
Compiler-in-the-Loop Compiler-in-the-Loop ADL-driven ADL-driven Early Architectural ExplorationEarly Architectural Exploration
Aviral Shrivastava1 Nikil Dutt1
Alex Nicolau1 Eugene Earlie2
1Center For Embedded Computer Systems,University of California, Irvine, CA, USA
2Strategic CAD Labs, Intel,Hudson, MA, USA
SSCCLL

2TechCon 2005 Copyright © 2005 UCI ACES Laboratory
Bypassing Improves PerformanceBypassing Improves Performance
Pipelining improves performance Pipelining improves performance Limited by pipeline hazards
Bypasses eliminate certain data hazardsBypasses eliminate certain data hazardsFurther improve performance
F D
RF
R1 R2 + R3R4 R4 + R1
F D OR X1
RF
X2 WB
R1 R2 + R3R4 R4 + R1
OR X1 X2 WB
R1R1
3TechCon 2005 Copyright © 2005 UCI ACES Laboratory
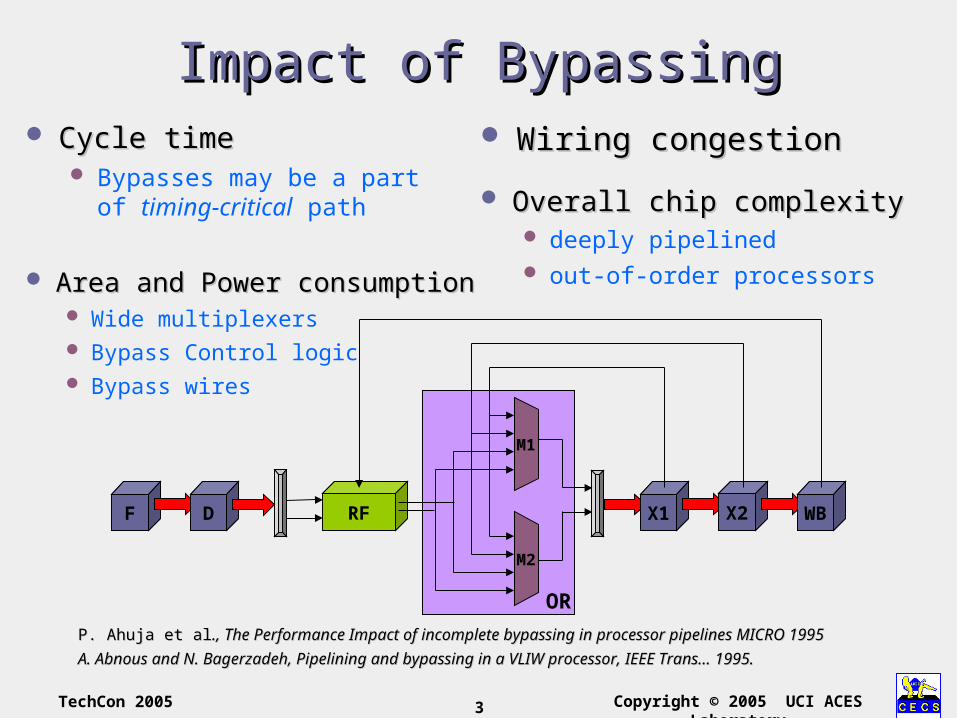
Area and Power consumptionArea and Power consumption Wide multiplexers Bypass Control logic Bypass wires
Impact of BypassingImpact of Bypassing Cycle timeCycle time
Bypasses may be a part of timing-critical path
F D X1RF X2 WB
M1
M2
Wiring congestionWiring congestion
Overall chip complexityOverall chip complexity deeply pipelined out-of-order processors
P. Ahuja et alP. Ahuja et al., The Performance Impact of incomplete bypassing in processor pipelines MICRO 1995., The Performance Impact of incomplete bypassing in processor pipelines MICRO 1995
A. Abnous and N. Bagerzadeh, Pipelining and bypassing in a VLIW processor, IEEE Trans... 1995.A. Abnous and N. Bagerzadeh, Pipelining and bypassing in a VLIW processor, IEEE Trans... 1995.
OR

4TechCon 2005 Copyright © 2005 UCI ACES Laboratory
Problem, Solution and ProblemProblem, Solution and Problem Problem – How do I customize bypasses?Problem – How do I customize bypasses?
Important for Embedded Systems Solution – Solution –
Keep only the most beneficial bypassesArea, Power and Performance trade-off
F D OR X1
RF
X2 WB
Problems – Problems – How to Compile for a processor with partial bypassing? Requires Compiler-in-the-Loop Exploration

5TechCon 2005 Copyright © 2005 UCI ACES Laboratory
Compiler-in-the-Loop ExplorationCompiler-in-the-Loop ExplorationHow to compile for Partial BypassingHow to compile for Partial Bypassing
Compiler in the exploration loopCompiler in the exploration loop
Power-Performance-Area TradeoffPower-Performance-Area Tradeoff

6TechCon 2005 Copyright © 2005 UCI ACES Laboratory
Bypass Sensitive SchedulingBypass Sensitive Scheduling
No Hazard
Bypasses transfer data between dependent Bypasses transfer data between dependent operationsoperations
Missing bypasses cause pipeline hazardMissing bypasses cause pipeline hazardHazard
F D OR X1
RF
X2 WB
R1 R2 + R3R4 R4 + R1 R1 R1 R2 + R3R1 R1 R2 + R3R1
Bypass-sensitive compiler should be able toBypass-sensitive compiler should be able todetect and avoid pipeline hazards

7TechCon 2005 Copyright © 2005 UCI ACES Laboratory
Operation TableOperation TableOperation Table for ADD R1 R2 R3
F D OR X1
RF
X2 WB
C1 C2 C3BRF
C4C5
Operation Table is a binding betweenOperation Table is a binding between Operation and Processor Resources
and Registers
Can detect Resource HazardsCan detect Resource Hazards OTs model processor resources
Can detect Data HazardsCan detect Data Hazards OTs model processor registers
1. F
2. D
3. OR
ReadOperands
R2
C1 RF
R3
C2 RF
C5 BRF
DestOperands
R1 RF
4. X1
WriteOperands
R1
C4 BRF
5. X2
6. XWB
WriteOperands
R1
C3 RF
Details are in the paper !!

8TechCon 2005 Copyright © 2005 UCI ACES Laboratory
Up to Up to 20%20% Performance Improvement on MiBench Performance Improvement on MiBench
0
5
10
15
20
25
% P
erf
orm
an
ce
Im
pro
ve
me
nt
Up to 20% performance improvementUp to 20% performance improvement

9TechCon 2005 Copyright © 2005 UCI ACES Laboratory
Compiler-in-the-Loop ExplorationCompiler-in-the-Loop ExplorationHow to compile for Partial BypassingHow to compile for Partial Bypassing
Compiler in the exploration loopCompiler in the exploration loop
Power-Performance-Area TradeoffPower-Performance-Area Tradeoff

10TechCon 2005 Copyright © 2005 UCI ACES Laboratory
Compiler-in-the-Loop ExplorationCompiler-in-the-Loop Exploration
ApplicationApplication
BypassConfiguration
gcc –O3
Executable
Traditional Cycles
Cycle AccurateSimulator
Traditional Exploration
CIL Cycles
OT-based Compiler
Executable
Cycle AccurateSimulator
Bypass-sensitive Compiler-in-the-Loop
Exploration

11TechCon 2005 Copyright © 2005 UCI ACES Laboratory
Bypass ExplorationBypass Exploration
7 pipeline stages can bypass result7 pipeline stages can bypass result We vary which pipeline stage bypasses a resultWe vary which pipeline stage bypasses a result
27 = 128 bypass configurations Encode bypass configuration
<DWB D2 MWB M2 XWB X2 X1><DWB D2 MWB M2 XWB X2 X1> Configuration 28 = <0011100>
Bypass paths from MWB, M2 and XWB are presentBypass paths from MWB, M2 and XWB are present
F1 F2 ID RF X1 X2 XWB
M1
D1 D2 DWB
MWBM2

12TechCon 2005 Copyright © 2005 UCI ACES Laboratory
Bypass Explorations on XScaleBypass Explorations on XScale
CIL-compiler can effectively exploit the bypass configurationCIL-compiler can effectively exploit the bypass configuration Significant performance differenceSignificant performance difference
bitcount
850000
900000
950000
1000000
1050000
1100000
1150000
1200000
1250000
0 32 64 96 128Bypass Source Configurations
Ex
ecu
tio
n C
ycle
s
Traditional
CIL

13TechCon 2005 Copyright © 2005 UCI ACES Laboratory
X-bypass explorations in XScaleX-bypass explorations in XScale
XWB X1 X2XWB X2
X2 X1XWB X1
XWB X2 X1
X-bypass Configuration
bitcount
850000
900000
950000
1000000
1050000
1100000
1150000
1200000
-
Ex
ecu
tio
n C
ycle
s
TraditionalCIL
Difference in trendsDifference in trendsF1 F2 ID RF X1 X2 XWB
M1
D1 D2 DWB
MWBM2
14TechCon 2005 Copyright © 2005 UCI ACES Laboratory
bitcount
875000
879000
883000
887000
891000
895000
- M2 MWB MWB M2M Bypass Configurations
Ex
ec
uti
on
Cy
cle
s
Traditional
CIL
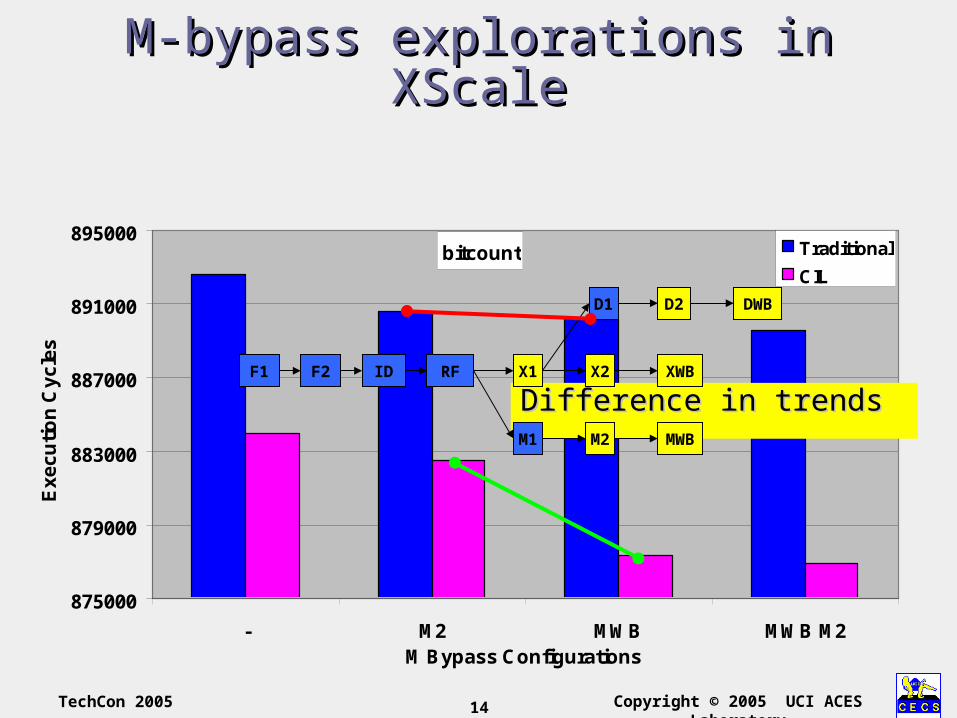
M-bypass explorations in XScaleM-bypass explorations in XScale
Difference in trendsDifference in trendsX1 X2 XWB
D1 D2 DWB
F1 F2 ID RF
M1 MWBM2

15TechCon 2005 Copyright © 2005 UCI ACES Laboratory
bitcount
860000
880000
900000
920000
940000
960000
980000
- DWB D2 DWB D2D Bypass Configurations
Exe
cuti
on
Cyc
les
Traditional
CIL
D-bypass exploration in XScaleD-bypass exploration in XScale
Difference in trendsDifference in trendsX1
D1 D2 DWB
F1 F2 ID RF X2 XWB
M1 MWBM2

16TechCon 2005 Copyright © 2005 UCI ACES Laboratory
Compiler-in-the-Loop ExplorationCompiler-in-the-Loop ExplorationHow to compile for Partial BypassingHow to compile for Partial Bypassing
Compiler in the exploration loopCompiler in the exploration loop
Power-Performance-Area TradeoffPower-Performance-Area Tradeoff
17TechCon 2005 Copyright © 2005 UCI ACES Laboratory
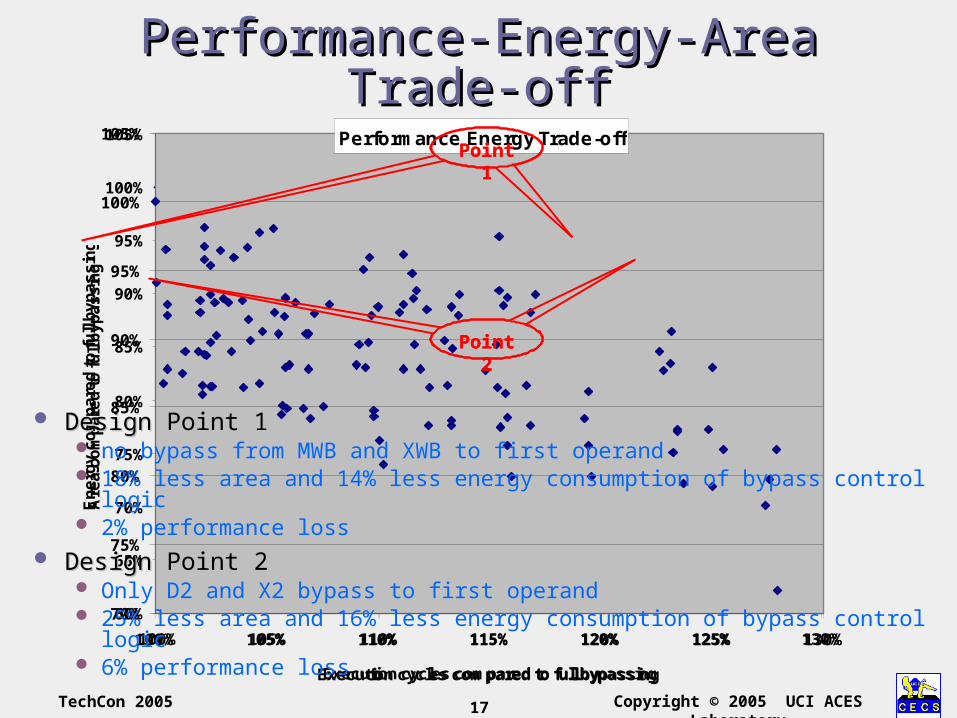
Performance-Energy-Area Trade-Performance-Energy-Area Trade-offoff
Performance Area Trade-off
60%
65%
70%
75%
80%
85%
90%
95%
100%
105%
100% 105% 110% 115% 120% 125% 130%
Execution cycles compared to full bypassing
Are
a c
om
pa
red
to
fu
ll b
yp
as
sin
g
1
2
Performance Energy Trade-off
70%
75%
80%
85%
90%
95%
100%
105%
100% 105% 110% 115% 120% 125% 130%
Execution cycles compared to full bypassing
En
erg
y c
om
pa
red
to
fu
ll b
yp
as
sin
g
12
Point 2
Point 2
Point 1
Point 1
Design Point 1Design Point 1 no bypass from MWB and XWB to first operand 18% less area and 14% less energy consumption of bypass control logic 2% performance loss
Design Point 2Design Point 2 Only D2 and X2 bypass to first operand 25% less area and 16% less energy consumption of bypass control logic 6% performance loss

18TechCon 2005 Copyright © 2005 UCI ACES Laboratory
SummarySummary Bypassing improves performance but is costly in Bypassing improves performance but is costly in
terms of area and powerterms of area and power
Partial bypassing presents valuable trade-offs, Partial bypassing presents valuable trade-offs, however poses challenges in compilationhowever poses challenges in compilation
We propose a compilation approach for partial We propose a compilation approach for partial bypassingbypassing Up to 20% performance improvement by bypass-
sensitive compiler
We propose Compiler-in-the-Loop Exploration of We propose Compiler-in-the-Loop Exploration of partial bypasses.partial bypasses. More meaningful exploration of design space
CIL Exploration of bypasses is able to discover CIL Exploration of bypasses is able to discover interesting pareto-optimal design pointsinteresting pareto-optimal design points
Recommended






![AVIRAL CLASSES ATSE-IX-2020-[CODE-P SET-1] AVIRAL TALENT …](https://img.pdfslide.net/doc/110x75/61bd754051ab81332d731b25/aviral-classes-atse-ix-2020-code-p-set-1-aviral-talent-.jpg)

![AVIRAL CLASSES ATSE-X-2020-[CODE-P SET-1] AVIRAL TALENT …](https://img.pdfslide.net/doc/110x75/6237fcb339268724387384e4/aviral-classes-atse-x-2020-code-p-set-1-aviral-talent-.jpg)








