
Nowcasting Indian GDP with Google Search data
Eric Qian
March 19, 2018
Abstract
Gross domestic product is an important indicator for measuring overall economic
health, and accurate forecasts are essential in crafting monetary and economic policy.
Developing economies are constrained by the availability and quality of economic time
series data. With increasing global Internet penetration, search data is an appealing
source for supplementing traditional economic data. Using India as a case study, this
paper uses a dynamic factor model with with a Kalman filter to generate predictions
for GDP. This paper has two contributions to the Indian context. First, a multifactor
model yielded better predictions than a single factor. Second, incorporating Google
Search data did not improve prediction accuracy.
1 Introduction
Monetary and economic policy heavily rely on accurate and timely information. How-
ever, since data releases are often delayed, current values are often not known until later
months. This produces a need for short run predictions. Academics and central banks
often use an approach called “nowcasting,”, which gives a framework for forecasting the
past, present, and near-future. This approach is especially important in predicting low
frequency macroeconomic variables with long publication lags, and is often used for pro-
ducing forecasts for GDP. A key advantage to this approach is the ability to incorporate
and interpret data releases in real-time. Much of the work is based on the model described
in Banbura, Giannone and Reichlin (2011).
The growth in search engines and data collection has made Internet data an attractive
source for supplementing traditional economic time series. As highlighted in the seminal
work by Choi and Varian (2012), aggregated Google search data provides a timely and
1

unfiltered measure for people’s preferences. Data are available in near real-time, and peo-
ple are unlikely to filter their search queries. These features are especially attractive for
macroeconomic prediction. As described in Vosen and Schmidt (2011), Google Search can
be used to measure economic sentiment ahead of traditional economic surveys.
Its direct connection to consumer sentiment makes Search data particularly appeal-
ing for forecasting prices (Pan, Chenguang Wu and Song, 2012; Goldfarb, Greenstein and
Tucker, 2015). More generally, Google data has also been used to study the Great Re-
cession (Suhoy, 2009; Schmidt and Vosen, 2012). Despite its advantages, Search has more
limited power when data quality is high and publication delays are low. For example, Li
(2016) found that in forecasting US initial jobless claims, incorporating Search data did
not improve forecasts. The comparative advantage to using search data is lower in contexts
where conventional data sources sufficiently capture consumer sentiment.
With the constraints in data timeliness and quality, there is promise in using Internet
data for emerging markets. Existing data sources are often not published at the same
standards as in developed economies. Swallow and Labbe (2010) and Seabold and Coppola
(2015) showcase the potential for Internet data in improving predictions by supplementing
traditional sources. In places where survey data are unavailable, search data can act as
a substitute for capturing consumer sentiment. This advantage has become more salient
over time, as mobile phone usage and Internet penetration have increased (World Bank,
2017).
The goal of this paper is to apply the nowcasting framework to the development context
and to study whether Internet data can be used as a solution for the imperfect data problem.
In particular, I aim to forecast Real Gross Domestic Product for India. India gives a
case study to creating predictions under imperfect conditions. Compared to developed
economies fewer economic time series are available and existing data are often lower quality
and more volatile. Moreover, high Internet penetration gives conditions where Google
Search data can quantify consumer sentiment.
2

2 Data
This paper incorporates two main sources of data. I first describe the traditional data
sources, which are series typically used in economic forecasting applications. I then discuss
the aggregated Google Search data.
2.1 Traditional data sources
The dataset containing traditional data sources was aggregated and collected from Bloomberg
and contains monthly time series data from January 2000 to August 2017. The series were
selected to give a full representation of the Indian economy and to mimic how market par-
ticipants respond to information. The choice of series is partially taken from Bragoli and
Fosten (2017) and (Giannone, Agrippino and Modugno, 2013a) which examine Indian and
Chinese GDP respectively. Because of the relative scarcity of qualitative sentiment data,
both papers primarily use hard data. While these series are less noisy, these are subject to
greater publication lag.
Different from developed economies, data quality is a substantial concern in the India
context. Even though the service sector represents approximately 58 % of the economy,
activity is undercounted in the economic census and through the unorganized sector (Bard-
han, 2013). Moreover, due to issues with survey coverage, price-indexing is often applied
inconsistently, with underrepresentation of low income groups. As a result, in the predic-
tion context, forecasting is a greater challenge. Economic time series information is less
consistent and noisier, so there is greater variation in the predictions themselves.
GDP in particular is subject to some uncertainty. Similar to other series, inputs to
publishing official GDP figures by the Central Statistics Organization (CSO) have quality
problems. As a result, published figures are subject to substantial data revisions. In some
cases, revisions between initial and final yearly growth rates were up to 2.5% (Sapre and
Sengupta, 2017). As a result, prediction values are also noisier.
The series fall into two primary categories: hard data and financial data. The hard data
are quantitative economic indicators. These series are meant to capture economic activity
in India broadly. Several series capture domestic production (India Industrial Production,
Crude Oil Production, Steel Production). Considering the connectedness of the broader
Indian economy, several several of the series focus on trade (Indian imports and Indian
exports). Similarly, several international series are included (US Industrial Production,
3
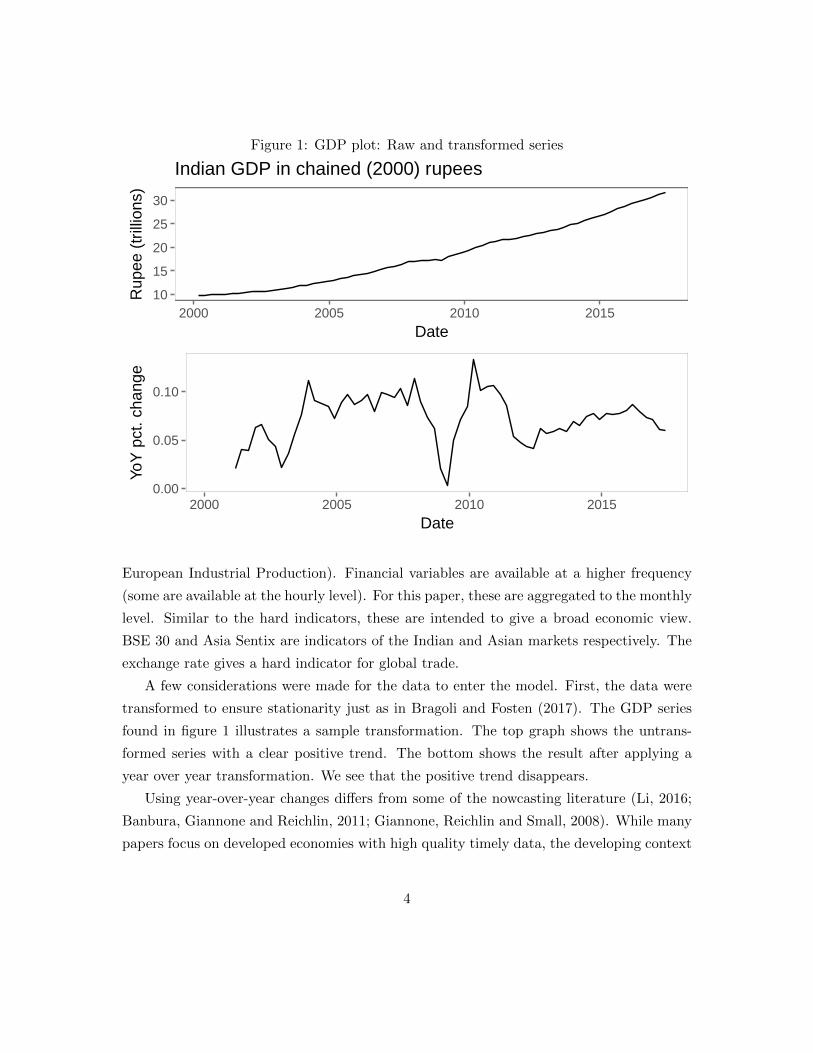
Figure 1: GDP plot: Raw and transformed series
10
15
20
25
30
2000 2005 2010 2015
Date
Rup
ee (
trill
ions
)
Indian GDP in chained (2000) rupees
0.00
0.05
0.10
2000 2005 2010 2015
Date
YoY
pct
. cha
nge
European Industrial Production). Financial variables are available at a higher frequency
(some are available at the hourly level). For this paper, these are aggregated to the monthly
level. Similar to the hard indicators, these are intended to give a broad economic view.
BSE 30 and Asia Sentix are indicators of the Indian and Asian markets respectively. The
exchange rate gives a hard indicator for global trade.
A few considerations were made for the data to enter the model. First, the data were
transformed to ensure stationarity just as in Bragoli and Fosten (2017). The GDP series
found in figure 1 illustrates a sample transformation. The top graph shows the untrans-
formed series with a clear positive trend. The bottom shows the result after applying a
year over year transformation. We see that the positive trend disappears.
Using year-over-year changes differs from some of the nowcasting literature (Li, 2016;
Banbura, Giannone and Reichlin, 2011; Giannone, Reichlin and Small, 2008). While many
papers focus on developed economies with high quality timely data, the developing context
4

Tab
le1:
Ser
ies,
tran
sfor
mat
ion
s,an
dlo
adin
gsN
ame
Mn
emon
icT
ran
sform
ati
on
Fre
qu
ency
Com
mon
Hard
Fin
an
cial
Ind
iaIn
du
stri
alP
rod
uct
ion
INP
IIN
DU
pcy
M1
10
Ind
iaE
xp
orts
INM
TE
XU
pcy
M1
10
Ind
iaIm
por
tsIN
MT
IMU
pcy
M1
10
Ind
iaP
MI
Ser
vic
esM
PM
IIN
SA
pcy
M1
10
Ind
iaP
MI
Man
ufa
ctu
ring
MP
MII
NM
Ap
cyM
11
0In
dia
Cru
de
Oil
Pro
du
ctio
nIN
RG
GT
GT
pcy
M1
10
Ind
iaS
teel
Pro
du
ctio
nIN
FR
ST
EL
pcy
M1
10
Ind
iaE
lect
rici
tyG
ener
atio
nIN
FR
EL
EC
pcy
M1
01
Ind
ian
Mon
eyS
up
ply
(M1)
INM
SM
1p
cyM
10
1In
dia
Exch
ange
Rat
e(R
up
ee/U
S$,
EO
P)
US
DIN
Rp
cyM
10
1In
dia
91-D
ayT
reas
ury
Bil
lIY
TB
3M
pcy
M1
01
Ind
iaS
tock
Pri
ces
Sen
sex/B
SE
30S
EN
SE
Xp
cyM
10
1In
dia
Ind
ust
rial
Wor
kers
Con
sum
erP
rice
INC
PII
ND
pcy
M1
10
Ind
iaA
gric
ult
ura
lL
abor
ers
Con
sum
erP
rice
INC
PA
GL
Bp
cyM
11
0In
dia
Ru
ral
Lab
orer
sC
onsu
mer
Pri
ceIN
CP
RU
LB
pcy
M1
10
Ind
iaC
onsu
mer
Pri
ceIN
FU
TO
Tp
cyM
11
0In
dia
Wh
oles
ale
Pri
ceIn
dex
(All
)IN
FIN
Fp
cyM
11
0In
dia
Wh
oles
ale
Pri
ceIn
dex
(Fu
elP
ower
)IN
FIF
UE
pcy
M1
10
US
Ind
ust
rial
Pro
du
ctio
nIn
dx
IPp
cyM
11
0U
SIS
MM
anu
fact
uri
ng
PM
IN
AP
MP
MI
lvl
M1
10
Eu
ro19
Indu
stri
alP
rod
uct
ion
EU
ITE
MU
Mlv
lM
11
0A
sia
(ex
Jap
an)
Sen
tix
over
all
Ind
exS
NT
EA
SG
Xp
cyM
10
1C
urr
ent
Pri
ceG
ross
Dom
esti
cP
rod
uct
inIn
dia
IND
GD
PN
QD
SM
EI
pcy
Q1
10
5

differs. Most time series lack seasonal adjustment, so including raw series in the model
would primarily capture seasonal variation rather than underlying trends. Taking a yearly
view addresses these concerns, and has previously been used in the development context
(Swallow and Labbe, 2010; Giannone, Agrippino and Modugno, 2013a). While some papers
have adjusted for seasonality upon input (such as implementing the US Census Bureau’s
X-13ARIMA-SEATS seasonal adjustment approach), this approach is less salient for the
GDP prediction, as two-sided filters are less context appropriate (Swallow and Labbe, 2010;
Vosen and Schmidt, 2011; Li, 2016).
2.2 Google Search data
I include Google Search data, which are publicly available through the Google Trends
interface 1. Each series gives relative search volume for a particular term, where values
are scaled so that the maximum search volume is 100. As a consequence, for some volatile
terms, the lowest level is 0 (even when raw search volume itself is nonzero). Users can
adjust search scope — globally, by country, or by state — and series frequency — hourly,
daily, weekly, and monthly. For this study, I examine search volume in India by monthly
frequency.
Its relatively high usage in India allows for Google search to be used to approximate
consumer sentiment. Figure 2 gives Google’s search market share in India over time.
By traffic volume, Google commands 96-97% of the market from 2009-2018 StatCounter
(2018). One explanation to Google’s spread is English’s widespread role, especially among
younger people. While other languages are are very regional (e.g. Hindi in the north,
Bengali in the east, Telugu in the south, Marathi in the west), English plays a large role
in schools nationally as its second official national language (Census of India, 2001). This
gives Google an advantage over regional language search variants, and provides a means
to measure preferences nationally.
Several studies have used Search data to capture consumer sentiment. In this context,
search data acts as a signal for people’s unfiltered expectations. The advantage to this
approach is in timeliness; search data are available in real-time.
The terms are categorized into three categories: economy, jobs, and household. These
are intended to holistically capture people’s feelings about the economy as a whole, similar
1https://trends.google.com/trends/
6

Figure 2: Google Search has maintained high market share over time
0
25
50
75
100
2010 2012 2014 2016 2018
Year
Mar
ket s
hare
(%
)
Search engine
Bing
Other
Indian search engine market share
to the approach found in Seabold and Coppola (2015). Search terms related to the economy
help indicate economic anxiety generally, where people search terms like “recession” and
“petrol prices” when nervous about the future. Similarly, in the “jobs” category, people
are likely to search for terms such as “salary” and “raise” for similar reasons. Finally, the
“household” category is intended to capture consumer aspirations, with searches such as
“cars” appearing during more positive economic outlooks.
Over its history, Google has provide varying degrees of language support for India.
Despite the increase in support, traffic volume is largely in English. Figure 3 gives an
illustration. Over time, English search volume is several times greater than that of mulya.
There are several approaches used for incorporating Google Trends data into the fore-
casting framework. The primary hurdle is extracting signal from many time series. Several
papers suggest creating composite indices from the Search terms, effectively reducing mul-
tiple time series to a single indicator via least squares (Vosen and Schmidt, 2011; Seabold
and Coppola, 2015). An advantage to this approach is its ease for being incorporated di-
rectly into VAR models. Considering choice of evaluation framework, factor models allow
these series to be directly inputted just as in Li (2016). This approach is consistent with
how the traditional data sources are incorporated. The factor model itself provides a form
7

Figure 3: Search volume for “price” is greater than that of mulya
0
25
50
75
100
2005 2010 2015
Year
Sea
rch
volu
me
(max
= 1
00)
Terms
price (English)
price (Hindi)
Relative search volume for 'price'
Table 2: Google Search terms and categoriesCategory Terms
Economy price, prices, cost, inflation, recession, petrol priceJobs salary, raise, unemployment, bankruptcy, insolvency, job, jobs,
job vacancy, jobs inHousehold rent, rent in, job salary, cars, rent house
of dimension reduction.
One shortcoming to Search data is the lack of seasonal adjustment. Consistent with the
other economic time series, I transform the series using a year-over-year percent change
transformation. Figure 4 displays a sample transformation. Qualitatively, the untrans-
formed series appears to be increasing over time. After performing the transformation, the
resulting series appears to be stationary.
8

Figure 4: Google Search: Example of year-over-year percent change transformation
40
60
80
100
2005 2010 2015
Date
Inde
x (m
ax =
100
)Google Search: "Salary"
0.0
0.4
0.8
2005 2010 2015
Date
Tran
sfor
med
(%
YoY
)
3 Model
A dynamic factor model with Kalman filtering was used to model the series dynamics
(Banbura, Giannone and Reichlin, 2011; Giannone, Reichlin and Small, 2008). This setup is
common in the economic forecasting context, with past works focusing on different countries
(China, India, U.K., Eurozone, United States) and for different time series (Li, 2016; Bragoli
and Fosten, 2017; Swallow and Labbe, 2010; Giannone, Agrippino and Modugno, 2013b).
The model is driven by two relationships. First, the monthly series have the follow the
following factor structure:
xMt = µ+ Λft + εt (1)
where xt gives the transformed data series (yearly growth rate or differences), µ gives
a constant, ft is a r × 1 vector containing r unobserved factors, and Λ gives the factor
coefficients. εt gives the idiosyncratic error. Call this factor structure the observation
equation. This approach effectively is a means for dimension reduction, as each data series
can be decomposed into several common components. In practice, from transformations,
the constant µ = 0.
9

Second, the factors themselves can be modeled as an AR(1) process where
ft = Aft−1 + ut (2)
for i.i.d. ut ∼ N(0, Q). Matrix A is r × r and contains autoregressive coefficients. This
relationship is called the transition equation, which can be understood as determining the
factor relationship across time.
Intuitively, for each period t, the value for each time series (e.g. Consumer Price Index)
is determined by the value of the unobserved factors fi. The values fi change over time
according to the dynamics of the transition equation.
The idiosyncratic component can also be modeled as an AR(1) process where
εi,t = αiεi,t−1 + ei,t (3)
for i.i.d ei,t ∼ N(0, σ2i ).
For this model, consistent with existing literature, we further impose structure onto
the factors driven by economic theory (Giannone, Reichlin and Small, 2008; Giannone,
Agrippino and Modugno, 2013a). In our case, we take number of factors r = 3 where
each factor can be written as ft = (fGt , fHt , f
Ft ) representing the “global”, “hard”, and
“financial” factors. Furthermore, the loadings matrix Λ is structured so that the global
factor loads onto each series. Depending on the type of data, each series also takes on
either a hard fHt or financial fFt loading:
Λ =
(ΛH,G ΛH,H 0
ΛF,G 0 ΛF,F
).
For the models incorporating Google Trends, four factors are used: “global”, “hard”,
“financial”, and “soft” where Trends data are assigned to the soft factor.
For the transition equation, factor dynamics are related to each factor’s own previous
state, so
Ai =
Ai,G 0 0
0 Ai,H 0
0 0 Ai,F
.
In order to incorporate mixed frequency data, quarterly data can be modeled as the
10

sum of monthly data. By convention, these series are placed at the end of the quarter
while preserving monthly indexing t. Using the approach found in Mariano and Murasawa
(2003), the quarterly series can be modeled as
yQt = yt + 2yt−1 + 3yt−2 + 2yt−3 + yt−4.
With the monthly analogue, the quarterly series can enter the transition and observation
equations using the same dynamics.
The model is estimated using an expectation maximization algorithm Giannone, Reich-
lin and Small (2008). This approach is often used in situations where missing observations
make direct maximization of the likelihood function computationally intractable. Broadly,
there are several steps. Factor estimates are first initialized using principal components.
Then, these initial conditions enter the expectation-maximization loop. In the expectation
step, the log-likelihood conditional on the data is computed based on values from the pre-
vious iteration. In the maximization step, new parameters are estimated by maximizing
the expected log-likelihood. Expectation and maximization are looped until estimates con-
verge, measured by the change in log-likelihood. Details on this procedure can be found in
Doz, Giannone and Reichlin (2006); Banbura and Modugno (2014).
11

Figure 5: Forecasting error by month number
RMSFE by month (difference from first month)
1 2 3
Month
-1
-0.8
-0.6
-0.4
-0.2
0
RM
SF
E (
diffe
ren
ce
fro
m f
irst
mo
nth
)10
-3
4 Results
To evaluate model performance, I use a pseudo-data vintage approach. The goal is to
simulate the real-world forecast creation process; as more information become available,
the forecasts are updated. Each month, a prediction for current quarter GDP is created
using information available at that month. Therefore, three predictions are generated for
the current quarter GDP (month 1, month 2, and month 3). This simulates the publication
delay for GDP figures, but abstracts away irregular release intervals (monthly series are
not updated concurrently) and data revisions (estimates are often revised after initial
estimates are published). While there is substantial literature taking data revisions and
release schedules into account, this will not be the focus of this paper (Giannone, Reichlin
and Small, 2008; Giannone, Agrippino and Modugno, 2013c).
Figure 5 illustrates improvements in model performance as more information becomes
available. On average, as time progresses, the forecasting error decreases. Month 1 has the
highest error, month 2 has lower error, and month 3 has the lowest error.
Figure 6 gives an illustration of the model’s mechanics. Each transformed series is
standardized and plotted (the colored series) alongside the common factor (in black). No-
tice that the common factor captures some comovement for the each of the series, which
12

Figure 6: Standardized data and common factor plot
2000 2002 2004 2006 2008 2010 2012 2014 2016 2018
-12
-10
-8
-6
-4
-2
0
2
4
6Standardized data and common factor
is especially apparent during and after the Great Recession. During the downturn, many
economic indicators downturns decreased in value, and afterwards, many decreased. This
figure does not give predictions: it illustrates that series have some degree of commonality.
Figures 7 and 8 display the four prediction models over time. On inspection, the
four approaches roughly track GDP throughout the period and perform best during low
volatility intervals. All four models perform relatively well from 2006-2008 and from 2012-
2015.
The four models share similar characteristics during high volatility periods. The models
overpredict GDP during the beginning of the Great Recession and underpredict its recovery
afterwards. Similarly, GDP is slightly overpredicted during the 2012 slowdown. Moreover,
all four slightly underpredict GDP from 2016 onwards, despite being a low volatility period.
One potential reason is a change in methodology in price measurement. In 2016, the Cen-
tral Statistics Office modified estimates for Wholesale Price Index and Index of Industrial
Production, which are used to compute GDP in constant prices. These changes resulted
in an upwards GDP revision of .5%. It is possible that the model provides predictions
without accounting for changes in methodology.
Figure 9 gives a more detailed account for prediction error over time. While the move-
13

Figure 7: Within quarter predictions (no search data)
2004 2006 2008 2010 2012 2014
Date
-0.02
0
0.02
0.04
0.06
0.08
0.1
0.12
0.14
0.16
Yo
Y G
DP
Current quarter predictions (baseline)
Data
Three factors
One factor
Figure 8: Within quarter predictions (with search data)
2004 2006 2008 2010 2012 2014
Date
-0.02
0
0.02
0.04
0.06
0.08
0.1
0.12
0.14
0.16
Yo
Y G
DP
Current quarter predictions (Google Trends)
Data
Four factors
One factor
14

Figure 9: Prediction error over time (no search data)
2006 2008 2010 2012 2014 2016
-0.06
-0.04
-0.02
0
0.02
0.04Residuals for 3 factor and 1 factor models (no Google trends)
3 factors
1 factor
Figure 10: GDP Root Mean Square ErrorSeries 3 factors 1 factor 4 factors (with trends) 1 factor (with trends)
RMSE 0.0139 0.0157 0.0143 0.0165
ments for the multifactor and single factor models are similar, the multifactor model is
more effective in predicting the higher volatility periods. For a more formal comparison
of forecasting performance, figure 10 shows root mean square error. For each set of data,
the single factor model performs worse than the multifactor model. Comparing the Trends
and non-Trends model, it appears that adding the Search data does not improve predic-
tions. From figure 11, notice that these performance differences are constant overtime.
Displaying the RMSFE, the three factor no Trends model consistently outperforms the
other three models from 2006-2018. Similarly, the other three models maintain the same
relative position, with all four models moving together.
Next, I generated predictions for the Indian Consumer Price Index series. This exercise
gives insight to the Google Trends “consumer sentiment” measurement hypothesis. Prices
are tied more closely to movements in sentiment than for GDP. If the Trends data is a
good indicator for sentiment, we would expect Trends data to increase the performance of
15

Figure 11: Models perform similarly over time
2006 2008 2010 2012 2014 2016
Year
0
0.005
0.01
0.015
0.02
0.025
RM
SF
E
Root mean squared forecast error over time
3 factor
1 factor
4 factor (Trends)
1 factor (Trends)
the model. Note that CPI is a monthly, not a quarterly series, so predictions are created
for the current month.
Figures 12 and 13 display predictions for CPI. The four models predict CPI fairly
well, as the prediction error is low. The improved prediction performance indicates that
forecasting CPI is an easier prediction problem than GDP. CPI’s relatively low volatility
and higher frequency make for better predictions. Monthly values make the series more
predictable. Moreover, the higher performance in the baseline models using only economic
data give little room for performance improvements in including Trends data. Figure 14
gives root mean squared error for CPI predictions. Just as before, the Google Trends
models perform slightly worse than the traditional economic models.
16

Figure 12: CPI predictions using economic data
2004 2006 2008 2010 2012 2014
Date
0.02
0.04
0.06
0.08
0.1
0.12
0.14
0.16
0.18
Yo
Y C
PI
Current quarter predictions
Data
Baseline (1 factor)
Baseline (3 factors)
Figure 13: CPI predictions using economic data plus search data
2004 2006 2008 2010 2012 2014
Date
0.02
0.04
0.06
0.08
0.1
0.12
0.14
0.16
0.18
Yo
Y C
PI
Current quarter predictions
Data
Trends (four factors)
Trends (one factor)
Figure 14: Root mean squared error for CPISeries 3 factors 1 factor 4 factors (with trends) 1 factor (with trends)
RMSE 0.0048 0.0059 0.0050 0.0048
17

5 Discussion
For Indian GDP, incorporating search data into the prediction procedure provides no im-
provement over the baseline model. However, incorporating a multifactor setup appears to
improve forecasts.
These differences reflect the difficulty of the problem. In some cases, the GDP figure
itself changed by greater than 1% (Sapre and Sengupta, 2017). Advanced estimates can
differ substantially from final numbers. As a result, forecasting can suffer from imprecision,
complementing existing problems with noisy and unreliable data.
Also, the current does not take into account the effect of staggered data releases on
changes to prediction. While releasing data concurrently is parsimonious, a more realistic
approach would be to add data according to a release calendar. Instead of modifying the
dataset each month, data can added on their release dates. This would allow for a more
careful study for how particular series releases move forecasts.
Perhaps more importantly, following a release calendar can help take timeliness into
account. Release sequencing is especially important for studying qualitative data. While
soft indicators generally are noisier, they are subject to shorter publication lag. These
series give an early signal (albeit less precise) to the direction of the target series. Without
release sequencing, these advantages disappear. The current simulation does not give an
environment for seeing the strengths of the Google Search data.
For the future, the study can be improved by more closely examining the mechanism
for measuring consumer sentiment. While this study includes a broad selection of terms,
more careful consideration for cultural and linguistic norms would likely aid the analysis.
India has the second most English speakers, but more closely examining ground-level search
patterns would shed light onto the specific transmission of economic attitudes.
18

References
Banbura, Marta, and Michele Modugno. 2014. “Maximum likelihood estimation of
factor models on datasets with arbitrary pattern of missing data.” Journal of Applied
Econometrics, 29(1): 133–160.
Banbura, Marta, Domenico Giannone, and Lucrezia Reichlin. 2011. “Nowcasting.”
Oxford Handbook of Economic Forecasting.
Bardhan, Pranab. 2013. “The State of Indian Economic Statistics : Data Quantity and
Quality Issues.”
Bragoli, Daniela, and Jack Fosten. 2017. “Nowcasting Indian GDP.” Oxford Bulletin
of Economics and Statistics (forthcoming).
Census of India. 2001. “Population by Bilingualism, Trilingualism, Age and Sex.”
Choi, Hyunyoung, and Hal Varian. 2012. “Predicting the Present with Google
Trends.” Economic Record, 88(SUPPL.1): 2–9.
Doz, Catherine, Domenico Giannone, and Lucrezia Reichlin. 2006. “A Quasi Max-
imum Likelihood Approach for Large Approximate Dynamic Factor Models.” European
Central Bank Working Paper Series, , (674).
Giannone, Domenico, Lucrezia Reichlin, and David Small. 2008. “Nowcasting:
The real-time informational content of macroeconomic data.” Journal of Monetary Eco-
nomics, 55(4): 665–676.
Giannone, Domenico, Silvia Miranda Agrippino, and Michele Modugno. 2013a.
“Nowcasting China Real GDP.”
Giannone, Domenico, Silvia Miranda Agrippino, and Michele Modugno. 2013b.
“Nowcasting China Real GDP.”
Giannone, Domenico, Silvia Miranda Agrippino, and Michele Modugno. 2013c.
“Nowcasting China Real GDP Forecast-Nowcast-Backcast : Q3-2013.” , (February): 1–
26.
19

Goldfarb, Avi, Shane M Greenstein, and Catherine E Tucker. 2015. Economic
Analysis of the Digital Economy Volume.
Li, Xinyuan. 2016. “Nowcasting with Big Data : is Google useful in Presence of other
Information ?” 1–41.
Mariano, Roberto S., and Yasutomo Murasawa. 2003. “A new coincident index of
business cycles based on monthly and quarterly series.” Journal of Applied Econometrics,
18(4): 427–443.
Pan, Bing, Doris Chenguang Wu, and Haiyan Song. 2012. Forecasting hotel room
demand using search engine data. Vol. 3.
Sapre, Amey, and Rajeswari Sengupta. 2017. “An analysis of revisions in Indian GDP
data.” , (September).
Schmidt, Torsten, and Simeon Vosen. 2012. “Using internet data to account for special
events in economic forecasting.” Ruhr Economic Paper, , (382).
Seabold, Skipper, and Andrea Coppola. 2015. “Nowcasting Prices Using Google
Trends An Application to Central America.” World Bank Policy Research Working Pa-
per, , (7398).
StatCounter. 2018. “Search Engine Market Share India.”
Suhoy, Tanya. 2009. “Query Indices and a 2008 Downturn: Israeli Data.” Bank of Israel
Discussion Paper Series, , (6).
Swallow, Yan Carriere, and Felipe Labbe. 2010. “Nowcasting with Google Trends in
an Emerging Market.” Documentos de Trabajo (Banco Central de Chile), 298(588): 1.
Vosen, Simeon, and Torsten Schmidt. 2011. “Forecasting private consumption:
Survey-based indicators vs. Google trends.” Journal of Forecasting, 30(6): 565–578.
World Bank. 2017. “World Development Indicators.”
20

A Structure of model
In practice, the monthly, quarterly, and idiosyncratic errors are stacked through block
matrices. The stacked version of the observation equation is displayed below. Notice that
the monthly series are ordered before the quarterly series by convention, and that the
monthly to quarterly interpolation scheme is listed.
(xt
yQt
)=
(µ
µQ
)+
(Λ 0 0 0 0 In 0 0 0 0 0
ΛQ 2ΛQ 3ΛQ 2ΛQ ΛQ 0 1 2 3 2 1
)
ft
ft−1
ft−2
ft−3
ft−4
εt
εQt
εQt−1
εQt−2
εQt−3
εQt−4
(4)
Similarly, the idiosyncratic and factor relationships are stacked for the transition equa-
tion. To be consistent with the quarterly to monthly interpolation scheme, five period for
factors f are used.
21
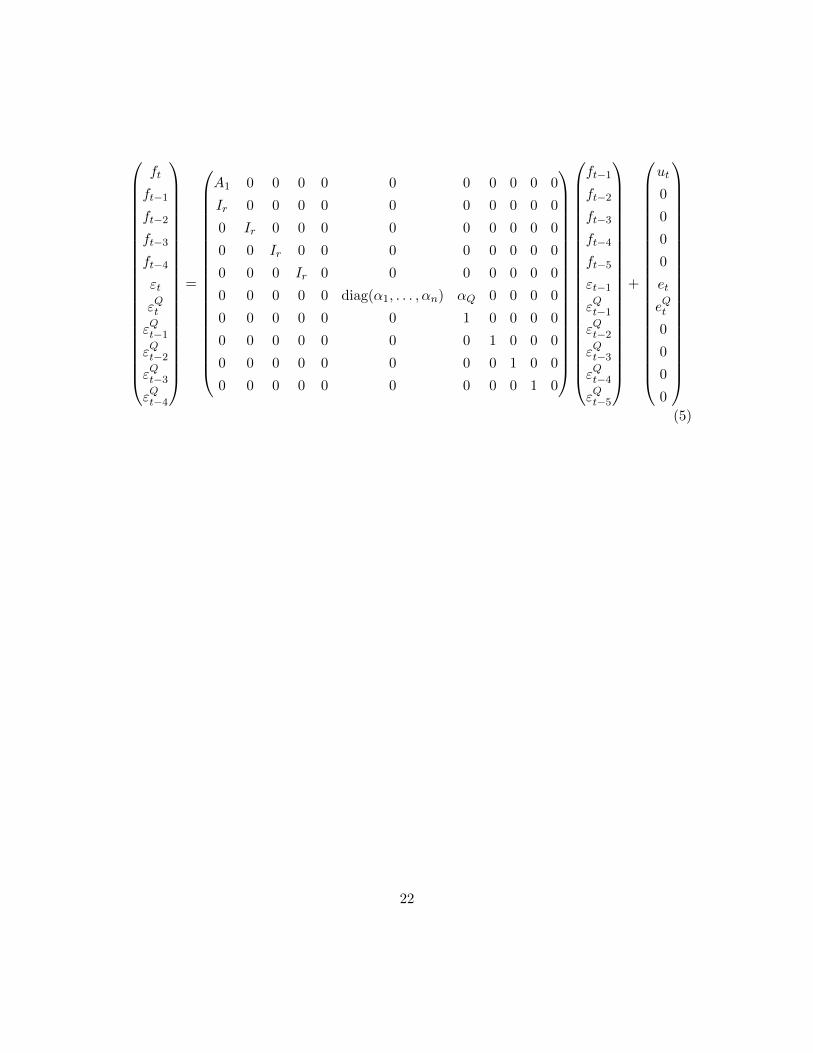
ft
ft−1
ft−2
ft−3
ft−4
εt
εQt
εQt−1
εQt−2
εQt−3
εQt−4
=
A1 0 0 0 0 0 0 0 0 0 0
Ir 0 0 0 0 0 0 0 0 0 0
0 Ir 0 0 0 0 0 0 0 0 0
0 0 Ir 0 0 0 0 0 0 0 0
0 0 0 Ir 0 0 0 0 0 0 0
0 0 0 0 0 diag(α1, . . . , αn) αQ 0 0 0 0
0 0 0 0 0 0 1 0 0 0 0
0 0 0 0 0 0 0 1 0 0 0
0 0 0 0 0 0 0 0 1 0 0
0 0 0 0 0 0 0 0 0 1 0
ft−1
ft−2
ft−3
ft−4
ft−5
εt−1
εQt−1
εQt−2
εQt−3
εQt−4
εQt−5
+
ut
0
0
0
0
et
eQt
0
0
0
0
(5)
22
Recommended

















