
Leveraging Lucene/Solr as a Knowledge Graph and Intent Engine Trey Grainger
Director of Engineering, Search & Recommendations
2015.10.15

Trey Grainger Director of Engineering, Search & Recommendations • Joined CareerBuilder in 2007 as a Software Engineer • MBA, Management of Technology – Georgia Tech • BA, Computer Science, Business, & Philosophy – Furman University • Mining Massive Datasets (in progress) - Stanford University
Fun outside of CB:
• Co-author of Solr in Action, plus a handful of research papers • Frequent conference speaker • Founder of Celiaccess.com, the gluten-free search engine • Lucene/Solr contributor
About Me

Agenda • Introduc/on • Defining the problem – the need for Seman/c Search • Building an Intent Engine -‐ Type-‐ahead predic/on -‐ Spelling Correc/on -‐ En/ty / En/ty-‐type Resolu/on -‐ Seman/c Query Parsing -‐ Query Augmenta/on -‐ The Knowledge Graph
• Conclusion Knowledge
Graph
At CareerBuilder, Solr Powers... At CareerBuilder, Solr Powers...

Search by the Numbers
5
Powering 50+ Search Experiences Including:
100 million + Searches per day
30+ SoRware Developers, Data
Scien/sts + Analysts
500+ Search Servers
1,5 billion + Documents indexed and
searchable
1 Global Search
Technology plaUorm
...and many more

What’s the problem we’re trying to solve today? User’s Query:
machine learning research and development Portland, OR soRware engineer AND hadoop, java
Tradi>onal Query Parsing: (machine AND learning AND research AND development AND portland) OR (soRware AND engineer AND hadoop AND java) Seman>c Query Parsing: "machine learning" AND "research and development" AND "Portland, OR" AND "soRware engineer" AND hadoop AND java Seman>cally Expanded Query: ("machine learning"^10 OR "data scien/st" OR "data mining" OR "ar/ficial intelligence") AND ("research and development"^10 OR "r&d") AND AND ("Portland, OR"^10 OR "Portland, Oregon" OR {!geofilt pt=45.512,-‐122.676 d=50 sfield=geo}) AND ("soRware engineer"^10 OR "soRware developer") AND (hadoop^10 OR "big data" OR hbase OR hive) AND (java^10 OR j2ee)
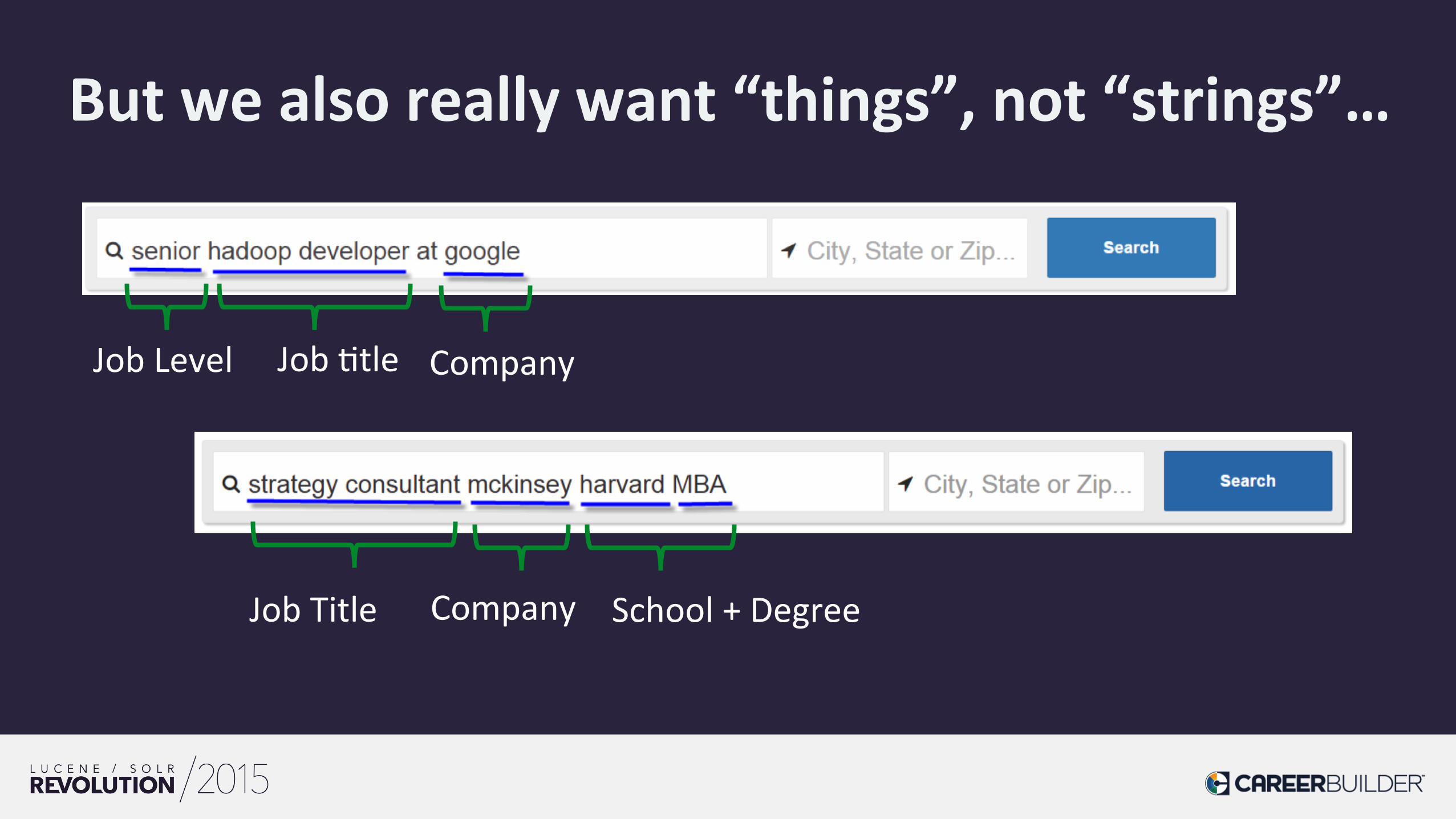
But we also really want “things”, not “strings”…
Job Level Job /tle Company
Job Title Company School + Degree
Type-‐ahead Predic/on
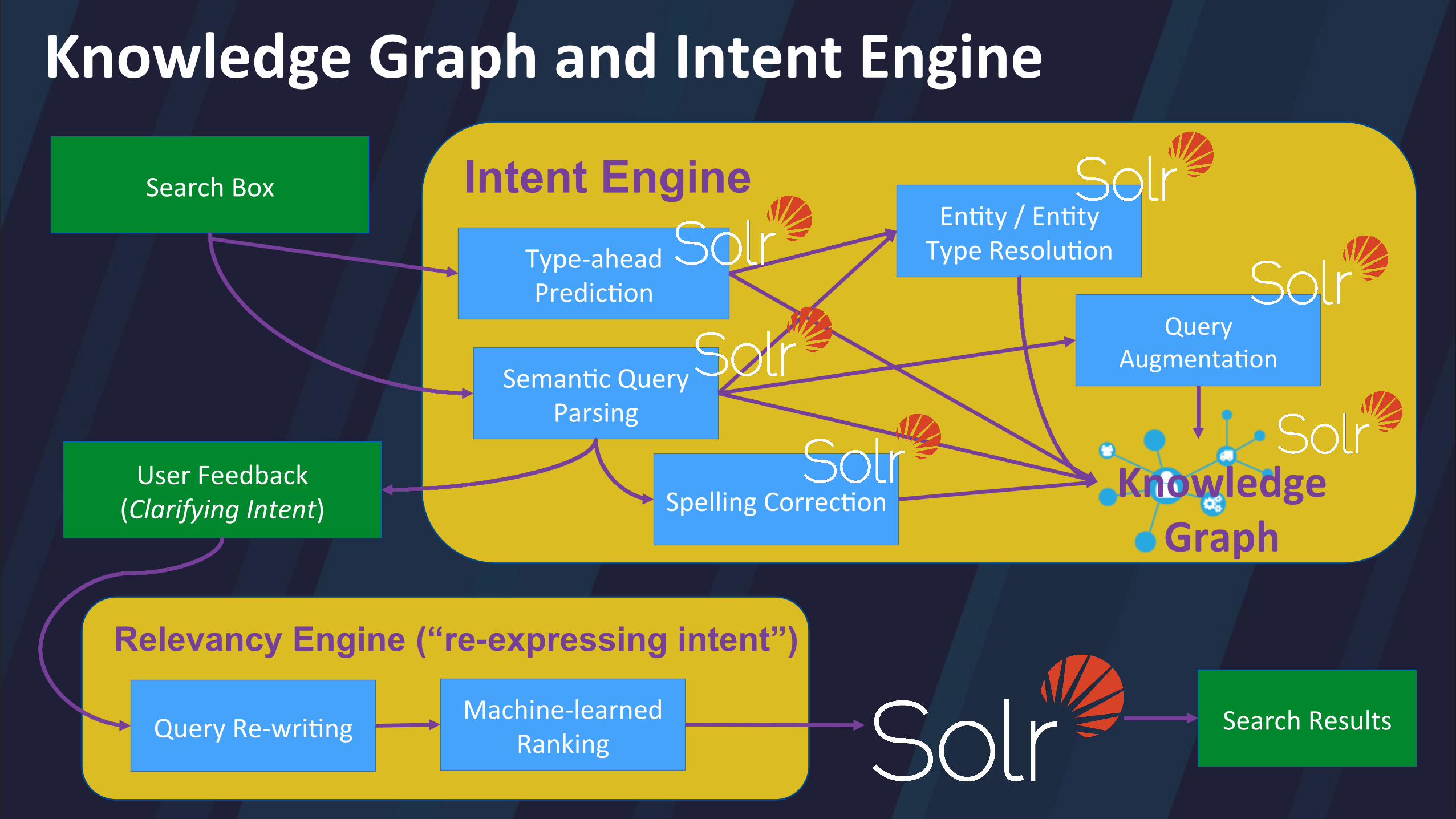
Knowledge Graph and Intent Engine
Search Box
Seman/c Query Parsing
Intent Engine
Spelling Correc/on
En/ty / En/ty Type Resolu/on
Machine-‐learned Ranking
Relevancy Engine (“re-expressing intent”)
User Feedback (Clarifying Intent)
Query Re-‐wri/ng Search Results
Query Augmenta/on
Knowledge Graph

Type-‐ahead Predic>ons
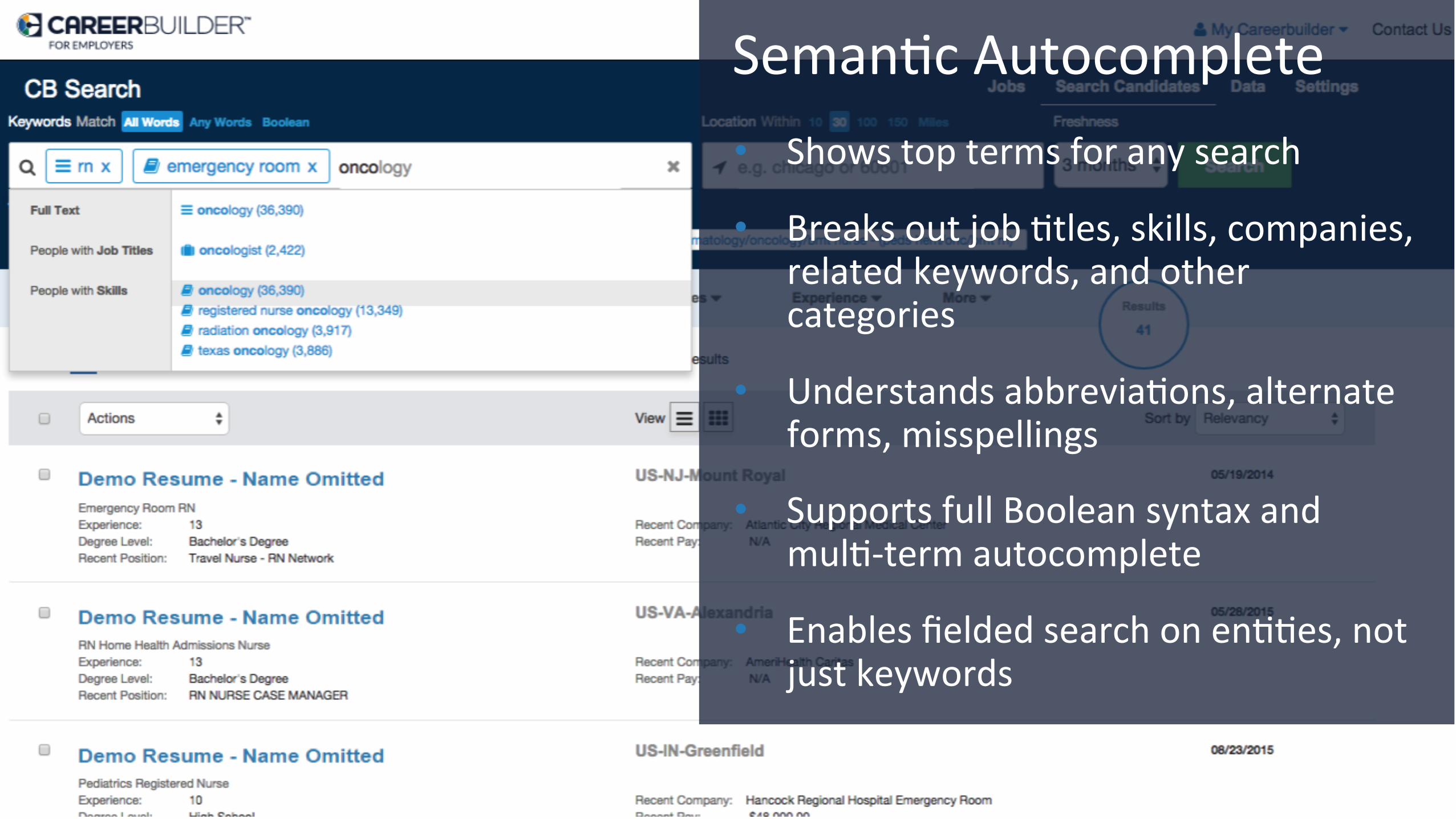
Seman/c Autocomplete • Shows top terms for any search • Breaks out job /tles, skills, companies,
related keywords, and other categories
• Understands abbrevia/ons, alternate
forms, misspellings • Supports full Boolean syntax and
mul/-‐term autocomplete • Enables fielded search on en//es, not
just keywords

Spelling Correc>on*
*Google “Solr Spell Check Component”
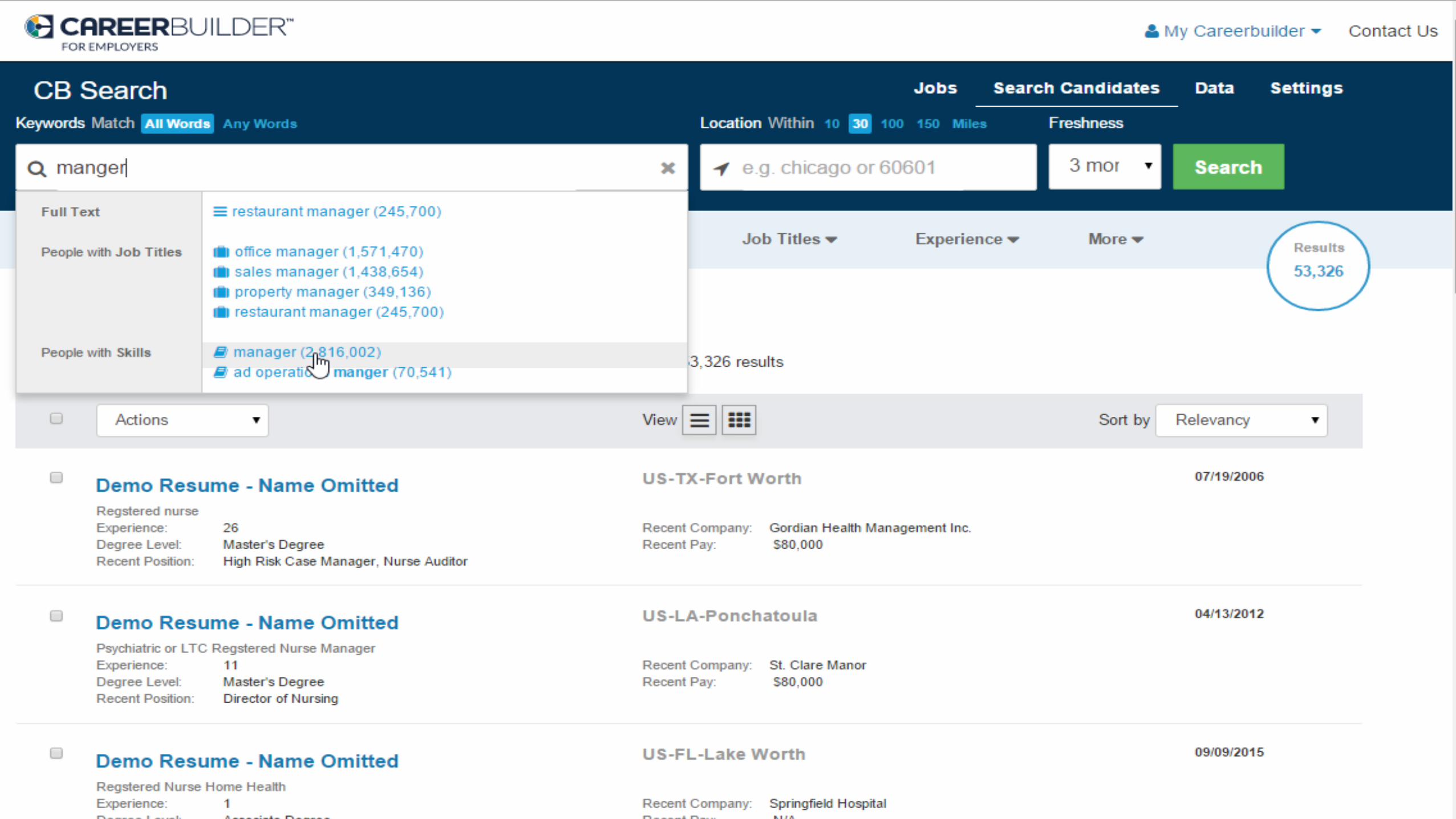

En>ty / En>ty-‐type Resolu>on

Differen>a>ng related terms
Synonyms: cpa => cer/fied public accountant rn => registered nurse r.n. => registered nurse Ambiguous Terms*: driver => driver (trucking) ~80% likelihood driver => driver (so5ware) ~20% likelihood Related Terms: r.n. => nursing, bsn hadoop => mapreduce, hive, pig *differen9ated based upon user and query context

Building a Taxonomy of En>>es Many ways to generate this: • Topic Modelling • Clustering of documents • Statistical Analysis of interesting phrases • Buy a dictionary (often doesn’t work for
domain-specific search problems) • … Our strategy: Generate a model of domain-specific phrases by mining query logs for commonly searched phrases within the domain [1]
[1] K. Aljadda, M. Korayem, T. Grainger, C. Russell. "Crowdsourced Query Augmentation through Semantic Discovery of Domain-specific Jargon," in IEEE Big Data 2014.
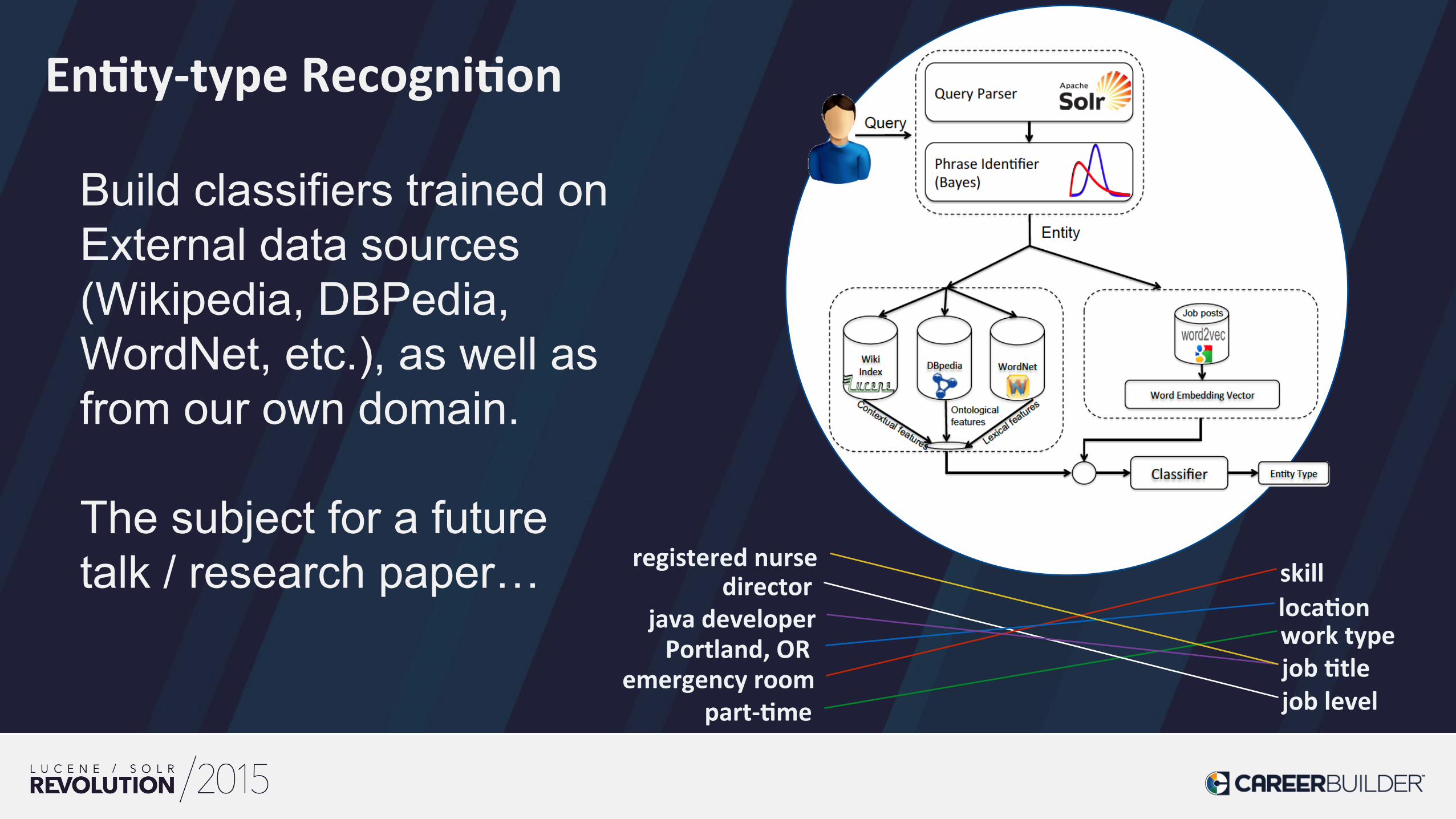
En>ty-‐type Recogni>on
Build classifiers trained on External data sources (Wikipedia, DBPedia, WordNet, etc.), as well as from our own domain. The subject for a future talk / research paper… java developer
registered nurse
emergency room
director
job >tle
skill
job level
loca>on work type Portland, OR
part-‐>me

Seman>c Query Parsing

Query Parsing: The whole is greater than the sum of the parts
project manager vs. "project" AND "manager" building architect vs. "building" AND "architect" soRware architect vs. "soRware" AND "architect"
Consider: a "soRware architect" designs and builds soRware a "building architect" uses soRware to design architecture
User’s Query: machine learning research and development Portland, OR soRware engineer AND hadoop java
Tradi>onal Query Parsing: (machine AND learning AND research AND development AND portland) OR (soRware AND engineer AND hadoop AND java)
≠
Identifying the correct phrase (not just the parts) is crucial here!
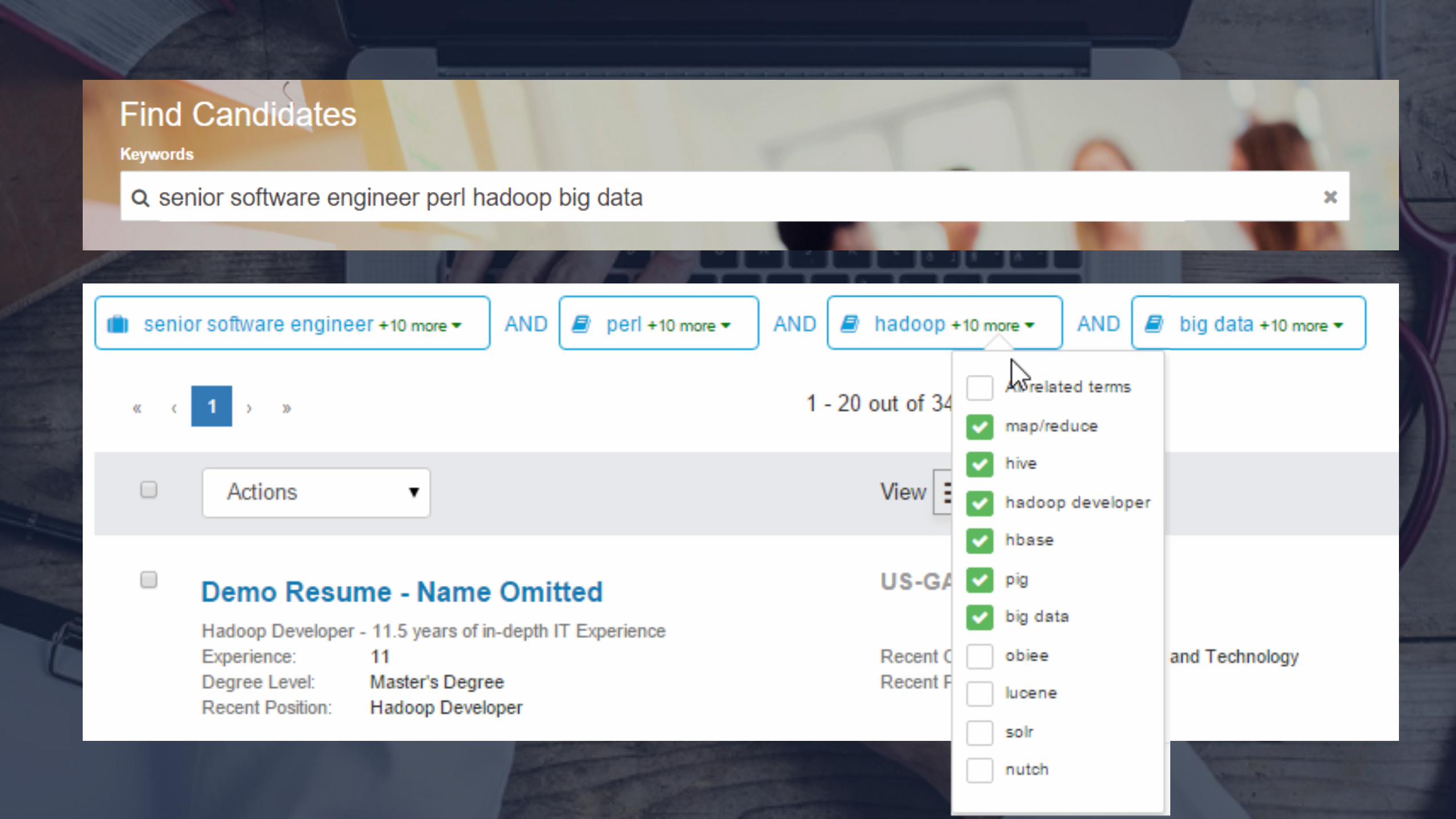

Probabilistic Query Parser
Goal: given a query, predict which combinations of keywords should be combined together as phrases Example: senior java developer hadoop Possible Parsings: senior, java, developer, hadoop "senior java", developer, hadoop "senior java developer", hadoop "senior java developer hadoop” "senior java", "developer hadoop” senior, "java developer", hadoop senior, java, "developer hadoop"

Input: senior hadoop developer java ruby on rails perl
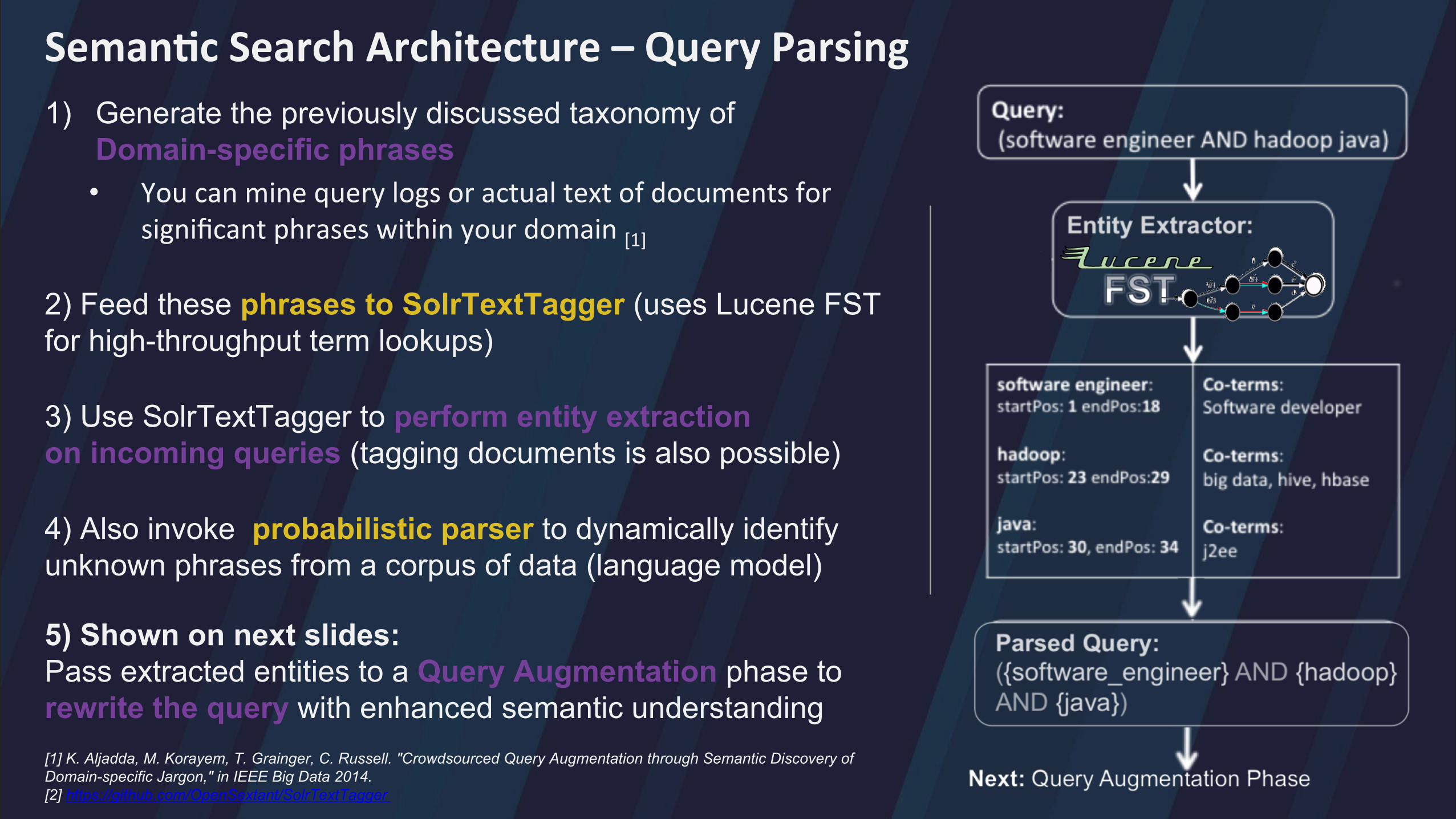
Seman>c Search Architecture – Query Parsing 1) Generate the previously discussed taxonomy of
Domain-specific phrases • You can mine query logs or actual text of documents for
significant phrases within your domain [1]
2) Feed these phrases to SolrTextTagger (uses Lucene FST for high-throughput term lookups)
3) Use SolrTextTagger to perform entity extraction on incoming queries (tagging documents is also possible)
4) Also invoke probabilistic parser to dynamically identify unknown phrases from a corpus of data (language model)
5) Shown on next slides: Pass extracted entities to a Query Augmentation phase to rewrite the query with enhanced semantic understanding [1] K. Aljadda, M. Korayem, T. Grainger, C. Russell. "Crowdsourced Query Augmentation through Semantic Discovery of Domain-specific Jargon," in IEEE Big Data 2014. [2] https://github.com/OpenSextant/SolrTextTagger

Query Augmenta>on
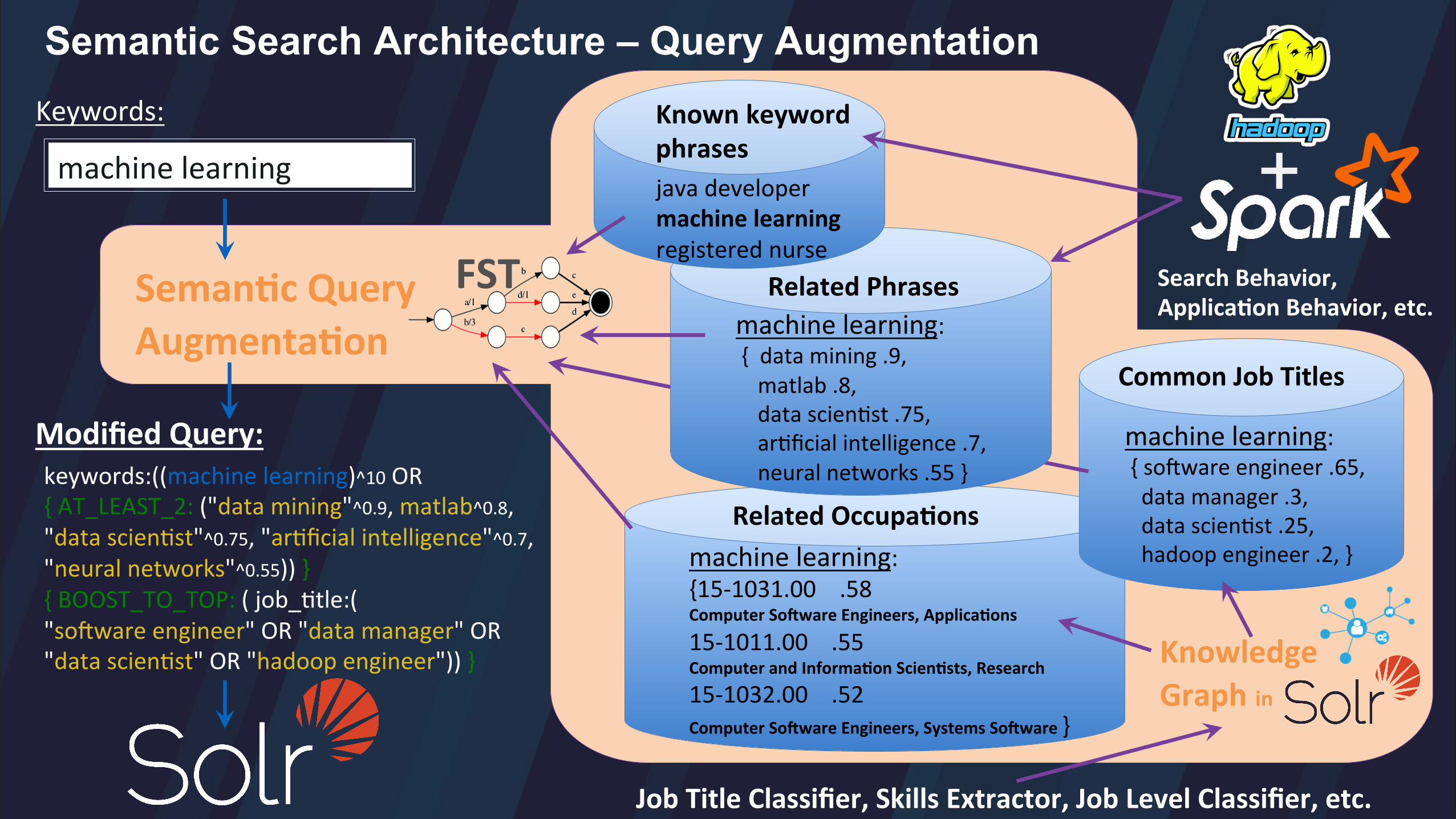
machine learning
Keywords:
Search Behavior, Applica>on Behavior, etc.
Job Title Classifier, Skills Extractor, Job Level Classifier, etc.
Seman>c Query Augmenta>on
keywords:((machine learning)^10 OR { AT_LEAST_2: ("data mining"^0.9, matlab^0.8, "data scien/st"^0.75, "ar/ficial intelligence"^0.7, "neural networks"^0.55)) } { BOOST_TO_TOP: ( job_/tle:( "soRware engineer" OR "data manager" OR "data scien/st" OR "hadoop engineer")) }
Modified Query:
Related Occupa>ons machine learning: {15-‐1031.00 .58 Computer So\ware Engineers, Applica>ons
15-‐1011.00 .55 Computer and Informa>on Scien>sts, Research
15-‐1032.00 .52 Computer So\ware Engineers, Systems So\ware }
machine learning: { soRware engineer .65, data manager .3, data scien/st .25, hadoop engineer .2, }
Common Job Titles
Semantic Search Architecture – Query Augmentation
Related Phrases
machine learning: { data mining .9, matlab .8, data scien/st .75, ar/ficial intelligence .7, neural networks .55 }
Known keyword phrases java developer machine learning registered nurse
FST
Knowledge Graph in
+
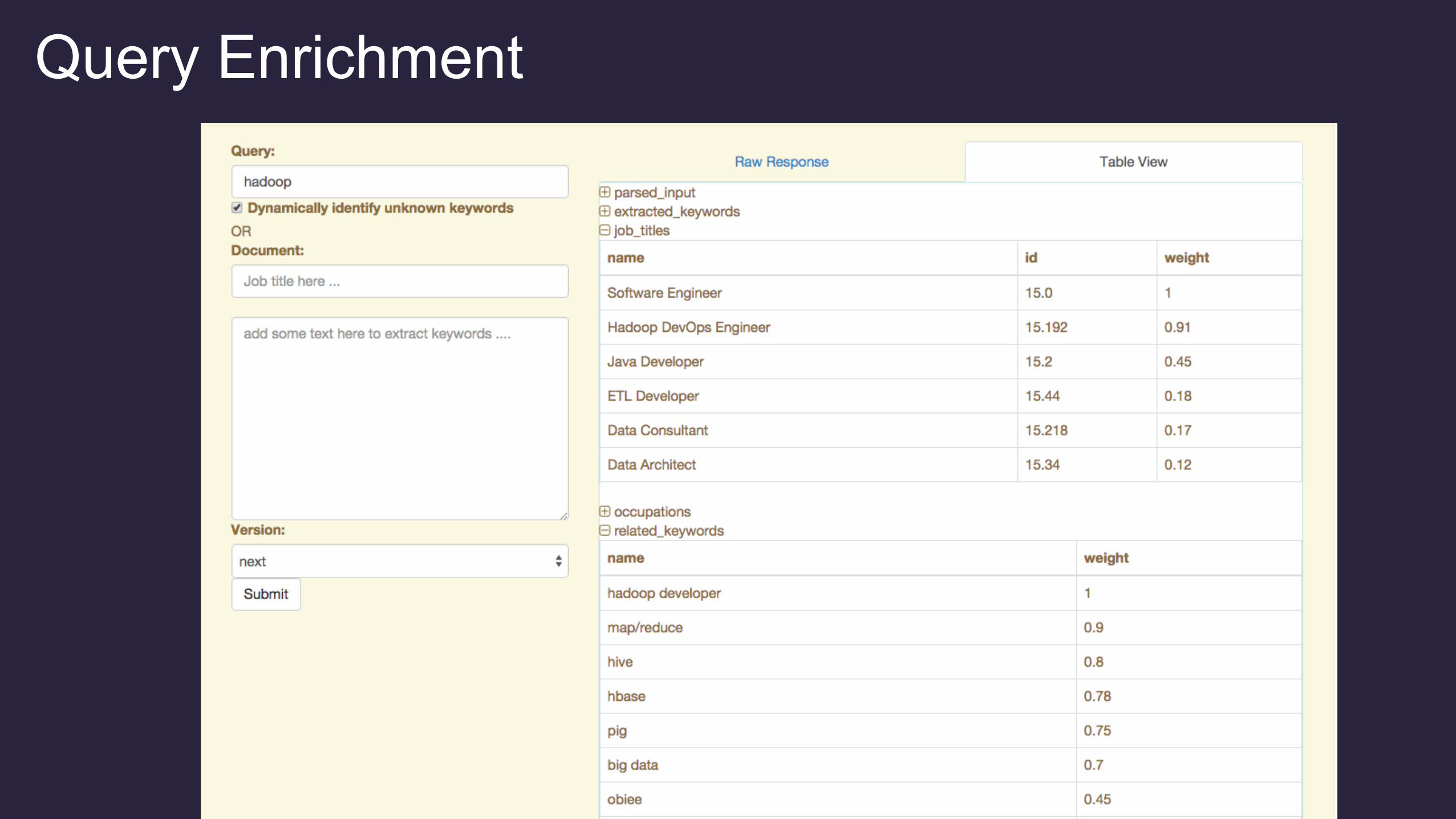
Query Enrichment
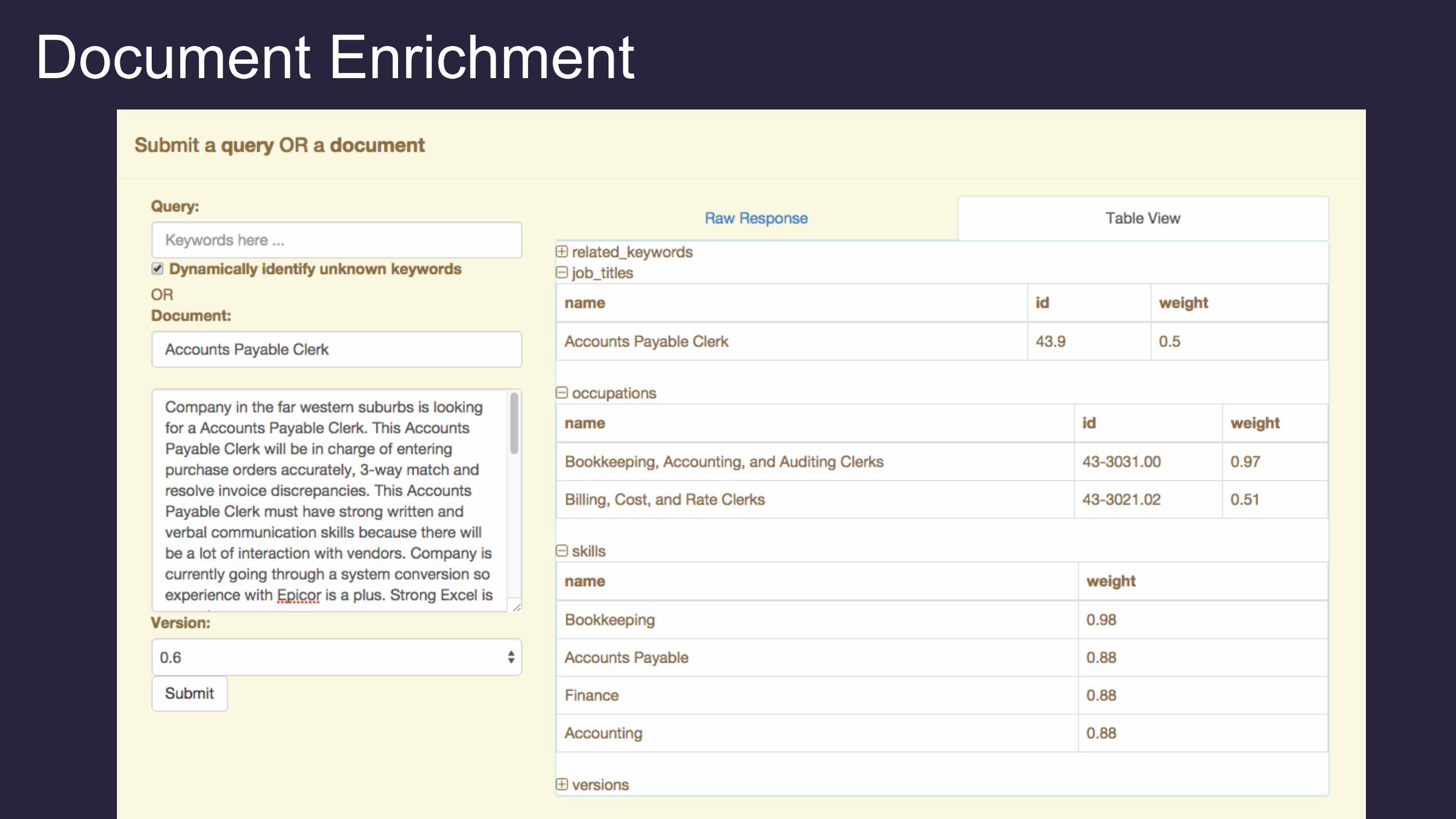
Document Enrichment
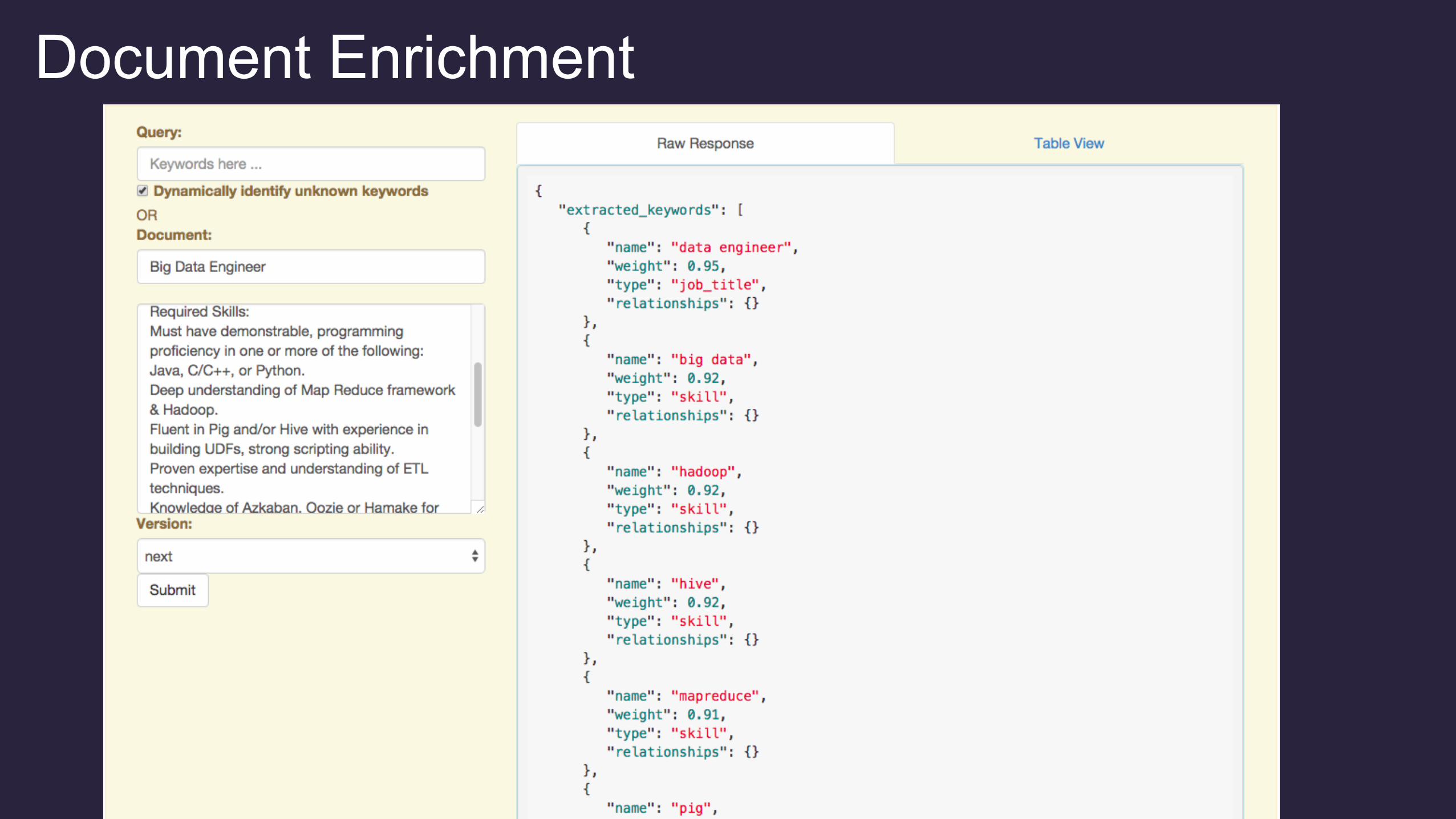
Document Enrichment

Knowledge Graph
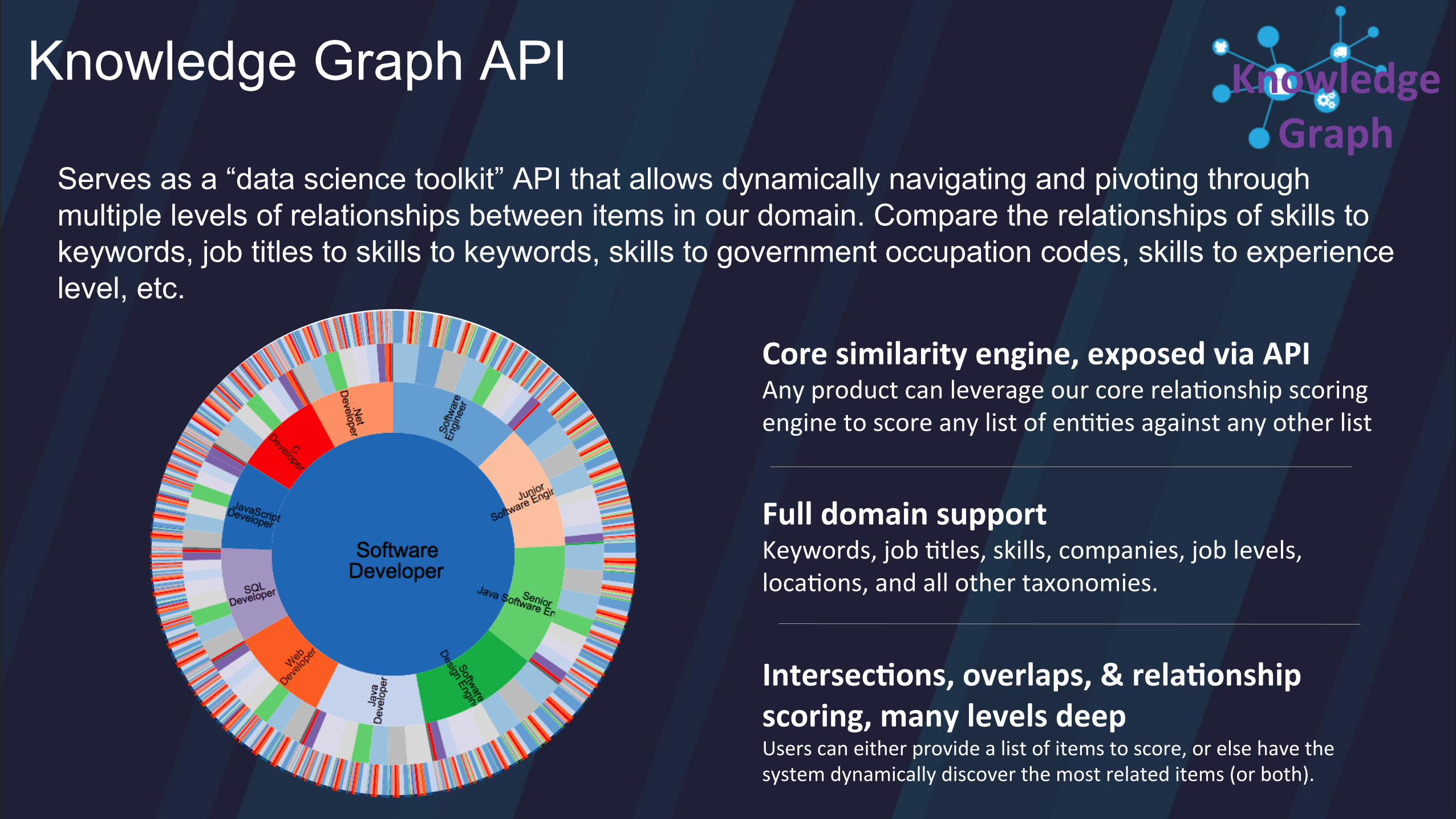
Serves as a “data science toolkit” API that allows dynamically navigating and pivoting through multiple levels of relationships between items in our domain. Compare the relationships of skills to keywords, job titles to skills to keywords, skills to government occupation codes, skills to experience level, etc.
Knowledge Graph API
Core similarity engine, exposed via API Any product can leverage our core rela/onship scoring engine to score any list of en//es against any other list
Full domain support Keywords, job /tles, skills, companies, job levels, loca/ons, and all other taxonomies.
Intersec>ons, overlaps, & rela>onship scoring, many levels deep Users can either provide a list of items to score, or else have the system dynamically discover the most related items (or both).
Knowledge Graph

So how does it work?
Foreground vs. Background Analysis Every term scored against it’s context. The more commonly the term appears within it’s foreground context versus its background context, the more relevant it is to the specified foreground context.
countFG(x) - totalDocsFG * probBG(x) z = -------------------------------------------------------- sqrt(totalDocsFG * probBG(x) * (1 - probBG(x)))
{ "type":"keywords”, "values":[ { "value":"hive", "relatedness":0.9773, "popularity":369 },
{ "value":"java", "relatedness":0.9236, "popularity":15653 },
{ "value":".net", "relatedness":0.5294, "popularity":17683 },
{ "value":"bee", "relatedness":0.0, "popularity":0 },
{ "value":"teacher", "relatedness":-0.2380, "popularity":9923 },
{ "value":"registered nurse", "relatedness": -0.3802 "popularity":27089 } ] }
We are essentially boosting terms which are more related to some known feature (and ignoring terms which are equally likely to appear in the background corpus)
+ -
Foreground Query: "Hadoop"
Knowledge Graph

Knowledge Graph – Potential Use Cases
Cross-‐walk between Types • Have an ID field, but want to enable free text search
on the most associated en/ty with that ID?
• Have a “state” (geo) search box, but want to accept any free-‐text loca/on and map it to the right state?
• Have an old classifica/on taxonomy and want to know how the values from the old system now map into the new values?
Build User Profiles from Search Logs • If someone searches for “Java”, and then “JQuery”, and then “CSS”, and then “JSP”, what do those have in common?
• What if they search for “Java”, and then “C++”, and then “Assembly”?
Discover Rela>onships Between Anything • If I want to become a data scien/st and know
Python, what libraries should I learn?
• If my last job was mid-‐level soRware engineer and my current job is Engineering Lead, what are my most likely next roles?
Traverse arbitrarily deep, Sort on anything • Build an instant co-‐occurrence matrix, sort the top
values by their relatedness, and then add in any number of addi/onal dimensions (RAM permi|ng).
Data Cleansing • Have dirty taxonomies and need to figure out which
items don’t belong? • Need to understand the conceptual cohesion of a
document (vs spammy or off-‐topic content)?
Knowledge Graph

2014 - 2015 Publications & Presentations Books: Solr in Action - A comprehensive guide to implementing scalable search using Apache Solr
Research papers: ● Crowdsourced Query Augmentation through Semantic Discovery of Domain-specific jargon - 2014 ● Towards a Job title Classification System - 2014 ● Augmenting Recommendation Systems Using a Model of Semantically-related Terms
Extracted from User Behavior - 2014 ● sCooL: A system for academic institution name normalization - 2014 ● PGMHD: A Scalable Probabilistic Graphical Model for Massive Hierarchical Data Problems - 2014 ● SKILL: A System for Skill Identification and Normalization – 2015 ● Carotene: A Job Title Classification System for the Online Recruitment Domain - 2015 ● WebScalding: A Framework for Big Data Web Services - 2015 ● A Pipeline for Extracting and Deduplicating Domain-Specific Knowledge Bases - 2015 ● Macau: Large-Scale Skill Sense Disambiguation in the Online Recruitment Domain - 2015 ● Improving the Quality of Semantic Relationships Extracted from Massive User Behavioral Data – 2015 ● Query Sense Disambiguation Leveraging Large Scale User Behavioral Data - 2015
Speaking Engagements: ● Over a dozen in the last year: Lucene/Solr Revolution 2014, WSDM 2014, Atlanta Solr Meetup, Atlanta Big Data Meetup, Second
International Syposium on Big Data and Data Analytics, RecSys 2014, IEEE Big Data Conference 2014 (x2), AAAI/IAAI 2015, IEEE Big Data 2015 (x6) Lucene/Solr Revolution 2015

So What’s Next?

machine learning
Keywords:
Search Behavior, Applica>on Behavior, etc.
Job Title Classifier, Skills Extractor, Job Level Classifier, etc.
Seman>c Query Augmenta>on
keywords:((machine learning)^10 OR { AT_LEAST_2: ("data mining"^0.9, matlab^0.8, "data scien/st"^0.75, "ar/ficial intelligence"^0.7, "neural networks"^0.55)) } { BOOST_TO_TOP: ( job_/tle:( "soRware engineer" OR "data manager" OR "data scien/st" OR "hadoop engineer")) }
Modified Query:
Related Occupa>ons machine learning: {15-‐1031.00 .58 Computer So\ware Engineers, Applica>ons
15-‐1011.00 .55 Computer and Informa>on Scien>sts, Research
15-‐1032.00 .52 Computer So\ware Engineers, Systems So\ware }
machine learning: { soRware engineer .65, data manager .3, data scien/st .25, hadoop engineer .2, }
Common Job Titles
Semantic Search Architecture – Query Augmentation
Related Phrases
machine learning: { data mining .9, matlab .8, data scien/st .75, ar/ficial intelligence .7, neural networks .55 }
Known keyword phrases java developer machine learning registered nurse
FST
Knowledge Graph in
+ This Piece: How do you construct the best possible queries? The answer… Learning to Rank (Machine-‐learned Ranking) That can be a topic for next /me…
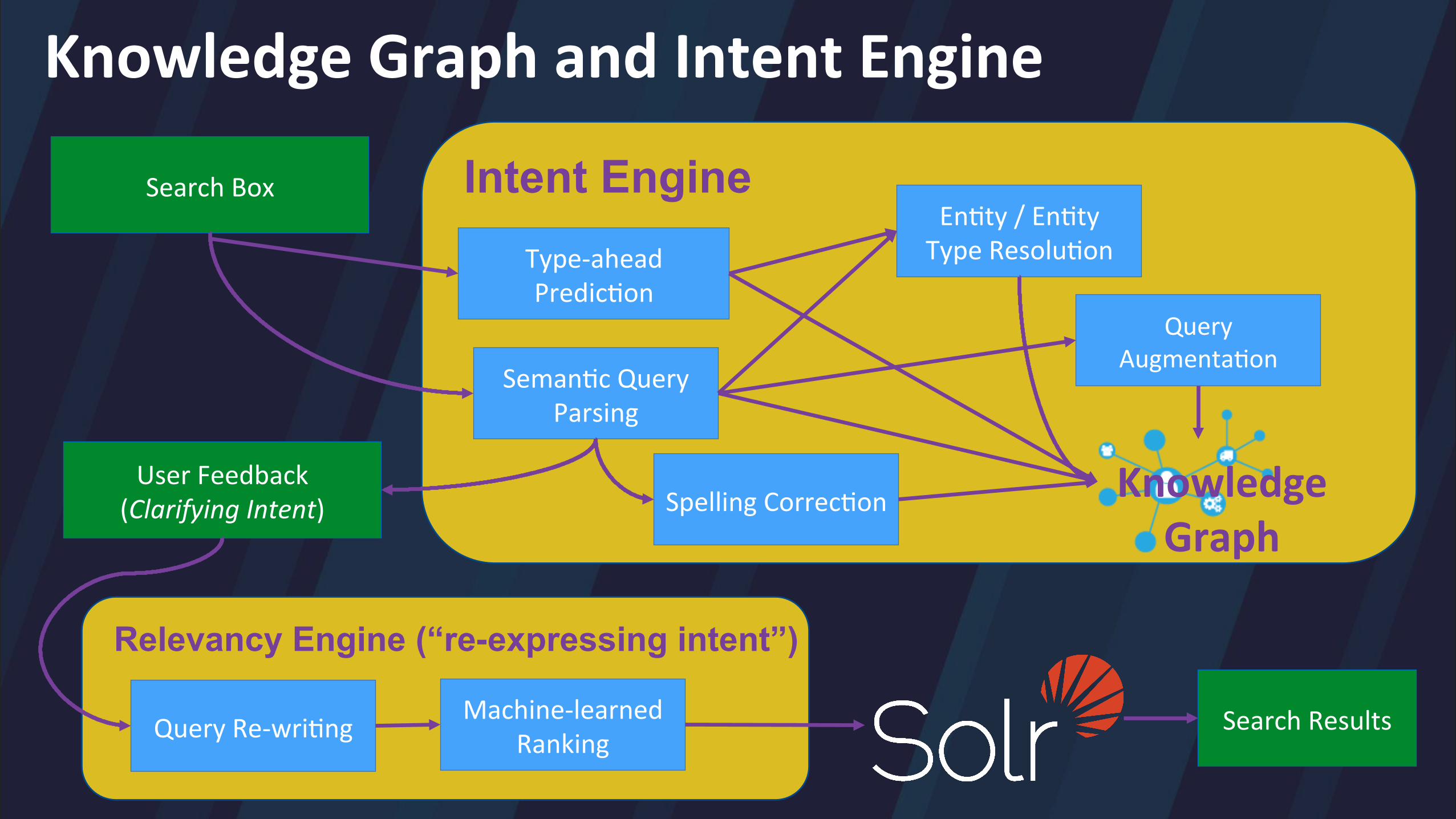
Type-‐ahead Predic/on
Knowledge Graph and Intent Engine
Search Box
Seman/c Query Parsing
Intent Engine
Spelling Correc/on
En/ty / En/ty Type Resolu/on
Machine-‐learned Ranking
Relevancy Engine (“re-expressing intent”)
User Feedback (Clarifying Intent)
Query Re-‐wri/ng Search Results
Query Augmenta/on
Knowledge Graph

Addi>onal References:
Contact Info
Yes, WE ARE HIRING @ . Come talk with me if you are interested…
Trey Grainger [email protected] @treygrainger
hcp://solrinac>on.com Conference discount (43% off): lusorevcftw
Other presenta>ons: hcp://www.treygrainger.com
Recommended

















