
Combinatorial Spill Code Optimization and
Ultimate Coalescing
Roberto Castaneda Lozano – SICS
Gabriel Hjort Blindell – KTH
Mats Carlsson – SICS
Christian Schulte – KTH
LCTES 2014

Outline
1 Introduction
2 Background
3 Alternative Temporaries
4 Results
5 Conclusion
2 / 24

Combinatorial Code Generation
Traditional approach
intermediatecode
instructionselection
instructionscheduling
registerallocation
assemblycode
heuristics, staging: suboptimal, complex
Combinatorial approach
model: variables, constraints, objectivesolve: integer programming, constraint programming . . .
intermediatecode
instructionselection
registerallocation
instructionscheduling
unifiedcombinatorial
problemsolver
assemblycode
optimization, integration: potentially optimal, flexible
3 / 24

Register Allocation
Global register allocation has many subproblems
Competitive approaches must capture all of them
Focus of this presentation:
spill code optimizationremove unnecessary spill instructions
coalescingremove unnecessary register-to-register movesbasic: coalesce temps related by movesultimate: even if their live ranges overlap
4 / 24

Our Approach
Alternative temporaries
program representationcombinatorial structure
Extends combinatorial reg. allocation and scheduling with
spill code optimizationultimate coalescing
Yields better code than
previous combinatorial approachestraditional heuristic approaches
Scales despite increased solution space
5 / 24

Related Approaches
Some models include spill code optimization
(Chang et al., 1997)(Bashford and Leupers, 1999)(Nagarakatte and Govindarajan, 2007)(Eriksson and Kessler, 2012)typically via a quadratic number of Boolean variables
Some models include basic coalescing
(Wilson et al., 1994)(Bashford and Leupers, 1999)(Castaneda et al., 2012)
No model includes ultimate coalescing
non-trivial when combined with scheduling
6 / 24

1 Introduction
2 Background
3 Alternative Temporaries
4 Results
5 Conclusion
7 / 24

Program Representation
add
abs
t
Dependency graph with processor instructions
8 / 24

Spill Code Optimization
Remove unnecessary spill load instructions
i
j k
t1
t1
t2
t3 t4
Before spilling
9 / 24

Spill Code Optimization
Remove unnecessary spill load instructions
i
store
load
j
load
k
t1
t1
t2
t3 t4
Spill everywhere: a load before each use
9 / 24

Spill Code Optimization
Remove unnecessary spill load instructions
i
store
load
j k
t1
t1
t2
t3
t4
Spill code optimization: reuse temp t3 to remove a load
9 / 24
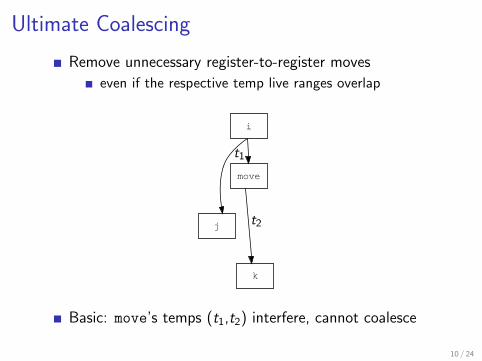
Ultimate Coalescing
Remove unnecessary register-to-register moves
even if the respective temp live ranges overlap
i
move
j
k
t1
t1
t2
Basic: move’s temps (t1,t2) interfere, cannot coalesce
10 / 24
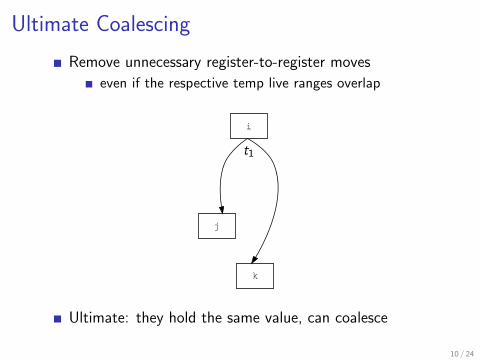
Ultimate Coalescing
Remove unnecessary register-to-register moves
even if the respective temp live ranges overlap
i
j
k
t1
t1
t2
Ultimate: they hold the same value, can coalesce
10 / 24

1 Introduction
2 Background
3 Alternative Temporaries
4 Results
5 Conclusion
11 / 24

Alternative Temporaries
Program representation and combinatorial structure
Augments model with
spill code optimizationultimate coalescing
Allows connection of alternative temps to each instruction
invariant: alternative temps hold the same value
12 / 24
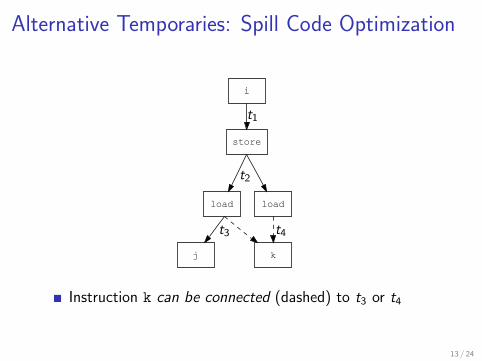
Alternative Temporaries: Spill Code Optimization
i
store
load
j
load
k
t1
t2
t3 t4
t4
Instruction k can be connected (dashed) to t3 or t4
13 / 24
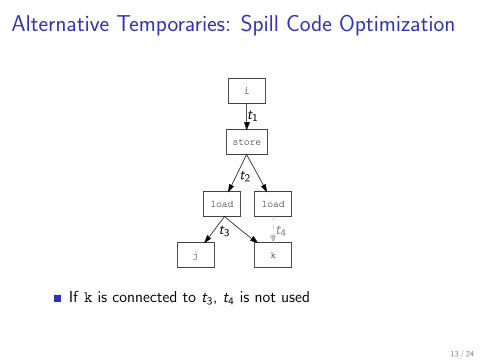
Alternative Temporaries: Spill Code Optimization
i
store
load
j
load
k
t1
t2
t3
t4
t4
If k is connected to t3, t4 is not used
13 / 24
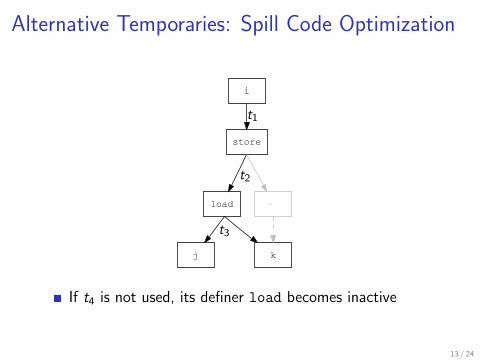
Alternative Temporaries: Spill Code Optimization
i
store
load
j
-
k
t1
t2
t3
t4t4
If t4 is not used, its definer load becomes inactive
13 / 24
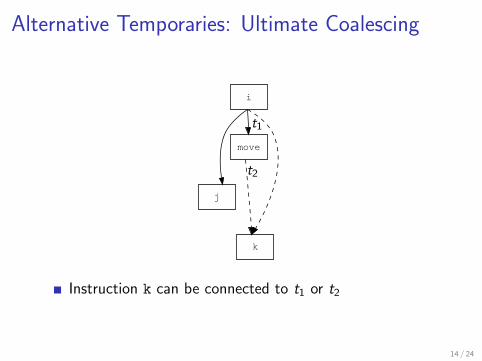
Alternative Temporaries: Ultimate Coalescing
i
move
j
k
t1
t2
t2
Instruction k can be connected to t1 or t2
14 / 24

Alternative Temporaries: Ultimate Coalescing
i
move
j
k
t1
t2
t2
If k is connected to t1, t2 is not used
14 / 24

Alternative Temporaries: Ultimate Coalescing
i
-
j
k
t1
t2t2
If t2 is not used, its definer move becomes inactive
14 / 24

Alternative Temporaries: Construction
i
{move,store}
{move,load}
j
{move,load}
k
t1
t2
t3 t4
1 Extend program with optional copiesafter definition: reg-to-reg move or memory store
before use: reg-to-reg move or memory load
2 Replace each temporary use with alternatives{t1, t2, t3, t4} all hold the same valuedue to copy semantics of move, store, and load
15 / 24

Combinatorial Model
minimize ∑
b∈Bweight(b) × cost(b) subject to
lt ⇐⇒ ∃p∈P ∶ (use(p) ∧ yp = t) ∀t∈T
adefiner(t) ⇐⇒ lt ∀t∈T
ao ⇐⇒ yp ≠ � ∀o∈O, ∀p∈operands(o)
ao ⇐⇒ io ≠ � ∀o∈O
ryp ∈class(io , p) ∀o∈O, ∀p∈operands(o)
disjoint2({⟨rt , rt+width(t) × lt , lst , let ⟩ ∶ t∈T(b)}) ∀b∈B
ryp = r ∀p∈P ∶ p▷r
ryp = ryq ∀p, q∈P ∶ p ≡ q
lt Ô⇒ lst = cdefiner(t) ∀t∈T
lt Ô⇒ let = maxo∈users(t)
co ∀t∈T
ao Ô⇒ co ≥ cdefiner(yp) + lat(idefiner(yp)) ∀o∈O, ∀p∈operands(o) ∶ use(p)
cumulative({⟨co ,con(io , r), dur(io , r)⟩ ∶o∈O(b)}, cap(r)) ∀b∈B,∀r∈R
Generic objective function: speed, code size, . . .
See the paper for details
16 / 24

1 Introduction
2 Background
3 Alternative Temporaries
4 Results
5 Conclusion
17 / 24

Experiment Setup
10 functions from each DSP application in MediaBench
medium size: 10 to 1000 instructionssampled by clustering (size, register pressure)
Selected Hexagon V4 instructions with LLVM 3.3
VLIW DSP in Qualcomm’s Snapdragon system-on-chip
Constraint-based code generator
uses Gecode 4.2.1 as the underlying constraint solveriterative scheme: finds better solutions every iterationfixed to 10 iterations (point of convergence)
LLVM as a traditional code generator
register allocation by priority-based coloringinstruction scheduling by list scheduling
18 / 24

Impact of Alternative Temporaries
Optimal solution improvement due to alternative temps
(compared to model by Castaneda et al., 2012)
0%
5%
10%
b c d a b f g j a b c d e f h i a b c d i b c i e i
⋮
⋮
⋮
⋮
mpeg2jpeggsmg721epicadpcm
62% of the functions are faster
None is slower – as expected
2% geometric mean improvement
19 / 24

Code Quality Compared to Traditional Approaches
Estimated speed up over LLVM
−10%
0%
10%
20%
30%
40%
a b c d e a b c d e f g h i j a b c d e f g h i j a b c d e f g h i j a b c d e f g h i j a b c d e f g h i j
◾
◾ ◾
◾
◾◾ ◾
◾
◾
◾ ◾
◾
◾
◾ ◾
◾
mpeg2jpeggsmg721epicadpcm
7% geometric mean improvement
Provably optimal code (◾) for 29% of the functions
↓
Model limitation: no rematerialization
20 / 24

Scalability
Solving time to reach LLVM’s quality
103
104
105
106
102 103
solv
ing
tim
e(m
s)
number of instructions
Θ(n1.93)
Quadratic average complexity up to 1000 instructions
Comparable to approach without alternative temps
21 / 24

Different Optimization Criteria
Code size improvement over LLVM
−10%
0%
10%
20%
a b c d e a b c d e f g h i j a b c d e f g h i j a b c d e f g h i j a b c d e f g h i j a b c d e f g h i j
◾◾◾◾ ◾
◾
◾ ◾◾
◾
mpeg2jpeggsmg721epicadpcm
1% geometric mean improvement
Low development effort to adapt the code generator
22 / 24

1 Introduction
2 Background
3 Alternative Temporaries
4 Results
5 Conclusion
23 / 24

Conclusion
Alternative temporaries completes combinatorial codegeneration with
spill code optimizationultimate coalescing
Yields a code generator that
delivers faster code than traditional onesis robust and scales to medium-size functionsadapts easily to different optimization criteria
Lots of future work
rematerializationglobal instruction schedulinghandle unknown instruction latenciesimprove runtime with different solving techniques
24 / 24
Recommended

















