
1© Copyright 2013 Pivotal. All rights reserved. 1© Copyright 2013 Pivotal. All rights reserved.
Apache Spark 101
what is Spark all about
Shahaf AzrielySr. Field Engineer Southern EMEA

2© Copyright 2013 Pivotal. All rights reserved.
Agenda
What is Spark
Spark Programming Model
– RDDs, log mining, word count …
Related Projects
– Shark, Spark SQL, Spark streaming, Graphx, Mllib and more …
So what next

3© Copyright 2013 Pivotal. All rights reserved. 3© Copyright 2013 Pivotal. All rights reserved.
What is Spark?

Pivotal Confidential–Internal Use Only
The Spark Challenge
• Data size is growing MapReduce greatly simplified big data analysis
• But as soon as it got popular, users wanted more:
- More complex, multi-stage applications (graph algorithms, machine learning)
- More interactive ad-hoc queries
- More real-time online processing
• All of these apps require fast data sharing across parallel jobs

Pivotal Confidential–Internal Use Only
Data Sharing in MapReduce
iter. 1 iter. 2 . . .
Input
HDFSread
HDFSwrite
HDFSread
HDFSwrite
Input
query 1
query 2
query 3
result 1
result 2
result 3
. . .
HDFSread
Slow due to replication, serialization, and disk IO

Pivotal Confidential–Internal Use Only
iter. 1 iter. 2 . . .
Input
Data Sharing in Spark
Distributedmemory
Input
query 1
query 2
query 3
. . .
one-timeprocessing
10-100× faster than network and disk

7© Copyright 2013 Pivotal. All rights reserved.
Spark is
Fast MapReduce-like engine.
– In memory storage for fast iterative computation.
– Design for low latency ~100ms jobs
Competitive with Hadoop storage APIs
– Read/write to any Hadoop supported systems including Pivotal HD.
Designed to work with data in memory
Programmatic or Interactive
Written in Scala but have bindings for Python/Java /Scala.
Make life easy and productive for Data Scientists
Spark is one of the most actively developed open source projects. It has over 465
contributors in 2014, making it the most active project in the Apache Software
Foundation and among Big Data open source projects.

8© Copyright 2013 Pivotal. All rights reserved.
Short History
Spark was initially started by Matei Zaharia at UC Berkeley AMPLab in 2009.
2010 Open Sourced
June 21 2013 the project was donated to the Apache Software Foundation and it’s founders created Databricks out of AmpLab.
Feb 27 2014 Spark becomes top level ASF project.
In November 2014, the engineering team at Databricks used Spark and set am amazing record in the Daytona GraySort sorting 100TB (1 trillion records) in 23 Min 4.27 TB/min.
http://databricks.com/blog/2014/11/05/spark-officially-sets-a-new-record-in-large-scale-sorting.html

9© Copyright 2013 Pivotal. All rights reserved. 9© Copyright 2013 Pivotal. All rights reserved.
Spark Programming
Model
RDDs in Detail

Pivotal Confidential–Internal Use Only
Programming Model
• Key idea: resilient distributed datasets (RDDs)
- Resilient – if data in memory is lost, it can be recreated.
- Distributed – stored in memory across the cluster.
- Dataset – initial data can be created from a file or programmatically.
• Parallel operations on RDDs
- Reduce, collect, foreach, …
• Interface
- Clean language-integrated API in Scala, Python, Java
- Can be used interactively

11© Copyright 2013 Pivotal. All rights reserved.
RDD Fault Tolerance
RDDs maintain lineage information that can be used to reconstruct lost partitions
cachedMsgs = textFile(...).map(_.split(‘\t’)(2)).filter(_.contains(“error”)).cache()
HdfsRDDpath: hdfs://…
FilteredRDDfunc: contains(...)
MappedRDDfunc: split(…)
CachedRDD

12© Copyright 2013 Pivotal. All rights reserved.
Demo: Intro & Log Mining
Create basic RDD in Scala:1 2Log Mining - Load error messages from a log into memory, then
interactively search for various patterns
Base RDD
Transformed RDD
Action

13© Copyright 2013 Pivotal. All rights reserved.
Transformation and Actions
Transformations
– Map
– filter
– flatMap
– sample
– groupByKey
– reduceByKey
– union
– join
– sort
Actions
– count
– collect
– reduce
– lookup
– save
Look at
http://spark.apache.org/docs/latest/progra
mming-guide.html#basics

14© Copyright 2013 Pivotal. All rights reserved.
More Demo: Word count & Joins
Word count in Scala and python shells 3 4 Join two RDDs

15© Copyright 2013 Pivotal. All rights reserved. 15© Copyright 2013 Pivotal. All rights reserved.
Example of Related
Projects

16© Copyright 2013 Pivotal. All rights reserved.
Related Projects
Shark is dead long live Spark SQL
Spark Streaming
GraphX
MLbase
Others

17© Copyright 2013 Pivotal. All rights reserved.
Shark is dead but what it was
Hive on Spark
– HiveQL, UDFs, etc.
Turn SQL into RDD
– Part of the lineage
Based on Hive, but takes advantage of Spark for
– Fast Scheduling
– Queries are DAGs of jobs, not chained M/R
– Fast broadcast variables
© Apache Software Foundation

18© Copyright 2013 Pivotal. All rights reserved.
Spark SQL
Lib in Spark Core to treat RDDs as relations SchemaRDD
RDDs are columnar memory store.
Dynamic query optimization
Lighter weight version of Shark
– No code from Hive
Import/Export in different Storage formats
– Parquet, learn schema from existing Hive warehouse

19© Copyright 2013 Pivotal. All rights reserved.
Spark SQL Code

20© Copyright 2013 Pivotal. All rights reserved.
Spark Streaming
• Framework for large scale stream processing
• Scales to 100s of nodes
• Can achieve second scale latencies
• Integrates with Spark’s batch and interactive processing
• Provides a simple batch-like API for implementing complex algorithm
• Can absorb live data streams from Kafka, Flume, ZeroMQ, etc.
21© Copyright 2013 Pivotal. All rights reserved.
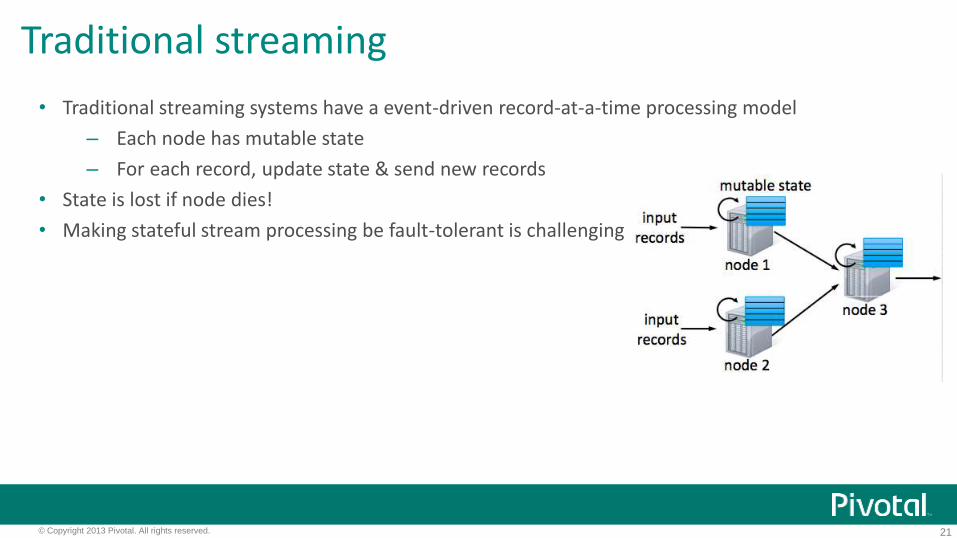
• Traditional streaming systems have a event-driven record-at-a-time processing model
– Each node has mutable state
– For each record, update state & send new records
• State is lost if node dies!
• Making stateful stream processing be fault-tolerant is challenging
Traditional streaming

22© Copyright 2013 Pivotal. All rights reserved.
Discretized Stream Processing
Run a streaming computation as a series of very small, deterministic batch jobs
22
Spark
SparkStreaming
batches of X seconds
live data stream
processed results
• Chop up the live stream into batches of X seconds
• Spark treats each batch of data as RDDs and processes them using RDD operations
• Finally, the processed results of the RDD operations are returned in batches

23© Copyright 2013 Pivotal. All rights reserved.
Discretized Stream Processing
Run a streaming computation as a series of very small, deterministic batch jobs
23
Spark
SparkStreaming
batches of X seconds
live data stream
processed results
• Batch sizes as low as ½ second, latency ~ 1 second
• Potential for combining batch processing and streaming processing in the same system

24© Copyright 2013 Pivotal. All rights reserved.
How Fast Can It Go?
Can process 4 GB/s (42M records/s) of data on 100 nodes at sub-second latency
Recovers from failures within 1 sec

25© Copyright 2013 Pivotal. All rights reserved.
Streaming how does it works

26© Copyright 2013 Pivotal. All rights reserved.
MLlib
MLlib is a Spark subproject providing machine learning primitives.
It ships with Spark as a standard component.
Many different Algorithms
– Classification, Regression, Collaborative Filtering:
o Regression: generalized linear regression (GLM)
o Collaborative filtering: alternating least squares (ALS)
o Clustering: k-means
o Decomposition: singular value decomposition (SVD), principal
o Component analysis (PCA)

27© Copyright 2013 Pivotal. All rights reserved.
Why MLlib
It is built on Apache Spark, a fast and general engine for large-scale data processing.
Run programs up to 100x faster than Hadoop MapReduce in memory, or 10x faster on disk.
Write applications quickly in Java, Scala, or Python.
You can use any Hadoop data source (e.g. HDFS, HBase, or local files), making it easy to plug into Hadoop workflows.

28© Copyright 2013 Pivotal. All rights reserved.
Spark SQL + MLlib

29© Copyright 2013 Pivotal. All rights reserved.
GraphX
What are Graphs? They are inherently recursive data-structures as properties of vertices depend on properties of their neighbors which in turn depend on properties of their neighbors.
GraphX unifies ETL, exploratory analysis, and iterative graph computation within a single system.
We can view the same data as both graphs and collections, transform and join graphs with RDDs.
For example Predicting things about people (eg: political bias)
– Look at posts, apply classifier, try to predict attribute
– Look at context of social network to improve prediction
30© Copyright 2013 Pivotal. All rights reserved.
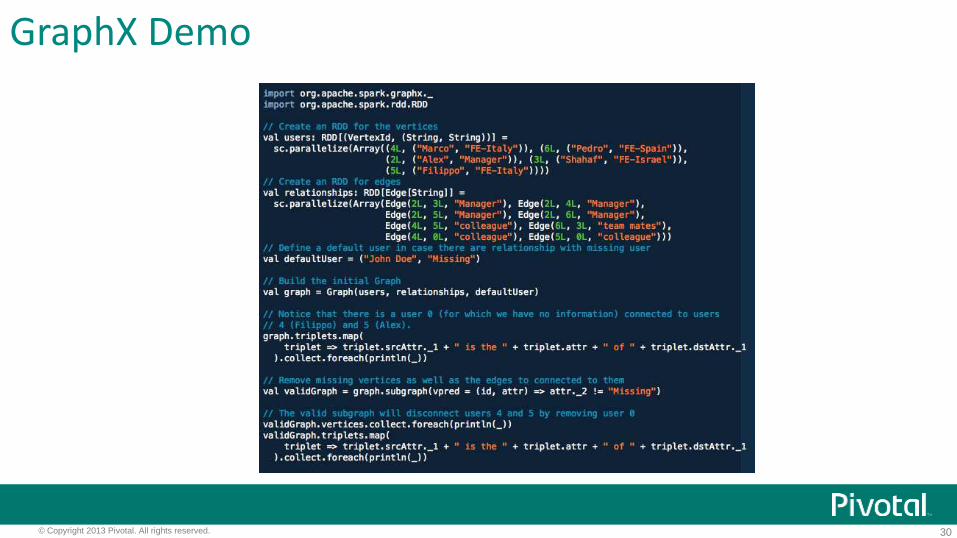
GraphX Demo

31© Copyright 2013 Pivotal. All rights reserved.
Others
Mesos
– Enable multiple frameworks to share same cluster resources
– Twitter is largest user: Over 6,000 servers
Tachyon
– In-memory, fault tolerant file system that exposes HDFS.
– Use as the FS for Spark.
Catalyst
– SQL Query Optimizer

32© Copyright 2013 Pivotal. All rights reserved. 32© Copyright 2013 Pivotal. All rights reserved.
So We is Spark
important for Pivotal

33© Copyright 2013 Pivotal. All rights reserved.
So How Real is Spark?
Leveraging modern MapReduce engine and techs from database, Spark support both SQL and complex analytics efficiently.
There are many indicators that Spark is heading to success
– Solid technology
– Good buzz
– Community is getting bigger https://cwiki.apache.org/confluence/display/SPARK/Committers

34© Copyright 2013 Pivotal. All rights reserved.
Pivotal’s Positioning of Spark
• PHD is a highly differentiated and the only platform that brings the benefits of closed loop analytics to enable business data lake
• With Spark we extend that differentiation by allowing up to 100x faster batch processing
HAWQMap-Reduce Gemfire XDSpark?
Batch Processing Near-Real Time Real TimeBetter/Faster
Batch Processing
35© Copyright 2013 Pivotal. All rights reserved.
Spark 1.0.0 on PHD https://support.pivotal.io/hc/en-us/articles/203271897-Spark-on-Pivotal-Hadoop-2-0-Quick-Start-Guide
Databrick’s announcing Pivotal certification https://databricks.com/blog/2014/05/23/pivotal-hadoop-integrates-the-full-apache-spark-stack.html
We attend Spark meetup’s
Join the SocialCast group!

36© Copyright 2013 Pivotal. All rights reserved. 36© Copyright 2013 Pivotal. All rights reserved.
Thank you
Q&A
Recommended
















![[Spark meetup] Spark Streaming Overview](https://img.pdfslide.net/doc/110x75/55a457161a28ab057e8b45fd/spark-meetup-spark-streaming-overview.jpg)
