
1/54
Statistiques mathematiques : cours 1
Guillaume Lecue
28 aout 2018
1/54

2/54
Organisation9 cours de 2h (18h) Guillaume Lecue
I mardi 28 a 10h15 ; mercredi 29 a 13h30 et 15h45 ; jeudi 30 a 10h15I lundi 3 a 17h ; mercredi 5 a 10h15 ; jeudi 6 a 10h15I mercredi 12 a 10h15I lundi 17 a 17h
Slides du cours et recueil d’exos et annales telechargeables a
http://lecueguillaume.github.io/2015/10/05/rappels-stats/
6 TD (12h) Lucas Gerin
vendredi 31 a 13h30 ; mercredi 5 et 12 a 8h30 ; mercredi 26 a 8h30 ; jeudi27 a 17h.
Examen
Fin octobre/ debut novembre
2/54

3/54
Presentation (succinte) du cours de stats math
I Echantillonnage et modelisation statistique. Fonction de repartitionempirique (2 cours)
I Methodes d’estimation classiques (2 cours)
I Information statistique, theorie asymptotique pour l’estimation (1cours)
I Decision statistique et tests (2 cours)
I Modele de regression (1 cours)
I Statistiques Bayesiennes(1 cours)
3/54

4/54
Aujourd’hui
Organisation du cours
Echantillonnage et modelisation statistiqueDonnees d’aujourd’huiExperience statistiqueModele statistique
Fonction de repartition empirique et theoreme fondamentale de lastatistique
Loi d’une variable aleatoireFonction de repartition empiriqueApproche non-asymptotique
4/54
5/54
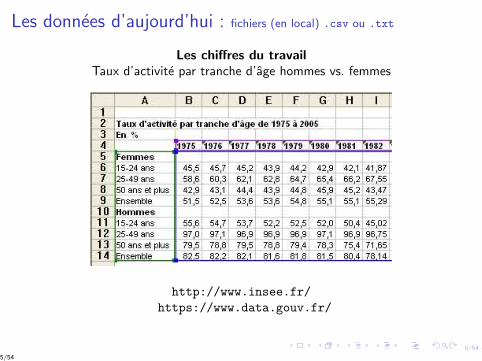
Les donnees d’aujourd’hui : fichiers (en local) .csv ou .txt
Les chiffres du travailTaux d’activite par tranche d’age hommes vs. femmes
http://www.insee.fr/
https://www.data.gouv.fr/
5/54

6/54
Les donnees d’aujourd’hui : series temporelles
Le monde de la finance
http://fr.finance.yahoo.com/
http://www.bloomberg.com/enterprise/data/
6/54

7/54
Les donnees d’aujourd’hui : grandes matrices
Biopuces et analyse d’ADN
7/54
8/54
Les donnees d’aujourd’hui : graphesacteurs de series
8/54

9/54
Les donnees d’aujourd’hui : le metier en data science
Problematique :
I stockage, requettage : expertise en base de donnees
I data “jujitsu”, data “massage”
I data-vizualization (Gephi, Tulip, widget python, power BI, etc.)
I mathematiques :
? modelisation (statistiques)? construction d’estimateurs
implementation d’algorithmes
I Python, R, H2O, TensorFlow, vowpal wabbit, spark,..., github,...
Pour s’entrainer aux metiers en “data science” :
• https://www.kaggle.com, https://www.datascience.net/
• notebooks python
• Coursera
9/54

10/54
Objectif du cours “statistiques mathematiques”
1. Construire des modeles statistiques pour des donnees classiques
2. Construire des estimateurs / tests classiques
3. Connaıtre leurs proprietes statistiques et les outils mathematiquesqui permettent de les obtenir
10/54

11/54
Problematique statistique
1) Point de depart : donnees (ex. : des nombres reels)
x1, . . . , xn
2) Modelisation statistique :I les donnees sont des realisations
X1(ω), . . . ,Xn(ω) de variable aleatoires reelles (v.a.r.) X1, . . . ,Xn.
(autrement dit, pour un certain ω, X1(ω) = x1, . . . ,Xn(ω) = xn)I La loi P(X1,...,Xn) de (X1, . . . ,Xn) est inconnue, mais appartient a une
famille donnee (a priori)Pnθ, θ ∈ Θ
: le modele
On pense qu’il existe θ ∈ Θ tel que P(X1,...,Xn) = Pnθ.
3) Problematiques : a partir de “l’observation” (X1, . . . ,Xn), peut-onestimer θ ? tester des proprietes de θ ?
11/54

12/54
Problematique statistique (suite)
I θ est le parametre et Θ l’ensemble des parametres.
I Estimation : a partir de X1, . . . ,Xn, construire ϕn(X1, . . . ,Xn) qui“approche au mieux” θ.
I Test : a partir des donnees X1, . . . ,Xn, etablir une decisionTn(X1, . . . ,Xn) ∈ ensemble de decisions concernant unehypothese sur θ.
DefinitionUne statistique est une fonction mesurable des donnees
!ATTENTION ! Une statistique ne peut pas dependre du parametreinconnu : une statistique se construit uniquement a partir des donnees !
12/54

13/54
Exemple du pile ou face
I On lance une piece de monnaie 18 fois et on observe (P = 0, F = 1)
0, 0, 0, 1, 1, 0, 1, 0, 0, 1, 1, 0, 1, 0, 0, 1, 1, 0
I Modele statistique : on observe n = 18 variables aleatoires (Xi )18i=1
independantes, de Bernoulli de parametre inconnu θ ∈ Θ = [0, 1].
I Estimation. Estimateur X18 = 118
∑18i=1 Xi
ici= 8/18 = 0.44. Quelle
precision ?I Test. Decision a prendre : la piece est-elle equilibree ? . Par
exemple : on compare X18 a 0.5. Si |X18 − 0.5| est petit , onaccepte l’hypothese la piece est equilibree . Sinon, on rejette.Quel seuil choisir ? et avec quelles consequences (ex. probabilite dese tromper) ?
13/54

14/54
Echantillonnage = repetition d’une meme experience
I L’experience statistique la plus centrale : on observe la realisation deX1, . . . ,Xn, v.a. ou les Xi sont independantes, identiquementdistribuees (i.i.d.), de meme loi commune PX ∈ Pθ : θ ∈ Θ.
I probleme : a partir des donnees X1, . . . ,Xn que dire de la loi PX
commune aux Xi ? (moyenne, moments, symetrie, densite, etc.)
14/54

15/54
Experience statistique
Consiste a determiner :
I l’espace des observations
Z (ex. : Z = 0, 118)
C’est l’espace ou vivent les observations
I Une tribu : Z (ex. : Z = P(Z) = tous les sous-ensembles de Z)
I Une famille de lois = modele
Pθ, θ ∈ Θ (ex. :Pθ = Pnθ = (θδ1 + (1− θ)δ0)⊗18)
15/54

16/54
Experience statistique
DefinitionUne experience statistique E est un triplet
E =(Z,Z,
Pθ, θ ∈ Θ
)ou
I(Z,Z
)espace mesurable (ex. : (Rn,B(Rn))),
I Pθ, θ ∈ Θ famille de probabilites definies simultanement sur lememe espace
(Z,Z
).
16/54

17/54
Modeles statistiques (jargon)
I Pθ, θ ∈ Θ est appele modele
I quand il existe k tel que Θ ⊂ Rk , on parle de modele parametrique
I quand θ est un parametre infini dimensionnel, on parle de modelenon-parametrique (ex. : densite)
I quand θ = (f , θ0) ou f est infini dimensionnel (souvent, parametrede nuisance) et θ0 ∈ Rk (parametre d’interet), on parle de modelesemi-parametrique
I quand θ ∈ Θ 7→ Pθ est injectif, on dit que le modele est identifiable
17/54

18/54
Modeles statistiques
Question centrale en statistiques : Quel modele estle plus adapte a ces donnees ?
Il existe deux manieres equivalentes de definir un modele :
1. soit en se donnant une famille de loi Pθ, θ ∈ Θ2. soit en se donnant une equation
18/54

19/54
Exemple de modele/modelisation (1)
On observe un n-uplet de variables aleatoires reelles :
Z = (X1, . . . ,Xn)
On peut modeliser ces observations de deux manieres (equivalentes) :
I par une famille de lois : Pθ : θ ∈ R ; par exemple,
Pθ =(N (θ, 1)
)⊗nI par une equation ; par exemple, pour tout i ∈ 1, . . . , n,
Xi = θ + gi
ou g1, . . . , gn sont n variables aleatoires Gaussiennes centreesreduites independantes.
19/54

20/54
Exemple de modele/modelisation (2)On observe un n-uplet de variables aleatoires reelles :
Z = (X1, . . . ,Xn).
On peut modeliser ces observations de deux manieres (equivalentes) :
I Par une equation : X1 = g1 et pour tout i ∈ 1, . . . , n − 1,
Xi+1 = θXi + gi
ou g1, . . . , gn sont iid N (0, 1).
I Famille de lois : Pθ : θ ∈ R ou
Pθ = fθ.λn
ou λn est la mesure de Lebesgue sur Rn et
fθ(x1, . . . , xn) = f (x1)f (x2 − θx1) · · · f (xn − θxn−1)
et f (x) = exp(−x2/2)√2π
.
20/54
21/54
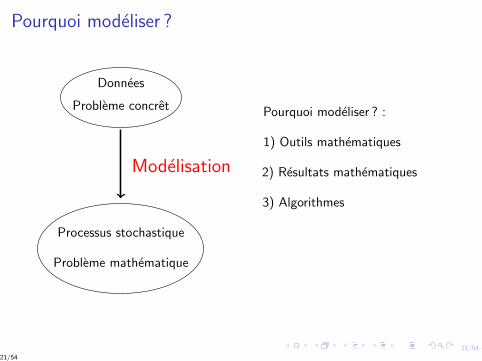
Pourquoi modeliser ?
Donnees
Probleme concret
Processus stochastique
Probleme mathematique
Modelisation
Pourquoi modeliser ? :
1) Outils mathematiques
2) Resultats mathematiques
3) Algorithmes
21/54

22/54
3 modeles (non-parametriques) classiques
1. Modele de densite : on observe un n-echantillon
X1, . . . ,Xn de v.a.r. de densite f tel que f ∈ C
ou C est une classe de densites sur R (Lebesgue).
2. Modele de regression : on observe un n-echantillon de couples(Xi ,Yi )
ni=1 tel que Yi ∈ R, Xi ∈ Rd et
Yi = f (Xi ) + ξi
ou ξi sont des v.a.r.i.i.d. independantes des Xi et f ∈ C.I quand f (Xi ) =
⟨θ,Xi
⟩: modele de regression lineaire,
I et quand ξi ∼ N (0, σ2) : modele lineaire Gaussien
3. modele de classification : on observe un n-echantillon (Xi ,Yi )ni=1 tel
que Yi ∈ 0, 1 et Xi ∈ X . Par ex. :
P[Yi = 1|Xi = x ] = σ(⟨x , θ⟩) ou σ(x) = (1 + e−x)
22/54

23/54
Partie 2
Fonction de repartition empirique et theoremefondamentale de la statistique
23/54

24/54
Question fondamentale
Considerons le modele d’echantillonnage sur R : on observe
X1, . . . ,Xn
qui sont i.i.d. de loi commune PX .Rem. : Comme la loi de l’observation (X1, . . . ,Xn) est P⊗nX , se donner unmodele est ici (pour le modele d’echantillonnage) equivalent a se donnerun modele sur PX .Par exemple : PX ∈ N (θ, 1) : θ ∈ R
Question fondamentaleOn considere le modele “total” = PX ∈ toutes les lois sur R. Est-ilpossible de connaıtre exactement PX quand le nombre n de donneestends vers ∞ ?
24/54

25/54
Rappel : loi d’une variable aleatoire reelle
Definition
X :(Ω,A,P
)−→
(R,B
)Loi de X : mesure de probabilite sur (R,B), notee PX , definie par
PX[A]
= P[X ∈ A], ∀A ∈ B.
Formule d’integration
E[ϕ(X )
]=
∫Ω
ϕ(X (ω)
)P(dω) =
∫Rϕ(x)PX (dx)
pour toute fonction test ϕ.
25/54

26/54
Loi d’une variable aleatoire (1/4)
Exemple 1 : X suit la loi de Bernoulli de parametre 1/3
I La loi de X est decrite par
P[X = 1
]= 1
3 = 1− P[X = 0
]I Ecriture de PX :
PX = 13δ1 + 2
3δ0
I Formule de calcul (ϕ fonction test)
E[ϕ(X )
]=
∫Rϕ(x)PX (dx)
= 13
∫Rϕ(x)δ1(dx) + 2
3
∫Rϕ(x)δ0(dx)
= 13 ϕ(1) + 2
3 ϕ(0)
26/54

27/54
Loi d’une variable aleatoire (2/4)
Exemple 2 : X ∼ loi de Poisson de parametre 2
I La loi de X est decrite par
P[X = k
]=
2k
k!e−2, k = 0, 1, . . .
I Ecriture de PX :
PX = e−2∑k∈N
2k
k! δk
I Formule de calcul (ϕ fonction test)
E[ϕ(X )
]=
∫Rϕ(x)PX (dx) = e−2
∑k∈N
ϕ(k) 2k
k!
27/54

28/54
Loi d’une variable aleatoire (3/4)
Exemple 3 : X ∼ N (0, 1) (loi normale standard).
I La loi de X est decrite par
P[X ∈ [a, b]
]=
∫[a,b]
e−x2/2 dx√
2π
I Ecriture de PX :
PX = f .λ ou f (x) = 1√2π
e−x2/2
λ : mesure de Lebesgue
I Formule de calcul
E[ϕ(X )
]=
∫Rϕ(x)PX (dx) =
∫Rϕ(x)e−x
2/2 dx√2π
28/54

29/54
Loi d’une variable aleatoire (4/4)
Exemple 4 : X = min(Z , 1), ou la loi de Z a une densite f par rapport ala mesure de Lebesgue sur R.
I Ecriture de PX :PX = g .λ+ P
[Z ≥ 1
]δ1,
ou g(x) = f (x)I(x < 1
),∀x ∈ R .
I Formule de calcul
E[ϕ(X )
]=
∫ 1
−∞ϕ(x)f (x)dx + P
[Z ≥ 1
]ϕ(1)
29/54

30/54
Fonction de repartition
Les lois sont des objets compliquees. On peut neanmoins les caracteriserpar des objets plus simples.
DefinitionSoit X variable aleatoire reelle. La fonction de repartition de X est :
F (x) := P[X ≤ x
], ∀x ∈ R .
I F est croissante, cont. a droite, F (−∞) = 0, F (+∞) = 1
I F caracterise la loi PX :
PX[(a, b]
]= P
[a < X ≤ b
]= F (b)− F (a)
I Si F est derivable alors PX << λ et fX = F ′
I Desormais, la loi de X designera indifferemment F ou PX .
30/54

31/54
Retour sur la question fondamentale
On “observe”X1, . . . ,Xn ∼i.i.d. F ,
F fonction de repartition quelconque, inconnue.Question : Est-il possible de retrouver exactement F quand n tends vers∞ ?Idee : On va chercher a estimer F sur R. Soit x ∈ R. F (x) = P[X ≤ x ]est la probabilite que X soit plus petit que x . On va alors compter lenombres de Xi qui sont plus petit que x et diviser par n :
1
n
n∑i=1
I (Xi ≤ x).
31/54

32/54
Fonction de repartition empirique
DefinitionFonction de repartition empirique associee au n-echantillon (X1, . . . ,Xn) :
Fn(x) =1
n
n∑i=1
I(Xi ≤ x
), x ∈ R .
(C’est une fonction aleatoire)
32/54

33/54
Proprietes asymptotiques de Fn(x)
Pour tout x ∈ R :
Fn(x)p.s.−→ F (x) quand n→∞
C’est une consequence de la loi forte des grands nombres appliquee a lasuite de v.a.r.i.i.d.
(I (Xi ≤ x)
)i.
On dit que Fn(x) est un estimateur fortement consistant de F (x).
33/54

34/54
Proprietes asymptotiques de Fn
Theorem (Glivenko-Cantelli)∥∥∥Fn − F∥∥∥∞
p.s.−→ 0 quand n→∞
Aussi appele Theoreme fondamental de la statistique.Interpretation : Avec un nombre infini de donnees dans le modeled’echantillonnage, on peut donc reconstruire exactement F et doncdeterminer exactement la loi des observations.
34/54

35/54
Notebooks
http://localhost:8888/notebooks/cdf_empirique.ipynb
Glivenko-Cantelli
35/54

36/54
Autres proprietes asymptotiques de Fn(x)
Soit x ∈ R. On sait que si n→∞ alors
Fn(x)p.s.−→ F (x)
Question : Quelle est la vitesse de convergence de Fn(x) vers F (x) ?Outil : Theoreme central-limite applique a la suite de v.a.r.i.i.d.(I (Xi ≤ x)
)i
:
√n(Fn(x)− F (x)
) d−→ N(0,F (x)(1− F (x))
)On dit que Fn(x) est asymptotiquement normal de variance asymptotiqueF (x)(1− F (x).
36/54

37/54
TCL et intervalle de confiance asymptotique
On a montre par le TCL que pour tout 0 < α < 1, quand n→∞,
P[∣∣Fn(x)− F (x)
∣∣ ≥ cασ(F )√
n
]→∫|x|>cα
exp(−x2/2)dx√2π
= α
ou σ(F ) = F (x)(1− F (x)) et cα = Φ−1(1− α/2).
I Attention ! ceci ne fournit pas un intervalle de confiance :
σ(F ) = F (x)1/2(1− F (x)
)1/2est inconnu !
I Solution : remplacer σ(F ) par σ(Fn) = Fn(x)1/2(1− Fn(x)
)1/2(qui
est observable), grace au lemme de Slutsky.
37/54

38/54
TCL et intervalle de confiance asymptotique
PropositionPour tout α ∈ (0, 1),
Iasympn,α =
[Fn(x)±
Fn(x)1/2(1− Fn(x)
)1/2
√n
Φ−1(1− α/2)
]
est un intervalle de confiance asymptotique pour F (x) au niveau deconfiance 1− α :
P[F (x) ∈ Iasympn,α
]→ 1− α.
38/54

39/54
Notebooks
http://localhost:8888/notebooks/cdf_empirique.ipynb
Glivenko-Cantelli
39/54

40/54
Vitesse de convergence dans le Theoreme de Glivenko-Cantelli
Theorem (Theoreme de Kolmogorov-Smirnov)Soit X une v.a.r. de fonction de repartition F qu’on suppose continue et(Xn)n une suite de v.a.r. i.i.d. de meme loi que X alors :
√n∥∥∥Fn − F
∥∥∥∞
d−→ K
ou K est une variable aleatoire telle que pour tout x ∈ R
P[K ≤ x ] = 1− 2∞∑k=1
(−1)k+1 exp(−2k2x2)
I Utile pour le test de Kolmogorov-Smirnov
40/54

41/54
resultats asymptotiques et non-asymptotiques
On classe les resultats statistiques en deux categories :
1. Un resultat obtenu quand n tend vers l’infini est un resultat ditasympotique
2. Un resultat obtenu a n fixe est un resultat dit non-asympotique
41/54

42/54
Estimation non-asymptotique de F (x) par Fn(x)
Soit 0 < α < 1 donne (petit). On veut trouver ε, le plus petit possible,de sorte que
P[|Fn(x)− F (x)| ≥ ε
]≤ α.
On a (Tchebychev)
P[|Fn(x)− F (x)| ≥ ε
]≤ 1
ε2Var[Fn(x)
]=
F (x)(1− F (x)
)nε2
≤ 1
4nε2
≤ α
Conduit a
ε =1
2√
nα
42/54

43/54
Intervalle de confiance non-asymptotique
Conclusion : pour tout n ≥ 1 et tout α > 0,
P[|Fn(x)− F (x)| ≥ 1
2√
nα
]≤ α.
TerminologieL’intervalle
In,α =
[Fn(x)± 1
2√
nα
]est un intervalle de confiance non-asymptotique pour F (x) au niveau deconfiance 1− α.
43/54

44/54
Inegalite de Hoeffding
PropositionY1, . . . ,Yn v.a.r.i.i.d. telles que a ≤ Y1 ≤ b p.s.. Alors
P
[∣∣∣∣∣1nn∑
i=1
Yi − EY1
∣∣∣∣∣ ≥ t
]≤ 2 exp
(− 2nt2
(a− b)2
)
Application : on pose Yi = I (xi ≤ x) et p = F (x). On en deduit
P[∣∣Fn(x)− F (x)
∣∣ ≥ ε] ≤ 2 exp(−2nε2).
On resout en ε :2 exp(−2nε2) = α,
soit
ε =
√1
2nlog
2
α.
44/54

45/54
Comparaison Tchebychev vs. Hoeffding
Nouvel intervalle de confiance
Ihoeffdingn,α =
[Fn(x0)±
√1
2nlog
2
α
]
a comparer avec
Itchebychevn,α =
[Fn(x0)± 1
2√
nα
]
I Meme ordre de grandeur en n.
I Gain significatif dans la limite α→ 0.
45/54

46/54
Observation finale
Comparaison des longueurs des 3 intervalles de confiance :
I Tchebychev (non-asymptotique) 2√n
12√α
I Hoeffding (non-asymptotique) 2√n
√12 log 2
α
I TCL (asymptotique) 2√n
Fn(x0)1/2(1− Fn(x0)
)1/2Φ−1(1− α/2).
I La longueur la plus petite est celle fournie par le TCL. Mais lalongueur de l’intervalle de confiance fournie par l’inegalite deHoeffding est comparable a celle du TCL en n et α (dans la limiteα→ 0).
46/54

47/54
Version non-asymptotique de Kolmogorov-Smirnov
X1, . . . ,Xn i.i.d. de loi F continue, Fn leur fonction de repartitionempirique.
Proposition (Inegalite de Dvoretsky-Kiefer-Wolfowitz)Pour tout ε > 0.
P[
supx∈R
∣∣Fn(x)− F (x)∣∣ ≥ ε] ≤ 2 exp
(− 2nε2
).
I Resultat difficile (theorie des processus empiriques).
I Permet de construire des regions de confiance avec des resultatssimilaires au cadre ponctuel :
P[∀x ∈ R,F (x) ∈
[Fn(x)±
√1
2n log 2α
]]≥ 1− α
47/54

48/54
Rappels de probabilites
48/54

49/54
Tribus et mesures de probabilite
Soit Z un ensemble.
1. Une tribu Z sur Z est un ensemble de parties de Z tel que :I Z est stable par union et intersection denombrableI Z est stable par passage au complementaireI Z ∈ Z
Les elements de Z sont appeles des evenements.
2. Une mesure de probabilite sur (Z,Z) est une appplicationP : Z 7→ [0, 1] telle que
I P[Z] = 1I Si (An) est une famille denombrable d’evenements disjoints alors
P[∪n An
]=∑n
P[An]
Le dernier point est aussi equivalent a : pour (An) une suitecroissante d’evenements on a P(An) ↑ P(∪An).
49/54

50/54
Type de convergence de suite de variables aleatoires
Soit (Zn) une suite de variable aleatoires et Z une variable aleatoire avaleurs dans (R,B) (toutes definies sur un espace probabilise (Ω,F ,P)).
1. (Zn) converge en loi vers Z , note Znd→ Z , quand pour pour toute
fonction continue bornee f : R 7→ R on a
E f (Zn)→ E f (Z )
2. (Zn) converge en probabilite, vers Z , note ZnP→ Z , quand pour tout
ε > 0,P[|Zn − Z | ≥ ε
]→ 0
3. (Zn) converge presque surement vers Z , note Znp.s.→ Z , quand il
existe un evenement Ω0 ∈ F tel que P[Ω0] = 1 et pour tout ω ∈ Ω0
Zn(ω)→ Z (ω)
50/54

51/54
Loi forte des grands nombres
TheoremSoit (Xn) une suite de v.a.r.i.i.d. telle que E |X1| <∞. Alors
1
n
n∑i=1
Xip.s.→ EX1
Il y a aussi une “equivalence” a ce resultat : si (Xn) est une suite de
v.a.r.i.i.d. telle que(
1n
∑ni=1 Xi
)n
converge presque surement alors
E |X1| <∞ et elle converge presque surement vers EX1.
51/54

52/54
Theoreme central-limite
TheoremSoit (Xn) une suite de v.a.r.i.i.d. telle que EX 2
1 <∞. Alors
√n
σ
(1
n
n∑i=1
Xi − EX1
)d→ N (0, 1)
I TCL : vitesse dans la loi des grands nombres.
I Interpretation du TCL :
1
n
n∑i=1
Yi = µ+σ√nξ(n), ξ(n) d
≈ N (0, 1).
I Le mode de convergence est la convergence en loi. Ne peut pas avoirlieu en probabilite.
52/54

53/54
Lemme de Slutsky
I Le vecteur (Xn,Yn)d→ (X ,Y ) si
E[ϕ(Xn,Yn)
]→ E
[ϕ(X ,Y )
],
pour ϕ continue bornee.
I Attention ! Si Xnd→ X et Yn
d→ Y , on n’a pas en general
(Xn,Yn)d→ (X ,Y ).
I Mais (lemme de Slutsky) si Xnd→ X et Yn
P→ c (constante), alors
(Xn,Yn)d→ (X ,Y ).
I Par suite, sous les hypotheses du lemme, pour toute fonction
continue g , on a g(Xn,Yn)d→ g(X ,Y ).
53/54

54/54
Continuous map theorem
Soit f : R 7→ R une fonction continue et (Xn) une suite de v.a.r.
1. si (Xn) converge en loi vers X alors f (Xn) converge en loi vers f (X )
2. si (Xn) converge en probabilite vers X alors f (Xn) converge enprobabilite vers f (X )
3. si (Xn) converge p.s. vers X alors f (Xn) converge p.s. vers f (X )
54/54
Recommended

















