
Netzwerksicherheit
Intrusion Detection Systems
Stephen Wolthusen

Kategorien für IDS
■ Externe PenetrationAngreifer hat keinen Zugriff auf Authentisierungsdaten oder kannRevision/Zugangskontrolle umgehen
■ Interne PenetrationAuch als „Maskerade“ bezeichnetAngreifer verwendet Authentisierungsdaten anderer Nutzer
■ MißbrauchLegitime Nutzer, die der Sicherheitspolitik zuwider handeln

Das Maskerade-Problem
■ Zuerst von Anderson (1980) beschrieben
■ Maskerade kann anhand von Revisionsdaten bestimmtwerden
Systemnutzung außerhalb „normaler“ ArbeitszeitenAbnorme NutzungshäufigkeitAbnorme Anzahl von Zugriffen auf DatenAbnorme Zugriffsmuster (Programme/Daten)

Begründung für automatisierte IDS
■ Problem: Feststellung abnormaler MusterRevisionsdatenvolumenMuster können sehr umfangreich seinVorgehen a la Cliff Stoll´s „The Cuckoo´s Egg“ ist zu aufwendig
■ Vorschlag von Anderson: Automatisierte Verfahren zurReduktion von Revisionsdaten
Extraktion relevanter Merkmale, AnomalienQualität der Revisionsdaten ist entscheidendBestimmung der Kriterien für Angriffe problematisch
Systemgrenze
Akt
ive
Ver
teid
igu
ng
Ab
len
kun
g,
"Ho
ney
po
ts"
Erke
nn
un
g v
on
An
gri
ffen
Inte
rne
Ab
sch
reck
un
g
Inte
rne
Präv
enti
on
Exte
rne
Ab
sch
reck
un
g
Exte
rne
Präv
enti
on
Präe
mp
tive
Geg
enm
aßn
ahm
en
Erfo
lgre
ich
e A
ng
reif
er
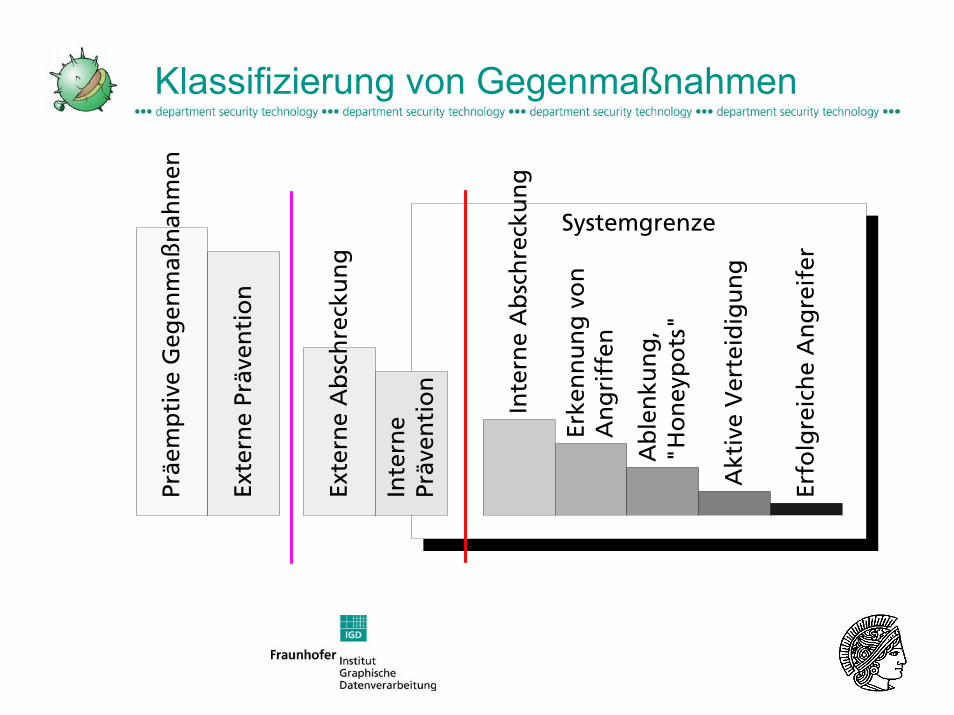
Klassifizierung von Gegenmaßnahmen

Gegenmaßnahmen (1)
■ Präemptive GegenmaßnahmenAktive Eliminierung einer Bedrohung ist i.d.R. nicht möglich, rechtlicheProbleme, Feststellung der Identität des Angreifers
■ Externe PräventionAufhalten von Angriffen außerhalb der eigenen Enklave: Firewall
■ Externe AbschreckungAndrohung strafrechtlicher Verfolgung, Ankündigung von Überwachung
■ Interne PräventionInterne Firewalls, „Härtung“ interner Systeme, regelmäßige Aktualisierung derSysteme nach ECOs

Gegenmaßnahmen (1)
■ Interne AbschreckungSanktionierung von Mitarbeitern bei Zuwiderhandlung gegen Sicherheitspolitik
■ Erkennung von AngriffenHier sind IDS angesiedelt, beinhaltet auch Reaktion auf Angriffe
■ AblenkungBereitstellung „attraktiverer“ Ziele („Honeypots/-nets“)
■ Aktive VerteidigungAktive / autonome Gegenmaßnahmen (Blockierung von Nutzerkonten...)
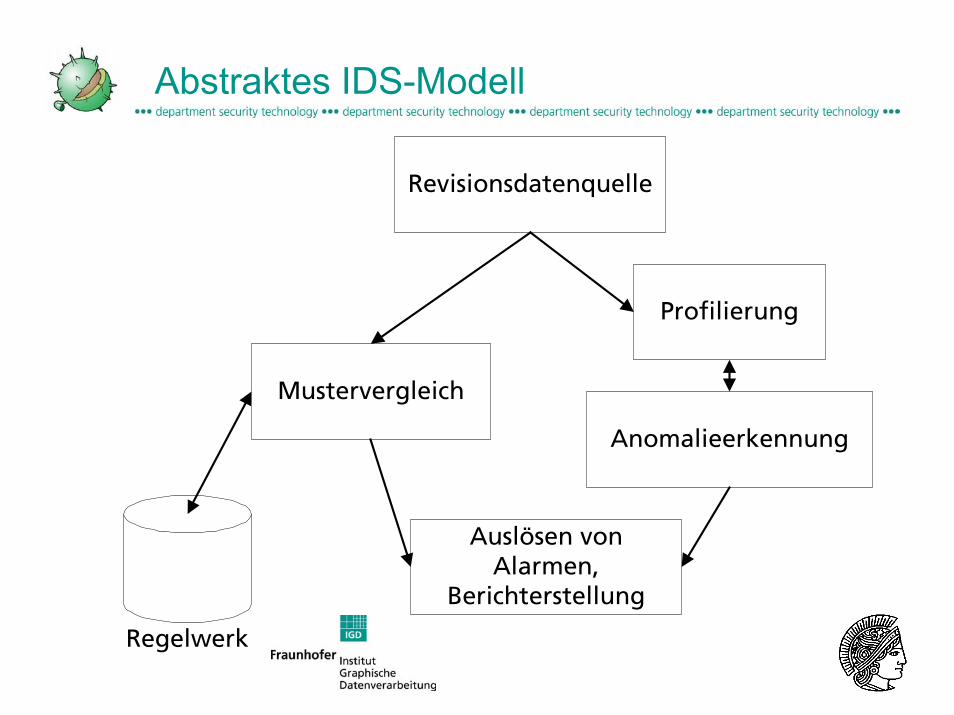
Abstraktes IDS-Modell
Regelwerk
Mustervergleich
Auslösen vonAlarmen,
Berichterstellung
Anomalieerkennung
Profilierung
Revisionsdatenquelle

ID-Verfahren: Anomalie-Erkennung (1)
■ Vorkonfigurierung von Angriffsmustern für Erkennungnicht notwendig
IDS lernt anhand von Systemverhalten normales Verhalten und erkenntabnormales Verhalten
▲ kann auch neue Verhaltensmuster erkennenKlare Trennung in „legales“ und „illegitimes Verhalten selten möglich,meist existiert Grauzone
▲ Identifikation aller möglicher verdächtiger Verhalten führt zuinakzeptabler Häufigkeit von Falschmeldungen

ID-Verfahren: Anomalie-Erkennung (2)
■ Nutzerverhalten ändert sich mit der Zeitneue Aufgaben, verbesserte Handhabung des Systems etc.Definition von „normal“ ändert sich entsprechend: „conceptual drift“
■ Anomalie-ID muß zur Vermeidung von Fehlalarmen dieseÄnderungen mitverfolgen und die Definition der Anomalielaufend anpassen
Angreifer kann gezielt Verhaltensmuster in Richtung unerwünschtenVerhaltens variieren bis der eigentliche Angriff keine Anomalie mehrdarstellt

ID-Verfahren: Anomalie-Erkennung (3)
■ Große Anzahl von Sensoren (Revisionsdaten vonBetriebssystemen, Pakete von Netzwerk-Sniffer,Logins, etc.)
■ Hohe zeitliche Auflösung der SensordatenHochdimensionale Räume für die Darstellung der SensorenAnalyse erfordert erhebliche Rechenleistung
■ Problem der Dejustierung von IDS bei EinführungPräsenz von Angreifern/Mißbrauch läßt Kalibrierung fürAnomalieerkennung ungenau werden

ID-Verfahren: Signatur-Erkennung
■ Revisionsdaten werden gegen vorgegebene Musterverglichen
Erstellung der Muster („Signaturen“) erfolgt i.d.R. in Handarbeit:aufwendig und fehleranfällig
▲ Erzeuger der Muster müssen System, Angreifer genau kennen undin der Lage sein kritische Merkmale aus Angriffen zu extrahieren
Ermöglicht deutliche Reduktion der FehlalarmeNur gegen bereits bekannte Angriffe wirksam
▲ Wenn Signatur überspezifiziert ist genügen bereits geringeÄnderungen an Angriff zur Nicht-Erkennung

ID-Verfahren: Spezifikationsbasierte Verfahren
■ Invertierung des Signatur-Erkennungs-AnsatzesFestlegung legitimer VerhaltensmusterAlarm bei Abweichung von spezifizierten Mustern
■ Verwendbarkeit für nicht triviale Anwendungsprogrammeund Systemprozesse fragwürdig
Selbst wenn Spezifikation/Quellen von Anwendungen vorliegen würden:Komplexität ist zu hoch um Verhalten hinreichend genau zu beschreibenAlternative ist zu grobe Spezifikation erlaubten Verhaltens
▲ Reduktion der Erkennungsrate

Taxonomische Merkmale von IDS (1)
■ Quelle der RevisionsdatenHost-basierte Quellen: Sensoren sind lokal auf zu überwachendemKnoten angebracht
▲ Direkte Verwendung der Revisionsdaten des Betriebssystems▲ Weitere Instrumentierung des Systems (system calls...)▲ Anwendungsspezifische Revisionsdaten
Netzwerk-basierte Quellen: Setzt voraus, daß relevanterNetzwerkverkehr von Sensor erfaßt werden kann (Switching)

Taxonomische Merkmale von IDS (2)
■ Reaktion auf erkannte AngriffePassive Reaktion: Benachrichtigung des AdministratorsAktive Reaktion
▲ Versuch ohne Interaktion mit Administrator Schaden zubegrenzen durch
Maßnahmen, die nur lokales System betreffen(z.B. Verstärken der Erfassung von Revisionsdaten)Maßnahmen, die mutmaßlich angreifendesSystem beeinflussen

Taxonomische Merkmale von IDS (3)
■ Verzögerung bis zur AngriffserkennungEchtzeit (feste obere Zeitschranke von Ereignis bis Erkennung) vs.annähernd Echtzeit-SystemePost Factum-Analyse wird von fast allen Systemen beherrscht
■ Granularität der VerarbeitungVerarbeitung der Sensordaten direkt bei Auftreten vs. Sammlung vonGruppen von Beobachtungen
■ Ort der Verarbeitung: Lokal, zentral
■ Ort der Datensammlung: Einzelne Sensoren,verteilte Systeme

Analytische Verfahren
■ Grundkonzepte der Anomalie-Erkennung:Anderson (1980)
■ Weiterentwicklung zum ersten formalisierten Modell amSRI durch Peter Neumann und Dorothy Denning
Grundlage für das IDES-System des SRI und fast alle modernen IDS
■ MetrikenEreigniszählerZeitintervalleRessourcenmaße

Statistische Modelle für Anomalieerkennung
■ Zufallsvariable x
■ Reihe von Beobachtungen x1,...,xn
■ Aufgrund einer oder mehrerer Beobachtungen xn+1 mußdas IDS entscheiden, ob eine Anomalie vorliegt
■ Einfachste Variante: Operative ModelleVergleiche Beobachtungen gegen feste GrenzwerteBei Überschreitung von Schwellwert wird Alarm ausgelöstBestimmung der Grenzwerte durch Heuristiken aus zuvor gesammeltenBeobachtungen
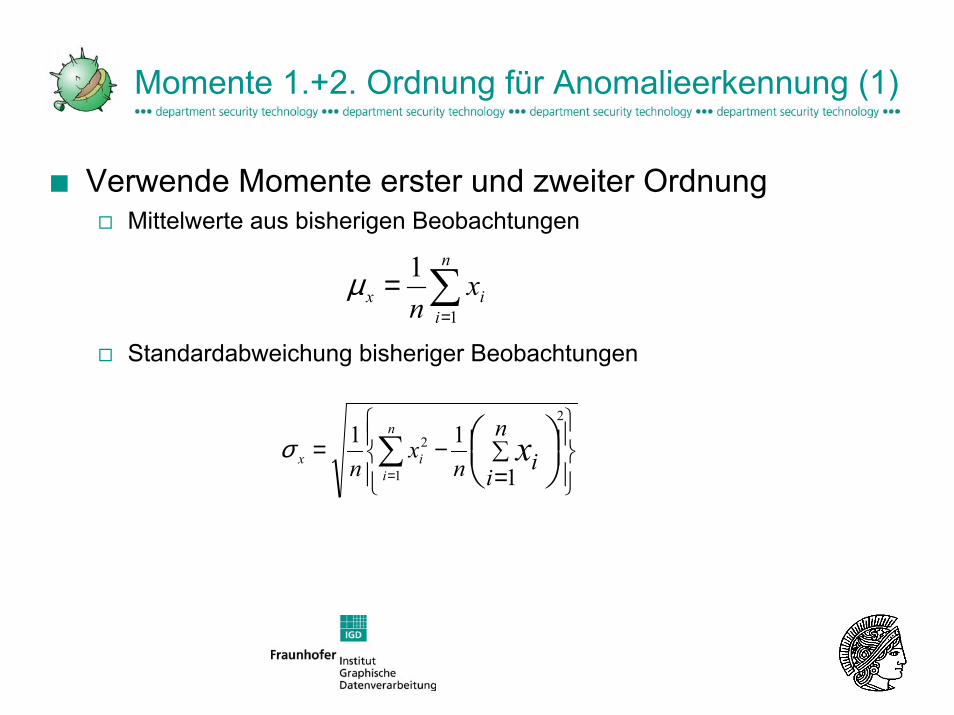
Momente 1.+2. Ordnung für Anomalieerkennung (1)
■ Verwende Momente erster und zweiter OrdnungMittelwerte aus bisherigen Beobachtungen
Standardabweichung bisheriger Beobachtungen
∑=
=n
iix x
n 1
1µ
∑=
−=
∑
=
n
iin
xn x
n
iix
1
112
1
2σ

Momente 1.+2. Ordnung für Anomalieerkennung (2)
■ Neue Beobachtungen xn+1 sind abnormal wenn sieaußerhalb des d Standardabweichungen entferntenKonfidenzintervalls liegen
Tschebyscheff´sche Ungleichung: Wahrscheinlichkeit, daß Beobachtungaußerhalb des Intervalls liegt ist 1/d2
■ Modell ist auf sämtliche Beobachtungen anwendbar
■ Wissen über Schranken muß nicht modelliert werden
■ Conceptual Drift kann durch stärkere Gewichtung neuererBeobachtungen einbezogen werden

Multivariate Methoden für Anomalieerkennung
■ Erweiterung einfacher statistischer Modelle: Korrelationenzwischen zwei oder mehr Metriken
Stellt Relationen zwischen Variablen fest
■ FaktoranalyseStellt Kovarianzen zwischen Menge von Variablen durchendliche Anzahl latenter Variable festAnnahmen: Variable hängen linear zusammen, kein unkorelliertesRauschen, gesonderte VariationenErlaubt Schätzung linearer Beziehungen,Betrag der Variationen

Multivariate Methoden: Multidimensionale Skalierung
■ Erlaubt Erkennung globaler Ähnlichkeiten zwischenBeobachtungen durch Reduktion des Darstellungsraums derÄhnlichkeiten zwischen den Beobachtungen
■ Definiere für je 2 Objekte i,j Proximitätsmaß pij (kleiner, jebesser die Ähnlichkeit von i,j)
■ Konfiguration X stellt Menge von n Punkten in m-dimensionalen Raum dar, n x n Matrix der n Koordinaten derPunkte auf m Achsen eines kartesischen Koordinatensystems.Distanz in X: ( )∑ −
=
=m
aij jaiad xx
1
2

MDS-Methoden
■ Verschiedene MDS werden durch Wahl einerAbbildungsfunktion f(pij ) bestimmt:
Absolute MDS: Distanz zwischen Punkten i,j: f(pij ) = dij
Verhältnis-MDS: Verwendet multiplikative Konstante b sodaß f(pij ) = bpij für alle definierten pij
Intervall-MDS: Verwendet lineare Funktion f()Nichtmetrische MDS: Operation findet nicht direkt auf Proximitätsmaßstatt; f() ist beliebige ordnungserhaltende Transformation derProximitätswerte

Markov-Prozesse für Anomalie-Erkennung
■ Zufallsprozeß, bei dem Übergangswahrscheinlichkeiten voneinem Zustand zum nächsten ausschließlich vomvorhergehenden abhängen:
■ Als Metrik sind nur Ereigniszähler geeignet, jede einzelneBeobachtung kann Zufallsvariable sein
■ Markov-Prozeß erster Ordnung: nur eine einzige vorherigeBeobachtung wird berücksichtigt
kann als 2d-Matrix aufgefaßt werdenAnomalie wenn Wert in Matrix zu groß ist
∏=
−==n
iiin sspspsspSp
2111 )|()()()( L

Zeitreihen für Anomalie-Erkennung
■ Reihenfolge und zeitliche Abstände zwischenBeobachtungenx1 ... xn werden erfaßt
■ Beobachtungen sind abnorm, wenn Wahrscheinlichkeit,daß Beobachtung zum gemessenen Zeitpunkt eintritt, zugering ist
■ Erlaubt Erfassung von Tendenzen über längere Zeitgegenüber einfachen Verfahren auf Grundlage vonMomenten 1. und 2. Ordnung
deutlich höherer Aufwand gegenüber einfachen Verfahren

Hidden Markov Modelle für Anomalieerkennung (1)
■ HMMs sind doppelt stochastische Prozesse undbestehen aus 4 Komponenten
Menge von k ZuständenZustandsübergangsmatrix A, die Wahrscheinlichkeiten der Übergängezwischen den einzelnen Zuständen erfaßt. Bei Markov-Prozessen ersterOrdnung ist dies
Ausgangsverteilung B (diskretes Alphabet, diskreteWahrscheinlichkeitsverteilung bj auf diesem Alphabet)Initiale Zustandsverteilung, die angibt, daß dasSystem im Zustand qi beginnt
)|( 1 itjtij sqsqpa === +

Hidden Markov Modelle für Anomalieerkennung (2)
■ Zur Anwendung von HMM müssen drei Probleme gelöstwerden:
■ BeobachtungswahrscheinlichkeitenGegeben eine Folge von Beobachtungen, Modell: Wahrscheinlichkeit, daß dieseFolge unter dem Modell auftritt
■ ZustandsfolgenauswahlBestimme Folge von Zuständen, die unter einem Optimierungskriterium höchsteWahrscheinlichkeit hat, Beobachtungsfolge zu erzeugen
■ TrainingOptimierung Parametermenge sodaß Beobachtungswahrscheinlichkeitenmaximiert werden

Hidden Markov Modelle für Anomalieerkennung (3)
■ Bestimmung der BeobachtungswahrscheinlichkeitenVerwende Forward-Backward-AlgorithmusForward-Schritt berechnet aufeinander folgende Wahr-scheinlichkeitenpartieller Folgen von BeobachtungenBerechnung aller Zustandsfolgen ist nicht notwendig:
▲ Ausnutzung der Markov-EigenschaftWahrscheinlichkeit einer Beobachtungsfolge x unter einem Modell kannin O(k2T) Schritten berechnet werden

Hidden Markov Modelle für Anomalieerkennung (4)
■ ZustandsfolgenauswahlMehrere Zustandsfolgen haben dieselben Beobachtungsfolgen: Kriteriumfür Auswahl der Folge genügt, es muß nicht genau eine bestimmtwerdenHäufig verwendetes Kriterium: Zustandsfolge die Wahrscheinlichkeit derFolge unter Präfix maximiert (Viterbi-Algorithmus)Wahrscheinlichkeit entlang von Pfaden, analog zuForward-Backward-AlgorithmusKann in O(k2T) Schritten berechnet werden

Hidden Markov Modelle für Anomalieerkennung (5)
■ TrainingsverfahrenOptimierung von Parametermenge sodaß Wahrscheinlich-keit einergegebenen Beobachtungsfolge maximal istGenerelles Optimierungsproblem, eine Möglichkeit: Baum-Welch-Verfahren
▲ Gradientenbasiert, findet nur lokale Maxima▲ Ausgangswert daher von großer Bedeutung▲ Iterativer Prozeß konvergiert, aber potentiell langsam
■ HMMs sind mächtiges Werkzeug,aber nur bedingt für Echtzeit-IDS geeignet

Genetische Algorithmen für Anomalieerkennung (1)
■ Iteratives Optimierungsverfahren
■ Versucht natürliche Selektion und Genetik nachzubildenVariable werden als Gene auf einem Chromosom abgebildetKandidaten für Lösung des Optimierungsproblems werden als initialePopulation betrachtet, Verbesserung der Population durch
▲ natürliche Selektion: günstige Charakteristiken pflanzen sich fort▲ Mutation und Rekombination: Zufällige Änderung, Vermischung von
„Eltern“-Chromosomen

Genetische Algorithmen für Anomalieerkennung (2)
■ Grundmuster genetischer AlgorithmenBestimmung initiale Population (zufällig, Modifikation bestehendenGenoms). Muß hinreichend vielfältig seinBewertung der Tauglichkeit einzelner Chromosomen: NumerischeRepräsentation z.B. durch Bohachevsky-FunktionSelektion der Chromosomen mit höchsten Tauglichkeits-werten,pseudozufällige Verknüpfung mit anderen hochwertigen Chromosomen,Entfernung niederwertiger C.Rekombination und Mutation: Zufällige Paarung von C. führt zu 2 neuenKind-C. Mutationen ändern lediglich Werte einzelner Gene

Neuronale Netze für Anomalieerkennung (1)
■ Nichtlineare Regressions-/Diskriminanz-/Datenreduktionsmodelle
■ Biophysikalische Analogie: Neuronen „feuern“, wennEingänge Schwellwerte erreichen. Schwellwertfunktion istdabei meist die Sigmoid-Funktion
■ Neuronen werden in Ebenen angeordnet und Verarbeitungmit Richtung vorgenommen
■ Summe der Klassifizierungsfehler für Trainingsdaten mußreduziert werden
Geeignete Auswahl der Gewichtung der Eingänge der Neuronen

Neuronale Netze für Anomalieerkennung (2)
■ Geeignete Auswahl der Schwellwertfunktion erlaubtDarstellung als Differentialgleichung
Ermöglicht Rückrechnung der Einflüsse von Gewichten über mehrereSchichtenAnpassung der Gewichte realisiert Gradientenverfahren
■ Andere Varianten:Radial-Basis-Funktionen
▲ meist nur mit einer AssoziationsebeneSelf-Organizing Maps
▲ Selbstkonfigurierende topologische Abbildungen

Einfaches Radial-Basis (analog: Perceptron) NN
h1(x) hj(x) hm(x)
xi xn
f(x)
wj
x1
. . . . . .
. . . . . .
w1 wm

Immunologisches Analogon für Anomalieerkennung
■ Natürliches Immunsystem von Vertebraten muß a prioriunbekannte Proteine von eigenen unterscheiden, alsgefährlich klassifizieren
Zufällige Erkennungsmuster werden in T-Helferzellen eingeprägtEliminierung von T-Zellen die Autoimmunreaktionen zeigen
■ Analogon mit Strings, die Vektoren von Beobachtungenenthalten als Proteinen, Detektoren für derartige Strings
Eliminierung von Detektoren für bekannt harmloses Verhalten

Produktionssysteme für Signaturerkennung
■ Mengen von Regeln mit Prämissenteil und mindestenseiner Konsequenz, evtl. auch mit Alternativzweig
Charakteristika von Angriffen oder Teilen werden von Experten inderartige Regeln gefaßtMeist interpretative Systeme (langsam)Stark abhängig von Qualität des von Experten eingegebenen Wissens
▲ Menge der Regeln muß möglichst minimal sein und dennoch allerelevanten Verhaltensmuster abdecken
▲ Ansonsten „Explosion“ von feuernden Regeln

Zustandsübergangsmodelle für Signaturerkennung
■ Modellierung von Angriffen/Vorfällen als Sequenz vondiskreten Ereignissen
Zuordnung von Ereignissen zu AkteurenZeitliche Abfolge von Ereignissen
■ Modellierung in Zustandsgraphen, Ereignisse sindÜbergänge, Knoten repräsentieren Zustände(z.B. Erlangung von root-Rechten)
Effiziente Darstellung durch endliche AutomatenParallele Bearbeitung mehrerer Automaten notwendigIntuitive Modellierung von ExpertenwissenUnabhängigkeit von zeitlichen Abständen

IDES, NIDES, EMERALD
■ Seit 1983 am SRI Forschung zu IDS: Folge von ProjektenViele Grundlagen und theoretische Modelle stammen aus diesem Projekt(Denning, Neumann, Lunt)IDES war primär Anomalieerkennung.
▲ Prämisse: Legitime Nutzer verhalten sich vorhersagbarSpäter: Signaturerkennung mit Experten-/ProduktionssystemNIDES ermöglichte Verwendung mehrerer Hosts als Quellen
▲ Daten wurden vor Verarbeitung an zentraler Stelle in kanonischeForm konvertiert
EMERALD ist verteilter Rahmen für Sensoren, Mechanismen

MIDAS
■ Für DOCKMASTER (NCSC, Multics) entwickeltes IDSExtern angeschlossene Symbolics-Maschine mit ExpertensystemRegelwerk bestand aus mehreren Ebenen, die Verdachtsmomentehierarchisch aufbauend konkretisiertenEbenfalls vorhanden: Analytische Komponente (statistisches Modellnach Neumann, Denning)DOCKMASTER wurde in mehr als 10 Jahren von 1984-1998 (öffentlichan das Internet angeschlossen, prominentes Ziel) nie kompromittiert

Network Security Monitor (NSM)
■ Netzwerk-basiertes IDSJedes zu überwachende Segment erhält Sensor, sämtliche Datenpaketewerden überwachtErfordert Zusammensetzung von Paketen höherer Protokollebene(IP-Fragmente, TCP-Segmente...)
▲ Hoher Speicheraufwand, RechenzeitExtraktion von bidirektionalen Kommunikationspfaden zwischeneinzelnen Hosts
▲ Reduziertes Datenvolumen wird von Expertensystem verarbeitet

Hyperview
■ Betrachtet Revisionsdaten als multivariate ZeitreiheNutzer sind „dynamische Prozesse“
■ Zwei Komponenten: Expertensystem und neuronalesNetzwerk
Zeitreihen werden auf NN abgebildetPartielle Rückkopplung der Ausgaben des Netzwerkes
▲ ermöglicht Speicherung innerhalb des NetzwerkesExpertensystem diente ebenfalls als Eingabemechanismus für Netzwerk:Zusätzliche Information für Entscheidungsprozeß

DIDS
■ Weiterentwicklung von NSM, Haystack
■ Drei Komponenten:Jeder Host hat lokalen IDS-Monitor der autonom agieren kann und Datenan DIDS Director weiterleitetJedes Netzwerksegment hat einen NSM-Monitor, der ebenfalls Daten anDIDS Director weiterleitetDIDS Director dient als Sammelstelle, zur Administration des verteiltenSystems

IDIOT und Snort
■ IDIOT modelliert Angriffe durch Colored Petri Netsermöglicht parallele Betrachtung mehrerer möglicher Alternativen fürAngriffeEs sind beliebig viele Pfade zwischen zwei beliebigen Knoten unterVerwendung unterschiedlicher Übergänge möglichModell kann anschaulich visualisiert werdenRelativ effizient, tauglich für Echtzeit-IDS
■ Snort ist einfaches regelbasiertes Netzwerk-IDSSensoren an konfigurierten Netzwerk-SchnittstellenFrei erhältlich, Regeln werden gut gepflegt
Recommended

















