
NetworksandOpera/ngSystemsChapter13:Scheduling
(252‐0062‐00)DonaldKossmann&TorstenHoefler
Frühjahrssemester2013
© Systems Group | Department of Computer Science | ETH Zürich

Last/me
• Processconceptsandlifecycle• Contextswitching• Processcrea/on• Kernelthreads• Kernelarchitecture• Systemcallsinmoredetail
• User‐spacethreads

Schedulingis…Decidinghowtoallocateasingleresourceamongmul/pleclients
– Inwhatorderandforhowlong
• UsuallyreferstoCPUscheduling– Focusofthistalk–wewilllookatselectedsystems/research– OSalsoschedulesotherresources(eg.diskandnetworkIO)
• CPUschedulinginvolvesdeciding:– WhichtasknextonagivenCPU?– Forhowlongshouldagiventaskrun?– Onwhichprocessorshouldataskrun?
Task:process,thread,domain,dispatcher,…

Scheduling
• Whatmetricistobeop/mized?– Fairness(butwhatdoesthismean?)
– Policy(ofsomekind)– Balance(keepeverythingbeingused)– Increasingly:Power(orEnergyusage)
• Usuallytheseareincontradic/on…

Objec/ves
• General:– Fairness– Enforcementofpolicy– Balance
• Othersdependonworkload,orarchitecture:– Batchjobs,Interac/ve,Real/meandmul/media
– SMP,SMT,NUMA,mul/‐node

Challenge:complexityofschedulingalgorithms
• SchedulerneedsCPUtodecidewhattoschedule– Any/mespentinscheduleris“wasted”/me– Wanttominimizeoverheadofdecisions
• Tomaximiseu/liza/onofCPU
– Butlowoverheadisnogoodifyourschedulerpicksthe“wrong”thingstorun!
⇒ Trade‐offbetween:schedulercomplexity/overheadand
op9malityofresul/ngschedule

Challenge:Frequencyofschedulingdecisions
• Increasedschedulingfrequency⇒increasingchanceofrunningsomethingdifferent
Leadstohighercontextswitchingrates,⇒lowerthroughput– Flushpipeline,reloadregisterstate– MaybeflushTLB,caches– Reduceslocality(eg.incache)

Batchworkloads
• “Runthisjobtocomple/on,andtellmewhenyou’redone”– Typicalmainframeuse‐case– Muchusedinoldtextbooks– Makingacomebackwithlargeclusters…
• Goals:– Throughput(jobsperhour)– Wait/me(/metoexecu/on)– Turnaround/me(submissiontotermina/on)– CPUU/liza/on(don’twasteresources)

Interac/veworkloads
• “Waitforexternalevents,andreactbeforetheusergetsannoyed”– Wordprocessing,browsing,fragging,etc.– CommonforPCs,phones,etc.
• Goals:– Response/me:howquicklydoessomethinghappen?
– Propor/onality:somethingsshouldbequicker

SojReal/meworkloads
• “Thistaskmustcompleteinlessthan50ms”,or
• “Thisprogrammustget10msCPUevery50ms”– Dataacquisi/on,I/Oprocessing– Mul/mediaapplica/ons(audioandvideo)
• Goals:– Deadlines– Guarantees– Predictability(real/me≠fast!)

HardReal/meworkloads
• “Ensuretheplane’scontrolsurfacesmovecorrectlyinresponsetothepilot’sac/ons”
• “Firethesparkplugsinthecar’sengineattheright/me”– Mission‐cri/cal,extremely/me‐sensi/vecontrolapplica/ons
• Notcoveredinthiscourse:verydifferenttechniquesrequired…

Schedulingassump/onsanddefini/ons

CPU‐andI/O‐boundtasks
CPUburst Wai/ngforI/O
CPU‐boundtask:
I/O‐boundtask:

Simplifyingassump/ons
• Onlyoneprocessor– We’llrelaxthis(much)later
• Processorrunsatfixedspeed– Real/me==CPU/me– Nottrueinrealityforpowerreasons– DVFS:DynamicVoltageandFrequencyScaling
– Inmanycases,however,efficiency⇒runflat‐outun/lidle.

Simplifyingassump/ons
• Weonlyconsiderwork‐conservingscheduling– Noprocessorisidleifthereisarunnabletask– Ques/on:isthisalwaysareasonableassump/on?
• Thesystemcanalwayspreemptatask– Rulesoutsomeverysmallembeddedsystems
– Andhardreal‐/mesystems…– AndearlyPC/MacOSes…

Whentoschedule?
When:1. Arunningprocessblocks– e.g.ini/atesblockingI/O,orwaitsonachild
2. Ablockedprocessunblocks– I/Ocompletes
3. Arunningorwai/ngprocessterminates4. Aninterruptoccurs– I/Oor/mer
• 2or4caninvolvepreemp%on

Preemp/on
• Non‐preemp/vescheduling:– Requireeachprocesstoexplicitlygiveupthescheduler
• StartI/O,executesa“yield()”call,etc.– Windows3.1,olderMacOS,someembeddedsystems
• Preemp/vescheduling:– Processesdispatchedanddescheduledwithoutwarning
• Ojenona/merinterrupt,pagefault,etc.
– ThemostcommoncaseinmostOSes– Soj‐real/mesystemsareusuallypreemp/ve– Hard‐real/mesystemsareojennot!

Overhead
• Dispatchlatency:– Timetakentodispatcharunnableprocess
• Schedulingcost=2x(halfcontextswitch)+(scheduling/me)
• Timesliceallocatedtoaprocessshouldbesignificantlymorethanschedulingoverhead!

Overheadexample(fromTanenbaum)
• Supposeprocessswitch/meis1ms• Runeachprocessfor4ms⇒20%ofsystem/mespentinscheduler
• Runeachprocessfor100ms50jobs⇒response/meupto5seconds
• Tradeoff:response/mevs.schedulingoverhead

Batch‐orientedscheduling

Batchscheduling:whybother?
• Mainframesaresooooo1970!• But:– Mostsystemshavebatch‐likebackgroundtasks
– Yes,evenphonesarebeginningto.– CPUburstscanbemodelledasbatchjobs– Webservicesarerequest‐based

First‐comefirst‐served
• Simplestalgorithm!
• Example:– Wai/ng/mes:0,24,27– Avg. =(0+24+27)/3
=17
• But..
Process Execu/on/me
A 24
B 3
C 3
B CA
0 24 27 30

First‐comefirst‐served
• Differentarrivalorder• Example:– Wai/ng/mes:6,0,3– Avg. =(0+3+6)/3=3
• Muchbewer• Butunpredictable
Process Execu/on/me
A 24
B 3
C 3
B C A
0 3 6 30

Convoyphenomenon
• Shortprocessesbackupbehindlong‐runningprocesses
• Well‐known(andwidelyseen!)problem– Famouslyiden/fiedindatabaseswithdiskI/O– Simpleformofself‐synchroniza/on
• Generallyundesirable…
• FIFOusedfor,e.g.memcached

Shortest‐JobFirst
• Alwaysrunprocesswiththeshortestexecu/on/me.
• Op/mal:minimizeswai/ng/me(andhenceturnaround/me)
Process Execu/on/me
A 6
B 8
C 7
D 3
D A C B

Op/mality
• Considernjobsexecutedinsequence,eachwithturnaround/me%,0<i<=n
• Meanturnaround/meis:
• Minimizedwhenshortestjobisfirst
• E.g.,for4jobs:

Execu/on/mees/ma/on
• Problem:whatistheexecu/on/me?– Formainframes,couldpunttouser– Andchargethemmoreiftheywerewrong
• Fornon‐batchworkloads,useCPUburst/mes– Keepexponen/alaverageofpriorbursts– C.f.TCPRTTes/mator
• Orjustuseapplica/oninforma/on– Webpages:sizeofwebpage

SJF&preemp/on
• Problem:jobsarriveallthe/me• “Shortestremaining/menext”– New,shortjobsmaypreemptlongerjobsalreadyrunning
• S/llnotanidealmatchfordynamic,unpredictableworkloads– Inpar/cular,interac/veones.

Schedulinginterac/veloads

Round‐robin
• Simplestinterac/vealgorithm
• Runallrunnabletasksforfixedquantuminturn• Advantages:– It’seasytoimplement
– It’seasytounderstand,andanalyze– Higherturnaround/methanSJF,butbewerresponse
• Disadvantages:– It’srarelywhatyouwant– Treatsalltasksthesame

Priority
• Verygeneralclassofschedulingalgorithms• Assigneverytaskapriority• Dispatchhighestpriorityrunnabletask• Priori/escanbedynamicallychanged
• Scheduleprocesseswithsamepriorityusing– RoundRobin– FCFS– Etc.

Priorityqueues
Priority100
Priority4
Priority3
Priority2
Priority1 T
T
T T
T T T
T
T
Runnabletasks
Priority
…

Mul/‐levelqueues
• Canscheduledifferentprioritylevelsdifferently:– Interac/ve,high‐priority:roundrobin– Batch,background,lowpriority:FCFS
• Ideallygeneralizestohierarchicalscheduling

Starva/on
• Strictpriorityschemesdonotguaranteeprogressforalltasks
• Solu/on:Ageing– Taskswhichhavewaitedalong/mearegraduallyincreasedinpriority
– Eventually,anystarvingtaskendsupwiththehighestpriority
– Resetprioritywhenquantumisusedup

Mul/levelFeedbackQueues
• Idea:penalizeCPU‐boundtaskstobenefitI/Oboundtasks– Reducepriorityforprocesseswhichconsumetheiren/requantum
– Eventually,re‐promoteprocess– I/Oboundtaskstendtoblockbeforeusingtheirquantum⇒remainathighpriority
• Verygeneral:anyschedulingalgorithmcanreducetothis(problemisimplementa/on)

Example:Linuxo(1)scheduler
• 140levelMul/levelFeedbackQueue– 0‐99(highpriority):
• sta/c,fixed,“real/me”
• FCFSorRR– 100‐139:Usertasks,dynamic
• Round‐robinwithinaprioritylevel• Priorityageingforinterac/ve(I/Ointensive)tasks
• Complexityofschedulingisindependentofno.tasks– Twoarraysofqueues:“runnable”&“wai/ng”– Whennomoretasksin“runnable”array,swaparrays

Example:Linux“completelyfairscheduler”
• Task’spriority=howliwleprogressithasmade– Adjustedbyfudgefactorsover/me
• Implementa/onusesRed‐Blacktree– Sortedlistoftasks– Opera/onsnowO(logn),butthisisfast
• Essen/ally,thisistheoldideaof“fairqueuing”frompacketnetworks– Alsocalled“generalizedprocessorscheduling”– Ensuresguaranteedservicerateforallprocesses– CFSdoesnot,however,expose(ormaintain)theguarantees

ProblemswithUNIXScheduling
• UNIXconflatesprotec/ondomainandresourceprincipal– Priori/esandschedulingdecisionsareper‐process
• However,maywanttoallocateresourcesacrossprocesses,orseparateresourcealloca/onwithinaprocess– E.g.,webserverstructure
• Mul/‐process• Mul/‐threaded• Event‐driven
– IfIrunmorecompilerjobsthanyou,IgetmoreCPU/me• In‐kernelprocessingisaccountedtonobody

ResourceContainers[Bangaetal.,1999]
NewOSabstrac/onforexplicitresourcemanagement,separatefromprocessstructure
• Opera/onstocreate/destroy,managehierarchy,andassociatethreadsorsocketswithcontainers
• Independentofschedulingalgorithmsused• Allkernelopera/onsandresourceusageaccountedtoa
resourcecontainer
⇒ Explicitandfine‐grainedcontroloverresourceusage⇒ ProtectsagainstsomeformsofDoSawack
• Mostobviousmodernform:virtualmachines

RealTime

Real‐/mescheduling
• Problem:givingreal/me‐basedguaranteestotasks– Taskscanappearatany/me– Taskscanhavedeadlines– Execu/on/meisgenerallyknown– Taskscanbeperiodicoraperiodic
• Mustbepossibletorejecttaskswhichareunschedulable,orwhichwouldresultinnofeasibleschedule

Example:mul/mediascheduling

Rate‐monotonicscheduling
• Scheduleperiodictasksbyalwaysrunningtaskwithshortestperiodfirst.– Sta/c(offline)schedulingalgorithm
• Suppose:– mtasks– Ciistheexecu/on/meofi’thtask– Piistheperiodofi’thtask
• ThenRMSwillfindafeasiblescheduleif:
• (Proofisbeyondscopeofthiscourse)

EarliestDeadlineFirst
• Scheduletaskwithearliestdeadlinefirst(duh..)– Dynamic,online.– Tasksdon’tactuallyhavetobeperiodic…– Morecomplex‐O(n)–forschedulingdecisions
• EDFwillfindafeasiblescheduleif:
• Whichisveryhandy.Assumingzerocontextswitch/me…

Guaranteeingprocessorrate
• E.g.youcanuseEDFtoguaranteearateofprogressforalong‐runningtask– Breaktaskintoperiodicjobs,periodpand/mes.
– Ataskarrivesatstartofaperiod– Deadlineistheendoftheperiod
• Providesareserva%onschedulerwhich:– Ensurestaskgetsssecondsof/meeverypseconds
– Approximatesweightedfairqueuing
• Algorithmisregularlyrediscovered…

Mul/processorScheduling
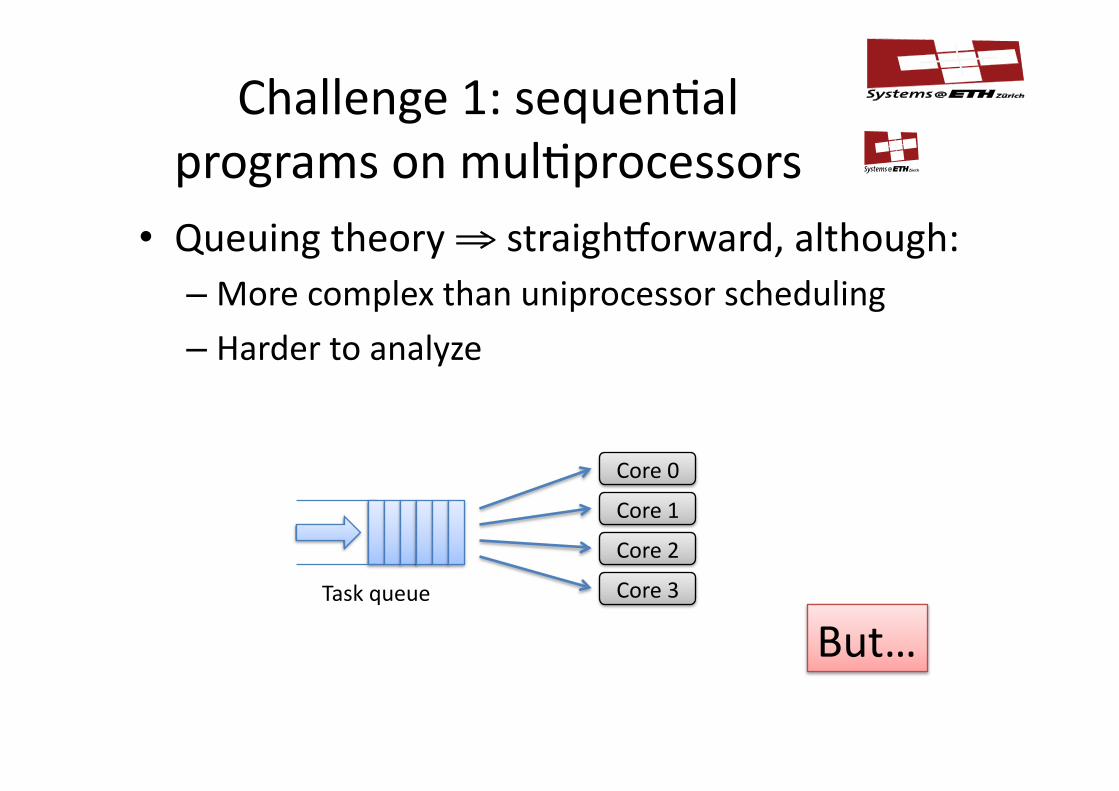
Challenge1:sequen/alprogramsonmul/processors
• Queuingtheory⇒straigh�orward,although:– Morecomplexthanuniprocessorscheduling
– Hardertoanalyze
Taskqueue
Core0
Core1
Core2
Core3
But…

It’smuchharder
• Overheadoflockingandsharingqueue– ClassiccaseofscalingbowleneckinOSdesign
• Solu/on:per‐processorschedulingqueues
Core0
Core1
Core2
Core3
Inprac/ce,eachismorecomplex
e.g.MFQ

It’smuchharder
• Threadsallocatedarbitrarilytocores⇒tendtomovebetweencores⇒tendtomovebetweencaches⇒Reallybadlocalityandhenceperformance
• Solu/on:affinityscheduling– Keepeachthreadonacoremostofthe/me– Periodicallyrebalanceacrosscores– Note:thisisnon‐work‐conserving!
• Alterna/ve:hierarchicalscheduling(Linux)

Challenge2:parallelapplica/ons
• Globalbarriersinparallelapplica/ons⇒Oneslowthreadhashugeeffectonperformance– CorollaryofAmdahl’sLaw
• Mul/plethreadswouldbenefitfromcachesharing• Differentapplica/onspolluteeachothers’caches• Leadstoconceptof“co‐scheduling”– Trytoscheduleallthreadsofanapplica/ontogether
• Cri/callydependentonsynchroniza%onconcepts

Mul/corescheduling
• Mul/processorschedulingistwo‐dimensional– Whentoscheduleatask?– Where(whichcore)toscheduleon?
• GeneralproblemisNPcomplete• Butit’sworsethanthat:– Don’twantaprocessholdingalocktosleep⇒Mightbeotherrunningtasksspinningonit
– Notallcoresareequal• Ingeneral,thisisawide‐openresearchproblem

Liwle’sLaw
• Assume,inatrainsta/on:– 100peoplearriveperminute– Eachpersonspends15minutesinthesta/on– Howbigdoesthesta/onhavetobe(househowmanypeople)
• Liwle’slaw:“Theaveragenumberofac%vetasksinasystemisequaltotheaveragearrivalratemul%pliedbytheaverage%meataskspendsinasystem”
Recommended

















