Prof. Dr. Peter Schmidt
SoSe 2010
Volkswirtschaftslehre und Statistik : (0421) 5905-4691
Fax: (0421) 5905-4862
www.schmidt-bremen.de QM
Quantitative Methoden Master of Business Administration
Modul 2, Unit 2
Wissenschaftliche Fragestellungen und Methoden
Vermittlung statistisch-methodischen Wissens
Gewinnung praktischer Erfahrung in der EDV-Umsetzung
Dokumentation der verwendeten Methoden
Hilfe bei der
täglichen Arbeit

Forschungsmethoden Seite i
Peter Schmidt, Hochschule Bremen 2010
Prof. Dr. Peter Schmidt
SoSe 2010
Volkswirtschaftslehre und Statistik : (0421) 5905-4691
Fax: (0421) 5905-4862
www.schmidt-bremen.de QM
Quantitative Methoden Master of Business Administration
Modul 2, Unit 2
A Zielsetzungen
Wissenschaftliche Fragestellungen und Methoden
Vermittlung statistisch-methodischen Wissens
Gewinnung praktischer Erfahrung in der EDV-Umsetzung
Außendarstellung durch Dokumentation der verwendeten Methoden
Hilfe bei der täglichen Arbeit
B Lehr- und Lernmethoden
Durch Übungen und Gruppenarbeiten und -präsentationen wird der im seminaristischen
Unterricht vorgestellte Stoff durch die Studierenden selbstständig vertieft und anwen-
dungsorientiert erlernt.
Seminaristischer Unterricht Vermittlung theoretischen Wissens
Übung am PC Vertiefung der Inhalte und PC-Praxis
Präsentationen Eigenständiges Erarbeiten und Darstellung
durch Studierende

Forschungsmethoden Seite ii
Peter Schmidt, Hochschule Bremen 2010
C Inhalt der Lehreinheit
1 Quantitative Methoden im täglichen Einsatz
1.1 Definitionen – Empirische Forschung / Statistik / Research Methods
1.2 Häufigkeiten und grafische Darstellungen
1.2.1 Eindimensionale und mehrdimensionale Häufigkeitsdarstellungen
1.2.2 Besondere Häufigkeitskonzepte
1.3 Lagemaße (Mittelwerte) und Streuungsmaße
1.4 Zusammenhänge zwischen mehreren Merkmalen
1.4.1 Zusammenhangmaße
1.4.2 Regressionsanalyse
1.5 Zeitreihen und Indexzahlen
2 Weitere Themen
2.1 Schließenden Statistik und Statistische Tests
2.2 Durchführung und Darstellung räumlicher Analysen (Business Mapping)
2.3 Multivariate Analysemethoden
2.4 Übersicht und Demonstration von Software
2.4.1 Auswertungen und Darstellungen in Excel
2.4.2 Statistikprogramme (z.B. SPSS, GrafStat, Stata, Eviews, ...)
Grundlagen und Möglichkeiten der Datenhaltung und -organisation in Statis-tikprogrammen
statistische Auswertungen - interaktiv und im Programm-Modus
Grafische Darstellungsmöglichkeiten
2.4.3 Ausblick auf weitere Programme und Anwendungsmöglichkeiten
3 Übungen am PC und Fallbeispiele

Forschungsmethoden Seite iii
Peter Schmidt, Hochschule Bremen 2010
D Literaturhinweise
Black, Thomas: “Understanding Social Science Research”, 2002
Bourier, Günther: „Beschreibende Statistik“ und „Wahrscheinlichkeitsrechung und Schließende Sta-
tistik“, Wiesbaden 2008
Backhaus, Erichson, Plinke, Weiber, „Multivariate Analysemethoden: Eine anwendungsorientierte
Einführung“, Heidelberg, 2005
Bamberg, Günter und Baur, Franz: ”Statistik”, München 2007 (mit Arbeitsbuch)
Bleymüller, Josef; Gehlert, Günther und Gülicher, Herbert: ”Statistik für Wirtschaftswissenschaft-
ler”, München 2008
Hippmann, Hans-Dieter: „Statistik für Wirtschafts- und Sozialwissenschaftler“, 2007
Kirk, Roger: „Statistics - An Introduction“, 1998
Krämer, Walter: ”Statistik verstehen” und: ”So lügt man mit Statistik”, München, 2001, 2000
Puhani, Josef: ”Statistik - Einführung mit praktischen Beispielen”, Würzburg 2005
Scharnbacher, Kurt: "Statistik im Betrieb", Wiesbaden 2004
Schwarze, Jochen: ”Grundlagen der Statistik”, Bände I und II, Herne/Berlin 2005/06
Praktisches am PC:
Bühl, Achim und Zöfel Peter, „SPSS Vers. 12 – Einführung in die moderne Datenanalyse unter Win-
dows, 2004
Brosius, Felix: ”SPSS 14 - Professionelle Statistik unter Windows”, 2006
Erben, Wilhelm: ”Statistik mit Excel 5 oder 7”, München 2004
Monka, Michael Schöneck, Nadine und Voß, Werner: ”Statistik am PC - Lösungen mit Excel”, 2008
(2005 / frühere Auflage für Excel bis Version 2003)
auch einige der oben genannten Bücher beschreiben die Anwendung der Methoden in Softwaremethoden, z.B. Black, Backhaus u.a.
Diese Hinweise sollen Ihnen erleichtern, sich einen eigenen Eindruck von der Fülle statistischer Literatur zu machen. Es
gibt nicht das Statistik-Buch, weder allgemein noch auf diese Veranstaltung bezogen. – Es wird stark empfohlen, sich
verschiedene Bücher anhand konkreter Themen anzuschauen und dann persönlich zu entscheiden, welches dem
eigenen Stil entspricht!
E Leistungsnachweis: Teil der Klausur am Ende des Moduls
F Unterrichtssprache: Deutsch, teilweise englische Ergänzungen

Quantitative Methoden Seite iv
Peter Schmidt, Hochschule Bremen 2010
G Inhalt der Unterlagen
1. Quantitative Methoden der deskriptiven Statistik Seite 1
Praxisbezogene Darstellung statistischer Methoden anhand von Beispielen, die in
Zusammenhang mit den begleitenden Excel-Tabellen erarbeitet werden können.
2. Ablauf einer statistischen Untersuchung + Fallbeispiel Seite 21
Studierendenbefragung an der Fakultät Wirtschaftswissenschaften
3. Material zur Schließenden Statistik Seite 32
4. Business Mapping durch Geoinformationssysteme Seite 56
Darstellung räumlicher Analysemethoden und deren Anwendung
in der volks- und betriebswirtschaftlichen Anwendung
5. Forschungsprojekt als Fallstudie: Seite 65
Regional Economic Impacts of Large Cultural Events
Does public funding of large cultural events make sense
from a regional economic point of view?
6. Formelsammlung: Seite 87
Die Unterlagen werden im Verlauf der Lehrveranstaltung erweitert um Materialien zu
Übungen und Fallbeispielen, die jeweils auch über die Veranstaltungs-Webseite verfügbar
sind.

Quantitative Methoden – Deskriptive Statistik - Seite 1 -
Peter Schmidt, Hochschule Bremen MBA
MBA Quantitative Methoden
Deskriptive Statistik
Peter Schmidt,
Hochschule Bremen
Inhalt
1 Quantitative Methoden; Statistik ................................................................ 3
1.1 Definitionen – Was ist Statistik? ...............................................................................4
1.2 Häufigkeiten und grafische Darstellungen .................................................................5
1.2.1 Eindimensionale und mehrdimensionale Häufigkeitsdarstellungen ...................5
1.2.2 Besondere Häufigkeitskonzepte..........................................................................8
1.3 Lagemaße (Mittelwerte) und Streuungsmaße ............................................................8
1.4 Zusammenhänge zwischen mehreren Merkmalen ...................................................11
1.4.1 Zusammenhangmaße.........................................................................................11
1.4.2 Regressionsanalyse............................................................................................13
1.5 Zeitreihen und Indexzahlen ......................................................................................17
2 Literaturhinweise und Weitere Informationen.......................................... 19
3 Schlagwortindex........................................................................................ 20
Hinweis: Dieser Beitrag ist erschienen in: Schmidt, Peter: „Betriebsstatistik“; in: Dey und Grauvogel
(Hrsg.): "Praxishandbuch – Wirtschaftswissen von A-Z für die erfolgreiche Betriebsratspraxis", Kissing, 2000-
2005

Quantitative Methoden – Deskriptive Statistik - Seite 2 -
Peter Schmidt, Hochschule Bremen MBA
Abbildungen:
Abbildung 1 Verdichtung von Information ...................................................................... 4
Abbildung 2 Skalierung von Merkmalen.......................................................................... 5
Abbildung 3 Absolute Häufigkeiten und zweidimensionales Säulendiagramm............... 7
Abbildung 4 Kreisdiagramme zur Darstellung von relativen Häufigkeiten ..................... 7
Abbildung 5 Einfache Häufigkeiten und Summenhäufigkeiten ....................................... 8
Abbildung 6 Verteilungen mit unterschiedlicher Streuung ............................................ 10
Abbildung 7 Abweichungen der Einzelbeobachtungen vom Mittelwert........................ 10
Abbildung 8 xy-Diagramm für Zusammenhang Überstunden / Energieverbrauch ........ 12
Abbildung 9 Stärke von Zusammenhängen und Werte des Korrelationskoeffizienten.. 12
Abbildung 10 Regressionsgrade Überstunden / Energieverbrauch ................................ 14
Abbildung 11 Regressionsanalyse .................................................................................. 14
Abbildung 12 Regressionsanalyse mit multiplen Einflussfaktoren ................................ 16
Abbildung 13 Umsatzentwicklung im Zeitablauf ........................................................... 17
Abbildung 14 Einkommensentwicklung absolut und als Indexzahlen ........................... 19
Verzeichnis der Tabellen:
Tabelle 1 Personaldaten (Beispiel für Ursprungsdaten).................................................... 6
Tabelle 2 Eindimensionale Häufigkeitstabelle – Anzahl Befragte nach Berufsstatus...... 6
Tabelle 3 Zweidimensionale Häufigkeitstabelle – Befragte nach Alter und Geschlecht.. 6
Tabelle 4 Prozentuale Häufigkeiten – Befragte nach Alter und Geschlecht..................... 7
Tabelle 5 Mittelwerte ........................................................................................................ 9
Tabelle 6 Beispiel für Lage- und Streuungsmaße ........................................................... 10
Tabelle 7 Wertetabelle für Zusammenhang Überstunden / Energieverbrauch ............... 11
Tabelle 8 Zusammenhangmaße für unterschiedliche Skalenniveaus.............................. 13
Tabelle 9 Zeitreihe einer Umsatzentwicklung ................................................................ 17
Tabelle 10 Entwicklung von Unternehmer- und Arbeitnehmereinkommen 1991-99 .... 18

Quantitative Methoden – Deskriptive Statistik - Seite 3 -
Peter Schmidt, Hochschule Bremen MBA
1 QUANTITATIVE METHODEN; STATISTIK
Statistik ist ein Gebiet, das mit vielen Vorbehalten und Vorurteilen behaftet ist. Sie dies die
Sorge vor zu viel Mathematik, Formeln und anderem schwer verständlichem. Oder seien es
Redensarten, die ein unbedarftes Herangehen an dieses Gebiet erschweren, wie der be-
rühmte Ausspruch (Winston Churchill zugeschrieben) „Ich traue keiner Statistik, die ich nicht
selbst gefälscht habe“ oder der beliebten Steigerung „Lüge – gemeine Lüge – Statistik“.
Trotzdem begegnet uns Statistik an vielen Stellen des täglichen (betrieblichen) Lebens und
es ist wichtig, damit umgehen zu können. Es ist nicht nötig, anhand kompliziert klingender
Begriffe davon auszugehen, dass das Gegenüber „schon Recht haben wird“, wenn man in
der Lage ist, fachkundig nachzufragen und Aussagen kritisch zu hinterfragen. Nicht alle
statistischen Modelle und Kennzahlen sind in allen Zusammenhängen und für alle Arten
von Daten anwendbar.
Aber nicht nur die Situation, vorgelegte statistische Auswertungen verstehen und (kritisch)
interpretieren zu müssen, kann in der täglichen Praxis auftauchen, sondern auch der
Wunsch, vorhandene Daten selbst auszuwerten und anschaulich darzustellen. Dies kann
die (grafische) Aufbereitung zur Präsentation der Daten sein, aber auch die Analyse von
statistischen Zusammenhängen bzw. Unterschieden von Daten oder Sachverhalten.
Daher werden in diesem Skript wichtige betriebsstatistische Methoden nicht nur vorge-
stellt, sondern können mit dem PC selbst nachvollzogen werden, da sich auf der Webseite
http://www.fbw.hs-bremen.de/pschmidt unter → „QM / mkm“ eine Excel-Datei befindet,
mit der die Beispiele aus dem Text nachvollzogen werden können.
Es wird hier beispielhaft das Tabellenkalkulationsprogramm Excel (aus dem Office Paket
der Firma Microsoft) verwendet, da dieses eine sehr große Verbreitung hat. In anderen
Tabellenkalkulationen können die dargestellten Methoden ebenso verwendet werden. Dar-
über hinaus gibt es spezielle Statistik-Programme, die die Verarbeitung von Daten zwar
erleichtern, für den täglichen Gebrauch jedoch i.d.R. nicht notwendig sind, z.B. SPSS,
SAS, Statgraphics, u.v.m. Auf diese wird hier nicht eingegangen.
Das vorliegende Material will mehr bieten als nur die Aufzählung verschiedener Methoden
und deren kurze verbale Beschreibung. Ziel ist eine lesbare und alltagstaugliche Übersicht
über gängige Methoden und nicht eine mathematisch umfassende Darstellung der Statistik.
Auf Formeln wird weitgehend verzichtet; zur Vergleichbarkeit mit bzw. Orientierung in
Nachschlagewerken werden die üblichen Symbole (Buchstaben, Abkürzungen) verwendet.
Am Ende des Artikels findet sich ein Schlagwortindex, der das Auffinden einzelner Begrif-
fe erleichtern soll. Für tiefergehende Fragen sind am Schluss einige Literaturhinweise zu-
sammengestellt.
Ziel dieses Skriptes ist es, zu zeigen, dass quantitative Methoden in der
täglichen Arbeit – v.a. durch den Einsatz von EDV-Programmen – ein-
fach zu erstellen und dadurch praktisch und nutzbringend einsetzbar
sind.
Begleitende
Excel-Datei

Quantitative Methoden – Deskriptive Statistik - Seite 4 -
Peter Schmidt, Hochschule Bremen MBA
1.1 Definitionen – Was ist Statistik?
Statistik ist ein Hilfsmittel, ein Werkzeug zur systematischen Darstellung und Auswertung
von Zahlenmaterial, meist kurz als „Daten“ bezeichnet. Mit statistischen Methoden werden
Kennzahlen gebildet, die dabei helfen, vorliegendes Datenmaterial - vor allem aber die
entsprechenden Sachverhalte - möglichst objektiv zu bewerten.
Es gibt zwei grundlegende Ziele statistischer Analysen:
Beschreibung vorhandener Daten: Beschreibende oder Deskriptive Statistik
Es liegen Daten (Zahlen) vor, die ausgewertet werden sollen: z.B. Alter und Einkom-
men von 20 Mitarbeitern oder 100 Gewichtsangaben von Werkstücken oder Umsatz-
zahlen in 16 Quartalen, ... usw.
Ableiten allgemeiner Aussagen Schließende oder
aus einer kleinen Auswahl von Daten Induktive Statistik
Es liegt nur eine (kleine) Stichprobe von Daten vor, aus diesen sollen allgemeingültige
Schlüsse über die Grundgesamtheit aller Daten gezogen werden: z.B.: Aus den Angaben
über Alter, Geschlecht und Provision von 50 Angestellten soll auf die entsprechenden
Werte aller 800 Mitarbeiter geschlossen werden oder aus den Umsatzentwicklungen
von 20 Betrieben soll die Branchenentwicklung abgeschätzt werden.
Dieser Artikel behandelt die beschreibende Statistik.
Verdichtung von Informationen – abhängig von der Skalierung der Daten
Eine Hauptaufgabe statistischer Methoden ist es, die oft sehr große Fülle von Informatio-
nen auf wenige (Kenn-) Zahlen zu verdichten. Beispiel: Von 500 Beschäftigten mögen z.B.
die Dauer der Betriebszugehörigkeit und die Ausbildung vorliegen, dies sind 1.000 Zahlen.
Statistisch sprechen wir von Merkmalen (z.B. Alter, Geschlecht) und deren Ausprägun-gen (z.B. 20 Jahre, 44 Jahre bzw. männl., weibl.).
Durch Auszählung von Häufigkeiten oder Angabe eines Mittelwertes können diese z.B.
auf drei Häufigkeitsangaben (z.B. 100 angelernte Arbeiter (Ar), 250 Facharbeiter (F) und
150 Angestellte (An)) oder im Fall der Betriebszugehörigkeit sogar auf einen Mittelwert
(z.B. Durchschnitt von 8,5 Jahren (J)).
Abbildung 1 Verdichtung von Information
Ursprungsdaten: Verdichtungen, z.B.:
Während in den Ursprungsdaten also alle Personen mit allen Eigenschaften enthalten sind,
enthalten Verdichtungen nur einzelne ausgewertete Kennzahlen.
Mittelwert : 8,5 Jahre
Betriebszugehörigkeit
beschrei-
bende
Statistik
schließende
Statistik
...............
...)9,()1,()1,()5,(
...)6,()2,()6,()6,(
...)3,()9,()10,()1,(
...)3,()2,()6,()4,(
JArJArJAnJAr
JArJArJFJAn
JAnJArJArJF
JFJAnJAnJAr
Häufigkeiten:
100 Angelernte 250 Facharbeiter 150 Angestellte
Verdich-
tung von
Daten-
material

Quantitative Methoden – Deskriptive Statistik - Seite 5 -
Peter Schmidt, Hochschule Bremen MBA
Es zeigt sich jedoch, dass nicht alle Maßzahlen für alle Merkmale möglich sind, so würde
ein Mittelwert beim Mitarbeiterstatus keinen Sinn machen. Genauer gesagt ist die Auswahl
der statistischen Maßzahlen von der Skalierung des Merkmals abhängig. Abbildung 2
zeigt die vier Skalen, die üblicherweise unterschieden werden.
Abbildung 2 Skalierung von Merkmalen
Verhältnisskalierte Daten beinhalten die meiste Information, nominal skalierte die wenigs-
te. Entsprechend stehen mehr oder weniger statistische Methoden zur Auswertung der Da-
ten zur Verfügung
Merkmale können in diskreter oder stetiger Form vorliegen. Diskrete Merkmale können
nur abzählbar viele Ausprägungen annehmen, wie z.B. oben der Berufsstatus, das Ge-
schlecht oder Farben. Stetige Merkmale hingegen können beliebig viele Ausprägungen
annehmen, oft werden sie in Dezimalzahlen gemessen, z.B. Geldbeträge, Gewichte oder
Mengen.
Die Unterscheidungen von Typen und Skalen werden im folgenden wichtig sein, wenn die
Methoden zur Auswertung beschrieben werden.
1.2 Häufigkeiten und grafische Darstellungen
Wie oben gesehen, ist auch die Auszählung von Häufigkeiten ein Mittel zur Verdichtung
von Daten, gerne wird diese grafisch dargestellt.
1.2.1 Eindimensionale und mehrdimensionale Häufigkeitsdarstellungen
Die Ursprungsdaten (oder Rohdaten - vgl. Abbildung 1) werden oft in Tabellen dargestellt,
die aus Zeilen und Spalten bestehen. Dabei stellt jede Zeile eine statistische Einheit (Per-
son, Werkstück, Summe, ...) und jede Spalte ein bestimmtes Merkmal dar.
Diese Darstellung wird auch in Tabellenkalkulationsprogrammen verwendet. Hier kann
dann jede Zelle (z.B. Zeile 3, Spalte 4) einzeln angesteuert bzw. berechnet werden. Bei-
spiele hierzu finden sich in den Excel-Dateien. Die laufende Nummer wird auch als (Lauf-)
Skalen
Metrische Skalen Rang- /
Ordinalskala Nominalskala
Verhältnisskala Intervallskala
Nur Rangfolgen können angege-
ben werden
Ausprägungen stehen gleich-
berechtigt nebeneinander
Verhältnisse können ange-geben werden
Nur Abstände (Intervalle) kön-nen angegeben
werden
Noten: sehr gut, ..., ungenügend; Handelsklassen, Tabellenplätze
Geschlecht, Farben, Beru-fe, Nationalität
Währungsbe-träge, Gewich-te, Alter, Maße
Temperatur, Lärmmessung, Meinungsskala
Skalie-
rung von
Daten als
Basis für
die An-
wendbar-
keit statis-
tischer
Methoden

Quantitative Methoden – Deskriptive Statistik - Seite 6 -
Peter Schmidt, Hochschule Bremen MBA
Index bezeichnet, daher die übliche Abkürzung i. Es können dann alle Angaben anhand
dieses Index angegeben werden. Z.B. ist die 3. Person seit 2 Jahren im Betrieb: B3 = 2.
Tabelle 1 Personaldaten (Beispiel für Ursprungsdaten)
Spalte
lfd. Nummer Geschlecht Betriebszu-gehörigkeit
Berufs- Status
Note im Eignungstest
i Gi Bi Si Ni
1 w 10 Ar 2
2 w 5 An 1
Zeile → 3 m 2 Ar 3
4 w 18 F 8
5 m 22 Ar 1 Zelle
6 m 9 An 9
7 m 14 F 2
Die einfachste Verdichtung von Daten ist die Angabe von Häufigkeiten, oft ebenfalls in
tabellarischer Form, wie Tabelle 2 für den Fall einer einfachen Häufigkeitstabelle für das
Merkmal „Berufsstatus“ zeigt.
Tabelle 2 Eindimensionale Häufigkeitstabelle – Anzahl Befragte nach Berufsstatus
Kürzel Status Anzahl
(Häufigkeit ni)
(Bezeichnung)
Status: Ar angelernte Arbeiter 100 = n1
F Facharbeiter 250 = n2
An Angestellte 50 = n3
Summe: 400 = n Beschäftigte
Der Buchstabe „n“ als Symbol für „Anzahl der Beobachtungen“ wird in der Statistik sehr
häufig verwendet. Wenn es sich auf die Grundgesamtheit aller statistischen Einheiten be-
zieht, wird auch ein großes „N“ verwendet.
Interessanter ist die Aufbereitung mehrerer Dimensionen, etwa die Auszählung der Anzahl
der Beschäftigten, diesmal nach Alter und Geschlecht, wie sie in Tabelle 3 vorgenommen
wird.
Tabelle 3 Zweidimensionale Häufigkeitstabelle – Befragte nach Alter und Geschlecht
Geschlecht
Betriebs-
zugehörigkeit weiblich männlich alle
Personen
Rand-
unter 10 Jahre 80 40 120 summen
10 - 20 Jahre 100 80 180 über 20 Jahre 120 80 200
alle Personen 300 200 500 Gesamt-
Randsummen summe
Ursprungs-
daten
Häufig-
keitstabelle
zweidi-
mensio-
nale
Häufig-
keiten

Quantitative Methoden – Deskriptive Statistik - Seite 7 -
Peter Schmidt, Hochschule Bremen MBA
In dieser Tabelle 3 sind zum einen die Einzelhäufigkeiten für die Kombinationen bestimm-
ter Eigenschaften angegeben (z.B. haben 40 Männer eine Betriebszugehörigkeit unter 10
Jahren), aber auch - in den „Randsummen“ - die Häufigkeitsauszählungen für die einzel-
nen Merkmale (z.B. insgesamt gibt es 180 Personen mit einer Betriebszugehörigkeit zwi-
schen 10 und 20 Jahren). Für das Merkmal Betriebszugehörigkeit wurden Klassen (von ...
bis ...) gebildet. Dies ist sinnvoll, wenn viele Ausprägungen vorhanden sind, so dass diese
nicht mehr übersichtlich in einer Tabelle oder Grafik dargestellt werden können.
Üblich ist auch die Darstellung von relativen oder prozentualen Häufigkeiten.
Tabelle 4 Prozentuale Häufigkeiten – Befragte nach Alter und Geschlecht
Zeilenprozente Spaltenprozente
Betriebs-
zugehörigkeit
weib-
lich
männ-
lich
alle Personen
weib-
lich
männ-
lich
alle Personen
unter 10 Jahre 66,7% 33,3% 100% 26,7% 20,0% 24,0%
10 - 20 Jahre 55,6% 44,4% 100% 33,3% 40,0% 36,0%
über 20 Jahre 60,0% 40,0% 100% 40,0% 40,0% 40,0%
alle Personen 60,0% 40,0% 100% 100% 100% 100%
Diese Häufigkeitsdarstellungen, ob in absoluten Zahlen oder relativen Anteilen gemessen,
werden oft grafisch dargestellt. So lassen sich die Zahlen aus Tabelle 2 z.B. in einem Bal-
ken- oder Säulendiagramm darstellen, wie in Abbildung 3 links dargestellt ist.
Abbildung 3 Absolute Häufigkeiten und zweidimensionales Säulendiagramm
Säulendiagramm
0
50
100
150
200
250
300
angelernte
Arbeiter
Facharbeiter Angestellte
An
za
hl
Balkendiagramm
0 100 200 300
Angestellte
Facharbeiter
Angelernte
unter 1
0 Jahre
10 - 20 Jahre
männlich
weiblich0
20
40
60
80
100
120
Betriebszugehörigkeit nach Geschlecht
Auch die zweidimensionalen Häufigkeiten aus Tabelle 3 lassen sich grafisch veranschauli-
chen (z.B. wie in Abbildung 3 recht oder Abbildung 4).
Abbildung 4 Kreisdiagramme zur Darstellung von relativen Häufigkeiten
Betriebszugehörigkeit
über 20
Jahre
40% 10 - 20
Jahre
36%
unter 10
Jahre
24%
27%
33%
40%
20%
40%
40%
unter 10 Jahre
10 - 20 Jahre
über 20 Jahre
Betriebs-
Zugehörigkeit:
Anteile nach
Geschecht
MännerFrauen
Grafiken wie die hier beispielhaft vorgestellten lassen sich mit Hilfe von Computerpro-
grammen relativ einfach erzeugen. Es gibt eine sehr große Anzahl von Darstellungsmög-
relative
Häufig-
keiten
Quantitative Methoden – Deskriptive Statistik - Seite 8 -
Peter Schmidt, Hochschule Bremen MBA
lichkeiten und es sollte jeweils aus dem konkreten Zusammenhang entschieden werden,
welche Darstellung hilfreich „für den Transport der Botschaft“ ist.
Die Daten und die hier dargestellten Beispiele finden sich in der begleitenden Excel-Datei.
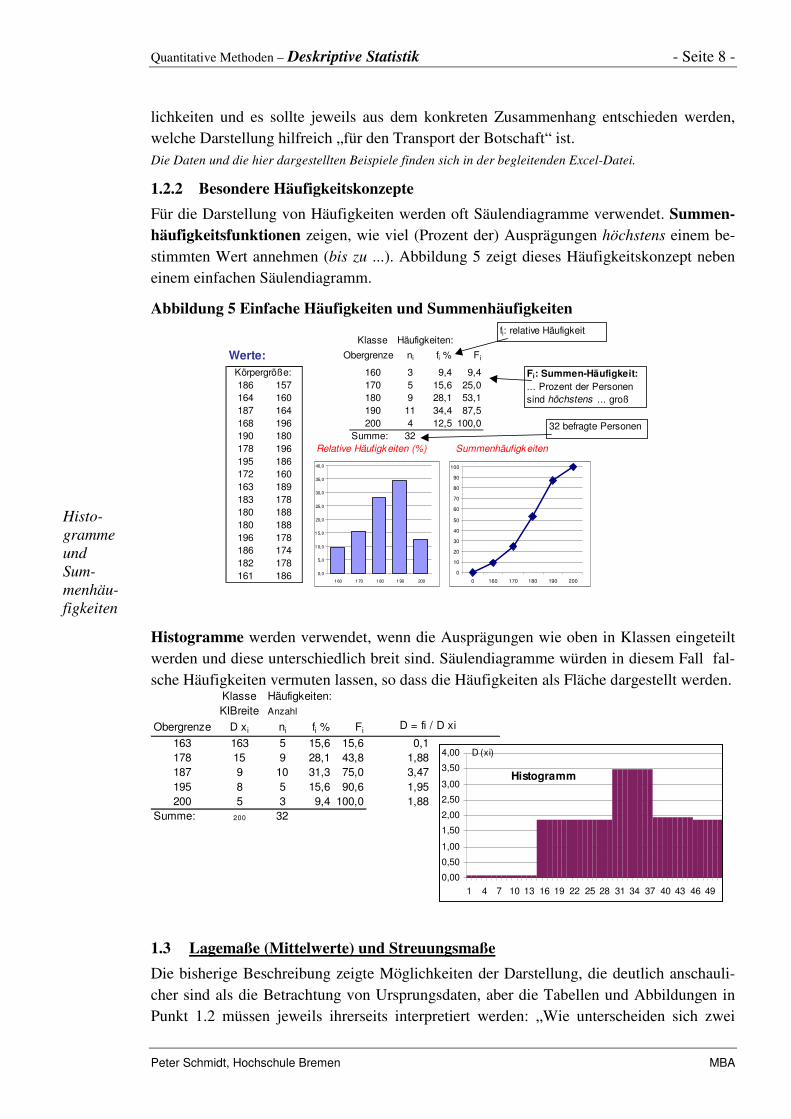
1.2.2 Besondere Häufigkeitskonzepte
Für die Darstellung von Häufigkeiten werden oft Säulendiagramme verwendet. Summen-häufigkeitsfunktionen zeigen, wie viel (Prozent der) Ausprägungen höchstens einem be-
stimmten Wert annehmen (bis zu ...). Abbildung 5 zeigt dieses Häufigkeitskonzept neben
einem einfachen Säulendiagramm.
Abbildung 5 Einfache Häufigkeiten und Summenhäufigkeiten
Klasse Häufigkeiten:
Werte: Obergrenze ni fi % Fi 0 0 0
160 3 9,4 9,4
186 157 170 5 15,6 25,0
164 160 180 9 28,1 53,1
187 164 190 11 34,4 87,5
168 196 200 4 12,5 100,0
190 180 Summe: 32
178 196 Relative Häufigkeiten (%) Summenhäufigkeiten
195 186
172 160
163 189
183 178
180 188
180 188
196 178
186 174
182 178
161 186
Körpergröße:
0,0
5,0
10,0
15,0
20,0
25,0
30,0
35,0
40,0
160 170 180 190 200
0
10
20
30
40
50
60
70
80
90
100
0 160 170 180 190 200
32 befragte Personen
fi: relative Häufigkeit
Fi: Summen-Häufigkeit:
... Prozent der Personen
sind höchstens ... groß
Histogramme werden verwendet, wenn die Ausprägungen wie oben in Klassen eingeteilt
werden und diese unterschiedlich breit sind. Säulendiagramme würden in diesem Fall fal-
sche Häufigkeiten vermuten lassen, so dass die Häufigkeiten als Fläche dargestellt werden. Klasse Häufigkeiten:
KlBreite Anzahl
Obergrenze D xi ni fi % Fi D = fi / D xi
163 163 5 15,6 15,6 0,1
178 15 9 28,1 43,8 1,88
187 9 10 31,3 75,0 3,47
195 8 5 15,6 90,6 1,95
200 5 3 9,4 100,0 1,88
Summe: 200 32
D (xi)
0,00
0,50
1,00
1,50
2,00
2,50
3,00
3,50
4,00
1 4 7 10 13 16 19 22 25 28 31 34 37 40 43 46 49
Histogramm
1.3 Lagemaße (Mittelwerte) und Streuungsmaße
Die bisherige Beschreibung zeigte Möglichkeiten der Darstellung, die deutlich anschauli-
cher sind als die Betrachtung von Ursprungsdaten, aber die Tabellen und Abbildungen in
Punkt 1.2 müssen jeweils ihrerseits interpretiert werden: „Wie unterscheiden sich zwei
Histo-
gramme
und
Sum-
menhäu-
figkeiten

Quantitative Methoden – Deskriptive Statistik - Seite 9 -
Peter Schmidt, Hochschule Bremen MBA
Grafiken?“; „Was ist das wichtige an dieser Tabelle?“ ... mögen die Fragen lauten. Daraus
ergibt sich der Wunsch, nach noch knapperen statistischen (bzw. betrieblichen) Kennzah-
len.
Die sicherlich bekanntesten statistischen Maße sind Mittelwerte, unter Ihnen der „promi-
nenteste“ das arithmetische Mittel, oft einfach als „Mittelwert“ bezeichnet. Aber nicht für
alle Daten (jeder Skalierung) kann ein arithmetische Mittel errechnet werden. In der be-
trieblichen Praxis sind die in Tabelle 5 angegebenen Mittelwerte relevant.
Wichtig ist hier, dass falsche Verwendung der Mittelwerte eben auch zu falschen (oder
verfälschten) Ergebnissen führt. So ist das arithmetische Mittel i.d.R. größer als das geo-
metrische Mittel. Würde man im letzten Beispiel (fälschlicherweise) ein arithmetisches
Mittel errechnen, so hätte dies einen Wert von 9 Prozent (10+20+5+1=36 / 4). Die tatsächliche
Lohnsteigerung der letzten vier Jahre würde also höher angegeben als sie tatsächlich war.
Mittelwerte werden auch als Lagemaße bezeichnet, da sie die Lage einer Verteilung (auf
der waagrechten Achse) angeben. So haben die Verteilungen von Abbildung 3 oder
Abbildung 5 ihren jeweiligen Schwerpunkt in ihren Mittelwerten.
Tabelle 5 Mittelwerte
Mittelwert für Skalen Definition Beispiel
Modus
(Modalwert)
alle Skalen
häufigster Wert
In Tabelle 2 ist F der Modal-
wert, da Facharbeiter (mit 250
Personen) die größte Einzel-
häufigkeit aufweisen
Median
oder
Zentralwert
Ordinalskalen
und metrische
Skalen
Mitte
aller geordneten
Ausprägungen
Alter: 44, 19, 24, 60, 21, 42, 11
geordnet: 11,19,21,24,42,44,60
Median = 24, da mittlerer
Wert, es stehen rechts und
links davon je drei Zahlen
arithmetisches
Mittel („Mittelwert“)
metrische
Skalen
Summe aller Werte
geteilt durch die
Anzahl der Beo-
bachtungen (n)
Alter: 44, 19, 24, 60, 21, 42, 11
JahrexttsalterDurchschni 6,31
7
11 42 2160 24 19 44
=
=++++++
geometrisches
Mittel
Steigerungsraten
von
Wachstumsdaten
(nur Verhältnis-
skalen)
n-te Wurzel aus
dem Produkt aller
Werte
Lohnsteigerung in 4 Jahren:
10 %, 20 %, 5 %, 1 %
oderGM 0877,1
01,105,120,110,14
=
⋅⋅⋅
rund 8,77 Prozent
Die einzelnen Berechnung können in der Excel-Datei nachvollzogen werden.
Streuungsmaße Neben der Lage einer Verteilung ist diese durch ihr Aussehen, etwa ihre „Breite“ bezeich-
net: Wie verteilen sich die Ausprägungen des Merkmals um den Mittelwert?. Statistisch
wird hier von Schwankung oder Streuung der Werte gesprochen, so dass die entsprechen-
Mittel-
werte:
auf die
Skala
achten
Streu-
ungs-
maße
Quantitative Methoden – Deskriptive Statistik - Seite 10 -
Peter Schmidt, Hochschule Bremen MBA
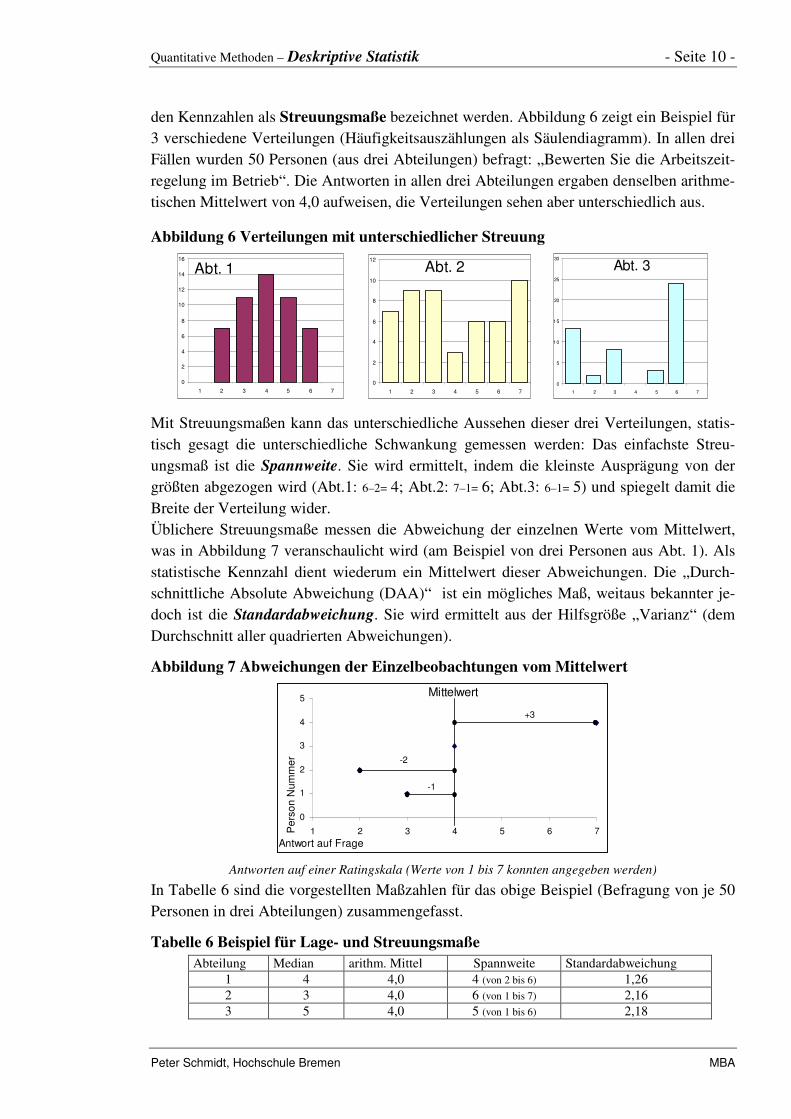
den Kennzahlen als Streuungsmaße bezeichnet werden. Abbildung 6 zeigt ein Beispiel für
3 verschiedene Verteilungen (Häufigkeitsauszählungen als Säulendiagramm). In allen drei
Fällen wurden 50 Personen (aus drei Abteilungen) befragt: „Bewerten Sie die Arbeitszeit-
regelung im Betrieb“. Die Antworten in allen drei Abteilungen ergaben denselben arithme-
tischen Mittelwert von 4,0 aufweisen, die Verteilungen sehen aber unterschiedlich aus.
Abbildung 6 Verteilungen mit unterschiedlicher Streuung
Abt. 1
0
2
4
6
8
10
12
14
16
1 2 3 4 5 6 7
Abt. 2
0
2
4
6
8
10
12
1 2 3 4 5 6 7
Abt. 3
0
5
10
15
20
25
30
1 2 3 4 5 6 7
Mit Streuungsmaßen kann das unterschiedliche Aussehen dieser drei Verteilungen, statis-
tisch gesagt die unterschiedliche Schwankung gemessen werden: Das einfachste Streu-
ungsmaß ist die Spannweite. Sie wird ermittelt, indem die kleinste Ausprägung von der
größten abgezogen wird (Abt.1: 6–2= 4; Abt.2: 7–1= 6; Abt.3: 6–1= 5) und spiegelt damit die
Breite der Verteilung wider.
Üblichere Streuungsmaße messen die Abweichung der einzelnen Werte vom Mittelwert,
was in Abbildung 7 veranschaulicht wird (am Beispiel von drei Personen aus Abt. 1). Als
statistische Kennzahl dient wiederum ein Mittelwert dieser Abweichungen. Die „Durch-
schnittliche Absolute Abweichung (DAA)“ ist ein mögliches Maß, weitaus bekannter je-
doch ist die Standardabweichung. Sie wird ermittelt aus der Hilfsgröße „Varianz“ (dem
Durchschnitt aller quadrierten Abweichungen).
Abbildung 7 Abweichungen der Einzelbeobachtungen vom Mittelwert
0
1
2
3
4
5
1 2 3 4 5 6 7
Antwort auf Frage
Pe
rso
n N
um
me
r
Mittelwert
-1
-2
+3
Antworten auf einer Ratingskala (Werte von 1 bis 7 konnten angegeben werden)
In Tabelle 6 sind die vorgestellten Maßzahlen für das obige Beispiel (Befragung von je 50
Personen in drei Abteilungen) zusammengefasst.
Tabelle 6 Beispiel für Lage- und Streuungsmaße Abteilung Median arithm. Mittel Spannweite Standardabweichung
1 4 4,0 4 (von 2 bis 6) 1,26 2 3 4,0 6 (von 1 bis 7) 2,16 3 5 4,0 5 (von 1 bis 6) 2,18

Quantitative Methoden – Deskriptive Statistik - Seite 11 -
Peter Schmidt, Hochschule Bremen MBA
Es mag sich angesichts dieses einfachen Beispiels die Frage stellen, welchen Sinn solche
recht aufwendigen Maßzahlen haben. Dieser liegt vor allem in der Verarbeitung großer
Datenmengen. Sind nicht nur drei Abteilungen, sondern z.B. 16 Bereiche und nicht nur
eine Frage sondern z.B. 35 zu bewerten und so zu verdichten, dass eine Orientierung „auf
einen Blick“ (oder zumindest wenige Blicke) möglich ist, so geht dies nur mit Hilfe von
Kennzahlen. Nicht alle sind an jeder Stelle geeignet. So zeigt hier das arithmetische Mittel
eine Übereinstimmung der drei Abteilungen an, was aber angesichts Abbildung 6 nicht zu
überzeugen vermag. Schon der Median, vor allem aber die Streuungsmaße zeigen - auch
ohne den Blick auf die Grafiken - dass die Antworten in Abteilung 1 recht einheitlich ver-
teilt sind, wogegen diejenigen in Abteilung 2 und 3 größere Schwankungen aufweisen.
Dort gehen also die Meinungen weiter auseinander, in unserem Beispiel könnte hiermit ein
Anhaltspunkt dafür gegeben sein, dass der Betriebsrat dort - etwa in Einzelgesprächen -
klären sollte, ob größere Unzufriedenheit unter den Angestellten herrscht, als in anderen
Abteilungen.
1.4 Zusammenhänge zwischen mehreren Merkmalen
Oft ist das Ziel statistischer Analysen nicht nur, ein einzelnes Merkmal zu beschreiben,
sondern es interessiert die Wirkung verschiedener Merkmale aufeinander. so wurde bereits
in Tabelle 4 und Abbildung 3 eine zweidimensionale Betrachtung angestellt.
Wiederum können zwei unterschiedliche Fragestellungen unterschieden werden:
Wird ein (zufälliger) Zusammenhang zwischen zwei Merkmalen untersucht, in dem
Sinne, dass die Merkmale sich gegenseitig beeinflussen; oder
wird ein ursächlicher Zusammenhang vermutet, in dem Sinne, dass bestimmte Merkma-
le ein anderes beeinflussen bzw. steuern (Kausalität)?
Für die erste Frage eignen sich Zusammenhangmaße, die zweite kann mit Regressionsmo-
dellen untersucht werden.
1.4.1 Zusammenhangmaße
Zusammenhangmaße beschreiben die Stärke eines Zusammenhangs. Die Geschäftsleitung
macht auf den steigenden Energieverbrauch einer Abteilung aufmerksam. Der Betriebsrat
vermutet, dass dies durch die wachsende Anzahl von Überstunden verursacht wird und
vergleicht die beiden Zahlenreihen X: Anzahl der Überstunden pro Woche und Y: Ener-
gieverbrauch miteinander. Es werden sechs Wochen (i = 1, ..., 6), entsprechend sechs Werte-
paare (xi, yi) miteinander verglichen. Diese sind in Tabelle 7 angegeben.
Tabelle 7 Wertetabelle für Zusammenhang Überstunden / Energieverbrauch
Woche Überstunden Energieverbrauch Woche Überstunden Energieverbrauch
i Xi Yi i Xi Yi
1 6 12 4 16 19
2 8 16 5 22 23
3 12 18 6 26 24
Da es sich um zwei metrisch skalierte Merkmale handelt, können sie - in Abbildung 8 - als
xy-Diagramm (Streu- oder Punktdiagramm) dargestellt werden.
Messen der
Stärke eines Zu-
sammen-
hangs

Quantitative Methoden – Deskriptive Statistik - Seite 12 -
Peter Schmidt, Hochschule Bremen MBA
In der folgenden Grafik ist ein Zusammenhang zu erkennen: Je höher die Anzahl der Über-
stunden, desto höher ist auch der Energieverbrauch. Das statistische Maß, welches die
Stärke eines solchen Zusammenhanges metrischer Merkmale misst, heißt Korrelationsko-
effizient (nach Bravais-Pearson), üblicherweise mit dem Buchstaben r (oder dem griechischen ρ)
bezeichnet. r gibt sowohl die Richtung des Zusammenhanges als auch dessen Stärke an,
denn er kann Werte zwischen -1 und 1 annehmen. Im vorliegenden Falle ergibt sich ein
Wert von r=0,97 und damit ein starker statistischer Zusammenhang zwischen Überstunden
(X) und Energieverbrauch (Y).
Abbildung 8 xy-Diagramm für Zusammenhang Überstunden / Energieverbrauch
0
5
10
15
20
25
30
0 5 10 15 20 25 30X-Achse: Überstunden
Y-Achse: Energieverbrauch
Ein positiver Zusammenhang (r größer als 0) heißt, dass je größer die Ausprägung des ei-
nen Merkmals (X), desto größer auch die des anderen Merkmals (Y); Ein negativer Zu-
sammenhang (r kleiner als 0) heißt, dass je größer die Ausprägung des einen Merkmals
(X), desto kleiner die des anderen Merkmals (Y), wobei der Zusammenhang desto stärker
ist, je näher r an 1 bzw. -1. Ein Korrelationskoeffizient nahe oder gleich Null bedeutet,
dass es keinen Zusammenhang zwischen X und Y gibt. Der Korrelationskoeffizient r ist
also eine Kennzahl, die eine große Menge an Informationen verdichten kann, indem das
Verhältnis beliebig vieler Wertepaare in einer Maßzahl r zusammengefasst wird.
Abbildung 9 Stärke von Zusammenhängen und Werte des Korrelationskoeffizienten vollk. positiver Zh (schwach) positiver Zh kein Zh (schwach) negativer Zh vollk. negativer Zh
r = +1
0
2
4
6
8
0 5 10
0 < r < 1
0
2
4
6
8
0 5 10
r = 0
0
2
4
6
8
0 5 10
0 > r > -1
0
2
4
6
8
0 5 10
r = -1
0
2
4
6
8
0 5 10
Auch hier gilt wieder, dass ein solches Maß besonders dann nützlich ist, wenn große Men-
gen von Daten betrachtet werden und nicht für jedes Merkmalspaar ein solches xy-
Diagramm erstellt werden kann. Es können dann mittels des Korrelationskoeffizienten
schnell diejenigen Merkmale herausgefunden werden, die einen starken Zusammenhang
aufweisen und diese näher untersucht werden. Korrelationskoeffizienten sind ein in der
betrieblichen Praxis sehr gebräuchliches Maß.
Allerdings kann der Korrelationskoeffizient r nach Bravais-Pearson nur für metrische
Merkmale ermittelt werden. Bei ordinal skalierten Merkmalen muss auf den Rangkorrela-
tionskoeffizienten rs zurückgegriffen werden; bei nominal skalierten Daten steht nur der

Quantitative Methoden – Deskriptive Statistik - Seite 13 -
Peter Schmidt, Hochschule Bremen MBA
Kontingenzkoeffizient zur Verfügung. Tabelle 8 zeigt die Zusammenhangmaße für die
verschiedenen Skalenniveaus.
Je größer der Informationsgehalt der Skala (vgl. Abbildung 2), desto höher ist auch die
Aussagekraft des Zusammenhangmaßes. Der Koeffizient rs kann nur Sortierungen verglei-
chen, aber keine Zahlenwerte, der Kontingenzkoeffizient C beinhaltet keine Richtung des
Zusammenhanges, bezüglich der Größe von C gilt ebenfalls, dass ein Wert von 0 keinen
Zusammenhang bedeutet und je näher C sich dem Wert 1 nähert, desto stärker ist der un-
tersuchte Zusammenhang zwischen den Merkmalen X und Y.
Tabelle 8 Zusammenhangmaße für unterschiedliche Skalenniveaus
Zusammenhangmaß für Skalen Wertebereich Beispiele
r Korrelationskoeffizient nach Bravais-Pearson
metrische Skalen, linearer Zus.hang
-1 ≤ r ≤ 1 - Produktionsmenge und Kosten - Alter und Einkommen
rs Korrelationskoeffizient nach Spearman
Ordinalskalen -1 ≤ rs ≤ 1 - Schulnote und Altersklasse - Schulabschluss Leistungsklasse
C Kontingenzkoeffizient Nominalskalen 0 ≤ C ≤ 1 - Geschlecht und Beruf
1.4.2 Regressionsanalyse
Bei metrisch skalierten Merkmalen wurden in Abbildung 8 und Abbildung 9 „Punktewol-
ken“ betrachtet, also die Verteilung der xy-Wertepaare in einem Koordinatensystem. Als
Referenz für die Messung von Stärke eines Zusammenhanges dient dabei eine gedachte
Linie durch die Punktewolke und die Betrachtung, wie die Bebachtungspunkte zu dieser
Linie liegen. Bei Korrelationskoeffizienten r = 1 und r = -1 liegen die Punkte auf dieser
gedachten Grade bzw. bilden diese Grade.
Im Beispiel der Tabelle 7 wurde ein statistischer Zusammenhang zwischen der Anzahl der
Überstunden und dem Energieverbrauch ermittelt. Es stellt sich im nächsten Schritt die
Frage, wie die beiden Merkmale zusammenhängen, welcher Art ihre Beziehung ist. Um
dies statistisch zu untersuchen, muss zunächst eine Annahme aufgestellt werden, diese sei:
inhaltlich: Der Energieverbrauch hängt von der Zahl der Überstunden ab
mathematisch: Der Energieverbrauch Y ist eine Funktion der Zahl der Überstunden X
Funktional: Y = f (X) und im linearen Fall: Y = a + b * X
In Worten bedeutet dies, dass eine Gerade gesucht wird, die durch das Zentrum der „Punk-
tewolke“ geht, wie Abbildung 10 zeigt.
Regressi-
onsanalyse
misst die
Art eines
Zusam-
menhanges

Quantitative Methoden – Deskriptive Statistik - Seite 14 -
Peter Schmidt, Hochschule Bremen MBA
Abbildung 10 Regressionsgrade Überstunden / Energieverbrauch
Y = 10,4 + 0,55 * X
R2 = 0,939
8
12
16
20
24
28
0 5 10 15 20 25 30X-Achse: Überstunden
Y-Achse: Energieverbrauch
Die „Regressionsgrade“ in Abbildung 10 wird bestimmt durch ihren Schnittpunkt mit der
Y-Achse (hier a = 10,4) und ihre Steigung (hier b = 0,55). Mit dieser Grade bzw. der For-
mel Y = a + b * X; hier Y = 10,4 + 0,55 * X kann für jede denkbare Anzahl von Überstun-
den ein erwarteter Wert für den Energieverbrauch errechnet werden. Daher hat das Modell
seinen Namen, denn „re-gressere“ kommt aus dem Lateinischen und bedeutet „zurückfüh-
ren“; hier wird also der Energieverbrauch auf die Anzahl der Überstunden zurückgeführt.
Dies kann zum einen geschehen durch einsetzen von X-Werten in die Formel, so ergibt
sich für 10 Überstunden ein erwarteter Energieverbrauch von Y =10,4 + 0,55 * 10 (Stun-
den) = 15,9 (kWh). X wird auch als das erklärende (unabhängige) und Y als das erklärte
(abhängige) Merkmal bezeichnet. Dies ist in Abbildung 11 verdeutlicht.
Abbildung 11 Regressionsanalyse
Y = 10,4 + 0,55 * X
8
10
12
14
16
18
20
22
24
0 5 10 15
X-Achse: Überstunden
Y-Achse: Energieverbrauch
Achsenabschnitt a (hier 10,4)
Steigung der Gerade
b = 0,55
Ablesebeispiel: X = 10;
zugehöriger Y-Wert: 15,9
Eine solche Regressionsanalyse kann in Computerprogrammen sehr einfach erzeugt werden. In der Excel-
Datei in der beiliegenden Datei finden Sie diese Grafiken, die zugrunde liegenden Zahlen und Hinweise zur
Erstellung der Analysen.
Eine Regressionsanalyse bietet somit zwei praktische Möglichkeiten:
Ein Zusammenhang kann formal beschrieben werden (wie hängen X und Y zusammen?)
Es kann für gegebene X-Werte ausgerechnet werden, welche Y-Werte zu erwarten sind.
Anwendung finden Regressionsanalysen in verschiedensten Bereichen der betrieblichen
Praxis und sind sehr verbreitet.

Quantitative Methoden – Deskriptive Statistik - Seite 15 -
Peter Schmidt, Hochschule Bremen MBA
Die Güte einer Regressionsanalyse bemisst sich daran, wie gut die Regressionsgrade den
tatsächlichen Zusammenhang beschreibt bzw. vorhersagt. Dies wird darin gemessen, wie
stark die einzelnen Beobachtungspunkte um die Gerade schwanken. Liegen alle Punkte auf
der Gerade, so ist die Regressionsschätzung perfekt. Liegen sie nahe neben der Grade, so
ist die Vorhersage, wie im obigen Beispiel, gut – je weiter die Werte von der Grade ent-
fernt liegen, desto „schlechter“ ist die Regression. Diese Darstellung erinnert an die des
Korrelationskoeffizienten und tatsächlich ist im bisher besprochen Fall der linearen Ein-
fachregression R2 = r2 (also das Quadrat des Korrelationskoeffizienten) ein Gütemaß für
die Regressionsanalyse. (Es wird allgemein als „R-Quadrat“ ausgesprochen, wobei dies als
Eigenname zu verstehen ist. Es gibt keine Zahl R, die dann quadriert wird, sondern das
Gütemaß heißt R2, bei machen Autoren aber auch B für Bestimmtheitsmaß). In Worten
sagt R2 aus, wie viel Prozent der Schwankungen der Y-Werte durch die X-Werte vorherge-
sagt werden. R2 liegt also zwischen 0 und 1 (0 < R2 < 1). Im obigen Beispiel ist in
Abbildung 10 das Gütemaß mit 93,9 Prozent angegeben, diese Beispielregression be-
schreibt die Daten also gut, was ja auch grafisch erkennbar ist.
In der Praxis sind allerdings die wenigsten zu untersuchenden Zusammenhänge so einfa-
cher Natur wie das obige Beispiel:
Der Zusammenhang kann nicht-linear sein, d.h. die Punktwolke kann nicht durch eine
Grade, sondern müsste durch eine Kurve beschrieben werden
Y hängt nicht genau von einer Erklärungsgröße X ab, sondern von mehreren.
Beide Erweiterungen des Regressionsmodells sind in der Praxis sehr gebräuchlich.
Abbildung 12 zeigt ein Beispiel für einen Zusammenhang zwischen einem abhängigen
Merkmal, der Absatzmenge eines Produktes und drei Einflussfaktoren, der Verkaufsfläche,
der Werbeausgaben und des Preises.
Gütemaß

Quantitative Methoden – Deskriptive Statistik - Seite 16 -
Peter Schmidt, Hochschule Bremen MBA
Abbildung 12 Regressionsanalyse mit multiplen Einflussfaktoren
Multivariate Zusammenhänge Beispiel: Absatzzahlen eines Kosmetikartikels
Absatz-
Menge
Verkaufs-
Fläche
Werbe-
Ausgaben
Preis pro
Einheit
Stück qm TEuro Euro
i yi x1i x2i x3i
Nr Absatz Fläche Werbung Preis
1 2.500 2.000 120 7,00
2 1.850 1.000 107 10,00
3 1.750 1.000 99 9,95
4 1.450 800 70 11,50
5 950 300 50 13,00
6 2.200 1.200 102 8,00
7 1.800 800 110 8,00
8 1.950 1.000 92 9,00
9 1.650 1.200 87 10,00
10 1.900 1.300 79 9,95
y = 0,848x + 901,12
R2 = 0,788
0
500
1.000
1.500
2.000
2.500
3.000
0 500 1.000 1.500 2.000 2.500Verkaufs-FlächeM
enge
y = 17,043x + 238,85
R2 = 0,7327
0
500
1.000
1.500
2.000
2.500
3.000
0 20 40 60 80 100 120 140WerbeausgabenM
enge
y = -219,16x + 3912,7
R2 = 0,8636
0
500
1.000
1.500
2.000
2.500
3.000
0,00 2,00 4,00 6,00 8,00 10,00 12,00 14,00 16,00 18,00PreisM
en
ge
In Abbildung 12 sind zunächst die Ursprungsdaten und die drei einzelnen Regressionen
dargestellt. Anhand der Gütemaße ist zu erkennen, dass der Preis (mit einem R2 von 86,4
%) den höchsten Erklärungsgrad aufweist, die Verkaufsfläche (R2 = 78,8 %) den zweit-
höchsten und auch die Werbeausgaben (R2 = 73,3 %) einen messbaren Einfluss auf die
Absatzmenge haben.
Die inhaltliche Aussage kann der Steigung der Regressionsgraden bzw. dem Vorzeichen
von b entnommen werden: Während die Verkaufsfläche, ebenso wie die Werbeausgaben,
positiv auf die Absatzmenge wirken, hat der Preis einen negativen Einfluss. Das heißt: je
größer die Verkaufsfläche einer Filiale und je höher die dortigen Werbeausgaben, desto
höher der Absatz. Je höher jedoch der Preis des Produktes, desto weniger Einheiten werden
abgesetzt.
Dies kann auch in einer einzigen, multiplen Regression errechnet werden. Die Bestim-
mungsgleichung für den Absatz Y lautet dann:
Y = a + b1 * X1 + b2 * X2 + b3 * X3
oder hier: Absatz = a + b1 * Fläche + b2 * Werbung + b3 * Preis
Die Durchführung der multiplen Regression in Excel ergibt das folgende Ergebnis:
Absatz = 2398 + 0,4 * Fläche + 1,7 * Werbung – 123,8 * Preis
Damit wird in einer Gleichung das oben dargestellte Ergebnis beschrieben. Eine Erhöhung
der Verkaufsfläche erhöht den Absatz um das 0,4-fache, also z.B. 100 qm mehr Verkaufs-
fläche bringen im Durchschnitt 40 Stück mehr Umsatz. Die Erhöhung der Werbeausgaben
Lineare
Mehrfach-
regression

Quantitative Methoden – Deskriptive Statistik - Seite 17 -
Peter Schmidt, Hochschule Bremen MBA
um 10 TEuro erhöht den Absatz um 17 Stück und eine Senkung des Preises um 1 Euro
würde zu einer Erhöhung des Absatzes um knapp 124 Stück führen. Damit ist auch eine
Rangfolge geeigneter Maßnahmen zur Absatzerhöhung erkennbar, die Preissenkung hat in
diesem Beispiel die stärkste Wirkung.
Regressionsanalysen finden in verschiedenen Varianten Anwendung. Die hier besprochene
lineare Regression wird oft auch als „KQ-Regression“ als Abkürzung für Kleinste-
Quadrate-Regression (weil mathematisch die Abstände zwischen den Beobachtungspunk-
ten und der Regressionsgrade quadriert werden und die Gerade dann so gewählt, dass die
Summe dieser quadrierten Abstände möglichst klein wird) oder OLS-Regression von der
englischen Bezeichnung „Ordinary Least Squares“-Regression.
Hinweise zur Durchführung von Regressionsrechnungen finden sich in der Excel-Datei.
1.5 Zeitreihenanalyse und Indexzahlen
Ein weiteres Anwendungsgebiet von Zusammenhangmaßen ergibt sich, wenn die Entwick-
lung eines Merkmals im Zeitablauf betrachtet werden soll, also quasi der Zusammenhang
zwischen diesem Merkmal und der Zeit.
Eine Zeitreihe wird dabei (künstlich) in mehrere Komponenten zerlegt:
Y = Trend-Komponente (+ Konjunktur-Komponente) + Saison-Komponente + Rest-Komponente
Beispielsweise seien Umsatzzahlen für die Quartale von 2005 bis 2008 (Tabelle 9) betrach-
tet, die in Abbildung 13 als Zeitreihe darstellt sind.
Tabelle 9 Zeitreihe einer Umsatzentwicklung (in Mio. Euro) Jahr 2005 2006 2007
Quartal 05-I 05-II 05-III 05-IV 06-I 06-II 06-III 06-IV 07-I 07-II 07-III 07-IV Zeitpunkt t 1 2 3 4 5 6 7 8 9 10 11 12
yt 20,8 23,1 22,9 21,7 24,0 26,3 26,1 24,9 27,2 29,5 29,3 28,1
Abbildung 13 Umsatzentwicklung im Zeitablauf
20,0
22,0
24,0
26,0
28,0
30,0
32,0
05-I 05-II 05-III 05-IV 06-I 06-II 06-III 06-IV 07-I 07-II 07-III 07-IV
Umsatzentwicklung als Zeitreihe
2005 20072006
y = 0,6993x + 20,871
R2 = 0,8051
20,0
22,0
24,0
26,0
28,0
30,0
32,0
05-I 05-II 05-III 05-IV
06-I 06-II 06-III 06-IV
07-I 07-II 07-III 07-IV
Umsatz TEuro
Prognose
Regression
Zeitreihe mit Trendgerade
2005 2006 20082007
Die linke Grafik in Abbildung 13 zeigt die Entwicklung des Umsatzes in den drei Jahren,
wobei erkennbar ist, dass sich in jedem Jahr eine recht regelmäßige Entwicklung wieder-
holt. Die saisonale Komponente zeigt ein Ansteigen des Umsatzes im 1. und 2. Quartal
sowie Rückgänge im 3. und 4. Quartal. Um diese Saisoneinflüsse zu bereinigen und den
Entwicklungstrend betrachten zu können, wird auch hier eine lineare Regression durchge-
führt, deren Ergebnis auf der rechten Seite von Abbildung 13 zu erkennen ist. Die Steigung

Quantitative Methoden – Deskriptive Statistik - Seite 18 -
Peter Schmidt, Hochschule Bremen MBA
der Regressionsgerade ist positiv, d.h. der Umsatztrend geht über die drei Jahre nach oben,
die Rückgänge in der zweiten Jahreshälfte sind nur saisonbedingt.
Es ist erkennbar, dass die Trendkomponente eine Glättung der schwankenden Zeitreihe
darstellt und damit eine Referenzgröße für die Ermittlung der Saisoneinflüsse darstellen
kann. Als weitere Methode zur Glättung von Zeitreihen sind Gleitende Durchschnitte (Mo-
ving Average) üblich, bei der aus jeweils vier Quartalswerten ein Mittelwert gebildet wird.
Die hier verwendete Methode der linearen Trendfunktion hat dabei den Vorteil, dass der
Trend für alle Beobachtungszeitpunkte gebildet werden kann und auch Prognosen über
diesen Zeitraum hinaus vorgenommen werden können.
Diese Möglichkeit sowie die Saisonbereinigung sind in der Excel-Datei dargestellt.
Indexzahlen
Indexzahlen (oder Indizes) sind gewichtete arithmetische Mittelwerte aus Messzahlen. Be-
kannt ist etwa der Preisindex der Lebenshaltung, der durch das Statistische Bundesamt
veröffentlicht wird, aber auch Aktienindizes, wie z.B. der Dow-Jones oder der DAX. Hier
werden die Preisentwicklungen aller Güter und Dienstleistungen, die Haushalte im Durch-
schnitt verbrauchen, zu einer mittleren Preissteigerung zusammengefasst. Dabei werden
die (relativen) Mengen und daraus folgend die Ausgabenanteile für diese Produkte berück-
sichtigt.
Bei Zeitreihenanalysen werden anstelle der absoluten Werte oft Reihen von Indexzahlen verwendet. Diese werden dadurch gebildet, dass ein Basiszeitraum = 100 (Prozent) gesetzt
wird und alle anderen Werte im Bezug auf dieses Basisjahr umgerechnet werden. Entwick-
lungen von Preisen, Umsätzen, Marktanteilen können damit für verschiedene Merkmale
verglichen werden, die eine unterschiedliche absolute Höhe haben und deshalb (z.B. in
einer Grafik) nicht „zusammen passen“. Tabelle 10 zeigt hierfür ein Beispiel.
Tabelle 10 Entwicklung von Unternehmer- und Arbeitnehmereinkommen 1991-2006
Jahr Unternehmer Arbeitnehmer Unternehmer Arbeitnehmer Unternehmer Arbeitnehmer
1991 345,6 847,0 - - 100,0 100,0
1995 400,2 997,0 15,8% 17,7% 115,8 117,7
1996 411,1 1.006,6 2,7% 1,0% 119,0 118,8
1997 427,9 1.010,7 4,1% 0,4% 123,8 119,3
1998 433,8 1.032,3 1,4% 2,1% 125,5 121,9
1999 427,8 1.059,5 -1,4% 2,6% 123,8 125,1
2000 424,4 1.100,1 -0,8% 3,8% 122,8 129,9
2001 440,2 1.120,6 3,7% 1,9% 127,4 132,3
2002 447,8 1.128,3 1,7% 0,7% 129,6 133,2
2003 465,3 1.131,7 3,9% 0,3% 134,6 133,6
2004 513,8 1.136,8 10,4% 0,5% 148,7 134,2
2005 545,9 1.129,3 6,2% -0,7% 158,0 133,3
2006 585,5 1.144,9 7,3% 1,4% 169,4 135,2
239,9 297,9 1,0414 1,0235
Mrd. Euro Mrd. Euro
4,14% 2,35%
Index 1991 = 100
Durchschnittliche
Steigerungsrate* :
entspricht
Absolute Steigerung
1991-2006
in Mrd. Euro Steigerungsrate
Spaltenbezeichnungen: Unternehmer = Einkommen aus Unternehmertätigkeit und Vermögen
Arbeitnehmer = Arbeitnehmer-Einkommen
* Geometrisches Mittel (da Durchschnitt aus Steigerungsraten; vgl. Punkt 1.3) Quelle: eigene Berechnung aus: "Zahlen zur wirtschaftlichen Entwicklung der Bundesrepublik Deutschland"
des IW Köln und Statistisches Jahrbuch 2007, Tab. 6.1
Glättung
von
Zeitreihen-
werten
Index-
zahlen

Quantitative Methoden – Deskriptive Statistik - Seite 19 -
Peter Schmidt, Hochschule Bremen MBA
Das Beispiel in Tabelle 10 zeigt den Unterschied zwischen absoluter und relativer Ent-
wicklung. Könnte auf Basis der ersten beiden Spalten formuliert werden, dass das Arbeit-
nehmereinkommen um mehr als den doppelten Betrag gestiegen ist, so zeigt sowohl die
Betrachtung der Steigerungsraten als auch der Indexzahlen, die so umgerechnet wurden
(Dreisatz), dass das Jahr 1991 den Wert 100,0 annimmt, das gegenteilige Ergebnis. Beide
Maßzahlen ergeben, dass die Einkommen aus Unternehmertätigkeit und Vermögen mit 2,9
Prozent stärker gestiegen sind als die Arbeitnehmer-Einkommen mit 2,4 Prozent.
Das Errechnen von Steigerungsraten oder Indexzahlen hat somit den Vorteil der besseren
Vergleichbarkeit. Auch lassen sich indizierte Werte besser in einer gemeinsamen Grafik
darstellen, wie die folgende Abbildung illustriert.
Abbildung 14 Einkommensentwicklung absolut und als Indexzahlen
0
200
400
600
800
1.000
1.200
1.400
19
91
19
95
19
96
19
97
19
98
19
99
20
00
20
01
20
02
20
03
20
04
20
05
20
06
Unternehmer Arbeitnehmer
80
90
100
110
120
130
140
150
160
170
1991
1995
1996
1997
1998
1999
2000
2001
2002
2003
2004
2005
2006
Unternehmer Arbeitnehmer
2 LITERATURHINWEISE UND WEITERE INFORMATIONEN
Aus der großen Menge guter Statistik-Bücher seien drei herausgegriffen, die jeweils prak-
tische Einführungen in die betriebliche Anwendung darstellen:
Bourier, Günther: „Beschreibende Statistik“ und „Wahrscheinlichkeitsrechung und Schließende Statistik“, Wiesbaden 2008
Backhaus, Erichson, Plinke, Weiber, „Multivariate Analysemethoden: Eine anwendungsorientierte Einführung“, Heidelberg, 2005
Krämer, Walter: ”Statistik verstehen” und: ”So lügt man mit Statistik”, München, 2001, 2000
Puhani, Josef: ”Statistik - Einführung mit praktischen Beispielen”, Würzburg 2005
Scharnbacher, Kurt: "Statistik im Betrieb", Wiesbaden 2004
Schwarze, Jochen: ”Grundlagen der Statistik”, Bände I und II, Herne/Berlin 2005/06
Spaß an der Statistik und trotzdem - oder eben deshalb - viele interessante Informationen
rund um das Thema und seine Anwendungen finden sich in:
Krämer, Walter: „So lügt man mit Statistik” und: „Statistik verstehen”, München 2001

Quantitative Methoden – Deskriptive Statistik - Seite 20 -
Peter Schmidt, Hochschule Bremen MBA
Praktische Arbeit am PC wird mit folgendem sehr empfehlenswerten Buch erleichtert, da
es neben dem theoretischen Hintergrund auch die praktische Umsetzung in Excel zeigt,
Text und Hinweise auf CD-ROM mitliefert und vor allem durch den erfrischenden
Schreibstil die statistische Arbeit zur Freude macht:
Monka, Michael, Schöneck, Nadine und Voß, Werner: ”Statistik am PC - Lösungen mit Ex-
cel”, München 2008
Weitere Information zur (amtlichen) Statistik sowie interessante Datengrundlagen können
im Internet gefunden werden. Wichtige Web-Adressen mit (betriebs-) wirtschaftlich rele-
vanten Informationen finden sich z.B. auf meiner Webseite: http://www.fbw.hs-
bremen.de/pschmidt - unter „links“.
3 SCHLAGWORTINDEX
Deskriptive Statistik .............4
Diskrete Merkmale...............5
Glättung..............................18
Gütemaß .............................15
Häufigkeiten Histogramm......................8 prozentuale Häufigkeiten..7 relative Häufigkeiten ........7 Summenhäufigkeit............8
Indexzahlen ........................18
Induktive Statistik ................4
Klassenbildung.....................7
Kontingenzkoeffizient........13
Korrelationskoeffizient.......12
Merkmale .............................4
Mittelwerte .....................9, 13 arithmetisches Mittel ........9 geometrisches Mittel.........9 Median..............................9 Modus ...............................9
Regression multiple Regression ........16 Regressionsanalyse.........14 Regressionsgrade ............14
Schwankung .........................9
Skalierung ............................5
Stetige Merkmale .................5
Stichprobe.............................4
Streuung ...............................9
Streuungsmaße DAA ...............................10 Spannweite......................10 Standardabweichung.......10 Varianz ...........................10
Zeitreihe .............................17 Trend(gerade) .................17
Zusammenhangmaße..........13

Prof. Dr. Peter Schmidt
SoSe 2008
Volkswirtschaftslehre und Statistik
: (0421) 5905-4691 Fax: (0421) 5905-4862
[email protected] www.fbw.hs-bremen.de/pschmidt
Quantitative Methoden
Master of Business Administration
Modul 2, Unit 2
Teil 2:
Ablauf einer statistischen Untersuchung
Fallbeispiel Studierendenbefragung

Quantitative Methoden Seite 21
Peter Schmidt, Hochschule Bremen 2008
Ablauf einer statistischen Untersuchung
Worum geht’s ? Arbeiten mit statistischen Methoden bedeutet nicht nur „dressieren von Zahlen“, sondern vor allem die präzise Planung und Durchführung realitätsbezogener Analysen
1. Planung1
• Aufgabenstellung Wer Will Was ?
• Zielsetzung Eigenes Ziel: gestellte Aufgabe mit ge-ringstmöglichem Aufwand lösen
• Kosten- und Zeitrahmen Welche Mittel und Welche Zeit stehen maxi-
mal zur Verfügung ?
2. Datenerhebung
2.1. Erhebungstechnik:
• Primärerhebung = Durchführen einer eigenen Befragung
• Sekundärstatistik = Nutzung vorhandener Daten
Primärstatistik Sekundärstatistik
Kosten hoch niedrig
Zeitaufwand hoch niedrig
Zielbezug stark teilweise eingeschränkt
Aktualität aktuell i.d.R. weniger aktuell
2.2. Erhebungsumfang:
Festlegung der Befragten (bzw. zu Befragenden):
• Vollerhebung ⇒ gesamte Gruppe befragen
• Teilerhebung ⇒ Stichprobe aus der Grundgesamtheit notwendig!
Die Stichprobentheorie wird in Abschnitt 8.1
der Vorlesung behandelt
Vollerhebung Teilerhebung
Kosten hoch niedrig
Zeitaufwand hoch niedrig
Aktualität aktuell i.d.R. weniger aktuell
Messgenauigkeit hoch teilweise geringer
Durchführbarkeit oft nicht möglich immer möglich
1 Die Darstellungen und Tabellen dieses Abschnitts basieren teilweise auf Bourier „Beschreibende Statistik“ (2000, S. 25 ff).

Quantitative Methoden Seite 22
Peter Schmidt, Hochschule Bremen 2008
2.3. Art der (Primär-) Erhebung:
• Beobachtung Messung, Zählungen, Sachverständige, usw.
• Schriftliche Befragung Fragebogen
• Mündliche Befragung Interview (telefonisch oder persönlich)
Beobachtung schriftliche Befragung
mündliche Befragung
Kosten eher niedrig eher niedrig eher hoch
Zeitaufwand eher niedrig eher niedrig eher hoch
Aktualität aktuell teilweise lange
Rücklaufzeiten
recht aktuell
Befragungstiefe eher oberflächlich detaillierter detailliert durch
Nachfragen
3. Datenaufbereitung
• Aufbereitung von Fragebogen / Interviewnotizen
• Eingabe in EDV (Statistikprogramm)
• Kontrolle (Vollständigkeit, Glaubwürdigkeit)
4. Auswertung und Darstellung der Daten – Datenanalyse
• Hauptaufgabe ist die „Verdichtung“ der Information
d.h. reduzieren der großen Menge der Rohdaten (Urliste)
auf wenige, aussagekräftige Kennzahlen.
• Die dazu relevanten Methoden werden v.a. im ersten Teil der Vorlesung, der
„Beschreibenden Statistik“ behandelt.
• Analyse:
Wie aus dem Datenmaterial über die reine Beschreibung der Daten hinaus
durch statistische Schlussfolgerungen gezogen werden, behandelt vor allem
der zweite Teil der Vorlesung, der „Schließende Statistik“.
5. Interpretation
• Die Erläuterung und Interpretation der Analyse des Datenmaterials und der
daraus gezogenen Schlüsse ist der Kern der empirischen Arbeit.
• Wenn Sie für einen Auftraggeber oder einen Vorgesetzten eine Statistik aufbe-
reiten sollen, reicht diesem nicht die Sammlung und Darstellung der Daten,
sondern die Kernfragen: „Was bringt die Analyse?“, „Was haben wir ge-
lernt?“ stehen im Zentrum des Interesses.

Quantitative Methoden Seite 23
Peter Schmidt, Hochschule Bremen 2008
Fallbeispiel: Durchführung einer empirischen Untersuchung
Aufgabenstellung
Fallbeispiel:
Planung und Durchführung einer empirischen Untersuchung
Sie sind nach erfolgreich abgeschlossenem Studium MitarbeiterIn der R&H Marktfor-
schung.
Ihrem Unternehmen liegen drei Anfragen von verschiedenen Auftraggebern vor. Sie ha-
ben die Aufgabe, eine empirische Untersuchung durchzuführen, mit der alle 3 Anfragen
beantwortet werden können.
Die Anfragen:
1. Verkehrsträgergesellschaft VBX:
„Für die Planung unserer Streckenführung und Produktpolitik benötigen wir Informationen,
a) welche Studierenden welche Verkehrsmittel benutzen, um zur Hochschule zu kom-
men
b) welches ggf. die Hinderungsgründe für Nicht-Nutzung des ÖPNV sind.“
2. HSC - Hochschule einer norddeutschen Hansestadt:
„Für die Planung von Wohnheimen benötigen wir Informationen darüber, in welchen
Wohnformen Studierende wohnen.“ ...
Für ihr Hochschulmarketing möchte die HSC möglichst genau wissen, welche Studieren-
den eingeschrieben sind („Soziodemographika“: Geschlecht, Bildung, Beruf, praktische
Erfahrung, berufliche Tätigkeiten neben dem Studium, Gesundheit, ... usw.), was diese
sich von ihrem Studium erwarten und auch, wie sie auf die Hochschule aufmerksam ge-
worden sind.
3. Gleichzeitig möchte der Dozent S. in seiner Statistikveranstaltung den Studierenden
gerne Beispieldaten zur eigenen Bearbeitung zur Verfügung stellen.
Dazu benötigt er Informationen darüber, ob den Studierenden privat PC’s zur Verfü-
gung stehen, ob sie ein Tabellenkalkulationsprogramm (z.B. Excel) oder ein Statistik-
Programm zur Verfügung haben und über Kenntnisse im Umgang damit verfügen.
Wie könnte eine statistische Untersuchung dieser Fragestellungen durch die R&H
aussehen (Art der Erhebung)?
An welchen Stellen greifen die Fragestellungen ineinander?
Welche Probleme sehen Sie bei der Auswertung der Daten bzw. welche Besonderhei-
ten müssen Sie beachten?
Diskutieren Sie diese Fragen in Arbeitsgruppen, die sich mit einer der Fragestellungen
befassen und stellen Sie Ihre Ergebnisse anschließend im Plenum vor.

Quantitative Methoden Seite 24
Peter Schmidt, Hochschule Bremen 2008
Fragebogen an die Studierenden des 1. Semesters (nur zum vorlesungsinternen Gebrauch – bitte keinen Namen angeben)
1. Studiengang: 2. Fachsemester: 3.Geschlecht w (1) m(0) 4.Alter: 5.Wohnheimwunsch?
6. Gewicht: 7. Körpergröße: 8. Familienstand: 9. Anzahl Kinder:
10. höchster Bildungsabschluss: Abitur (1) Fachabitur (2) Sonstig. (3)
11. abgeschlossene Berufsausbildung ? Ja (1) Nein (0)
12. Wie lange waren Sie vor Ihrem Studium bereits berufstätig? (Jahre; 0 = Nein)
13. Wenn Sie berufstätig waren:
angestellt (1) selbständig (2) freiberuflich (3)
14. Geburtsort: Bremen (1) Ausland
(20) sonst. D → bitte Bundesland: ........
(2-15)
15. Entfernung (km) Wohnung → HSB
16. Wegzeit (Min) Wohnung → HSB
17. Wichtigstes Verkehrsmittel: für Weg zur Hochschule
18. Weiteres Verkehrsmittel: (bitte je nur ein wichtigstes und ein zweites)
19. Wohnort (Stadt/Gemeinde): + Bremen - City / Wall /Bhf. / ¼ (1) - rechts der Weser West (Gröpell.-Findorff) (2) NO (Schwachh-Horn-Lehe) (3) Ost (4) - links der Weser (5) - Bremen Nord (6) + 50 km umzu (7) + sonstig (8)
20. Nicht-ÖPNV-Nutzer (d.h. 17. Ist nicht Bus / Bahn):
Gründe für Nicht-Nutzung: Zu teuer (1)
Zu langsam (Fahrt) (2) Wartezeiten (3) Erreichbarkeit (4) Umbequemlichkeit (5) sonstiges (6)
21. Aufmerksam geworden auf HS: über Schule (1) Studienführer (2) Veranstaltungen der HS (3) Werbung der HS (4) Zeitung / Medien (5) ....................... (6) sonstiges (7): und zwar: ................................
22. Wohnung: eigenständig (allein / (1) mit PartnerIn / Familie) WG (2) Untermiete (3) Eltern (4) sonstiges (5)
23. Computer privat verfüg-bar: keinen (0) PC (1) wenn bis 486er (1 a) bekannt: Pentium unter 400 Mhz (1 b) Pentium mit mehr als 400 Mhz (1 c)
andere (3)
24. Programme verfügbar: Textverarbeitung (24-1) Tabellenkalkulation (24-2) Grafikprogramm (24-3) Statistikprogramm (24-4)
priv. Internet-Zugang (24-5)
25. Nebenjob J (1) N (0) 26. Einkommen (in 100 Euro)
27. BaFöG J (1) N (0)
Kenntnisse in den folgenden Programmen bitte in einem der Felder ankreuzen (nicht dazwischen) keine wenig ... ... sehr viel 28. Textverarbeitung 29. Tabellenkalkulation 30. Präsentationsprogramm 31. Statistikprogramm 32. Internet-Anwendung 33. Internet-Programmierung (HTML, Java)
0 1 2 3 4
Genaueres zur Tabellenkalkulation Excel: -- Können Sie die folgenden Operationen durchführen: und wie sicher wären Sie sich dabei ? Nein unsicher ... ... sehr sicher 34. Addieren von Zahlen 35. Formeln verwenden 36. Tabelle (für Druck) formatieren 37. Erstellen eines Diagrammes 38. Anlegen einer Pivot-Tabelle 39. (Auto-) Filter benutzen 40. Statistische Auswertungen
41. Erwartungen an das Studium (→ Rückseite)

Quantitative Methoden Seite 25
Peter Schmidt, Hochschule Bremen 2008
Datenaufbereitung
Auswertung: Erster Schritt: Codierung der verbalen Antworten.
Zur Eingabe in ein Statisik-Programm (oder wie hier die Ta-bellenkalkulati-on Excel) müs-sen verbale An-gaben in Zah-lenwerte umge-wandelt werden. Dieser Schritt heißt Codie-rung.
Codierung für Fragebogen Statistik I 21. Aufmerksam 14. Bundesländer 1.Studiengänge geworden über
1 Bremen 1 BW 1 Schule
2 Bayern 2 EFA 2 Studienführer
3 Berlin 3 ISVW 3 Veranst. HS
4 Brandenburg sonstige bitte direkt eintragen 4 Werbung HS
5 Baden-Württemberg 5 Zeitung/Medien
6 Hamburg 17/18. Verkehrsmittel 6 Internet
7 Hessen 1 Bus / Straßenbahn 7
8 Mecklenburg-Vorpommern 2 Bahn (DB) 8
9 Niedersachsen 3 Fahrrad 9 sonstiges
10 Nordrhein-Westfalen 4 zu Fuß (bei Mehrfachnennung alle Zahlen (z.B. 124))
11 Rheinland-Pfalz 5 Auto sonstiges bitte in
12 Saarland 6 sonstiges Textfelder eintragen
13 Sachsen 41. Erwartungen an Studium14 Sachsen-Anhalt Mehrfachnennungen: 41.1 praxisorientierter Stoff
15 Schleswig-Holstein 41.2 Möglichst guten Job
16 Thüringen 41.3 Interessante Inhalte
41.4 Allgemeinwissen
20 Ausland 41.5
....
41.9 sonstiges
Eingabe der Daten.
Frage 1 2 3 4 5 6 7 8 9 10
Übung Stud-GangSemester Geschlecht Alter Raucher Gewicht Groesse FamStandKinder Bildung
1 0 1 1 1 19 0 65 179 1 0 2
2 0 1 1 1 20 1 57 170 1 0 2
3 0 1 1 1 22 0 64 166 1 0 2
4 0 1 1 1 23 1 57 171 1 0 2
5 0 1 1 1 20 0 46,5 163 1 0 1
6 0 1 1 0 29 1 72 182 0 1 2
7 1 3 1 0 20 0 72 185 1 0 2
8 1 3 1 0 26 0 83 170 0 1 1
9 1 3 1 1 19 0 56 178 1 0 1
10 1 3 1 0 21 0 92 192 1 0 1
11 1 3 1 0 22 0 65 173 1 0 1
12 1 3 1 0 21 0 69 180 1 0 1
13 1 3 1 0 21 1 69 178 1 0 1
14 1 3 1 0 21 1 76 180 1 0 1
15 1 3 1 0 26 1 84 180 1 0 3
16 1 3 1 1 20 0 65 166 1 0 1
17 1 3 1 1 25 0 46 164 1 0 3
18 1 3 1 0 22 1 85 188 1 0 1
19 1 1 1 0 24 0 86 198 1 0 1
20 2 1 1 0 24 0 65 178 1 0 1
21 2 1 1 0 24 0 83 193 1 0 2
22 2 1 1 24 1 70 180 1 0 2
In jeder Zeile befindet sich ein Datensatz, d.h. eine befragte Person. In jeder Spalte finden sich die Angaben zu einer bestimmten Frage. Deshalb beinhalten die Spaltenköpfe die Fragennummern und die Bezeichnung der Merkmale.

Quantitative Methoden Seite 26
Peter Schmidt, Hochschule Bremen 2008
Analyse der Daten durch statistische Maße - Möglichkeiten in Excel (2003)
Einfache Statistische Maße
In der Excel-Datei (www.fbw.hs-bremen.de/pschmidt/FraBoDat2001.xls) ist diese Tabelle noch ausführli-cher:
• in den obersten Zeilen werden einfache beschreibende Statistiken dargestellt (Anm: Anmerkung zu diesem Merkmal“; MW: (arithmetischer) Mittelwert; Antworten: Anzahl der gültigen Antworten auf diese Frage; Min: Kleinster Wert; Max: Größter Wert; StAbw: Standardabweichung)
• Es wurden Spalten mit verbalen Erläuterungen und „Indikatormerkmalen“ eingefügt. Ein Indikatormerkmal nimmt den Wert 1 an, wenn ein Merkmal gegeben ist, sonst ist es 0. Beispiel Geschlecht: eine 1 in der dritten Spalte bedeutet, dass diese Zeile die Angaben einer Studentin bein-halten.
Frage 1 1.1 1.2 1.3 2 2.a 3 3-T 4 4-Text 4.1 4.2 4.3
Stud-GangStudGangSg_BW Sg_Efa Sg_VW Semester ErstSemesterGeschlecht GeschlechtTAlter AltersgruppeA_bis22 A_23-25 A_26+
Anm (1-3) 1. Sem 1=weiblich (3 Klassen)
MW 0,74 0,19 0,07 1,07 0,97 0,47 23,16 0,41 0,43 0,16
Antworten 163 163 163 163 152 152 162 160 164 160 160 160
Min 1 0 0 0 1 0 0 18 0 0 0
Max 3 1 1 1 5 1 1 32 1 1 1
StAbW 0,44 0,39 0,26 0,46 0,16 0,50 2,65 0,49 0,50 0,36
Nr Stud-GangStudGangSg_BW Sg_Efa Sg_VW Semester ErstSemesterGeschlecht GeschlechtTAlter AltersgruppeA_bis22 A_23-25 A_26+
1 1 BW 1 0 0 1 1 1 weiblich 19 22-jünger 1 0 0
2 1 BW 1 0 0 1 1 1 weiblich 20 22-jünger 1 0 0
3 1 BW 1 0 0 1 1 1 weiblich 22 22-jünger 1 0 0
4 1 BW 1 0 0 1 1 1 weiblich 23 23-25 0 1 0
5 1 BW 1 0 0 1 1 1 weiblich 20 22-jünger 1 0 0
6 1 BW 1 0 0 1 1 0 männlich 29 26++ 0 0 1
7 3 ISVW 0 0 1 1 1 0 männlich 20 22-jünger 1 0 0
8 3 ISVW 0 0 1 1 1 0 männlich 26 26++ 0 0 1
9 3 ISVW 0 0 1 1 1 1 weiblich 19 22-jünger 1 0 0
10 3 ISVW 0 0 1 1 1 0 männlich 21 22-jünger 1 0 0
11 3 ISVW 0 0 1 1 1 0 männlich 22 22-jünger 1 0 0
12 3 ISVW 0 0 1 1 1 0 männlich 21 22-jünger 1 0 0
13 3 ISVW 0 0 1 1 1 0 männlich 21 22-jünger 1 0 0
14 3 ISVW 0 0 1 1 1 0 männlich 21 22-jünger 1 0 0
15 3 ISVW 0 0 1 1 1 0 männlich 26 26++ 0 0 1
Pivot-Tabellen
Ein wesentliches Mittel zur Analyse von Daten in Excel sind Pivot-Tabellen. In Excel finden Sie diese im Menü Daten - PivotTable. Es sind Zeilen, Spalten und Inhalt der Tabellen anzugeben. Interessieren wir uns beispielsweise für die Anzahl der Befragten nach Alter und Geschlecht, bietet sich ein solches Tabellenlayout an:

Quantitative Methoden Seite 27
Peter Schmidt, Hochschule Bremen 2008
Die Pivot-Tabelle zeigt dann folgende Auszählung:
Anzahl - Nr Altersgruppe
GeschlechtT 22-jünger 23-25 26++ Gesamtergebnis
weiblich 41 25 9 75
männlich 25 44 16 85
Gesamtergebnis 66 69 25 160
Also 160 Befragte (eigentlich 164, aber nur 160 haben Alter und Geschlecht angegeben), von denen 85 Männer waren, 9 Frauen über 25 Jahre, usw.) Diese Darstellung von Anzahlen wird in der Statis-tik als absolute Häufigkeit bezeichnet.
Wir könnten den Inhalt der Tabelle auch an (Prozent-) Anteile darstellen lassen.
Anzahl - Nr Altersgruppe
GeschlechtT 22-jünger 23-25 26++ Gesamtergebnis
weiblich 62% 36% 36% 47%
männlich 38% 64% 64% 53%
Gesamtergebnis 100% 100% 100% 100%
Diese Darstellung von Anzahlen wird in der Statistik als relative Häufigkeit (hier dargestellt als „Zeilenprozente“) bezeichnet.
In Pivot-Tabellen können aber auch Anteile, Mittelwerte, Schwankungsmaße u.a. angegeben wer-den. Dies sind zwar Maße, die erst im weiteren Verlauf der Vorlesung behandelt werden, aber neh-men wir den allgemein bekannten Mittelwert (das „arithmetische Mittel“), zum Beispiel den des Merkmals „Berufsausbildung“:
Mittelwert - Berufsausb.Altersgruppe
GeschlechtT 22-jünger 23-25 26++ Gesamtergebnis
weiblich 44% 84% 78% 61%
männlich 12% 88% 88% 65%
Gesamtergebnis 32% 87% 84% 64%
Zur Interpretation dieser Anteilswerte ist zu beachten, dass das Merkmal Berufsausbildung ein „In-dikatormerkmal“ ist, ein Merkmal, das nur die Werte 0 oder 1 annehmen kann. Der Wert 1 steht für die Ausprägung „Ja“, der Wert 0 entsprechend für die Ausprägung „Nein“. Der Mittelwert eines Indikatormerkmals gibt direkt den Anteil der Personen mit Berufsausbildung an. Solche Mittelwerte von Indikatormerkmalen (oder auch „Indikatorvariablen“) werden wir im folgenden sehr oft anschauen, einfach weil es so praktisch ist, gleich mit dem Mittelwert den Anteil der Befragten zu erhalten, die ein bestimmtes Merkmal haben.
Wenn Sie sich die große Tabelle der folgenden Seiten anschauen, sehen Sie, dass dort sogar eine ganze Menge von Merkmalen so „umcodiert“ wurden, dass sie wieder Indika-tormerkmale sind. Beispielsweise das Alter, das in die drei Indikatorvariablen „A_bis22“, „A_23bis25“ und „A_26plus“ umgewandelt wurde. Die Prozentanteile 0,41; 0,49 und 0,16 addieren sich naturgemäß zu 100. Analog wurde mit dem Bildungsabschluss „B_...“, dem Berufsstatuts „St_...“, dem Geburtsort „G_...“ verfahren. Viel Spaß beim Daten-stöbern.
Wir dürfen gespannt sein, ob die Ergebnisse der diesjährigen Befragung anders sind ...
Quantitative Methoden Seite 28
Peter Schmidt, Hochschule Bremen 2008
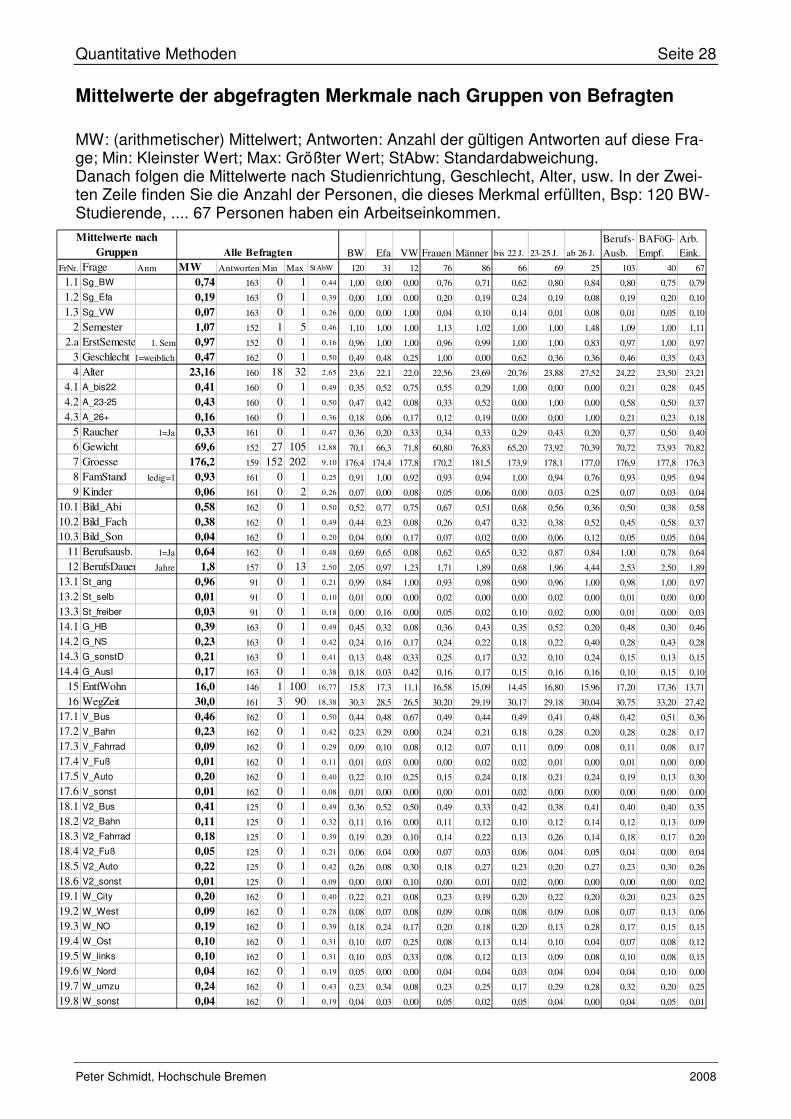
Mittelwerte der abgefragten Merkmale nach Gruppen von Befragten
MW: (arithmetischer) Mittelwert; Antworten: Anzahl der gültigen Antworten auf diese Fra-ge; Min: Kleinster Wert; Max: Größter Wert; StAbw: Standardabweichung. Danach folgen die Mittelwerte nach Studienrichtung, Geschlecht, Alter, usw. In der Zwei-ten Zeile finden Sie die Anzahl der Personen, die dieses Merkmal erfüllten, Bsp: 120 BW-Studierende, .... 67 Personen haben ein Arbeitseinkommen.
Alle Befragten BW Efa VW Frauen Männer bis 22 J. 23-25 J. ab 26 J.
Berufs-
Ausb.
BAFöG-
Empf.
Arb.
Eink.
FrNr. Frage Anm MW Antworten Min Max StAbW 120 31 12 76 86 66 69 25 103 40 67
1.1 Sg_BW 0,74 163 0 1 0,44 1,00 0,00 0,00 0,76 0,71 0,62 0,80 0,84 0,80 0,75 0,79
1.2 Sg_Efa 0,19 163 0 1 0,39 0,00 1,00 0,00 0,20 0,19 0,24 0,19 0,08 0,19 0,20 0,10
1.3 Sg_VW 0,07 163 0 1 0,26 0,00 0,00 1,00 0,04 0,10 0,14 0,01 0,08 0,01 0,05 0,10
2 Semester 1,07 152 1 5 0,46 1,10 1,00 1,00 1,13 1,02 1,00 1,00 1,48 1,09 1,00 1,11
2.a ErstSemester 1. Sem 0,97 152 0 1 0,16 0,96 1,00 1,00 0,96 0,99 1,00 1,00 0,83 0,97 1,00 0,97
3 Geschlecht 1=weiblich 0,47 162 0 1 0,50 0,49 0,48 0,25 1,00 0,00 0,62 0,36 0,36 0,46 0,35 0,43
4 Alter 23,16 160 18 32 2,65 23,6 22,1 22,0 22,56 23,69 20,76 23,88 27,52 24,22 23,50 23,21
4.1 A_bis22 0,41 160 0 1 0,49 0,35 0,52 0,75 0,55 0,29 1,00 0,00 0,00 0,21 0,28 0,45
4.2 A_23-25 0,43 160 0 1 0,50 0,47 0,42 0,08 0,33 0,52 0,00 1,00 0,00 0,58 0,50 0,37
4.3 A_26+ 0,16 160 0 1 0,36 0,18 0,06 0,17 0,12 0,19 0,00 0,00 1,00 0,21 0,23 0,18
5 Raucher 1=Ja 0,33 161 0 1 0,47 0,36 0,20 0,33 0,34 0,33 0,29 0,43 0,20 0,37 0,50 0,40
6 Gewicht 69,6 152 27 105 12,88 70,1 66,3 71,8 60,80 76,83 65,20 73,92 70,39 70,72 73,93 70,82
7 Groesse 176,2 159 152 202 9,10 176,4 174,4 177,8 170,2 181,5 173,9 178,1 177,0 176,9 177,8 176,3
8 FamStand ledig=1 0,93 161 0 1 0,25 0,91 1,00 0,92 0,93 0,94 1,00 0,94 0,76 0,93 0,95 0,94
9 Kinder 0,06 161 0 2 0,26 0,07 0,00 0,08 0,05 0,06 0,00 0,03 0,25 0,07 0,03 0,04
10.1 Bild_Abi 0,58 162 0 1 0,50 0,52 0,77 0,75 0,67 0,51 0,68 0,56 0,36 0,50 0,38 0,58
10.2 Bild_Fach 0,38 162 0 1 0,49 0,44 0,23 0,08 0,26 0,47 0,32 0,38 0,52 0,45 0,58 0,37
10.3 Bild_Son 0,04 162 0 1 0,20 0,04 0,00 0,17 0,07 0,02 0,00 0,06 0,12 0,05 0,05 0,04
11 Berufsausb. 1=Ja 0,64 162 0 1 0,48 0,69 0,65 0,08 0,62 0,65 0,32 0,87 0,84 1,00 0,78 0,64
12 BerufsDauer Jahre 1,8 157 0 13 2,50 2,05 0,97 1,23 1,71 1,89 0,68 1,96 4,44 2,53 2,50 1,89
13.1 St_ang 0,96 91 0 1 0,21 0,99 0,84 1,00 0,93 0,98 0,90 0,96 1,00 0,98 1,00 0,97
13.2 St_selb 0,01 91 0 1 0,10 0,01 0,00 0,00 0,02 0,00 0,00 0,02 0,00 0,01 0,00 0,00
13.3 St_freiber 0,03 91 0 1 0,18 0,00 0,16 0,00 0,05 0,02 0,10 0,02 0,00 0,01 0,00 0,03
14.1 G_HB 0,39 163 0 1 0,49 0,45 0,32 0,08 0,36 0,43 0,35 0,52 0,20 0,48 0,30 0,46
14.2 G_NS 0,23 163 0 1 0,42 0,24 0,16 0,17 0,24 0,22 0,18 0,22 0,40 0,28 0,43 0,28
14.3 G_sonstD 0,21 163 0 1 0,41 0,13 0,48 0,33 0,25 0,17 0,32 0,10 0,24 0,15 0,13 0,15
14.4 G_Ausl 0,17 163 0 1 0,38 0,18 0,03 0,42 0,16 0,17 0,15 0,16 0,16 0,10 0,15 0,10
15 EntfWohn 16,0 146 1 100 16,77 15,8 17,3 11,1 16,58 15,09 14,45 16,80 15,96 17,20 17,36 13,71
16 WegZeit 30,0 161 3 90 18,38 30,3 28,5 26,5 30,20 29,19 30,17 29,18 30,04 30,75 33,20 27,42
17.1 V_Bus 0,46 162 0 1 0,50 0,44 0,48 0,67 0,49 0,44 0,49 0,41 0,48 0,42 0,51 0,36
17.2 V_Bahn 0,23 162 0 1 0,42 0,23 0,29 0,00 0,24 0,21 0,18 0,28 0,20 0,28 0,28 0,17
17.3 V_Fahrrad 0,09 162 0 1 0,29 0,09 0,10 0,08 0,12 0,07 0,11 0,09 0,08 0,11 0,08 0,17
17.4 V_Fuß 0,01 162 0 1 0,11 0,01 0,03 0,00 0,00 0,02 0,02 0,01 0,00 0,01 0,00 0,00
17.5 V_Auto 0,20 162 0 1 0,40 0,22 0,10 0,25 0,15 0,24 0,18 0,21 0,24 0,19 0,13 0,30
17.6 V_sonst 0,01 162 0 1 0,08 0,01 0,00 0,00 0,00 0,01 0,02 0,00 0,00 0,00 0,00 0,00
18.1 V2_Bus 0,41 125 0 1 0,49 0,36 0,52 0,50 0,49 0,33 0,42 0,38 0,41 0,40 0,40 0,35
18.2 V2_Bahn 0,11 125 0 1 0,32 0,11 0,16 0,00 0,11 0,12 0,10 0,12 0,14 0,12 0,13 0,09
18.3 V2_Fahrrad 0,18 125 0 1 0,39 0,19 0,20 0,10 0,14 0,22 0,13 0,26 0,14 0,18 0,17 0,20
18.4 V2_Fuß 0,05 125 0 1 0,21 0,06 0,04 0,00 0,07 0,03 0,06 0,04 0,05 0,04 0,00 0,04
18.5 V2_Auto 0,22 125 0 1 0,42 0,26 0,08 0,30 0,18 0,27 0,23 0,20 0,27 0,23 0,30 0,26
18.6 V2_sonst 0,01 125 0 1 0,09 0,00 0,00 0,10 0,00 0,01 0,02 0,00 0,00 0,00 0,00 0,02
19.1 W_City 0,20 162 0 1 0,40 0,22 0,21 0,08 0,23 0,19 0,20 0,22 0,20 0,20 0,23 0,25
19.2 W_West 0,09 162 0 1 0,28 0,08 0,07 0,08 0,09 0,08 0,08 0,09 0,08 0,07 0,13 0,06
19.3 W_NO 0,19 162 0 1 0,39 0,18 0,24 0,17 0,20 0,18 0,20 0,13 0,28 0,17 0,15 0,15
19.4 W_Ost 0,10 162 0 1 0,31 0,10 0,07 0,25 0,08 0,13 0,14 0,10 0,04 0,07 0,08 0,12
19.5 W_links 0,10 162 0 1 0,31 0,10 0,03 0,33 0,08 0,12 0,13 0,09 0,08 0,10 0,08 0,15
19.6 W_Nord 0,04 162 0 1 0,19 0,05 0,00 0,00 0,04 0,04 0,03 0,04 0,04 0,04 0,10 0,00
19.7 W_umzu 0,24 162 0 1 0,43 0,23 0,34 0,08 0,23 0,25 0,17 0,29 0,28 0,32 0,20 0,25
19.8 W_sonst 0,04 162 0 1 0,19 0,04 0,03 0,00 0,05 0,02 0,05 0,04 0,00 0,04 0,05 0,01
Mittelwerte nach Gruppen

Quantitative Methoden Seite 29
Peter Schmidt, Hochschule Bremen 2008
Alle Befragten BW Efa VW Frauen Männer bis 22 J. 23-25 J. ab 26 J.
Berufs-
Ausb.
BAFöG-
Empf.
Arb.
Eink.
FrNr. Frage Anm MW Antworten Min Max StAbW 120 31 12 76 86 66 69 25 103 40 67
20.1 NoÖV_teuer 0,10 52 0 1 0,30 0,10 0,00 0,25 0,00 0,17 0,05 0,05 0,38 0,09 0,09 0,10
20.2 NoÖV_langsam 0,46 52 0 1 0,50 0,46 0,33 0,75 0,43 0,48 0,55 0,36 0,50 0,38 0,27 0,52
20.3 NoÖV_WarteZeit 0,42 52 0 1 0,50 0,41 0,33 0,75 0,22 0,59 0,36 0,45 0,50 0,29 0,45 0,38
20.4 NoÖV_Erreichb. 0,12 52 0 1 0,32 0,12 0,00 0,00 0,17 0,07 0,09 0,14 0,13 0,09 0,18 0,10
20.5 NoÖV_unbequem 0,40 52 0 1 0,50 0,41 0,17 0,75 0,22 0,55 0,32 0,50 0,38 0,32 0,27 0,34
20.6 NoÖV_sonst 0,17 52 0 1 0,38 0,17 0,33 0,00 0,22 0,14 0,18 0,18 0,13 0,21 0,18 0,17
21.1 Auf_Schule Ja 0,16 162 0 1 0,37 0,20 0,00 0,17 0,11 0,21 0,14 0,18 0,20 0,14 0,15 0,18
21.2 Auf_StFührer Ja 0,27 162 0 1 0,45 0,26 0,32 0,25 0,30 0,23 0,33 0,25 0,08 0,23 0,26 0,24
21.3 Auf_HSB Ja 0,08 162 0 1 0,27 0,09 0,06 0,08 0,11 0,06 0,03 0,13 0,08 0,12 0,13 0,08
21.4 Auf_Werb Ja 0,06 162 0 1 0,23 0,06 0,03 0,08 0,07 0,05 0,08 0,01 0,12 0,07 0,03 0,06
21.5 Auf_Medien Ja 0,06 162 0 1 0,24 0,04 0,16 0,00 0,07 0,06 0,11 0,04 0,00 0,04 0,03 0,03
21.6 Auf_WWW Ja 0,07 162 0 1 0,25 0,03 0,16 0,25 0,09 0,05 0,11 0,04 0,04 0,04 0,05 0,05
22.1 WO_Eigen 0,40 163 0 1 0,49 0,46 0,27 0,17 0,32 0,48 0,23 0,42 0,80 0,48 0,40 0,43
22.2 WO_WG 0,16 163 0 1 0,37 0,10 0,33 0,33 0,19 0,14 0,22 0,13 0,12 0,13 0,20 0,19
22.3 WO_Unt 0,04 163 0 1 0,20 0,02 0,10 0,17 0,07 0,02 0,06 0,01 0,04 0,01 0,05 0,01
22.4 WO_Eltern 0,37 163 0 1 0,49 0,41 0,23 0,33 0,40 0,35 0,46 0,42 0,04 0,37 0,35 0,34
22.5 WO_sonst 0,02 163 0 1 0,13 0,01 0,07 0,00 0,03 0,01 0,03 0,01 0,00 0,02 0,00 0,01
23.1 Kein_PC keinen 0,12 157 0 1 0,33 0,11 0,10 0,18 0,18 0,06 0,13 0,15 0,00 0,09 0,11 0,11
23.2 PC_allg(486 oder unbekannt)Ja 0,13 158 0 1 0,34 0,14 0,10 0,17 0,19 0,08 0,14 0,11 0,16 0,14 0,11 0,13
23.3 P-400 Ja 0,36 158 0 1 0,48 0,38 0,31 0,33 0,30 0,42 0,33 0,35 0,52 0,40 0,38 0,36
23.3 P400++ Ja 0,27 158 0 1 0,45 0,24 0,34 0,33 0,15 0,39 0,27 0,32 0,20 0,27 0,30 0,27
23.4 PC_Mac Ja 0,00 158 0 0 0,00 0,00 0,00 0,00 0,00 0,00 0,00 0,00 0,00 0,00 0,00 0,00
23.5 PC_anders Ja 0,11 158 0 1 0,32 0,12 0,14 0,00 0,19 0,05 0,14 0,08 0,12 0,10 0,11 0,13
24.1 Pg_Text Ja 0,88 162 0 1 0,32 0,89 0,84 1,00 0,88 0,91 0,88 0,87 1,00 0,91 0,83 0,90
24.2 Pg_Tabk Ja 0,78 162 0 1 0,42 0,79 0,77 0,67 0,71 0,86 0,74 0,78 0,96 0,84 0,75 0,82
24.4 Pg_Grafik Ja 0,51 162 0 1 0,50 0,56 0,45 0,25 0,49 0,53 0,45 0,50 0,72 0,53 0,50 0,58
24.5 Pg_Stat Ja 0,08 162 0 1 0,27 0,10 0,03 0,00 0,11 0,06 0,06 0,07 0,16 0,10 0,08 0,12
24.6 Pg_InterNet Ja 0,65 162 0 1 0,48 0,62 0,65 0,92 0,60 0,71 0,59 0,62 0,96 0,69 0,55 0,73
25 Arbeit Ja 0,49 138 0 1 0,50 0,52 0,28 0,58 0,45 0,51 0,52 0,42 0,63 0,49 0,50 1,00
26 Einkommenin 100 DM-Kl. 3,42 90 0 150 15,92 4,51 0,87 0,85 1,48 4,71 2,03 5,47 1,87 4,66 1,29 4,55
27 BAFöG Ja 0,30 132 0 1 0,46 0,30 0,36 0,17 0,23 0,37 0,19 0,36 0,50 0,37 1,00 0,32
28 Kn_Text (1-5) 2,63 163 0 5 1,01 2,61 3,03 1,83 2,63 2,62 2,48 2,80 2,68 2,88 2,75 2,68
29 Kn_Tabk Ja 1,81 162 0 5 1,20 1,84 2,27 0,58 1,62 2,00 1,55 2,01 2,08 2,21 1,90 1,95
30 Kn_Präs Ja 0,93 162 0 4 1,06 0,85 1,60 0,25 0,74 1,13 0,88 0,93 1,24 1,11 0,80 0,89
31 Kn_Stat Ja 0,32 159 0 3 0,60 0,31 0,41 0,27 0,21 0,43 0,33 0,27 0,50 0,31 0,41 0,40
32 Kn_InterNet Ja 2,10 162 0 4 1,08 2,05 2,37 2,00 2,00 2,19 2,02 2,16 2,24 2,25 2,05 2,28
33 Kn_HTML Ja 0,28 162 0 4 0,66 0,25 0,30 0,58 0,12 0,43 0,23 0,25 0,52 0,31 0,23 0,40
34 X-Addition Ja 2,76 162 0 5 1,53 2,81 3,33 1,00 2,62 2,92 2,45 3,04 3,04 3,17 2,98 2,66
35 X-Formeln Ja 2,02 162 0 5 1,43 2,05 2,57 0,50 1,89 2,14 1,80 2,16 2,36 2,40 2,20 1,92
36 X-formatieren Ja 2,10 162 0 12 1,74 2,17 2,63 0,33 1,93 2,27 1,97 2,19 2,40 2,55 2,18 2,17
37 X-Diagramm Ja 1,93 161 0 37 3,16 1,99 2,48 0,25 1,52 2,32 2,16 1,70 2,20 2,14 1,90 1,78
38 X-Pivot Ja 0,54 162 0 5 0,89 0,53 0,80 0,08 0,49 0,60 0,56 0,46 0,72 0,69 0,60 0,62
39 X-Filter Ja 0,92 162 0 5 1,34 0,85 1,57 0,08 0,80 1,05 0,84 0,88 1,32 1,27 1,03 1,08
40 X-Statistik Ja 0,55 162 0 5 0,86 0,49 1,00 0,08 0,47 0,63 0,67 0,46 0,52 0,64 0,48 0,60
41.1 Erw_Praxis Ja 0,37 94 0 1 0,49 0,37 0,47 0,25 0,50 0,29 0,51 0,28 0,20 0,32 0,34 0,22
41.2 Erw_Job Ja 0,41 93 0 1 0,49 0,38 0,67 0,18 0,48 0,36 0,41 0,37 0,47 0,47 0,38 0,28
41.3 Erw_Inhalte Ja 0,23 94 0 1 0,43 0,26 0,33 0,00 0,21 0,25 0,18 0,23 0,40 0,35 0,24 0,17
41.4 Erw_Allgem Ja 0,14 94 0 1 0,35 0,17 0,07 0,08 0,09 0,17 0,05 0,15 0,33 0,21 0,10 0,06
Mittelwerte nach Gruppen

Quantitative Methoden Seite 30
Peter Schmidt, Hochschule Bremen 2008
Hinweise zur Erstellung von Fragebogen
Es sollen hier einige (technische) Hinweise zur Erstellung von Fragebogen (in Word) ge-geben werden, die zum einen die Erstellung / Layout betreffen, zum zweiten aber auch bereits die Erfassung vorbereitend erleichtern.
Allgemeines
Ein Fragebogen sollte ansprechend aussehen und nicht durch seine bloße äußere Form abschrecken. Zu Beginn bietet sich (als Blickfang) an, das Logo oder die Logos der betei-ligten Institutionen auf den Kopf des Fragebogens zu platzieren.
Nach einer kurzen Anrede sollte der Bogen mit Fragen beginnen, die in das Thema ein-führen und das Interesse der Befragten wecken. Zu vermeiden sind hier allgemeine An-gaben über Alter, Geschlecht, Situation, ...., diese gehören an den Schluss des Bogens.
Fragen
Die Fragen sollten fortlaufend nummeriert werden, diese Nummerierung dient später auch als Variablennummer in der Auswertungsdatei. (siehe jeweils Beispiel unten)
Es ist zu unterscheiden zwischen offenen Fragen (Raum für Einträge - V1) und ge-schlossenen Fragen (Items zum Ankreuzen vorgegeben). Bei letzteren ist schon im Vor-feld zu klären, ob nur eine Alternative gewählt werden kann, oder Mehrfachnennungen möglich sind. Im ersten Fall sind die Items Ausprägungen der Variable (V2), im zweiten Fall ist jede der möglichen Nennungen eine Variable (V2 - V5).
Beispiel:
1. Wie oft waren Sie im letzten Jahr in der Kunsthalle Bremen? (V1)
____________________Mal
2. Sie Sind hergekommen, um sich anzusehen: (V2)
(1) nur die Sonderausstellung
(2) nur die ständige Sammlung
(3) beides
3. Was hat Sie dazu bewegt, die Sonderausstellung „Der Blaue Reiter“ zu
besuchen?
Werbemaßnahmen (V3)
Mund Propaganda (V4)
Sonstiges ____________________ (V5)
Technische Hinweise zum Nummerieren: Die Nummerierung wurde mittels Feldern (in WinWord - siehe ggf. Hilfe-Funktion) erzeugt und es wird nachdrücklich empfohlen, dies zu tun, da sonst jede Verschiebung der Fragenreihenfolge mit erheblichem Aufwand ver-

Quantitative Methoden Seite 31
Peter Schmidt, Hochschule Bremen 2008
bunden ist. Sie können erkennen, wie die Nummerierung erzeugt sind, indem Sie in die-sem (WinWord-) Dokument die Feldfunktionen sichtbar machen. Dies geht entweder über das Menu Extras-Optionen-Ansicht-Feldfunktionen oder mittels der Tastenkombination Alt-F9. Sie erkennen dann, dass in diesem Beispiel die Funktion Seq (sequentielles Nummerie-ren) in zwei Varianten benutzt wird. Die Fragen werden nummeriert mittels Seq f, der einfachsten Anwendung dieses Feldes - f ist dabei eine beliebige Bezeichnung, diese kann frei gewählt werden, Word nummeriert alle Seq-Felder mit der gleichen Bezeichnung aufsteigend. Die Fragen sind nummeriert, indem eine andere Bezeichnung verwendet wird; (VSeq Frage) erzeugt die Variablennummern, bei denen der Buchstabe V unmittel-bar von der Zahl gefolgt wird. Bei der Nummerierung der Alternativen ist es erforderlich, dass diese in jeder Frage wieder von vorne beginnt. Daher muss bei der ersten Alternative der Schalter „\r 1“ gesetzt werden (renumber): (Seq Alt \r 1), danach wird laufend nummeriert: (Seq Alt).
Pretest
Wenn machbar, ist es sehr sinnvoll, einen Pretest durchzuführen, d.h. den Fragebogen mit einigen Test-Personen auszuprobieren und die Daten einzugeben. Die Testpersonen sollten nach Anregungen gefragt, der Fragebogen - nach Feedback und Dateneingabe - auf mögliche Inkonsistenzen untersucht und diese vor der Hauptbefragung beseitigt wer-den.
Diesen Text und auch ein Anwendungsbeispiel (Fragebogen als Word-Datei sowie Daten
und Auswertung als Excel-Dateien) finden Sie auf der Webseite für den MBA-Kurs.

Material zur
Schließenden Statistik
Inhalt
1. Kombinatorik & Wahrscheinlichkeitsrechnung........................................34
Definition von Wahrscheinlichkeiten .................................................................................. 35
Rechnen mit Wahrscheinlichkeiten...................................................................................... 36
2. Theoretische Verteilungen............................................................................38
Wahrscheinlichkeits-Dichte – und Verteilungsfunktion ...................................................... 38
Stetige Verteilungen............................................................................................................. 39
Zentraler Grenzwertsatz ....................................................................................................... 42
3. Schluss von der Stichprobe auf die Grundgesamtheit...............................44
3.1 Schätztheorie .................................................................................................................. 44
3.2 Konfidenzintervalle (für den Mittelwert) .................................................................... 44
3.3 Hypothesentests.............................................................................................................. 46
3.4 Parametrische Tests........................................................................................................ 49
3.4.1 Testen von Mittelwerten................................................................................................................. 49
3.4.2 Zweistichprobentests ...................................................................................................................... 53
3.4.3 Testen der Aussagekraft der Regressionskoeffizienten bei Multipler Regression .......................... 54
3.4.4 Fallbeispiel College Town.............................................................................................................. 55

Schließende Statistik 1 Kombinatorik & Wahrscheinlichkeitsrechnung
P. Schmidt, Hochschule Bremen Seite 33
=
Stichprobe Grundgesamtheit
ermittelt werden z.B. Statistiken Parameter
Mittelwert µ
Standardabweichung s σ
Anzahl der Beobachtungen n Ν
Beispiel:
Als Leiter der Qualitätsabteilung einer Glühbirnenfirma, muss ich wissen, wie lange die pro-
duzierten Glühbirnen im Durchschnitt brennen. Problem: Ich kann nicht alle ausprobieren ...
Deshalb entnehme ich aus der laufenden Produktion 20 Glühbirnen und messe, wie lange die-
se brennen. Es ergibt sich eine durchschnittliche Brenndauer von 290 Stunden
Grundgesamtheit
Stichprobe
x = 290 Stunden s= 30 Stunden
Auf dieser Basis schätze ich ab (statistischer Schluss), dass auch die Grundgesamtheit der
Glühbirnen eine Brenndauer von 290 Stunden hat, stimmt das?
Ausgangspunkt: Man will allgemeine Aussagen über die Grundgesamtheit treffen, diese
ist jedoch gar nicht näher bekannt ( z.B. Mittelwert, Standardabweichung etc.)
Bekannt sind dagegen Aussagen über eine Stichprobe
Ziel: Schluss von der Stichprobe →→→→ auf die Grundgesamtheit

Schließende Statistik 1 Kombinatorik & Wahrscheinlichkeitsrechnung
P. Schmidt, Hochschule Bremen Seite 34
Problem: Wie groß ist die Wahrscheinlichkeit,
„6 Richtige“ im Lotto zu haben?
1. Kombinatorik & Wahrscheinlichkeitsrechnung
Schon in der Antike tritt der Gedanke auf, dass die Naturgesetze durch eine sehr große Anzahl von zufälligen Ereignissen zur Geltung kommen. Die Aufdeckung der Gesetzmäßigkeiten, auf deren Auftreten zahlreiche individuelle Einflüsse einwirken, die nicht oder fast nicht mitein-ander verbunden sind, war auch Ziel der Gelehrten, die die Wahrscheinlichkeitsrechnung we-sentlich beeinflussten.
Vor allem die mit Glücksspielen zusammenhängenden Probleme bildeten den Anlass dafür, dass sich bedeutende Gelehrte mit Fragen der Zufälligkeit von Ereignissen u.a. beschäftigten.
Problem: Wie groß ist die Wahrscheinlichkeit, eine „6“ zu würfeln?
Anzahl der günstigen Ausgänge __________________ Anzahl der möglichen Ausgänge
W = = = =
Anzahl der günstigen Ausgänge __________________ Anzahl der möglichen Ausgänge
W = = = =

Schließende Statistik 1 Kombinatorik & Wahrscheinlichkeitsrechnung
P. Schmidt, Hochschule Bremen Seite 35
Definition von Wahrscheinlichkeiten
Was ist eine Wahrscheinlichkeit?
Watt is en’ Wahrscheinlichkeit? – Da stelle mer uns ens janz dumm:
Et kütt drupp ahn:
a) subjektive Wahrscheinlichkeit → auf welches Ereignis würde ich einen bestimmten Geldbetrag setzen?
b) Klassische Definition nach Laplace c) Statistische (empirische) Definition nach Mises W(A) = f(A) d) Axiomatische Definition nach ΚΟΛΜΟΓΟΡΟΒΚΟΛΜΟΓΟΡΟΒΚΟΛΜΟΓΟΡΟΒΚΟΛΜΟΓΟΡΟΒ (=Kolmogoroff)
(vgl. Formel (6-9))
1. immer ≥ 0 2. W (Ω) = 1 3. additiv
⇒ 0 ≤ W ≤ 1
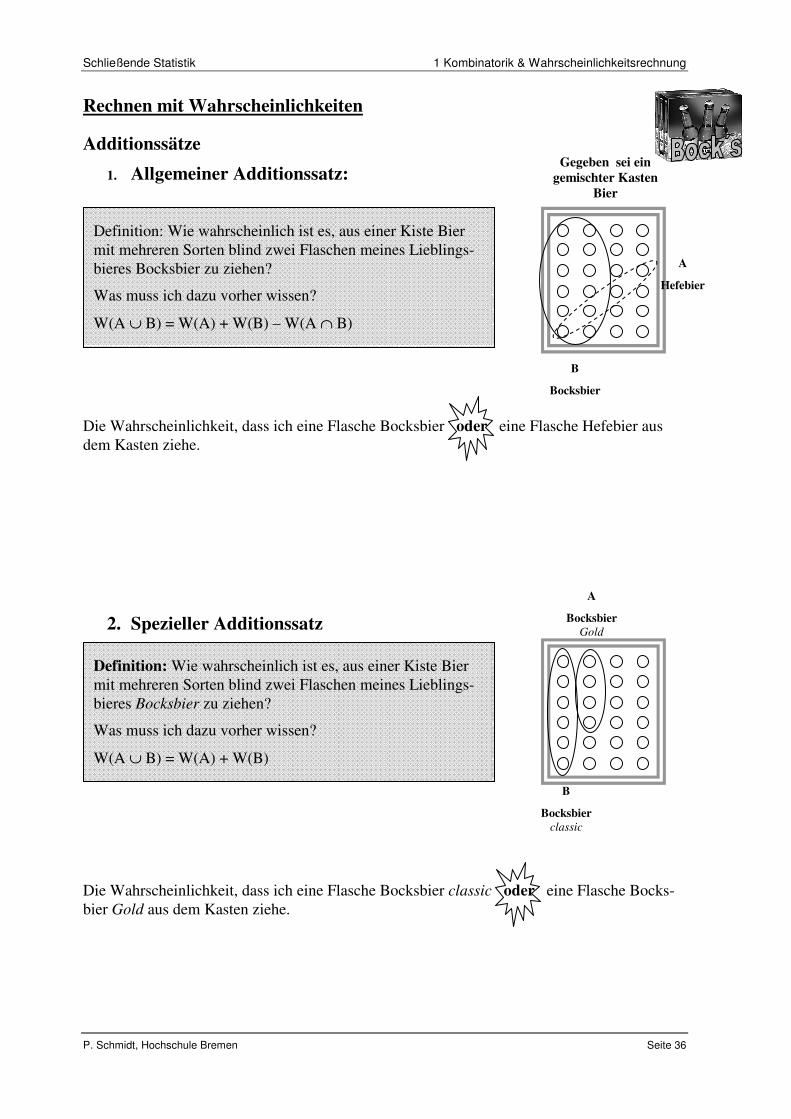
Schließende Statistik 1 Kombinatorik & Wahrscheinlichkeitsrechnung
P. Schmidt, Hochschule Bremen Seite 36
Rechnen mit Wahrscheinlichkeiten
Additionssätze
1. Allgemeiner Additionssatz:
Die Wahrscheinlichkeit, dass ich eine Flasche Bocksbier oder eine Flasche Hefebier aus dem Kasten ziehe.
2. Spezieller Additionssatz
Die Wahrscheinlichkeit, dass ich eine Flasche Bocksbier classic oder eine Flasche Bocks-bier Gold aus dem Kasten ziehe.
Definition: Wie wahrscheinlich ist es, aus einer Kiste Bier mit mehreren Sorten blind zwei Flaschen meines Lieblings-bieres Bocksbier zu ziehen?
Was muss ich dazu vorher wissen?
W(A ∪ B) = W(A) + W(B)
Definition: Wie wahrscheinlich ist es, aus einer Kiste Bier mit mehreren Sorten blind zwei Flaschen meines Lieblings-bieres Bocksbier zu ziehen?
Was muss ich dazu vorher wissen?
W(A ∪ B) = W(A) + W(B) – W(A ∩ B)
A
Hefebier
B
Bocksbier
B
Bocksbier classic
A
Bocksbier Gold
Gegeben sei ein gemischter Kasten
Bier

Schließende Statistik 1 Kombinatorik & Wahrscheinlichkeitsrechnung
P. Schmidt, Hochschule Bremen Seite 37
Bo ck´s
Allgemeiner Multiplikationssatz
Nach der Übung kaufe ich mir an der Tankstelle einen gemischten 6Pack mit je 2 Flaschen Bocksbier classic, Bocksbier Gold und Bocksbier bleifrei. Ich nehme 3 Flaschen heraus.
Wie groß ist die Wahrscheinlichkeit, dass ich zuerst ein A, dann ein B und dann ein C er-wische?
1. Griff 2. Griff 3. Griff
Formel: W(A ∩ B ∩ C) = W(A) W(B|A) W(C| A ∩ B) (6-16)
Beim Multiplikationssatz ist also die Wahrscheinlichkeit gesucht, dass ich eine Flasche classic und eine Flasche Gold und eine Flasche bleifrei aus dem Kasten ziehe.
Definition: Wie wahrscheinlich ist es, aus einer Kiste Bier mit mehreren Sorten blind meine Lieblingsbiere Bocksbier
zu ziehen?
Was muss ich dazu vorher wissen?
A: Bocksbier classic
B: Bocksbier Gold
C: Bocksbier bleifrei
A
B
C

Schließende Statistik 2 Theoretische Verteilungen
P. Schmidt, Hochschule Bremen Seite 38
2. Theoretische Verteilungen
Wahrscheinlichkeits-Dichte – und Verteilungsfunktion
Zu einem der beliebtesten Experimente in der Statistik gehört das Werfen von Münzen, viel-leicht auch, weil die möglichen Ausgänge dabei sehr begrenzt sind: Kopf/Wappen (W) oder Zahl (Z). Eine abzählbare Anzahl möglicher Ergebnisse deutet auf diskrete Merkmale hin:
In diesem Fall soll eine Münze dreimal geworfen werden. Die ZV X entspricht dabei der Anzahl der geworfenen Wappen:
ΩΩΩΩ Wahrscheinlichkeit X W (X=x)
f(x) F(x)
ZZZ 0,125
ZZW 0,125
ZWZ 0,125
WZZ 0,125
WWZ 0,125
WZW 0,125
ZWW 0,125
WWW 0,125
∑ 1
Wahrscheinlichkeits-Funktion
Wie groß ist die Wahr-scheinlichkeit, dass die Zu-fallsvariable X den Wert x annimmt.
f(x) = W(X = x)
Verteilungs-Funktion
Wie groß ist die Wahr-scheinlichkeit, dass die Zu-fallsvariable X höchstens den Wert x annimmt.
F(x) = W(X x) =x i
≤
≤
∑ f xi
x
( )

Schließende Statistik 2 Theoretische Verteilungen
P. Schmidt, Hochschule Bremen Seite 39
Stetige Verteilungen
1) Normalverteilung (nach ihrem Erfinder, dem Mathematiker, Physiker und Astronomen auch Gauß´sche Glockenkurve genannt, der bei der Suche nach einem Verteilungsgesetz für zufällige Beobachtungsfehler im Zusammenhang mit astronomischen Untersuchungen darauf stieß)
Charakteristika:
-
-
-
- Dichtefunktion:
Formel:
2
2
1
2
1),|(
−−
⋅
⋅Π
=σ
µ
σ
σµ
x
exf (7-24)
Fläche unter dem Intervall
Intervall Fläche
Beispiel: Der Durchmesser von Handelsklasse A Melonen sei normalverteilt mit dem Mittelwert 4,5 cm und einer Standardabweichung von 1 cm.
oder kürzer: X →→→→ N (4,5 ; 14,5 ; 14,5 ; 14,5 ; 1)
Schließende Statistik 2 Theoretische Verteilungen
P. Schmidt, Hochschule Bremen Seite 40
Lageparameter
Streuungsparameter
Verteilungsfunktion

Schließende Statistik 2 Theoretische Verteilungen
P. Schmidt, Hochschule Bremen Seite 41
2) Standardnormalverteilung
Folgt eine Zufallsvariable X einer Normalverteilung mit dem Mittelwert µ=0 und der Stan-dardabweichung σ =1, ist sie standardnormalverteilt.
Man macht in diesem Fall nichts anderes, als dass eine Transformation der x-Werte in z-Werte erfolgt. Tragen Sie dies bitte in den obigen Graphen ein!
Durch diese Transformation lassen sich Wahrscheinlichkeiten aus Tabellen leicht ablesen und müssen nicht mittels komplizierter Formel errechnet werden (Formelsammlung, Tafel 4)
Die Tabellen geben dabei die Fläche unter der Kurve an, dabei wird immer von links angefan-gen zu messen, also die Wahrscheinlichkeit, dass die ZV höchstens den (abgelesenen Wert) z annimmt Formelsammlung S. 25.
Schreibweise:

Schließende Statistik 2 Theoretische Verteilungen
P. Schmidt, Hochschule Bremen Seite 42
Zentraler Grenzwertsatz
Verteilung der Grundgesamtheit
Verteilung möglicher Stichproben
Verteilung der Stichprobenmittelwerte
µ
Wichtig(st)e Basis für Schätzen und Testen !!

Schließende Statistik 2 Theoretische Verteilungen
P. Schmidt, Hochschule Bremen Seite 43
Beispiel: Eine Grundgesamtheit bestehe aus 5 Angestellten mit den Jahreseinkommen (TEuro):
Angestellte/r Einkommen
Xi ( )
2
∑ − XXi
1. Anne 39 1
2. Ben 41 1
3. Cäsar 25 225
4. Doris 55 225
5. Eva 40 0
ΣΣΣΣXi =200 452
Mittelwert:
Standardabweichung:
Stichproben und Stichprobenmittelwerte:
Stichprobe
1. ABC 35 25.00
2. ABD 45 25.00
3. ABE 40 0.00
4. ACD 39.67 0.11
5. ACE 34.67 28.44
6. ADE 44.67 21.78
7. BCD 40.33 0.11
8. BCE 35.33 21.78
9. BDE 45.33 28.44
10. CDE 40 0.00
Σ X i =400 150.67
Mittelwert:
Standardabweichung:

Schließende Statistik 3 Schluss von der Stichprobe auf die Grundgesamtheit
P. Schmidt, Hochschule Bremen Seite 44
3. Schluss von der Stichprobe auf die Grundgesamtheit
3.1 Schätztheorie
Damit ist das Abschätzen der Parameter der Grundgesamtheit (σ und µ) auf Basis derer einer Stichprobe gemeint.
Bei einer Punktschätzung werden die konkreten Parameter direkt durch die der Stichprobe geschätzt.
Beispiel für eine Punktschätzung : x=µ s=σ
Dies ist unter Umständen sehr ungenau! Daher behandeln wir im Folgenden Intervallschätzungen:
3.2 Konfidenzintervalle (für den Mittelwert))))
Hier wird davon ausgegangen, dass ein Parameter nur mit einer bestimmten Wahrscheinlich-keit (Signifikanz) vorausgesagt werden kann, also nur „ungefähr“.
Daraus ergibt sich ein symmetrisches Intervall um den Mittelwert der Stichprobe x herum.
Wir sprechen von einer Ober- (go) und einer Untergrenze (gu) des Intervalls.
ασσ µ −=+≤≤− 1)(XcXc
zxzxW
Wiederholung Symbole Parameter der Grundgesamtheit Statistiken der Stichprobe
Mittelwert
Standardabweichung
Anzahl Beobachtungen
Die Stichproben-Standardabweichung X
σ ist dabei abhängig von der Größe der Grundge-
samtheit und der Stichprobe. In der Formelsammlung auf S. 16 sind diese Fallunterscheidun-gen genau aufgeführt.
Im einfachsten Fall gilt: n
X
σσ =
f(x)
95 %
gu go
x
Zc Zc
„critical“
Untergrenze Obergrenze

Schließende Statistik 3 Schluss von der Stichprobe auf die Grundgesamtheit
P. Schmidt, Hochschule Bremen Seite 45
ασσ µ −=+≤≤− 1)(XcXc
zxzxW
W( < µ < ) = 0,95
Frage: Wie groß ist die Wahrscheinlichkeit, dass ich mich irre?
Frage: Welche Unter- und Obergrenzen kann ich damit definieren, in dessen Intervall 95 % aller weiteren Chipstüten liegen wird (also in dem der unbekannte Mittelwert µ der Grundgesamtheit liegt?
Problem: In einem Geschäft entdecke ich Chipstüten, auf denen die genaue Inhaltsanga-be vergessen wurde. Bevor ich beim Hersteller anrufe, nicht nur weil diese fehlende An-gabe rechtswidrig ist, sondern weil ich mir eine Belohnung ausrechne, starte ich Testkäu-fe, weil ich nun wirklich wissen will, was drin ist.
Meine Stichprobenwerte (errechnet aus 60 Stichproben) ergeben ein x von 50 g und ein s von 5 g.
Frage: Welches Konfidenzintervall ergibt sich für die Grundgesamtheit?

Schließende Statistik 3 Schluss von der Stichprobe auf die Grundgesamtheit
P. Schmidt, Hochschule Bremen Seite 46
3.3 Hypothesentests
Vorbemerkung zum Statistischen Testen
Mit Statistik kann man nichts beweisen ! (weil doch irgendwie alles Zufall ist)!
Man kann nur zeigen, dass Aussagen falsch sind (mittels Gegenbeispiel)
- widerlegen
- ablehnen
- „falsifizieren“
Daher wird oft nicht die gewünschte Aussage selbst untersucht, sondern das Ge-genteil – in der Hoffnung, dieses Gegenteil zu widerlegen. Diese Gegenteilige Aussage wird dabei zu einem „Strohmann“ (der verbrannt werden soll).
Statistisch sprechen wir bei diesen Aussagen von Hypothesen. Diese nummerieren wir:
H0 ist die Ausgangshypothese des Tests, die untersucht wird. Diese kann als eventuell widerlegt werden.
H1 ist die Gegenhypothese oder Alternativhypothese. Sie kann eventuelle unterstützt (belegt) werden, indem H0 widerlegt wird

Schließende Statistik 3 Schluss von der Stichprobe auf die Grundgesamtheit
P. Schmidt, Hochschule Bremen Seite 47
Hypothesentests: Beispiel und Vorgehen
Bei statistischen Tests geht es um die Überprüfung einer Hypothese/einer Behauptung.
Die Schritte im Einzelnen
0. Schritt: Informationen über die Stichprobe und Grundgesamtheit
(je nach Typ des Tests andere oder gar keine Parameter):
Umfang Mittelwert Standardabw.
Grundgesamtheit N = ? µ = ? σ = ?
Stichprobe n = ? x = ? s = ?
1. Schritt: Aufstellen der Hypothesen
• H0 = zu widerlegende Ausgangsbehauptung („Händler“) • H1 = zu untersuchende Gegenbehauptung, anhand derer widerlegt
wird ( S. 79)
2. Schritt: Festlegen des Signifikanzniveaus α
• (ist in der Regel angegeben oder aus der Aufgabe abzuleiten)
Problem: Die Firma Studentenfit hat sich auf Müsliriegel spezialisiert, die den Lerner-folg bei Studenten massiv erhöhen. Der Kohlenhydratgehalt von 100 g dieses Müslirie-gels liegt bei 70 g. Der Riegel darf nicht zu wenig Kohlenhydrate aufweisen, soll die lernfördernde Wirkung des Müsliriegels aufrechterhalten werden (σ = 7g). Bei zu vielen Kohlenhdraten streiken jedoch die Studenten, da sie dem Lernerfolg nicht ihre gute Figur opfern wollen.
Eine zufällige Stichprobe 100 ergibt ein x von 68,9 g.
Frage: Stimmen die Angaben auf der Packung aus statistischer Sich – oder nicht?

Schließende Statistik 3 Schluss von der Stichprobe auf die Grundgesamtheit
P. Schmidt, Hochschule Bremen Seite 48
3. Schritt: Gegebenenfalles Fallunterscheidung bei der Berechnung von X
σ
• σ bekannt oder unbekannt? • Größe der Stichprobe beachten!!!
S. 16 Formelsammlung
4. Schritt: Ablesen in der Tabelle (z.B. der Standardnormalverteilung FSN)
• ein- und zweiseitige Hypothesen beachten!
5. Schritt: Ablesen bzw. Berechnen des kritischen Wertes
• ein- und zweiseitige Hypothesen beachten!
6. Schritt: Anwenden der Entscheidungsregeln
• H0 verwerfen oder nicht verwerfen („annehmen“)
7. Schritt: Interpretation der Ergebnisse
Wozu das Ganze?
Beispielzeichnung für einen parametrischen Test:

Schließende Statistik 3 Schluss von der Stichprobe auf die Grundgesamtheit
P. Schmidt, Hochschule Bremen Seite 49
3.4 Parametrische Tests
3.4.1 Testen von Mittelwerten
Bei diesem Test ist der Mittelwert der Grundgesamtheit unbekannt. Es gibt aber eine Vermu-tung (Behauptung), er betrage µ0 . Es soll nun überprüft werden, ob es sich bei µ0 um den wahren Mittelwert µ handeln kann.
Dies wird auf Basis der Stichprobe ermittelt.
Ist nur die Überschreitung in eine Richtung nicht möglich, handelt es sich um einen
→einseitigen Test
Für das Ablesen des zc ergibt sich: FSN ( zc ) = 1 – α
(einseitiger Test, linksseitig kritischer Bereich kann auch abgelesen werden mittels: FSN (–zc) = α
Sind zu beiden Seiten des Mittelwertes Grenzen gesetzt, handelt es sich um einen
→zweiseitigen Test Für das Ablesen des zc ergibt sich: D ( zc ) = 1 – α dies entspricht: FSN ( zc ) = 1 – α/2
→ Tabellierung der Standardnormalverteilung, Tafel 4.
α
2
x
µcu µ0 µc
o
1 - α
Annahmebereich
x µc
u µ0
1 - α α
Annahmebereich
f ( x )
f ( x )

Schließende Statistik 3 Schluss von der Stichprobe auf die Grundgesamtheit
P. Schmidt, Hochschule Bremen Seite 50
Ermittlung des Annahmebereiches:
Um den Annahmebereich zu ermitteln, gibt es 2 Varianten → Formelsammlung Kapitel 8.3
Variante A:
Testentscheidung auf Basis absoluter Werte: kritischen Grenzen µµµµc (bzw. pc), indem vom an-genommenen Mittelwert µ0 zc Standardabweichungen in die entsprechenden Richtungen abge-tragen werden:
5. Xc
u
cz σµµ ⋅−= 0 bzw.
pc
u
czpp ˆ0 σ⋅−= (8-35)
Xc
o
cz σµµ ⋅+= 0 bzw.
pc
u
czpp ˆ0 σ⋅+= (8-36)
6. Entscheidungsregel: Ablehnung von H0, wenn: (analog für Testwerte t und χ2
)
x > o
cµ bzw. o
cpp >ˆ bei rechts- oder zweiseitigem Test oder (8-37)
x < u
cµ bzw. u
cpp <ˆ bei links- oder zweiseitigem Test (8-38)
7. Interpretation des Ergebnisses
Variante B: (einfacher aber fehleranfälliger) „Z-Test“
Testentscheidung auf Basis der standardisierten Z-Werte
Als Prüfgröße ergibt sich z.B.: X
X
x
z
σ
µ0−= ,
n
s
x
tX
0µ−= oder
p
p
pp
z
ˆ
0ˆ
ˆ
σ
−=
womit im Grunde x bzw. p auf die Z-Achse (oder t-Achse) übertragen werden. Für die Er-
mittlung von X
σ ist auch hier eine Fallunterscheidung nötig.
5. Berechnung der Prüfgröße X
z (bzw. x
t , p
z ˆ , χ2 oder t – siehe Kapitel 8.4.1 bis 8.4.4)
6. Anwendung der Entscheidungsregel (analog für die anderen Prüfgrößen) wenn |
X
z | > | zc | ⇒ Ablehnung von H0 (8-39)
7. Interpretation des Ergebnisses
Am besten betrachten wir dies anhand der folgenden Beispiele ...

Schließende Statistik 3 Schluss von der Stichprobe auf die Grundgesamtheit
P. Schmidt, Hochschule Bremen Seite 51
Beispiel für einen zweiseitigen Test über den Mittelwert µµµµ Der Durchmesser von in Großserie hergestellten Eisenstäben ist nach Angaben des Herstellers
normalverteilt mit Mittelwert µ = 10 mm und einer Standardabweichung von 0,7 mm.
Ein Kunde, der die Eisenstäbe nur verwenden kann, wenn sie die angegebenen Toleranzen
einhalten, entnimmt der laufenden Produktion 144 Eisenstäbe. Deren Untersuchung ergibt
einen Mittelwert von 10,15 mm. Wird der Kunde die Eisenstäbe von diesem Hersteller beziehen, wenn ein Test mit einem Sig-
nifikanzniveau von α = 0,05 durchgeführt wird?
Vorab: Zusammenstellung der vorhandenen Informationen:
Grundgesamtheit: µ = µ0 = 10 ; σ = 0,7 Stichprobe: x = 10,15 ; n=144
„Schritte eines statistischen Hypothesentests“
7. Aufstellen von H0 und H1
H0: µ = µ0 = 10
H1: µ ≠ µ0 → zweiseitig kritischer Bereich
8. Festlegen des Signifikanzniveaus
α = 0,05 in der Aufgabe vorgegeben
9. Bestimmen der geeigneten Prüfverteilung → Fallunterscheidung
σ ist bekannt, n > 50 ⇒ 1. Fall keine Endlichkeitskorrektur, da N sehr groß (Großserie)
⇒ 05833,012
7,0===
nX
σσ
10. Ermittlung der Testgröße durch Ablesen in der Tabelle der Standardnormalverteilung
zweiseitiger Test ⇒ FSN (zc) = 1-a/2 = 0,975
⇒ kritisches |zc| = 1,960
Variante 1: Testentscheidung auf Basis absoluter Werte → kritischer µ-Wert
5. Berechnung der kritischen Wertes
Xc
u
cz σµµ ⋅−= 0 = 10 – 1,96 0,05833 = 9,886
Xc
o
cz σµµ ⋅+= 0 = 10 + 1,96 0,05833 = 10,114
6. Anwendung der Entscheidungsregel
Wenn x > o
cµ oder x < u
cµ soll H0 abgelehnt werden.
Da 10,15 > 10,114 ⇒ Ablehnung von H0
7. Interpretation des Ergebnisses
Der Kunde wird die Eisenstäbe nicht von diesem Hersteller beziehen!

Schließende Statistik 3 Schluss von der Stichprobe auf die Grundgesamtheit
P. Schmidt, Hochschule Bremen Seite 52
Variante 2: Testentscheidung auf Basis der (standardisierten) Z-Werte → „Z-Test“
Zweiseitiger Test über den Mittelwert µ
Schritte 1 bis 4 bleiben gleich.
11. Berechnung der Prüfgröße
2,57150,05833
1010,150=
−=
−=
X
X
x
z
σ
µ
12. Anwendung der Entscheidungsregel
Wenn |X
z | > | zc | soll H0 abgelehnt werden.
Da 2,5715 > 1,96 ⇒ Ablehnung von H0
13. Interpretation des Ergebnisses
Der Kunde wird die Eisenstäbe nicht von diesem Hersteller beziehen!

Schließende Statistik 3 Schluss von der Stichprobe auf die Grundgesamtheit
P. Schmidt, Hochschule Bremen Seite 53
3.4.2 Zweistichprobentests Test auf Mittelwertdifferenz
Problem: Klausuraufgabe: Im Unterricht „Zaubertränke“ bei Prof. Snape gibt es zwei Gruppen von Schülern: 22 Schüler aus Gryffindor (Gruppe G) und 26 Schüler aus Hufflepuff (Gruppe H). Der durchschnittliche Punktabzug für Schwatzen während des Unterrichts beträgt bei G 10,1 Punkte und bei H 9,6 Punkte jeweils mit einer Standardabweichung von 2 Punkten. [Gesamt: 18 Punkte]
Snape geht davon aus, dass er beide Gruppen gleich behandelt. Testen Sie diese Aussage mit einem Konfidenzniveau von 95 %. [7 Punkte]
1. Schritt: Zusammenstellen der Informationen:
Informationen ni Mittelwerte Standardabweichungen
Stichprobe 1 (G) n1 = x1 = s1 =
Stichprobe 2 (M) n2 = x 2 = s2 =
1) Hypothese: Ho: x1 - x2 = 0 ⇒ x1 = x2 2) α = 0,05 lt. Aufgabenstellung
3) bei Mittelwertdifferenz keine Fallunterscheidung (auch keine Ermittlung von x
σ oder p
σ )
4) tc = .......... 5)
2
22
1
21
21
n
s
n
s
xx
t
+
−= = ..........
6) |tx| > |tc| ? →→→→ H0 verwerfen ??
7) Interpretation:

Schließende Statistik 3 Schluss von der Stichprobe auf die Grundgesamtheit
P. Schmidt, Hochschule Bremen Seite 54
3.4.3 Testen der Aussagekraft der Regressionskoeffizienten bei Multipler Regression
Beispielaufgabe von Seite 37 / 38 (Absatzzahlen Kosmetikartikel)
AUSGABE der Excel-Funktion "Analysefunktionen - Regression"
Regressions-Statistik
Multipler Korrelationskoeffizient 0,97280
Bestimmtheitsmaß 0,94635
Adjustiertes Bestimmtheitsmaß 0,91952
Standardfehler 117,91933
Beobachtungen 10
ANOVA
Freiheitsgrade (df)Quadratsummen (SS)Mittlere Quadratsumme (MS)Prüfgröße (F) F krit
Regression 3 1471570,2 490523,4 35,27684 0,00033
Residue 6 83429,812 13904,969
Gesamt 9 1555000
Koeffizienten Standardfehler t-Statistik P-Wert Untere 95% Obere 95% Untere 95,0%Obere 95,0%
Schnittpunkt 2398,7909 982,3009 2,4420 0,0503 -4,8144 4802,3963 -4,8144 4802,3963
Fläche 0,4151 0,1373 3,0225 0,0233 0,0791 0,7512 0,0791 0,7512
Werbung 1,6903 4,4560 0,3793 0,7175 -9,2131 12,5937 -9,2131 12,5937
Preis -123,8227 58,8809 -2,1029 0,0802 -267,8991 20,2537 -267,8991 20,2537
Zusammenfassung und Formatierung der Ergebnisse einer multiplen Regression:
Gütemaß R2: 0,920 entspricht 92,0 %
p-Wert 95% 90%
Die Schätzergebnisse (Koeffizienten) lauten:
Schnittpunkt mit y-Achse a 2398,8 0,05 nein * ja*
Erklärende Größen:
X1 Fläche b1 0,4 0,02 * ja* * ja*
X2 Werbung b2 1,7 0,72 nein nein
X3 Preis b3 -123,8 0,08 nein * ja*
Signifikanz:
Was wollen uns diese „Worte“ sagen ?

Schließende Statistik 3 Schluss von der Stichprobe auf die Grundgesamtheit
P. Schmidt, Hochschule Bremen Seite 55
3.4.4 Fallbeispiel College Town
(folgt als Kopie)

Quantitative Methoden – 3. Business Mapping / GIS - Seite 56 -
Peter Schmidt, Hochschule Bremen MBA
Business Mapping
durch GeoInformationsSysteme GIS
Jutta Schmidt, Gis.direkt 1
Peter Schmidt, Hochschule Bremen 2
Inhalt
1 Was ist Business Mapping? ...................................................................... 57
2 Geodaten – Basis des Business Mapping ................................................. 58
3 Software .................................................................................................... 60
4 Datenquellen und Geodatenanbieter ......................................................... 60
5 Anwendungsfelder .................................................................................... 61
5.1 Standortmanagement ................................................................................................62
5.2 Zielgruppenanalyse ..................................................................................................63
5.3 Penetrationsanalyse (Marktdurchdringung) .............................................................63
5.4 Tourenplanung .........................................................................................................64
6 Literaturhinweise ...................................................................................... 64
Hinweis: Teile dieser Darstellung sind erschienen in: Schmidt, Jutta und Schmidt, Peter: „Business
Mapping “; in: Dey und Grauvogel (Hrsg.): "Praxishandbuch – Wirtschaftswissen von A-Z für die erfolgreiche
Betriebsratspraxis", Kissing, 2000-2003
1 Kontakt: [email protected]
2 Kontakt: [email protected]

Quantitative Methoden – 3. Business Mapping / GIS - Seite 57 -
Peter Schmidt, Hochschule Bremen MBA
1 WAS IST BUSINESS MAPPING?
Business Mapping steht für die Betrachtung von Daten im Raum: Adressen, Standorte,
Gebiete, Verbindungen, ... und deren Darstellung als Karte (engl. „map“).
„Eine Karte sagt mehr als tausend Worte“ – der Raumbezug von Daten in den Entschei-
dungen von Unternehmen schon immer eine wichtige Rolle gespielt, konnte aber bis vor
kurzem nur unzureichend dargestellt und genutzt werden.
Raumbezug von Daten
Ob es sich um Vertriebsgebiete von Außendienstmitarbeitern, die Standortplanung eines
Filialisten oder Ermittlung neuer Kundenpotenziale handelt – 80% der unternehmerischen
Fragestellungen haben einen konkreten Raumbezug. Mit der Landkarte an der Wand,
Stecknadeln, Fähnchen und Bindfäden wurde diese Tatsache auch schon länger genutzt. In
den letzten 10 Jahren hat sich, bedingt durch die rasche Entwicklung der Computerkarto-
grafie und der Verfügbarkeit des PC praktisch auf jedem Schreibtisch, eine weitaus mäch-
tigere Visualisierungs- und Analysemethode verbreitet, die allgemein als „Business Map-
ping“ bezeichnet wird. Begriffe wie Business Geographics, Geomarketing, Desktop Map-
ping werden analog verwandt. Allen gemeinsam dienen als Grundlage „Geoinformations-
systeme“, kurz GIS genannt.
Geoinformationssysteme
„Geoinformationssysteme“ sind computergestützte Systeme zur Erstellung, Verwaltung,
Analyse und Ausgabe raumbezogener und themenbezogener Daten. Digitale Landkarten
lassen sich mit Daten anreichern, auswerten und darstellen. Hierdurch können räumliche
Strukturen und Entwicklungen aufgezeigt werden.
Abbildung 1: Bevölkerungsdichte Bremer Ortsteile, Beispiel für den Zusammenhang von tabellarischen Da-
ten und kartografischer Darstellung. (Quelle: Daten des statistischen Landesamtes Bremen)
Ein Geoinformationssystem besteht grundsätzlich aus einem Kartografie-Modul, einem
Datenbank-Modul sowie Analysemethoden verschiedenen Funktionsumfanges. Die Reali-
sierungsmöglichkeiten sind vielfältig, vom einfachen Auskunftsarbeitsplatz bis hin zum
Forschungsarbeitsplatz sind diverse Stufen möglich. Während erstere leicht von geschul-
tem Personal bedient werden können, sind für letztere ausgebildete GIS-Fachleute notwen-
dig.

Quantitative Methoden – 3. Business Mapping / GIS - Seite 58 -
Peter Schmidt, Hochschule Bremen MBA
Abbildung 2: Bausteine eines Geoinformationssystems
Geoinformationssysteme werden seit Jahrzehnten in vielen Bereichen eingesetzt, (z.B. Na-
tur- und Umweltschutz, Raumplanung, Verkehrsplanung, Energieversorgung). Mit Beginn
der neunziger Jahre verzeichnet das „Business Mapping“ hohe Wachstumsraten.
Business Mapping
Zunehmende Marktsättigung, verstärkte Nachfrage nach mehr Service und Individualität
sowie wachsende Konkurrenz sind Ursachen dafür, dass Geoinformationssysteme verstärkt
in der Wirtschaft, insbesondere bei Dienstleistern wie z.B. Banken und Versicherungen,
bei Handel oder Industrie genutzt werden. „Business Mapping“ kann als Oberbegriff für
alle Einsatzbereiche von Geoinformationssystemen in der Wirtschaft verstanden werden.
Beispielhafte Anwendungsfelder sind:
Geomarketing
Vertriebsplanung
Standortmanagement
Mediaplanung
Routenplanung
Facility Management
2 GEODATEN – BASIS DES BUSINESS MAPPING
Grundsätzlich benötigt Business Mapping Geodaten, d.h. Daten, die durch Angabe von
Koordinaten einen eindeutigen Bezug zum Raum haben.
Raster- und Vektordaten
Es wird grundsätzlich zwischen Raster- und Vektordaten unterschieden. Rasterkarten sind
Bilder, die aus einzelnen Punkten bestehen. Sie enthalten keine weiteren Informationen
außer dem Farbwert und wirken rein als Bild auf den Betrachter. Beliebt sind sie aufgrund
ihres „vertrauten“ Aussehens, z.B. in Form von Stadtplänen. Vektordaten entstehen durch
Digitalisierung. Diese punkt-, linien- oder flächenhaften Elemente lassen sich beliebig mit
weiteren Informationen anreichern, z.B. kann ein Punkt einen Standort darstellen und mit
einem dazugehörigen Datensatz verknüpft werden. Ein solcher Datensatz kann z.B. die
Adresse, Ansprechpartner, Absatzmengen, Datum der Lieferung, o.ä. enthalten. Aus die-
Benutzeroberfläche
Digitale Landkarten
Analyse-methoden
GIS-Software Hardwarekomponenten
Sach- daten

Quantitative Methoden – 3. Business Mapping / GIS - Seite 59 -
Peter Schmidt, Hochschule Bremen MBA
sem Grunde werden gerade im Business Mapping Vektordaten bevorzugt eingesetzt, wäh-
rend Rasterkarten lediglich der Orientierung dienen.
Ein Business Mapping System setzt sich je nach Fragestellung aus verschiedenen Datenbe-
ständen zusammen:
Geografische Daten (beispielhaft)
Administrative Daten, z.B. Landes- und Kreisgrenzen
Ortspunkte
Straßennetze, Straßenverzeichnisse
Flächennutzungen, topographische Angaben
Thematische Sachdaten
Externe Sachdaten, z.B. demografische Daten (Bevölkerungsdichte, Altersstruktur...)
und Marktdaten, (Kaufkraftkennziffern...)
Unternehmensinterne Daten, z.B. Umsatzkennziffern, Kundenadressen, Fahrtrouten
Informationen in Schichten
Die Daten werden im Geoinformationssystem in Schichten gehalten. Dies ist ähnlich vor-
zustellen, wie durchsichtige Folien, die übereinander gelegt werden, wobei das GIS die
inhaltlichen Informationen der Schichten (anhand ihrer räumlichen Lage) verknüpfen kann.
Der Anwender kann die Daten, die er für seine jeweilige Fragestellung benötigt „überein-
anderschichten“, um dann spezielle Analysen vorzunehmen.
Abbildung 3: Entwicklung einer thematischen Karten aus verschiedenen überlagerten Informationsschichten
Entscheidend für die Datenqualität sind verschiedene Faktoren wie Aktualität, Flächenab-
deckung und geometrische Konsistenz (d.h. die verschiedenen Datenschichten müssen in
ihrem räumlichen Bezug „zusammenpassen“). Nicht zu unterschätzen ist die Bedeutung
der sogenannten Metadaten („Informationen über Informationen“), ohne die die Datenbe-
stände kaum nutzbar sind, wie z.B. Zeitpunkt der Erhebung und notwendige inhaltliche
Erläuterungen. Eine weitere Schwierigkeit liegt in der „Schnittstelle“, d.h. den verschiede-
nen Datenformaten, insbesondere bei der Verwendung verschiedener Datenquellen.

Quantitative Methoden – 3. Business Mapping / GIS - Seite 60 -
Peter Schmidt, Hochschule Bremen MBA
Software für verschiedene Ansprüche
3 SOFTWARE
Die Datenbestände werden in einer leistungsfähigen GIS-Software zusammengeführt, die
mindestens über folgenden Funktionsumfang verfügen sollte:
Datenverwaltung, d.h. Verwaltung von Daten unterschiedlicher Herkunft (Rasterkarten,
Datenbanken, Grafiken)
Dateneingabe zum Aufbau eigener Datenbestände durch Digitalisieren und tabellarische
Datenpflege
Datenvisualisierung bzw. Präsentation (Erstellung von thematischen Karten)
Datenanalyse (Abfragen, statistische Auswertungen, raumbezogene Analysen)
Abbildung 4: Beispiel für eine GIS-Benutzeroberfläche (ArcView 3.2 der Firma ESRI)(Datenquelle: Statisti-
sches Landesamt Bremen)
4 DATENQUELLEN UND GEODATENANBIETER
Die meisten Geodaten müssen vom Unternehmen dazugekauft werden. Nur ein Teil wird
selbst erstellt werden, da dies größeren Aufwand erfordert und höchstens für unterneh-
mensinterne Daten sinnvoll ist. Der Geodatenmarkt ist inzwischen fast unüberschaubar
groß geworden. Sowohl amtliche als auch kommerzielle Anbieter bieten Geobasisdaten
sowie Sachdaten an. Daneben gibt es zunehmend branchenspezifisches Komplettlösungen,
d.h. Softwarepakete mit integrierten Datenpaketen.

Quantitative Methoden – 3. Business Mapping / GIS - Seite 61 -
Peter Schmidt, Hochschule Bremen MBA
Die Betrachtungsebene ist entscheidend
Amtliche Geobasisdaten
Die Vermessungs- und Katasterverwaltungen der einzelnen Bundesländer bieten topografi-
sche Daten als Vektor- und Rasterkarten an. Topografische Vektorkarten umfassen ver-
schiedene Objekte, z.B. Straßen, bebaute Flächen, Gebäude, Gemeindegrenzen. Außerdem
werden Höhenmodelle und Luftbilddaten angeboten. Luftbilder und Rasterkarten dienen
vor allem der Orientierung, da mit ihnen keine weiteren Analysen durchgeführt werden
können. Bezugsquellen sind die jeweiligen Landesvermessungsämter.
Kommerzielle Geobasisdaten
Da das Vermessungswesen Ländersache ist, sind die o.a. Angebote auf das jeweilige Bun-
desland beschränkt. Diese Einschränkung haben die kommerziellen Datenanbieter nicht.
Ihr Angebot geht inzwischen weit über das Angebot amtlicher Anbieter hinaus. Neben
Rasterkarten werden Gebietsgrenzen wie administrative Gebietseinteilungen, Postleitzahl-
bereiche, Telefonvorwahlbereiche angeboten. Interessant sind vor allem Straßendaten, die
z.T. hausnummerngenau digitalisiert sind und sowohl für Routing als auch Geokodierung
genutzt werden können. Für Marktforschung und Marketing relevant sind die Marktzellen,
bestehend aus 10 – 15 Straßenabschnitten. Anbieteradressen werden im Anhang genannt.
Amtliche Sachdaten
Die statistischen Landesämter geben gemeinsam das Datenpaket „Statistik Regional“ her-
aus mit Informationen für die Landkreise und kreisfreien Städte heraus. Es umfasst Anga-
ben zu 16 Fachgebieten. Auf Gemeindeebene sind z.T. noch feiner gegliederte Angaben
beim jeweiligen Statistischen Amt erhältlich. Auch andere Ämter und Behörden bieten
raumbezogene (Spezial-) Daten an. Auf Bundesebene ist hier v.a. die Bundesamt für Bau-
wesen und Raumordnung zu nennen, aber auch Regionalverbände, Städtetage u.v.m. lie-
fern Geodaten. Daneben bieten Industrie- und Handelskammern Daten ihrer Kammerbe-
zirke an.
Kleinräumige Marktdaten
Kommerzielle Sachdaten
Auf verschiedenen räumlichen Ebenen, bis hin zu Marktzellen, bestehend aus 7 bis 15
Haushalten, sind Daten zu Bevölkerung, Bebauung, Branchen, Kaufkraftkennziffern und
PKW-Besitz erhältlich. Fachspezifische Branchenpotenzialdaten, Angaben zu Wahlverhal-
ten und Konsumverhalten u.v.m. wird von einer Vielzahl kommerzieller Datenanbieter
erhoben und gepflegt. Außerdem bieten die meisten von ihnen Geokodierdienste an, d.h.
unternehmensinterne Adressdatenbestände erhalten über die Zuordnung von Koordinaten
räumlichen Bezug, sodass z.B. die räumliche Verteilung von Kundenadressen dargestellt
werden kann.
5 ANWENDUNGSFELDER
Die Verknüpfung unternehmensbezogener Daten mit geografischen und marktbezogenen
Daten verdeutlicht Zusammenhänge zwischen Geschäfts- und Marktdaten. Unternehmeri-
sche Fragestellungen gewinnen unter Berücksichtigung der räumlichen Aspekte erweiterte

Quantitative Methoden – 3. Business Mapping / GIS - Seite 62 -
Peter Schmidt, Hochschule Bremen MBA
Erkenntnisse, sorgen für höhere Kundenpotenzialausschöpfung, höhere Umsätze, geringere
Streuverluste:
Standortmanagement: welche Einzugsgebiete deckt das bestehende Filialnetz ab?
Zielgruppenanalyse, Marktdurchdringung: wie gut werden Kundenpotenziale ausge-
schöpft ?
Konkurrenzanalyse: wo sind Mitbewerber ?
Tourenplanung: wie wird Fahrtzeit, Wegstrecke, Ladevorgänge, Kundenbesuche...
optimiert ?
Beispielhaft werden die Möglichkeiten des Business Mapping für vier Bereiche skizziert.
Szenarien in der Standortplanung
5.1 Standortmanagement
Die Standortanalyse und -planung eines Unternehmens, beispielsweise eines Einzelhan-
delsfilialisten, kann unter Nutzung des Business Mapping effektiver und umfassender wer-
den: Durch die EDV-Unterstützung wird es vereinfacht, verschiedene Szenarien zu entwi-
ckeln.
Beispiel Standortanalyse:
In einem ersten Schritt werden die eigenen Standorte visualisiert, sowie verschiedene Fak-
toren, z.B. Verkaufsfläche, Umsatz, Sortiment der Filialen. Ebenso kann die Wettbewerbs-
situation dargestellt werden. Hierfür werden die Adressen der Mitbewerber und anderer
„points of interest“ geokodiert. Dies kann - je nach gewünschter Genauigkeit - stra-
ßen(abschnitts)- oder sogar hausnummerngenau erfolgen.
Nun wird der Einzugsbereich der Filialen festgelegt: auf Grundlage eines Straßennetzes
werden hierfür Entfernung oder Fahrzeit zum Standort berücksichtigt. Im nächsten Schritt
können sie mit der „Schicht“ der Sachdaten „verschnitten“ werden. Es kann z.B. ermittelt
werden:
− wie viele Haushalte im Einzugsbereich leben (Kundenpotenzial);
− wie die Haushaltsstruktur im Einzugsbereich ist (Alter, Familiengröße – Zielgrup-
penanalyse);
− wie groß das Umsatzpotential (Kaufkraft) ist.

Quantitative Methoden – 3. Business Mapping / GIS - Seite 63 -
Peter Schmidt, Hochschule Bremen MBA
Abbildung 5: Einzugsbereich eines Standortes nach Fahrtzeit
5.2 Zielgruppenanalyse
Visualisierung der Mitbewerber und Kunden
In ähnlicher Weise können die potentiellen Zielgruppen „verortet“ werden: Ist eine solche
Zielgruppe vom Unternehmen einmal definiert, kann sie mit statistischen Daten für das
Untersuchungsgebiet abgeglichen werden. So wird die räumliche Verteilung einer Ziel-
gruppe dargestellt und dient als wesentliche Grundlage für weitere Analysen, z.B. Markt-
potenziale oder Marketingmaßnahmen.
5.3 Penetrationsanalyse (Marktdurchdringung)
Welchen Anteil am Markt schöpft das jeweilige Unternehmen aus? Die Visualisierung der
Marktdurchdringung kann durch verschiedene Verfahren erfolgen, z.B mittels Darstellung
des gesamten Marktvolumens und der Gegenüberstellung des Unternehmensumsatzes. Die
weitere Differenzierung, z.B. nach Marktsegmenten werden Stärken und Schwächen des
Vertriebs sichtbar und räumlich zugeordnet.
Abbildung 6: Visualisierung der Marktausschöpfung

Quantitative Methoden – 3. Business Mapping / GIS - Seite 64 -
Peter Schmidt, Hochschule Bremen MBA
5.4 Tourenplanung
Business Mapping wird auch bei der Tourenplanung eingesetzt: erweiternde Software
macht es möglich, Wege zu optimieren. Dabei geht es nicht nur um die logistische Fragen,
sondern auch um eine optimale Außendienstplanung. Neben einem sogenannten „routing-
fähigen“ Straßennetz und den geokodierten Adressen können auch Besuchsdauer und Be-
suchshäufigkeit berücksichtigt werden. Auf dieser Grundlage können Gebiete der Außen-
dienstmitarbeiter optimiert werden, d.h. die Gebiete werden für die Mitarbeiter strategisch
günstig und zugleich überschneidungsfrei ermittelt.
6 LITERATURHINWEISE
Leiberich (Hrsg.) „Business Mapping im Marketing“, Heidelberg 1997.
Fally/Strobl (Hrsg.) “Business Geographics”, Heidelberg 2000
Weitere Information sowie interessante Datengrundlagen können im Internet gefunden
werden. Wichtige Web-Adressen mit (betriebs-) wirtschaftlich relevanten Informationen
(am Anwendungsbeispiel GIS in der Kommunalen Wirtschaftsförderung) finden sich z.B.
auf der Webseite: http://www.fbw.hs-bremen.de/pschmidt - unter „GIS“.

- 65-
Prof. Dr. Peter Schmidt
SoSe 2008
Volkswirtschaftslehre und Statistik
: (0421) 5905-4691
Fax: (0421) 5905-4862
www.fbw.hs-bremen.de/pschmidt
Quantitative Methoden
Part 5
Forschungsprojekt als Fallstudie
Das folgende Arbeitspapier „Regional Economic Impacts of Large Cultural Events – Does
public funding of large cultural events make sense from a regional economic point of view?“;
wurde präsentiert auf der Tagung der Academy of Economics and Finance, Nash-
ville/Tennessee, Februar 2008. Es wird Ende des Jahres in den Papers and Proceedings der
Academy of Economics and Finance erscheinen.

Regional Economic Impacts of Large Cultural Events
P. Schmidt, April 2008 - 66-
Regional Economic Impacts of Large Cultural Events
Does public funding of large cultural events make sense
from a regional economic point of view?
Peter Schmidt1
Bremen University of Applied Sciences (Hochschule Bremen) / Germany
April 2008
PRELIMINARY VERSION – please do not quote
1 Prof. Dr. Peter Schmidt ([email protected]), Bremer Institut für empirische Handels- und Regionalstrukturfor-
schung der Hochschule Bremen (Bremen Institut of Empirical Research in Trade and Regional Structur at Bremen University of Applied Sciences) and University of North Carolina Wilmington. The help and co-operation of Astrid Kurzeja-Christinck and Jutta Schmidt from GIS.direkt is gratefully acknowledged. Of cour-se all remaining errors are mine. Some of the results are based on earlier joint work with Aldona Kucharczuk.
market.research.culture (markt.forschung.kultur)
Research team at
Werderstrasse 73 D-28199 Bremen / Germany
Phone: +49+ (0) 421 5905-4691 Fax: +49+ (0) 421 5905-4692
email: [email protected] http://www.markt-forschung-kultur.de

Regional Economic Impacts of Large Cultural Events
P. Schmidt, April 2008 - 67-
Abstract
This paper analyzes the impacts of cultural events from a regional economic perspective.
The research question is whether it is worthwhile for a region or a city to fund large cultural
events like arts exhibitions. The basic idea is that there are indirect effects for the regional
economy if visitors travel long distances to attend the event and also spend time and money
in the region. This way of indirect re-financing of public funding (as an investment) is called
indirect impact (or to translate the German expression literally: ‘detour return on investment’)
One question is whether such an indirect effect can be measured for large exhibitions at the
Kunsthalle Bremen (Arts museum) in northern Germany. The exhibition Van Gogh: The Fields
(2002/03) that was visited by more than 300,000 people is analyzed mainly but altogether
there seven surveys have been conducted in the last 8 years and the estimations are also
conduced for the other exhibitions. In this paper the indirect impact of arts exhibitions is esti-
mated in three steps. First the expenditures of out-of-town visitors are estimated, secondly
the resulting regional value added. In the third step, a preliminary estimate of fiscal impacts is
conducted and some further (non-monetary) aspects are discussed.
The analysis shows that for the Van Gogh exhibition around 200,000 people came to Bre-
men primarily to visit the exhibition and travelled at least 100 km. The estimated expendi-
tures by out-of-town visitors for this exhibition range between € 10 and 12.6 million, leading
to an estimated regional value added of between € 14 and 17.6 million. A preliminary esti-
mate of a potential additional tax revenue due to the exhibition amounts to between € 1.6
and 2 million.
So the research question can be answered with: Yes, in fact the public funding turns out to
be a good ‘investment’ for the city.

Regional Economic Impacts of Large Cultural Events
P. Schmidt, April 2008 - 68-
Contents
1. Introduction: Arts and Economics – Contradiction or Complements?................................69
2. The Visitors – describing the target group.........................................................................70 2.1 Socio-demographic characteristics............................................................................................70 2.2 Origin of the visitors ...................................................................................................................72 2.3 Motives, Activities and Overnight Stays of Out-of-Town Visitors ..............................................74
2.3.1 Special Exhibition as (main) Reason to visit the City / Region ..................................................... 74 2.3.2 Duration and Type of Overnight Stay ........................................................................................... 75 2.3.3 Further Activities of the Visitors.................................................................................................... 76
3. Regional Economic Impacts of the Arts Exhibitions ..........................................................77 3.1 Estimation of the Expenditures of Out-of-Town Visitors............................................................77 3.2 Regional Value Added: Direct and Indirect Impacts, Regional Multiplier ..................................81 3.3 Fiscal Impacts............................................................................................................................83 3.4 Additional effects: Expenditures of Other Out-of-Town and Local Visitors (Import
Substitution) ...............................................................................................................................84
4. References .......................................................................................................................86
Figures
Figure 1 (Event) Exhibitions and visitors’ surveys at Kunsthalle Bremen........................................70
Figure 2 Age group and Gender at the Van Gogh exhibition...........................................................71
Figure 3 Average Age of visitors at different exhibitions..................................................................71
Figure 4 Origin of the Visitors (Van Gogh exhibition).......................................................................72
Figure 5 Origin of visitors from Germany .........................................................................................73
Figure 6 Out-of-town Visitors with Exhibition as the Reason to Travel to Bremen, Van Gogh........74
Figure 7 Out-of-town Visitors with Exhibition as the Reason to Travel to Bremen, all
Exhibitions..........................................................................................................................75
Figure 8 Average duration of stay (Van Gogh Exhibition)................................................................75
Figure 9 Type of Accommodation of out-of-town visitors.................................................................76
Figure 10 Average duration - overnight stay of out-of-town visitors explicitly coming for the
event ..................................................................................................................................76
Figure 11 Further activities of out-of-town visitors .............................................................................76
Figure 12 Further activities of out-of-town visitors .............................................................................77
Figure 13 Estimation of average daily expenditures of out-of-town visitors.......................................78
Figure 14 Estimation of expenditures of out-of-town visitors staying in hotels ..................................79
Figure 15 Estimation of expenditures of out-of-town visitors staying with friends/family...................79
Figure 16 Estimation of expenditures by out-of-town one day visitors ..............................................79
Figure 17 Estimation total expenditures of out-of-town visitors .........................................................80
Figure 18 Projected Expenditures of Out-of-Town Visitors during event exhibitions (estimated
direct impacts - in 1 000 000 €)..........................................................................................80
Figure 19 Total direct and indirect impacts estimated in the multiplier ..............................................82
Figure 20 Regional Value Added of Out-of-Town Visitors during event exhibitions (estimated
direct plus indirect impacts - in 1 000 000 €) .....................................................................83
Figure 21 Preliminary Estimate of Possible Tax Revenues ...............................................................83

Regional Economic Impacts of Large Cultural Events
P. Schmidt, April 2008 - 69-
1. Introduction: Arts and Economics – Contradiction or Complements?
The financing of arts institutions in Germany is traditionally (and also established in the Ger-
man constitution) a task of the government – on all levels: national, states and cities. With
increasing financial problems of public households, the public funding has been substantially
reduced over the last years. This paper analyzes from an economic and finance point of view
whether the public “investment” in arts institutions and here especially in large events can
turn out to have a positive “return on investment”. This argumentation is relatively new in the
public debate in Germany as traditionally public funding of arts was primarily discussed as a
part of the government’s (educational) mission. Visitors’ surveys performed professionally on
basis of statistically reliable data bases, also as a means of evaluation of the own perform-
ance, are rarely performed by German museums.
In a traditional discussion the question occurs whether the Arts on the one hand and eco-
nomic / business aspects on the other can go together as complements or whether the two
concepts are a contradiction in itself. The independence of arts has a high value in public
opinion and the question whether this is endangered by private financial engagement in
(public) arts institutions exceeds the scope of this paper.
An interesting aspect of this discussion has been highlighted by authors like Richard Florida
who published his book ’The rise of the creative class ... and how it’s transforming work, lei-
sure, community & every day life’ in 2002. His argument is that regions that want to improve
their economic performance are well advised to open up to creative people. These do not
only include artists in the narrower definition but all creative people. The more a region en-
courages creative activity the more likely is a positive economic development.
Kunsthalle Bremen
The “Kunsthalle Bremen”, founded in 1849, is the traditional arts museum in the city of Bre-
men in Northern Germany. Bremen is the tenth largest city in Germany with around 550 000
inhabitants. Since the year 2000 the Kunsthalle has been organizing several big exhibitions
events, all accompanied by intense and creative marketing. In this period, mar-
ket.research.culture has been performing seven large visitors surveys: the five large exhibi-
tion events (the current is still ongoing up to end of February 2008) und two surveys in “quiet
times” (without event) in order to compare the visitors and impacts of big special exhibitions
with those visiting “only” the permanent exhibition of the Kunsthalle Bremen. Altogether more
than 11 000 visitors took part in these seven surveys as shown in Figure 1.
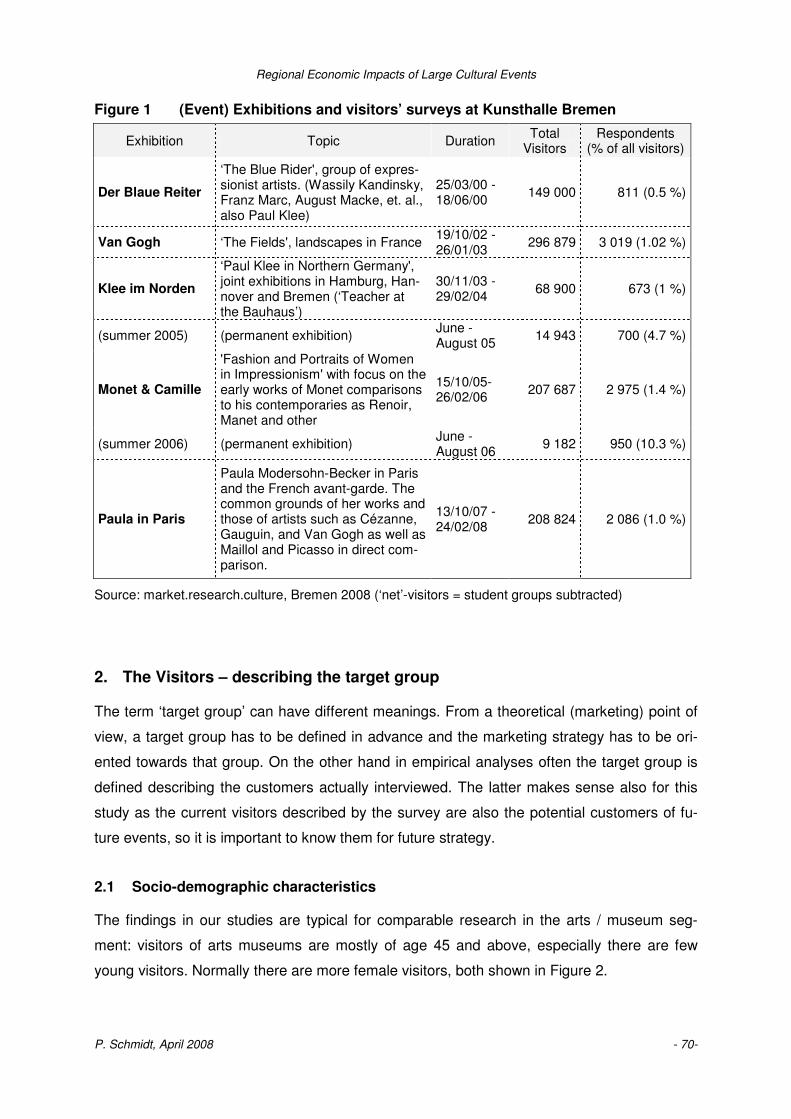
Regional Economic Impacts of Large Cultural Events
P. Schmidt, April 2008 - 70-
Figure 1 (Event) Exhibitions and visitors’ surveys at Kunsthalle Bremen
Exhibition Topic Duration Total
Visitors Respondents
(% of all visitors)
Der Blaue Reiter
‘The Blue Rider', group of expres-sionist artists. (Wassily Kandinsky, Franz Marc, August Macke, et. al., also Paul Klee)
25/03/00 - 18/06/00
149 000 811 (0.5 %)
Van Gogh ‘The Fields', landscapes in France 19/10/02 - 26/01/03
296 879 3 019 (1.02 %)
Klee im Norden
‘Paul Klee in Northern Germany', joint exhibitions in Hamburg, Han-nover and Bremen (‘Teacher at the Bauhaus’)
30/11/03 - 29/02/04
68 900 673 (1 %)
(summer 2005) (permanent exhibition) June - August 05
14 943 700 (4.7 %)
Monet & Camille
'Fashion and Portraits of Women in Impressionism' with focus on the early works of Monet comparisons to his contemporaries as Renoir, Manet and other
15/10/05-26/02/06
207 687 2 975 (1.4 %)
(summer 2006) (permanent exhibition) June - August 06
9 182 950 (10.3 %)
Paula in Paris
Paula Modersohn-Becker in Paris and the French avant-garde. The common grounds of her works and those of artists such as Cézanne, Gauguin, and Van Gogh as well as Maillol and Picasso in direct com-parison.
13/10/07 - 24/02/08
208 824 2 086 (1.0 %)
Source: market.research.culture, Bremen 2008 (‘net’-visitors = student groups subtracted)
2. The Visitors – describing the target group
The term ‘target group’ can have different meanings. From a theoretical (marketing) point of
view, a target group has to be defined in advance and the marketing strategy has to be ori-
ented towards that group. On the other hand in empirical analyses often the target group is
defined describing the customers actually interviewed. The latter makes sense also for this
study as the current visitors described by the survey are also the potential customers of fu-
ture events, so it is important to know them for future strategy.
2.1 Socio-demographic characteristics
The findings in our studies are typical for comparable research in the arts / museum seg-
ment: visitors of arts museums are mostly of age 45 and above, especially there are few
young visitors. Normally there are more female visitors, both shown in Figure 2.

Regional Economic Impacts of Large Cultural Events
P. Schmidt, April 2008 - 71-
Figure 2 Age group and Gender at the Van Gogh exhibition
Agegroup by Gender (absolute numbers)
0
50
100
150
200
250
300
350
400
450
20 or
younger
20-29 30-39 40-49 50-59 60-69 70 plus
male female
Source: market.research.culture, Bremen 2008: Van Gogh visitors, n = 3 019.
It is interesting to see that the average age of the visitors steadily increases in the subse-
quent exhibitions. One possible explanation might be that many visitors return for the next
exhibition - around two years older.
Figure 3 Average Age of visitors at different exhibitions
Average age
49.2
47.36
49.09
46.48
51.15
45.57
44.77
40
42
44
46
48
50
52
Blauer
Reiter
Van Gogh Klee im
Norden
(Summer
05)
Monet &
Camille
(Summer
06)
Paula in
Paris
Source: market.research.culture, Bremen 2008
So one result is that the most important target group consists of (female) visitors aged 45
and above. In addition all surveys show that the majority of visitors has a high level of educa-
tion, in all studies around 50% of all visitors had a university degree, another quarter a col-
lege education.

Regional Economic Impacts of Large Cultural Events
P. Schmidt, April 2008 - 72-
The typical visitor of an arts exhibition is a woman between 45 and 50 years of age with a
university degree. This is worth noting for the estimation of the expenditures, as these target
groups are wealthier and so are likely to spend more than average tourists of a city / region.
2.2 Origin of the visitors
The visitors were asked for their city and German zip code. From this we developed a classi-
fication based on the distance from their place of residence to the Kunsthalle Bremen. Figure
4 shows the categories and their frequencies for the Van Gogh exhibition. The figure shows
that 84% of all respondents came from out-of-town.
Figure 4 Origin of the Visitors (Van Gogh exhibition)
1. Bremen 490
16.47%
2. Neighborhood 414
13.92%
3. up to 250 km 1451
48.77%
4. 250 plus 506
17.01%
5. Abroad 114
3.83%
Total 2975
Abroad
4%250 plus
17%
up to 250 km
49%
Bremen
16%Neighborhood
14%
Source: market.research.culture, Bremen 2008: Van Gogh visitors, n = 2 975.
This emphasizes the huge success of the exhibition as this corresponds to a projected num-
ber of more than 250 000 out-of-town visitors. More than 83 % of these visitors travelled
more than 100 km to Bremen. This can also be seen on a map depicting the German two-
digit zip codes in Figure 5, which also visualizes the categories of origin. Here the larger cit-
ies in a neighborhood of 120 km, Hamburg and Hannover as well as Berlin and the Ruhr
(Ruhrgebiet) in Western Germany can be identified.
114 visitors from abroad took part in the survey, which is around 4% or the respondents, cor-
responding to a projection of around 11 000 visitors.

Regional Economic Impacts of Large Cultural Events
P. Schmidt, April 2008 - 73-
Figure 5 Origin of visitors from Germany
$
$
$
$
$
$
$
$
$
$
$
$
$
$
$
$
$
$
$
$
$
$
$
$
$
$
$$$
$$$$
$
$$$$
$$$$$$$$$ $$
$$$$$$ $
$
$
$
$
$
$
$$$
$$
$$
$$$
$$$
$$ $
$
$
$$
$
$
$
$
$
$
$
$
$$
$
$$$$$
$
$
$$$$
$$$$$$ $$
$
$
$
$$$$$$$$$$
$
$$$$$$$$$$$
$
$
$
$$
$
$
$
$
$
$
$
$
$
$ $
$
$
$
$
$
$
$
$
$
$
$
$
$
$
$$
$
$
$
$
$
$$
$
$
$$
$
$
$
$
$
$
$
$
$
$
$ $
$
$
$
$
$
$
$
$
$
$ $
$$$
$
$$
$
$$
$$
$
$$
$ $
$
$$
$$
$
$
$
$
$
$
$
$
$
$
$
$
$
$
$
$
$
$
$
$
$
$$
$
$
$
$$ $
$$
$$
$
$ $$
$
$$
$$$$ $
$
$
$$ $$
$
$
$
$$$
$$
$
$
$$
$
$
$
$
$
$
$
$$
$
$
$
$
$
$$ $
$
$$
$
$
$
$
$
$ $
$
$$
$
$
$
$$$
$
$
$
$ $ $$
$
$$$
$
$
$
$
$$
$
$$
$
$
$
$
$$
$
$
$$
$
$
$
$$
$
$
$ $$
$$
$
$$
$$
$
$
$ $
$
$
$
$
$
$$
$
$
$
$
$$$
$
$
$
$
$$
$$
$
$
$ $
$
$$
$
$
$
$
$
$
$
$$$
$$$
$
$
$
$$
$
$
$
$
$
$
$$
$
$
$
$$
$
$$
$
$
$ $
$
$
$
$
$$
$
$
$
$
$
$
$
$
$
$
$
$
$
$
$
$
$
$
$
$
$
$
$
$
$
$
$
$$
$
$
$
$
$
$
$
$
$$
$
$
$
$
$
$
$
$
$
$
$
$$
$
$
$
$
$
$
$
$
$
$
$
$
$
$
$
$$
$
$
$
$
$
$
$
$
$
$
$
$
$
$
$
$
$
$
$
$
$
$
$
$
$$$
$$
$
$
$
$
$
$
$
$
$
$
$
$
$
$
$
$
$
$
$
$
$
$
$$$
$
$
$
$
$
$
$
$
$
$
$
$
$
$
$
$
$
$$
$$$
$
$
$
$
$$ $
$
$
$$
$
$
$
$
$$
$
$
$
$
$
$
$
$
$
$
$
$
$
$
$
$
$
$
$
$
$
$$
$
$
$
$$
$
$
$
$
$
$
$
$
$
$
$$
$$
$
$
$
$
$
$
$
$
$
$
$
$
$
$
$
$$
$
$
$
$ $
$
$
$
$
$
$
$$
$
$
$
$
$
$
$
$
$
$
$
$
$
$
$$
$
$
$
$
$
$
$
$
$
$
$
$
$$
$
$
$
$
$
$
$$
$$
$
$
$$
$
$
$
$
$
$
$
$
$
$
$
$
$
$
$
$
$
$
$
$
$
$
$
$$
$
$
$
$$$
$
$
$
$
$
$
$
$
$$
$
$
$$
$
$
$
$
$
$
$
$
$
$
$
$
$
$
$
$ $
$
$
$
$
$
$
$
$
$
$
$
$
$
$
$
$
$
$
$
$$
$
$
$
$
$
$
$
$
$
$
$
$
$$
$
$
$ $
$
$
$
$
$
$
$
$$
$
$
$$
$
$
$
$
$
$
$
$
$
$
$
$
$
$
$
$
$
$
$
$
$
$$
$
$
$
$
$
$
$
$
$
$
$
$
$$
$
$
$
$
$
$
$
$$
$
$
$
$
$
$
$
$
$
$
$
$
$
$$
$
$
$
$
$$
$
$
$
$
$
$
$
$
$
$
$
$
$
$
$
$
$
$$
$
$$
$
$
$
$
$
$
$
$
$
$
$
$
$
$
$
$
$
$
$
$
$
$
$
$
$
$
$
$
$
$
$
$
$$
$
$
$
$
$
$
$
$
$
$
$
$$
$
$
$
$
$
$
$
$
$
$
$
$
$
$
$
$
$
$
$$
$
$
$
$
$
$
$
$
$
$
$
$
$
$
$
$
$
$
$
$
$
$
$
$ $
$
$
$
$
$
$
$
$
$
$
$
$
$
$
$$
$
$
$
$
$
$
$
$
$
$
$
$
$
$
$
$$
$
$
$
$
$
$
$
$
$
$
$
$
$
$
$
$
$
$$
$
$
$
$
$
$
$
$$
$
$
$
$
$
$
$
$
$
$
$
$
$
$
$
$
$
$
$
$
$
$
$
$
$
$
$
$
$
$
$
$$
$
$$
$
$ $
$
$
$
$ $
$
$
$
$
$
$
$$
$
$
$
$
$$
$
$
$$$
$
$
$
$
$
$
$
$
$ $
$
$
$$
$$
$
$
$
$$
$
$
$$
$
$
$
$
$
$
$$
$
$
$
$
$$
$
$
$$
$
$
$
$
$
$$
$
$
$
$
$
$
$$
$$
$
$
$
$
$$
$
$
$
$
$$
$
$
$
$
$
$
$ $$
$
$$
$$
$
$$
$
$
$
$
$$ $$
$
$
$
$
$
$$
$
$
$
$
$
$
$
$
$
$
$$
$$
$
$
$
$$
$
$
$
$
$
$$
$
$
$
$
$
$
$
$
$
$
$
$$
$
$
$$
$$$
$
$$
$
$
$
$$
$
$
$
$$
$
$
$
$ $
$
$
$
$
$
$
$$
$
$$
$
$$
$
$
$
$
$
$
$$
$$$
$
$
$
$
$
$
$$
$
$
$
$
$$$
$
$$
$
$
$
$$
$
$
$
$
$ $
$
$$
$
$
$
$
$$
$
$
$
$
$
$$
$
$
$
$
$$
$
$
$
$
$
$
$
$
$
$$
$$
$
$
$
$$
$
$$
$
$
$
$
$
$$
$
$
$$$
$
$
$
$
$
$
$$
$
$$
$
$
$
$
$$
$
$
$
$
$
$
$
$
$
$
$$
$
$$
$
$
$
$
$
$
$$
$
$
$
$
$
$
$$$
$
$
$
$
$
$
$
$$
$
$
$
$
$$
$
$
$
$
$
$
$
$
$
$$
$
$$
$
$
$$
$
$
$
$
$
$$
$ $
$
$$
$
$
$
$
$
$
$$
$
$
$
$
$
$
$
$$ $$
$
$
$
$
$
$
$
$
$$
$
$
$
$
$
$
$
$
$
$
$
$
$
$
$
$
$
$
$$
$
$
$
$$
$
$
$
$
$
$
$
$
$
$$$
$
$
$
$
$
$ $
$
$
$
$
$
$
$
$
$
$
$$
$$$
$$
$$
$
$$
$
$
$$
$$
$
$
$
$$
$
$$$
$
$$
$$$
$
$
$
$
$
$ $
$
$
$$
$
$
$
$ $$
$
$
$
$
$
$$
$$
$
$
$
$
$
$
$
$
$
$
$$
$$
$
$
$
$
$
$
$
$$
$
$$
$
$$
$
$$
$
$$ $
$$
$
$
$
$
$
$
$
$
$
$
$
$
$
$
$
$
$
$
$$
$
$$
$
$
$
$
$
$
$
$
$$
$
$
$
$$
$
$
$
$
$ $
$
$
$
$
$
$
$
$
$
$
$$$
$
$$$$
$
$
$
$
$
$
$
$
$
$$
$
$
$
$$
$
$
$
$$
$
$
$
$
$$ $
$
$$
$
$$
$
$
$$
$
$
$
$
$
$
$
$ $
$$
$
$
$ $$
$
$
$
$
$
$
$
$
$
$
$
$
$
$$
$
$
$
$
$
$
$
$
$
$
$
$
$
$
$
$
$
$
$
$$
$
$
$
$$
$
$
$
$
$
$
$
$
$ $ $
$$
$
$
$
$$
$
$
$
$
$
$$$
$
$$
$
$
$
$$$$
$
$
$
$$
$
$
$
$
$
$
$$
$
$
$
$
$
$
$
$
$
$
$
$
$
$
$
$
$
$$$
$
$
$
$
$
$
$
$
$
$
$
$ $
$
$
$
$
$
$
$
$
$
$
$
$
$
$
$
$
$
$
$
$
$
$$
$
$
$
$
$$
$
$
$
$$$
$
$
$
$
$
$
$
$
$
$
$
$
$
$
$
$
$$
$
$
$
$
$
$
$
$
$
$
$
$
$
$
$
$ $
$
$$
$
$
$
$
$
$
$
$
$
$
$
$
$
$
$
$
$$
$
$
$
$
$
$
$
$$
$
$
$
$
$
$
$
$ $
$
$
$
$
$
$$
$
$
$
$$
$
$
$
$
$
$
$
$
$
$
$
$
$$$
$$
$
$
$
$
$
$
$
$
$$
$
$
$$
$
$ $
$
$
$
$
$
$
$
$
$
$
$
$
$
$
$
$
$
$
$
$
$
$$
$
$
$
$
$
$$ $
$
$
$
$
$
$
$
$
$
$$
$
$
$
$
$
$
$
$
$
$
$
$
$ $
$
$
$$
$
$
$
$
$$
$
$
$
$
$
$
$
$
$
$
$
$$ $
$
$
$
$
$
$$
$
$
$
$
$
$
$
$
$
$$
$
$
$$
$
$
$
$
$
$
$
$
$
$
$
$
$
$
$
$
$
$
$
$
$
$
$
$
$
$
$
$
$
$
$
$
$
$$
$
$
$
$
$
$
$
$
$
$
$
$
$
$
$
$
$
$
$
$
$
$
$
$
$
$
$
$
$
$$
$
$
$
$
$
$
$
$
$
$$
$
$
$
$
$
$$
$
$
$$
$$
$
$
$$
$
$
$
$$
$
$
$$
$
$
$
$$
$$
$
$$ $$ $
$$
$
$
$$
$$
$$$
$
$
$
$$
$
$
$
$
$
$
$$$
$
$
$
$
$
$
$$ $
$ $
$
$
$$$
$
$
$
$
$
$
$
$
$$
$
$
$
$
$
$$
$
$
$
$
$
$
$
$
$
$
$
$
$
$$
$
$
$$
$
$
$
$
$
$
$
$
$$
$
$
$
$
$
$$
$
$
$
$$
$$
$
$
$
$
$
$$
$
$
$
$
$
$
$
$
$
$
$
$
$
$
$$
$
$
$
$
$ $
$
$$
$
$
$
$$
$
$
$$
$
$
$
$
$
$$
$
$ $
$
$
$
$
$
$
$
$
$
$
$
$
$
$
$
$
$
$ $$
$
$
$
$
$
$
$$
$
$
$
$
$
$
$
$
$
$
$
$
$
$
$
$
$
$
$
$
$
$
$
$
$
$
$
$$$
$
$
$
$
$
$
$
$
$
$
$
$
$
$
$
$
$
$
$
$$
$
$
$$$
$
$
$
$
$
$
$
$
$
$$
$
$
$
$
$ $$
$$
$
$ $
$
$
$
$
$
$$
$$
$
$
$$
$
$
$
$
$
$
$
$
$$
$
$$
$
$
$
$
$
$$
$
$
$
$
$$
$
$
$
$
$$ $
$
$$
$$
$
$
$
$
$
$
$
$
$
$
$
$
$
$
$
$
$
$
$
$
$$$
$
$$
$ $$ $
$
$
$
$
$
$$
$
$
$
$
$
$$
$
$
$
$
$
$
$
$
$
$
$
$
$
$
$
$
$
$
$
$
$$
$
$
$
$
$
$
$
$
$
$
$$
$$
$
$
$
$
$
$
$$
$
$
$
$
$
$
$
$
$
$
$
$
$
$$
$
$
$
$
$
$$$
$
$$
$
$$$
$
$$$
$
$
$
$
$
$
$
$
$
$
$
$
$
$$
$
$
$
$
$$
$
$
$
$$
$$
$
$
$
$
$
$$
$
$
$
$
$
$
$
$
$
$
$
$
$
$
$
$
$
$
$
$
$$
$
$
$$ $
17
06
39
16
97
49
29
91
19
15
26 27
99
14
94
04
86
24
38
37
83
31
92
84
01
18
21
25
34
74
88
54
3635
48
7285
59
23
56
79
93
95
07
66
87
96
89
02
53
63
09
82
67
55
78
0333
57
98
76 73
32
08
77
65
64
52
47
46
58
71
51
75
41
90
30
28
45
69
61
50
22
42
68
44
40
70
1213
60
80
20
BremenUmlandTagesgästeTouristen
$ 1 Punkt = 1 Befragte/r
Source: GIS.direkt, data: market.research.culture, Bremen 2008: Van Gogh visitors’ origin (2 digit zip codes)
Bremen Neighborhood up to 250 250 +
1 dot = 1 respondent

Regional Economic Impacts of Large Cultural Events
P. Schmidt, April 2008 - 74-
2.3 Motives, Activities and Overnight Stays of Out-of-Town Visitors
The next important question is whether the out-of-town visitors explicitly came to see the ex-
hibition. If this is the case, they can be taken into account for the estimation of the economic
impacts.
2.3.1 Special Exhibition as (main) Reason to visit the City / Region
All out-of-town visitors were asked ‘Is the exhibition the reason for your visit to Bremen?’ to
which 77 % gave an affirmative answer. This percentage differed with the origin of the re-
spondents, see Figure 6. Towards the end of the exhibition the percentage of out-of-town
visitors coming explicitly to see the exhibition increased, presumably reflecting the success of
the word-of-mouth recommendations, but also marketing and reports.
Figure 6 Out-of-town Visitors with Exhibition as the Reason to Travel to Bremen, Van Gogh
0%
10%
20%
30%
40%
50%
60%
70%
80%
90%
100%
2
Neigborhood
3 up to 250 4 250 plus 5 Abroad Total
Source: market.research.culture, Bremen 2008
Figure 7 illustrates that percentages of out-of-town visitors vary across the exhibitions as
does the percentage of the out-of-town visitors stating that they came because of exhibition.
The most successful event exhibitions Van Gogh, Monet & Camille and currently Paula in
Paris obviously attract many out-of-town visitors. This indicates that the large scale and crea-
tive marketing for these events is an important key to its success. These numbers are an
important basis for the estimation of economic impacts.

Regional Economic Impacts of Large Cultural Events
P. Schmidt, April 2008 - 75-
Figure 7 Out-of-town Visitors with Exhibition as the Reason to Travel to Bremen, all Exhibitions
Blauer Reiter
Van Gogh
Klee im Norden
(Summer 05)
Monet &
Camille
(Summer 06)
Paula in
Paris
Percentage out-of-town
71% 84% 75% 61% 80% 66% (81%)
Percentage out-of-town, coming because of exhibition
n/a 77% 73% 31% 71% 24% 78%
Source: market.research.culture, Bremen 2008
2.3.2 Duration and Type of Overnight Stay
Out-of-town visitors on average stayed in Bremen for 1.5 days. Those out-of-town visitors
who came explicitly to visit the exhibition only spent an average time of 1.2 days in the city.
Figure 8 shows the average length of stay by origin of the visitors – this length increases with
the travel distance of the visitors.
Figure 8 Average duration of stay (Van Gogh Exhibition)
Bayern
Niedersachsen
Hessen
Brandenburg
Sachsen
Baden-
Württemberg
Nordrhein-
Westfalen
Thüringen
Sachsen-
Anhalt
Rheinland-
Pfalz
Mecklenburg-
Vorpommern
Schleswig-
Holstein
Saarland
Berlin
Hamburg
durchschnittliche Besuchsdauer
1 Tag1 - 2 Tage2 - 3 Tage3 - 4 Tageüber 4 TageKeine Befragten
Source: GIS.direkt, data: market.research.culture, Bremen 2008: Van Gogh visitors’ origin
During the Van Gogh exhibition most of the out-of-town visitors (85%) only spent one day in
Bremen without staying overnight. Of those spending the night in the city 52 % lodged in a
Average duration of visit
1 day 1-2 days 2-3 days 3-4 days 4 + days n/a

Regional Economic Impacts of Large Cultural Events
P. Schmidt, April 2008 - 76-
hotel, 43 % stayed with friends. Figure 9 shows how these percentages vary between the
exhibitions
Figure 9 Type of Accommodation of out-of-town visitors
Blauer Reiter
Van Gogh
Klee im Norden
(Summer 05)
Monet &
Camille
(Summer 06)
Paula in
Paris
Hotel 60% 52% 62% 25% 32% 18% 61%
Friends/family 31% 43% 18% 53% 63% 75% 34%
other 9% 5% 21% 22% 5% 7% 5%
Source: market.research.culture, Bremen 2008
For the estimation of out-of-town visitors’ expenditures, a differentiation of duration is neces-
sary between those staying in a hotel and those staying with friends, as shown in Figure 10.
Figure 10 Average duration - overnight stay of out-of-town visitors explicitly coming for the event
Blauer Reiter
Van Gogh
Klee im Norden
(Summer 05)
Monet &
Camille
(Summer 06)
Paula in
Paris
All types of accommo-dation
n/a 2.2 1.88 1.7 1.59 1.94 n/a
In hotels n/a 2.32 1.50 2.95 2.31 2.16 2.72
With friends / family n/a 2.02 1.67 1.30 1.90 2.40 2.81
Source: market.research.culture, Bremen 2008
2.3.3 Further Activities of the Visitors
Another aspect of out-of-town visitors’ expenditures is the question whether they combine
their visit with other activities in Bremen. The answer to this question is shown in Figure 11.
Figure 11 Further activities of out-of-town visitors – all exhibitions
Blauer Reiter
Van Gogh
Klee im Norden
(Summer 05)
Monet &
Camille
(Summer 06)
Paula in
Paris
Visiting other museums n/a n/a n/a 31% 12% 32% 32%
Other cultural activities 12% 20% 20% 21% 11% 24% 13%
Shopping 22% 33% 36% 30% 35% 34% 31%
Restaurant 24% 47% 49% 37% 47% 35% 39%
Sightseeing 16% 33% 29% 37% 31% 39% 22%
Source: market.research.culture, Bremen 2008

Regional Economic Impacts of Large Cultural Events
P. Schmidt, April 2008 - 77-
The answer to this question varies substantially by origin of the visitor. While around half of
the visitors intended to eat out, the percentage of respondents visiting other cultural institu-
tions and also of sightseeing increases by distance.
Figure 12 Further activities of out-of-town visitors (Van Gogh)
10% 11%
19%
30%
42%
38%
41%
29%
33%
44%
54%
50%48%
39% 40%
8%
14%
36%
47% 46%
13%
19%22% 22%
18%
0%
10%
20%
30%
40%
50%
60%
1 Bremen 2 Neigborhood 3 up to 250 4 250 plus 5 Abroad
Other cultural institutions Shopping Restaurants Sightseeing Other activities
Source: market.research.culture, Bremen 2008: Van Gogh visitors
3. Regional Economic Impacts of the Arts Exhibitions
The impact of arts exhibitions is estimated in three steps. First the expenditures of out-of-
town visitors are estimated, secondly the resulting regional value added. In the third step, a
preliminary estimate of fiscal impacts is conducted and some further (non-monetary) aspects
are discussed.
3.1 Estimation of the Expenditures of Out-of-Town Visitors
To estimate the expenditures of out-of-town visitors, only those visitors (respondents) are
taken into account who reported that the visit of the expenditure was the reason to come to
Bremen. Furthermore, different categories of visitors had to be differentiated. This was done

Regional Economic Impacts of Large Cultural Events
P. Schmidt, April 2008 - 78-
with respect to the question, whether, how long, and where they stayed (over night) in the
city/region.2
The expenditures of out-of-town visitors were estimated as follows:
Exp = Σ PVx • AEx • DSx
= PVday • AEday • DSday + PVhot • AEhot • DShot + PVfam • AEfam • DSfam
with: PVx = Respx • EF
and:
Exp Expenditures of out-of-town visitors
Respx Number of respondents in category x
EF Expansion factor (total visitors of the exhibition / respondents in the survey)
(reciprocal of ‘(% of all visitors)’ in Figure 1)
PVx Projected number of out-of-town visitors in category x
DSx Duration of stay of the out-of-town visitors in category x
AEx Average expenditures of out-of-town visitors (tourists) in category x
where x represents:
day one-day visitors
hot visitors staying in a hotel
fam visitors staying with friends/family
For AE the following estimates for Germany have been used:
Figure 13 Estimation of average daily expenditures of out-of-town visitors
source:
Estimated Expendi-tures of one-day
visitors
Estimated Expendi-tures of visitors stay-
ing in hotels
Estimated Expendi-tures of visitors staying
with friends/family
DWIF´93 HB 27.26 €
DWIF´95 26.36 € 128.64 € 67.39 €
DWIF´00 HB 152.81 € 86.40 €
ITF´96 BHV 38.90 € 53.25 €
BTZ´00 HB 45.69 € 126.26 € 59.85 €
Sources: DWIF 93/95 – Deutsches Wirtschaftswissenschaftliches Institut für Fremdenverkehr e.V. an der Uni München; B.
Harrer, Dr. M. Zeiner, Dr. J. Maschke, S. Scherr; Tagesreisen der Deutschen; 1993 und 1995 DWIF 02 – Deutsches Wirtschaftswissenschaftliches Institut für Fremdenverkehr e.V. an der Uni München; Dr. B. Harrer, S.
Scherr; Ausgaben der Übernachtungsgäste in Deutschland; 2002 DWIF05 – Deutsches Wirtschaftswissenschaftliches Institut für Fremdenverkehr e.V. an der Uni München; Dr. B. Harrer, S.
Scherr; Ausgaben der Übernachtungsgäste in Deutschland; 2005 BITF – Bremer Institut für Tourismuswirtschaft und Freizeitforschung; Gästebefragung Stadt Bremen – 2000 (im Auftrag der
BTZ Bremen)
2 Other possible differentiations could have been the further activities reported by the respondents (see 2.3.3), but the average expenditures in the literature sources used for this paper didn’t contain this differentiation.
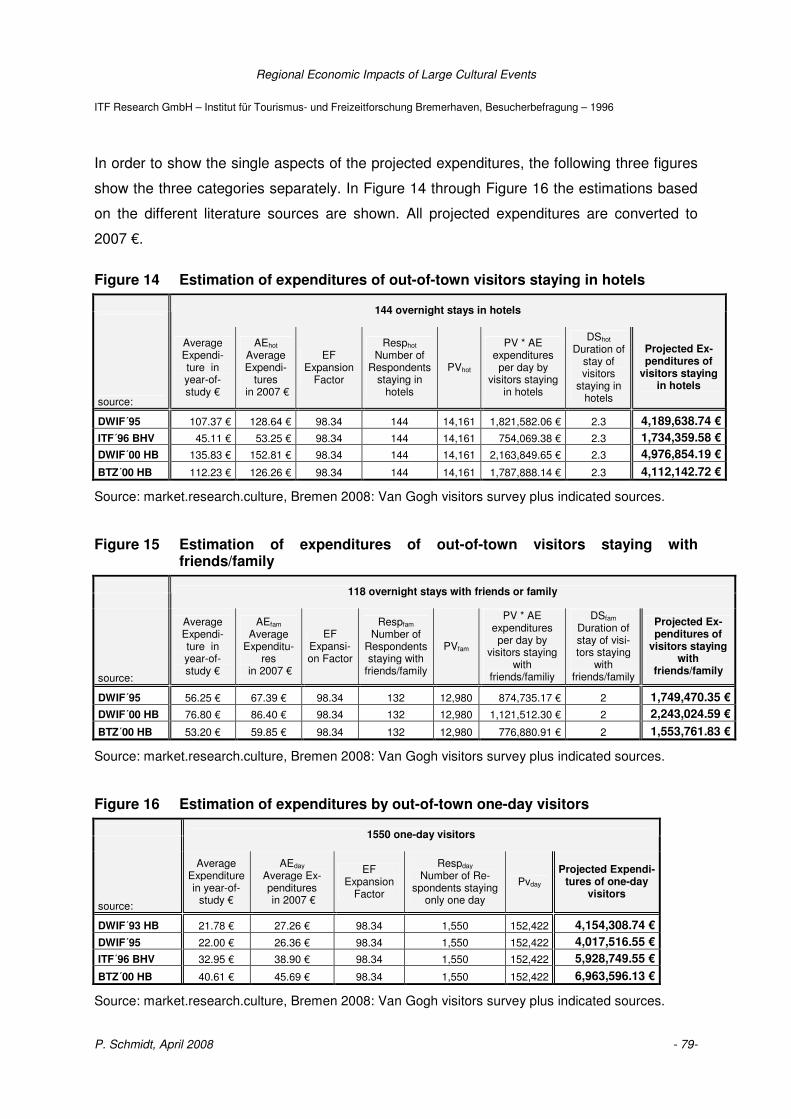
Regional Economic Impacts of Large Cultural Events
P. Schmidt, April 2008 - 79-
ITF Research GmbH – Institut für Tourismus- und Freizeitforschung Bremerhaven, Besucherbefragung – 1996
In order to show the single aspects of the projected expenditures, the following three figures
show the three categories separately. In Figure 14 through Figure 16 the estimations based
on the different literature sources are shown. All projected expenditures are converted to
2007 €.
Figure 14 Estimation of expenditures of out-of-town visitors staying in hotels
144 overnight stays in hotels
source:
Average Expendi-ture in year-of-study €
AEhot Average Expendi-
tures in 2007 €
EF Expansion
Factor
Resphot Number of
Respondents staying in
hotels
PVhot
PV * AE expenditures per day by
visitors staying in hotels
DShot Duration of
stay of visitors
staying in hotels
Projected Ex-penditures of
visitors staying in hotels
DWIF´95 107.37 € 128.64 € 98.34 144 14,161 1,821,582.06 € 2.3 4,189,638.74 €
ITF´96 BHV 45.11 € 53.25 € 98.34 144 14,161 754,069.38 € 2.3 1,734,359.58 €
DWIF´00 HB 135.83 € 152.81 € 98.34 144 14,161 2,163,849.65 € 2.3 4,976,854.19 €
BTZ´00 HB 112.23 € 126.26 € 98.34 144 14,161 1,787,888.14 € 2.3 4,112,142.72 €
Source: market.research.culture, Bremen 2008: Van Gogh visitors survey plus indicated sources.
Figure 15 Estimation of expenditures of out-of-town visitors staying with friends/family
118 overnight stays with friends or family
source:
Average Expendi-ture in year-of-study €
AEfam Average
Expenditu-res
in 2007 €
EF Expansi-on Factor
Respfam Number of
Respondents staying with
friends/family
PVfam
PV * AE expenditures per day by
visitors staying with
friends/familiy
DSfam Duration of stay of visi-tors staying
with friends/family
Projected Ex-penditures of
visitors staying with
friends/family
DWIF´95 56.25 € 67.39 € 98.34 132 12,980 874,735.17 € 2 1,749,470.35 €
DWIF´00 HB 76.80 € 86.40 € 98.34 132 12,980 1,121,512.30 € 2 2,243,024.59 €
BTZ´00 HB 53.20 € 59.85 € 98.34 132 12,980 776,880.91 € 2 1,553,761.83 €
Source: market.research.culture, Bremen 2008: Van Gogh visitors survey plus indicated sources.
Figure 16 Estimation of expenditures by out-of-town one-day visitors
1550 one-day visitors
source:
Average Expenditure in year-of-
study €
AEday Average Ex-penditures in 2007 €
EF Expansion
Factor
Respday Number of Re-
spondents staying only one day
Pvday Projected Expendi-
tures of one-day visitors
DWIF´93 HB 21.78 € 27.26 € 98.34 1,550 152,422 4,154,308.74 €
DWIF´95 22.00 € 26.36 € 98.34 1,550 152,422 4,017,516.55 €
ITF´96 BHV 32.95 € 38.90 € 98.34 1,550 152,422 5,928,749.55 €
BTZ´00 HB 40.61 € 45.69 € 98.34 1,550 152,422 6,963,596.13 €
Source: market.research.culture, Bremen 2008: Van Gogh visitors survey plus indicated sources.

Regional Economic Impacts of Large Cultural Events
P. Schmidt, April 2008 - 80-
Figure 17 delivers a summary of all estimated expenditures of out-of-town visitors. As not all
sources include values for every category of visitors, the total expenditures were only com-
puted for those sources containing all information. In addition, lowest and a highest projec-
tion estimation was conducted.
Figure 17 Estimation total expenditures of out-of-town visitors
source:
Projected Ex-penditures of
one-day visitors
Projected Ex-penditures of
visitors staying in hotels
Projected Expen-ditures of visitors
staying with friends/family
Exp Projected Ex-penditures of
all out-of-town visitors
DWIF´93 HB 4,154,309 € --
DWIF´95 4,017,517 € 4,189,639 € 1,749,470 € 9,956,626 €
DWIF´ 00 HB 4,976,854 € 2,243,025 € --
ITF´96 BHV 5,928,750 € 1,734,360 € --
BTZ´00 HB 6,963,596 € 4,112,143 € 1,553,762 € 12,629,501 €
lowest projection 4,017,517 € 1,734,360 € 1,553,762 € 7,305,638 €
highest projection 6,963,596 € 4,976,854 € 2,243,025 € 14,183,475 €
Source: market.research.culture, Bremen 2008: Van Gogh visitors survey plus indicated sources.
This approach results in a very broad interval for the estimation of projected expenditures, so
the lowest and highest projection values are not taken into further account. On average the
estimation amounts to approximately 11 million €.
Similar estimations were conducted for the other surveys; the results are shown in Figure 18.
Figure 18 Projected Expenditures of Out-of-Town Visitors during event exhibitions (estimated direct impacts - in 1 000 000 €)
Blauer Reiter
Van Gogh
Klee im Norden
(Summer 05)
Monet &
Camille
(Summer 06)
Paula in Paris
Minimum estimation 9.957 1.165 0.245 7.154 0.128 10.967
Maximum estimation 6.2873
12.629 1.694 0.276 8.789 0.143 11.682
Source: market.research.culture, Bremen 2008
This results show huge differences between the projected expenditures of the different exhi-
bitions. One clear result is that the economic impacts of the permanent exhibitions of an arts
museum are negligible. Not only are the numbers of visitors very small as compared to the
3 The value shown for the ‚Der Blaue Reiter’ exhibition is not completely comparable as the visitors were not asked whether they came to Bremen because of the exhibition. So this percentage was es-timated on basis of the other studies.

Regional Economic Impacts of Large Cultural Events
P. Schmidt, April 2008 - 81-
events although the time period of the survey is comparable, but also the percentage of peo-
ple coming to Bremen in order to visit the arts museum as was shown in Figure 7. In addition
it can be concluded from the fact that also the Klee exhibition did not result in a comparably
high value of projected expenditures, that joint exhibitions with other large cities which are
‘not far enough away’ also do not pay off as high as events that are focused on and pro-
moted in one city.
3.2 Regional Value Added: Direct and Indirect Impacts, Regional Multipliers
The second step in the analysis of economic impacts is to examine the contribution of these
additional expenditures in the city / region to the local economy. To not only take into account
the direct effects - the direct spending of those visitors who came from outside the town in
order to visit the exhibition as described above - but also the economic transactions caused
by these expenditures called indirect effects, regional multipliers are applied. They measure
the additional regional economic value added. The multiplier analysis was introduced by
John Maynard Keynes who designed this analysis for the macro economy of countries. Here
the multiplier takes into account the marginal propensity of a leakage out of the economy
(MPL): multiplier k = 1 / MPL
with: MPL = MPS + MPM + MPT
where MPS is the marginal propensity so save, MPM the marginal propensity to import and
MPT to be taxed, all measuring the percentage of the additional income not increasing the
total expenditure.4 On a national level the multiplier can take relatively high values.
Using a multiplier the Regional Value Added (RVA) can be estimated:
RVA = Exp + indirect Effects
= Exp • ( 1 + k )
4 Tribe, J. (2005), pages 266 to 271

Regional Economic Impacts of Large Cultural Events
P. Schmidt, April 2008 - 82-
Figure 19 Total direct and indirect impacts estimated in the multiplier
Source: Figure on the basis of Baum, H., Schneider, J., Esser, K., Kurte, J. (2004), page 10.
Looking at regional multipliers however, the effects are not so clear. ‘Leakages’ already oc-
cur, when some part of the additional expenditures are not spent within the city but in the
surrounding area, belonging to another municipality. This is called the (regional) incidence
(which percentage of the expenditures stays in the city / region?). Depending on the assump-
tions about the leakages and incidence the value of the multiplier to be applied varies sub-
stantially. Tribe quotes Tourism Income Multipliers for different countries for Canada (TIM =
2.5), UK (TIM = 1.8), Iceland (TIM = 0.6), and Edinburgh (TIM = 0.4).5 For cultural events for
example Grozea-Helmenstein, Slavova and Treitler use a multiplier of 1.736 in Austria, also
RIMS II multipliers of the U.S. Department of Commerce, Bureau of Economic Analysis vary
around 1.757
As the leakages are subtracted they lead to a smaller multiplier. We can observe that on av-
erage the smaller the region to be analyzed, the smaller the multiplier.
Bremen is a city state - although it only has 550 000 inhabitants it is one of the 16 German
states (Bundesländer)8 and thus has a certain fiscal autonomy. This also means that the re-
gional incidence is very important in order to evaluate the economic and fiscal effectiveness
of a public activity - and the ‘regional economy’ of Bremen is small. There have been several
attempts to estimate a multiplier for Bremen. Taubmann and Behrens, one of the first and
most quoted German studies about economic impacts of cultural institutions, used a multi-
5 Tribe, J. (2005), page 271
6 Grozea-Helmenstein, D., Slavova, T., Treitler, R. (2004), page 61
7 Chang, S (2002), page 14, using the Regional Input-Output Modeling System (RIMS II), cf. Regional Economic Accounts of the Bureau of Economic Analysis (http://www.bea.gov/bea/regional/rims)
8 The Bundesland Bremen consists of the cities Bremen and Bremerhaven, which add up to a popula-tion of around 660 000.
Exhibition Event
Increased demand in
regional firms
Increased demand for
intermediate products
Impact at Kunst-
halle Bremen
Impact for re-
gional firms
Impact for (re-
gional) producers
RVA
Total
direct
and
indirect
impacts

Regional Economic Impacts of Large Cultural Events
P. Schmidt, April 2008 - 83-
plier of 1.5, Schönert and Wehling9, in a study about another Bremen museum use the value
of 1.4 quoting Schaefers10 study from the year 2000. Heinemann and Kastin apply a multi-
plier of 1.311. So as a careful estimation a multiplier of 1.4 seems to be appropriate for this
analysis.
Figure 20 shows the magnitude of the direct expenditures plus indirect effects induced by the
exhibition events of Kunsthalle Bremen.
Figure 20 Regional Value Added of Out-of-Town Visitors during event exhibitions (estimated direct plus indirect impacts - in 1 000 000 €)
Blauer Reiter
Van Gogh
Klee im Norden
(Summer 05)
Monet &
Camille
(Summer 06)
Paula in
Paris
Minimum estimation 13.940 1.631 0.343 10.016 0.179 15.353
Maximum estimation 8.802
17.681 2.372 0.386 12.305 0.200 16.654
Source: market.research.culture, Bremen 2008
3.3 Fiscal Impacts
An in-depth analysis of the fiscal implications of the estimated Regional Value Added would
imply a detailed derivation of employment effects, computed on basis of the industry specific
labor productivity which goes beyond the scope of this paper.
Based on an approach of Baum, H., Schneider, et al.12 we assume an average effective tax
rate (after redistribution) of 22.5%13 which is divided between the political subdivisions as
shown in Figure 21, from which we derive a very preliminary and provisional estimate of pos-
sible tax revenues and their division.
Figure 21 Preliminary Estimate of Possible Tax Revenues
Blauer Reiter
Van Gogh
Klee im Norden
(Summer 05)
Monet &
Camille
(Summer 06)
Paula in
Paris
federal (min) 1.367 0.160 0.034 0.983 0.018 1.506
(43.7%) (max)
0.863 1.734 0.233 0.038 1.207 0.020 1.634
9 Schönert and Wehling (2003), page 22
10 Schaefer, H. (2000)
11 Heinemann, A., Kastin, S. (2007), page 21
12 Baum, H., Schneider, J., Esser, K., Kurte, J. (2004), page 50 – 52.
13 Quoted from the German Statistical Office (Statistisches Bundesamt) Statistisches Jahrbuch 2003, page 663.
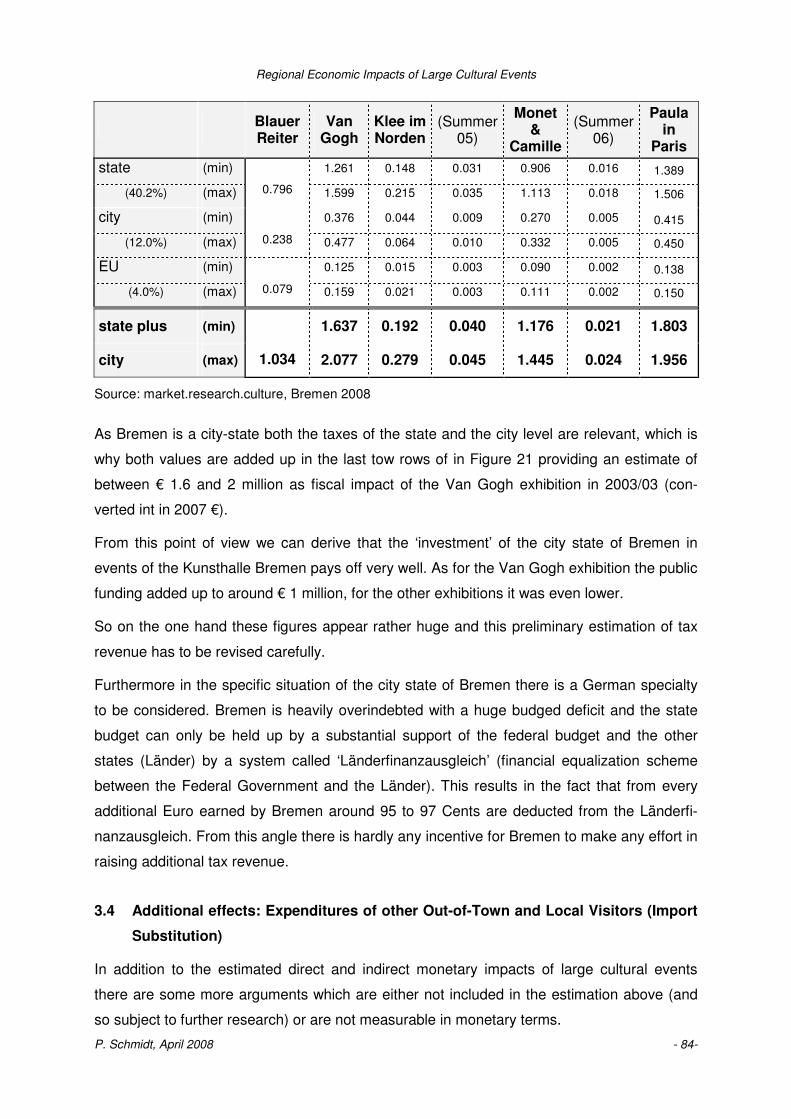
Regional Economic Impacts of Large Cultural Events
P. Schmidt, April 2008 - 84-
Blauer Reiter
Van Gogh
Klee im Norden
(Summer 05)
Monet &
Camille
(Summer 06)
Paula in
Paris
state (min) 1.261 0.148 0.031 0.906 0.016 1.389
(40.2%) (max)
0.796 1.599 0.215 0.035 1.113 0.018 1.506
city (min) 0.376 0.044 0.009 0.270 0.005 0.415
(12.0%) (max)
0.238 0.477 0.064 0.010 0.332 0.005 0.450
EU (min) 0.125 0.015 0.003 0.090 0.002 0.138
(4.0%) (max)
0.079 0.159 0.021 0.003 0.111 0.002 0.150
state plus (min) 1.637 0.192 0.040 1.176 0.021 1.803
city (max)
1.034 2.077 0.279 0.045 1.445 0.024 1.956
Source: market.research.culture, Bremen 2008
As Bremen is a city-state both the taxes of the state and the city level are relevant, which is
why both values are added up in the last tow rows of in Figure 21 providing an estimate of
between € 1.6 and 2 million as fiscal impact of the Van Gogh exhibition in 2003/03 (con-
verted int in 2007 €).
From this point of view we can derive that the ‘investment’ of the city state of Bremen in
events of the Kunsthalle Bremen pays off very well. As for the Van Gogh exhibition the public
funding added up to around € 1 million, for the other exhibitions it was even lower.
So on the one hand these figures appear rather huge and this preliminary estimation of tax
revenue has to be revised carefully.
Furthermore in the specific situation of the city state of Bremen there is a German specialty
to be considered. Bremen is heavily overindebted with a huge budged deficit and the state
budget can only be held up by a substantial support of the federal budget and the other
states (Länder) by a system called ‘Länderfinanzausgleich’ (financial equalization scheme
between the Federal Government and the Länder). This results in the fact that from every
additional Euro earned by Bremen around 95 to 97 Cents are deducted from the Länderfi-
nanzausgleich. From this angle there is hardly any incentive for Bremen to make any effort in
raising additional tax revenue.
3.4 Additional effects: Expenditures of other Out-of-Town and Local Visitors (Import
Substitution)
In addition to the estimated direct and indirect monetary impacts of large cultural events
there are some more arguments which are either not included in the estimation above (and
so subject to further research) or are not measurable in monetary terms.

Regional Economic Impacts of Large Cultural Events
P. Schmidt, April 2008 - 85-
• In only taking into account the out-of-town visitors we underestimate the effect that also
the visitors from the city on Bremen themselves may spend more money during and
around the visit of an exhibition (museum shop, restaurants, ...).
• This is especially true if the inhabitants of Bremen otherwise would have travelled to
another city/region, visited an exhibition and also spent money there (an amount com-
parable to that we estimated the out-of-town visitors to spend in Bremen). As the visit
of art events in another city from an economic point of view is regarded as an import of
services this effect is called import substitution.
• But there are also non-monetary benefits from such events. First to mention is the edu-
cational success. In attracting new visitor for cultural arts a society develops a higher
level of general education and by this the creative potential is increased – also in the
sense of the creative class approach of Richard Florida mentioned above.
• Additionally the (repeated) presentation of nationally and internationally appreciated
exhibitions improves the image of city or region. This may on the one hand lead to a
higher identification of the citizens with their region, but can also be regarded as a loca-
tion factor for future business decisions. This may lead –in an even more indirect way –
to increased economic performance in the future.

Regional Economic Impacts of Large Cultural Events
P. Schmidt, April 2008 - 86-
4. References
Baum, H., Schneider, J., Esser, K., Kurte, J. (2004), Die regionalwirtschaftlichen Auswirkungen des Low cost-
Marktes im Raum Köln/Bonn
BITF – Bremer Institut für Tourismuswirtschaft und Freizeitforschung (2000), Gästebefragung Stadt Bremen
Bornemann, H., Kaiser, P., Netzer, U. (2002), Wirkungsanalyse des Investitionssonderprogramms (ISP) des Lan-
des Bremen, Evaluierungsgutachten, Endbericht, Prognos AG, Bremen
Bremer Touristik-Zentrale (BTZ) (2000), Touristisches Marketing Bremen: 1999/2000 und Vorschau 2001, Bre-
men
Chang, Semoon (2002), Estimating the Economic Impact of Bay Fest 2001, CBER Report 50, Mobile, Alabama
DWIF (1993, 1995), Deutsches Wirtschaftswissenschaftliches Institut für Fremdenverkehr e.V. an der Uni Mün-
chen; B. Harrer, Dr. M. Zeiner, Dr. J. Maschke, S. Scherr; Tagesreisen der Deutschen
DWIF (2002), Deutsches Wirtschaftswissenschaftliches Institut für Fremdenverkehr e.V. an der Uni München; Dr.
B. Harrer, S. Scherr; Ausgaben der Übernachtungsgäste in Deutschland
DWIF (2005), Deutsches Wirtschaftswissenschaftliches Institut für Fremdenverkehr e.V. an der Uni München; Dr.
B. Harrer, S. Scherr; Ausgaben der Übernachtungsgäste in Deutschland
Florida, R (2004) The rise of the creative class ... and how it’s transforming work, leisure, community & every day
life, New York
Grozea-Helmenstein, D., Slavova, T., Treitler, R. (2004), Umwegrentabilität der Bregenzer Festspiele
Grabow, B., Henckel; D., Hollbach-Grömig, B. (1995), Weiche Standortfaktoren, Schriften des Deutschen Instituts
für Urbanistik 89, Stuttgart
Harrer, B., Zeiner, J., Maschke, S., Scherr, S. (1995), Tagesreisen der Deutschen; DWIF – Deutsches Wirt-
schaftswissenschaftliches Institut für Fremdenverkehr, München
Heinemann, A., Kastin, S. (2007), Die Bedeutung der Universität für Bremen vor dem Hintergrund der extremen
Haushaltsnotlage, Bremen
Hummel, M. (2000), Die volkswirtschaftliche Bedeutung von Kunst, Kultur, und Medien in der Bundesrepublik
Deutschland, Kurzfassung, ifo-Institut für Wirtschaftsforschung
ITF Research GmbH – Institut für Tourismus- und Freizeitforschung Bremerhaven (1996), Besucherbefragung
Kucharczuk, A. (2001), Kultur und Standort – Eine empirische Untersuchung zu der Sonderausstellung Der Blaue
Reiter in Bremen (unpublished Diploma thesis)
Kucharczuk, A., Schmidt, P. (2004), Regionalwirtschaftliche Implikationen von Kulturereignissen - am Beispiel der
Kunstausstellung Van Gogh: Felder; in: H. Bass (ed.), Facetten volkswirtschaftlicher Forschung, Münster /
Hamburg / New York
Kucharczuk, A., Schmidt, P. (2003 through 2007), diverse research reports
Miller, J (1996) Nutzen-Kosten-Analyse - Der fiskalische Nutzen eines Arbeitsplatzes im Land Bremen, BAW-
Arbeitspapier Nr. 11
Pohl, M. (2001), Fiskalische Bedeutung von Arbeitsplätzen, BAW Diskussionsbeitrag 2, Bremen
Pohl, M., Schönert, M. (2002), Regionalwirtschaftliche Bedeutung des Bremer Ratskellers, BAW Monatsbericht
11, Bremen
Riebel, J. (1993), Imageanalyse: Was sind wesentliche Analyse- und Gestaltungsfelder für das Stadtimage? In:
Töpfer, A., Stadtmarketing; FBO-Fachverlag für Büro- und Organisationstechnik GmbH, Baden-Baden
Schaefer, H. (2000), Ermittlung regionaler Multiplikatoren für das Land Bremen, Anlageband IV, Teilgutachten
externer Gutachter, Prognos AG, Bremen
Schönert, M., Wehling, W. (2003), Regionalwirtschaftliche Bewertung des Überseemuseums Bremen, BAW Bre-
men
Taubmann, W., Behrens, F. (1986), Wirtschaftliche Auswirkungen von Kulturangeboten in Bremen, Universität
Bremen
Tribe, J. (2005), The Economics of Recreation, Leisure & Tourism
Wehling, W. (2001), Regionalbericht Bremen 2000, BAW Monatsbericht 11, Bremen

Prof. Dr. Peter Schmidt
Fachbereich Wirtschaft Volkswirtschaftslehre und Statistik
: (0421) 5905-4691 Telefax: (0421) 5905-4862
[email protected] homepages.hs-bremen.de/~pschmidt
–––––––––– ΣΣΣΣ ττττ αααα ττττ ιιιι σσσσ ττττ ιιιι κκκκ ––––––––––
Auflage 5.1 -- edition 5.1
Dies ist die fünfte, überarbeitete Auflage der Formelsammlung. Trotz aller Bemühungen, den Druck-felerteuffel fernzuhalten, dürften einzelne Stellen Anlass zu konstruktiver Kritik bieten. Für diese bin ich dankbar. This is a basic version of a “bilingual” edition. Most of the statistical terms have been translated, but some parts are still missing. The idea was to present the international terms and abbreviations; you may need them when studying abroad - or simply in reading literature in English Language. There may be (translation-) errors. Please let me know any mistakes, missing topics, comments, … Thank you!
♦ Wenn bei Summen kein expliziter Laufindex angegeben ist, läuft die Summe von i=1 bis n.
♦ Diese Formelsammlung ist für Prüfungen zugelassen - allerdings nur in der Originalheftung. Es dürfen daher KEINE Erläuterungen, Kommentare, Beispiele usw. hinzugefügt werden. Zu-sätzliche Formeln (Umformungen) sind zulässig.
Anregungen und Hinweise Nachdruck und Vervielfältigung nur mit sind sehr willkommen ausdrücklicher Genehmigung des Autors
2 Auswertung und Darstellung eindimensionaler Daten – Analysing and Displaying One-dimensional Data
Formelsammlung Statistik, Auflage 5.1 2007/08 Seite 1
1 Grundlagen – Fundamentals
X, Y, ... Merkmal (Variable) mit einzelnen Beobachtungen (Ausprägungen) Variable with single observation
N Anzahl der Elemente einer Population (Grundgesamtheit) Number of elements of a population
n Anzahl der Elemente einer Stichprobe (Anzahl der Beobachtungen) Number of elements of a sample (number of observations)
Merkmalsausprägungen Values X = ( x1, x2, ... xn ) → xi mit i = 1,2, ...., n
2 Auswertung und Darstellung eindimensionaler Daten – Analysing and Displaying
One-dimensional Data
2.1 Häufigkeiten – Frequencies
Absolute Häufigkeiten von k verschiedenen Merkmalsausprägungen – Absolute Frequencies
ni = h(xi) → Anzahl der Werte mit der Merkmalsausprägung xi.
Relative Häufigkeiten von k Merkmalsausprägungen (Klassen) – Relative Frequencies
n
ni = fi [oder auch f(xi)] mit i = 1, ... k (2-1)
messen den Anteil der Merkmalsausprägung xi an allen Merkmalsausprägungen.
Daher ist 11
=∑=
k
i
if (2-2)
Prozentuale Häufigkeit (Prozentanteil) der Merkmalsausprägung xi – Percentage (proportion)
100100 ⋅=⋅i
i
f
n
n
(2-3)
Klassierte Daten – Classes
xi* → Klassenmitte: (Untergrenze + Obergrenze) / 2
Häufigkeitsdichte (für Histogramm) – Frequency Density
i
i
i
i
i
i
x
xf
oder
x
n
x
xh
also
iteKlassenbre
Häufigkeit
D
∆∆
=
∆
=
)()( **
(2-4)
Klassenbreite ∆ xi = Obergrenze xi - Obergrenze xi-1 (2-5)
Summenhäufigkeiten →→→→ "kumulierte" Häufigkeiten „bis zu“ einem vorgegebenen Wert xj
Cumulative Frequency → cumulated frequencies (counts) „up to“ a given value xj
Absolute Summenhäufigkeit – cumulated absolute frequencies
∑∑==
==
j
i
i
j
i
ijnxhxH
11
)()( (2-6)
Relative Summenhäufigkeit – cumulated relative frequencies
F(xj) = ∑∑=≤
=
j
i
i
xxi
ixfxf
j1
)()( (2-7)

2 Auswertung und Darstellung eindimensionaler Daten – Analysing and Displaying One-dimensional Data
Formelsammlung Statistik, Auflage 5.1 2007/08 Seite 2
Konzentrationsmessung: Measuring Concentration (Ermittlung der Zwischenschritte sinnvollerweise in Prozent)
Merkmalssumme der einzelnen Merkmalsausprägungen: iii
nxm ⋅= (2-8)
Merkmalssumme aller Merkmalsausprägungen: ∑=i
mm (2-9)
Relative Merkmalssumme: m
m
gi
i= (2-10)
Kumulierte relative Merkmalssumme: ∑=
=
j
i
ijgG
1
(2-11)
Einzelfläche unter der Lorenzkurve: ( )2
1ii
iii
gf
GfFl
⋅
+⋅=−
(2-12)
Gesamtfläche unter der Lorenzkurve: ∑=i
FlFl (2-13)
Lorenz‘sches Konzentrationsmaß (LKM): LKM 5000
1Fl
−= (2-14)
2.2 Lagemaße (Mittelwerte) – Measures of Central Tendency (Averages)
Arithmetisches Mittel: µ → arithmetisches Mittel einer Grundgesamtheit (Population)
Arithmetic Mean x → arithmetisches Mittel einer Stichprobe (Sample)
Einfaches arithmetisches Mittel bei (diskreten) Einzelwerten
simple arithmetic Mean
∑=
⋅=
n
i
ix
n
x
1
1 (2-15)
Gewichtetes arithmetisches Mittel (bei Häufigkeitsverteilungen)
Weighted arithmetic Mean
i
i
inx
n
x
k
∑=
⋅=
1
1 ⇒ ∑
=
⋅=
k
i
i
i
n
n
xx
1
(2-16)
Im Fall von Klassen Klassenmitte x*i verwenden.
Zentralwert (Median) – Median
1) Zentralwert = ZW = 50%-Anteil (Percentil) = 2. Quartil
2) i) sortieren aller Ausprägungen x1, ..., xn nach Größe ii) Suchen der Position von ZW → Ermittlung des Index m, für den xm in der Mitte aller Werte steht
3) ungerades n: ZW = xm mit 2
1+=
n
m (2-17)
gerades n: 2
21 ZWZW
ZW
+
= (2-18)
mit: ZW1 = xm mit
2
n
m = und ZW2 = xu mit
2
2+=
n
u (2-19)
Quantile (Percentile) – Quantiles (Percentiles)
p-Quantil: Q
px = xi mit: F(xi) > p und F(xi-1) < p (2-20)
Häufigster Wert (Modus) – Mode
xmod = xi mit )(maxi
i
xf (2-21)
2 Auswertung und Darstellung eindimensionaler Daten – Analysing and Displaying One-dimensional Data
Formelsammlung Statistik, Auflage 5.1 2007/08 Seite 3
Schiefe – Skewness x = ZW → symmetrische Verteilung x > ZW → rechtsschiefe Verteilung (2-22) x < ZW → linksschiefe Verteilung
Geometrisches Mittel – Geometric Mean
n
n
i
i
n
nxxxxGM ∏
=
=⋅⋅⋅=
121 ... (2-23)
oder alternativ: n
eauAnfangsniv
Endniveau
GM = (2-24)
2.3 Streuungsmaße – Measures of Variability / Deviation
Spannweite – Range: SW = xMax – xMin (2-25)
Durchschnittliche (mittlere) absolute Abweichung – Mean Absolute Deviation (MAD)
∑=
−=
n
i
ixx
n
DAA
1
1 (Einzelwerte) (2-26)
n
n
xxDAAi
n
i
i⋅−=∑
=1
(Häufigkeitsauszählungen) (2-27)
Anm.: Es kann auch ZW statt x verwendet werden.
Hilfsgröße: Varianz – Variance (auxiliary measure) Stichprobe – s² – Sample Population – σ² – Population
a) Einzelwerte
( )
2
1
2
1
1∑
=
−
−
=
n
i
ixx
n
s (2-28) ( )
2
1
2 1∑
=
−=
n
i
ix
N
µσ (2-29)
b) Klassierte Werte / Häufigkeiten
( )
( )1
1
1
1
2
1
22
−
⋅−=
⋅−⋅
−
=
∑
∑
=
=
n
n
xx
nxx
n
s
i
k
i
i
i
k
i
i
(2-30)
( )
( )N
n
x
nx
N
i
k
i
i
i
k
i
i
⋅−=
⋅−⋅=
∑
∑
=
=
1
2
1
22 1
µ
µσ
(2-31)
Standardabweichung – Standard Deviation
2
ss = 2σσ = (2−32)
Variationskoeffizient – Coefficient of Variance
x
s
VC = µ
σ=VC (2-33)
(Standardisierter) Z-Score – Z-Score
s
xx
zi
−
= σ
µ−
=i
x
z (2-34)

3 Zusammenhänge zwischen mehrdimensionalen Daten – Relations between Multi-Dimensional Variables
Formelsammlung Statistik, Auflage 5.1 2007/08 Seite 4
3 Zusammenhänge zwischen mehrdimensionalen Daten – Relations between Multi-
Dimensional Variables
3.1 Allgemeine Grundbegriffe – Basic Concepts
Randverteilungen (Zeilen / Spalten) – Marginal Distributions (Columns / Rows)
Zeilensumme ∑q
1=kj );(=)h(x
kjyxh → Zeilenprozente )100(
)h(x
);(h);(
j
⋅=kj
kj
yx
yxf (3-1)
Spaltensumme ∑m
1j=k );(=)h(y
kjyxh → Spaltenprozente )100(
)h(y
);(h);(
k
⋅=kj
kj
yx
yxf (3-2)
∑∑q
1=k
m
1j=
)(=)(=nkj
yhxh ist die Anzahl der Beobachtungen (3-3)
3.2 Zusammenhänge zwischen metrisch skalierten Merkmalen – Correlation of metrically scaled Variables
Kovarianz – Covariance ∑=
−−=
n
i
iiyyxx
n
YXCov
1
))((1
),( (3-4)
Korrelationskoeffizient – Correlation Coefficient (Bravais-Pearson)
YXss
YXCov
r
),(= (3-5)
∑∑
∑
==
=
−−
−−
=n
i
i
n
i
i
n
i
ii
yyxx
yyxx
r
1
2
1
2
1
)()(
))((
(3-6)
Lineare Regression – Linear Regression
Regressionsfunktion: xbay ⋅+=ˆ (3-7)
Beobachtungswerte: exbay +⋅+= (3-8)
Residuen: yye ˆ−= (3-9)
Lineare Einfachregression nach der Methode der Kleinsten Quadrate (KQ) :
Ordinary Least Squares Regression (OLS): ( ) !2
Minei
→∑ ⇒
( )
( )22
22
2
∑∑∑ ∑∑
∑∑∑∑∑∑
−
−
=
−
−
=
ii
iiii
ii
iiiii
xxn
yxyxn
b
xxn
yxxyx
a
(3-10)
alternative Ermittlung der Koeffizienten a und b:
∑
∑
=
=
−
−−
=
−=
n
i
i
n
i
ii
xx
yyxx
b
xbya
1
2
1
)(
))(( (3-11)
3 Zusammenhänge zwischen mehrdimensionalen Daten – Relations between Multi-Dimensional Variables
Formelsammlung Statistik, Auflage 5.1 2007/08 Seite 5
Bestimmtheitsmaß / Gütemaß R² – Goodness of Fit / Coefficient of Determination R2
( )
( )2
2
2ˆ
∑∑
−
−
=
yy
yy
R
i
i
(3-12)
2
2
2
2ˆ2 1
y
e
y
y
s
s
s
s
R −== (3-13)
Bei linearer Einfachregression gilt: R² = r² (3-14)
(Vorhergesagte) Schätzwerte – Estimated (predicted) Values y
Die geschätzten (vorhergesagten) Werte, d.h. die Werte auf der Regressionsgerade, können
unmittelbar aus der Regressionsfunktion ii
xbay ⋅+=ˆ (3-15)
errechnet werden, indem die ermittelten Werte von a und b sowie jedes einzelne xi eingesetzt werden.
Dies ist etwa zur Ermittlung des R², für Prognosen und Glättung von Zeitreihen erforderlich.
3.3 Rangkorrelationen für ordinal skalierte Merkmale (nach Spearman) –
Rank Correlation for ordinal Variables (Spearman’s ρ)
( )1
61
2
2
−
−=∑nn
d
ri
s [mit: di = xi - yi] (3-16)
3.4 Kontingenzanalyse bei nominal skalierten Variablen – Contingency Measures (As-
sociation of nominal Variables)
Der χ2-Wert als Hilfsgröße (für den Unabhängigkeitstest siehe Kapitel 8.3.4)
1. Schritt: Ermittlung der erwarteten Häufigkeiten he in der Kontingenztabelle:
n
yhxh
hkj
e
)()( ⋅
= (3-17)
2. Schritt: Errechnen von χ2 durch Summieren aller Felder:
( )
);(
);();(2
11
2
kje
kjekj
q
k
m
jyxh
yxhyxh −
= ∑∑==
χ (3-18)
Kontingenzkoeffizient – Coefficient of Contingency
einfacher: n
C
+
=2
2
χ
χ (3-19)
korrigierter: 11 *
*
2
2
*
*
−
⋅
+
=
−
⋅=
K
K
nK
K
CCkorr
χ
χ (3-20)
mit: K* = Min(m;q)

4 Elemente der Zeitreihenanalyse – Time Series Analysis (TSA)
Formelsammlung Statistik, Auflage 5.1 2007/08 Seite 6
4 Elemente der Zeitreihenanalyse – Time Series Analysis (TSA)
4.1 Komponenten einer Zeitreihe – Components of a Time Series
Yt = TK + KK + SK + RK (4-1)
4.2 Glättung durch Gleitende Durchschnitte – Smoothing with Moving Averages (MA)
Gegeben sei eine Zeitreihe von T Werten yt (t=1, ..., T)
a) Gleitende Durchschnitte ungerader Ordnung
∑
−+
−−=
−+
−+
−−
−−
−−
+==
++++++=
2
1
2
1
2
1
2
3
2
3
2
1
2
1,...,
2
11
......1
k
t
k
ti
i
k
t
k
t
tk
t
k
t
kt
k
T
k
tfüry
k
yyyyy
k
y
(4-2)
b) Gleitende Durchschnitte gerader Ordnung
2,...,1
22
1
2
11
2
12
12
2
k
T
k
tfüryyy
k
yk
t
k
t
k
ti
ik
t
kt −+=
++=+
−+
+−=
−
∑ (4-3)
4.3 Glättung durch lineare Trendfunktion – Smoothing with a Linear Trend Function
Allgemeine Trendfunktion: )(ˆ tfy =
Lineare Trendfunktion: tbay ⋅+=ˆ
Es ergibt sich die Formel zur Ermittlung von a und b analog (3-10):
( )
( )22
22
2
∑∑∑ ∑∑
∑∑∑∑∑∑
−
−
=
−
−
=
ii
iiii
ii
iiiii
ttn
ytytn
b
ttn
yttyt
a
(4-4)
Hinweis:
Durch Transformation des Zeitindex t, so dass 0*=∑ i
t wird
z.B. mittels: tttii
−=* (4-5)
vereinfacht sich (4-4) zu:
∑
∑==
=
2*
*
*
*
i
ii
t
yt
bb
ya
(4-6)
4 Elemente der Zeitreihenanalyse – Time Series Analysis (TSA)
Formelsammlung Statistik, Auflage 5.1 2007/08 Seite 7
4.4 Ermittlung der (additiven) Saisonkomponente und Saisonbereinigung – Analysis
of Seasonality
1. Schritt: Saisonale Abweichung aller Einzelwerte vom Trend (kt
y oder t
y )
kttt
yySK −= (bei GD) oder (4-7 a)
ttt
yySK ˆ−= (bei KQ) (4-7 b)
2. Schritt: durchschnittliche saisonale Abweichung der Zeiteinheiten
Saisonkomponente – Seasonal Component: ∑∈
=
jtZeiteinheit
tjSK
Q
SK*
1 (4-8)
Q* = Anzahl der Beobachtungen in der jeweiligen SKj (Tertiale, Quartale, Monate, ....)
3. Schritt: saisonbereinigte Reihe – seasonally adjusted series
jtt
SKyy −=~ (4-9)
es verbleibt die Irreguläre oder Rest-Komponente
tktt
yyRK~
−= bzw. ttt
yyRK~ˆ −= (4-10)
4.5 Prognosen – Forecasting
Einfache Prognosen – Simple Forecasts
Konstante Entwicklung tt
yy =+
*1 (4-11)
Additive Entwicklung ( )1*
1 −+−+=
ttttyyyy (4-12)
Multiplikative Entwicklung 1
*1
−
+⋅=
t
t
tt
y
y
yy (4-13)
Prognosen auf Basis von Trendfunktionen – Forecasts based on Trend Analysis
können auf Basis der Fortschreibung der vorhergesagten Werte )(ˆ *tfy
t=
(vergleiche (3-15)) ermittelt werden, indem für t zukünftige Werte eingesetzt werden:
tbayt
⋅+=*ˆ (4-14)
Saisonale Einflüsse bei linearer Trendprognose – Forecasts considering Seasonality
Für die Prognose wird die SK addiert (analog mit t* und a*):
( )jt
SKtbay +⋅+=*ˆ (4-15)

5 Maß- und Indexzahlen – Indices
Formelsammlung Statistik, Auflage 5.1 2007/08 Seite 8
5 Maß- und Indexzahlen – Indices
5.1 Verhältniszahlen – Ratios
(5.1.1.) Gliederungszahl → relative Häufigkeit )(i
i
xf
n
n
= (5-1)
Beziehungszahl: x
n
x
EinheitenhenstatistiscderAnzahl
sprägungenMerkmalsauderSumme
BZi
=≈=∑
(5-2)
(5.1.2.) Messziffern oder Messzahlen:
X = Reihe von Werten xt mit t = 0, ..., T.
0 = Basisperiode
t = Berichtsperiode.
Messzahl für die „Periode t zur Basis 0“ )100(0
0 ⋅=
x
x
Mtt (5-3)
Reihen von Messziffern – Series of Measures
Verschiedene t
M 0 Werte für laufendes t (d.h. in Bezug zur Vorperiode):
Zuwachsrate: 111
1
10
100
−=
−
=
−
=
−−
−
−
−
t
t
t
tt
t
tt
t
x
x
x
xx
M
MM
Z (⋅ 100 [%]) (5-4)
Wachstumsfaktor: 11
+==
−
t
t
t
tZ
x
x
W Growth Rate (5-5)
Durchschnittlicher Wachstumsfaktor zwischen zwei Zeitpunkten:
( ) n
n
t t
t
t
x
x
WGMW ∏= −
==
1 1
(⋅ 100 [%]) [vgl. auch (2-23)] (5-6)
Umbasierung und Verketten von Messziffern:
(A = altes Basisjahr; N = neues Basisjahr)
N
A
t
At
N
M
M
M = (⋅ 100 [%]) oder (wenn N
AM nicht bekannt) A
N
t
A
t
NMMM ⋅= (⋅ 100 [%]) (5-7)
5.2 Preis- und Mengenindizes – Price and Quantity Indices
pti → Preis des Produktes (Faktors) i zum Zeitpunkt t
qti → Menge des Produktes (Faktors) i zum Zeitpunkt t
Preisindex Mengenindex
Laspeyres ∑∑
=
ii
ii
P
qp
qp
L
00
01 ⋅ 100 (5-8)
∑∑
=
ii
ii
M
pq
pq
L
00
01 ⋅ 100 (5-9)
Paasche ∑∑
=
ii
ii
P
qp
qp
P
10
11 ⋅ 100 (5-10)
∑∑
=
ii
ii
M
pq
pq
P
10
11 ⋅ 100 (5-11)
Wertindex: ∑∑
===
ii
ii
MPMP
qp
qp
LPPLWI
00
11 ⋅ 100 (5-12)
Aus diesen – jeweils zwei Perioden vergleichenden – Messzahlen werden in der Regel Indexreihen gebildet, mit denen wie im Abschnitt 5.1 beschrieben verfahren werden kann.
6 Kombinatorik & Wahrscheinlichkeitsrechnung – Theory of Combination & Probabilities
Formelsammlung Statistik, Auflage 5.1 2007/08 Seite 9
6 Kombinatorik & Wahrscheinlichkeitsrechnung – Theory of Combination & Probabili-
ties
6.1 Kombinatorik – Combination Theory
Anzahl der Permutationen (Anordnungen) von n Elementen → Fakultäten: n! = 1 ⋅ 2 ⋅3 ⋅ ... ⋅ n (wobei: 0! = 1) (6-1)
Binomialkoeffizient:
)!(!
!
!
)1(...)2()1(
nNn
N
n
nNNNN
n
N
−⋅
=+−⋅−⋅−⋅
=
(6-2)
Anzahl der Kombinationen n-ter Ordnung aus N Elementen:
mit Zurücklegen ohne Zurücklegen
Berücksichtigung Reihenfolge
Nn (6-3) N
N n
!
( )!−
(6-4)
keine Berücksichtigung der Reihenfolge
N n
n
+ −
1 (6-5)
N
n
(6-6)
6.2 Grundbegriffe und Definitionen der Wahrscheinlichkeitsrechnung – Basic Con-
cepts and Definitions of Calculus of Probabilities
Ε = e1, e2, e3, ... → Menge der Elementarereignisse – Events
A, B, C, ... → Ereignisse: alle Untermengen von E (Kombinationen der ei)
Ω = A, B, C, ... → Ereignisraum: Menge aller möglichen Ereignisse
W(A) → Wahrscheinlichkeit dafür, dass Ereignis A eintritt
A → komplementäres Ereignis zu A
mit: W( A ) = 1 – W(A)
( )BAW ∪ → Wahrscheinlichkeit, dass Ereignis A oder Ereignis B eintreten
( )BAW ∩ → Wahrscheinlichkeit, dass Ereignis A und Ereignis B eintreten
Definitionen von Wahrscheinlichkeiten – Definitions of Probabilities
Klassische Definition nach Laplace (a-priori-Wahrscheinlichkeiten)
W A
Anzahl der günstigen Ereignisse
Anzahl der gleichmöglichen Ereignisse
( )" "
= (6-7)
Empirische Wahrscheinlichkeiten (statistische Definition nach Mises) (a-posteriori-Wlk)
W(A) = f (A) → relative Häufigkeit (Anteil) des Ereignisses A (6-8) bei großen Stichproben (Grenzwert) als Anhalt für die realisierte Wahrscheinlichkeit
Axiomatische Definition nach Kolmogoroff [ΚΟΛΜΟΓΟΡΟΒ]
Axiom 1: W ist nichtnegativ: W(A) ≥ 0
Axiom 2: W ist normiert: W(Ω) =1 (6-9)
Axiom 3: W ist additiv: W(A ∪ B) = W(A) + W(B) für W(A ∩ B) = 0

6 Kombinatorik & Wahrscheinlichkeitsrechnung – Theory of Combination & Probabilities
Formelsammlung Statistik, Auflage 5.1 2007/08 Seite 10
6.3 Rechnen mit Wahrscheinlichkeiten – Calculation with Probabilities
Wahrscheinlichkeiten zusammengesetzter Ereignisse – Probabilities of Unions of Events
Allgemeiner Additionssatz
W(A ∪ B) = W(A) + W(B) – W(A ∩ B) (6-10)
W(A∪B∪C) = W(A) + W(B) + W(C) - W(A∩B) - W(A∩C) - W(B∩C) + W(A∩B∩C) (6-11)
Dieser vereinfacht sich für sich ausschließende Ereignisse (W(A ∩ B) = 0) zu:
Spezieller Additionssatz
W(A ∪ B) = W(A) + W(B) (6-12)
W(A ∪ B ∪ C) = W(A) + W(B) + W(C) (6-13)
Bedingte Wahrscheinlichkeiten – Conditional Probabilities
[ ]W B A
W A B
W A
mit W A( | )( )
( )( )=
∩
> 0 lies: „W von B gegeben A“) (6-14)
[ ]W A B
W A B
W B
mit W B( | )( )
( )( )=
∩
> 0 lies: „W von A gegeben B“) (6-15)
Allgemeiner Multiplikationssatz
W(A ∩ B) = W(A) W(B|A) = W(B) W(A|B) (6-16)
W(A ∩ B ∩ C) = W(A) W(B|A) W(C| A ∩ B) (6-17)
(Stochastische) Unabhängigkeit – stochastic Independence
Es seien die Ereignisse A, B, C mit W(A) >0, W(B) > 0 und W(C) > 0, dann sind die Ereignisse A und B voneinander (stochastisch) unabhängig, wenn A unabhängig von B ist (6-18 a) und B unabhängig von A (6-18 b):
W(A | B) = W(A | B ) = W( A ) und (6-18 a)
W(B | A) = W(B | A ) = W( B ) (6-18 b)
Analog sind die Ereignisse A, B und C voneinander (stochastisch) unabhängig, wenn gilt:
W(A | B) = W(A | C) = W(A | B ∩ C) = W(A) und (6-19 a) W(B | A) = W(B | C) = W(B | A ∩ C) = W(B) und (6-19 b) W(C | A) = W(C | B) = W(C | A ∩ B) = W(C) (6-19 c)
Spezieller Multiplikationssatz
für stochastisch unabhängige Ereignisse vereinfacht sich der Multiplikationssatz wie folgt:
W(A ∩ B) = W(A) W(B) (6-20)
W(A ∩ B ∩ C) = W(A) W(B) W(C) (6-21)
7 Theoretische Verteilungen – Theoretical Distributions
Formelsammlung Statistik, Auflage 5.1 2007/08 Seite 11
7 Theoretische Verteilungen – Theoretical Distributions
7.1 Zufallsvariablen – Random Variables
X – Zufallsvariable (ZV) mit den Ausprägungen x1, x2, ... xn
7.1.1 Dichte- und Verteilungsfunktion – Density and Distribution Function (Cumulated
Density function - cdf)
Diskrete ZV – Discrete Random Variables
Wahrscheinlichkeitsfunktion → Wahrscheinlichkeit, dass die ZV X den Wert x annimmt
f(x) = W(X = x) (7-1)
Verteilungsfunktion → Wahrscheinlichkeit, dass die ZV X höchstens den Wert x annimmt
F(x) = W(X x) =xi
≤
≤
∑ f xi
x
( ) (7-2)
Stetige ZV – Continuous Random Variables
Dichtefunktion (Wahrscheinlichkeitsdichte): → Wahrscheinlichkeit, dass die ZV X
einen Wert annimmt, der in einem infinitesimal kleinen Intervall um x liegt
f(x) = W(x-ε ≤ X ≤ x+ε) [für ε→ 0] (7-3)
mit: f(x) ≥ 0 und 1)( =∫+∞
∞−
dxxf (7-4)
Intervall: ∫=≤<
b
a
dxxfbXaW )()( (7-5)
Verteilungsfunktion → Wahrscheinlichkeit, dass die ZVX höchstens den Wert x annimmt
∫∞−
=≤=
x
dvvfxXWxF )()()( (7-6)
7.1.2 Parameter von Verteilungen – Parameters of Distributions
Erwartungswert E einer diskreten ZV – Expected Value of a Discrete Random Variable
EX = µ = x f xi i⋅∑ ( ) (7-7)
Erwartungswert E einer stetigen ZV – Expected Value of a Continuous Random Variable
EX = µ = x f x dx⋅
−∞
+∞
∫ ( ) (7-8)
Varianz einer ZV (allgemeine Form) – Variance
VX = σ2 = E(X – EX)2 = EX2 – (EX)2 (7-9)
Varianz einer diskreten ZV
VX = σ2 = ( )x EX f xi i
− ⋅∑2
( ) (7-10)
Varianz einer stetigen ZV
VX = σ2 = ( ) dxxfEXx∫+∞
∞−
⋅− )(2
(7-11)

7 Theoretische Verteilungen – Theoretical Distributions
Formelsammlung Statistik, Auflage 5.1 2007/08 Seite 12
7.2 Einige spezielle Verteilungen – Specific Distributions
7.2.1 Diskrete Verteilungen – Discrete Distributions
Binomialverteilung – Binomial Probability Distribution
N → Anzahl der Elemente in der Grundgesamtheit – Elements of the population n → Anzahl der (unabhängigen) Experimente = Stichprobenumfang – sample size p → Wahrscheinlichkeit des Erfolgs („günstigen“ Ausganges) eines Experiments,
bei dem nur zwei Ereignisse möglich sind. x → Anzahl der Erfolge („günstigen“ Ereignisse) in der Stichprobe
( )xnx
pp
x
n
xXWpnxf−
−⋅⋅
=== 1)();|( (7-12)
EX = n ⋅ p (7-13)
VX = n ⋅ p ⋅ (1-p) (7-14)
Multinomialverteilung – Multinomial Probability Distribution
f1,2,...k (x1, x2, ... xk) = W(X1 = x1, ... Xk = xk) kx
k
xx
k
ppp
xxx
n
⋅⋅⋅⋅
⋅⋅⋅
= ...!...!!
! 221
21
1 (7-15)
mit: ∑=
=
k
i
inx
1
und ∑=
=
k
i
ip
1
1
EX = n ⋅ pi (7-16)
VX = n ⋅ pi ⋅ (1-pi) (7-17)
Hypergeometrische Verteilung – Hypergeometric Probability Distribution
n → Stichprobenumfang N → Anzahl der Elemente in der Grundgesamtheit M → Anzahl der Erfolge in der Grundgesamtheit
=> p
M
N
= (7-18)
f (x | n ; N ; p) =
−
−⋅
⋅
n
N
xn
pN
x
pN )1(
=
M
x
N M
n x
N
n
−
−
(7-19)
EX = n ⋅ p (7-20)
VX = n ⋅ p ⋅ (1-p) ⋅
N n
N
−
− 1 (7-21)
Poissonverteilung – Poisson Probability Distribution
f (x | µ) = µ
µ
x
x
e
!⋅
− (mit: e = 2,7183... → Euler’sche Zahl) (7-22)
EX = VX = µ (7-23)
Gleichverteilung – Uniform Distribution
f (x) = N
1 (7-24)
EX = µ = x f xi i⋅∑ ( ) VX = σ2 = ( )x EX f x
i i− ⋅∑
2( ) (7-25)
7 Theoretische Verteilungen – Theoretical Distributions
Formelsammlung Statistik, Auflage 5.1 2007/08 Seite 13
7.2.2 Stetige Verteilungen – Continuous Distributions
Normalverteilung Normal Distribution 2
2
1
2
1),|(
−−
⋅
⋅Π
=σ
µ
σ
σµ
x
exf (7-26)
F x f v dv
x
( | , ) ( | , )µ σ µ σ=
−∞
∫ (7-27)
EX = µ (7-28)
VX = σ2 (7-29)
Die übliche Schreibweise dafür, dass eine Zufallsvariable X einer Normalverteilung
mit Mittelwert µ und Standardabweichung σ folgt, ist:
X →→→→ N (µ, σµ, σµ, σµ, σ) (7-30)
Standardnormalverteilung – Standard Normal Distribution
Wenn X normalverteilt ist mit N(µ, σ), dann ist
Z
X
=
− µ
σ standardnormalverteilt [Z → N (0, 1)] (7-31)
mit:
EX = 0 (7-32)
VX = 1 (7-33)
χχχχ2 2 2 2 –Verteilung [„Chi-Quadrat“] – χχχχ2 2 2 2
Distribution
Seien Z1, Z2, ... Zν unabhängige standardnormalverteilte Zufallsvariable, dann ist die Summe:
Z Z Z12
22 2
+ + +...ν
χχχχ2222- verteilt mit: (7-34)
E( Z Z Z12
22 2
+ + +...ν
) = ν (7-35)
V( Z Z Z12
22 2
+ + +...ν
) = 2ν (7-36)
t –Verteilung (Studentverteilung) – t–Distribution (Student’s Distribution)
Ist Z eine standardnormalverteilte und Y eine mit ν Freiheitsgraden χ2-verteilte Zufallsvariable und sind Z und Y unabhängig, dann ist die Zufallsvariable
T
Z
Y
=
ν
t – verteilt mit: (7-37)
ET = 0 für ν ≥ 2 (7-38)
VT = ν
ν − 2 für ν ≥ 3 (7-39)

7 Theoretische Verteilungen – Theoretical Distributions
Formelsammlung Statistik, Auflage 5.1 2007/08 Seite 14
7.2.3 Zentraler Grenzwertsatz – Central Limit Theorem
Seien X1, X2, ...., Xn als Stichproben aus einer Grundgesamtheit mit Mittelwert µ und Standardabwei-chung σ gleich verteilte Zufallsvariablen, dann ist der arithmetische Mittelwert dieser Verteilungen:
n
XXX
Xn
+++
=
...21 (7-40)
als Stichprobenfunktion normalverteilt mit
µ=XE und (7-41)
n
XV
2σ
= , (7-42)
so dass sich die Stichprobenstandardabweichung ergibt:
σ
σ
X
n
= (7-43)
7.2.4 Approximationen von Verteilungen – Approximation of Distributions Bei Vorliegen der angegebenen Bedingungen können Verteilungen und ihre Parameter durch andere Verteilungen angenähert (approximiert) werden.
Approximation der hypergeometrischen Verteilung durch die Binomialverteilung
n
N
≤ 0 05, (7-44)
Approximation der Binomialverteilung durch die Poissonverteilung n ≥ 100 ; p ≤ 0,05 (7-45)
Approximation der hypergeometrischen Verteilung durch die Poissonverteilung
n
N
≤ 0 05, ; n ≥ 100 ; p ≤ 0,05 (7-46)
Approximation der Binomialverteilung durch die Normalverteilung
n ⋅ p ⋅ (1-p) > 9 ( )
⇒ >
⋅ −
n
p p
9
1 (7-47)
Approximation der hypergeometrischen Verteilung durch die Normalverteilung
n ⋅ p ⋅ (1-p) > 9 und n
N
≤ 0,05 (7-48)
Approximation der Poissonverteilung durch die Normalverteilung
µ > 9 (7-49)
Approximation der χ2 –Verteilung durch die Normalverteilung
ν ≥ 100 (7-50)
Approximation der t –Verteilung durch die Standardnormalverteilung
ν ≥ 30 bei normalverteilten Grundgesamtheiten (7-51) ν ≥ 50 bei nicht normalverteilten Grundgesamtheiten (7-52)
8 Schluss von der Stichprobe auf die Grundgesamtheit – Statistical Inference
Formelsammlung Statistik, Auflage 5.1 2007/08 Seite 15
8 Schluss von der Stichprobe auf die Grundgesamtheit – Statistical Inference
8.1 Schätztheorie: Stichprobenfunktionen – Estimation Theory
Stichprobenmittel – Sample Mean
X Schätzfunktion „Stichprobenmittel“ (vgl. Abschnitt 7.2.3) (8-1)
x Stichprobenmittelwert (einer Stichprobe) (8-2)
µ Mittelwert der Grundgesamtheit (8-3)
σ2 Varianz der Grundgesamtheit (8-4)
N n
N
−
− 1 Endlichkeitskorrektur - nur wenn 05,0>
N
n
. (8-5)
EX = µ (8-6)
VX
nX
= =σ
σ22
[ggf. zu multiplizieren mit Endlichkeitskorrektur, vgl.(8-5)] (8-7)
Stichprobenanteil – Sample Proportion
$P Schätzfunktion „Stichprobenanteil“ (8-8) p Stichprobenanteil (einer Stichprobe) (8-9)
p Anteil der relevanten Elemente in der Grundgesamtheit = Anteil der Erfolge = „empirische Wahrscheinlichkeit“ (8-10)
EP$ = p (8-11)
VP
p p
nP
$( )
$= =
⋅ −
σ2 1
[ggf. zu multiplizieren mit Endlichkeitskorrektur, vgl. (8-5)] (8-12)
8.2 Konfidenzintervalle zur Parameterschätzung – Confidence Intervals
gu / go Untere / obere Grenze des Vertrauensbereiches (8-13)
1-α Sicherheitsgrad (Konfidenzniveau) (8-14)
8.2.1 Konfidenzintervall für den Mittelwert – Confidence Interval for the Mean (µ = „wahrer“ Mittelwert der Population)
Xcuzxg σ−= (8-15)
Xcozxg σ+= (8-16)
Konfidenzintervall – Confidence Interval
ασσ µ −=+≤≤− 1)(XcXc
zxzxW (8-17)
mit:
zc kritischer Z-Wert – critical value (Standardnormalverteilung Z → N (0, 1)) für den vor gegebenen Sicherheitsgrad 1-α
→ Tabellierung der Standardnormalverteilung, Tafel 4
Achtung, für zc wird immer nur der positive Wert verwendet
Xσ die Standardabweichung des Stichprobenmittels – standard error of the mean (SEM)
für diese ist eine Fallunterscheidung erforderlich →

8 Schluss von der Stichprobe auf die Grundgesamtheit – Statistical Inference
Formelsammlung Statistik, Auflage 5.1 2007/08 Seite 16
Fallunterscheidung zur Ermittlung der Stichprobenstandardabweichung – Standard Error of the Mean (SEM)
Xσ
1. Fall: σ bekannt; Grundgesamtheit normalverteilt oder n ≥ 50
σ
σ
X
n
= bei Stichproben mit Zurücklegen oder n
N
≤ 0 05, (8-18)
σ
σ
X
n
=
N n
N
−
− 1 bei Stichproben ohne Zurücklegen und 05,0>
N
n (8-19)
[Vergleiche zur Endlichkeitskorrektur (8-5)]
2. Fall: σ unbekannt; Verteilung der Grundgesamtheit unbekannt; n ≥ 50 und
3. Fall: σ unbekannt; Grundgesamtheit normalverteilt; n > 30
Verwendung der Stichprobenstandardabweichung s statt σ
mit ( )
2
11
1∑
=
−
−
=
n
i
ixx
n
s (8-20)
so dass für die Standardabweichung des Stichprobenmittels gilt:
n
s
X=σ bei Stichproben mit Zurücklegen oder n
N
≤ 0 05, (8-21)
n
s
X=σ
N n
N
−
− 1 bei Stichproben ohne Zurücklegen und 05,0>
N
n (8-22)
[Vergleiche zur Endlichkeitskorrektur (8-5)]
4. Fall: σ unbekannt; Grundgesamtheit normalverteilt; n ≤ 30
Verwendung der Stichprobenstandardabweichung s (nach (8-20)) statt σ.
Verwendung der Studentverteilung statt der Standardnormalverteilung, d.h. tc statt zc:
tc der kritische (critical) t-Wert (Studentverteilung) für den vorgegebenen Sicherheitsgrad 1-α
→ Tabellierung der Studentverteilung, Tafel 6 mit ν = n – 1 Freiheitsgraden
Ablesen von tc jeweils an der Stelle:
→ zweiseitiger Test: F ( tc | ν ) = 1 – α/2 oder D ( tc | ν ) = 1 – α
→ einseitiger Test: F ( tc | ν ) = 1 – α
Überblick über Fälle für Stichprobenstandardabweichung X
σ (8-23)
Standardabweichung σ der Grundgesamtheit
bekannt unbekannt
Stichprobe mit Zurücklegen
n
X
σσ =
Stichprobe ohne
n
N
≤ 0 05, n
X
σσ ≈
n
s
X≈σ
Zurücklegen 05,0>
N
n
nX
σσ =
N n
N
−
− 1
n
s
X≈σ
N n
N
−
− 1
8 Schluss von der Stichprobe auf die Grundgesamtheit – Statistical Inference
Formelsammlung Statistik, Auflage 5.1 2007/08 Seite 17
8.2.2 Konfidenzintervall für den Anteilswert – Confidence Interval for the Proportion
Bei einem ausreichend großen Stichprobenumfang: )1(
9
pp
n
−
> (8-24)
ist der Stichprobenanteil p annähernd normalverteilt.
pcuzpg ˆˆ σ−= (8-25)
pcozpg ˆˆ σ+= (8-26)
Konfidenzintervall – Confidence Interval
ασσ −=+≤≤− 1)ˆˆ( ˆˆPcPc
zppzpW (8-27)
Dabei ist (analog zum Vertrauensbereich für den Mittelwert):
( )
n
pp
P
ˆ1ˆˆ
−=σ bei Stichproben mit Zurücklegen oder n
N
≤ 0 05, (8-28)
( )
n
pp
P
ˆ1ˆˆ
−=σ
N n
N
−
− 1 bei Stichproben ohne Zurücklegen und 05,0>
N
n (8-29)
[Vergleiche zur Endlichkeitskorrektur (8-5)]
8.2.3 Notwendiger Stichprobenumfang – Sample Size
ε maximaler absoluten Fehler
Schätzung des Mittelwertes µ:
Bei bekannter Standardabweichung σ:
2
22
ε
σc
z
n ≥ bei Stichproben mit Zurücklegen (8-30)
222
22
)1( σε
σ
c
c
zN
Nz
n
+−
≥ bei Stichproben ohne Zurücklegen (8-31)
Wenn Standardabweichung σ nicht bekannt ist:
Verwendung von s (nach (8-20)) statt σ und der Studentverteilung → tc statt zc:
2
22
ε
st
nc
≥ (8-32)
Mindestens muss in diesem Fall jedoch n > 50 sein. Schätzung des Anteilswertes p:
2
2 )ˆ1(ˆ
ε
ppz
nc
−≥ bei Stichproben mit Zurücklegen (8-33)
)ˆ1(ˆ)1(
)ˆ1(ˆ22
2
ppzN
ppNz
n
c
c
−+−
−≥
ε
bei Stichproben ohne Zurücklegen (8-34)

8 Schluss von der Stichprobe auf die Grundgesamtheit – Statistical Inference
Formelsammlung Statistik, Auflage 5.1 2007/08 Seite 18
8.3 Hypothesentests – Hypothesis Testing
H0 Nullhypothese (zu testende Ausgangshypothese) – null hypothesis
H1 Alternativhypothese
1-α Sicherheitsgrad (Konfidenzniveau - aber auch „Signifikanzniveau“ s.u.) – significance
α Signifikanzniveau (Irrtumswahrscheinlichkeit - Achtung, Bezeichnung von α und 1-α in der Literatur uneinheitlich)
z c kritischer Wert (bzw. tc oder 2c
χ ) → aus Tabelle abzulesen critical value
X
z Prüfgröße (bzw. t oder χ2) → zu errechnen
Schritte eines Hypothesentests
1. Aufstellen von H0 und H1
2. Festlegen des Signifikanzniveaus (hier i.d. Aufgabenstellung - in der Praxis selbst zu tun)
3. Bestimmen von X
σ (Fallunterscheidung)
4. Aufstellen der Entscheidungsregeln über die Ablehnung von H0: Ermittlung der Testgröße durch Ablesen in der entsprechenden Tabelle
→ kritischer Wert zc (bzw. tc oder 2c
χ )
Variante A: Testentscheidung auf Basis absoluter Werte: kritischen Grenzen µµµµc (bzw. pc):
5. Ermittlung der kritischen Grenzen (Unter- und Obergrenze) für x bzw. p
Xc
u
cz σµµ ⋅−= 0 bzw.
pc
u
czpp ˆ0 σ⋅−= (8-35)
Xc
o
cz σµµ ⋅+= 0 bzw.
pc
u
czpp ˆ0 σ⋅+= (8-36)
6. Entscheidungsregel: Ablehnung von H0, wenn: (analog für Testwerte t und χ2
)
x > o
cµ bzw. o
cpp >ˆ bei rechts- oder zweiseitigem Test oder (8-37)
x < u
cµ bzw. u
cpp <ˆ bei links- oder zweiseitigem Test (8-38)
7. Interpretation des Ergebnisses
Variante B: (einfacher aber fehleranfälliger) „Z-Test“
Testentscheidung auf Basis der standardisierten Z-Werte
5. Berechnung der Prüfgröße X
z (bzw. x
t , p
z ˆ , χ2 oder t – siehe Kapitel 8.4 bis 8.4.4)
6. Anwendung der Entscheidungsregel (analog für die anderen Prüfgrößen)
wenn |X
z | > | zc | ⇒ Ablehnung von H0 (8-39)
7. Interpretation des Ergebnisses
Bei Verwendung von Variante B muss die entsprechende Prüfgröße (je nach Fragestellung aus Kapitel 8.4 bis 8.4.4) ermittelt werden:
8 Schluss von der Stichprobe auf die Grundgesamtheit – Statistical Inference
Formelsammlung Statistik, Auflage 5.1 2007/08 Seite 19
8.4 Parametrische Tests – Parametric Tests
8.4.1 Testen von Mittelwerten – Testing Means
µ0 vermuteter bzw. angegebener Wert, von dem mit dem statistischen Test untersucht werden soll, ob er – auf Basis der Daten – der wahre Mittelwert der Grundgesamtheit sein kann.
Prüfgröße:
X
X
x
z
σ
µ0−= (8-40)
Ablesen von zc jeweils an der Stelle: → zweiseitiger Test – two-tailed test: D ( zc ) = 1 – α dies entspricht: FSN ( zc ) = 1 – α/2
→ einseitiger Test – one-tailed test: FSN ( zc ) = 1 – α
(einseitiger Test, linksseitig kritischer Bereich kann auch abgelesen werden mittels: FSN (–zc) = α
→ Tabellierung der Standardnormalverteilung, Tafel 4.
Für die Ermittlung von X
σ ist die in Punkt „Konfidenzintervalle“ dargestellte Fallunterscheidung
notwendig (vgl. Abschnitt 8.2.1).
Dabei ergibt sich im 4. Fall (σ unbekannt; Grundgesamtheit normalverteilt; n ≤ 30) die
Prüfgröße:
n
s
x
tx
0µ−=
(8-41)
8.4.2 Testen von Anteilswerten – Testing Proportions
p0 vermuteter bzw. angegebener Anteilswert, von dem mit dem statistischen Test unter- sucht werden soll, ob er – auf Basis der Daten – der wahre Anteilswert der Grundge-samtheit sein kann.
Für )1(
9
pp
n
−
> ergibt sich die (8-24) (s.o.)
Prüfgröße:
p
p
pp
z
ˆ
0ˆ
ˆ
σ
−= (8-42)
Dabei ist wiederum die in Abschnitt 8.2.2 vorgenommene Fallunterscheidung für p
σ zu beachten.

8 Schluss von der Stichprobe auf die Grundgesamtheit – Statistical Inference
Formelsammlung Statistik, Auflage 5.1 2007/08 Seite 20
8.4.3 Zweistichprobentests – Two Sample Tests
Es liegen zwei unabhängige Stichproben X1, X2 vor. Die Frage ist, ob die beiden aus gleichen Grund-gesamtheiten stammen können oder ob sich die Populationen signifikant unterscheiden.
H0: Die Stichproben stammen aus der gleichen Grundgesamtheit.
Mittelwertdifferenz zweier unabhängiger Stichproben („t-Test“)
H0: µ1 = µ2 ⇒ µ1 – µ2 = 0 (8-43)
Prüfgröße:
2
22
1
21
21
n
s
n
s
xx
t
+
−= (8-44)
ist t-verteilt mit ν = n1 + n2 - 2 Freiheitsgraden
Differenzen von Anteilswerten zweier unabhängiger Stichproben
H0: p1 = p2 ⇒ p1 – p2 = 0 (8-45)
Prüfgröße: 21
2211
21
21
21ˆˆ
:
)1(
ˆˆ
nn
npnp
Pmit
nn
nn
PP
pp
z
+
+=
⋅
+⋅−⋅
−= (für n1 > 30 und n2 > 30) (8-46)
8.4.4 Testen der Regressionskoeffizienten bei Mehrfachregression – Testing Coeffi-
cients of Multivariate Regressions
Wird das Modell der linearen Einfachregression (3-7) um die Berücksichtigung mehrerer Einflussfak-
toren erweitert, so sprechen wir von multipler Regression oder Mehrfachregression:
kkxbxbxbby ++++= ...ˆ
22110 (8-47)
Es ergeben sich für die k einzelnen Schätzkoeffizienten bi (die gesuchten „wahren“ Werte)
jeweils Schätzwerte i
b und Standardabweichungen sbi.
Es ist zu testen, ob die einzelnen xi einen signifikanten Einfluss auf y haben.
Ausgangshypothesen: kein signifikanter Einfluss:
H0 : bi = 0 ( ∀ i = 1, …. k ) (8-48)
Daraus ergibt sich als
Prüfgröße:
ib
ˆ
s
b
ti
i= (8-49)
die mit ν = n – k Freiheitsgraden studentverteilt ist.
→ Tabellierung der Studentverteilung, Tafel 6
Der Test wird für jedes bi einzeln durchgeführt.
8 Schluss von der Stichprobe auf die Grundgesamtheit – Statistical Inference
Formelsammlung Statistik, Auflage 5.1 2007/08 Seite 21
8.5 Nicht-Parametrische Tests – Non-Parametric Tests
8.5.1 Chi-Quadrat Unabhängigkeitstest – Chi-Square Test of Independence
Test der Hypothese H0, dass zwei Zufallsvariable X und Y voneinander unabhängig sind.
Anwendbar ab dem Mindestwert für erwartete Häufigkeiten: he(xj , yk) > 5 ∀ j, k (8-50)
Ermittlung des χ2-Wertes mit Hilfe der erwarteten Häufigkeiten he aus der Kontingenztabelle:
Prüfgröße: ( )
);(
);();(2
11
2
kje
kjekj
q
k
m
jyxh
yxhyxh −
= ∑∑==
χ (3-18) (s.o.)
Ablesen des kritischen χ2-Wertes 2c
χ in der Tabelle mit
ν = (m-1) ⋅ (q-1) Freiheitsgraden – degrees of freedom (dof) (8-51)
8.5.2 Chi-Quadrat Anpassungstest – Chi-Square Test for Distributions
H0: Die Grundgesamtheit folgt einer bestimmten Verteilung. (für hei > 5 ∀ i - vgl. (8-50))
Ermittlung des χ2-Wertes mit Hilfe der erwarteten Häufigkeiten he aus der Kontingenztabelle:
Prüfgröße: ( )
e
i
e
ii
n
ih
hh
2
1
2 −=∑
=
χ (8-52)
Ablesen des kritischen χ2-Wertes 2c
χ in der Tabelle mit ν = (n-1) Freiheitsgraden. (8-53)
9 Tabellenanhang
Formelsammlung Statistik, Auflage 5.1 2007/08 Seite 22
9 Tabellenanhang
Dieser Tabellenanhang wurde teilweise entnommen aus: Puhani, Josef: „Kleine Formelsammlung zur Statistik“ 1994, BVB Bamberg. Vgl. die weiteren Quellenangaben.
TAFELANHANG:
Tafel 1: Einige Zufallsziffern
Tafel 2: Binomialverteilung
Tafel 3: Poissonverteilung
Tafel 4: Standardnormalverteilung
Tafel 5: Chi-Quadrat-Verteilung
Tafel 6: Student’sche t-Verteilung
Tafel 1: Einige Zufallsziffern
9 Tabellenanhang
Formelsammlung Statistik, Auflage 5.1 2007/08 Seite 23
Tafel 2: Binomialverteilung

9 Tabellenanhang
Formelsammlung Statistik, Auflage 5.1 2007/08 Seite 24
Tafel 3: Poissonverteilung
9 Tabellenanhang
Formelsammlung Statistik, Auflage 5.1 2007/08 Seite 25
Tafel 4: Standardnormalverteilung
Werte der Verteilungsfunktion für gegebene Werte z einer
standardnormalverteilten Zufallsvariablen
Ablesen der Tabellen der Standardnormalverteilung:
FSN(z) = 12
−
α
misst die Fläche links des positiven Wertes z:
)()()( zZWdxxfzF
z
SN≤== ∫
∞−
, d.h. die Wahrscheinlichkeit,
dass die standardisierte Zufallsvariable Z höchstens den Wert z annimmt.
D(z) = 1-α misst die Fläche des symmetrischen Sicherheitsbereiches:
)()()()()( zFzFzZzWdxxfzDSNSN
z
z
−−=≤≤−== ∫−
,
d.h. die Wahrscheinlichkeit, dass die standardisierte Zufallsvariable Z einen Wert zwischen –z und z annimmt.

9 Tabellenanhang
Formelsammlung Statistik, Auflage 5.1 2007/08 Seite 26
Tafel 4: Standardnormalverteilung (Fortsetzung)
z FSN (-z) FSN (z) D(z) z FSN (-z) FSN (z) D(z) z FSN (-z) FSN (z) D(z)
0 0,5 0,5 0 0,5 0,3085 0,6915 0,3829 1 0,1587 0,8413 0,6827
0,01 0,4960 0,5040 0,0080 0,51 0,3050 0,6950 0,3899 1,01 0,1562 0,8438 0,6875
0,02 0,4920 0,5080 0,0160 0,52 0,3015 0,6985 0,3969 1,02 0,1539 0,8461 0,6923
0,03 0,4880 0,5120 0,0239 0,53 0,2981 0,7019 0,4039 1,03 0,1515 0,8485 0,6970
0,04 0,4840 0,5160 0,0319 0,54 0,2946 0,7054 0,4108 1,04 0,1492 0,8508 0,7017
0,05 0,4801 0,5199 0,0399 0,55 0,2912 0,7088 0,4177 1,05 0,1469 0,8531 0,7063
0,06 0,4761 0,5239 0,0478 0,56 0,2877 0,7123 0,4245 1,06 0,1446 0,8554 0,7109
0,07 0,4721 0,5279 0,0558 0,57 0,2843 0,7157 0,4313 1,07 0,1423 0,8577 0,7154
0,08 0,4681 0,5319 0,0638 0,58 0,2810 0,7190 0,4381 1,08 0,1401 0,8599 0,7199
0,09 0,4641 0,5359 0,0717 0,59 0,2776 0,7224 0,4448 1,09 0,1379 0,8621 0,7243
0,1 0,4602 0,5398 0,0797 0,6 0,2743 0,7257 0,4515 1,1 0,1357 0,8643 0,7287
0,11 0,4562 0,5438 0,0876 0,61 0,2709 0,7291 0,4581 1,11 0,1335 0,8665 0,7330
0,12 0,4522 0,5478 0,0955 0,62 0,2676 0,7324 0,4647 1,12 0,1314 0,8686 0,7373
0,13 0,4483 0,5517 0,1034 0,63 0,2643 0,7357 0,4713 1,13 0,1292 0,8708 0,7415
0,14 0,4443 0,5557 0,1113 0,64 0,2611 0,7389 0,4778 1,14 0,1271 0,8729 0,7457
0,15 0,4404 0,5596 0,1192 0,65 0,2578 0,7422 0,4843 1,15 0,1251 0,8749 0,7499
0,16 0,4364 0,5636 0,1271 0,66 0,2546 0,7454 0,4907 1,16 0,1230 0,8770 0,7540
0,17 0,4325 0,5675 0,1350 0,67 0,2514 0,7486 0,4971 1,17 0,1210 0,8790 0,7580
0,18 0,4286 0,5714 0,1428 0,68 0,2483 0,7517 0,5035 1,18 0,1190 0,8810 0,7620
0,19 0,4247 0,5753 0,1507 0,69 0,2451 0,7549 0,5098 1,19 0,1170 0,8830 0,7660
0,2 0,4207 0,5793 0,1585 0,7 0,2420 0,7580 0,5161 1,2 0,1151 0,8849 0,7699
0,21 0,4168 0,5832 0,1663 0,71 0,2389 0,7611 0,5223 1,21 0,1131 0,8869 0,7737
0,22 0,4129 0,5871 0,1741 0,72 0,2358 0,7642 0,5285 1,22 0,1112 0,8888 0,7775
0,23 0,4090 0,5910 0,1819 0,73 0,2327 0,7673 0,5346 1,23 0,1093 0,8907 0,7813
0,24 0,4052 0,5948 0,1897 0,74 0,2296 0,7704 0,5407 1,24 0,1075 0,8925 0,7850
0,25 0,4013 0,5987 0,1974 0,75 0,2266 0,7734 0,5467 1,25 0,1056 0,8944 0,7887
0,26 0,3974 0,6026 0,2051 0,76 0,2236 0,7764 0,5527 1,26 0,1038 0,8962 0,7923
0,27 0,3936 0,6064 0,2128 0,77 0,2206 0,7794 0,5587 1,27 0,1020 0,8980 0,7959
0,28 0,3897 0,6103 0,2205 0,78 0,2177 0,7823 0,5646 1,28 0,1003 0,8997 0,7995
0,29 0,3859 0,6141 0,2282 0,79 0,2148 0,7852 0,5705 1,29 0,0985 0,9015 0,8029
0,3 0,3821 0,6179 0,2358 0,8 0,2119 0,7881 0,5763 1,3 0,0968 0,9032 0,8064
0,31 0,3783 0,6217 0,2434 0,81 0,2090 0,7910 0,5821 1,31 0,0951 0,9049 0,8098
0,32 0,3745 0,6255 0,2510 0,82 0,2061 0,7939 0,5878 1,32 0,0934 0,9066 0,8132
0,33 0,3707 0,6293 0,2586 0,83 0,2033 0,7967 0,5935 1,33 0,0918 0,9082 0,8165
0,34 0,3669 0,6331 0,2661 0,84 0,2005 0,7995 0,5991 1,34 0,0901 0,9099 0,8198
0,35 0,3632 0,6368 0,2737 0,85 0,1977 0,8023 0,6047 1,35 0,0885 0,9115 0,8230
0,36 0,3594 0,6406 0,2812 0,86 0,1949 0,8051 0,6102 1,36 0,0869 0,9131 0,8262
0,37 0,3557 0,6443 0,2886 0,87 0,1922 0,8078 0,6157 1,37 0,0853 0,9147 0,8293
0,38 0,3520 0,6480 0,2961 0,88 0,1894 0,8106 0,6211 1,38 0,0838 0,9162 0,8324
0,39 0,3483 0,6517 0,3035 0,89 0,1867 0,8133 0,6265 1,39 0,0823 0,9177 0,8355
0,4 0,3446 0,6554 0,3108 0,9 0,1841 0,8159 0,6319 1,4 0,0808 0,9192 0,8385
0,41 0,3409 0,6591 0,3182 0,91 0,1814 0,8186 0,6372 1,41 0,0793 0,9207 0,8415
0,42 0,3372 0,6628 0,3255 0,92 0,1788 0,8212 0,6424 1,42 0,0778 0,9222 0,8444
0,43 0,3336 0,6664 0,3328 0,93 0,1762 0,8238 0,6476 1,43 0,0764 0,9236 0,8473
0,44 0,3300 0,6700 0,3401 0,94 0,1736 0,8264 0,6528 1,44 0,0749 0,9251 0,8501
0,45 0,3264 0,6736 0,3473 0,95 0,1711 0,8289 0,6579 1,45 0,0735 0,9265 0,8529
0,46 0,3228 0,6772 0,3545 0,96 0,1685 0,8315 0,6629 1,46 0,0721 0,9279 0,8557
0,47 0,3192 0,6808 0,3616 0,97 0,1660 0,8340 0,6680 1,47 0,0708 0,9292 0,8584
0,48 0,3156 0,6844 0,3688 0,98 0,1635 0,8365 0,6729 1,48 0,0694 0,9306 0,8611
0,49 0,3121 0,6879 0,3759 0,99 0,1611 0,8389 0,6778 1,49 0,0681 0,9319 0,8638
0,5 0,3085 0,6915 0,3829 1 0,1587 0,8413 0,6827 1,5 0,0668 0,9332 0,8664
Tafel 4: Standardnormalverteilung (Fortsetzung)
9 Tabellenanhang
Formelsammlung Statistik, Auflage 5.1 2007/08 Seite 27
z FSN (-z) FSN (z) D(z) z FSN (-z) FSN (z) D(z) z FSN (-z) FSN (z) D(z)
1,5 0,0668 0,9332 0,8664 2 0,0228 0,9772 0,9545 2,5 0,0062 0,9938 0,9876
1,51 0,0655 0,9345 0,8690 2,01 0,0222 0,9778 0,9556 2,51 0,0060 0,9940 0,9879
1,52 0,0643 0,9357 0,8715 2,02 0,0217 0,9783 0,9566 2,52 0,0059 0,9941 0,9883
1,53 0,0630 0,9370 0,8740 2,03 0,0212 0,9788 0,9576 2,53 0,0057 0,9943 0,9886
1,54 0,0618 0,9382 0,8764 2,04 0,0207 0,9793 0,9586 2,54 0,0055 0,9945 0,9889
1,55 0,0606 0,9394 0,8789 2,05 0,0202 0,9798 0,9596 2,55 0,0054 0,9946 0,9892
1,56 0,0594 0,9406 0,8812 2,06 0,0197 0,9803 0,9606 2,56 0,0052 0,9948 0,9895
1,57 0,0582 0,9418 0,8836 2,07 0,0192 0,9808 0,9615 2,57 0,0051 0,9949 0,9898
1,58 0,0571 0,9429 0,8859 2,08 0,0188 0,9812 0,9625 2,58 0,0049 0,9951 0,9901
1,59 0,0559 0,9441 0,8882 2,09 0,0183 0,9817 0,9634 2,59 0,0048 0,9952 0,9904
1,6 0,0548 0,9452 0,8904 2,1 0,0179 0,9821 0,9643 2,6 0,0047 0,9953 0,9907
1,61 0,0537 0,9463 0,8926 2,11 0,0174 0,9826 0,9651 2,61 0,0045 0,9955 0,9909
1,62 0,0526 0,9474 0,8948 2,12 0,0170 0,9830 0,9660 2,62 0,0044 0,9956 0,9912
1,63 0,0516 0,9484 0,8969 2,13 0,0166 0,9834 0,9668 2,63 0,0043 0,9957 0,9915
1,64 0,0505 0,9495 0,8990 2,14 0,0162 0,9838 0,9676 2,64 0,0041 0,9959 0,9917
1,65 0,0495 0,9505 0,9011 2,15 0,0158 0,9842 0,9684 2,65 0,0040 0,9960 0,9920
1,66 0,0485 0,9515 0,9031 2,16 0,0154 0,9846 0,9692 2,66 0,0039 0,9961 0,9922
1,67 0,0475 0,9525 0,9051 2,17 0,0150 0,9850 0,9700 2,67 0,0038 0,9962 0,9924
1,68 0,0465 0,9535 0,9070 2,18 0,0146 0,9854 0,9707 2,68 0,0037 0,9963 0,9926
1,69 0,0455 0,9545 0,9090 2,19 0,0143 0,9857 0,9715 2,69 0,0036 0,9964 0,9929
1,7 0,0446 0,9554 0,9109 2,2 0,0139 0,9861 0,9722 2,7 0,0035 0,9965 0,9931
1,71 0,0436 0,9564 0,9127 2,21 0,0136 0,9864 0,9729 2,71 0,0034 0,9966 0,9933
1,72 0,0427 0,9573 0,9146 2,22 0,0132 0,9868 0,9736 2,72 0,0033 0,9967 0,9935
1,73 0,0418 0,9582 0,9164 2,23 0,0129 0,9871 0,9743 2,73 0,0032 0,9968 0,9937
1,74 0,0409 0,9591 0,9181 2,24 0,0125 0,9875 0,9749 2,74 0,0031 0,9969 0,9939
1,75 0,0401 0,9599 0,9199 2,25 0,0122 0,9878 0,9756 2,75 0,0030 0,9970 0,9940
1,76 0,0392 0,9608 0,9216 2,26 0,0119 0,9881 0,9762 2,76 0,0029 0,9971 0,9942
1,77 0,0384 0,9616 0,9233 2,27 0,0116 0,9884 0,9768 2,77 0,0028 0,9972 0,9944
1,78 0,0375 0,9625 0,9249 2,28 0,0113 0,9887 0,9774 2,78 0,0027 0,9973 0,9946
1,79 0,0367 0,9633 0,9265 2,29 0,0110 0,9890 0,9780 2,79 0,0026 0,9974 0,9947
1,8 0,0359 0,9641 0,9281 2,3 0,0107 0,9893 0,9786 2,8 0,0026 0,9974 0,9949
1,81 0,0351 0,9649 0,9297 2,31 0,0104 0,9896 0,9791 2,81 0,0025 0,9975 0,9950
1,82 0,0344 0,9656 0,9312 2,32 0,0102 0,9898 0,9797 2,82 0,0024 0,9976 0,9952
1,83 0,0336 0,9664 0,9328 2,33 0,0099 0,9901 0,9802 2,83 0,0023 0,9977 0,9953
1,84 0,0329 0,9671 0,9342 2,34 0,0096 0,9904 0,9807 2,84 0,0023 0,9977 0,9955
1,85 0,0322 0,9678 0,9357 2,35 0,0094 0,9906 0,9812 2,85 0,0022 0,9978 0,9956
1,86 0,0314 0,9686 0,9371 2,36 0,0091 0,9909 0,9817 2,86 0,0021 0,9979 0,9958
1,87 0,0307 0,9693 0,9385 2,37 0,0089 0,9911 0,9822 2,87 0,0021 0,9979 0,9959
1,88 0,0301 0,9699 0,9399 2,38 0,0087 0,9913 0,9827 2,88 0,0020 0,9980 0,9960
1,89 0,0294 0,9706 0,9412 2,39 0,0084 0,9916 0,9832 2,89 0,0019 0,9981 0,9961
1,9 0,0287 0,9713 0,9426 2,4 0,0082 0,9918 0,9836 2,9 0,0019 0,9981 0,9963
1,91 0,0281 0,9719 0,9439 2,41 0,0080 0,9920 0,9840 2,91 0,0018 0,9982 0,9964
1,92 0,0274 0,9726 0,9451 2,42 0,0078 0,9922 0,9845 2,92 0,0018 0,9982 0,9965
1,93 0,0268 0,9732 0,9464 2,43 0,0075 0,9925 0,9849 2,93 0,0017 0,9983 0,9966
1,94 0,0262 0,9738 0,9476 2,44 0,0073 0,9927 0,9853 2,94 0,0016 0,9984 0,9967
1,95 0,0256 0,9744 0,9488 2,45 0,0071 0,9929 0,9857 2,95 0,0016 0,9984 0,9968
1,96 0,0250 0,9750 0,9500 2,46 0,0069 0,9931 0,9861 2,96 0,0015 0,9985 0,9969
1,97 0,0244 0,9756 0,9512 2,47 0,0068 0,9932 0,9865 2,97 0,0015 0,9985 0,9970
1,98 0,0239 0,9761 0,9523 2,48 0,0066 0,9934 0,9869 2,98 0,0014 0,9986 0,9971
1,99 0,0233 0,9767 0,9534 2,49 0,0064 0,9936 0,9872 2,99 0,0014 0,9986 0,9972
2 0,0228 0,9772 0,9545 2,5 0,0062 0,9938 0,9876 3 0,0013 0,9987 0,9973

9 Tabellenanhang
Formelsammlung Statistik, Auflage 5.1 2007/08 Seite 28
Tafel 5: Chi-Quadrat-Verteilung
Werte χ2 einer chi-quadrat-verteilten Zufallsvariable für vorgegebene Werte der Verteilungs-
funktion F(χ2) mit ν Freiheitsgraden
F (χχχχ2)
ν 0,6 0,75 0,9 0,95 0,975 0,98 0,99 0,995 0,999
1 0,708 1,323 2,706 3,841 5,024 5,412 6,635 7,879 10,827
2 1,833 2,773 4,605 5,991 7,378 7,824 9,210 10,597 13,815
3 2,946 4,108 6,251 7,815 9,348 9,837 11,345 12,838 16,266
4 4,045 5,385 7,779 9,488 11,143 11,668 13,277 14,860 18,466
5 5,132 6,626 9,236 11,070 12,832 13,388 15,086 16,750 20,515
6 6,211 7,841 10,645 12,592 14,449 15,033 16,812 18,548 22,457
7 7,283 9,037 12,017 14,067 16,013 16,622 18,475 20,278 24,321
8 8,351 10,219 13,362 15,507 17,535 18,168 20,090 21,955 26,124
9 9,414 11,389 14,684 16,919 19,023 19,679 21,666 23,589 27,877
10 10,473 12,549 15,987 18,307 20,483 21,161 23,209 25,188 29,588
11 11,530 13,701 17,275 19,675 21,920 22,618 24,725 26,757 31,264
12 12,584 14,845 18,549 21,026 23,337 24,054 26,217 28,300 32,909
13 13,636 15,984 19,812 22,362 24,736 25,471 27,688 29,819 34,527
14 14,685 17,117 21,064 23,685 26,119 26,873 29,141 31,319 36,124
15 15,733 18,245 22,307 24,996 27,488 28,259 30,578 32,801 37,698
16 16,780 19,369 23,542 26,296 28,845 29,633 32,000 34,267 39,252
17 17,824 20,489 24,769 27,587 30,191 30,995 33,409 35,718 40,791
18 18,868 21,605 25,989 28,869 31,526 32,346 34,805 37,156 42,312
19 19,910 22,718 27,204 30,144 32,852 33,687 36,191 38,582 43,819
20 20,951 23,828 28,412 31,410 34,170 35,020 37,566 39,997 45,314
21 21,992 24,935 29,615 32,671 35,479 36,343 38,932 41,401 46,796
22 23,031 26,039 30,813 33,924 36,781 37,659 40,289 42,796 48,268
23 24,069 27,141 32,007 35,172 38,076 38,968 41,638 44,181 49,728
24 25,106 28,241 33,196 36,415 39,364 40,270 42,980 45,558 51,179
25 26,143 29,339 34,382 37,652 40,646 41,566 44,314 46,928 52,619
26 27,179 30,435 35,563 38,885 41,923 42,856 45,642 48,290 54,051
27 28,214 31,528 36,741 40,113 43,195 44,140 46,963 49,645 55,475
28 29,249 32,620 37,916 41,337 44,461 45,419 48,278 50,994 56,892
29 30,283 33,711 39,087 42,557 45,722 46,693 49,588 52,335 58,301
30 31,316 34,800 40,256 43,773 46,979 47,962 50,892 53,672 59,702
40 41,622 45,616 51,805 55,758 59,342 60,436 63,691 66,766 73,403
50 51,892 56,334 63,167 67,505 71,420 72,613 76,154 79,490 86,660
100 102,946 109,141 118,498 124,342 129,561 131,142 135,807 140,170 149,449
9 Tabellenanhang
Formelsammlung Statistik, Auflage 5.1 2007/08 Seite 29
Tafel 6 a
t-Verteilung Verteilungsfunktion
F (t) (1−α) 0,7 0,8 0,9 0,95 0,975 0,99 0,995
α 0,3 0,2 0,1 0,05 0,025 0,01 0,005
ν α / 2 0,15 0,1 0,05 0,025 0,0125 0,005 0,0025
1 0,727 1,376 3,078 6,314 12,706 31,821 63,656
2 0,617 1,061 1,886 2,920 4,303 6,965 9,925
3 0,584 0,978 1,638 2,353 3,182 4,541 5,841
4 0,569 0,941 1,533 2,132 2,776 3,747 4,604
5 0,559 0,920 1,476 2,015 2,571 3,365 4,032
6 0,553 0,906 1,440 1,943 2,447 3,143 3,707
7 0,549 0,896 1,415 1,895 2,365 2,998 3,499
8 0,546 0,889 1,397 1,860 2,306 2,896 3,355
9 0,543 0,883 1,383 1,833 2,262 2,821 3,250
10 0,542 0,879 1,372 1,812 2,228 2,764 3,169
11 0,540 0,876 1,363 1,796 2,201 2,718 3,106
12 0,539 0,873 1,356 1,782 2,179 2,681 3,055
13 0,538 0,870 1,350 1,771 2,160 2,650 3,012
14 0,537 0,868 1,345 1,761 2,145 2,624 2,977
15 0,536 0,866 1,341 1,753 2,131 2,602 2,947
16 0,535 0,865 1,337 1,746 2,120 2,583 2,921
17 0,534 0,863 1,333 1,740 2,110 2,567 2,898
18 0,534 0,862 1,330 1,734 2,101 2,552 2,878
19 0,533 0,861 1,328 1,729 2,093 2,539 2,861
20 0,533 0,860 1,325 1,725 2,086 2,528 2,845
21 0,532 0,859 1,323 1,721 2,080 2,518 2,831
22 0,532 0,858 1,321 1,717 2,074 2,508 2,819
23 0,532 0,858 1,319 1,714 2,069 2,500 2,807
24 0,531 0,857 1,318 1,711 2,064 2,492 2,797
25 0,531 0,856 1,316 1,708 2,060 2,485 2,787
26 0,531 0,856 1,315 1,706 2,056 2,479 2,779
27 0,531 0,855 1,314 1,703 2,052 2,473 2,771
28 0,530 0,855 1,313 1,701 2,048 2,467 2,763
29 0,530 0,854 1,311 1,699 2,045 2,462 2,756
30 0,530 0,854 1,310 1,697 2,042 2,457 2,750
40 0,529 0,851 1,303 1,684 2,021 2,423 2,704
50 0,528 0,849 1,299 1,676 2,009 2,403 2,678
60 0,527 0,848 1,296 1,671 2,000 2,390 2,660
80 0,526 0,846 1,292 1,664 1,990 2,374 2,639
100 0,526 0,845 1,290 1,660 1,984 2,364 2,626
150 0,526 0,844 1,287 1,655 1,976 2,351 2,609
300 0,525 0,843 1,284 1,650 1,968 2,339 2,592
1000 0,525 0,842 1,282 1,646 1,962 2,330 2,581
99999999 0,524 0,842 1,282 1,645 1,960 2,326 2,576

9 Tabellenanhang
Formelsammlung Statistik, Auflage 5.1 2007/08 Seite 30
Tafel 6 b
t-Verteilung Symmetrisches Intervall um den Mittelwert
D (t) (1−α) 0,7 0,8 0,9 0,95 0,975 0,99 0,998
α 0,3 0,2 0,1 0,05 0,025 0,01 0,002
ν α / 2 0,15 0,1 0,05 0,025 0,0125 0,005 0,001
1 1,963 3,078 6,314 12,706 25,452 63,656 318,289
2 1,386 1,886 2,920 4,303 6,205 9,925 22,328
3 1,250 1,638 2,353 3,182 4,177 5,841 10,214
4 1,190 1,533 2,132 2,776 3,495 4,604 7,173
5 1,156 1,476 2,015 2,571 3,163 4,032 5,894
6 1,134 1,440 1,943 2,447 2,969 3,707 5,208
7 1,119 1,415 1,895 2,365 2,841 3,499 4,785
8 1,108 1,397 1,860 2,306 2,752 3,355 4,501
9 1,100 1,383 1,833 2,262 2,685 3,250 4,297
10 1,093 1,372 1,812 2,228 2,634 3,169 4,144
11 1,088 1,363 1,796 2,201 2,593 3,106 4,025
12 1,083 1,356 1,782 2,179 2,560 3,055 3,930
13 1,079 1,350 1,771 2,160 2,533 3,012 3,852
14 1,076 1,345 1,761 2,145 2,510 2,977 3,787
15 1,074 1,341 1,753 2,131 2,490 2,947 3,733
16 1,071 1,337 1,746 2,120 2,473 2,921 3,686
17 1,069 1,333 1,740 2,110 2,458 2,898 3,646
18 1,067 1,330 1,734 2,101 2,445 2,878 3,610
19 1,066 1,328 1,729 2,093 2,433 2,861 3,579
20 1,064 1,325 1,725 2,086 2,423 2,845 3,552
21 1,063 1,323 1,721 2,080 2,414 2,831 3,527
22 1,061 1,321 1,717 2,074 2,405 2,819 3,505
23 1,060 1,319 1,714 2,069 2,398 2,807 3,485
24 1,059 1,318 1,711 2,064 2,391 2,797 3,467
25 1,058 1,316 1,708 2,060 2,385 2,787 3,450
26 1,058 1,315 1,706 2,056 2,379 2,779 3,435
27 1,057 1,314 1,703 2,052 2,373 2,771 3,421
28 1,056 1,313 1,701 2,048 2,368 2,763 3,408
29 1,055 1,311 1,699 2,045 2,364 2,756 3,396
30 1,055 1,310 1,697 2,042 2,360 2,750 3,385
40 1,050 1,303 1,684 2,021 2,32893 2,704 3,307
50 1,047 1,299 1,676 2,009 2,31092 2,678 3,261
60 1,045 1,296 1,671 2,000 2,29905 2,660 3,232
80 1,043 1,292 1,664 1,990 2,28437 2,639 3,195
100 1,042 1,290 1,660 1,984 2,27566 2,626 3,174
150 1,040 1,287 1,655 1,976 2,26412 2,609 3,145
300 1,038 1,284 1,650 1,968 2,25271 2,592 3,118
1000 1,037 1,282 1,646 1,962 2,24478 2,581 3,098
99999999 1,036 1,282 1,645 1,960 2,2414 2,576 3,090
Inhaltsverzeichnis
Formelsammlung Statistik, 5. Auflage WS 2002 / 2003 Seite i
Inhalt der Formelsammlung – Formula Table of Contents
Teil I Deskriptive (beschreibende) Statistik
Descriptive Statistics
1 Grundlagen – Fundamentals ......................................................................................... 1
2 Auswertung und Darstellung eindimensionaler Daten – Analysing and Displaying One-dimensional Data ................................................... 1
2.1 Häufigkeiten – Frequencies ...................................................................................................... 1
2.2 Lagemaße (Mittelwerte) – Measures of Central Tendency (Averages).................................... 2
2.3 Streuungsmaße – Measures of Variability / Deviation......................................................... 3
3 Zusammenhänge zwischen mehrdimensionalen Daten – Relations between Multi-Dimensional Variables...................................................... 4
3.1 Allgemeine Grundbegriffe – Basic Concepts ......................................................................... 4
3.2 Zusammenhänge zwischen metrisch skalierten Merkmalen – Correlation of metrically scaled Variables ................................................................................... 4
3.3 Rangkorrelationen für ordinal skalierte Merkmale (nach Spearman) – Rank Correlation for ordinal Variables (Spearman’s ρ).............................................................. 5
3.4 Kontingenzanalyse bei nominal skalierten Variablen – Contingency Measures
(Association of nominal Variables) .............................................................................................. 5
4 Elemente der Zeitreihenanalyse – Time Series Analysis (TSA) ............................. 6
4.1 Komponenten einer Zeitreihe – Components of a Time Series .............................................. 6
4.2 Glättung durch Gleitende Durchschnitte – Smoothing with Moving Averages (MA) ................ 6
4.3 Glättung durch lineare Trendfunktion – Smoothing with a Linear Trend Function .................. 6
4.4 Ermittlung der (additiven) Saisonkomponente und Saisonbereinigung – Analysis of Seasonality................................................................................................................ 7
4.5 Prognosen – Forecasting ........................................................................................................... 7
5 Maß- und Indexzahlen – Index Numbers .................................................................... 8
5.1 Verhältniszahlen – Ratios ........................................................................................................ 8
5.2 Preis- und Mengenindizes – Price and Quantity Indices .......................................................... 8

Inhaltsverzeichnis – Table of contents
Formelsammlung Statistik, Auflage 5.1 2007/08 Seite ii
Teil II Induktive (schließende) Statistik
Statistical Inference
6 Kombinatorik & Wahrscheinlichkeitsrechnung – Combination Theory & Probabilities ....................................................................................................................... 9
6.1 Kombinatorik – Combination Theory........................................................................................ 9
6.2 Grundbegriffe und Definitionen der Wahrscheinlichkeitsrechnung – Basic Concepts and Definitions of Calculus of Probabilities ....................................................... 9
6.3 Rechnen mit Wahrscheinlichkeiten – Calculation with Probabilities...................................... 10
7 Theoretische Verteilungen – Theoretical Distributions .......................................... 11
7.1 Zufallsvariablen – Random Variables..................................................................................... 11 7.1.1 Dichte- und Verteilungsfunktion –
Density and Distribution Function (Cumulated Density function - cdf) ............................... 11 7.1.2 Parameter von Verteilungen – Parameters of Distributions .................................................. 11
7.2 Einige spezielle Verteilungen – Specific Distributions............................................................ 12 7.2.1 Diskrete Verteilungen – Discrete Distributions ....................................................................... 12 7.2.2 Stetige Verteilungen – Continuous Distributions .................................................................... 13 7.2.3 Zentraler Grenzwertsatz – Central Limit Theorem .................................................................. 14 7.2.4 Approximationen von Verteilungen – Approximation of Distributions ................................. 14
8 Schluss von der Stichprobe auf die Grundgesamtheit – Statistical Inference ...... 15
8.1 Schätztheorie: Stichprobenfunktionen – Estimation Theory.................................................. 15
8.2 Konfidenzintervalle zur Parameterschätzung – Confidence Intervals .................................... 15 8.2.1 Konfidenzintervall für den Mittelwert – Confidence Interval for the Mean........................... 15 8.2.2 Konfidenzintervall für den Anteilswert – Confidence Interval for the Proportion.............. 17 8.2.3 Notwendiger Stichprobenumfang – Sample Size ................................................................... 17
8.3 Hypothesentests – Hypothesis Testing ............................................................................... 18
8.4 Parametrische Tests – Parametric Tests ................................................................................ 19 8.4.1 Testen von Mittelwerten – Testing Means.............................................................................. 19 8.4.2 Testen von Anteilswerten – Testing Proportions.................................................................... 19 8.4.3 Zweistichprobentests – Two Sample Tests ............................................................................ 20 8.4.4 Testen der Regressionskoeffizienten bei Mehrfachregression –
Testing Coefficients of Multivariate Regressions .................................................................. 20
8.5 Nicht-Parametrische Tests – Non-Parametric Tests .............................................................. 21 8.5.1 Chi-Quadrat Unabhängigkeitstest – Chi-Square Test of Independence.............................. 21 8.5.2 Chi-Quadrat Anpassungstest – Chi-Square Test for Distributions ........................................ 21
9 Tabellenanhang ................................................................................................................. 22
Recommended