Info 3950 Lecture 211 Feb 2021

Rise of the Machines:Deep Learning from Backgammon to Skynet
Over the past seven years, there have been significant advances in applications of artificial intelligence, machine learning, and specifically deep learning, to a variety of familiar tasks. From image and speech recognition, self-driving cars, and machine translation, to beating the Go champion, it's been difficult to stay abreast of all the breathless reports of superhuman machine performance. There has as well been a recent surge in applications of machine learning ideas to research problems in the hard sciences and medicine. I will endeavor to provide an outsider's overview of the ideas underlying these recent advances and their evolution over the past few decades, and project some prospects and pitfalls for the near future.
Paul Ginsparg, Physics and InfoSciCornell Univ
Aspen 16 Jan 2019

video games, poker, chess, go,speech recognition, language translation,
medical applications (dermatology, ophthalmology), chemical synthesis,
data analysis,self-driving cars
Plan:Teaser
How it all worksHistorical highlights
Future
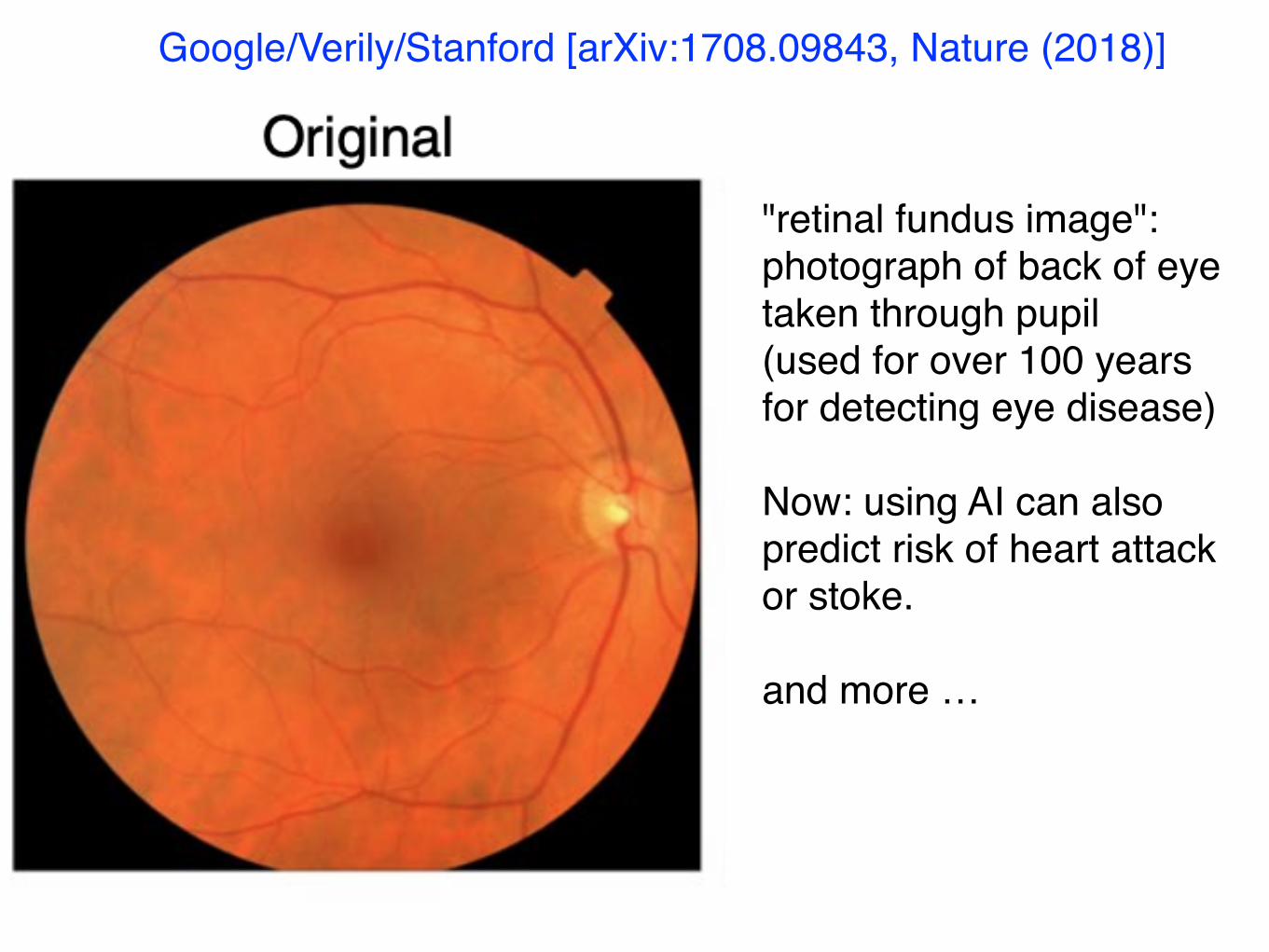
Google/Verily/Stanford [arXiv:1708.09843, Nature (2018)]
"retinal fundus image": photograph of back of eye taken through pupil(used for over 100 years for detecting eye disease)
Now: using AI can also predict risk of heart attack or stoke.
and more …
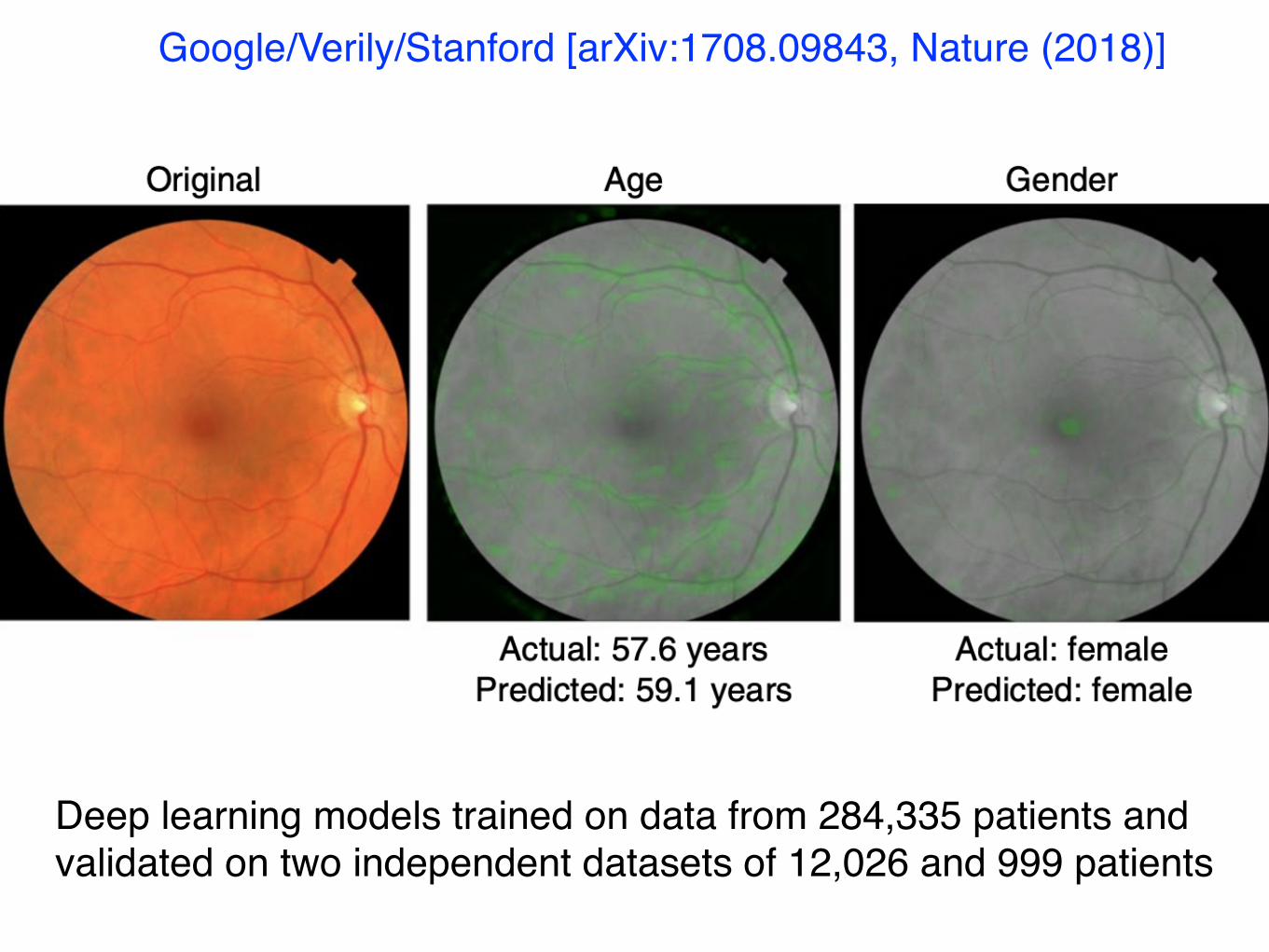
Google/Verily/Stanford [arXiv:1708.09843, Nature (2018)]
Deep learning models trained on data from 284,335 patients and validated on two independent datasets of 12,026 and 999 patients
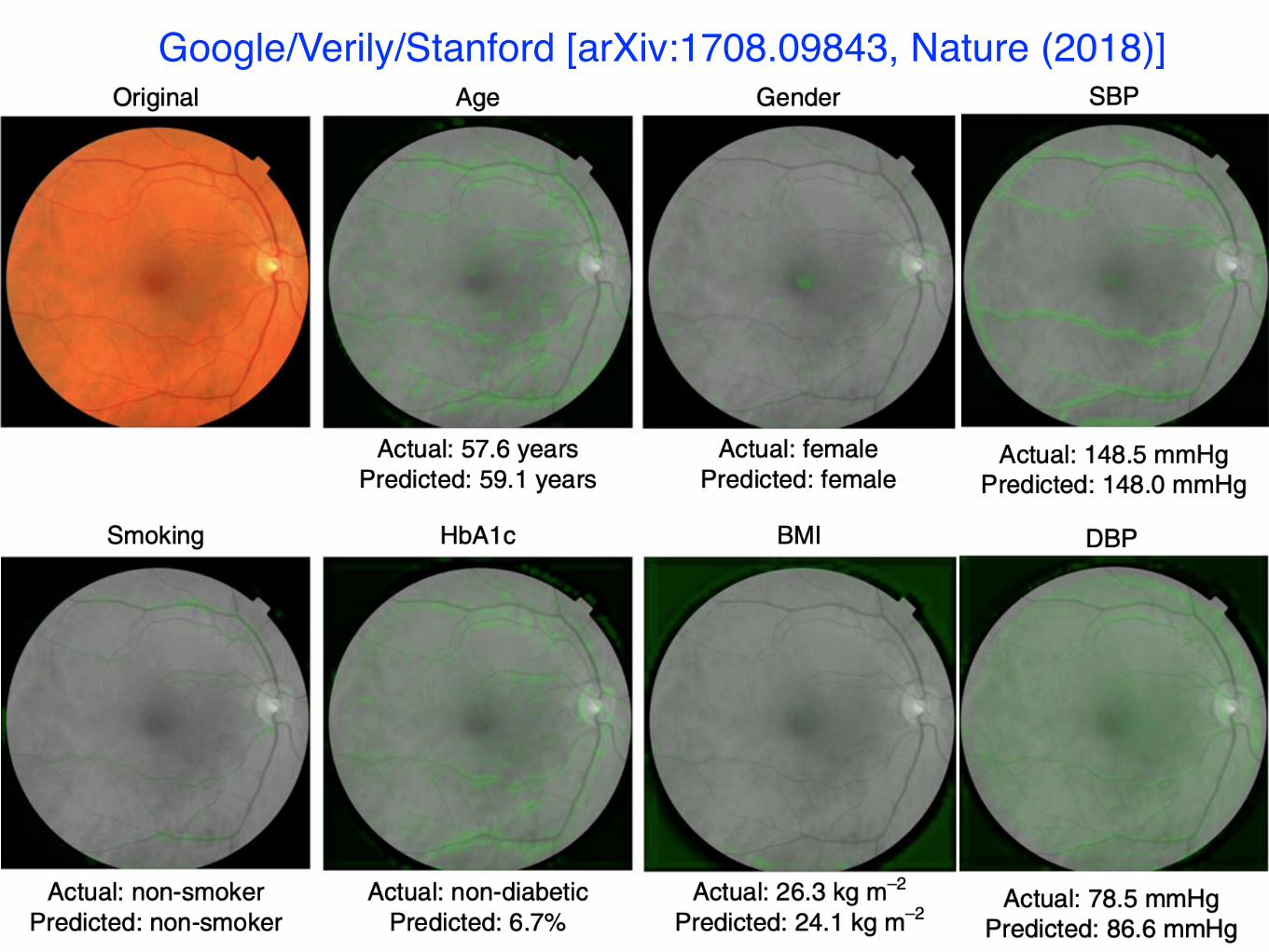
Google/Verily/Stanford [arXiv:1708.09843, Nature (2018)]
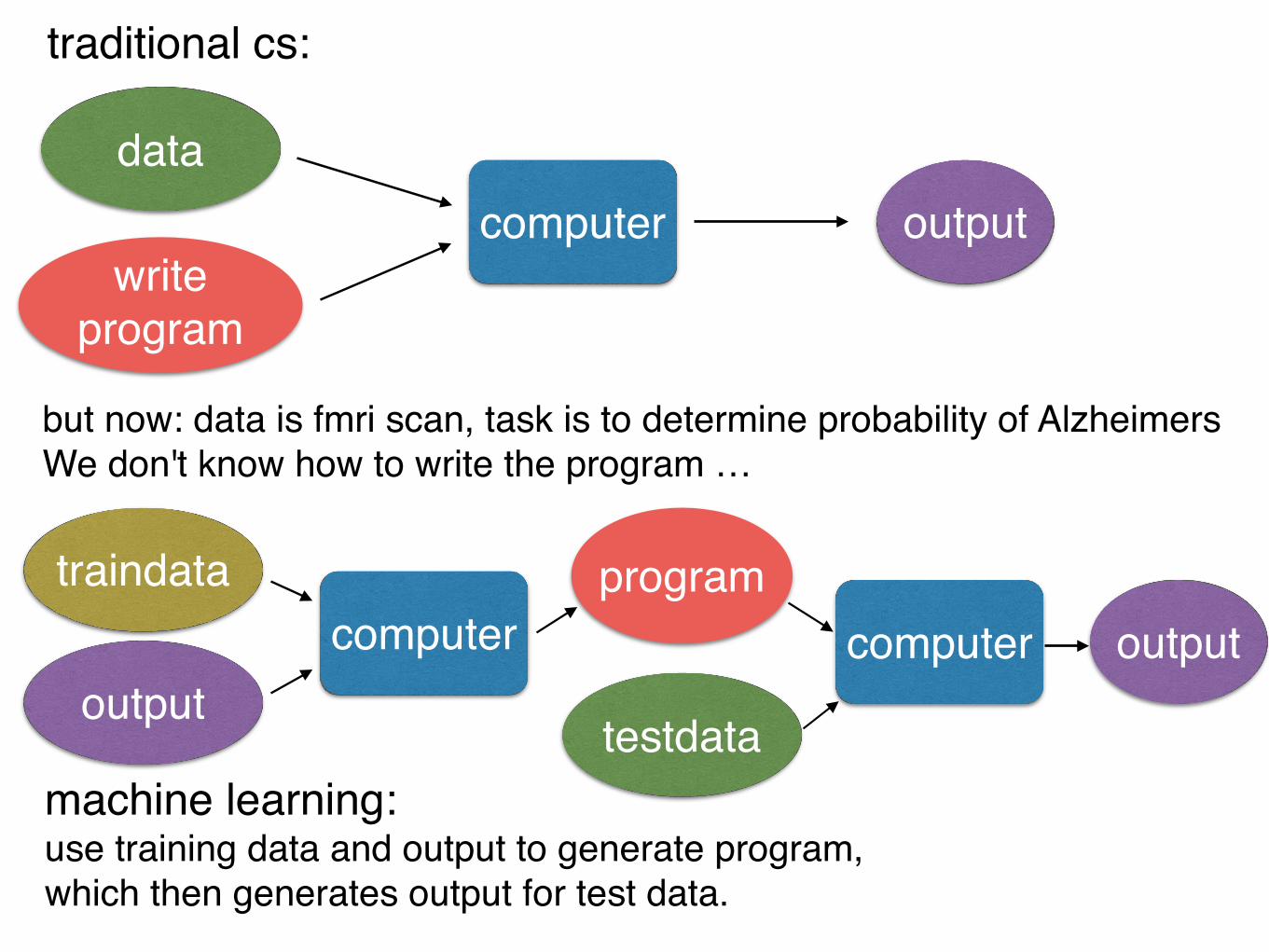
but now: data is fmri scan, task is to determine probability of AlzheimersWe don't know how to write the program …
data
traditional cs:
write program
outputcomputer
traindata
outputcomputer
program
machine learning:use training data and output to generate program,which then generates output for test data.
testdata
computer output
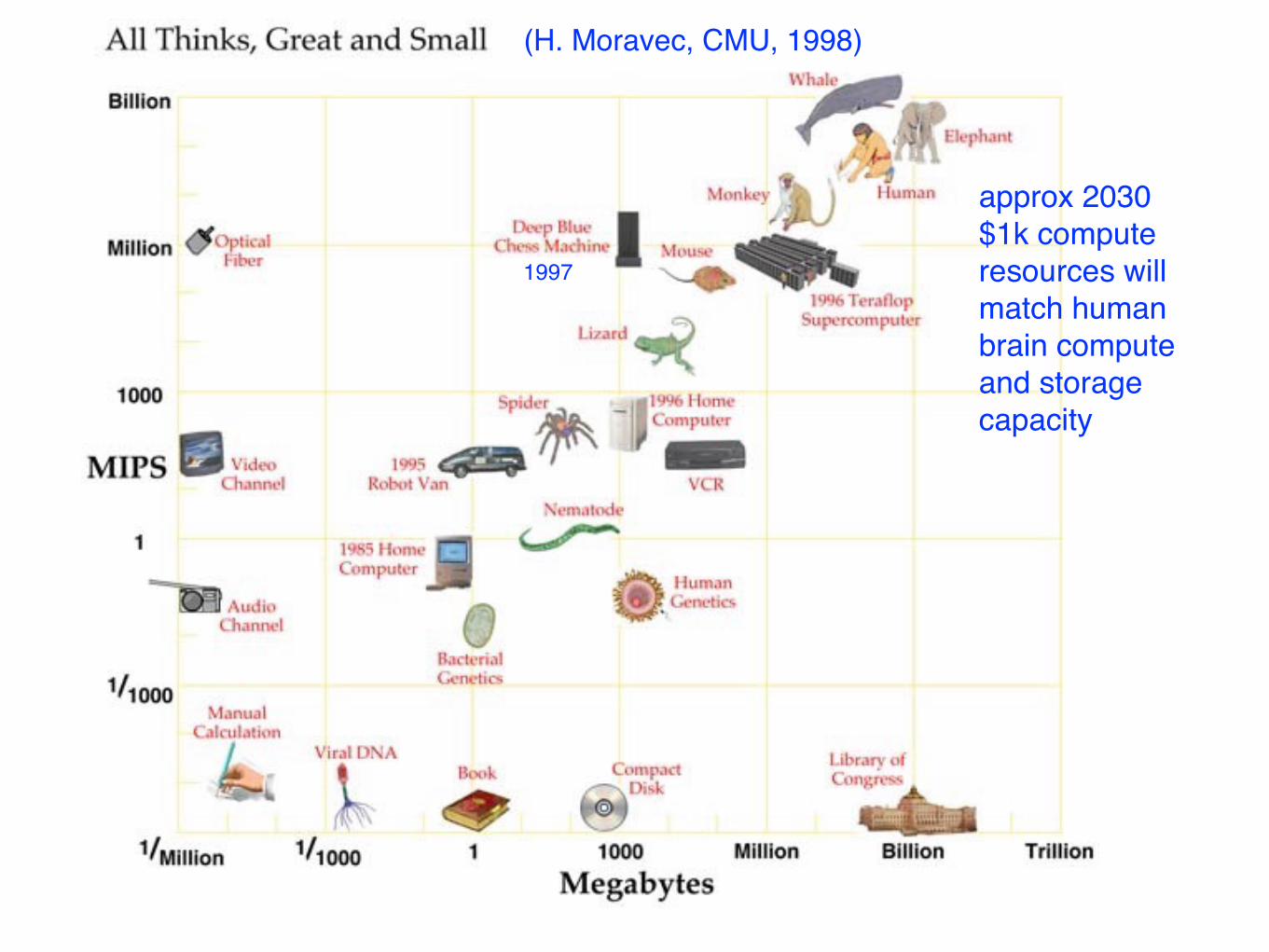
approx 2030 $1k compute resources will match human brain compute and storage capacity
(H. Moravec, CMU, 1998)
1997

1943
McCullogh-Pittsneurons
1950
Hebbianlearning
1958
Rosenblattperceptron
100
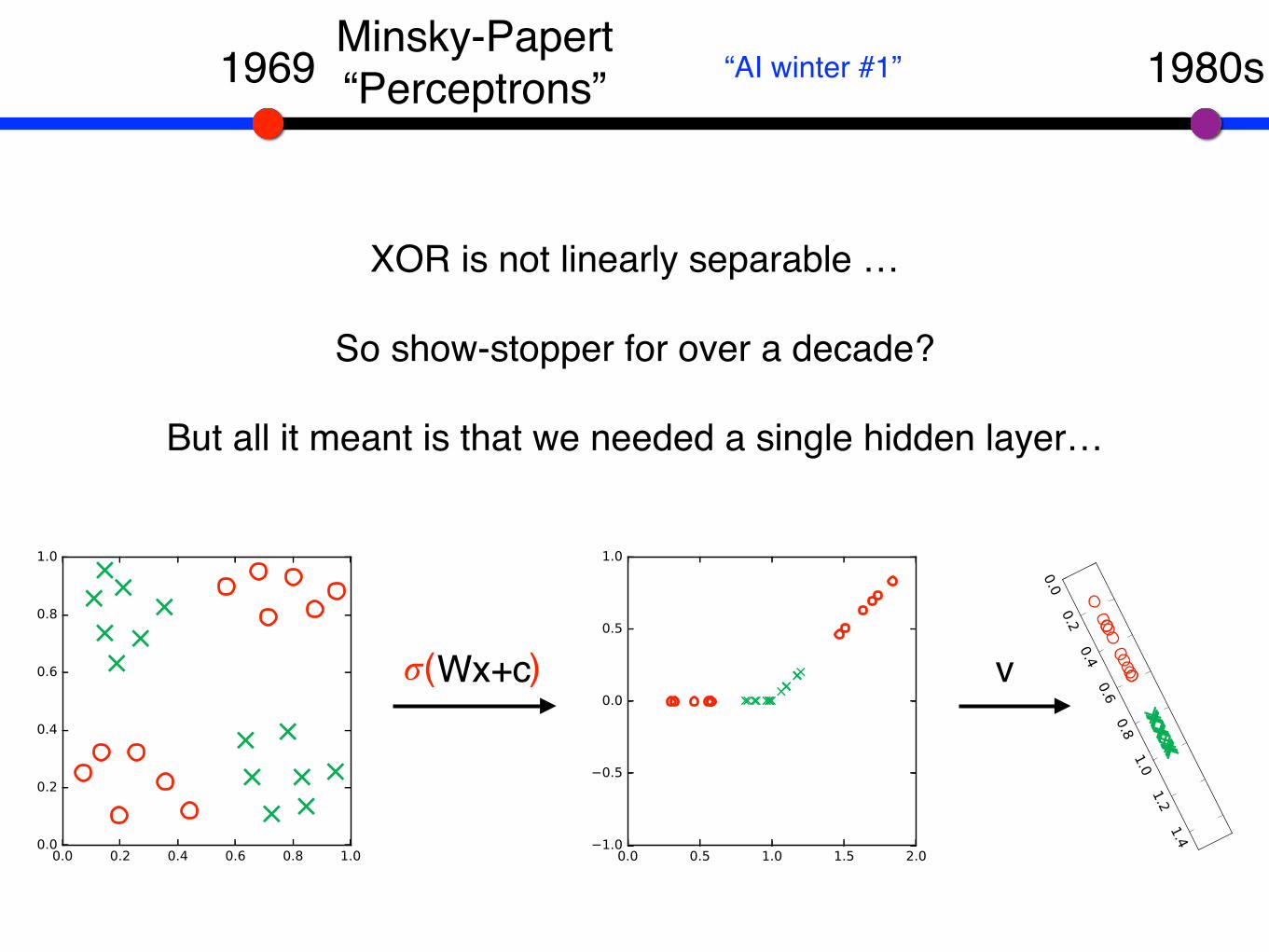
1969 1980sMinsky-Papert“Perceptrons” “AI winter #1”
v
XOR is not linearly separable …
So show-stopper for over a decade?
But all it meant is that we needed a single hidden layer…
Wx+c!( )
101
1969 1980sMinsky-Papert“Perceptrons” “AI winter #1”
IBM Watsonwins
Jeopardy
2010BIG
Data! 2012
Hinton students ->Google, Microsoft
(e.g., Android speechrecognition)
GPU 70x fasterto train (week->hrs)
Choice ofActivationmatters
.35% on MNIST
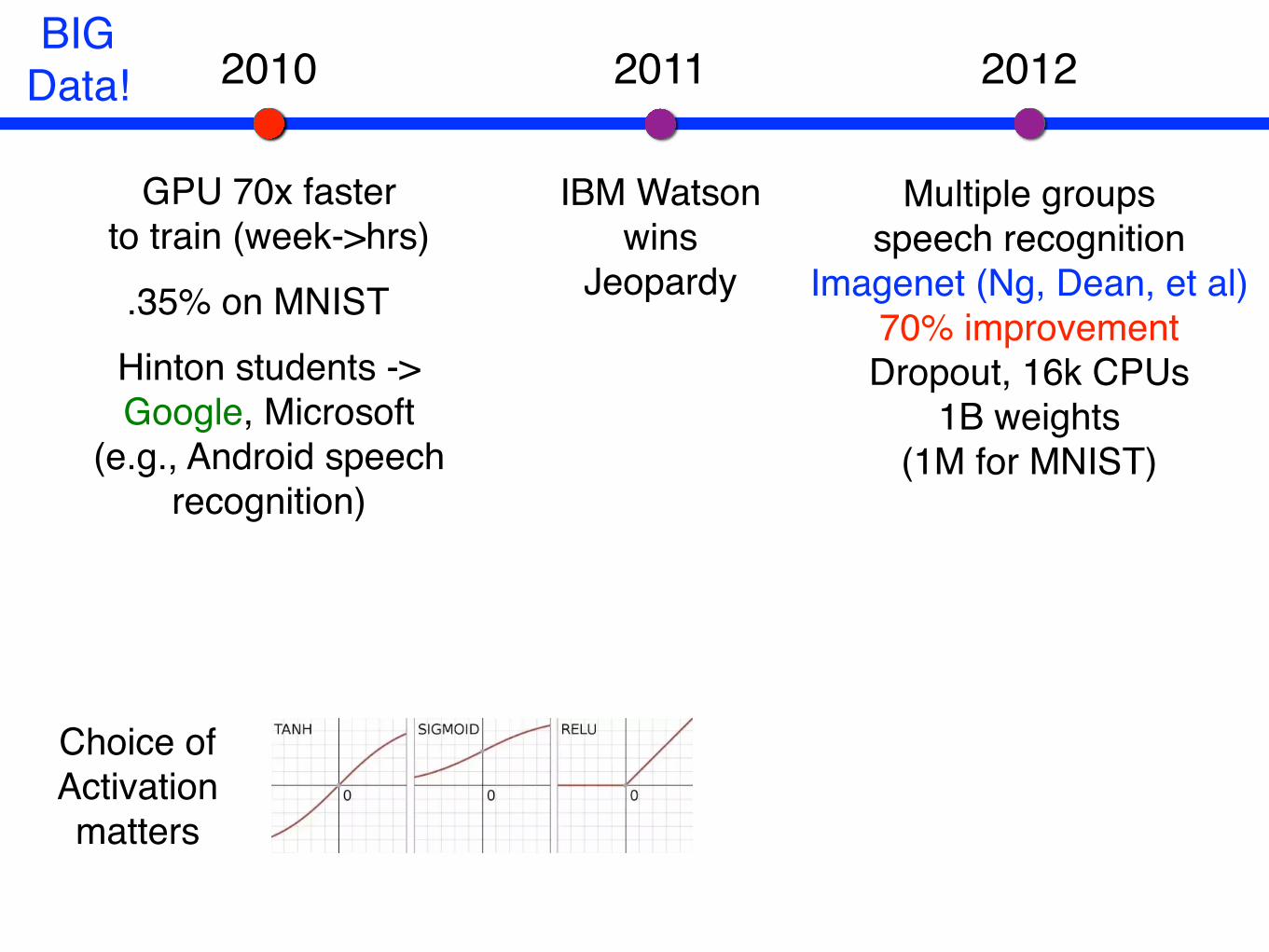
Multiple groupsspeech recognition
Imagenet (Ng, Dean, et al)70% improvementDropout, 16k CPUs
1B weights(1M for MNIST)
2011

IBM Watsonwins
Jeopardy
2010BIG
Data! 2012
Hinton students ->Google, Microsoft
(e.g., Android speechrecognition)
GPU 70x fasterto train (week->hrs).35% on MNIST
Multiple groupsspeech recognition
Imagenet (Ng, Dean, et al)70% improvementDropout, 16k CPUs
1B weights(1M for MNIST)
2011

IBM Watsonwins
Jeopardy
2010BIG
Data! 2012
Hinton students ->Google, Microsoft
(e.g., Android speechrecognition)
GPU 70x fasterto train (week->hrs).35% on MNIST
Multiple groupsspeech recognition
Imagenet (Ng, Dean, et al)70% improvementDropout, 16k CPUs
1B weights(1M for MNIST)
9 layer sparse autoencoder1B parameters
10M 200x200 imagesdown to 18x1816000 cores
visual cortex is 1M x larger
2011

IBM Watsonwins
Jeopardy
2010BIG
Data! 2012
Hinton students ->Google, Microsoft
(e.g., Android speechrecognition)
GPU 70x fasterto train (week->hrs).35% on MNIST
Multiple groupsspeech recognition
Imagenet (Ng, Dean, et al)70% improvementDropout, 16k CPUs
1B weights(1M for MNIST)
2011
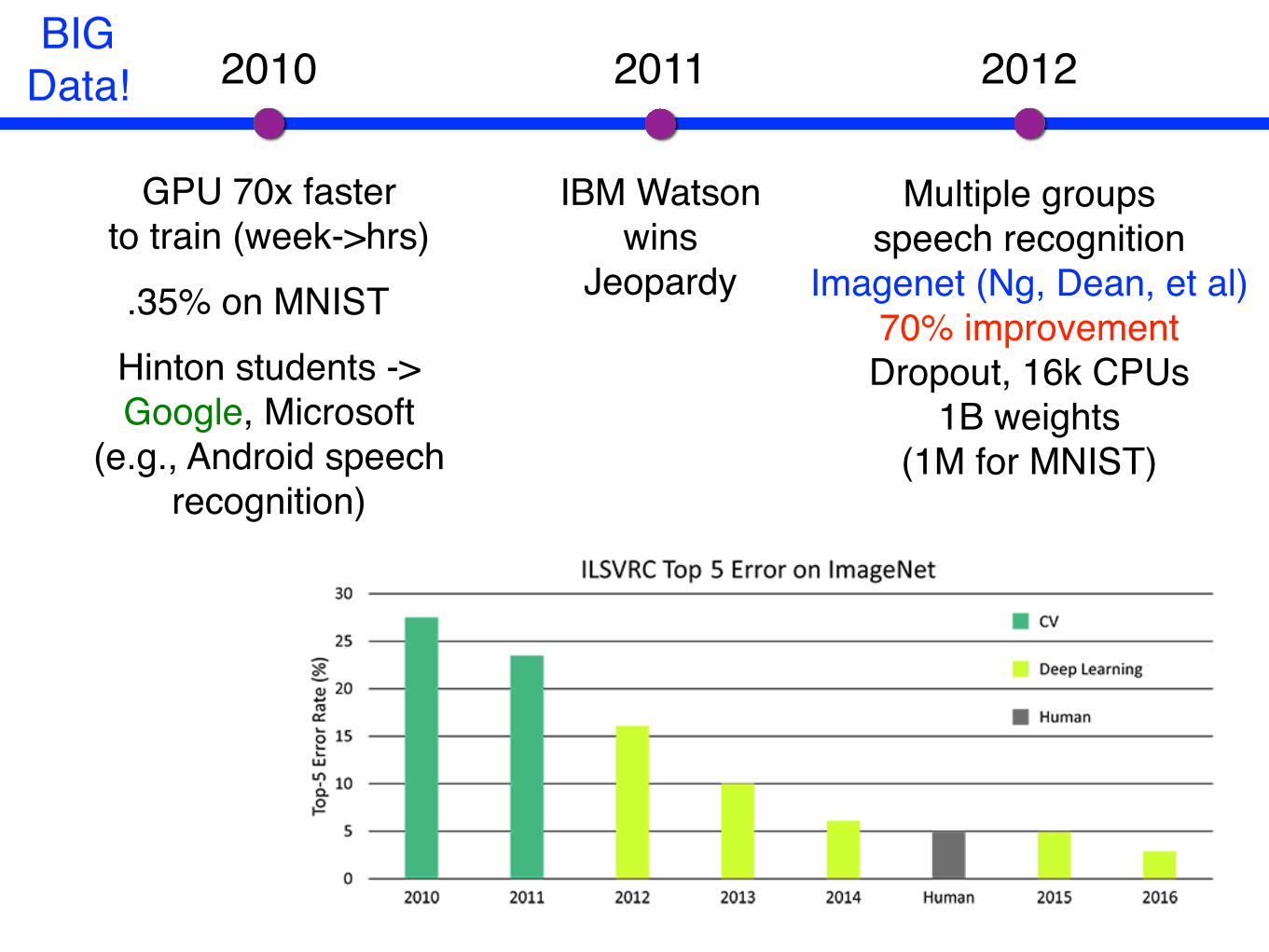
ImageNet Challenge
• Large Scale Visual Recognition Challenge (ILSVRC)• 1.2M training images with
1K categories • Measure top-5 classification error
44
Image classificationEasiest classes
Hardest classes
UVA DEEP LEARNING COURSE – EFSTRATIOS GAVVES DEEPER INTO DEEP LEARNING AND OPTIMIZATIONS - 93
o Yearly ImageNet competition ◦ Automatically label 1.4M images with 1K objects◦ Measure top-5 classification error
ImageNet Large Scale Visual Recognition Challenge
OutputScaleT-shirtSteel drumDrumstickMud turtle
OutputScaleT-shirtGiant pandaDrumstickMud turtle
✔ ✗
93
OutputScaleT-shirtSteel drumDrumstickMud turtle
OutputScaleT-shirtGiant pandaDrumstickMud turtle
J. Deng, Wei Dong, R. Socher, L.-J. Li, K. Li and L. Fei-Fei , “ImageNet: A Large-Scale Hierarchical Image Database”, CVPR 2009.O. Russakovsky et al., “ImageNet Large Scale Visual Recognition Challenge”, Int. J. Comput. Vis.,, Vol. 115, Issue 3, pp 211-252, 2015.
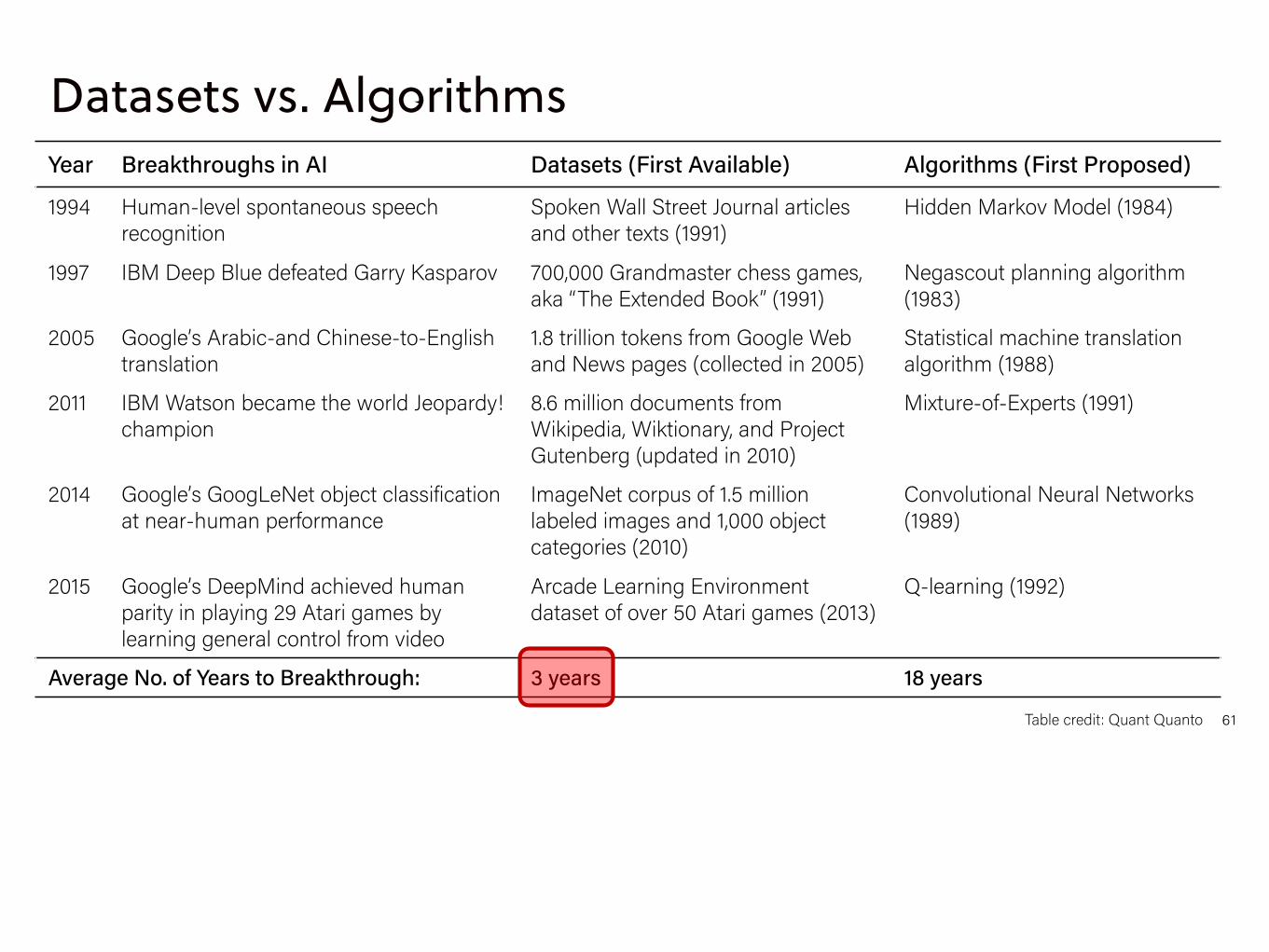
Datasets vs. AlgorithmsYear Breakthroughs in AI Datasets (First Available) Algorithms (First Proposed)
1994 Human-level spontaneous speech recognition
Spoken Wall Street Journal articles and other texts (1991)
Hidden Markov Model (1984)
1997 IBM Deep Blue defeated Garry Kasparov 700,000 Grandmaster chess games, aka “The Extended Book” (1991)
Negascout planning algorithm (1983)
2005 Google’s Arabic-and Chinese-to-English translation
1.8 trillion tokens from Google Web and News pages (collected in 2005)
Statistical machine translation algorithm (1988)
2011 IBM Watson became the world Jeopardy! champion
8.6 million documents from Wikipedia, Wiktionary, and Project Gutenberg (updated in 2010)
Mixture-of-Experts (1991)
2014 Google’s GoogLeNet object classification at near-human performance
ImageNet corpus of 1.5 million labeled images and 1,000 object categories (2010)
Convolutional Neural Networks (1989)
2015 Google’s DeepMind achieved human parity in playing 29 Atari games by learning general control from video
Arcade Learning Environmentdataset of over 50 Atari games (2013)
Q-learning (1992)
Average No. of Years to Breakthrough: 3 years 18 years
Table credit: Quant Quanto 61
IBM Watsonwins
Jeopardy
2010BIG
Data! 2012
Hinton students ->Google, Microsoft
(e.g., Android speechrecognition)
GPU 70x fasterto train (week->hrs).35% on MNIST
Multiple groupsspeech recognition
Imagenet (Ng, Dean, et al)70% improvementDropout, 16k CPUs
1B weights(1M for MNIST)
2011

IBM Watsonwins
Jeopardy
2010BIG
Data! 2012
Hinton students ->Google, Microsoft
(e.g., Android speechrecognition)
GPU 70x fasterto train (week->hrs).35% on MNIST
Multiple groupsspeech recognition
Imagenet (Ng, Dean, et al)70% improvementDropout, 16k CPUs
1B weights(1M for MNIST)
2011
102
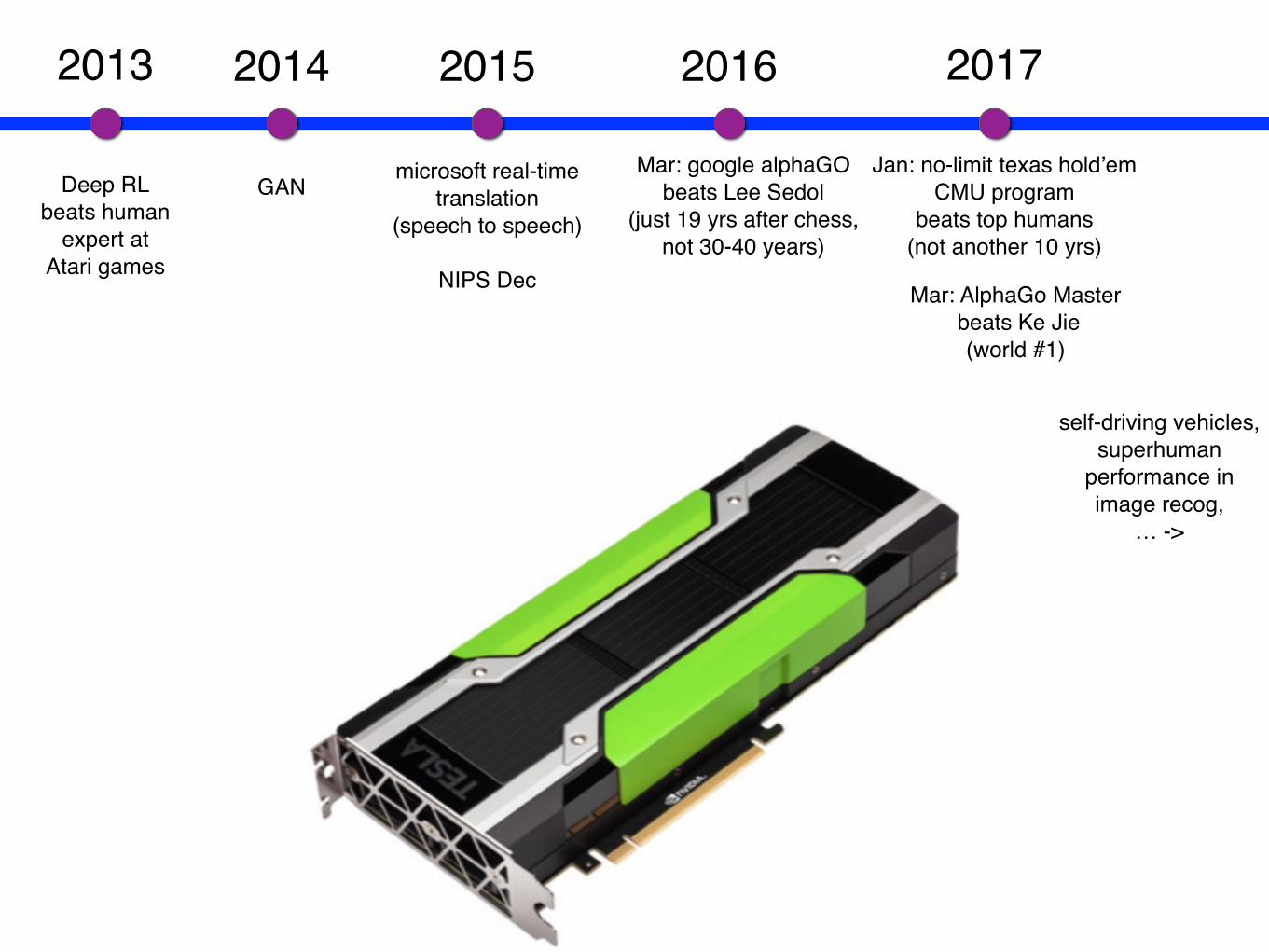
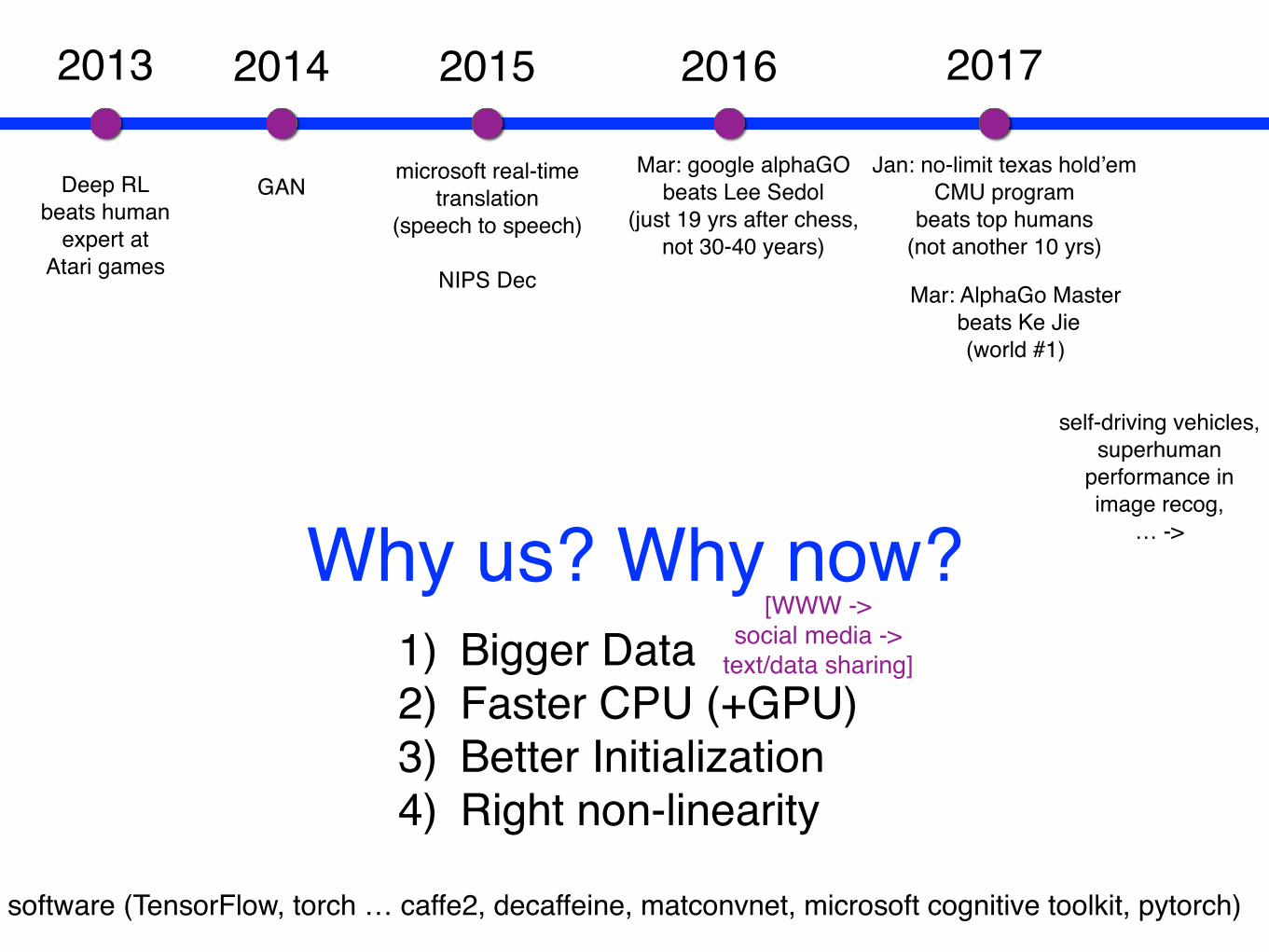
Why us? Why now?1) Bigger Data2) Faster CPU (+GPU)3) Better Initialization4) Right non-linearity
2013 2017
microsoft real-timetranslation
(speech to speech)
NIPS Dec
2015 2016
Mar: google alphaGObeats Lee Sedol
(just 19 yrs after chess,not 30-40 years)
Jan: no-limit texas hold’emCMU program
beats top humans(not another 10 yrs)
self-driving vehicles,superhuman
performance in image recog,
… ->
Mar: AlphaGo Master beats Ke Jie
(world #1)
2014
GANDeep RLbeats human
expert atAtari games
Why us? Why now?1) Bigger Data2) Faster CPU (+GPU)3) Better Initialization4) Right non-linearity
2013 2017
microsoft real-timetranslation
(speech to speech)
NIPS Dec
2015 2016
Mar: google alphaGObeats Lee Sedol
(just 19 yrs after chess,not 30-40 years)
Jan: no-limit texas hold’emCMU program
beats top humans(not another 10 yrs)
self-driving vehicles,superhuman
performance in image recog,
… ->
Mar: AlphaGo Master beats Ke Jie
(world #1)
2014
GANDeep RLbeats human
expert atAtari games
software (TensorFlow, torch … caffe2, decaffeine, matconvnet, microsoft cognitive toolkit, pytorch)
[WWW -> social media ->
text/data sharing]
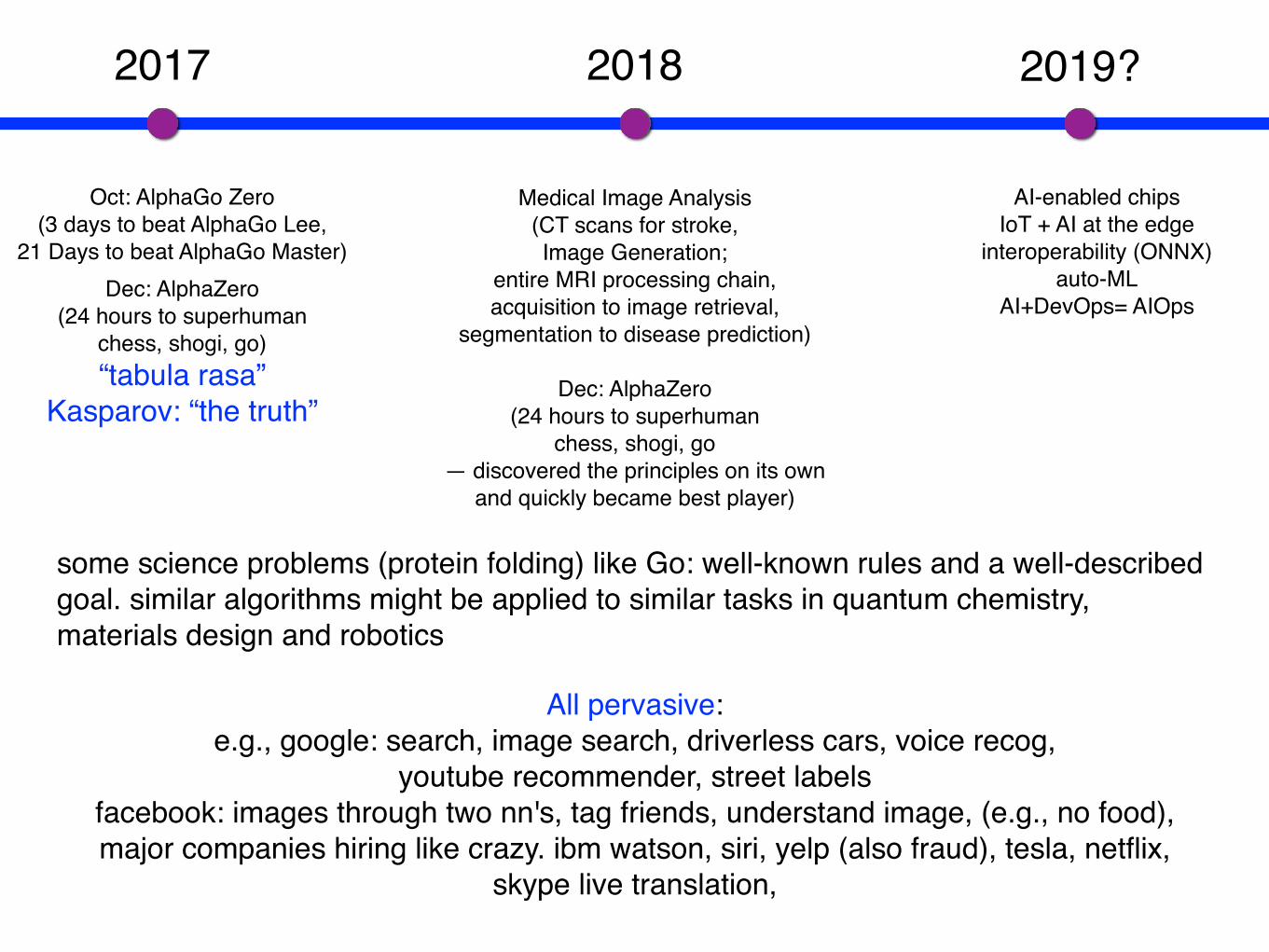
2017
Oct: AlphaGo Zero(3 days to beat AlphaGo Lee,
21 Days to beat AlphaGo Master)
2018 2019?
AI-enabled chipsIoT + AI at the edge
interoperability (ONNX)auto-ML
AI+DevOps= AIOpsDec: AlphaZero
(24 hours to superhumanchess, shogi, go)“tabula rasa”
Kasparov: “the truth”
Medical Image Analysis(CT scans for stroke, Image Generation;
entire MRI processing chain, acquisition to image retrieval,
segmentation to disease prediction)
All pervasive:e.g., google: search, image search, driverless cars, voice recog,
youtube recommender, street labelsfacebook: images through two nn's, tag friends, understand image, (e.g., no food), major companies hiring like crazy. ibm watson, siri, yelp (also fraud), tesla, netflix,
skype live translation,
Dec: AlphaZero(24 hours to superhuman
chess, shogi, go— discovered the principles on its own
and quickly became best player)
some science problems (protein folding) like Go: well-known rules and a well-described goal. similar algorithms might be applied to similar tasks in quantum chemistry, materials design and robotics


How does it all work?
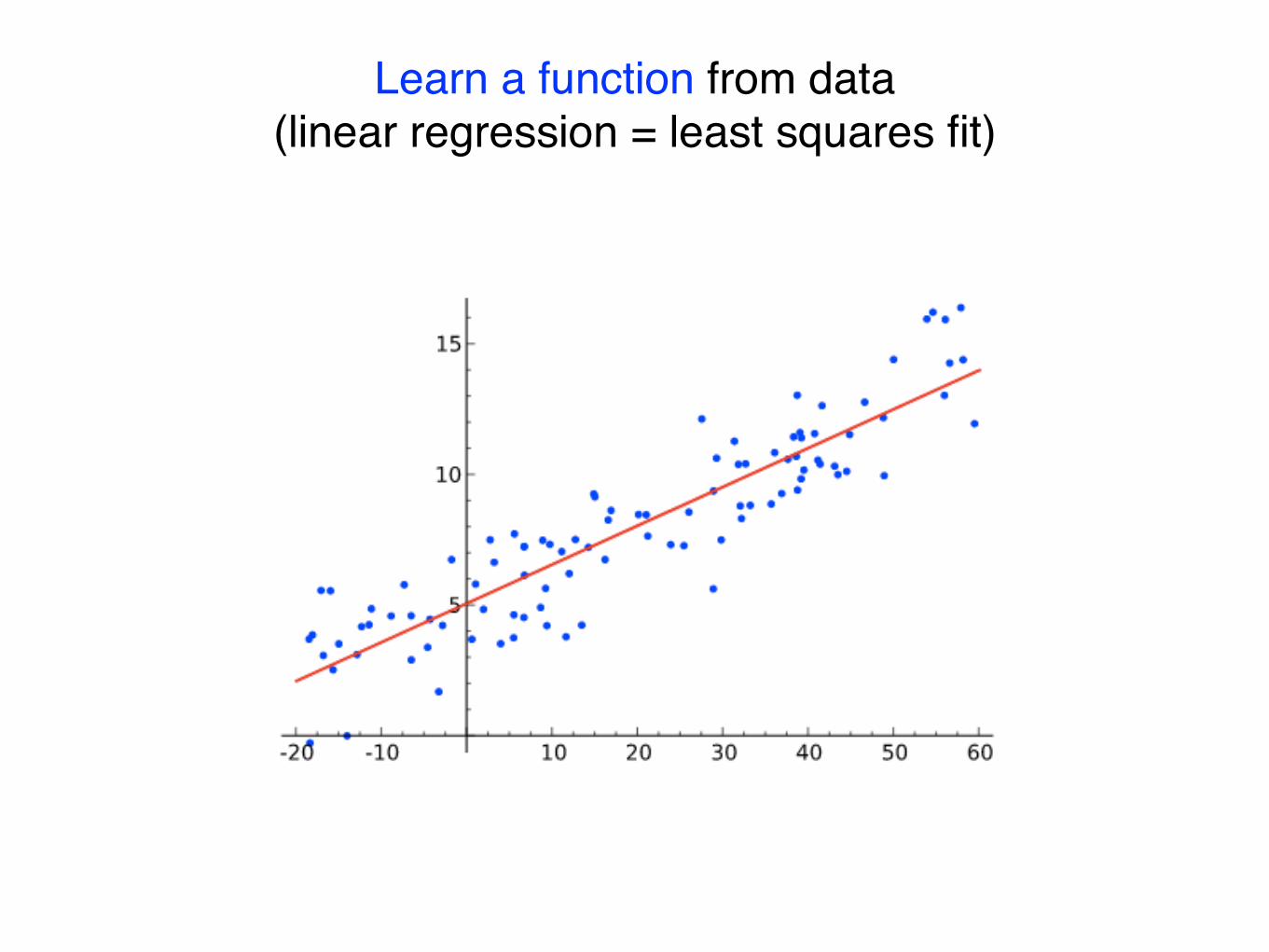
Learn a function from data(linear regression = least squares fit)
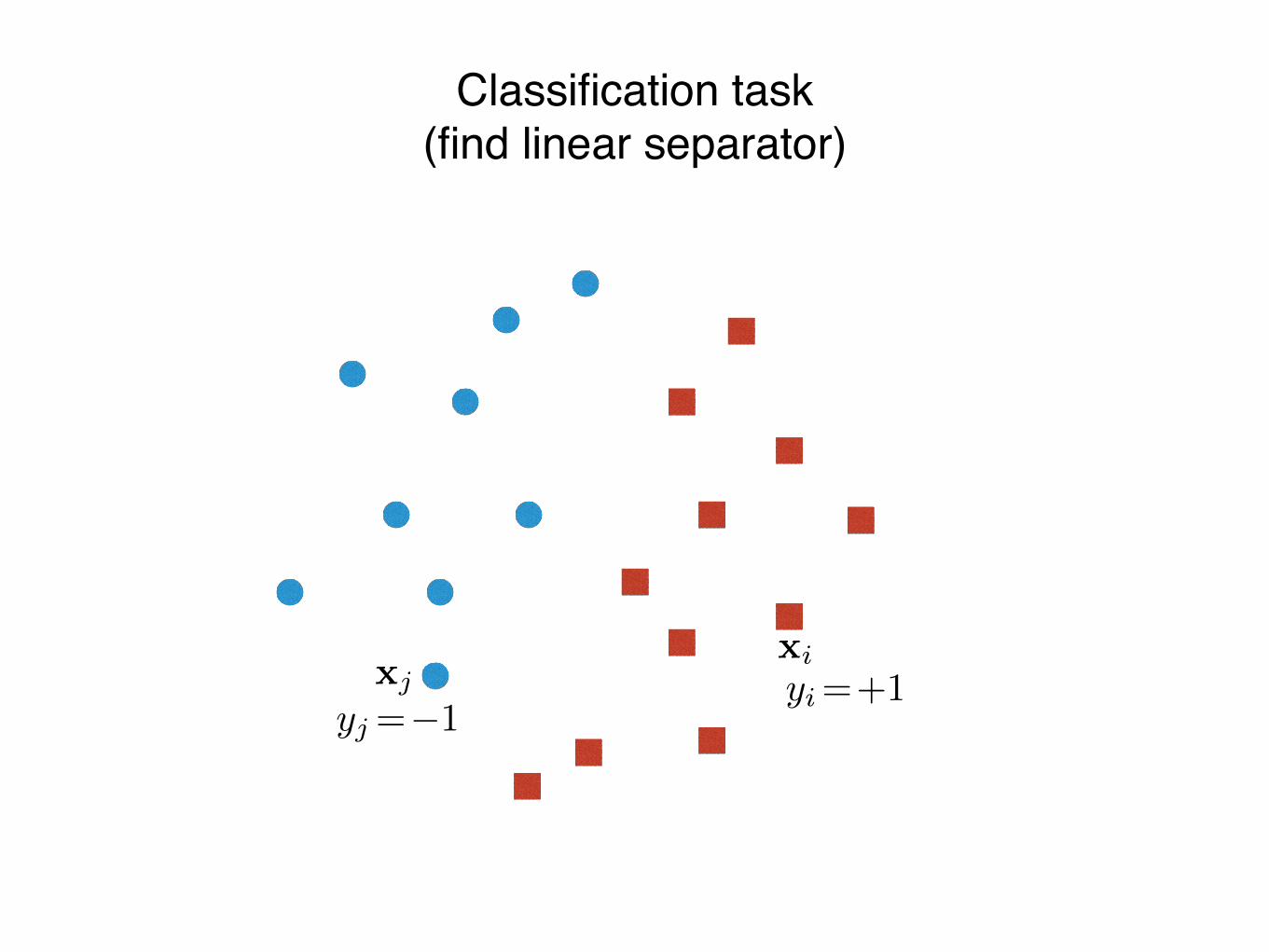
xi
yi=+1yj=�1
xj
Classification task(find linear separator)

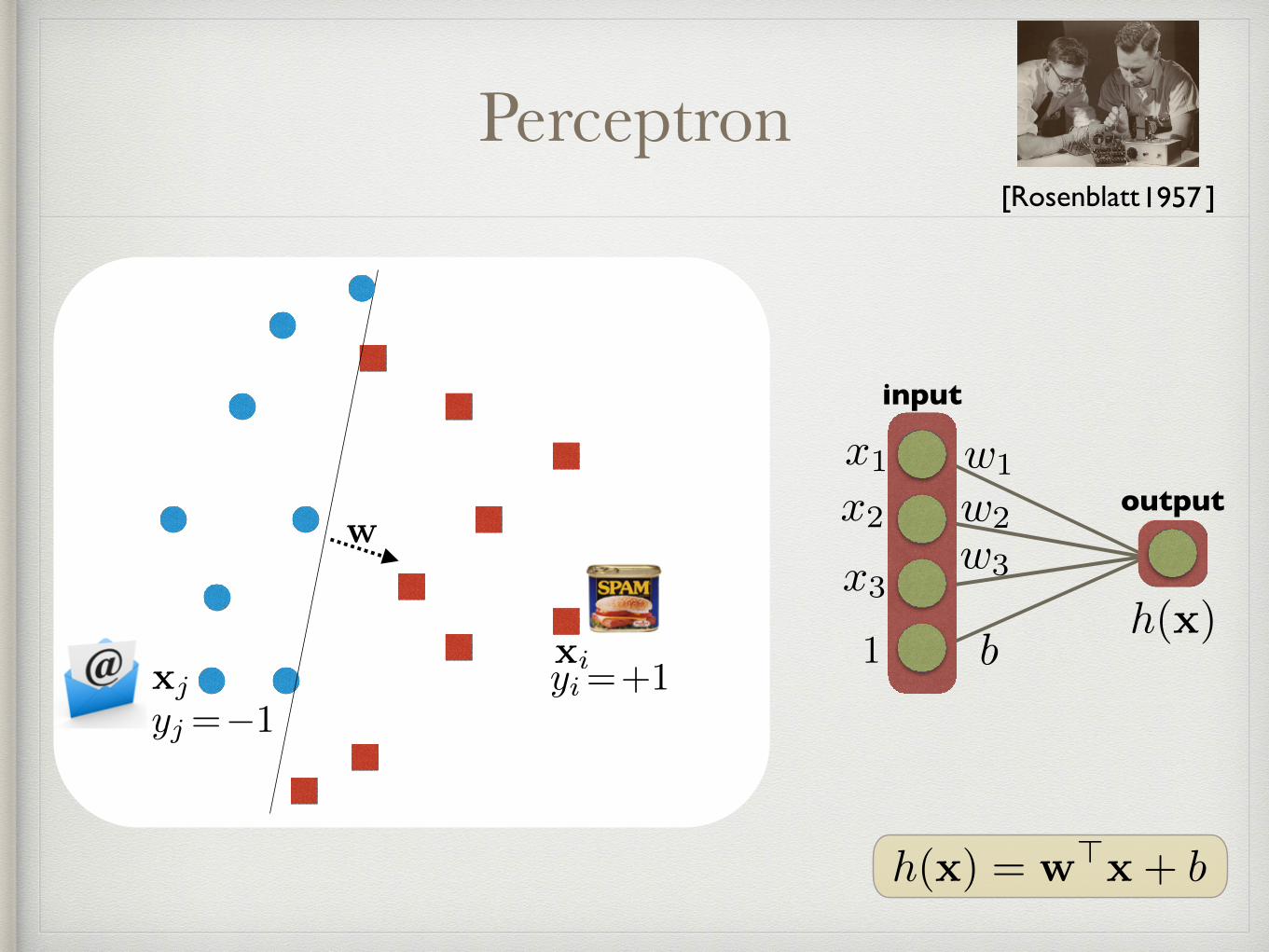
Perceptron
w
xiyi=+1
yj=�1xj
h(x) = w>x+ bh(x) = w>x+ bh(x) = w>x+ b
[Rosenblatt ]1957
F. Rosenblatt, “The perceptron: A probabilistic model for information storage and organization in the brain”,
Psych. Review, Vol. 65, 1958
Perceptron
w
xiyi=+1
yj=�1xj
output
input
h(x)
x1
x2
x3
b
w1
w2w3
1
[Rosenblatt ]
h(x) = w>x+ bh(x) = w>x+ bh(x) = w>x+ b
1957
Dependences are not always linear
Dependences are not always linear
(Except in … )
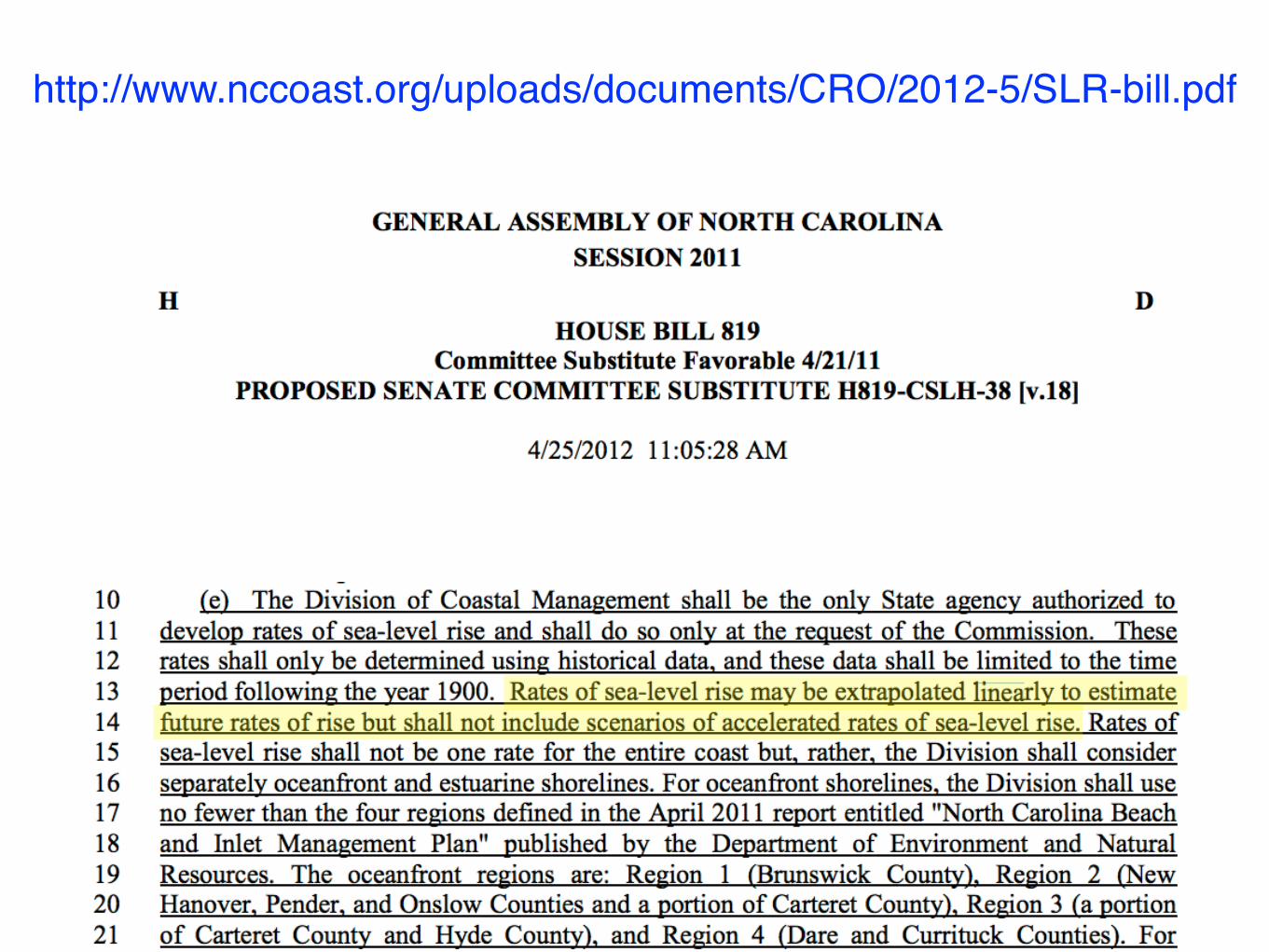
http://www.nccoast.org/uploads/documents/CRO/2012-5/SLR-bill.pdf
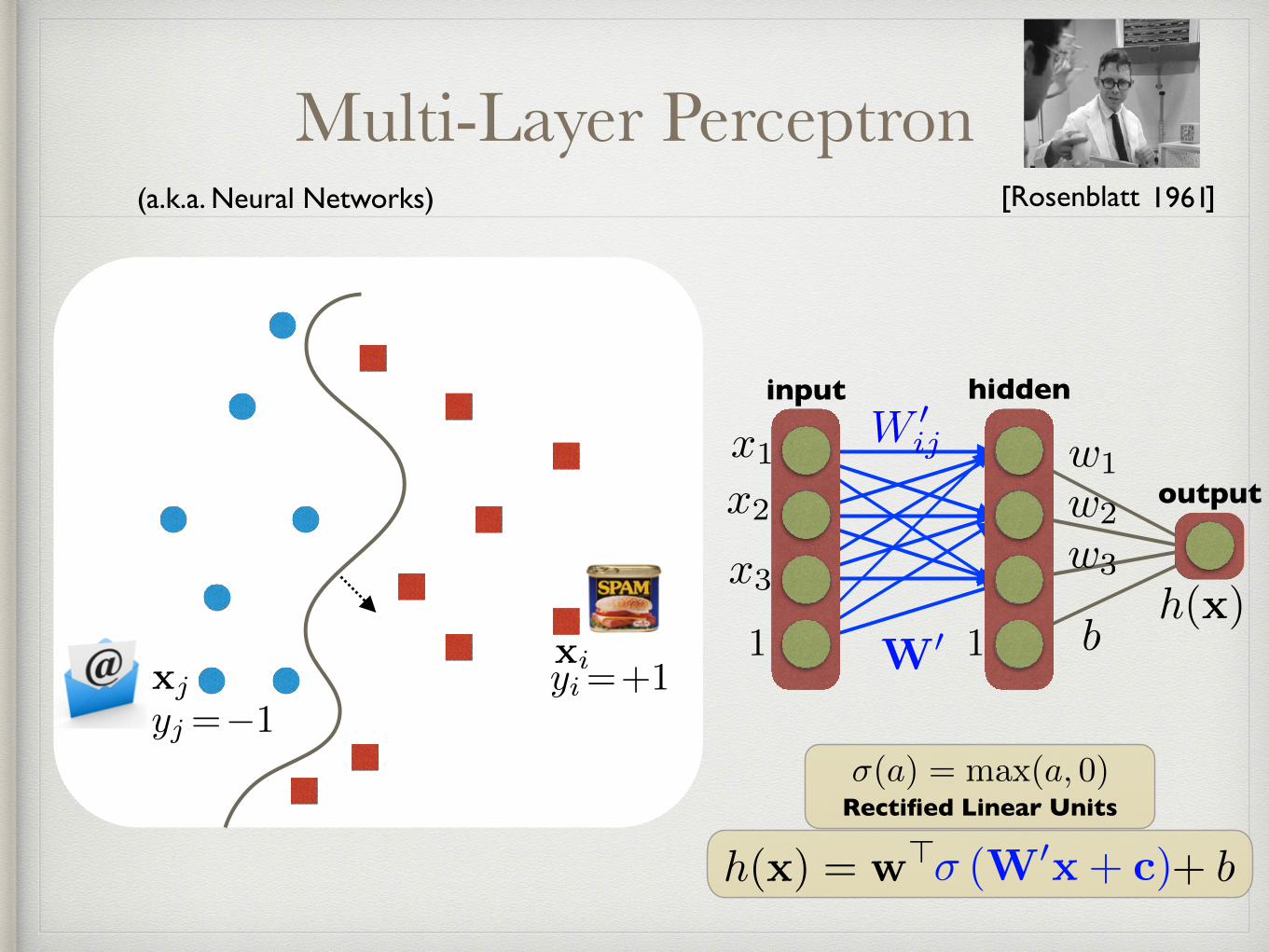
Multi-Layer Perceptron
xiyi=+1
yj=�1xj
�(a) = max(a, 0)Rectified Linear Units
(a.k.a. Neural Networks)
h(x) = w>x+ bh(x) = w>x+ b� (W0x+ c)
hidden
b
w1
w2
w3
input
x1
x2
x3
1
output
h(x)1W0
W 0ij
[Rosenblatt ]1961
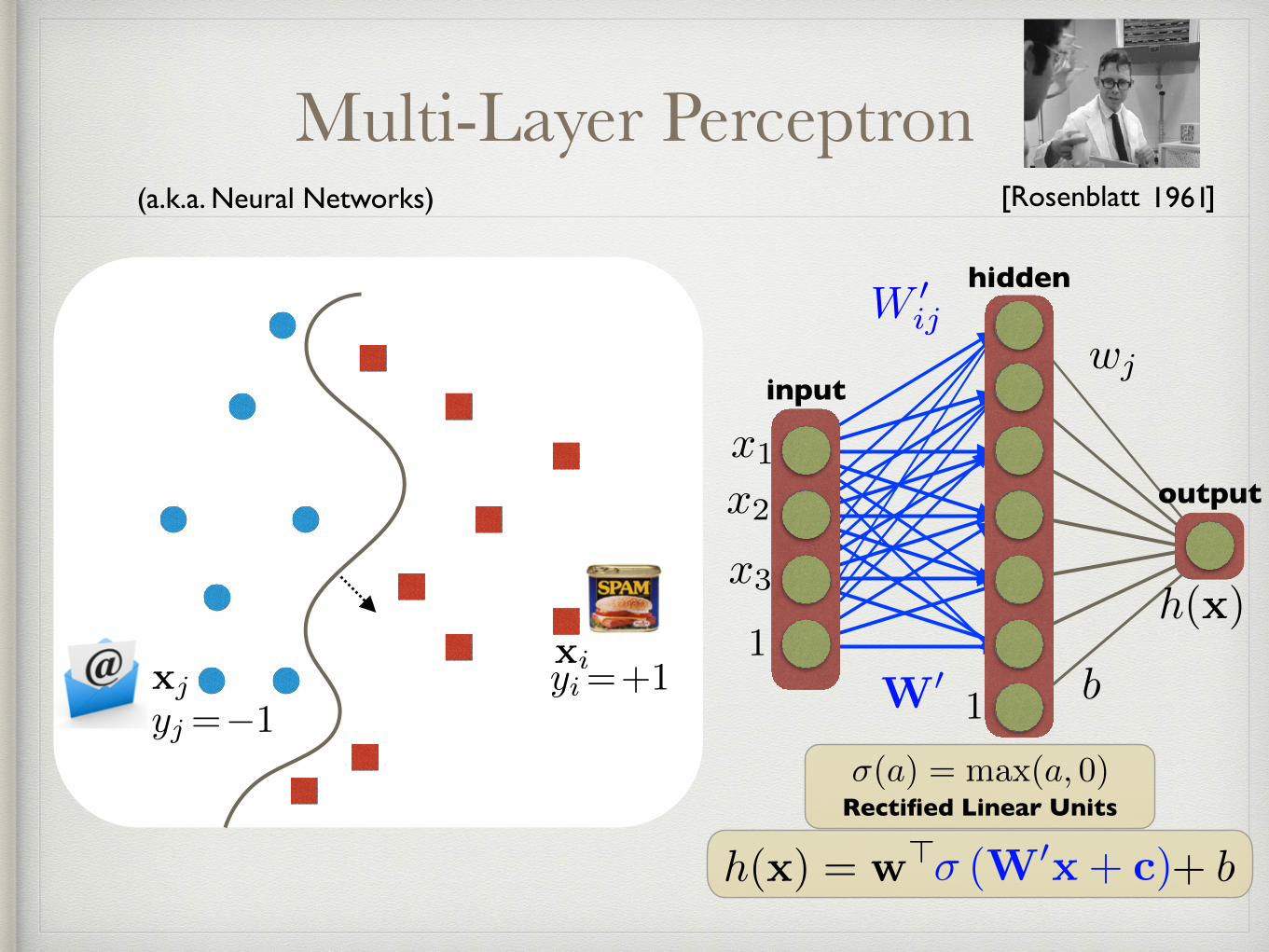
Multi-Layer Perceptron
xiyi=+1
yj=�1xj
�(a) = max(a, 0)Rectified Linear Units
(a.k.a. Neural Networks)
h(x) = w>x+ bh(x) = w>x+ b� (W0x+ c)
hidden
b
input
x1
x2
x3
1
output
h(x)
1
W 0ij
[Rosenblatt ]
wj
W0
1961
Recommended