
Scientific Computing on Graphical Processors: FMM, Flagon, Signal
Processing, Plasma
Ramani Duraiswami and Nail GumerovComputer Science & UMIACS
University of Maryland, College Park
Joint work with Yuancheng Luo, Adam O’Donovan, Bill Dorland and students of CMSC 828 E (Scientific Computing on Graphical Processors)www.umiacs.umd.edu/~ramani/cmsc828e_gpusci

FMM on the GPU N.A. Gumerov and R. Duraiswami, Fast multipole methods on
graphics processors. Journal of Computational Physics, 227, 8290-8313, 2008.
N-body problems - important in stellar dynamics, molecular modeling, etc.
Several papers implement quadratic algorithms on the GPU (but restricted to O(104) particles)
To go to O(106) and beyond we need the FMM Reduces quadratic complexity to linear order Complex algorithm which relies on a balance between
local interactions (brute force) and tree-based far field

Direct summation on GPU
Cost =A1 N+B1 N/s+C1 Ns.
Compare GPU final summation complexity:
and total FMM complexity:
Cost = AN+BN/s+CNs.
sopt = (B1 /C1 )1/2,
Optimal cluster size for direct summation step of the FMM
This leads to
Cost =(A+A1 )N+(B+B1 )N/s+C1 Ns,
and sopt = ((B+B1 )/C1 )1/2 .
FMM requires a balance between direct summation and the rest of the algorithm

Performance on a 8800 GTX
661.761 s116.1 sp=12
721.227 s88.09 sp=8
290.979 s28.37 sp=4
RatioGPUserial CPU
(potential only) N=1,048,576
481.395 s66.56 sp=12
560.908 s51.17 sp=8
330.683 s22.25 sp=4
RatioGPUserial CPU
(potential+forces (gradient)) N=1,048,576
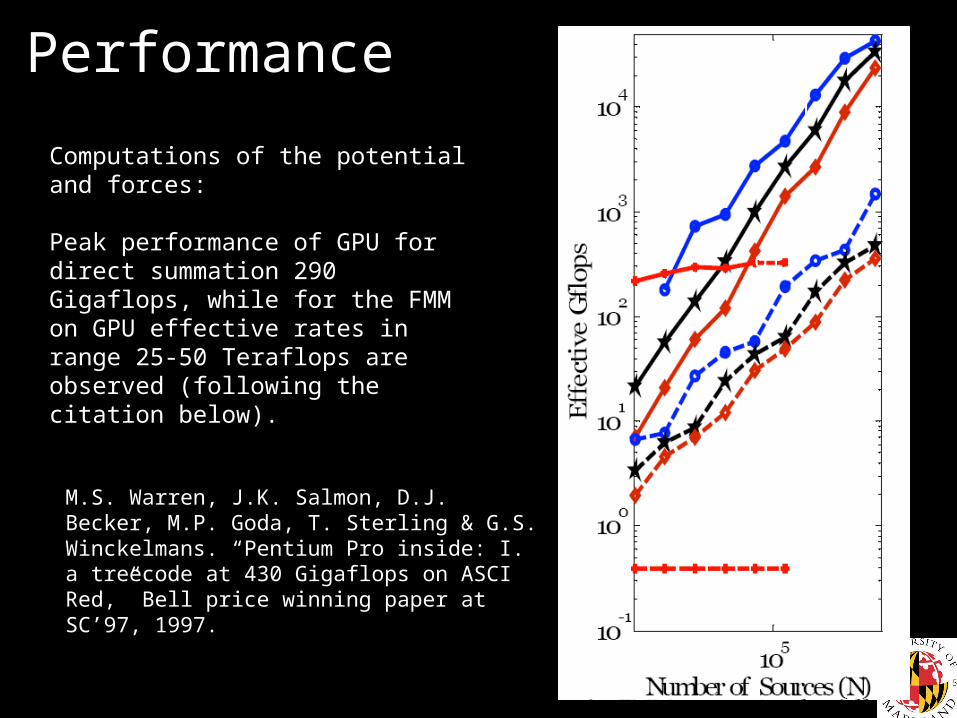
Performance
Computations of the potential and forces:
Peak performance of GPU for direct summation 290 Gigaflops, while for the FMM on GPU effective rates in range 25-50 Teraflops are observed (following the citation below).
M.S. Warren, J.K. Salmon, D.J. Becker, M.P. Goda, T. Sterling & G.S. Winckelmans. “Pentium Pro inside: I. a treecode at 430 Gigaflops on ASCI Red,” Bell price winning paper at SC’97, 1997.
CPU
GPU
direct
dir
FMM
FMM
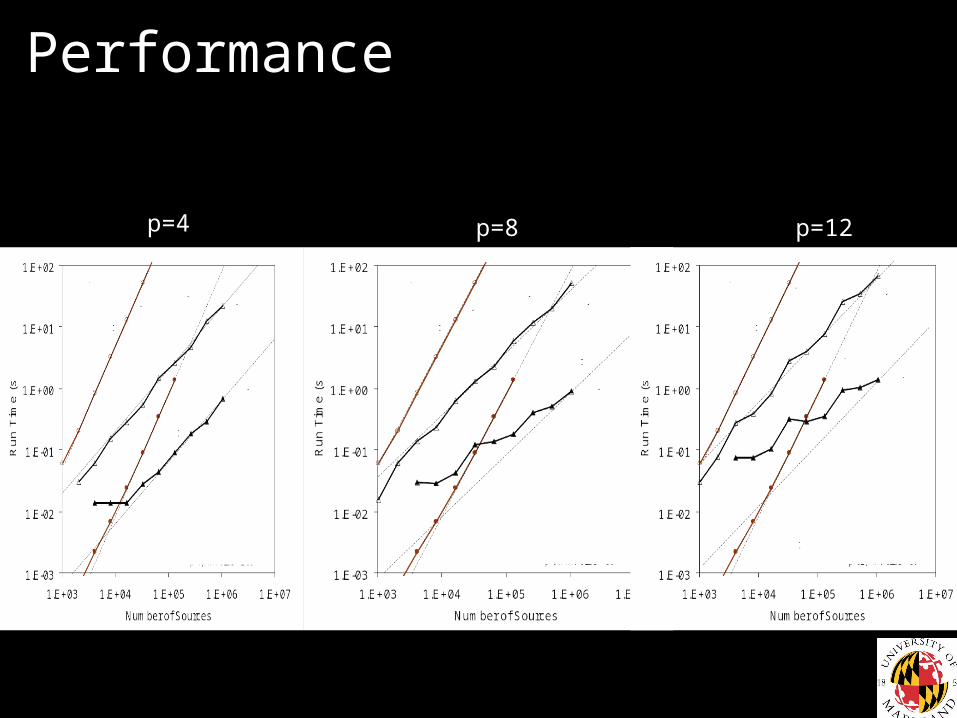
Performance
p=4 p=8 p=12

What is more accurate for solution of large problems on GPU: direct summation or FMM?
1.E-09
1.E-08
1.E-07
1.E-06
1.E-05
1.E-04
1.E-03
1.E-02
1.E+02 1.E+03 1.E+04 1.E+05 1.E+06 1.E+07
Number of Sources
L2-r
elat
ive
erro
r
p=4
p=8
p=12
Direct
CPU
GPU
FMM
FMM
FMM
Filled = GPU, Empty = CPU
Error in computations of potential
Error computedover a grid of 729 sampling points, relative to “exact” solution, which is direct summation with double precision.
Possible reason why the GPU error in direct summation grows: systematic roundoff error in computation of function 1/sqrt(x).(still a question).

Flagon: Use GPUs via extensible libraries GPUs are great as we all have heard But require you to program in extended version of C Need NVIDIA toolchain What if you have an application that is
In Fortran 9x/2003, Matlab, C/C++ Too large to fit on the GPU and needs to use the CPU cores, MPI, etc. as
part of a larger application, but take advantage of GPU Offload computations which have good speedups on the GPU to it using
library calls in your programming environment
Enter the FLAGON An extensible open source library and a middleware framework
that allows use of GPU Implemented currently for Fortran-9X, and preliminarily for C++ and
MATLAB

Programming on the GPU GPU organized as 2-30 groups of
multiprocessors (8 relatively slow processors) with small amount of own memory and fast access to common shared memory, and slow access to global memory
Factor of 100s difference in speed as one goes up the memory hierarchy
To achieve gains problems must fit the SPMD paradigm and manage memory
Research issues: Identifying important tasks and mapping them to the
architecture Making it convenient for programmers to call GPU code
from host code
Local memory~50kB
GPU global memory
~1GB
Host memory~2-32 GB

Approach to use GPU: Flagon Middleware
Defines Module/Class that provides pointers on CPU to Device Variables on the GPU
Execute small, well written, CU functions to perform primitive operations on device avoid data transfer overhead by Initially using pinned memory copies and pointers Subsequently transfer data to CPU only when necessary
Provide wrappers to BLAS, FFT, and other software (random number, sort, screen dump, etc.)
Allow incorporation of existing mechanisms for doing distributed programming (OpenMP, MPI, etc.) to handle clusters
Allow relatively easy conversion of existing code

Sample scientific computing applications Radial basis function fitting Plasma turbulence computations Fast Multipole Force calculation in particle systems Machine Learning Numerical Relativity Space Turbulence Signal Processing Integral Equations

FLAGON Device Variables User instantiates device
variables in Fortran Encapsulates parameters
and attributes of the data structure transferred between host and device
Tracks (via pointers) allocated memory on the device
Stores data attributes (type and dimensions) on the host and device
FLAGON Structure
devVar
Device Pointer
Device Dimensions
Device Leading
Dimensions
Device Status
Device Data Type
Pointer to device memory
address
Data type stored on device
Allocation status on device
X, Y, Z dimensions of vector
or matrix on host
XL, XY
Lleading dimensions
of vector or matrix on
device

FLAGON Work-Cycle Compiling and link library
to user Fortran code Load library into memory Allocate device variables
and copy host data to device Work-cycle allows
subsequent computations to be performed solely on the device
Data transfer from device to host when done
Discard/free data on the device
FLAGON Work Cycle
Load FLAGON Library
Allocate Device
Variable(s )
Memory Transfer
Host to Device
Work
Memory Transfer
Device to Host
Allocates and pads
memory on GPU Device
Transfer host data from
Fortran to CUDA global
memory
Call CUBLAS, CUFFT,
CUDPP, CUDA functions
and perform all
calculations on the GPU
Transfer data back from
device to host
Specify GPU device,
load CUBLAS library
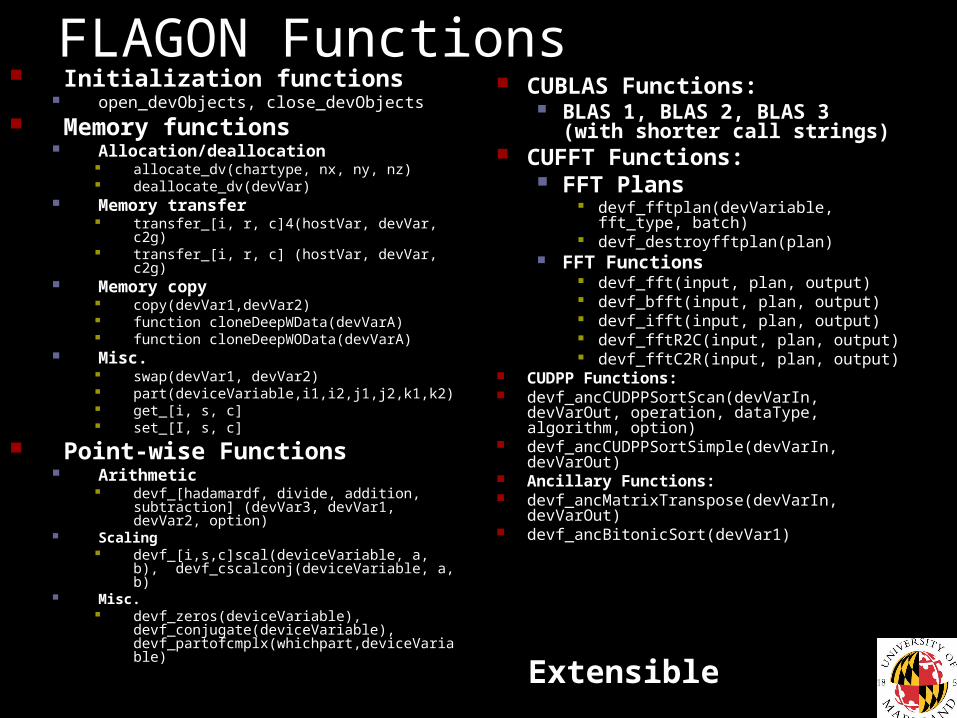
FLAGON Functions Initialization functions
open_devObjects, close_devObjects Memory functions
Allocation/deallocation allocate_dv(chartype, nx, ny, nz) deallocate_dv(devVar)
Memory transfer transfer_[i, r, c]4(hostVar, devVar, c2g) transfer_[i, r, c] (hostVar, devVar, c2g)
Memory copy copy(devVar1,devVar2) function cloneDeepWData(devVarA) function cloneDeepWOData(devVarA)
Misc. swap(devVar1, devVar2) part(deviceVariable,i1,i2,j1,j2,k1,k2) get_[i, s, c] set_[I, s, c]
Point-wise Functions Arithmetic
devf_[hadamardf, divide, addition, subtraction] (devVar3, devVar1, devVar2, option)
Scaling devf_[i,s,c]scal(deviceVariable, a, b),
devf_cscalconj(deviceVariable, a, b) Misc.
devf_zeros(deviceVariable), devf_conjugate(deviceVariable), devf_partofcmplx(whichpart,deviceVariable)
CUBLAS Functions: BLAS 1, BLAS 2, BLAS 3 (with
shorter call strings) CUFFT Functions:
FFT Plans devf_fftplan(devVariable, fft_type,
batch) devf_destroyfftplan(plan)
FFT Functions devf_fft(input, plan, output) devf_bfft(input, plan, output) devf_ifft(input, plan, output) devf_fftR2C(input, plan, output) devf_fftC2R(input, plan, output)
CUDPP Functions: devf_ancCUDPPSortScan(devVarIn, devVarOut,
operation, dataType, algorithm, option) devf_ancCUDPPSortSimple(devVarIn,
devVarOut) Ancillary Functions: devf_ancMatrixTranspose(devVarIn, devVarOut) devf_ancBitonicSort(devVar1)
Extensible

Example of code conversion

Plasma turbulence computations spectral code, solved via a standard Runge-Kutta time advance, coupled with a
pseudo-spectral evaluation of NL terms. Derivatives are evaluated in k−space, while multiplications in Eq. (2) are carried
out in real space. standard 2/3 rule for dealiasing is applied, and small “hyperviscous” damping
terms are added to provide stability at the grid scale. results agree with analytic expectations and same on both CPU & GPU.
32x speedup!with Bill Dorland

Audio Camera spherical array of microphones Use beamforming algorithms we developed can find sounds coming from
particular directions Run several beamformers, one “look
direction” and assign output to an “Audio pixel”
Compose audio image. Transform the spherical array into
a camera for audio images Requires significant processing to
form pixels from all directions in a frame before the next frame is ready
Azimuth
Elevation
Azimuth
Adam O’Donovan
O’Donovan et al. : Several papers in IEEE CVPR, IEEE ICASSP, WASPAA (2007-2008) Movies at www.umiacs.umd.edu/~odonovan/Audio_Camera

Plasma Computations via PIC
Image courtesy: George Stanchev and Bill Dorland

Data structures for coalesced access Particles modeling a density or real particles Right hand side of evolution equation controlled by
a PDE for field solved on a regular grid Either spectrally or via finite differences Before/After time step require interpolation of field
quantities at grid nodes to/from particles
Organized particles in a box using octrees created via bit interleaving resulting in a Morton curve layout
Update procedures at the end of each time step
George Stantchev, William Dorland, Nail Gumerov “Fast parallel particle-to-grid interpolation for plasma PIC simulations on the GPU,” J. Parallel Distrib. Comput., 2008

Numerical relativity Beginning collaboration with Prof. Tiglio's group Student (John Dickerson) project in CMSC 828 E Spectral –element computations of Kerr tails in
numerical relativity accelerated using FLAGON

Kernel Methods on Balaji V. GPUs Srinivasan Kernel methods are very popular in computational
statistics and computational ML kernel density estimation (KDE), Renyi entropy based distances
between distributions (KRD) Gaussian process regresion Acceleration of 10x to 100x on
a GT240
Optimized bandwith based KDE

Map Reduce framework Aparnafor large scale video Kothaanalysis Video data is extremely large and ubiquitous Particular motivation 30,000 hours of biological
video (courtship rituals of Australian bowebirds) Algorithm framework – reduce frames to a few
features and compare frame-based features Ripe for Map-reduce type operations Simple bird-locator and activity detector
3 X speed-up
More complex video processing: larger speedups
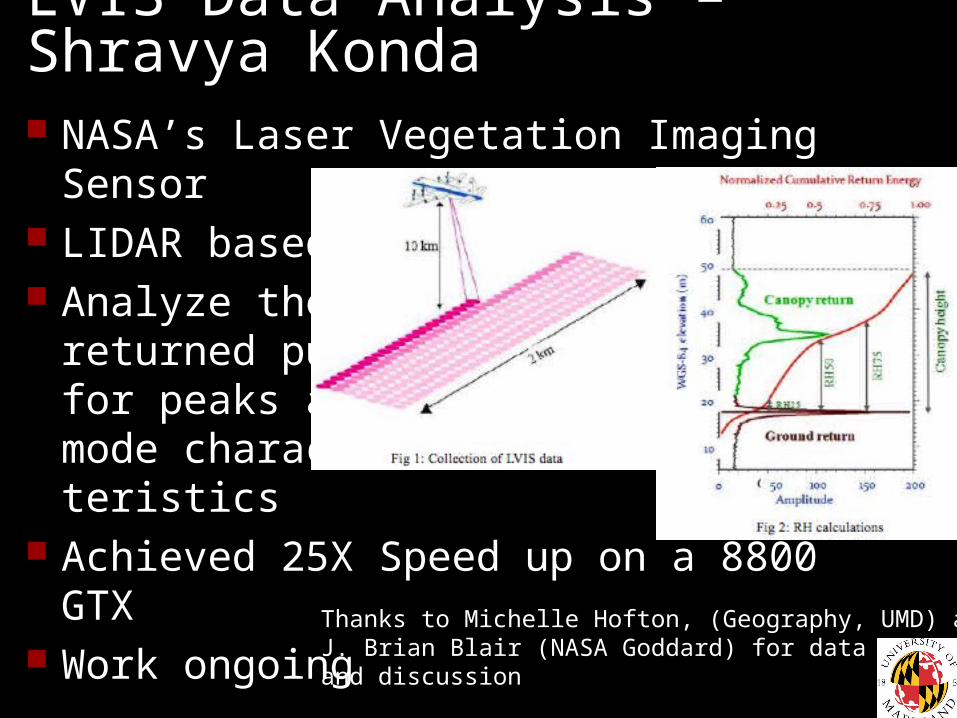
LVIS Data Analysis – Shravya Konda NASA’s Laser Vegetation Imaging Sensor LIDAR based Analyze the
returned pulsefor peaks and mode charac-teristics
Achieved 25X Speed up on a 8800GTX
Work ongoing Thanks to Michelle Hofton, (Geography, UMD) and J. Brian Blair (NASA Goddard) for data and discussion

Adding QR, LU, random Lipinginitialization to FLAGON Liu Flagon allows Fortran-9X users to define GPU based variables
as pointers, copy data to them, and use GPU Allows custom functions for extensibility Lightweight no-overhead GPU use Added dense matrix decompositions to FLAGON
LU for linear systems QR for least squares
Random number initialization (uniform and normal) Port of work of Volkov/Demmel (Berkley) and Giles (Oxford) Achieved speed ups reported by these authors but in Flagon
framework

Displaying Flagon objects Adam during simulation O’Donovan A much discussed application of GPUs –
monitoring computations as they proceed Perhaps use it for computational steering A mechanism to throw up
line-graphs (vector data), matrix data (colour maps) and slice data on screen
Issues: OpenGL thread model and interaction with CUDA computations

Other CMSC 828E projects Implementing a caching scheme for GPU computing
Kapil Anand Accelerating the Approximate Nearest Neighbor
library Daniel Hakim Adding MultiGPU MPI capabilities to Flagon
Kate DeSpain Support Vector Machines for Speaker ID on CUDA
Samuel Lamphier
Recommended

















