
FFT Accelerator ProjectRohit PrakashAnand Silodia
Date: June 7th , 2007

Objectives
• Analysis using random input points
• %age improvement (from the previous implementations)
• Cache profiling

Improvements
• Calls to sine/cosine decreased• Separate arrays for power, some
other terms– Division decreased– Multiplications decreased
• Error in last time corrected (FFTW floating point)

System Configuration
• Intel Pentium 4 (HT) 3.0Ghz• RAM : 1GB• Cache : 1MB L2• O.S. : Fedora Core 3• Compiler icc• Flags used : -xW, -O3, -ipo-prec-
div, -static

User time : vs. FFTW (single precision)
Radix-4 works 1.5 times slower than fftw
Radix-8 works 1.6 times slower than fftw
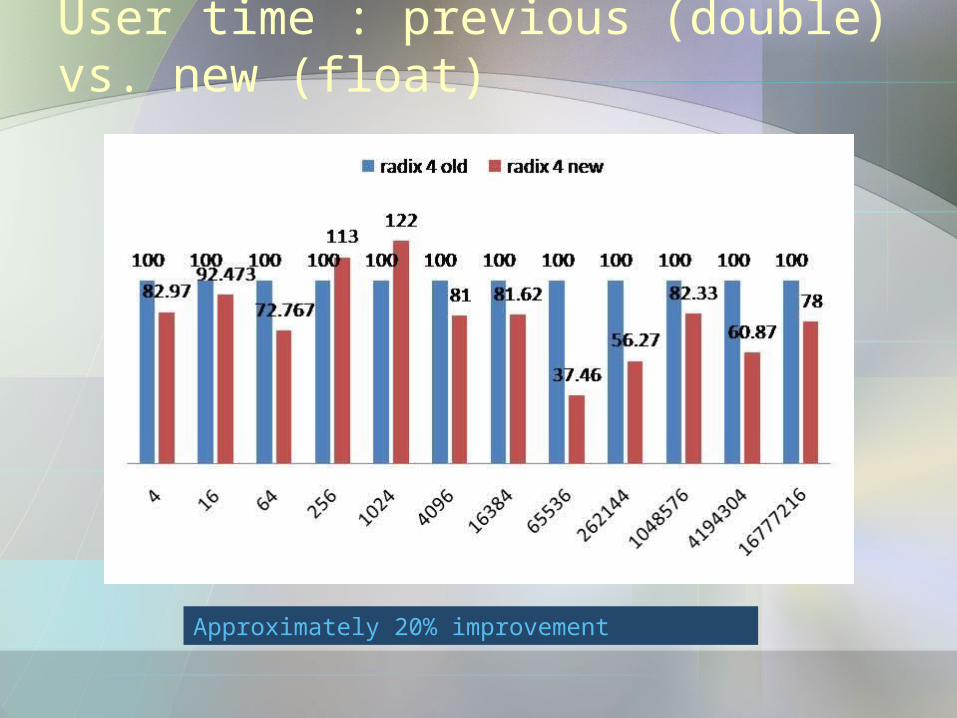
User time : previous (double) vs. new (float)
Approximately 20% improvement

User time : previous (double) vs new (float)
Approximately 19% improvement

Cache Organization
Cache Level
Size Associativity
Line size
L2 1 MB 8-way 64
I1 16 KB 4-way 64
D1 16KB 4-way 64

Radix-4 L2 misses
Approximately 30% less L2 misses

Radix-4 D1 misses
Approximately 1.6% less D1 misses
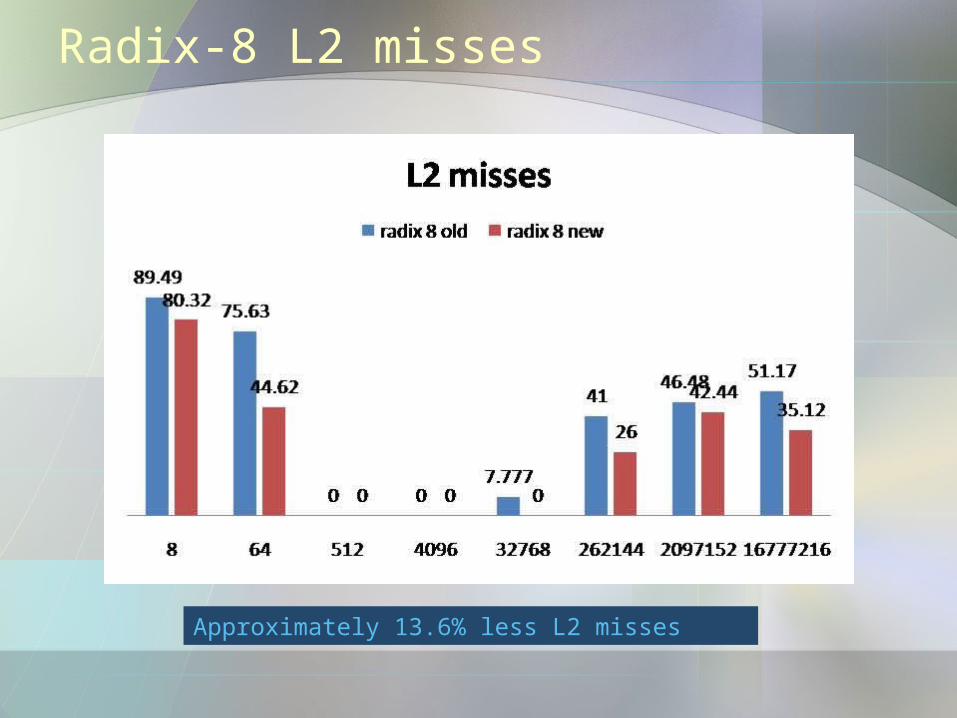
Radix-8 L2 misses
Approximately 13.6% less L2 misses
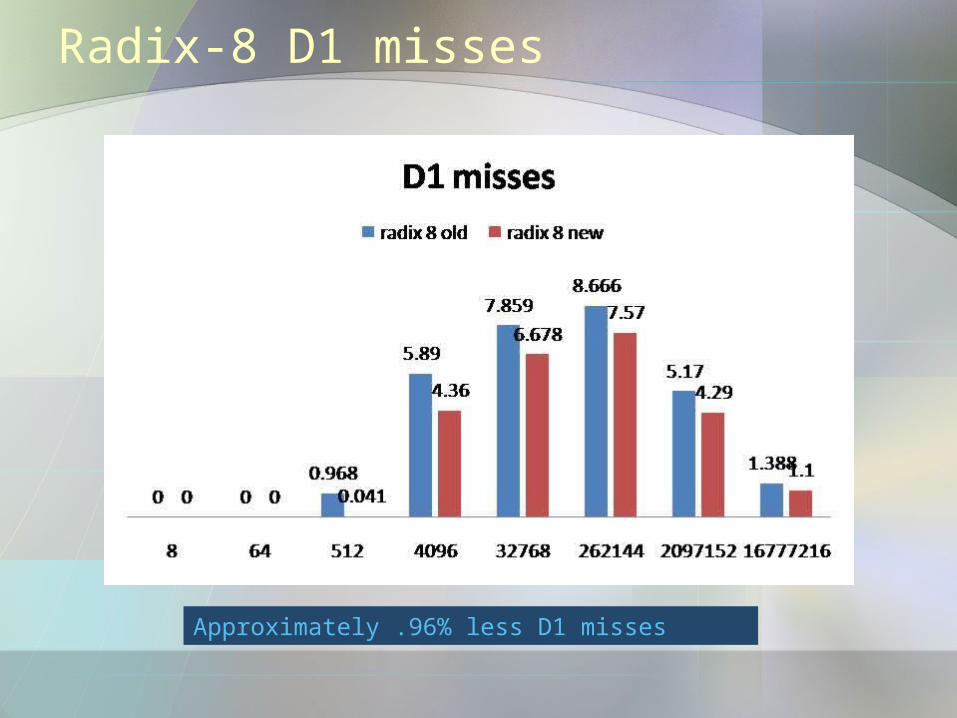
Radix-8 D1 misses
Approximately .96% less D1 misses

Profiling results: using vtune

Profiling results: using gprof

Profiling results : using vtune

Profiling results: using gprof

Profiling results: using vtune
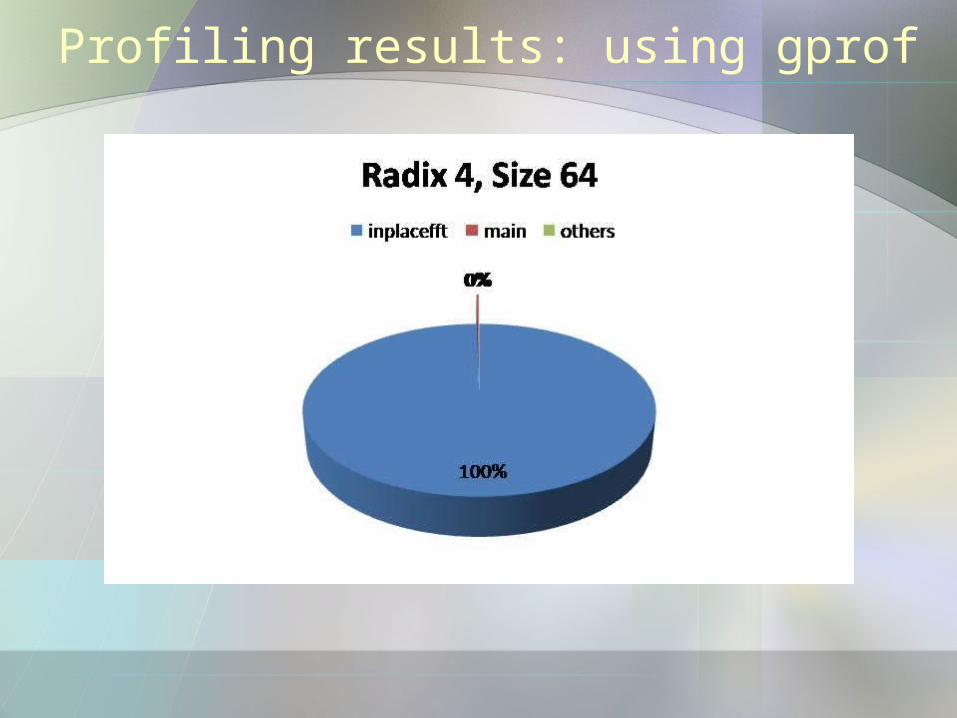
Profiling results: using gprof

Profiling results: using vtune

Profiling results: using gprof

Profiling results: using vtune

Profiling results: using vtune

Profiling results: using vtune

Profiling results: using vtune

Profiling results: using vtune

Profiling results: using vtune

Profiling results: using gprof

Profiling results: using gprof

Further Improvements : use sse instructions• Vectorize the loop
TA[r]Uw*A[r+p]Vw*w*A[r+2*p]Ww*w*w*A[r+3*p]----------------------------------Complex temp[4];For(i = 1; i<4;i++){
temp[i] = twiddle[i*p]*A[r+ i*l]
}

Thank You
Recommended







![INDEX []...Sampada Joshi Srijita Sarkar INTERIM TEAM Craig Pinto Ishita Grover Rashmi Pillai Rohit Tandekar R. Prakash Vibhav Bisht JUNIOR TEAM Craig Pinto Ishita Grover Rashmi Pillai](https://img.pdfslide.net/doc/110x75/5f664a8dafae3c1f563692ce/index-sampada-joshi-srijita-sarkar-interim-team-craig-pinto-ishita-grover.jpg)









