
Real-time fraud detection in credit cardtransactions
Mariusz Rafało Warsaw, February 28th, 2017

About me…
Professional: Co-founder and partner at Sorigo
Academic: Lecturer at Warsaw School of Economics
Contact details: [email protected] http://www.linkedin.com/in/mrafalo

Agenda
1. What is the best approach to prevent specific type of fraud?
2. How to configure Big Data tools to detect frauds?
3. Is Big Data architecture flexible enough for fraud detection?
3

BATCH VS STREAM APPROACH
4
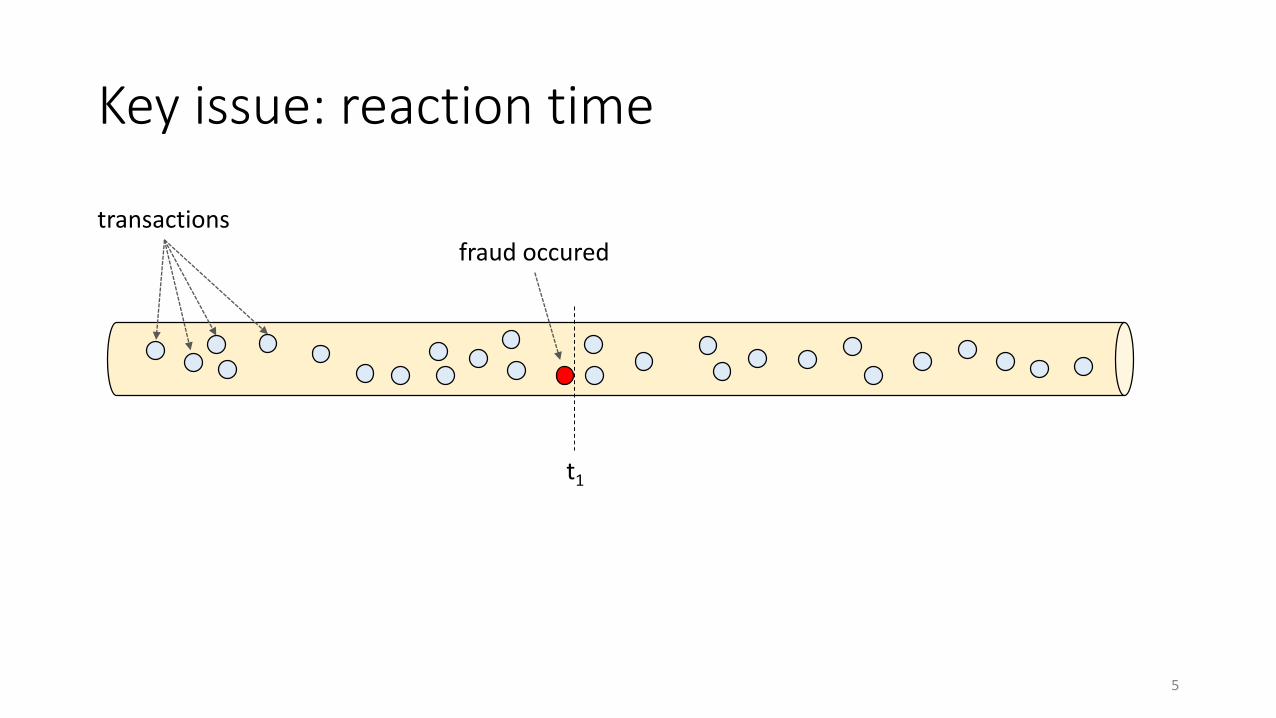
Key issue: reaction time
transactionsfraud occured
t1
5
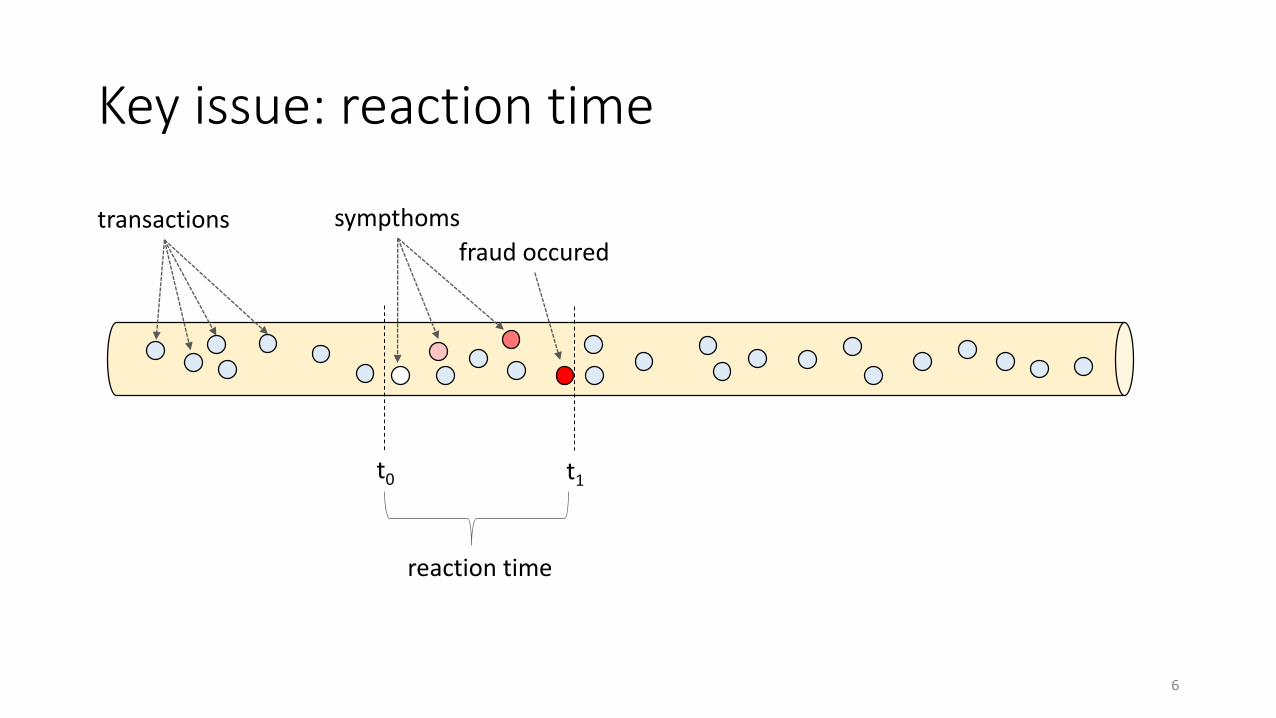
sympthoms
Key issue: reaction time
transactions
t1
fraud occured
t0
reaction time
6
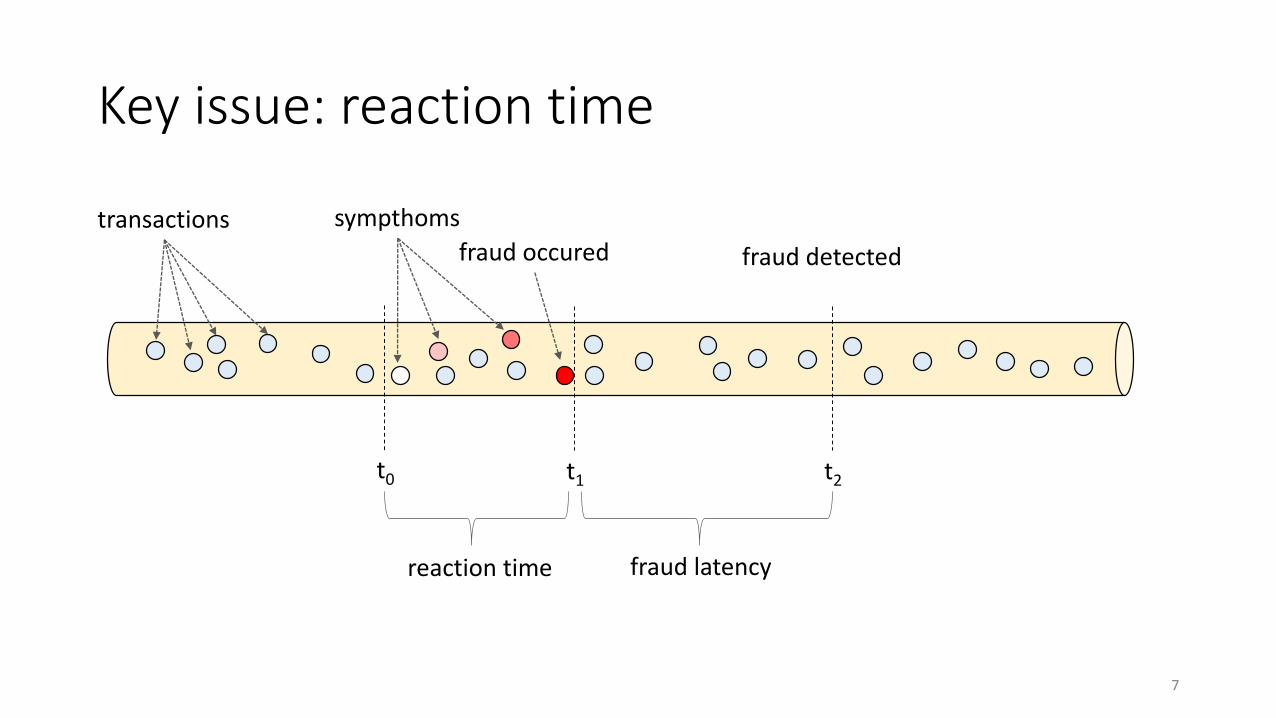
sympthoms
fraud detected
Key issue: reaction time
transactions
t2t1
fraud occured
fraud latency
t0
reaction time
7
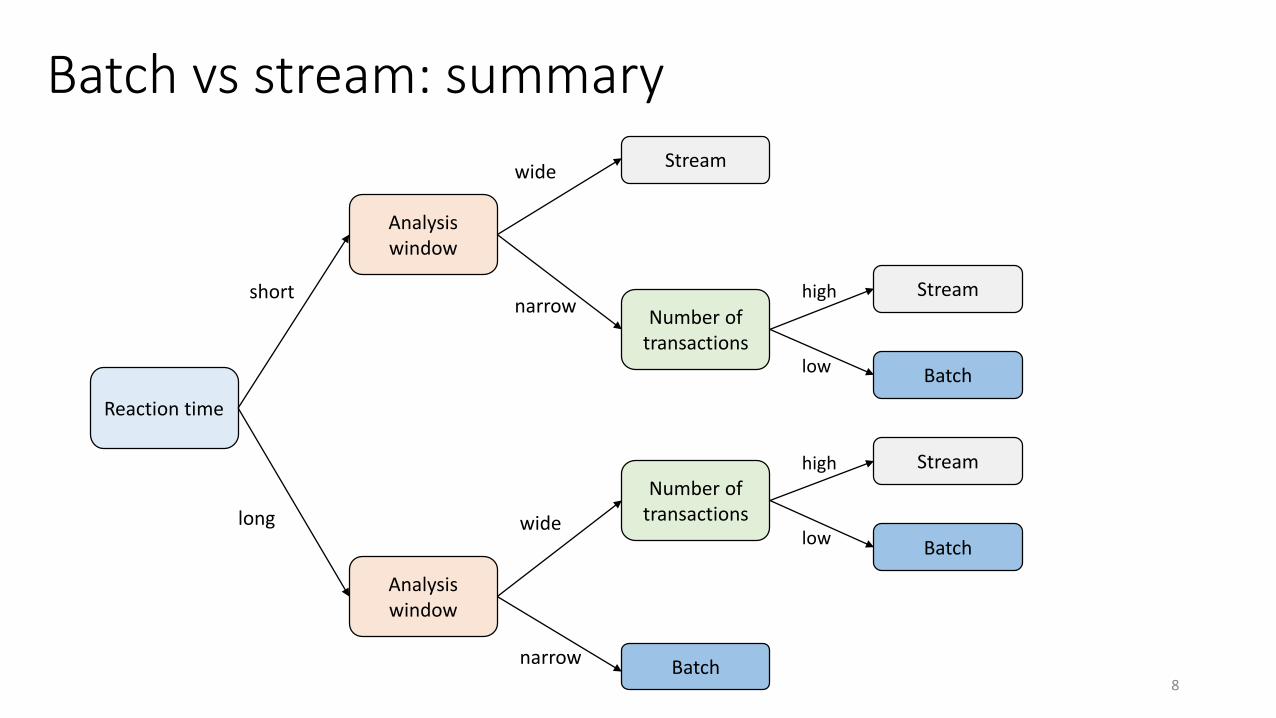
Reaction time
Number of transactions
Analysis window
Analysis window
Number of transactions
Stream
Batch
Stream
Batch
short
long
wide
narrow
wide
narrow
high
low
high
low
Stream
Batch
Batch vs stream: summary
8
ARCHITECTURE
9
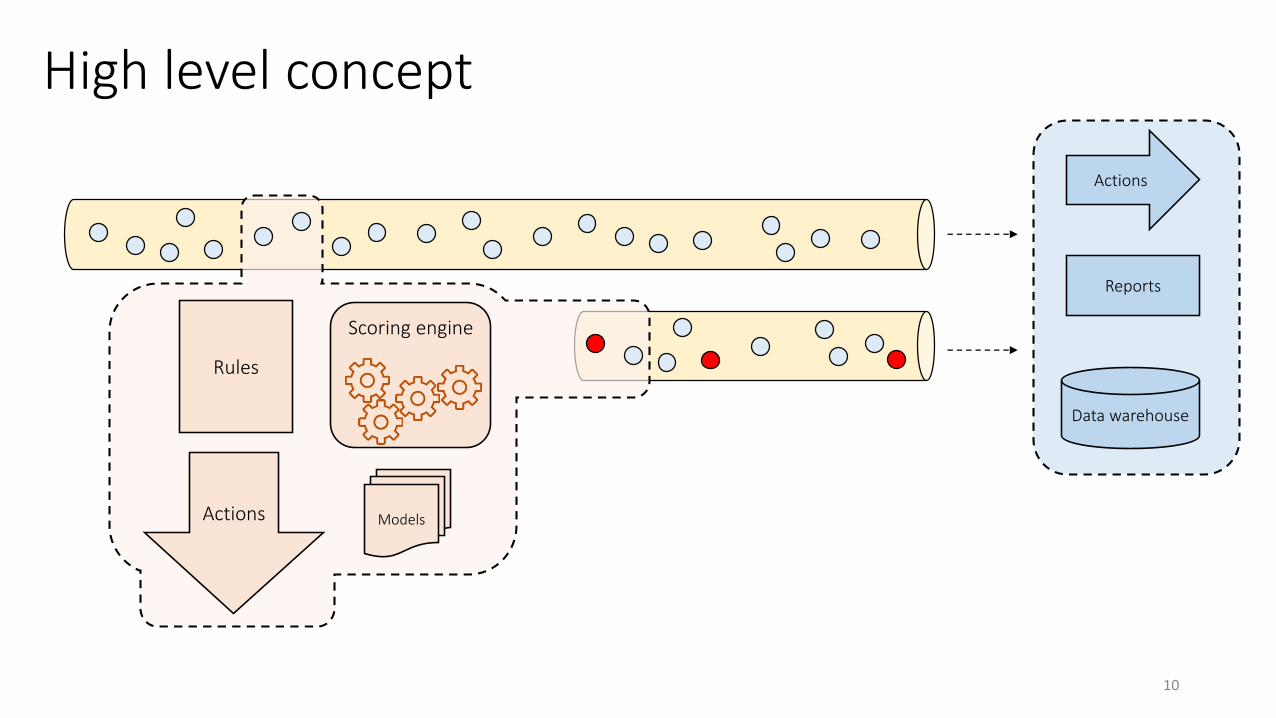
Data warehouse
Scoring engine
High level concept
Reports
Actions
Models
Rules
Actions
10

DATA ANALYSIS
11

Data at first glace
284 807 unique observations (1-3 transactions per second)
30 variables + timestamp + target
Unbalanced dataset: 0.17% frauds (492 vs 284 315)
12
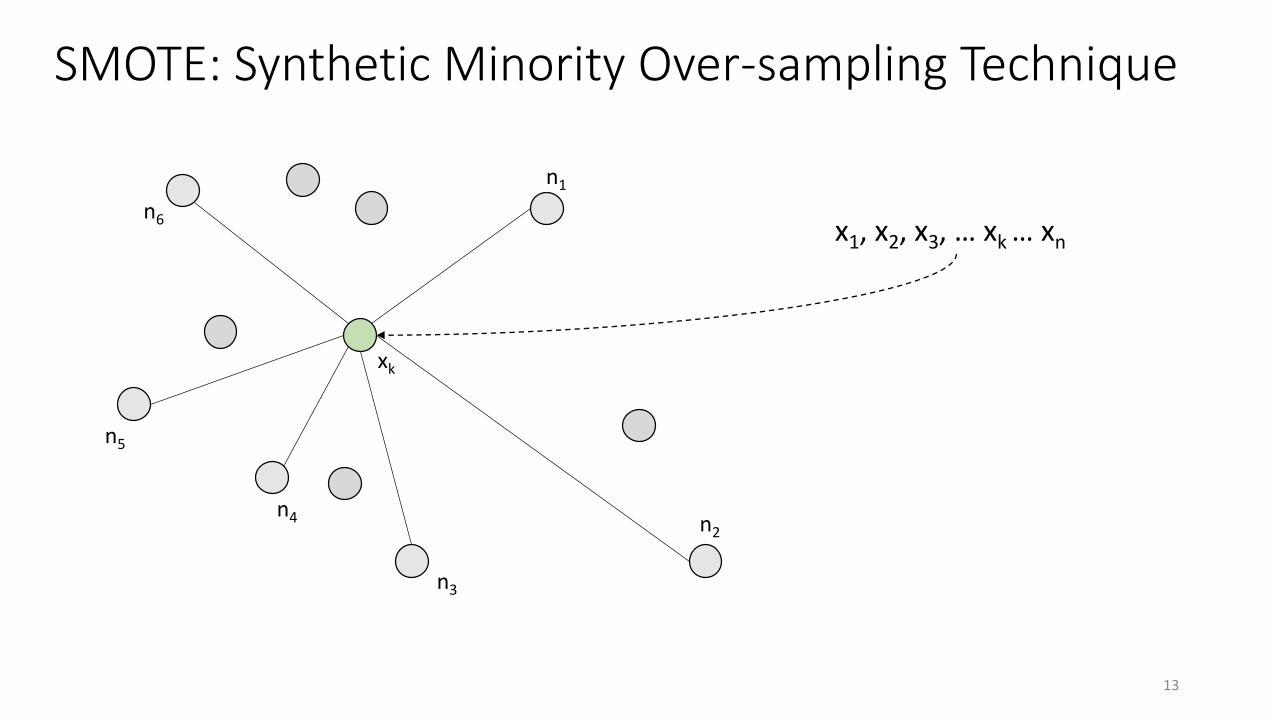
SMOTE: Synthetic Minority Over-sampling Technique
xk
n1
n2
n3
n4
n5
n6x1, x2, x3, … xk … xn
13
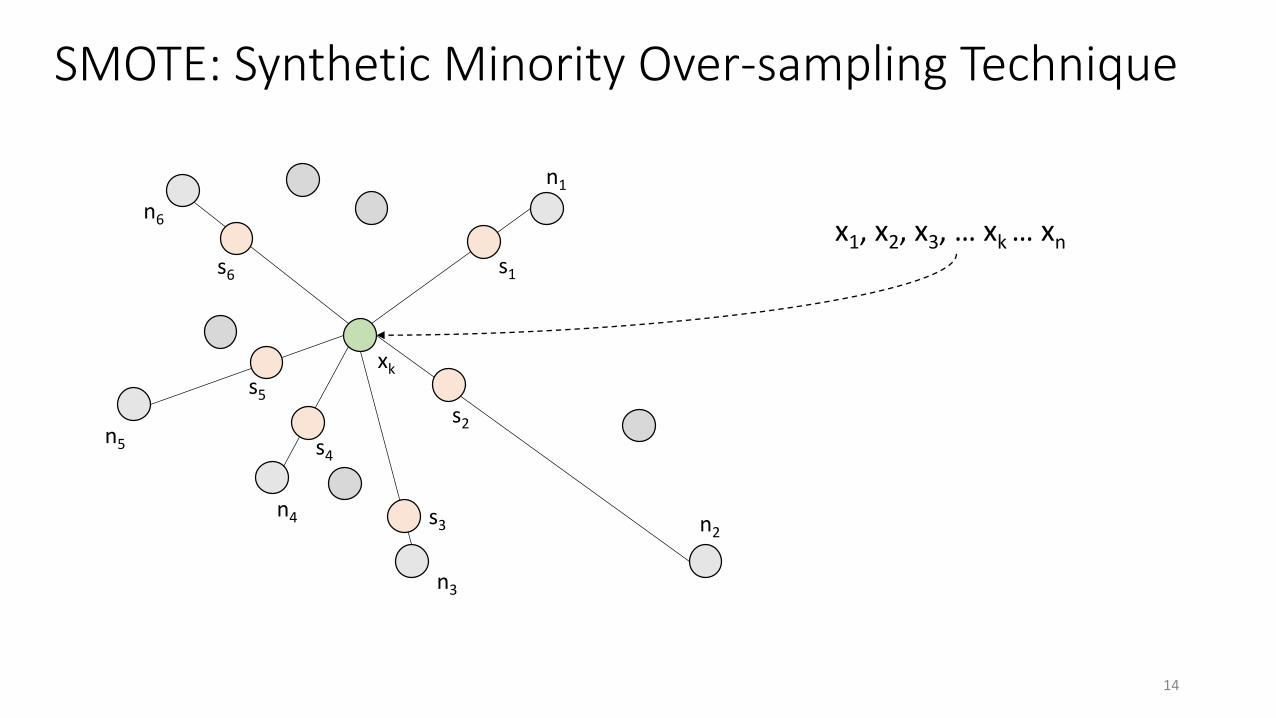
SMOTE: Synthetic Minority Over-sampling Technique
xk
n1
n2
n3
n4
n5
n6
s1
s2
s3
s4
s5
s6
x1, x2, x3, … xk … xn
14
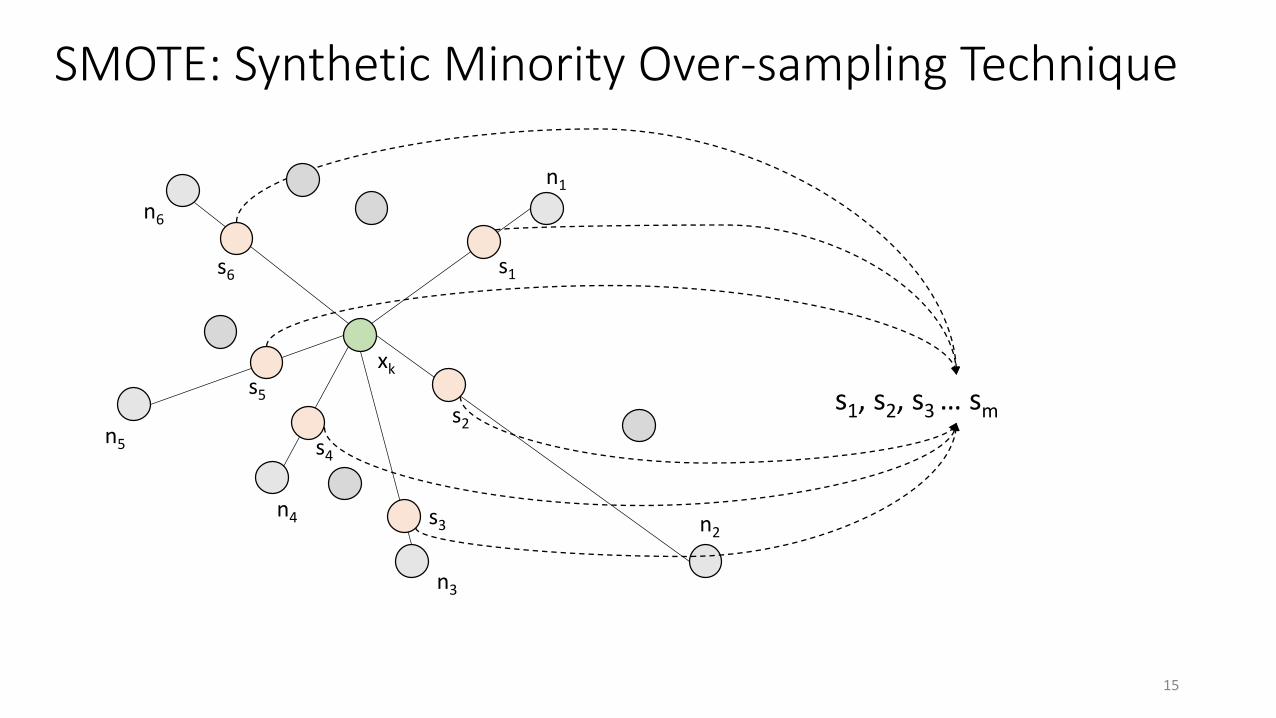
SMOTE: Synthetic Minority Over-sampling Technique
xk
n1
n2
n3
n4
n5
n6
s1
s2
s3
s4
s5
s6
s1, s2, s3 … sm
15
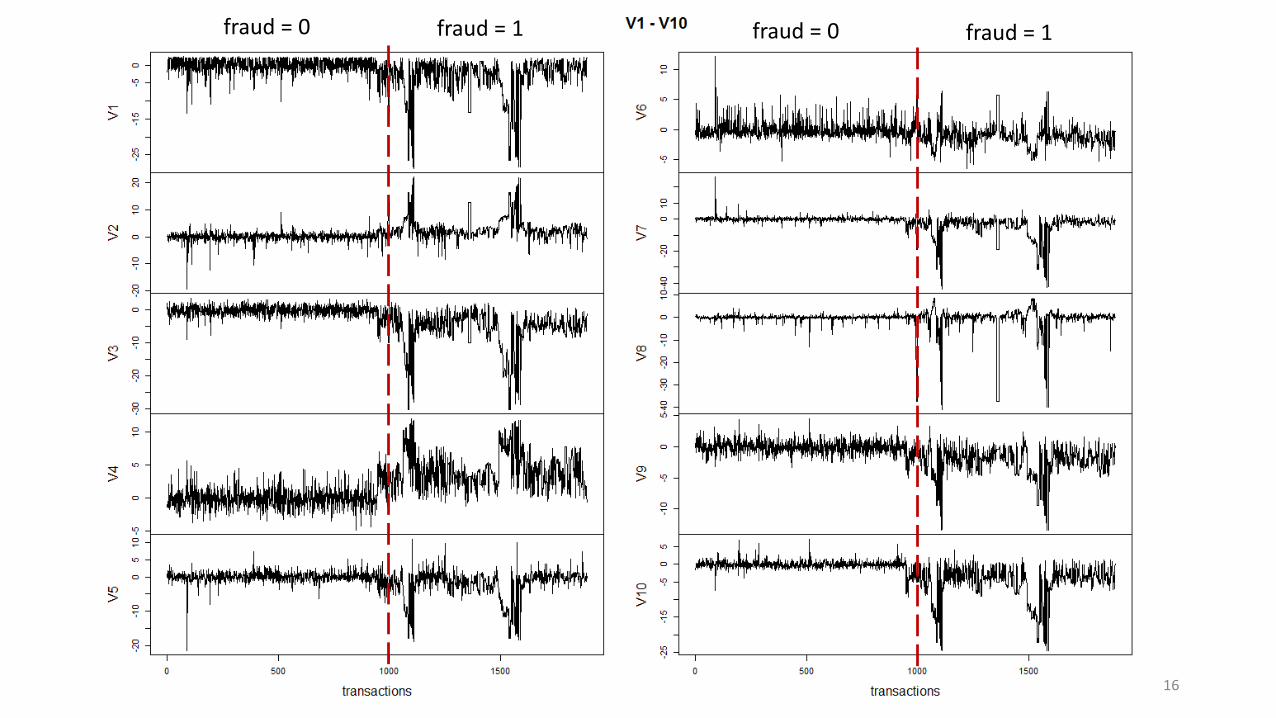
16
fraud = 0 fraud = 1 fraud = 0 fraud = 1
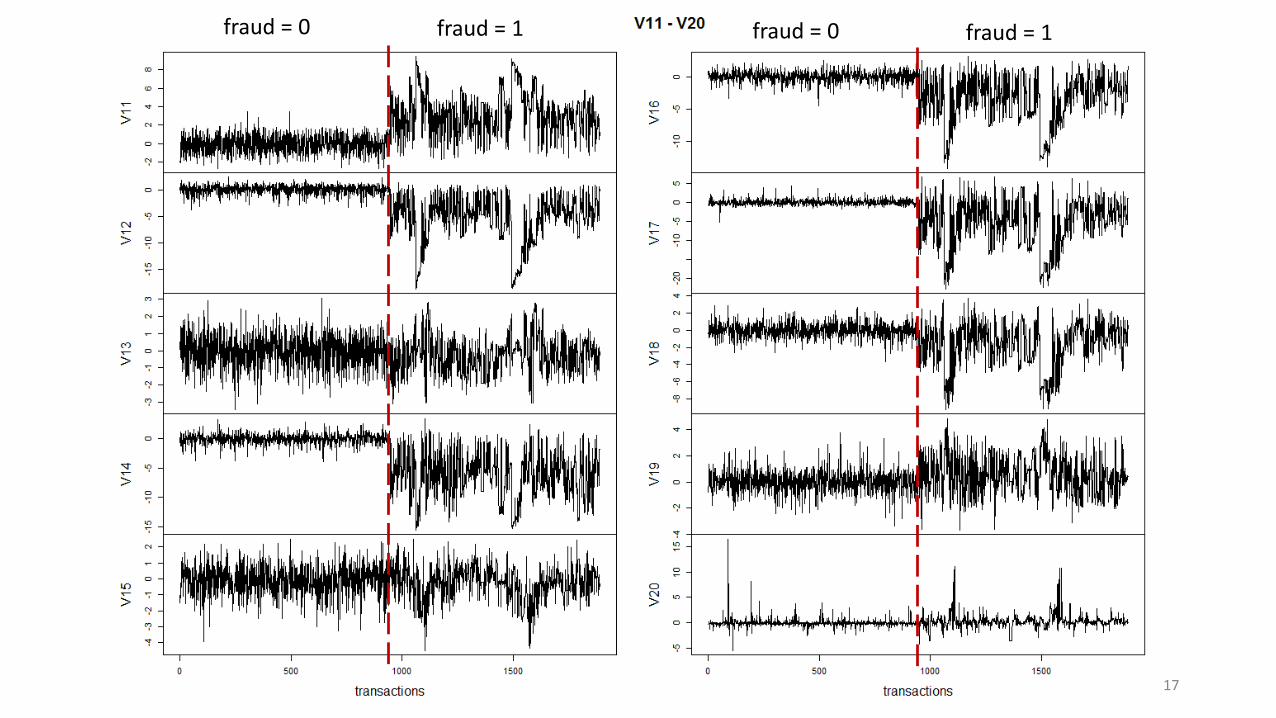
17
fraud = 0 fraud = 1 fraud = 0 fraud = 1
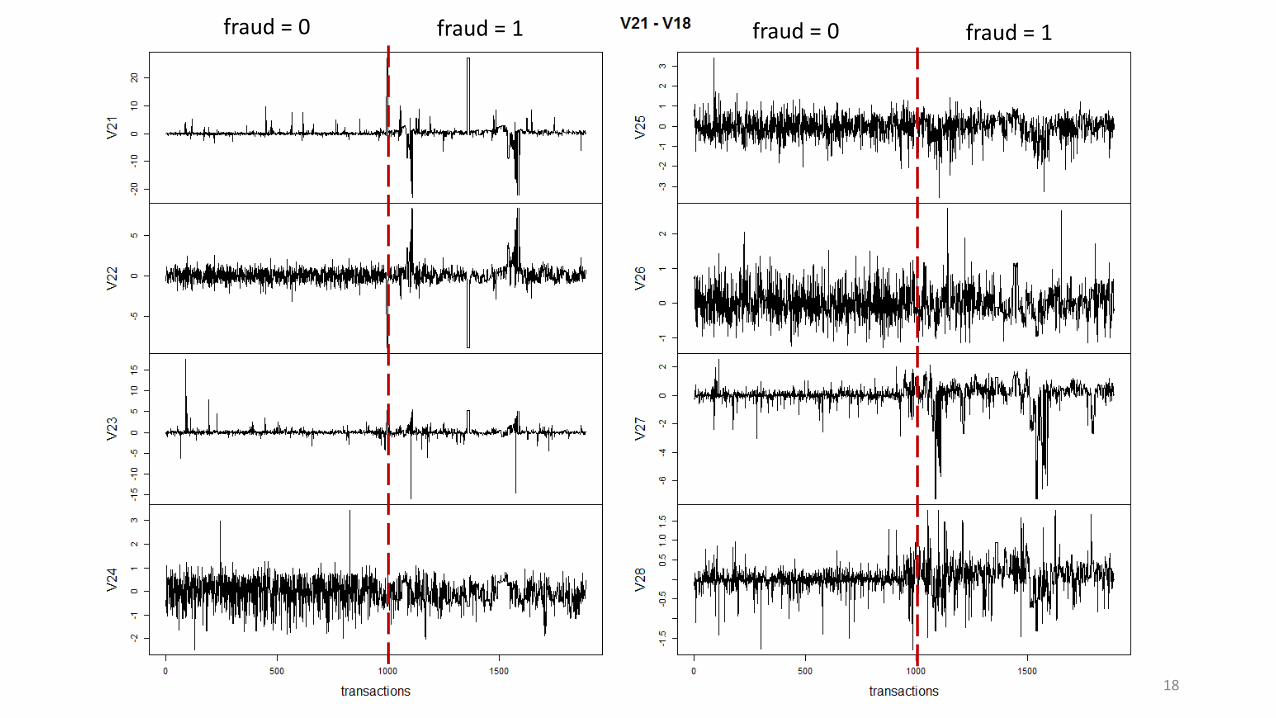
18
fraud = 0 fraud = 1 fraud = 0 fraud = 1
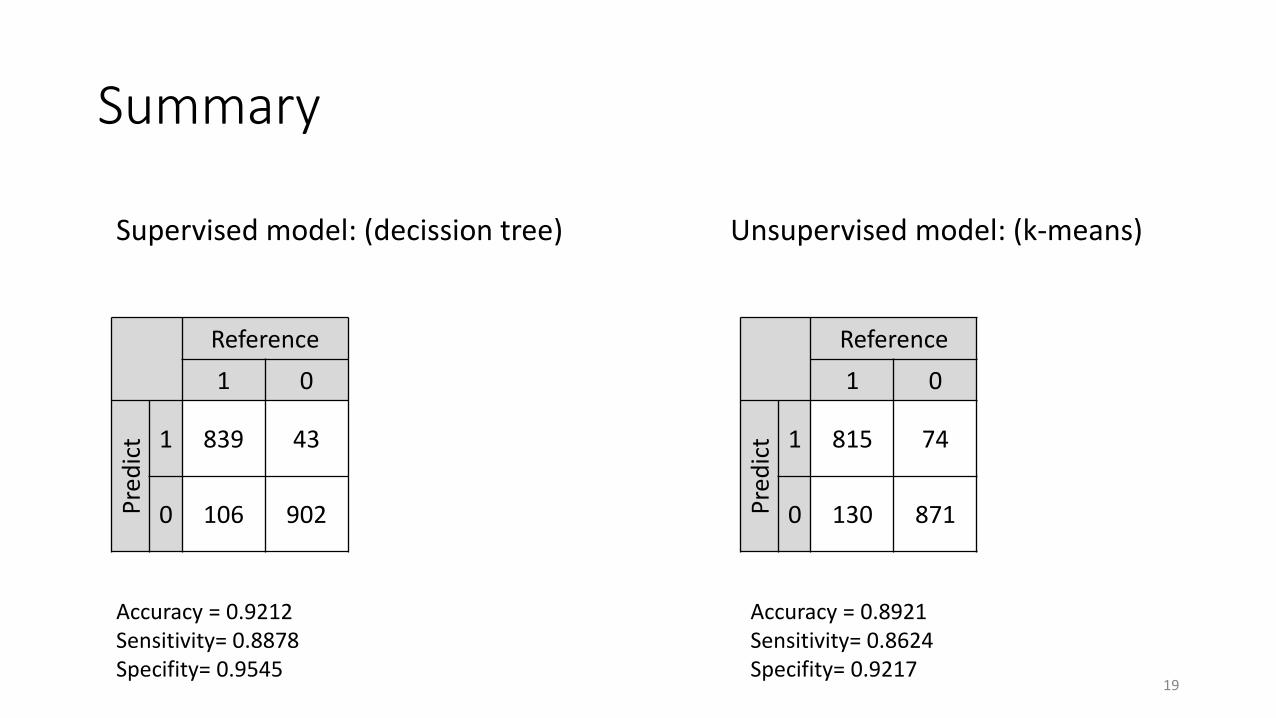
Summary
Supervised model: (decission tree) Unsupervised model: (k-means)
Reference
1 0
Pre
dic
t 1 839 43
0 106 902
Reference
1 0
Pre
dic
t 1 815 74
0 130 871
Accuracy = 0.9212Sensitivity= 0.8878Specifity= 0.9545
Accuracy = 0.8921Sensitivity= 0.8624Specifity= 0.9217
19

TECHNOLOGIES
20
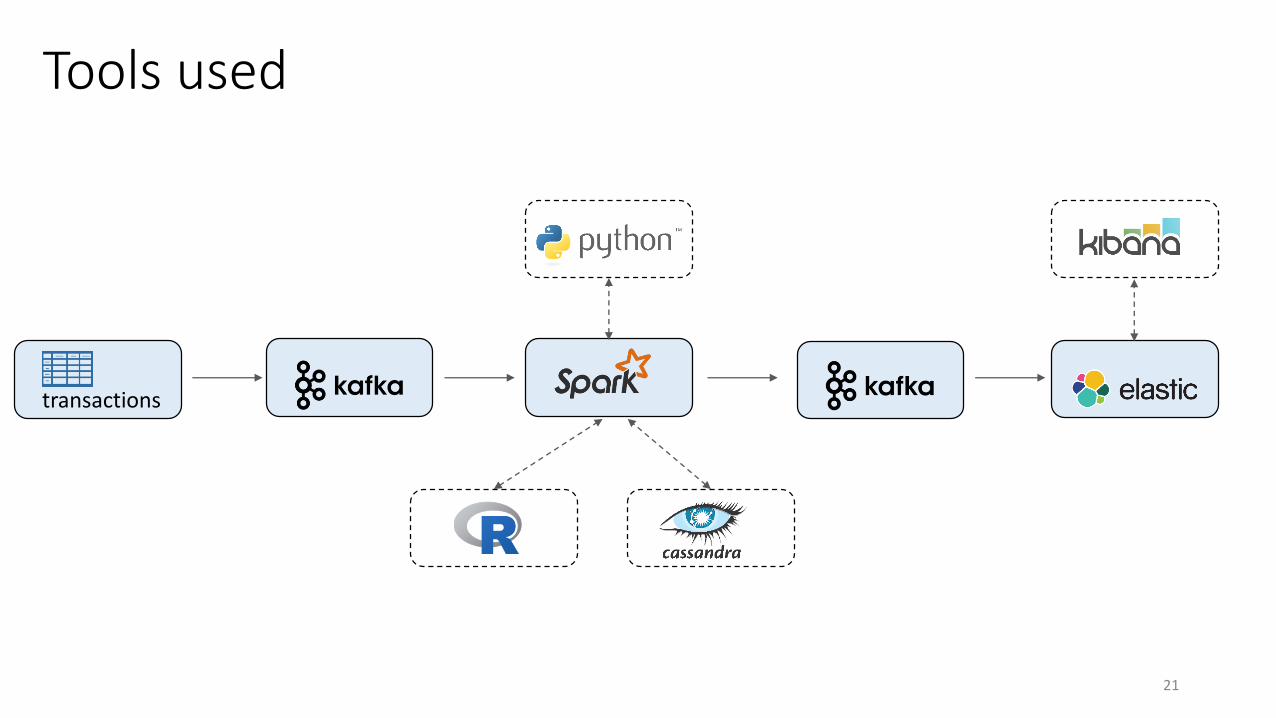
Tools used
transactions
21
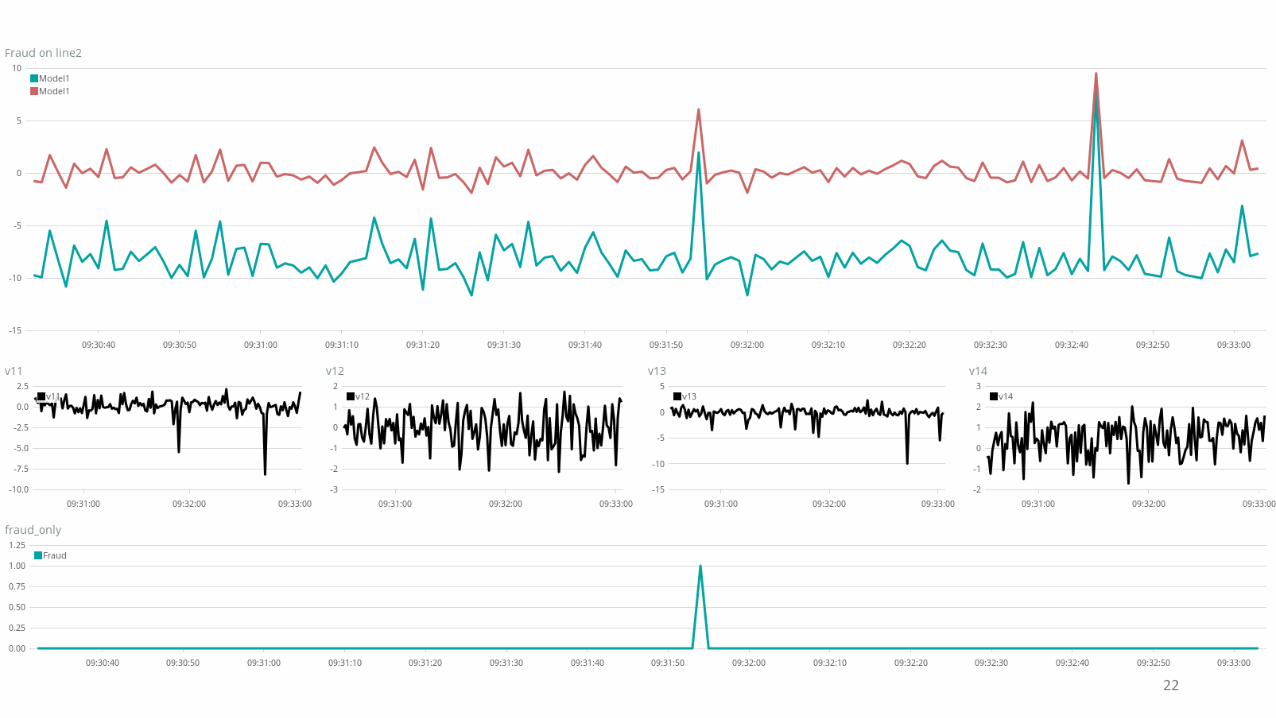
22

SUMMARY
23

Conculsions
For most cases, batch processing is good enough
Flexibility decreases as the system is based on multiple technologies
Consider independent module design with
24
Recommended


















