
Real-Time Distributed and Reactive Systems
with Apache Kafka and Apache Accumulo

Joe Stein• Developer, Architect & Technologist
• Founder & Principal Consultant => Big Data Open Source Security LLC - http://stealth.ly
Big Data Open Source Security LLC provides professional services and product solutions for the collection, storage,
transfer, real-time analytics, batch processing and reporting for complex data streams, data sets and distributed
systems. BDOSS is all about the "glue" and helping companies to not only figure out what Big Data Infrastructure
Components to use but also how to change their existing (or build new) systems to work with them.
• CEO => Elodina, Inc.
Expanding BDOSS from just consulting, Elodina is an ISV & SaaS provider of stream solutions & open source software.
Elodina helps make data streams actionable.
• Apache Kafka Committer & PMC member
• Blog & Podcast - http://allthingshadoop.com
• Twitter @allthingshadoop

Overview
● Real-time distributed reactive systems
● Quick Intro to Apache Kafka
● Quick Intro to Apache Mesos
● Kafka on Mesos
● Accumulo & HDFS on Mesos
● Real-time distributed reactive systems
● Bringing it all together with Accumulo

Real-Time Distributed and Reactive Systems
A distributed system for asynchronous stream processing with
non-blocking back pressure where complex event processing
systems can influence the response without coupling the
business logic of processing. The response can be calculated
by parallel operations with concurrent orthogonal processing
engines computing their influence towards the final result.
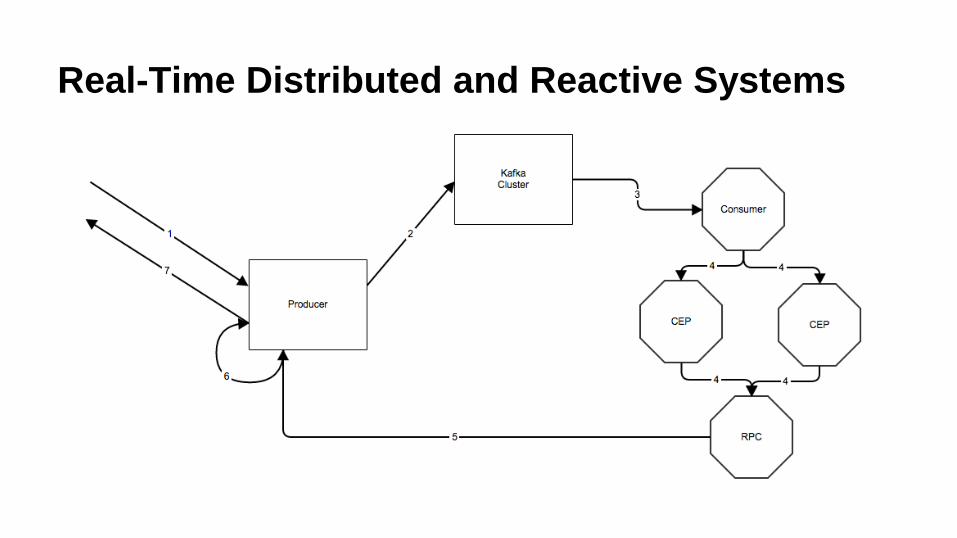
Real-Time Distributed and Reactive Systems

Apache Kafka
• Apache Kafka
o http://kafka.apache.org
• Apache Kafka Source Code
o https://github.com/apache/kafka
• Documentation
o http://kafka.apache.org/documentation.html
• Wiki
o https://cwiki.apache.org/confluence/display/KAFKA/Index

Producers, Consumers, Brokers
• Producers - ** push **
o Batching
o Compression
o Sync (Ack), Async (auto batch)
o Replication
o Sequential writes, guaranteed ordering within each partition
• Consumers - ** pull **
o No state held by broker
o Consumers control reading from the stream
• Zero Copy for producers and consumers to and from the broker
http://kafka.apache.org/documentation.html#maximizingefficiency
• Message stay on disk when consumed, deletes on TTL or compaction
https://kafka.apache.org/documentation.html#compaction
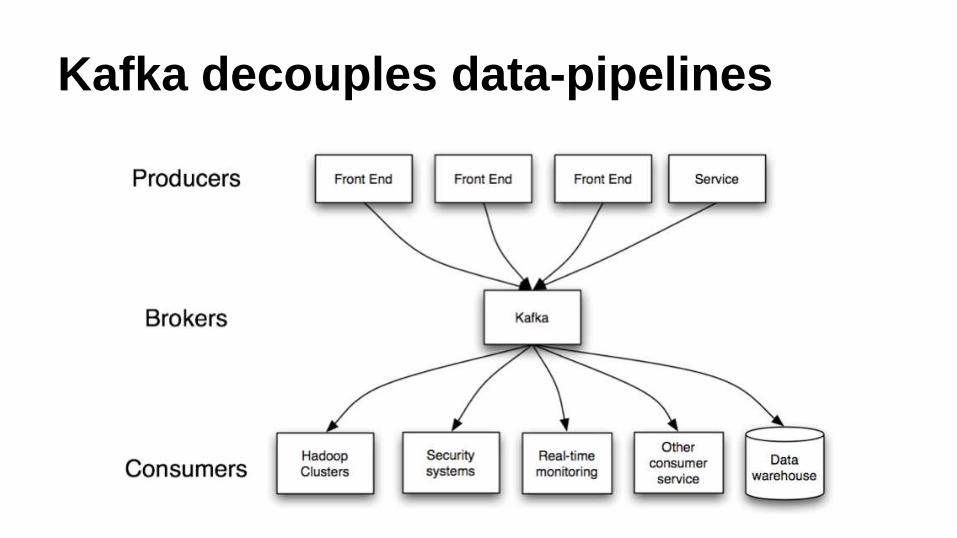
Kafka decouples data-pipelines

Client Libraries
Community Clients https://cwiki.apache.org/confluence/display/KAFKA/Clients
• Python - Pure Python implementation with full protocol support. Consumer and Producer
implementations included, GZIP and Snappy compression supported.
• C - High performance C library with full protocol support
• C++ - Native C++ library with protocol support for Metadata, Produce, Fetch, and Offset.
• Go (aka golang) Pure Go implementation with full protocol support. Consumer and Producer
implementations included, GZIP and Snappy compression supported.
• Ruby - Pure Ruby, Consumer and Producer implementations included, GZIP and Snappy
compression supported. Ruby 1.9.3 and up (CI runs MRI 2.
• Clojure - Clojure DSL for the Kafka API
• JavaScript (NodeJS) - NodeJS client in a pure JavaScript implementation
• stdin & stdout
Wire Protocol Developers Guide
https://cwiki.apache.org/confluence/display/KAFKA/A+Guide+To+The+Kafka+Protocol

Really Quick Start (Scala)
1) Install Vagrant http://www.vagrantup.com/
2) Install Virtual Box https://www.virtualbox.org/
3) git clone https://github.com/stealthly/scala-kafka
4) cd scala-kafka
5) vagrant up
Zookeeper will be running on 192.168.86.5
BrokerOne will be running on 192.168.86.10
All the tests in ./src/test/scala/* should pass (which is also /vagrant/src/test/scala/* in the vm)
6) ./gradlew test

Really Quick Start (Go)
1) Install Vagrant http://www.vagrantup.com/
2) Install Virtual Box https://www.virtualbox.org/
3) git clone https://github.com/stealthly/go-kafka
4) cd go-kafka
5) vagrant up
6) vagrant ssh brokerOne
7) cd /vagrant
8) sudo ./test.sh

Origins
Mesos: A Platform for Fine-Grained Resource Sharing in the Data Center
http://static.usenix.org/event/nsdi11/tech/full_papers/Hindman_new.pdf
Google Borg - https://research.google.com/pubs/pub43438.html
Google Omega: flexible, scalable schedulers for large compute clusters
http://eurosys2013.tudos.org/wp-
content/uploads/2013/paper/Schwarzkopf.pdf

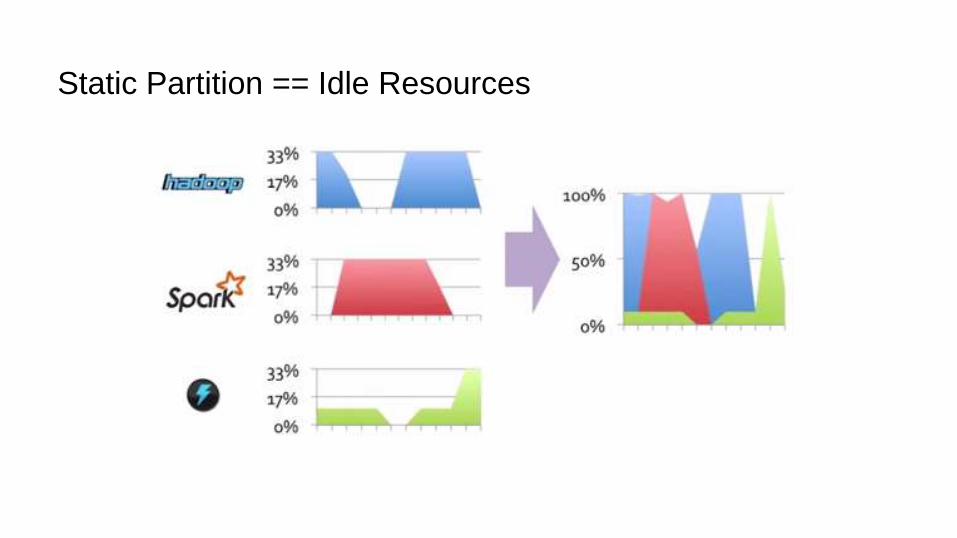
Static Partition == Idle Resources
Operating System === Datacenter
Mesos => data center “kernel”
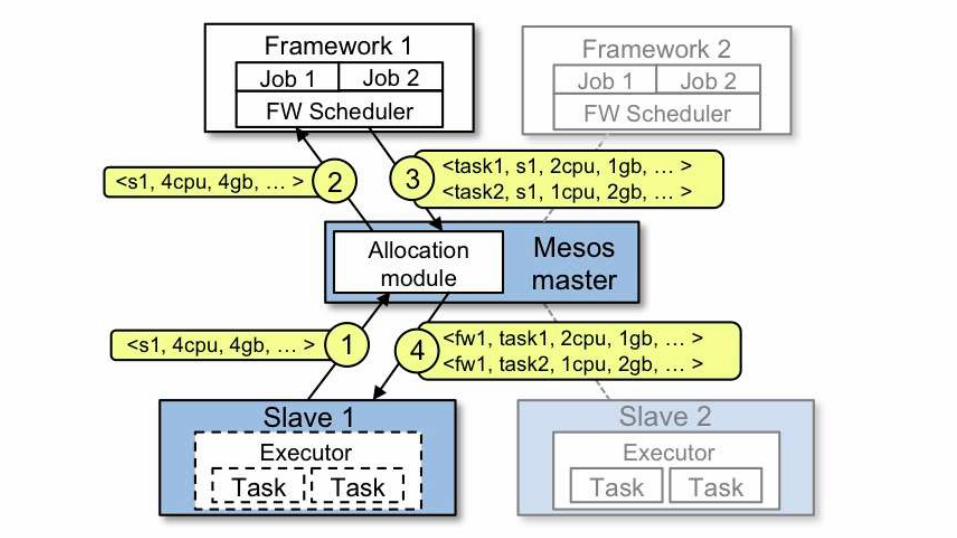

Apache Mesos
● Scalability to 10,000s of nodes
● Fault-tolerant replicated master and slaves using ZooKeeper
● Support for Docker containers
● Native isolation between tasks with Linux Containers
● Multi-resource scheduling (memory, CPU, disk, and ports)
● Java, Python and C++ APIs for developing new parallel applications
● Web UI for viewing cluster state

Sample Frameworks
C++ - https://github.com/apache/mesos/tree/master/src/examples
Java - https://github.com/apache/mesos/tree/master/src/examples/java
Python - https://github.com/apache/mesos/tree/master/src/examples/python
Scala - https://github.com/mesosphere/scala-sbt-mesos-framework.g8
Go - https://github.com/mesosphere/mesos-go

Kafka on Mesos
● The Mesos Kafka framework https://github.com/mesos/kafka
○ Smart broker.id assignment.
○ Preservation of broker placement.
○ Ability to-do configuration changes.
○ Rolling restarts.
○ Auto-scaling the cluster up and down.
Accumulo on Mesos
No framework yet, but you can use Marathon, no problem!
Marathon https://github.com/mesosphere/marathon is a cluster-
wide init and control system for services in cgroups or docker
based on Apache Mesos
HDFS on Mesos https://github.com/mesosphere/hdfs (more on
this in a bit)


Real-Time Distributed and Reactive Systems
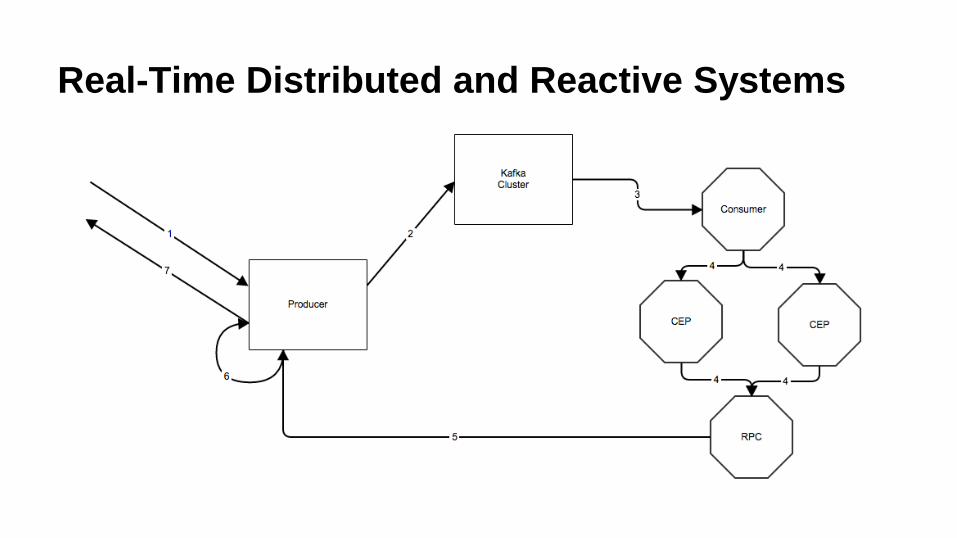
Real-Time Distributed and Reactive Systems

Where does Accumulo fit in?
● Iterators
○ Accumulo iterators are a real time processing framework with
“reduce like” functionality
● Multi HDFS Volume Support
○ Spin up HDFS clusters when they are needed
● Streaming Large Blobs
○ Post files in producers, process and respond to scans
● More!
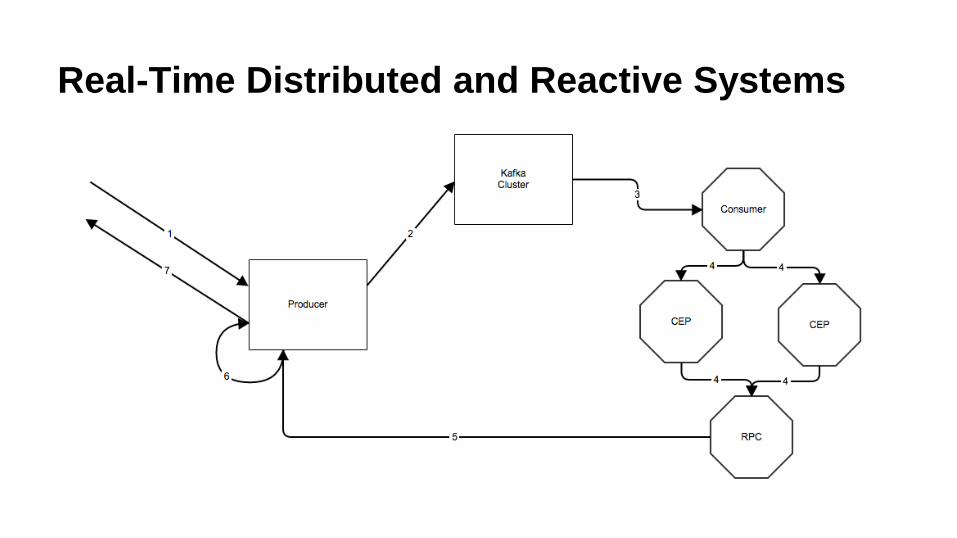
Real-Time Distributed and Reactive Systems

Questions?
/*******************************************
Joe Stein
CEO, Elodina, Inc
http://www.stealth.ly
Twitter: @allthingshadoop
********************************************/
Recommended



![Evaluation of Apache Kafka in Real-Time Big Data Pipeline ... · Apache Kafka in the pipeline architecture. 3.1 Apache Kafka Architecture . Kafka [9] is an open source, distributed](https://img.pdfslide.net/doc/110x75/5ea885d2f35fca1745303e93/evaluation-of-apache-kafka-in-real-time-big-data-pipeline-apache-kafka-in-the.jpg)


![Accumulo Summit 2015: Real-Time Distributed and Reactive Systems with Apache Kafka and Apache Accumulo [Leveraging Accumulo]](https://img.pdfslide.net/doc/110x75/55a5e41a1a28ab37368b4776/accumulo-summit-2015-real-time-distributed-and-reactive-systems-with-apache-kafka-and-apache-accumulo-leveraging-accumulo.jpg)











![Accumulo Summit 2015: Apache Accumulo at Bloomberg [Keynote]](https://img.pdfslide.net/doc/110x75/55a5e4b81a28ab28368b4817/accumulo-summit-2015-apache-accumulo-at-bloomberg-keynote.jpg)
