Embed Size (px)
Citation preview

Wrap Up
Matthias Gries Chidamber KulkarniKaushik Ravindran
EE 290A – Fall 2002

2
Outline• Motivation for CSA• Course objectives• CSA discussions
– Applications and programming environments– Platforms and programming models– Mapping
• Conclusions• Comments
3
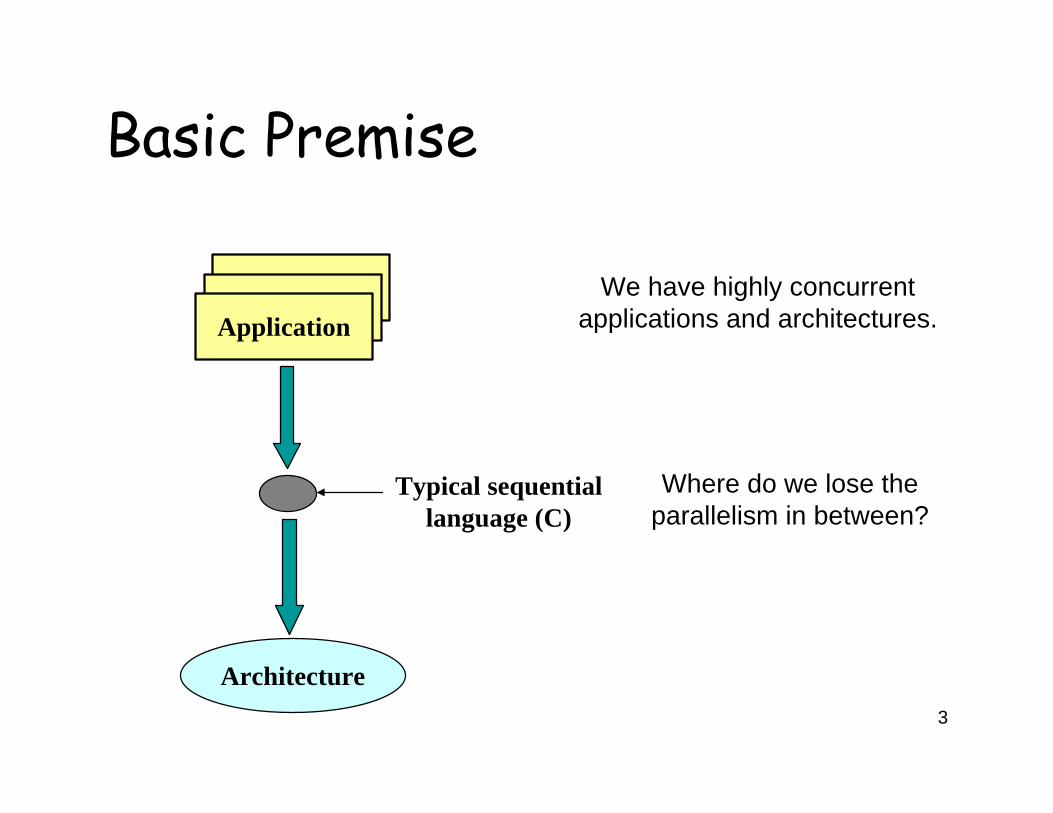
Basic Premise
Application
Architecture
Typical sequential language (C)
We have highly concurrent applications and architectures.
Where do we lose the parallelism in between?

4
Motivation• Concurrency of application must find natural
reflection in the concurrency of target architecture
• Models of Computation– A formalism for expressing concurrency in communication
and control
• But also important to formalize the structure of computation– Hence, need concurrent system architecture (CSA)
descriptions with the models of computation
5
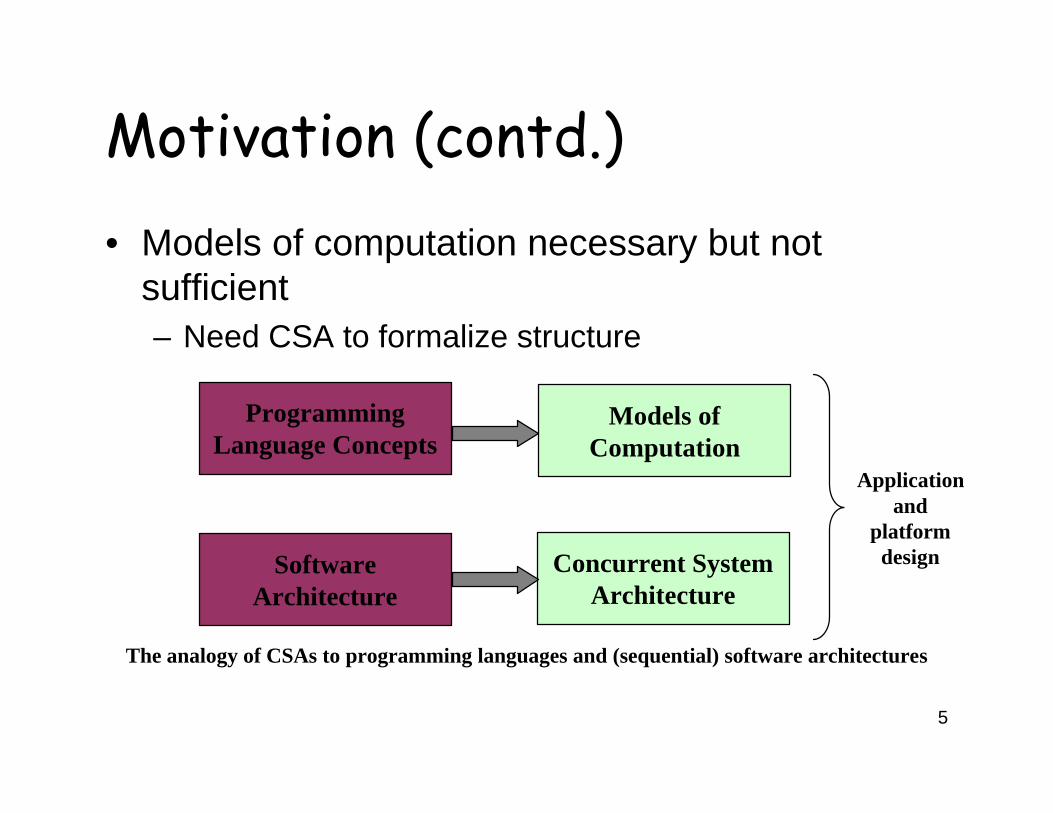
Motivation (contd.)• Models of computation necessary but not
sufficient– Need CSA to formalize structure
The analogy of CSAs to programming languages and (sequential) software architectures
Programming Language Concepts
Models of Computation
Software Architecture
Concurrent System Architecture
Applicationand
platform design

6
System architecture• Decisions about organization of a computing system
– Architectural styles and design patterns– Invariants
• Identifying subsystems and establishing framework for subsystem control– Structural elements and interfaces– Behavior– Composition– Architectural style
• Constituent parts– Components– Communicators– Interfaces– Configurations

7
Course Objectives• Develop a formal notion of concurrent-system
architectures as well as a set of CSA’s that help to model the applications and devices that we are looking at.
• Understand the role of CSAs in – Designing programming environments for applications– Designing programming models for platforms– Mapping applications onto target platforms

8
The journey so far…• Programming environment for applications
– Click for network applications– VoIP– E-machine
• Programming models for platforms– Broadcom Calisto– SCORE– IWarp– RAW– Cypress PSoC– Tensilica Xtensa
• Mapping: three case studies– IPv4 packet forwarding on IXP1200– MPEG-2 decoding on Philips Nexperia– Mixed version IP Router on Virtex-II Pro

9
Programming Environments for Applications
• Properties of programming environments– Indigenous to the application domain– Proper abstraction of implementation details
• Role of CSAs– Define application structure hierarchically (using one
or more CSAs)– Guide choice of models of computation for
components and connectors

10
Programming Models for Platforms
• Properties of programming models– Abstract underlying hardware in an application domain specific
way so as to efficiently program the platform– Expose key features (bottle-necks) of platforms while hiding less
essential details
• Role of CSAs– Define configuration of platform components hierarchically (using
multiple CSAs)– Describe computation elements and communication connectors

11
Mapping• Mapping is the translation of an application,
written in a programming environment, onto the target platform, described by its programming model
• Course goal– Evaluate the extent to which CSA’s are useful in the
mapping from programming environments of our target applications onto programming models of our target platforms

12
• H1: The only successful mapping will be an identity mapping– Either the programming environment models map directly onto the platform –
e.g. ASM, micro-C, – the programming model for the platform is itself an acceptable programming
environment for the application domain – Broadcom Calisto
• H2: You must constrain user input such that it is easily and consistently mappable to the device, but not necessarily directly mappable to the device:
– Kahn Process Networks – Philips Nexperia– Compute planes – Score project, Caspi, DeHon, John W. - UC Berkeley
• H3: A theory of mapping from one CSA to another CSA must be developed – (theory of compilation, transformation)
– Mapping from distinct programming environments onto distinct platforms IS possible, but additional theory is required
Hypotheses for Mapping

13
Four-layers of mapping• Four layers• What happens from one layer to the next?
– Concept/policy
• What occurs at a layer?– Discipline

14
Applications: Case studies• VoIP• Click for Network Applications

15
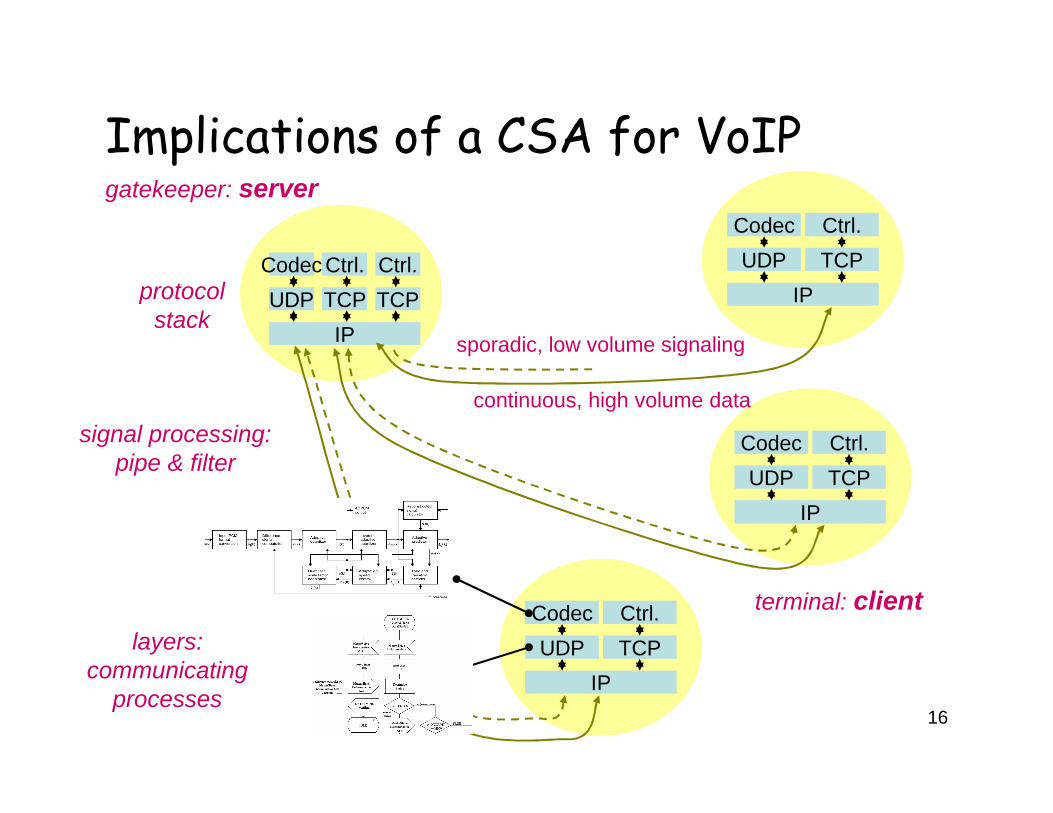
Implications on a CSA for VoIP• Data (codec): Pipe and filter
– Non-transforming connectors– Feedback loops– Asynchronous transforms of sets of voice samples
• Protocols: Layered system– Control topology: stack, partly lockstep, parallel– Used for signaling: sporadic, low volume, mode: passed– Used for data: continuous, high volume, mode: passed– Run-time identification of partner for transfer-of-control/data– Control/data direction: could be same as well as opposite
• Terminal – gatekeeper relation: client-server• Terminal – terminal relation: communication processes:
– Asynchronous: signaling– Synchronous: during call (regular exchange of state updates)
16
signal processing: pipe & filter
layers:communicating
processes
UDP TCP
Ctrl.Codec
IPUDP TCP
Ctrl.Codec
IP
TCP
Ctrl.
UDP TCP
Ctrl.Codec
IP
UDP TCP
Ctrl.Codec
IP
sporadic, low volume signaling
continuous, high volume data
gatekeeper: server
terminal: client
protocol stack
Implications of a CSA for VoIP

17
Programming Models for Platforms
• Properties of programming models– Abstract underlying hardware in an application domain specific
way so as to efficiently program the platform– Expose key features (bottle-necks) of platforms while hiding less
essential details
• Role of CSAs– Define configuration of platform components hierarchically (using
multiple CSAs)– Describe computation elements and communication connectors

18
Platforms: Case studies• SCORE• IWarp• RAW• Cypress PSoC• Tensilica Xtensa• Broadcom Calisto
11/21/02 19
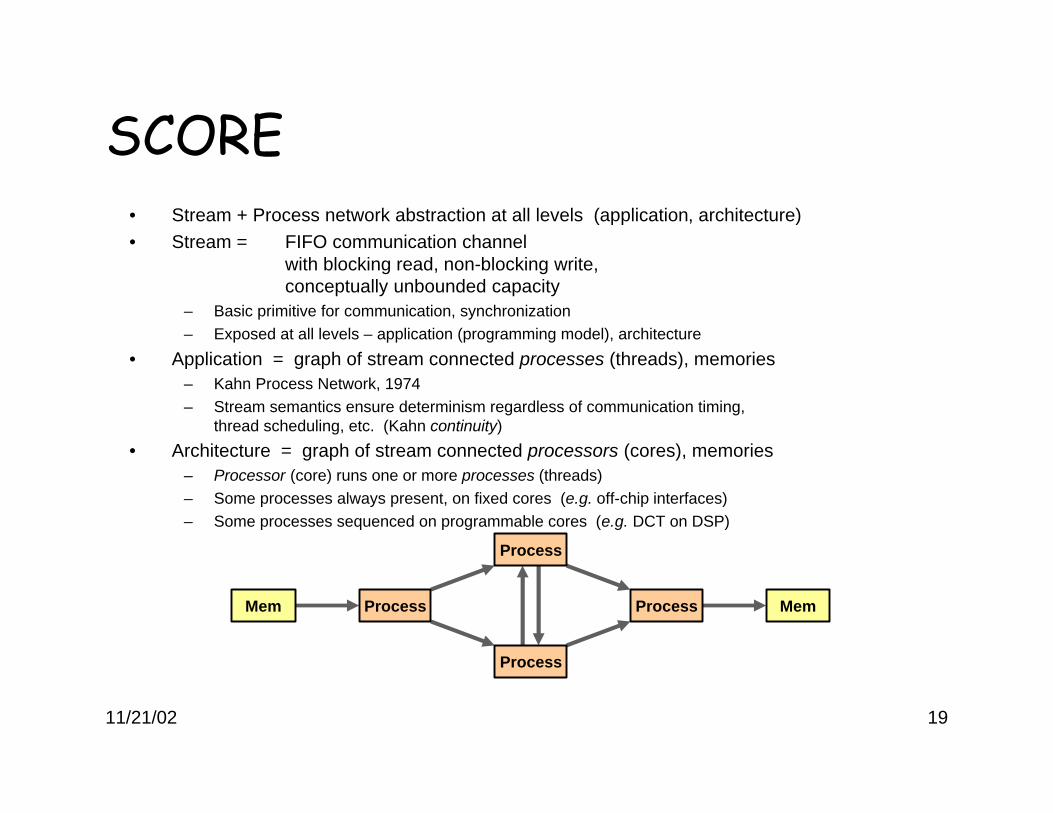
SCORE• Stream + Process network abstraction at all levels (application, architecture)• Stream = FIFO communication channel
with blocking read, non-blocking write,conceptually unbounded capacity
– Basic primitive for communication, synchronization– Exposed at all levels – application (programming model), architecture
• Application = graph of stream connected processes (threads), memories– Kahn Process Network, 1974– Stream semantics ensure determinism regardless of communication timing,
thread scheduling, etc. (Kahn continuity)
• Architecture = graph of stream connected processors (cores), memories– Processor (core) runs one or more processes (threads)– Some processes always present, on fixed cores (e.g. off-chip interfaces)– Some processes sequenced on programmable cores (e.g. DCT on DSP)
Process
Process
Process
ProcessMem Mem
3/6/01 20
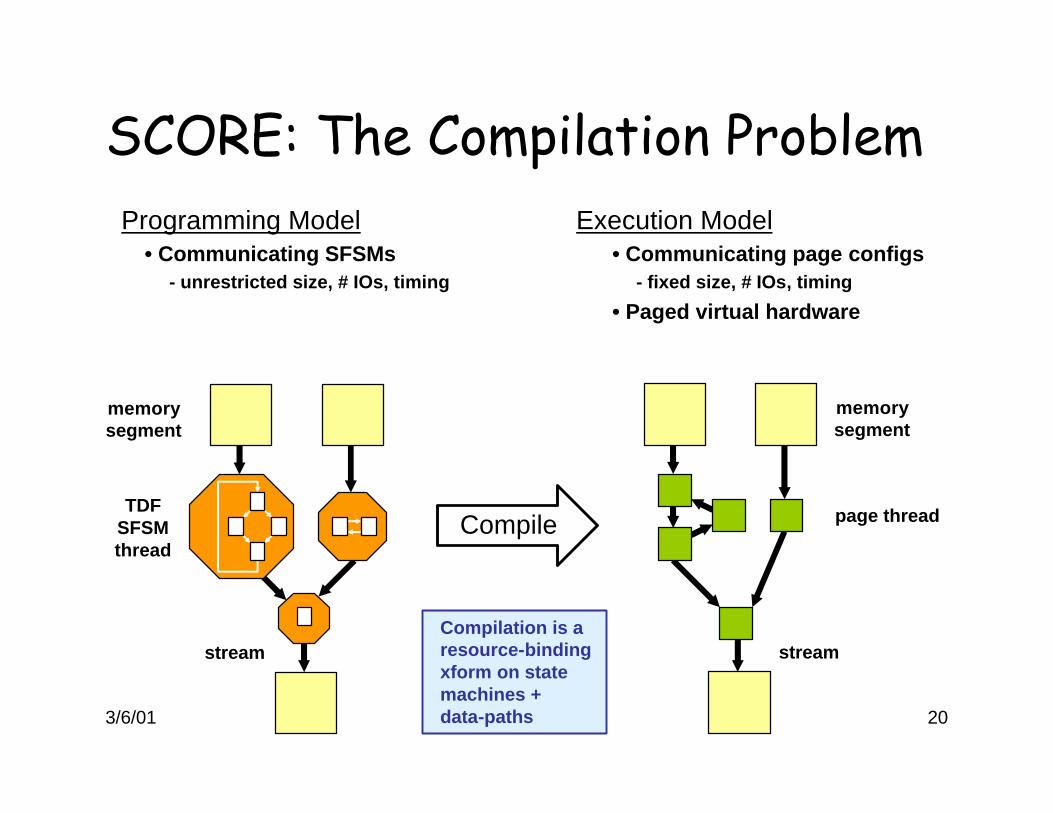
SCORE: The Compilation ProblemProgramming Model Execution Model
• Communicating SFSMs • Communicating page configs- unrestricted size, # IOs, timing - fixed size, # IOs, timing
• Paged virtual hardware
Compile
memorysegment
TDFSFSMthread
stream
memorysegment
page thread
streamCompilation is a resource-binding xform on state machines +data-paths
21
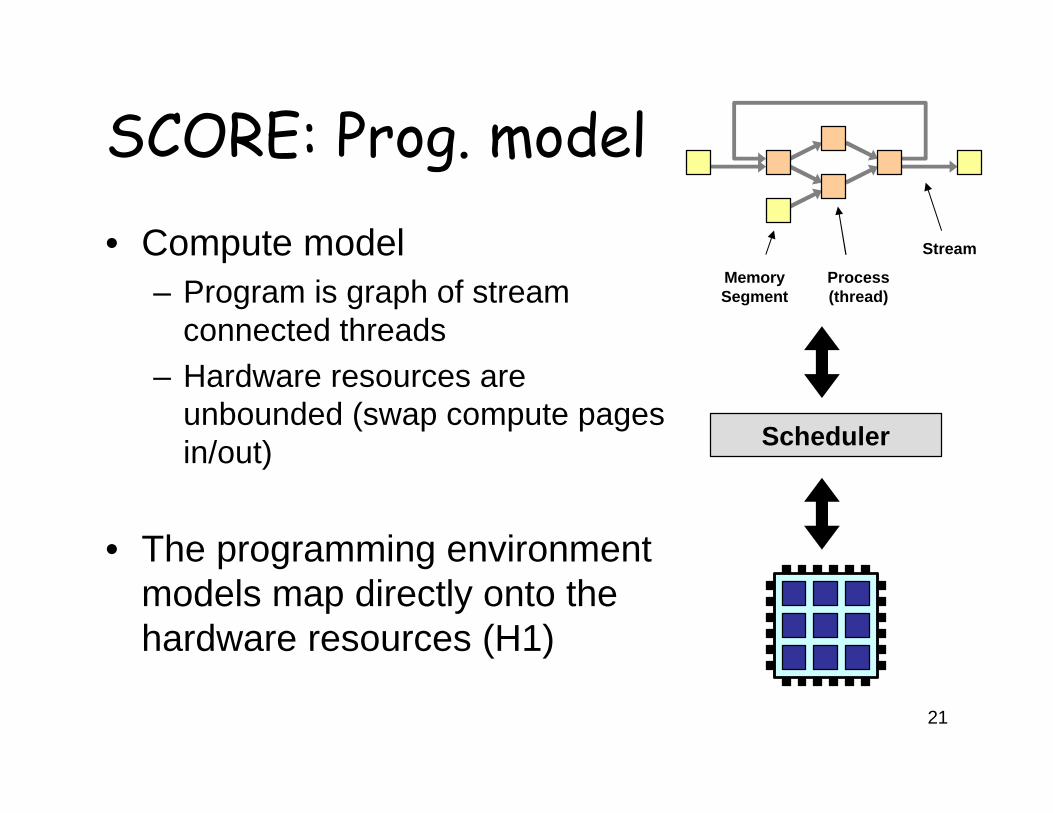
SCORE: Prog. model• Compute model
– Program is graph of stream connected threads
– Hardware resources are unbounded (swap compute pages in/out)
• The programming environment models map directly onto the hardware resources (H1)
MemorySegment
Process(thread)
Stream
Scheduler
22
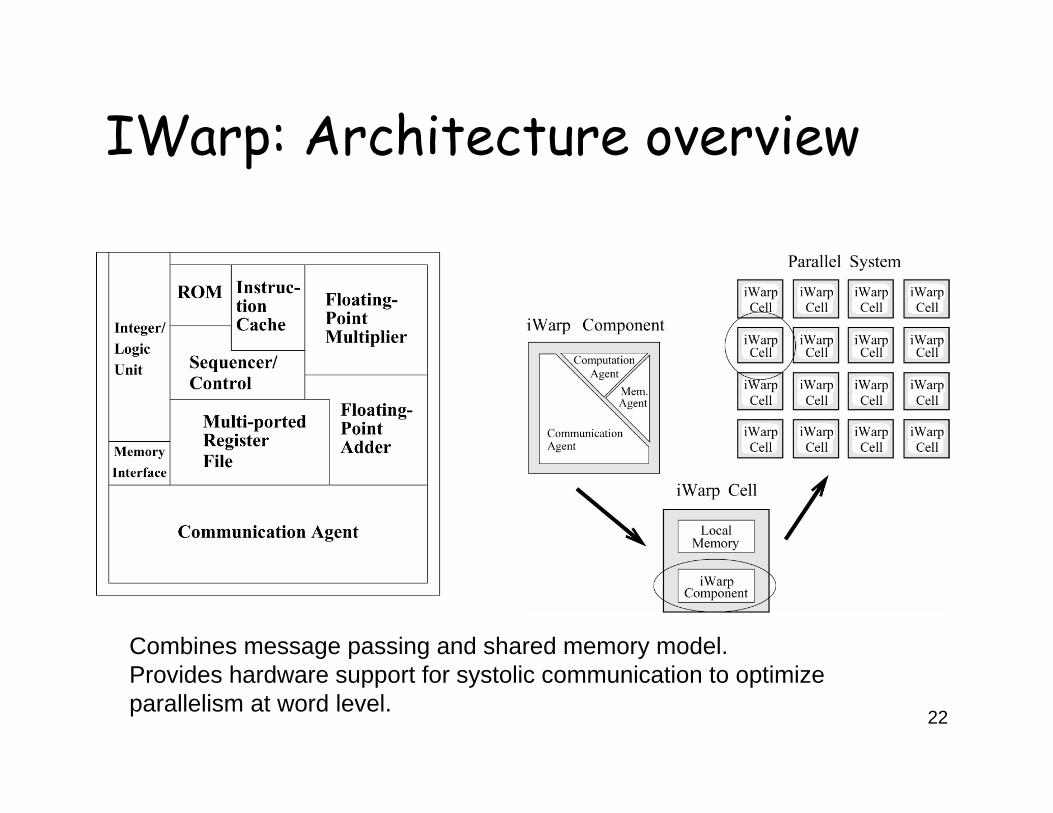
IWarp: Architecture overview
Combines message passing and shared memory model.Provides hardware support for systolic communication to optimizeparallelism at word level.
23
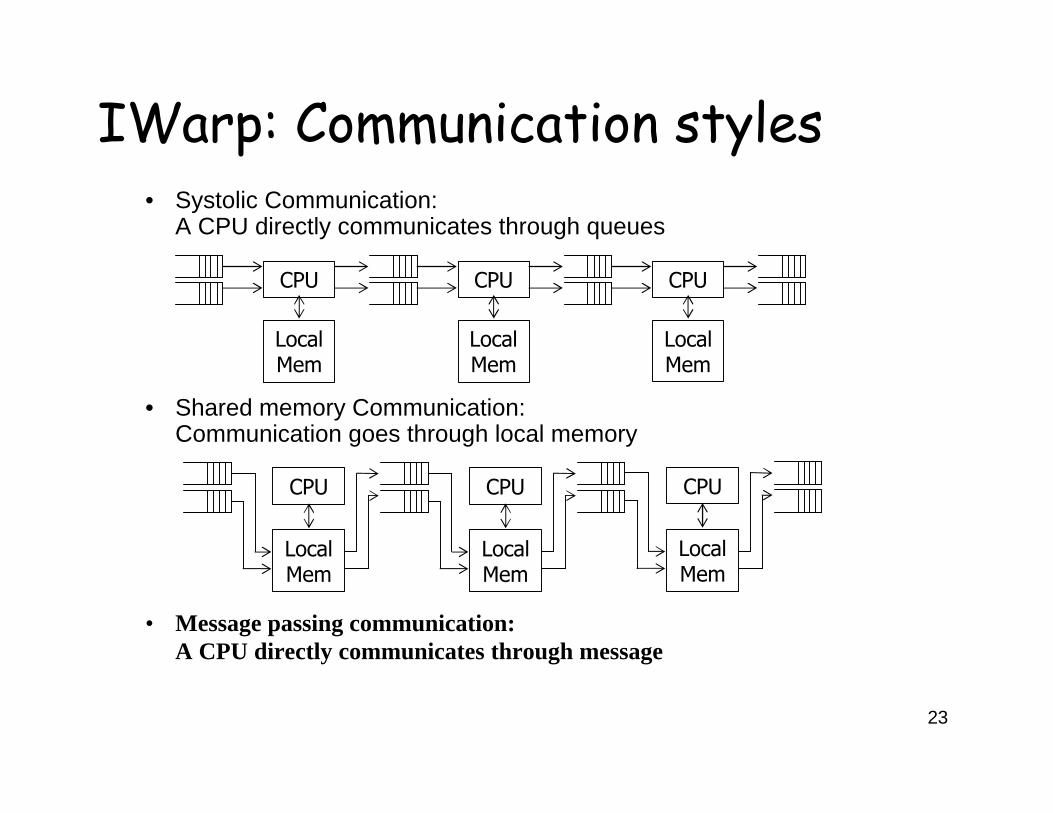
IWarp: Communication styles
CPU
Local Mem
CPU
Local Mem
CPU
Local Mem
CPU
Local Mem
CPU
Local Mem
CPU
Local Mem
• Systolic Communication:A CPU directly communicates through queues
• Message passing communication:A CPU directly communicates through message
• Shared memory Communication:Communication goes through local memory

24
IWarp: Programming model• Program in C or FORTRAN• Code partition, placement, and routing
– Program each cells individually using explicit communication directives
• Compile partitioned code with uni-processor compiler
• Supports multiple CSA models– Based on shared memory model this is repository– Based on systolic communication this is pipe and filter
• Pipe and filter is more efficiently supported by the hardware
25
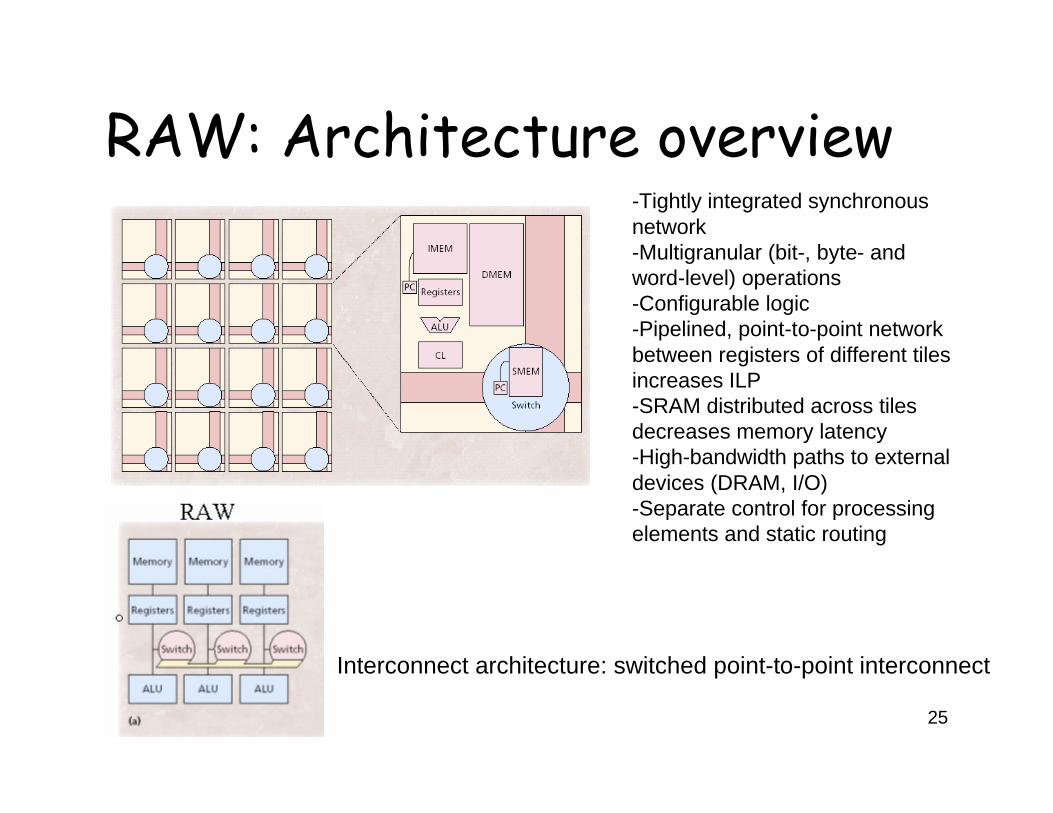
RAW: Architecture overview
Interconnect architecture: switched point-to-point interconnect
-Tightly integrated synchronous network-Multigranular (bit-, byte- and word-level) operations-Configurable logic-Pipelined, point-to-point network between registers of different tiles increases ILP-SRAM distributed across tiles decreases memory latency-High-bandwidth paths to external devices (DRAM, I/O)-Separate control for processing elements and static routing

26
RAW: Programming model• Basic model is just sequential Von Neumann machine –
programmable in C with user-defined threads
• Sophisticated compiler maps program onto multiple tiles– Parallelizes C code onto static network– View N tiles as functional units for ILP– Partition parallel code to tiles– Placement of threads to physical tiles– Routing and global scheduling– Logic synthesis for custom operations
27
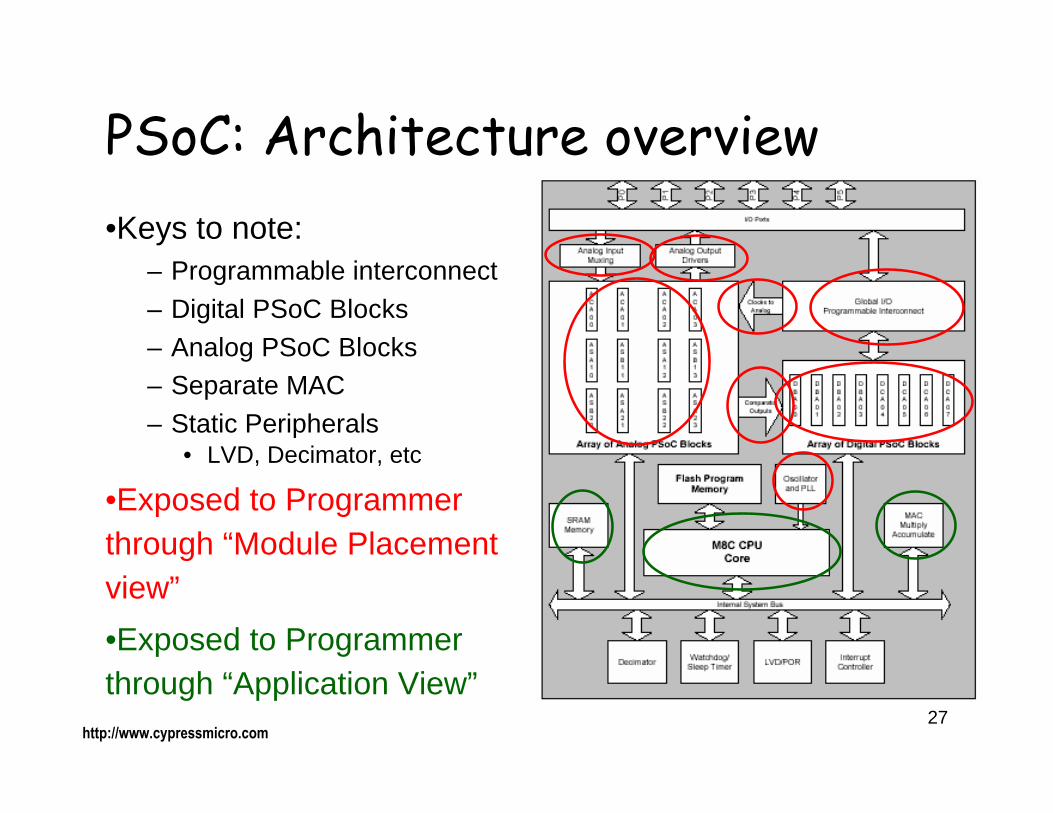
PSoC: Architecture overview•Keys to note:
– Programmable interconnect– Digital PSoC Blocks– Analog PSoC Blocks– Separate MAC– Static Peripherals
• LVD, Decimator, etc
•Exposed to Programmer through “Module Placement view”
•Exposed to Programmer through “Application View”
http://www.cypressmicro.com

28
PSoC: Programming Model• Programming the PSoC
– Identify what user modules and peripherals are required for a particular application
– Generate configuration and use the provided APIs to program the application
• Can use the resources to model the application as you choose• C or M8C Assembly
• Pipe and Filter– Peripherals (Filters); Reconfigurable Interconnect (Pipe)– Can chain peripherals together
• Process Control Systems– Provide dynamic control from some plant– Inputs received by peripherals, State in memory, Output via
peripherals
29
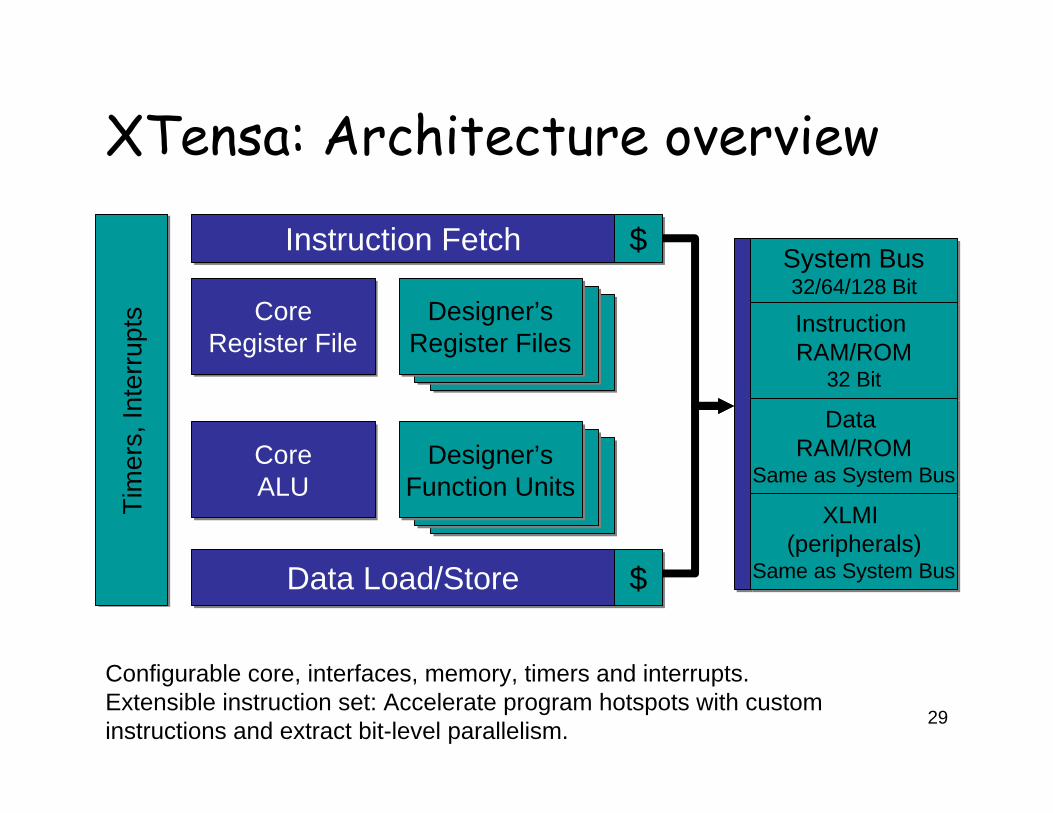
XTensa: Architecture overview
CoreRegister File
CoreRegister File
CoreALUCoreALU
Designer’sRegister Files
Designer’sRegister Files
Designer’sFunction Units
Designer’sFunction Units
Tim
ers,
Inte
rrup
tsT
imer
s, In
terr
upts
Instruction FetchInstruction Fetch
Data Load/StoreData Load/Store
$$
$$
System Bus32/64/128 Bit
System Bus32/64/128 Bit
Instruction RAM/ROM
32 Bit
Instruction RAM/ROM
32 Bit
Data RAM/ROM
Same as System Bus
Data RAM/ROM
Same as System Bus
XLMI (peripherals)
Same as System Bus
XLMI (peripherals)
Same as System Bus
Configurable core, interfaces, memory, timers and interrupts. Extensible instruction set: Accelerate program hotspots with custom instructions and extract bit-level parallelism.

30
XTensa: Programming Model• Programming the Xtensa
– Start with Xtensa core with no TIE– Profile application on core to find hotspots– Restructure application to isolate hotspots in functions– Develop TIE instructions– Replace hotspot functions with TIE
• Programming model is the ISA for a uni-processor RISC core
– But not quite: the ISA itself can be extended by the programmer/designer
31
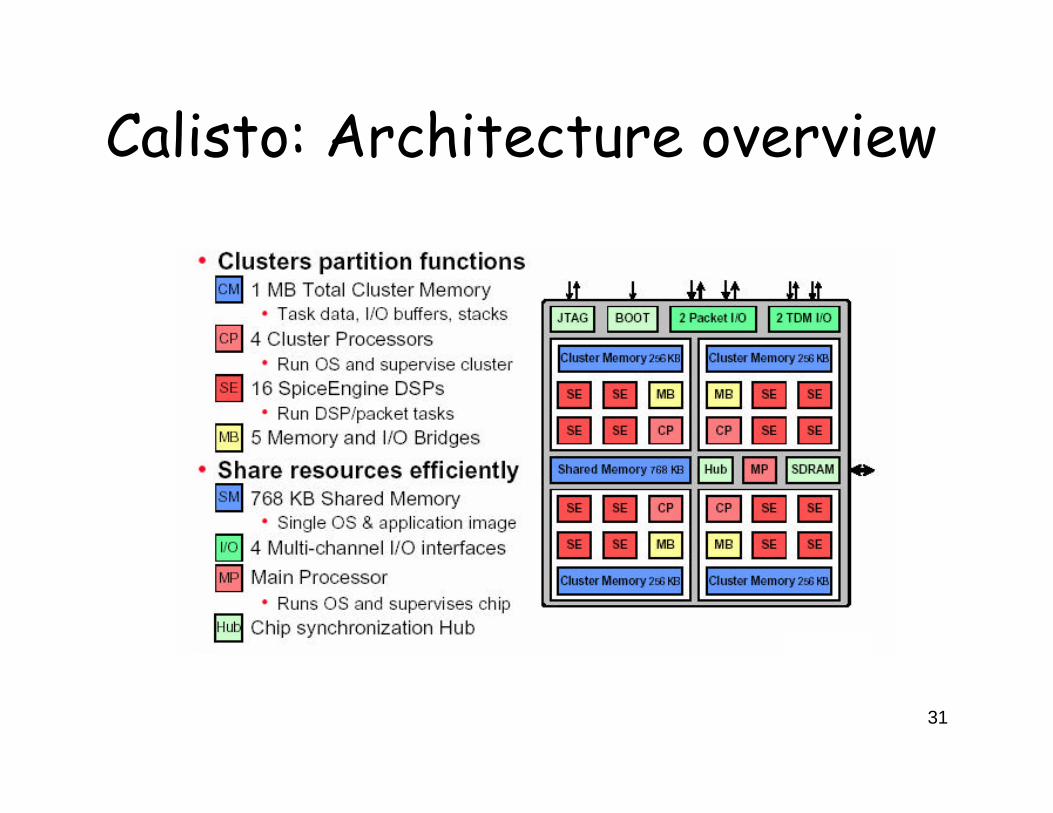
Calisto: Architecture overview
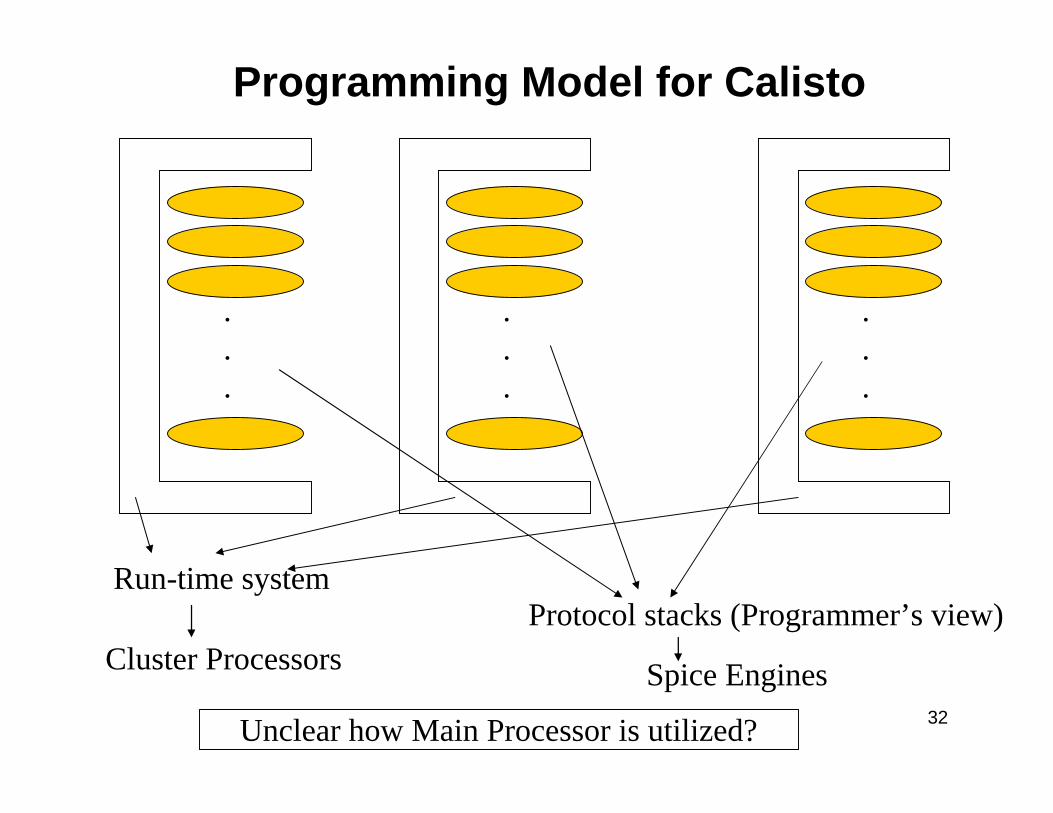
32
.
.
.
.
.
.
.
.
.
Run-time systemProtocol stacks (Programmer’s view)
Cluster Processors Spice Engines
Programming Model for Calisto
Unclear how Main Processor is utilized?

33
Mapping• Mapping is the translation of an application,
written in a programming environment, onto the target platform, described by its programming model
• Course goal– Evaluate the extent to which CSA’s are useful in the
mapping from programming environments of our target applications onto programming models of our target platforms

34
• H1: The only successful mapping will be an identity mapping– Either the programming environment models map directly onto the platform –
e.g. Teja OR – the programming model for the platform is itself an acceptable programming
environment for the application domain – e.g. Broadcom’s Calisto VoIP chip
• H2: You must constrain user input such that it is easily mappable to the device, but not necessarily directly mappable to the device:
– Kahn Process Networks – Philips Nexperia– Compute planes – Score project, Caspi, DeHon, John W. - UC Berkeley
• H3: A theory of mapping from one CSA to another CSA must be developed
– Mapping from distinct programming environments onto distinct platforms IS possible, but additional theory is required
Hypotheses for Mapping

35
Mapping: Case studies• IPv4 Packet Forwarding on IXP1200• MPEG2 Decoding on Philips Nexperia• Mixed version IP Router (MIR) on Virtex-II Pro
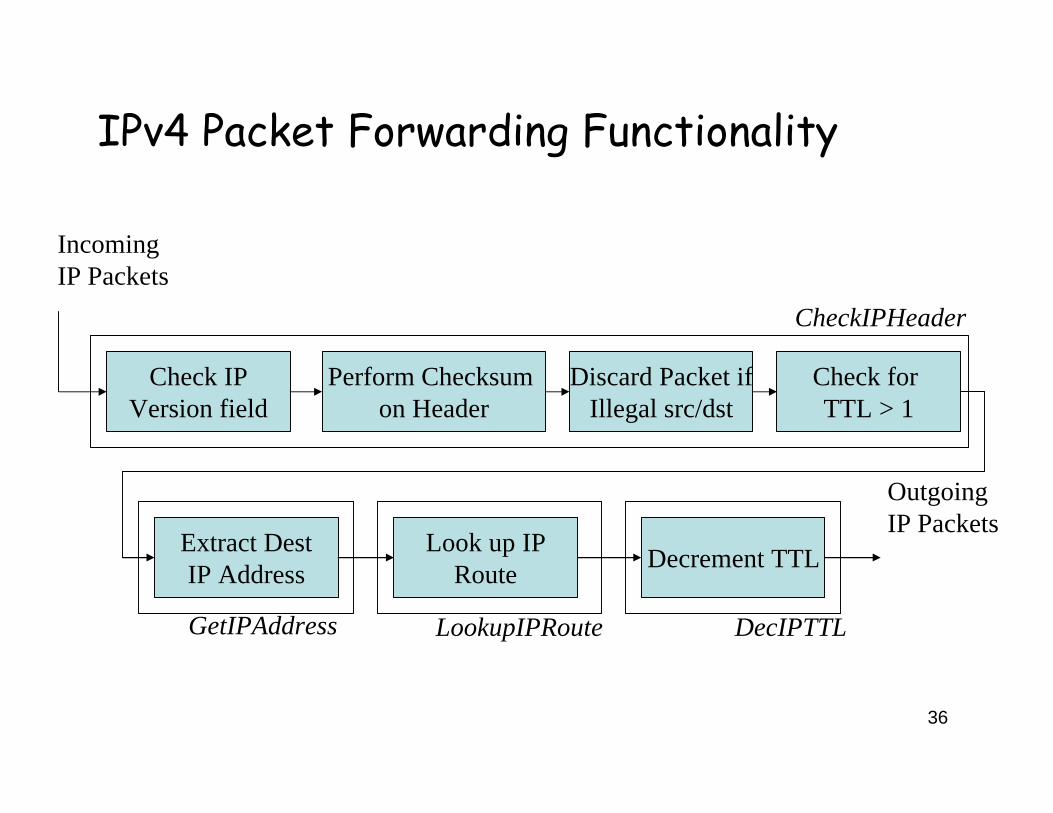
36
IPv4 Packet Forwarding Functionality
OutgoingIP Packets
Check IPVersion field
Perform Checksum on Header
Discard Packet ifIllegal src/dst
Check for TTL > 1
Extract DestIP Address
Look up IPRoute Decrement TTL
CheckIPHeader
GetIPAddress LookupIPRoute DecIPTTL
IncomingIP Packets
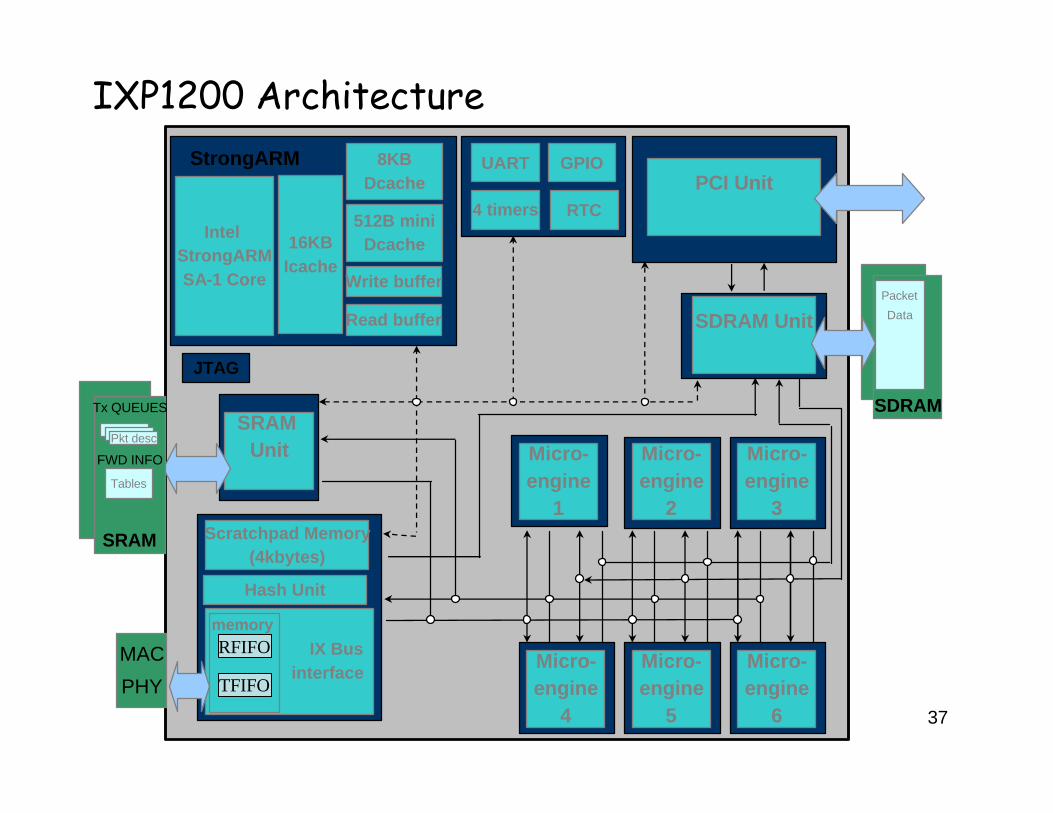
37
IXP1200 Architecture
IX Businterface
Hash Unit
Scratchpad Memory(4kbytes)
JTAG
UART
4 timers RTC
GPIO
SRAM Unit
PCI Unit
SDRAM Unit
Micro-engine
1
Micro-engine
2
Micro-engine
3
Micro-engine
4
Micro-engine
5
Micro-engine
6
Tx QUEUES
FWD INFO
SRAM
MAC
PHY
memory
SDRAM
Pkt desc
Tables
Packet
Data
8KBDcache
16KBIcache
Intel StrongARMSA-1 Core
512B miniDcache
Write buffer
Read buffer
StrongARM
RFIFO
TFIFO
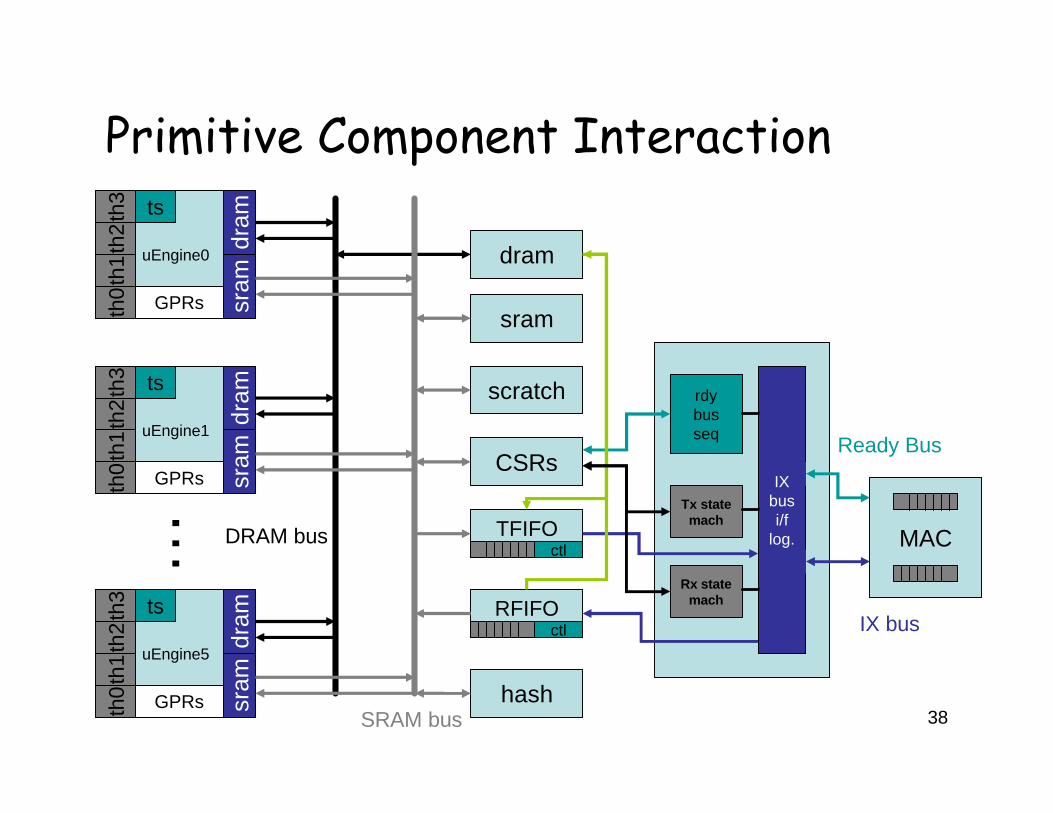
38
Primitive Component Interaction
SRAM bus
dram
sram
scratch
CSRs
TFIFO
RFIFO
hash
…
uEngine0
th0
th1
th2
th3
GPRs
dram
sram
uEngine1
th0
th1
th2
th3
GPRs
dram
sram
uEngine5
th0
th1
th2
th3
GPRs
dram
sram
DRAM bus
ts
ts
ts
IX bus i/f
log. MAC
IX bus
rdybus seq
Tx state mach
Rx state mach
Ready Bus
ctl
ctl
39
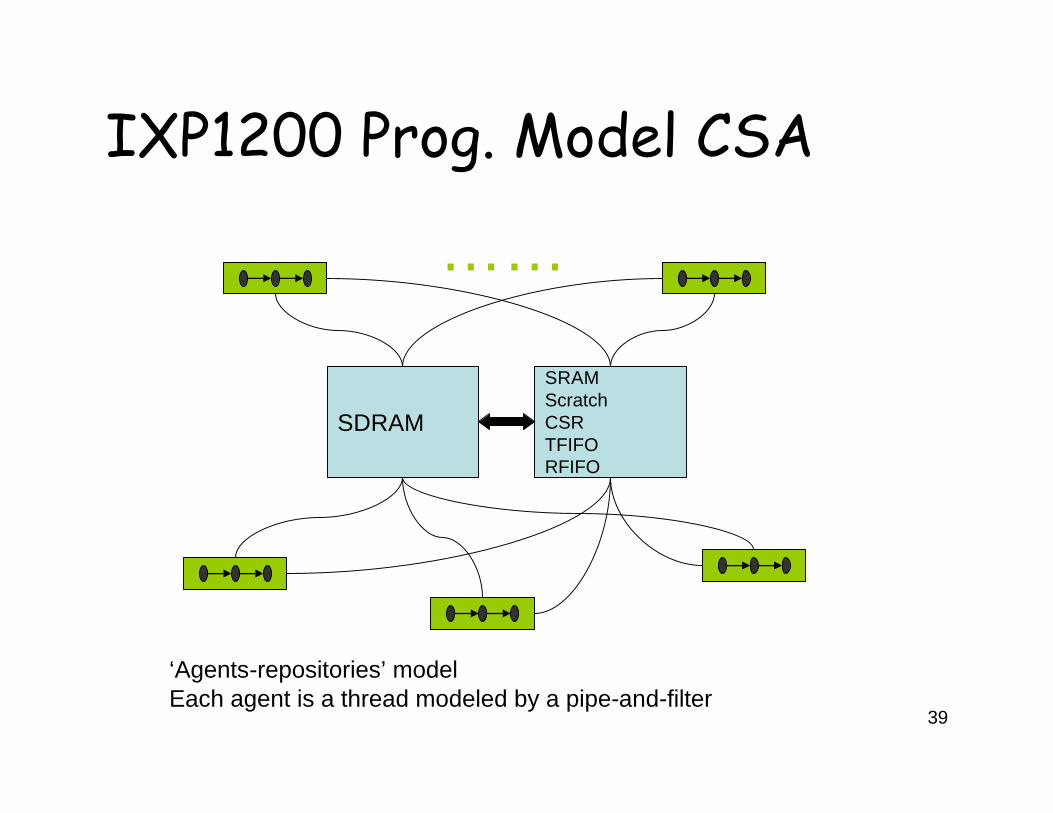
IXP1200 Prog. Model CSA
SDRAM
SRAMScratch CSRTFIFORFIFO
……
‘Agents-repositories’ modelEach agent is a thread modeled by a pipe-and-filter
40
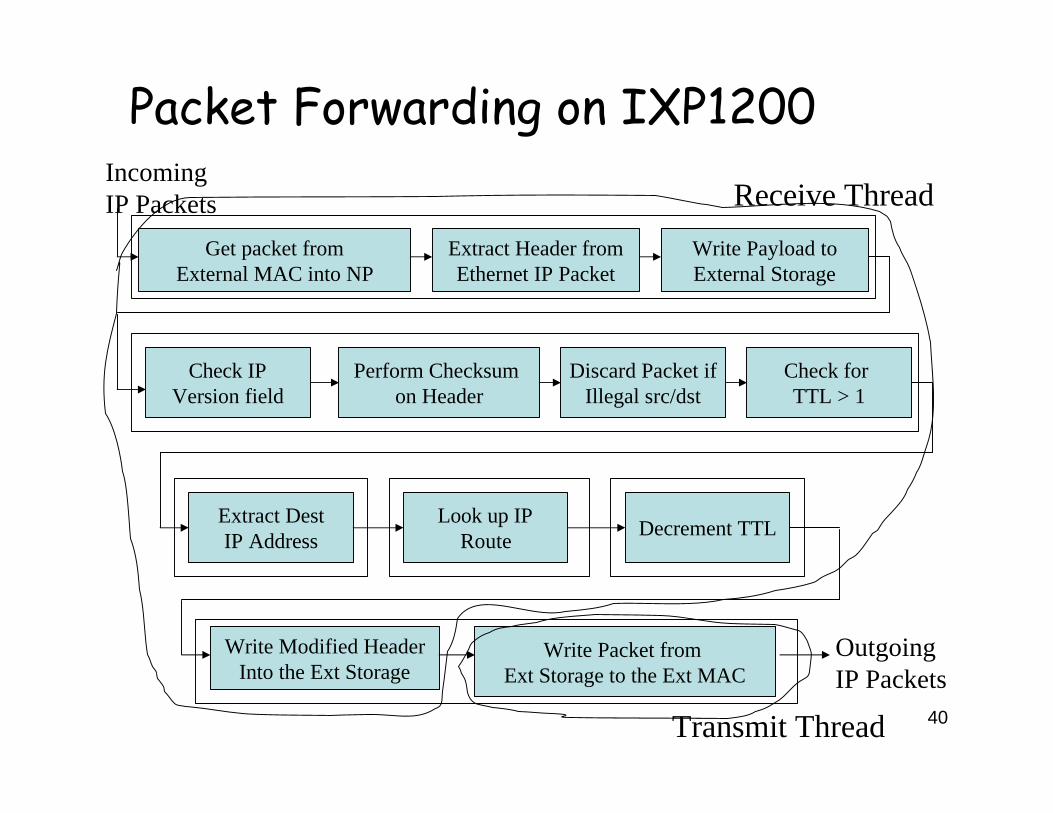
Packet Forwarding on IXP1200
Check IPVersion field
Perform Checksum on Header
Discard Packet ifIllegal src/dst
Check for TTL > 1
Extract DestIP Address
Look up IPRoute Decrement TTL
OutgoingIP Packets
Get packet fromExternal MAC into NP
Extract Header fromEthernet IP Packet
Write Payload toExternal Storage
Write Modified HeaderInto the Ext Storage
Write Packet from Ext Storage to the Ext MAC
IncomingIP Packets Receive Thread
Transmit Thread
41
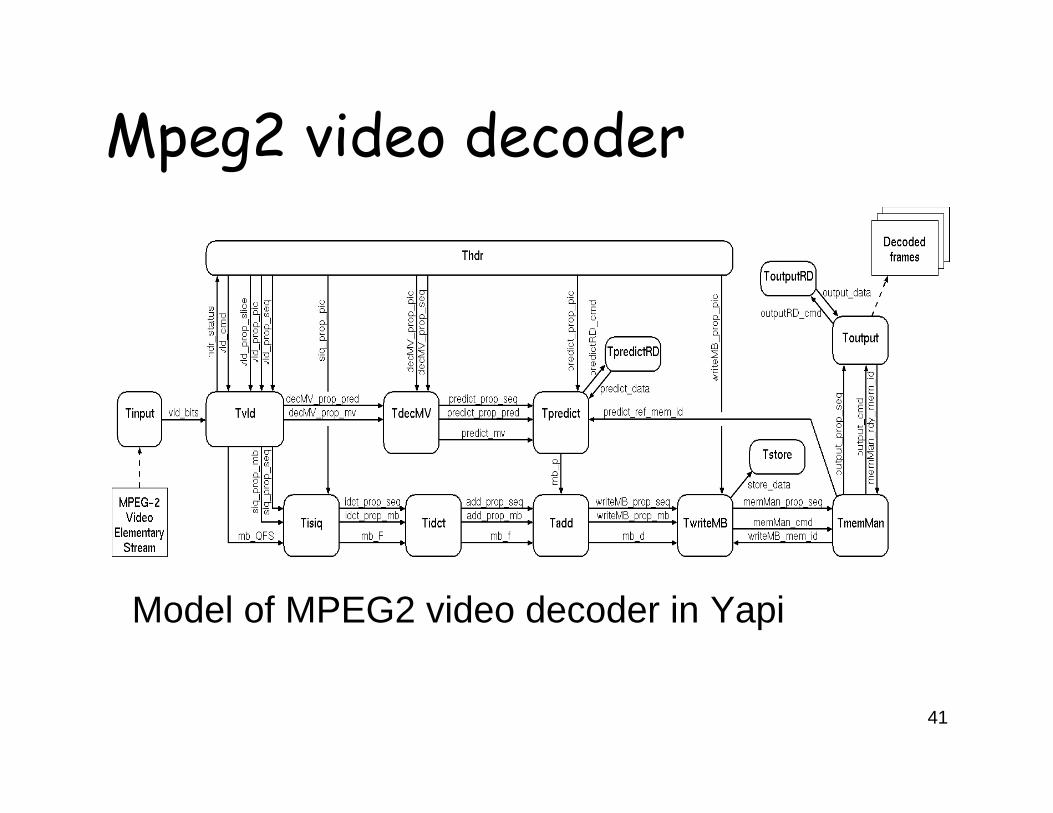
Mpeg2 video decoder
Model of MPEG2 video decoder in Yapi

42
TM-xxxxD$
I$
TriMedia CPU
DEVICE I/P BLOCK
DEVICE I/P BLOCK
DEVICE I/P BLOCK
.
.
.
DVP System Silicon
VLIW Media Processor:• 100 to 300+ MHz• 32-bit or 64-bit
NexperiaSystem Busses• PI bus• Memory bus• 32-128 bit
PI B
US
SDRAM
MMI
DV
P M
EM
OR
Y B
US
DEVICE I/P BLOCK
PRxxxxD$
I$
MIPS CPU
DEVICE I/P BLOCK.
.
.DEVICE I/P BLOCK
PI B
US
General Purpose RISC Processor• 50 to 300+ MHz• 32-bit or 64-bitLibrary of Device Blocks• Image
coprocessors• DSPs• UART• 1394• USB
•…and more
TriMediaTMMIPSTM
Philips NexperiaTM
Flexible architecture for digital video applications
43
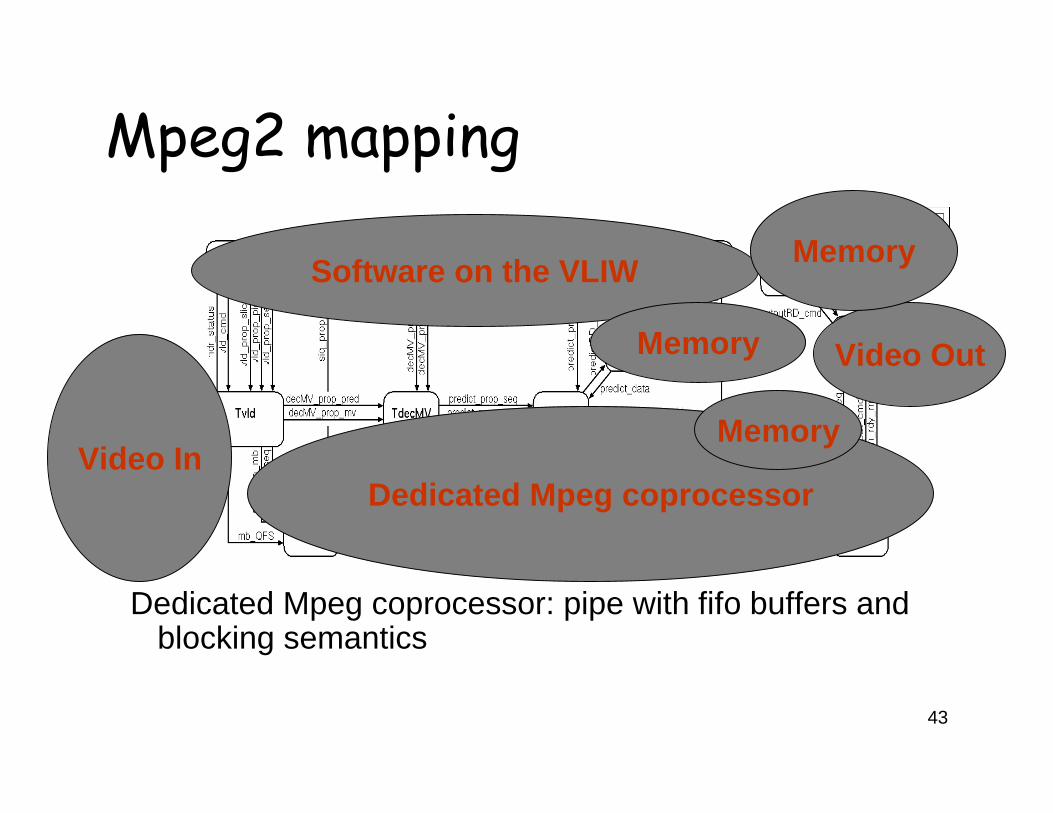
Mpeg2 mapping
Dedicated Mpeg coprocessor: pipe with fifo buffers and blocking semantics
Software on the VLIW
Video In
Video Out
Memory
Memory
Dedicated Mpeg coprocessor
Memory

44
CSA - Conclusions• CSA intended to attack the mapping problem• The basic questions CSA tries to answer
– Given a device and an application, will the device run the application efficiently?
– How do we translate an application (designed in a domain specific programming environment) to a platform (abstracted by its programming model)?

45
CSA – Open Questions• What is still unclear
– No concrete definition of CSA (granularity) or examples
– No defined metrics for evaluation– How CSA complements (or obviates) the Y-chart
mapping methodology





























