
Inducing Predictive Clustering Trees forDatatype properties Values
Giuseppe Rizzo, Claudia d’Amato, Nicola Fanizzi, Floriana Esposito
Semantic Machine Learning, 10th July 2016
G.Rizzo et al. (Univ. of Bari) 10th July 2016 1 / 18

Outline
1 The Context and Motivations
2 Basics
3 The approach
4 Empirical Evaluation
5 Conclusion & Further Extensions
G.Rizzo et al. (Univ. of Bari) 10th July 2016 2 / 18

The Context and Motivations
• Goal: approximating the (numerical) datatype property valuesthrough regression models in the Web of Data
• Web of data: a large number of knowledge bases, datasets andvocabularies exposed in a standard format (RDF, OWL)
• (numerical) property values can hardly be derived by usingreasoning services• Open World Assumption• a large number of missing information
• The informative gap can be filled by using regression models
G.Rizzo et al. (Univ. of Bari) 10th July 2016 3 / 18

The context and Motivations
• Solving a regression problem• two or more property values may be related (e.g. crime rate and
population of a place)• correlations should improve the predictiveness
• Predicting more numerical values at once (multi-targetregression) through Predictive Clustering approaches• Predictive Clustering Trees (PCTs) as a generalization of decision
trees
• PCTs compliant to the representation languages for the Web ofData (e.g. Description Logics)• target values: the numeric role fillers for the properties
G.Rizzo et al. (Univ. of Bari) 10th July 2016 4 / 18

Description LogicsSyntax & Semantics
• Atomic concepts (classes), NC and roles (relations), NR to modeldomains
• Operators to build complex concept descriptions• Concrete domains: string, boolean, numeric values• Semantics defined through interpretations I = (∆I , ·I)
• ∆I : domain of the interpretation• ·I : intepretation function
• for each concept C ∈ NC , CI ⊆ ∆I
• for each role R ∈ NR , RI ⊆ ∆I ×∆I
ALC operatorsTop concept: > ∆I
Bottom concept: ⊥ ∅Concept: C CI ⊆ ∆I
Full Complement: ¬C ∆ \ CI
Intersection: C u D CI ∩ DI
Disjunction: C t D CI ∪ DI
Universal restriction ∀R.D {x ∈ ∆I | ∀y ∈ ∆I (x, y) ∈ RI → y ∈ DI}Existential restriction ∃R.D {x ∈ ∆I | ∃y ∈ ∆I (x, y) ∈ RI ∧ y ∈ DI}
G.Rizzo et al. (Univ. of Bari) 10th July 2016 5 / 18

Description LogicsKnowledge bases
• Knowledge base: a couple K = (T ,A) where• T (TBox): axioms concerning concepts/roles
• Subsumption axioms C v D: iff for every interpretation I,CI ⊆ DI holds
• Equivalence axioms C ≡ D: iff for every interpretation I,CI ⊆ DI and I, DI ⊆ CI holds
• A (ABox): class assertions, C (a) and role assertions,R(a, b) abouta set of individuals is denoted by Ind(A)
• Reasoning services:• subsumption: a concept is more general than a given one• satisfiability: given a concept description C and an interpretationI, CI 6= ∅
• instance checking: for every interpretation, I C (a) holds (a is aninstance for C )
G.Rizzo et al. (Univ. of Bari) 10th July 2016 6 / 18

The problem
Given:
• a knowledge base K = (T ,A);
• the target functional roles Ri , 1 ≤ i ≤ t, ranging on the domainsDi , whose analytic forms are unknown;
• a training set Tr ⊆ Ind(A) for which the numeric fillers areknown,Tr = {a ∈ Ind(A) | Ri (a, vi ) ∈ A, vi ∈ Di , 1 ≤ i ≤ t}
Build a regression model for {Ri}ti=1, i.e. a functionh : Ind(A)→ D1×· · ·×Dt such that it minimizes a loss function overTr. A possible loss function may be based on the mean square error.
G.Rizzo et al. (Univ. of Bari) 10th July 2016 7 / 18
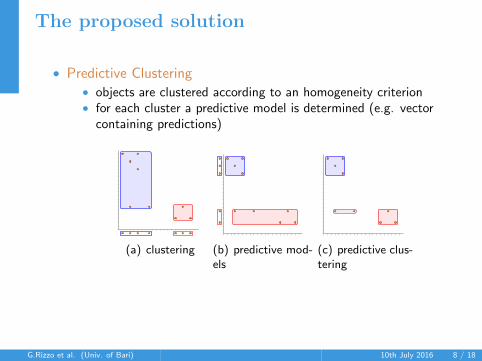
The proposed solution
• Predictive Clustering• objects are clustered according to an homogeneity criterion• for each cluster a predictive model is determined (e.g. vector
containing predictions)
(a) clustering (b) predictive mod-els
(c) predictive clus-tering
G.Rizzo et al. (Univ. of Bari) 10th July 2016 8 / 18
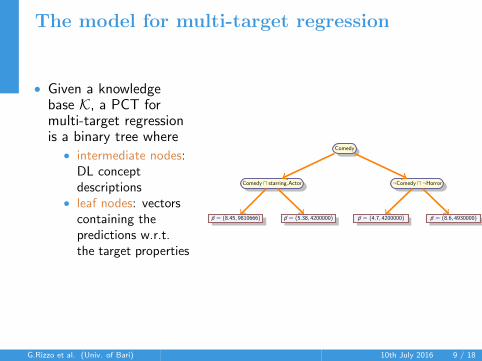
The model for multi-target regression
• Given a knowledgebase K, a PCT formulti-target regressionis a binary tree where• intermediate nodes:
DL conceptdescriptions
• leaf nodes: vectorscontaining thepredictions w.r.t.the target properties
Comedy
Comedy u starring.Actor
~p = (8.45, 9810666) ~p = (5.38, 4200000)
¬Comedy u ¬Horror
~p = (4.7, 4200000) ~p = (8.6, 4930000)
G.Rizzo et al. (Univ. of Bari) 10th July 2016 9 / 18

Learning PCTs
• Divide-and-conquer strategy
• For the current node:• the refinement operator generates the candidate concepts• The most promising concept E∗ is selected by maximizing the
homogeneity w.r.t. the target variables simultaneously.• Best concept: the one minimizing the RMSE of the standardized
target properties values• Stop conditions:
• maximum number of levels• size of the training (sub)set• Leaf: the i-th component contains the average value for the i-th
target property over the instances sorted to the node
G.Rizzo et al. (Univ. of Bari) 10th July 2016 10 / 18

Installing new DL concepts as inner nodes
• The candidate concept descriptions are generated by using arefinement operator• A quasi ordering relation over the space of the concept
descriptions• The subsumption between concepts in Description Logics
• Downward refinement operator ρ(·) to obtain specializations E ofa concept description D (E v D)
• Each concept can be obtained:• by introducing a new concept name (or its complement) as a
conjuct• by replacing a sub-description in the scope of an existential
restriction• by replacing a sub-description in the scope of an universal
restriction
G.Rizzo et al. (Univ. of Bari) 10th July 2016 11 / 18

Prediction
• Given an unseen individual a, the properties values aredetermined by traversing the tree structure
• Given a test concept D:• if K |= D(a) the left branch is followed• if K |= ¬D(a) the right branch is followed• otherwise, a default model is returned
G.Rizzo et al. (Univ. of Bari) 10th July 2016 12 / 18

ExperimentsSettings
• Ontologies extracted from DBPedia via crawling
• Maximum depth for PCTs: 10, 15,20
• Comparison w.r.t. Terminological regression trees (TRT),
multi-target k-nn regressor (with k =√
Tr) and multi-targetlinear regression model• atomic concepts as features set for k-nn regressor and multi-target
linear regression model
• 10-fold cross validation
• performance in terms of RRMSE
G.Rizzo et al. (Univ. of Bari) 10th July 2016 13 / 18
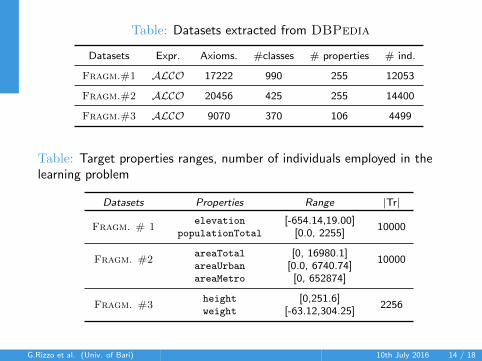
Table: Datasets extracted from DBPedia
Datasets Expr. Axioms. #classes # properties # ind.
Fragm.#1 ALCO 17222 990 255 12053
Fragm.#2 ALCO 20456 425 255 14400
Fragm.#3 ALCO 9070 370 106 4499
Table: Target properties ranges, number of individuals employed in thelearning problem
Datasets Properties Range |Tr|
Fragm. # 1elevation [-654.14,19.00]
10000populationTotal [0.0, 2255]
Fragm. #2areaTotal [0, 16980.1]
10000areaUrban [0.0, 6740.74]areaMetro [0, 652874]
Fragm. #3height [0,251.6]
2256weight [-63.12,304.25]
G.Rizzo et al. (Univ. of Bari) 10th July 2016 14 / 18
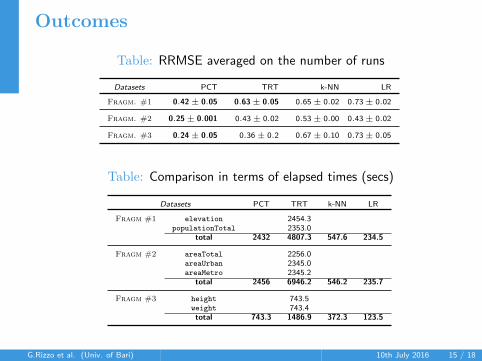
Outcomes
Table: RRMSE averaged on the number of runs
Datasets PCT TRT k-NN LR
Fragm. #1 0.42± 0.05 0.63± 0.05 0.65± 0.02 0.73± 0.02
Fragm. #2 0.25± 0.001 0.43± 0.02 0.53± 0.00 0.43± 0.02
Fragm. #3 0.24± 0.05 0.36± 0.2 0.67± 0.10 0.73± 0.05
Table: Comparison in terms of elapsed times (secs)
Datasets PCT TRT k-NN LR
Fragm #1 elevation 2454.3populationTotal 2353.0
total 2432 4807.3 547.6 234.5
Fragm #2 areaTotal 2256.0areaUrban 2345.0areaMetro 2345.2
total 2456 6946.2 546.2 235.7
Fragm #3 height 743.5weight 743.4total 743.3 1486.9 372.3 123.5
G.Rizzo et al. (Univ. of Bari) 10th July 2016 15 / 18

Discussion
• PCTs more performant than TRT• the different heuristic allows to choose more promising concepts• standardization mitigated abnormal values increasing the error
• PCT more performant than k-nn• curse of dimensionality
• k-nn more performant than LR• spurious individuals were excluded to determine the local model
• PCTs more efficient than TRTs
G.Rizzo et al. (Univ. of Bari) 10th July 2016 16 / 18

Conclusion and Further Outlooks
• We proposed an extension of predictive clustering trees compliantto DL representation languages for solving the problem ofpredicting datatype properties
• Further extensions• New refinement operators• Further heuristics• linear models at leaf nodes
G.Rizzo et al. (Univ. of Bari) 10th July 2016 17 / 18

Questions?
G.Rizzo et al. (Univ. of Bari) 10th July 2016 18 / 18
Recommended

















