
IRCS Workshop on Linguistic Databases • 11-13 December 2001 • Philadelphia
Standards for Language Resources
Nancy IDEDepartment of Computer Science Vassar College
Laurent ROMARYEquipe Langue et Dialogue
LORIA/INRIA

IRCS Workshop on Linguistic Databases • 11-13 December 2001 • Philadelphia
Goals
• present an abstract data model for linguistic annotations and its implementation using XML, RDF and related standards
• outline work of newly formed ISO committee: TC 37/SC 4 Language Resource Management– Using the work described as its starting point– Solicit the participation of members of the
research community

IRCS Workshop on Linguistic Databases • 11-13 December 2001 • Philadelphia
Goals of ISO TC 37/SC 4
• prepare international standards/guidelines for effective language resource (LR) management in mono- and multi-lingual applications
• develop principles and methods for creating, coding, processing and managing LR– written corpora, lexical corpora, speech corpora,
dictionary compiling and classification schemes
• Focus : – data modeling– data exchange, evaluation

IRCS Workshop on Linguistic Databases • 11-13 December 2001 • Philadelphia
Standardization Process
• Two-phases: 1. Develop basic architecture to support
wide-range of applications 2. Use as basis for building more precise
standards for LR management
• Liaison with ISLE – Incorporate existing standards where
possible– Broaden by including additional
languages (e.g. Asian)

IRCS Workshop on Linguistic Databases • 11-13 December 2001 • Philadelphia
Standardization is Tricky
• Skepticism within the community
• Arguments against LR standardization: 1. diversity of theoretical approaches makes
standardization impractical or impossible
2. vast amounts of existing data and processing software will be rendered obsolete by the acceptance of new standards

IRCS Workshop on Linguistic Databases • 11-13 December 2001 • Philadelphia
SC4 Approach• Efforts geared toward defining abstract
models and general frameworks for creation and representation of language resources– In principle, abstract enough to accommodate
diverse theoretical approaches
• Situate development squarely in the framework of XML and related standards – Ensure compatibility with established and widely
accepted web-based technologies– Ensure feasibility of transduction from legacy
formats into newly defined formats

IRCS Workshop on Linguistic Databases • 11-13 December 2001 • Philadelphia
Call for Participation
• Success of the committee depends on community’s awareness of its activity, in order to ensure widespread adoption
• Involve from the outset broad range of potential users of the standards

IRCS Workshop on Linguistic Databases • 11-13 December 2001 • Philadelphia
The General Framework
• Model for linguistic annotation that can– be instantiated in a standard
representational format– serve as a pivot format into and out of
which proprietary formats may be transduced to enable• comparison• merging• manipulation via common tools

IRCS Workshop on Linguistic Databases • 11-13 December 2001 • Philadelphia
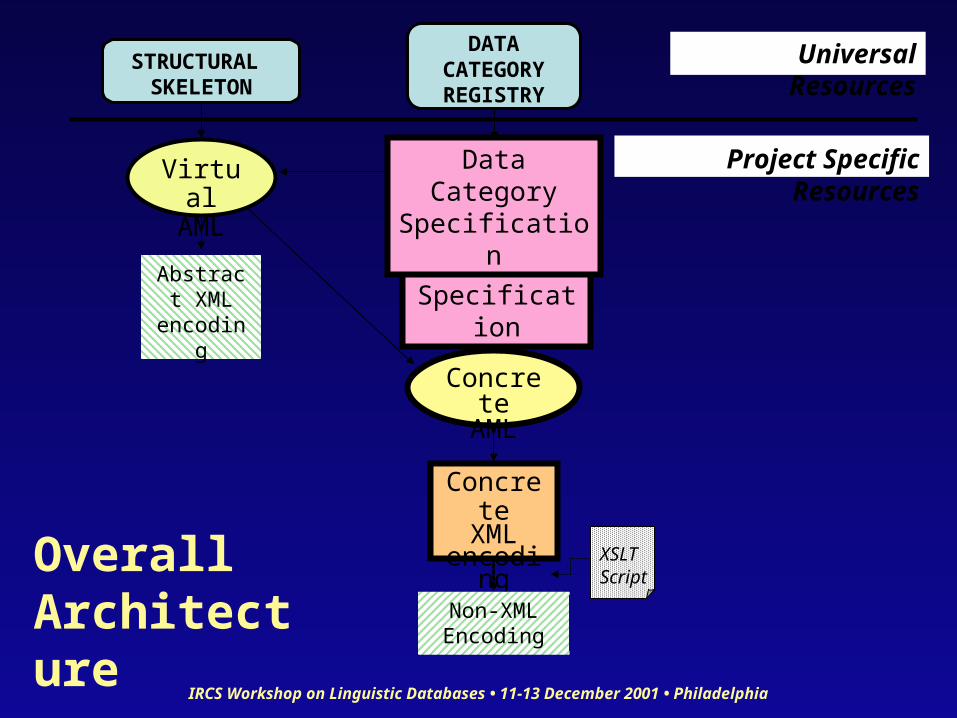
Overall Plan
FormatA
FormatC
Abstract Format
Operation via common tools, merging, etc
FormatB
Annotation Format Tower of Babel
IRCS Workshop on Linguistic Databases • 11-13 December 2001 • Philadelphia
DialectSpecification
DATACATEGORY REGISTRY
VirtualAML
ConcreteAML
Data CategorySpecification
STRUCTURAL SKELETON
Abstract XML
encoding
ConcreteXML
encoding
Non-XML Encoding
Universal Resources
Project Specific Resources
XSLT Script
Overall Architecture

IRCS Workshop on Linguistic Databases • 11-13 December 2001 • Philadelphia
N.B.
• We do not expect XML to necessarily serve as the internal format used by tools etc.
• We do not care about creating yet another “standard” format
• We do not care (for this work) about designing specific annotation formats

IRCS Workshop on Linguistic Databases • 11-13 December 2001 • Philadelphia
Data Model• Identify a consistent underlying data
model for data and its annotations– Formalized description of data objects
• Composition• Attributes• Class membership• Applicable procedures, etc
– Formalized description of relations among data objects
– Independent of instantiation in any particular form

IRCS Workshop on Linguistic Databases • 11-13 December 2001 • Philadelphia
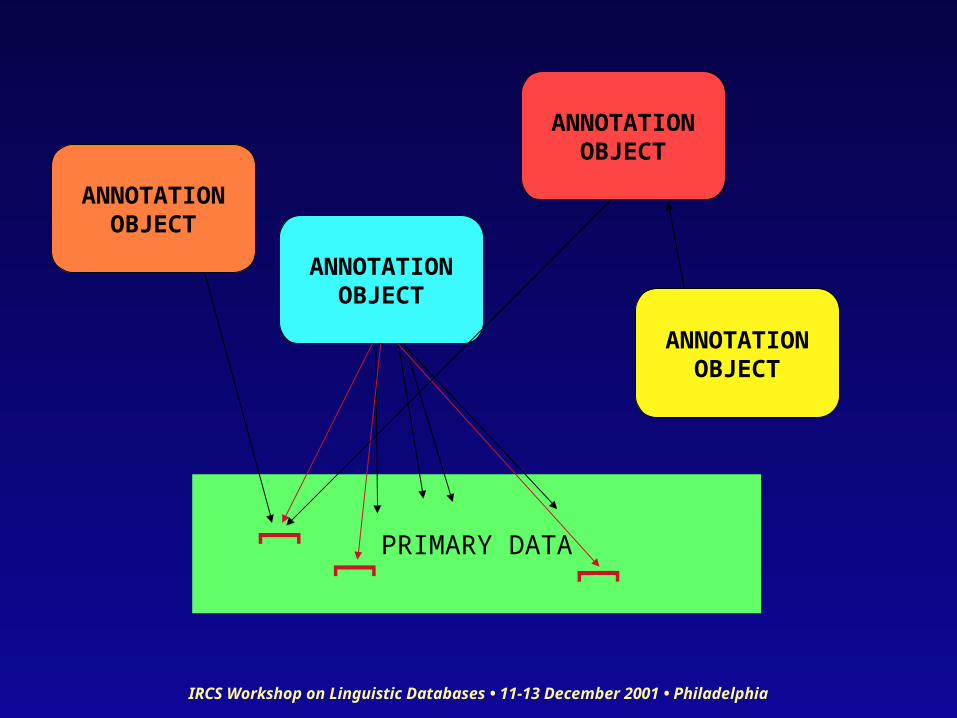
(Most) Abstract Model
• An annotation is a set of data or information associated with some other data
• More precise: an annotation is a one- or two-way link between – an annotation object, and – a point or span (or a list/set of points or spans)
within a “base” data set
• Links may or may not have a semantics• Points and spans may be objects, or sets/lists
of objects
IRCS Workshop on Linguistic Databases • 11-13 December 2001 • Philadelphia
PRIMARY DATA
[
[ [
ANNOTATIONOBJECT
ANNOTATIONOBJECT
ANNOTATIONOBJECT
ANNOTATIONOBJECT

IRCS Workshop on Linguistic Databases • 11-13 December 2001 • Philadelphia
Observations
Granularity of the data representation and encoding is critical
Must be possible to represent objects and relations in some form that prevents information loss

IRCS Workshop on Linguistic Databases • 11-13 December 2001 • Philadelphia
Representing Annotation Objects
• Annotation objects may be relatively complex• Abstract representation
– graph of elementary structural nodes to which one or more information units are attached
– distinction between structure and information units is critical to the design of a truly general model
• Annotations may be structured in several ways– Most common: hierarchical
• phrase structure analyses of syntax • lexical and terminological information • etc.

IRCS Workshop on Linguistic Databases • 11-13 December 2001 • Philadelphia
Relations Among Annotations
1. Parallelism– two or more annotations refer to the same
data object
2. Alternatives– two or more annotations comprise a set of
mutually exclusive alternatives
3. Aggregation– two or more annotations comprise a list or
set that should be taken as a unit

IRCS Workshop on Linguistic Databases • 11-13 December 2001 • Philadelphia
Information Units• Also called data categories
– provide the semantics of the annotation– most theory and application-specific part of an
annotation scheme
• No attempt to define data categories – Proposal : development of a Data Category Registry – Define data categories with RDF schemas – Formalize properties and relations – Templates that describe how objects are instantiated– Inheritance of appropriate properties

IRCS Workshop on Linguistic Databases • 11-13 December 2001 • Philadelphia
Data Category Registry
• Several functions1. provide a precise semantics for annotation
categories• can be used “off the shelf” or modified
2. provide a set of reference categories onto which scheme-specific names can be mapped
3. provide a point of departure for definition of variant or more precise categories
• Overall goal– Ensure that semantics of data categories are
well-defined and understood

IRCS Workshop on Linguistic Databases • 11-13 December 2001 • Philadelphia
Generic Mapping Tool (GMT)
• Instantiation of abstract format in XML• Why XML?
– Supported standard– Built-in representation for hierarchies
(nested tags)– Sophisticated linking mechanisms
• Can link to points, spans, use explicit locations or tags
– XSLT for transduction, XML Schemas for validation, etc.

IRCS Workshop on Linguistic Databases • 11-13 December 2001 • Philadelphia
A Few Simple Tags• <struct>
• represents a structural node in the annotation• may be recursively nested at any level
• <feat> – provides information attached to the node
represented by the enclosing <struct> – type attribute identifies data category – Contents:
• string providing a value for the data category • recursively nested <feat> elements (for complex structures)• empty--points via a target attribute to an object in another
document

IRCS Workshop on Linguistic Databases • 11-13 December 2001 • Philadelphia
Other Tags• <alt>
– brackets alternative annotations• <rel>
– points to a non-contiguous related element• <seg>
– points to the data to which the annotation applies
– assume the use of stand-off annotation– target attribute uses XML Pointers
• <brack> – groups information to be regarded as a unit

IRCS Workshop on Linguistic Databases • 11-13 December 2001 • Philadelphia
• Tag names etc. unimportant– It is the underlying data model that counts– Essentially uses feature structures
• GMT sufficiently powerful to represent information across annotation types
• Demonstrated applicability to – terminological and lexical information (Ide, et al.,
2000) – syntactic annotation (Ide and Romary, 2001)
• Existing formats (XML or other) mapped to the GMT for merging, manipulation via common tools, etc.; then re-map to original formats for use in in-house tools and applications. etc.

IRCS Workshop on Linguistic Databases • 11-13 December 2001 • Philadelphia
Examples
• Morpho-syntactic annotation– involves the identification of word classes
over a continuous stream of word tokens– may refer to the segmentation of the input
stream into word tokens– may also involve grouping together
sequences of tokens or identifying sub-token units (or morphemes
– description of word classes may include one or several features
• syntactic category, lemma, gender, number,…

IRCS Workshop on Linguistic Databases • 11-13 December 2001 • Philadelphia
Representation in GMT
• Single type of structural node – represents a word-level structure
unit
• One or several information units associated with each structural node

IRCS Workshop on Linguistic Databases • 11-13 December 2001 • Philadelphia
Simple Case<struct> <struct type=”W-level”>
<feat type=”lemma”>Paul</feat><feat type=”pos”>PNOUN</feat><seg target=”#w1”/>
</struct> <struct type=”W-level”>
<feat type=”lemma”>aimer</feat><feat type=”pos”>VERB</feat><feat type=”tense”>present</feat><feat type=”person”>3</feat><seg target=”#w2”/>
</struct> <struct type=”W-level”>
<feat type=”lemma”>le</feat><feat type=”pos”>DET</feat><feat type=”number”>plural</feat><seg target=”#w3”/>
</struct> <struct type=”W-level”>
<feat type=”lemma”>croissant</feat><feat type=”pos”>NOUN</feat><feat type=”number”>plural</feat><seg target=”#w4”/>
</struct></struct>
“Paul aime les croissants”
Pointers to data in primary document

IRCS Workshop on Linguistic Databases • 11-13 December 2001 • Philadelphia
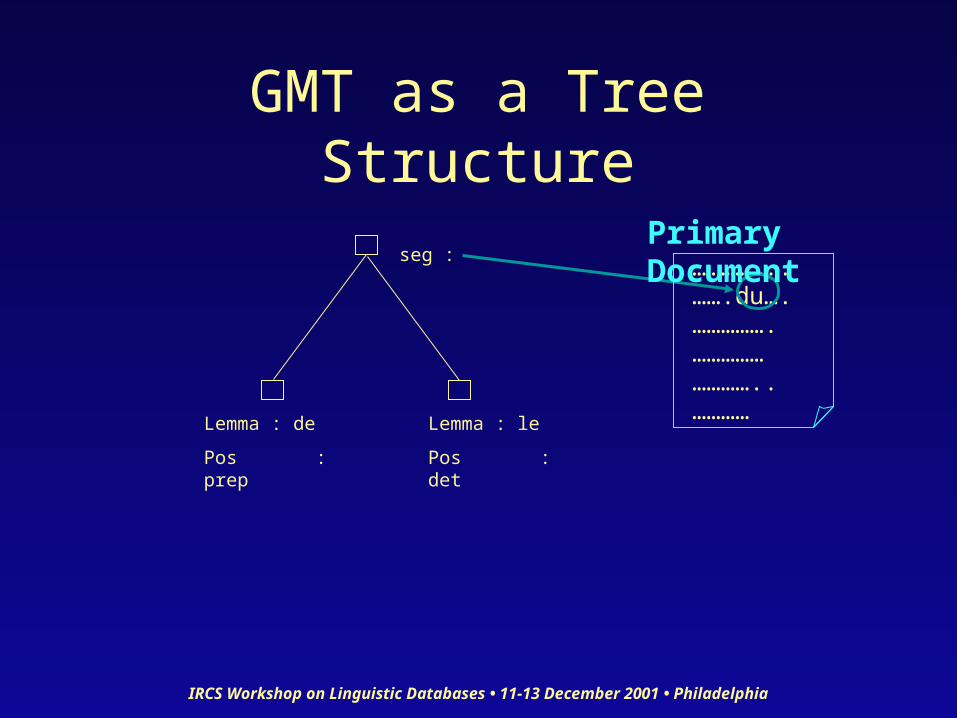
Representing More Complex Cases
<struct type=”W-level”><seg target=”#w1”/><struct type=”W-level”> <feat type=”lemma”>de</feat> <feat type=”pos”>PREP</feat></struct><struct type=”W-level”> <feat type=”lemma”>le</feat> <feat type=”pos”>DET</feat></struct>
</struct>
Example: “du” = “de” + “le” in French
Points to “du” in text
Gives the structure of the “word” underlying the word
IRCS Workshop on Linguistic Databases • 11-13 December 2001 • Philadelphia
GMT as a Tree Structure
….………..…….du….…………….………………………..…………
Primary Document
Lemma : de
Pos : prep
seg :
Lemma : le
Pos : det

IRCS Workshop on Linguistic Databases • 11-13 December 2001 • Philadelphia
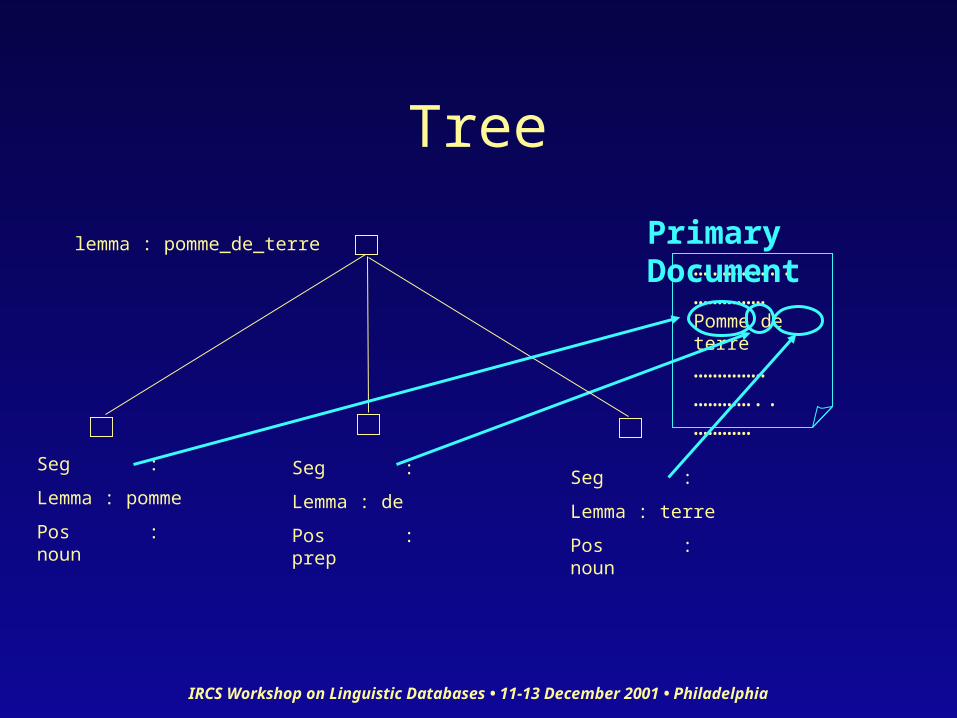
Compound Words
<struct type=”W-level”><feat type=”lemma”>pomme_de_terre</feat><feat type=”pos”>NOUN</feat>
<struct type=”W-level”> <seg target=”#w1”/> <feat type=”lemma”>pomme</feat> <feat type=”pos”>NOUN</feat>
</struct> <struct type=”W-level”>
<seg target=”#w2”/> <feat type=”lemma”>de</feat> <feat type=”pos”>PREP</feat>
</struct> <struct type=”W-level”>
<seg target=”#w3”/> <feat type=”lemma”>terre</feat> <feat type=”pos”>NOUN</feat>
</struct></struct>
Example: “pomme de terre”
Componentlemmas
Primarylemma
IRCS Workshop on Linguistic Databases • 11-13 December 2001 • Philadelphia
Tree
….………..……………Pomme de terre
………………………..…………
Primary Document
Seg :
Lemma : pomme
Pos : noun
lemma : pomme_de_terre
Seg :
Lemma : de
Pos : prep
Seg :
Lemma : terre
Pos : noun

IRCS Workshop on Linguistic Databases • 11-13 December 2001 • Philadelphia
Advantages
• Enables specification of the required level of granularity – granularity of the segmentation in (or associated
with) primary data may not correspond to that required for the annotation
• Can define relations over the tree independently– Compositional for morpho-syntax, syntax, etc.– Partitions in lexical data– …
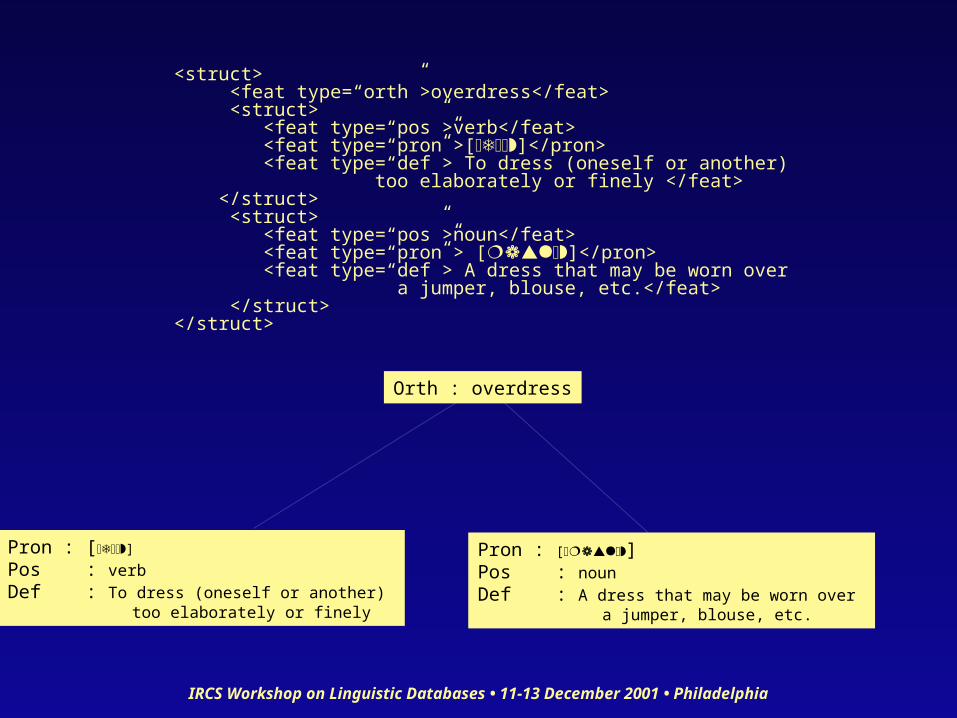
IRCS Workshop on Linguistic Databases • 11-13 December 2001 • Philadelphia
Orth : overdress
Pron : [ ]
Pos : verbDef : To dress (oneself or another) too elaborately or finely
Pron : [ ]Pos : nounDef : A dress that may be worn over a jumper, blouse, etc.
<struct> <feat type=“orth”>overdress</feat> <struct> <feat type=“pos”>verb</feat> <feat type=“pron”>[ ]</pron> <feat type=“def”> To dress (oneself or another) too elaborately or finely </feat> </struct> <struct> <feat type=“pos”>noun</feat> <feat type=“pron”> [ ]</pron> <feat type=“def”> A dress that may be worn over a jumper, blouse, etc.</feat> </struct></struct>

IRCS Workshop on Linguistic Databases • 11-13 December 2001 • Philadelphia
Alternatives<struct type=”W-level”> <seg target=”#w1”/> <brack>
<alt> <feat type=”lemma”>boucher</feat> <feat type=”pos”>VERB</feat> <feat type=”tense”>present</feat> <feat type=”confidence”>0.4</feat>
</alt><alt> <feat type=”lemma”>bouche</feat> <feat type=”pos”>NOUN</feat> <feat type=”confidence”>0.6</feat>
</alt> </brack></struct>

IRCS Workshop on Linguistic Databases • 11-13 December 2001 • Philadelphia
Relating Annotation Levels
• Three ways:1. Temporal anchoring
• associates positional information with each structural level
2. Event-based anchoring• introduces a structural node to represent a
location in the text to which all annotations can refer
3. Object-based anchoring• enables pointing from a given level to one or
several structural nodes at another level

IRCS Workshop on Linguistic Databases • 11-13 December 2001 • Philadelphia
Temporal Anchoring• Positional information
– Usually, a pair of numbers expressing the starting and ending point of segment
• Attributes for <seg>:• /startPosition/: the temporal or offset position of the
beginning of the current structural node;• /endPosition/: the temporal or offset position of the
end of the current structural node.
• Example:<struct type=”phonetic”> <seg startsAt=”2300” endsAt=”3200”/> <feat type=”phone”>iy</feat></struct>

IRCS Workshop on Linguistic Databases • 11-13 December 2001 • Philadelphia
Event-based Anchoring
• Useful when:– Not possible/desirable to modify the primary
data by inserting markup to identify specific objects or points in the data
– Primary data is marked with “milestones” (e.g., time stamps in speech data), where spans across the various milestones must be identified• Here,<struct> elements represent markup for
segmentation (e.g., segmentation into words, sentences, etc.).

IRCS Workshop on Linguistic Databases • 11-13 December 2001 • Philadelphia
GMT Rendering
• Structural node (landmark) referred to by annotations for the defined span
<struct type=”landmark”>
<seg startsAt=”2300” endsAt=”3200”/>
</struct>
• Annotation graph formalism explicitly designed for this

IRCS Workshop on Linguistic Databases • 11-13 December 2001 • Philadelphia
GMT Advantages• AG formalism reifies the “arc” vs.
identification via XML tags• GMT : the two methods are analogous
– annotator can use either method
• AG not well-suited to hierarchically organized annotations– requires special mechanisms
• GMT: exploits the hierarchical structure built in to XML – “flat” and hierarchical annotations treated using the
same mechanisms

IRCS Workshop on Linguistic Databases • 11-13 December 2001 • Philadelphia
Object-based Anchoring
• Useful to make dependencies between two or more annotation levels explicit – Example: syntactic annotation can
refer directly to the relevant nodes in a morpho-syntactically annotated corpus
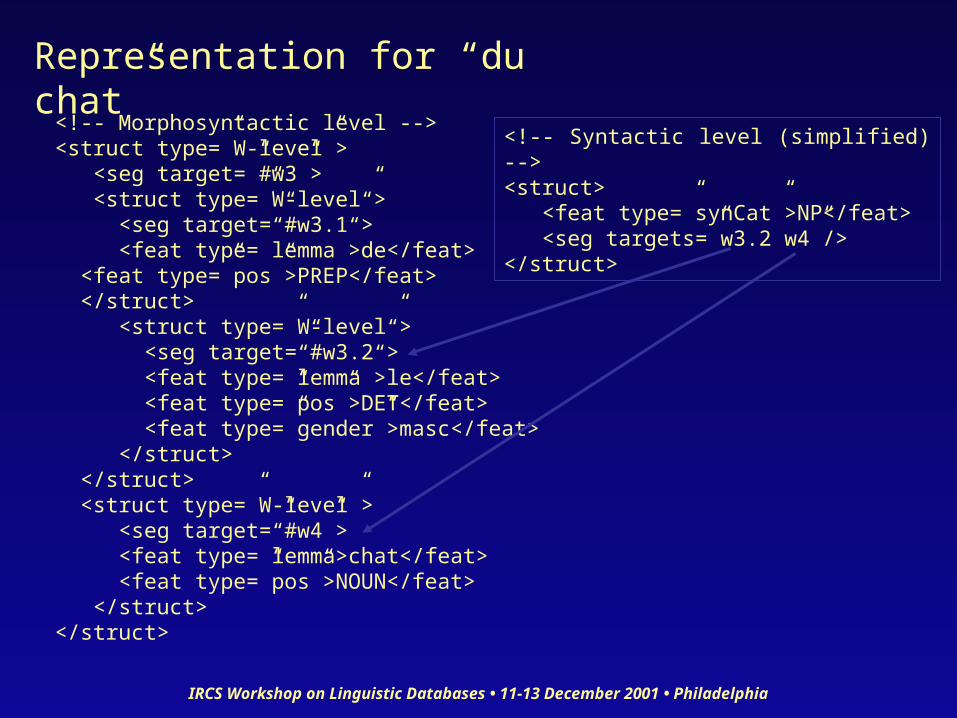
IRCS Workshop on Linguistic Databases • 11-13 December 2001 • Philadelphia
<!-- Morphosyntactic level --><struct type=”W-level”> <seg target=”#w3”> <struct type=”W-level”> <seg target=”#w3.1”> <feat type=”lemma”>de</feat> <feat type=”pos”>PREP</feat> </struct> <struct type=”W-level”> <seg target=”#w3.2”> <feat type=”lemma”>le</feat> <feat type=”pos”>DET</feat> <feat type=”gender”>masc</feat> </struct> </struct> <struct type=”W-level”> <seg target=”#w4”> <feat type=”lemma>chat</feat> <feat type=”pos”>NOUN</feat> </struct></struct>
<!-- Syntactic level (simplified) --><struct> <feat type=”synCat”>NP</feat> <seg targets=”w3.2 w4”/></struct>
Representation for “du chat”

IRCS Workshop on Linguistic Databases • 11-13 December 2001 • Philadelphia
GMT as a Modeling Tool• Rendering various formats into GMT
representation has revealed some problems, inconsistencies in existing formats– Penn Treebank : inconsistent indication of
relations (see Ide and Romary, ACL 2001 or Abeillé Treebank book, forthcoming)
– NOMLEX lexicon : no (automatically perceivable) distinction between lists and alternatives
• The abstract format serves the unexpected purpose of providing a “template” for fundamental annotation properties

IRCS Workshop on Linguistic Databases • 11-13 December 2001 • Philadelphia
Jumping Ahead…• Is XML distracting us from our real work?
– YES, because• Focus on details of using XML and related standards can
obscure the real work of data modeling– BUT
• Datas models are no use only in the abstract - need means to implement
• XML, schemas, RDF, etc. are powerful data modeling tools based on years of research in this area
• Need to know how to best exploit them for our purposes
• Need a synergy between modeling efforts and implementation in XML, RDF, etc.
• Need to remember that using XML is just a vehicle to ensure flexibility, convertability, and compatibility with evolving technologies

IRCS Workshop on Linguistic Databases • 11-13 December 2001 • Philadelphia
Conclusion
• ISO committee – Work is continually evolving
• Try to stay at the leading edge of data representation
– We are only at the “assembly language” level
– We need to do this right to enable a “web of databases”
• Call for participation!!!

IRCS Workshop on Linguistic Databases • 11-13 December 2001 • Philadelphia
Thank You
Contacts
US Expert, ISO TC37 SC4Nancy [email protected]
Chairman, ISO TC37 SC4Laurent [email protected]
Recommended

















