
ENGS 116 Lecture 12 1
Caches
Vincent H. Berk
October 21, 2005
Reading for Wednesday: Sections 5.1 – 5.4
Reading for Friday: Sections 5.5 – 5.8(Jouppi article)
ENGS 116 Lecture 12 2
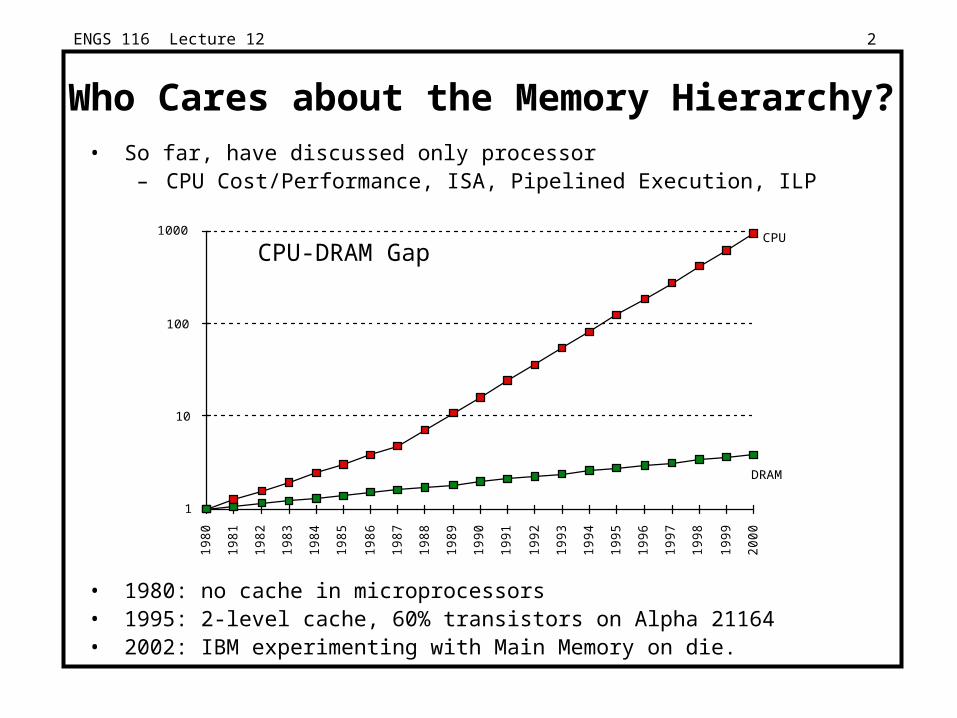
Who Cares about the Memory Hierarchy?• So far, have discussed only processor
– CPU Cost/Performance, ISA, Pipelined Execution, ILP
• 1980: no cache in microprocessors • 1995: 2-level cache, 60% transistors on Alpha 21164• 2002: IBM experimenting with Main Memory on die.
1
10
100
1000
1980
1981
1982
1983
1984
1985
1986
1987
1988
1989
1990
1991
1992
1993
1994
1995
1996
1997
1998
1999
2000
DRAM
CPU
CPU-DRAM Gap
ENGS 116 Lecture 12 3
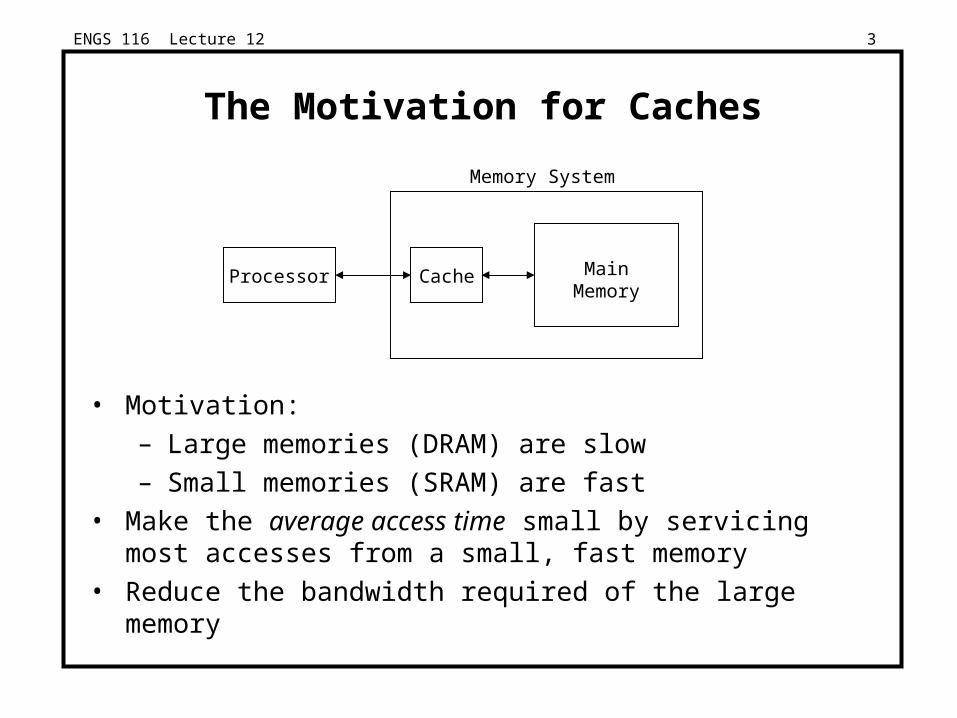
The Motivation for Caches
• Motivation:
– Large memories (DRAM) are slow
– Small memories (SRAM) are fast
• Make the average access time small by servicing most accesses from a small, fast memory
• Reduce the bandwidth required of the large memory
Processor Cache MainMemory
Memory System

ENGS 116 Lecture 12 4
Principle of Locality of Reference
• Programs do not access their data or code all at once or with equal probability
– Rule of thumb: Program spends 90% of its execution time in only 10% of the code
• Programs access a small portion of the address space at any one time
• Programs tend to reuse data and instructions that they have recently used
• Implication of locality: Can predict with reasonable accuracy what instructions and data a program will use in the near future based on its accesses in the recent past
ENGS 116 Lecture 12 5
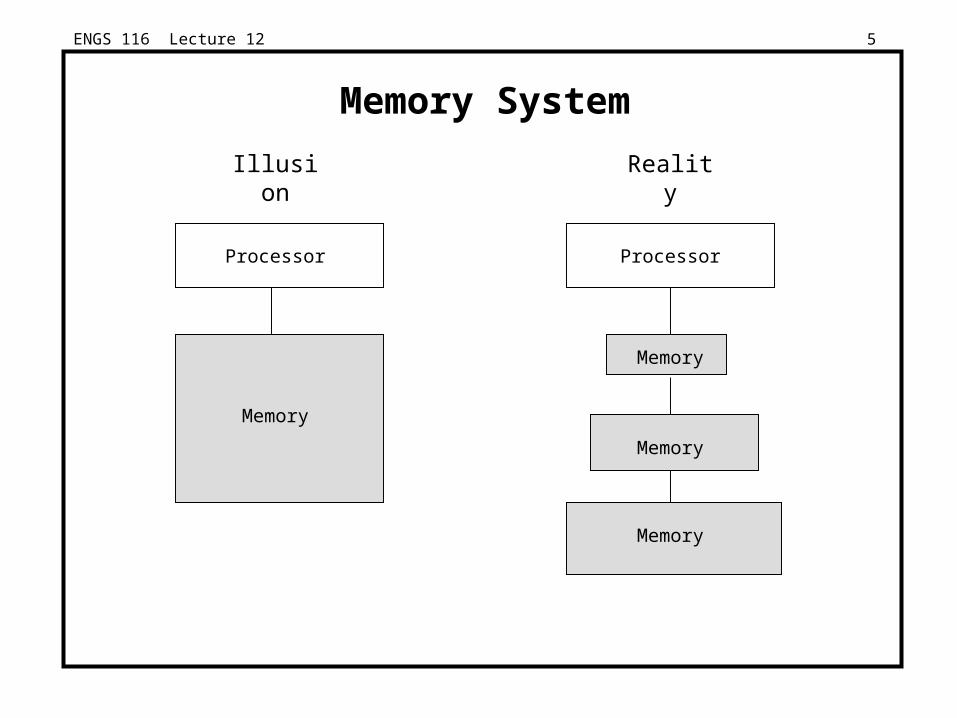
Memory System
Processor
Illusion Reality
Processor
Memory
Memory
Memory
Memory

ENGS 116 Lecture 12 6
General Principles
• Locality
– Temporal Locality: referenced again soon
– Spatial Locality: nearby items referenced soon
• Locality + smaller HW is faster memory hierarchy
– Levels: each smaller, faster, more expensive/byte than level below
– Inclusive: data found in top also found in lower levels
• Definitions
– Upper is closer to processor
– Block: minimum, address aligned unit that fits in cache
– Address = Block frame address + block offset address
– Hit time: time to access upper level, including hit determination

ENGS 116 Lecture 12 7
Cache Measures
• Hit rate: fraction of accesses found in that level– So high that we usually talk about the miss rate– Miss rate fallacy: miss rate induces miss penalty,
determines average memory performance
• Average memory-access time (AMAT) = Hit time + Miss rate Miss penalty (ns or clocks)
• Miss penalty: time to replace a block from lower level, including time to copy to and restart CPU– access time: time to lower level = ƒ(lower level latency)
– transfer time: time to transfer block = ƒ(BW upper &
lower, block size)
ENGS 116 Lecture 12 8
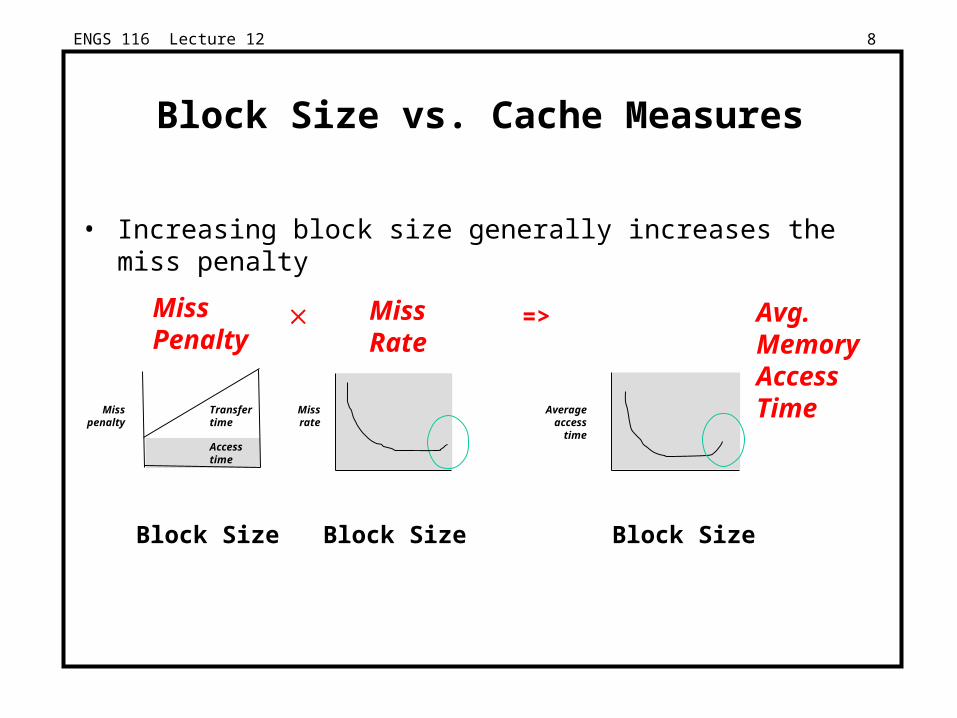
Block Size vs. Cache Measures
• Increasing block size generally increases the miss penalty
Block Size Block Size Block Size
MissRate
MissPenalty
Avg.MemoryAccessTime
=>
Misspenalty
Transfer time
Access time
Missrate
Average access
time

ENGS 116 Lecture 12 9
Key Points of Memory Hierarchy
• Need methods to give illusion of large, fast memory
• Programs exhibit both temporal locality and spatial locality
– Keep more recently accessed data closer to the processor
– Keep multiple contiguous words together in memory blocks
• Use smaller, faster memory close to processor – hits are processed quickly; misses require access to larger, slower memory
• If hit rate is high, memory hierarchy has access time close to that of highest (fastest) level and size equal to that of lowest (largest) level

ENGS 116 Lecture 12 10
Implications for CPU
• Fast hit check since every memory access needs this check
– Hit is the common case
• Unpredictable memory access time
– 10s of clock cycles: wait
– 1000s of clock cycles: (Operating System)
» Interrupt & switch & do something else
» Lightweight: multithreaded execution

ENGS 116 Lecture 12 11
Four Memory Hierarchy Questions
• Q1: Where can a block be placed in the upper level?(Block placement)
• Q2: How is a block found if it is in the upper level?(Block identification)
• Q3: Which block should be replaced on a miss?(Block replacement)
• Q4: What happens on a write?(Write strategy)
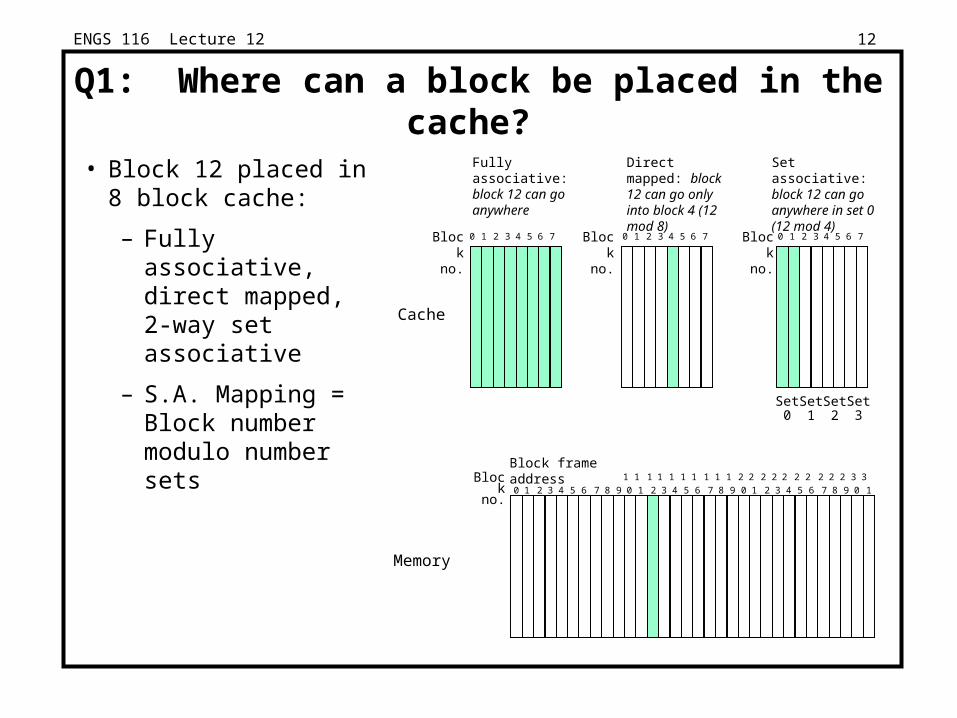
ENGS 116 Lecture 12 12
Q1: Where can a block be placed in the cache?
• Block 12 placed in 8 block cache:
– Fully associative, direct mapped, 2-way set associative
– S.A. Mapping = Block number modulo number sets
4 53210 76
4 53210 76 08 9 4 5321 76 8 9 4 53210 76 08 9 1
1 1 1 1 1 11 1 1 1 332 2 2 2 2 22 2 2 2
Fully associative: block 12 can go anywhere
Direct mapped: block 12 can go only into block 4 (12 mod 8)
Set associative: block 12 can go anywhere in set 0 (12 mod 4)
Block no.
Block no.
Block no.
4 53210 76 4 53210 76
Cache
Memory
Block no.
Block frame address
Set0
Set1
Set2
Set3
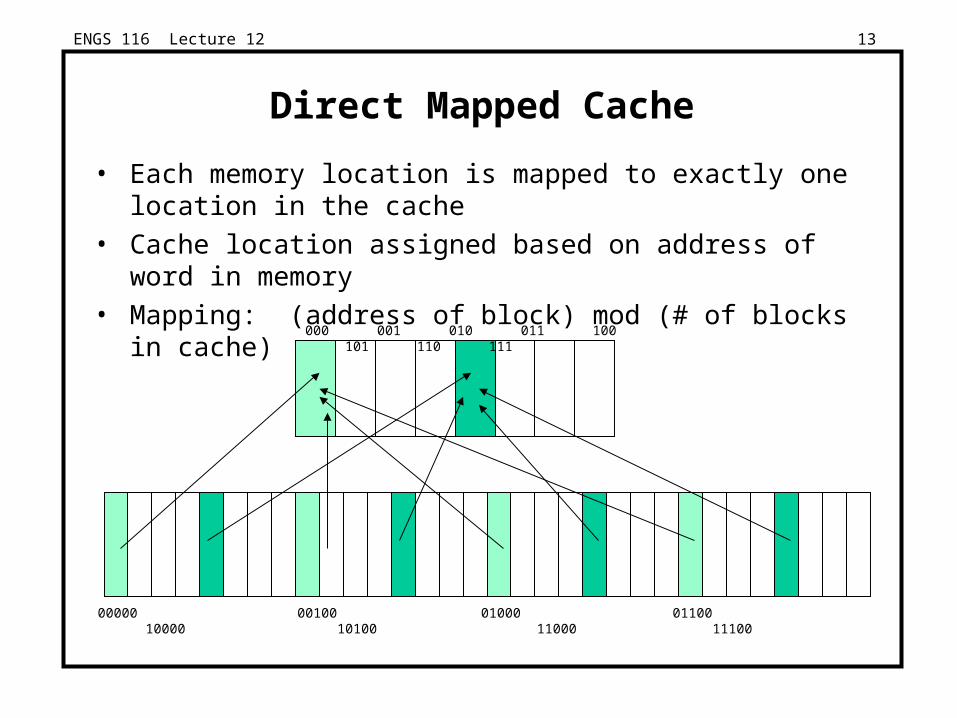
ENGS 116 Lecture 12 13
Direct Mapped Cache
• Each memory location is mapped to exactly one location in the cache
• Cache location assigned based on address of word in memory
• Mapping: (address of block) mod (# of blocks in cache)
000 001 010 011 100 101 110 111
00000 00100 01000 01100 10000 10100 11000 11100

ENGS 116 Lecture 12 14
Associative Caches
• Fully Associative: block can go anywhere in the cache
• N-way Set Associative: block can go in one of N locations in the set

ENGS 116 Lecture 12 15
Q2: How is a block found if it is in the cache?
• Tag on each block
– No need to check index or block offset
• Increasing associativity shrinks index, expands tag
Fully Associative: No index
Direct Mapped: Large index
Block Address
Tag Index
Block Offset

ENGS 116 Lecture 12 16
Examples• 512-byte cache, 4-way set associative, 16-byte blocks, byte
addressable
• 8-KB cache, 2-way set associative, 32-byte blocks, byte addressable

ENGS 116 Lecture 12 17
Q3: Which block should be replaced on a miss?
• Easy for direct mapped• Set associative or fully associative:
– Random (large associativities)– LRU (smaller associativities)– FIFO (large associativities)
Associativity: 2-way 4-way
Size LRU Random FIFO LRU Random FIFO
16 KB 114.1 117.3 115.5 111.7 115.1 113.3
64 KB 103.4 104.3 103.9 102.4 102.3 103.1
256 KB 92.2 92.1 92.5 92.1 92.1 92.5

ENGS 116 Lecture 12 18
Q4: What Happens on a Write?
• Write through: The information is written to both the block in the cache and to the block in the lower-level memory.
• Write back: The information is written only to the block in the cache. The modified cache block is written to main memory only when it is replaced.
– Is block clean or dirty?
• Pros and Cons of each:
– WT: read misses cannot result in writes (because of replacements)
– WB: no writes of repeated writes
• WT always combined with write buffers so that we don’t wait for lower level memory
• WB write buffer, giving a read-miss precedence
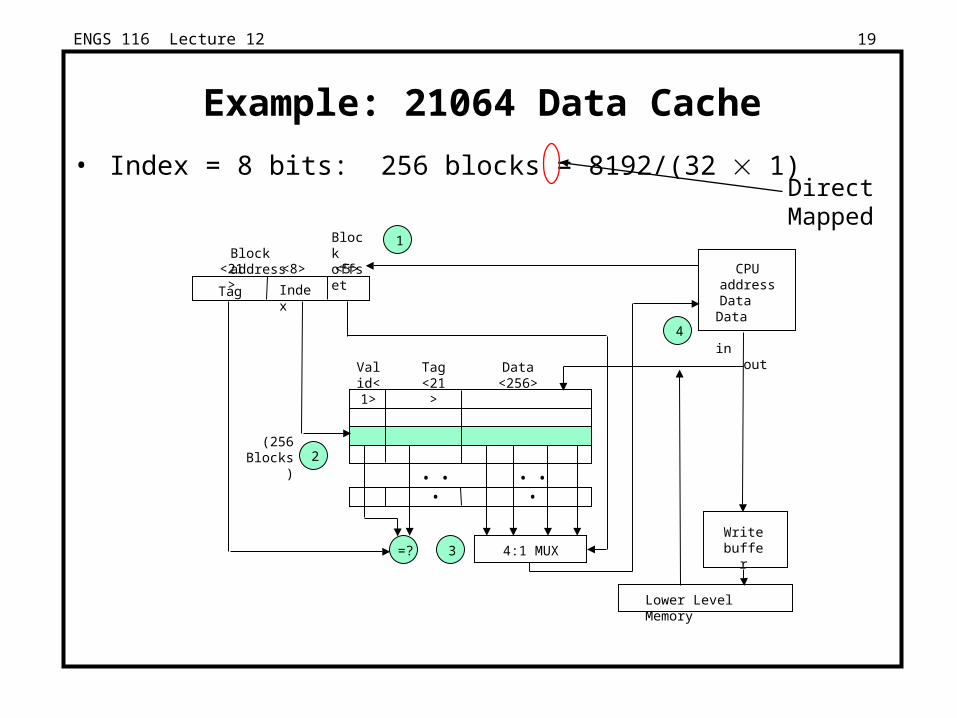
ENGS 116 Lecture 12 19
Example: 21064 Data Cache
• Index = 8 bits: 256 blocks = 8192/(32 1)DirectMapped
4
CPU address
Data Data in
out
Lower Level Memory
Write buffer
2
Valid<1>
Tag <21>
Data <256>
(256 Blocks)
=? 3 4:1 MUX
• • • • • •
Block address1Block
offset<5><21> <8>
IndexTag
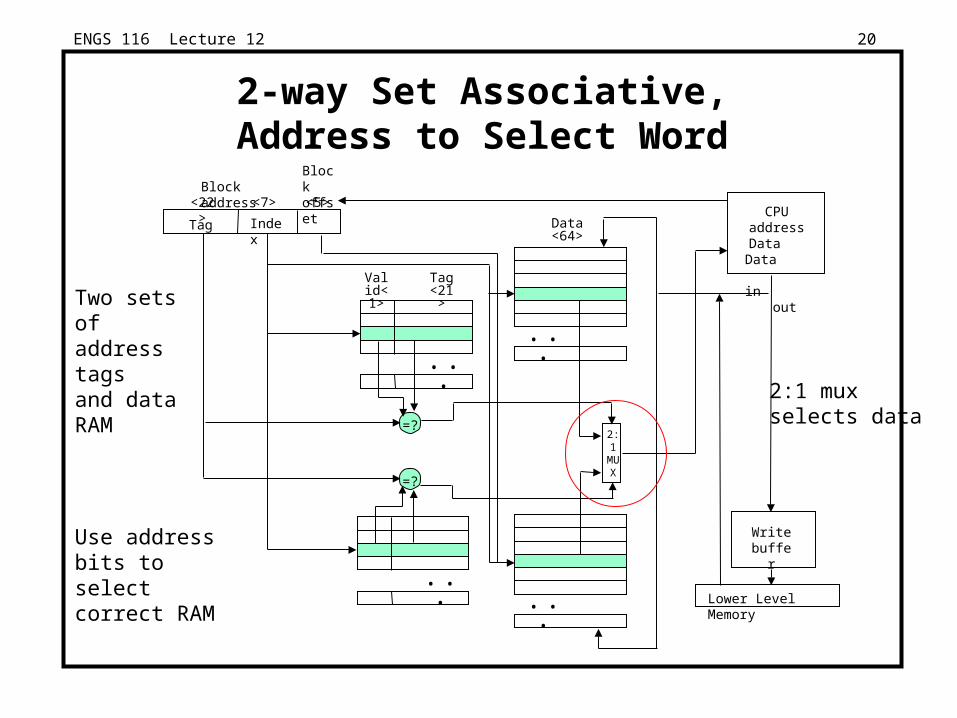
ENGS 116 Lecture 12 20
• • •
2-way Set Associative,Address to Select Word
CPU address
Data Data in
out
Lower Level Memory
Write buffer
Block addressBlock offset<5><22> <7>
IndexTag
2:1 muxselects data
Two sets ofaddress tagsand data RAM
Use addressbits to selectcorrect RAM
2:1 MU X
=?
=?
Data <64>
• • •
Valid<1>
Tag <21>
• • •
• • •
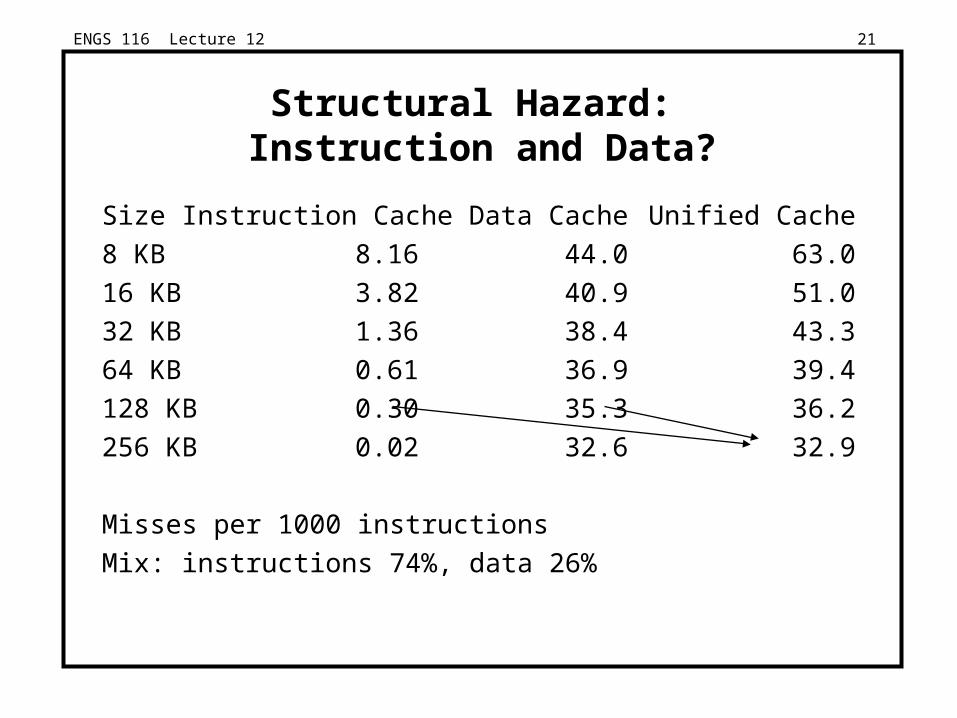
ENGS 116 Lecture 12 21
Structural Hazard: Instruction and Data?
Size Instruction Cache Data Cache Unified Cache
8 KB 8.16 44.0 63.0
16 KB 3.82 40.9 51.0
32 KB 1.36 38.4 43.3
64 KB 0.61 36.9 39.4
128 KB 0.30 35.3 36.2
256 KB 0.02 32.6 32.9
Misses per 1000 instructions
Mix: instructions 74%, data 26%
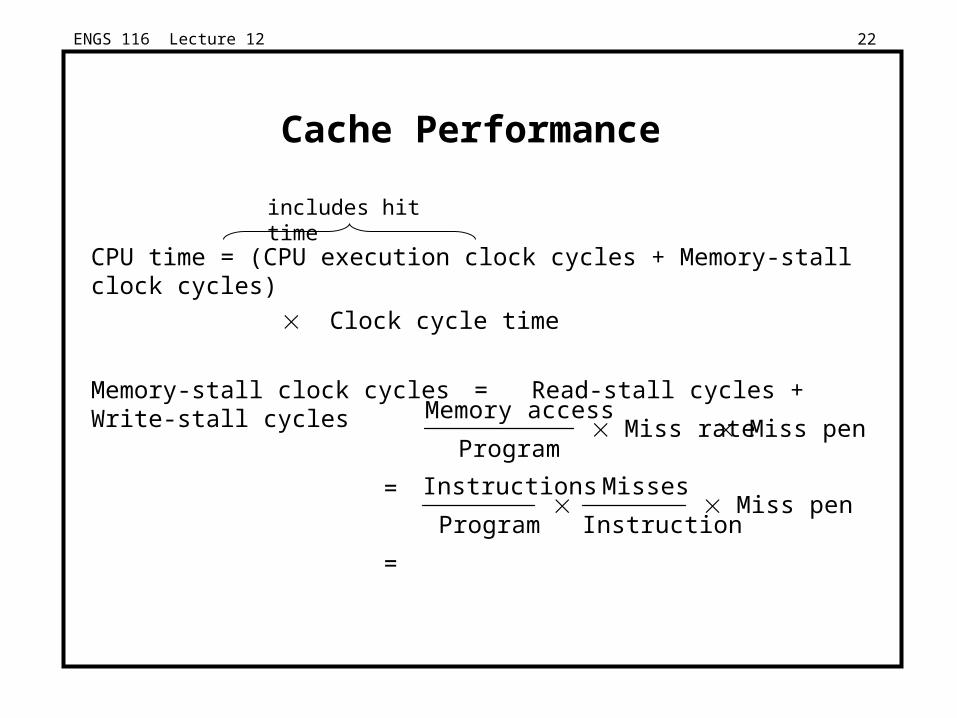
ENGS 116 Lecture 12 22
Cache Performance
CPU time = (CPU execution clock cycles + Memory-stall clock cycles)
Clock cycle time
Memory-stall clock cycles = Read-stall cycles + Write-stall cycles
=
=
Memory access
Program Miss rate Miss penalty
Instructions
Program
Misses
Instruction Miss penalty
includes hit time

ENGS 116 Lecture 12 23
Cache Performance
CPU time = IC (CPIexecution + Mem accesses per instruction Miss rate Miss penalty) Clock cycle time
Misses per instruction = Memory accesses per instruction Miss rate
CPU time = IC (CPIexecution + Misses per instruction Miss penalty) Clock cycle time

ENGS 116 Lecture 12 24
Summary of Cache Basics
• Associativity
• Block size (cache line size)
• Write Back/Write Through, write buffers, dirty bits
• AMAT as a basic performance measure
• Larger block size decreases miss rate but can increase miss penalty
• Can increase bandwidth of main memory to transfer cache blocks more efficiently
• Memory system can have significant impact on program execution time, memory stalls can be over 100 cycles
• Faster processors memory stalls more costly

ENGS 116 Lecture 12 25
Improving Cache Performance
• Average memory-access time (AMAT) = Hit time + Miss rate Miss penalty (ns or clocks)
• Improve performance by:
1. Reducing the miss penalty (5.4)
2. Reducing the miss rate (5.5)
3. Reducing through parallelism (5.6)
4. Reducing the time to hit in the cache (5.7)

ENGS 116 Lecture 12 26
Reducing Miss Penalty
• Multilevel Caches
• Critical Word First and Early Restart
• Read Misses over Writes
• Merging Write Buffer
• Victim Caches
• Subblock Placement

ENGS 116 Lecture 12 27
1. Reduce Miss Penalty: L2 Caches
• L2 EquationsAMAT = Hit TimeL1 + Miss RateL1 Miss PenaltyL1
Miss PenaltyL1 = Hit TimeL2 + Miss RateL2 Miss PenaltyL2
AMAT = Hit TimeL1 + Miss RateL1 (Hit TimeL2 + Miss RateL2 Miss PenaltyL2)
• Definitions:– Local miss rate — misses in this cache divided by the total
number of memory accesses to this cache (Miss rateL2)– Global miss rate — misses in the cache divided by the total
number of memory accesses generated by the CPU (Miss RateL1 Miss RateL2)
– Global miss rate is what matters —indicates what fraction of memory accesses from CPU go all the way to main memory
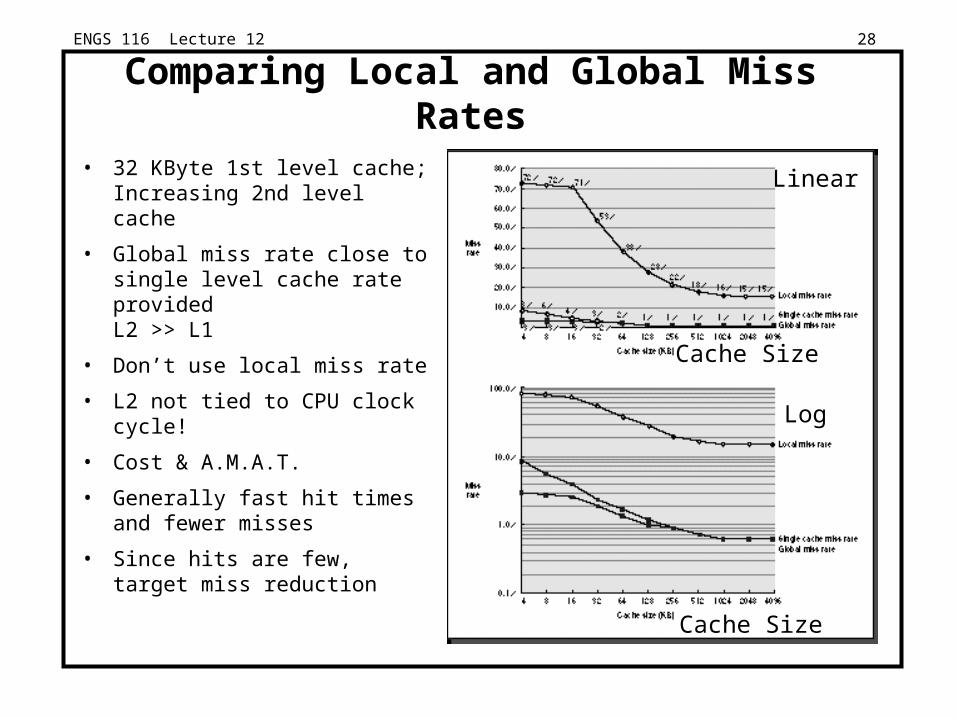
ENGS 116 Lecture 12 28
Comparing Local and Global Miss Rates
• 32 KByte 1st level cache;Increasing 2nd level cache
• Global miss rate close to single level cache rate provided L2 >> L1
• Don’t use local miss rate
• L2 not tied to CPU clock cycle!
• Cost & A.M.A.T.
• Generally fast hit times and fewer misses
• Since hits are few, target miss reduction
Linear
Log
Cache Size
Cache Size
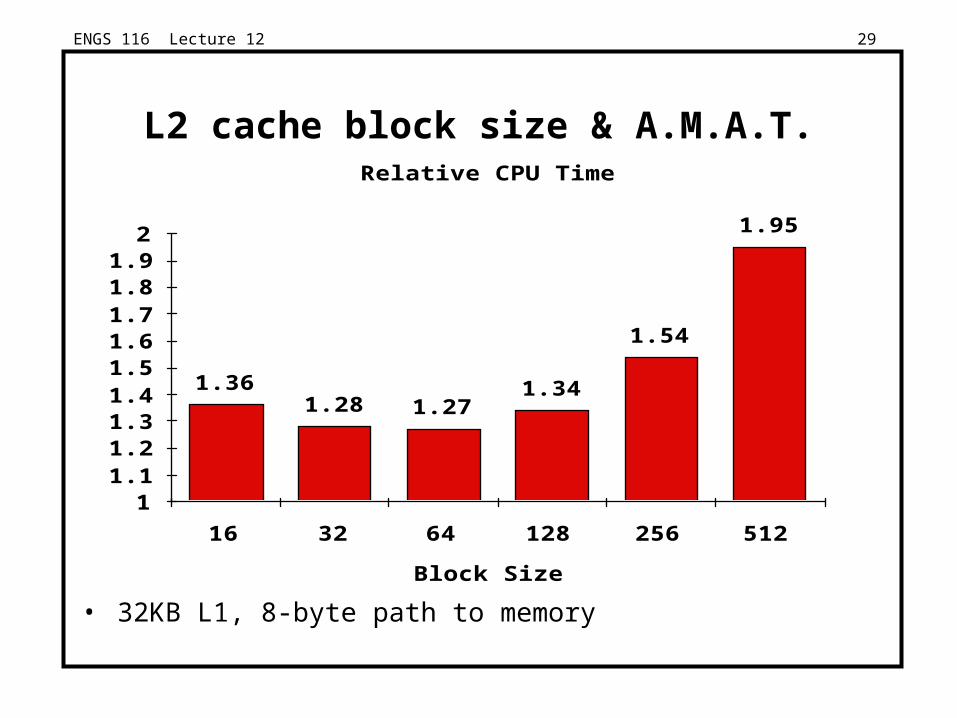
ENGS 116 Lecture 12 29
Relative CPU Time
Block Size
11.11.21.31.41.51.61.71.81.9
2
16 32 64 128 256 512
1.361.28 1.27
1.34
1.54
1.95
L2 cache block size & A.M.A.T.
• 32KB L1, 8-byte path to memory

ENGS 116 Lecture 12 30
2 . Reduce Miss Penalty: Early Restart and Critical Word First
• Don’t wait for full block to be loaded before restarting CPU
– Early restart — As soon as the requested word of the block arrives, send it to the CPU and let the CPU continue execution
– Critical Word First — Request the missed word first from memory and send it to the CPU as soon as it arrives; let the CPU continue execution while filling the rest of the words in the block. Also called wrapped fetch and requested word first.
• Generally useful only in large blocks,
• Spatial locality a problem; tend to want next sequential word, so not clear if benefit by early restart
block

ENGS 116 Lecture 12 31
3. Reduce Miss Penalty: Read Priority over Write on Miss
• Write through with write buffers offer RAW conflicts with main memory reads on cache misses
• If simply wait for write buffer to empty, might increase read miss penalty (old MIPS 1000 by 50%)
• Check write buffer contents before read; if no conflicts, let the memory access continue
• Write Back?
– Read miss replacing dirty block
– Normal: Write dirty block to memory, and then do the read
– Instead copy the dirty block to a write buffer, then do the read, and then do the write
– CPU stalls less frequently since restarts as soon as read finished
ENGS 116 Lecture 12 32
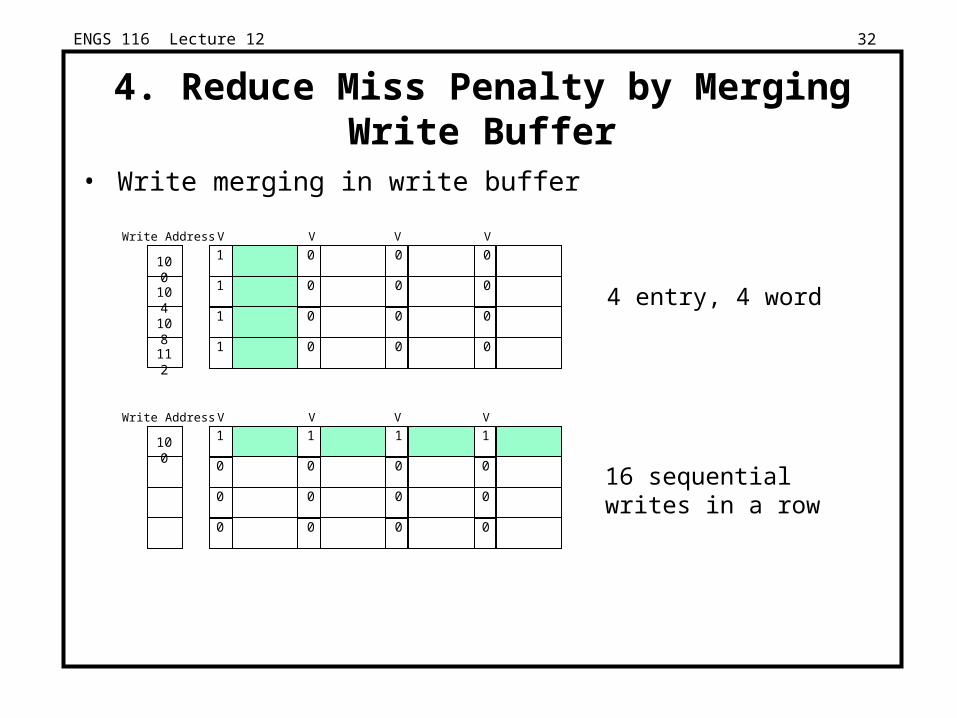
4. Reduce Miss Penalty by Merging Write Buffer
• Write merging in write buffer
4 entry, 4 word
16 sequentialwrites in a row
1 000
1 000
1 000
1 000
1 111
0 000
0 000
0 000
100
100
104
108
112
Write Address V VV V
Write Address V VV V
ENGS 116 Lecture 12 33
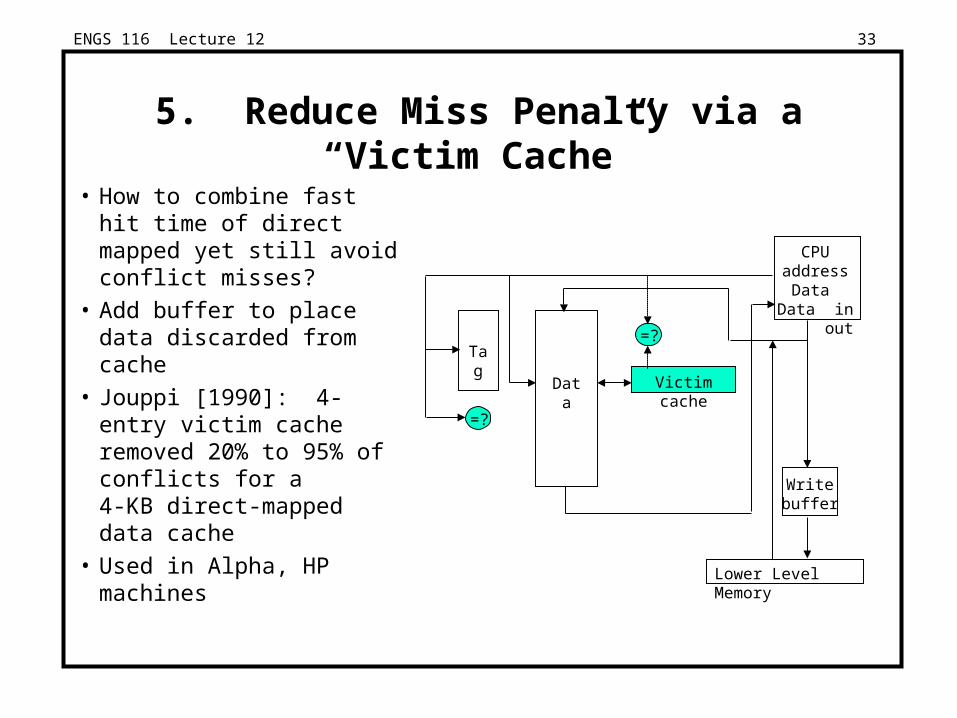
Victim cache
5. Reduce Miss Penalty via a “Victim Cache”
• How to combine fast hit time of direct mapped yet still avoid conflict misses?
• Add buffer to place data discarded from cache
• Jouppi [1990]: 4-entry victim cache removed 20% to 95% of conflicts for a 4-KB direct-mapped data cache
• Used in Alpha, HP machines
CPU address
Data Data in out
Write buffer
Lower Level Memory
Tag
Data
=?
=?
ENGS 116 Lecture 12 34
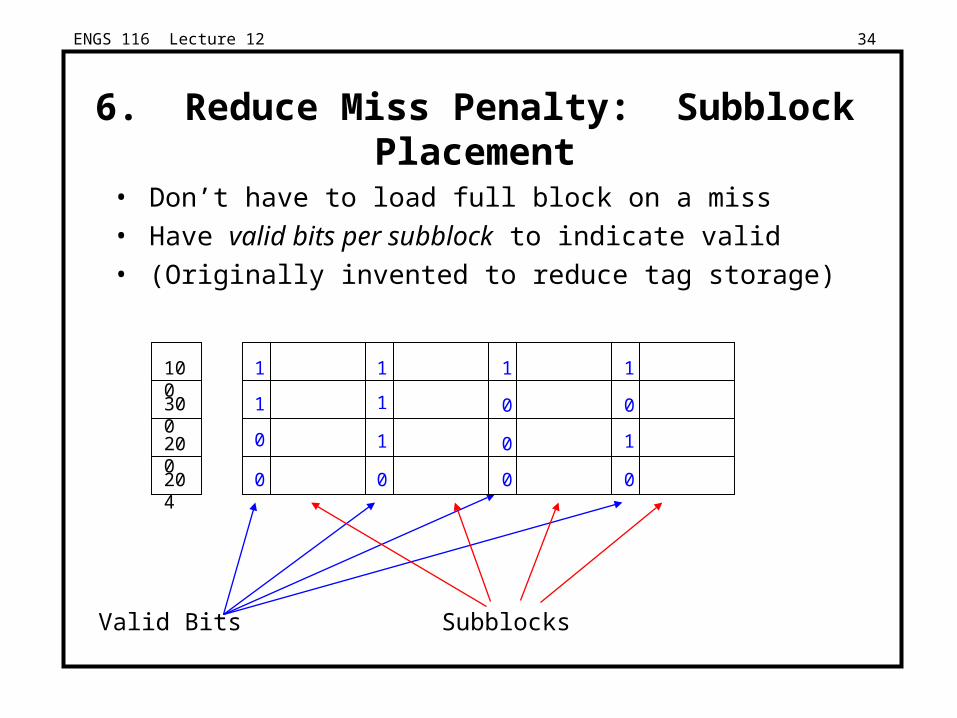
6. Reduce Miss Penalty: Subblock Placement
• Don’t have to load full block on a miss
• Have valid bits per subblock to indicate valid
• (Originally invented to reduce tag storage)
Valid Bits Subblocks
100
300
200
204
1
1
1
1 1 1
10 1 0
0 0
00
0 0

ENGS 116 Lecture 12 35
Reducing Miss Rate
• Larger Block Size
• Larger Caches
• Higher Associativity
• Way Prediction and Pseudoassociative Caches
• Compiler Optimizations:
– Merging Arrays
– Loop Interchange
– Loop Fusion
– Blocking

ENGS 116 Lecture 12 36
Classifying Misses: 3 Cs
• Compulsory: The first access to a block is not in the cache, so the block must be brought into the cache. Also called cold start misses or first reference misses. (Misses even in an infinite cache)
• Capacity: If the cache cannot contain all the blocks needed during execution of a program, capacity misses will occur due to blocks being discarded and later retrieved. (Misses in fully associative, size X cache)
• Conflict: If block-placement strategy is set associative or direct mapped, conflict misses (in addition to compulsory & capacity misses) will occur because a block can be discarded and later retrieved if too many blocks map to its set. Also called collision misses or interference misses. (Misses in N-way set associative, size X cache)
ENGS 116 Lecture 12 37
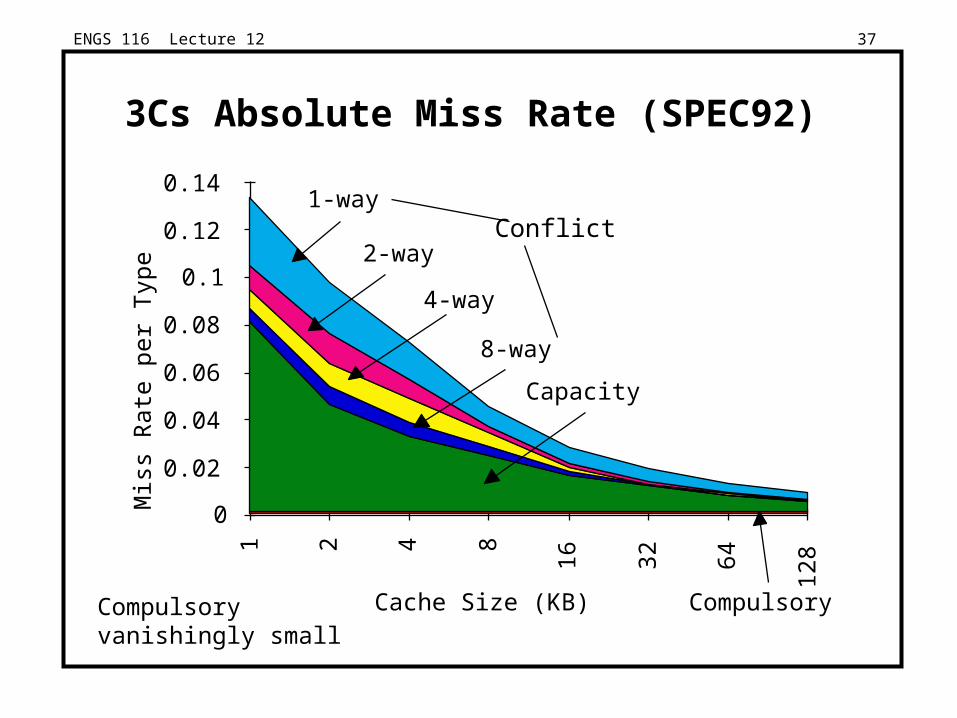
3Cs Absolute Miss Rate (SPEC92)
Conflict
Cache Size (KB)
Mis
s R
ate
per
Typ
e
0
0.02
0.04
0.06
0.08
0.1
0.12
0.14
1 2 4 8
16 32 64
128
1-way
2-way
4-way
8-way
Capacity
Compulsory Compulsory vanishingly small
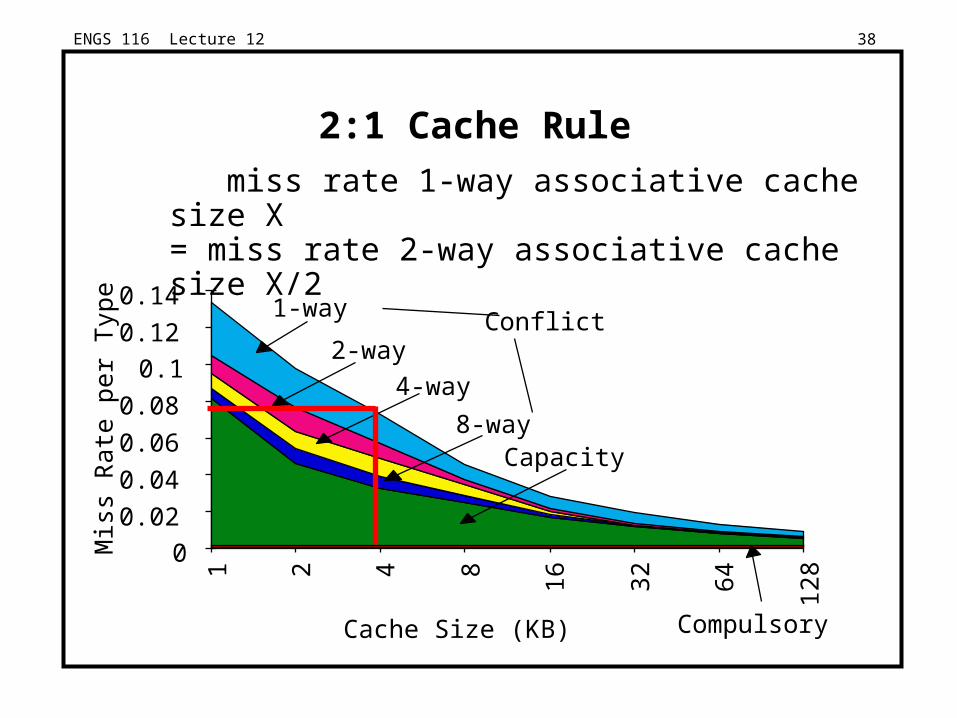
ENGS 116 Lecture 12 38
2:1 Cache Rule
Cache Size (KB)
Mis
s R
ate
per
Typ
e
0
0.02
0.04
0.06
0.08
0.1
0.12
0.14
1 2 4 8 16 32 64 128
1-way
2-way
4-way
8-wayCapacity
Compulsory
Conflict
miss rate 1-way associative cache size X = miss rate 2-way associative cache size X/2
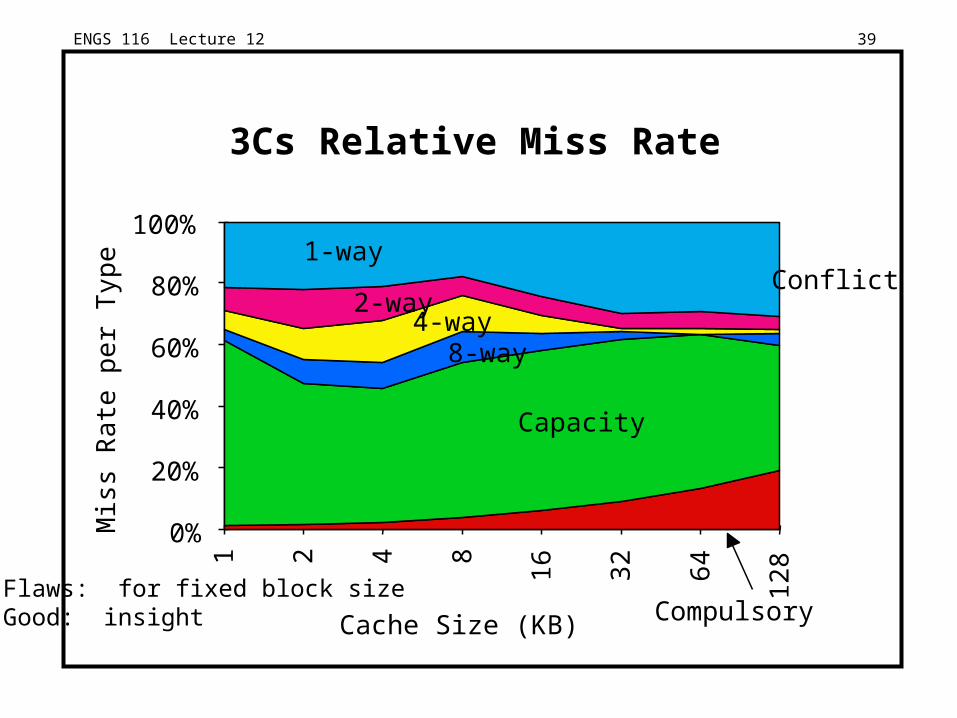
ENGS 116 Lecture 12 39
3Cs Relative Miss Rate
Cache Size (KB)
Mis
s R
ate
per
Typ
e
0%
20%
40%
60%
80%
100%1 2 4 8
16 32 64
128
1-way
2-way4-way
8-way
Capacity
Compulsory
Conflict
Flaws: for fixed block sizeGood: insight

ENGS 116 Lecture 12 40
How Can We Reduce Misses?
• 3 Cs: Compulsory, Capacity, Conflict
• In all cases, assume total cache size not changed
• What happens if we:
1) Change Block Size: Which of 3Cs is obviously affected?
2) Change Associativity: Which of 3Cs is obviously affected?
3) Change Compiler: Which of 3Cs is obviously affected?
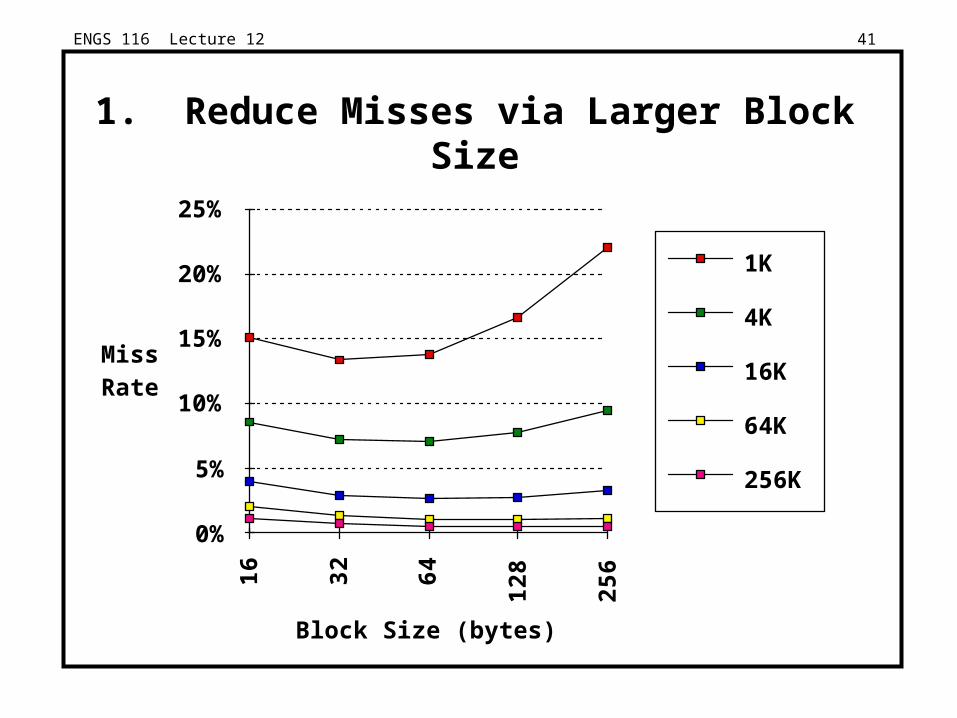
ENGS 116 Lecture 12 41
Block Size (bytes)
Miss Rate
0%
5%
10%
15%
20%
25%
16
32
64
12
8
25
6
1K
4K
16K
64K
256K
1. Reduce Misses via Larger Block Size

ENGS 116 Lecture 12 42
2. Reduce Misses: Larger Cache Size
• Obvious improvement
but:
• Longer hit time
• Higher cost
• Each cache size favors a block-size, based on memory bandwidth

ENGS 116 Lecture 12 43
3. Reduce Misses via Higher Associativity
• 2:1 Cache Rule:
– Miss Rate DM cache size N ≈ Miss Rate 2-way SA cache size N/2
• Beware: Execution time is final measure!
– Will clock cycle time increase?
• 8-Way is almost fully associative
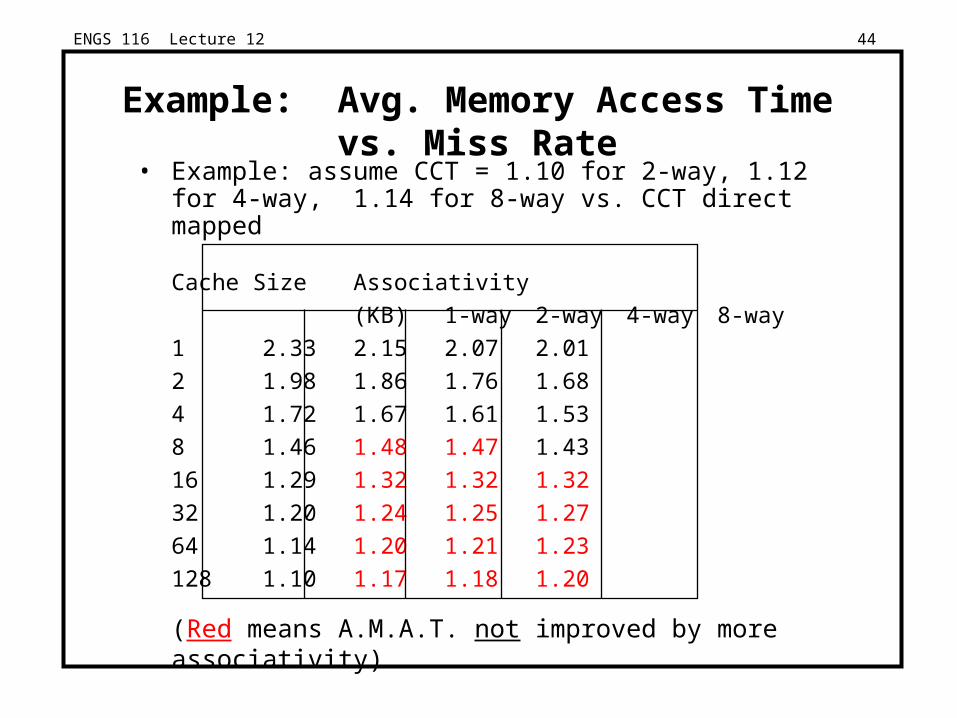
ENGS 116 Lecture 12 44
Example: Avg. Memory Access Time vs. Miss Rate• Example: assume CCT = 1.10 for 2-way, 1.12 for 4-way,
1.14 for 8-way vs. CCT direct mapped
Cache Size Associativity
(KB) 1-way 2-way 4-way 8-way
1 2.33 2.15 2.07 2.01
2 1.98 1.86 1.76 1.68
4 1.72 1.67 1.61 1.53
8 1.46 1.48 1.47 1.43
16 1.29 1.32 1.32 1.32
32 1.20 1.24 1.25 1.27
64 1.14 1.20 1.21 1.23
128 1.10 1.17 1.18 1.20
(Red means A.M.A.T. not improved by more associativity)

ENGS 116 Lecture 12 45
4. Reducing Misses via “Pseudo-Associativity” or way prediction
• How to combine fast hit time of Direct Mapped and have the lower conflict misses of 2-way SA cache?
• Divide cache: on a miss, check other half of cache to see if there, if so have a pseudo-hit (slow hit)
• Way Prediction: keep prediction bits to decide what comparison is made first
• Drawback: CPU pipeline is hard if hit takes 1 or 2 cycles– Better for caches not tied directly to processor (L2)– Used in MIPS R1000 L2 cache, similar in UltraSPARC
Hit Time
Pseudo Hit Time Miss Penalty
Time
Recommended

















