
Robert Wrembel
Politechnika Poznańska
Instytut Informatyki
www.cs.put.poznan.pl/rwrembel
Hurtownie Danych i Business Intelligence: przegląd
technologii
2 R.Wrembel - Politechnika Poznańska, Instytut Informatyki
Architektury systemu hurtowni danych
Business Intelligence
Przetwarzanie OLTP vs. OLAP
Wstęp do technologii BigData
Tematyka

3 R.Wrembel - Politechnika Poznańska, Instytut Informatyki
Cele stosowania HD
1. Zapewnienie jednolitego dostępu do wszystkich danych gromadzonych w ramach przedsiębiorstwa
2. Dostarczenie technologii (platformy) przetwarzania analitycznego - technologii OLAP/BI
Business Intelligence
OLAP - On-Line Analytical Processing
klasyczna analiza danych (dane historyczne, predykcja - what if analysis)
• analiza trendów sprzedaży
• analiza nakładów reklamowych i zysków
• analiza ruchu telefonicznego
• credit scoring
• churn analysis
• customer profiling
najczęściej SQL
4 R.Wrembel - Politechnika Poznańska, Instytut Informatyki

Business Intelligence
BI = OLAP+
eksploracja danych
• reguły asocjacyjne, profile zachowań
analiza tekstów (Facebook, Tweeter, ...)
• hot topics, bezpieczeństwo narodowe
analiza sieci powiązań
• liderzy, zależności
analiza logów przeglądarek
5 R.Wrembel - Politechnika Poznańska, Instytut Informatyki
6 R.Wrembel - Politechnika Poznańska, Instytut Informatyki
OLTP a OLAP
użytkownik
funkcja
dane
aplikacje
dostęp
transakcja
l. przetwarzanych rek.
l. użytkowników
DB size
metric
"zwykły"
bieżące operacje, kluczowe dla działania firmy
bieżące, elementarne
powtarzalność działań
odczyt/zapis
krótka
kilka, kilkadziesiąt
kilkudzies., tysiące, setki tys.
kilka - setki TB
przepustowość (l. transakcji w jednostce czasu)
analityk
wspomaganie decyzji
elementarne, zagregowane, historyczne
ad hoc
odczyt
długa (godziny)
miliony lub więcej
kilku, kilkunastu
> setki TB
czas odpowiedzi
OLTP OLAP

Aplikacje BI
Zapytania ad-hoc (okolo 10% aplikacji firmowych)
prosty interfejs prezentacji wyników
obliczenia ad-hoc
drill-down, drill-accross
Raporty firmowe (około 90% aplikacji firmowych)
zaawansowany układ graficzny
biblioteka predefiniowanych raportów
subskrypcja raportów, harmonogram odświeżania raportów i ich dystrybucji
uprawnienia użytkowników do raportów
7 R.Wrembel - Politechnika Poznańska, Instytut Informatyki
Aplikacje BI
Dedykowane aplikacje analityczne
analiza przychodów i promocji
przewidywanie trendów, symulacje
zawierają specjalizowane algorytmy dla dziedziny zastosowań
Pulpity (dashboards), karty wynikowe (scorecards), kokpity menadżerskie (management cockpits)
interaktywny interfejs
prezentacja zbiorcza najważniejszych danych
miary jakości przedsięwzięcia (KPI - key performance indicators)
alerty
8 R.Wrembel - Politechnika Poznańska, Instytut Informatyki

Aplikacje BI
Eksploracja danych
złożone obliczeniowo algorytmy
dedykowane algorytmy dla dziedziny zastosowań
wizualizacja wyników
9 R.Wrembel - Politechnika Poznańska, Instytut Informatyki
Użytkownicy
Aktywni: 10% wszystkich użytkowników systemu BI
Równocześnie pracujący: 1% użytkowników systemu BI
10 R.Wrembel - Politechnika Poznańska, Instytut Informatyki
storyborads

Wielkość systemu
Mały system HD
HD: kilkaset MB
kilkadziesiąt tabel
kilka mln rekordów w tabeli faktów
300 użytkowników
kilkadziesiąt raportów, kilka kostek
Duży system HD
HD: kilkaset TB
kilkaset tabel
kilkaset mln rekordów w tabeli faktów
kilka tysięcy użytkowników
ponad 1000 raportów, kilkaset kostek
11 R.Wrembel - Politechnika Poznańska, Instytut Informatyki
Business Intelligence
Dwie kategorie danych
wewnątrzfirmowe
zewnętrzne (Internet)
Dwie różne architektury/technologie analizy danych
klasyczne
BigData
12 R.Wrembel - Politechnika Poznańska, Instytut Informatyki
13 R.Wrembel - Politechnika Poznańska, Instytut Informatyki
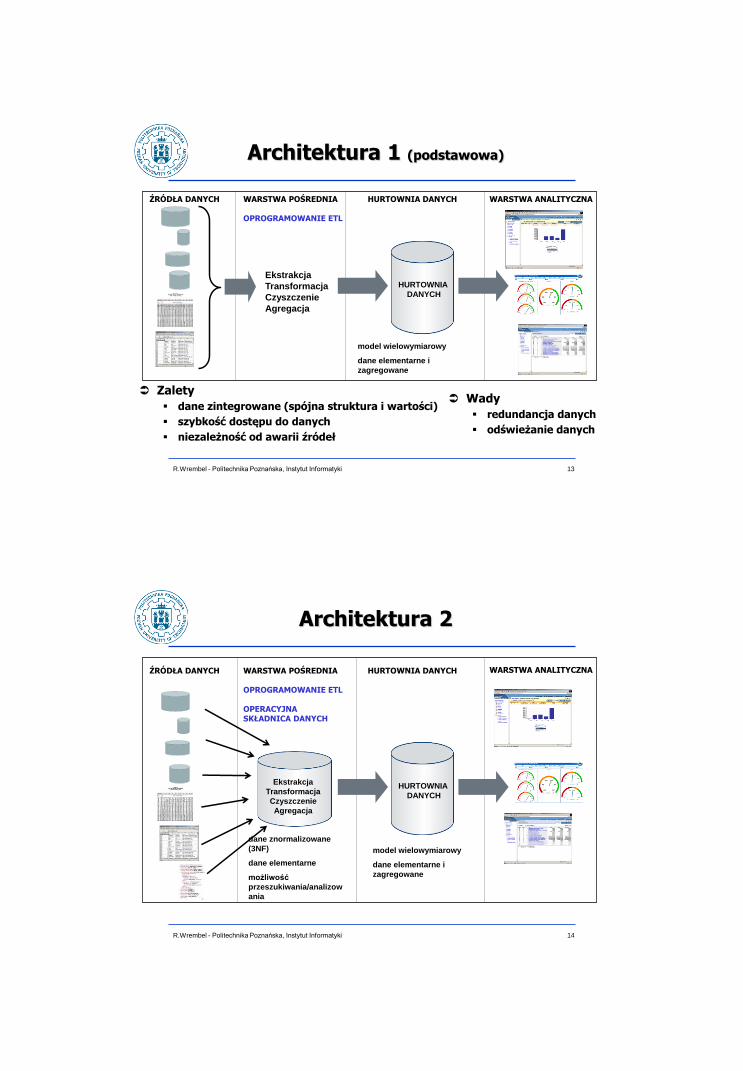
Architektura 1 (podstawowa)
HURTOWNIA
DANYCH
model wielowymiarowy
dane elementarne i
zagregowane
ŹRÓDŁA DANYCH WARSTWA POŚREDNIA OPROGRAMOWANIE ETL
HURTOWNIA DANYCH WARSTWA ANALITYCZNA
Zalety
dane zintegrowane (spójna struktura i wartości)
szybkość dostępu do danych
niezależność od awarii źródeł
Wady
redundancja danych
odświeżanie danych
Ekstrakcja
Transformacja
Czyszczenie
Agregacja
14 R.Wrembel - Politechnika Poznańska, Instytut Informatyki
Architektura 2
Ekstrakcja
Transformacja
Czyszczenie
Agregacja
HURTOWNIA
DANYCH
model wielowymiarowy
dane elementarne i
zagregowane
ŹRÓDŁA DANYCH WARSTWA POŚREDNIA OPROGRAMOWANIE ETL OPERACYJNA SKŁADNICA DANYCH
HURTOWNIA DANYCH
dane znormalizowane
(3NF)
dane elementarne
możliwość
przeszukiwania/analizow
ania
WARSTWA ANALITYCZNA

15 R.Wrembel - Politechnika Poznańska, Instytut Informatyki
Architektura 3
Ekstrakcja
Transformacja
Czyszczenie
Agregacja
HURTOWNIA
DANYCH
Hurtownie
tematyczne
ŹRÓDŁA DANYCH HURTOWNIA DANYCH
model wielowymiarowy
dane elementarne i
zagregowane
WARSTWA POŚREDNIA OPROGRAMOWANIE ETL OPERACYJNA SKŁADNICA DANYCH
dane znormalizowane
(3NF)
dane elementarne
możliwość
przeszukiwania/analizow
ania
WARSTWA ANALITYCZNA
16 R.Wrembel - Politechnika Poznańska, Instytut Informatyki
HD Allegro
C. Maar, R. Kudliński: Allegro on the way from XLS based controlling to a modern BI environment. National conference on Data Warehousing and Business Intelligence, Warsaw, 2008
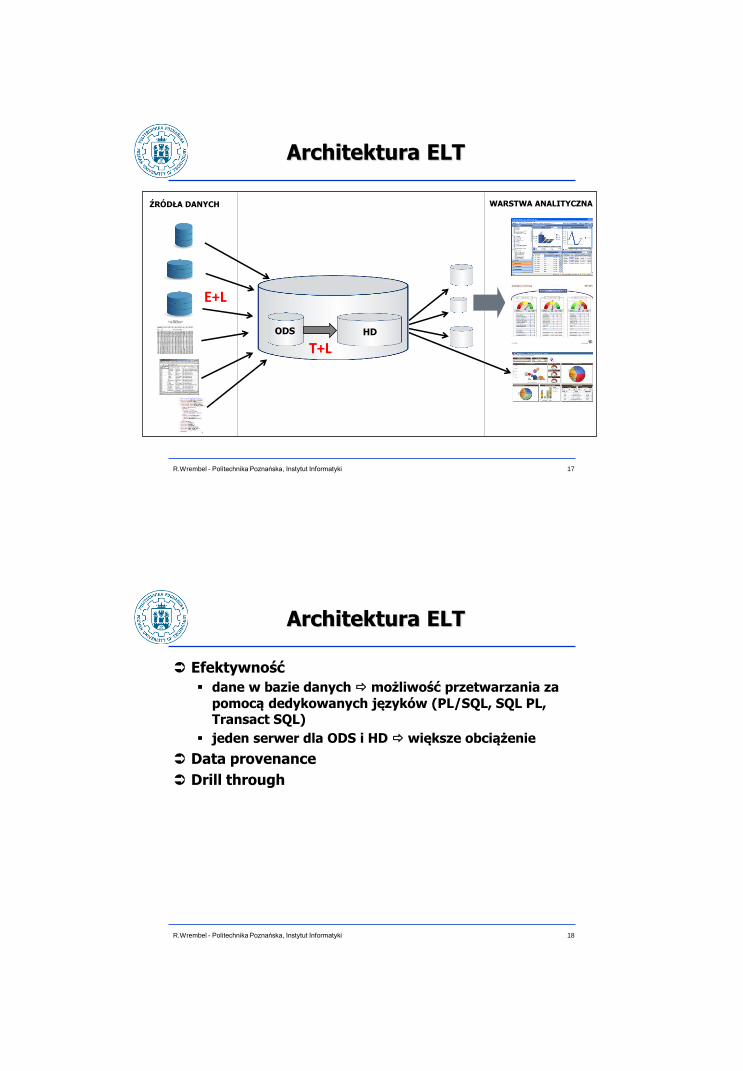
Architektura ELT
17 R.Wrembel - Politechnika Poznańska, Instytut Informatyki
ŹRÓDŁA DANYCH WARSTWA ANALITYCZNA
HD ODS
T+L
E+L
Architektura ELT
Efektywność
dane w bazie danych możliwość przetwarzania za
pomocą dedykowanych języków (PL/SQL, SQL PL, Transact SQL)
jeden serwer dla ODS i HD większe obciążenie
Data provenance
Drill through
18 R.Wrembel - Politechnika Poznańska, Instytut Informatyki

Experiment I
P. Wróblewski, M. Wojdowski: Implementacja i porównanie wydajności architektur ETL i ELT. Master thesis, Poznan University of Technology, 2014
Data sources
Internet auctions
Oracle11g (Object-Relational model)
MySQL
PostgreSQL
XML
a collection/table composed of 11 attributes
Data warehouse: Oracle11g
19 R.Wrembel - Politechnika Poznańska, Instytut Informatyki
Experiment I
DW schema
20 R.Wrembel - Politechnika Poznańska, Instytut Informatyki
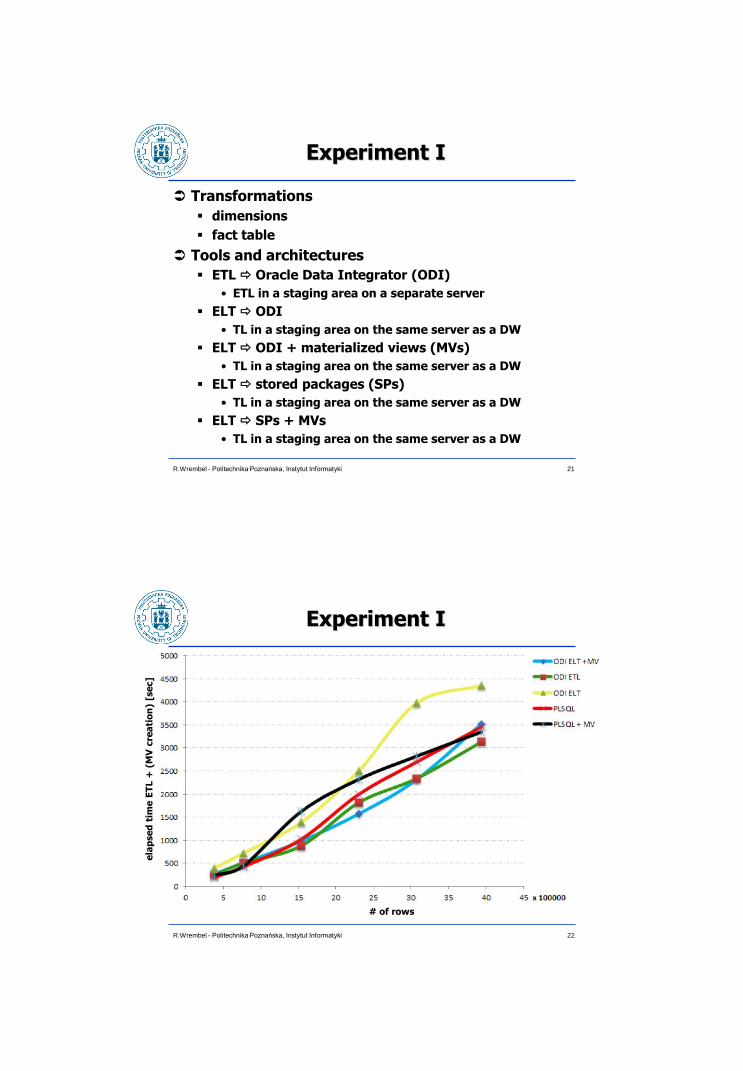
Experiment I
Transformations
dimensions
fact table
Tools and architectures
ETL Oracle Data Integrator (ODI)
• ETL in a staging area on a separate server
ELT ODI
• TL in a staging area on the same server as a DW
ELT ODI + materialized views (MVs)
• TL in a staging area on the same server as a DW
ELT stored packages (SPs)
• TL in a staging area on the same server as a DW
ELT SPs + MVs
• TL in a staging area on the same server as a DW
21 R.Wrembel - Politechnika Poznańska, Instytut Informatyki
Experiment I
22 R.Wrembel - Politechnika Poznańska, Instytut Informatyki
ela
pse
d t
ime
ET
L +
(M
V c
rea
tio
n)
[se
c]
# of rows

Experiment II
K. Prałat, T. Skrzypczak, G. Stolarek: Efektywność ETL i ELT. Postrgaduate studies, term project, Poznan University of Technology, 2014
Data source
flight and weather data in the US, from 1986 until 2008
6 tables in Oracle11g
Data warehouse: Oracle11g
23 R.Wrembel - Politechnika Poznańska, Instytut Informatyki
Experiment II
Data source schema
24 R.Wrembel - Politechnika Poznańska, Instytut Informatyki
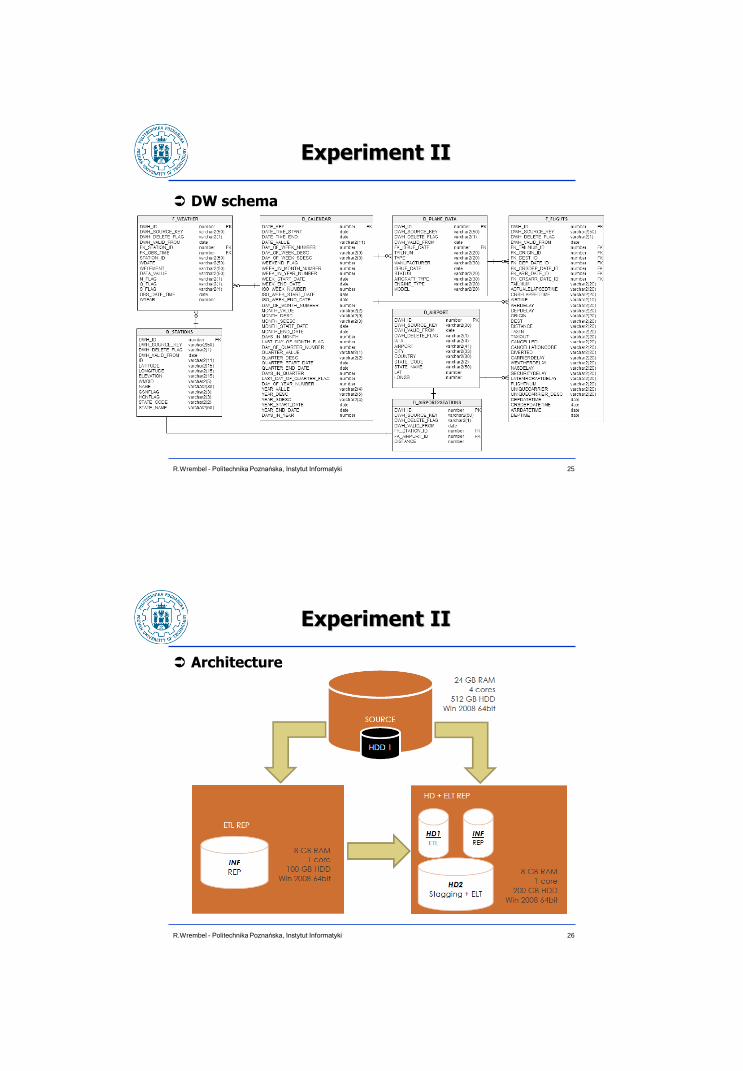
Experiment II
DW schema
25 R.Wrembel - Politechnika Poznańska, Instytut Informatyki
Experiment II
Architecture
26 R.Wrembel - Politechnika Poznańska, Instytut Informatyki
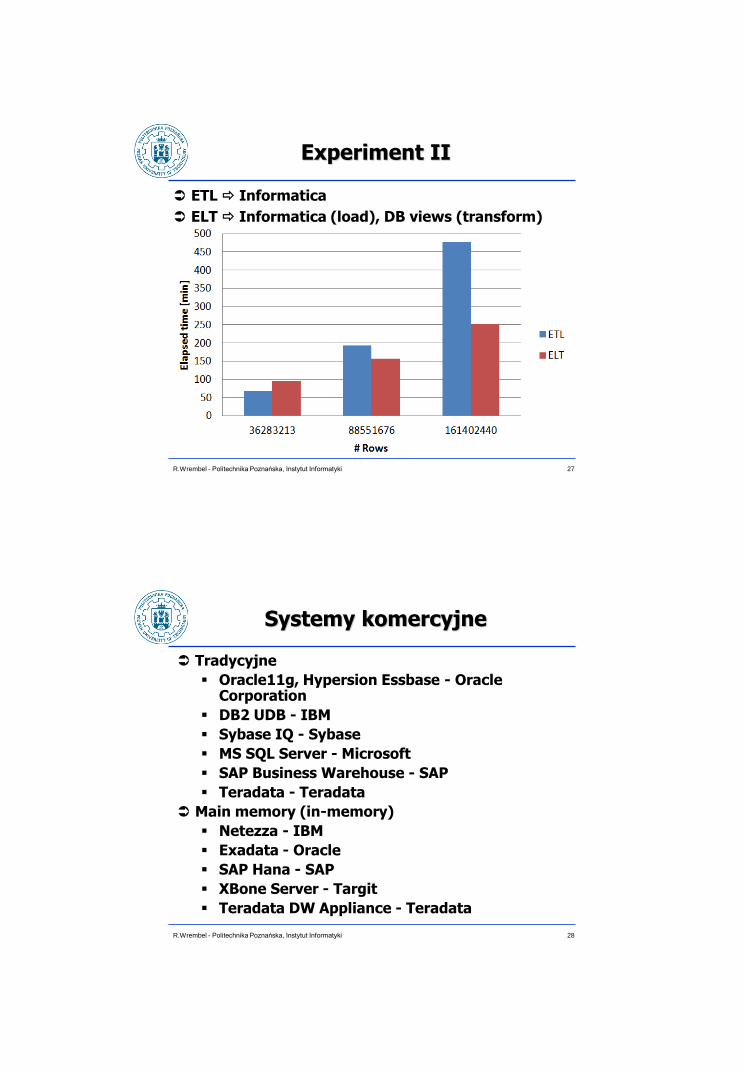
Experiment II
ETL Informatica
ELT Informatica (load), DB views (transform)
27 R.Wrembel - Politechnika Poznańska, Instytut Informatyki
28 R.Wrembel - Politechnika Poznańska, Instytut Informatyki
Systemy komercyjne
Tradycyjne
Oracle11g, Hypersion Essbase - Oracle Corporation
DB2 UDB - IBM
Sybase IQ - Sybase
MS SQL Server - Microsoft
SAP Business Warehouse - SAP
Teradata - Teradata
Main memory (in-memory)
Netezza - IBM
Exadata - Oracle
SAP Hana - SAP
XBone Server - Targit
Teradata DW Appliance - Teradata

Gartner Report
29 R.Wrembel - Politechnika Poznańska, Instytut Informatyki
Gartner Report
http://www.gartner.com/technology/reprints.do?id=1-1DZLPEP&ct=130207&st=sb
Assessment criteria
Integration
BI infrastructure
Metadata management
Development tools
Collaboration
Information Delivery
Reporting
Dashboards
Ad hoc query
Microsoft Office integration
Mobile BI
30 R.Wrembel - Politechnika Poznańska, Instytut Informatyki
Analysis
Online analytical processing (OLAP) - multidimensional analysis, what-if
Interactive visualization
Predictive modeling and data mining
Scorecards- aligining KPIs with a strategic objective
Prescriptive modeling, simulation and optimization

OLAP/BI - technologie
Modele
ROLAP
MOLAP
HOLAP
Składowanie danych
indeksy
perspektywy zmaterializowane
partycjonowanie
column storage / row storage
kompresja danych i indeksów
Przetwarzanie zapytań
top-n
gwiaździste
Przetwarzanie równoległe i rozproszone
Jakość danych i ETL/ELT 31 R.Wrembel - Politechnika Poznańska, Instytut Informatyki
OLAP/BI
Trends
Big Data
mobile BI
in-memory BI
real-time /right-time /active BI
cloud computing
32 R.Wrembel - Politechnika Poznańska, Instytut Informatyki

Big Data
33 R.Wrembel - Politechnika Poznańska, Instytut Informatyki
internal company BI system
Big Data analytics
Big Data storage
Big Data
Huge Volume
Every minute:
48 hours of video are uploaded onto Youtube
204 million e-mail messages are sent
600 new websites are created
600000 pieces of content are created
over 100000 tweets are sent (~ 80GB daily)
Sources:
social data
web logs
machine generated
34 R.Wrembel - Politechnika Poznańska, Instytut Informatyki

Big Data
35 R.Wrembel - Politechnika Poznańska, Instytut Informatyki
Sensors
mechanical installations (refineries, jet engines, crude oil platforms, traffic monitoring, utility installations, irrigation systems)
• one sensor on a blade of a turbine generates 520GB daily
• a single jet engine can generate 10TB of data in 30 minutes
telemedicine
telecommunication
Big Data
High Velocity of
data volume growth
uploading the data into an analytical system
Variety (heterogeneity) of data formats
structured - relational data and multidimensional cube data
unstructured or semistructured - text data
semantic Web XML/RDF/OWL data
geo-related data
sensor data
Veracity (Value) - the quality or reliability of data
36 R.Wrembel - Politechnika Poznańska, Instytut Informatyki

Big Data - Problems
Storage
volume
fast data access
fast processing
Real-time analysis
analyzing fast-arriving streams of data
37 R.Wrembel - Politechnika Poznańska, Instytut Informatyki
Types of processing
Batch processing - standard DW refreshing
Real-time / near real-time data analytics
answers with the most updated data up to the moment the query was sent
the analytical results are updated after a query has been executed
Streaming analytics
a system automatically updates results about the data analysis as new pieces of data flow into the system
as-it-occurs signals from incoming data without the need to manually query for anything
38 R.Wrembel - Politechnika Poznańska, Instytut Informatyki

Real-time / Near real-time architecture
39 R.Wrembel - Politechnika Poznańska, Instytut Informatyki
data stream active component main-memory engine
OLTP + OLAP
Real-time / Near real-time refreshing
40 R.Wrembel - Politechnika Poznańska, Instytut Informatyki
users
refreshing
traditional DW
users
refreshing
real-time DW
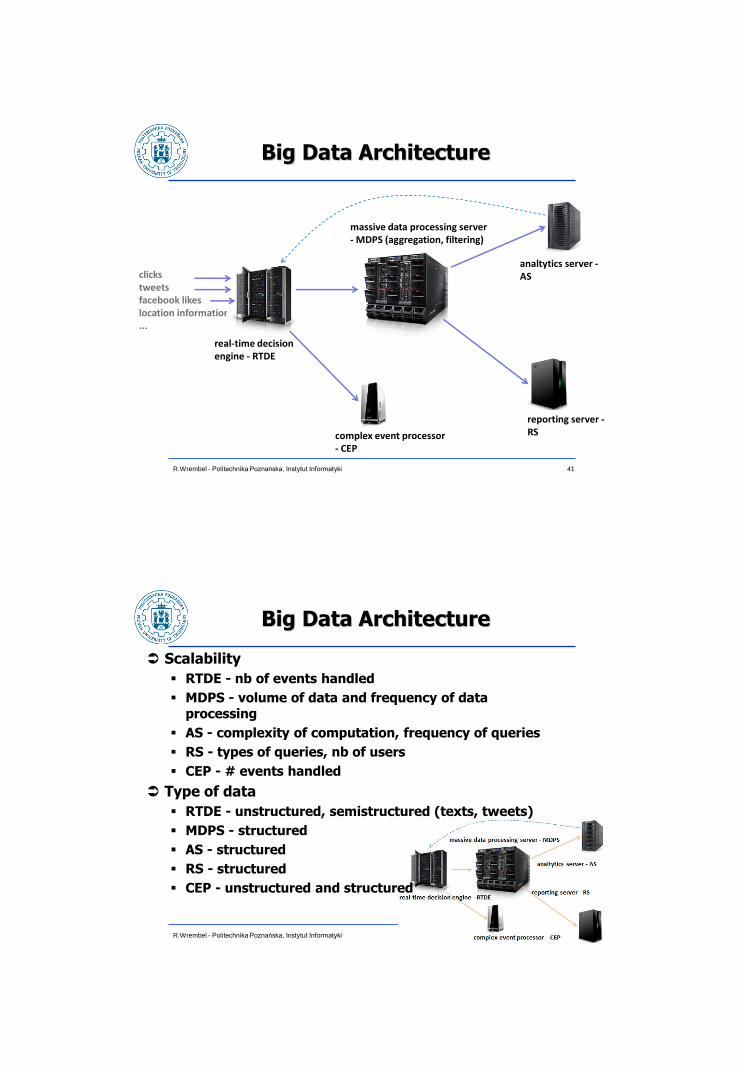
Big Data Architecture
41 R.Wrembel - Politechnika Poznańska, Instytut Informatyki
clicks tweets facebook likes location information ...
massive data processing server - MDPS (aggregation, filtering)
analtytics server - AS
reporting server - RS complex event processor
- CEP
real-time decision engine - RTDE
42
Big Data Architecture
Scalability
RTDE - nb of events handled
MDPS - volume of data and frequency of data processing
AS - complexity of computation, frequency of queries
RS - types of queries, nb of users
CEP - # events handled
Type of data
RTDE - unstructured, semistructured (texts, tweets)
MDPS - structured
AS - structured
RS - structured
CEP - unstructured and structured
R.Wrembel - Politechnika Poznańska, Instytut Informatyki

Big Data Architecture
Workload
RTDE - high write throughput
MDPS - long-running data processing (I/O and CPU intensive): data transformations, ...
AS - compute intensive (I/O and CPU intensive)
RS - various types of queries
Technologies
RTDE - key-value, in-memory
MDPS - Hadoop
AS - analytic appliences
RS - in-memory, columnar DBs
Conclusion
very complex architecture with multiple components
the need of integration
43 R.Wrembel - Politechnika Poznańska, Instytut Informatyki
IBM Architecture
Data warehouse augmentation: the queryable data store. IBM software solution brief.
44 R.Wrembel - Politechnika Poznańska, Instytut Informatyki

Big Data Architecture
45 R.Wrembel - Politechnika Poznańska, Instytut Informatyki
46 R.Wrembel - Politechnika Poznańska, Instytut Informatyki
Big Data Architecture
data ingest
high level language for processing MapReduce
coordinate and schedule workflows
columnar storage and query
coordinate and manage all the components
http://www.cloudera.com/content/cloudera/en/resources/library/training/apache-hadoop-ecosystem.html

Big Data Architecture
47 R.Wrembel - Politechnika Poznańska, Instytut Informatyki
columnar storage and query based on BigTable manages TB of data
coordinate and manage all the components service discovery, distributed locking, ...
high level language for processing MapReduce
SQL-like language for data analysis supports selection, join, group by, ...
user interface to Hive
web log loader (log scrapper), periodical loading into Hadoop aggregating log entries (for offline analysis)
Big Data Architecture
48 R.Wrembel - Politechnika Poznańska, Instytut Informatyki
coordinate and schedule workflows schedule and manage Pig, Hive, Java, HDFS actions
RDB-like interface to data stored in Hadoop
high level languages for processing MapReduce
distributed web log loader (log scrapper), periodical loading into Hadoop (for offline analysis)
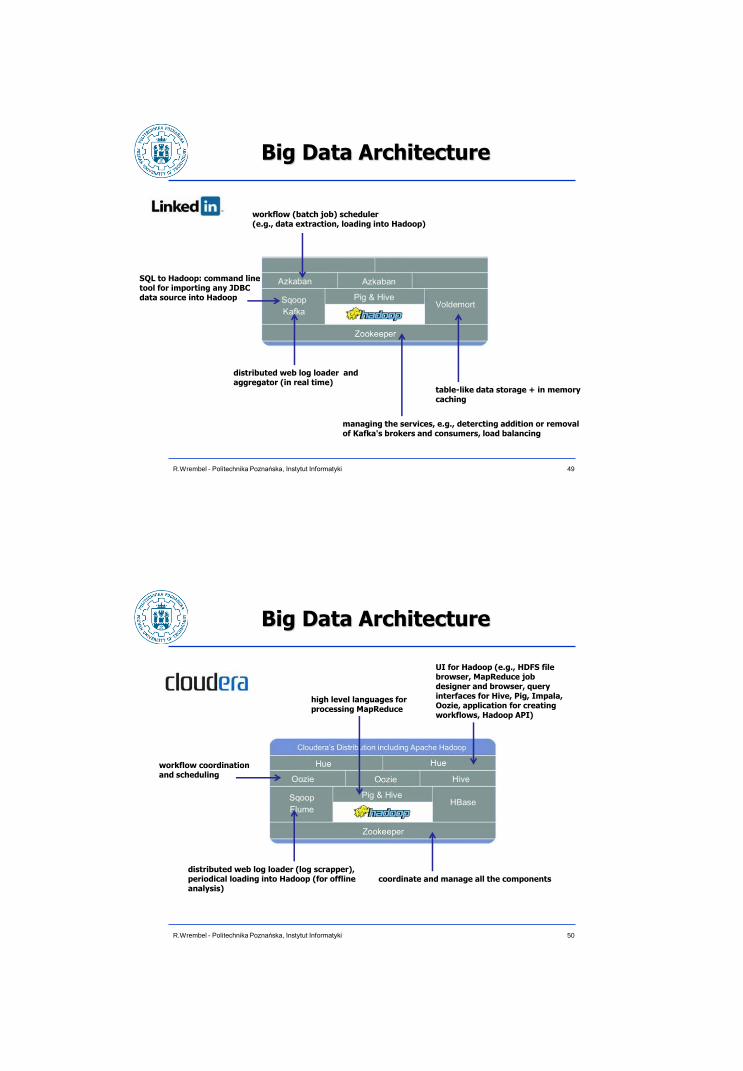
Big Data Architecture
49 R.Wrembel - Politechnika Poznańska, Instytut Informatyki
SQL to Hadoop: command line tool for importing any JDBC data source into Hadoop
distributed web log loader and aggregator (in real time)
workflow (batch job) scheduler (e.g., data extraction, loading into Hadoop)
table-like data storage + in memory caching
managing the services, e.g., detercting addition or removal of Kafka's brokers and consumers, load balancing
Big Data Architecture
50 R.Wrembel - Politechnika Poznańska, Instytut Informatyki
workflow coordination and scheduling
high level languages for processing MapReduce
coordinate and manage all the components distributed web log loader (log scrapper), periodical loading into Hadoop (for offline analysis)
UI for Hadoop (e.g., HDFS file browser, MapReduce job designer and browser, query interfaces for Hive, Pig, Impala, Oozie, application for creating workflows, Hadoop API)

Big Data Architecture
51 R.Wrembel - Politechnika Poznańska, Instytut Informatyki
Windows Azure
Java OM Streaming
OM HiveQL PigLatin (T)SQL
.NET/C#/F
NOSQL ETL
Tomasz Kopacz - Microsoft Polska: prezentacja Windows Azure, Politechnika Poznańska, czerwiec 2013
Data Stores
NoSQL
Key-value DB
data structure collection, represented as a pair:
key and value
data have no defined internal structure the
interpretation of complex values must be made by an application processing the values
operations create, read, update (modify), and
delete (remove) individual data - CRUD
the operations process only a single data item selected by the value of its key
Voldemort, Riak, Redis, Scalaris, Tokyo Cabinet, MemcacheDB, DynamoDB
52 R.Wrembel - Politechnika Poznańska, Instytut Informatyki

Data Stores
Column family (column oriented, extensible record, wide column)
definition of a data structure includes
• key definition
• column definitions
• column family definitions
column family stored separately, common to all
data items (~ shared schema)
column stored with a data item, specific for the
data item
CRUD interface
H-Base, HyperTable, Cassandra, BigTable, Accumulo, SimpleDB
53 R.Wrembel - Politechnika Poznańska, Instytut Informatyki
Data Stores
Document DB
typically JSON-based structure of documents
SimpleDB, MongoDB, CouchDB, Terrastore, RavenDB, Cloudant
Graph DB
nodes, edges, and properties to represent and store data
every node contains a direct pointer to its adjacent element
Neo4j, FlockDB, GraphBase, RDF Meronymy SPARQL
54 R.Wrembel - Politechnika Poznańska, Instytut Informatyki

GFS
Google implementation of DFS (cf. The Google File System
- whitepaper)
Distributed FS
For distributed data intensive applications
Storage for Google data
Installation
hundreds of TBs of storage, thousands of disks, over a thousand cheep commodity machines
The architecture is failure sensitive
fault tolerance
error detection
automatic recovery
constant monitoring is required
55 R.Wrembel - Politechnika Poznańska, Instytut Informatyki
GFS
Typical file size: multiple GB
Operations on files
mostly appending new data multiple large
sequential writes
no updates of already appended data
mostly large sequential reads
small random reads occur rarely
file size at least 100MB
millions of files
56 R.Wrembel - Politechnika Poznańska, Instytut Informatyki

GFS
Files are organized hierarchically in directories
Files are identified by their pathnames
Operations on files: create, delete, open, close, read, write, snapshot (creates a copy of a file or a directory tree), record append (appends data to the same file concurrently by multiple clients)
GFS cluster includes
single master
multiple chunk servers
57 R.Wrembel - Politechnika Poznańska, Instytut Informatyki
GFS
58 R.Wrembel - Politechnika Poznańska, Instytut Informatyki
S. Ghemawat, H. Gobioff, S-T. Leung. The Google File System. http://research.google.com/archive/gfs.html
master client
chunk server chunk server
..... ..... .....
chunk server
.....
1: file name, chunk index
2: chunk handle, chunk replica locations
3: chunk handle, byte range sent to one replica
4: data
management + heartbit messages

Hadoop
Apache implementation of DFS
http://hadoop.apache.org/docs/stable/hdfs_design.html
59 R.Wrembel - Politechnika Poznańska, Instytut Informatyki
Example
In 2010 Facebook stored over 30PB in Hadoop
Assuming:
30,000 1TB drives for storage
typical drive has a mean time between failure of 300,000 hours
2.4 disk drive fails daily
60 R.Wrembel - Politechnika Poznańska, Instytut Informatyki

Integration with Hadoop
IBM BigInsights Cloudera distribution + IBM custom version of Hadoop called GPFS
Oracle BigData appliance based on Cloudera for
storing unstructured content
Informatica HParser to launch Informatica
process in a MapReduce mode, distributed on the Hadoop servers
Microsoft dedicated Hadoop version supported
by Apache for Microsoft Windows and for Azure
EMC Greenplum, HP Vertica, Teradata Aster Data, SAP Sybase IQ provide connectors directly to
HDFS
61 R.Wrembel - Politechnika Poznańska, Instytut Informatyki
Technology Application
% of organizations surveyed
62 R.Wrembel - Politechnika Poznańska, Instytut Informatyki

Programming Languages
Top Languages for analytics, data mining, data science
Sept 2013, source:
http://www.datasciencecentral.com/profiles/blogs/top-languages-for-analytics-data-mining-data-science
The most popular languages continue to be
R (61%)
Python (39%)
SQL (37%)
SAS (20%)
63 R.Wrembel - Politechnika Poznańska, Instytut Informatyki
Programming Languages
Growth from 2012 to 2013
Pig Latin/Hive/other Hadoop-based languages
19%
R 16%
SQL 14% (the result of increasing number of SQL
interfaces to Hadoop and other Big Data systems?)
Decline from 2012 to 2013
Lisp/Clojure 77%
Perl 50%
Ruby 41%
C/C++ 35%
Unix shell/awk/sed 25%
Java 22%
64 R.Wrembel - Politechnika Poznańska, Instytut Informatyki

Big Data
Questionnaire: 339 experts of data management (XII, 2012)
Question: what are the plans of using Big Data in their organizations
Answers:
14% highly probable
19% no plans
Problems
21% not enough knowledge on Big Data
15% no clear profits from using Big Data
9% poor data quality
65 R.Wrembel - Politechnika Poznańska, Instytut Informatyki
Data Scientist
66 R.Wrembel - Politechnika Poznańska, Instytut Informatyki

RDBMS vs. NoSQL: the Future?
TechTarget: Relational database management system guide: RDBMS still on top
http://searchdatamanagement.techtarget.com/essentialguide/Relational-database-management-system-guide-RDBMS-still-on-top
"While NoSQL databases are getting a lot of attention, relational database management systems remain the technology of choice for most applications"
67 R.Wrembel - Politechnika Poznańska, Instytut Informatyki
RDBMS vs. NoSQL: the Future?
R. Zicari: Big Data Management at American Express. Interview with Sastry Durvasula and Kevin Murray.
ODBMS Industry Watch. Trends and Information on Big Data, New Data Management Technologies, and Innovation. Oct, 2014, available at: http://www.odbms.org/blog/2014/10/big-data-management-american-express-interview-sastry-durvasula-kevin-murray/
"The Hadoop platform indeed provides the ability to efficiently process large-scale data at a price point we haven’t been able to justify with traditional technology. That said, not every technology process requires Hadoop; therefore, we have to be smart about which processes we deploy on Hadoop and which are a better fit for traditional technology (for example, RDBMS)."–Kevin Murray.
68 R.Wrembel - Politechnika Poznańska, Instytut Informatyki

RDBMS
Conceptual and logical modeling methodologies and tools
Rich SQL functionality
Query optimization
Concurrency control
Data integrity management
Backup and recovery
Performance optimization
buffers' tuning
storage tuning
advanced indexing
in-memory processing
Application development tools
69 R.Wrembel - Politechnika Poznańska, Instytut Informatyki
NoSQL
Flexible "schema" suitable for unstructured data
Massively parallel processing
Cheap hardware + open source software
70 R.Wrembel - Politechnika Poznańska, Instytut Informatyki

Some other trends
Apache Derby: Java-based ANSI SQL database
Splice Machine
Derby (redesigned query optimizer to support parallel processing) on HBase (parallel processing) + Hadoop (parallel storage and processing)
71 R.Wrembel - Politechnika Poznańska, Instytut Informatyki
Recommended

















