
1CEA/DEN/DANS/DM2S/SERMA
HPC for reactor physics
C. Calvin - C. Diop
CEA – Nuclear Energy Division
CEA/DEN/DANS/DM2S/SERMA

2CEA/DEN/DANS/DM2S/SERMA
Outline
• Introduction: today and future solutions for HPC (a short intro.)– Hardware zoology
– Software
– CEA/DEN tools in this landscape
• HPC for reactor physics– Objectives and simulation targets
• HPC in deterministic simulations– APOLLO2, CRONOS2, APOLLO3
• HPC in Monte Carlo simulations– TRIPOLI-4

3CEA/DEN/DANS/DM2S/SERMA
Hardware & software zoology
• Hardware– Vector machines : CRAY X1, NEC SX9– Parallel machines
• Based on standard processors (Intel, AMD, IBM Power)• Network of workstations (NOW)• Cluster of SMP (SGI, IBM, HP, SUN, BULL)• MPP (IBM Blue Gene, CRAY XT4))
– Trends• All the processors are multi-core ones ↑↑↑↑• Petaflops ���� power / Flops• Accelerators (GPU, Cell, Clearspeed, FPGAs, …) -Hyb rid architecture
(CRAY XT5h)• Software
– Today: Mainly 2:• Explicit message passing between processors (MPI)• Communication through memory and multithreading (OpenMP)
– Today +1:• Specific language for accelerators (CUDA, CELL SDK, …)• Tentative of generalization (RapidMind, CAPS HMPP, …)
– Tomorrow:• New languages for managing complexity of
– Hybrid architecture– Massive multi-cores in a node– Machine with many many cores (>100 000)
• UPC, CAF, X10, Chapel

4CEA/DEN/DANS/DM2S/SERMA
TOP 500 List – June 2008 - Europe
51
46
50
49
60
54
60
64
63
62
94
126
156
111
123
139
223
RPeak
5548Cray XT4Cray Inc.Univ. of Bergen47
16384Blue GeneIBMFZJ46
5336ACTION ClusterACTIONGdansk45
7680Novascale 3045Bull SACEA42
6400Cluster Platform 3000 DL140HPNSC40
5376BladeCenter HS21IBMHPC2N39
5000T-Platforms T60, T-PlatformsMoscow Univ.36
9968NovaScale 5160,Bull SACEA32
11328Cray XT4, 2.8 GHzCray Inc.Univ. of Edinburgh29
9728Altix 4700 1.6 GHzSGILeibniz27
10240BladeCenter JS21 ClusterIBMBSC26
6720Power 575IBMRZG/Max-Planck19
8320Power 575IBMECMWF18
32768Blue Gene/P SolutionIBMEDF R&D13
10240SGI Altix ICE 8200EXSGITotal10
40960Blue Gene/P SolutionIBMIDRIS9
65536Blue Gene/P SolutionIBMFZJ6
ProcComputerManuf.SiteRank

5CEA/DEN/DANS/DM2S/SERMA
CEA/DEN tools in this landscape
• Hardware:
– Production:• Vector machine (NEC SX8+ - CCRT)
• NOW (Dep.)• SMP and cluster of SMPs (Dep. + BULL Novascale CCRT)
– Experimentation• MPP (Blue Gene)
• Accelerators (Cell, GPU – CCRT)
• Software:
– MPI, PVM, OpenMP Machine NEC2 TflopsMémoire 0.9ToDisques 40 To
Système de stockage
1 Gb/s
utilisateursutilisateurs
Cluster HP Opteron2.4 TflopsMémoire 0,8 ToDisques 12 To
Niveau 1 : 520To disques Sata DDN
Serveur NFS
6 Liens 10 Gb/s
Backbone CCRT10 Gbits/s
2*SGI Altix 450+ DMF
Niveau 2 : robotique STK (9940, T10000)
8 Liens 10 Gb/s
Cluster BULL47.7 Tflops Mémoire 23.2 ToDisques 420 To
8 Liens 1Gb/s
4 Liens 1 Gb/s
Machine NEC2 TflopsMémoire 0.9ToDisques 40 To
Système de stockage
1 Gb/s
utilisateursutilisateurs
Cluster HP Opteron2.4 TflopsMémoire 0,8 ToDisques 12 To
Niveau 1 : 520To disques Sata DDN
Serveur NFS
6 Liens 10 Gb/s
Backbone CCRT10 Gbits/s
2*SGI Altix 450+ DMF
Niveau 2 : robotique STK (9940, T10000)
8 Liens 10 Gb/s
Cluster BULL47.7 Tflops Mémoire 23.2 ToDisques 420 To
8 Liens 1Gb/s
4 Liens 1 Gb/s
CCRT
2008: 48TFlops (CCRT)+ 2TFlops (2008: 48TFlops (CCRT)+ 2TFlops (DepDep.).)2009: +103TFlops + 192 2009: +103TFlops + 192 TFlopsTFlops (GPU) (GPU) -- CCRTCCRT
End 2009: 350TFlopsEnd 2009: 350TFlops
End 2010: 1PFlops (PRACE)End 2010: 1PFlops (PRACE)

6CEA/DEN/DANS/DM2S/SERMA
CEA/DEN tools in this landscape
RoadRunnerRoadRunner: 1st 1PFlops : 1st 1PFlops sustainedsustained –– JuneJune 20082008
IBM IBM HybridHybrid architecture architecture –– OpteronOpteron+CELL BE+CELL BE
�� NextNext stepstep EXAFLOPSEXAFLOPS

7CEA/DEN/DANS/DM2S/SERMA
0s 3 years 50 years 10 6 years time
Core physics, criticality, radiation shielding, Instrumentation
Application fields and challenges
. Particles propagation– neutrons, …-
. Isotopic depletion
. Energy range: 0. – 20 MeV
. Domain size: ���� 30 000 m3 ≡≡≡≡ 3. 1010 cm3
radioactivity α, β, γ, n,
In core stayPool storage
Fuel transport, refining, production
Dismantling Geological warehousing

8CEA/DEN/DANS/DM2S/SERMA
HPC For reactor physics: simulation targets
• To provide simulation capabilities in order to:– To simulate specific situations for safety reasons
•• Sensibility calculations, Transient simulations Sensibility calculations, Transient simulations – Allow fast design of complex reactors
•• Design simulationsDesign simulations– Validate and qualify models and calculation routes
when experiments are not possible or to expensive
•• Reference simulationsReference simulations– Improve reactor management
•• Real time simulationReal time simulation
• These simulations have to be the most realistic as possible and this implies use of very fine 3D 3D modelingmodeling .
New reactor generation New reactor generation �������� new approach for design and safety new approach for design and safety �������� new code generationnew code generation
With controlled uncertaintiesWith controlled uncertainties
9CEA/DEN/DANS/DM2S/SERMA
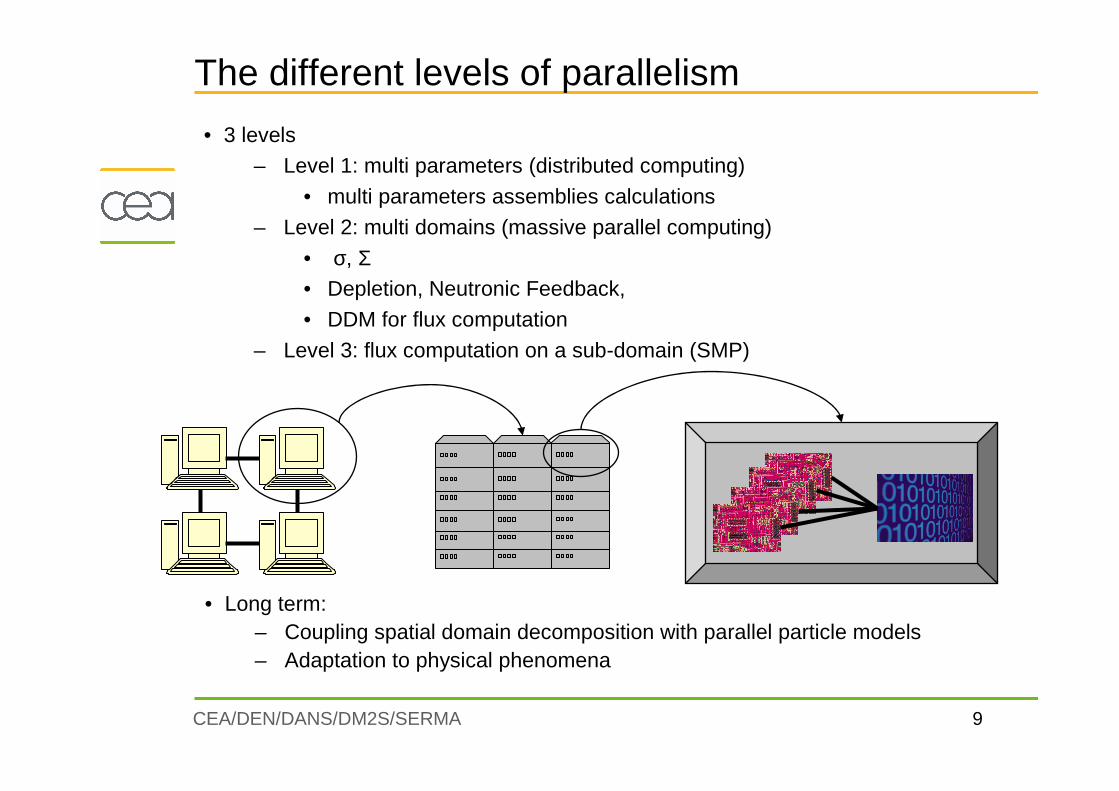
The different levels of parallelism
• 3 levels– Level 1: multi parameters (distributed computing)
• multi parameters assemblies calculations
– Level 2: multi domains (massive parallel computing)
• σ, Σ• Depletion, Neutronic Feedback,
• DDM for flux computation
– Level 3: flux computation on a sub-domain (SMP)
• Long term:– Coupling spatial domain decomposition with parallel particle models– Adaptation to physical phenomena

10CEA/DEN/DANS/DM2S/SERMA
Some existing references (SERMA)
• Solvers parallelization:– MINOS Parallelization and depletion solver in CRONOS2 :
• MINOS : OpenMP between 60% (4 threads) and 80% (2 threads) efficiency
• Micro depletion: MPI, > 90% (CRONOS2.8)•• «« Application of multiApplication of multi--threaded computing and domain decomposition to 3D threaded computing and domain decomposition to 3D
neutronicsneutronics FEM code CRONOSFEM code CRONOS »», J. Ragusa, SNA 2003, J. Ragusa, SNA 2003
•• «« Implementation of multithreaded computing in the MINOS Implementation of multithreaded computing in the MINOS neutronicsneutronics solver solver of the CRONOS codeof the CRONOS code »», J. Ragusa, Nuclear Mathematical and Computational , J. Ragusa, Nuclear Mathematical and Computational Sciences Sciences –– 20032003
– CP solver parallelization in APOLLO2 :
• Coupling APOLLO2 C90 – CP solver // T3e – Sp = 17 on 32 proc (Ts on C90)
•• «« Advanced plutonium assembly parallel calculations using the APOLAdvanced plutonium assembly parallel calculations using the APOLLO2 LO2 codecode »», Z. , Z. StankovskiStankovski, A. , A. PuillPuill, L. , L. DullierDullier, M&C, M&C’’9797
• 2 levels parallelism:
– On energy groups using PVM
– In one energy group, trajectories parallelization using OpenMP•• «« ArlequinArlequin: an integrated java application: an integrated java application »», Z. , Z. StankovskiStankovski, Java Grande, Java Grande’’2001 2001

11CEA/DEN/DANS/DM2S/SERMA
T1: Multi-parameters calculations and sensibilities
• Parameterization of nuclear data with APOLLO2 (EDF, AREVA): – All the computations are independent and are achieved in //– 50 000 computation 2D / assembly level– Example:
• Lib. UO2: 160h with 1P, from 12 to 20h with 13 P.• Lib. Gado : 256h with 1P, 37h with 13 P•• Note SERMA/LENR/RT/02Note SERMA/LENR/RT/02--3123/A, J. Ragusa3123/A, J. Ragusa
• Nuclear fuel optimization using genetic algorithms: – APOLLO3 diffusion solver: MINOS – 200 000 2D core calculations in 30 minutes using 30
processors–– Note SERMA/LLPR/RT/07Note SERMA/LLPR/RT/07--4332/A, G. Arnaud et al. 4332/A, G. Arnaud et al.
• Simulation of incidental or accidental configuration of power plants.
– CRONOS2 - FLICA4 with sensibilities analyses (10-4s time step)
– Already effective 3D power map - RIA simulation (CRONOS-2/FLICA-4 codes )
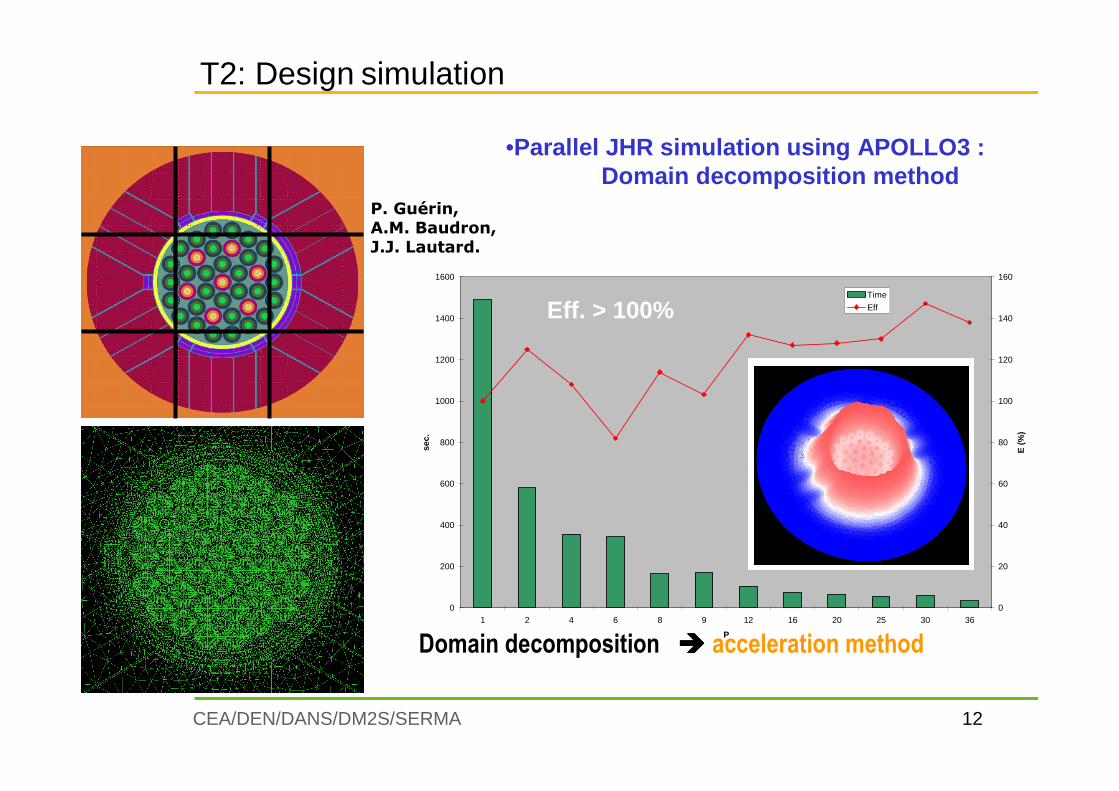
12CEA/DEN/DANS/DM2S/SERMA
•Parallel JHR simulation using APOLLO3 :Domain decomposition method
0
200
400
600
800
1000
1200
1400
1600
1 2 4 6 8 9 12 16 20 25 30 36
P
sec.
0
20
40
60
80
100
120
140
160
E (
%)
Time
Eff
Domain decomposition ���� acceleration method
T2: Design simulation
Eff. > 100%
P. Guérin, A.M. Baudron, J.J. Lautard.
13CEA/DEN/DANS/DM2S/SERMA
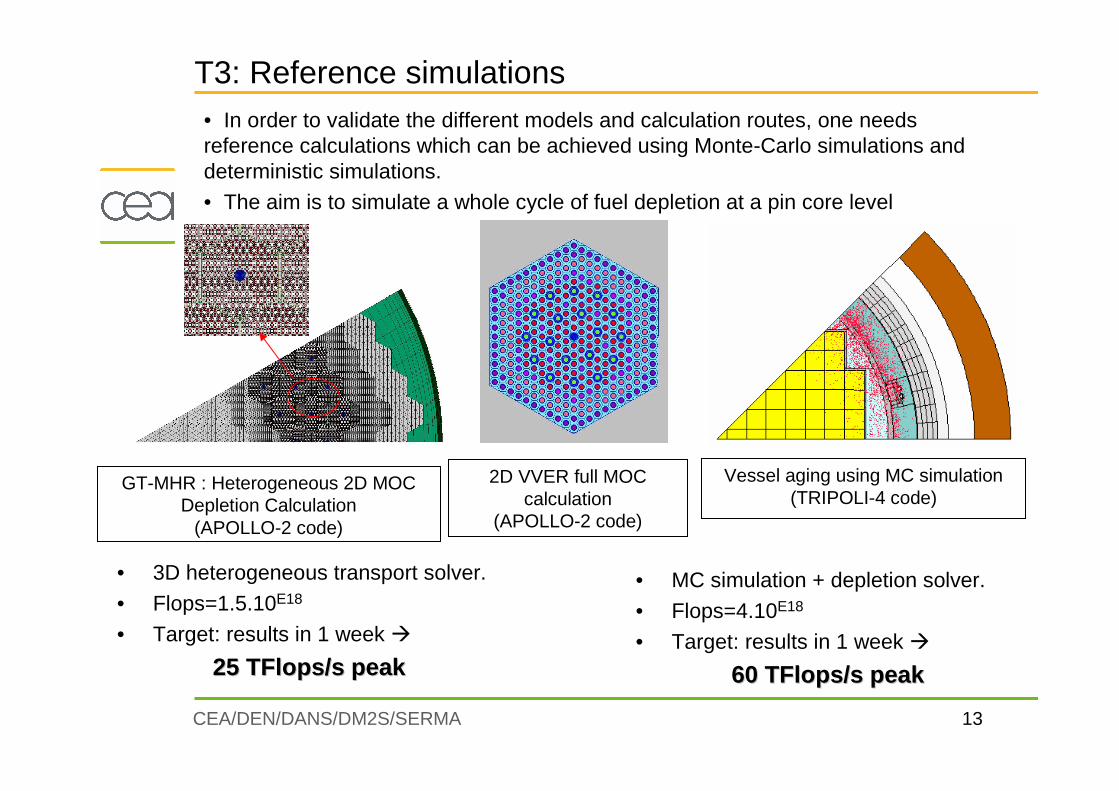
T3: Reference simulations• In order to validate the different models and calculation routes, one needs reference calculations which can be achieved using Monte-Carlo simulations and deterministic simulations. • The aim is to simulate a whole cycle of fuel depletion at a pin core level
GT-MHR : Heterogeneous 2D MOCDepletion Calculation
(APOLLO-2 code)
Vessel aging using MC simulation (TRIPOLI-4 code)
• 3D heterogeneous transport solver.
• Flops=1.5.10E18
• Target: results in 1 week �
25 25 TFlops/sTFlops/s peakpeak
• MC simulation + depletion solver.
• Flops=4.10E18
• Target: results in 1 week �
60 60 TFlops/sTFlops/s peakpeak
2D VVER full MOC calculation
(APOLLO-2 code)

14CEA/DEN/DANS/DM2S/SERMA
T4: Real time neutronics
• Objectives– Simulator: real time simulation of the reactor behavior
(training, optimization)
– Real time control: Embedded calculator in order to control the reactor behavior
• Mainly simplified models in order to reach real time
– � Try to have more accurate modeling (3D, TH feedbacks, …)
• Computing time: TARGET 1s time/step
• Industrial scheme
– Homogenized description, Diffusion, 2g, Simp. TH/TM, depl.
• � 30s / time step• With moderated parallelism < 5s (8 cores)
• Fine modeling
– Pin/pin description, SPn,Multi-groups, Simp. TH/TM, depl.
• � 3 000s / time step � >2 TFlops
APOLLO3

15CEA/DEN/DANS/DM2S/SERMA
T4: Real time neutronics
• Real time simulation neutronics cannot be achieved using massive parallel computing:
– Either for simulator or industry, need to have “reachable” architecture
• How to obtain real time simulation without using >>100 processors ?
• Use of the other side of HPC: obtain the best performance as possible of limited hardware:
– Overcome 20% of peak performance of standard processor– Maximum use of “limited” parallelism (around 10 proc.)– Exploit high performance processing units (Cell, GPU, FPGA)
• Fine modeling � >2 TFlops• Cell processor 200 GFlops/s � 1 rack over 10 TFlops/s
• Tesla: 500 GFlops/s – Server over 4TFlops/s
• It is possible to reach real time even for fine modeling using a “moderate” architecture
x10 x10 accelerationacceleration –– Power Power methodmethod
16CEA/DEN/DANS/DM2S/SERMA
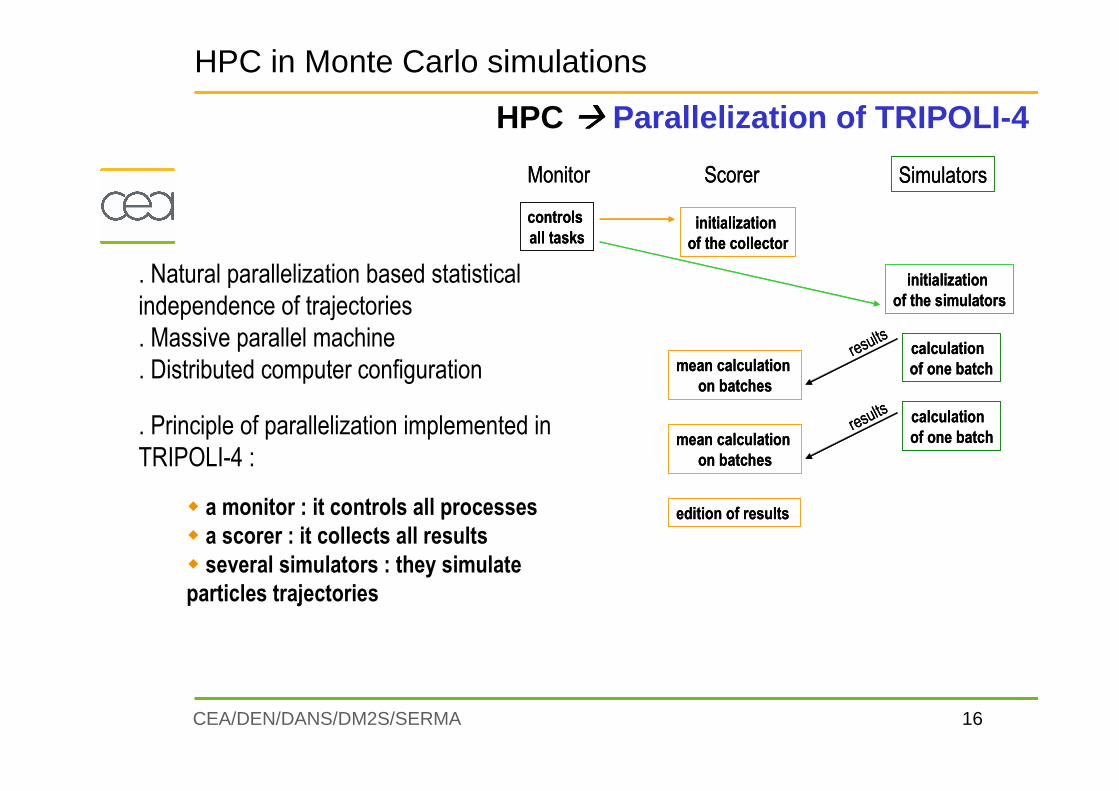
HPC ���� Parallelization of TRIPOLI-4
. Principle of parallelization implemented in
TRIPOLI-4 :
� a monitor : it controls all processes
� a scorer : it collects all results
� several simulators : they simulate
particles trajectories
HPC in Monte Carlo simulations
. Natural parallelization based statistical
independence of trajectories
. Massive parallel machine
. Distributed computer configuration
Monitor Scorer Simulators
controls
all tasksinitialization
of the collector
initialization
of the simulators
calculation
of one batch
calculation
of one batch
mean calculation
on batches
mean calculation
on batches
edition of results
results
results
Monitor Scorer Simulators
controls
all tasksinitialization
of the collector
initialization
of the simulators
calculation
of one batch
calculation
of one batch
mean calculation
on batches
mean calculation
on batches
edition of results
results
results
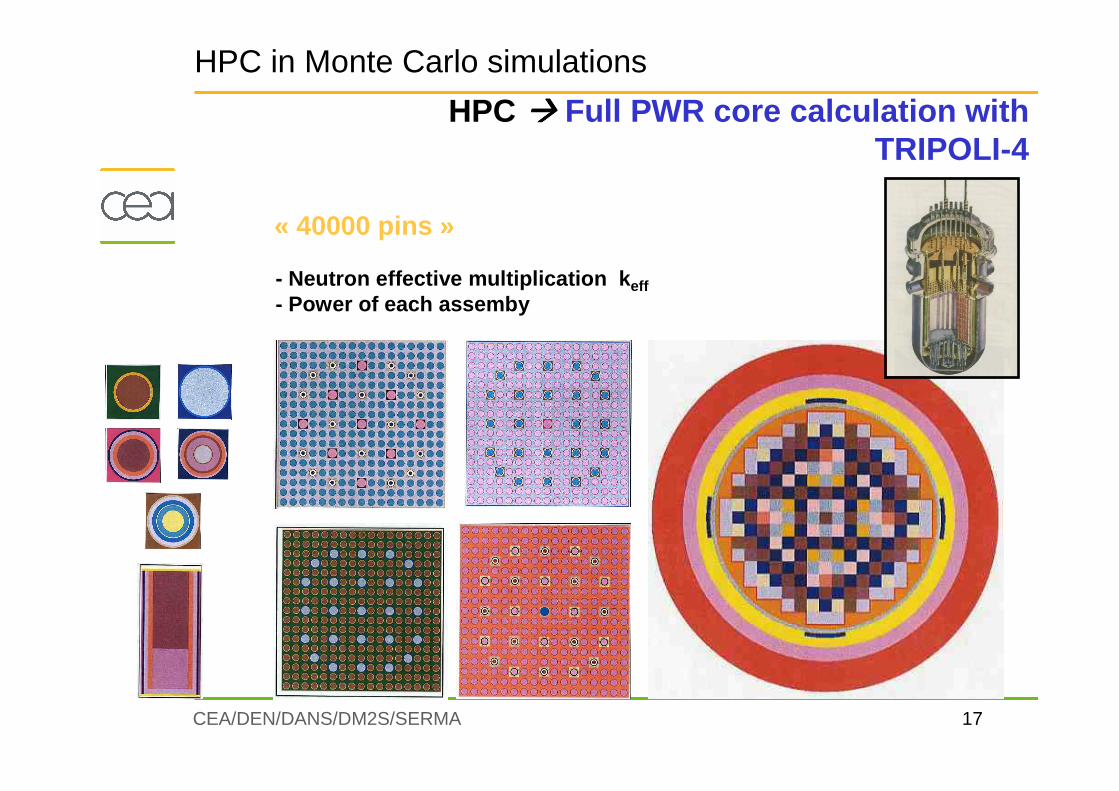
17CEA/DEN/DANS/DM2S/SERMA
« 40000 pins »
- Neutron effective multiplication k eff- Power of each assemby
HPC in Monte Carlo simulations
HPC ���� Full PWR core calculation withTRIPOLI-4

18CEA/DEN/DANS/DM2S/SERMA
keff and power of each assemblyconvergence study : calculation of variancetaking into account batch correlations
� 1,3 billions of neutron histories� 20 processors of 3 Ghz� ~ 24 hours� precision : k eff ~ 3 pcm ;
power à ~ 0,1 %
E. DumonteilF.X. Hugot
HPC in Monte Carlo simulations
HPC ���� Full PWR core calculation withTRIPOLI-4
19CEA/DEN/DANS/DM2S/SERMA
R23R26
R2
R1
R3
R7
R5
R4
R8R6 R9
R10R11
R12
R13
R14
R15
R16
R17
R18R19
R20
R21R22
R24R25
R27R28
R29
R30
senspositif
R1-1
R1-10
R23R26
R2
R1
R3
R7
R5
R4
R8R6 R9
R10R11
R12
R13
R14
R15
R16
R17
R18R19
R20
R21R22
R24R25
R27R28
R29
R30
senspositif
R1-1
R1-10
core
pressure vessel
concrete
barrel
water
water
core
pressure vessel
concrete
barrel
water
water
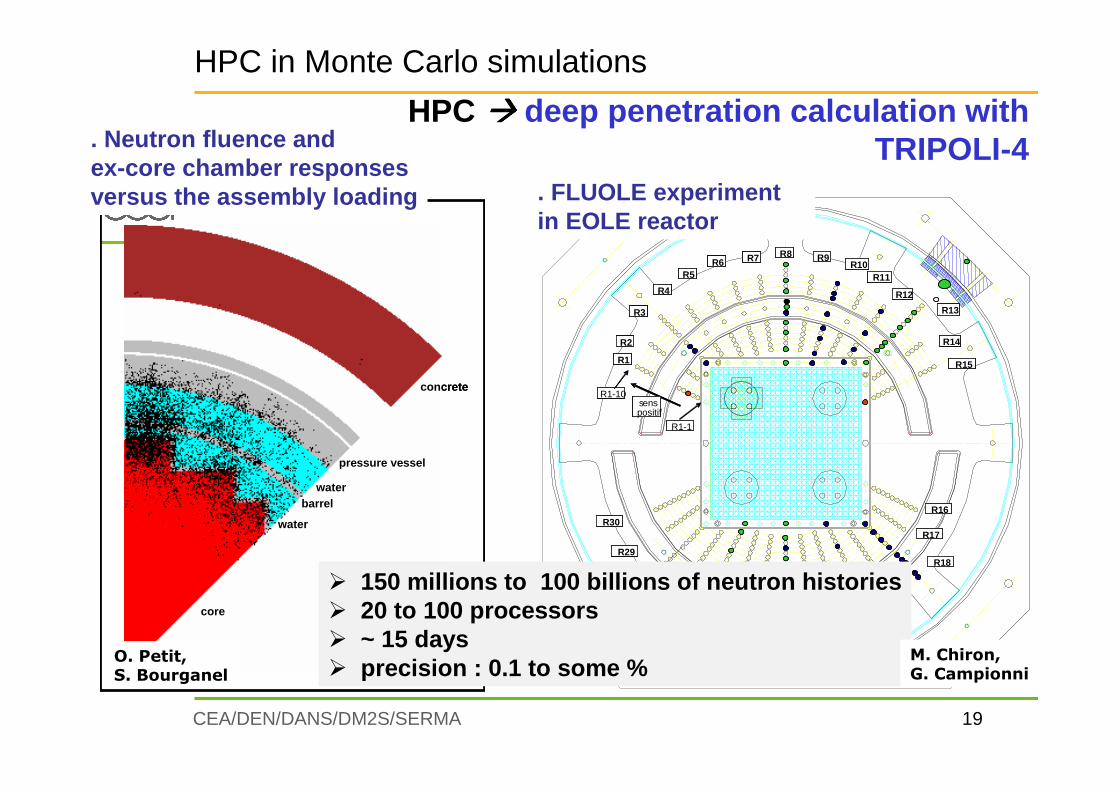
� 150 millions to 100 billions of neutron histories� 20 to 100 processors� ~ 15 days� precision : 0.1 to some %
. Neutron fluence and ex-core chamber responsesversus the assembly loading . FLUOLE experiment
in EOLE reactor
O. Petit, S. Bourganel
M. Chiron, G. Campionni
HPC in Monte Carlo simulations
HPC ���� deep penetration calculation withTRIPOLI-4

20CEA/DEN/DANS/DM2S/SERMA
Number of processorsE
ffici
ency
���� decreasing of communications between processors
���� increasing of virtual memory needs : . Nuclear data. Post-processing of the simulation features
���� increasing the number of files opened
F.X. Hugot
TRIPOLI-4 calculationswith 1000 processors :
number of histories x number of collisions xnumber of parameters xnumber of octets/parameter :
1011 x 10 x 20 x 8 = 160 TBytes
HPC in Monte Carlo simulations
HPC ���� TRIPOLI-4 adaptations needed
Example of size needed to store the simulation
information related to the particles :
21CEA/DEN/DANS/DM2S/SERMA
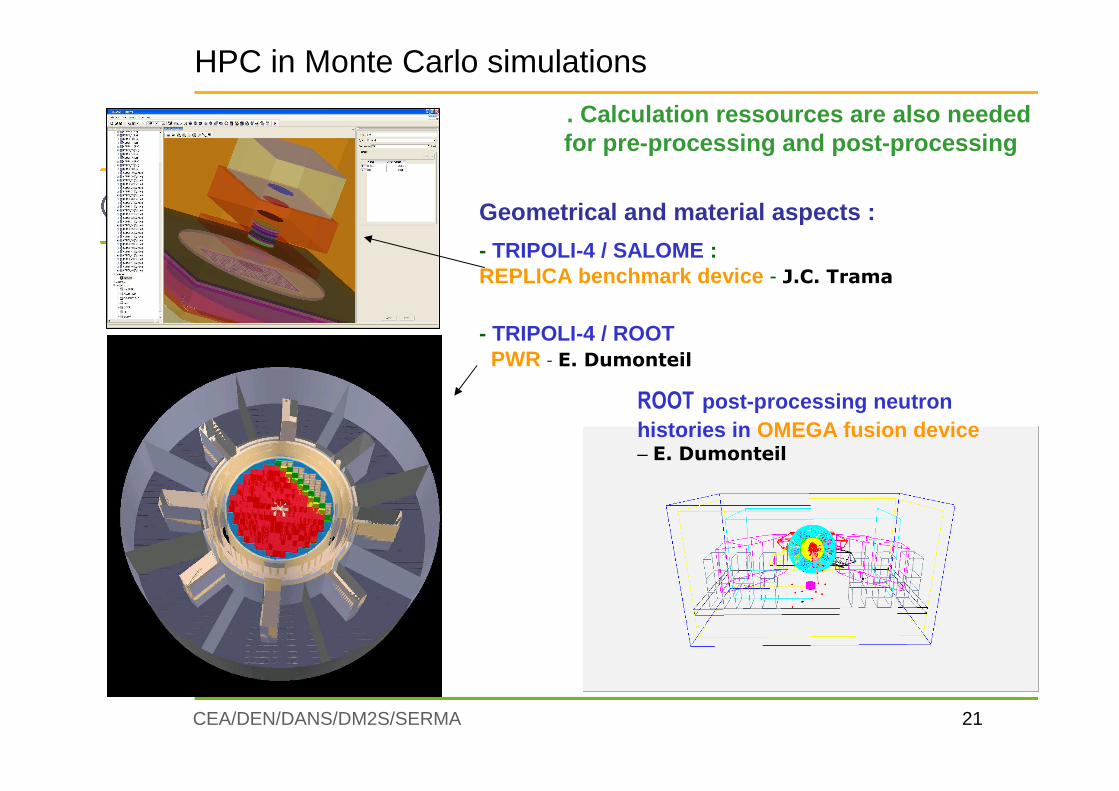
Geometrical and material aspects :
- TRIPOLI-4 / SALOME : REPLICA benchmark device - J.C. Trama
- TRIPOLI-4 / ROOTPWR - E. Dumonteil
. Calculation ressources are also neededfor pre-processing and post-processing
ROOT post-processing neutron histories in OMEGA fusion device– E. Dumonteil
HPC in Monte Carlo simulations

22CEA/DEN/DANS/DM2S/SERMA
Conclusion
• HPC for core physics
– Parametric studies � Decrease margin by decreasing uncertainties– Finer physics, “Numerical Nuclear Reactor” � Design optimization
– “Generalized” MC approach � Improve safety
• Classes of HPC
– Distributed computing: (X x 100P) � Parametric studies– Extensive computing (>> 1000P) � Reference calculations
– Intensive computing (“TFlops in a box”) � Real time neutronics

23CEA/DEN/DANS/DM2S/SERMA
Conclusion
• R&D and training– Thesis
• Efficient use of accelerators and prog. Model• …
– Participation to working groups on HPC related to nuclear reactor applications
– Organization of Summer school on HPC and Petascale– Collaboration with other institutes and countries:
• PAAP France-Japan / ANL / CEA/DEN – JAEA
• Challenges– Uncertainties; mesh refinement; sensitivity analysis ... �
management tools– Efficiency vs portability– Efficient use of computing resources (intensive and extensive)– Fault tolerance– Training
Recommended

















