
CS252Graduate Computer Architecture
Lecture 21
Multiprocessor Networks (con’t)
John Kubiatowicz
Electrical Engineering and Computer Sciences
University of California, Berkeley
http://www.eecs.berkeley.edu/~kubitron/cs252

4/15/2009 cs252-S09, Lecture 21 2
Review: On Chip: Embeddings in two dimensions
• Embed multiple logical dimension in one physical dimension using long wires
• When embedding higher-dimension in lower one, either some wires longer than others, or all wires long
6 x 3 x 2

4/15/2009 cs252-S09, Lecture 21 3
Review:Store&Forward vs Cut-Through Routing
Time: h(n/b + ) vs n/b + h OR(cycles): h(n/w + ) vs n/w + h
• what if message is fragmented?• wormhole vs virtual cut-through
23 1 0
23 1 0
23 1 0
23 1 0
23 1 0
23 1 0
23 1 0
23 1 0
23 1 0
23 1 0
23 1 0
23 1
023
3 1 0
2 1 0
23 1 0
0
1
2
3
23 1 0Time
Store & Forward Routing Cut-Through Routing
Source Dest Dest
4/15/2009 cs252-S09, Lecture 21 4
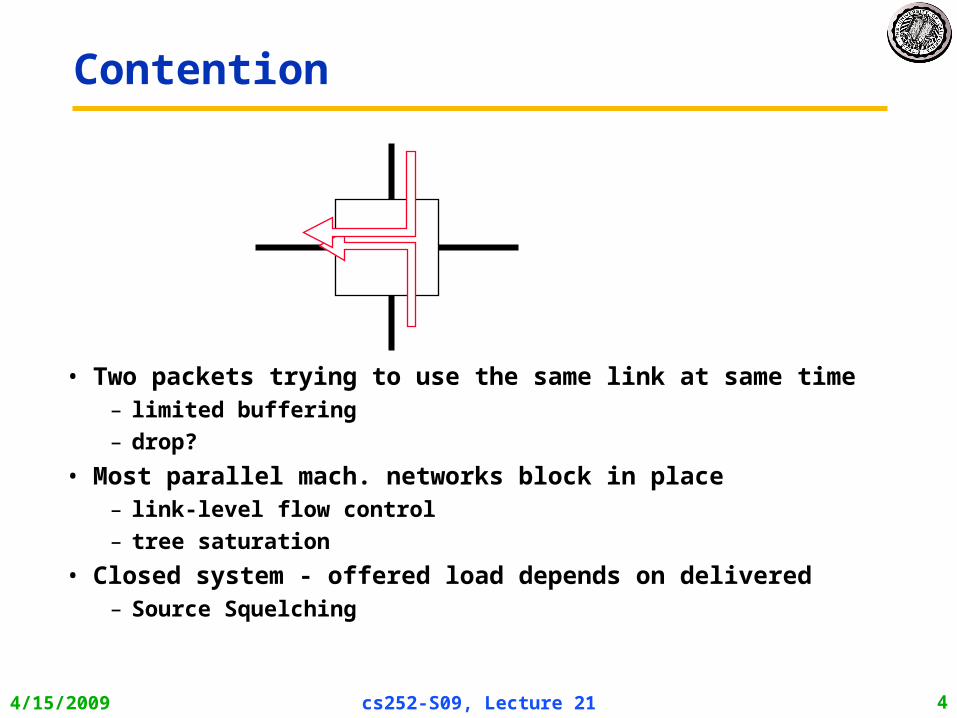
Contention
• Two packets trying to use the same link at same time– limited buffering
– drop?
• Most parallel mach. networks block in place– link-level flow control
– tree saturation
• Closed system - offered load depends on delivered– Source Squelching

4/15/2009 cs252-S09, Lecture 21 5
Bandwidth• What affects local bandwidth?
– packet density b x ndata/n
– routing delay b x ndata /(n + w)
– contention» endpoints
» within the network
• Aggregate bandwidth– bisection bandwidth
» sum of bandwidth of smallest set of links that partition the network
– total bandwidth of all the channels: Cb
– suppose N hosts issue packet every M cycles with ave dist » each msg occupies h channels for l = n/w cycles each
» C/N channels available per node
» link utilization for store-and-forward: = (hl/M channel cycles/node)/(C/N) = Nhl/MC < 1!
» link utilization for wormhole routing?
4/15/2009 cs252-S09, Lecture 21 6
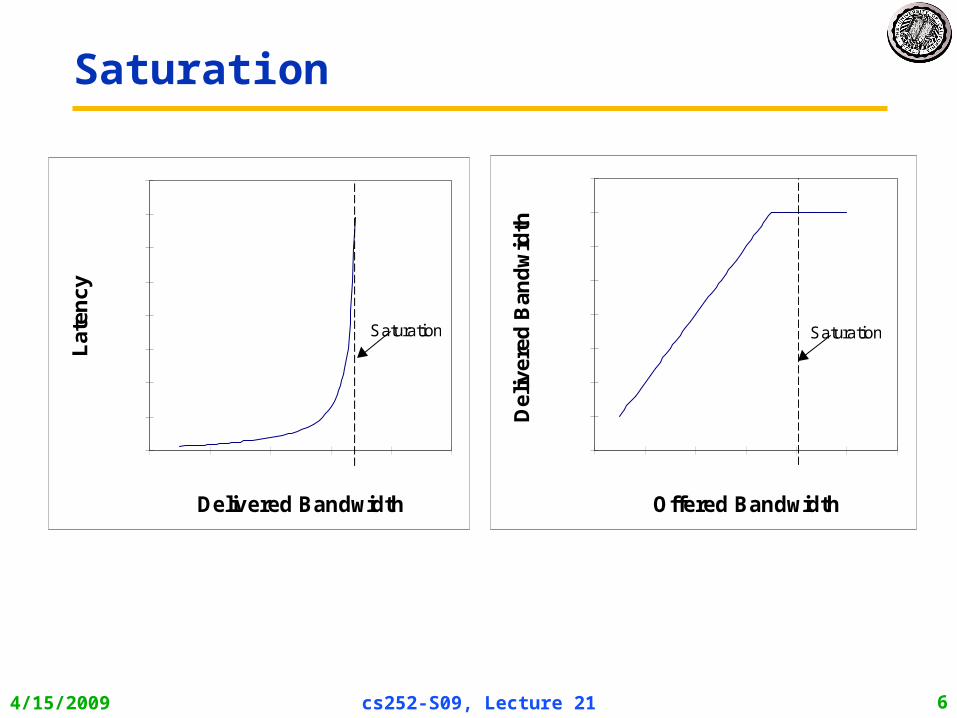
Saturation
0
10
20
30
40
50
60
70
80
0 0.2 0.4 0.6 0.8 1
Delivered Bandwidth
Lat
ency
Saturation
0
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0 0.2 0.4 0.6 0.8 1 1.2
Offered BandwidthD
eliv
ered
Ban
dw
idth
Saturation

4/15/2009 cs252-S09, Lecture 21 7
How Many Dimensions?• n = 2 or n = 3
– Short wires, easy to build
– Many hops, low bisection bandwidth
– Requires traffic locality
• n >= 4– Harder to build, more wires, longer average length
– Fewer hops, better bisection bandwidth
– Can handle non-local traffic
• k-ary d-cubes provide a consistent framework for comparison
– N = kd
– scale dimension (d) or nodes per dimension (k)
– assume cut-through
4/15/2009 cs252-S09, Lecture 21 8
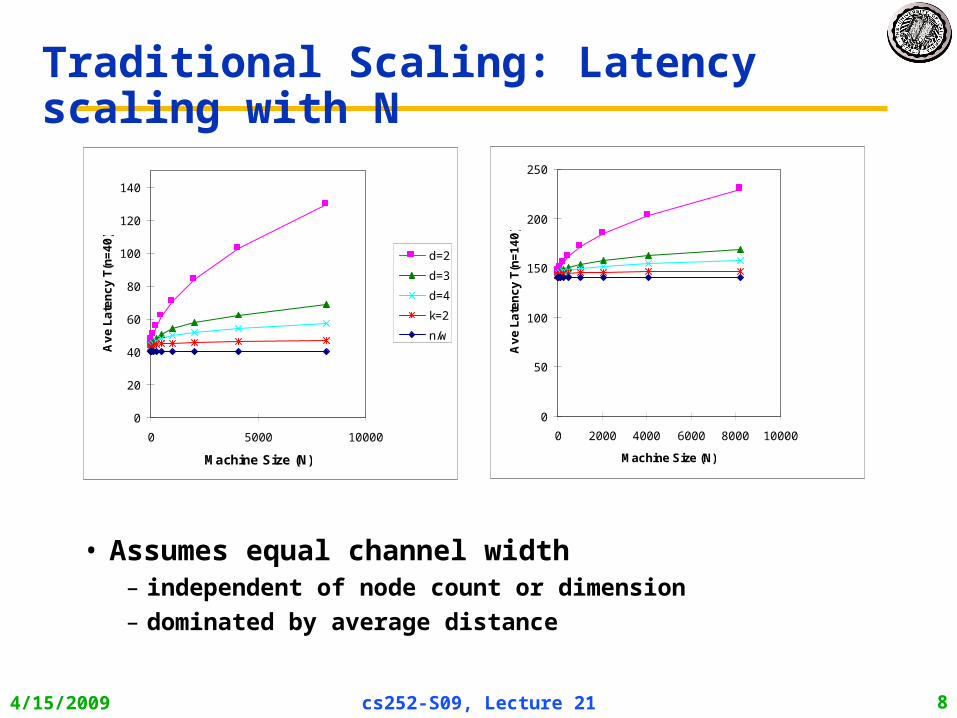
Traditional Scaling: Latency scaling with N
• Assumes equal channel width– independent of node count or dimension
– dominated by average distance
0
20
40
60
80
100
120
140
0 5000 10000
Machine Size (N)
Ave L
ate
ncy T
(n=40)
d=2
d=3
d=4
k=2
n/w
0
50
100
150
200
250
0 2000 4000 6000 8000 10000
Machine Size (N)
Ave L
ate
ncy T
(n=140)
4/15/2009 cs252-S09, Lecture 21 9
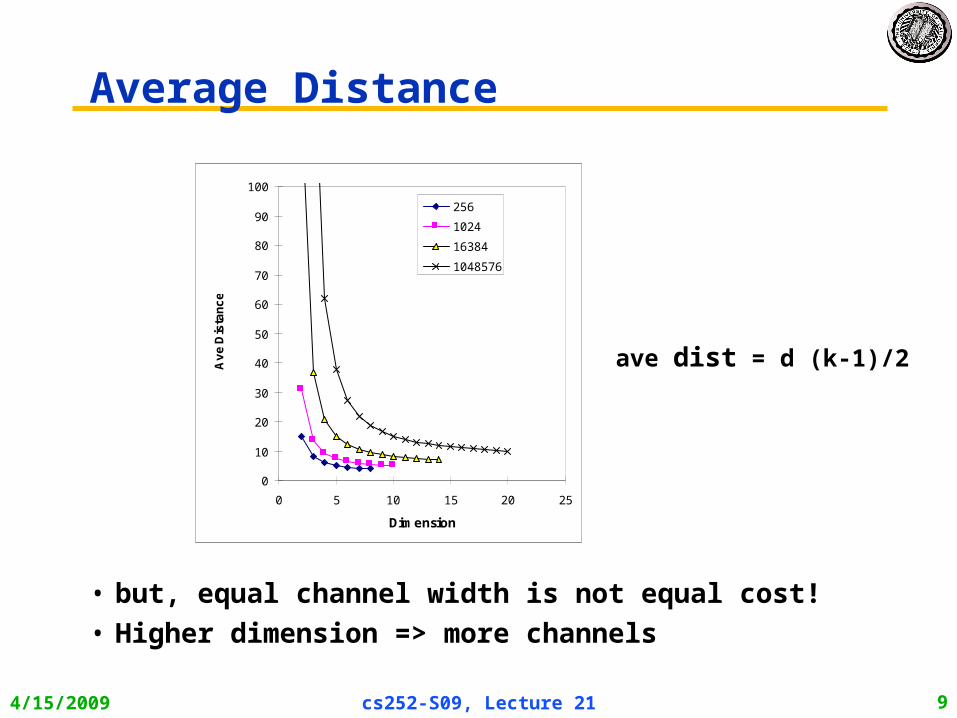
Average Distance
• but, equal channel width is not equal cost!
• Higher dimension => more channels
0
10
20
30
40
50
60
70
80
90
100
0 5 10 15 20 25
Dimension
Ave D
ista
nce
256
1024
16384
1048576
ave dist = d (k-1)/2

4/15/2009 cs252-S09, Lecture 21 10
In the 3D world• For n nodes, bisection area is O(n2/3 )
• For large n, bisection bandwidth is limited to O(n2/3 )– Bill Dally, IEEE TPDS, [Dal90a]
– For fixed bisection bandwidth, low-dimensional k-ary n-cubes are better (otherwise higher is better)
– i.e., a few short fat wires are better than many long thin wires
– What about many long fat wires?
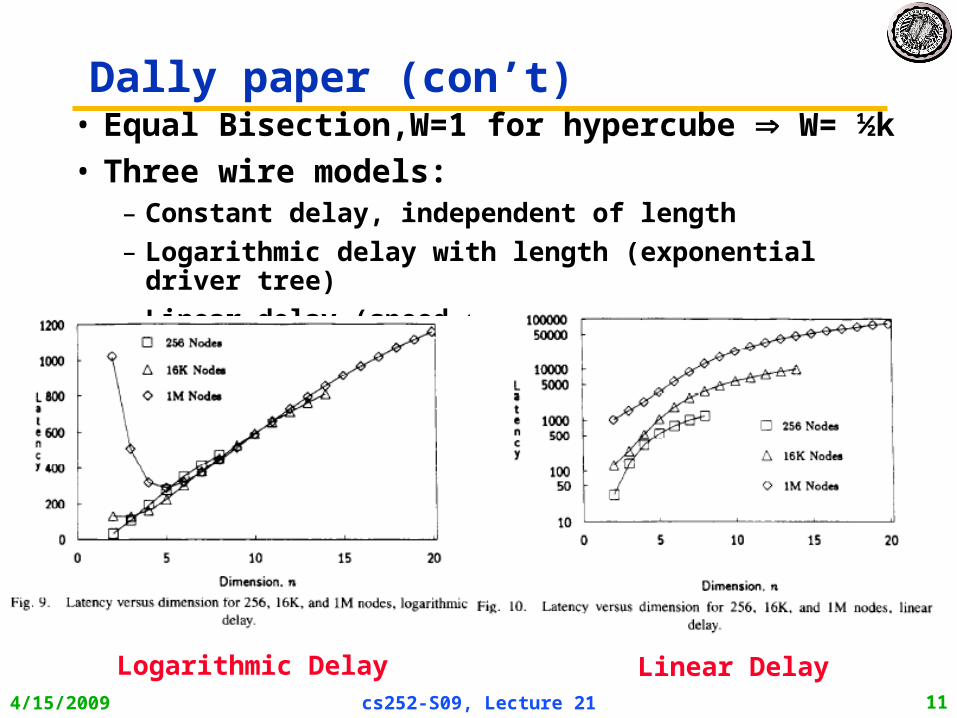
4/15/2009 cs252-S09, Lecture 21 11
Dally paper (con’t)• Equal Bisection,W=1 for hypercube W= ½k
• Three wire models:– Constant delay, independent of length
– Logarithmic delay with length (exponential driver tree)
– Linear delay (speed of light/optimal repeaters)
Logarithmic Delay Linear Delay

4/15/2009 cs252-S09, Lecture 21 12
Equal cost in k-ary n-cubes• Equal number of nodes?• Equal number of pins/wires?• Equal bisection bandwidth?• Equal area?• Equal wire length?
What do we know?• switch degree: d diameter = d(k-1)• total links = Nd• pins per node = 2wd• bisection = kd-1 = N/k links in each directions• 2Nw/k wires cross the middle
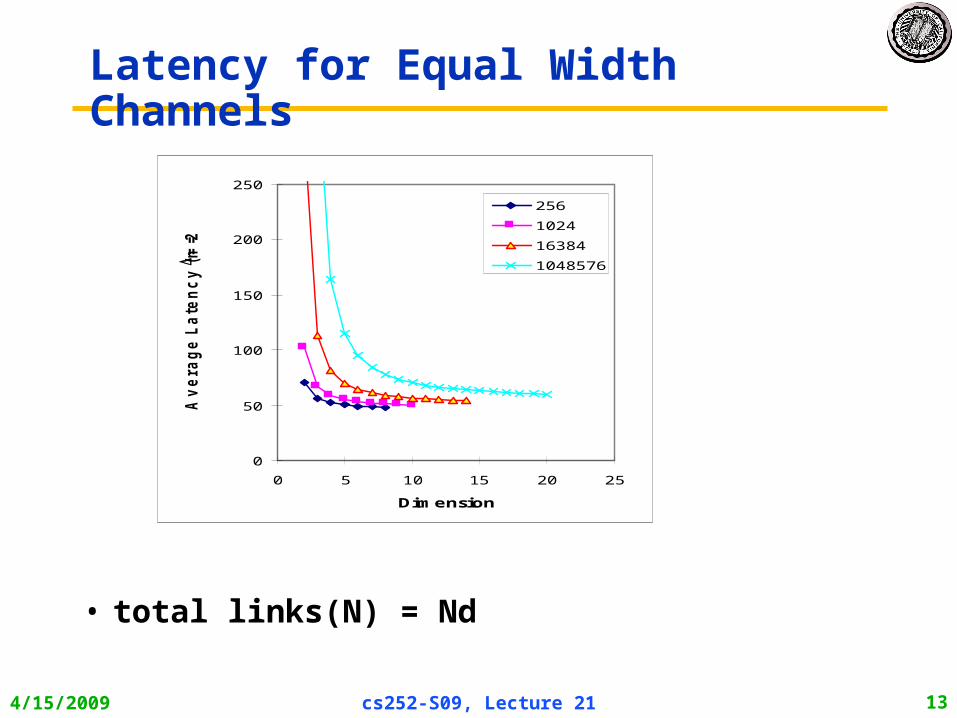
4/15/2009 cs252-S09, Lecture 21 13
Latency for Equal Width Channels
• total links(N) = Nd
0
50
100
150
200
250
0 5 10 15 20 25
Dimension
Average L
ate
ncy (n =
40,
= 2
)256
1024
16384
1048576
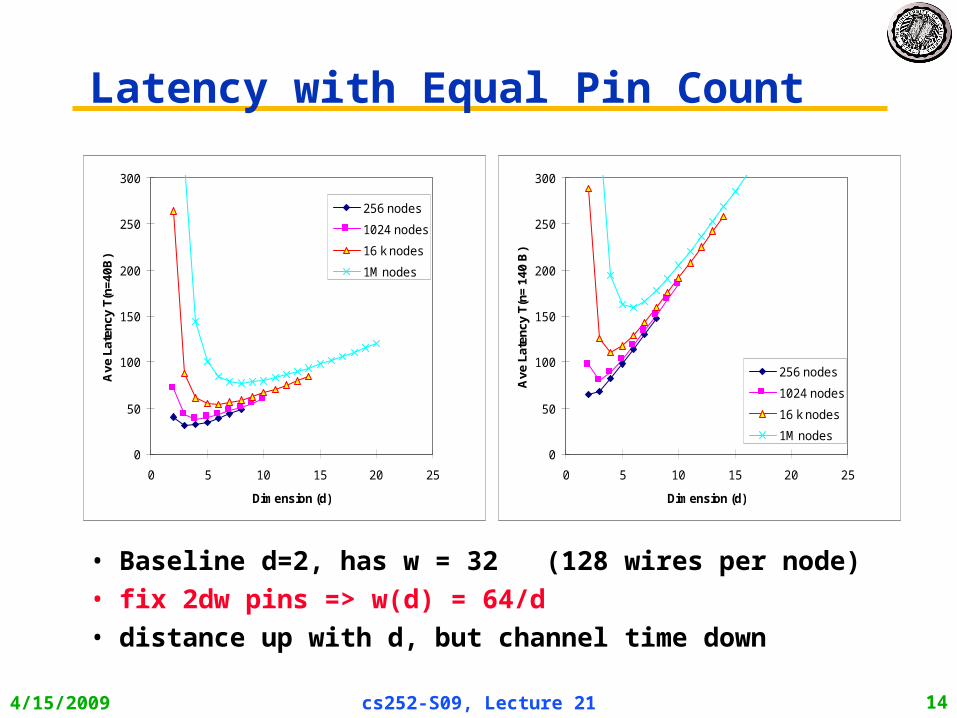
4/15/2009 cs252-S09, Lecture 21 14
Latency with Equal Pin Count
• Baseline d=2, has w = 32 (128 wires per node)
• fix 2dw pins => w(d) = 64/d
• distance up with d, but channel time down
0
50
100
150
200
250
300
0 5 10 15 20 25
Dimension (d)
Ave
Lat
ency
T(n
=40B
)
256 nodes
1024 nodes
16 k nodes
1M nodes
0
50
100
150
200
250
300
0 5 10 15 20 25
Dimension (d)
Ave
Lat
ency
T(n
= 14
0 B
)
256 nodes
1024 nodes
16 k nodes
1M nodes
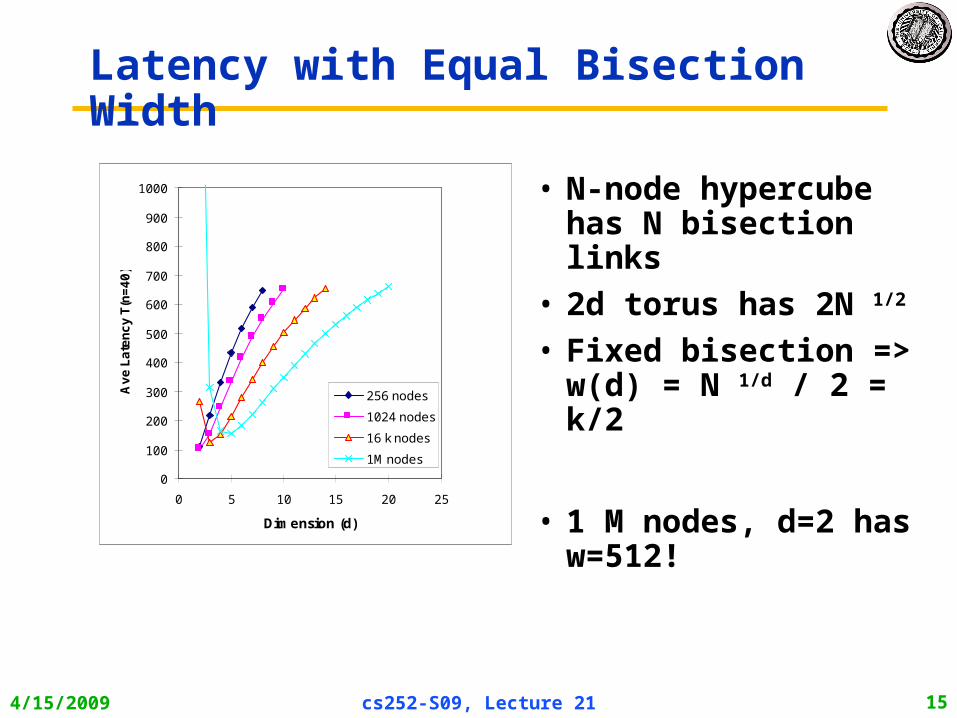
4/15/2009 cs252-S09, Lecture 21 15
Latency with Equal Bisection Width
• N-node hypercube has N bisection links
• 2d torus has 2N 1/2
• Fixed bisection => w(d) = N 1/d / 2 = k/2
• 1 M nodes, d=2 has w=512!0
100
200
300
400
500
600
700
800
900
1000
0 5 10 15 20 25
Dimension (d)
Ave L
ate
ncy T
(n=40)
256 nodes
1024 nodes
16 k nodes
1M nodes
4/15/2009 cs252-S09, Lecture 21 16
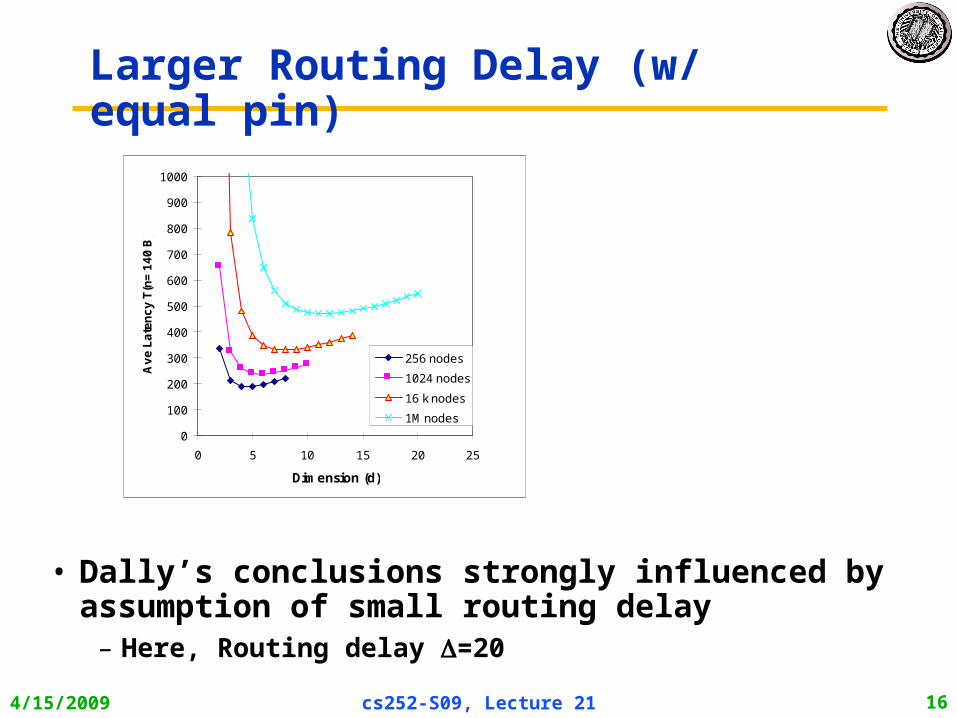
Larger Routing Delay (w/ equal pin)
• Dally’s conclusions strongly influenced by assumption of small routing delay
– Here, Routing delay =20
0
100
200
300
400
500
600
700
800
900
1000
0 5 10 15 20 25
Dimension (d)
Ave L
ate
ncy T
(n= 1
40 B
)
256 nodes
1024 nodes
16 k nodes
1M nodes
4/15/2009 cs252-S09, Lecture 21 17
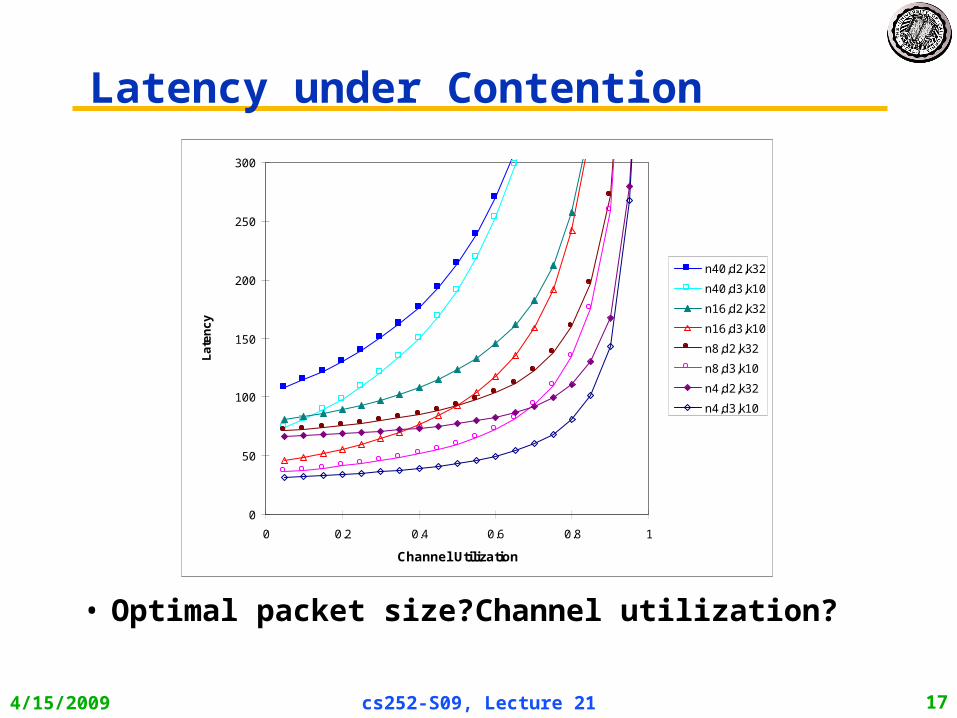
Latency under Contention
• Optimal packet size? Channel utilization?
0
50
100
150
200
250
300
0 0.2 0.4 0.6 0.8 1
Channel Utilization
Late
ncy
n40,d2,k32
n40,d3,k10
n16,d2,k32
n16,d3,k10
n8,d2,k32
n8,d3,k10
n4,d2,k32
n4,d3,k10
4/15/2009 cs252-S09, Lecture 21 18
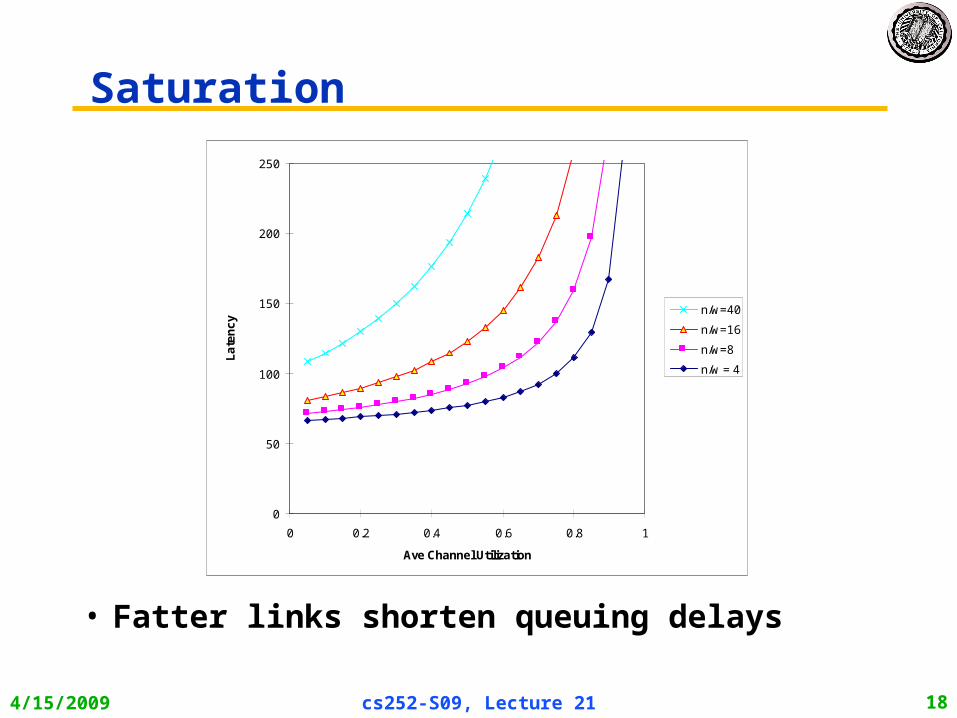
Saturation
• Fatter links shorten queuing delays
0
50
100
150
200
250
0 0.2 0.4 0.6 0.8 1
Ave Channel Utilization
Late
ncy
n/w=40
n/w=16
n/w=8
n/w = 4
4/15/2009 cs252-S09, Lecture 21 19
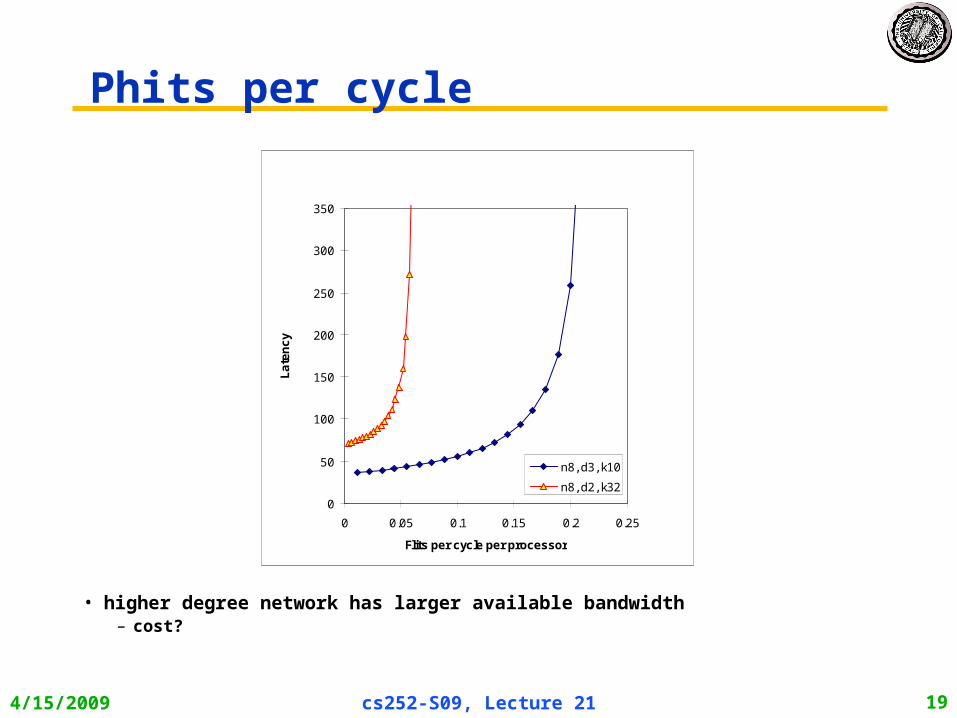
Phits per cycle
• higher degree network has larger available bandwidth– cost?
0
50
100
150
200
250
300
350
0 0.05 0.1 0.15 0.2 0.25
Flits per cycle per processor
Late
ncy
n8, d3, k10
n8, d2, k32

4/15/2009 cs252-S09, Lecture 21 20
Discussion• Rich set of topological alternatives with deep
relationships
• Design point depends heavily on cost model– nodes, pins, area, ...
– Wire length or wire delay metrics favor small dimension
– Long (pipelined) links increase optimal dimension
• Need a consistent framework and analysis to separate opinion from design
• Optimal point changes with technology

4/15/2009 cs252-S09, Lecture 21 21
• Problem: Low-dimensional networks have high k– Consequence: may have to travel many hops in single dimension– Routing latency can dominate long-distance traffic patterns
• Solution: Provide one or more “express” links
– Like express trains, express elevators, etc» Delay linear with distance, lower constant» Closer to “speed of light” in medium» Lower power, since no router cost
– “Express Cubes: Improving performance of k-ary n-cube interconnection networks,” Bill Dally 1991
• Another Idea: route with pass transistors through links
Another Idea: Express Cubes
4/15/2009 cs252-S09, Lecture 21 22
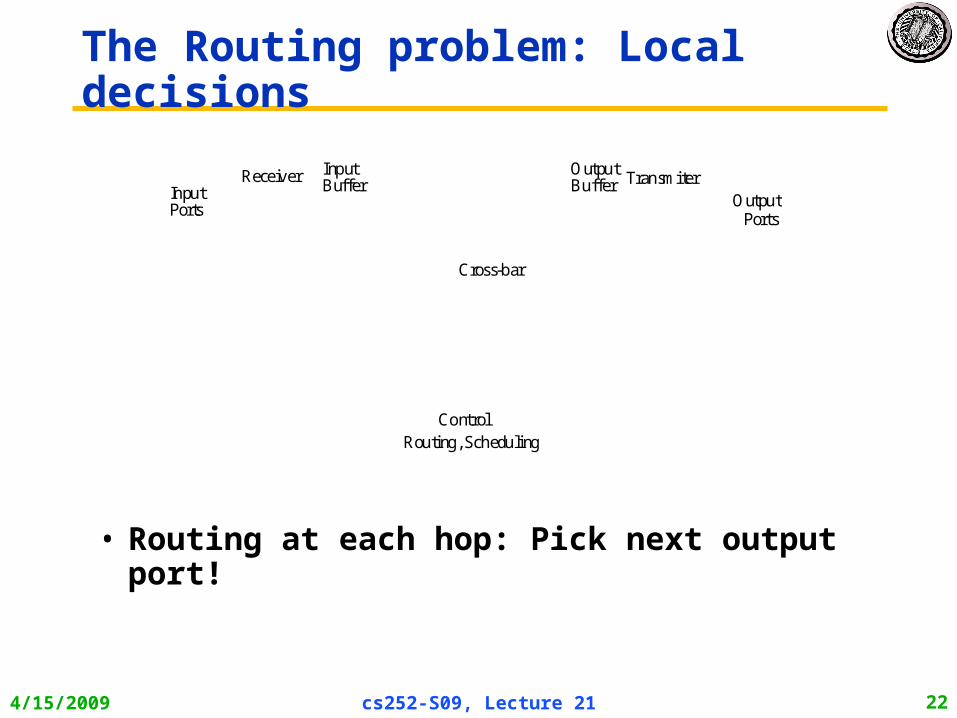
The Routing problem: Local decisions
• Routing at each hop: Pick next output port!
Cross-bar
InputBuffer
Control
OutputPorts
Input Receiver Transmiter
Ports
Routing, Scheduling
OutputBuffer

4/15/2009 cs252-S09, Lecture 21 23
How do you build a crossbar?
Io
I1
I2
I3
Io I1 I2 I3
O0
Oi
O2
O3
RAMphase
O0
Oi
O2
O3
DoutDin
Io
I1
I2
I3
addr

4/15/2009 cs252-S09, Lecture 21 24
Input buffered swtich
• Independent routing logic per input– FSM
• Scheduler logic arbitrates each output– priority, FIFO, random
• Head-of-line blocking problem
Cross-bar
OutputPorts
Input Ports
Scheduling
R0
R1
R2
R3

4/15/2009 cs252-S09, Lecture 21 25
Output Buffered Switch
• How would you build a shared pool?
Control
OutputPorts
Input Ports
OutputPorts
OutputPorts
OutputPorts
R0
R1
R2
R3

4/15/2009 cs252-S09, Lecture 21 26
Output scheduling
• n independent arbitration problems?– static priority, random, round-robin
• simplifications due to routing algorithm?
• general case is max bipartite matching
Cross-bar
OutputPorts
R0
R1
R2
R3
O0
O1
O2
InputBuffers

4/15/2009 cs252-S09, Lecture 21 27
Switch Components
• Output ports– transmitter (typically drives clock and data)
• Input ports– synchronizer aligns data signal with local clock domain– essentially FIFO buffer
• Crossbar– connects each input to any output– degree limited by area or pinout
• Buffering• Control logic
– complexity depends on routing logic and scheduling algorithm
– determine output port for each incoming packet– arbitrate among inputs directed at same output

4/15/2009 cs252-S09, Lecture 21 28
Properties of Routing Algorithms• Routing algorithm:
– R: N x N -> C, which at each switch maps the destination node nd to the next channel on the route
– which of the possible paths are used as routes?– how is the next hop determined?
» arithmetic» source-based port select» table driven» general computation
• Deterministic– route determined by (source, dest), not intermediate state (i.e. traffic)
• Adaptive– route influenced by traffic along the way
• Minimal– only selects shortest paths
• Deadlock free– no traffic pattern can lead to a situation where packets are deadlocked
and never move forward

4/15/2009 cs252-S09, Lecture 21 29
Routing Mechanism• need to select output port for each input packet
– in a few cycles
• Simple arithmetic in regular topologies– ex: x, y routing in a grid
» west (-x) x < 0
» east (+x) x > 0
» south (-y) x = 0, y < 0
» north (+y) x = 0, y > 0
» processor x = 0, y = 0
• Reduce relative address of each dimension in order– Dimension-order routing in k-ary d-cubes
– e-cube routing in n-cube

4/15/2009 cs252-S09, Lecture 21 30
Deadlock Freedom• How can deadlock arise?
– necessary conditions:» shared resource» incrementally allocated» non-preemptible
– think of a channel as a shared resource that is acquired incrementally
» source buffer then dest. buffer» channels along a route
• How do you avoid it?– constrain how channel resources are allocated– ex: dimension order
• How do you prove that a routing algorithm is deadlock free?
– Show that channel dependency graph has no cycles!

4/15/2009 cs252-S09, Lecture 21 31
Consider Trees
• Why is the obvious routing on X deadlock free?– butterfly?
– tree?
– fat tree?
• Any assumptions about routing mechanism? amount of buffering?

4/15/2009 cs252-S09, Lecture 21 32
Up*-Down* routing for general topology• Given any bidirectional network
• Construct a spanning tree
• Number of the nodes increasing from leaves to roots
• UP increase node numbers
• Any Source -> Dest by UP*-DOWN* route– up edges, single turn, down edges
– Proof of deadlock freedom?
• Performance?– Some numberings and routes much better than others
– interacts with topology in strange ways

4/15/2009 cs252-S09, Lecture 21 33
Turn Restrictions in X,Y
• XY routing forbids 4 of 8 turns and leaves no room for adaptive routing
• Can you allow more turns and still be deadlock free?
+Y
-Y
+X-X

4/15/2009 cs252-S09, Lecture 21 34
Minimal turn restrictions in 2D
West-first
north-last negative first
-x +x
+y
-y

4/15/2009 cs252-S09, Lecture 21 35
Example legal west-first routes
• Can route around failures or congestion
• Can combine turn restrictions with virtual channels

4/15/2009 cs252-S09, Lecture 21 36
General Proof Technique• resources are logically associated with channels
• messages introduce dependences between resources as they move forward
• need to articulate the possible dependences that can arise between channels
• show that there are no cycles in Channel Dependence Graph
– find a numbering of channel resources such that every legal route follows a monotonic sequence no traffic pattern can lead to deadlock
• network need not be acyclic, just channel dependence graph
4/15/2009 cs252-S09, Lecture 21 37
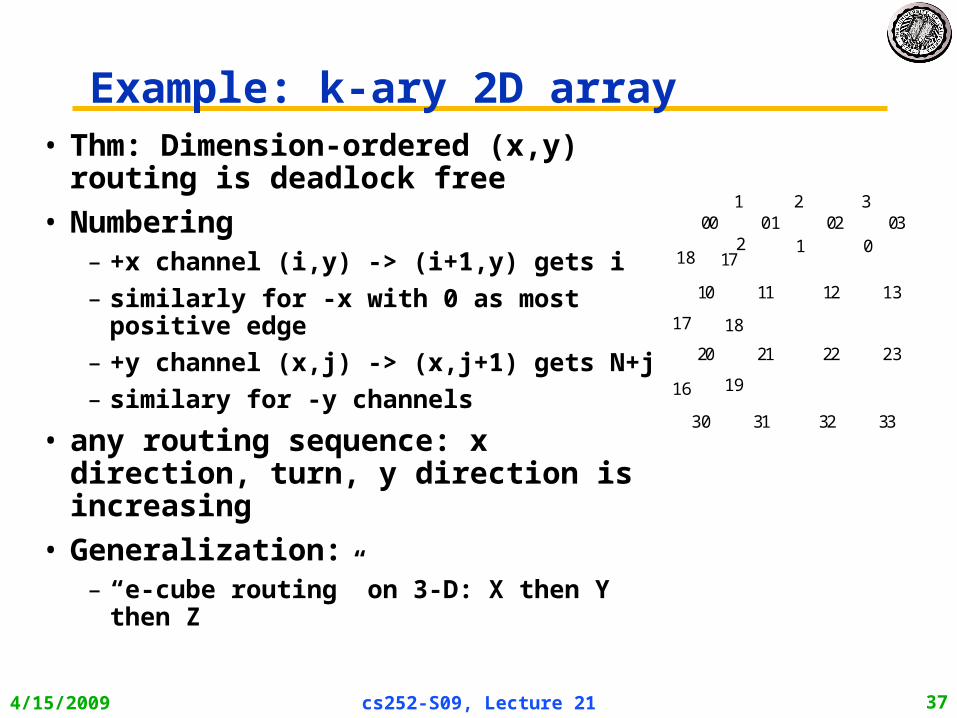
Example: k-ary 2D array• Thm: Dimension-ordered (x,y) routing
is deadlock free
• Numbering– +x channel (i,y) -> (i+1,y) gets i
– similarly for -x with 0 as most positive edge
– +y channel (x,j) -> (x,j+1) gets N+j
– similary for -y channels
• any routing sequence: x direction, turn, y direction is increasing
• Generalization: – “e-cube routing” on 3-D: X then Y then Z
1 2 3
01200 01 02 03
10 11 12 13
20 21 22 23
30 31 32 33
17
18
1916
17
18
4/15/2009 cs252-S09, Lecture 21 38
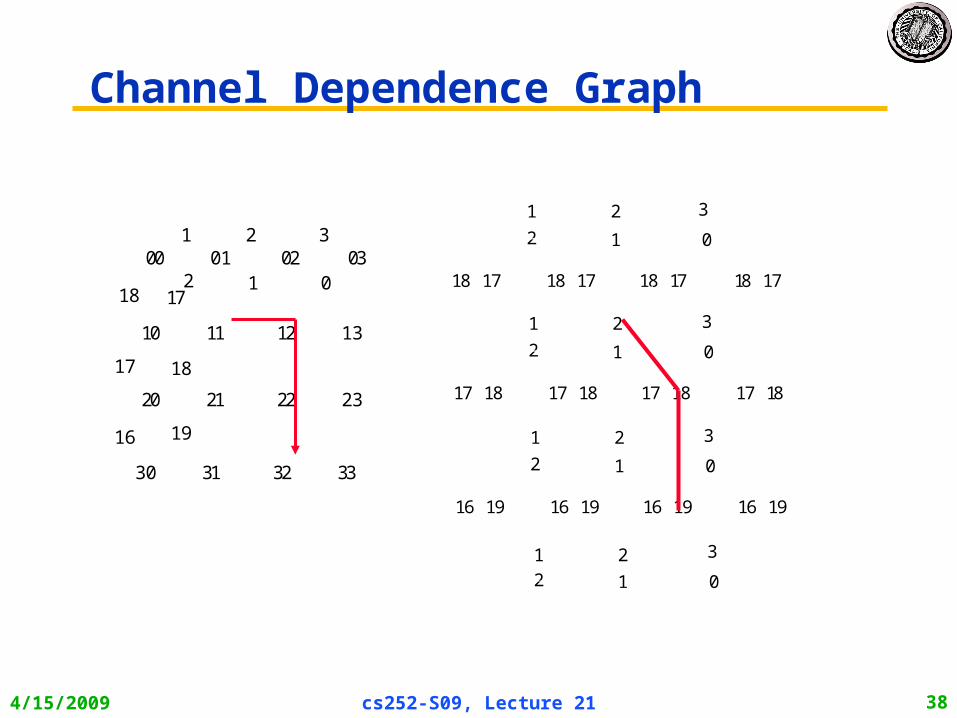
Channel Dependence Graph
1 2 3
01200 01 02 03
10 11 12 13
20 21 22 23
30 31 32 33
17
18
1916
17
18
1 2 3
012
1718 1718 1718 1718
1 2 3
012
1817 1817 1817 1817
1 2 3
012
1916 1916 1916 1916
1 2 3
012
4/15/2009 cs252-S09, Lecture 21 39
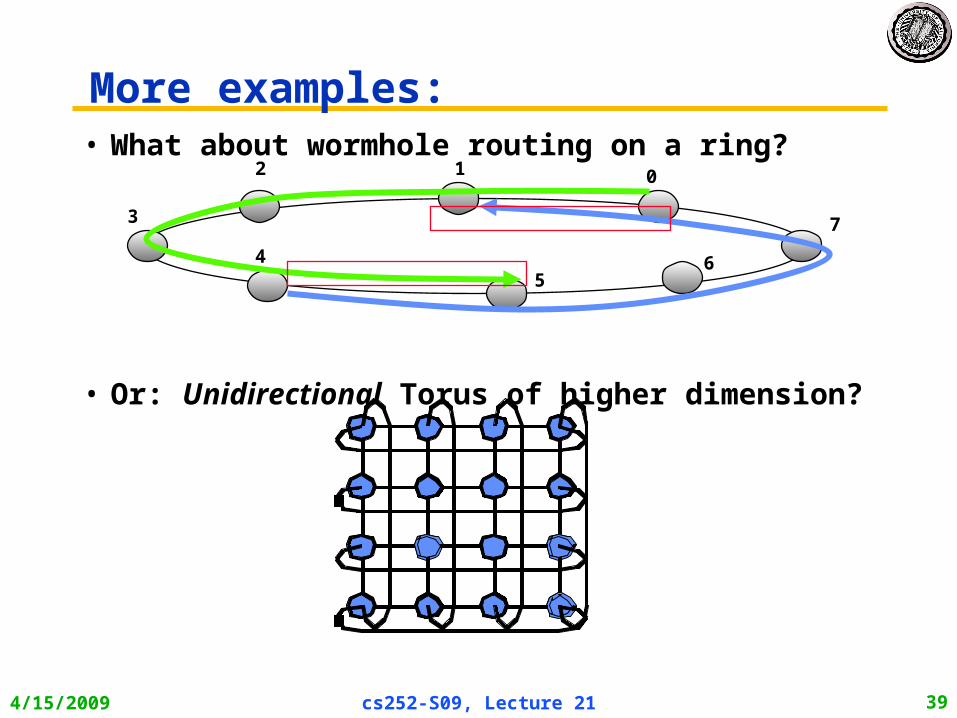
More examples:• What about wormhole routing on a ring?
• Or: Unidirectional Torus of higher dimension?
012
3
45
6
7

4/15/2009 cs252-S09, Lecture 21 40
Deadlock free wormhole networks?• Basic dimension order routing techniques don’t work for
unidirectional k-ary d-cubes– only for k-ary d-arrays (bi-directional)– And – dimension-ordered routing not adaptive!
• Idea: add channels!– provide multiple “virtual channels” to break the dependence cycle
– good for BW too!
– Do not need to add links, or xbar, only buffer resources
• This adds nodes to the CDG, remove edges?
OutputPorts
Input Ports
Cross-Bar

4/15/2009 cs252-S09, Lecture 21 41
When are virtual channels allocated?
• Two separate processes:– Virtual channel allocation– Switch/connection allocation
• Virtual Channel Allocation– Choose route and free output virtual channel
• Switch Allocation– For each incoming virtual channel, must negotiate switch on
outgoing pin
• In ideal case (not highly loaded), would like to optimistically allocate a virtual channel
OutputPorts
Input Ports
Cross-Bar
Hardware efficient designFor crossbar

4/15/2009 cs252-S09, Lecture 21 42
Breaking deadlock with virtual channels
Packet switchesfrom lo to hi channel

4/15/2009 cs252-S09, Lecture 21 43
Paper Discusion: Linder and Harden
• Paper: “An Adaptive and Fault Tolerant Wormhole Routing Stategy for k-ary n-cubes”
– Daniel Linder and Jim Harden
• General virtual-channel scheme for k-ary n-cubes– With wrap-around paths
• Properties of result for uni-directional k-ary n-cube:– 1 virtual interconnection network
– n+1 levels
• Properties of result for bi-directional k-ary n-cube:– 2n-1 virtual interconnection networks
– n+1 levels per network
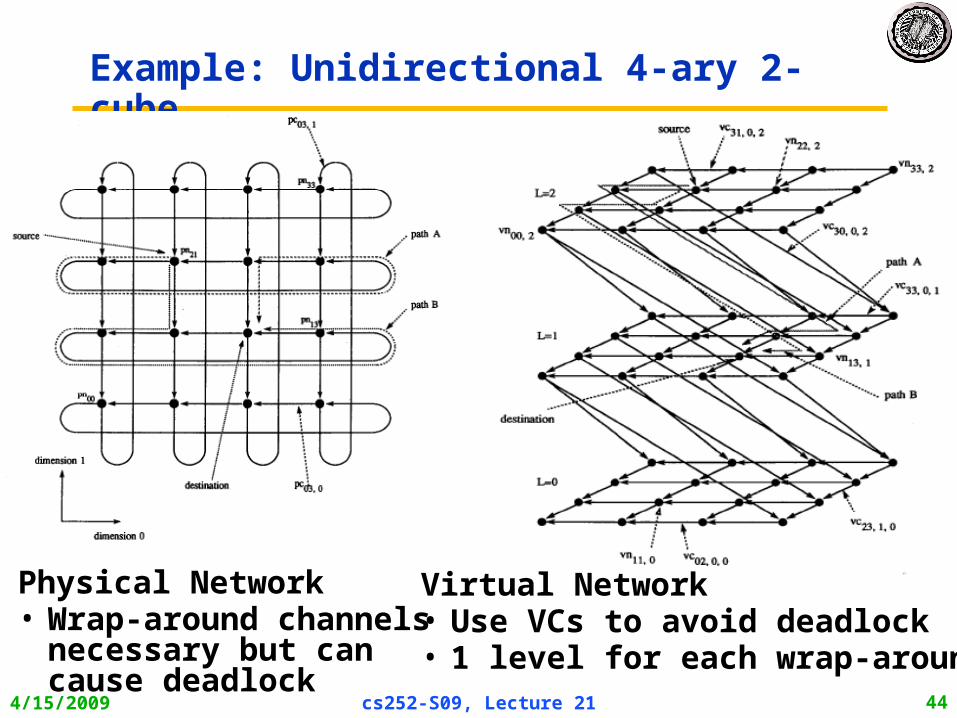
4/15/2009 cs252-S09, Lecture 21 44
Example: Unidirectional 4-ary 2-cube
Physical Network• Wrap-around channels
necessary but cancause deadlock
Virtual Network• Use VCs to avoid deadlock• 1 level for each wrap-around
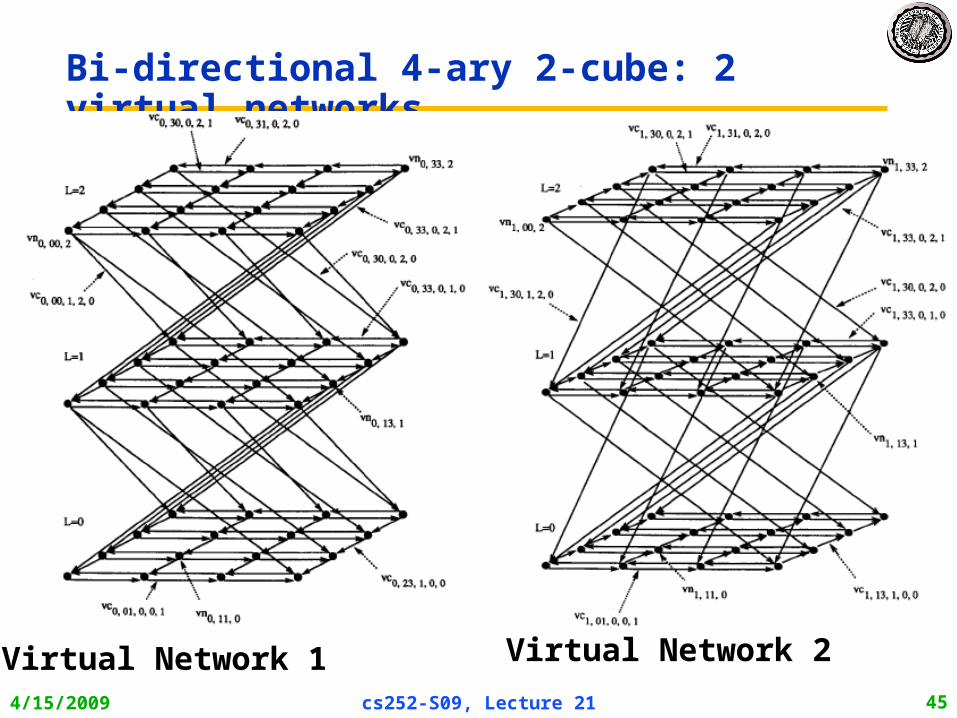
4/15/2009 cs252-S09, Lecture 21 45
Bi-directional 4-ary 2-cube: 2 virtual networks
Virtual Network 1 Virtual Network 2
Recommended

















