
A GraphChi Cluster
MTP Report submitted to
Indian Institute of Technology Mandi
for the award of the degree
of
B. Tech
by
Khushpreet Singh(B11016)
under the guidance of
Dr. Arti Kashyap
SCHOOL OF COMPUTING AND ELECTRICAL ENGINEERING
INDIAN INSTITUTE OF TECHNOLOGY MANDI
JUNE 2015

CERTIFICATE OF APPROVAL
Certified that the thesis entitled A GraphChi CLuster, submitted by Khushpreet Singh ,
to the Indian Institute of Technology Mandi, for the award of the degree of B. Tech has been
accepted after examination held today.
Date :
Mandi, 175001Faculty Advisor

CERTIFICATE
This is to certify that the thesis titled A GraphChi Cluster, submitted by Khushpreet
Singh, to the Indian Institute of Technolog, Mandi, is a record of bonafide work under my
(our) supervision and is worthy of consideration for the award of the degree of B. Tech of
the Institute.
Date :
Mandi, 175001Dr. Arti Kashyap

DECLARATION BY THE STUDENT
This is to certify that the thesis titled A GraphChi Cluster, submitted by me to the Indian
Institute of Technology Mandi for the award of the degree of B. Tech is a bonafide record
of work carried out by me under the supervision of Dr. Arti Kashyap. The contents of this
MTP, in full or in parts, have not been submitted to any other Institute or University for the
award of any degree or diploma.
Date :
Mandi, 175001Khushpreet Singh

Acknowledgments
Foremost, I would like to express my sincere gratitude to my project advisor/mentor Dr. Arti
Kashyap for the continuous support of our project and research, for her patience, motivation
and enthusiasm. Her guidance helped me in all the time of Major project and writing of this
thesis.
Besides my advisor, I would like to thank the faculty advisor: Dr. Dileep A. D. and rest
of the evaluation commitee: —– for their encouragement, insightful comments, and hard
questions.
I thank my fellow team partners for this project: Fatehjeet Sra, Ritish Rana for the
stimulating discussions, for the sleepless nights we were working together before deadlines,
and for all the fun we have had during our project. I could never imagine better partners than
you two for any project.
Khushpreet Singh
i

Abstract
Graph computation is a hot topic in research for past few years. With incresing data day by
day we need a faster and efficient paradign to process this amount of information. It will be
useful for lab experiments, online computation analyzing social network data. GraphChi is
a disk based graph computation system that is written in a vertex centric model for asyn-
chronous processing. It used parallel sliding window algorithm to load data into main mem-
ory and perform the queries that user has entered. Disk based approach makes graphchi
faster than commercialy used clusters with more number of machine used for graph com-
putaion. By deploying GraphChi and run it in a parallel fashion on a cluster might improve
its performance than used on a single machine. We used raspberry pis, low cost small com-
puting devices in order to configure cluster and wrote distributed queries for new system.
Various approaches, challanges, outputs and conclusion are discussed in the later chapter on
the thesis.
Keywords: GraphChi, Graph computation, Cluster, Raspberry pi, Graph partitioning
ii

Contents
Abstract ii
Abbreviations v
List of Symbols vi
List of Tables vii
List of Figures 1
1 Introduction 2
1.1 Objective . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3
1.2 Scope . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 4
2 Background and Related Work 5
2.1 Graph partitioning . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 5
2.1.1 PowerGraph . . . . . . . . . . . . . . . . . . . . . . . . . . . . 6
2.1.2 Edge partitioning . . . . . . . . . . . . . . . . . . . . . . . . . . 6
2.2 Neo4j . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 7
2.3 GraphChi . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 8
2.3.1 Features of GraphChi . . . . . . . . . . . . . . . . . . . . . . . . 8
2.4 Working of Graphchi . . . . . . . . . . . . . . . . . . . . . . . . . . . . 9
2.4.1 Parallel Sliding Window . . . . . . . . . . . . . . . . . . . . . . 9
2.4.1.1 Loads the graph from disk . . . . . . . . . . . . . . . . 9
2.4.1.2 Updates the vertices and edges . . . . . . . . . . . . . 9
iii

2.4.1.3 Writes updated values to disk . . . . . . . . . . . . . . 10
3 Implementation and Working 11
3.1 Performance Evaluation . . . . . . . . . . . . . . . . . . . . . . . . . . . 11
3.2 Graph Partition . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 12
3.2.1 Sub-Graph . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 13
3.3 Multi-Hop query . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 13
3.4 Cluster of GraphChi Nodes . . . . . . . . . . . . . . . . . . . . . . . . . 14
3.5 Raspberry Pi . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 15
4 Experimental Studies and Results 16
4.1 Algorithm Complexities . . . . . . . . . . . . . . . . . . . . . . . . . . 17
4.1.1 For single Machine . . . . . . . . . . . . . . . . . . . . . . . . . 17
4.1.2 For Cluster . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 17
4.2 Cluster Performance . . . . . . . . . . . . . . . . . . . . . . . . . . . . 18
4.2.1 Subsequent Query . . . . . . . . . . . . . . . . . . . . . . . . . 19
4.2.2 Query Output . . . . . . . . . . . . . . . . . . . . . . . . . . . . 19
4.2.3 Distribution Time . . . . . . . . . . . . . . . . . . . . . . . . . . 20
4.3 Raspberry Pi Cluster . . . . . . . . . . . . . . . . . . . . . . . . . . . . 20
5 Conclusion and Future Work 21
References 22
iv

Abbreviations
PSW - Parallel Sliding window
FTP - file transfer protocol
OS - Operating System
RAM - Random Access Memory
SSD - Secondary Storage Device
CMU - Carnegie Mellon University
SQL - Standard Query Language
I/O - Input/Output
v

Symbols
O - Upper Bound
vi

List of Tables
2.1 Runtime for different data sets for different query apps . . . . . . . . . . 8
4.1 Runtime for different data sets on two different computation environments 16
4.2 Time analysis for Different Data sets for different custer specification . . . 18
4.3 Time analysis for second Query . . . . . . . . . . . . . . . . . . . . . . 19
4.4 Outputs . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 19
4.5 Distribution overhead . . . . . . . . . . . . . . . . . . . . . . . . . . . . 20
4.6 Raspberry Pi result . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 20
vii

List of Figures
2.1 A vertex cut . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 6
2.2 Edge Partitioning . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 7
2.3 Neo4j Graph . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 7
3.1 Sub-Graph Formation. . . . . . . . . . . . . . . . . . . . . . . . . . . . 13
3.2 Flow chart of cluster working . . . . . . . . . . . . . . . . . . . . . . . . 14
1

Chapter 1
Introduction
With the increase in information and data available for the digital computing devices it is
becoming more and more challenging to store, process and analyze this enormous amount
of data. Database is a generic name for the collection of information and its relations and
dependencies on other information. After relational database reaching to its highest limit,
computer researches started working on new data storage and computing paradigms that has
never been even thought of by humanity. Graph database is a way of storing information in
common data structure called Graph. In which we store information as nodes and edges of
the graph. This makes traversal over the data very easy and free. Dependencies are more
clear. But with increase in data sets it is becoming very difficult to perform computations
on these graph, it possible time complexities of these algorithms used is very high or the
execution time is too much. So researches worldwide are trying to find and develop new
paradigms in graph computations to lower the complexity or time by any means. Distribu-
tive and parallel computing played a great role for this purpose. Dividing computation over
number of connected machine and operating in parallel lowers the the total effective execu-
tion time.
The main focus of our project was to develop a cluster of GraphChi nodes [1]. GraphChi
is a disk based graph computation tool developed by research scholars: Aapo Kyrola at CMU
university. GraphChi performs various graph computation on a single machine in compara-
ble time against a large cluster of over thousand nodes. By breaking large graph into small
subgraphs and utilizing novel algorithms like parallel sliding windows method, I enables
2

GraphChi to execute a number of advanced data mining [2], graph mining [3], and machine
learning algorithms on very large graphs, using just a single consumer-level computer. It
process graph from the disk itself following this algorithm. Programs for GraphChi are
written in the vertex-centric model [4], proposed by GraphLab and Google Pregel. using
GraphChi changes and update written to edges are immediately visible to subsequent com-
putation, running vertex-centric programs asynchronously and in parallel [5]. It saves you
from the hassle and costs of working with a distributed cluster or cloud services because
promise of GraphChi is to bring web-scale graph computation, such as analysis of social
networks, available to anyone with a modern laptop. In some cases GraphChi can solve
bigger problems in reasonable time than many other available distributed frameworks. In
our project we developed a cluster of raspberry pis and configured GraphChi on each node
run multi-hop queries to evaluate the difference between single machine. As we have al-
ready seen that GraphChi on single node is effectively comparable than a cluster consisting
multiple machines. By running GraphChi in distributed manner in order to enhance the
performance of the novel algorithm. Various features, research outcomes, challenges and
working is discussed under different sections.
1.1 Objective
Objectives completed over the period of last one year i.e. August 2014 - June 2015
1. Configure Neo4j on a machine
2. Configure GraphChi on a node with similar hardware/software configuration
3. Run same multi-hop queries on both machines using different graph computation tools
4. Evaluate performance and time and space complexity comparison
5. configure cluster of Raspberry pis, configure GraphChi on each node
6. Write distributed multi-hop queries to perform same functionalities
7. Run and collect data about time and space complexities, Compare the performance
with existing data.
3

8. Conclude and summarize the performance of distributed GraphChi system.
1.2 Scope
As the information is increasing exponentially, it is happening for the first time in history
that we have enormous amount of data to store and process so humanity doesn’t have an
effective paradigm to handle this problem. This is a open problem and scholars worldwide
are viewing it from all angles. With GraphChi we can perform computations on large graph
data sets even comparable to huge clusters. If we can enhance its performance by distributing
it over a small cluster. We can reduce the hardware cost even for large scale computation by
building cost-effective GraphChi cluster using cheap computing devices such as Raspberry
pis. But scalability can still be a big issue.
4

Chapter 2
Background and Related Work
This chapter contains background and inspiration behind the project and related work done
in the field of graph computation and graph partitioning, two prime keywords for our project.
An asynchronous system for graph traversals on external and semi-external memory pro-
posed by Pearce et al [6]. Their solution does not allow changes to the graph but unlike
GraphChi, stores the graph structure on disk using the compressed sparse row format Vertex
values are stored in memory, and computation is scheduled using concurrent work queues.
Their system is designed for graph traversals, while GraphChi is designed for general large-
scale graph computation and has lower memory requirements. Another method is based
on simulating parallel PRAM algorithms, and requires a series of disk sorts, and would not
be efficient for the types of algorithms we consider. For this a collection of I/O efficient
fundamental graph algorithms in the external memory setting was proposed by Chiang et.
al. [7]. Many real-world graphs are sparse, and it is unclear which bound is better in prac-
tice. A similar approach was recently used by Blelloch et. al. for I/O efficient Set Covering
algorithms.
2.1 Graph partitioning
Graph partition is how to divide graph such that it is easy for an application or user to
use based on a specific scenario [8], is a huge problem and different approaches have been
discovered and taken into consideration for the project by out team. Some of the approaches
5

are discussed below.
2.1.1 PowerGraph
GraphLab developed a new way of partition the graph [9]. ”Think like a vertex”. A single
vertex is shared by different sub graphs to ensure the integrity of the edges and the relations,
the degree is split accordingly. Edges are given the high priority. Now that vertex can be part
of different partitions independently, Results can be joined after the execution on different
partitions is done. This approach is useful when we have restricted memory resources,
because we do not have to store extra information about the partitioning and the critical
edges that are shared between a cut. Vertex cut is shown in Figure 2.1.
Fig. 2.1: A vertex cut
2.1.2 Edge partitioning
A very basic approach is cutting graph from the edges! [10] shown in Figure 2.2, but in such
a way that we have minimum edge cuts to minimize the information stored about the cut.
Because edges having both end points in same sub graph can be processed in parallel but the
critical edges that are part of a cut we have to process in a sequential manner. That will take
more time and limit the parallelism. In case of million or billion of edges the information to
be stored and processed serially will be huge resulting into an inefficient system.
6
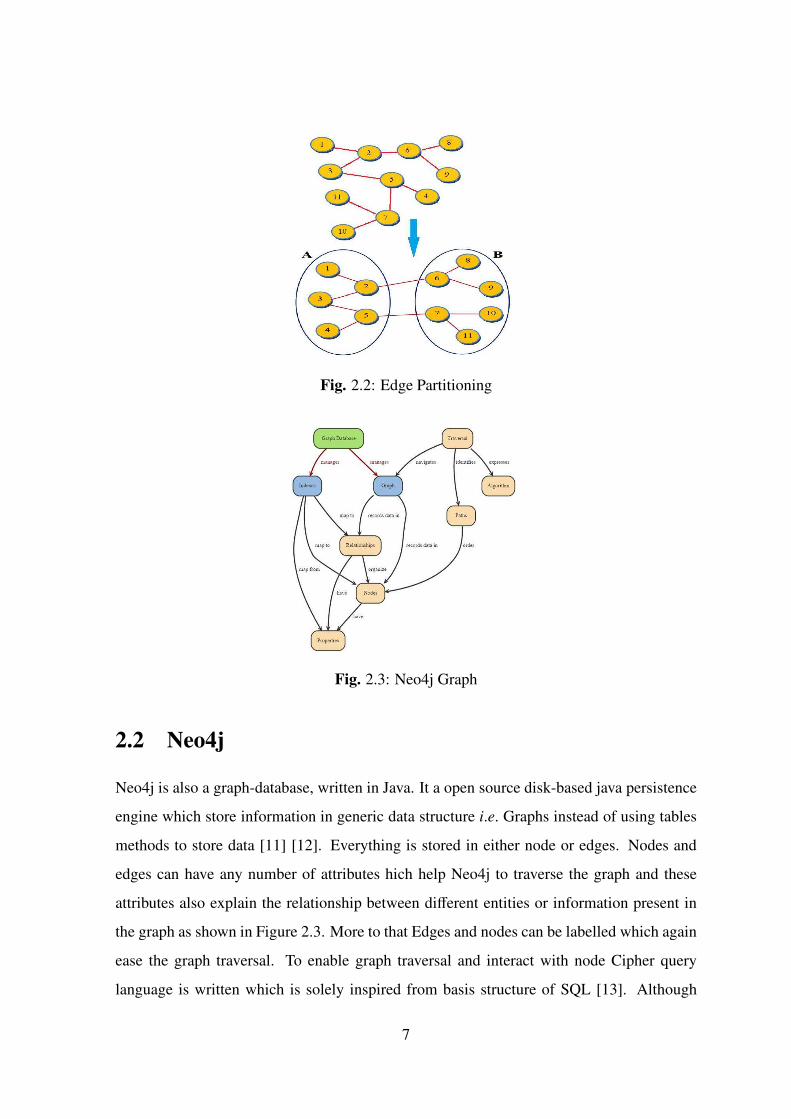
Fig. 2.2: Edge Partitioning
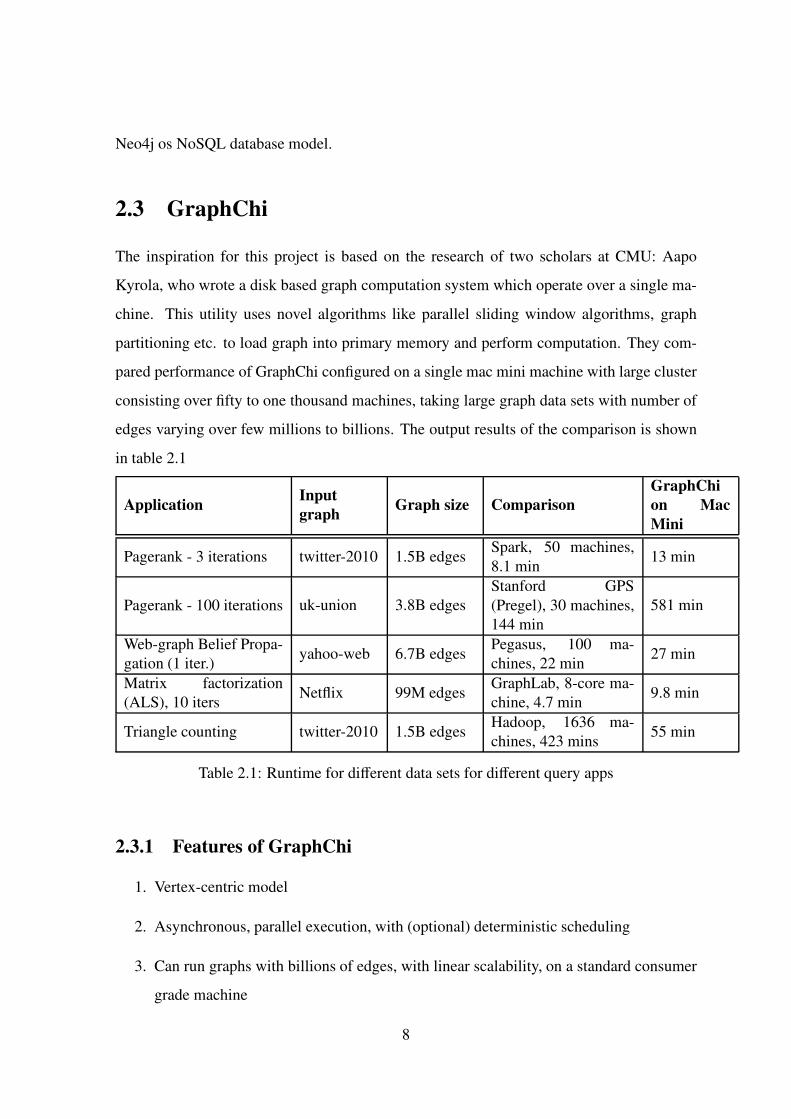
Fig. 2.3: Neo4j Graph
2.2 Neo4j
Neo4j is also a graph-database, written in Java. It a open source disk-based java persistence
engine which store information in generic data structure i.e. Graphs instead of using tables
methods to store data [11] [12]. Everything is stored in either node or edges. Nodes and
edges can have any number of attributes hich help Neo4j to traverse the graph and these
attributes also explain the relationship between different entities or information present in
the graph as shown in Figure 2.3. More to that Edges and nodes can be labelled which again
ease the graph traversal. To enable graph traversal and interact with node Cipher query
language is written which is solely inspired from basis structure of SQL [13]. Although
7
Neo4j os NoSQL database model.
2.3 GraphChi
The inspiration for this project is based on the research of two scholars at CMU: Aapo
Kyrola, who wrote a disk based graph computation system which operate over a single ma-
chine. This utility uses novel algorithms like parallel sliding window algorithms, graph
partitioning etc. to load graph into primary memory and perform computation. They com-
pared performance of GraphChi configured on a single mac mini machine with large cluster
consisting over fifty to one thousand machines, taking large graph data sets with number of
edges varying over few millions to billions. The output results of the comparison is shown
in table 2.1
ApplicationInput
graphGraph size Comparison
GraphChi
on Mac
Mini
Pagerank - 3 iterations twitter-2010 1.5B edgesSpark, 50 machines,
8.1 min13 min
Pagerank - 100 iterations uk-union 3.8B edges
Stanford GPS
(Pregel), 30 machines,
144 min
581 min
Web-graph Belief Propa-
gation (1 iter.)yahoo-web 6.7B edges
Pegasus, 100 ma-
chines, 22 min27 min
Matrix factorization
(ALS), 10 itersNetflix 99M edges
GraphLab, 8-core ma-
chine, 4.7 min9.8 min
Triangle counting twitter-2010 1.5B edgesHadoop, 1636 ma-
chines, 423 mins55 min
Table 2.1: Runtime for different data sets for different query apps
2.3.1 Features of GraphChi
1. Vertex-centric model
2. Asynchronous, parallel execution, with (optional) deterministic scheduling
3. Can run graphs with billions of edges, with linear scalability, on a standard consumer
grade machine
8

4. Works well on both hard-drive and SSD.
5. Evolving graphs, streaming graph updates
6. Easy to install, headers-only, no dependencies.
2.4 Working of Graphchi
GraphChi can perform computation on large graph data sets having over billion edges us-
ing parallel sliding window algorithm. It splits the graph in p number of parts termed as
shards [14].
2.4.1 Parallel Sliding Window
With only a small number of non-sequential disk accesses, PSW can process a graph with
mutable edge values efficiently from disk, while supporting the asynchronous model of com-
putation [15]. PSW processes graphs in three stages:
2.4.1.1 Loads the graph from disk
In PWS methos we split graph in disjoint intervals and associate shards with it. A shard
contains all the edges having destination in these interval, stored in the order of the source.
So when loading th graph it loads one of the p shards completely into the primary, termed as
memory shard. Then parts of the other shards are loaded into the memory that have in-edge
in the memory shard, termed as sliding shard. That make it a subgraph that is loaded into the
memory on which the computation is done. Similarly next shard is loaded into the memory
with respective sliding shards so the window that have in edges keep sliding for next edges.
2.4.1.2 Updates the vertices and edges
After fully loading interaval p subgraph into the memory from the disk, this algorithm ex-
ecutes the update-function for each vertex defines by user, in parallel. We enforce external
determinism to prevent adjacent vertices from accessing edges concurrently, As update-
functions can modify the edge values. It make sure that each execution of parallel sliding
9

window produces exactly the same result. This plays an important role for the accuracy of
the results. Critical edges are updated in sequential order. Non-critical vertices can be up-
dated safely in parallel. This solution, of course, limits the amount of effective parallelism.
For some algorithms.
2.4.1.3 Writes updated values to disk
When GraphChi is done updating and writing edge values, they need to be written back to the
disk. Because it needs to be visible to next execution interval. PSW can do this efficiently:
The edges are cached in memory ny loading them in large blocks from the disk. After creat-
ing subgraph for an interval, pointers to the cached blocks are used as reference to the edges.
That is, modifications to edge values directly modify the data blocks themselves. After fin-
ishing the updates for the execution interval, PSW writes the modified blocks back to disk,
replacing the old data. In this process the memory-shard is completely rewritten, while only
the active sliding window of each sliding shard is rewritten to disk. When PSW moves to
next interval, it reads the new values from disk, thus implementing the asynchronous model.
10

Chapter 3
Implementation and Working
Main focus of this project was large scale graph computation in a distributed way using
Graphchi, a single machine based graph computation framework. But before that perfor-
mance of Graphchi was evaluated with respective to existing graph computation tools. Later
in the next phase of the project to distribute computation over the cluster of Graphchi nodes,
main challenge was to divide the subjected graph, distribute the sub graphs over the cluster
and combining the results from different nodes in order ot get full output for a user query
accurately.Primary features and parts of the project are discussed below:
1. Performance evaluation and results.
2. Graph partition
3. Multi-hop query
4. Cluster of GraphChi Nodes
5. Raspberry Pi
3.1 Performance Evaluation
In the beginning performance of GraphChi was compared with that of Neo4j graph compu-
tation framework. This measurements were taken for single machines with same hardware
and software specifications. Respective nodes were configured with GraphChi and Neo4j.
11

Graph data sets of different sizes based on number of vertices and average degree of vertex
i.e. number of edges varying from 1 Million to few Billion edge were taken for the bench-
marking purposes. Graphs were taken in Edgelist format in GraphChi.
To query a graph with GraphChi framework, existing user programming apps based on
structure and libraries of GraphChi were used. These apps are written to be compatible with
working plan of the GraphChi it uses all the features like storing and excessing graph from
the disk, ensuring random excess to get efficient retrieval of data. Then as explained in work-
ing of Graphi sharding, loading into Ram, computations updating the nodes is done in order
to get the output of the user query performed using user programming app. On other hand
Neo4j takes graph input in .csv format. Graph in Neo4j contains more information about
nodes and relations between them. To query a graph with Neo4j, as it is a NoSQL database
so it has its own querying language called Cipher [13]. Same queries as GraphChi apps
were written in Cipher to perform on Neo4j graph. Time of preprocessing and Execution
were recorder for both for different size graph data sets and compare them after. With the
comparison it came out that for larger graphs GraphChi outrun the performance of Neo4j
with a considerable difference. Some of the numeric results are shown in table 4.1 in chapter.
3.2 Graph Partition
In order to develop a cluster of GraphChi nodes and distribute computation over this cluster,
a huge challenge was how to divide graph in an efficient manner to get accurate results with
least amount of computation and communication overheads. As discussed in chapter 2, dif-
ferent approaches were taken into consideration and implementation to test their respective
benefits and drawbacks for this project both theoretically as well as practically. Some of the
approaches were edge partitioning, vertex cut, Power Graph etc. Every partition paradigm
its different significances. But compatibility with existing GraphChi structure was a big is-
sue. So GraphChi also use partition algorithm to load parts of graphs into main memory
for computation i.e. Sharding was taken into consideration. As this algorithm is already
compatible with our framework and uses GraphChi libraries only.
12

3.2.1 Sub-Graph
As explained in Chapter 2, main inspiration behind this algorithm of partition is PSW. Firstly
Graph is divided into intervals based on the number of vertices, but in case of cluster it is
number of machines connected to server or Master node. Every interval then is connected to
a shard which contains all the in-edges, known as Memory Shard. But when it is loaded into
main memory some part of other shards i.e. Sliding shards are also loaded which contain
out-edges starting from the vertices in memory shard. we have all the information about the
memory shard nodes. It makes a complete graph independent of other parts of the parent
graph and can be used independently on one of the nodes in cluster. So memory shard
and sliding shards gives the sub graphs shown in Figure 3.1. Instead of loading them into
memory for computation, we store all sub graphs from the parent graph into graph files on
Master node to be distributed over the cluster for parallel computation.
Fig. 3.1: Sub-Graph Formation.
3.3 Multi-Hop query
For a multi-hop query, Friends of Friends was chosen as suggested by the initial objectives
of the project. A user programming app is written for this purpose taking advantage of
GraphChi libraries. This is a two step query. After getting Vertex-Id input from user it find
all the nodes having edges directed to the input vertex i.e. friends. Same query is again run
13

for all those output nodes from the first step. Final output gives search results with depth
equal to 2.
Fig. 3.2: Flow chart of cluster working
3.4 Cluster of GraphChi Nodes
To develop cluster nodes raspberry pis, small computing devices were used. Server-client
architecture was implemented for this. Cluster scripts were written in python using sockets
and ssh. Nodes were physically connected using Ethernet cables and switch. GraphChi was
configured on each node before performing any query. There is no communication between
clients. Master node process the graph and divide it into sub graphs using the sharding
algorithm explained above. Then it distribute sub graphs to the clients in the structure using
threads for parallel transfer of data. Now every client has an independent graph to work
on. Input is given as the id of vertex for which we want to find friends of friends. Server
send this input to client having that node in its interval and get back list of its friends by
performing search of single depth. Server then distribute this list on the network depending
on which client has what interval. Same query is run for those vertices on respective clients
in parallel fashion. Finally all the results from clients are collected and merged to get final
14

results using python scripts. working of the cluster is shown in Figure 3.2.
3.5 Raspberry Pi
Raspberry Pis are small and cheap computing devices. It comes with small computing
power. There are number of versions available for operating systems to be used in a rasp-
berry pi, Raspbian was used for this project. SD card was used for additional space required
by Graphchi to process and create graph files. In order to use them as a cluster static IP
address by changing its network files. These operating system comes with the support for
python, sockets etc., that were used in the cluster management scripts. After that GraphChi
was configured on each node, using them as client nodes.
15

Chapter 4
Experimental Studies and Results
In the first half of the project performance GraphChi was compared with Neo4j. Different
multi-hop queries were executed on different data sets varying the number of edges in order
to compute the total time of execution. The results are shown in Table 4.1.
Graph Algorithm Neo4j GraphChi
Twitter Social Network PageRank 684s 495s
Twitter Social Network Connected Components 643s 548s
Table 4.1: Runtime for different data sets on two different computation environments
It was very clear that GraphChi outperform Neo4j for large data sets having edges in
few millions to billions. For small graphs there was not any considerable difference. As
we are dealing with large data set of information hence it is safe to conclude that GraphChi
is better that Neo4j in single machine. Also referring to the original CMU research papers
GraphChi have a execution time comparable with cluster of machine having fifty to one
thousand nodes.
Then a cluster of Raspberry pis were set up. After configuring GraphChi on each node.
Queries like friends of friends were executed in a distributed manner. Cluster programs were
written in python to communicate and exchange data between server and client. Reason
behind using Server-client architecture is that we only need working client to communicate
with server which has all the information needed for the computation for example server
provide the vertex to find friends for and client can work independent of other nodes after
that. So By using this way the message passing and internode communication overhead was
16

neglected.
4.1 Algorithm Complexities
This section contains methamatical complexities of the various algorithms used for writing
programs and user apps.
Notations
NF→ Number of Friends of QV
N→ Number of shards or Intervals
TF→ Number of Friends of Friends Qv
M→ Number of Machines
Fi→ Number of Friends of Qv on machinei
4.1.1 For single Machine
For single machinw total time taken majorly depends on firstly degree of vertex queried plus
degree of the vertices returned as friends for input vertex. Execution Time, T = T1 +T2 +T3
where, T1 = running freinds query on Qv,
T2 = running freinds query on each friends of Qv,
T3 = Extracting the result of friends of friends
Let runtime of friends query be O(x)
T = O(X) + O(FX) + O(T F)
T = O(FX) + O(T F)
4.1.2 For Cluster
For cluster new factor of number of machines present also there. First find query vertex and
its friends that is in order of its degree. retreived results are then returned to the master.
after that same query is run for all vertex but they are distributed based on interval they are
present in. So Interval with maximum number of query vertices will become the deciding
17

factor and degree of vertex present in it. Execution Time, T = T1 + T2 + T3 + T4 + T5
where, T1 = finding machine containing Qv,
T2 = running freinds query on Qv,
T3 = creating sub-lists for different machines of the cluster
T4 = running friends query parallely on all machines,
T5 = extracting results from different machines.
Let runtime of friends query be O(X)
T = O(M) + O(X) + O(FM) + O(max(Fi) ∗ X) + O(T F)
T = O(FM) + O(max(Fi) ∗ X) + O(T F)
4.2 Cluster Performance
After developing distributed user programming app, computation were performed using dif-
ferent cluster specification with different number of nodes. Also queries were performed on
varying size data sets. Results of cluster with 1 to 4 machines (1 Server, 3 clients) are shown
in Table 4.2. It contains Preprocessing time as well as execution time to return the output.
Preprocessing is time taken by GraphChi to load graphs, sharding and create subgraphs, then
after sub graph distribution on each client set up its own GraphChi over received subgraph.
Nodes is the number of clients present in working cluster. These process was followed for
graphs of different sizes carrying number of vertices from approx. .37 Million to approx. 11
Million.
GraphSmall Medium Large
Vertex Id: 3 Vertex Id: 45784 Vertex Id: 45784
Nodes Preprocessing
Time(s)
Run
Time(s)
Preprocessing
Time(s)
Run
Time(s)
Preprocessing
Time(s)
Run
Time(s)
1 18.14642 54.3895 37.4096 551.1842 54.4182 523.206
2 90.9967 24.57306 113.8601 376.0392 145.1398 450.3001
3 95.9638 29.4926 127.3752 392.7315 160.0045 432.5887
Table 4.2: Time analysis for Different Data sets for different custer specification
18
4.2.1 Subsequent Query
Once the cluster is setup completely and for second query there will not be any preprocessing
overhead anymore. So another query was performed with other vertex id on previously setup
and processed system. Table 4.3 contains run times for second queries for same data sets.
To be noted there is no preprocessing time once the system is set up and done performing
one user query.
Graph Small Medium Large
Vertex Id 22190 43989 43989
Nodes Run Time(s) Run Time(s) Run Time(s)
1 154.5285 1282.0674 1208.2224
2 132.5277 1043.1365 815.8312
3 210.5277 858.1176 780.4372
Table 4.3: Time analysis for second Query
4.2.2 Query Output
This section contains output results for Vertices used for different graph data sets. Table 4.4
contains number of Friends and Friends returned by our FriendsofFriends user programming
app. Friends is th enumber of nodes returned by client as the output of first query then this
list will also contain vertex ids of al friends which will be distributed to other cllients to get
final number as well as vertex id of friends of friends.
Sr.No. vertex Id Friends Friends of
Friends
Graph Type
1 3 51 14022 Small
2 221290 123 651423 Small
3 45784 455 1644664 Medium
4 43989 1069 172509 Medium
5 45784 455 16801.7 Large
6 43989 1069 195400 Large
Table 4.4: Outputs
19

4.2.3 Distribution Time
On the initial setup of a graph, there is a one time distribution overhead that is transferring
sub-graphs to the clients nodes after partitioning. To minimize this time we implemented
threads so that subgraph file can be sent from server to all clients simultaneously. Table 4.5
contains distribution overhead in terms of time for different cluster specifications.
Number of
Nodes
Distribution
Time(s)
Graph
Type
Attributes
2 60.8105Small Vertices: 378, 049 Edges: 48, 723, 273
3 81.4019
2 82.7607Medium Vertices: 1, 051, 092 Edges: 67, 706, 979
3 154.0388
2 115.1917Large Vertices: 11, 316, 811 Edges: 85, 331, 846
3 Pending
Table 4.5: Distribution overhead
4.3 Raspberry Pi Cluster
Final expected output for this project was to develop a working prototype of GraphChi
cluster working on cheap small computing devices e.g. Raspberry pis. So we port developed
distributed Grapchi on configured raspberry pi cluster and performed friends of friends query
for a small graph and the data and output result are shown in Table 4.6.
GraphVertices: 45687
Edges: 18, 705, 331
Preprocessing Time 308.75346s
Run Time 417.54757
Distribution Time 127.67022s
Output Friends: 51
Vetex: 3 Friends of Friends:
13789
Table 4.6: Raspberry Pi result
20

Chapter 5
Conclusion and Future Work
Now we know that what kind of power GraphChi has for graph computation and how it
has enables us to perform large scale computations on a consumer level pc. Which is a
huge deal. Existing graph computational frameworks are either commmercial or have a
large cluster requirements. which makes GraphChi so special. It not only outrun a large
cluster performance but also cheap in terms of capital. In our project we tried to see if its
performance can be enhanced with the help of cluster and a distributive GraphChi functions.
Extracted results significantly show that query time can be further minimized by distributing
over a small cluster.
But with progress in this project many things came up, which can be taken into consid-
eration for further deleopment of this project some them are disscussed below:
1. This was the first attempt to divide graph but it leads to new way of partitioning graph
because we get total independent subgraph.
2. Network latency and physical media lead to more subgraph distribution overhead. If
we can decrease this latency by using on chip processing units it will effectively lower
the total execution time.
3. Our main focus was on social media graph analysis e.g. Friends of Friends query but
other apps can also be developed centered on machine learning and data mining or
e.g. Pagerank etc.
21

References
[1] A. Kyrola, “Introdunction to graphchi,” vol. 2, 2012, Description available at
https://github.com/GraphChi/graphchi-cpp.
[2] J. Frand, “Data mining: What is data mining?” 2011, Article available at
http://www.anderson.ucla.edu/faculty/jason.frand/teacher/technologies/palace/datamining.htm.
[3] Takashi Washio, and Hiroshi Motoda, “State of the art of graph-based data mining,”
Research Thesis, Osaka University, Japan.
[4] Yuanyuan Tian, and Andrey Balmin, and Severin Andreas Corsten, and Shirish
Tatikonda , and John McPherson, “From,” Master’s thesis.
[5] Robert Ryan McCune, Tim Weninger, and Greg Madey, “Thinking like a vertex: a
survey of vertex-centric frameworks for large-scale distributed graph processing,” Re-
search Thesis, University of Notre Dame, Jan 2015.
[6] Manuel Then, and Moritz Kaufmann, and Fernando Chirigati, and Thomas Neumann,
“The more the merrier:efficient multi-source graph traversal,” Research Thesis, New
York University, 2011.
[7] Michael T. Goodrich, and Lars Arge, and Nodari Sitchinava, “Parallel external memory
graph algorithms,” Research Thesis, University of California, 2012.
[8] Ulrich Elsner, “Graph partitioning - a survey,” Research Thesis, Technische Universitat
Chemnitz, Dec 1997.
[9] JosephE.Gonzalez, YuchengLow, HaijieGu, DannyBickson, and CarlosGuestrin,
“PowerGraph distributed graph - parallel computationon natural graphs,” Research
Thesis, CarnegieMellonUniversity, 2010.
[10] wiki, “Cut (graph theory),” 2012, http://en.wikipedia.org/wiki/Cut graph theory.
22

[11] Wikipedia, “Neo4j,” 2013, Description available at
https://github.com/GraphChi/graphchi-cpp/wiki/Introduction-To-GraphChi.
[12] lutovich, “Neo4j,” Code available at https://github.com/neo4j/neo4j.
[13] “Cipher query language,” Description available at
http://neo4j.com/docs/stable/cypher-query-lang.html.
[14] aapo Kyrola, “How graphchi works,” vol. 2, 2012, Description available at
http://en.wikipedia.org/wiki/Neo4j.
[15] Cagri Balkesen, and Nesime Tatbul, “Scalable data partitioning techniques for parallel
sliding window processing over data streams,” Research Thesis, ETH Zurich, Switzer-
land, 2011.
23

Curriculum Vitae
Name: Khushpreet Singh
Date of birth: 18 January, 1994
Education qualifications:
• [2011 - 2015] Bachelor of Technology (B.Tech),
Computer Science and Engineering,
Indian Indtitute of Technology,
Himachal Pradesh, India.
Permanent address:
H# 625, W.No 8, Labh Singh St.
Near bus stand, New court road
Mansa, Punjab, India, 151505.
Ph: +918988095924
24
Recommended













![[ACM-ICPC] Traversal](https://img.pdfslide.net/doc/110x75/555602ded8b42a8a5f8b55a7/acm-icpc-traversal.jpg)



