A W-test for main effect and epistasis testing in GWAS data
Maggie Haitian Wang, PhDCentre for Clinical Research and Biostatistics (CCRB)
Faculty of Medicine, The Chinese University of Hong Kong (CUHK)[email protected]
http://www2.ccrb.cuhk.edu.hk/statgene
GIW2016, Shanghai

2
• Genetic association studies aim to identify disease associated bio-markers, to discover disease mechanism, potential drug targets, and disease sub-typing.
Background
http://www.mediapharma.it/wp-content/uploads/2012/06/personalised-medicine.jpg
Disease mechanism Drug target identification Precision medicine

3
Technology Data types Methods
http://www.nature.com/polopoly_fs/7.14984.1389810620!/image/HiSeqX_Ten_Single_Instrument_630.jpg_gen/derivatives/landscape_630/HiSeqX_Ten_Single_Instrument_630.jpg
• lasso• t-test• Chi-squaredtest• Tree-based….
Genetic association study

4
• Next generation sequencing (NGS) data: – More than 99% of the single nucleotide polymorphisms (SNPs) have minor
allele frequency (MAF) < 1% – Rare variants methods
• Genome-wide association studies (GWAS): – Majority of the SNPs have MAF > 5%– Common variant Methods: Fisher’s exact test, Chi-squared, Odds ratio, linear
or logistic regressions • The low frequency SNPs (1%< MAF< 5%) remain largely under-studied.
– Loss of function alleles are enriched in low frequency variants. (MacArthur et al. 2015 Science)
Methods by data types

5
• Ultra-high data dimension: – Burden of multiple testing:
GWAS data: 500,000 SNPs, NGS: > 10 million SNPs– Requirement on test efficiency – Difficulty to consider interaction effects due to data size and sparsity
• Results validation– Crucial to replicate GWAS results (Kraft, Zeggini and Ioannix 2009)
Common challengesof Genetic association studies
Kraft,Zeggini andIoannix (2009)Replicationingenome-wideassociation study,StatisticalScience

6
• Basic hypothesis:
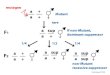
• Under a co-dominant model: – the genotype X can be coded to takes values: (0, 1, 2)– a pair of SNPs (X1, X2): forms a 2 by 9 contingency table
The W-test formulation
Thestatisticaldistributionsofasetofdisease-associatedmarkersaredifferentinthecasegroupfromthatinthecontrolgroup.
n01
n11
ControlCase
n02
n12
n0k
n1k
…
…
n0i
n1i
…
… k=9

7
• The cell distribution of (X1, X2) in the case and control group:
– n1i : number of case subjects in the ith cell– n0i : number of control subjects in the ith cell – N1 : total number of cases– N0 : total number of controls
The W-test formulation
,)1|Pr(ˆ1
11 N
nYXp ii === ki
NnYXp i
i ,...,1,)0|Pr(ˆ0
00 ====

8
• First, combine the normalized log odds ratios of the cell probability distributions:
where,
• The squared terms in the summation are not independent
The W-test formulation
2
1 00
112
)ˆ1/(ˆ)ˆ1/(ˆlog∑
=⎥⎦
⎤⎢⎣
⎡
−−
=k
ii
ii
ii SEppppX
€
SEi =1n0i
+1n1i
+1
N0 − n0i+
1N1 − n1i
n01
n11
.
.
.
ControlCase
ControlCase
1logOR
2logOR
3logOR
kORlog
.
.
.
( )
221
22
~
log
f
k
iii
hXW
SEORX
χ=
=∑=
Original cell divisionn02
n12
n0k
n1k
…
…
n0i
n1i
…
…
ControlCase
ControlCase

9
• The actual distribution of the X2 can be estimated by matching its first two moments to a random variable R:
• Let
The W-test formulation
2fcR χ=
).,cov(22
),cov(2)(),cov()(
)(
22
22
1
22222
2
jiji
jijii
k
ii
jji
xxk
xxxVarxxX
kXE
∑∑
∑∑∑ ∑∑
<
<=
+=
+==
=
σ
⎩⎨⎧
=
=
fcXcfXE222
2
2)()(
σ
Chuang and Shih (2012), Hou (2005)

10
• The c and f are:
• Let h=1/c, we have
The W-test formulation
,2
),cov(22
)(2)(
22
2
22
k
xxk
XEXc
jiji∑∑<
+
==σ
),cov(22
2)()]([2
22
2
22
22
jiji
xxk
kXXEf
∑∑<
+==
σ
22
1 00
11 ~)ˆ1/(ˆ)ˆ1/(ˆ
log f
k
ii
ii
ii SEpppphW χ∑
=⎥⎦
⎤⎢⎣
⎡
−−
=

11
• In real data the h and f are estimated using bootstrapped samples
• Cov is estimated by large sample theories.
• h and f converge when – B> 200 – bootstrap NB= min (1000, N) – PB= min (1000, P)
• Empirically: h ≈ (k − 1)/k, f ≈ k − 1
Distribution of W-test
µσ
=vCCoefficient of variation: measures estimated h and f convergence

12
• The W-test follows a Chi-squared distribution, in which the degrees of freedom is estimated using smaller bootstrapped samples – It’s probability distribution is data-adaptive– No need of permutations to calculate p-values – important for genome data
• Model free– Odds ratio based, suitable for case-control data set
• Flexible– Handles SNP-SNP interactions– Handles main effect
• When k=2, it reduces to a classical odds ratio test for 2x2 table.
Properties

13
• Important Genetic architectures that will influence testing power:– MAF > 5% (common) – 1% < MAF < 5% (low frequency) – Linkage Disequilibrium (LD) <20% (Low)– 20%<LD<80%(mid)– LD>80%(high)
Simulation studies design

• Phenotype determined by: – A linear model:
– A non-linear model: without any main effect:
14
Simulation studies design
⎪⎩
⎪⎨
⎧
=
=+++
=+++
==
4.03.03.0
)]1([
8
43746354
21322110
ppXXXXpXXXX
YPLOGITβ
ββββ
ββββ
⎪⎩
⎪⎨
⎧
=
=+
=+
=
4.01,03.0)2(mod3.0)2(mod
43
21
ppXXpXX
Y

15
• Power: 1000 simulations• Type I error: 1 million simulations• Number of candidates SNPs: 50• Number of pairs: 1,225• Causal pairs: 2• Bonferroni corrected significance level for 5% alpha: 4.1×10-5
Power and type I error

16
Methods Low LD Moderate LD High LD
Logistic 68.5% 76.9% 83.3%
Chi-squared 60.0% 67.2% 74.5%
W 71.1% 81.0% 86.7%
Power for linear model
Methods Low LD Moderate LD High LD
Logistic 47.1% 62.5% 71.1%
Chi-squared 42.2% 65.2% 74.0%
W 49.8% 79.5% 83.8%
MAF > 5%
1%< MAF < 5%

17
Methods LowLD ModerateLD HighLD
Logistic 5.9% 1.7% 0.6%
Chi-squared 72.6% 69.4% 62.8%
W 88.0% 86.6% 79.4%
Power for non-linear model
Methods Low LD Moderate LD High LD
Logistic 61.7% 31.8% 43.7%
Chi-squared 67.4% 43.9% 49.1%
W 95.6% 83.3% 83.9%
MAF > 5%
1%< MAF < 5%

18
Type I error - nominal
Methods LowLD ModerateLD HighLD
Logistic 3.92% 5.88% 3.92%
Chi-squared 2.82% 1.72% 3.06%
W 5.39% 6.00% 5.51%
Methods LowLD ModerateLD HighLD
Logistic 4.53% 5.27% 5.64%
Chi-squared 0.37% 0.25% 0.25%
W 4.04% 5.15% 6.74%
MAF > 5%
1%< MAF < 5%

19
• Onlaptopcomputerwith2.4GHzCPUand8GBmemory,thetimeelapsedforcomputing1000subjectsand50SNPsinteractionseffectexhaustivelyis:
Computing Speed
7.4 7.7
45.7
0
10
20
30
40
50
W-test Chi-square Logistric
Time (s)
Time (s)

20
W-test is robust when sample size reduces
LowfrequencymidLDenvironmentNon-linearmodel

21
• Dataset 1. Welcome Trust Case-control Consortium (WTCCC) bipolar data set (Burton, Clayton et al. 2007).
- 2,000 cases and 3,000 controls- 414,682 SNPs after QC
• Dataset 2. Genetic Association Information Network (GAIN) bipolar project in dbGaP database (McInnis, Dick et al. 2003)
- 1,079 cases and 1,089 controls- 729,304 SNPs after QC
Real data application

22
Q-Q Plot of W-test on real GWAS
Noinflationofspuriousassociation

(a)WTCCCdata
(a)GAINdata
• MaineffectmarkersareselectedatGenome-widesignificantP-values
23
Main effect - Manhattan plots

24
• 51 Genome-wide significant SNPs in WTCCC• 76.4% of the significant markers identified are low frequency variants.• PARK2 (rs2849605, 6q5.2) has been identified. • Neuron functions genes: HTR3B (rs17116117, 11q23.1) and CNTNAP5
(rs1919835, 2q14.3). – The HTR3B is a neuron transmitter and causes fast, depolarizing responses in
neurons after activation (Davies et al 1999). – The CNTNAP5 has been identified by many previous independent genetic and
pedigree data sets on bipolar disorder (Djurovic, Gustafsson et al. 2010), schizophrenia (Levinson, Shi et al. 2012), and autism (Pagnamenta, Bacchelli et al. 2010)
•
Significant main effects - WTCCC
MAF=4.2%
MAF=1.1%

25
• RTN4R(SNP_A-8429018,22q11.21)– encodesanogo receptor– mediatesaxonalgrowthinhibitionandmayplayaroleinregulatingaxonalregeneration
andplasticityinthecentralnervoussystem– Studiesreportedthatthedeletionofthegenewillcauseabnormalityinbrainwhite
matters(Perlstein,Chohan etal.2014);– humanandmousegeneticstudysuggestedthegenetobeacandidatemarkerfor
schizophrenia(Hsu,Woodroffe etal.2007).• Thoughnumerousevidencesofthegene’sroleinneurologydisordersfrombiomedical
experimentsandgeneticstudies,thegenehasnotbeenpreviouslydiscoveredfromtheGAINdataset(McInnis,Dicketal.2003).
Significant main effects
MAF=12.2%

26
Replicated significant epistasis effect
Genes replicated in WTCCC and GAIN datasetsOnly identified in GAIN dataMain effect not significant
Main effect significant Only identified in WTCCC data Significant interaction Weak interactions
CENPN
NRXN3
PTPRTTMEM132D
SLIT3
DPP10
CSMD1
RTN4R
A2BP1
NDST4
MYO16
ELMO1
ACCN1
PARK2
HNT
RTN4R
CNTNAP2
MACROD2

27
• A majority of these replicated genes are marginally insignificant -undiscoverable through main effect screening
Replicated significant epistasis effect
SNP Gene Position MAF* P-value of pair*
rs6741692 DPP10 2q14 0.303 5.8E-38rs2407594 CSMD1 8p23 0.029 9.8E-36rs1864952 SLIT3 5q35 0.046 1.9E-35rs2849605 PARK2 6q5.2 0.021 3.3E-29rs3867492 TMEM132D 12q24.33 0.030 1.0E-27rs11222695 HNT 11q25 0.012 2.7E-25rs1494451 CNTNAP2 7q35 0.025 1.3E-21rs2785061 ACCN1 17q12 0.028 9.8E-19rs17135053 A2BP1 16p13.3 0.025 3.9E-18rs17170832 ELMO1 7p14.1 0.017 3.9E-18rs9559408 MYO16 13q33.3 0.035 4.8E-17

28
• DPP10: facilitates neuronal excitability and its aberrant distribution is associated with Alzheimer’s disease as revealed by immunohistochemistry (Chen et al 2010 Biomed Res Int.)
• TMEM132D: a transmembrane protein expressed in white matter in the spinal cord and optic nerve. (Nomoto 2003 J Biochem)
• PTPRT : a receptor-type protein tyrosine phosphatase for signal transduction and neurite extension, which promotes synapse formation and is reported to be highly expressed in the central nervous system (Lin 2009 Embo J)
Replicated epistasis genes

29
• wtest is submitted to CRAN, and on our website: www2.ccrb.cuhk.edu.hk/statgene
R-package: wtest
- MHWang, RSun, JGuo,HWeng, JLee,IHu,PShamandBCYZee(2016). AfastandpowerfulW-testforpairwise epistasistesting.NucleicAcidsResearch.- RSun, BChang,BCYZee,MHWang.wtest:anRpackagefortestingmainandinteractioneffectingenotypedata withbinarytraits.

30
• PhD Student: Rui Sun• Programming Support: Junfeng Guo• wtest software: www2.ccrb.cuhk.edu.hk/wtest/download.html• Our group: www2.ccrb.cuhk.edu.hk/statgene
• Grants supported this work: – Hong Kong RGC-GRF Grant [476013]– NSFC [81473035, 31401124]– CUHK Direct Grant [2014.01]
Acknowledgement

© Faculty of Medicine The Chinese University of Hong Kong
Thank you!
Maggie H. Wang: [email protected]
Recommended