
TITLE: Lenovo HPC and AI strategy Abstract: Eighteen months after the transition from IBM System x, Lenovo is number 2 in Top500 and won several highly visible accounts. This talk will explain why this happened by presenting Lenovo strategy for HPC and AI both from a hardware, software and innovation perspective. Presenter’s Bio: Luigi Brochard, Distinguished Engineer Luigi Brochard is Distinguished Engineer in Lenovo HPC & AI WW team. As IBM, he was the lead architect of many large HPC systems installed in Europe with POWER, Blue Gene and x86 processor architecture. He also led the development of the Energy Aware Scheduling feature which is included in IBM Spectrum Load Sharing Facility (LSF). At Lenovo, he is leading the Application team and the Open Source SW strategy for HPC and AI. Luigi has a Ph.D. in Applied Mathematics and a HDR in Computer Sciences from Pierre & Marie Curie University in Paris, France.

Lenovo HPC & AIStrategy
EAGE 2017, Paris, June 13-15, 2017
Luigi Brochard – Distinguished Engineer, WW HPC & AI, [email protected]

2
Lenovo Proven Trusted HPC Partner
Co-Innovation with LRZ
FirstWARM WATER
COOLED SUPER COMPUTER
Number 12 on TOP500World’s #3 KNL/OPA System
SUPERCOMPUTER INEMEA
2nd
Largest
#2 WW – 99 listings#1 China
Multiple PFLOP+ SKL wins
FastestGROWING
TOP 500 HPC VENDOR
2017 Lenovo. All rights reserved.

332017 Lenovo confidential. All rights reserved.
HPC PORTFOLIO AND ROADMAP
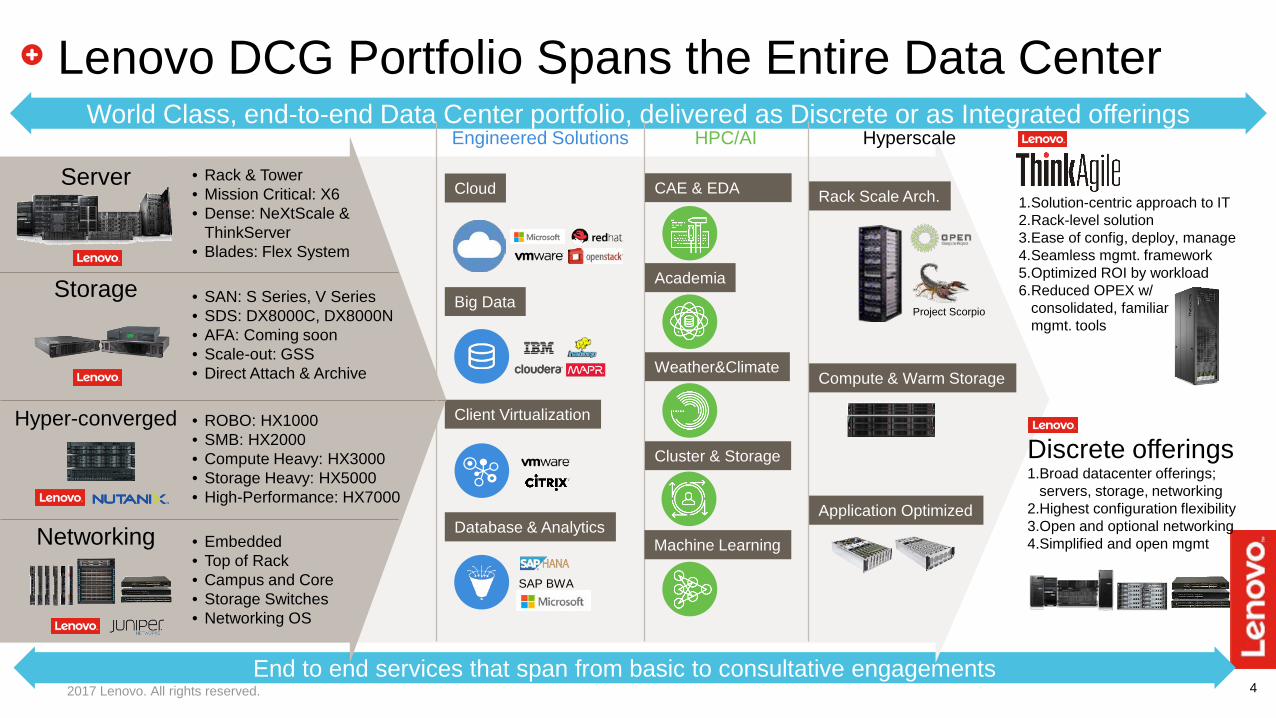
4End to end services that span from basic to consultative engagements
Lenovo DCG Portfolio Spans the Entire Data Center
SAP BWA
Cloud
Big Data
Client Virtualization
Database & Analytics
Rack Scale Arch.
Application Optimized
Compute & Warm Storage
Project Scorpio
1.Solution-centric approach to IT2.Rack-level solution3.Ease of config, deploy, manage4.Seamless mgmt. framework5.Optimized ROI by workload6.Reduced OPEX w/
consolidated, familiarmgmt. tools
Discrete offerings1.Broad datacenter offerings;
servers, storage, networking2.Highest configuration flexibility3.Open and optional networking4.Simplified and open mgmt
World Class, end-to-end Data Center portfolio, delivered as Discrete or as Integrated offeringsEngineered Solutions HPC/AI Hyperscale
Server • Rack & Tower• Mission Critical: X6• Dense: NeXtScale &
ThinkServer• Blades: Flex System
Storage • SAN: S Series, V Series• SDS: DX8000C, DX8000N• AFA: Coming soon• Scale-out: GSS• Direct Attach & Archive
Hyper-converged • ROBO: HX1000• SMB: HX2000• Compute Heavy: HX3000• Storage Heavy: HX5000• High-Performance: HX7000
Networking • Embedded• Top of Rack• Campus and Core• Storage Switches• Networking OS
CAE & EDA
Weather&Climate
Machine Learning
Academia
Cluster & Storage
2017 Lenovo. All rights reserved.

5
Moving forward into a decade of dense HPC
iDataPlex – Air / DWCdx360 - Harpertowndx360M2 - Nehalemdx360M3 - Westmeredx360M4 - Sandy Bridge
NeXtScale – Air / DWCnx360M4 - Sandy Bridge/Ivy Bridge nx360M5 - Haswell/Broadwell
Stark – Air Skylake/Icelake
NeXtScale – DWC Skylake/Icelake
2017 Lenovo. All rights reserved.
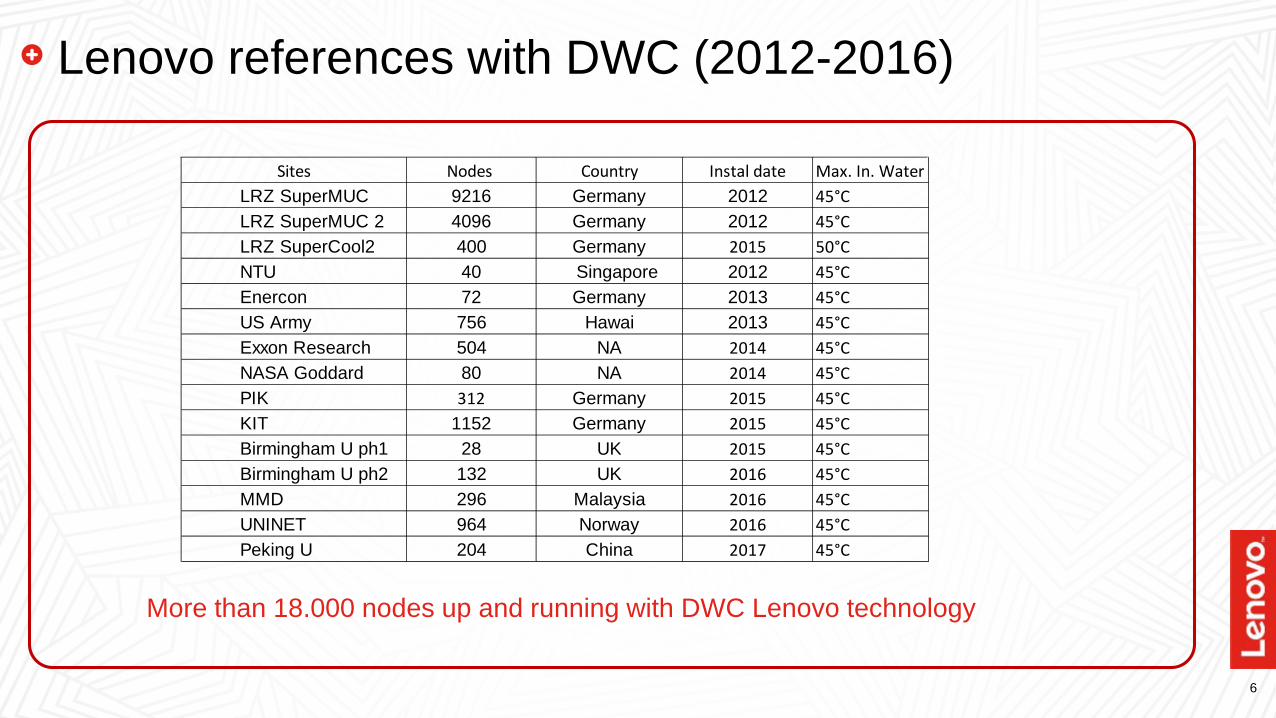
6
Lenovo references with DWC (2012-2016)
Sites Nodes Country Instal date Max. In. WaterLRZ SuperMUC 9216 Germany 2012 45°CLRZ SuperMUC 2 4096 Germany 2012 45°CLRZ SuperCool2 400 Germany 2015 50°CNTU 40 Singapore 2012 45°CEnercon 72 Germany 2013 45°CUS Army 756 Hawai 2013 45°CExxon Research 504 NA 2014 45°CNASA Goddard 80 NA 2014 45°CPIK 312 Germany 2015 45°CKIT 1152 Germany 2015 45°CBirmingham U ph1 28 UK 2015 45°CBirmingham U ph2 132 UK 2016 45°CMMD 296 Malaysia 2016 45°CUNINET 964 Norway 2016 45°CPeking U 204 China 2017 45°C
More than 18.000 nodes up and running with DWC Lenovo technology

7
Deliver Results Faster With HPC
Challenge What is Possible Best cost, speed and skill Deliver Unique Thinking
Helping Researchers and Companies Make Immediate Impact
2017 Lenovo. All rights reserved.

82017 Lenovo confidential. All rights reserved.
Recent wins• CINECA • BSC• Aramco

9
• ~20 Pflops cluster over 3 deliveries of technologies with Xeon and Xeon Phi in 2016 and 2017 on a single OmniPath fabric
• Step 1: 1512 Lenovo nx360M5 ( 2 Petaflops) – 21 racks – 126 NeXtScale Chassis– 3,024 Intel Broadwell-EP E5-2697v4 (2.3GHz, 145W)– 54.432Processor Cores– 12.096 16GB DIMMs– 6 GSS26 16PB raw in total
- >100GB/s
• Step 2 : KNL (~ 11 Petaflops)• Step 3: Skylake/Purley
Highest HPL performance on OPA in Top500 June 2016 !!
1.72 PF
2016 Lenovo. All rights reserved.

10
• 3600 Adamspass KNL nodes ( 11 Petaflops)– 50 Racks with 72 KNL nodes in Each Rack– 3.600 120GB SSD‘s– 244.800 cores– 345.600 GB RAM in 21.600 16GB DIMMs– 1.680 Optical cables
• 1512 Stark nodes (>4 Petaflops)– 21 racks – 3,024 Intel SkyLake– 72.576 cores– 4.9 Pflops peak
6.2 PF

112016 Lenovo Internal. All rights reserved.
CINECA – Pruned Fat tree topology , 2:1 blocking ratio OPA
768p DirectorOPA
768p Director
OPA 48p Edge
3p3p
OPA 48p Edge
3p 3p
3600 KNL nodesin 50 racks
1512 SKL nodesin 21 racks
1512 BDW nodesin 21 racks
32 NeXtScale BDW nodes32 KNL/ SKL nodes
OPA 48p
~12 PByte in 4 racks
OPA 48p
FDR
EDF 48pEdge (1:1)
1 rack
EDF 48pEdge (1:1)
32 NSD servers (1p/srv)
3x GSS26 @ 8TB (6 servers)
12p (2p/srv)

12
BSC MareNostrum 448 x Compute racks3,456 nodes, Intel Skylake 8160165,888 Cores11PF+Omni-Path interconnect

13
BSC Omni-Path network – overview
1 3
24 nodes
24
24 nodes
Each core:8 double Spine modules20 leaf modules640 ports, 592 used48 Free ports (7.5%) 4 free slot for leaf modules
Total:Up to 4,608 ports3,552 ports used 1,056 free ports
C1
44 4 4
141 144
24 nodes 24 nodes
C48
1 2
Storage edge switches
1 2
Mgt edge switches
4 44
44 4 4 4
Leaf 101Leaf 103Leaf 105Leaf 107Leaf 109Leaf 111Leaf 113Leaf 115Leaf 117Leaf 119
FreeFree
Leaf 102Leaf 104Leaf 106Leaf 108Leaf 110Leaf 112Leaf 114Leaf 116Leaf 118Leaf 120
FreeFree
Leaf 101Leaf 103Leaf 105Leaf 107Leaf 109Leaf 111Leaf 113Leaf 115Leaf 117Leaf 119
FreeFree
Leaf 102Leaf 104Leaf 106Leaf 108Leaf 110Leaf 112Leaf 114Leaf 116Leaf 118Leaf 120
FreeFree
OPA Core 6OPA Core 1
C
8 free ports in each core switch for CTE uplinks

142017 Lenovo Internal. All rights reserved.
Saudi Aramco Seismic 2015 Cluster
The Company• Saudi Multinational Oil & Gas CompanyThe Objective• Replace old Seismic Cluster (supporting 4 research groups on global level)Solution• Lenovo Scalable Infrastructure HPC SolutionTechnology• 77 Lenovo racks with nodes (7 rack OPA & 70 rack 10Gbps)• 1.498 Lenovo NeXtScale nodes E5-2680V4 SKU (1.459 Compute nodes)• 41.944 CPU cores• For Compute, 269TB DDR4 RAM• 128 nodes now on OPA interconnect i.s.o. 10Gbps EthernetBenefits• Reduced runtimes for the Seismic workloads of the 4 research groups
http://www.saudiaramco.com/en/home.html

15152017 Lenovo confidential. All rights reserved.
AI STRATEGY

16
AI vs Machine Learning vs Deep Learning
Human Intelligence Exhibited by Machines
An Approach to Achieve Artificial IntelligenceAlgorithms to parse data, learn from it, and then make a determination or prediction about something in the world
AI
Machine Learning
A Technique for Implementing Machine LearningDeep Learning
Multi layer neural networks

17
New Hardware for Machine Learning / AI
train
inference
remoteedge
JetsonTesla
DGX-1/GPU
TPU/2
XeonPhi /FPGA
Zeroth, Snapdragon
Eyeriss
Nervana
M1
Dynamic IQ
Radeon Instinct (GPU)
Radeon Instinct (GPU)
FPGA, Xeon Phi
VirtexFPGA
TrueNorth

18
ML/DL: Disrupting traditional programming model.....Deep learning
(learn by examples)Traditional programming
(learn by rules)Program
rulesTrain with
data
Inspired by the human brain
ExecutionOutput
Inference
2017 Lenovo Internal. All rights reserved.
InputLayer
HiddenLayer 1
HiddenLayer 2
HiddenLayer 3
OutputLayer
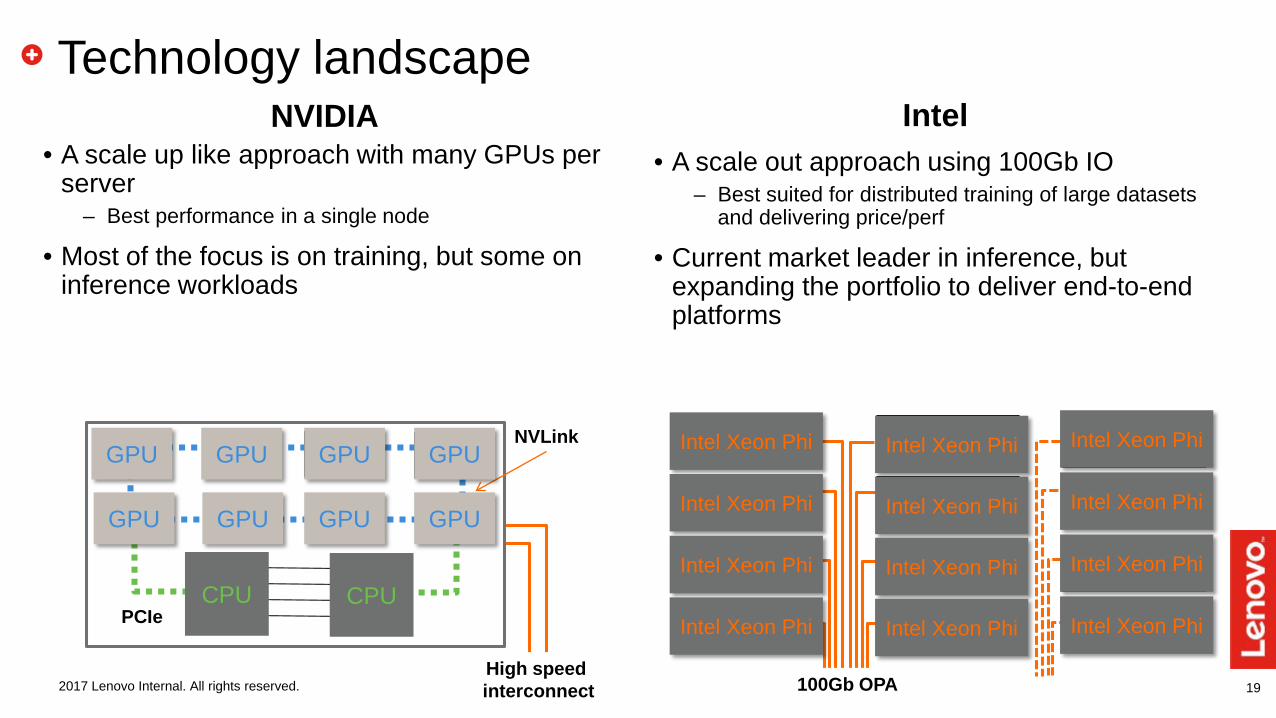
19
Technology landscapeNVIDIA
• A scale up like approach with many GPUs per server
– Best performance in a single node
• Most of the focus is on training, but some on inference workloads
2017 Lenovo Internal. All rights reserved.
PCIe
NVLink
High speed interconnect
Intel• A scale out approach using 100Gb IO
– Best suited for distributed training of large datasets and delivering price/perf
• Current market leader in inference, but expanding the portfolio to deliver end-to-end platforms
100Gb OPA
GPU GPU GPU GPU
GPUGPUGPUGPU
CPU CPU
Intel Xeon Phi
Intel Xeon Phi
Intel Xeon Phi
Intel Xeon Phi
Intel Xeon Phi
Intel Xeon Phi
Intel Xeon Phi
Intel Xeon Phi
Intel Xeon Phi
Intel Xeon Phi
Intel Xeon Phi
Intel Xeon Phi

20
Big data and HPC driving workflowsRequires specialized architectures for each process step
2017 Lenovo Internal. All rights reserved.
Store Train Deploy
ModelDataClassificationDetectionSegmentation
• Storage• Preparation• Feeding• Hadoop/Spark
• HPC characteristics- Compute intensive- Scale up and out- Accelerators/high-
speed networks
• Enterprise/device computing
• Scale out architectures• CPU+FPGA
Input
Big Data Training Inference/Scoring

21
Pain Points for deploying AITiers Stack Pain points
ApplicationAI workload
Workflow Complexity: Data preprocessing, setting up and validating models
FrameworksStack Complexity: Open Source stack is difficult to configure or orchestrate
Libraries
HWXeon, Xeon Phi, FPGA, GPU
Scale: Distributed training is very difficult for enterprise customers
Store Train Deploy
ModelDat aClassificationDetectionSegmentation
I nput
Big Data Training Inference/Scoring
Each part of the workflow demands specialized architectures for big data, training, and inference
Systems w/ Nvidia GPUs
Intel CPUs orAccelerators
C/C++Caffe
NVIDIA CUDAcuDNN
Intel® Math Kernel Library(Intel® MKL)
Intel® MKL-DNN
AI application
E2E Solution

22
Industry Verticals
Applications
Healthcare
FinanceAcademia
Hyperscale
Big Data AnalyticsImage/Video Recognition
Voice RecognitionText Recognition
Language Processing
Lenovo‘s Unique Approach to AI
2017 Lenovo Internal. All rights reserved.
Manufacturing
Developer tools
Frameworks
Optimized libsSystem mgmt
HW platforms AI software stack
ScalableFlexible
Optimized for AI
Value
Easy to deploy
Leno
vo o
rche
stra
tion
softw
are
Bringing scalable AI platforms to market
Servers
Storage
Networking
AI innovation centerBuilding university partnerships to demonstrate AI capabilities to industry while building expertise and
talent to lead the market in future

23
Deep Learning HW portfolio
x3650 + 2 GPU (P40)
To be announced later
x3650 + 2GPU
BDW Xeon (x3550/3650)
Intel Knights Landing server
TOMORROWTODAY
NeXtScale + 4GPU (P100/P40)
Infe
renc
e
2017 Lenovo Internal. All rights reserved.
INTEL NVIDIA INTEL NVIDIA
Develop HW
To be announced later
To be announced later
To be announced later

24
Lenovo HPC Software StackLenovo OpenSource HPC Stack
An OpenSource IaaS suite to run and manage optimally and transparently HPC, Big Data
and Workflows on a virtualized infrastructure adjusting dynamically to user and datacenter
needs through energy policies
• Build on top of OpenHPC with xCAT• Enhanced with Lenovo configuration,
plugins and scripts • Add in IBM Spectrum Scale, Singularity*• Add in Lenovo Antilles and Energy Aware
run time• Integrated and supported
A ready to use HPC Stack
* collaborating w/ Greg Kurtzer from Lawrence Berkeley National Lab
Demo at ISC‘17
2017 Lenovo. All rights reserved.
Customer Applications
Parallel File Systems
IBM Spectrum Scale & Lustre NFS
Ente
rpris
e Pr
ofes
siona
l Ser
vice
sIn
stalla
tion
and
custo
m se
rvice
s, m
ay n
ot in
clude
se
rvice
supp
ort f
or th
ird p
arty
softw
are
User / Operator Web Portal
Antilles - Simplified User Job View / Customized
OS OFED
Compute Storage Network
Lenovo System x Virtual, Physical, Desktop, Server
OmniPath
xCATExtreme CloudAdmin. Toolkit
Confluent
Infiniband
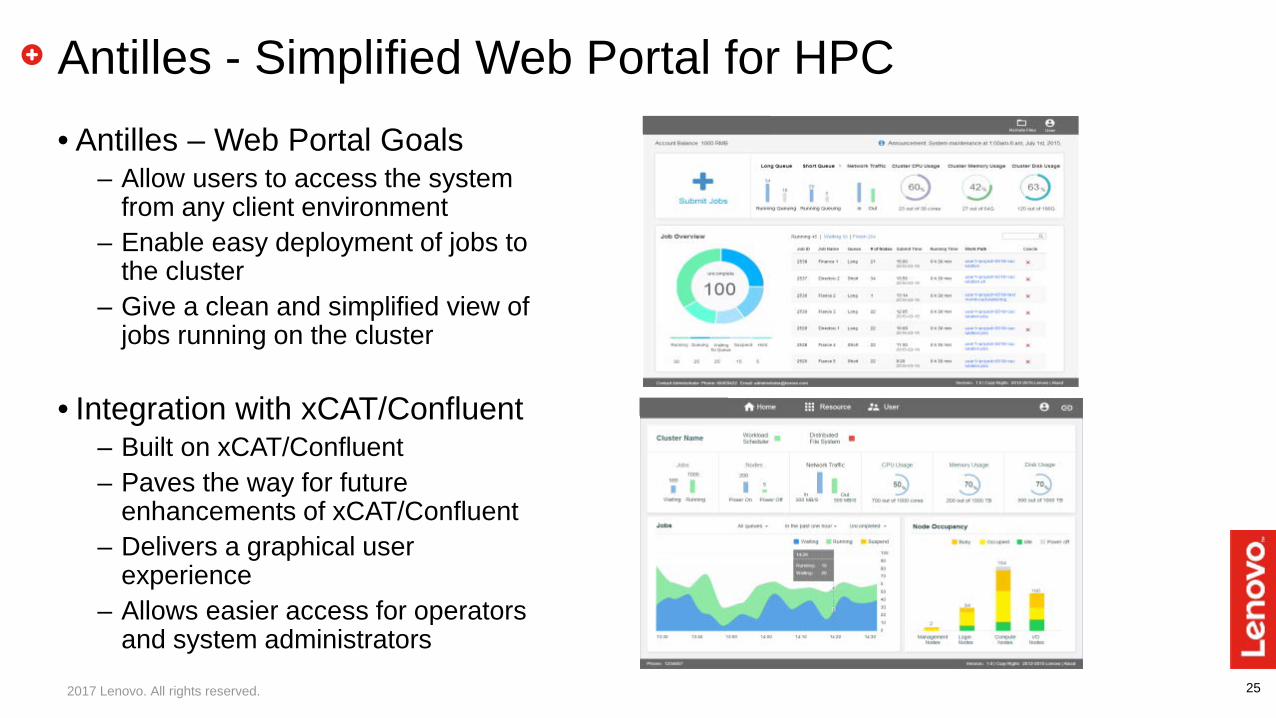
25
Antilles - Simplified Web Portal for HPC• Antilles – Web Portal Goals
– Allow users to access the system from any client environment
– Enable easy deployment of jobs to the cluster
– Give a clean and simplified view of jobs running on the cluster
• Integration with xCAT/Confluent– Built on xCAT/Confluent– Paves the way for future
enhancements of xCAT/Confluent– Delivers a graphical user
experience– Allows easier access for operators
and system administrators
2017 Lenovo. All rights reserved.
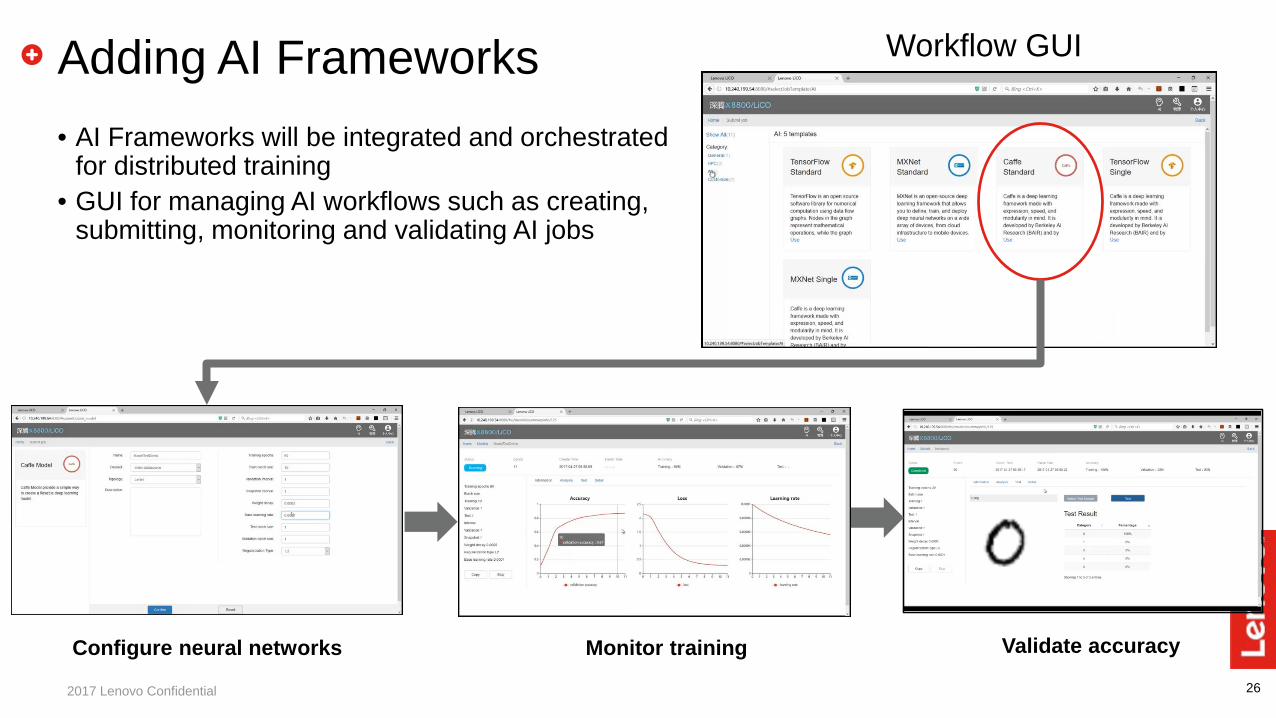
262017 Lenovo Confidential
Adding AI Frameworks• AI Frameworks will be integrated and orchestrated
for distributed training• GUI for managing AI workflows such as creating,
submitting, monitoring and validating AI jobs
Workflow GUI
Configure neural networks Monitor training Validate accuracy
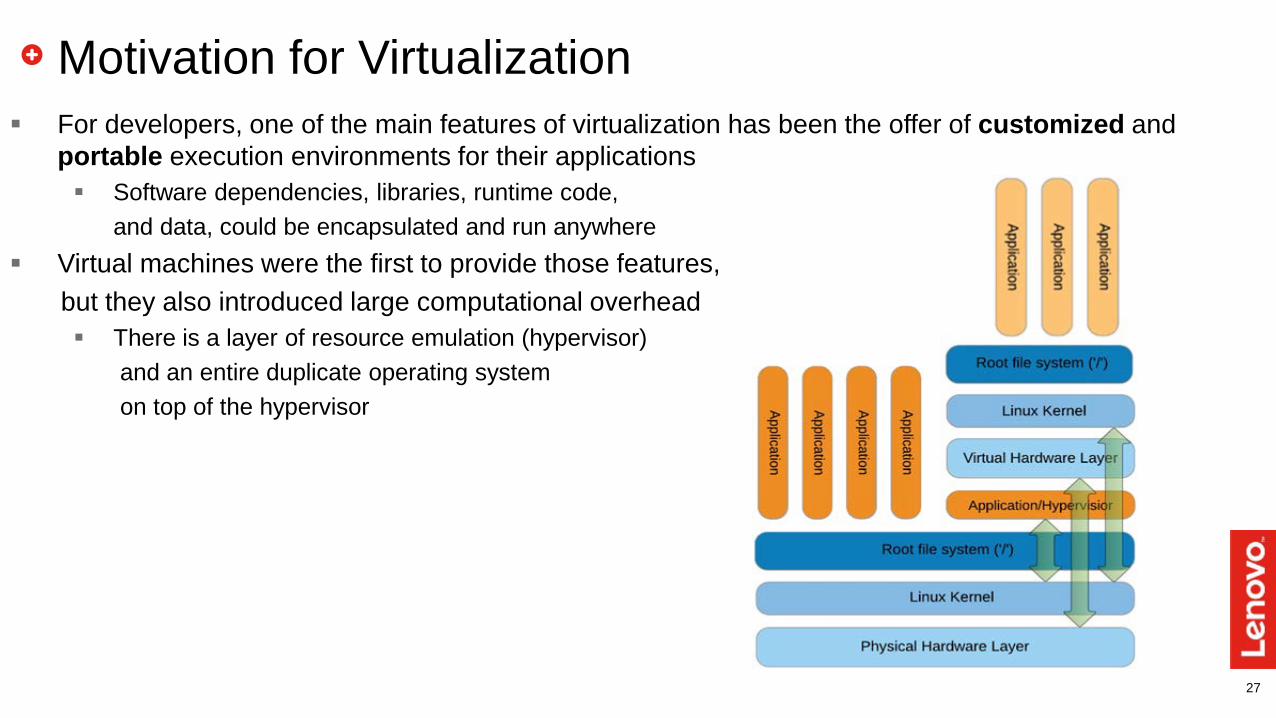
27
Motivation for Virtualization For developers, one of the main features of virtualization has been the offer of customized and
portable execution environments for their applications Software dependencies, libraries, runtime code,
and data, could be encapsulated and run anywhere Virtual machines were the first to provide those features,
but they also introduced large computational overhead There is a layer of resource emulation (hypervisor)
and an entire duplicate operating system on top of the hypervisor

28
Motivation for Docker• Containers (i.e. Docker) avoid the computational overhead by implementing
lightweight OS virtualization– Multiple isolated user-space instances share a single operating system with little overhead
(no emulation)– Namespaces: Containers can have their own view of system: UIDs, file systems, processes,
networks, …– Cgroups: Metering and limiting container resources
But Docker features are very much aligned with enterprise micro-services and web-enabled cloud applications, not with HPC– e.g. security concerns (container is
spawned as a child of a root owned Docker daemon) and hard integration with HPC resources

29
Motivation for Singularity• Singularity supports mobility of compute while avoiding the Docker issues on
HPC environments– Simple integration with schedulers, InfiniBand, GPUs, MPI, file systems– Limits user’s privileges (inside user == outside user)– No root owned container daemon
Singularity uses the smallest number of namespaces necessary– By default share most everything,
low isolation– More isolation can be configured
as neededCgroups not touched by Singularity

30
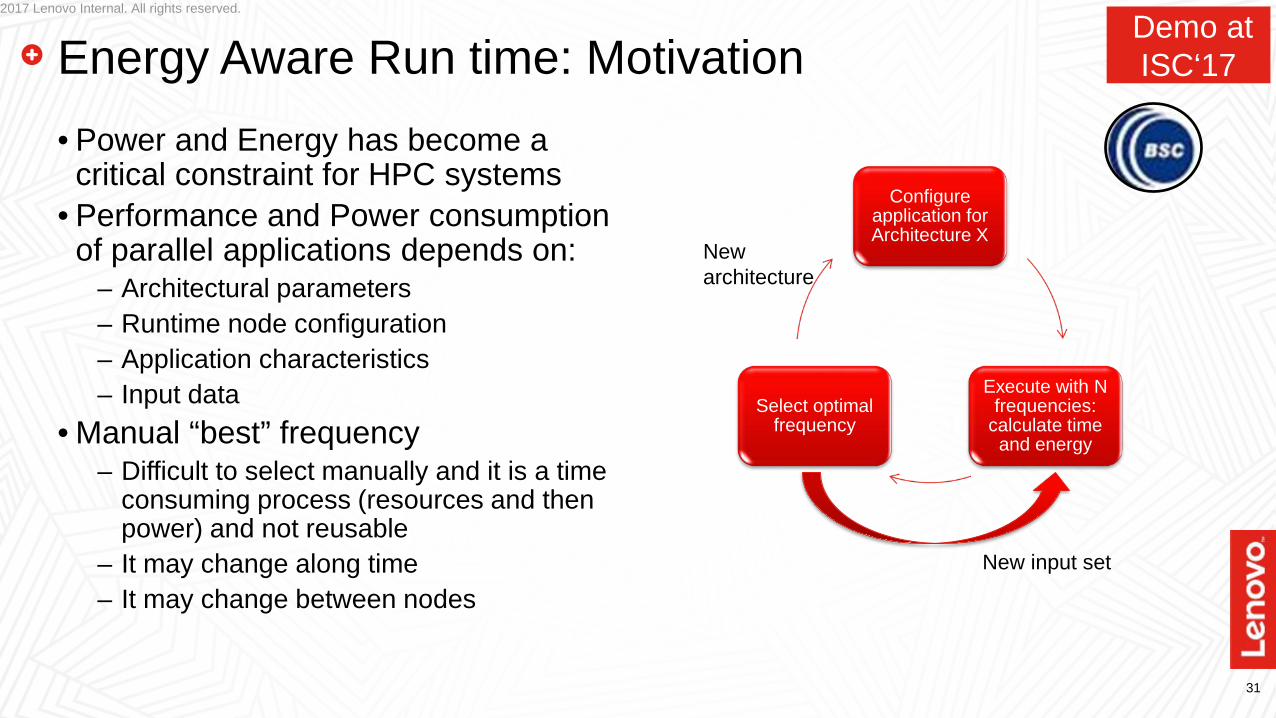
Overhead of Docker vs Singularity Performance degradation can be important with some applications when running several Docker
containers per host
0.0
0.2
0.4
0.6
0.8
1.0
1.2
BARE METAL DOCKER SINGULARITY SINGULARITY+CG
Nor
mal
ized
TFL
OP/
s
HPCC: G-FFT28 MPIs - 28 CPUs (exactly-subscribed)
1 VMs/HOST 7 VMs/HOST 28 VMs/HOST
0.0
0.2
0.4
0.6
0.8
1.0
1.2
BARE METAL DOCKER SINGULARITY SINGULARITY+CG
Nor
mal
ized
GFL
OP/
s
HPCC: EP-DGEMM28 MPIs - 28 CPUs (exactly-subscribed)
1 VMs/HOST 7 VMs/HOST 28 VMs/HOST
31
2017 Lenovo Internal. All rights reserved.
Energy Aware Run time: Motivation• Power and Energy has become a
critical constraint for HPC systems• Performance and Power consumption
of parallel applications depends on: – Architectural parameters– Runtime node configuration – Application characteristics – Input data
• Manual “best” frequency– Difficult to select manually and it is a time
consuming process (resources and then power) and not reusable
– It may change along time– It may change between nodes
Configure application for Architecture X
Execute with N frequencies:
calculate time and energy
Select optimal frequency
New input set
Newarchitecture
Demo at ISC‘17

32
EAR proposal• Automatic and dynamic frequency selection based on:
– Architecture characterization– Application characterization
- Outer loop detection (DPD)- Application signature computation (CPI,GBS,POWER,TIME)
– Performance and power projection– Users/System policy definition for frequency selection (configured with thresholds)
- MINIMIZE_ENERGY_TO_SOLUTION- Goal: To save energy by reducing frequency (with potential performance degradation)- We limit the performance degradation with a MAX_PERFORMANCE_DEGRADATION threshold
- MINIMIZE_TIME_TO_SOLUTION - Goal: To reduce time by increasing frequency (with potential energy increase) - We use a MIN_PERFORMANCE_EFFICIENCY_GAIN threshold to avoid that application that do not
scale with frequency to consume more energy for nothing
2017 Lenovo Internal. All rights reserved.

332017 Lenovo Internal. All rights reserved.
BQCD_CPU with EAR MIN_ENERGY_TO_SOLUTION
MPI
RANK
0
MPI
RANK
8
Big loop detected
Policy is appliedF: 2.6Ghz2.4Ghz
Power is reduced
Iteration time issimilar
34
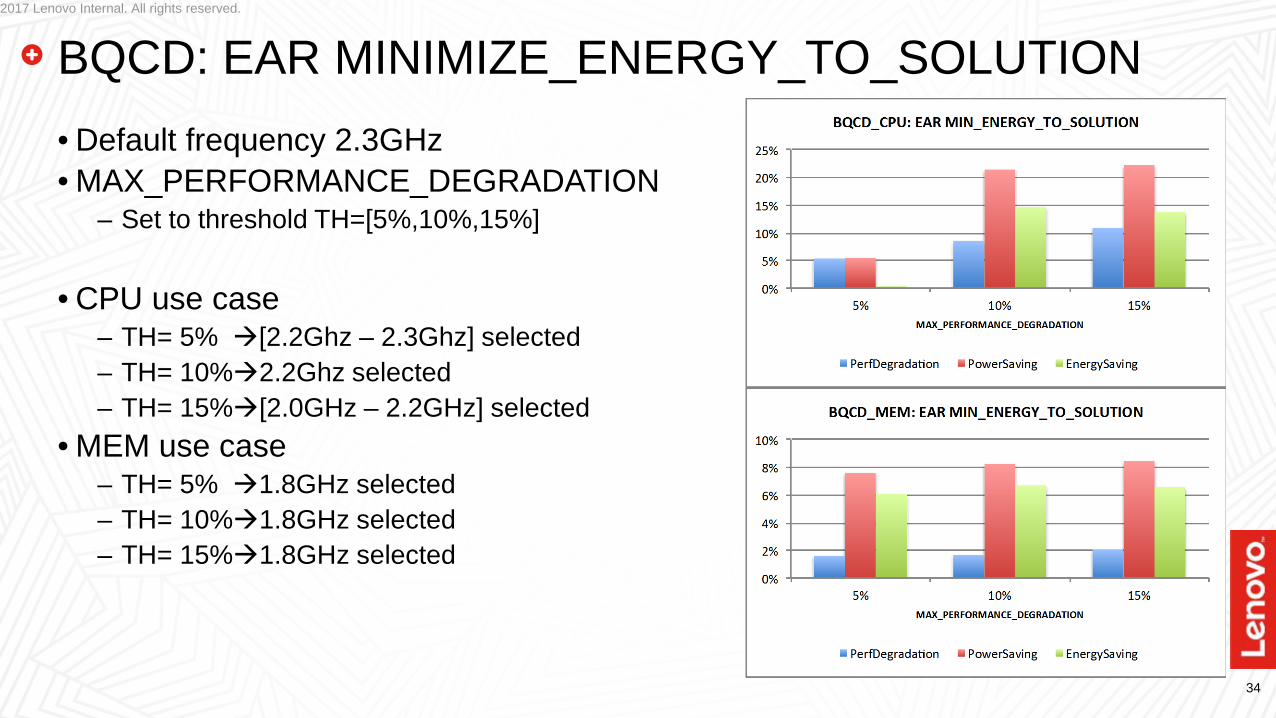
2017 Lenovo Internal. All rights reserved.
BQCD: EAR MINIMIZE_ENERGY_TO_SOLUTION• Default frequency 2.3GHz• MAX_PERFORMANCE_DEGRADATION
– Set to threshold TH=[5%,10%,15%]
• CPU use case– TH= 5% [2.2Ghz – 2.3Ghz] selected– TH= 10%2.2Ghz selected– TH= 15%[2.0GHz – 2.2GHz] selected
• MEM use case– TH= 5% 1.8GHz selected– TH= 10%1.8GHz selected– TH= 15%1.8GHz selected
35
2017 Lenovo Internal. All rights reserved.
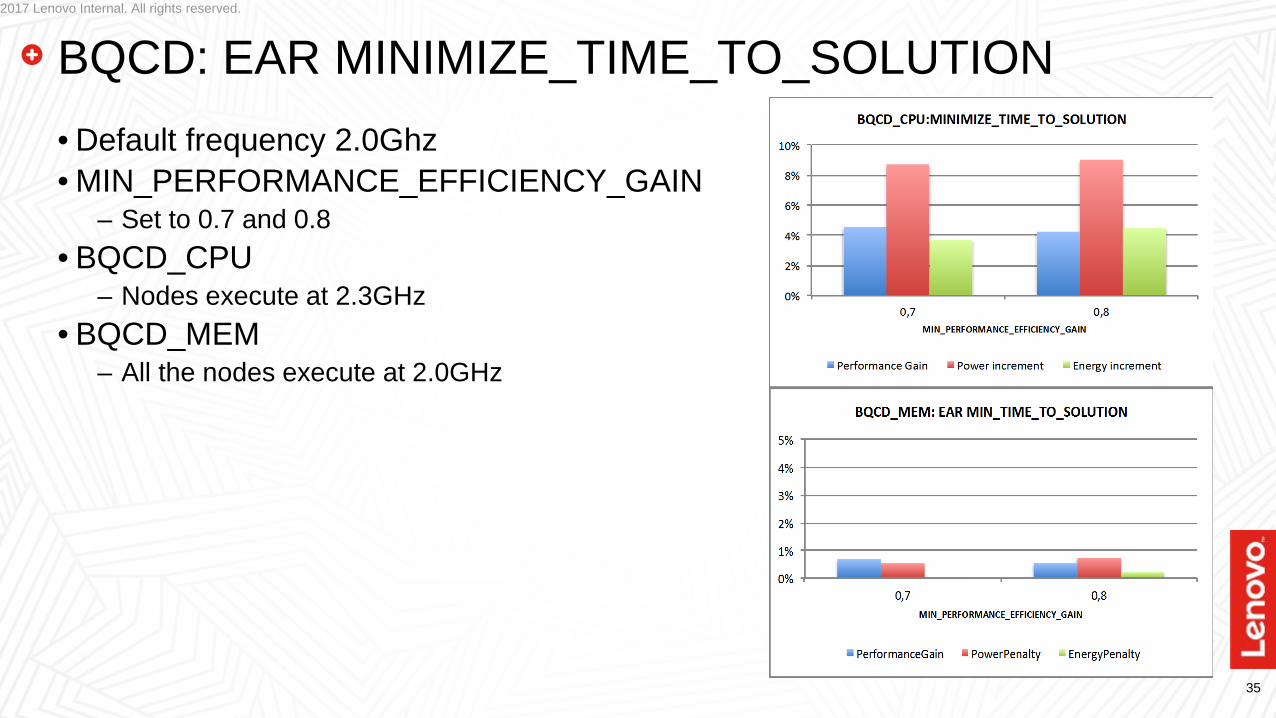
BQCD: EAR MINIMIZE_TIME_TO_SOLUTION• Default frequency 2.0Ghz• MIN_PERFORMANCE_EFFICIENCY_GAIN
– Set to 0.7 and 0.8• BQCD_CPU
– Nodes execute at 2.3GHz• BQCD_MEM
– All the nodes execute at 2.0GHz

36362017 Lenovo confidential. All rights reserved.
LENOVO SERVICE

37
Services• Implementation
– Project Management– Physical Setup– Software Setup
• Operation Support– Onsite Managed Service– Remote Managed Service
• Application Support– Onsite Application Service
• Maintenance Support– Based on the classification of components
2017 Lenovo. All rights reserved.

382017 Lenovo Internal. All rights reserved.
Lenovo ISC17 Booth
Table 1
Table 2
Table 3
HW Interactive
Show & TellStark HWExcelero
demo
Rack with various HW
EAR demo AI demo
NXS WTC demo
Open HPC Software
Stack

Recommended

















