
Computación Cluster y GridComputación Cluster y GridComputación Cluster y Grid
Computación Cluster y Grid
Gestión de ProcesosGestión de Procesos
111

Gestión de ProcesosC t t í T b j i t1. Conceptos y taxonomías: Trabajos y sistemas paralelosPl ifi ió á i2. Planificación estática:
Planificación de tareas dependientesPl ifi ió d l lPlanificación de tareas paralelasPlanificación de múltiples tareas
3. Planificación dinámica:Equilibrado de cargaMigración de procesosMigración de datosE ilib d d iEquilibrado de conexiones
Computación Cluster y Grid2

Escenario de Partida: TérminosT b j C j t d t ( hil )Trabajos: Conjuntos de tareas (procesos o hilos) que demandan: (recursos x tiempo)
R D t di iti CPU t i itRecursos: Datos, dispositivos, CPU u otros requisitos (finitos) necesarios para la realización de trabajos.Tiempo: Periodo durante el cual los recursos estánTiempo: Periodo durante el cual los recursos están asignados (de forma exclusiva o no) a un determinado trabajo.jRelación entre las tareas: Las tareas se deben ejecutar siguiendo unas restricciones en relación a los datos que generan o necesitan (dependientes y concurrentes)
Planificación: Asignación de trabajos a los nodos de proceso correspondientes. Puede implicar
i dit i i ió
Computación Cluster y Grid3
revisar, auditar y corregir esa asignación.
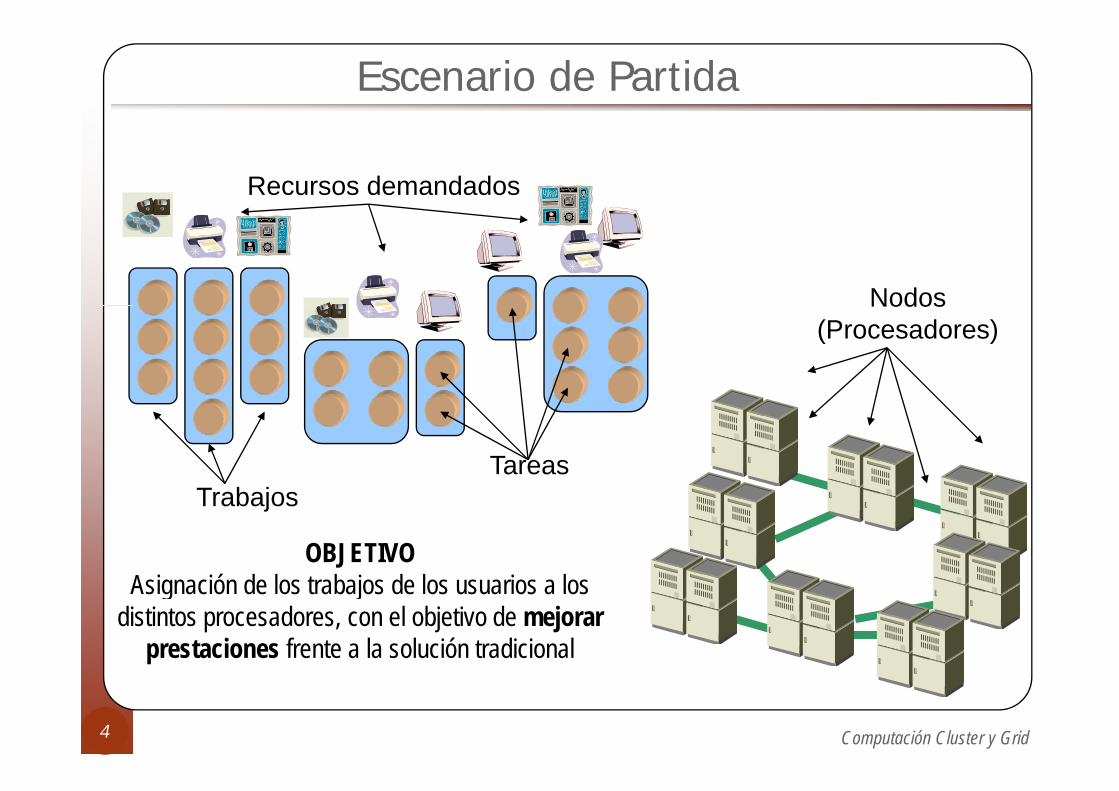
Escenario de Partida
Recursos demandados
NodosNodos(Procesadores)
TareasTrabajos
OBJETIVOA i ió d l b j d l i l Asignación de los trabajos de los usuarios a los
distintos procesadores, con el objetivo de mejorarprestaciones frente a la solución tradicional
Computación Cluster y Grid4

Características de un Sistema DistribuidoSi t i tidSistemas con memoria compartida
Recursos de un proceso accesibles desde todos los procesadoresp
Mapa de memoriaRecursos internos del SO (ficheros/dispositivos abiertos, puertos, etc.)
Reparto/eq ilibrio de carga (load sharing/balancing) a tomáticoReparto/equilibrio de carga (load sharing/balancing) automáticoSi el procesador queda libre puede ejecutar cualquier proceso listo
Beneficios del reparto de carga:p gMejora uso de recursos y rendimiento en el sistemaAplicación paralela usa automáticamente procesadores disponibles
Si t di t ib idSistemas distribuidosProceso ligado a procesador durante toda su vidaRecursos de un proceso accesibles sólo desde procesador localRecursos de un proceso accesibles sólo desde procesador local
No sólo mapa de memoria; También recursos internos del SOReparto de carga requiere migración de procesos
Computación Cluster y Grid5

Escenario de Partida: TrabajosQ é ti j t ?¿Qué se tiene que ejecutar?
Tareas en las que se dividen los trabajos:Tareas disjuntas
Procesos independientesPertenecientes a distintos usuarios
Tareas cooperantesInteraccionan entre síPertenecientes a una misma aplicaciónPueden presentar dependenciasO Pueden requerir ejecución en paralelo
Computación Cluster y Grid6 Sistemas Operativos Distribuidos6
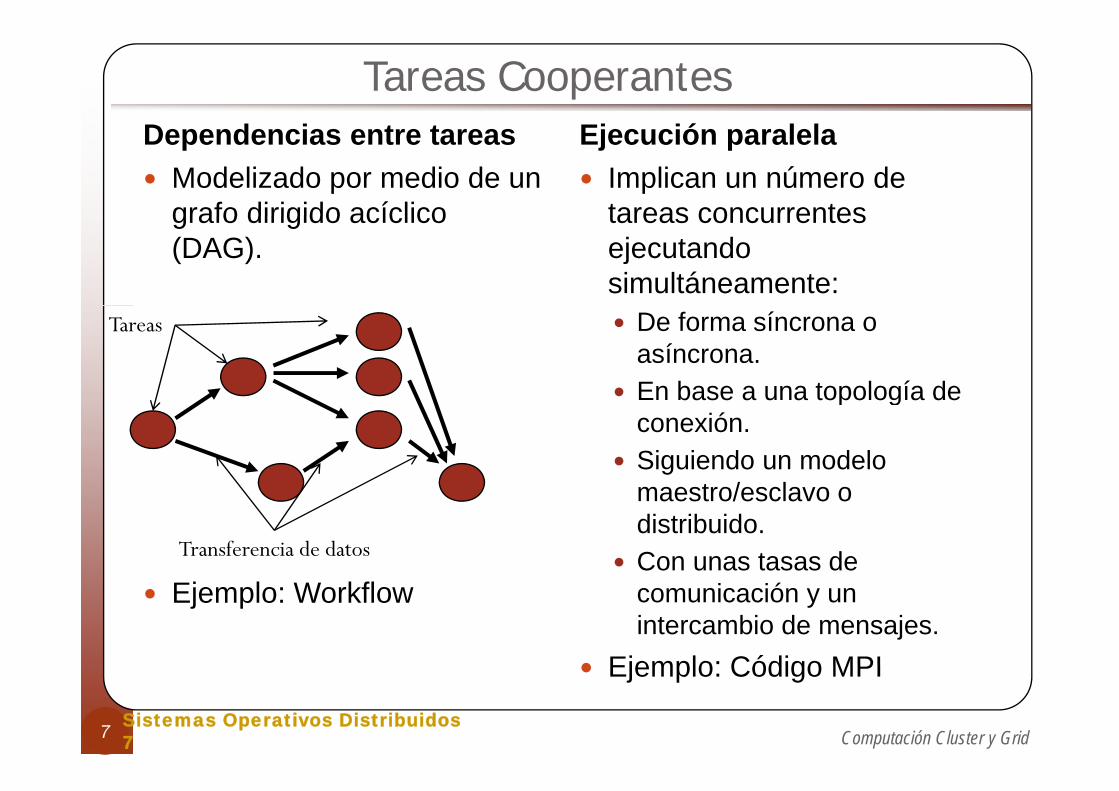
Tareas CooperantesD d i t t Ej ió l lDependencias entre tareas
Modelizado por medio de un grafo dirigido acíclico
Ejecución paralelaImplican un número de tareas concurrentesgrafo dirigido acíclico
(DAG).tareas concurrentes ejecutando simultáneamente:
De forma síncrona o asíncrona.En base a una topología de
Tareas
En base a una topología de conexión.Siguiendo un modelo
t / lmaestro/esclavo o distribuido.Con unas tasas de Transferencia de datos
Ejemplo: Workflow comunicación y un intercambio de mensajes.
Ejemplo: Código MPI
Computación Cluster y Grid7 Sistemas Operativos Distribuidos7
Ejemplo: Código MPI

Escenario de Partida: ObjetivosQ é “ j d t i ” i ?¿Qué “mejoras de prestaciones” se espera conseguir?
Tipología de sistemas:Sistemas de alta disponibilidadSistemas de alta disponibilidad
HAS: High Availability SystemsQue el servicio siempre esté operativoQue el servicio siempre esté operativoTolerancia a fallos
Sistemas de alto rendimiento HPC: High Performance ComputingQue se alcance una potencia de cómputo mayorEjecución de trabajos pesados en menor tiempoEjecución de trabajos pesados en menor tiempo
Sistemas de alto aprovechamiento HTS: High Troughput SystemsHTS: High Troughput SystemsQue el número de tareas servidas sea el máximo posibleMaximizar el uso de los recursos o servir a más clientes (puede
Computación Cluster y Grid8 Sistemas Operativos Distribuidos8
no ser lo mismo).

Sistemas de CómputoD d d i t d l i tDependen de uso previsto del sistema:
Máquinas autónomas de usuarios independientesU i d d á i ól d táUsuario cede uso de su máquina pero sólo cuando está desocupada¿Qué ocurre cuando deja de estarlo?¿ j
Migrar procesos externos a otros nodos inactivosContinuar ejecutando procesos externos con prioridad baja
S óSistema dedicado sólo a ejecutar trabajos paralelosSe puede hacer una estrategia de asignación a prioriO ajustar el comportamiento del sistema dinámicamenteO ajustar el comportamiento del sistema dinámicamenteSe intenta optimizar tiempo de ejecución de la aplicación o el aprovechamiento de los recursos
Sistema distribuido general (múltiples usuarios y aplicaciones)
S i t t l t d d d
Computación Cluster y Grid9 Sistemas Operativos Distribuidos9
Se intenta lograr un reparto de carga adecuado

Tipología de ClustersHi h P f Cl tHigh Performance Clusters
Beowulf; programas paralelos; MPI; dedicación a un problema
High Availability ClustersHigh Availability ClustersServiceGuard, Lifekeeper, Failsafe, heartbeat
High Throughput ClustersHigh Throughput ClustersWorkload/resource managers; equilibrado de carga; instalaciones de supercomputación
Según servicio de aplicación:Según servicio de aplicación:Web-Service Clusters
LVS/Piranha; equilibrado de conexiones TCP; datos replicadosLVS/Piranha; equilibrado de conexiones TCP; datos replicados
Storage ClustersGFS; sistemas de ficheros paralelos; identica visión de los datos desde cada nodo
Database ClustersOracle Parallel Server;
Computación Cluster y Grid10 Sistemas Operativos Distribuidos10
Oracle Parallel Server;

PlanificaciónL l ifi ió i t l d li d lLa planificación consiste en el despliegue de las tareas de un trabajo sobre unos nodos del sistema:
Atendiendo a las necesidades de recursosAtendiendo a las necesidades de recursosAtendiendo a las dependencias entre las tareas
El rendimiento final depende de diversos factores:El rendimiento final depende de diversos factores:Concurrencia: Uso del mayor número de procesadores simultáneamente.Grado de paralelismo: El grado más fino en el que se pueda descomponer la tarea.Costes de comunicación: Diferentes entreCostes de comunicación: Diferentes entre procesadores dentro del mismo nodo y procesadores en diferentes nodos.Recursos compartidos: Uso de recursos (como la memoria) comunes para varios procesadores dentro del mismo nodo
Computación Cluster y Grid11
del mismo nodo.

PlanificaciónD di ió d l dDedicación de los procesadores:
Exclusiva: Asignación de una tarea por procesador.Tiempo compartido: En tareas de cómputo masivo conTiempo compartido: En tareas de cómputo masivo con E/S reducida afecta dramáticamente en el rendimiento. Habitualmente no se hace.
La planificación de un trabajo puede hacerse de dos formas:
Pl ifi ió táti I i i l t d t iPlanificación estática: Inicialmente se determina dónde y cuándo se va a ejecutar las tareas asociadas a un determinado trabajo. Se determina antes de quea un determinado trabajo. Se determina antes de que el trabajo entre en máquina.Planificación dinámica: Una vez desplegado un t b j d d l t i t d l i ttrabajo, y de acuerdo al comportamiento del sistema, se puede revisar este despliegue inicial. Considera que el trabajo ya está en ejecución en la máquina.
Computación Cluster y Grid12
q j y j q

Gestión de Procesos
Planificación Estática
Computación Cluster y Grid13

Planificación EstáticaG l t li t d iti lGeneralmente se aplica antes de permitir la ejecución del trabajo en el sistema.El planificador (a menudo llamado resourceEl planificador (a menudo llamado resource manager) selecciona un trabajo de la cola (según política) y si hay recursos disponibles lo pone en p ) y y p pejecución, si no espera.
Cola de Trabajos
Planificador
í
TrabajosSistema
Recursos? sí
no
Computación Cluster y Grid14
pesperaj

Descripción de los TrabajosP d t l d i i di tPara poder tomar las decisiones correspondientes a la política del planificador, éste debe disponer de información sobre los trabajos:información sobre los trabajos:
Número de tareas (ejecutables correspondientes)PrioridadRelación entre ellas (DAG)Estimación de consumo de recursos (procesadores,
i di )memoria, disco)Estimación del tiempo de ejecución (por tarea)Otros parámetros de ejecuciónOtros parámetros de ejecuciónRestricciones aplicables
Estas definiciones se incluyen en un fichero deEstas definiciones se incluyen en un fichero de descripción del trabajo, cuyo formato depende del planificador correspondiente.
Computación Cluster y Grid15

Planificación de Tareas Dependientes C id l i i t tConsidera los siguientes aspectos:
Duración (estimada) de cada tarea.V l d d t t itid l fi li l t (Volumen de datos transmitido al finalizar la tarea (e.g. fichero)Precedencia entre tareas (una tarea requiere laPrecedencia entre tareas (una tarea requiere la finalización previa de otras).Restricciones debidas a la necesidad de recursosRestricciones debidas a la necesidad de recursos especiales.
221
Una opción consiste en transformar todos los datos a las mismas unidades (tiempo):
7
11 2
31
12
1
(tiempo):Tiempo de ejecución (tareas)Tiempo de transmisión (datos)
4 54 1 3
Representado por medio de un grafo acíclico dirigido
La Heterogeneidad complica estas estimación:
Ejecución dependiente de procesador
Computación Cluster y Grid16
Representado por medio de un grafo acíclico dirigido (DAG)
procesadorComunicación dependiente de
conexión

Planificación de Tareas Dependientes Pl ifi ió i t l i ió d tPlanificación consiste en la asignación de tareas a procesadores en un instante determinado de tiempo:tiempo:
Para un solo trabajo existen heurísticas eficientes: buscar camino crítico (camino más largo en grafo) ybuscar camino crítico (camino más largo en grafo) y asignar tareas implicadas al mismo procesador.Algoritmos con complejidad polinomial cuando sóloAlgoritmos con complejidad polinomial cuando sólo hay dos procesadores.Es un problema NP-completo con N trabajos.p p jEl modelo teórico se denomina multiprocessor scheduling.
Computación Cluster y Grid17

Ejemplo de Tareas Dependientes
1 210 10
N1 N21 2
20
1 1 2 1
N1 N20
Planificador4320
20
1
1
10
11 3 4
305 5
530
36
N1 N2El tiempo de comunicación entre procesos depende de su despliegue en el mismo nodo:
Tiempo ~0 si están en el mismo nodo
Computación Cluster y Grid18
Tiempo 0 si están en el mismo nodoTiempo n si están en diferentes
nodos

Algoritmos de ClusteringP l l li l it dPara los casos generales se aplican algoritmos de clustering que consisten en:
A l t ( l t )Agrupar las tareas en grupos (clusters).Asignar cada cluster a un procesador.La asignación óptima es NP completaLa asignación óptima es NP-completaEste modelo es aplicable a un solo trabajo o a varios en paraleloen paralelo.Los clusters se pueden construir con:
Métodos linealesMétodos linealesMétodos no-linealesBúsqueda heurística/estocástica
Computación Cluster y Grid19

Planificación con Clustering
2 12
AA
2
24
123456B
C B CD
2 3 2
43 1 1
3
6789
10
B
D EG
DE
F2 3 2
5 212
1011121314
D E FG
F
313
141516
H 1718
H
2I
1819202122
I
Computación Cluster y Grid20
22

Uso de la Replicación
2 12
AA
2
24
123456B
C B C1
DC2
2 3 2
43 1 1
3
6789
10
B
D EG
D E
F2 3 2
5 212
1011121314
D E FG
H31
3
141516
H 1718
2I
1819202122
I
Algunas tareas se ejecutan en varios
Computación Cluster y Grid21
22Algunas tareas se ejecutan en varios nodos para ahorrar en la comunicación

Migraciones con Procesos DependientesEl d t t i i t i it j lEl uso de estrategias migratorias permite mejorar el aprovechamiento.
S d d fi i l l ifi ió tátiSe pueden definir en la planificación estática.Lo más habitual es que formen parte de las estrategias dinámicasdinámicas.
N1 N2N1 N2
Con migración 21
N1 N2
1 2
N1 N20 0
1
3
1 2
2
22
3 23
Computación Cluster y Grid22
4
C id l i i t t
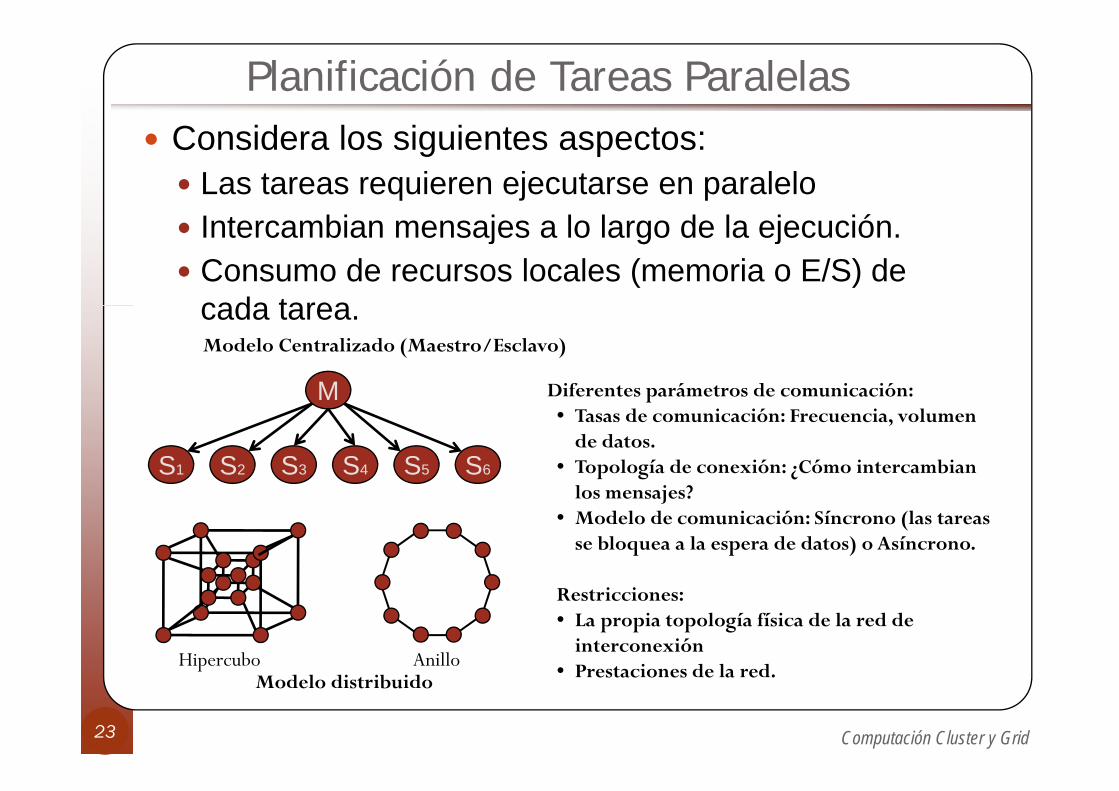
Planificación de Tareas ParalelasConsidera los siguientes aspectos:
Las tareas requieren ejecutarse en paraleloI t bi j l l d l j ióIntercambian mensajes a lo largo de la ejecución. Consumo de recursos locales (memoria o E/S) de cada tareacada tarea.
Diferentes parámetros de comunicación:M
Modelo Centralizado (Maestro/Esclavo)
Diferentes parámetros de comunicación:• Tasas de comunicación: Frecuencia, volumen
de datos.• Topología de conexión: ¿Cómo intercambian
l j ?
M
S1 S2 S3 S4 S5 S6los mensajes?
• Modelo de comunicación: Síncrono (las tareas se bloquea a la espera de datos) o Asíncrono.
Restricciones:• La propia topología física de la red de
interconexiónP i d l dHipercubo Anillo
Computación Cluster y Grid23
• Prestaciones de la red.Modelo distribuidoHipercubo Anillo

Rendimiento de la PlanificaciónEl di i t d l d l ifi ióEl rendimiento del esquema de planificación depende:
C di i d bl ( ilib d d )Condiciones de bloqueo (equilibrado de carga)Estado del sistemaEficiencia de las com nicaciones latencia ancho deEficiencia de las comunicaciones: latencia y ancho de bandaEnvio no bloqueante
Recepción bloqueante
Barrera de sincronización
Ejecución
BloqueadoRecepción no bloqueante
Envio bloqueante
Computación Cluster y Grid24
Bloqueado
Ocioso
Envio bloqueante

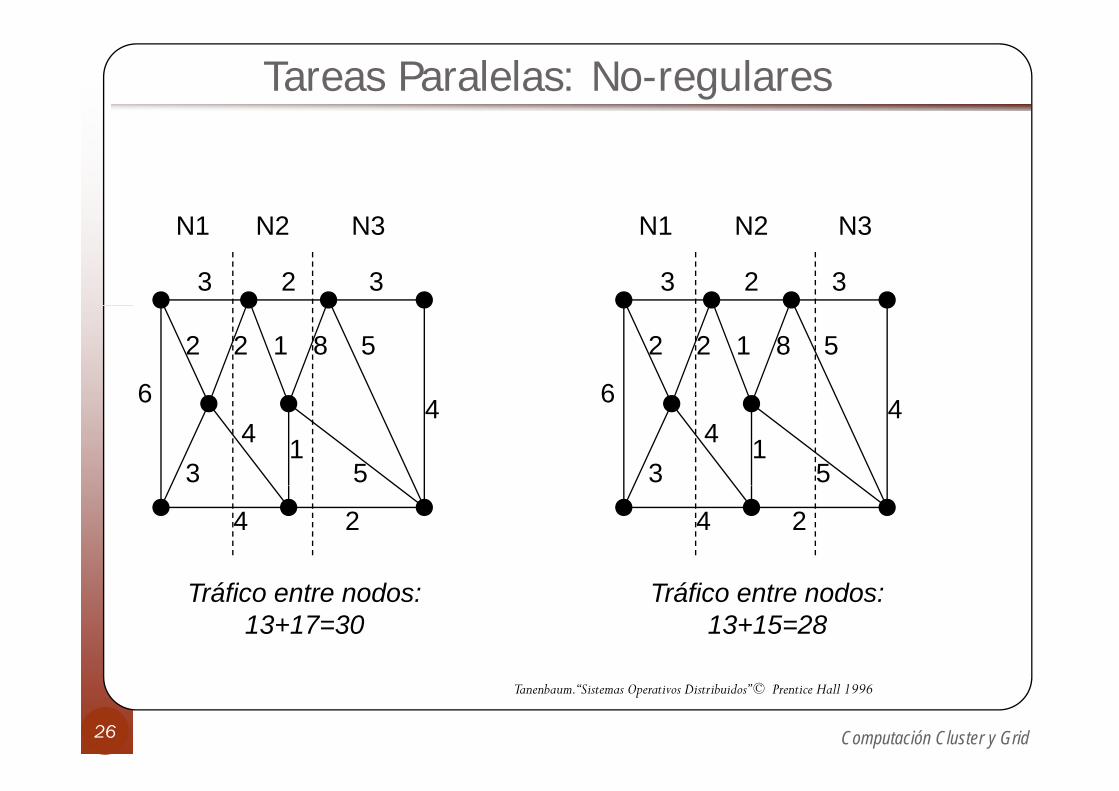
Tareas Paralelas: No-regularesE l l t l í d ióEn algunos casos las topologías de conexión no son regulares:
Modelado como grafo no dirigido donde:Modelado como grafo no dirigido donde:Nodo representa un proceso con necesidades de CPU y memoria Arcos incluye etiqueta que indica cantidad de datos que intercambian nodos implicados (tasa de comunicación)comunicación)
El problema en su forma general es NP-completoEn el caso general se utilizan heurísticas:En el caso general se utilizan heurísticas:
P. ej. corte mínimo: Para P procesadores buscar P-1 cortes tal que se minimice el flujo entre cada partición q j pResultado: Cada partición (procesador) engloba a un conjunto de procesos “fuertemente acoplados”N t ill l d l í
Computación Cluster y Grid25
No tan sencillo en los modelos asíncronos
Tareas Paralelas: No-regulares
N1 N2 N3 N1 N2 N3
3 2 3
N1 N2 N3
3 2 3
N1 N2 N3
2 2 1 8 5
6
2 2 1 8 5
6
34 1
5
6 4
34 1
5
6 4
4 2 4 2
Tráfico entre nodos: 13+17=30
Tráfico entre nodos: 13+15=28
Computación Cluster y Grid26
Tanenbaum. “Sistemas Operativos Distribuidos” © Prentice Hall 1996

Planificación de Múltiples TrabajosC d d b l ifi i t b j lCuando se deben planificar varios trabajos el planificador debe:
S l i l i i t t b j d á iSeleccionar el siguiente trabajo a mandar a máquina.Determinar si hay recursos (procesadores y de otro tipo) para poder lanzarlotipo) para poder lanzarlo.De no ser así, esperar hasta que se liberen recursos.
Cola de Trabajos
Planificador
í
TrabajosSistema
Recursos? sí
no
Computación Cluster y Grid27
pesperaj

Planificación de Múltiples TrabajosCó l i l i i t t b j i t t j t ?¿Cómo se selecciona el siguiente trabajo a intentar ejecutar?:Política FCFS (first-come-first-serve): Se respeta el orden de remisión de trabajos.jPolítica SJF (shortest-job-first): El trabajo más pequeño en primer lugar, medido en:
Recursos número de procesadores oRecursos, número de procesadores, o Tiempo solicitado (estimación del usuario).
Política LJF (longest-job-first): Ídem pero en el caso inverso.Basadas en prioridades: Administrativamente se define unos criterios de prioridad, que pueden contemplar:
Facturación del coste de recursosFacturación del coste de recursos.Número de trabajos enviados.Deadlines de finalización de trabajos. (EDF – Earliest-deadline-first)
Computación Cluster y Grid28

BackfillingB kfilliBackfilling es una modificación aplicable a cualquiera de las políticascualquiera de las políticas anteriores:
Si el trabajo seleccionado porSe buscan trabajos que demanden menos procesadoresSi el trabajo seleccionado por
la política no tiene recursos para entrar entonces,
menos procesadores
p ,Se busca otro proceso en la cola que demande menos
Planificador
recursos y pueda entrar.Permite aprovechar mejor el i t
Recursos? sí
nosistema no
Backfilling
Computación Cluster y Grid29

Backfilling con ReservasL i tLas reservas consisten en:
Determinar cuándo se podría ejecutar la tarea inicialmenteejecutar la tarea inicialmente seleccionada, en base a las estimaciones de tiempos
La técnica de Backfilling puede hacer que trabajos que demanden muchos recursos nunca se ejecutenestimaciones de tiempos
(deadline)Se dejan entrar trabajos que
ejecuten
j j qdemandan menos recursos (backfilling) siempre y cuando fi li t d l d dli
Planificador
finalicen antes del deadline.Aumenta el aprovechamiento del sistema pero no retrasa
Recursos? sí
nodel sistema, pero no retrasa indefinidamente a los trabajos grandes.
no
Backfilling
Computación Cluster y Grid30
g

Gestión de Procesos
Planificación Dinámica
Computación Cluster y Grid31

Planificación DinámicaL l ifi ió táti d id iLa planificación estática decide si un proceso se ejecuta en el sistema o no, pero una vez lanzado no se realiza seguimiento de élse realiza seguimiento de él.La planificación dinámica:
Evalúa el estado del sistema y toma accionesEvalúa el estado del sistema y toma acciones correctivas.Resuelve problemas debidos a la paralelización del
bl (d ilib i t l t )problema (desequilibrio entre las tareas).Reacciona ante fallos en nodos del sistema (caídas o falos parciales)falos parciales).Permite un uso no dedicado o exclusivo del sistema.Requiere una monitorización del sistema (políticas de (gestión de trabajos):
En la planificación estática se contabilizan los recursos comprometidos.
Computación Cluster y Grid32
comprometidos.

Load Balancing vs. Load SharingL d Sh iLoad Sharing:
Que el estado de los procesadores no sea diferenteUn procesador ociosoUn procesador ociosoUna tarea esperando a ser servida en otro procesador
AsignaciónLoad Balancing:
Que la carga de los procesadores sea igual.
Asignación
g p gLa carga varía durante la ejecución de un trabajo¿Cómo se mide la carga?
Son conceptos muy similares, gran parte de las estrategias usadas para LS vale para LBestrategias usadas para LS vale para LB (considerando objetivos relativamente diferentes). LB tiene unas matizaciones particulares.
Computación Cluster y Grid33
LB tiene unas matizaciones particulares.

Medición de la CargaQ é d i ti ?¿Qué es un nodo inactivo?Estación de trabajo: “lleva varios minutos sin recibir entrada del teclado o ratón y no está ejecutando procesos interactivos”y j pNodo de proceso: “no ha ejecutado ningún proceso de usuario en un rango de tiempo”.Pl ifi ió táti “ l h i d i t ”Planifiación estática: “no se le ha asignado ninguna tarea”.
¿Qué ocurre cuando deja de estar inactivo?No hacer nada → El nuevo proceso notará mal rendimientoNo hacer nada → El nuevo proceso notará mal rendimiento.Migrar el proceso a otro nodo inactivo (costoso)Continuar ejecutando el proceso con prioridad baja.
Si en lugar de considerar el estado (LS) se necesita conocer la carga (LB) hacen falta métricas específicas.
Computación Cluster y Grid34

Políticas de Gestión de TrabajosT d l tió d t b j b i dToda la gestión de trabajos se basa en una serie de
decisiones (políticas) que hay que definir para una serie de casos:serie de casos:
P líti d i f ió á d lPolítica de información: cuándo propagar la información necesaria para la toma de decisiones.P líti d t f i d id á d t f iPolítica de transferencia: decide cuándo transferir. Política de selección: decide qué procesot f itransferir.Política de ubicación: decide a qué nodo transferir.
Computación Cluster y Grid35

Política de InformaciónC á d t it i f ió b l dCuándo se transmite información sobre el nodo:
Bajo demanda: únicamente cuando desea realizar una transferenciauna transferencia.Periódicas: se recoge información periódicamente, la información está disponible en el momento de realizarinformación está disponible en el momento de realizar la transferencia (puede estar obsoleta).Bajo cambio de estado: cada vez que un nodoBajo cambio de estado: cada vez que un nodo cambia de estado.
Ámbito de información:Completa: todos los conocen toda la información del sistema.Parcial: cada nodo sólo conoce el estado de parte de los nodos del sistema.
Computación Cluster y Grid36

Política de InformaciónQ é i f ió t it ?¿Qué información se transmite?:
La carga del nodo ¿qué es la carga?
Diferentes medidas:%CPU en un instante de tiempoNúmero de procesos listos para ejecutar (esperando)Nú d f ll d á i / iNúmeros de fallos de página / swapingConsideración de varios factores.
Se pueden considerar casos de nodos h t é ( dif t id d )heterogéneos (con diferentes capacidades).
Computación Cluster y Grid37

Política de TransferenciaG l t b d b lGeneralmente, basada en umbral:
Si en nodo S carga > T unidades, S emisor de tareasSi d S T id d S t d tSi en nodo S carga < T unidades, S receptor de tareas
Tipos de transferencias:Expulsivas: se pueden transferir tareas ejecutadasparcialmente.
Supone: transferir el estado del proceso asociado a la tarea (migración) o reiniciar su ejecución(migración) o reiniciar su ejecución.
No expulsivas: las tareas ya en ejecución no pueden ser transferidas.
Computación Cluster y Grid38
Política de SelecciónEl i l d t (t f iElegir los procesos de tareas nuevas (transferencia no expulsiva).S l i l i dSeleccionar los procesos con un tiempo de transferencia mínimo (poco estado, mínimo uso de los recursos locales)los recursos locales).Seleccionar un proceso si su tiempo de finalización
d t l ti den un nodo remoto es menor que el tiempo de finalización local.
El tiempo de finalización remoto debe considerar elEl tiempo de finalización remoto debe considerar el tiempo necesario para su migración.El tiempo de finalización puede venir indicado en laEl tiempo de finalización puede venir indicado en la descripción del trabajo (estimación del usuario).De no ser así, el sistema debe estimarlo por sí mismo.
Computación Cluster y Grid39
, p

Política de UbicaciónM t lt d t d tMuestreo: consulta de otros nodos para encontrar adecuado.Alternativas:Alternativas:
Sin muestreo (se manda a uno aleatoriamente).Muestreo secuencial o paralelo.Muestreo secuencial o paralelo.Selección aleatoria.Nodos más próximos.Enviar un mensaje al resto de nodos (broadcast).Basada en información recogida anteriormente.
Tres tipos de políticas:Iniciadas por el emisor (Push) → emisor busca receptoresreceptoresIniciadas por el receptor (Pull) → receptor solicita procesos
Computación Cluster y Grid40
pSimétrica → iniciada por el emisor y/o por el receptor.

Ejecución Remota de Procesos¿Cómo ejecutar un proceso de forma remota?
Crear el mismo entorno de trabajo:Variables de entorno directorio act al etcVariables de entorno, directorio actual, etc.
Redirigir ciertas llamadas al sistema a máquina origen:g
P. ej. interacción con el terminalMigración (transferencia expulsiva) mucho más
l jcompleja:“Congelar” el estado del procesoTransferir a máquina destinoTransferir a máquina destino“Descongelar” el estado del proceso
Numerosos aspectos complejos:Numerosos aspectos complejos:Redirigir mensajes y señales¿Copiar espacio de swap o servir fallos de pág.
Computación Cluster y Grid41
¿ p p p p gdesde origen?

Migración de ProcesosDif t d l d i ióDiferentes modelos de migración:
Migración débil: Restringida a determinadas aplicaciones (ejecutadas en máquinas virtuales) o en ciertos momentos.
ó fMigración fuerte: Realizado a nivel de código nativo y una vez que la t h i i i d j ió ( l i t )tarea ha iniciado su ejecución (en cualquier momento)De propósito general: Más flexible y más compleja
Mi ió d d tMigración de datos: No se migran procesos sino sólo los datos sobre los que estaba trabajandoque estaba trabajando.
Computación Cluster y Grid42

Migración: RecursosL i ió d t bié d d d lLa migración de recursos también depende de la relación de éstos con las máquinas.
Unatachment resource. Ejemplo: un fichero de datos d l idel programa a migrar.Fastened resource. Son recursos movibles, pero con un alto coste Ejemplo: una base de datos un sitioun alto coste. Ejemplo: una base de datos, un sitio web.Fixed resource. Están ligados estrechamente a unaFixed resource. Están ligados estrechamente a una máquina y no se pueden mover. Ejemplo: dispositivos locales
Computación Cluster y Grid43

Migración: Datos de las TareasL d t t t bié d bLos datos que usa una tarea también deben migrarse:
D t di E i t i d i t d fi hDatos en disco: Existencia de un sistema de ficheros común.Datos en memoria: Requiere “congelar” todos losDatos en memoria: Requiere congelar todos los datos del proceso correspondiente (páginas de memoria y valores de registros). Técnicas de y g )checkpointing:
Las páginas de datos del proceso se guardan a disco.Se puede ser más selectivo si las regiones que definen el estado están declaradas de alguna forma específica (lenguajes/librerías especiales).( g j p )Es necesario guardar también los mensajes enviados que potencialmente no hayan sido entregados.Útiles también para casos en los que no hay migración: Fallos
Computación Cluster y Grid44
Útiles también para casos en los que no hay migración: Fallos en el sistema.

Migración DébilL i ió débil d ti l d l i i t fLa migración débil se puede articular de la siguiente forma:
Ejecución remota de un nuevo proceso/programaEn UNIX podría ser en FORK o en EXECEn UNIX podría ser en FORK o en EXECEs más eficiente que nuevos procesos se ejecuten en nodo donde se crearon pero eso no permite reparto de carga
Hay que transferir cierta información de estado aunque no estéHay que transferir cierta información de estado aunque no esté iniciado
Argumentos, entorno, ficheros abiertos que recibe el proceso, etc. Ciertas librerías pueden permitir al programador establecer puntos en los cuales el estado del sistema de almacena/recupera y que pueden ser usados para realizar la migración.y q p p gEn cualquier caso el código del ejecutable debe ser accesible en el nodo destino:
Sistema de ficheros comúnSistema de ficheros común.
Computación Cluster y Grid45

Migración DébilE l j ( J )En lenguajes (como Java):
Existe un mecanismo de serialización que permite transferir el estado de un objeto en forma de “serie detransferir el estado de un objeto en forma de “serie de bytes”.Se porporciona un mecanismo de carga bajo demandaSe porporciona un mecanismo de carga bajo demanda de las clases de forma remota.
A=3instancia A=3serialización
Proceso.classCargadordinámico
Solicitud de clase
Nodo 1 Proceso.class Nodo 2
Computación Cluster y Grid46

Migración Fuerte
Solución naïve:Copiar el mapa de memoria: código, datos, pila, ...Crear un nuevo BCP (con toda la información salvaguardada en el cambio de contexto).
Hay otros datos (almacenados por el núcleo) que son i D i d t d t d lnecesarios: Denominado estado externo del proceso
Ficheros abiertosS ñ l di tSeñales pendientesSocketsS áfSemáforosRegiones de memoria compartida.....
Computación Cluster y Grid47

Migración Fuerte
Existen diferentes aproximaciones a posibles implementaciones:A nivel de kernel:
Versiones modificadas del núcleoDispone de toda la información del proceso
A nivel de usuario:Librerias de checkpointingProtocolos para desplazamiento de socketsIntercepción de llamadas al sistema
Otros aspectos:PID único de sistema
Computación Cluster y Grid
Credenciales y aspectos de seguridad48
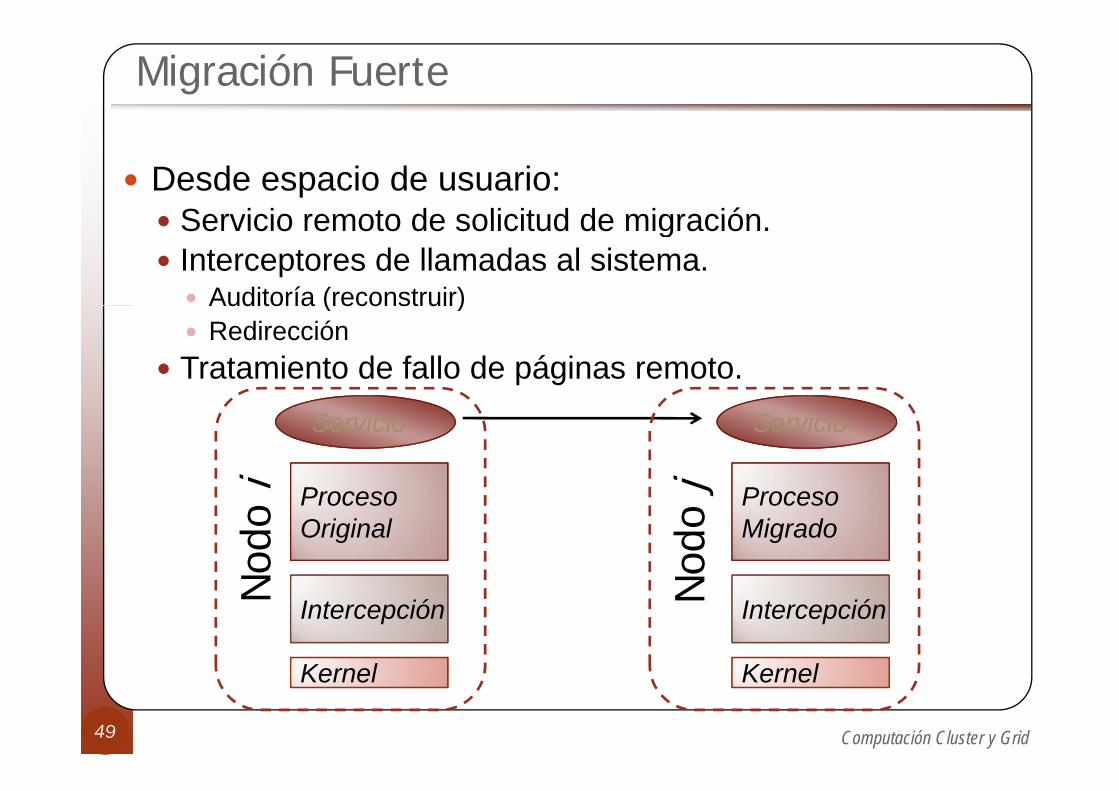
Migración Fuerte
Desde espacio de usuario:Servicio remoto de solicitud de migraciónServicio remoto de solicitud de migración.Interceptores de llamadas al sistema.
Auditoría (reconstruir)Auditoría (reconstruir)Redirección
Tratamiento de fallo de páginas remoto.
Servicio Servicio
i jProcesoOriginal
ProcesoMigrado
odo
i
odo
jK l
Intercepción
K l
IntercepciónN NComputación Cluster y Grid
Kernel Kernel
49

Migración Fuerte
Servicio de solicitud de migración:1 I t tú l ( í bibli t t j l )1. Interactúa con los procesos (vía biblioteca ptrace, por ejemplo).2. Suspende la ejecución del proceso original3 Obtiene datos del proceso (valores de registros o mapa de3. Obtiene datos del proceso (valores de registros o mapa de
memoria)4. Crea nuevo proceso destino5. Modifica valores de los registros6. Monitoriza, en términos generales, el estado de los procesos
Servicio Servicio
tfork+
ProcesoOriginal
ProcesoMigrado
ptrace +ptrace
Computación Cluster y Grid50

Migración Fuerte
Interceptores de llamadas al sistema:1 N i l t d t1. Necesarios para conocer el estado externo2. Sobrescribir las funciones asociadas a las llamadas al sistema3 Despliegue por medio de bibliotecas dinámicas (e g3. Despliegue por medio de bibliotecas dinámicas (e.g.,
LD_PRELOAD)4. Se conoce la secuencia de llamadas hechas (se puede repetir)( )5. Se puede redirigir una llamada a otro sitio (vía el servicio).
ProcesoServicio
ProcesoOriginal
open(…) open( )IntercepciónLD_PRELOAD=foo.so
open(…)
Kernelopen(…)
Computación Cluster y Grid
Kernel
51
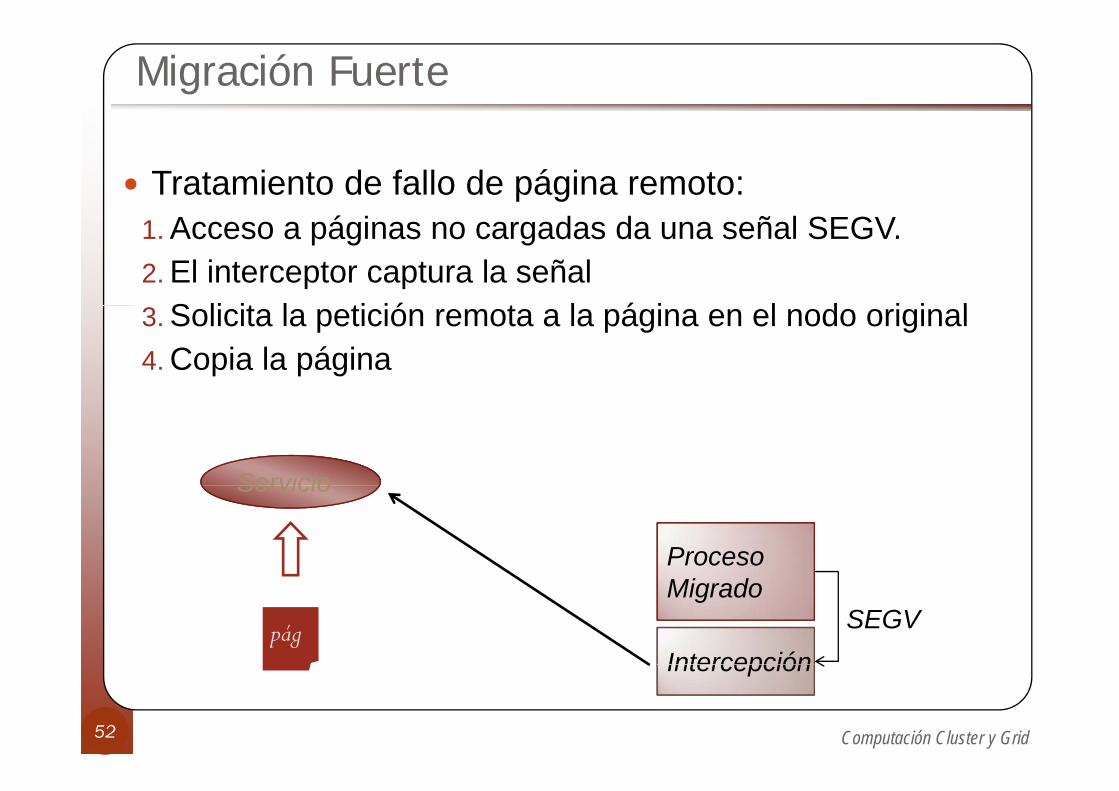
Migración Fuerte
Tratamiento de fallo de página remoto:A á i d d l SEGV1. Acceso a páginas no cargadas da una señal SEGV.
2. El interceptor captura la señalS li it l ti ió t l á i l d i i l3. Solicita la petición remota a la página en el nodo original
4. Copia la página
ServicioServicio
ProcesoMigrado
SEGVIntercepción
pág
Computación Cluster y Grid
Intercepción
52

Migración Fuerte
Se debe intentar que proceso remoto se inicie cuanto antesCopiar todo el espacio de direcciones al destinoC i ól á i difi d l d ti t di áCopiar sólo páginas modificadas al destino; resto se pedirán como fallos de página desde nodo remoto servidas de swap de origenorigenNo copiar nada al destino; las páginas se pedirán como fallos de página desde el nodo remoto
servidas de memoria de nodo origen si estaban modificadasservidas de swap de nodo origen si no estaban modificadas
Volcar a swap de nodo origen páginas modificadas y no copiarVolcar a swap de nodo origen páginas modificadas y no copiar nada al destino: todas las páginas se sirven de swap de origenPrecopia: Copia de páginas mientras ejecuta proceso en origeng j g
Páginas de código (sólo lectura) no hay que pedirlas:Se sirven en nodo remoto usando SFD
Computación Cluster y Grid53

Migración Fuerte
Migración de conexiones:Afecta a las conexiones entrantes y salientes.Solución por medio de proxies:
En realidad todas las direcciones son de un único servidor que redirige al nodo donde está el proceso en cada momentoredirige al nodo donde está el proceso en cada momento.El problema es que no es escalable.
Solución a nivel IP:Se asigna una dirección IP por proceso del sistema (vía DHCP)Paquetes “Gratuitous ARP” para informar de cambio de MAC al
i lmigrar el proceso.El problema es el rango de direcciones disponibles (red privada virtual).)
Computación Cluster y Grid54

Beneficios de la Migración de ProcesosM j di i t d l i t t dMejora rendimiento del sistema por reparto de cargaPermite aprovechar proximidad de recursos
Proceso que usa mucho un recurso: migrarlo al nodoProceso que usa mucho un recurso: migrarlo al nodo del mismo
Puede mejorar algunas aplicaciones cliente/servidorPuede mejorar algunas aplicaciones cliente/servidorPara minimizar transferencias si hay un gran volumen de datos:
Servidor envía código en vez de datos (p. ej. applets)O cliente envía código a servidor (p. ej. cjto. de accesos a b. de datos))
Tolerancia a fallos ante un fallo parcial en un nodoDesarrollo de “aplicaciones de red”p
Aplicaciones conscientes de su ejecución en una redSolicitan migración de forma explícita
Computación Cluster y Grid55
Ejemplo: Sistemas de agentes móviles

Migración de Datos
Usando en aplicaciones de tipo maestro/esclavo.Maestro: Distribuye el trabajo entre los trabajadores.Esclavo: Trabajador (el mismo código pero con diferentes datos).
Representa un algoritmo de distribución de trabajo (en t d t )este caso datos) que:Evite que un trabajador esté parado porque el maestro no transmite datostransmite datos.No asigne demasiado trabajo a un nodo (tiempo final del proceso es el del más lento)proceso es el del más lento)Solución: Asignación de trabajos por bloques (más o menos pequeños).
Computación Cluster y Grid
p q )
56

Migración de Datos
Mejoras de rendimiento:Equilibrado de carga:
Solución: Definir muchos paquetes de trabajo e ir despachándolos bajo demanda (finalización del anterior).
Intentar lanzar rápido los trabajos iniciales:Intentar lanzar rápido los trabajos iniciales:Solución: Uso de broadcast en el envío de paquetes inicial.
Si todos los nodos son homogéneos y realizan el mismo g ytrabajo finalizarán casi a la vez:
Plantea un posible problema de saturación del maestro que deriva t d h t d t b jen un retraso en despachar nuevos paquetes de trabajo.
Solución: Asignación inicial en distintos tamaños.
Computación Cluster y Grid57

Planificación Dinámica vs. Estática
Los sistemas pueden usar indistintamente una, otro o l dlas dos.
Planificación adaptativa: Se mantiene Estática
Estrategias de equilibrado de carga: No Estática
un control central sobre los trabajos lanzados al sistema, pero se dispone de los mecanismos necesarios para ám
ica Los trabajos se arrancan libremente en
los nodos del sistema y por detrás un servicio de equilibrado de carga/estado p
reaccionar a errores en las estimaciones o reaccionar ante problemas.D
iná q g
ajusta la distribución de tareas a los nodos.
Gestor de recursos (con asignación batch): Los procesadores se asignan de forma exclusiva y el gestor de recursos m
ica Cluster de máquinas sin planificación
alguna: Que sea lo que Dios quiera… forma exclusiva y el gestor de recursos mantiene información sobre los recursos comprometidos.
o D
inám
Computación Cluster y Grid
No
58
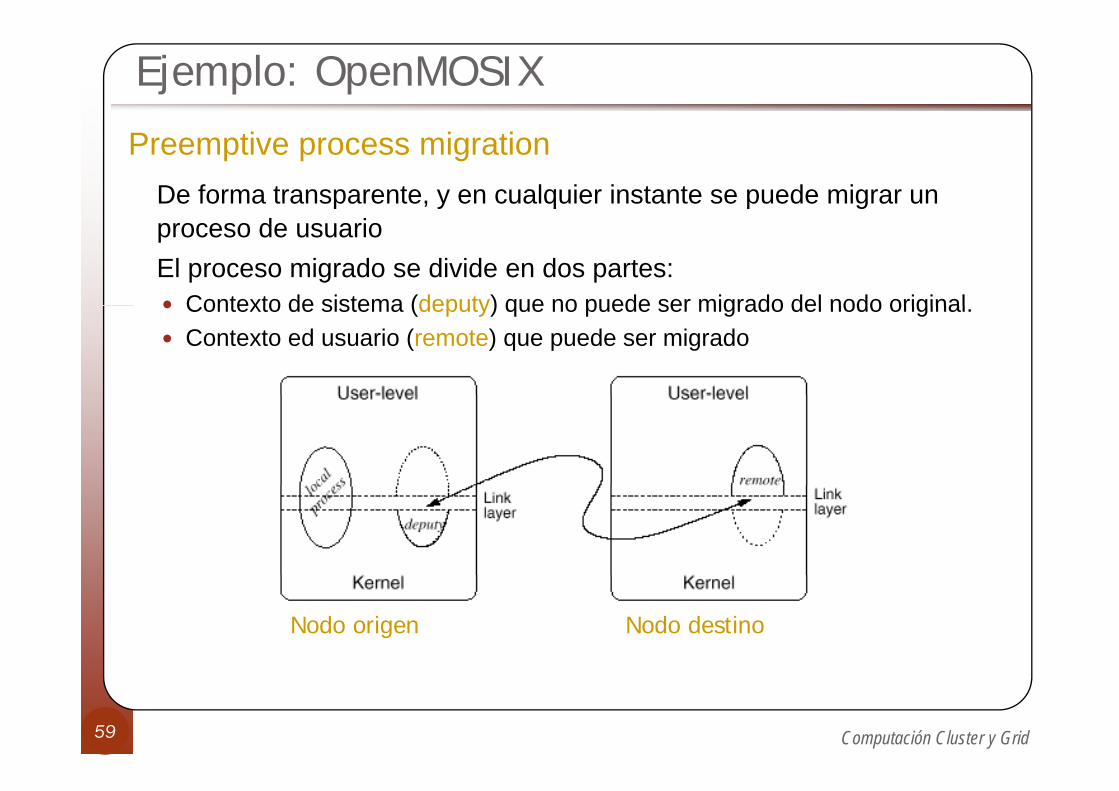
Ejemplo: OpenMOSIX
Preemptive process migrationDe forma transparente, y en cualquier instante se puede migrar un proceso de usuarioEl proceso migrado se divide en dos partes:
Contexto de sistema (deputy) que no puede ser migrado del nodo originalContexto de sistema (deputy) que no puede ser migrado del nodo original.Contexto ed usuario (remote) que puede ser migrado
Nodo origen Nodo destino
Computación Cluster y Grid59

Ejemplo: OpenMOSIX
Dynamic load balancingSe inician los procesos de migración con la intención de equilibrar la carga de los nodoscarga de los nodosSe ajusta de acuerdo a la variación de carga de los nodos, características de la ejecución y número y potencia de los nodosIntenta en cada momento reducir la diferencia de carga de cada pareja de nodosL líti i ét i d t li d (t d l d j t lLa política es simétrica y descentralizada (todos los nodos ejecutan el mismo algoritmo)
Memory sharingMemory sharingDe mayor prioridad.Intenta equilibrar el uso de memoria entre los nodos del sistemaEvita, en la medida de lo posible, hacer swapping.La toma de decisiones de qué proceso migrar y donde migrarlo se
lú b l tid d d i di ibl
Computación Cluster y Grid
evalúa en base a la cantidad de memoria disponible.
60

Ejemplo: OpenMOSIX
Probabilistic information dissemination algorithmsProporciona a cada nodo (a su algoritmo) suficiente información sobre los recursos disponibles en otros nodos Sin hacer pollinglos recursos disponibles en otros nodos. Sin hacer polling.Mide la cantidad de recursos disponibles en cada nodoLa emisión de esta información se hace a intervalos regulares de tiempoLa emisión de esta información se hace a intervalos regulares de tiempo a un subconjunto aleatorio de los nodos.En el ejecución de una migración, cada asignación de un proceso i li i d d t l l l d d b j t l ( dimplica un periodo durante el cual el nodo debe ejecutarlo (no puede migrarlo de nuevo).
Computación Cluster y Grid61

Referencias
BProc: Beowulf Distributed Process Space
• Open MOSIXhtt // i f t/Process Space
http://bproc.sourceforge.net/Scyld Computer
http://openmosix.sourceforge.net/• OpenSSI
htt // i /Corporationhttp://www.scyld.com/
http://www.openssi.org/
• A Dynamic Load Balancing System for Parallel ClusterComputing (1996)p g ( )B. J. Overeinder, P. M. A. Sloot, R. N. Heederik. Future GenerationComputer Systems
• Transparent Process Migration: Design Alternatives and the Sprite Implementation (1991)
Computación Cluster y Grid
p p ( )Fred Douglis, John Ousterhout. Software - Practice and Experience
62
Recommended

















