
Motivation for Parallel Databases (The Database Problem)
☞ I/O bottleneck (or memory access bottleneck):
• Speed(disk) < speed(RAM) < speed(microprocessor)
☞ Predictions
• (Micro-) processor speed growth : 0.5× per year
• DRAM capacity growth : 4× every three years
• Disk throughput : 2× in the last ten years
☞ Conclusion : the I/O bottleneck worsens
Spring, 2006 Arturas Mazeika Page 3
Parallel Databases
☞ Introduction, General Idea, Motivation
☞ Parallel Architectures
☞ Parallel DBMS Techniques
Motivation for Parallel Databases (The Solution)
☞ Increase the I/O bandwidth
• Data partitioning
• Parallel data access
☞ Origins (1980’s): database machines
• Hardware-oriented (failure due to bad cost-performance)
☞ 1990’s: same solution but using standard hardware components integrated in amultiprocessor
• Software-oriented
• Standard essential to exploit continuing technology improvements
Spring, 2006 Arturas Mazeika Page 4
The Target Architecture
Shared Memory (SM) Shared Disk (SD)
Shared Nothing (SN)
Spring, 2006 Arturas Mazeika Page 2

Parallel Data Processing (Data Based Parallelism)
☞ Databases archive parallelism through inter-operations and intra-operations
☞ Inter-operation: one query is broken into a number of operations that are run in parallel
☞ Intra-operation the same query is run on different portions of the data in parallel
Spring, 2006 Arturas Mazeika Page 7
Motivation for Parallel Databases (Multiprocessor Objectives)
☞ High-performance with better cost-performance than mainframe or vector supercomputer
☞ Use many nodes, each with good cost- performance, communicating through network
• Good cost via high-volume components
• Good performance via bandwidth
☞ Trends
• Microprocessor and memory (DRAM): off-the-shelf
• Network (multiprocessor edge): custom
☞ The real challenge is to parallelize applications to run with good load balancing
Spring, 2006 Arturas Mazeika Page 5
Parallel Data Processing (Objectives of Parallel DBMS 1/3)
☞ High-performance through parallelism
☞ High availability and reliability by exploiting data replication
☞ Extensibility with the ideal goals
• Linear speed-up
• Linear scale-up
Spring, 2006 Arturas Mazeika Page 8
Parallel Data Processing (General Idea)
☞ Three ways of exploiting high-performance multiprocessor systems:
• Automatically detect parallelism in sequential programs (e.g., Fortran)
• Augment an existing language with parallel constructs (e.g., C, Fortran90)
• Offer a new language in which parallelism can be expressed or automatically inferred
☞ Critique
• Hard to develop parallelizing compilers, limited resulting speed-up
• Enables the programmer to express parallel computations but too low-level
• Can combine the advantages of both (1) and (2)
Spring, 2006 Arturas Mazeika Page 6
Parallel Data Processing (Barriers to Parallelism)
☞ Startup
• The time needed to start a parallel operation may dominate the actual computationtime (especially for small queries)
☞ Interference
• When accessing shared resources, each new process slows down the others (twoprocesses access the same data item)
☞ Skew
• The response time of a set of parallel processes is the time of the slowest one (oneprocess has lots of work, while the others are idle)
Spring, 2006 Arturas Mazeika Page 11
Parallel Data Processing (Objectives of Parallel, Linear Speed-Up DBMS 2/3)
☞ Every system component (processor, memory, disk) increases the performance by aconstant (the performance is proportional to the number of components)
Spring, 2006 Arturas Mazeika Page 9
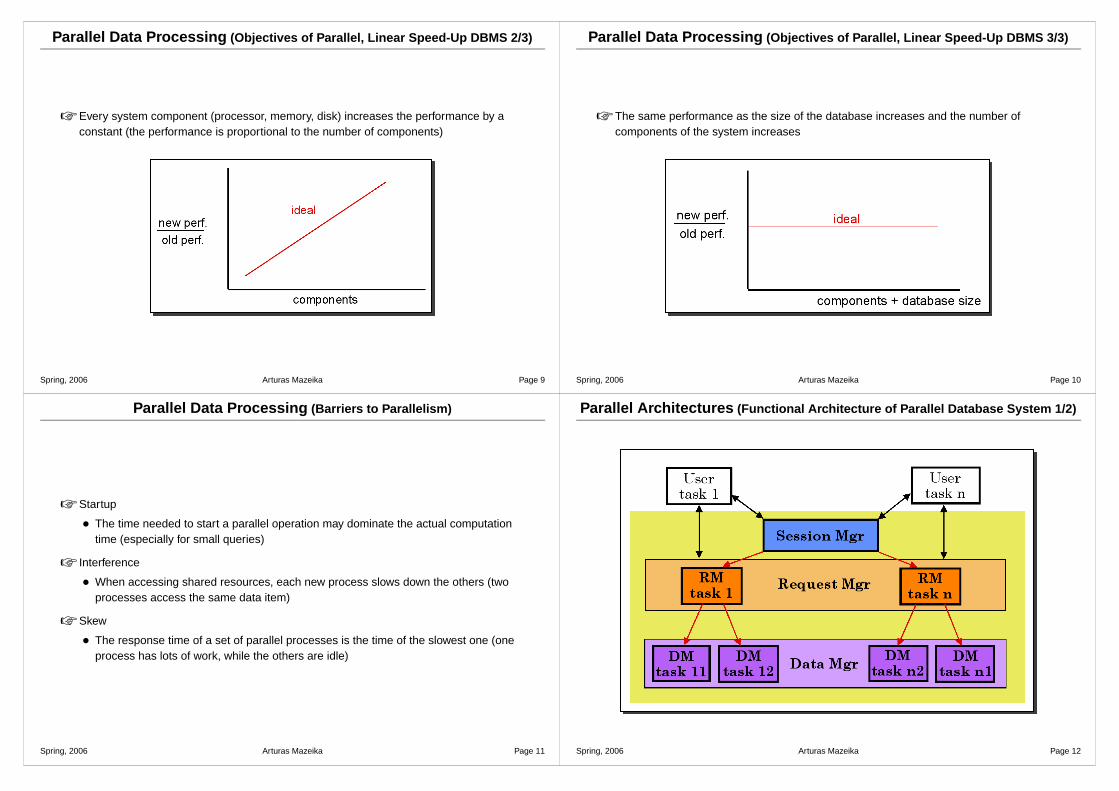
Parallel Architectures (Functional Architecture of Parallel Database System 1/2)
Spring, 2006 Arturas Mazeika Page 12
Parallel Data Processing (Objectives of Parallel, Linear Speed-Up DBMS 3/3)
☞ The same performance as the size of the database increases and the number ofcomponents of the system increases
Spring, 2006 Arturas Mazeika Page 10
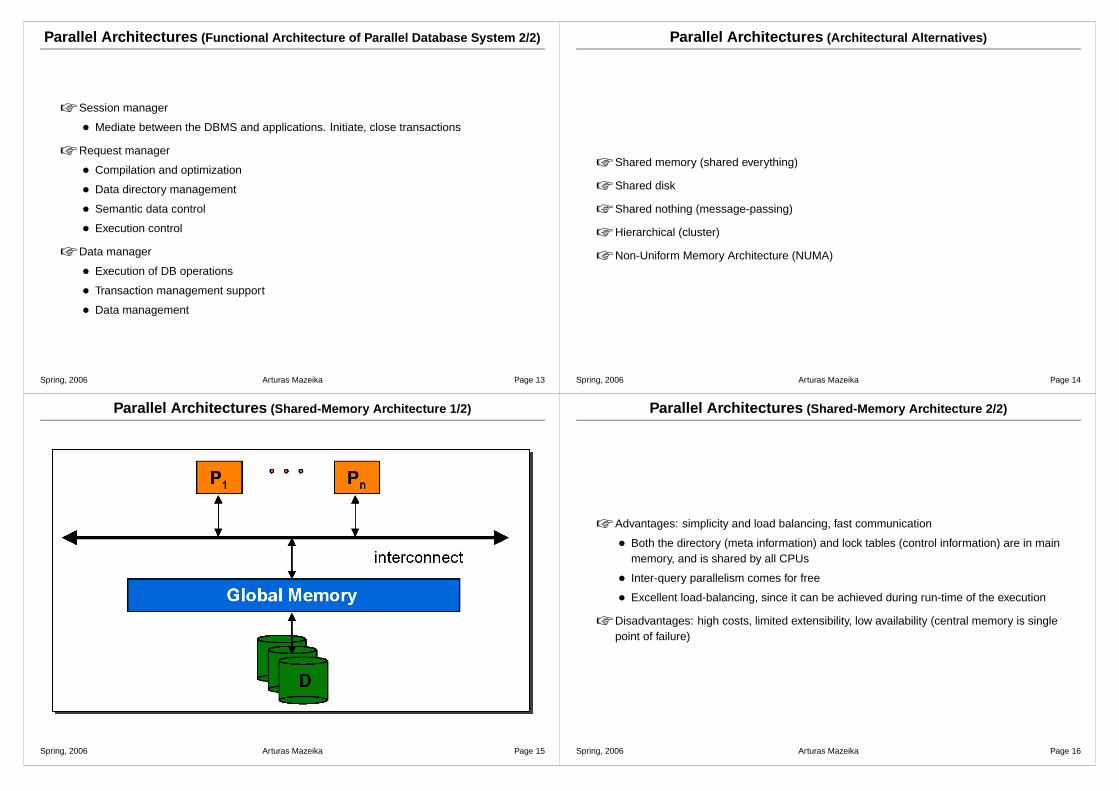
Parallel Architectures (Shared-Memory Architecture 1/2)
Spring, 2006 Arturas Mazeika Page 15
Parallel Architectures (Functional Architecture of Parallel Database System 2/2)
☞ Session manager
• Mediate between the DBMS and applications. Initiate, close transactions
☞ Request manager
• Compilation and optimization
• Data directory management
• Semantic data control
• Execution control
☞ Data manager
• Execution of DB operations
• Transaction management support
• Data management
Spring, 2006 Arturas Mazeika Page 13
Parallel Architectures (Shared-Memory Architecture 2/2)
☞ Advantages: simplicity and load balancing, fast communication
• Both the directory (meta information) and lock tables (control information) are in mainmemory, and is shared by all CPUs
• Inter-query parallelism comes for free
• Excellent load-balancing, since it can be achieved during run-time of the execution
☞ Disadvantages: high costs, limited extensibility, low availability (central memory is singlepoint of failure)
Spring, 2006 Arturas Mazeika Page 16
Parallel Architectures (Architectural Alternatives)
☞ Shared memory (shared everything)
☞ Shared disk
☞ Shared nothing (message-passing)
☞ Hierarchical (cluster)
☞ Non-Uniform Memory Architecture (NUMA)
Spring, 2006 Arturas Mazeika Page 14

Parallel Architectures (Shared-Nothing 1/2)
Spring, 2006 Arturas Mazeika Page 19
Parallel Architectures (Shared-Disk Architecture 1/2)
Spring, 2006 Arturas Mazeika Page 17
Parallel Architectures (Shared-Nothing 2/2)
☞ advantages: cost, extensibility, availability
• smooth, incremental growth
• replication of data to nodes increases availability
☞ disadvantages: complexity, difficult load balancing
• good fragmentation and replication is required to achieve high performance
• distribution of data plays an important role in load balance, not only the load of theeach cpu
• addition of discs might require redistribution of data in order to achieve highperformance
Spring, 2006 Arturas Mazeika Page 20
Parallel Architectures (Shared-Disk Architecture 2/2)
☞ Advantages: network cost, extensibility, easy migration from uniprocessor
☞ Disadvantages: higher complexity and potential performance problems
• Distributed database protocols are required: two-phase commit, distributed locking
• Shared disk might be a bottleneck
• High communication between nodes
Spring, 2006 Arturas Mazeika Page 18
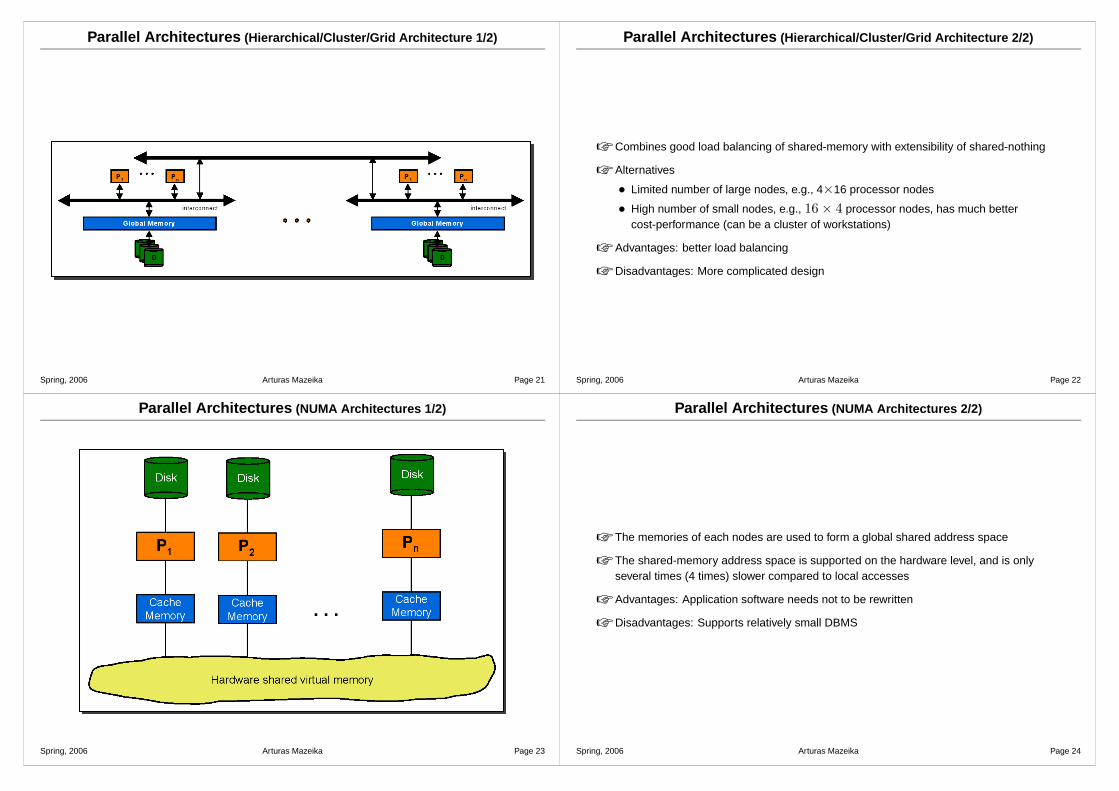
Parallel Architectures (NUMA Architectures 1/2)
Spring, 2006 Arturas Mazeika Page 23
Parallel Architectures (Hierarchical/Cluster/Grid Architecture 1/2)
Spring, 2006 Arturas Mazeika Page 21
Parallel Architectures (NUMA Architectures 2/2)
☞ The memories of each nodes are used to form a global shared address space
☞ The shared-memory address space is supported on the hardware level, and is onlyseveral times (4 times) slower compared to local accesses
☞ Advantages: Application software needs not to be rewritten
☞ Disadvantages: Supports relatively small DBMS
Spring, 2006 Arturas Mazeika Page 24
Parallel Architectures (Hierarchical/Cluster/Grid Architecture 2/2)
☞ Combines good load balancing of shared-memory with extensibility of shared-nothing
☞ Alternatives
• Limited number of large nodes, e.g., 4×16 processor nodes
• High number of small nodes, e.g., 16 × 4 processor nodes, has much bettercost-performance (can be a cluster of workstations)
☞ Advantages: better load balancing
☞ Disadvantages: More complicated design
Spring, 2006 Arturas Mazeika Page 22
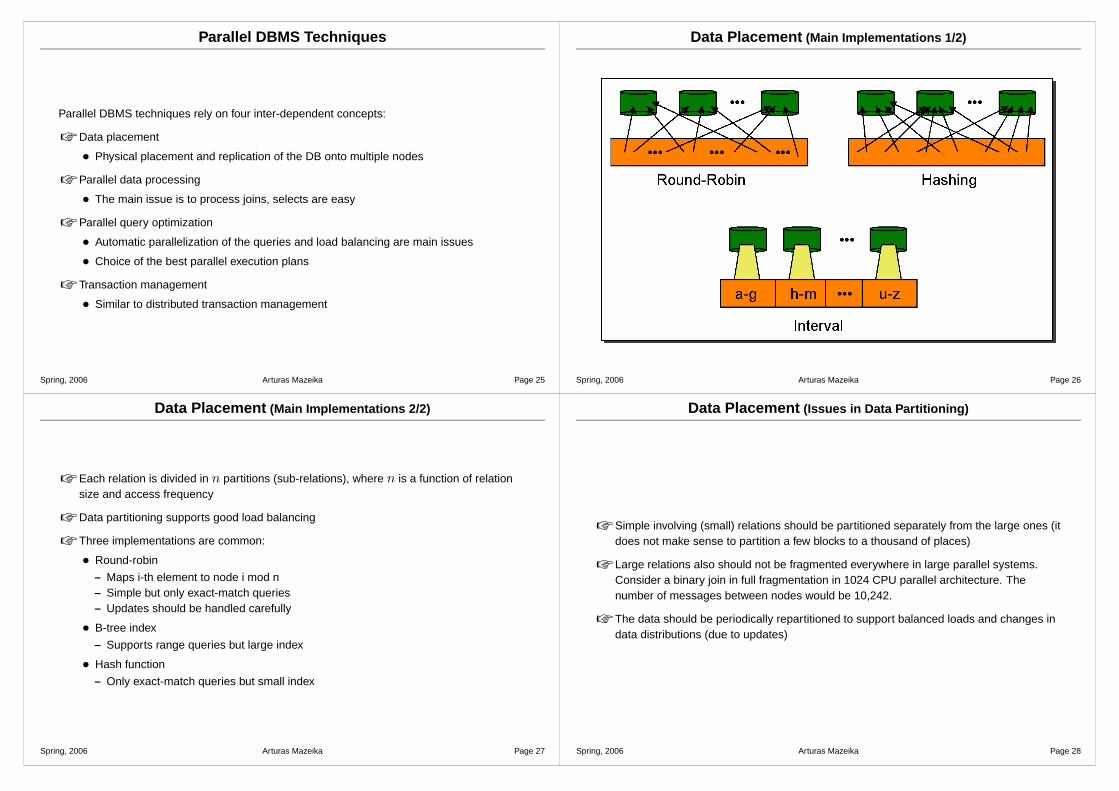
Data Placement (Main Implementations 2/2)
☞ Each relation is divided in n partitions (sub-relations), where n is a function of relationsize and access frequency
☞ Data partitioning supports good load balancing
☞ Three implementations are common:
• Round-robin
– Maps i-th element to node i mod n– Simple but only exact-match queries– Updates should be handled carefully
• B-tree index
– Supports range queries but large index
• Hash function
– Only exact-match queries but small index
Spring, 2006 Arturas Mazeika Page 27
Parallel DBMS Techniques
Parallel DBMS techniques rely on four inter-dependent concepts:
☞ Data placement
• Physical placement and replication of the DB onto multiple nodes
☞ Parallel data processing
• The main issue is to process joins, selects are easy
☞ Parallel query optimization
• Automatic parallelization of the queries and load balancing are main issues
• Choice of the best parallel execution plans
☞ Transaction management
• Similar to distributed transaction management
Spring, 2006 Arturas Mazeika Page 25
Data Placement (Issues in Data Partitioning)
☞ Simple involving (small) relations should be partitioned separately from the large ones (itdoes not make sense to partition a few blocks to a thousand of places)
☞ Large relations also should not be fragmented everywhere in large parallel systems.Consider a binary join in full fragmentation in 1024 CPU parallel architecture. Thenumber of messages between nodes would be 10,242.
☞ The data should be periodically repartitioned to support balanced loads and changes indata distributions (due to updates)
Spring, 2006 Arturas Mazeika Page 28
Data Placement (Main Implementations 1/2)
Spring, 2006 Arturas Mazeika Page 26
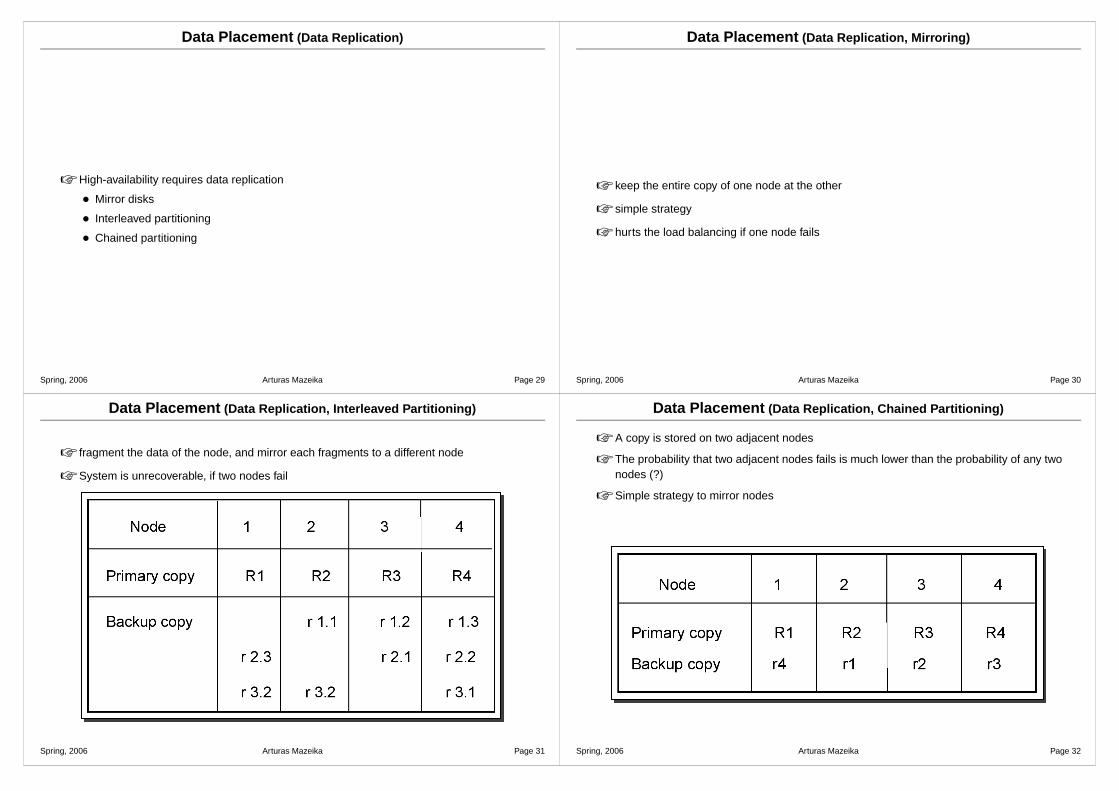
Data Placement (Data Replication, Interleaved Partitioning)
☞ fragment the data of the node, and mirror each fragments to a different node
☞ System is unrecoverable, if two nodes fail
Spring, 2006 Arturas Mazeika Page 31
Data Placement (Data Replication)
☞ High-availability requires data replication
• Mirror disks
• Interleaved partitioning
• Chained partitioning
Spring, 2006 Arturas Mazeika Page 29
Data Placement (Data Replication, Chained Partitioning)
☞ A copy is stored on two adjacent nodes
☞ The probability that two adjacent nodes fails is much lower than the probability of any twonodes (?)
☞ Simple strategy to mirror nodes
Spring, 2006 Arturas Mazeika Page 32
Data Placement (Data Replication, Mirroring)
☞ keep the entire copy of one node at the other
☞ simple strategy
☞ hurts the load balancing if one node fails
Spring, 2006 Arturas Mazeika Page 30
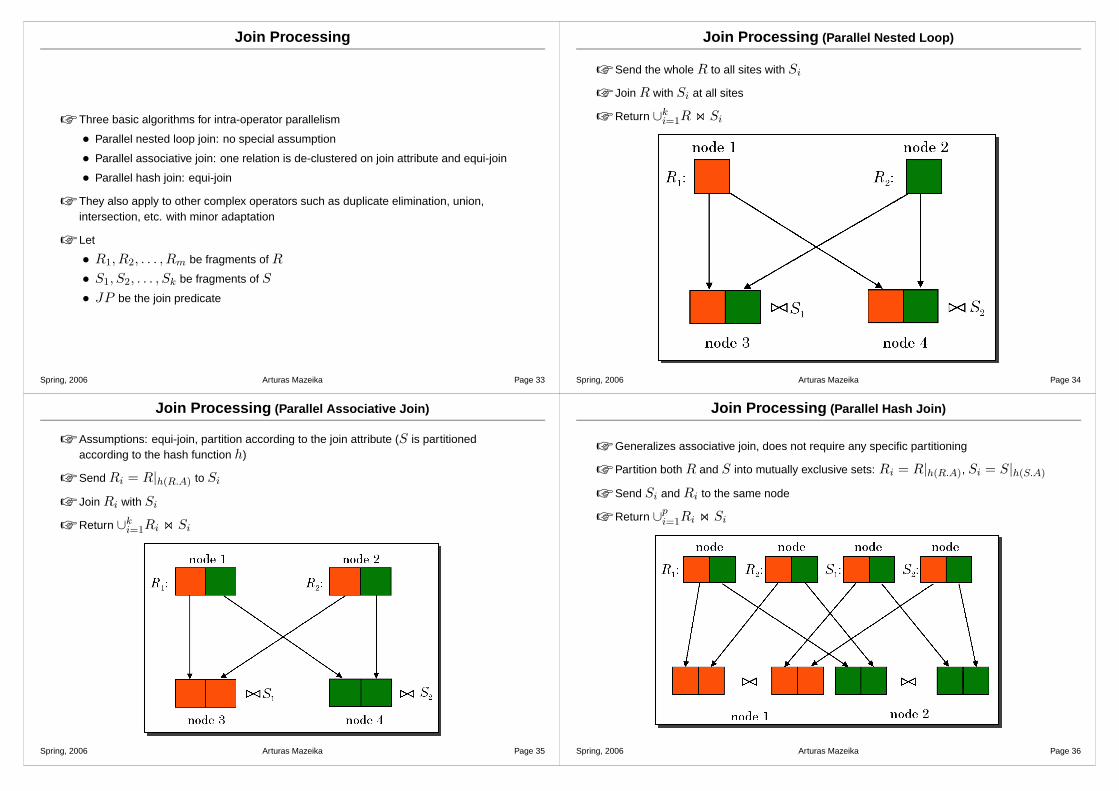
Join Processing (Parallel Associative Join)
☞ Assumptions: equi-join, partition according to the join attribute (S is partitionedaccording to the hash function h)
☞ Send Ri = R|h(R.A) to Si
☞ Join Ri with Si
☞ Return ∪ki=1Ri on Si
Spring, 2006 Arturas Mazeika Page 35
Join Processing
☞ Three basic algorithms for intra-operator parallelism
• Parallel nested loop join: no special assumption
• Parallel associative join: one relation is de-clustered on join attribute and equi-join
• Parallel hash join: equi-join
☞ They also apply to other complex operators such as duplicate elimination, union,intersection, etc. with minor adaptation
☞ Let
• R1, R2, . . . , Rm be fragments of R
• S1, S2, . . . , Sk be fragments of S
• JP be the join predicate
Spring, 2006 Arturas Mazeika Page 33
Join Processing (Parallel Hash Join)
☞ Generalizes associative join, does not require any specific partitioning
☞ Partition both R and S into mutually exclusive sets: Ri = R|h(R.A), Si = S|h(S.A)
☞ Send Si and Ri to the same node
☞ Return ∪pi=1Ri on Si
Spring, 2006 Arturas Mazeika Page 36
Join Processing (Parallel Nested Loop)
☞ Send the whole R to all sites with Si
☞ Join R with Si at all sites
☞ Return ∪ki=1R on Si
Spring, 2006 Arturas Mazeika Page 34

Parallel Query Optimization (Search Space)
☞ Two subsequent operations are executed through the pipeline
☞ One operand of the pipeline usually should be stored (hash table in case of the join)
☞ Build and probe steps are typical phases of the pipeline (first the hash table is built thenit is queried for joining)
Two Hash-Join Trees with Different Scheduling
Spring, 2006 Arturas Mazeika Page 39
Join Processing (Complexity)
☞ Cost of the algorithms is
Cost = CostCommunication + CostProcessing
☞ Fragments R1, R2, . . . , Rm, S1, S2, . . . , Sk, CostLocal(m, n) - process cost of thelocal join
☞ Nested loop (without the broadcast):
• CostCommunication = m · n · msg(Card(R)m
)
• CostProcessing = n · CostLocal(Card(R), Card(S)/n)
☞ Associative join:
• CostCommunication = m · n · msg(Card(R)m cot n
)
• CostProcessing = n · CostLocal(Card(R)/n, Card(S)/n)
☞ Hash join
• CostCommunication = m · p · msg(Card(R)m cot p
) + n · p · msg(Card(S)n cot p
)
• CostProcessing = n · CostLocal(Card(R)/n, Card(S)/n)
☞ Associative join minimizes the communication cost, hash join trades the communicationwrt the processing cost
Spring, 2006 Arturas Mazeika Page 37
Parallel Query Optimization (Search Strategy)
☞ Conceptually search strategy is not different from the centralized or distributedenvironments
☞ The search space is substantially larger
• left-deep trees express full materialization
• right-deep trees express full pipelining
• right-deep trees consumes more memory, though are more efficient
• Zig-zag trees tradeoff pipelining with memory
• Bushy trees tradeoff parallelism with memory
Spring, 2006 Arturas Mazeika Page 40
Parallel Query Optimization
☞ The objective is to select the ”best” parallel execution plan for a query using the followingcomponents
☞ Search space
• Models alternative execution plans as operator trees
• Left-deep vs. Right-deep vs. Bushy trees
☞ Search strategy
• Dynamic programming for small search space
• Randomized for large search space
☞ Cost model
• Physical schema info. (partitioning, indexes, etc.)
• Statistics and cost functions
Spring, 2006 Arturas Mazeika Page 38
Parallel Execution Problems (Initialization)
☞ Serial time is required to start parallel setup (initialization of threads, for e.g.)
☞ Initial time might outlast the processing time of small queries
☞ Let N be number of tuples, n be the number of processors, tp be average processingtime, ti initialization time per processor. Then
Response Time = ti · n +tp · N
n
☞ Optimal number of processors nO and maximal speedup Sm is then
nO =√
tp·N
tiSm = n0
2
Spring, 2006 Arturas Mazeika Page 43
Parallel Query Optimization (Cost Model)
☞ Three parameters are typically important: total work (TW), response time (RT), andmemory consumption (MC).
☞ Total work and response time shows the tradeoff between the throughput and responsetime
☞ The cots is typically modeled in the following way:
Cost(αRT , αTW ) =
{
αRT · RT + αTW · TW iff MC fits in RAM
∞ oterwise
Good choice of constants αRT and αTW is a challenge.
☞ Response time:
RT (phases) =∑
p∈phases
maxOp∈p
(RT (Op) + Pipe Delay(Op) + Store Delay(Op))
Spring, 2006 Arturas Mazeika Page 41
Parallel Execution Problems (Interference)
☞ Interference occurs when two CPUs simultaneously access the same resource
☞ Solution: duplicate resources or use shared variables (allowing only one CPU to accessthe data)
Spring, 2006 Arturas Mazeika Page 44
Parallel Execution Problems
☞ Initialization
☞ Interference
☞ Load Balancing
Spring, 2006 Arturas Mazeika Page 42

Parallel Hierarchical Architecture (2/2)
Spring, 2006 Arturas Mazeika Page 47
Parallel Execution Problems (Load Balancing)
☞ Problems arise for intra-operator parallelism with skewed data distributions
• attribute data skew (AVS)
• tuple placement skew (TPS)
• selectivity skew (SS)
• redistribution skew (RS)
• join product skew (JPS)
☞ Solutions
• sophisticated parallel algorithms that predicts (deals) with skew
• dynamic processor allocation (at execution time)
Spring, 2006 Arturas Mazeika Page 45
Parallel Hierarchical Architecture (1/2)
☞ The parallel hierarchical architecture is based on the following concepts
• Divide the query tree into activations. Assign each activation to a shared memory(SM) machine. Activation is the smallest unit of sequential processing that cannot befurther partitioned
• Make sure that there are more fragments than CPUs. In this case the SM is stillpossible to enjoy parallelism
• Run more threads in one SM that there are CPUs. In this case CPUs will be busy,though some threads are blocked due to unavailable recourses.
• Maximize parallelism in one SM, minimize parallelism between different SMs.
• Allow parallelism SM, so busy SMs give work to idle SMs. Compute the benefit of thetransfer of the work. As a rule of thumb send builds to idle SMs, rather than the data.
Spring, 2006 Arturas Mazeika Page 46
Recommended

















