
ENABLE FAST BIG DATA ANALYTICS ON CEPH WITH ALLUXIOAdit Madan
March 2017

ABOUT ME
Adit Madan, Software Engineer @ Alluxio, Inc
Master’s @ Carnegie Mellon University
Bachelor’s @ Indian Institute of Technology, Delhi
Email: [email protected]
2

ALLUXIO INTRODUCTION
3
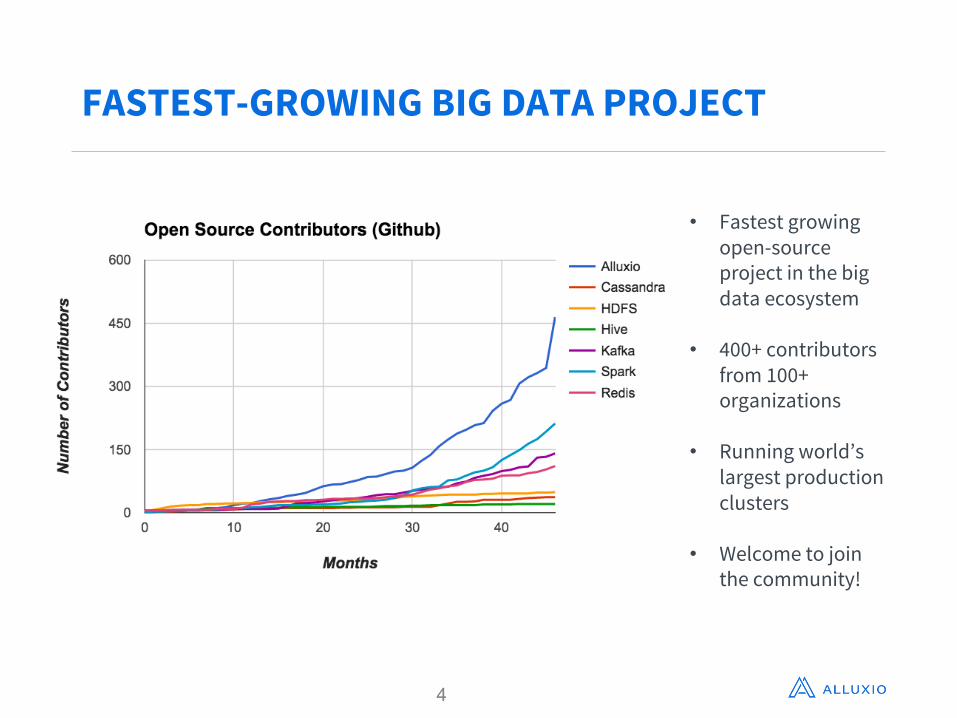
FASTEST-GROWING BIG DATA PROJECT
• Fastest growing open-source project in the big data ecosystem
• 400+ contributors from 100+ organizations
• Running world’s largest production clusters
• Welcome to join the community!
4
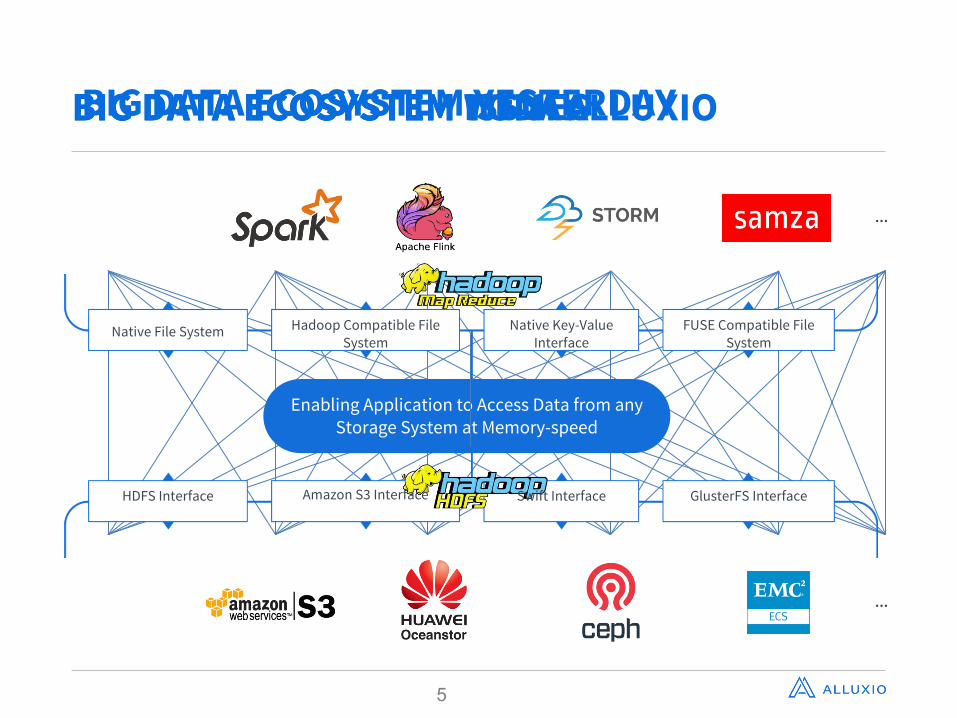
BIG DATA ECOSYSTEM TODAYBIG DATA ECOSYSTEM WITH ALLUXIOBIG DATA ECOSYSTEM YESTERDAY
…
…
FUSE Compatible File System
Hadoop Compatible File System
Native Key-Value Interface
Native File System
Enabling Application to Access Data from any Storage System at Memory-speed
BIG DATA ECOSYSTEM ISSUES
GlusterFS InterfaceAmazon S3 Interface Swift InterfaceHDFS Interface
5

WHY ALLUXIO
Co-located with compute, provides memory-speed access to data
Virtualized across different storage systems under a unified global namespace
Distributed system, scale-out architecture
Software only, no change needed to existing application
6

ALLUXIO BENEFITS
Unification
New workflows across any data in any storage system
Orders of magnitude improvement in run time
Choice in compute and storage – grow each independently, buy only what is needed
Performance Flexibility
7

USE CASE – ACCELERATE I/O TO/FROM REMOTE STORAGE
8
• Compute and Storage Separation• Advantages• Meet different compute and storage hardware
requirements efficiently• Scale compute and storage independently• Store data in Traditional filers/SANs and object
stores cost effectively• Compute on data in existing storage via Big Data
Computational frameworks• Disadvantage• Accessing data requires remote I/O
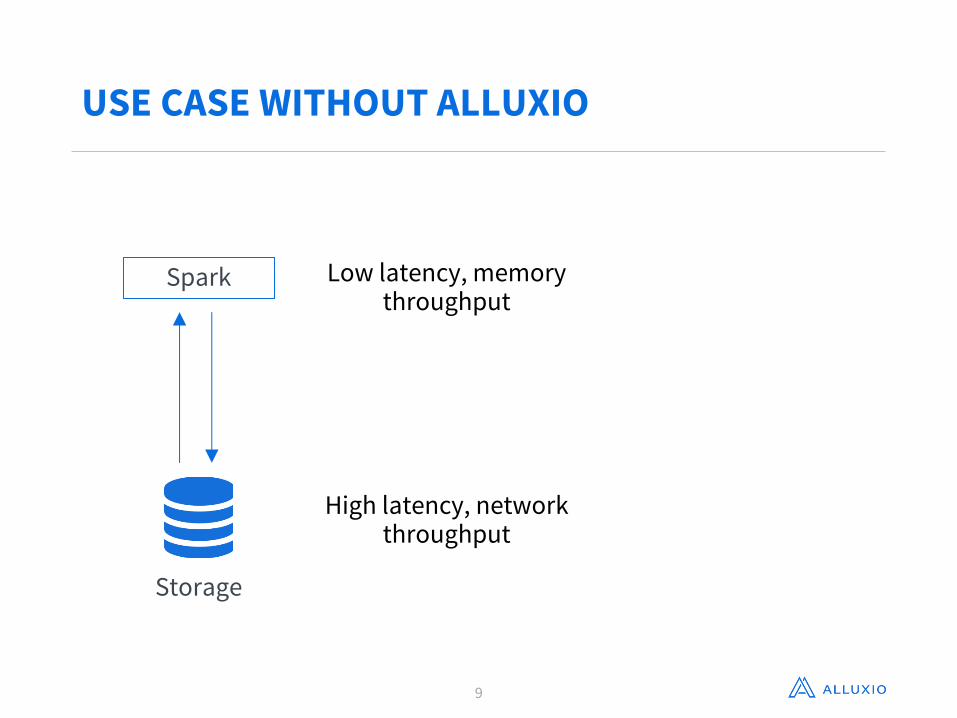
USE CASE WITHOUT ALLUXIO
9
Spark
Storage
Low latency, memory throughput
High latency, network throughput
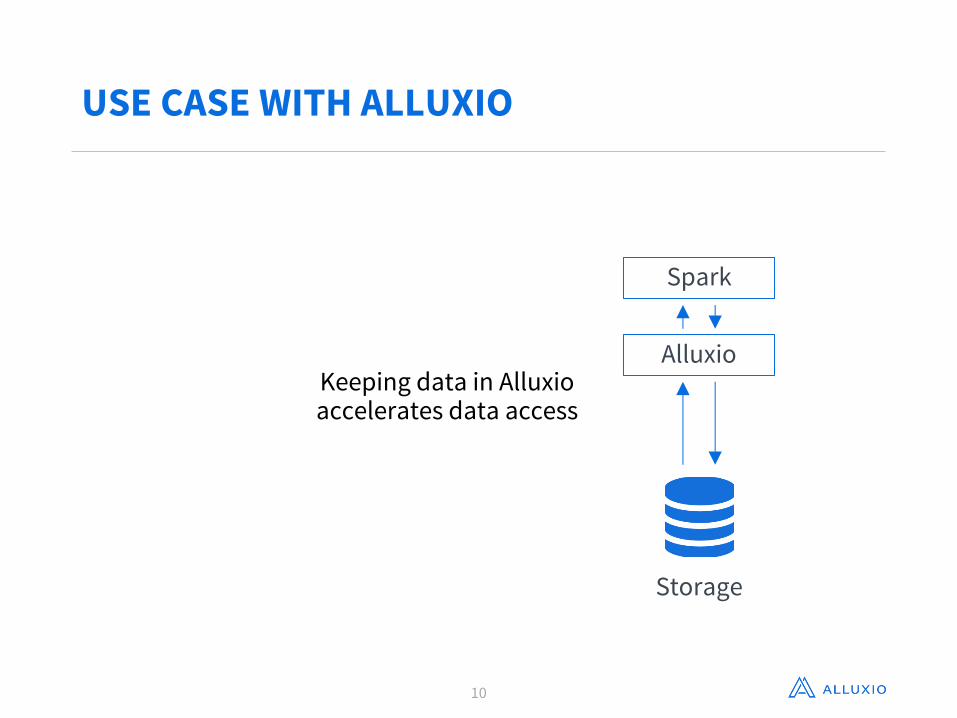
USE CASE WITH ALLUXIO
10
Spark
Storage
AlluxioKeeping data in Alluxio accelerates data access

ACCELERATE I/O TO/FROM REMOTE STORAGE
The performance was amazing. With Spark SQL alone, it took 100-150 seconds to finish a query; using Alluxio, where data may hit local or remote Alluxio nodes, it took 10-15 seconds.- Baidu
RESULTS
• Data queries are now 30x faster with Alluxio
• Alluxio cluster runs stably, providing over 50TB of RAM space
• By using Alluxio, batch queries usually lasting over 15 minutes were transformed into an interactive query taking less than 30 seconds
Baidu’s PMs and analysts run
interactive queries to gain insights
into their products and business
• 200+ nodes deployment
• 2+ petabytes of storage
• Mix of memory + HDD
ALLUXIO
Baidu File System
11

ALLUXIO ON CEPH
12

ALLUXIO ON CEPH
13
Spark
Ceph Object Storage
Alluxio
● Connect using RADOS Gateway ○ Swift Object Storage API

EC2 CONFIGURATION
14
● 1 Compute Master○ Spark and Alluxio Masters
● 3 Compute Workers○ Spark and Alluxio Workers
● 1 Storage Manager○ Ceph RadosGW and Monitor
● 2 Storage Devices○ Ceph OSDs
● Instance type: r3.xlarge● Availability Zone: us-east-1a

SOFTWARE VERSIONS
15
● Ceph Version: 0.94.9
● Alluxio Version: 1.4.0○ Custom JOSS library 0.9.13-SNAPSHOT
● Spark Version 1.6.1

DEMO OF THE SOLUTION
16
● Spark, Alluxio and Ceph Cluster pre-deployed
● Ceph pre-populated with a 60GB dataset
● Launch spark shella. First ‘count’b. Second ‘count’c. <Restart shell>d. Third ‘count’
● Ad-hoc queries w/ Alluxioa. ‘wordcount’ w/ intermediate data
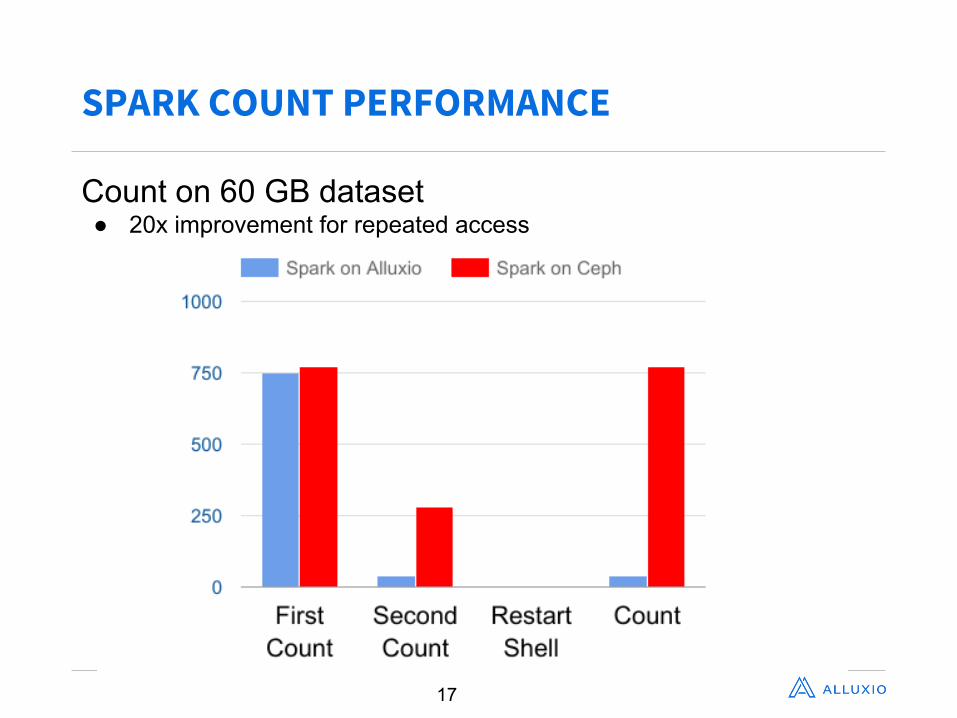
SPARK COUNT PERFORMANCE
17
Count on 60 GB dataset● 20x improvement for repeated access
FOR MORE INFORMATION ….
18
Please take a look at our Whitepaper!
● Blog: https://alluxio.com/blog/accelerating-data-analytics-on-ceph-object-storage-with-alluxio
● Whitepaper: https://alluxio.com/resources/accelerating-data-analytics-on-ceph-object-storage-with-alluxio
Thank you!Contact: [email protected] or [email protected]: @AlluxioWebsites: www.alluxio.com and www.alluxio.org
19
Recommended

















