
IEEE TRANSACTIONS ON INDUSTRIAL INFORMATICS, VOL. 6, NO. 1, FEBRUARY 2010 93
Overrun Methods and Resource HoldingTimes for Hierarchical Scheduling ofSemi-Independent Real-Time Systems
Moris Behnam, Student Member, IEEE, Thomas Nolte, Member, IEEE, Mikael Sjödin, andInsik Shin, Member, IEEE
Abstract—The Hierarchical Scheduling Framework (HSF) hasbeen introduced as a design-time framework to enable composi-tional schedulability analysis of embedded software systems withreal-time properties. In this paper, a software system consists ofa number of semi-independent components called subsystems.Subsystems are developed independently and later integrated toform a system. To support this design process, in the paper, theproposed methods allow non-intrusive configuration and tuning ofsubsystem timing-behavior via subsystem interfaces for selectingscheduling parameters.
This paper considers three methods to handle overruns due toresource sharing between subsystems in the HSF. For each one ofthese three overrun methods corresponding scheduling algorithmsand associated schedulability analysis are presented together withanalysis that shows under what circumstances one or the other ispreferred. The analysis is generalized to allow for both Fixed Pri-ority Scheduling (FPS) and Earliest Deadline First (EDF) sched-uling. Also, a further contribution of the paper is the techniqueof calculating resource-holding times within the framework underdifferent scheduling algorithms; the resource holding times beingan important parameter in the global schedulability analysis.
Index Terms—Hierarchical scheduling, operating system, real-time systems, scheduling, resource sharing, synchronization.
I. INTRODUCTION
T HE Hierarchical Scheduling Framework (HSF) hasbeen introduced to support hierarchical resource sharing
among applications under different scheduling services. The hi-erarchical scheduling framework can be generally representedas a tree of nodes, where each node represents an applicationwith its own scheduler for scheduling internal workloads (e.g.,threads), and resources are allocated from a parent node to itschildren nodes.
Manuscript received July 13, 2009; revised October 02, 2009 and November17, 2009; accepted November 24, 2009. First published December 31, 2009;current version published February 05, 2010. This work was supported in partby the Swedish Foundation for Strategic Research (SSF), via the research pro-gram PROGRESS, IT R&D program of MKE/KEIT of Korea [2009-F-039-01],the National Research Foundation of Korea (2009-0086964), and KAIST ICC,KIDCS, KNCC, and OLEV grants. Paper no. TII-09-07-0153.R2.
M. Behnam, T. Nolte, and M. Sjödin are with the Mälardalen Real-TimeResearch Centre, P SE-721 23 Västerâs, Sweden (e-mail: [email protected]; [email protected]; [email protected]).
I. Shin is with the Department of Computer Science, Korea Advanced In-stitute of Science and Technology (KAIST), Daejeon, South Korea 305-701(e-mail: [email protected]).
Color versions of one or more of the figures in this paper are available onlineat http://ieeexplore.ieee.org.
Digital Object Identifier 10.1109/TII.2009.2037918
The HSF provides means for decomposing a complex systeminto well-defined parts. In essence, the HSF provides a mech-anism for timing-predictable composition of course-grainedcomponents or subsystems. In the HSF, a subsystem pro-vides an interface that specifies the timing properties of thesubsystem precisely [1]. This means that subsystems canbe independently developed and tested, and later assembledwithout introducing unwanted temporal behavior. Also, theHSF facilitates reusability of subsystems in timing-criticaland resource constrained environments, since the well definedinterfaces characterize their computational requirements.
Earlier efforts have been made in supporting compositionalsubsystem integration in the HSFs, preserving the indepen-dently analyzed schedulability of individual subsystems. Onecommon assumption shared by earlier studies is that subsys-tems are independent. This paper relaxes this assumption byaddressing the challenge of enabling efficient compositionalintegration for independently developed semi-independentsubsystems interacting through sharing of mutual exclusionaccess logical resources. Here, semi-independence means thatsubsystems are allowed to synchronize by the sharing of logicalresources.
To enable sharing of logical resources in HSFs, Davis andBurns proposed a synchronization protocol implementing theoverrun mechanism, allowing the subsystem to overrun (itsbudget) to complete the execution of a critical section [2]. Twoversions of overrun mechanisms were presented in [2], calledoverrun without payback and overrun with payback, and in theremainder of this paper these overrun mechanisms are calledBasic Overrun (BO), and Basic Overrun with Payback (PO),respectively. The study presented by Davis and Burns providesschedulability analysis for both overrun mechanisms; however,the schedulability analysis does not allow independent analysisof individual subsystems. Hence, the presented schedula-bility analysis does not naturally support composability ofsubsystems.
The schedulability analysis of Davis and Burns’ has beenextended assessing composability in [3] for systems runningthe Earlier Deadline First (EDF) scheduling algorithm. In ad-dition, in the same paper a new overrun mechanism has beenpresented, called Enhanced Overrun (EO), that potentially in-creases schedulability within a subsystem by providing CPUallocations more efficiently. Also, in the paper this new mecha-nism has been evaluated against PO.
1551-3203/$26.00 © 2009 IEEE

94 IEEE TRANSACTIONS ON INDUSTRIAL INFORMATICS, VOL. 6, NO. 1, FEBRUARY 2010
The contributions of this paper are as follows; First, BO, thesecond version of overrun mechanism presented in [2], is in-cluded in the comparison between overrun mechanisms pre-sented in [3] and it is shown under which circumstances a certainoverrun mechanism is the preferred one among all three (BO,PO, and EO) presented mechanisms. In addition, the sechedu-lability analysis of local and global schedulers is generalized byincluding Fixed Priority Scheduling (FPS) in the schedulabilityanalysis, as the results of [3] were limited to the EDF schedulingalgorithm. Finally, the simplified equation to calculate resourceholding time using the EDF scheduling algorithm (presented in[3]) is proven to be valid also when using the FPS schedulingalgorithm. Hence, using the results of this paper it is possible touse either FPS or EDF.
The outline of this paper is as follows: Section II presentsrelated work, while Section III presents the system model. InSection IV, the schedulability analysis for the system modelis presented. Section V presents the three overrun mechanisms(BO, PO, and EO), and Section VI presents their analytical com-parison. In Section VII, it is shown how to calculate the resourceholding times under both FPS and EDF, and finally, Section VIIIconcludes.
II. RELATED WORK
This section presents related work in the areas of HSFs aswell as resource sharing protocols.
A. Hierarchical Scheduling
The HSF for real-time systems, originating in open systems[4] in the late 1990s, has been receiving an increasing researchattention. Since Deng and Liu [4] introduced a two-level HSF,its schedulability has been analyzed under fixed-priority globalscheduling [5] and under EDF-based global scheduling [6], [7].Mok et al. [8] proposed the bounded-delay resource model toachieve a clean separation in a multilevel HSF, and schedula-bility analysis techniques [9], [10] have been introduced for thisresource model. In addition, Shin and Lee [1], [11] introducedanother periodic resource model (to characterize the periodicresource allocation behavior), and many studies have been pro-posed on schedulability analysis with this resource model underfixed-priority scheduling [12]–[14] and under EDF scheduling[1]. More recently, Easwaran et al. [15] introduced the ExplicitDeadline Periodic (EDP) resource model. However, a commonassumption shared by all these studies is that tasks are requiredto be independent.
B. Resource Sharing
In many real systems, tasks are semi-independent, interactingwith each other through mutually exclusive resource sharing.Many protocols have been introduced to address the priority in-version problem for semi-independent tasks, including the Pri-ority Inheritance Protocol (PIP) [16], the Priority Ceiling Pro-tocol (PCP) [17], and Stack Resource Policy (SRP) [18]. Re-cently, Fisher et al. addressed the problem of minimizing the re-source holding time [19] under SRP. There have been studies onextending SRP for HSFs, for sharing of logical resources withina subsystem [5], [20] and across subsystems [2], [21], [22].Davis and Burns [2] proposed the Hierarchical Stack Resource
Fig. 1. Two-level HSF with resource sharing.
Policy (HSRP) supporting sharing of logical resources on thebasis of an overrun mechanism. Behnam et al. [21] proposed theSubsystem Integration and Resource Allocation Policy (SIRAP)protocol that supports subsystem integration in the presence ofshared logical resources, on the basis of skipping. Fisher et al.[22] proposed the BROE server that extends the Constant Band-width Server (CBS) [23] in order to handle sharing of logical re-sources in a HSF. Behnam et al. [24] compared between SIRAP,HSRP, and BROE and showed that there is no one silver bulletsolution available today, providing an optimal HSF and syn-chronization protocol for use in open environments. Lipari etal. proposed the BandWidth Inheritance protocol (BWI) [25]which extends the resource reservation framework to systemswhere tasks can share resources. The BWI approach is basedon using the CBS algorithm together with a technique that isderived from the PIP. Particularly, BWI is suitable for systemswhere the execution time of a task inside a critical section cannot be evaluated.
III. SYSTEM MODEL AND BACKGROUND
A. Resource Sharing in the HSF
The Hierarchical Scheduling Framework (HSF) has been in-troduced to support CPU time sharing among applications (sub-systems) under different scheduling policies. In this paper, a twolevel-hierarchical scheduling framework is considered, whichworks as follows: a global (system-level) scheduler allocatesCPU time to subsystems, and a local (subsystem-level) sched-uler subsequently allocates CPU time to its internal tasks.
Having such a HSF also allows for the sharing of logical re-sources among tasks in a mutually exclusive manner (see Fig. 1).Specifically, tasks can share local logical resources within a sub-system as well as global logical resources across (in-between)subsystems. However, note that this paper focuses around mech-anisms for sharing of global logical resources in a HSF, whilelocal logical resources can be supported by traditional synchro-nization protocols such as SRP (see, e.g., [2], [5], and [20]).
B. Virtual Processor Models
The notion of real-time virtual processor (resource) modelwas first introduced by Mok et al. [8] to characterize the CPUallocations that a parent node provides to a child node in aHSF. The CPU supply of a virtual processor model refers to theamounts of CPU allocations that the virtual processor model canprovide. The supply bound function of a virtual processor modelcalculates its minimum possible CPU supply for any given timeinterval of length .
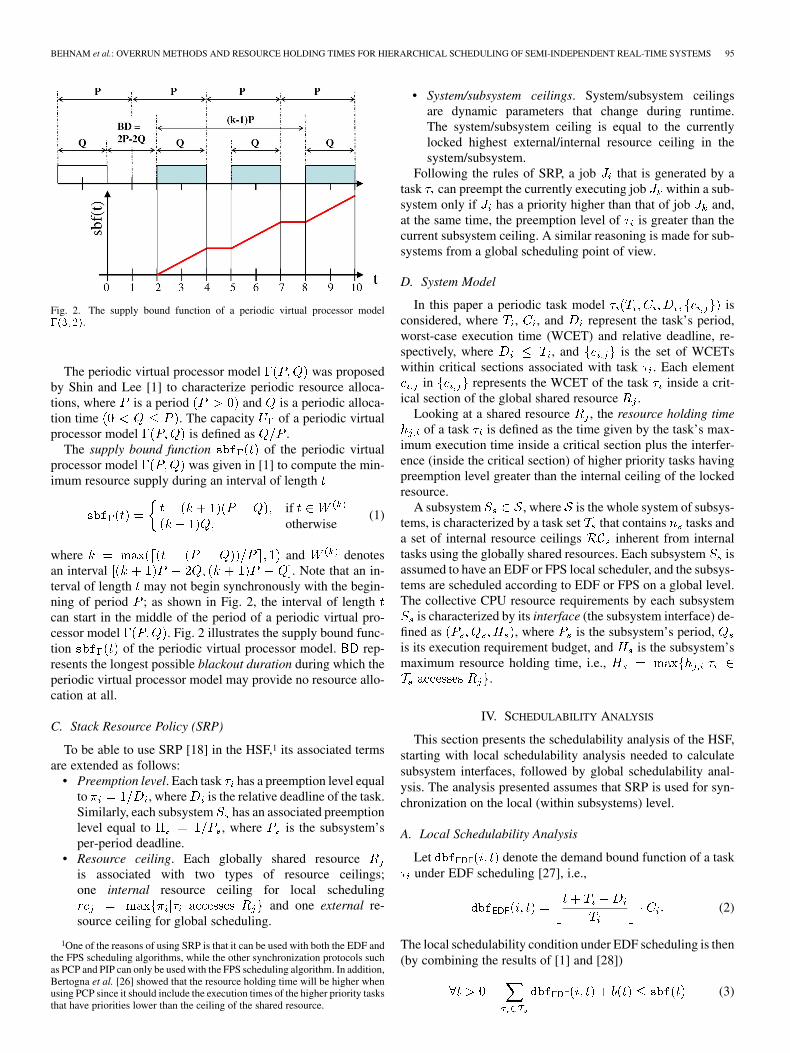
BEHNAM et al.: OVERRUN METHODS AND RESOURCE HOLDING TIMES FOR HIERARCHICAL SCHEDULING OF SEMI-INDEPENDENT REAL-TIME SYSTEMS 95
Fig. 2. The supply bound function of a periodic virtual processor model���� ��.
The periodic virtual processor model was proposedby Shin and Lee [1] to characterize periodic resource alloca-tions, where is a period and is a periodic alloca-tion time . The capacity of a periodic virtualprocessor model is defined as .
The supply bound function of the periodic virtualprocessor model was given in [1] to compute the min-imum resource supply during an interval of length
ifotherwise
(1)
where and denotesan interval . Note that an in-terval of length may not begin synchronously with the begin-ning of period ; as shown in Fig. 2, the interval of lengthcan start in the middle of the period of a periodic virtual pro-cessor model . Fig. 2 illustrates the supply bound func-tion of the periodic virtual processor model. rep-resents the longest possible blackout duration during which theperiodic virtual processor model may provide no resource allo-cation at all.
C. Stack Resource Policy (SRP)
To be able to use SRP [18] in the HSF,1 its associated termsare extended as follows:
• Preemption level. Each task has a preemption level equalto , where is the relative deadline of the task.Similarly, each subsystem has an associated preemptionlevel equal to , where is the subsystem’sper-period deadline.
• Resource ceiling. Each globally shared resourceis associated with two types of resource ceilings;one internal resource ceiling for local scheduling
and one external re-source ceiling for global scheduling.
1One of the reasons of using SRP is that it can be used with both the EDF andthe FPS scheduling algorithms, while the other synchronization protocols suchas PCP and PIP can only be used with the FPS scheduling algorithm. In addition,Bertogna et al. [26] showed that the resource holding time will be higher whenusing PCP since it should include the execution times of the higher priority tasksthat have priorities lower than the ceiling of the shared resource.
• System/subsystem ceilings. System/subsystem ceilingsare dynamic parameters that change during runtime.The system/subsystem ceiling is equal to the currentlylocked highest external/internal resource ceiling in thesystem/subsystem.
Following the rules of SRP, a job that is generated by atask can preempt the currently executing job within a sub-system only if has a priority higher than that of job and,at the same time, the preemption level of is greater than thecurrent subsystem ceiling. A similar reasoning is made for sub-systems from a global scheduling point of view.
D. System Model
In this paper a periodic task model isconsidered, where , , and represent the task’s period,worst-case execution time (WCET) and relative deadline, re-spectively, where , and is the set of WCETswithin critical sections associated with task . Each element
in represents the WCET of the task inside a crit-ical section of the global shared resource .
Looking at a shared resource , the resource holding timeof a task is defined as the time given by the task’s max-
imum execution time inside a critical section plus the interfer-ence (inside the critical section) of higher priority tasks havingpreemption level greater than the internal ceiling of the lockedresource.
A subsystem , where is the whole system of subsys-tems, is characterized by a task set that contains tasks anda set of internal resource ceilings inherent from internaltasks using the globally shared resources. Each subsystem isassumed to have an EDF or FPS local scheduler, and the subsys-tems are scheduled according to EDF or FPS on a global level.The collective CPU resource requirements by each subsystem
is characterized by its interface (the subsystem interface) de-fined as , where is the subsystem’s period,is its execution requirement budget, and is the subsystem’smaximum resource holding time, i.e.,
.
IV. SCHEDULABILITY ANALYSIS
This section presents the schedulability analysis of the HSF,starting with local schedulability analysis needed to calculatesubsystem interfaces, followed by global schedulability anal-ysis. The analysis presented assumes that SRP is used for syn-chronization on the local (within subsystems) level.
A. Local Schedulability Analysis
Let denote the demand bound function of a taskunder EDF scheduling [27], i.e.,
(2)
The local schedulability condition under EDF scheduling is then(by combining the results of [1] and [28])
(3)

96 IEEE TRANSACTIONS ON INDUSTRIAL INFORMATICS, VOL. 6, NO. 1, FEBRUARY 2010
where is the blocking function [28] (according to SRP) thatrepresents the longest blocking time during which a job with
may be blocked by a job with when bothjobs access the same resource. Note that can be selected withina finite set of scheduling points using the same techniques from[27].2
For Fixed Priority Scheduling (FPS) [30], let de-note the request bound function of a task , i.e.,
��
(4)
where is the set of tasks with priorities higher than thatof . The local schedulability analysis under FPS can then beextended from the results of [1], [18] as follows:
(5)
where is the maximum blocking (i.e., extra CPU demand)imposed to a task when is blocked by lower priority tasksthat are accessing resources with ceiling greater than or equal tothe priority of . Note that can be selected within a finite setof scheduling points [31].
B. Subsystem Interface Calculation
Given a subsystem , , and , letdenote a function that calculates the smallest sub-
system budget that satisfies (3) for EDF and (5) for FPSscheduling. Hence, . Re-cently, Fisher et al. [29] presented an algorithm that finds theexact smallest subsystem budget using EDF as a local sched-uler, called MINIMUMCAPACITY. This work is extended forthe FPS local scheduler with a corresponding new algorithmcalled FPMINIMUMCAPACITY [32]. Both algorithms do notconsider resource sharing, however, they can support resourcesharing by using (3) for EDF and (5) for FPS scheduling. Thecomplexity of both algorithms is pseudo-polynomial with re-spect to time.
C. Global Schedulability Analysis
Following [28, Th. 1], global schedulability analysis underEDF scheduling is given using the system load bound function
as follows:
(6)
where
(7)
and the system-level blocking function represents the max-imum blocking time (according to SRP) during which a sub-system may be blocked by another subsystem , where
and . is defined as
(8)
2Note that although the work in [27] does not consider hierarchical sched-uling, the same technique can be used in the context of hierarchical scheduling[22], [29].
Under global FPS scheduling, the subsystem load boundfunction is as follows [on the basis of a similar reasoningof (4)]:
(9)
where
���
(10)
where is the set of subsystems with priority higher thanthat of . Let denote the maximum blocking (i.e., extraCPU demand) imposed to a subsystem , when it is blockedby lower-priority subsystems
(11)
where is the set of subsystems with priority lower thanthat of .
A global schedulability condition under FPS is then
(12)
V. OVERRUN MECHANISMS
This section explains three overrun mechanisms that can beused to handle budget expiry during a critical section in theHSF. Consider a global scheduler that schedules subsystems ac-cording to their periodic interfaces . The subsystembudget is said to expire at the point when one or more internal(to the subsystem) tasks have executed a total of time unitswithin the subsystem period . Once the budget is expired, nonew task within the same subsystem can initiate its executionuntil the subsystem’s budget is replenished. This replenishmenttakes place in the beginning of each subsystem period, wherethe budget is replenished to a value of .
Budget expiration may cause a problem if it happens while ajob of a subsystem is executing within a critical sectionof a global shared resource . If another job , belongingto another subsystem, is waiting for the same resource , thisjob must wait until is replenished again so can continue toexecute and finally release the lock on resource . This waitingtime exposed to can be potentially very long, causing tomiss its deadline.
In this paper, an overrun mechanism is considered as follows;when the budget of subsystem expires and has a jobthat is still locking a globally shared resource, job continuesits execution until it releases the locked resource. The extra timethat needs to execute after the budget of expires is denotedas overrun time . The maximum occurs when locks a re-source that gives the longest resource holding time just beforethe budget of expires.
Here, two versions of overrun mechanisms [2] are considered;1) The overrun mechanism with payback, introduced as PO
and later EO: whenever overrun happens, the subsystempays back in its next execution instant, i.e., the subsystembudget will be decreased by for the subsystem’s ex-ecution instant following the overrun (note that only theinstant following the overrun is affected).

BEHNAM et al.: OVERRUN METHODS AND RESOURCE HOLDING TIMES FOR HIERARCHICAL SCHEDULING OF SEMI-INDEPENDENT REAL-TIME SYSTEMS 97
2) The overrun mechanism without payback, introduced asBO: in this version of the overrun mechanism, no furtheractions will be taken after the event of an overrun.
Hereinafter, the overrun mechanism with payback is calledPO, and the overrun mechanism without payback is called BO.Both are versions of the basic overrun mechanism. Also, an ex-tended mechanism with payback is introduced as EO.
A. Basic Overrun—Overrun Mechanism 1 and 2
Davis et al. [2] presented schedulability analysis for both (BOand PO) versions of basic overrun, however, the presented anal-ysis is not suitable for open environments [4] as it requires de-tailed information of all tasks in the system in order to calcu-late global schedulability. This section discusses how to extendthe existing schedulability analysis for the basic overrun mech-anisms, making them suitable for open environments.
1) Global Analysis With Basic Overrun:a) PO—Basic overrun with payback: First, the demand
bound function (and the request bound function) of a subsystemwith the basic overrun mechanism with payback is extended.Looking at the PO mechanism in a subsystem , the maximumcontribution on for EDF scheduling and forFPS scheduling is . When overruns with its maximum,which is , the subsystem’s resource demand within the sub-system period will be increased to . Following this,the budget of the next period will be decreased to dueto the payback mechanism. Then, suppose that the subsystemoverruns again. Now, during the next subsystem period, the sub-system’s resource demand will be . Here, itis easy to observe that the subsystem’s resource demand will beat most during subsystem periods. Hence, the de-mand bound function of a subsystem with the basicoverrun mechanism using EDF scheduling globally is
(13)
where is the subsystem budget when using the PO mecha-nism and
ifotherwise
(14)
The schedulability condition of (6) can then be extended by sub-stituting with .
When using a global FPS scheduler, the request bound func-tion is
���
(15)b) BO—Basic overrun without payback: This version of
overrun does not payback the budget after overrun happens. Thismeans that the system resource demands within the period of
can be up to for all periods considering that themaximum overrun will happen every period, which is the worstcase scenario. Then, for EDF global scheduling, the maximumdemand bound function using the BO mechanism is
(16)
where is the subsystem budget when using the BOmechanism.
For a global FPS scheduler, the request bound functionis
���
(17)2) Independent Analysis With Basic Overrun: Using PO,
there is no single worst-case resource supply scenario. In fact,there are two scenarios that constitute the worst-case scenario;the worst-case scenario is either of those two scenarios, de-pending on an interval length . In the first case [“Case A”shown in Fig. 4(a)], the greatest Blackout Duration (BD) is
assuming that a task is activated upon the sub-system budget expiration and the given budget was .While in the second case [“Case C” shown in Fig. 4(c)], thesubsystem can not be supplied by more than if a taskis released upon the subsystem budget expiration and the sub-system has experienced overrun by in the previous instant.Note that when a system is feasible from a global schedulingperspective, the latest CPU resource availability for a subsystem
will be even during the payback period, see Fig. 4(c)within the payback period the latest finalization time ofis guaranteed to be at least before the next activation of .
Let’s define two functions, function for “Case A” andfor “Case C,” to represent the minimum resource supply
for each case. Then, the supply bound function for POis defined accordingly as the minimum of these two functions(see Fig. 4). It is defined as follows:
(18)
where isifotherwise
(19)
where and denotesan interval , andis
ififotherwise
(20)
where , denotes an interval, and denotes an interval.
The existing schedulability conditions of (3) can then be ex-tended by substituting with .
For BO—basic overrun without payback—(1) can still beused without modification to evaluate the supply bound functionsince the Blackout Duration is [as shown in Fig. 3(b)],i.e., the supply bound function using BO will equal to
.
B. Enhanced Overrun—Overrun Mechanism 3
As seen in Section V-A, the PO mechanism works with amodified supply bound function that is less efficientin terms of CPU resource usage compared with the original
, as illustrated in Fig. 4. While for the BO mechanism, therequest/demand bound function will be increased by
in all periods which may require more resources as

98 IEEE TRANSACTIONS ON INDUSTRIAL INFORMATICS, VOL. 6, NO. 1, FEBRUARY 2010
Fig. 3. Basic and enhanced overrun mechanisms. (a) Basic overrun mecha-nism with payback (PO). (b) Basic overrun mechanism without payback (BO).(c) Enhanced overrun mechanism (EO).
well. In the following, an enhanced overrun mechanism (EO) isproposed. This new overrun mechanism makes it possible to im-prove and at the same time the request/demand boundfunction will be for the first instance andthen only for the following periods when applying globalschedulability analysis.
The EO mechanism is based on imposing an offset (delayingthe budget replenishment of subsystem) equal to the amount ofan overrun to the execution instant that follows asubsystem overrun (at this instant, the subsystem budget is
). As shown in Fig. 3(c), the execution of the subsystem willbe delayed by after a new period followed by overrun even ifthat subsystem has the highest priority at that time. By this themaximum BD will be decreased to compared withPO (basic overrun with payback) shown in Fig. 3(a). By this, theeffect of is removed from the supply bound function whichmakes the supply bound function for EO, better than when usingPO. The supply bound function for EO is
(21)
Note that the schedulability analysis of both the PO and theEO mechanisms presented in [3] are not accurate since the CPUsupply “Case C” shown in Figs. 4 and 5 has not been taken intoaccount.
1) Global Analysis With Enhanced Overrun: In the fol-lowing, a demand bound function is presented forEDF global scheduling of a subsystem that upper-boundsthe demand requested by under the EO mechanism. Now,
includes the offset as follows:
(22)
where is the subsystem budget when using the EO mecha-nism and
ifotherwise
(23)
The schedulability condition of (6) can then be extended by sub-stituting with .
Using an FPS global scheduler, the offset imposed by the EOmechanism for each subsystem can be modeled as a releasejitter with the range of so . The upper boundof the request bound function calculation is as follows:
���
(24)The schedulability analysis then
(25)
where
(26)
VI. COMPARISON BETWEEN THE
THREE OVERRUN MECHANISMS
In this section, the efficiency of the three overrun mechanisms(BO, PO, and EO) are compared. First, the effect of using eachone of them locally is shown, i.e., on a subsystem level. Then,their effect globally is shown, i.e., on a system level.
A. Subsystem-Level Comparison
We will explain the effect of using each of the three overrunmechanisms, on the minimum subsystem budget . As de-scribed in Section IV-B, should be the smallest value thatsatisfy (3) for EDF and (5) for FPS scheduling. Note that thedemand bound function (request bound function
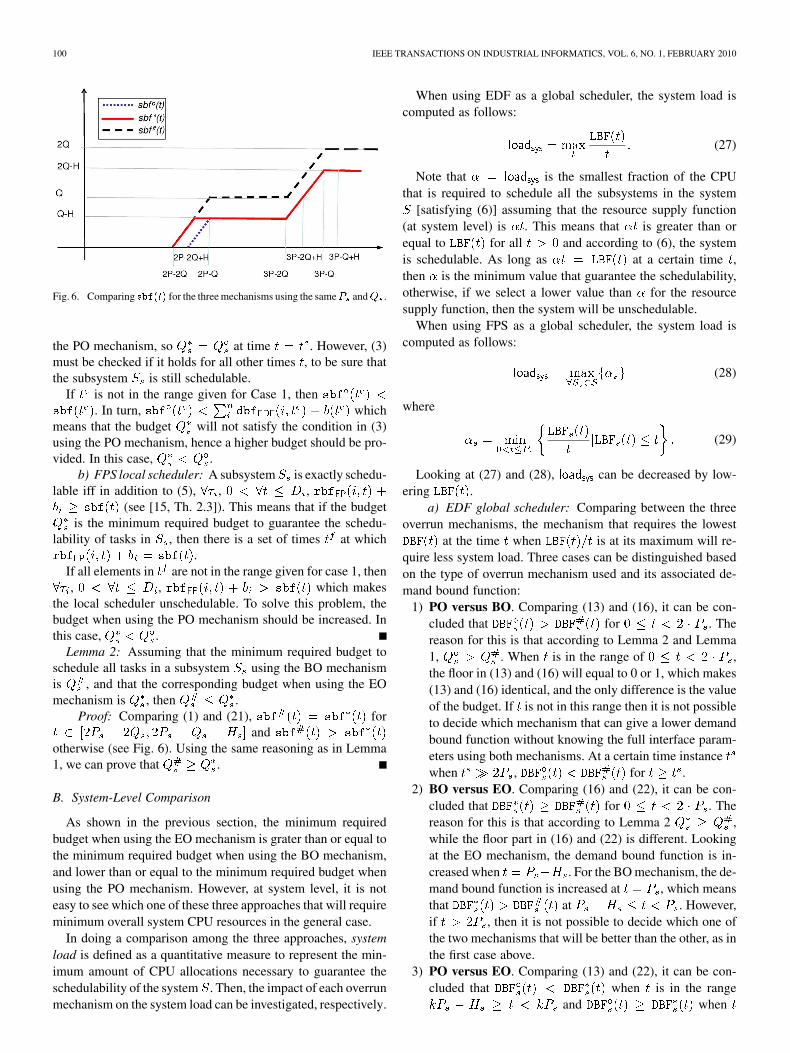
) will not be changed when using the BO, PO, and EOmechanisms. The only thing that changes when using one of themechanisms in the subsystem level is the supply bound function,as described in the previous section. Fig. 6 shows the supplybound function for the three mechanisms using the same and
. We will show in the following lemmas that the mechanismsthat have higher supply bound function will require smaller .
The following lemma shows that the minimum required sub-system budget when using the EO mechanism will be lower thanor equal to the minimum required budget when using the POmechanism for both FPS and EDF local schedulers.
Lemma 1: Assuming that the minimum required budget toschedule all tasks in a subsystem using the PO mechanismis , and that the corresponding budget when using the EOmechanism is , then .
Proof: The proof is split into two parts, proving the caseof having an EDF local scheduler and an FPS local scheduler,respectively.
a) EDF local scheduler: A subsystem is exactlyschedulable iff in addition to (3),
for s.t.(see [15, Th. 2.2]). This means that if the budget isthe minimum required budget to guarantee the schedula-bility of tasks in , then there is a set of times at which
. Without loss of generality,assume that includes one element. If the same subsystembudget is used when running the PO mechanism and the
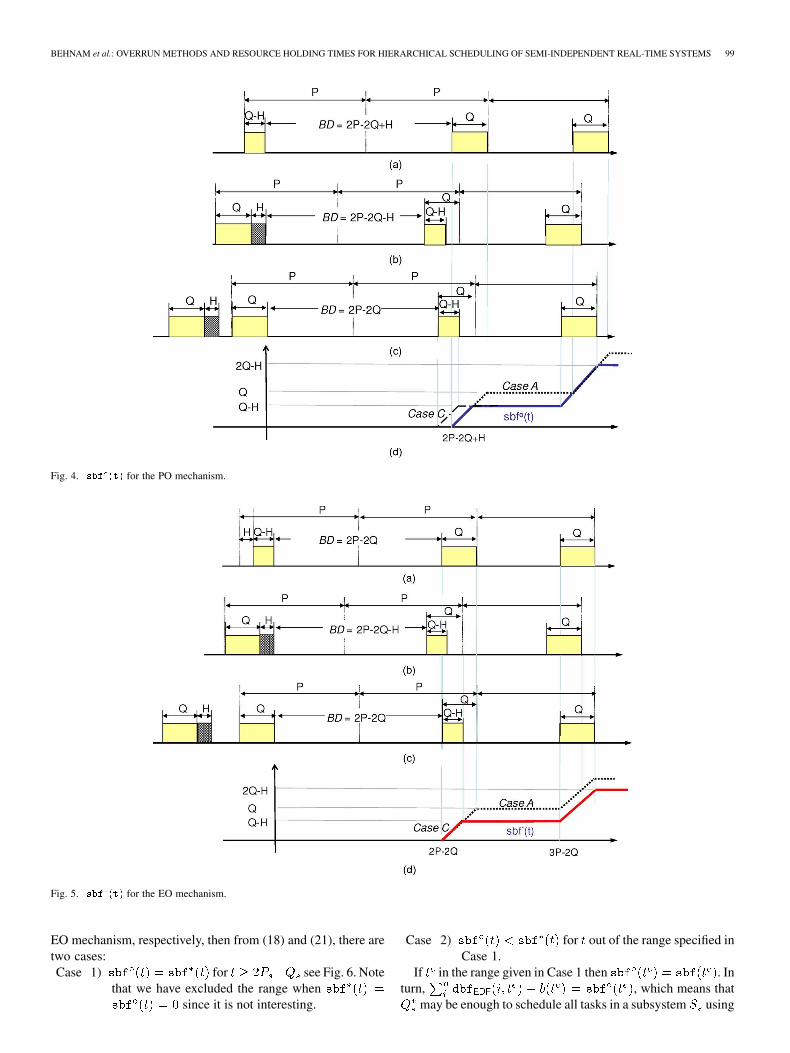
BEHNAM et al.: OVERRUN METHODS AND RESOURCE HOLDING TIMES FOR HIERARCHICAL SCHEDULING OF SEMI-INDEPENDENT REAL-TIME SYSTEMS 99
Fig. 4. ��� ��� for the PO mechanism.
Fig. 5. ��� ��� for the EO mechanism.
EO mechanism, respectively, then from (18) and (21), there aretwo cases:Case 1) for see Fig. 6. Note
that we have excluded the range whensince it is not interesting.
Case 2) for out of the range specified inCase 1.
If in the range given in Case 1 then . Inturn, , which means that
may be enough to schedule all tasks in a subsystem using
100 IEEE TRANSACTIONS ON INDUSTRIAL INFORMATICS, VOL. 6, NO. 1, FEBRUARY 2010
Fig. 6. Comparing ������ for the three mechanisms using the same� and� .
the PO mechanism, so at time . However, (3)must be checked if it holds for all other times , to be sure thatthe subsystem is still schedulable.
If is not in the range given for Case 1, then. In turn, which
means that the budget will not satisfy the condition in (3)using the PO mechanism, hence a higher budget should be pro-vided. In this case, .
b) FPS local scheduler: A subsystem is exactly schedu-lable iff in addition to (5), , ,
(see [15, Th. 2.3]). This means that if the budgetis the minimum required budget to guarantee the schedu-
lability of tasks in , then there is a set of times at which.
If all elements in are not in the range given for case 1, then, , which makes
the local scheduler unschedulable. To solve this problem, thebudget when using the PO mechanism should be increased. Inthis case, .
Lemma 2: Assuming that the minimum required budget toschedule all tasks in a subsystem using the BO mechanismis , and that the corresponding budget when using the EOmechanism is , then .
Proof: Comparing (1) and (21), forand
otherwise (see Fig. 6). Using the same reasoning as in Lemma1, we can prove that .
B. System-Level Comparison
As shown in the previous section, the minimum requiredbudget when using the EO mechanism is grater than or equal tothe minimum required budget when using the BO mechanism,and lower than or equal to the minimum required budget whenusing the PO mechanism. However, at system level, it is noteasy to see which one of these three approaches that will requireminimum overall system CPU resources in the general case.
In doing a comparison among the three approaches, systemload is defined as a quantitative measure to represent the min-imum amount of CPU allocations necessary to guarantee theschedulability of the system . Then, the impact of each overrunmechanism on the system load can be investigated, respectively.
When using EDF as a global scheduler, the system load iscomputed as follows:
(27)
Note that is the smallest fraction of the CPUthat is required to schedule all the subsystems in the system
[satisfying (6)] assuming that the resource supply function(at system level) is . This means that is greater than orequal to for all and according to (6), the systemis schedulable. As long as at a certain time ,then is the minimum value that guarantee the schedulability,otherwise, if we select a lower value than for the resourcesupply function, then the system will be unschedulable.
When using FPS as a global scheduler, the system load iscomputed as follows:
(28)
where
(29)
Looking at (27) and (28), can be decreased by low-ering .
a) EDF global scheduler: Comparing between the threeoverrun mechanisms, the mechanism that requires the lowest
at the time when is at its maximum will re-quire less system load. Three cases can be distinguished basedon the type of overrun mechanism used and its associated de-mand bound function:
1) PO versus BO. Comparing (13) and (16), it can be con-cluded that for . Thereason for this is that according to Lemma 2 and Lemma1, . When is in the range of ,the floor in (13) and (16) will equal to 0 or 1, which makes(13) and (16) identical, and the only difference is the valueof the budget. If is not in this range then it is not possibleto decide which mechanism that can give a lower demandbound function without knowing the full interface param-eters using both mechanisms. At a certain time instancewhen , for .
2) BO versus EO. Comparing (16) and (22), it can be con-cluded that for . Thereason for this is that according to Lemma 2 ,while the floor part in (16) and (22) is different. Lookingat the EO mechanism, the demand bound function is in-creased when . For the BO mechanism, the de-mand bound function is increased at , which meansthat at . However,if , then it is not possible to decide which one ofthe two mechanisms that will be better than the other, as inthe first case above.
3) PO versus EO. Comparing (13) and (22), it can be con-cluded that when is in the range
and when

BEHNAM et al.: OVERRUN METHODS AND RESOURCE HOLDING TIMES FOR HIERARCHICAL SCHEDULING OF SEMI-INDEPENDENT REAL-TIME SYSTEMS 101
Fig. 7. Comparing between ��� ���, ��� ���, and ��� ���.
is in , where is an integervalue greater and . Note that, at a certain time in-stance when , forif .
The example shown in Fig. 7 explains the three cases de-scribed above.
Defining the time as the time at which the system load isevaluated from (27), then, depending on the value of and thetype of overrun mechanism used, it would be possible to esti-mate which one of the three overrun mechanisms that will re-quire the lowest system load. For example, if and
is the shortest subsystem period, then the subsystem loadwhen using the BO mechanism is less than or equal to the sub-system load when using any of the other two overrun mecha-nisms. However, if then the possibility of having goodresults when using the BO mechanism is very low. Another as-pect that can be considered is when for all subsystems,then the system load using the PO mechanism will always beless than or equal to the system load when using EO. Otherwise,all subsystem parameters should be given in order to evaluatewhich one of the three mechanisms that can give better resultsin terms of lowest system load.
b) FPS global scheduler: Looking at (29), in order to mini-mize the system load of the subsystem that generatesthe maximum should be minimized. The overrun mechanismthat generates the lowest request bound function for thesubsystem , will require the lowest system load. However,may not be the same subsystem when using different overrunmechanisms, and also, at a certain time instance , the value of
when using one of the overrun mechanisms will be lessthan when using another overrun mechanism, and for anothertime instance the value of might be less when usingthe second mechanism. It can be concluded that none of the threeoverrun mechanisms can perform better than the other two in thegeneral case, as it depends directly of the system parameters.
The comparison between the three overrun mechanisms interms of request bound function is shown below:
1) PO versus BO. Comparing (15) and (17), it easy to showthat for . The reason isthat the interference from other higher priority tasks is al-ways for both cases and . If then
the mechanism that requires a lower request bound functionis different depending on the system parameters. It can beconcluded that if the subsystem periods of all subsystemsare equal, then the BO mechanism will require less systemload than using the PO mechanism. Another interesting ob-servation is that if the subsystem that generates maximumin (29) has the highest priority, then the BO mechanism willrequire less system load compared to using the PO mecha-nism. The reason for this is inherent in the subsystem pri-ority; as the subsystem has higher priority, then there willbe no interference from other lower priority subsystems.
2) BO versus EO. Comparing (17) and (24), it is easy to showthat for . If , thenfinding the best mechanism that requires the least systemload depends on the system parameters.
3) PO versus EO. Comparing (15) and (24), it can be con-cluded that when is in the range
and whenis in , where is an integervalue greater and .
The following examples show some of the cases discussedabove.
c) Example 1: Suppose that a system consists of threesubsystems with parameters as shown below:
The global scheduler is EDF. Using the PO mechanismand maximum is at , using the BO
mechanism and maximum is at , andfor the EO mechanism and maximum is at
.d) Example 2: Suppose that a system consists of three
subsystems with parameters as shown below:
The global scheduler is EDF. Using the PO mechanismand maximum is at , using the BO
mechanism and maximum is at , andfor the EO mechanism and maximum is at
.e) Example 3: Suppose that a system consists of three
subsystems with parameters as shown in the equation at thebottom of the next page.
The global scheduler is FPS. Using the PO mechanismand maximum is at , using the BO
mechanism and maximum is at , andfor the EO mechanism and maximum is at
.

102 IEEE TRANSACTIONS ON INDUSTRIAL INFORMATICS, VOL. 6, NO. 1, FEBRUARY 2010
VII. COMPUTING RESOURCE HOLDING TIME
This section explains how to compute the resource holdingtime , a very important parameter in the global analysis. Theresource holding time is the time given by the tasks maximumexecution time inside a critical section plus the interference (in-side the critical section) of higher priority tasks having preemp-tion level greater than the internal ceiling of the locked resource.That means the internal resource ceiling is one of the pa-rameters that can have a great effect on resource holding timesof the global shared resources [see (30) and (31)]. Setting thevalue of according to SRP may make the resource holdingtimes values, very high. One way to handle this problem is bypreventing the preemption inside the subsystem when a task isaccessing a shared resource. However, Fisher et al. [19] showedthat preventing preemption while accessing a global shared re-source may violate the local schedulability of the subsystem andproposed an algorithm based on increasing the ceiling of all re-sources in steps as much as possible without violating the localschedulability. Finally, Shin et al. [33] showed that there is atradeoff between decreasing the value of and the minimumsubsystem budget required to guarantee the schedulability of thesubsystem. The result of this paper does not depend on any ofthe discussed methods to set the internal resource ceiling.
For nonhierarchical scheduling, Bertogna et al. [26] andFisher et al. [19], [26] presented a method to evaluate theresource holding time assuming FPS and EDF schedulingalgorithms, respectively. The resource holding time of ashared resource accessed by is the smallest positive time
such that , with computed as follows:
(30)
where is the maximum execution time oftask inside the critical section of the resource and is theset of tasks such that .
Finally, the resource holding time of a resource isfor all access resource .
Now, for a hierarchical scheduling framework that uses theoverrun mechanism, the following equation shows how to eval-uate the resource holding time for a task that accesses a re-source :
(31)
The difference between (31) and (30) is that all tasks that canpreempt inside the critical section are assumed to be executedonly once. The reason for why it is safe to assume only one
Fig. 8. Resource holding times for the case � � � .
execution of each preempting task inside the critical section isgiven in the following lemma, showing that if a task executesmore than one time inside the critical section, the subsystemwill become unschedulable.
Lemma 3: For a subsystem that uses an overrun mechanismto arbitrate access to a global shared resource under the periodicvirtual processor model, each task that is allowed to preempt theexecution of another task currently inside the critical section ofa globally shared resource can, in the worst case, only execute(cause interference) once independent if the local scheduler isEDF or FPS.
Proof: This lemma will be proved by contradiction to showthat if more than one job of a task preempts a critical section thenthe system utilization will be greater than one. The followingtwo cases are considered in the proof:
1) (where for all ), ifthe task having period executes 2 or more times insidethe critical section, this means that the resource will belocked during this period, i.e., thenwhich, in turn, means that the CPU utilization required bythe subsystem will be .
2) If , should provide at least at timeto ensure the schedulability test in (3) for the
EDF scheduler and in (4) for the FPS scheduler. Note thatduring so,
which means . Then,the minimum subsystem budget is
(32)
Let us define as the maximum time in which a subsystemmay not get any budget within the subsystem period be-cause of preemptions from other higher priority subsystems,then (see Fig. 8) and substituting by theminimum subsystem budget in (32)
(33)

BEHNAM et al.: OVERRUN METHODS AND RESOURCE HOLDING TIMES FOR HIERARCHICAL SCHEDULING OF SEMI-INDEPENDENT REAL-TIME SYSTEMS 103
The maximum number of activations (release) of thewithin while a lower priority task accessing a global sharedresource, will happen when is release at the beginning of thesubsystem period just after the lower priority task has lockeda global shared resource (see Fig. 8). Now, lets assume that
will execute two times while the global shared resourceis locked, then the subsystem budget given to the subsystemwithin the first period of should be low enough such thatthe shared resource will not be released before the secondactivation of . Let us define as the minimum subsystembudget that will be supplied to the subsystem within the firstperiod of , and from (33), we get
(34)
The task can execute two times while a global shared re-source is locked only if evaluated from (31) is greater than
i.e., , otherwise, the shared resourcewill be released before the new activation of task . Hence,
which means .From Lemma 3, it can be concluded that all tasks that can
preempt the execution of a critical section should do so max-imum one time in order to keep the utilization of a subsystemless than one. If a task preempts the execution of a critical sec-tion more than one time then it will be seen from (31) such that
. This proves the correctness of (31) which isbased on the assumption that all tasks can interfere only once asa worst case while a task is in the critical section of the resource
. If the value of becomes greater than thenit can be concluded that the subsystem will not be schedulableand no further calculation towards finding an exact value ofis needed.
VIII. SUMMARY
This paper presents three different overrun mechanisms thatall can handle the problem of sharing of logical resources ina hierarchical scheduling framework while at the same timesupporting independent subsystem development (open environ-ments). Compared to previous work [3], results have been gen-eralized by also allowing for the FPS scheduling algorithm forboth local and global schedulers, which is suitable for usagein open environments. In addition, a third overrun mechanism,basic overrun without payback (BO), is included in the com-parison between the overrun mechanisms. Also, this compar-ison is performed considering both FPS and EDF schedulingalgorithms. The results from this comparison show that it is nottrivial to evaluate, in the general case, which overrun methodthat is better than the other, as their impact on the CPU utiliza-tion is highly dependent on global system parameters such assubsystem periods and budgets. Finally, the calculation of re-source holding times when using the periodic virtual processormodel with both the EDF and FPS scheduling algorithms is pre-sented, as the resource holding time is a very important param-eter in the global schedulability analysis.
Future work includes comparing the enhanced overrun mech-anism (EO) with other synchronization mechanisms such asBWI [25], the BROE server [22] and SIRAP [21]. In addition,
implementing the three overrun mechanisms and comparing theimplementation overhead of each mechanism is important. Fi-nally, as the global schedulability analysis gives an upper boundfor EO, it will be interesting to find an exact or less pessimisticschedulability analysis.
REFERENCES
[1] I. Shin and I. Lee, “Periodic resource model for compositional real-timeguarantees,” in Proc. 24th IEEE Int. Real-Time Syst. Symp. (RTSS’03),Dec. 2003, pp. 2–13.
[2] R. I. Davis and A. Burns, “Resource sharing in hierarchical fixed pri-ority pre-emptive systems,” in Proc. 27th IEEE Int. Real-Time Syst.Symp. (RTSS’06), Dec. 2006, pp. 389–398.
[3] M. Behnam, I. Shin, T. Nolte, and M. Nolin, “Scheduling of semi-in-dependent real-time components: Overrun methods and resourceholding times,” in Proc. 13th IEEE Int. Conf. Emerging Technol.Factory Autom. (ETFA’08), Sep. 2008, pp. 575–582.
[4] Z. Deng and J.-S. Liu, “Scheduling real-time applications in anopen environment,” in Proc. 18th IEEE Int. Real-Time Syst. Symp.(RTSS’97), Dec. 1997, pp. 308–319.
[5] T.-W. Kuo and C.-H. Li, “A fixed-priority-driven open environment forreal-time applications,” in Proc. 20th IEEE Int. Real-Time Syst. Symp.(RTSS’99), Dec. 1999, pp. 256–267.
[6] G. Lipari and S. K. Baruah, “Efficient scheduling of real-time multi-task applications in dynamic systems,” in Proc. 6th IEEE Real-TimeTechnol. Appl. Symp. (RTAS’00), May–Jun. 2000, pp. 166–175.
[7] G. Lipari, J. Carpenter, and S. Baruah, “A framework for achievinginter-application isolation in multiprogrammed hard-real-time environ-ments,” in Proc. 21th IEEE Int. Real-Time Syst. Symp. (RTSS’00), Dec.2000, pp. 217–226.
[8] A. Mok, X. Feng, and D. Chen, “Resource partition for real-time sys-tems,” in Proc. IEEE Real-Time Technol. Appl. Symp. (RTAS’01), May2001, pp. 75–84.
[9] I. Shin and I. Lee, “Compositional real-time scheduling framework,”in Proc. 25th IEEE Int. Real-Time Syst. Symp. (RTSS’04), Dec. 2004,pp. 57–67.
[10] X. Feng and A. Mok, “A model of hierarchical real-time virtual re-sources,” in Proc. 23th IEEE Int. Real-Time Syst. Symp. (RTSS’02),Dec. 2002, pp. 26–35.
[11] I. Shin and I. Lee, “Compositional real-time scheduling frameworkwith periodic model,” ACM Trans. Embedded Comput. Syst., vol. 7,no. 3, pp. (30)1–(30)39, Apr. 2008.
[12] S. Saewong, R. R. Rajkumar, J. P. Lehoczky, and M. H. Klein, “Anal-ysis of hierarhical fixed-priority scheduling,” in Proc. 14th EuromicroConf. Real-Time Syst. (ECRTS’02), Jun. 2002, pp. 152–160.
[13] G. Lipari and E. Bini, “Resource partitioning among real-time appli-cations,” in Proc. 15th Euromicro Conf. Real-Time Syst. (ECRTS’03),Jul. 2003, pp. 151–158.
[14] R. I. Davis and A. Burns, “Hierarchical fixed priority pre-emptivescheduling,” in Proc. 26th IEEE Int. Real-Time Syst. Symp. (RTSS’05),Dec. 2005, pp. 389–398.
[15] A. Easwaran, M. Anand, and I. Lee, “Compositional analysis frame-work using EDP resource models,” in Proc. 28th IEEE Int. Real-TimeSyst. Symp. (RTSS’07), 2007, pp. 129–138.
[16] L. Sha, J. P. Lehoczky, and R. Rajkumar, “Task scheduling in dis-tributed real-time systems,” in Proc. Int. Conf. Ind. Electron., Control,Instrum. (IECON’87), Nov. 1987, pp. 909–916.
[17] R. Rajkumar, L. Sha, and J. P. Lehoczky, “Real-time synchronizationprotocols for multiprocessors,” in Proc. 9th IEEE Int. Real-Time Syst.Symp. (RTSS’88), Dec. 1988, pp. 259–269.
[18] T. P. Baker, “Stack-based scheduling of realtime processes,” Real-TimeSyst., vol. 3, no. 1, pp. 67–99, Mar. 1991.
[19] N. Fisher, M. Bertogna, and S. Baruah, “Resource-locking durations inEDF-scheduled systems,” in Proc. 13th IEEE Real Time and EmbeddedTechnol. Appl. Symp. (RTAS’07), 2007, pp. 91–100.
[20] L. Almeida and P. Pedreiras, “Scheduling within temporal partitions:Response-time analysis and server design,” in Proc. 4th ACM Int. Conf.Embedded Softw. (EMSOFT ’04), Sep. 2004, pp. 95–103.
[21] M. Behnam, I. Shin, T. Nolte, and M. Nolin, “SIRAP: A synchroniza-tion protocol for hierarchical resource sharing in real-time open sys-tems,” in Proc. 7th ACM and IEEE Int. Conf. Embedded Softw. (EM-SOFT’07), Oct. 2007, pp. 279–288.

104 IEEE TRANSACTIONS ON INDUSTRIAL INFORMATICS, VOL. 6, NO. 1, FEBRUARY 2010
[22] N. Fisher, M. Bertogna, and S. Baruah, “The design of an EDF-sched-uled resource-sharing open environment,” in Proc. 28th IEEE Int. Real-Time Syst. Symp. (RTSS’07), Dec. 2007, pp. 83–92.
[23] L. Abeni and G. Buttazzo, “Integrating multimedia applications inhard real-time systems,” in Proc. 19th IEEE Int. Real-Time Syst. Symp.(RTSS’98), Dec. 1998, pp. 4–13.
[24] M. Behnam, T. Nolte, M. Âsberg, and I. Shin, “Synchronizationprotocols for hierarchical real-time scheduling frameworks,” in Proc.1st Workshop on Compositional Theory and Technol. Real-TimeEmbedded Syst. (CRTS’08) in Conjunction With the 29th IEEE Int.Real-Time Syst. Symp. (RTSS’08), Nov. 2008, pp. 53–60.
[25] G. Lipari, G. Lamastra, and L. Abeni, “Task synchronization’ in reser-vation-based real-time systems,” IEEE Trans. Computers, vol. 53, no.12, pp. 1591–1601, Dec. 2004.
[26] M. Bertogna, N. Fisher, and S. Baruah, “Static-priority scheduling andresource hold times,” in Proc. 15th Int. Workshop on Parallel and Dis-trib. Real-Time Syst. (WPDRTS’07), Mar. 2007, pp. 1–8.
[27] S. Baruah, A. Mok, and L. Rosier, “Preemptively scheduling hard-real-time sporadic tasks on one processor,” in Proc. 11th IEEE Int. Real-Time Syst. Symp. (RTSS’90), Dec. 1990, pp. 182–190.
[28] S. K. Baruah, “Resource sharing in EDF-scheduled systems: A closerlook,” in Proc. 27th IEEE Int. Real-Time Syst. Symp. (RTSS’06), Dec.2006, pp. 379–387.
[29] N. Fisher and F. Dewan, “Approximate bandwidth allocation for com-positional real-time systems,” in Proc. 21st Euromicro Conf. Real-TimeSyst. (ECRTS’09), 2009, pp. 87–96.
[30] J. Lehoczky, L. Sha, and Y. Ding, “The rate monotonic schedulingalgorithm: Exact characterization and average case behavior,” in Proc.20th IEEE Int. Real-Time Syst. Symp. (RTSS’89), Dec. 1989, pp.166–171.
[31] G. Lipari and E. Bini, “A methodology for designing hierarchicalscheduling systems,” J. Embedded Comput., vol. 1, no. 2, pp. 257–269,2005.
[32] F. Dewan and N. Fisher, “Approximate bandwidth allocation forfixed-priority-scheduled periodic resources,” Dept. Comput. Sci.,Wayne State Univ., Detroit, MI, Tech. Rep., 2009.
[33] I. Shin, M. Behnam, T. Nolte, and M. Nolin, “Synthesis of optimalinterfaces for hierarchical scheduling with resources,” in Proc. 29thIEEE Int. Real-Time Syst. Symp. (RTSS’08), Dec. 2008, pp. 209–220respectively, .
Moris Behnam (S’06) received the B.Eng. andM.Sc. degrees in computer and control engineeringfrom the University of Technology, Iraq, in 1995and 1998, respectively, and the M.Sc. and Licentiatedegrees in real-time systems from MälardalenUniversity (MDH), Västerâs, Sweden, in 2005 and2008, respectively. He is currently working towardsthe Ph.D. degree at MDH.
He was a Visiting Researcher at Wayne State Uni-versity, in 2009. His research interests include real-time hierarchical scheduling, synchronization proto-
cols, multiprocessor/multicore systems, and real-time control systems.
Thomas Nolte (S’01–M’09) received the B.Eng.,M.Sc., Licentiate, and Ph.D. degrees in computerengineering from Mälardalen University (MDH),Västerâs, Sweden, in 2001, 2002, 2003, and 2006,respectively.
He has been a Visiting Researcher at the Univer-sity of California, Irvine (UCI), in 2002, and a Vis-iting Researcher at the University of Catania, Italy, in2005. He has been a Postdoctoral Researcher at theUniversity of Catania in 2006, and at MDH in 2006to 2007. He became an Assistant Professor at MDH
in 2008. He has been an Associate Professor of Computer Science at MDHsince 2009. His research interests include predictable execution of embeddedsystems, design, modeling and analysis of real-time systems, multicore systems,distributed embedded real-time systems.
Prof. Nolte is Program Leader of the PROGRESS National StrategicResearch Centre, President of The Swedish National Real-Time Association(SNART), and Co-Chair of the IEEE IES TCFA Real-Time Fault TolerantSystems Subcommittee. He is a Member of the Editorial Board of Elsevier’sJournal of Systems Architecture: Embedded Software Design, since 2009, GuestEditor of the IEEE TRANSACTIONS ON INDUSTRIAL INFORMATICS, 2008 to 2010,Co-organizer of international events including the International Workshop onCompositional Theory and Technology for Real-Time Embedded Systems(CRTS), 2008 and 2009, and Program Co-Chair of the IEEE InternationalConference on Emerging Technologies and Factory Automation (ETFA), theReal-Time and (Networked) Embedded Systems track, 2008, 2009 and 2010,and the IEEE International Workshop on Factory Communication Systems(WFCS), the Work-in-Progress (WIP) Track, 2008.
Mikael Sjödin received the M.Sc. and Ph.D. degreesfrom Uppsala University, Uppsala, Sweden, in 1995and 2000 respectively.
Since 2002, he has been pursuing research in dis-tributed embedded systems at Mälardalen Real-TimeResearch Centre (MRTC). In 2007, he joined the fac-ulty as a Professor of Computer Science with spe-cial focus in real-time systems and vehicular softwaretechnology. He has since 2000 also worked full-timeand part-time in industry as a software engineer in thevehicular sector. Currently, the focus of his research
is towards analysis of nonfunctional properties, predictable execution, and effi-cient design of correct software.
Insik Shin (M’07) received the B.S. degree in com-puter science from Korea University, Seoul, in 1994,the M.Sc. degree in computer science from StanfordUniversity, Stanford, CA, in 1998, and the Ph.D. de-gree on compositional schedulability analysis in real-time embedded systems from the University of Penn-sylvania, Philadelphia, in 2006.
He has been a Postdoctoral Research Fellow atMälardalen University (MDH), Västerâs, Sweden,and a Visiting Scholar at the University of Illinois,Urbana–Champaign, until 2008. He is currently
an Assistant Professor with the Department of Computer Science, KAIST,since 2008. His research interests lie in cyber-physical systems and real-timeembedded systems.
Prof. Shin received the Best Paper Award from the IEEE International Real-Time Systems Symposium (RTSS) in 2003. He has been a Co-Organizer of theInternational Workshop on Compositional Theory and Technology for Real-Time Embedded Systems (CRTS), 2008 and 2009 (co-located with the IEEEInternational Real-Time Systems Symposium (RTSS), 2008 and 2009). He alsoserved various program committees in real-time embedded systems.
Recommended



![Hierarchical Scheduling for Diverse Datacenter Workloadsalig/papers/h-drf.pdf · Hierarchical Scheduling for Diverse Datacenter Workloads ... DRF [1], to support hi- ... book cluster](https://img.pdfslide.net/doc/110x75/5b2580d47f8b9a5c428b49d1/hierarchical-scheduling-for-diverse-datacenter-workloads-aligpapersh-drfpdf.jpg)













