
Online aggregation
Joseph M. Hellerstein University of California,
Berkley
Peter J. Haas IBM Research Division
Helen J. Wang University of California,
Berkley
Presented By:Arjav Dave

Overview
• Introduction• Goals• Implementation• Performance Evaluation• Future Work

Problems with Aggregation
• Aggregation is performed in batch mode: a query is submitted, the system processes a large volume of data over a long period of time and then the final answer is returned.
• Users are forced to wait without feedback while the query is being processed.
• Aggregate queries are generally used to get a rough picture of a large body, yet they are computed with painstaking precision.

What is Online Aggregation and Why?
• Permits users to observe the progress of their aggregation.
• Controls the execution on the fly.

Example
• Consider the query:
select avg(final_grade) from grades where course_name=‘cse186’
• Without index the query will scan all records before returning the answer.
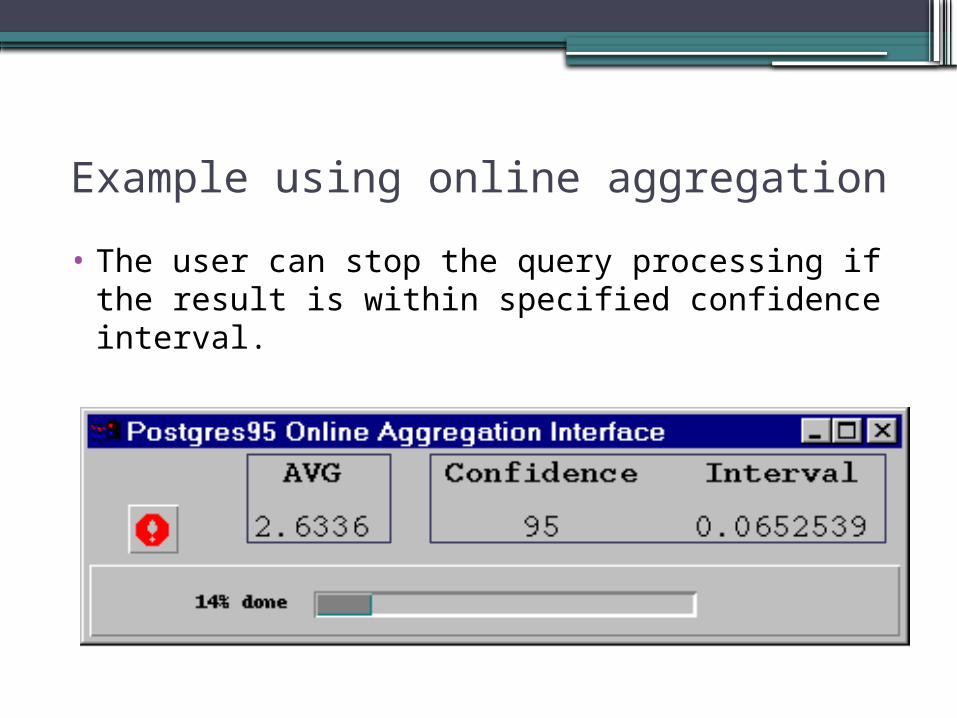
Example using online aggregation
• The user can stop the query processing if the result is within specified confidence interval.

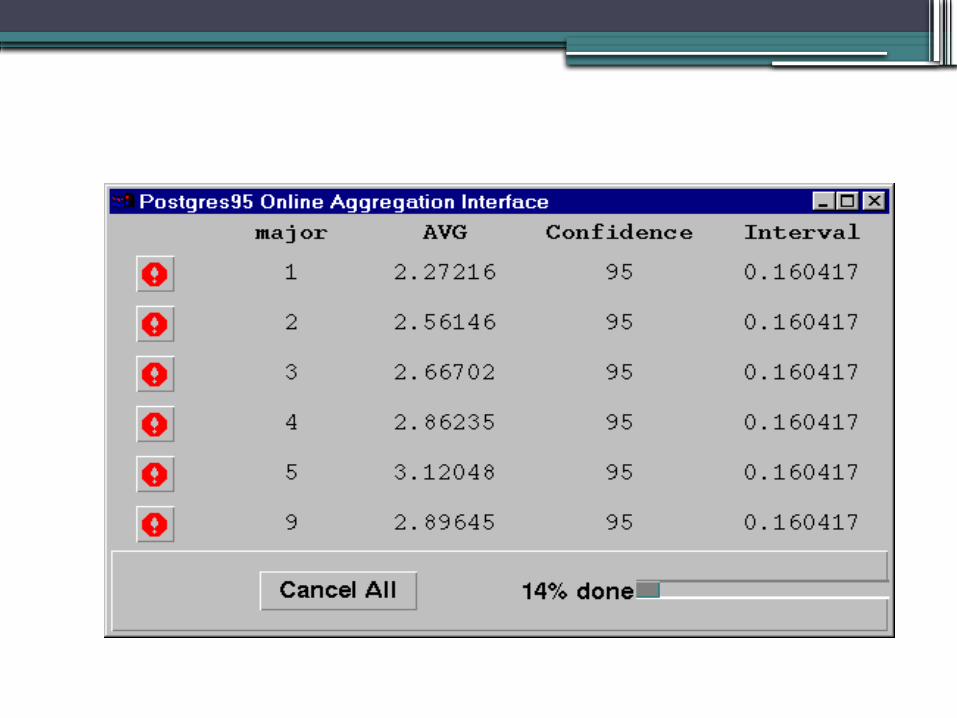
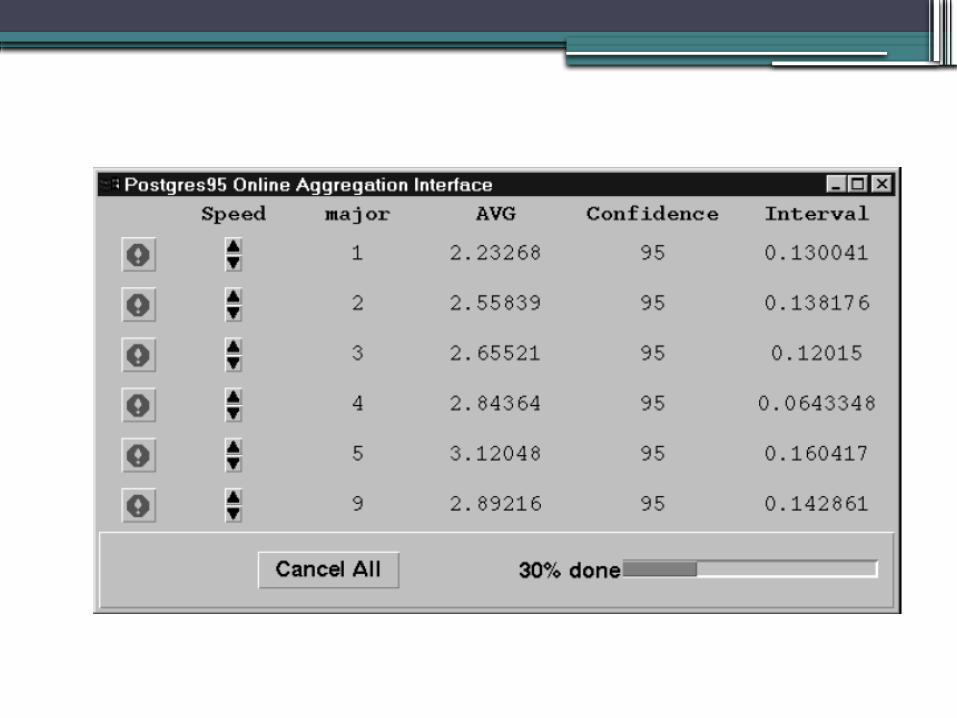
Interface with groups
• Consider a query with group by clause having 6 groups in output
• There are 6 stop signs each for one group. They can be used to stop the group processing.
• Such an interface is easy for the non-statistical users.

Usability Goals
• Continuous Observation: Statistical, Graphical and other intuitive interfaces. Interfaces must be extensible for each aggregate function.
• Control of Time/Precision: User should be able to terminate processing at any time controlling trade off between time and precision.
• Control of Fairness/Partiality: Users can control the relative rate at which different running aggregates are updated.

Performance Goals
• Minimum time to Accuracy: Minimize time required to produce useful estimate of the final answer.
• Minimize time to completion: Minimize the time required to produce the final answer.
• Pacing: The running aggregates should be updated at regular rates, without being so frequent that they overburden the user or user interface.

Building a system for Online AggregationTwo Approaches:•Naïve Approach•Modifying a DBMS

Naive Approach
• Consider the query:select running_avg(final_grade),running_confidence(final_grade),running_interval(final_grade) from grades;
• POSTGRES supports user defined function which can be defined for simple aggregates. For complex aggregates performance and functional issues arise.

Modifying a DBMS
• Modify the database engine to support online aggregation.
• Random access to Data:▫ Necessary to get the statistically meaningful estimates
of the precision of running aggregates.
• Access Methods:▫ Heap Scan▫ Index Scan▫ Sampling from Indices

Types of Access Methods
• Heap Scan: ▫ Generally stored in random order, so easy to fetch▫ In clustered files there may be some logical order, so
choose other access method for queries over that attributes.
• Index Scan:▫ Returns tuples based on some attribute or in groups
based on some attribute.
• Sampling from Indices: ▫ Ideal for producing meaningful confidence intervals. ▫ Less efficient than other two.

Fair, Non-Blocking Group By
• Traditional technique does sorting and then grouping. But sorting blocks
• Instead hash the input relation on its grouping columns. But does not perform better as the number of groups increases.
• Hybrid hashing or its optimized version Hybrid Cache can be used.
• For DISTINCT queries same technique can be used.

Index Striding
• Update for the group with few members will be very infrequent.
• Index Striding: It uses Round-Robin technique to fetch tuples from different groups fairly.
• Advantages:▫ Output is updated according to default or user settings.▫ Delivery of tuples of a group can be stopped, so delivery
of tuples for other groups is much faster.

Non-Blocking Join Algorithms
• Sort-Merge Join: Sorting blocks.• Merge Join: Not acceptable for access methods
that fetch tuples in sorted order.• Hybrid Hash Join: Acceptable if inner relation is
small, as it blocks to hash the inner relation.• Pipeline Hash: Less Efficient than hybrid hash
join. But efficient if both the relations are large.• Nested-Loops join: Not useful for joins with large
inner relation non-indexed.

Optimization
• Avoid Sorting
• Function to calculate cost for Blocking sub-operations (e.g. Hashing inner relation in hybrid hash join) according to processing time should be exponential.
• Maximize user control.
• Trade off need to be evaluated between the output rate and the time to completion.

Aggregate Functions
• New aggregate functions must be defined to return running confidence intervals.
• Query Executor must be modified to provide running aggregate values for display.
• An API must be provided to control the rate e.g. stopGroup, speedupGroup, slowDownGroup, setSkipFactor.

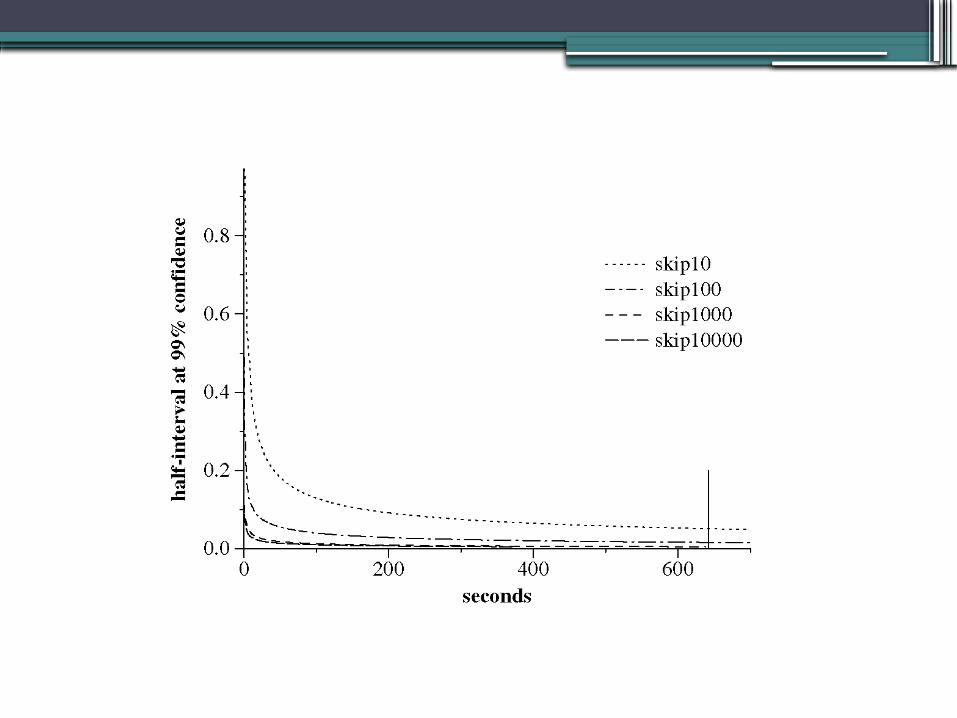
Running Confidence Intervals
• Precision of running aggregates is given by running confidence intervals
• Three types:▫ Conservative Confidence Interval▫ Large Sample Intervals▫ Deterministic Confidence Interval

Future Work
• Enhancing User Interface• Support for Nested Queries• Checkpointing and Continuation• Tracking online queries

QUESTIONS?
Recommended

















