
A memory-based learning-plus-inference approach to morphological analysis
Antal van den Bosch
With Walter Daelemans, Ton Weijters, Erwin Marsi, Abdelhadi Soudi, and Sander Canisius
ILK / Language and Information Sciences Dept.Tilburg University, The Netherlands
FLaVoR Workshop, 17 November 2006, Leuven

Learning plus inference
• Paradigmatic solution to natural language processing tasks
• Decomposition:– The disambiguation of local, elemental
ambiguities in context– A holistic, global coordination of local
decisions over the entire sequence

Learning plus inference
• Example: grapheme-phoneme conversion
• Local decisions – The mapping of a vowel letter in context to
a vowel phoneme with primary stress
• Global coordination– Making sure that there is only one primary
stress

Learning plus inference
• Example: dependency parsing• Local decisions
– The relation between a noun and a verb is of the “subject” type
• Global coordination– The verb only has one subject relation

Learning plus inference
• Example: named entity recognition• Local decisions
– A name that can be a location or a person, is a location in this context
• Global coordination– Everywhere in the text this name always
refers to the location

Learning plus inference
• Local decision making by learning– All NLP decisions can be recast as classification tasks
• (Daelemans, 1996: segmentation or identification)
• Global coordination by inference– Given local proposals that may conflict, find the best
overall solution• (e.g. minimizing conflict, or adhering to language
model)
• Collins and colleagues; Manning and Klein and colleagues; Dan Roth & colleagues; Marquez and Carreras; etc.

L+I and morphology
• Segmentation boundaries, spelling changes, and PoS tagging recast as classification
• Global inference checks for– Noun stem followed by noun inflection– Infix in a noun-noun compound is
surrounded by two nouns– Etc.

Talk overview
• English morphological segmentation– Easy learning– Inference not really needed
• Dutch morphological analysis– Learning operations rather than simple decisions– Reasonably complex inference
• Arabic morphological analysis– Learning as an attempt at lowering the massive
ambiguity– Inference as an attempt to separate the chaff from
the grain

English segmentation
• (Van den Bosch, Daelemans, Weijters, NeMLaP 1996)• Morphological segmentation as classification• Versus traditional approach:
– E.g. Mitalk’s DECOMP, analysing scarcity:• First analysis: scar|city - both stems found in morpheme
lexicon, and validated as a possible analysis• Second analysis: scarc|ity - stem scarce found due to
application of e-deletion rule; suffix -ity found; validated as a possible analysis
• Cost-based heuristic prefers stem|derivation over stem|stem
• Ingredients: morpheme lexicons, finite state analysis validator, spelling changing rules, cost heuristics– Validator, rules, and cost heuristics are costly knowledge-
based resources

English segmentation
• Segmentations as local decisions– To segment or not to segment– If segment, identify start (or end) of
• Stem• Affixes• Inflectional morpheme

English segmentation
• Three tasks: given a letter in context, is it the start of– a segment or not– a derivational morpheme (stem or affix),
inflection, or not– a stem, a stress-affecting affix, a stress-
neutral affix, an inflection, or not

English segmentation

Local classification
• Memory-based learning– k-nearest neighbor classification– (Daelemans & Van den Bosch, 2005)
• E.g. instance # 9– m a l i t i e ?
• Nearest neighbors: a lot of evidence for “2”:
Instance distance clonesm a l i t i e 2 0 2xt a l i t i e 2 1 3xu a l i t i e 2 1 2xi a l i t i e 2 1 11xg a l i t i e 2 1 2xn a l i t i e 2 1 7xr a l i t i e 2 1 5xc a l i t i e 2 1 7xp a l i t i e 2 1 2xh a l i t i c s 2 1x…

Memory-based learning
€
Δ(X,Y ) = wiδ(x i,y i)i=1
n
∑Similarity function:•X and Y are instances
• n is the number of features
• xi is the value of the ith feature of X
• wi is the weight of the ith feature

Similarity function components

Generalizing lexicon
• A memory-based morphological analyzer is– A lexicon: 100% accurate reconstruction of all
examples in training material– At the same time, capable of processing unseen
words
• In essence, unseen words are the only problem remaining– CELEX Dutch has +300k words; average coverage of
text is 90%-95%– Evaluation should focus solely on unseen words– So, a held-out test from CELEX is fairly
representative of unseen words

Experiments
• CELEX English– 65,558 segmented words– 573,544 instances
• 10-fold cross-validation– Measuring accuracy– M1: 88.0% correct test words– M2: 85.6% correct test words– M3: 82.4% correct test words

Add inference
• (Van den Bosch and Canisius, SIGPHON 2006)
• Original approach: only learning• Now: inference
– Constraint satisfaction inference– Based on Van den Bosch and Daelemans
(CoNLL 2005) trigram prediction

Constraint satisfaction inference
• Predict trigrams, and use them as complete as possible
• Formulate the inference procedure as a constraint satisfaction problem
• Constraint satisfaction– Assigning values to a number of variables while
satisfying certain predefined constraints
• Constraint satisfaction for inference– Each token maps to a variable, the domain of which
corresponds to the three candidate labels – Constraints are derived from the predicted trigrams

_h h {
ha { n
{n n t
nd d _
input output
Trigram constraintsh,a,n → h,{,na,n,d → {,n,t
Bigram constraintsh,a → h,{ h,a → h,{a,n → {,n a,n → {,nn,d → n,t n,d → n,d
Unigram constraintsh → h h → h
a → { a → { a → {n → n n → n n → nd → t d → d
(1)
(2)
(3)
(4)
Constraint satisfaction inference

_h h {
ha { n
{n n t
nd d _
input output
Trigram constraintsh,a,n → h,{,na,n,d → {,n,t
Bigram constraintsh,a → h,{ h,a → h,{a,n → {,n a,n → {,nn,d → n,t n,d → n,d
Unigram constraintsh → h h → h
a → { a → { a → {n → n n → n n → nd → t d → d
(1)
(2)
(3)
(4)
Constraint satisfaction inference

_h h {
ha { n
{n n t
nd d _
input output
Trigram constraintsh,a,n → h,{,na,n,d → {,n,t
Bigram constraintsh,a → h,{ h,a → h,{a,n → {,n a,n → {,nn,d → n,t n,d → n,d
Unigram constraintsh → h h → h
a → { a → { a → {n → n n → n n → nd → t d → d
(1)
(2)
(3)
(4)
Constraint satisfaction inference

_h h {
ha { n
{n n t
nd d _
input output
Trigram constraintsh,a,n → h,{,na,n,d → {,n,t
Bigram constraintsh,a → h,{ h,a → h,{a,n → {,n a,n → {,nn,d → n,t n,d → n,d
Unigram constraintsh → h h → h
a → { a → { a → {n → n n → n n → nd → t d → d
(1)
(2)
(3)
(4)
Constraint satisfaction inference

_h h {
ha { n
{n n t
nd d _
input output
Trigram constraintsh,a,n → h,{,na,n,d → {,n,t
Bigram constraintsh,a → h,{ h,a → h,{a,n → {,n a,n → {,nn,d → n,t n,d → n,d
Unigram constraintsh → h h → h
a → { a → { a → {n → n n → n n → nd → t d → d
(1)
(2)
(3)
(4)
ConflictingConflictingconstraintsconstraints
Constraint satisfaction inference

Weighted constraint satisfaction
• Extension of constraint satisfaction to deal with overconstrainedness
– Each constraint has a weight associated to it
– Optimal solution assigns those values to the variables that optimise the sum of weights of the constraints that are satisfied
• For constrained satisfaction inference, a constraint's weight should reflect the classifier's confidence in its correctness

Example instances
Left focus right uni tri_ _ _ _ _ a b n o r m 2 -20_ _ _ _ a b n o r m a 0 20s_ _ _ a b n o r m a l s 0s0_ _ a b n o r m a l i 0 s00_ a b n o r m a l i t 0 000a b n o r m a l i t i 0 000b n o r m a l i t i e 0 000n o r m a l i t i e s 0 001o r m a l i t i e s _ 1 010r m a l i t i e s _ _ 0 100m a l i t i e s _ _ _ 0 000a l i t i e s _ _ _ _ 0 00il i t i e s _ _ _ _ _ i 0i-

Results
• Only learning:– M3: 82.4% correct unseen words
• Learning + CSI:– M3: 85.4% correct unseen words
• Mild effect.

Dutch morphological analysis
• (Van den Bosch & Daelemans, 1999; Van den Bosch & Canisius, 2006)
• Task expanded to– Spelling changes– Part-of-speech tagging– Analysis generation
• Dutch is mildly productive– Compounding– A bit more inflection than in English– Infixes, diminutives, …

Dutch morphological analysis
Left focus right uni tri_ _ _ _ _ a b n o r m A -A0_ _ _ _ a b n o r m a 0 A00_ _ _ a b n o r m a l 0 000_ _ a b n o r m a l i 0 000_ a b n o r m a l i t 0 000a b n o r m a l i t e 0 000b n o r m a l i t e i 0 00+Dan o r m a l i t e i t +Da 0+DaA_->No r m a l i t e i t e A_->N +DaA_->N0r m a l i t e i t e n 0 A_->N00m a l i t e i t e n _ 0 000a l i t e i t e n _ _ 0 000l i t e i t e n _ _ _ 0 00plurali t e i t e n _ _ _ _ plural 0plural0t e i t e n _ _ _ _ _ 0 plural0-

Spelling changes
• Deletion, insertion, replacement
b n o r m a l i t e i 0n o r m a l i t e i t +Dao r m a l i t e i t e A_->N
• abnormaliteiten analyzed as [[abnormaal]A iteit]N[en]plural
• Root form has double a, wordform drops one a

Part-of-speech
• Selection processes in derivation
n o r m a l i t e i t +Dao r m a l i t e i t e A_->Nr m a l i t e i t e n 0
• Stem abnormaal is an adjective;• Affix -iteit seeks an adjective to its left
to turn it into a noun

Experiments
• CELEX Dutch:– 336,698 words– 3,209,090 instances
• 10-fold cross validation• Learning only: 41.3% correct unseen
words• With CSI: 51.9% correct unseen words• Useful improvement

Arabic analysis(Marsi, Van den Bosch, and Soudi, 2005)

Arabic analysis
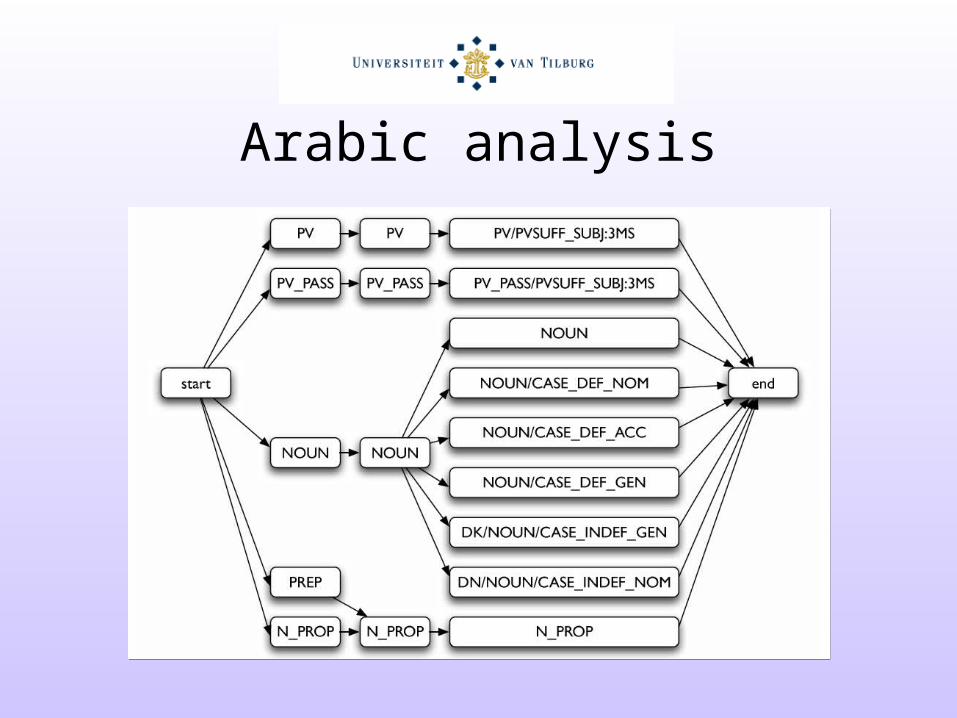
Arabic analysis

Arabic analysis
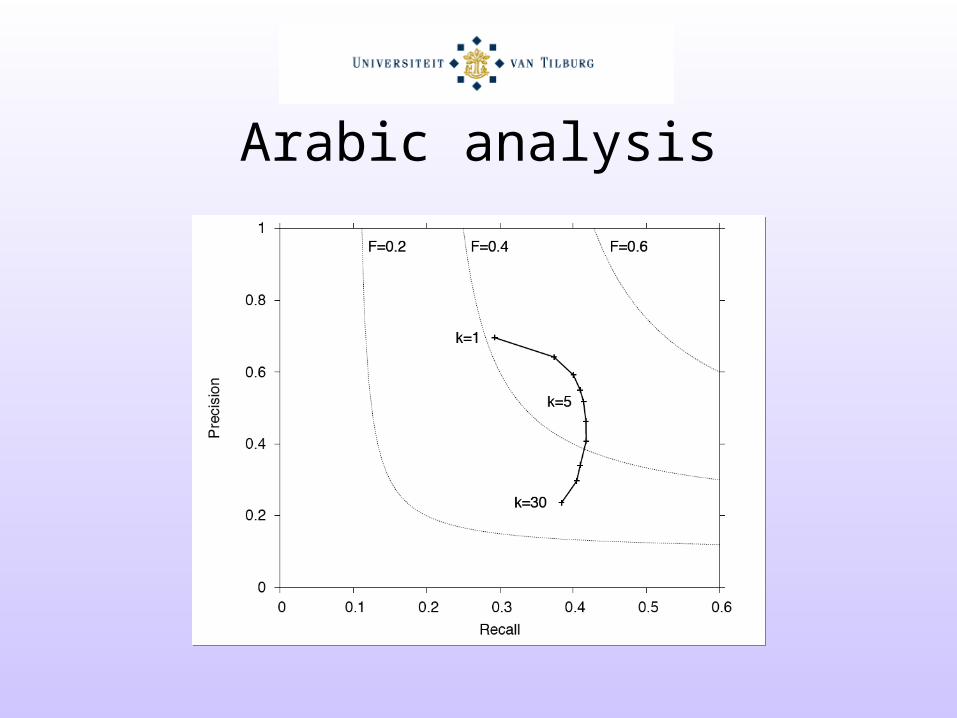
Arabic analysis

Arabic analysis
• Problem of undergeneration and overgeneration of analyses
• Undergeneration: at k=1, – 7 out of 10 analyses of unknown words are correct,
but– 4 out of 5 of the real analyses are not generated
• Overgeneration: at k=10,– Only 3 out of 5 are missed, but– Half of the generated analyses is incorrect
• Harmony at k=3 (F-score 0.42)

Discussion (1)
• Memory-based morphological analysis– Lexicon and analyzer in one– Extremely simple algorithm
• Unseen words are the remaining problem• Learning: local classifications
– From simple boundary decisions– To complex operations– And trigrams
• Inference:– More complex morphologies need more inference
effort

Discussion (2)
• Ceiling not reached yet; good solutions still wanted– Particularly for unknown words with
unknown stems– Also, recent work by De Pauw!
• External evaluation needed– Integration with part-of-speech tagging
(software packages forthcoming)– Effect on IR, IE, QA– Effect in ASR
Recommended


















