
Performance modeling in Germany
Why care about cluster performance?
G. Wellein, G. Hager, T. Zeiser, M. Meier
Regional Computing Center Erlangen (RRZE)Friedrich-Alexander-University Erlangen-Nuremberg
April 16, 2008IDC hpcuserforum

16.04.2008 [email protected] 2IDC - hpcuserforum
BerlinHannover
FZ Jülich
HLRS-Stuttgart
LRZ-München
LRZ Munich: SGI Altix (62 TFlop/s)HLR Stuttgart: 12 TFlop/s NEC SX8
Erlangen/ Nürnberg
Jülich Supercomputing Center
8,9 TFlop/s IBM Power4+ 46 TFlop/s BlueGene/L
228 TFlop/s BlueGene/P
HPC Centers in Germany: A view from Erlangen

16.04.2008 [email protected] 3IDC - hpcuserforum
Friedrich-Alexander-University Erlangen-Nuremberg(FAU)
2nd largest university in Bavaria
26.500+ students
12.000+ employees
11 faculties
83 institutes
23 hospitals
265 chairs (C4 / W3)
141 fields of study
250 buildings scattered through 4 cities (Erlangen, Nuremberg, Fürth, Bamberg)
WS 06/07
FFAAUU
RRZE provides all “IT” services for the university

16.04.2008 [email protected] 4IDC - hpcuserforum
Theoretical PhysicsFluid Dynamics
Material Sciences
Life Sciences / Chemistry
Nano-Sciences
Applied Mathematics
Applied Physics
Computational Sciences
Compute Cycles in 2007 (RRZE only)> 8 Mio. CPU-hrs
SScc
iieennccee
&&
RReesseeaa
rrcchh
Introduction: Modeling and Simulation – Interdisciplinary Research Focus of FAU
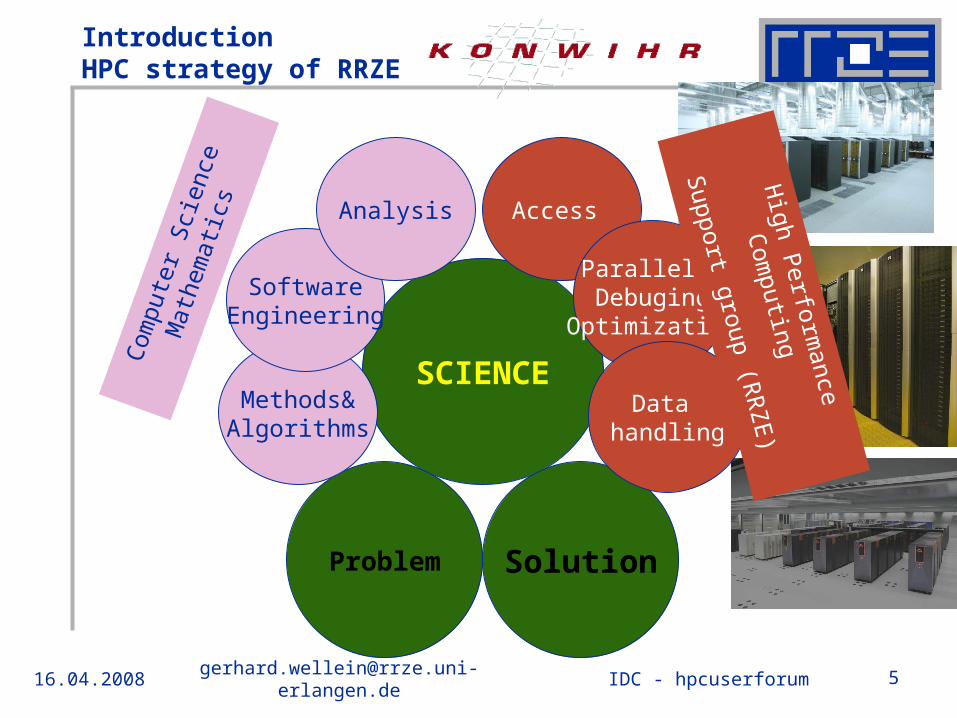
16.04.2008 [email protected] 5IDC - hpcuserforum
IntroductionHPC strategy of RRZE
SCIENCE
Problem Solution
Methods&Algorithms
SoftwareEngineering
Analysis
Com
pute
r S
cien
ceM
athe
mat
ics Access
Parallel./Debuging
Optimization
Data handling
High P
erformance C
omputing
Support group (R
RZ
E)

16.04.2008 [email protected] 6IDC - hpcuserforum
Introduction RRZE: Compute Resources (2003-2007)
216 2-way compute nodes: 86 nodes: Intel Xeon 2.6 GHz; FSB533 64 nodes: Intel Xeon 3.2 GHz; FSB800 66 nodes: Intel Xeon 2.66 GHZ; Dual-Core
25 4-way compute nodes: AMD Opteron270 (2.0 GHz); Dual-Core
GBit Ethernet network Infiniband: 24 nodes (SDR) + 66 nodes (DDR) 5,5+13 TByte Disc Space Installation: 4/ 2003 ; Upgrades: 12 / 2004,
Q4/2005, Q3/2007
Compute cluster
Compute ServersSGI Altix3700
• 32 Itanium2 1.3 GHz
• 128 GByte Memory
• 3 TByte Disc Space
• Inst.: 11 / 2003
SGI Altix330
• 16 Itanium2 1.5 GHz
• 32 GByte Memory
• Inst.: 3 / 2006
4+16 CPUs paid by scientists‘ funding
374 / 532 CPUs paid by scientists‘ money

16.04.2008 [email protected] 7IDC - hpcuserforum
RRZE “Woody” ClusterHP / Bechtle
876 Intel Xeon5160 processor cores 3.0 GHz -> 12 GFlop/s per core HP DL140 G3 compute node (217 compute + 2 login) nodes
Peak performance: 10512 GFlop/s LINPACK 7315 GFlop/s
Main memory: 8 GByte / compute node
Voltaire „DDRx“ IB-switch: 240 ports
OS: SLES9
Parallel filesystem (SFS): 15 TByte(4 OSS)
NFS filesystem: 15 TByte
Installation: Oct. 2006
Top500 Nov. 2006:
Rank 124 (760 cores)
Top500 Nov. 2007:
Rank 329 (876 cores)
Power consumption > 100 kW

16.04.2008 [email protected] 8IDC - hpcuserforum
RRZE Our HPC backbone
Dr. Hager
Physics
Dr. Zeiser
CFD
M. Meier
Computer Science
User support; software; Parallelization & Optimization; Evaluation of new hardware; HPC tutorials & lectures
Dr. Wellein
Physics
System administration

Architecture of cluster nodesArchitecture of cluster nodesccNUMA – why care about it?ccNUMA – why care about it?

16.04.2008 [email protected] 10IDC - hpcuserforum
Dual CPU Intel Xeon node (old) Dual socket Intel “Core” node
Dual socket AMD Opteron node
PC
Chipset(northbridge)
Memory
PC
Chipset
Memory
PC
C
PC
PC
C
PC
PC
C C
MI
Memory
PC
PC
C C
MI
Memory
CPCC
Cluster nodesBasic architecture of compute nodes
Intel platform provides 1 path per socket to memory (still UMA)
HT provides scalable bandwidth for Opteron systems but introduces ccNUMA architecture: Where does my data finally end up?
Intel will move to ccNUMA with QuickPath (CSI) technology

16.04.2008 [email protected] 11IDC - hpcuserforum
double precision f(0:xMax+1,0:yMax+1,0:zMax+1,0:18,0:1)!$OMP PARALLEL DO PRIVATE(Y,X,…) SCHEDULE(RUNTIME)do z=1,zMax do y=1,yMax do x=1,xMax
if( fluidcell(x,y,z) ) then
LOAD f(x,y,z, 0:18,t)
Relaxation (complex computations) SAVE f(x ,y ,z , 0,t+1) SAVE f(x+1,y+1,z , 1,t+1)
… SAVE f(x ,y-1,z-1, 18,t+1)
endif enddo enddoenddo
Cluster nodes: ccNUMA pitfallsSimple Lattice Boltzmann Method (LBM) kernel
Collide
Stream
#load operations: 19*xMax*yMax*zMax + 19*xMax*yMax*zMax
#store operations: 19*xMax*yMax*zMax

16.04.2008 [email protected] 12IDC - hpcuserforum
Cluster nodes: ccNUMA pitfallsSimple LBM kernel: 2-socket Intel Xeon (UMA)
UMA node
Correct parallel initializationDifferent thread scheduling in initialization and compute step Sequential initialization of data

16.04.2008 [email protected] 13IDC - hpcuserforum
Cluster nodes: ccNUMA pitfallsSimple LBM kernel: 4-socket DC Opteron (ccNUMA)
ccNUMA node Co
rrec
t p
aral
lel
init
iali
zati
on
Dif
fere
nt
thre
ad s
ched
uli
ng
in
in
itia
liza
tio
n a
nd
co
mp
ute
ste
p
Seq
uen
tial
in
itia
liza
tio
n o
f d
ata

16.04.2008 [email protected] 14IDC - hpcuserforum
Cluster nodes: ccNUMA pitfallsFilesystem cache: 2 socket server – UMA vs. ccNUMA
for x in `seq 1 41` do dd if=/dev/zero of=/scratch/justatest bs=1M count=${x}00 sync mpirun_rrze –np 4 ./triad.x < input.triads ; done
PC
PC
C C
MI
Memory
PC
PC
C C
MI
Memory

Main memory bandwidth – Main memory bandwidth – Did you ever check the stream number of your Did you ever check the stream number of your compute nodes?compute nodes?

16.04.2008 [email protected] 16IDC - hpcuserforum
Cluster nodesMain memory bandwidth within a compute node
Theoretical (aggregate) bandwidth of Intel Xeon51xx (“Woodcrest”) – 2 sockets:
21.3 GByte/s ( = 2 * 1333 MHz * 8 Byte)
Intel Conroe / Xeon 30XX – 1 socket:8.5 GByte/s ( = 1 * 1066 MHz * 8 Byte) Intel Kentsfield / QX6850 – 1 socket:10.6 GByte/s ( = 1 * 1333 MHz * 8 Byte)
AMD Opteron/Barcelona (memory controller on-chip) Socket F 10.6 GByte/s per socket (DDR2-667 DIMMs)
Popular kernels to measure real-world bandwidth stream: A=B; A=s*B; A=B+C; A=B+s*C
“Optimized version”: Suppress additional RFO for A (nontemporal stores)
Array size = 20.000.000 & offset=0

16.04.2008 [email protected] 17IDC - hpcuserforum
Cluster nodes (Dual-Cores)Optimized version of stream running on all cores
sockets/node
COPY[MB/s]
SCALE[MB/s]
ADD
[MB/s]TRIAD[MB/s]
Intel Slides3.0 GHz (WC; GC)
2 8204 8192 7680 7680
RRZE: Intel EA Box2.66 GHz (WC; BF)
2 6195 6198 6220 6250
RRZE:HP DL1403.0 GHz (WC; GC)
2 7521 7519 6145 6149
RRZE: transtec3.0 GHz (WC; GC)
2 8193 8159 6646 6796
RRZE: CUDA Workstation2.33 GHz (CT; GC)
2 8952 8962 7766 7796
There is not a single stream number even though CPU & Chipset & memory DIMM speed are identical!

16.04.2008 [email protected] 18IDC - hpcuserforum
Cluster nodes (Quad-Cores) Optimized version of stream running on all cores
sockets/node
COPY[MB/s]
SCALE[MB/s]
ADD
[MB/s]TRIAD[MB/s]
RRZE:HP DL1403.0 GHz (WC; GC)
2 7521 7519 6145 6149
RRZE: Intel EAX5482 - FSB16003.2 GHz („Hapertown“)
2 8180 8170 8840 9080
RRZE: AMD OpteronBarcelona 2 GHz/DDR2-667
2 17027 15500 16684 16700
RRZE: Intel EA*X38ML Server BoardQX6850 (3.0 GHz)
1 6587 6566 6969 6962
* FSB1333; use 2 threads only

16.04.2008 [email protected] 19IDC - hpcuserforum
Cluster nodes (Quad-Cores) “Optimized stream”: The vendors always choose the best measurements..
We do not yet know what happens here but we are working very hard
AMD K10 (“Barcelona”)
Barcelona design: relative memory alignments constraints?

16.04.2008 [email protected] 20IDC - hpcuserforum
Parallelization by compilerThe first thing they do is reducing performance…
Sequential performance
Lat
tice
Bo
ltzm
ann
so
lve
r
OMP_NUM_THREADS=1
PC
PC
C
PC
PC
C
Chipset
Sequential version4 cores: Speed-up ~ 30%

16.04.2008 [email protected] 21IDC - hpcuserforum
Intra socket scalabilityHaving a low baseline makes things easier…
single core Intel Q6850
Scalability is important but never forget the baseline
Lat
tice
Bo
ltzm
ann
so
lve
r
PCC
PCC
MI / HT
PCC
PCC
L3 cache

Experiences with cluster performanceExperiences with cluster performance
Tales from the trenches..Tales from the trenches..

16.04.2008 [email protected] 23IDC - hpcuserforum
Cluster nodes Single socket nodes: Intel S3000PT board
Intel S3000PT board: 1 socket: Intel Xeon30XX series 2 boards/ 1 U FSB1066 – Un-buffered DDR2 1 PCIe-8X 2 SATA ports Intel AMT
http://www.intel.com/design/servers/boards/s3000PT/index.htm
Optimized for
MPI apps with high memory and/or MPI bandwidth requirements!
Not optimized for
Maximum LINPACK/$$

16.04.2008 [email protected] 24IDC - hpcuserforum
Cluster nodes Single socket nodes: Intel S3000PT board
RRZE S3000PT Cluster (Installation: 09/2007) 66 compute nodes
2,66 GHz Xeon 3070 (Dual-Core) 4 GB memory (DDR2-533)
72-port Flextronics IB DDR-Switch (max. 144 ports) Delivered by transtec
Application performance compared with WOODY Performance measured by parallel RRZE benchmark suite
Strong scaling CoresPerformance
S3000PT/WOODY
AMBER8/pmemd (MD – Chemistry) 32 1,01
IMD (MD – Materials Sciences) 64 1,12
EXX (Quantum Chemistry) 16 1,14
OAK3D (Theoretical Physics) 64 1,29
trats/BEST (LBM solver – CFD) 64 1,37

16.04.2008 [email protected] 25IDC - hpcuserforum
ClustersNever trust them…. (S3000PT cluster)
STREAM triad performance on arrival
STREAM triad performance after
•Choosing correct BIOS
•Removing bad memory DIMMsDIMMs:
Samsung
Kingston

16.04.2008 [email protected] 26IDC - hpcuserforum
ClustersNever trust them… DDRx Voltaire IB Switch (WOODY)
Simple ping pong should get
~1500 MB/s (DDR)
~1000 MB/s (SDR)
Several reboots& firmware upgs.
1510 MB/s 950 MB/s
First measurement of BW for each link

16.04.2008 [email protected] 27IDC - hpcuserforum
ClustersNever trust them….
A “cheap cluster” acquired by a local research group
Putting DDR IB cards into PCIe-4x slots may work but is not a good idea….

16.04.2008 [email protected] 28IDC - hpcuserforum
ClustersNever trust anyone….
A “cheap cluster” acquired by a local research group “We were told that AMD is the best processor available!”
2-way nodes (AMD Opteron Dual-Core 2.2 GHz) + DDR IB network “Why buy a commercial compiler when a free one is available?”
gfortran Target application: AMBER9/pmemd
Runtime [s]
SUN Studio12OpenMPI
3500
gfortranIntel MPI
3000
Intel64/9.1.Intel MPI
2700
4 MPI processes on one node of woody
Runtime [s]
Opteron cluster (2.2 GHz)
2*2*2 1930
Woody cluster(3.0 GHz)
2*2*2 1430
2 x Intel QX6850 (3.0 GHz)
2*1*4 1440
8 MPI processes (Intel64/9.1. + IntelMPI)

16.04.2008 [email protected] 29IDC - hpcuserforum
ClustersYet another Cluster OS ????
7 AMD Opteron nodes (Dual Core / Dual Socket)
4 GB per node
Windows 2003 Enterprise + Compute Cluster Pack
Visual Studio 2005,Intel compilers, MKL, ACML
Star-CD
Gbit Ethernet Access via RDP or ssh (sshd from Cygwin)
GUI tool for job control: Cluster Job Manager / CLI: job.cmd script
New users for RRZE: Chair for Statistics and Econometrics

16.04.2008 [email protected] 30IDC - hpcuserforum
ClustersWindows CCS is really fast (in migrating processes)
0
100
200
300
400
500
600
700
800
N
ML
UP
s/s
placement+pinning placement only no placement
4MB L2 limit NUMA placement: +60%
additional pinning: +30%
Pinning benefit is only due to better NUMA locality!
Per
form
ance
of
2D J
acob
i (he
at c
ondu
ctio
n) s
olve
r

What’s next ???? What’s next ???? SUN Niagara2 / IBM Cell / GPUsSUN Niagara2 / IBM Cell / GPUs
C4C3C2C1
L2$ BankL2$ BankL2$ BankL2$ Bank
Crossbar16 KB I$
8 KB D$
16 KB I$
8 KB D$
16 KB I$
8 KB D$
16 KB I$
8 KB D$
C8C7C6C5
16 KB I$
8 KB D$
16 KB I$
8 KB D$
16 KB I$
8 KB D$
16 KB I$
8 KB D$
L2$Bank
Memorycontroller
Memorycontroller
Memorycontroller
FPU
SPU
FPU
SPU
FPU
SPU
FPU
SPU
FPU
SPU
FPU
SPU
FPU
SPU
FPU
SPU
Crossbar
Memorycontroller
L2$Bank
L2$Bank
L2$Bank
L2$Bank
L2$Bank
L2$Bank
L2$Bank
SSI, JTAGDebug port
Dual-channelFB-DIMM
Dual-channelFB-DIMM
Dual-channelFB-DIMM
Dual-channelFB-DIMM
NIU PCIe
10 Gb Ethernet X8 @ 2.5 GHz2 GB/s each direction
42 GB/s read, 21 GB/s write
4 MB L2$
8 threads per core2 execution pipes1 op/cycle per pipe
x10 writex14 read@ 4.0 GT/s
2–8 DIMMs
Sys I/Fbuffer switch
core
© S
un
•Massive parallelism
•Programming / Optimization models completely new for most of us:Porting of kernels only Amdahl’s law
•Most “accelerators” will stay in niche markets (Remember: Itanium did fail because of complex optimization and missing SW compatibility!)

16.04.2008 [email protected] 32IDC - hpcuserforum
Summary
Cluster provide tremendous compute capacity at a low price tag but they are far away from being a standard product designed for optimal performance on HPC apps a solution for highly parallel high end apps
(Heterogeneous) Multi-/Many-Core architectures will further improve price/performance ratio but increase programming complexity
Most users of HPC systems will not be able to adequately address the challenges and problems pointed out in this talk!
Recommended






![Relaunch IdM-Portal der FAU mit dem neuen FAU-Adressbuch · 2016. 10. 27. · REGIONALES RECHENZENTRUM ERLANGEN [RRZE] Relaunch IdM-Portal der FAU mit dem neuen FAU-Adressbuch RRZE-Campustreffen,](https://img.pdfslide.net/doc/110x75/611e4e26525d6d085d3d554f/relaunch-idm-portal-der-fau-mit-dem-neuen-fau-adressbuch-2016-10-27-regionales.jpg)









![REGIONALES RECHENZENTRUM ERLANGEN [RRZE] Webmaster-Campustreffen 14. November 2013](https://img.pdfslide.net/doc/110x75/55204d7049795902118c168a/regionales-rechenzentrum-erlangen-rrze-webmaster-campustreffen-14-november-2013.jpg)
