
www.sungard.com/globalservicesProprietary and Confidential. Not to be distributed or reproduced without permission
Raptor: Real-time Analytics on Hadoop
Aditya YadavATS/Research Head, SunGard India
Soundar VeluProduct Architect, Advanced Technology, SunGard
Information Excellence Summit,February 25, 2012 Bangalorehttp://informationexcellence.wordpress.com/

www.sungard.com/globalservicesProprietary and Confidential. Not to be distributed or reproduced without permission
Aditya Yadav
1
Aditya Yadav heads the ATS/R&D at SunGard India, An Applied Research and Consulting Group which works with Emerging Technologies like Cloud Computing, BigData/Hadoop, GPGPU, Visualization, Statistics and Analytics.
Aditya lead the team that create Raptor - Realtime Hadoop Analytics and is working now on bringing OLAP over Bigdata to the Open Source community. Aditya has earlier worked with Thoughtworks where he worked on Internet Scale Systems, Agile Coaching and Cloud Computing Evangelist.
He is an author of a dozen open source projects, 7+ books and reports. Ran a boutique consulting company and was the CTO at one of the Top 25 Indian Startups.
Aditya YadavHead ATS/R&D
SunGard India

www.sungard.com/globalservicesProprietary and Confidential. Not to be distributed or reproduced without permission
Soundararajan Velu
2
Soundararajan Velu is a product architect with the Advanced Technology team in SunGard.
With extensive experience building enterprise applications and distributed computing products, Soundar’s specialties include building large scale applications and frameworks using Apache-Hadoop and related technologies.
He consults on building low-latency applications and Service Oriented Architectures. Soundar is the creator of some of the highly reused products like SOA Accelerator, CORL Engine and Raptor.
He holds a Computer Science and Engineering degree with distinction from VTU India.
Soundararajan Velu
Product ArchitectSungard

www.sungard.com/globalservicesProprietary and Confidential. Not to be distributed or reproduced without permission
Who We Are, Who Am I, What We Do?
Who We Are & What We Do? Fortune 500 Company Financial Services Firm Provide software & consulting services across the industry Exploring impacts of Big Data approach for last 2+ years
Who Am I?
Part of Applied Research & Consulting group based out of Bangalore, India
We focus on latest technology trends
3

www.sungard.com/globalservicesProprietary and Confidential. Not to be distributed or reproduced without permission
Agenda
Financial Services and Data Problems
Raptor Architecture Overview
Raptor Components
Benchmarks
Future Enhancements
4

www.sungard.com/globalservicesProprietary and Confidential. Not to be distributed or reproduced without permission
Financial Services & Typical “data intensive” Problems
Portfolio Construction Price Forecasting
Risk Calculation
Compliance Surveillance Batch Processing
Demand ForecastingTargeted Marketing
Fraud Detection
Who
lesa
le M
arke
tsR
etai
l M
arke
ts
5
www.sungard.com/globalservicesProprietary and Confidential. Not to be distributed or reproduced without permission
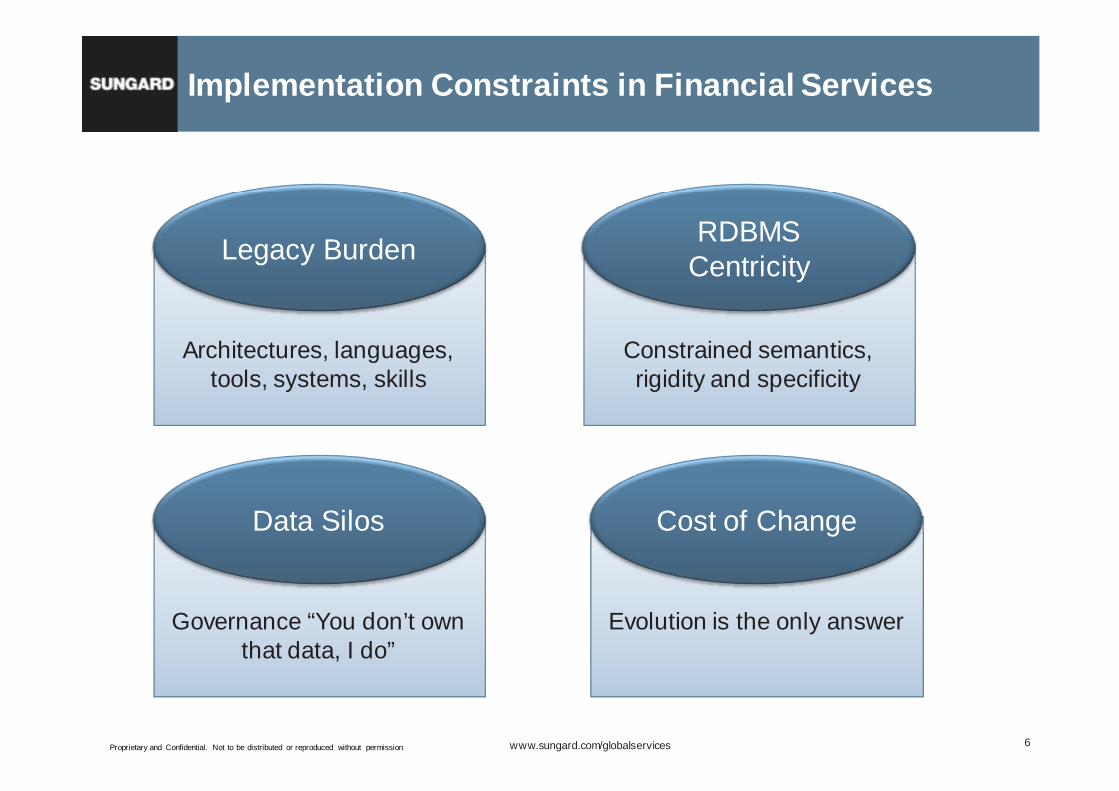
Architectures, languages, tools, systems, skills
Implementation Constraints in Financial Services
Legacy Burden
Governance “You don’t own that data, I do”
Data Silos
Constrained semantics, rigidity and specificity
RDBMS Centricity
Evolution is the only answer
Cost of Change
6

www.sungard.com/globalservicesProprietary and Confidential. Not to be distributed or reproduced without permission
What Did We Need?
A generic, reliable, and cost effective analytics solution with a wide range of application areas
Query execution and analytics at soft real-time windows (acceptable and consistent latencies)
Minimum customization, seamless integration and ease of use
Policy around data storage and processing
Adaptive segmentation algorithms for optimized data search (Indexing, partitioning and filtering)
7

www.sungard.com/globalservicesProprietary and Confidential. Not to be distributed or reproduced without permission
Some Limitations with Traditional Hadoop
8
Jobs are executed in a brute force fashion, causing complete scans of files for every single query
Long warm up time for jobs, performs poorly for relatively smaller data sets.
Scheduling imbalance in HDFS operations and job execution
Limitations around the kind of jobs that can be executed with MapReduce, (non equality joins not supported)
Open bugs and lacking features, memory management bottlenecks
Only for batch mode based applications, does not fit real-time analytics scenarios
www.sungard.com/globalservicesProprietary and Confidential. Not to be distributed or reproduced without permission
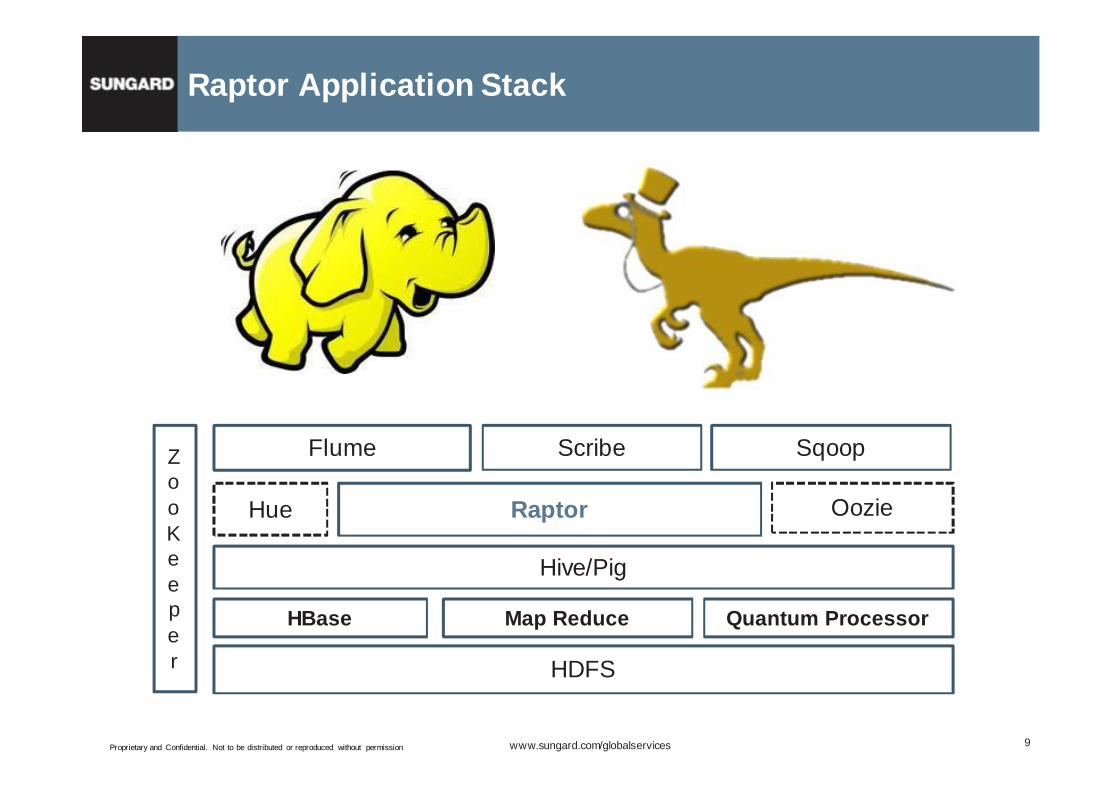
Raptor Application Stack
9
HDFS
Map Reduce
ZooKeeper
HBase
Hive/Pig
Raptor
Flume Sqoop
OozieHue
Quantum Processor
Scribe

www.sungard.com/globalservicesProprietary and Confidential. Not to be distributed or reproduced without permission
Raptor Architecture
10
www.sungard.com/globalservicesProprietary and Confidential. Not to be distributed or reproduced without permission
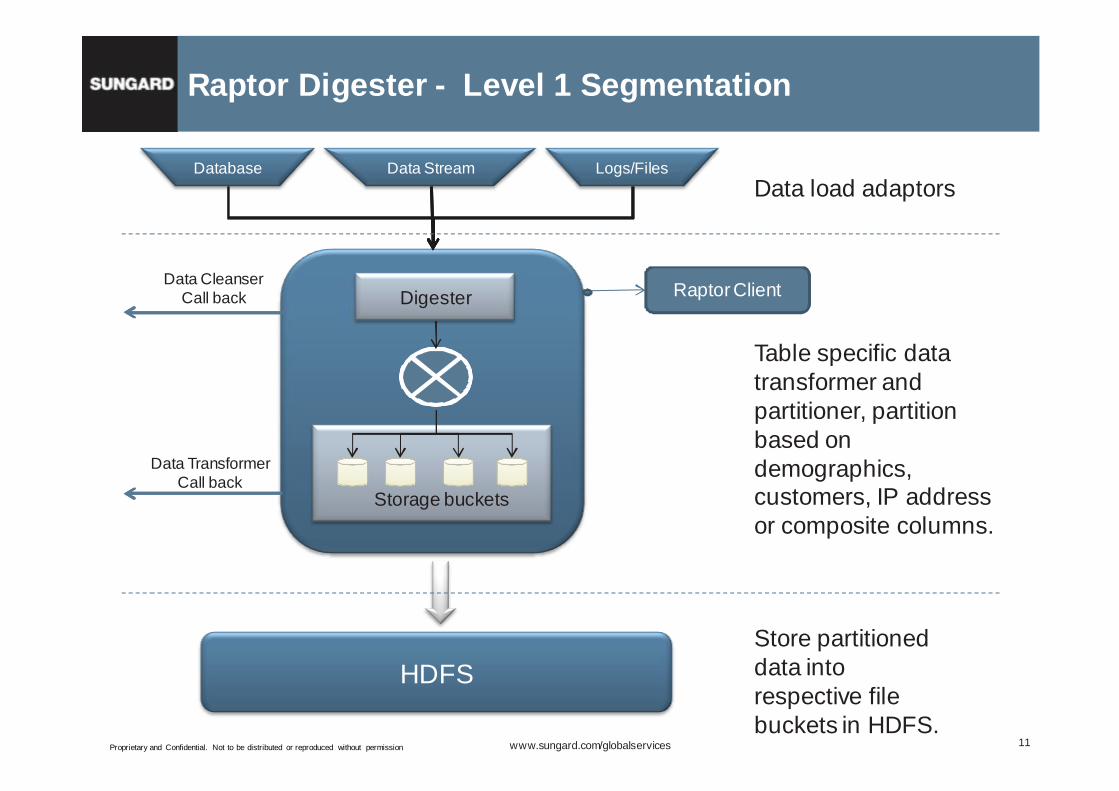
Raptor Digester - Level 1 Segmentation
11
Digester
Storage buckets
HDFS
Database Data Stream Logs/FilesData load adaptors
Table specific data transformer and partitioner, partition based on demographics, customers, IP address or composite columns.
Store partitioned data into respective file buckets in HDFS.
Data CleanserCall back
Data TransformerCall back
Raptor Client

www.sungard.com/globalservicesProprietary and Confidential. Not to be distributed or reproduced without permission
Get
Inde
xer
for
Blo
ck
Raptor Block Analyzer – Level 2 Segmentation
12
DataXceiver
Write Block
Block Analyzer
Thor Block Index Cache
BlockReceiver
DataBlock
DataBlock
Index Queue
Offer BlockID for async-Indexing
Asynchronously analyze/Index Block
Store column meta information, Block index map and column level bloom filters in ThorCache.
Every block is asynchronously analyzed and the resulting column level blooms, index tree and column level meta information is stored in ThorCache. All this happens within the DataNode Context.
Indexer BloomFilter
IndexFactory
Raptor client

www.sungard.com/globalservicesProprietary and Confidential. Not to be distributed or reproduced without permission
Raptor Client Framework
13
Raptor Client
NameNode
DataNode
Raptor-Hive
Block Analyzer
Raptor Executor
Raptor Optimizer
Policy Manager
• Invoke Quantum Processor Services• Manage Indexes• Execute Jobs• Get Block analyzers• Deploy generated infrastructure patch
• Get indexer for block/table• Get Hive Meta-data for table• Get adaptive metrics for table• Get Raptor Meta Data for table• Get digester for Table• Deploy generated infrastructure patch
• Get block info for file• Get file stats
• Get Indexer for block• Mirror Indexer to replica nodes
• Execute internal task• Clean up task• Get result segments
• Get analyzer for table• Get Indexer for table• Get adaptive metrics
• Auto shard buckets• Drop indexes for buckets• Archive Buckets
Digester• Get Digester for table• Get Analyzer for table
Code Generator
Deploy Generated Code
Adaptive Engine
Raptor Client is similar to dfsclient or jobclient, it stands as a primary interface into Raptor.
Re-Index BlockRe-Balance blocks

www.sungard.com/globalservicesProprietary and Confidential. Not to be distributed or reproduced without permission
Getting Results Out – End to End Flow
14
Client Application
Hive JDBC Connection
Execute HQL
StatementThrift Client
Raptor-Hive
Execution
HDFS
Write Results
ResultSetThrift Client
Fetch Task
Client applications create a hive JDBCconnection to Raptor-HiveServer. Client fires HQLQueries over the connection. The query isexecuted by Raptor and a Hive ResultSet isreturned as Result. This is the interface used byClients to access data in HDFS.
Thrift Hive Server
Fetch Results
e.g. “Select Name, CNO, TxID, floor(TxAmt) from Credit_Tx order by CNO”
Quantum ProcessorRaptor Client
Execute Non-HQL queries directly with raptor Client,

www.sungard.com/globalservicesProprietary and Confidential. Not to be distributed or reproduced without permission
Raptor-Hive Processing Engine
15
JDBC Client
HiveMetaStore
Compile
Optimize
Execution Plan
Raptor Executor
MapReduce RaptorQuantum Processor
HBase
Raptor Optimizer
RaptorMetaStore
HiveServer
Raptor Adaptive Engine
Metrics published to Adaptive engine
Get Table Block
AnalyzersDatanodes
Raptor Client

www.sungard.com/globalservicesProprietary and Confidential. Not to be distributed or reproduced without permission
Quantum Processor Framework
16
QuantumProcessor
SearchBlockGetNodeStats
Manage Indexes
ExecuteInternalTask
ExecuteExternalTaskGet File analyzers
ReadResultSegment
ReadBoundaryRecord
RaptorProtocolHelperRaptorClient
QuantumNode is a service similar toDataXceiver on DataNode. AllRaptor operations are executed bythe Quantum Processor framework.
Quantum Node
Hive Executor

www.sungard.com/globalservicesProprietary and Confidential. Not to be distributed or reproduced without permission
Raptor Block Searcher/Processor
17
RaptorClient Process/Search Block
BlockSearcher
Seq Block ReaderBlock Index
/Bloom Available
No
Thor Block Index Cache
Block Index
Column Level Bloom
Column Meta Data
Yes
Result Writer
Quantum Operator
HDFS
QuantumProcessor
Block Searcher analyzes theblock indexes and bloom filtersand extracts the resultantindexed records via indexbased offset reader or if noindexes are available then itdoes a complete blockscan.
Hive Executor
Search Index Tree
Index Block Reader
Process ResultRecords
Process AllRecords

www.sungard.com/globalservicesProprietary and Confidential. Not to be distributed or reproduced without permission
Quantum Operator
18
Quantum OperatorBlock Searcher
Has reduce child?
LocalSegment FileHDFS
No
Yes
Write Result
Inspect Rows Apply UDF
Read Remote Seg
Quantum Operator takes block records as input and performs the required field inspections, and applies UDFs and aggregation. The resultant records are either written to local segment files or to HDFS directly based on the operator type.
Quantum Operators: SelectOperator, JoinOperator, SortByOperator, GropuByOperator, GPUOperator, etc…
Evaluate rows
Offer result rows Read k-remote segment files, if reduce operator.
Write results to k-segmented local files, if child is a reduce operator.
Apply Join/Merge

www.sungard.com/globalservicesProprietary and Confidential. Not to be distributed or reproduced without permission
Adaptive Indexing
19
Raptor Adaptive Engine
Raptor Metadata
Adaptive Index
Scheduler
Collect Execution Metrics
DataNode DataNode DataNode
HDFS
Re Analyze/Index Blocks based on usage/query Metrics
ThorIndex Cache
DataNode
Asynchronous Adaptive Indexer
Execute Hive Queries
Raptor adaptive engine collects metricsfrom the executed queries. Metricsinclude the columns and tables involvedin the query, the types of aggregationexecuted on columns etc… these metricsare used by the adaptive index schedulerto schedule re-indexing of the blocksbased on these usage metrics.

www.sungard.com/globalservicesProprietary and Confidential. Not to be distributed or reproduced without permission
Code Generation and Data Definition Framework
20
Raptor Code Generator
HiveServer
Raptor Adaptive Engine
Hive Metadata
Raptor Metadata
Generate Table Specific Indexers, Bloom Filter , Column Analyzers and digester
Create Hive Table Definitions
Create Raptor Table Metadata
User supplies table schema in an XML format.Based on the Xml table schema and hints,Raptor code generator generates metadata inhive metadata store, HBase and raptor metadatastore. It also generates table specific indexercolumnanalyzers and bloom filter classes.
Raptor Client
Deploy Generated code to Raptor- HiveServer and DataNodes
HBase

www.sungard.com/globalservicesProprietary and Confidential. Not to be distributed or reproduced without permission
…
Raptor Policy Manager – Time Based Shard
21
Raptor Policy Manager
Raptor Metadata
Bucket-1 Bucket-2 Bucket-3
HDFS
Time based auto sharding, as per thepolicy defined by the user. Table bucketsare moved from highly segmented timeshards to sparsely segmented archivestore over time.
Primary Time-Shard
Bucket-1 Bucket-2 Bucket-3 Secondary Time-Shard-1
Bucket-1 Bucket-2 Bucket-3 Archive Store
Completely Segmented
PartiallySegmented
All Segments Mergedand Indexes dropped

www.sungard.com/globalservicesProprietary and Confidential. Not to be distributed or reproduced without permission
Infrastructure Enhancements
Adaptive compression based on network congestion statistics
Scheduling of jobs via raptor client (via Hive) in conjunction
with enhanced NameNode block policy
Computation intensive jobs scheduled on GPU enabled nodes
Object Pools across the Hadoop-Raptor ecosystem
Hand-shake mechanism between clients and DataNodes to
avoid imminent operation failures
Interactive user console for managing the cluster, tasks, data
policy, filters etc…
22

www.sungard.com/globalservicesProprietary and Confidential. Not to be distributed or reproduced without permission
Benchmark Raptor
23
Benchmark carried out on a 5 node cluster with commodity hardware { Core2-Duo, 4GB RAM, 1TB storage, 100Mbps NIC, 64MB block size, Replication factor 3, Network Compression enabled}
Table with 13 columns and mixed types. Sample data generated with node.js with moderate entropy. (table with 1 group index{3 columns} and 0 column bloom filters, 1 bucket}
5 Node Cluster Raptor Map/Reduce
Operation\Table Size 256MB 1GB 10GB 256MB 1GB 10GB
Load Time 4.8s 22s 4.2m 54.6s 3.5m 36.0m
Simple select without predicate 6.9s 22s 3.2m 21.6s 50.5s 9.5m
Select with complex Predicate 0.8s 1.7s 0.9m 9.2s 32.2s 4.1m
Select with Order By 1.6s 6.5s 1.1m 41.0s 3.2m 5.6m
Select with Group By 0.6s 1.2s 0.8m 61.3s 1.5m 4.0m
Simple Join 2.9s 5.7s 1.7m 1.2m 3.4m 9.2m
User Defined row level Function 0.6s 1.1s 0.9m 13.2s 49s 7.3m

www.sungard.com/globalservicesProprietary and Confidential. Not to be distributed or reproduced without permission
Response-Time Trends
24
0
500
1000
1500
2000
256MB 1GB 10GB 50GB 100GB
Map/Reduce
0
20
40
60
80
100
120
256MB 1GB 10GB 50GB 100GB
Raptor
Almost Linear
Almost Logarithmic
Sec
onds
Sec
onds

www.sungard.com/globalservicesProprietary and Confidential. Not to be distributed or reproduced without permission
Case Study: Credit Card Fraud Detection
25
Scribe Server
Scribe Clients
Scribe Clients
Scribe Clients
Cache
Raptor-Hadoop
Raptor Classifier
Mapreduce QuantumProcessor
Raptor Digester
Segment Data into Subsets/Buckets/Partitions
Apply Data Mining Techniques to generate Classifiers in parallel
Combine resultant base models to generate a Meta-Classifier
Raptor Policy ManagerPruning - Removes redundant Classifiers from ensemble
Raptor-HivePeriodic Fraud Report Generation
PG SQL
Analytics Results & ReportsFlagging Cluster
uses Meta-Classifiers to Flag Transactions
Notifications ClusterSends out Notifications
Credit Card Fraud Application

www.sungard.com/globalservicesProprietary and Confidential. Not to be distributed or reproduced without permission
Other Raptor Use Cases
Smart customer care solution
Financial fraud analytics
Media usage log analytics
Computation intensive jobs using GPUs
Predictive trading
26

www.sungard.com/globalservicesProprietary and Confidential. Not to be distributed or reproduced without permission
Roadmap
Merge Raptor into Next Generation MapReduce
Dimensions and Cubes (MRCubes)
Cloud ready Raptor
Roles and security
Job failover management
Rules and triggers
Planning to open source
Starter Kits/Examples of various Use Cases
27

www.sungard.com/globalservicesProprietary and Confidential. Not to be distributed or reproduced without permission
Benefits
Query responses at soft real-time windows.
Code generation framework, for table specific raptor
infrastructure code.
Zero down time, with hot deployment of generated
infrastructure code.
Seamless integration into existing infrastructure with
multiple ingress options.
Automatic time based sharding and data archival.
Distribute & execute non-MR jobs on the Hadoop Cluster28

www.sungard.com/globalservicesProprietary and Confidential. Not to be distributed or reproduced without permission
Contacts
Soundar VeluProduct [email protected]: @greyquest
Aditya YadavATS/Research [email protected]

www.sungard.com/globalservicesProprietary and Confidential. Not to be distributed or reproduced without permission
References
Optimizing Distributed Joins with Bloom Filterswww.l3s.de/web/upload/documents/1/analysis.pdf
Apache Hadoop Goes Realtime at Facebookborthakur.com/ftp/RealtimeHadoopSigmod2011.pdf
Data Mining with MAPREDUCE: Graph and Tensor Algorithms with MRwww.ml.cmu.edu/research/dap-papers/tsourakakisdap.pdf
Distributed Cube Materialization on Holistic Measures∗www.eecs.umich.edu/~congy/work/icde11a.pdf
HadoopDB in Action: Building Real World Applicationswww.cs.yale.edu/homes/dna/papers/hadoopdb-demo.pdf
TeraByte Sort on Apache Hadoopsortbenchmark.org/YahooHadoop.pdf
Mahouth in Actionwww.amazon.com/Mahout-Action-Sean-Owen/dp/1935182684
Web-Scale K-Means Clustering www.eecs.tufts.edu/~dsculley/papers/fastkmeans.pdf
Hive – A Petabyte Scale Data Warehouse Using Hadoopinfolab.stanford.edu/~ragho/hive-icde2010.pdf
30

www.sungard.com/globalservicesProprietary and Confidential. Not to be distributed or reproduced without permission 31
CONFIDENTIALITY STATEMENT
Copyright © 2011 by SunGard Data Systems (or its subsidiaries, “SunGard”). All rights reserved. No parts of this document may be reproduced, transmitted or stored electronically without SunGard’s prior written permission.
This document contains SunGard's confidential or proprietary information. By accepting this document, you agree that: (A)(1) if a pre-existing contract containing disclosure and use restrictions exists between your company and SunGard, you and your company will use this information subject to the terms of the pre-existing contract; or (2) if no such pre-existing contract exists, you and your Company agree to protect this information and not reproduce or disclose the information in any way; and (B) SunGard makes no warranties, express or implied, in this document, and SunGard shall not be liable for damages of any kind arising out of use of this document.

www.sungard.com/globalservicesProprietary and Confidential. Not to be distributed or reproduced without permission
Raptor: Real-time Analytics on Hadoop
32
Recommended




![Making Sense of Performance in Data Analytics …people.csail.mit.edu/.../courses/6.888/papers/analytics.pdfLarge-scale data analytics frameworks such as Hadoop [13] and Spark [51]](https://img.pdfslide.net/doc/110x75/5f886876312b932b271639d8/making-sense-of-performance-in-data-analytics-large-scale-data-analytics-frameworks.jpg)












![ApproxHadoop: Bringing Approximations to MapReduce Frameworks · Hadoop. Hadoop is the best-known, publicly available im-plementation of MapReduce [1]. Hadoop comprises two main parts:](https://img.pdfslide.net/doc/110x75/5e724ec4d1d40462e73e6089/approxhadoop-bringing-approximations-to-mapreduce-frameworks-hadoop-hadoop-is.jpg)