
Introduction
Swapnil Bawaskar@sbawaskar
(incubating)
William Markito@william_markito

• Introduction • What? • Who? • Why? • How? • DEBS • Roadmap
• Q&A
2
Agenda

3
Introduction

A distributed, memory-based data management platform for data oriented apps that need: • high performance, scalability, resiliency and continuous
availability • fast access to critical data set • location aware distributed data processing • event driven data architecture
4
Introduction

• 1000+ systems in production (real customers) • Cutting edge use cases
5
Incubating… but rock solid
2004 2008 2014
• Massive increase in data volumes
• Falling margins per transaction
• Increasing cost of IT maintenance
• Need for elasticity in systems
• Financial Services Providers (every major Wall Street bank)
• Department of Defense
• Real Time response needs • Time to market constraints • Need for flexible data
models across enterprise • Distributed development • Persistence + In-memory
• Global data visibility needs • Fast Ingest needs for data • Need to allow devices to
hook into enterprise data • Always on
• Largest travel Portal • Airlines • Trade clearing • Online gambling
• Largest Telcos • Large mfrers • Largest Payroll processor • Auto insurance giants • Largest rail systems on
earth

• 17 billion records in memory • GE Power & Water's Remote Monitoring & Diagnostics Center
• 3 TB operational data in-memory, 400 TB archived • China Railways
• 4.6 Million transactions a day / 40K transactions a second • China Railways
• 120,000 Concurrent Users • Indian Railways
6
Incubating… but rock solid

World: ~7,349,000,000
~36% of the world population
Population: 1,251,695,6161,401,586,609
China RailwayCorporation
Indian Railways

Incubating… but rock solid
8
oper
atio
ns p
er s
econ
d
0
200000
400000
600000
800000
YCSB Workloads
A Re
ads
A U
pdat
es
B Re
ads
B U
pdat
es
C R
eads
D In
serts
D R
eads
F Re
ads
F U
pdat
es
CassandraGeode

Horizontal scaling for reads, consistent latency and CPU
0
4.5
9
13.5
18
Speedu
p
0
1.25
2.5
3.75
5
ServerHosts2 4 6 8 10
speeduplatency(ms)CPU%
• Scaled from 256 clients and 2 servers to 1280 clients and 10 servers• Partitioned region with redundancy and 1K data size

What makes it go fast?
• Minimize copying
• Minimize contention points
• Run user code in-process
• Partitioning and parallelism
• Avoid disk seeks
• Automated benchmarks

• Clone & Build
11
Hands-on: Build & run
gitclonehttps://github.com/apache/incubator-geodecdincubator-geode./gradlewbuild-Dskip.tests=true
• Start a servercdgemfire-assembly/build/install/apache-geode./bin/gfshgfsh>startlocator--name=locatorgfsh>startserver--name=servergfsh>createregion--name=myRegion--type=REPLICATE
$dockerrun-itapachegeode/geode:1.0.0-incubating.M1gfsh
• Docker

Hands on

• Cache • Region • Member • Client Cache • Functions • Listeners • High Availability • Serialization
13
Concepts

• Cache
• In-memory storage and management for your data
• Configurable through XML, Java API or CLI
• Collection of Region
14
Concepts
Region
Region
Region
Cache
JVM

• Region
• Distributed java.util.Map on steroids (Key/Value)
• Consistent API regardless of where or how data is stored
• Observable (reactive)
• Highly available, redundant on cache Member (s).
15
Concepts
Region
Cache
java.util.Map
JVM
Key Value
K01 May
K02 Tim

• Region
• Local, Replicated or Partitioned
• In-memory or persistent
• Redundant
• LRU
• Overflow
16
Concepts
Region
Cache
java.util.Map
JVM
Key Value
K01 May
K02 Tim
Region
Cache
java.util.Map
JVM
Key Value
K01 May
K02 Tim
LOCALLOCAL_HEAP_LRULOCAL_OVERFLOWLOCAL_PERSISTENTLOCAL_PERSISTENT_OVERFLOWPARTITIONPARTITION_HEAP_LRUPARTITION_OVERFLOWPARTITION_PERSISTENTPARTITION_PERSISTENT_OVERFLOWPARTITION_PROXYPARTITION_PROXY_REDUNDANTPARTITION_REDUNDANTPARTITION_REDUNDANT_HEAP_LRUPARTITION_REDUNDANT_OVERFLOWPARTITION_REDUNDANT_PERSISTENTPARTITION_REDUNDANT_PERSISTENT_OVERFLOWREPLICATEREPLICATE_HEAP_LRUREPLICATE_OVERFLOWREPLICATE_PERSISTENTREPLICATE_PERSISTENT_OVERFLOWREPLICATE_PROXY

• Persistent Regions
• Durability
• WAL for efficient writing
• Consistent recovery
• Compaction
17
Concepts
Modify k1->v5
Create k6->v6
Create k2->v2
Create k4->v4 Oplog2.crf
Member 1
Modify k4->v7 Oplog3.crf
Put k4->v7
Region
Cache
java.util.Map
JVM
Key Value
K01 May
K02 Tim
Region
Cache
java.util.Map
JVM
Key Value
K01 May
K02 Tim
Server 1 Server N
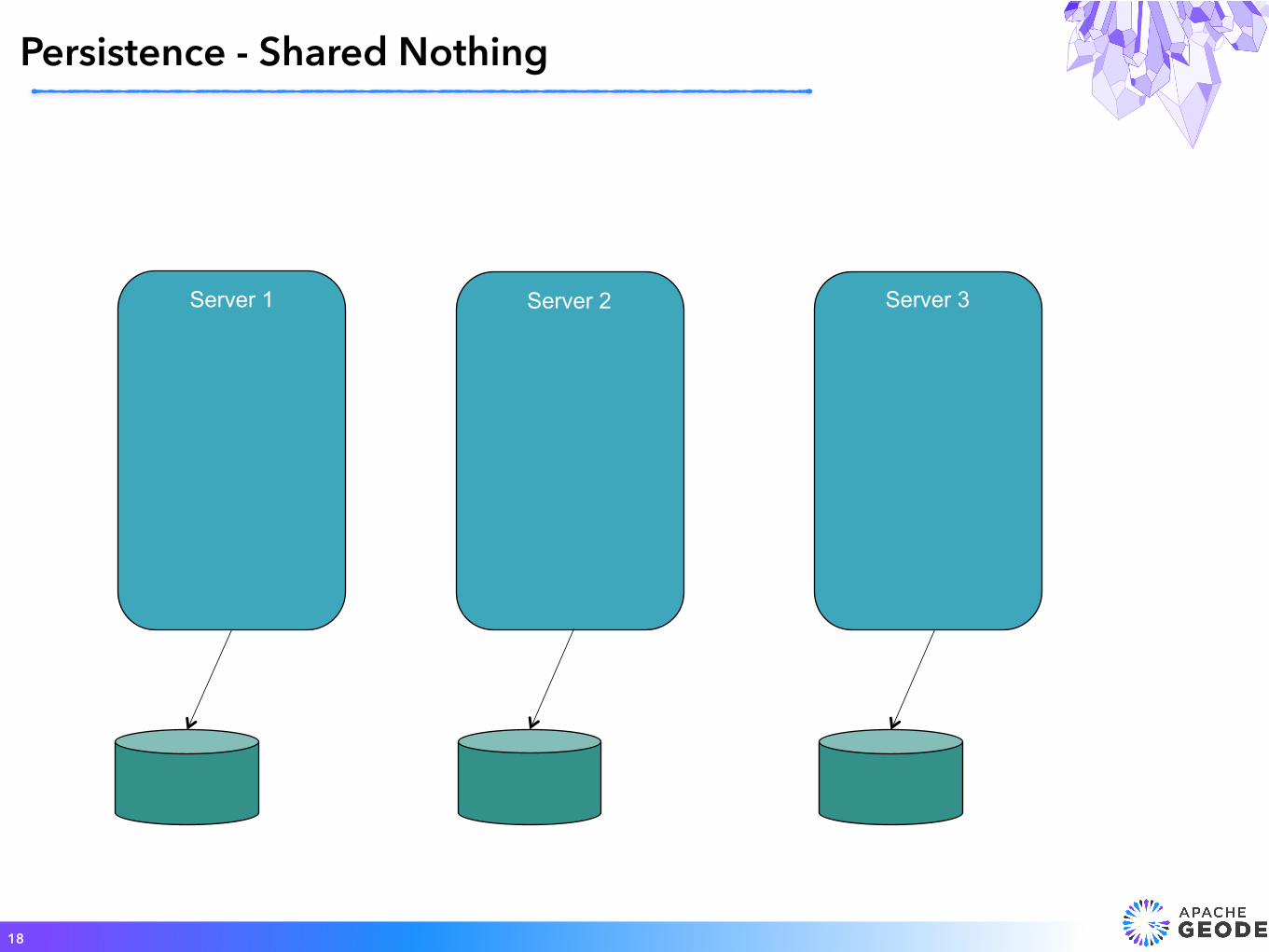
Persistence - Shared Nothing
18
Server 3Server 2Server 1

Persistence - Shared Nothing
19
Server 3Server 2Server 1
B1
B3
B2
B1
B3
B2
Primary
Secondary

Persistence - Shared Nothing
20
Server 3Server 2Server 1
B1
B3
B2
B1
B3
B2
Primary
Secondary
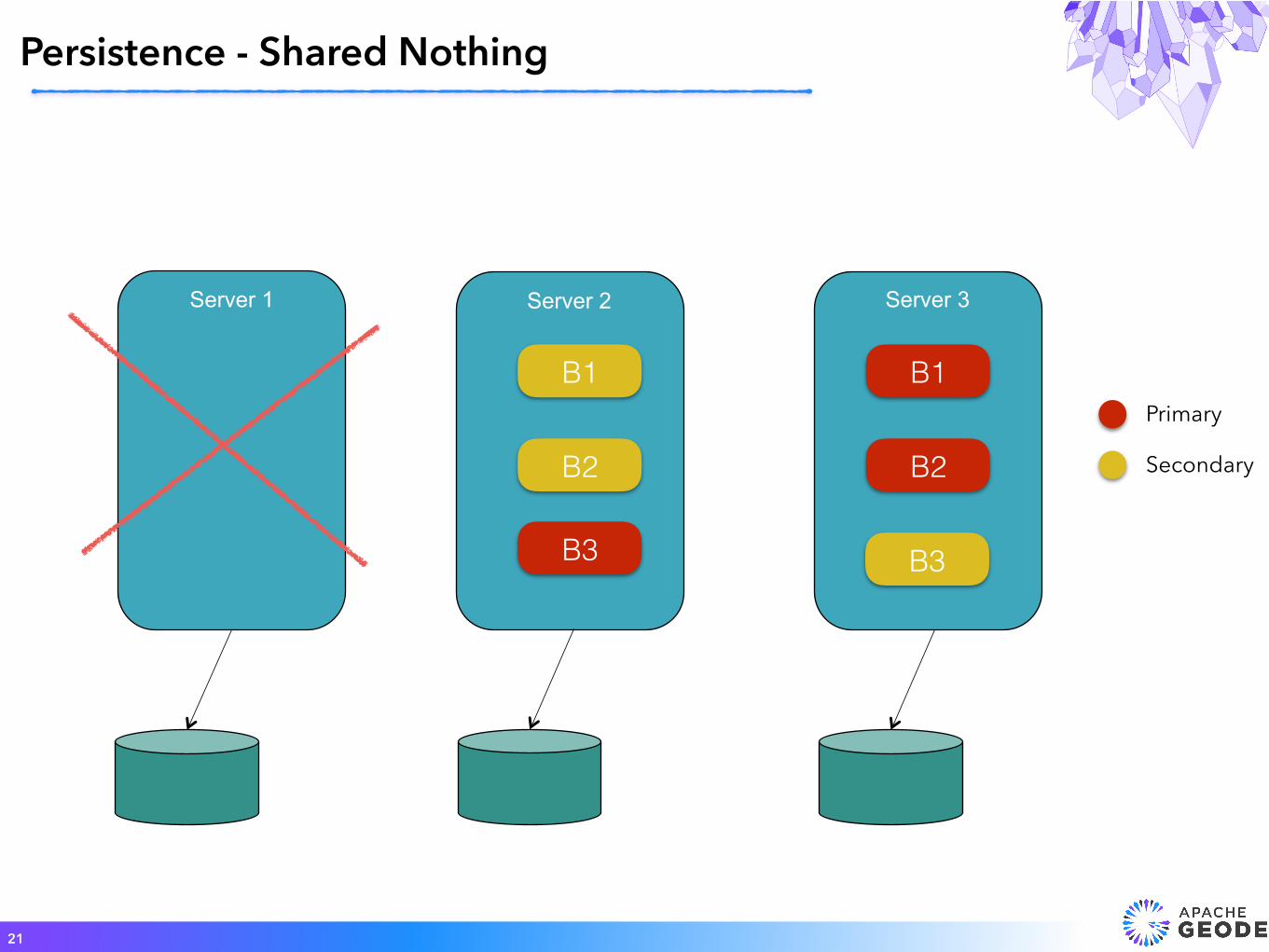
Persistence - Shared Nothing
21
Server 3Server 2Server 1
B1
B3
B2
B1
B3
B2
Primary
Secondary

Persistence - Shared Nothing
22
Server 3Server 2Server 1
B1
B3
B2
B1
B3
B2
Primary
Secondary
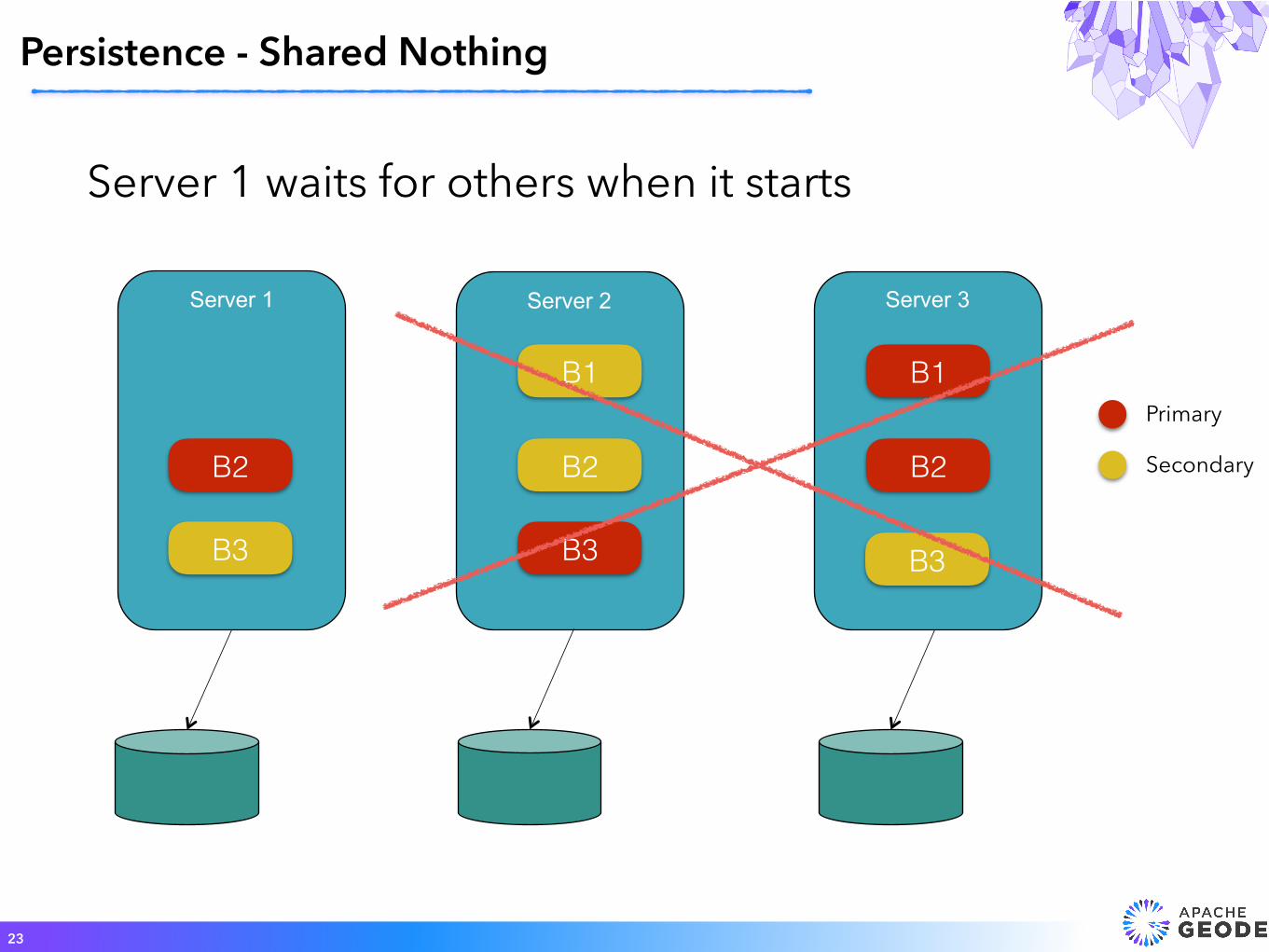
Persistence - Shared Nothing
23
Server 3Server 2Server 1
B1
B3
B2
B1
B3
B2
Primary
Secondary
B3
B2
Server 1 waits for others when it starts

Persistence - Shared Nothing
24
Server 3Server 2Server 1
B1
B3
B2
B1
B3
B2
Primary
Secondary
Fetches missed operations on restart

Persistence - Operational Logs
25
Create k1->v1
Create k2->v2
Modifyk1->v3
Create k4->v4
Modify k1->v5
Create k6->v6
Member 1Put k6->v6
Oplog2.crf
Oplog1.crf
Append to operation log

Persistence - Operational Logs - Compaction
26
Create k1->v1
Create k2->v2
Modifyk1->v3
Create k4->v4
Modify k1->v5
Create k6->v6
Member 1Put k6->v6
Oplog2.crf
Oplog1.crf
Append to operation log
Copy live data forward

• Member
• A process that has a connection to the system
• A process that has created a cache
• Embeddable within your application
27
Concepts
Client
Locator
Server

• Client cache
• A process connected to the Geode server(s)
• Can have a local copy of the data
• Run OQL queries on local data
• Can be notified about events on the servers
28
Concepts
Application
GemFire Server
Region
Region
Region Client Cache

• Client Notifications • Register Interest
• Individual Keys OR RegEx for Keys • Updates Local Copy
• Examples: • region.registerInterest(“key-1”); • region1.registerInterestRegex(“[a-z]+“);
• Continuous Query • Receive Notification when Query condition met
on server • Example:
• SELECT * FROM /tradeOrder t WHERE t.price > 100.00
• Can be DURABLE
Concepts
29

• Functions
• Used for distributed concurrent processing (Map/Reduce, stored procedure)
• Highly available
• Data oriented
• Member oriented
30
Concepts
Submit (f1)
f1 , f2 , … fn
Execute Functions
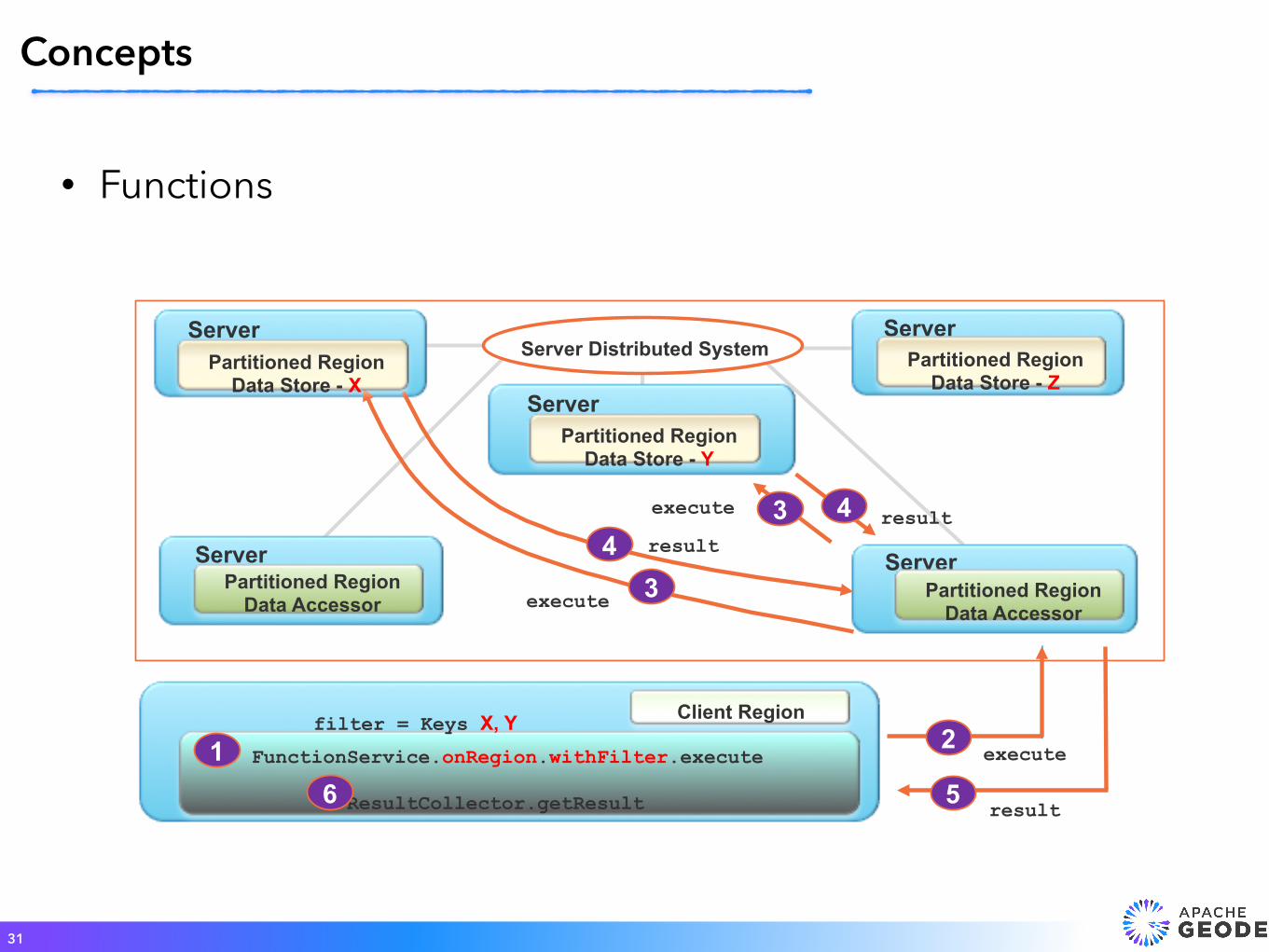
31
Concepts
Server
Server
FunctionService.onRegion.withFilter.execute ResultCollector.getResult
Server Distributed System
execute
Server
Server
6
1
result
execute
execute
result result
2
5
3
4 3 4
Server
Partitioned Region Data Store - X
Partitioned Region Data Store - Y
Partitioned Region Data Store - Z
Partitioned Region Data Accessor
Partitioned Region Data Accessor
filter = Keys X, Y Client Region
• Functions

• Listeners
• CacheWriter / CacheListener
• AsyncEventListener (queue / batch)
• Parallel or Serial
• Conflation
32
Concepts

Concepts - HA
33

Fixed or flexible schema?
id name age pet_id
or
{id:1,name:“Fred”,age:42,pet:{name:“Barney”,type:“dino”}}

C#, C++, Java, JSON
No IDL, no schemas, no hand-coding Schema evolution (Forward and Backward Compatible)
* domain object classes not required
|header|data||pdx|length|dsid|typeid|fields|offsets|
Portable Data eXchange

Efficient for queries
{id:1,name:“Fred”,age:42,pet:{name:“Barney”,type:“dino”}}
SELECTp.nameFROM/PersonpWHEREp.pet.type=“dino”
single field deserialization

But how to serialize data?
Benchmark: https://github.com/eishay/jvm-serializers

Schema evolutionMember A Member B
Distributed Type Definitions
v2v1
Application #1
Application #2
v2 objects preserve data from missing fields
v1 objects use default values to fill in new fields
PDX provides forwards and backwards compatibility, no code required

Adapters
39

• write-through as opposed to cache-aside
• Stale Cache • Inconsistent Cache • Thundering Heards
memcached
40

• Scalable Data-Structures • Use All Cores • WAN Replication
Redis
41

TAXI TRIP ANALYSIS (DEBS GRAND-CHALLENGE)
WITH APACHE GEODE
William Markito Oliveira
(INCUBATING)
TAXI TRIP ANALYSIS (DEBS GRAND-CHALLENGE)
WITH APACHE GEODE
Swapnil [email protected]

INTRODUCTION
DEBS
▸ Distributed Event-Based Systems
▸ Grand challenges (2013, 2014, 2015, 2016…)
▸ Analyze NY Taxi Trip information 2013*
▸ 12 GB in size and ~173 million events.
▸ Most profitable areas
▸ Most frequent routes
* FOIL (The Freedom of Information Law)

INTRODUCTION
DEBS


IMPLEMENTATION

IMPLEMENTATION
HOW
▸ AsyncEvent Listener
▸ Parallel or Serialpublic class FrequentRouterListener implements AsyncEventListener, Declarable { … public boolean processEvents(List<AsyncEvent> list) { … // PDX object deserializing single field pickupDatetime = (Date) taxiTrip.getField("pickup_datetime"); … // some processing with events
}
}
- Memory - Threads - Persistence - Batch size - Batch interval
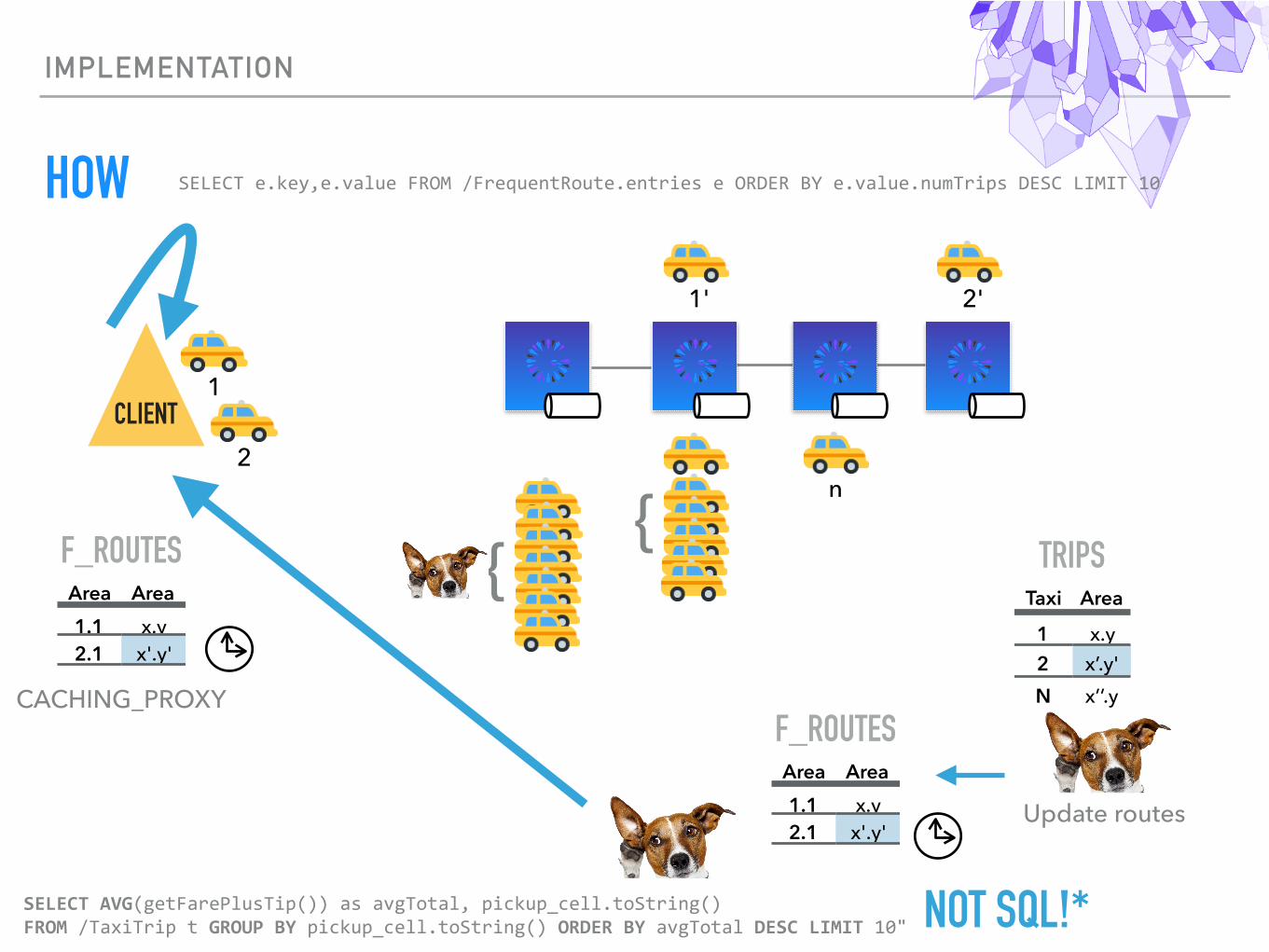
IMPLEMENTATION
HOW
CLIENT1
1'
2
3
2 n
{{
TRIPSTaxi Area
1 x.y2 x’.y' N x’’.y
F_ROUTESArea Area1.1 x.y2.1 x'.y'
Update routes
SELECTAVG(getFarePlusTip())asavgTotal,pickup_cell.toString() FROM/TaxiTriptGROUPBYpickup_cell.toString()ORDERBYavgTotalDESCLIMIT10"
F_ROUTESArea Area1.1 x.y2.1 x'.y'
CACHING_PROXY
NOT SQL!*
2'
SELECTe.key,e.valueFROM/FrequentRoute.entrieseORDERBYe.value.numTripsDESCLIMIT10

IMPLEMENTATION
HOW
TRIPSTaxi Area
1 x.y2 x’.y' N x’’.y
F_ROUTESArea Area1.1 x.y2.1 x'.y'
‣ Evict entries older than 15 seconds ‣ Replicated ‣ Listener attached
‣ Historical with memory eviction to disk ‣ Partitioned across nodes ‣ Async listener with queue

Demo

• Off-heap memory storage • Cloud Foundry service • Lucene Search* • HDFS Persistence* • Spark Integration*
51
Roadmap
* -Experimental and waiting community feedback

• Code • New features • Bug fixes • Writing tests
• Documentation • Wiki • Web site • User guide
52
How to Contribute
• Community • Join the mailing list
• Ask or answer • Join our HipChat • Become a speaker • Finding bugs • Testing an RC/Beta

• Website http://geode.incubator.apache.org/ • JIRA
https://issues.apache.org/jira/browse/GEODE • Wiki
cwiki.apache.org/confluence/display/GEODE • GitHub
https://github.com/apache/incubator-geode • Mailing lists
mail-archives.apache.org/mod_mbox/incubator-geode-dev/
53
Links

54
Thank youhttp://geode.incubator.apache.org
https://github.com/Pivotal-Open-Source-Hub
Recommended

















