
Introduction to Machine LearningJonathan Dinu
Co-Founder, Zipfian [email protected]
@clearspandex
Ryan OrbanCo-Founder, Zipfian Academy
[email protected]@ryanorban
@ZipfianAcademy
Zipfian Academy

• What is it and why do I care?
• Supervised Learning
• Regression and Classification
• Unsupervised Learning
• Clustering and Dimensionality Reduction
• In Practice
• Q&A
Outline
Zipfian Academy -- June 11th, 2013

What?
Field of study that gives computers the
ability to learn without being explicitly
programmed.“-Arthur Samuel circa 1959

What?
A computer program is said to learn
from experience E with respect to
some class of tasks T and performance
measure P, if its performance at tasks in
T, as measured by P, improves with
experience E.
“-Tom M. Mitchell

What?
Learning ≠ Thinking

What?
NOT Machine learning is:
• Hard coded logic by programmer: ifs and elses...
• Predefined results: completely deterministic
• Burden is placed on programmer at design time
• Must anticipate all inputs to program, and react

What?
Machine learning is:
• Automated knowledge acquisition through input
• Iterative improvement as more data is seen
• Adaptive Algorithms

Discrete
Labeled Data
Unlabeled Data
Continuous
Clustering/Dimensionality Reduction
Regression
Association Analysis
Classification
Apriori
FP-GrowthPCA
K-means
Machines
GLM
Linear
TreesLogisticTrees
SVM
kNN
SVD

Discrete
Labeled Data
Unlabeled Data
Continuous
Clustering/Dimensionality Reduction
Regression
Association Analysis
Classification
Apriori
FP-GrowthPCA
K-means
Today!
GLM
Linear
TreesLogisticTrees
SVM
kNN
SVD

Applications
Regression:
• Stock Market Analysis: trend analysis
• Utilities: smart grid load forecasting
• Web: page traffic prediction
• Bioinformatics: protein binding site prediction
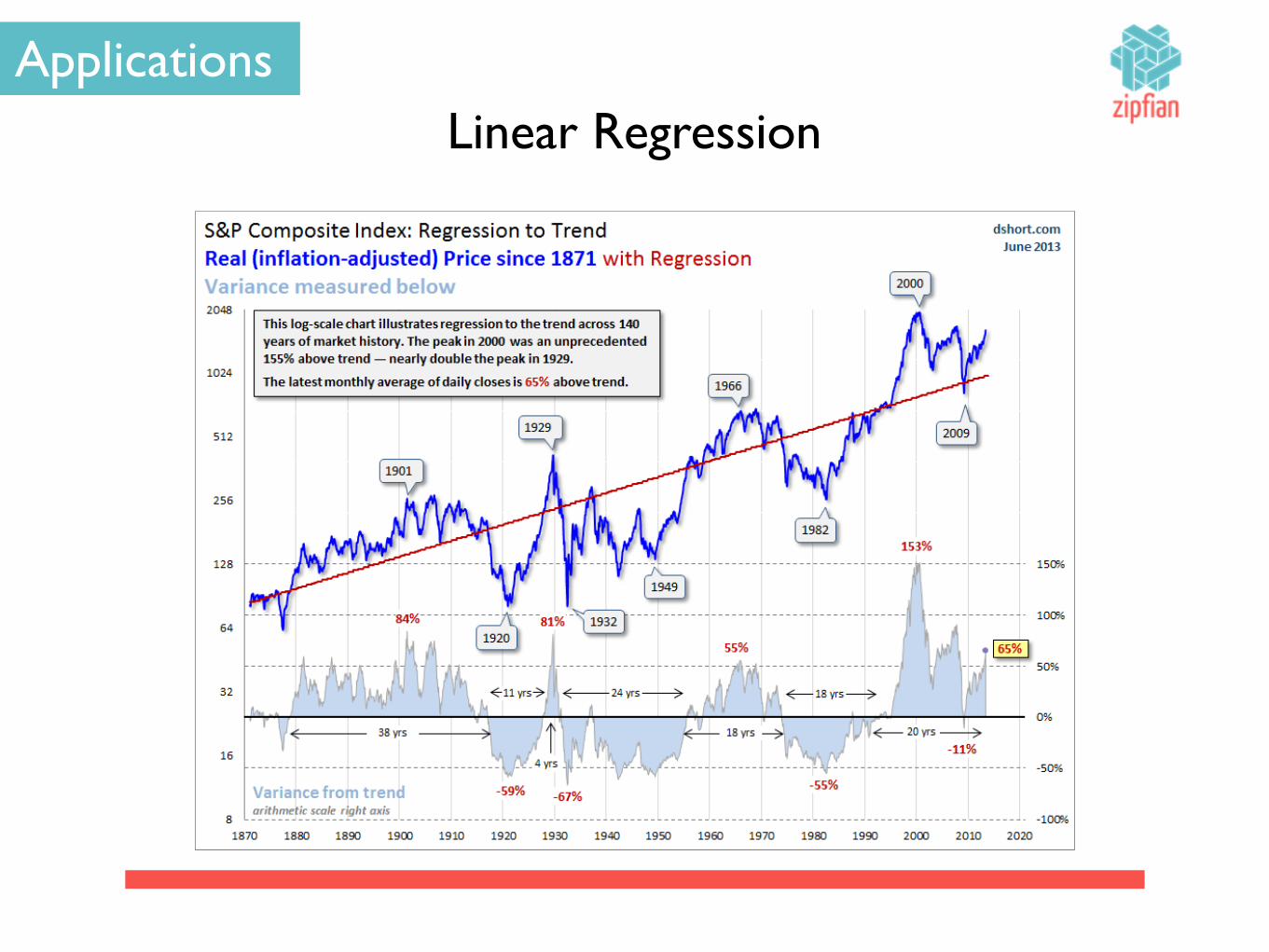
ApplicationsLinear Regression

Applications
Classification:
• Spam Filtering and document classification
• Finance: Fraud detection and loan default prediction
• Sentiment Analysis: People like to do this with Tweets
• National Security: ??? PRISM!
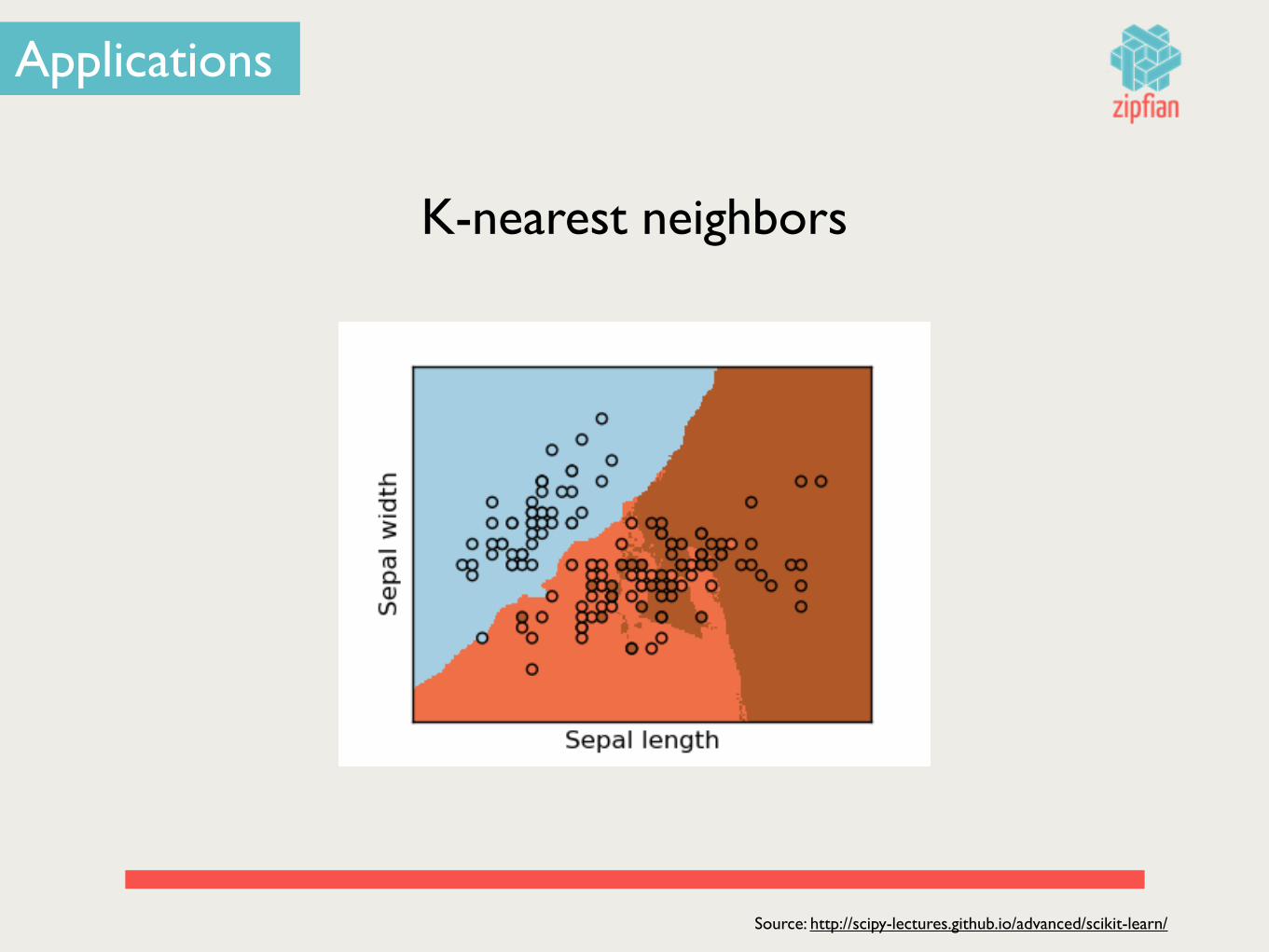
Applications
K-nearest neighbors
Source: http://scipy-lectures.github.io/advanced/scikit-learn/

Applications
Clustering:
• Product Marketing: Cohort Analysis
• Oncology: Malignant cell identification
• Computer Vision: entity recognition
• Census: demographics analysis

Applications
Source: http://www.flickr.com/photos/kylemcdonald/3866231864/
K-means clustering

Discovery
Unknown Properties
Unsupervised
Ex: K-means Clustering
Prediction
Known Properties
Supervised
Ex: Naïve Bayes Classification
Machine Learning Data Mining
Applications

Pitfalls
Considerations -- Performance
Number of Features
Train vs. Predict
Online vs. Batch
Multinomial

In Practice
Source: http://recsys.acm.org/more-data-or-better-models/

• What is it and why do I care?
• Supervised Learning
• Regression and Classification
• Unsupervised Learning
• Clustering and Dimensionality Reduction
• In Practice
• Q&A
Outline

Supervised
Inferring a function from labeled training data, e.g. learning from experience

• What is it and why do I care?
• Supervised Learning
• Regression and Classification
• Unsupervised Learning
• Clustering and Dimensionality Reduction
• In Practice
• Q&A
Outline
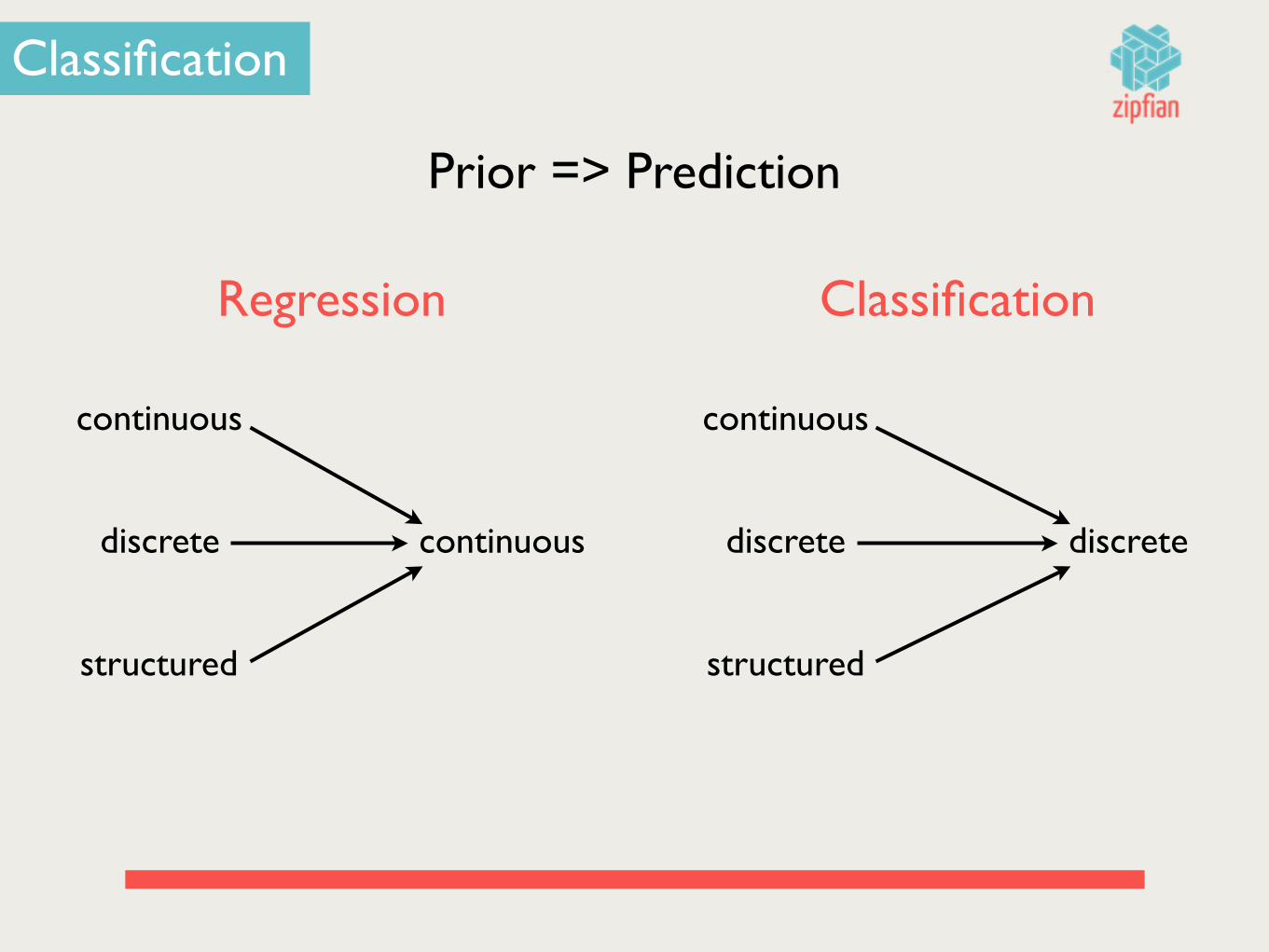
Classification
Regression Classification
Prior => Prediction
structured
discrete
continuous
discrete
structured
discrete
continuous
continuous

ClassificationLogistic Regression
(contrary to its name... actually used to classify)
Source: http://cvxopt.org/examples/book/logreg.html
threshold = 0.5

Classification
Source: http://www.stepbystep.com/difference-between-linear-and-logistic-regression-103607/
Logistic Regression(contrary to its name... actually used to classify)

Process
1. Obtain -- convert to numeric
2. Train -- pre-labeled data
3. Test -- cross validation
4. Use -- unknown label data
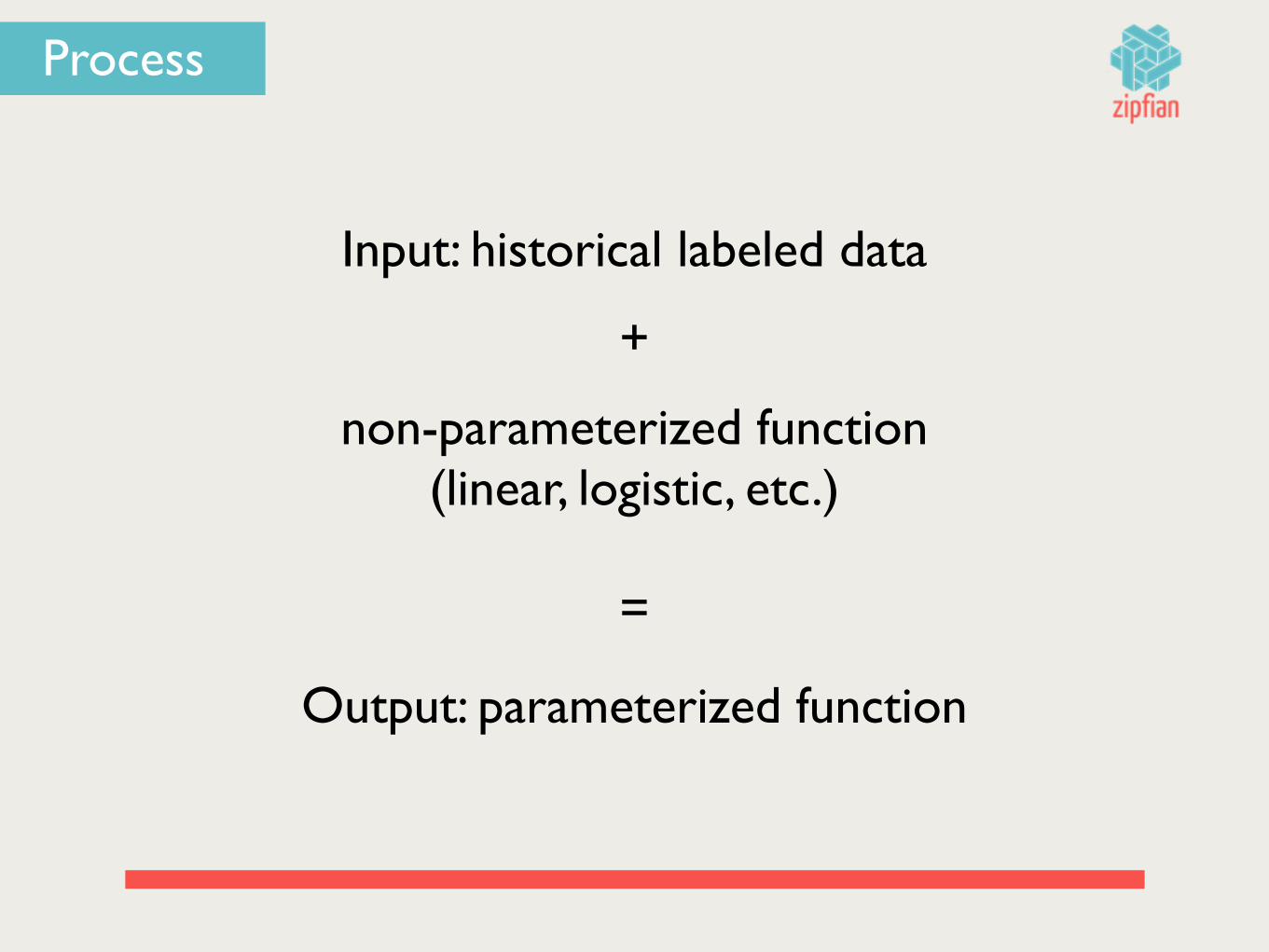
Process
Input: historical labeled data
+
non-parameterized function(linear, logistic, etc.)
=
Output: parameterized function

Products
A model is just a function

Products
Inputs...

Products
Outputs...

Others
Today: Logistic Regression

Source: http://www.sjsu.edu/faculty/gerstman/EpiInfo/cont-mult1.jpg
Α = β0 + β1x1 + β2x2 + ...+ βnxn
threshold = 0.5
Logistic Regression
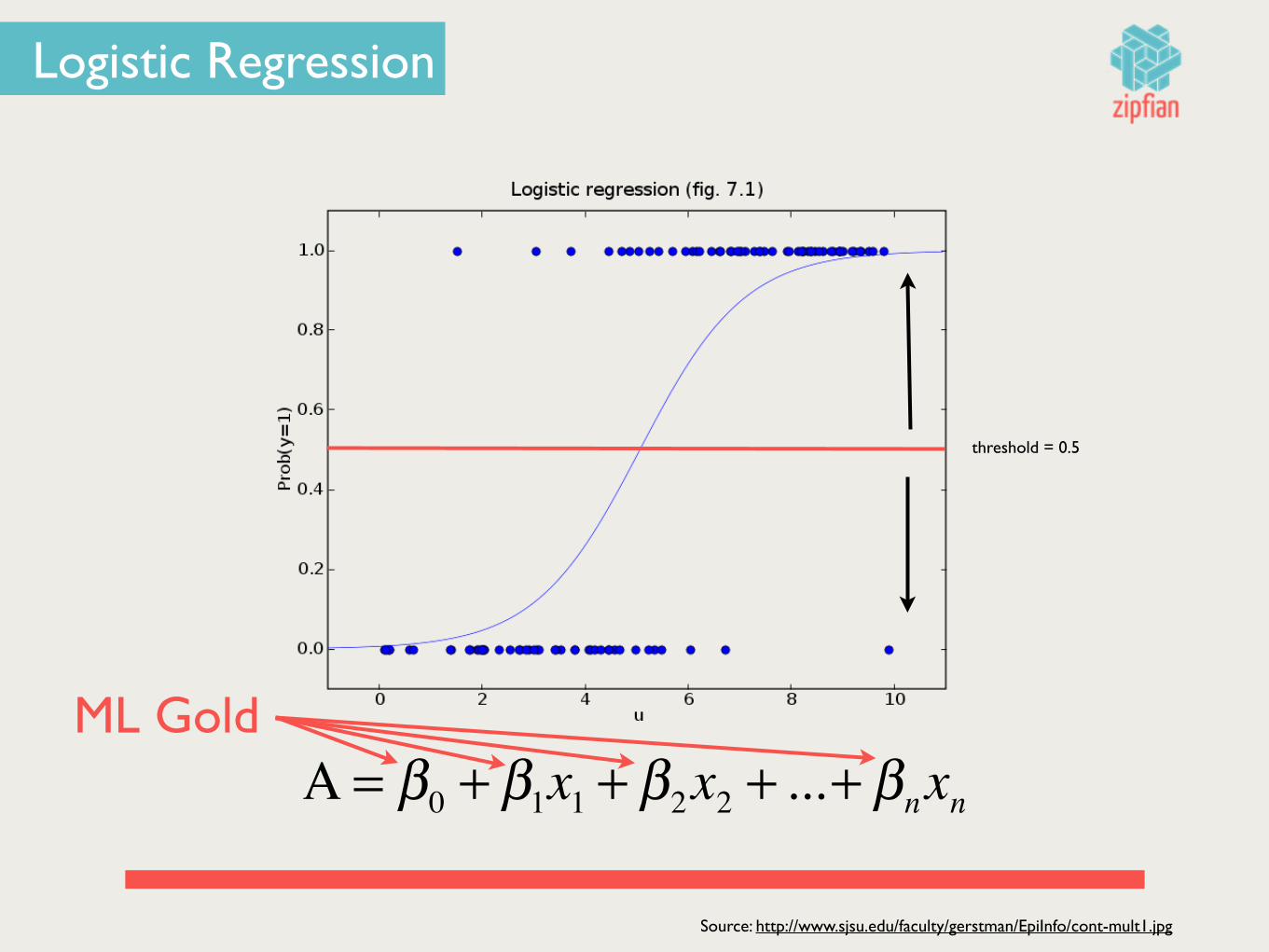
Source: http://www.sjsu.edu/faculty/gerstman/EpiInfo/cont-mult1.jpg
Α = β0 + β1x1 + β2x2 + ...+ βnxn
threshold = 0.5
ML Gold
Logistic Regression
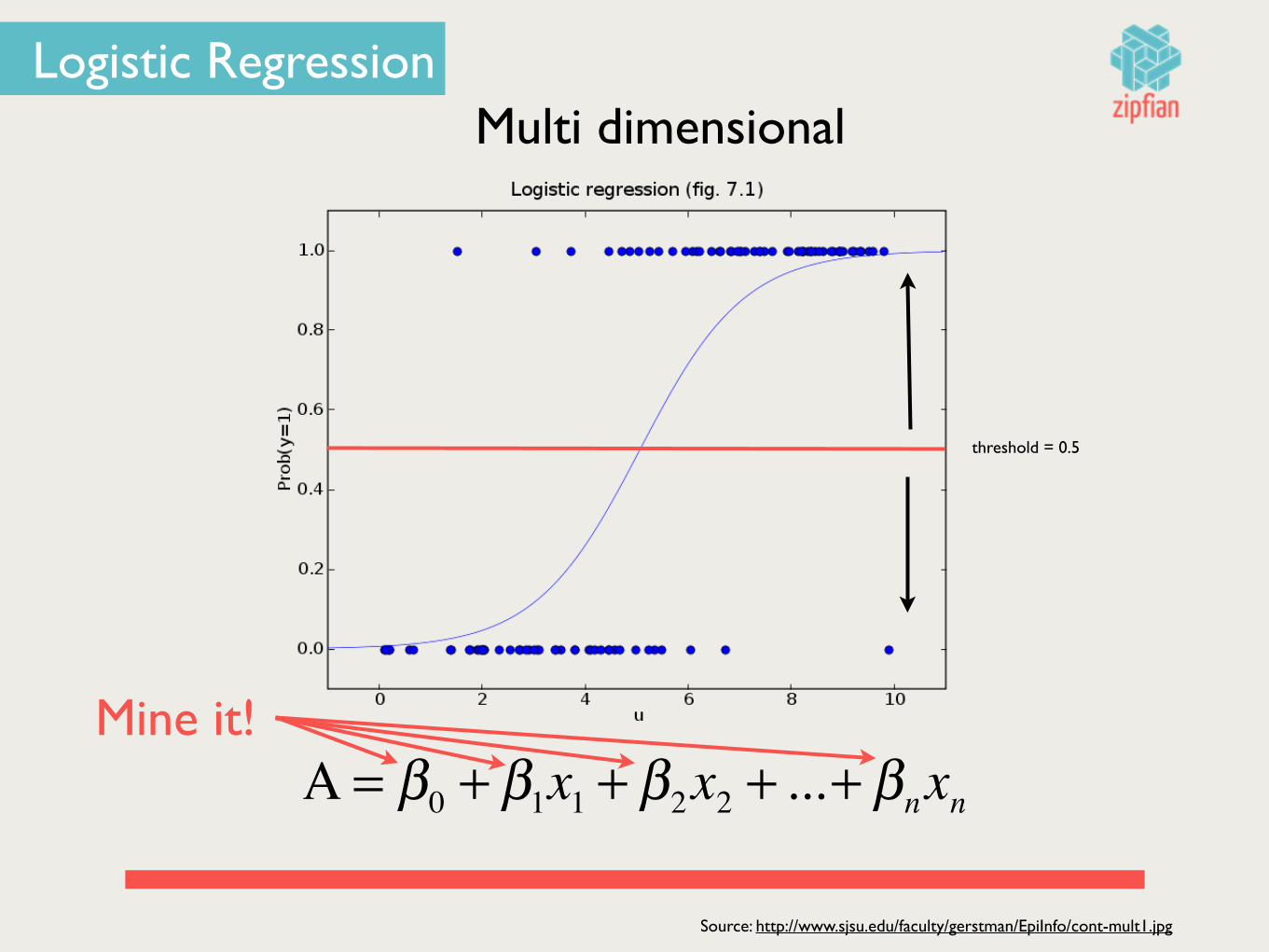
Multi dimensional
Source: http://www.sjsu.edu/faculty/gerstman/EpiInfo/cont-mult1.jpg
Α = β0 + β1x1 + β2x2 + ...+ βnxn
threshold = 0.5
Mine it!
Logistic Regression

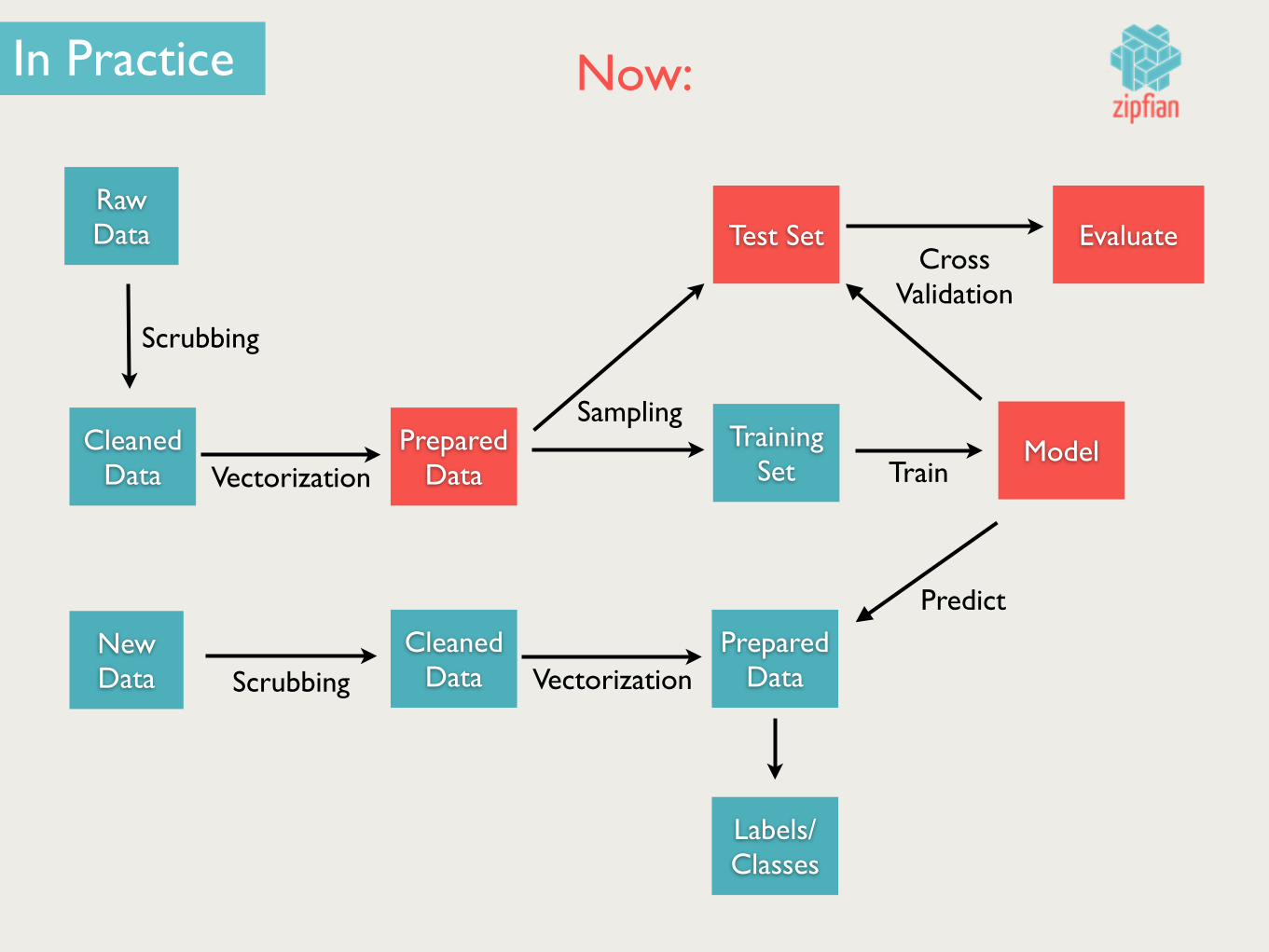
Raw Data
Cleaned Data
Scrubbing
Prepared DataVectorization
New Data
Test Set
TrainingSet Train
ModelSampling
EvaluateCross
Validation
Cleaned Data
Prepared DataVectorizationScrubbing
Predict
Labels/Classes
In Practice

Raw Data
Cleaned Data
Scrubbing
Prepared DataVectorization
New Data
Test Set
TrainingSet Train
ModelSampling
EvaluateCross
Validation
Cleaned Data
Prepared DataVectorizationScrubbing
Predict
Labels/Classes
In Practice Now:

Others
Work Time!

Others
Additional Methods

Classification
Source: http://en.wikipedia.org/wiki/K-nearest_neighbor_algorithm
Nearest Neighbors

Classification
Source: http://digitheadslabnotebook.blogspot.com/2011/11/support-vector-machines.html
Support Vector Machine (SVM)
Kernel transform Linear classifiernon-linear input space

Pitfalls
Overcoming the labeling problem
Unsupervised/Semi-supervised Learning
Label your data by hand
Have someone else label your data by hand (Mechanical Turk)
Online/Active learning

Logistic Regression
Gotchas
1. Normalize Values
2. Outliers

Others
(Cross) Validation
Raw Data
Cleaned Data
Scrubbing
Prepared DataVectorization
New Data
Test Set
TrainingSet Train
ModelSampling
EvaluateCross
Validation
Cleaned Data
Prepared DataVectorizationScrubbing
Predict
Labels/Classes
In Practice Now:

Evaluate:
Split labeled articles into a training set and a test set
Naïve Bayes
Whatever you do, DO NOT cross the streams

Focus
Do Don’t
Evaluate theefficacy of your
algorithm
Blindly trust theoryor intuition

• What is it and why do I care?
• Supervised Learning
• Regression and Classification
• Unsupervised Learning
• Clustering and Dimensionality Reduction
• In Practice
• Q&A
Outline

Unsupervised
Finding hidden structure in unlabeled data

Unsupervised
How is this different?
• Unlabeled input data
• No error for evaluation
• Exploratory
• Past rather than Future

• What is it and why do I care?
• Supervised Learning
• Regression and Classification
• Unsupervised Learning
• Clustering and Dimensionality Reduction
• Q&A
Outline

ClusteringK-means
Source: http://shabal.in/visuals.html

K-means
Assumptions/Weaknesses
1. Needs numeric features
2. Greedy/converge on local minima
3. Iterative -- slow on large data sets

Dimensionality Reduction
Source: http://www.nlpca.org/pca_principal_component_analysis.html

Practice
Data Science in Practice

Counting
Data Science....

Counting
It’s just like...

Counting
Counting!

Source: http://www.troll.me/images/x-all-the-things/count-all-the-things.jpg
Counting
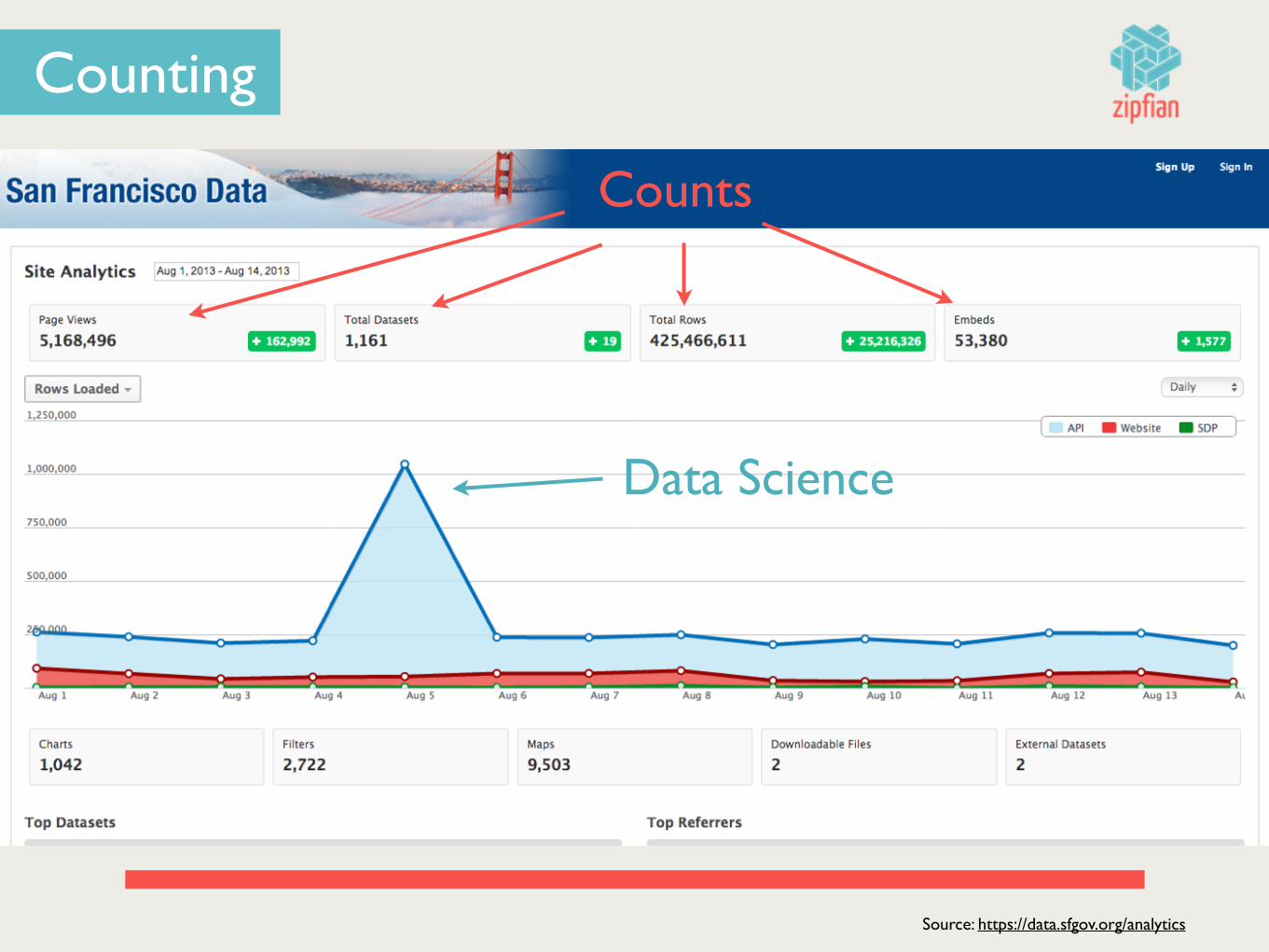
Source: https://data.sfgov.org/analytics
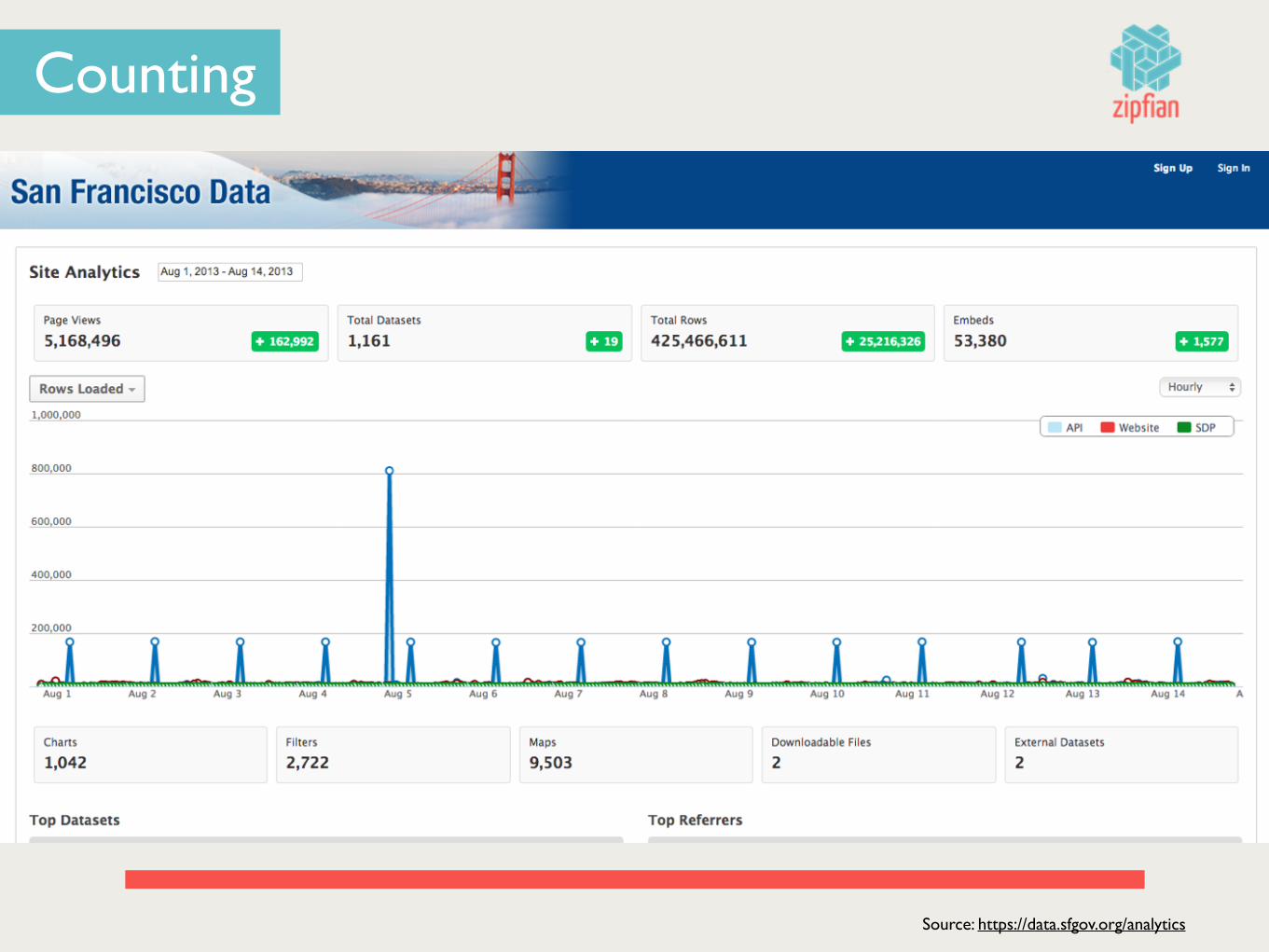
Counting
Counts
Data Science
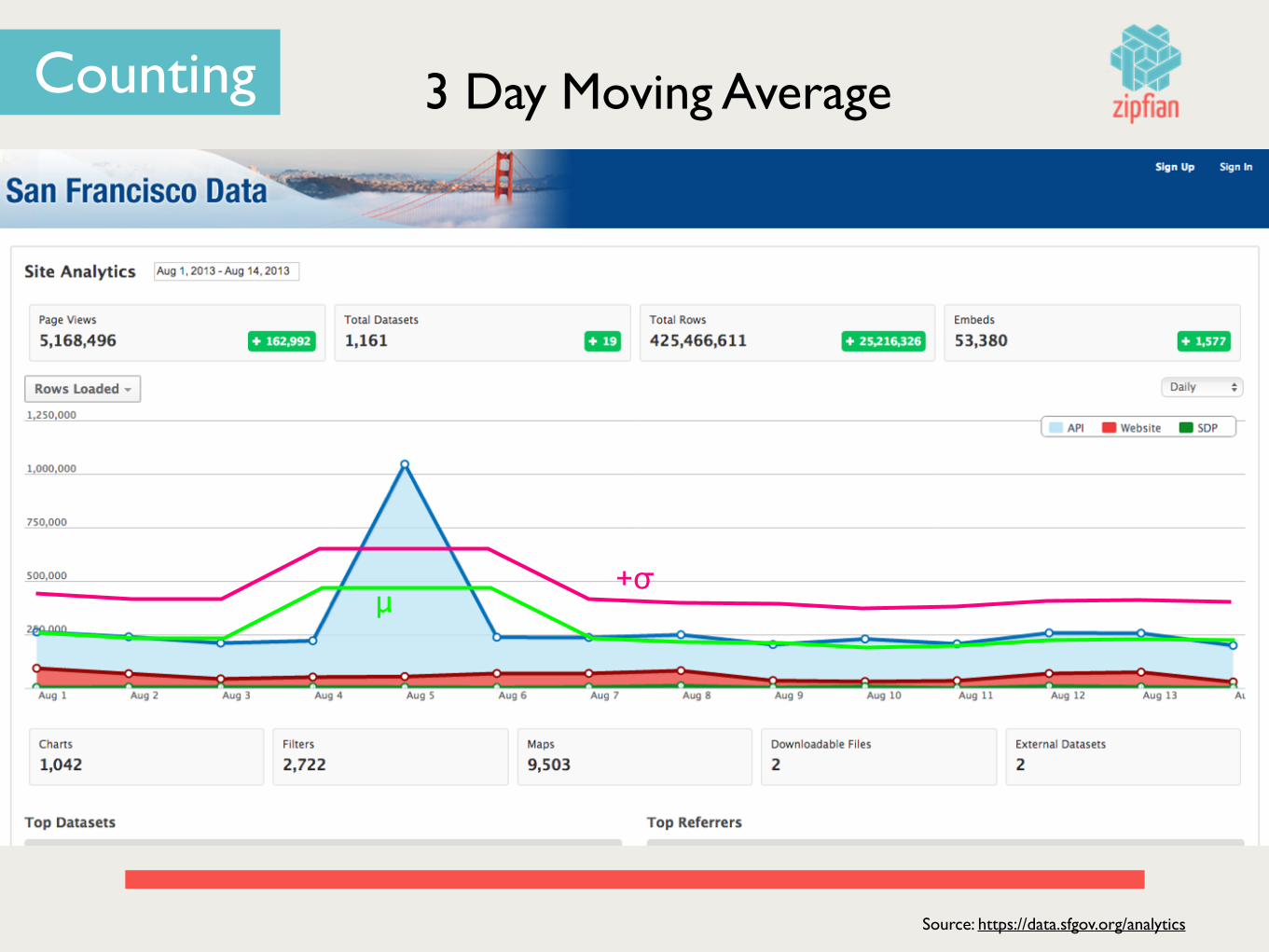
Source: https://data.sfgov.org/analytics
Counting
+σμ
3 Day Moving Average
Counting
Source: https://data.sfgov.org/analytics

Counting
What Happened on Aug. 5th?

Counting
Both Passive and Active measurement

Counting
Passively measure time user spends on page (or slide)

Source: http://tctechcrunch2011.files.wordpress.com/2010/10/awesome.jpg
Counting
Actively solicit users feedback
e.g.

Counting
But it doesn’t stop at simple Statistics

Approach
Naïve Bayes
Source: http://www.emeraldinsight.com/journals.htm?articleid=1550453&show=html

A Short Divergence:
How do we turn an article full of words into something an algorithm can
understand?
Naïve Bayes

Source: http://users.livejournal.com/_winnie/361188.html
Vectorization

A Short Divergence:
Put it in a Bag!
Vectorization

A Short Divergence:
original document dictionary of word counts
feature vector: width of “vocabulary” of English
language
The brown fox{ “the” : 1, “brown”: 1, “fox” : 1}
[0,0,1,0,1,0,...]
brown fox
Tokenization Vectorization
Bag of Words
Counts!

Naïve Bayes
Train:
P(Y | F1,…,Fn )∝ P(Y ) P(Fi | Y )
i∏
[0,0,1,0,1,0,...]
brown fox
Newspaper Section (what we want to
predict)

Naïve Bayes
Train:
P(Fi | Y )
Conditional Probability
Count occurrence of each word in training data
count(x)total #words(with label Y)

Naïve Bayes
Train:
P(Fi | Sports) P(Fi | Nature)P(Y )
Sports : 0.32
Social Media : 0.12
Nature : 0.41
News : 0.10...
the : 0.156
to : 0.153
ball : 0.0045
bat : 0.0033
she : 0.0083
Boston : 0.0002...
the : 0.189
us : 0.0167
trees : 0.0945
bat : 0.0068
she : 0.017
Brazil : 0.0042...

Pitfalls
Overcoming the labeling problem
Unsupervised/Semi-supervised Learning
Label your data by hand
Have someone else label your data by hand (Mechanical Turk)
Online/Active learning

Source: http://www.glogster.com/mrsallenballard/pickles-i-love-em-/g-6mevh13be74mgnc9i8qifa0
Persistence

Persistence
SerDes
• Disk
• Database
• Memory
•

Scale
Issues?

Scale
Issues?
• Batch Oriented Algorithms• Data Preparation•Output?
Scale

Scale
Train vs. Predict
Source: http://clincancerres.aacrjournals.org/content/5/11/3403/F4.expansion
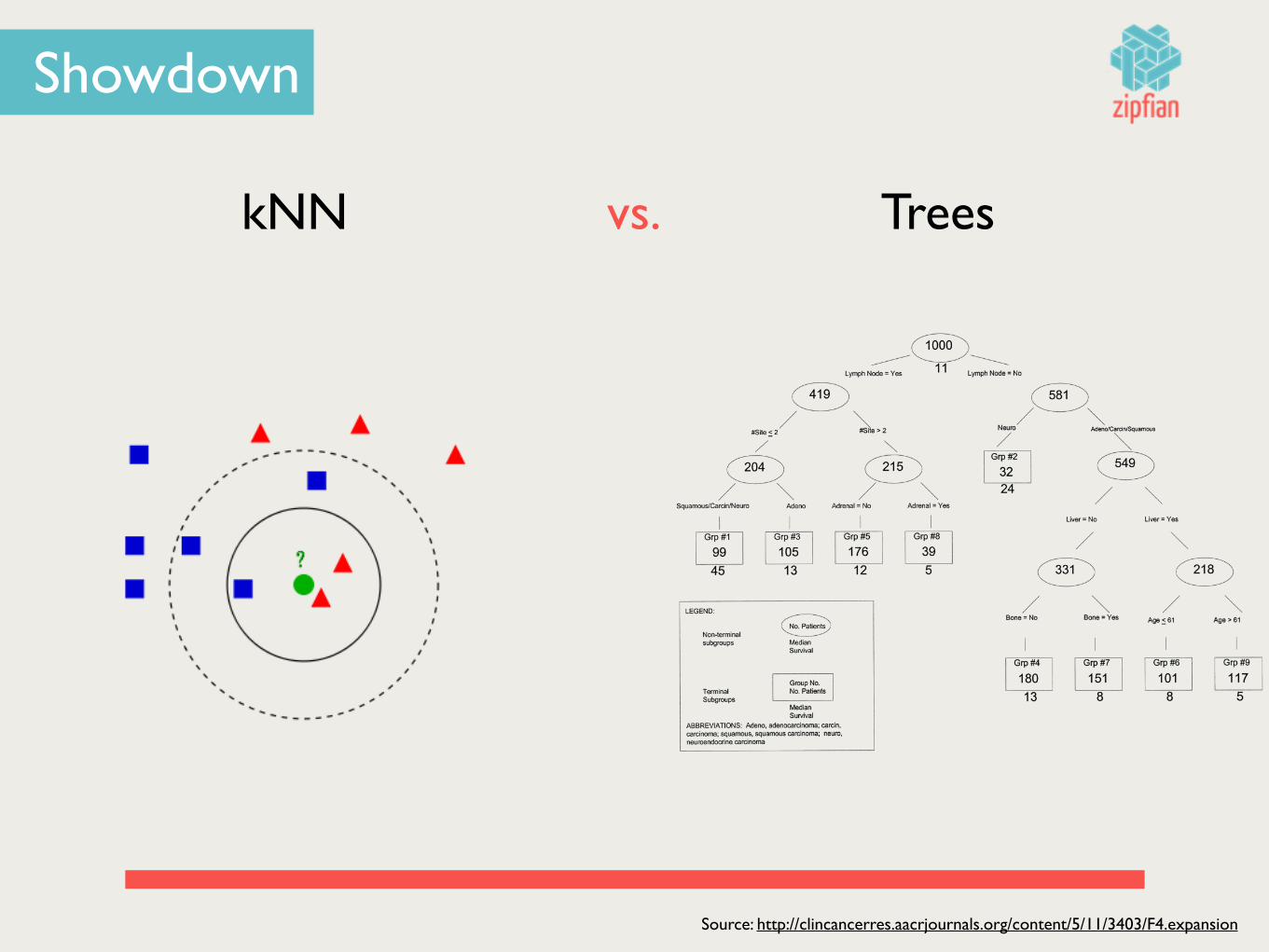
Showdown
kNN Treesvs.

Exposé

Exposé
APIs and Interfaces
• Internal
• ReSTful
• Public
• (Web) Application

• Present a guest lecture or share a data story
• Donate datasets and propose projects
• Sponsor a scholarship
• Donate cluster time or resources
• Attend our Hiring Day (Nov. 20th)
Get Involved

• Full Time Instructors
• Part Time Instructors
• Curriculum Developers
• TAs
We’re Hiring!

•Monday: Machine Learning Workshop
• Tuesday: Hiring Mixer
• Wednesday: Why I Teach (Data Science)
• Thursday: Why Knowing Your Data is Invaluable to Startups Panel
• Nighttime: DATAVIZ ART + TECH
DataWeek

Outline
Q&A

Thank You!Jonathan Dinu
Co-Founder, Zipfian [email protected]
@clearspandex
Ryan OrbanCo-Founder, Zipfian Academy
[email protected]@ryanorban
Recommended

















