
Thank you SPSKC15 sponsors!

Agenda
• Introduction• Logical architecture
– Search Components– Search Databases
• Create Search Service Application– Using Central Administration– Using PowerShell
• Search Topology– Search Components on multiple servers
• SharePoint 2013 Search Query APIs• Content Source• Demo• Questions

Introduction
• A newly improved version of Search, different from all previous versions
• Fundamentally integrated into several features like – eDiscovery, Site Navigation, Topic Pages, Catalog for Internet / Internal Sites etc.
• Installed by default when you run Farm Configuration wizard
2010 and before SharePoint 2013
SharePoint Foundation
Different Offerings like WSS Search, Microsoft Search Server, Search Server Express etc.
SharePoint Foundation Search
SharePoint Server
Separate versions called SharePoint Search and FAST Search
Built on Combination of FAST Search and SharePoint Search Components(SharePoint Server Search)
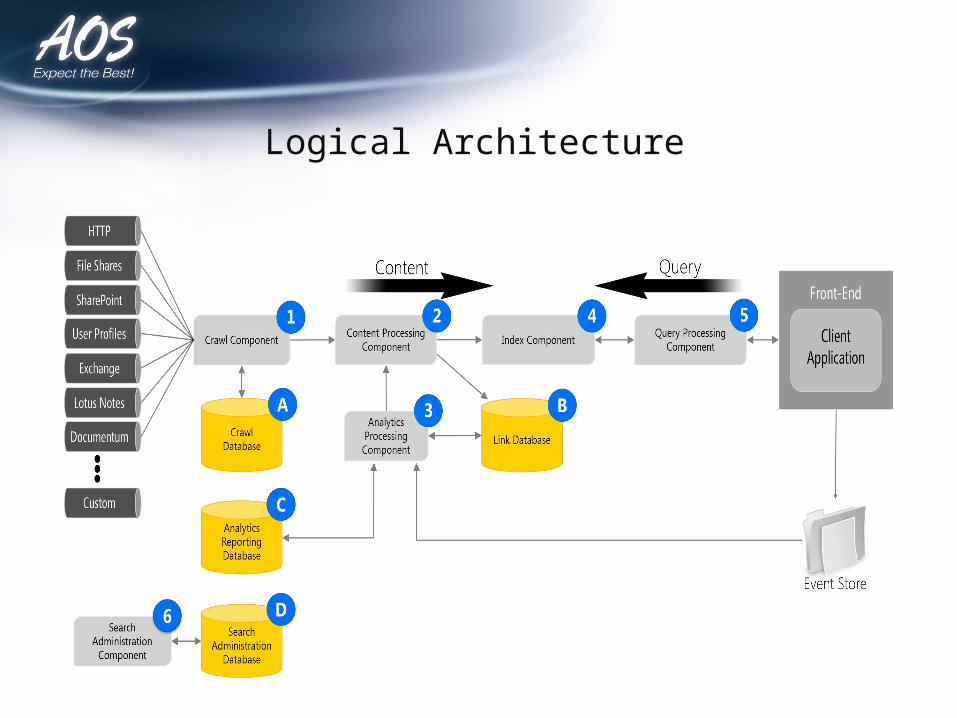
Logical Architecture

List of Search Components• Crawl Component (based on SharePoint Search)• Content Processing Component (CPC) - (New to
2013)• Analytics Components (New to SharePoint 2013)• Index Component (based on FAST Search)• Query Processing Component
– Query Engine (based on FAST Search)– Query processing pipelines (New to SharePoint 2013)
• Search Administration Component

List of Search Databases• Crawl Database - contains detailed tracking and
historical information about crawled items• Link Database - Stores the information extracted
by the content processing component and also stores click-through information
• Analytics Reporting Database - stores the result of usage analysis
• Search Administration Database - contains configuration & topology information
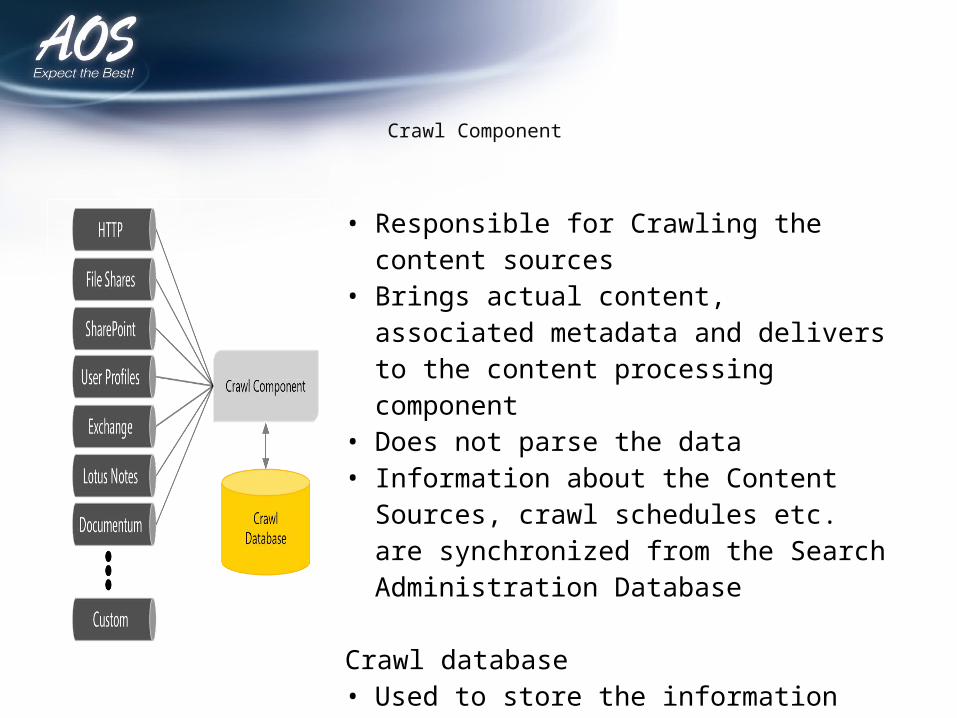
Crawl Component
• Responsible for Crawling the content sources• Brings actual content, associated metadata and
delivers to the content processing component• Does not parse the data• Information about the Content Sources, crawl
schedules etc. are synchronized from the Search Administration Database
Crawl database • Used to store the information about crawled
items and track the crawl history• Holds information such as
• Last crawl time• Last crawl ID• Type of update during last crawl process

Content Processing Component (CPC)
• Responsible for Processing crawled items and feed those items to Index Component
• Includes document parsing using new parser handlers or iFilter
Once the document is parsed, it performs following• Transforms crawled items into artifacts
which can be included in the search index• Performs linguistic processing at index
time• Writes information about links and URLs
to the Link Database directly• Generates phonetic name variations for
people search
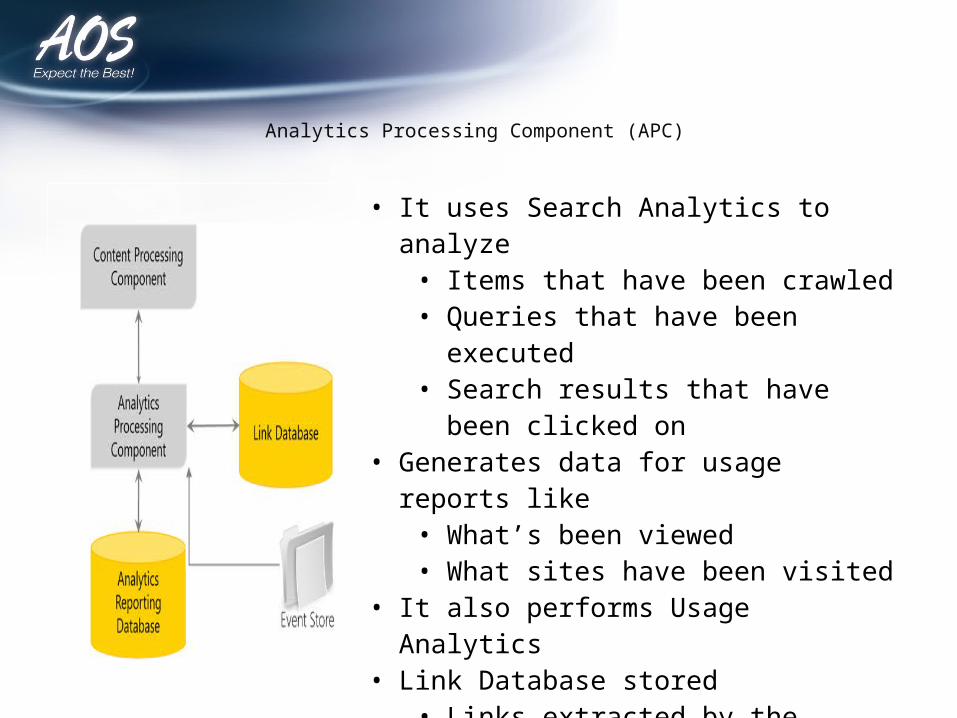
Analytics Processing Component (APC)
• It uses Search Analytics to analyze• Items that have been crawled• Queries that have been executed• Search results that have been clicked on
• Generates data for usage reports like• What’s been viewed• What sites have been visited
• It also performs Usage Analytics• Link Database stored
• Links extracted by the content processing component
• Information about number of times people click on result from the search results page
• Analytics Reporting Database stores results of Usage Analysis as well as Search Reports

Index Component
Feed / Query• Feeding – receives processed items from the Content Processing
Component and persists those items to index files• Query – receives queries from the query processing component and
return the results set
Replication• Replicates Index content between replicas within the same index partition
Topology Changes • Responsible to apply index partition changes when there is change in
Search Topology

Search Administration
• Responsible for Search Provisioning and Topology Changes
• Manages the lifecycle and monitor state for Crawling, Content Processing, Query Processing, Analytics and Indexing
• Supports multiple Admin Components for fault tolerance
• Stores Search Configuration data like• Topology• Crawl Rules• Query Rules• Content Sources• Crawl Schedules• Managed property mappings

Query Processing Component
• Perform Linguistic processing at Query Time – Word breaking, stemming, spell check, thesaurus etc.
• Responsible to check Query Rules, Analyze and process the queries• Submits the processed query to Index Component(s)• Returns a result set back to query processing component which processes
it before sending it back to client application
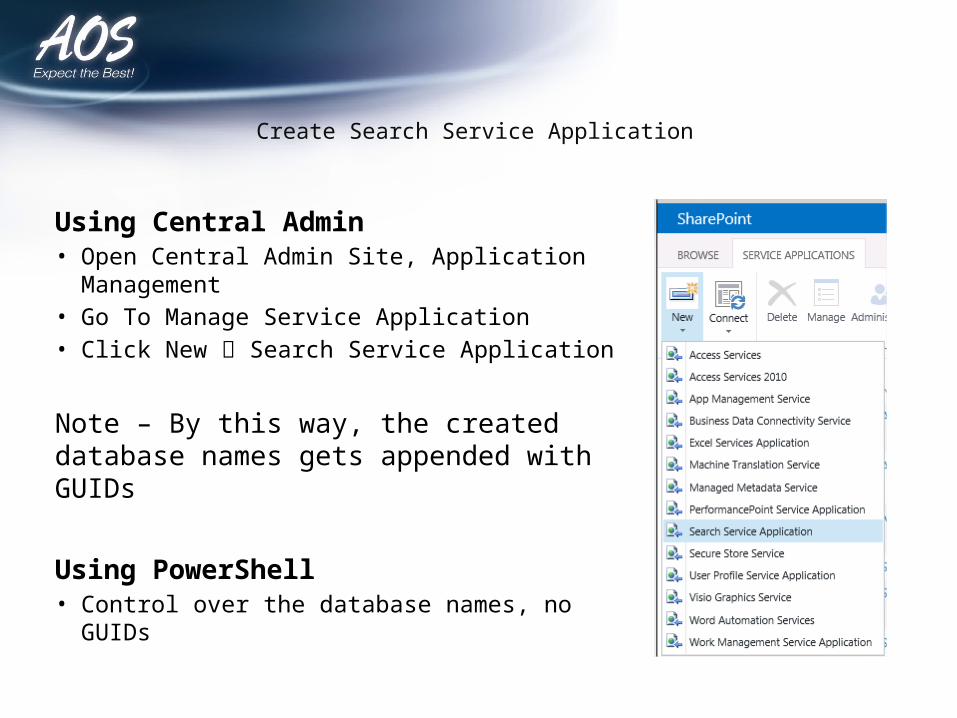
Create Search Service Application
Using Central Admin • Open Central Admin Site, Application
Management• Go To Manage Service Application• Click New Search Service Application
Note – By this way, the created database names gets appended with GUIDs
Using PowerShell• Control over the database names, no GUIDs
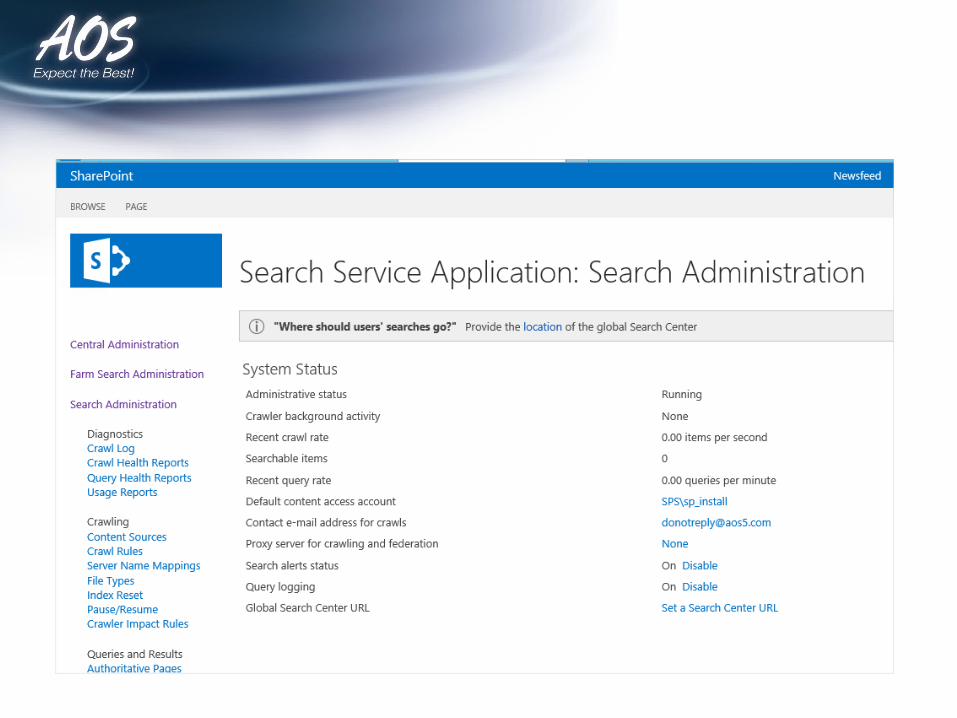
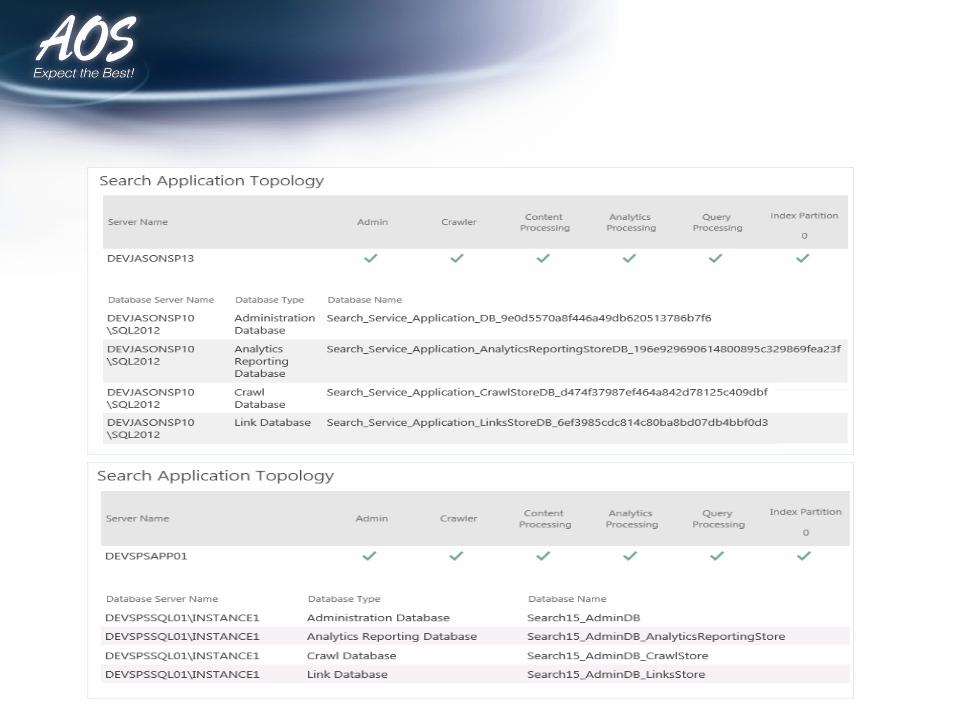
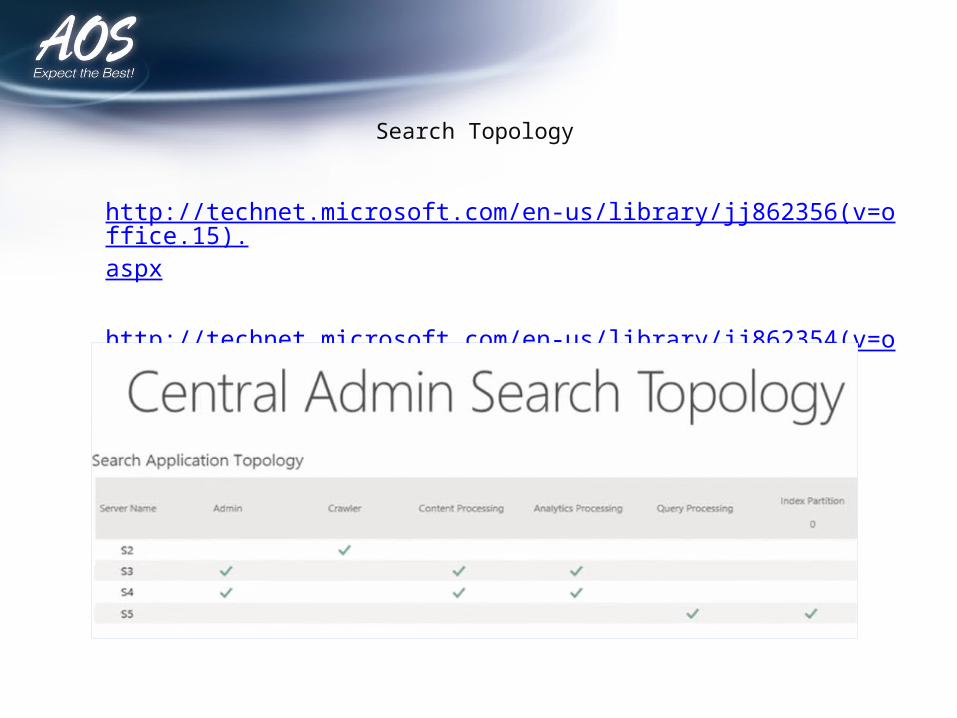
Search Topology
http://technet.microsoft.com/en-us/library/jj862356(v=office.15).aspx
http://technet.microsoft.com/en-us/library/jj862354(v=office.15).aspx
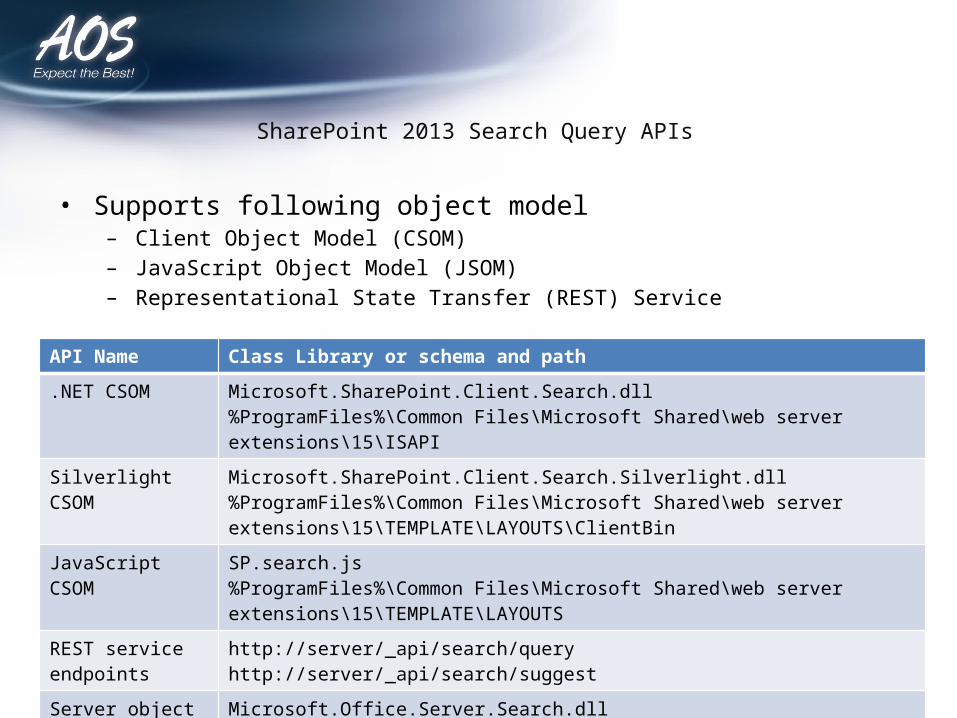
SharePoint 2013 Search Query APIs
• Supports following object model– Client Object Model (CSOM)– JavaScript Object Model (JSOM)– Representational State Transfer (REST) Service
API Name Class Library or schema and path
.NET CSOM Microsoft.SharePoint.Client.Search.dll%ProgramFiles%\Common Files\Microsoft Shared\web server extensions\15\ISAPI
Silverlight CSOM Microsoft.SharePoint.Client.Search.Silverlight.dll%ProgramFiles%\Common Files\Microsoft Shared\web server extensions\15\TEMPLATE\LAYOUTS\ClientBin
JavaScript CSOM SP.search.js%ProgramFiles%\Common Files\Microsoft Shared\web server extensions\15\TEMPLATE\LAYOUTS
REST service endpoints
http://server/_api/search/queryhttp://server/_api/search/suggest
Server object model Microsoft.Office.Server.Search.dll%ProgramFiles%\Common Files\Microsoft Shared\web server extensions\15\ISAPI

Query using the .NET CSOM
• The Search in SharePoint 2013 CSOM is built on the SharePoint 2013 CSOM.
• Therefore, your client code first needs to access the SharePoint 2013 CSOM and then access the Search in SharePoint 2013 CSOM

Query using JSOM
• For the JavaScript JSOM, get a Client Context instance• And then use the object model in the SP.Search.js file

Query using .NET Server Object Model
• Applications that use the server object model must run directly on a server that is running SharePoint 2013
• search Query server object model resides in the ”Microsoft.Office.Server.Search.Query” namespace, which is located in “Microsoft.Office.Server.Search.dll”
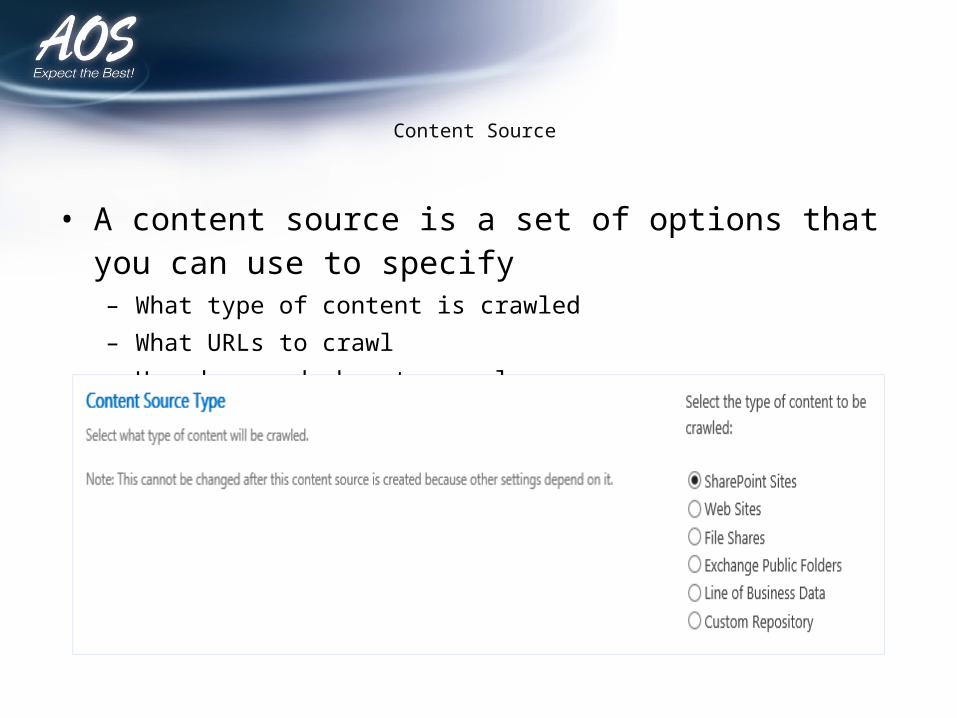
Content Source
• A content source is a set of options that you can use to specify – What type of content is crawled– What URLs to crawl– How deep and when to crawl.
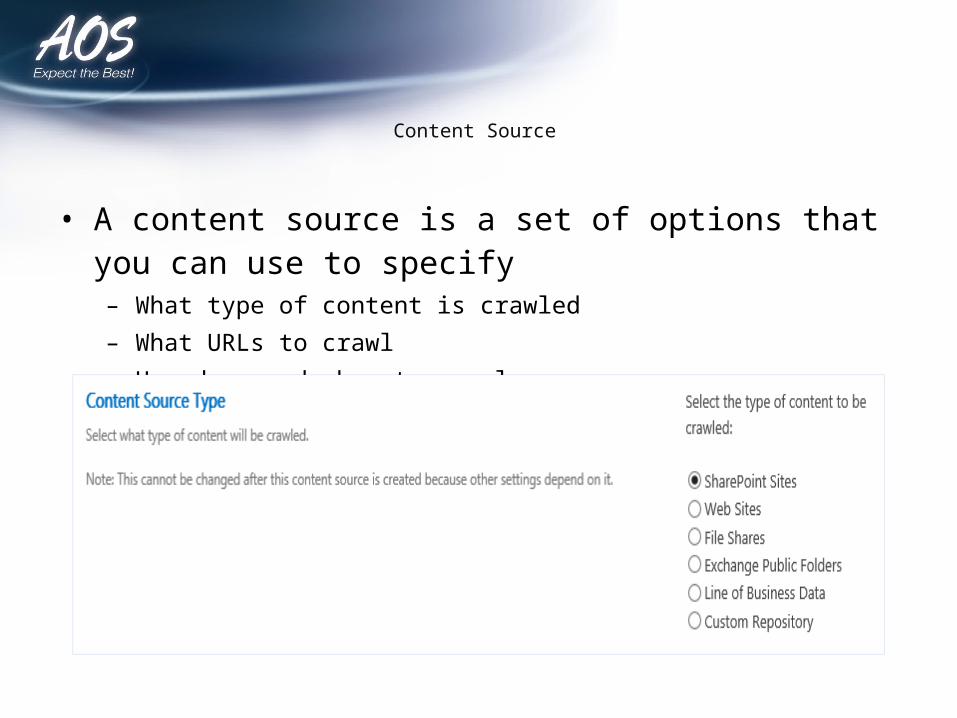
Content Source
• A content source is a set of options that you can use to specify – What type of content is crawled– What URLs to crawl– How deep and when to crawl.
Helpful Links
• Plan Enterprise Search Architecture• http://technet.microsoft.com/en-us/library/dn342836(v=office.15).aspx • Create and Configure Search Service Application• http://technet.microsoft.com/en-us/library/gg502597(v=office.15).aspx• Change Default Search Topology• http://technet.microsoft.com/en-us/library/jj862356(v=office.15).aspx • Manage Search Components• http://technet.microsoft.com/en-us/library/jj862354(v=office.15).aspx• Enterprise Search overview – training video• http://technet.microsoft.com/en-us/office/dn756397.aspx
• http://blogs.msdn.com/b/kristopherloranger/archive/2013/05/30/sharepoint-2013-crawler-troubleshooting-concepts.aspx
• http://channel9.msdn.com/Events/SharePoint-Conference/2014/SPC375

Questions?

Thank you SPSKC15 sponsors!
Recommended


















