www.cineca.it
CINECA HPC Infrastructure: state of the art and road map
• Carlo Cavazzoni, HPC department, CINECA

Installed HPC Engines
hybrid cluster
64 nodes
1024 SandyBridge cores
64 K20 GPU
64 Xeon PHI coprocessor
150 TFlops peak
10240 nodes
163840 PowerA2 cores
2PFlops peak
Hybrid cluster
274 nodes
3288 Westmere cores
548 nVidia M2070 (Fermi)
300TFlops peak
Eurora (Eurotech)FERMI, (IBM BGQ) PLX, (IBM DataPlex)

FERMI @ CINECAPRACE Tier-0 System
Architecture: 10 BGQ Frame
Model: IBM-BG/Q
Processor Type: IBM PowerA2, 1.6 GHz
Computing Cores: 163840
Computing Nodes: 10240
RAM: 1GByte / core
Internal Network: 5D Torus
Disk Space: 2PByte of scratch space
Peak Performance: 2PFlop/s
Available for ISCRA & PRACE call for projects

The PRACE RI provides access to distributed persistent pan-European world class HPC computing and data
management resources and services. Expertise in efficient use of the resources is available through
participating centers throughout Europe. Available resources are announced for each Call for Proposals..
Peer reviewed open access
PRACE Projects (Tier-0)
PRACE Preparatory (Tier-0)
DECI Projects (Tier-1)
European
Local
Tier 0
Tier 1
Tier 2
National
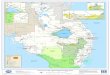
1. Chip:
16 P
cores
2. Single Chip Module
4. Node Card:
32 Compute Cards,
Optical Modules, Link Chips, Torus
5a. Midplane:
16 Node Cards
6. Rack: 2 Midplanes
7. System:
20PF/s
3. Compute card:
One chip module,
16 GB DDR3 Memory,
5b. IO drawer:
8 IO cards w/16 GB
8 PCIe Gen2 x8 slots
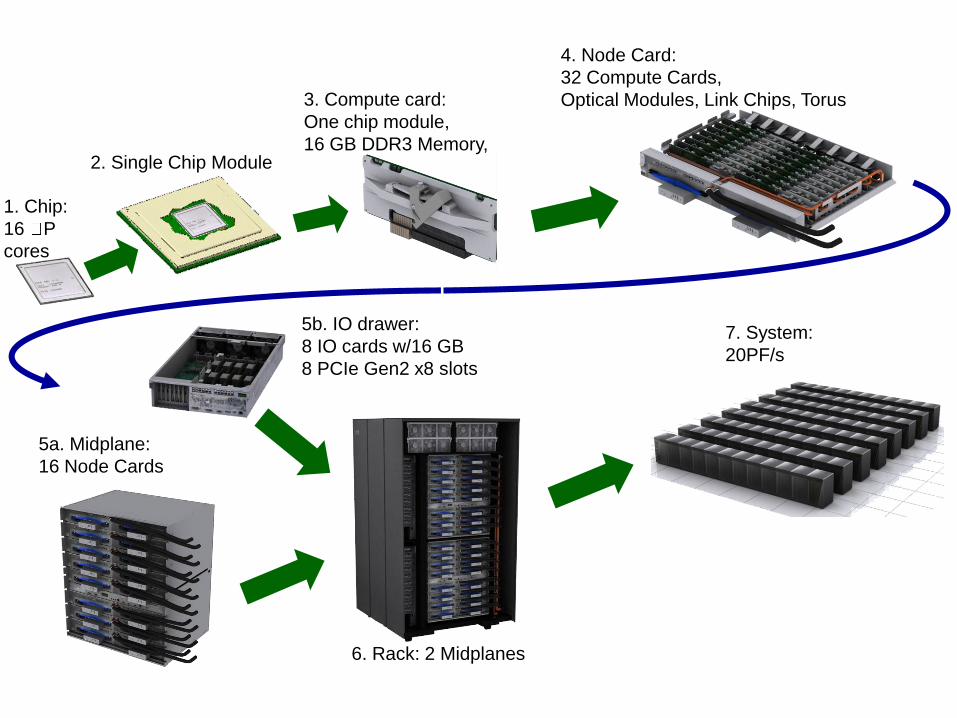
BG/Q I/O architecture
BG/Q compute racks BG/Q IO Switch File system servers
IB
PCI_EIB
IB SAN

I/O drawers
I/O nodesPCIe
8 I/O nodes
At least one I/O node for each partition/job
Minimum partition/job size: 64 nodes, 1024 cores

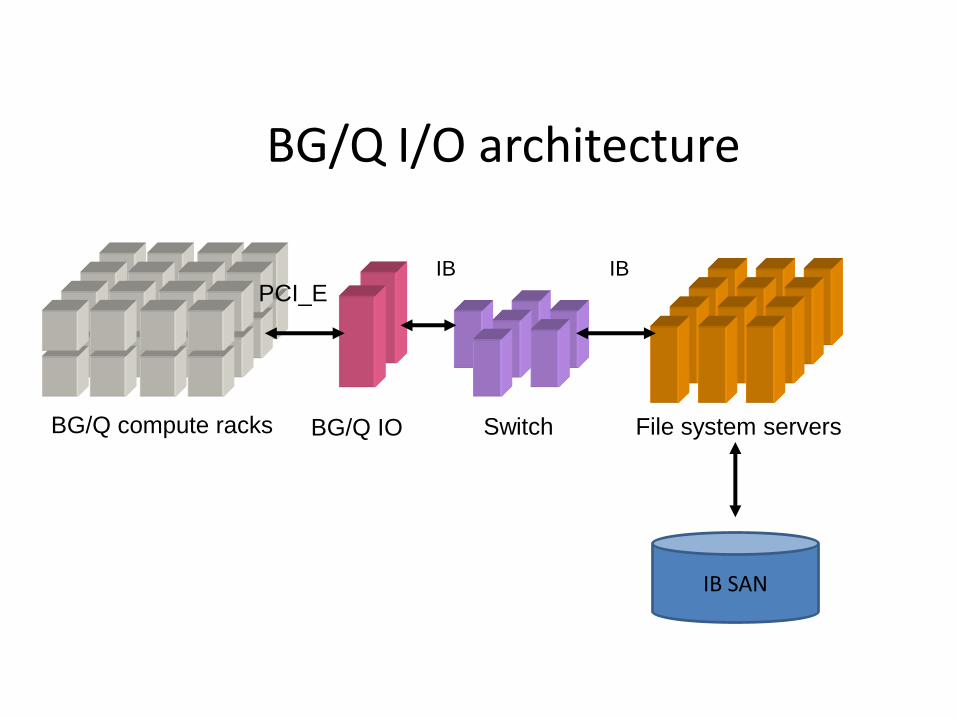
PowerA2 chip, basic info
• 64bit RISC Processor
• Power instruction set (Power1…Power7, PowerPC)
• 4 Floating Point units per core & 4 way MT
• 16 cores + 1 + 1 (17th Processor core for system functions)
• 1.6GHz
• 32MByte cache
• system-on-a-chip design
• 16GByte of RAM at 1.33GHz
• Peak Perf 204.8 gigaflops
• power draw of 55 watts
• 45 nanometer copper/SOI process (same as Power7)
• Water Cooled
9
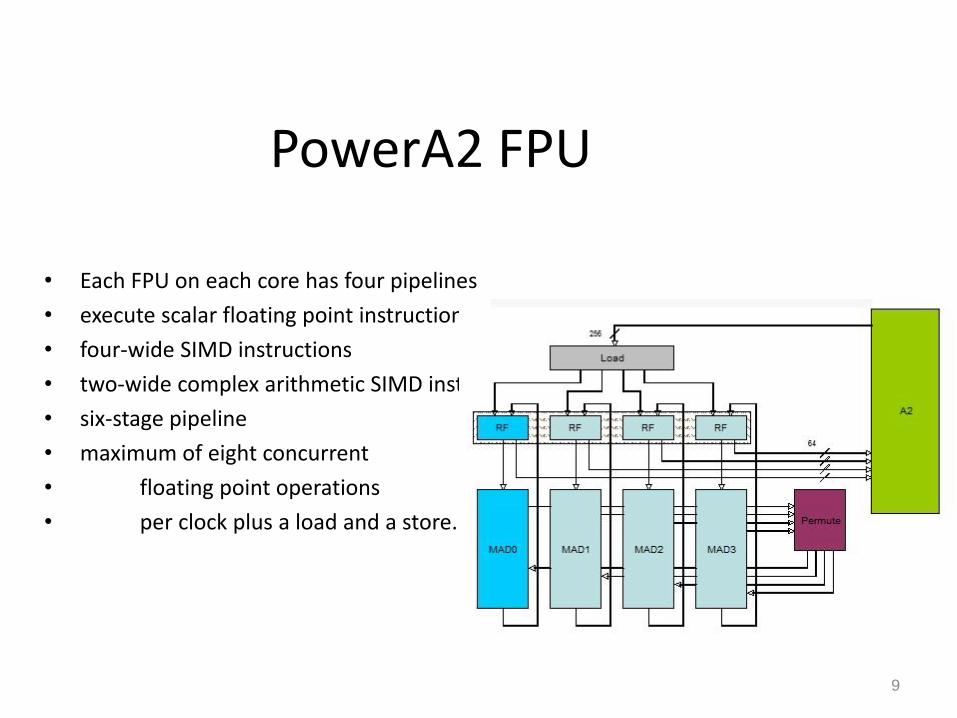
PowerA2 FPU
• Each FPU on each core has four pipelines
• execute scalar floating point instructions
• four-wide SIMD instructions
• two-wide complex arithmetic SIMD inst.
• six-stage pipeline
• maximum of eight concurrent
• floating point operations
• per clock plus a load and a store.

EURORA
#1 in The Green500 List June
2013
What EURORA stant for?
EURopean many integrated cORe Architecture
What is EURORA?
Prototype Project
Founded by PRACE 2IP EU project Grant agreement number: RI-283493
Co-designed by CINECA and EUROTECH
Where is EURORA?
EURORA is installed at CINECA
When EURORA has been installed?
March 2013
Who is using EURORA?
All Italian and EU researchers through PRACE
Prototype grant access program3,200MFLOPS/W – 30KW

Why EURORA? (project objectives)
Address Today HPC Constraints:
Flops/Watt,
Flops/m2,
Flops/Dollar.
Efficient Cooling Technology:
hot water cooling (free cooling);
measure power efficiency, evaluate (PUE &
TCO).
Improve Application Performances:
at the same rate as in the past (~Moore’s
Law);
new programming models.
Evaluate Hybrid (accelerated)
Technology:
Intel Xeon Phi;
NVIDIA Kepler.
Custom Interconnection Technology:
3D Torus network (FPGA);
evaluation of accelerator-to-
accelerator communications.

64 compute cards
128 Xeon SandyBridge (2.1GHz, 95W and 3.1GHz, 150W)
16GByte DDR3 1600MHz per node
160GByte SSD per node
1 FPGA (Altera Stratix V) per node
IB QDR interconnect
3D Torus interconnect
128 Accelerator cards (NVIDA K20 and INTEL PHI)
EURORA
prototype configuration
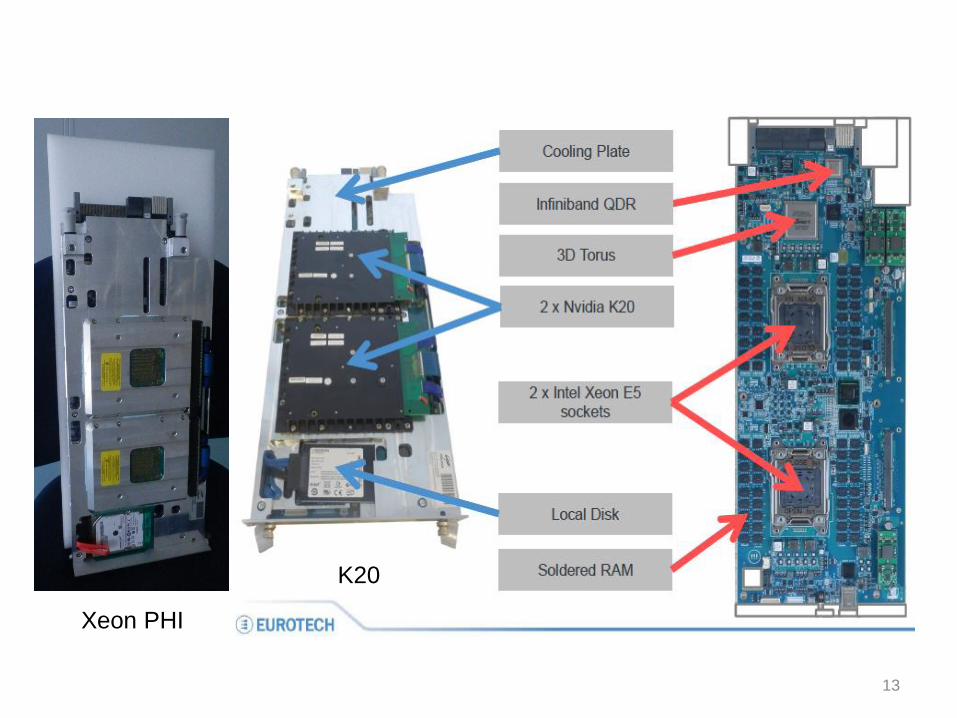
Node card
13
Xeon PHI
K20
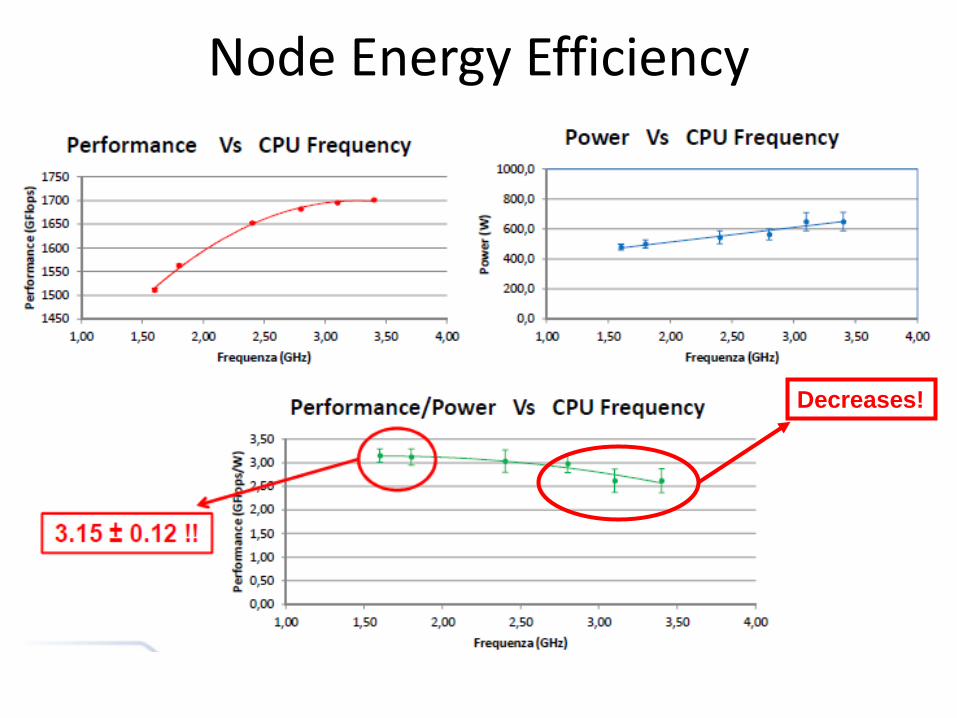
Node Energy Efficiency
14
Decreases!

HPC Service
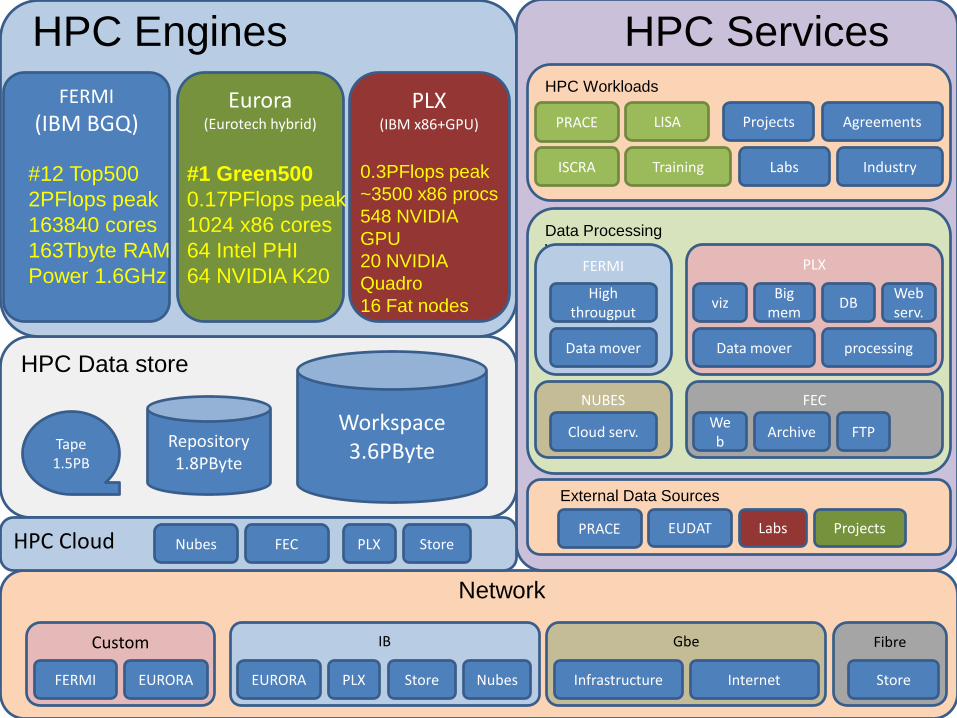
FERMI
(IBM BGQ)PLX
(IBM x86+GPU)
Eurora(Eurotech hybrid)
HPC Data store
Workspace3.6PByteRepository
1.8PByteTape1.5PB
HPC Engines
Network
Custom
FERMI EURORA
IB
EURORA PLX Store Nubes
Gbe
Infrastructure Internet
Fibre
Store
External Data Sources
LabsPRACE EUDAT Projects
Data Processing
WorkloadsFERMI PLX
vizHigh
througputBig
memDB
Data mover Data mover processing
Webserv.
FECNUBES
Cloud serv.Web
Archive FTP
HPC Workloads
PRACE
ISCRA
LISA
Labs Industry
AgreementsProjects
Training
HPC Services
HPC Cloud FEC PLX StoreNubes
#12 Top500
2PFlops peak
163840 cores
163Tbyte RAM
Power 1.6GHz
#1 Green500
0.17PFlops peak
1024 x86 cores
64 Intel PHI
64 NVIDIA K20
0.3PFlops peak
~3500 x86 procs
548 NVIDIA
GPU
20 NVIDIA
Quadro
16 Fat nodes

CINECA services
• High Performance Computing
• Computational workflow• Storage• Data analytics• Data preservation (long term)• Data access (web/app)• Remote Visualization• HPC Training• HPC Consulting• HPC Hosting• Monitoring and Metering• …
For academia and industry

Road Map
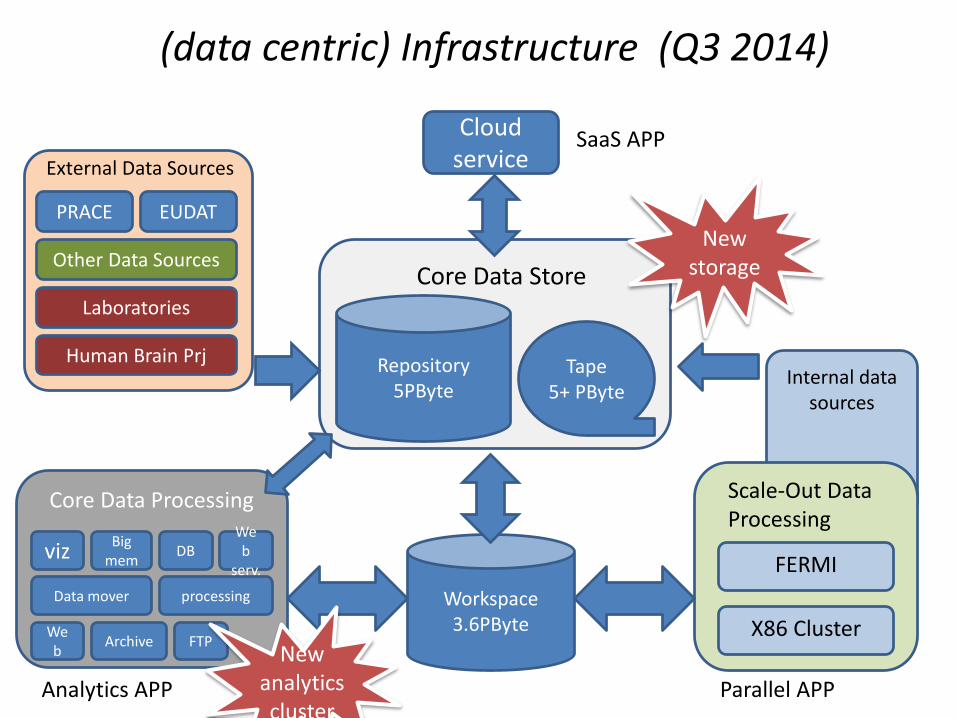
Workspace3.6PByte
Core Data Processing
vizBig
memDB
Data mover processing
Web
serv.
Web
Archive FTP
Core Data Store
Repository5PByte
Tape5+ PByte
Internal data sources
(data centric) Infrastructure (Q3 2014)
Cloud service
Scale-Out Data Processing
FERMI
X86 Cluster
Laboratories
PRACE EUDAT
Other Data Sources
External Data Sources
Human Brain Prj
SaaS APP
Analytics APP Parallel APP
New analyticscluster
New storage

Requisiti di alto livello del sistema
Potenza elettrica assorbita: 400KW
Dimensione fisica del sistema: 5 racks
Potenza di picco del sistema (CPU+GPU): nell'ordine di 1PFlops
Potenza di picco del sistema (solo CPU): nell'ordine di 300TFlops
New Tier 1 CINECA
Procurement Q3 2014

Requisiti di alto livello del sistema
Architettura CPU: Intel Xeon Ivy Bridge
Numero di core per CPU: 8 @ >3GHz, oppure 12 @ 2.4GHz
La scelta della frequenza ed il numero di core dipende dal TDP del socket, dalla densità del
sistema e dalla capacità di raffreddamento
Numero di server: 500 - 600,
( Peak perf = 600 * 2socket * 12core * 3GHz * 8Flop/clk = 345TFlops )
Il numero di server del sistema potrà dipendere dal costo o dalla geometria della configurazione
in termini di numero di nodi solo CPU e numero di nodi CPU+GPU
Architettura GPU: Nvidia K40
Numero di GPU: >500
( Peak perf = 700 * 1.43TFlops = 1PFlops )
Il numero di schede GPU del sistema potrà dipendere dal costo o dalla
geometria della configurazione in termini di
numero di nodi solo CPU e numero di nodi CPU+GPU
Tier 1 CINECA

Requisiti di alto livello del sistema
Vendor identificati: IBM, Eurotech
DRAM Memory: 1GByte/core
Verrà richiesta la possibilità di avere un sottoinsieme di nodi
con una quantità di memoria più elevata
Memoria non volatile locale: >500GByte
SSD/HD a seconda del costo e dalla configurazione del sistema
Cooling: sistema di raffreddamento a liquido con opzione di free cooling
Spazio disco scratch: >300TByte (provided by CINECA)
Tier 1 CINECA

Roadmap 50PFlops
Power consumption
EURORA 50KW, PLX 350 KW, BGQ 1000KW + ENI
EURORA or PLX upgrade 400KW;
BGQ 1000KW, Data repository 200KW; -
ENI
R&D EuroraEuroExa STM / ARM
boardEuroExa STM / ARM
prototypePCP Proto 1PF in a
rackEuroExa STM / ARM
PF platformETP proto
towards exascaleboard
Deployment Eurora industrial prototype 150 TF
Eurora or PLX upgrade 1PF peak,
350TF scalar
multi petaflopsystem
Tier-0 50PFTier-1 towards
exascale
Time line 2013 2014 2015 2016 2017 2018 2019 2020
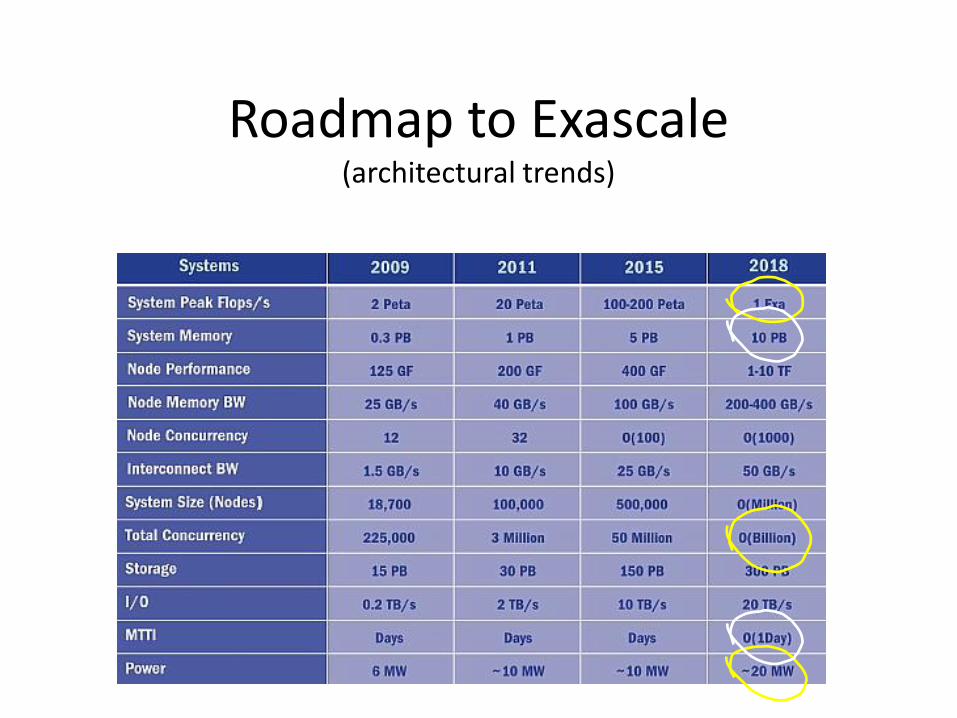
Roadmap to Exascale(architectural trends)
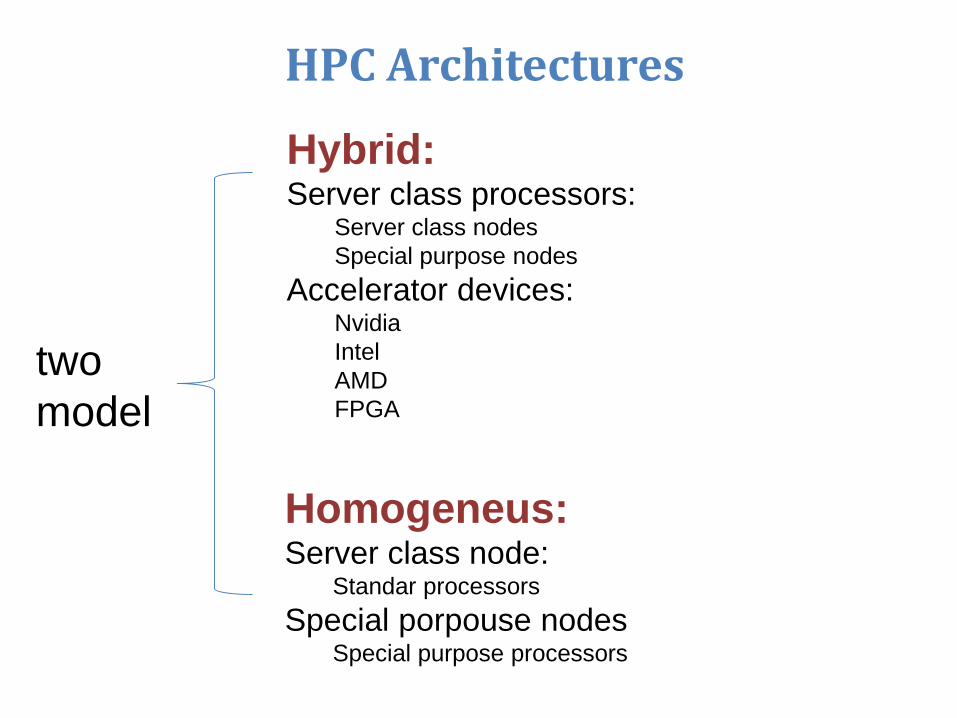
HPC Architectures
two
model
Hybrid:Server class processors:
Server class nodes
Special purpose nodes
Accelerator devices:Nvidia
Intel
AMD
FPGA
Homogeneus:Server class node:
Standar processors
Special porpouse nodesSpecial purpose processors

Architectural trends
Peak Performance Moore law
FPU Performance Dennard law
Number of FPUs Moore + Dennard
App. Parallelism Amdahl's law

Programming Models
fundamental paradigm:Message passing
Multi-threads
Consolidated standard: MPI & OpenMP
New task based programming model
Special purpose for accelerators:CUDA
Intel offload directives
OpenACC, OpenCL, Ecc…
NO consolidated standard
Scripting:python
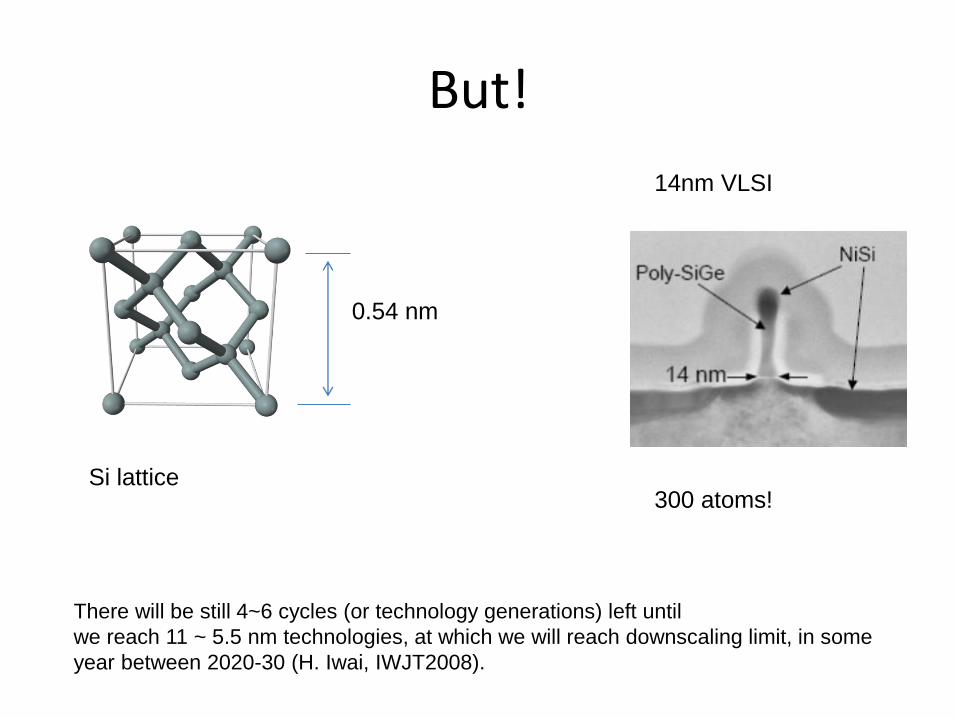
But!
Si lattice
0.54 nm
There will be still 4~6 cycles (or technology generations) left until
we reach 11 ~ 5.5 nm technologies, at which we will reach downscaling limit, in some
year between 2020-30 (H. Iwai, IWJT2008).
300 atoms!
14nm VLSI

Thank you
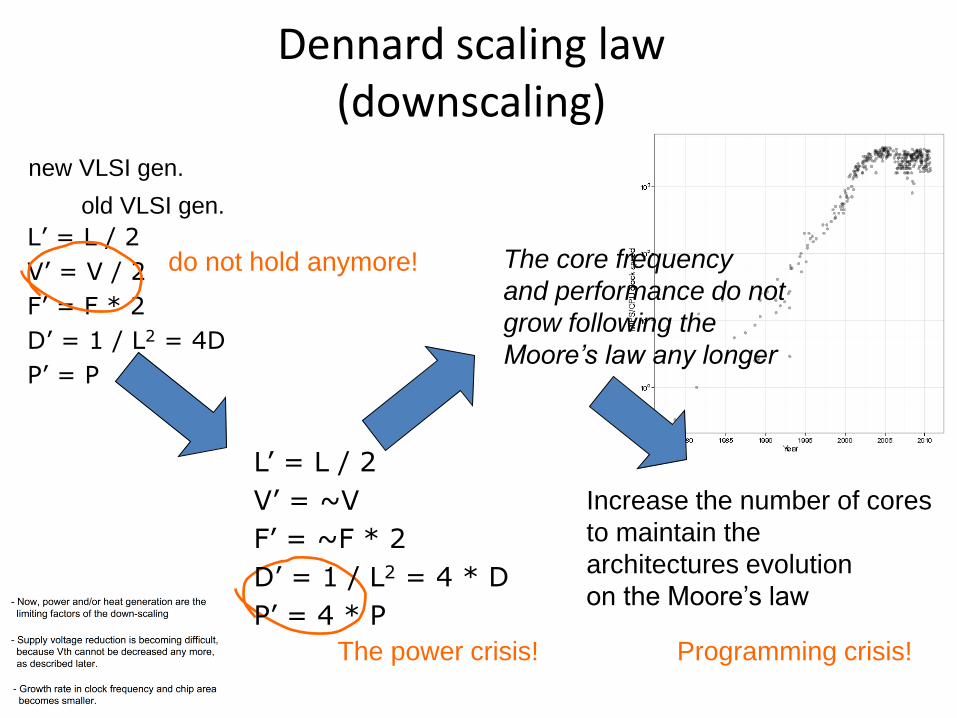
Dennard scaling law(downscaling)
L’ = L / 2
V’ = V / 2
F’ = F * 2
D’ = 1 / L2 = 4D
P’ = P
do not hold anymore!
The power crisis!
L’ = L / 2
V’ = ~V
F’ = ~F * 2
D’ = 1 / L2 = 4 * D
P’ = 4 * P
Increase the number of cores
to maintain the
architectures evolution
on the Moore’s law
Programming crisis!
The core frequency
and performance do not
grow following the
Moore’s law any longer
new VLSI gen.
old VLSI gen.

The cost per chip “is going down more than the capital intensity is going up,” Smith said, suggesting
Intel’s profit margins should not suffer because of heavy capital spending. “This is the economic
beauty of Moore’s Law.”
And Intel has a good handle on the next production shift, shrinking circuitry to 10 nanometers. Holt
said the company has test chips running on that technology. “We are projecting similar kinds of
improvements in cost out to 10 nanometers,” he said.
So, despite the challenges, Holt could not be induced to say there’s any looming end to Moore’s
Law, the invention race that has been a key driver of electronics innovation since first defined by
Intel’s co-founder in the mid-1960s.
Moore’s Law
Economic and market law
From WSJ
Stacy Smith, Intel’s chief financial officer, later gave
some more detail on the economic benefits of staying
on the Moore’s Law race.
It is all about the number of chips per Si wafer!
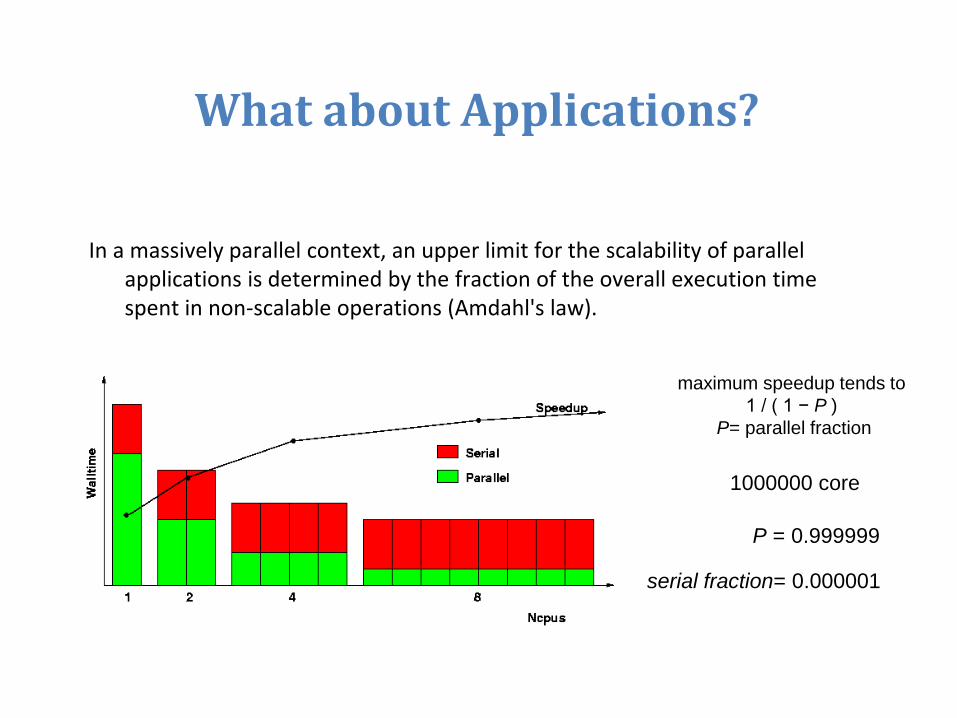
What about Applications?
In a massively parallel context, an upper limit for the scalability of parallel applications is determined by the fraction of the overall execution time spent in non-scalable operations (Amdahl's law).
maximum speedup tends to
1 / ( 1 − P )
P= parallel fraction
1000000 core
P = 0.999999
serial fraction= 0.000001
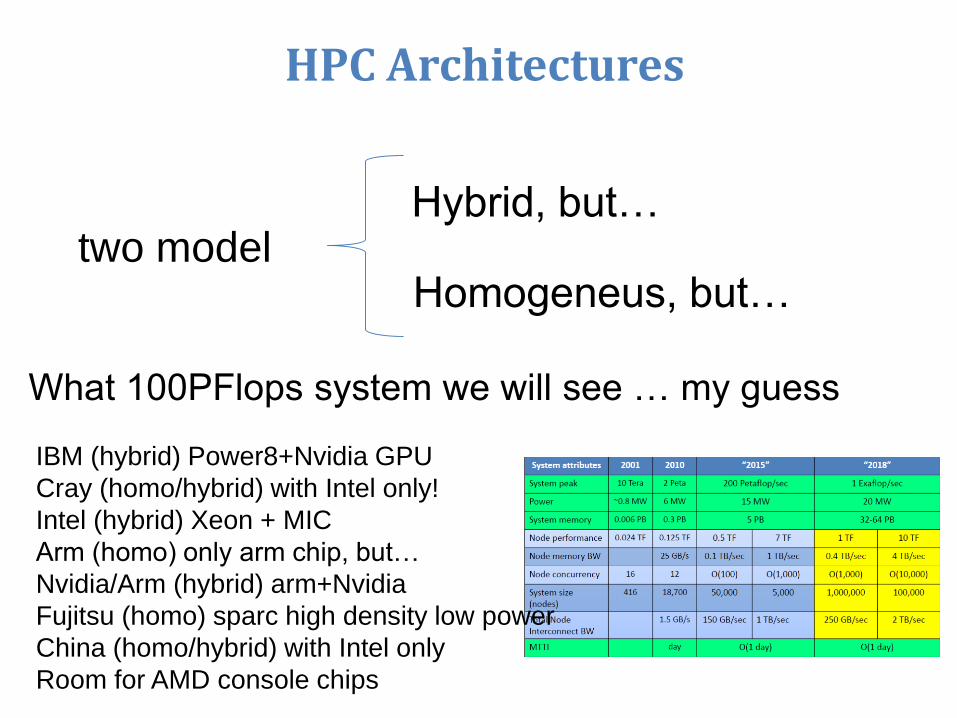
HPC Architectures
two modelHybrid, but…
Homogeneus, but…
What 100PFlops system we will see … my guess
IBM (hybrid) Power8+Nvidia GPU
Cray (homo/hybrid) with Intel only!
Intel (hybrid) Xeon + MIC
Arm (homo) only arm chip, but…
Nvidia/Arm (hybrid) arm+Nvidia
Fujitsu (homo) sparc high density low power
China (homo/hybrid) with Intel only
Room for AMD console chips
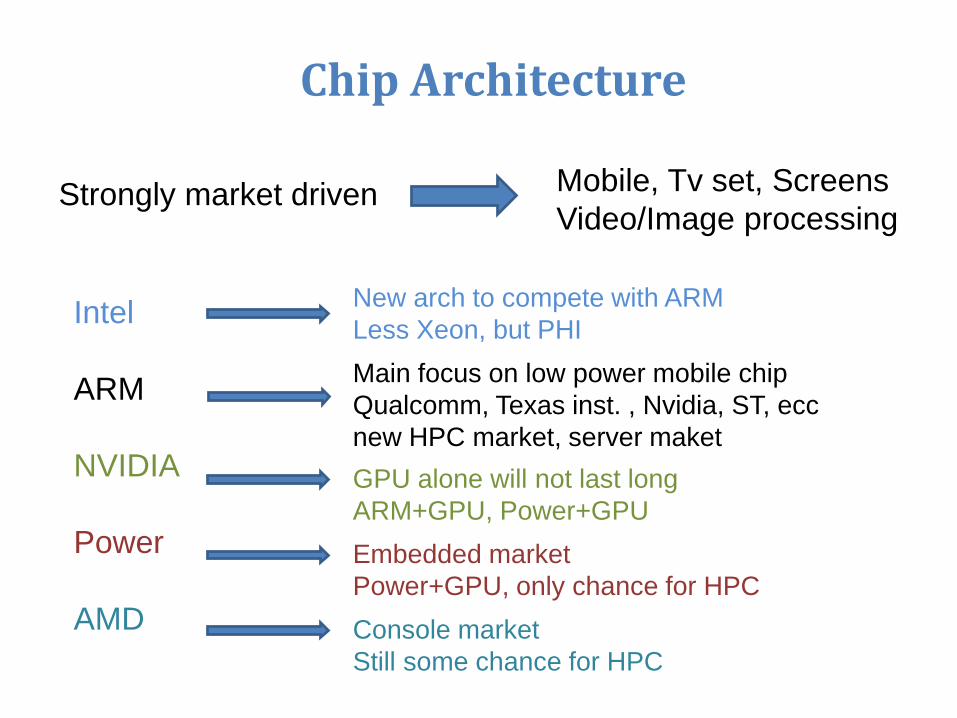
Chip Architecture
Intel
ARM
NVIDIA
Power
AMD
Strongly market driven Mobile, Tv set, Screens
Video/Image processing
New arch to compete with ARM
Less Xeon, but PHI
Main focus on low power mobile chip
Qualcomm, Texas inst. , Nvidia, ST, ecc
new HPC market, server maket
GPU alone will not last long
ARM+GPU, Power+GPU
Embedded market
Power+GPU, only chance for HPC
Console market
Still some chance for HPC
Recommended