
Hadoop Fundamentals
Satish Mittal
InMobi

Why Hadoop?

Big Data
• Sources: Server logs, clickstream, machine, sensor, social…
• Use-cases: batch/interactive/real-time

Scalable
o Petabytes of data
Economical
o Use commodity hardware
o Share clusters among many applications
Reliable
o Failure is common when you run thousands of machines. Handle it well in
the SW layer.
Simple programming model
o Applications must be simple to write and maintain
What is needed from a Distributed Platform?

Hadoop is peta-byte scale distributed data storage and data
processing infrastructure
Based on Google GFS & MR paper
Contributed mostly by Yahoo! in the initial years and now have a
more widespread developer and user base
1000s of nodes, PBs of data in storage
What is Hadoop?

• Cheap JBODs for storage
• Move processing to where data is
Location awareness (topology)
• Assume hardware failures to be the norm
• Map & Reduce primitives are fairly simple yet powerful
Most set operations can be performed using these primitives
• Isolation
Hadoop Basics

Hadoop Distributed File System
(HDFS)

Goals:
Fault tolerant, scalable, distributed storage system
Designed to reliably store very large files across machines in a
large cluster
Assumptions:
Files are written once and read several times
Applications perform large sequential streaming reads
Not a Unix-like, POSIX file system
Access via command line or Java API
HDFS

• Data is organized into files and directories
• Files are divided into uniform sized blocks and distributed across
cluster nodes
• Blocks are replicated to handle hardware failure
• Filesystem keeps checksums of data for corruption detection and
recovery
• HDFS exposes block placement so that computes can be migrated
to data
HDFS – Data Model

HDFS - Architecture

• Namenode is SPOF (HA for NN is now available in 2.0
Alpha)
• Responsible for managing a list of all active data nodes,
FS name system (files, directories, blocks and their
locations)
• Block placement policy
• Ensuring adequate replicas
• Writing edit logs durably
Namenode

• Service to allow data to be streamed in & out
• Block is the unit of data that data node understands
• Block reports to Namenode periodically
• Checksum checks, disk usage stats are managed by datanode
• Clients talk to datanode for actual data
• As long as there is at least one data node available to service file
blocks, failures in datanodes can be tolerated, albeit at lower
performance.
Datanode

HDFS – Write pipeline
DFS Client Namenode
Data node 1
Data node 2
Data node 3
Rack 2
Create file, get Block Loc (1)
DN 1, 2 & 3 (2)
Stream file (5)
Ack (5a)
Ack (4a)
Ack (3a)
Complete file (3b)
Rack 1

• Default is 3 replicas, but configurable
• Blocks are placed (writes are pipelined):
On same node
On different rack
On the other rack
• Clients read from closest replica
• If the replication for a block drops below target, it is automatically re-replicated.
HDFS – Block placement

• Data is checked with CRC32
• File Creation
‣ Client computes checksum per block
‣ DataNode stores the checksum
• File access
‣ Client retrieves the data and checksum from DataNode
‣ If Validation fails, Client tries other replicas
HDFS – Data correctness

Simple commands
• hadoop fs -ls, -du, -rm, -rmr, -chown, -chmod
Uploading files
• hadoop fs -put foo mydata/foo
• cat ReallyBigFile | hadoop fs -put - mydata/ReallyBigFile
Downloading files
• hadoop fs -get mydata/foo foo
• hadoop fs -get - mydata/ReallyBigFile | grep “the answer is”
• hadoop fs -cat mydata/foo
Admin
• hadoop dfsadmin –report
• hadoop fsck
Interacting with HDFS

Map-Reduce

Say we have 100s of machines available to us. How do we write
applications on them?
As an example, consider the problem of creating an index for search.
‣ Input: Hundreds of documents
‣ Output: A mapping of word to document IDs
‣ Resources: A few machines
Map-Reduce Application

The problem : Inverted Index
Farmer1 has the
following animals:
bees, cows, goats.
Some other
animals …
Animals: 1, 2, 3, 4, 12
Bees: 1, 2, 23, 34
Dog: 3,9
Farmer1: 1, 7
…

Building an inverted index
Machine1
Machine2
Machine3
Animals: 1,3
Dog: 3
Animals:2,12
Bees: 23
Dog:9
Farmer1: 7
Machine4
Animals: 1,3
Animals:2,12
Bees:23
Machine5
Dog: 3
Dog:9
Farmer1: 7
Machine4
Animals: 1,2,3,12
Bees:23
Machine5
Dog: 3,9
Farmer1: 7

In our example
‣ Map: (doc-num, text) ➝ [(word, doc-num)]
‣ Reduce: (word, [doc1, doc3, ...]) ➝ [(word, “doc1, doc3, …”)]
General form:
‣ Two functions: Map and Reduce
‣ Operate on key and value pairs
‣ Map: (K1, V1) ➝ list(K2, V2)
‣ Reduce: (K2, list(V2)) ➝ (K3, V3)
‣ Primitives present in Lisp and other functional languages
Same principle extended to distributed computing
‣ Map and Reduce tasks run on distributed sets of machines
This is Map-Reduce

Abstracts functionality common to all Map/Reduce applications
‣ Distribute tasks to multiple machines
‣ Sorts, transfers and merges intermediate data from all machines from the Map phase to the Reduce phase
‣ Monitors task progress
‣ Handles faulty machines, faulty tasks transparently
Provides pluggable APIs and configuration mechanisms for writing applications
‣ Map and Reduce functions
‣ Input formats and splits
‣ Number of tasks, data types, etc…
Provides status about jobs to users
Map-Reduce Framework

MR – Architecture
Job Client Job Tracker
DFS ClientDFS Client
DFS ClientDFS Client
DFS ClientDFS ClientTask Tracker
Heartbeat Task Assignment
Shuffle
Submit
Progress
H
D
F
S

• All user code runs in isolated JVM
• Client computes splits
• JT just schedules these splits (one mapper per split)
• Mapper, Reducer, Partitioner and Combiner and any custom
Input/OutputFormat runs in user JVM
• Idempotence
Map-Reduce

Hadoop HDFS + MR cluster
Machines with Datanodes and Tasktrackers
D D D DTT
JobTracker
Namenode
T T TD
Client
Submit Job
HTTP Monitoring UIGet Block
Locations

• Input: A bunch of large text files
• Desired Output: Frequencies of Words
WordCount: Hello World of Hadoop
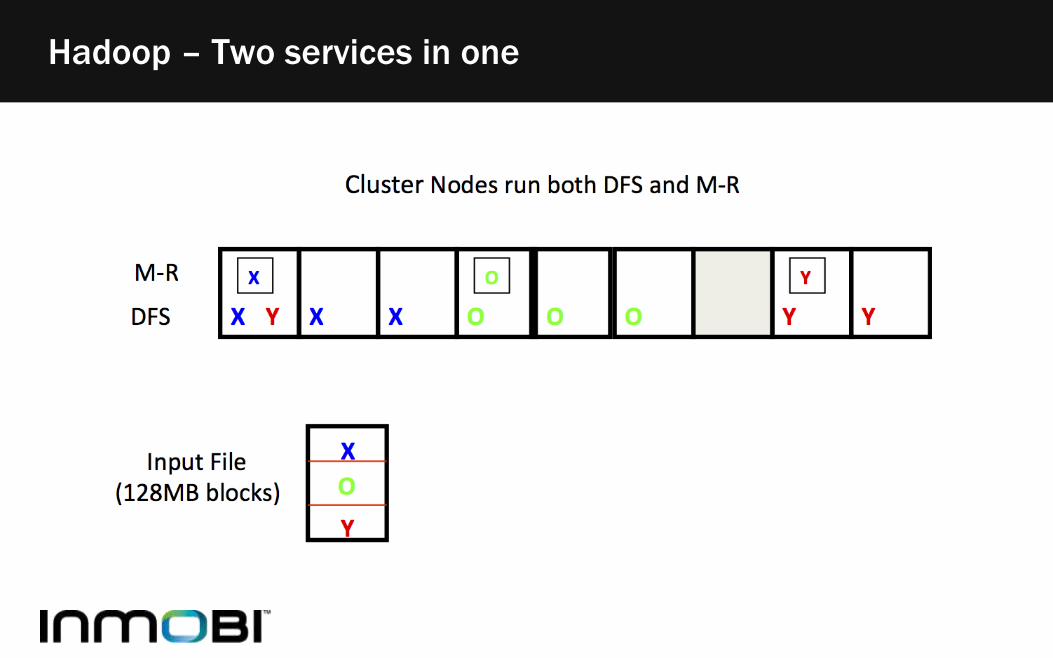
Hadoop – Two services in one

Mapper
‣ Input: value: lines of text of input
‣ Output: key: word, value: 1
Reducer
‣ Input: key: word, value: set of counts
‣ Output: key: word, value: sum
Launching program
‣ Defines the job
‣ Submits job to cluster
Word Count Example

Questions ?

Thank You!mailto: [email protected]
Recommended

















