
LAPORAN AKHIR METODE KOMPUTASI
ADAPTIVE NETWORK
Disusun Oleh:
Prama Adistya W. G54080081
Farichatul Ivada G5410006
Marini Izmalita G54100014
Shoviatun Nisa G54100024
Eka Pujiyanti G54100039
Hani Asri G. G54100046
Ego Praniki S. G54100079
Danang Kalistyo G54100095
Bilyan Ustazila G54100101
DEPARTEMEN MATEMATIKA
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM
INSTITUT PERTANIAN BOGOR
BOGOR
2013

1. Jaringan Adaptif
Jaringan Adaptif adalah struktur jaringan yang terdiri dari sejumlah node
(neuron) yang terhubung melalui penghubung secara langsung (Directional
Links). Jaringan Adaptif terdiri dari Node atau Neuron dan Directional Link. Tiap
node menggambarkan sebuah unit pemroses dalam sebuah jaringan. Direction
links merupakan penghubung antar node yang menentukan hubungan kausal
antara node yang saling berhubungan, serta menentukan arah perambatannya.
Node menurut sifatnya terdiri dari Adaptive Node dan Fixed Node.
Adaptive Node artinya keluaran (output) dari node tersebut bergantung pada
parameter, sedangkan output yang tidak bergantung pada parameter disebut Fixed
Node. Setiap node menerima input data, memprosesnya, kemudian mengeluarkan
sebuah output tunggal.
Jaringan merupakan kumpulan node-node yang terhubung, yang
dikelompokkan dalam lapisan-lapisan (layers). Arsitektur Jaringan Adaptif
berguna untuk mengatur pola hubungan dalam lapisan dan antar lapisan. Jaringan
dapat dirancang untuk menerima sekumpulan nilai input yang berupa nilai biner
atau kontinu. Dalam hal arsitektur berlapis, ada 2 struktur dasar:
1. Single Layer: struktur 2 lapisan yang terdiri input dan output.
2. Multi Layer: struktur 3 lapisan yang terdiri dari input, intermediate atau
hidden dan output.
Input dapat berasal dari data mentah maupun dari outpun yang lain,
sedangkan output dapat berupa produk final, ataupun menjadi input bagi node
lainnya.Input layer menerima data dari luar lalu mengirimkan output ke lapisan
berikutnya. Hidden layer atau intermediate tidak berinteraksi secara langsung
dengan dunia luar, tetapi dapat menambah tingkat kompleksitas agar jaringan
dapat beroperasi dalam masalah yang lebih kompleks. Output dari sebuah jaringan
adalah solusi dari masalah.
Jaringan adaptif berdasarkan pola koneksinya: feedforward dan feedback
(recurrent). Jaringan Adaptif dikatakan Feedforward jika signal bergerak dari
input kemudian melewati lapisan tersembunyi (hidden layer) dan akhirnya
mencapai unit output (mempunyai struktur perilaku yang stabil). Tipe jaringan
feedforward mempunyai sel syaraf yang tersusun dari beberapa lapisan. Yang

termasuk dalam struktur feedforward : Single-layer perceptron, Multilayer
perceptron, Radial-basis function networks, Higher-order networks, dan
Polynomial learning networks. Suatu jaringan dikatakan Recurrent jika suatu
jaringan berulang (mempunyai koneksi kembali dari output ke input) akan
menimbulkan ketidakstabilan dan akan menghasilkan dinamika yang sangat
kompleks. Yang termasuk dalam stuktur recurrent (feedback : Competitive
networks, Self-organizing maps, Hopfield networks dan Adaptive-resonance
theory models.
Gambar 1
Jaringan adaptif dalam penerapannya dibagi menjadi dua yaitu Jaringan
Saraf Tiruan dan ANFIS (Adaptif Neural Fuzzy Inference System). Jaringan Saraf
Tiruan adalah jaringan adaptif yang directional link-nya memiliki bobot. Bobot
atau parameter ini merupakan kekuatan relatif dari berbagai koneksi yang
mentransfer data dari layer ke layer lainnya. Bobot ini sangat berperan penting
dalam menghasilkan output yang diinginkan. Dalam Jaringan Saraf Tiruan
terdapat pula fungsi aktivasi yang dipakai untuk metode pembelajaran
backpropagation yang harus memiliki sifat kontinu, tak terturunkan, dan
merupakan fungsi tidak turun. Backpropagation merupakan metode turunan
gradient untuk meminimalkan total error measure, yaitu perbedaan antara output
yang diinginkan dan output jaringan yang sebenarnya. ANFIS adalah Jaringan
Adaptif yang berbasis fuzzy inference system.
Jaringan Adaptif dapat digunakan sistem identifikasi. Sistem identifikasi
ini adalah masalah penentuan model matematis untuk sistem yang diketahui atau
sistem target dengan mengamati pasangan data input-outputnya.
Contoh Jaringan Adaptif:
1. Jaringan adaptif dengan sharing parameter

Pada gambar 2 (a). Misal: , dimana dan adalah input dan
output, sedangkan adalah parameternya. Dalam kasus ini, tidak ada input
sehingga output-nya adalah parameter itu sendiri. Hal ini dapat digunakan dalam
kasus gambar 2 (b) parameter sharing, dimana ada 2 node adaptif, u = g(x,a) dan
v = h(y,a) yang berbagi dengan parameter yang sama yaitu .
(a) (b)
Gambar 2
Topological Ordering Representation merupakan kasus khusus dari layered
representation dimana setiap layernya hanya terdapat satu node seperti Gambar 3.
Gambar 3
2. Jaringan adaptif dengan single linear node
Pada Gambar 4. Misal:
, dimana dan adalah input dan adalah output, sedangkan dan
adalah parameternya yang dapat diubah-ubah. Output didapat dari
dengan parameternya yaitu dan .
Gambar 4
3. Jaringan Perseptron
Jaringan Perseptron biasanya digunakan untuk mengklasifikasikan suatu
tipe pola tertentu yang sering dikenal dengan istilah pemisahan secara linear. Pada
dasarnya, Jaringan perseptron dengan satu lapisan memiliki bobot yang bisa diatur
dan suatu nilai ambang. Pada Gambar 5. Misal:
dan

{
.
Fungsi sigmoid biner :
Jaringan perseptron menggunakan fungsi sigmoid biner karena jaringan ini
membutuhkan nilai output yang terletak pada interval 0 sampai 1, serta Output
terus menerus berubah-ubah tetapi tidak berbentuk linear. Fungsi sigmoid ini juga
memiliki sifat kontinu, terturunkan dan merupakan fungsi tak turun. Output
didapatkan dari fungsi dimana adalah dengan parameternya
dan .
Gambar 5
4. Multilayer Perceptron
Multilayer Perceptron adalah jaringan perseptron yang memiliki input
layer, hidden layer, dan output layer. Pada Gambar 6. Misal:
( ) dimana dan adalah input, adalah
bobot, adalah fungsi threshold, sedangkan dan adalah output. Pada fungsi
threshold, output diatur satu dari dua tingkatan tergantung dari jumlah input yang lebih
besar atau lebih kecil dari nilai ambang. Pada gambar ini menunjukkan terdapat tiga
input, dua output, dan tiga hidden layer.
Gambar 6

2. Backpropagation
Backpropagation merupakan model jaringan adaptif dengan multiple
layer. Backpropagation melatih jaringan untuk mendapatkan keseimbangan antara
kemampuan jaringan untuk mengenali pola yang digunakan selama pelatihan serta
kemampuan jaringan untuk memberikan respon yang benar terhadap pola
masukan yang serupa (tapi tidak sama) dengan pola yang dipakai selama
pelatihan.
Fungsi Aktivasi pada Backpropagation
Dalam backpropagation, fungsi aktivasi yang dipakai harus memenuhi
beberapa syarat sebagai berikut.
1. Kontinu
2. Terdiferensial dengan mudah
3. Merupakan fungsi yang tidak turun
Backpropagation pada Jaringan Feedfoward
Pada jaringan feedfoward (umpan maju) pelatihan dilakukan dalam rangka
perhitungan bobot sehingga pada akhir pelatihan akan diperoleh bobot-bobot yang
baik. Selama proses pelatihan, bobot-bobot diatur secara iteratif untuk
meminimumkan error (kesalahan) yang terjadi. Error (kesalahan) dihitung
berdasarkan rata-rata kuadrat kesalahan (MSE). Rata-rata kuadrat kesalahan juga
dijadikan dasar perhitungan unjuk kerja fungsi aktivasi. Sebagian besar pelatihan
untuk jaringan feedfoward (umpan maju) menggunakan gradien dari fungsi
aktivasi untuk menentukan bagaimana mengatur bobot-bobot dalam rangka
meminimumkan kinerja. Gradien ini ditentukan dengan menggunakan suatu
teknik yang disebut backpropagation.
Pelatihan backpropagation meliputi 3 fase sebagai berikut.
a) Fase 1, yaitu propagasi maju.
Pola masukan dihitung maju mulai dari input layer hingga output layer
menggunakan fungsi aktivasi yang ditentukan.
b) Fase 2, yaitu propagasi mundur.
Selisih antara keluaran jaringan dengan target yang diinginkan merupakan
kesalahan yang terjadi. Kesalahan yang terjadi itu dipropagasi mundur.
Dimulai dari garis yang berhubungan langsung dengan unit-unit di output
layer.
c) Fase 3, yaitu perubahan bobot.
Modifikasi bobot untuk menurunkan kesalahan yang terjadi. Ketiga fase
tersebut diulang-ulang terus hingga kondisi penghentian dipenuhi.
Pemilihan bobot awal sangat mempengaruhi jaringan aditif dalam
mencapai minimum global (atau mungkin lokal saja) terhadap nilai error
(kesalahan) dan cepat tidaknya proses pelatihan menuju kekonvergenan.

Apabila bobot awal terlalu besar maka input (masukan) ke setiap hidden
layer atau output layer (keluaran) akan jatuh pada daerah dimana turunan
fungsi aktivasinya akan sangat kecil. Apabila bobot awal terlalu kecil,
maka input (masukan) ke setiap hidden layer atau output layer (keluaran)
akan sangat kecil. Hal ini akan menyebabkan proses pelatihan berjalan
sangat lambat. Biasanya bobot awal diinisialisasi secara random dengan
nilai antara -0.5 sampai 0.5 (atau -1 sampai 1 atau interval yang lainnya).
Setelah pelatihan selesai dilakukan, jaringan dapat dipakai untuk
pengenalan pola. Dalam hal ini, hanya propagasi maju saja yang dipakai
untuk menentukan keluaran jaringan.
Backpropagation pada Jaringan Recurrent
Backpropagation Through Time ( BPTT )
Jaringan dioperasikan secara serentak dalam mengidentifikasi satu set
parameter yang akan membuat output dari node (atau beberapa node) mengikuti
lintasan yang diberikan dalam domain waktu diskrit. Metode penyelesaian di sini
dilakukan dengan mengubah jaringan berulang menjadi feedforward satu, selama
waktu tidak melebihi maksimum . Ide ini awalnya diperkenalkan oleh Minsky
dan Papen dan dikombinasikan dengan backpropagation oleh Rumelhart, et al.
Gambar di (a) mempunyai konfigurasi yang sama dengan gambar (b) tetapi
variabel input dan dihilangkan agar bentuknya lebih sederhana. Gambar (b)
berbentuk jaringan feedforward dengan indeks waktu berjalan dari 1 sampai 4.
Jaringan recurrent mengevaluasi pada masing-masing fungsi simpul tersebut
dengan , kita dapat hanya menduplikasi semua unit waktu dan
mengatur jaringan yang dihasilkan dengan cara berlapis. Dua
jaringan pada Gambar (a) dan (b) berperilaku identik untuk sampai ,
asalkan semua salinan parameter di waktu yang berbeda langkah tetap sama.
(a) synchronously operated recurrent network
(b) feedforward equivalent obtained via unfolding of time

Real-Time Recurrent Learning (RTRL)
BPTT umumnya bekerja dengan baik untuk sebagian besar masalah, satu-
satunya komplikasi adalah bahwa Hal ini membutuhkan sumber daya yang luas
komputasi ketika panjang urutan besar, karena duplikasi node membuat kedua
persyaratan memori dan simulasi waktu sebanding dengan . Oleh karena itu,
untuk urutan sangat panjang atau urutan panjang tidak diketahui harus digunakan
Real-Time Recurrent Learning (RTRL) (untuk memperbarui parameter sementara
jaringan berjalan bukan pada akhir urutan yang disajikan). Untuk menyimpan
perhitungan dan kebutuhan memori , pilihan yang masuk akal adalah untuk
meminimalkan pada setiap langkah waktu daripada mencoba untuk
meminimalkan pada akhir urutan.
Jaringan Operasi kontinu
Menentukan nilai error propagation dari jaringan recurrent dalam waktu
yang kontinu, salah satu metode yang dipergunakan adalah dengan
menggunakan rumus Mason gain.
Rumus Masson’s Gain dipergunakan untuk menentukan hubungan antara
input varible dan output variable dalam grafik aliran sinyal sebab dapat dipakai
dalam penyelesaian bentuk-bentuk kasus praktis. Dimana transmisi antara input
node dan output node merupakan penguatan keseluruhan, atau transmisi
keseluruhan antara dua buah node.
Rumus Mason’s Gain:
∑
∑
∑
Keterangan:
= total semua gain
= gain atau transmisi lintasan maju
= determinan grafik
= ∑
∑
∑
∑
= Jumlah dari semua penguatan loop yang berbeda
∑
=
Jumlah hasil kali penguatan dari semua,
kombinasi yang mungkin dari dua
loop yang tidak bersentuhan.

∑
=
Jumlah hasil kali penguatan dari semua kombinasi
yang mungkin dari tiga loop yang tidak
bersentuhan. dst.
=
Kofaktor dari determinan lintasan maju ke
dengan menghilangkan loop-loop yang menyentuh
lintasan maju ke .
Contoh mencari error propagation menggunakan Rumus Mason’s Gain
Tentukan error propagation yang melewati node 3
Jawab: terdapat dua input yang bisa mengalir ke node 3.
a. Maka kita tinjau terlebih dahulu input I1 (5-4-3-5 dan 5-6-4-3-5)
Tentukan terlebih dahulu loop yang ada di dalam diagram yang dilewati
input 1 seperti berikut.
Hitung jumlah loop. Dari diagram di atas diketahui ada 3 loop, yang nanti
diberi nama dan
Loop 1 (5-4-3); ,
Loop 2 (5-6-4-3); ,
Loop 3 (6);
Tentukan terlebih dahulu dan tentukan loop mana yang tidak saling
bersentuhan
Dua loop yang tidak saling bersentuhan adalah loop 1 dan loop 3, dan
tidak ada tiga loop yang tidak bersentuhan, maka
Karena ada dua sinyal alir yang bisa melewati node 3 yakni melalu node 5-
4-3 dan 5-6-4-3, maka
Kemudian cari dan masing-masing. Mencari sesuai bobot sinyal
alir yang dilewati menuju node 3, sedangkan untuk rumus mencari
(∑ yang tidak menyentuh sinyal alir)

= 1 sinyal alir (5-4-3) = 2 sinyal alir (5-6-4-3)
= =
1 (semua loop menyentuh sinyal
alir)
(Karena hanya loop 3 saja yang tidak menyentuh sinyal alir 1) maka dari
input 1 diperoleh :
∑
b. Kemudian kita tinjau input 2 (6-4-3-5-6). Dengan cara yang sama dari
input 1
Tentukan terlebih dahulu loop yang ada di dalam diagram yang dilewati
input 2 seperti berikut.
Dengan sinyal alir dari input ke input lagi yakni 6-4-3-5-6. Sama
seperti input 1, terdapat 3 loop sehingga nilai
.
Karena hanya ada satu sinyal alir yang bisa melewati node 3 yakni
melalu node 6-4-3 saja, maka
Kemudian cari dan masing-masing.
= 1 sinyal alir (6-4-3)
=
(semua loop menyentuh sinyal alir)
Maka dari input 2 diperoleh :
∑
Total sinyal error dari node 3

3. HYBRID LEARNING RULE :COMBINING STEEPEST DESCENT dan
LSE
Sebenarnya ada dua paradigma pembelajaran bagi jaringan adaptif.
Dengan metode Batch Learning (atau off-line learning) yang dilakukan dengan
cara meng-update rumus untuk parameter didasarkan pada
∑
dan tindakan pembaruan terjadi hanya setelah data pelatihan seluruhnya telah
disajikan, yakni hanya setelah setiap epoch ( iterasi).
Di sisi lain, Pattern-By-Pattern Learning (atau on-line Learning) adalah
metode pembelajaran yang menginginkan parameter yang akan diperbarui segera
setelah masing-masing pasangan input-output telah disajikan, maka rumus
pembaruan didasarkan pada
∑
1. Hybrid Learning: Off-Line Learning (Batch Learning)
Meskipun kita dapat menerapkan metode gradien untuk mengidentifikasi
parameter dalam jaringan adaptif, metode ini umumnya lambat dan cenderung
hanya menemukan minimum lokal. Untuk mengatasi hal ini, ada sebuah
pembelajaran hibrida yang menggabungkan Metode Gradien dan Metode Kuadrat
Terkecil (LSE) untuk mengidentifikasi parameter.
Untuk mempermudah, asumsikan bahwa jaringan adaptif hanya memiliki satu
output
Keterangan:
: himpunan variabel input
S : himpunan parameter
Jika terdapat fungsi dan fungsi adalah linear dalam beberapa
elemen dari , maka elemen-elemen ini dapat diidentifikasi dengan metode
kuadrat terkecil.
dengan adalah vektor yang elemen-elemennya diketahui parameter di S1 .

Setiap zaman prosedur pembelajaran hybrid ini terdiri dari lulus maju dan lulus
mundur. Keterangan:
S1 = bobot dan ambang batas lapisan tersembunyi
S2 = bobot dan ambang batas lapisan output
Oleh karena itu, kita dapat menerapkan aturan pembelajaran
backpropagasi untuk menyesuaikan parameter dalam lapisan tersembunyi, dan
parameter pada lapisan output dapat diidentifikasi dengan metode kuadrat terkecil.
Contoh Off-Line learning :
Trainning set berisi 500 input-output pasang, maka masing-masing berat dalam
jaringan saraf disesuaikan 1000 kali.
2. On-Line Learning (Pattern-By-Pattern Learning)
Pattern-By-Pattern (On-Line) Learning adalah memperbarui parameter
setelah setiap penyajian data. Paradigma pembelajaran ini sangat penting untuk
sistem dengan perubahan karakteristik. Untuk sekuensial kuadrat terkecil formula
untuk memperhitungkan karakteristik waktu bervariasi dari data yang masuk, kita
perlu melakukan transformasi data lama sebagai pasangan data baru. Salah satu
metode sederhana adalah merumuskan ukuran kesalahan squared yang
memberikan bobot yang lebih tinggi untuk lebih banyak pasangan data terbaru.
Dengan menggunakan pembelajaran prosedur hybrid, arsitektur yang
diusulkan dapat memperbaiki fuzzy aturan if-then yang diperoleh dari para pakar
untuk menggambarkan input-output perilaku sistem yang kompleks . Namun, jika
tidak ada ahli pakar, kita masih bisa mengatur secara intuitif (berdasarkan data,
percobaan, dll) fungsi keanggotaan awal dan proses pembelajaran untuk
menghasilkan satu set fuzzy aturan if-then untuk mendekati yang diinginkan. Contoh On-Line Learning:
Trainning set berisi 500 input-output pasang, mode ini menyesuaikan bobot 500
kali untuk setiap kali algoritma melalui set trainning. Jika algoritma konvergen
setelah 1000 iterasi, masing-masing berat disesuaikan total 50.000 kali
3. Different Ways of Combining Steepest Descent and LSE
Perhitungan metode kuadrat terkecil lebih kompleks dibandingkan dengan
Steepest Descent. Ada empat metode untuk memperbarui parameter , seperti yang
tercantum di bawah ini sesuai dengan kompleksitas :
1. One pass of LSE only
2. Steepest Descent Only
Semua parameter diperbarui oleh keturunan gradien .
3. One Pass of LSE followed by SD

4. The LSE
Diterapkan hanya sekali di awal untuk mendapatkan nilai awal parameter
konsekuen dan kemudian gradient descent mengambil alih untuk
memperbarui semua parameter.
5. Steepest Descent dan LSE
6. LSE only
4. Aplikasi
Pada makalah ini, akan dibahas pula penerapan atau aplikasi dari materi
yang telah dijelaskan sebelumnya. Aplikasi dari materi ini disadur dari Skripsi
yang ditulis oleh Suwarno (Alumni Departemen Matematika 42) dengan judul
“Aplikasi Jaringan Syaraf Tiruan Berbasis Metode Backpropagasi untuk
Memprediksi Konsentrasi Gula Darah”.
Dalam ilmu kedokteran, gula darah adalah tingkat glukosa di dalam darah.
Konsentrasi gula darah atau tingkat glukosa serum diatur di dalam tubuh.
Konsentrasi gula darah dalam tubuh yang melebihi ambang batas menyebabkan
komplikasi penyakit, salah satunya risiko serangan jantung. Oleh sebab itu,
mengetahui konsentrasi gula darah di dalam tubuh sangat penting untuk setiap
orang. Penelitian ini memberikan suatu metode untuk memprediksi konsentrasi
gula darah yang diharapkan dapat mengefisienkan biaya dan waktu proses, relatif
dibanding dengan metode konvensional.
Pada penerapan aplikasi ini, dijelaskan cara menggunakan jaringan syaraf
tiruan untuk mengetahui tingkat glukosa di dalam darah seseorang. Penentuan
nilai konsentrasi gula darah membutuhkan data masukan (input) untuk
membangun struktur jaringan syaraf tiruan. Data input berupa data kuat arus
listrik (i) dan waktu (t), sedangkan data output berupa data konsentrasi gula darah
(s). Data input ini diperoleh dari nilai keluaran suatu alat yang dinamakan alat
biosensor amperometrik, yaitu berupa data kuat arus listrik, waktu reaksi dengan
enzim, dan konsentrasi gula darah. Sistem jaringan syaraf ini akan digabungkan
dengan alat biosensor amperometrik.
Gambar 1 Alat biosensor amperometrik.

Berikut ini adalah data masukan (input) dan data keluaran (output) yang
merupakan target yang diharapkan. Data ini diperoleh dengan menggunakan alat
biosensor amperometrik.
Tabel 1 Data Input dan Output
Implementasi jaringan syaraf tiruan (JST) dilakukan dengan menggunakan
software MATLAB R2008b yang didesain untuk menyelesaikan suatu model
jaringan syaraf tiruan backpropagation. Perambatan galat mundur
(backpropagation) adalah metode sistematik untuk pelatihan multilayer jaringan
syaraf tiruan. Algoritma backpropagation meliputi tiga fase sebagai berikut:
1. Fase propagasi maju
2. Fase propagasi mundur
3. Fase perubahan bobot
Ketiga fase tersebut diulang terus menerus hingga kondisi penghentian
terpenuhi. Struktur jaringan syaraf tiruan (JST) yang digunakan dalam aplikasi ini
diasumsikan sebagai struktur jaringan syaraf tiruan yang dibentuk terdiri dari
lapisan input dengan 2 neuron, lapisan tersembunyi dengan 3 neuron, dan lapisan
output dengan 1 neuron, seperti yang terlihat pada gambar berikut:
Gambar 2 Struktur JST multilayer net.
dengan → , → , 𝑏 𝑏 → & 𝑏 𝑠 → 𝑣 dan 𝑠 → .
Dilakukan metode algoritma backpropagation dengan mengambil data
input dan data ouput sebagai target yang telah dijelaskan pada gambar 2. Namun,
untuk mengolah data tersebut, diperlukan juga nilai bobot dan bias yang diperoleh
dengan cara membangkitkan bilangan acak yang sangat kecil oleh komputer serta

fungsi aktivasi. Fungsi aktivasi yang digunakan adalah fungsi sigmoid biner,
yaitu: 1
( )1 x
f xe
dengan fungsi turunannya
2
'( )1
x
x
ef x
e
.
Dalam backpropagation, fungsi aktivasi yang digunakan harus memenuhi
beberapa syarat yaitu kontinu, terdiferensial dengan mudah, dan merupakan fungsi
yang tidak turun. Salah satu fungsi yang memenuhi ketiga syarat tersebut
sehingga sering digunakan adalah fungsi sigmoid biner yang memiliki range Misalkan juga diperoleh nilai data-data sebagai berikut:
Bobot Lapisan
Tersembunyi
Bobot Lapisan
Output Bias
11 0.1w 21 0.1w 1 0.1v 11 0.1bias
12 0.2w 22 0.2w 2 0.2v 𝑏 𝑠
13 0.1w 23 0.1w 3 0.1v
Tabel 2 Nilai Bobot dan Bias
Pada tabel 1 nomor 1, terdapat data input dengan 884 733 𝑠
9 dan pada tabel 2, terdapat 11 0.1w 21 0.1w
11 0.1bias
Fase Propagasi Maju
1. Tentukan nilai 𝑧
11 1 11 2 21 11
0.8841 0.1 0.1 0.1 0.
9 1
1
0.1 84
netz x w x w bias
2. Gunakan fungsi aktivasi untuk menghitung nilai 1z
1 11
0.19841
0.19841
0.54941
1
netz f z
f
e
3. Hitung nilai
seperti cara 1
1 1 1 1
0.5494 0.1 0.
0.2549
2
nety z v bias

4. Gunakan fungsi aktivasi kembali untuk menghitung nilai y
1
0.2549
1
1
0.2549
0.5633
nety f y
f
e
Fase Propagasi Mundur
Bandingkan nilai y yang diperoleh dengan cara perhitungan dengan target
nilai y yang diperoleh dengan alat biosensor amperometrik. Karena
diperoleh nilai 0.5633y (perhitungan) tidak sama dengan nilai target
𝑠 9 (alat biosensor amperometrik) maka perlu dilakukan pencarian
bobot yang baru sehingga nilai erornya menjadi sangat kecil.
Fase Perubahan Bobot
1. Tentukan nilai bobot baru
1 1
0.5633
20.5633
'
0.9 0.56331
0.0778356
nett y f y
e
e
dengan adalah unit kesalahan (eror).
11 1 1
0.5 0.0778356 0.884
0.03
1
44
w x
dengan adalah laju pembelajaran yang nilainya kita tentukan
sendiri.
11 11 11
0.1 0.0344
0.1344
w baru w lama w
2. Tentukan nilai bias baru seperti
1 1 1
0.5 0.077 08356 .5494
0.0213
v z

1 1 1
0.1 0.0213
0.1213
v baru v lama v
Setelah bobot dan bias baru diperoleh, dilakukan perhitungan kembali seperti pada
FASE PROPAGASI MAJU. Hal ini dilakukan secara terus menerus hingga
diperoleh error yang sangat kecil.
5. KESIMPULAN
Proses ini dilakukan terus menerus hingga menemukan struktur jaringan
syaraf tiruan (JST) yang optimal sehingga jika terdapat data yang baru maka nilai
prediksi tidak jauh berbeda dengan nilai sebenarnya. Disebut jaringan adaptif
karena sistem dapat memperbaiki kesalahan sehingga diperoleh unit kesalahan
(error) yang sangat kecil.
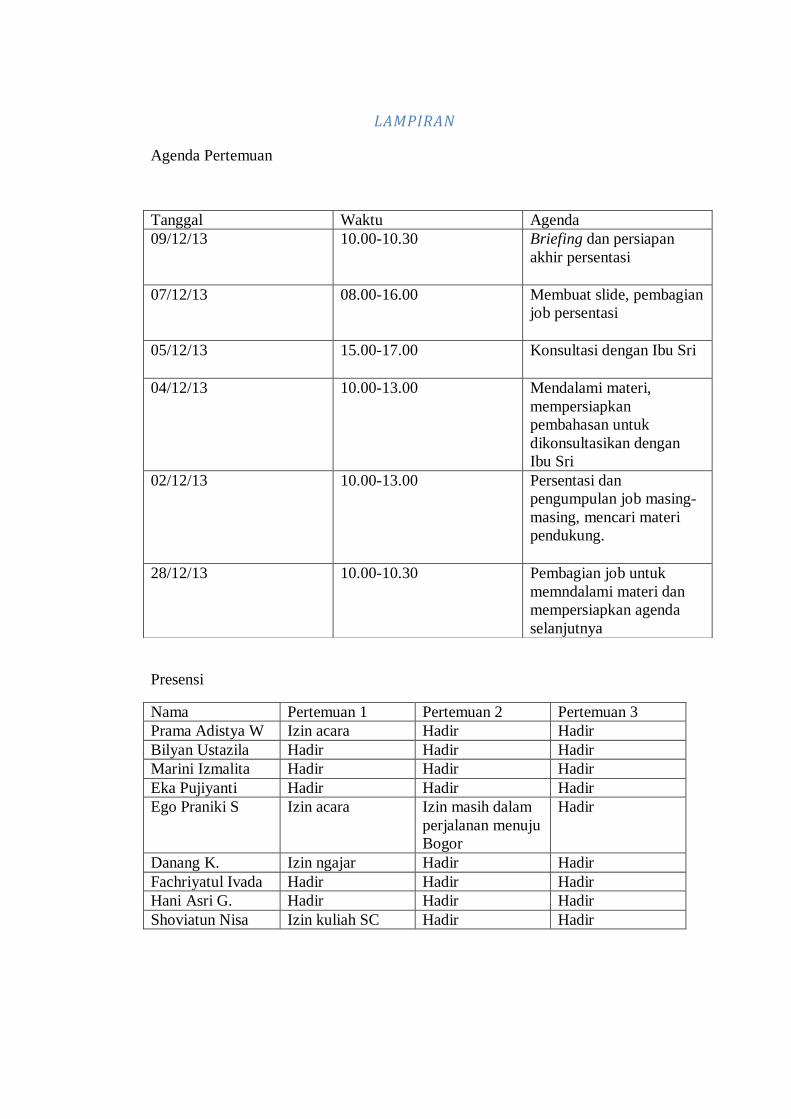
LAMPIRAN
Agenda Pertemuan
Presensi
Nama Pertemuan 1 Pertemuan 2 Pertemuan 3
Prama Adistya W Izin acara Hadir Hadir
Bilyan Ustazila Hadir Hadir Hadir
Marini Izmalita Hadir Hadir Hadir
Eka Pujiyanti Hadir Hadir Hadir
Ego Praniki S Izin acara Izin masih dalam
perjalanan menuju
Bogor
Hadir
Danang K. Izin ngajar Hadir Hadir
Fachriyatul Ivada Hadir Hadir Hadir
Hani Asri G. Hadir Hadir Hadir
Shoviatun Nisa Izin kuliah SC Hadir Hadir
Tanggal Waktu Agenda
09/12/13 10.00-10.30 Briefing dan persiapan
akhir persentasi
07/12/13 08.00-16.00 Membuat slide, pembagian
job persentasi
05/12/13 15.00-17.00 Konsultasi dengan Ibu Sri
04/12/13 10.00-13.00 Mendalami materi,
mempersiapkan
pembahasan untuk
dikonsultasikan dengan
Ibu Sri
02/12/13 10.00-13.00 Persentasi dan
pengumpulan job masing-
masing, mencari materi
pendukung.
28/12/13 10.00-10.30 Pembagian job untuk
memndalami materi dan
mempersiapkan agenda
selanjutnya
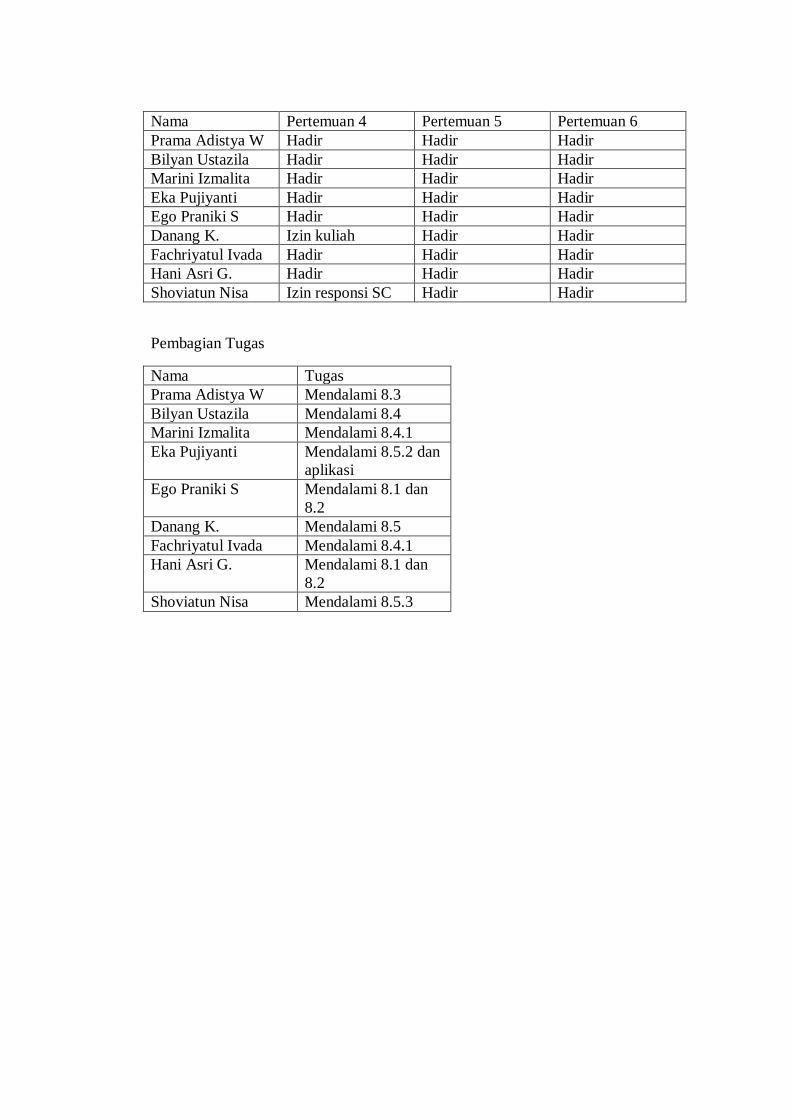
Nama Pertemuan 4 Pertemuan 5 Pertemuan 6
Prama Adistya W Hadir Hadir Hadir
Bilyan Ustazila Hadir Hadir Hadir
Marini Izmalita Hadir Hadir Hadir
Eka Pujiyanti Hadir Hadir Hadir
Ego Praniki S Hadir Hadir Hadir
Danang K. Izin kuliah Hadir Hadir
Fachriyatul Ivada Hadir Hadir Hadir
Hani Asri G. Hadir Hadir Hadir
Shoviatun Nisa Izin responsi SC Hadir Hadir
Pembagian Tugas
Nama Tugas
Prama Adistya W Mendalami 8.3
Bilyan Ustazila Mendalami 8.4
Marini Izmalita Mendalami 8.4.1
Eka Pujiyanti Mendalami 8.5.2 dan
aplikasi
Ego Praniki S Mendalami 8.1 dan
8.2
Danang K. Mendalami 8.5
Fachriyatul Ivada Mendalami 8.4.1
Hani Asri G. Mendalami 8.1 dan
8.2
Shoviatun Nisa Mendalami 8.5.3
Recommended

















