
Agenda
• Websearch– Crawling– Ordering– PageRank– Ads

Next topic: Websearch
• Create a search engine for searching the web
• DBMS queries use tables and (optionally) indices
• First thing to understand about websearch:– we never run queries on the web– Way too expensive, for several reasons
• Instead:– Build an index of the web– Search the index– Return the results

Crawling• To obtain the data for the index, we crawl
the web– Automated web-surfing– Conceptually very simple– But difficult to do robustly
• First, must get pages– Put start page in a queue– Repeat {
remove and store first element;insert all its links into queue
} until …

Crawling issues in practice
• DNS bottleneck– to view page by text link, must get address– BP claim: 87% crawling time ~ DNS look-up
• Search strategy?
• Refresh strategy?
• Primary key for webpages– Use artificial IDs, not URLs– more popular pages get shorter DocIDs (why?)

Crawling issues in practice
• Content-seen test– compute fingerprint/hash (again!) of page content
• robots.txt– http://www.robotstxt.org/wc/robots.html
• Bad HTML– Tolerant parsing
• Non-responsive servers
• Spurious text

Inverted indices
• What’s needed to answer queries:– Create inverted index mapping words to pages
• First, think of each webpage as a tuple– One column for each possible word– True means the word appears on the page– Index on all columns
• Now can search: john bolton
select * from T where john=T and bolton=Tselect * from T where john=T and bolton=T

Inverted indices• Can simplify somewhat:
1. For each field index, delete False entries2. True entries for each index become a bucket
Create an inverted index:– One entry for each search word
• the lexicon– Search word entry points to corresponding bucket– Bucket points to pages with its word
• the postings file
• Final intuition: the inverted index doesn’t map URLs to words
– It maps words to URLs

Inverted Indices
• What’s stored?
• For each word W, for each doc D– relevance of D to W– #/% occurs. of W in D– meta-data/context: bold, font size, title, etc.
• In addition to page importance, keep in mind:– this info is used to determine relevance of
particular words appearing on the page

Google-like infrastructure
• Very large distributed system– File sizes routines in GBs Google File System
• Block size = 64MB (not kb)!
– 100k+ low-quality Linux boxes system failures are the rule, not exception
• Divide index up by words into many barrels– lexicon maps word ids to word’s barrel– also, do RAID-like strategy two-D matrix of servers
• many commodity machines frequent crashes
– Draw picture– May have more duplication for popular pages…

Google-like infrastructure
• To respond to single-word query Q(w):– send to the barrel column for word w
• pick random server in that column– return (some) sorted results
• To respond to multi-word query Q(w1…wn):– for each word wi, send to the barrel column for wi
• pick random server in that column– for all words in parallel, merge and prune
• step through until find doc containing all words, add to results
• index ordered on word;docID, so linear time– return (some) sorted results

New topic: Sorting Results
• How to respond to Q(w1,w2,…,wn)?– Search index for pages with w1,w2,…,wn
– Return in sorted order (how?)
• Soln 1: current order– Return 100,000 (mostly) useless results
• Sturgeon's Law: “Ninety percent of everything is crud.”
• Soln 2: sort by relevance– Use tech.s from Information Retrieval Theory– library science + CS = IR

Simple IR-style approach• for each word W in a doc D, compute
– # occurs of W in D / total # word occurs in D each document becomes a point in a space
– one dimension for every possible word• Like k-NN and k-means
– value in that dim is ratio from above (maybe weighted, etc.)– Choose pages with high values for query words
• A little more precisely: each doc becomes a vector in space– Values same as above– But: think of the query itself as a document vector– Similarity between query and doc = dot product / cos– Draw picture

Information Retrieval Theory
• With some extensions, this works well for relatively small sets of quality documents
• But the web has 600 billion docs– Prob: based just on percentages very short
pages with query words score very high– BP: query a “major search engine” for “bill
clinton” “Bill Clinton Sucks” page

Soln 3: sort by rel. and “quality”
• What do you mean by quality?
• Hire readers to rate my webpage (early Yahoo)
• Problem: doesn’t scale well– more webpages than Yahoo employees…

Soln 4: count # citations (links)
• Idea: you don’t have to hire webpage raters
• The rest of the web has already voted on the quality of my webpage
• 1 link to my page = 1 vote
• Similar to counting academic citations– Peer review

Soln 5: Google’s PageRank
• Count citations, but not equally – weighted sum• Motiv: we said we believe that some pages are
better than others those pages’ votes should count for more
• A page can get a high PageRank many ways• Two cases at ends of a continuum:
– many pages link to you– yahoo.com links to you
• Capitalist, not democratic

PageRank
• More precisely, let P be a page;
• for each page Li that links to P,
• let C(Li) be the number of pages Li links to.
• Then PR0(P) = SUM(PR0(Li)/C(Li)))
• Motiv: each page votes with its quality;– its quality is divided among the pages it votes for– Extensions: bold/large type/etc. links may get
larger proportions…

Understanding PageRank (skip?)• Analogy 1: Friendster/Orkut
– someone “good” invites you in– someone else “good” invited that person in, etc.
• Analogy 2: PKE certificates– my cert authenticated by your cert– your cert endorsed by someone else's…
• Both cases here: eventually reach a foundation
• Analogy 3: job/school recommendations– three people recommend you– why should anyone believe them?
• three other people rec-ed them, etc.• eventually, we take a leap of faith

Understanding PageRank
• Analogy 4: Random Surfer Model
• Idealized web surfer:– First, start at some page– Then, at each page, pick a random link…
• Turns out: after long time surfing,– Pr(were at some page P right now) = PR0(P)
– PRs are normalized

Computing PageRank• For each page P, we want:
– PR(P) = SUM(PR(Li)/C(Li)))
• But its circular – how to compute?
• Meth 1: for n pages, we've got n linear eqs and n unknowns– can solve for all PR(P)s, but too hard– see your linear algebra course…
• Meth 2: iteratively– start with PR0(P) set to E for each P– iterate until no more significant change– PB: O(50) iterations for O(30M) pages/O(300M) links
• #iters req. grows only with log of web size

Problems with PageRank
• Example (from Ullman):– A points to Y, M;– Y points to self, A;– M points nowhere draw picture
• Start A,Y,M at 1:– http://pages.stern.nyu.edu/~mjohnson/dbms/archive/spring05/eg/PageRank.java
–
• (1,1,1) (0,0,0)– The rank dissipates
• Soln: add (implicit) self link to any dead-end
C:\ java PageRankC:\ java PageRank

Problems with PageRank
• Example (from Ullman):– A points to Y, M;– Y points to self, A;– M points to self
• Start A,Y,M at 1:– http://pages.stern.nyu.edu/~mjohnson/dbms/archive/spring05/eg/PageRank2.java
–
• (1,1,1) (0,0,3)– Now M becomes a rank sink– RSM interp: we eventually end up at M and then get stuck
• Soln: add “inherent quality” E to each page
C:\ java PageRank2C:\ java PageRank2

Modified PageRank
• Apart from inherited quality, each page also has inherent quality E:– PR(P) = E + SUM(PR(Li)/C(Li)))
• More precisely, have weighted sum of the two terms:– PR(P) = .15*E + .85*SUM(PR(Li)/C(Li)))– http://pages.stern.nyu.edu/~mjohnson/dbms/archive/spring05/eg/PageRank3.java
–
• Leads to a modified random surfer model
C:\ java PageRank3C:\ java PageRank3

Random Surfer Model’
• Motiv: if we (qua random surfer) end up at page M, we don’t really stay there forever– We type in a new URL
• Idealized web surfer:– First, start at some page– Then, at each page, pick a random link– But occasionally, we get bored and jump to a random new
page
• Turns out: after long time surfing,– Pr(we’re at some page P right now) = PR(P)

Understanding PageRank
• One more interp: hydraulic model– picture the web graph again
– imagine each link as a tube bet. two nodes
– imagine quality as fluid
– each node is a reservoir initialized with amount E of fluid
• Now let flow…
• Steady state is: each node P w/PR(P) amount of fluid– PR(P) of fluid eventually settles in node P
– equilibrium

• Sornette: “Why Stock Markets Crash”– Si(t+1) = sign(ei + SUM(Sj(t))– trader buys/sells based on1. is inclination and2. what is associates are saying
• directions. of magnet det-ed by1. old direction and2. dirs. of neighbors
• activation of neuron det-ed by1. its props and2. activation of neighbors connected by synapses
• PR of P based on1. its inherent value and2. PR of in-links
Supervenience in PR & elsewhere (skip?)

Non-uniform Es (skip?)• So far, assumed E was const for all pages• But can make E a function E(P)
– vary by page
• How do we choose E(P)?• Idea 1: set high for pages with high PR from
earlier iterations• Idea 2: set high for pages I like
– BP paper gave high E to John McCarthy’s homepage pages he links to get high PR, etc.– Result: his own personalized search engine– Q: How would google.com get your prefs?

Next: Tricking search engines
• PR assumes linking is “honest”– Just as Stable Marr. alg assumes honesty
• “Search Engine Optimization”
• Challenge: include on your page lots of words you think people will query on– maybe hidden with same color as background
• Response: popularity ranking– the pages doing this probably aren't linked to that
much– but…

Tricking search engines• Goal: make my page look popular to Google• Chal:: create a page with 1000 links to my page• Resp: those links don’t matter
• Challenge: Create 1000 other pages linking to it• Response: limit the weight a single domain can
give to itself
• Challenge: buy a second domain and put the 1000 pages there
• Response: limit the weight from any single domain…

Another good idea: Use anchor text
• Motiv: pages may not give best descrips of selves– most S.E. pages don’t contain "search engine"– BP claim: only 1 of 4 “top search engines” could find
themselves on query "search engine"
• Anchor text also describes page:– many pages link to google.com– many of them likely say "search engine" in/near the link Treat anchor text words as part of page
• Search for “US West” or for “g++”

Tricking search engines
• This provides a new way to trick Google• Use of anchor text is a big part of result quality
– but has potential for abuse– Lets you influence when other people’s pages appear
• Google Bombs– put up lots of pages linking to my page, using some
particular phrase in the anchor text– result: search for words you chose produces my page– Examples: "talentless hack", "miserable failure",
“waffles", the last name of a prominent US senator…

Next: Ads
• Google had two really great ideas:1. PageRank
2. Bidding for ads
• Fundamental difficulty with mass-ads:– Most of the audience does want it– Most people don’t want what you’re selling– Think of car commercials on TV
• But some of them do!

Bidding for ads
• If you’re selling widgets, how do you know who wants them?– Hard question, so answer its inversion
• If someone is searching for widgets, what should you try to sell them?– Easy – widgets!– Or widget cases, etc…
• Whatever the user searches for, display ads relevant to that query

Bidding for ads• Q: How to choose correspondences?• A: Create a market, and let it decide
• Each company places the bid it’s willing to pay for an ad responding to a particular query
• Ad auction “takes place” at query-time– Relevant ads displayed in descending bid order– Company pays only if user clicks
• AdSense: place ads on external webpages, auction based on page content instead of query
• Huge huge huge business
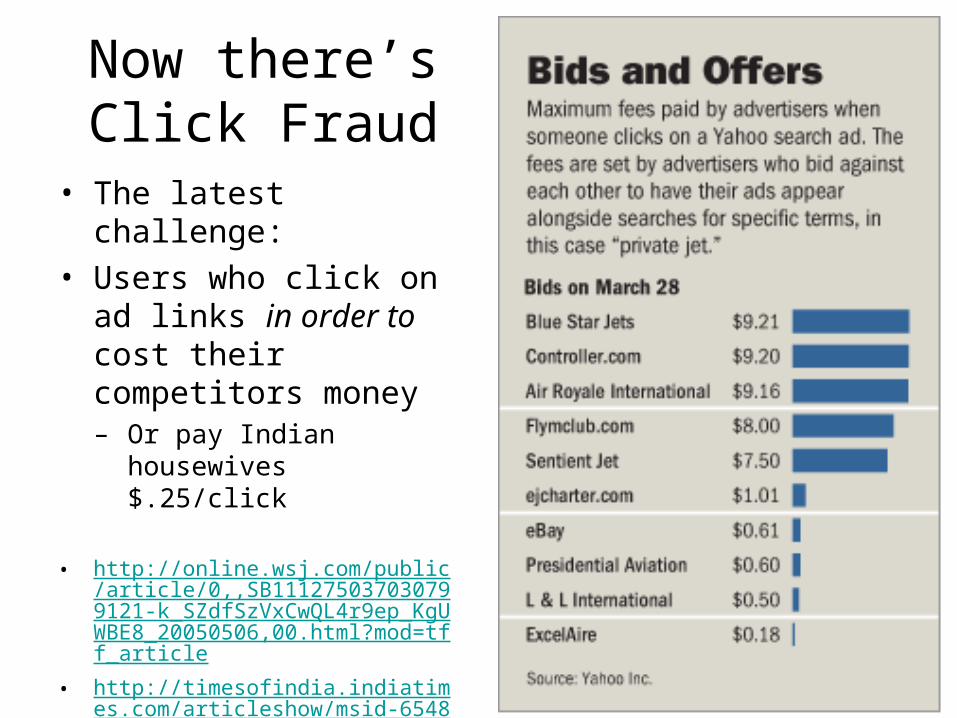
Now there’sClick Fraud
• The latest challenge:• Users who click on ad
links in order to cost their competitors money– Or pay Indian housewives
$.25/click
• http://online.wsj.com/public/article/0,,SB111275037030799121-k_SZdfSzVxCwQL4r9ep_KgUWBE8_20050506,00.html?mod=tff_article
• http://timesofindia.indiatimes.com/articleshow/msid-654822,curpg-1.cms

For more info
• See sources drawn upon here:• Prof. Davis (NYU/CS) search engines course
– http://www.cs.nyu.edu/courses/fall02/G22.3033-008/
• Original research papers by Page & Brin:– The PageRank Citation Ranking: Bringing Order to the Web– The Anatomy of a Large-Scale Hypertextual Web
Search Engine• Links on class page• Interesting and very accessible
• Google Labs: http://labs.google.com
Recommended


















