
Advanced Distributed Computing 1
Introduction to Information Retrieval
(Supplementary Material)
Zhou Shuigeng
March 17, 2006

Advanced Distributed Computing 2
Text Databases and IRText databases (document databases)
Large collections of documents from various sources: news articles, research papers, books, digital libraries, e-mail messages, and Web pages, library database, etc.
Data stored is usually semi-structured
Information retrievalA field developed in parallel with database systems
Information is organized into (a large number of) documents
Information retrieval problem: locating relevant documents based on user input, such as keywords or example documents

Advanced Distributed Computing 3
Information RetrievalTypical IR systems
Online library catalogsOnline document management systems
Information retrieval vs. database systemsSome DB problems are not present in IR, e.g., update, transaction management, complex objectsSome IR problems are not addressed well in DBMS, e.g., unstructured documents, approximate search using keywords and relevance

Advanced Distributed Computing 4
Basic Measures for Text RetrievalPrecision: the percentage of retrieved documents that are in fact relevant to the query (i.e., “correct” responses)
Recall: the percentage of documents that are relevant to the query and were, in fact, retrieved
|}{||}{}{|
RelevantRetrievedRelevantprecision ∩
=
|}{||}{}{|
RetrievedRetrievedRelevantprecision ∩
=
recall
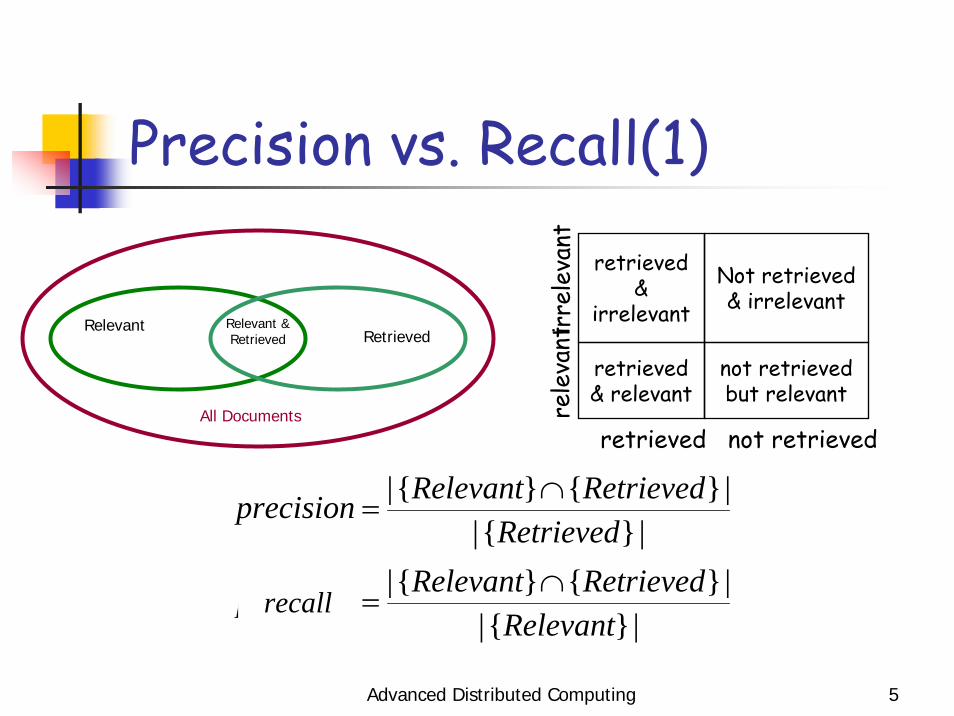
Advanced Distributed Computing 5
Precision vs. Recall(1)
Relevant Relevant & Retrieved Retrieved
All Documents
|}{||}{}{|
RetrievedRetrievedRelevantprecision ∩
=
|}{||}{}{|
RelevantRetrievedRelevantprecision ∩
=recall
retrieved & relevant
not retrieved but relevant
retrieved &
irrelevant
Not retrieved & irrelevant
retrieved not retrieved
rele
vant i
rrel
evan
t
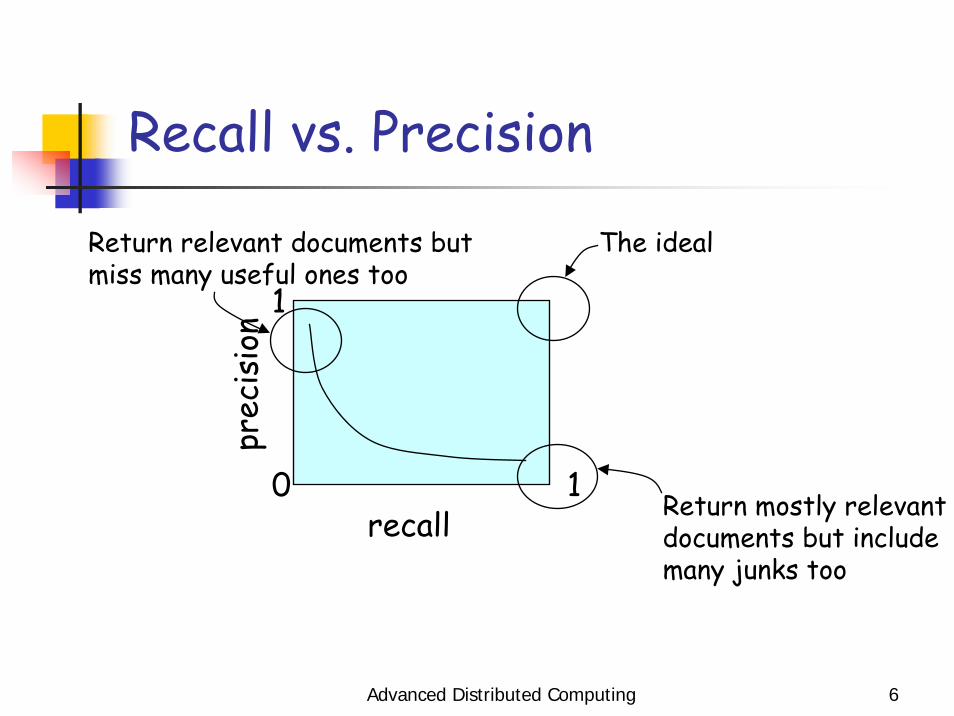
Advanced Distributed Computing 6
Recall vs. Precision
10
1
recall
prec
isio
n
Return mostly relevantdocuments but includemany junks too
The idealReturn relevant documents butmiss many useful ones too

Advanced Distributed Computing 7
IR Techniques(1)Basic Concepts
A document can be described by a set of representative keywords called index terms.Different index terms have varying relevance when used to describe document contents.This effect is captured through the assignment of numerical weights to each index term of a document. (e.g.: frequency, tf-idf)
DBMS AnalogyIndex Terms AttributesWeights Attribute Values

Advanced Distributed Computing 8
IR Techniques(2)Index Terms (Attribute) Selection:
Stop listWord stemIndex terms weighting methods
Terms Documents Frequency MatricesInformation Retrieval Models:
Boolean ModelVector ModelProbabilistic Model

Advanced Distributed Computing 9
Stop WordsFrom a given Stop Word List
[a, about, again, are, the, to, of, …]Remove them from the documents
Or, determine stop wordsGiven a large enough corpus of common EnglishSort the list of words in decreasing order of their occurrence frequency in the corpusZipf’s law: Frequency * rank ≈ constant
most frequent words tend to be shortmost frequent 20% of words account for 60% of usage
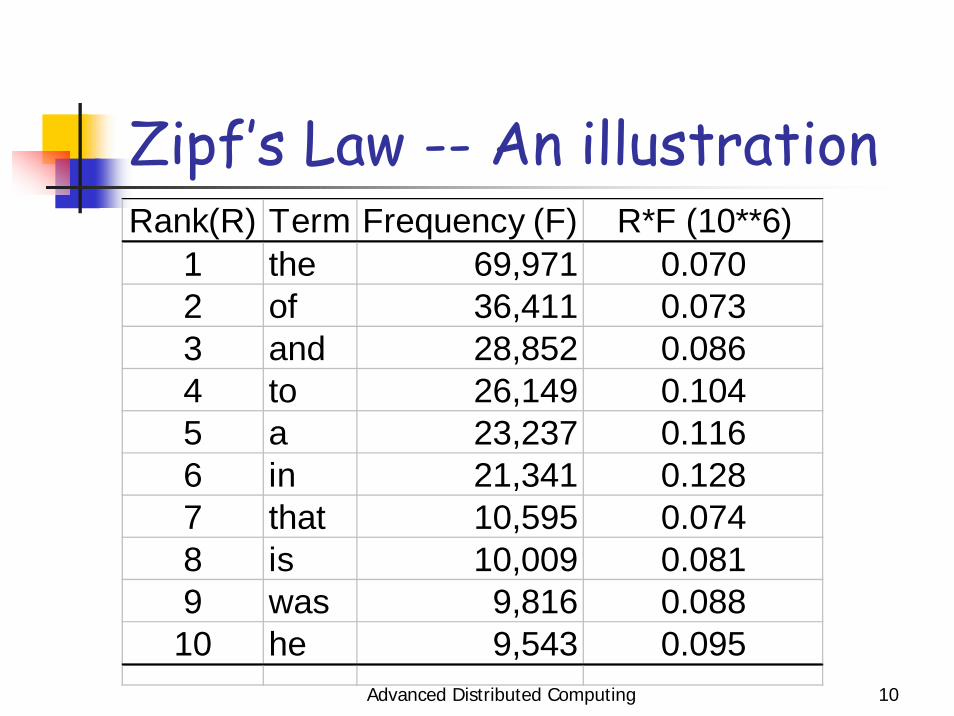
Advanced Distributed Computing 10
Zipf’s Law -- An illustrationRank(R) Term Frequency (F) R*F (10**6)
1 the 69,971 0.0702 of 36,411 0.0733 and 28,852 0.0864 to 26,149 0.1045 a 23,237 0.1166 in 21,341 0.1287 that 10,595 0.0748 is 10,009 0.0819 was 9,816 0.08810 he 9,543 0.095
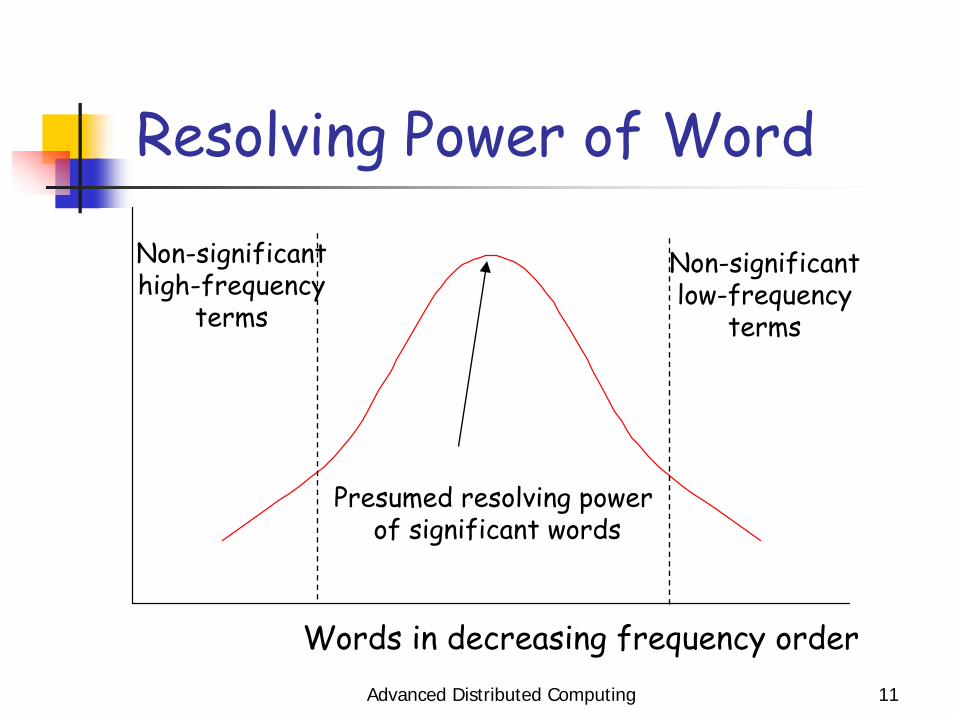
Advanced Distributed Computing 11
Resolving Power of Word
Words in decreasing frequency order
Non-significanthigh-frequency
terms
Non-significantlow-frequency
terms
Presumed resolving powerof significant words

Advanced Distributed Computing 12
Simple Indexing Scheme Based on Zipf’s Law
Compute frequency of term k in document i, FreqikDetermine total collection frequency
TotalFreqk = ∑ Freqik for i = 1, 2, …, nArrange terms in order of collection frequencySet thresholds - eliminate high and low frequency termsUse remaining terms as index terms
Use term frequency information only:

Advanced Distributed Computing 13
StemmingStemming: transforming words to root form
Computing, Computer, Computation comput
Suffix based methodsRemove “ability” from “computability”“…”+ness, “…”+ive, remove
Suffix list + context rules

Advanced Distributed Computing 14
Thesaurus RulesA thesaurus aims at
classification of words in a languagefor a word, it gives related terms which are broader than, narrower than, same as(synonyms) and opposed to (antonyms) of the given word (other kinds of relationships may exist, e.g., composed of)
Static Thesaurus Tables[anneal, strain], [antenna, receiver], …Roget’s thesaurusWordNet at Preinceton

Advanced Distributed Computing 15
Thesaurus Rules can also be LearnedFrom a search engine query log
After typing queries, browse…If query1 and query2 leads to the same document
Then, Similar(query1, query2)If query1 leads to Document with title keyword K,
Then, Similar(query1, K)Then, transitivity…

Advanced Distributed Computing 16
Indexing TechniquesInverted index
Maintains two hash- or B+-tree indexed tables: document_table: a set of document records <doc_id, postings_list> term_table: a set of term records, <term, postings_list>
Answer query: Find all docs associated with one or a set of terms+ easy to implement– do not handle well synonymy and polysemy, and posting lists could be too long (storage could be very large)
Signature fileAssociate a signature with each documentA signature is a representation of an ordered list of terms thatdescribe the documentOrder is obtained by frequency analysis, stemming and stop lists

Advanced Distributed Computing 17
Boolean ModelConsider that index terms are either present or absent in a documentAs a result, the index term weights are assumed to be all binariesA query is composed of index terms linked by three connectives: not, and, and or
e.g.: car and repair, plane or airplaneThe Boolean model predicts that each document is either relevant or non-relevant based on the match of a document to the query

Advanced Distributed Computing 18
Boolean Model: Keyword-Based RetrievalA document is represented by a string, which can be identified by a set of keywordsQueries may use expressions of keywords
E.g., car and repair shop, tea or coffee, DBMS but notOracleQueries and retrieval should consider synonyms, e.g., repair and maintenance
Major difficulties of the modelSynonymy: A keyword T does not appear anywhere in the document, even though the document is closely related to T, e.g., data miningPolysemy: The same keyword may mean different things in different contexts, e.g., mining

Advanced Distributed Computing 19
The Vector-Space ModelThe distinct terms are available; call them index terms or the vocabularyThe index terms represent important terms for an application a vector to represent the document
<T1,T2,T3,T4,T5> or <W(T1),W(T2),W(T3),W(T4),W(T5)>
T1=architectureT2=busT3=computerT4=databaseT5=xml
computer sciencecollection
index terms or vocabularyof the collection

Advanced Distributed Computing 20
The Vector-Space ModelAssumptions: words are uncorrelated
T1 T2 …. TtD1 d11 d12 … d1tD2 d21 d22 … d2t: : : :: : : :Dn dn1 dn2 … dnt
Given:1. N documents and a Query2. Query considered a document
too2. Each represented by t terms
3. Each term j in document i hasweight
4. We will deal with how to compute the weights later
ijdt21 qqqQ ...
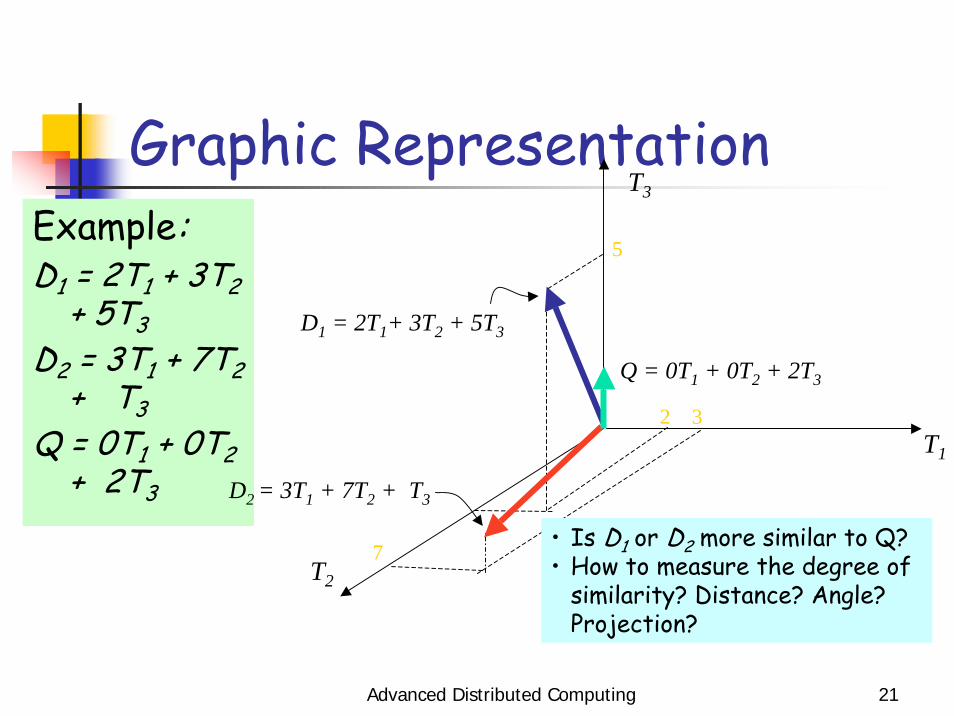
Advanced Distributed Computing 21
Graphic RepresentationExample:D1 = 2T1 + 3T2
+ 5T3D2 = 3T1 + 7T2
+ T3Q = 0T1 + 0T2
+ 2T3
T3
T1
T2
D1 = 2T1+ 3T2 + 5T3
D2 = 3T1 + 7T2 + T3
Q = 0T1 + 0T2 + 2T3
7
32
5
• Is D1 or D2 more similar to Q?• How to measure the degree of
similarity? Distance? Angle? Projection?

Advanced Distributed Computing 22
Similarity Measure - Inner Product
Similarity between documents Di and query Qcan be computed as the inner vector product:
sim ( Di , Q ) = (Di • Q)
Binary: weight = 1 if word present, 0 o/wNon-binary: weight represents degree of similary
Example: TF/IDF we explain later
k
t
=∑
1
∑=
=t
jjij qd
1*

Advanced Distributed Computing 23
Inner Product -- Examples
Binary:D = 1, 1, 1, 0, 1, 1, 0
Q = 1, 0 , 1, 0, 0, 1, 1
sim(D, Q) = 3
retrie
val
database
archite
cture
computer
textman
agement
informati
on Size of vector = size of vocabulary = 7
WeightedD1 = 2T1 + 3T2 + 5T3
Q = 0T1 + 0T2 + 2T3sim(D1 , Q) = 2*0 + 3*0 + 5*2 = 10

Advanced Distributed Computing 24
Properties of Inner Product
The inner product similarity is unboundedFavors long documents
long document ⇒ a large number of unique terms, each of which may occur many timesmeasures how many terms matched but not how many terms not matched

Advanced Distributed Computing 25
Cosine Similarity MeasuresCosine similarity measures the cosine of the angle between two vectorsInner product normalized by the vector lengths θ2
t3
t1
t2
D1
D2
Q
θ1
∑ ∑
∑
= =
=
•
•
t
k
t
k
t
kkik
qd
qd
kik1 1
22
1)(
CosSim(Di, Q) =

Advanced Distributed Computing 26
Cosine Similarity: an Example
D1 = 2T1 + 3T2 + 5T3 CosSim(D1 , Q) = 5 / √ 38 = 0.81D2 = 3T1 + 7T2 + T3 CosSim(D2 , Q) = 1 / √ 59 = 0.13Q = 0T1 + 0T2 + 2T3
D1 is 6 times better than D2 using cosine similarity but only 5 times better using inner product

Advanced Distributed Computing 27
Document and Term WeightsDocument term weights are calculated using frequencies in documents (tf) and in collection (idf)
tfij = frequency of term j in document idf j = document frequency of term j
= number of documents containing term jidfj = inverse document frequency of term j
= log2 (N/ df j) (N: number of documents in collection)Inverse document frequency -- an indication of term values as a document discriminator.

Advanced Distributed Computing 28
Term Weight CalculationsWeight of the jth term in ith document:
dij = tfij• idfj = tfij• log2 (N/ df j)
TF Term FrequencyA term occurs frequently in the document but rarely in the remaining of the collection has a high weightLet maxl{tflj} be the term frequency of the most frequent term in document jNormalization: term frequency = tfij /maxl{tflj}

Advanced Distributed Computing 29
An example of TFDocument=(A Computer Science Student Uses Computers)Vector Model based on keywords (Computer, Engineering, Student)Tf(Computer) = 2Tf(Engineering)=0Tf(Student) = 1Max(Tf)=2TF weight for:
Computer = 2/2 = 1Engineering = 0/2 = 0Student = ½ = 0.5

Advanced Distributed Computing 30
Inverse Document FrequencyDfj gives the number of times term jappeared among N documentsIDF = 1/DFTypically use log2 (N/ df j) for IDFExample: given 1000 documents, computer appeared in 200 of them,
IDF= log2 (1000/ 200) =log2(5)

Advanced Distributed Computing 31
TF IDFdij = (tfij /maxl{tflj}) • idfj
= (tfij /maxl {tflj}) • log2 (N/ df j)Can use this to obtain non-binary weightsUsed in the SMART Information Retrieval System by the late Gerald Salton and MJ McGill, Cornell University to tremendous success, 1983
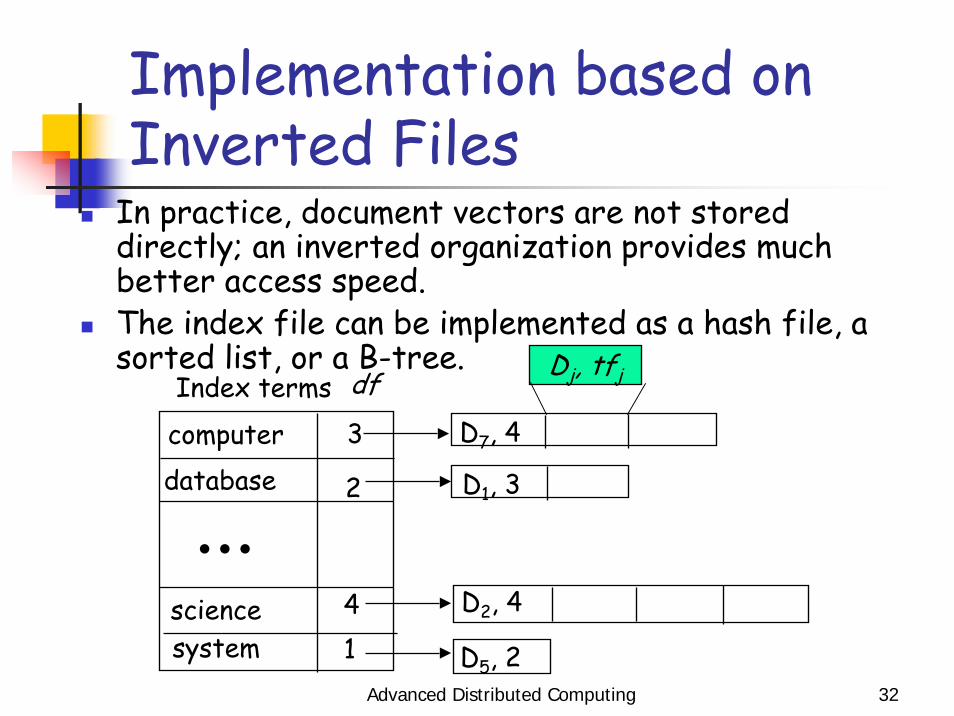
Advanced Distributed Computing 32
Implementation based on Inverted Files
In practice, document vectors are not stored directly; an inverted organization provides much better access speed. The index file can be implemented as a hash file, a sorted list, or a B-tree.
system
computerdatabase
science D2, 4
D5, 2
D1, 3
D7, 4Index terms df
3
2
41
Dj, tfj
• • •

Advanced Distributed Computing 33
Latent Semantic Indexing (1)Basic idea
The size of the term frequency matrix is very largeUse a singular value decomposition (SVD) techniques to reduce the size of frequency tableRetain the K most significant rows of the frequency table
MethodCreate a term x document weighted frequency matrix ASVD construction: A = U * S * V’Define K and obtain Uk ,, Sk , and Vk.Create query vector q’ .Project q’ into the term-document space: Dq = q’ * Uk * Sk
-1
Calculate similarities: cos α = Dq . D / ||Dq|| * ||D||
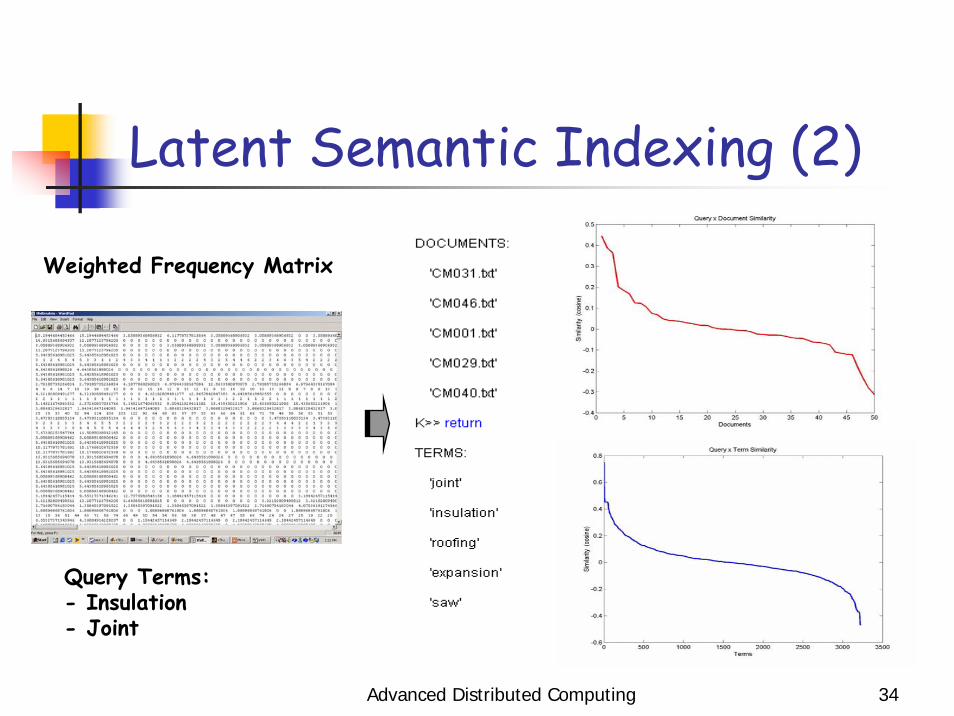
Advanced Distributed Computing 34
Latent Semantic Indexing (2)
Weighted Frequency Matrix
Query Terms:- Insulation- Joint

Advanced Distributed Computing 35
Probabilistic ModelBasic assumption: Given a user query, there is a set of documents which contains exactly the relevant documents and no other (ideal answer set)Querying process as a process of specifying the properties of an ideal answer set. Since these properties are not known at query time, an initial guess is madeThis initial guess allows the generation of a preliminary probabilistic description of the ideal answer set which is used to retrieve the first set of documentsAn interaction with the user is then initiated with the purpose of improving the probabilistic description of the answer set

Advanced Distributed Computing 36
ReferenceRichardo Baeza-Yates, Berthir Ribeiro-Neto, Modern Information Retrieval, Addison Wesley, 机械工业出版社影印出版, 2004
Recommended

















