model may improve performance here as well
Cell/B.E.: 3-4 months • Very good performance, complex solution
GPU: 1 month (still in progress)
??

52/79.95
Outline
►One introduction►Cell/B.E. case-studies
Sweep3D, Marvel, CellSortRadioastronomyAn Empirical Performance Checklist
►Alternatives GP-MC, GPUs
►Views on parallel applications… and multiple conclusions

53/79.95
A view from Berkeley

54/79.95
A view from Holland

55/79.95
Overall …
► Cell/B.E. is NOT hard to program unless … High performance or high productivity are required
► Still in the case-studies phase Everything can run on the Cell … but how and when ?!
► Optimizations Low-level: may be delegated to a compiler (difficult) High-level: must be user-assisted
► Programming models Offer partial solutions, but none seems complete Various approaches, with limited loss in efficiency

56/79.95
… but …
► Cell/B.E. is NOT the only option Choosing a multi-core platform is *highly* application
dependent Efficiency is essential, more so than performance
► In-core optimizations pay off for *all* platforms Are roughly predictable too
► Higher level optimizations make the difference Data management and distribution Task scheduling Isolation and proper implementation of dynamic behavior
(e.g., scheduling)

57/79.95
Take-home messages [1/2]
►It’s not multi-core processors that are difficult to program, but more that applications are difficult to parallelize.
►There is no silver bullet for all applications to perform great on the Cell/B.E., but there are common practices for getting there.

58/79.95
Take-home messages [2/2]
►The application design, implementation, and optimization principles for the Cell/B.E. hold for most multi-core platforms.
►Applications must have a massive influence on next generation multi-core processor design

59/79.95
Thank you!
►(Any more) Questions ?
http://www.pds.ewi.tudelft.nl/~varbanescu








![Tom&Jerry-Katalog WEB draft0 rev4-small - TJ Labels sticky notes ppp tj-cherry zez tj-bird tj-car tj-fruit model flags t]-garden tj-candy tj-sea](https://img.pdfslide.net/doc/110x75/5ae5d4947f8b9a9e5d8cec91/tomjerry-katalog-web-draft0-rev4-small-tj-sticky-notes-ppp-tj-cherry-zez-tj-bird.jpg)



















