Embed Size (px)
Citation preview

+
グループミーティング@zakktakk

+本⽇の発表内容
⾦融テキストマイニングØ Web上の⼤量のテキスト情報と市場変動の関連性を分析
(⾦融テキストマイニング研究の紹介,和泉潔)
Ø 対象となるテキストのリソースは量,質ともに様々
Ø 経済指標などの数値情報では指標化されていない情報をテキストから素早く⾃動的に抽出することが期待される

+研究例:Twitter
Bollenらの研究(2011)
Ø ユーザの⼼的状態を明⾔している投稿のみを分析対象とする
Ø テキストの内容から平穏・警戒・確信・活気・善意・幸福の6次元の尺度を計算
GPOMS指数
Ø GPOMS指数とダウ平均株価指数の因果性を検定
◯ ⼿法
◯ 結果Ø 「平穏」の尺度と株価に因果性があった
Ø 翌⽇の株価の騰落の⽅向性を86.7%の精度で予測(テキスト情報を⽤いない場合は73.3%の精度)
“I am”とか”I feel”が含まれた投稿を⼼的状態を明⾔している投稿とみなす
+研究例:Twitter
Ruizらの研究(2012)
◯ ⼿法Ø ツイート情報からツイート・ユーザ・ハッシュタグ・URLをノード,RT・引⽤・作成をリンクとするグラフを構築
実際は企業名をハッシュタグに⽤いているツイートを分析対象とする
+研究例:Twitter
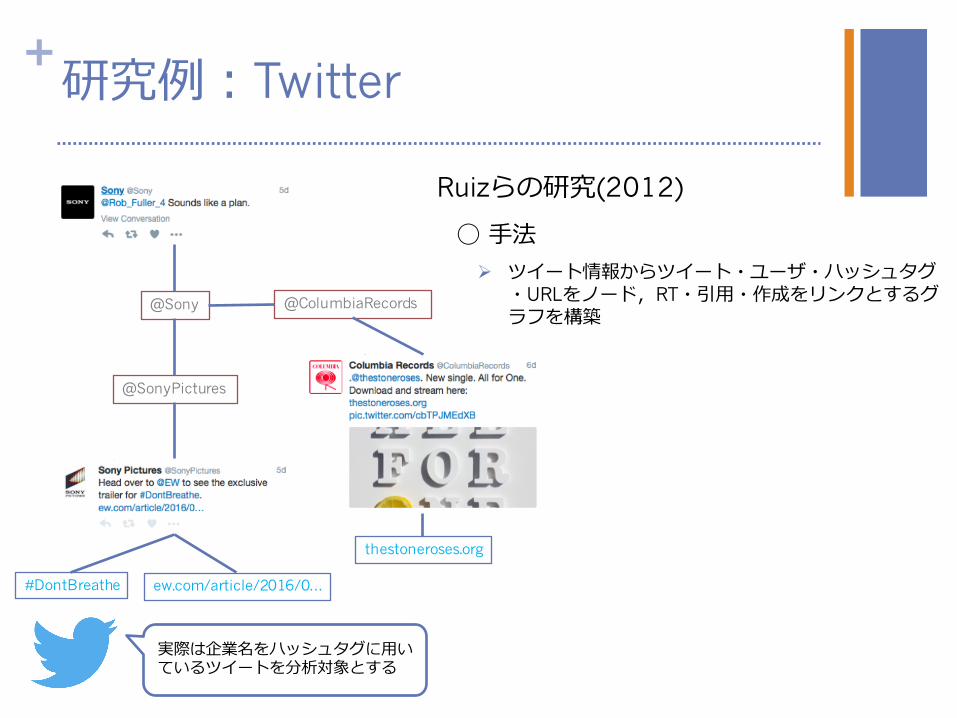
Ruizらの研究(2012)
◯ ⼿法
@Sony @ColumbiaRecords
@SonyPictures
#DontBreathe
thestoneroses.org
ew.com/article/2016/0…
Ø ツイート情報からツイート・ユーザ・ハッシュタグ・URLをノード,RT・引⽤・作成をリンクとするグラフを構築
実際は企業名をハッシュタグに⽤いているツイートを分析対象とする

+研究例:Twitter
Ruizらの研究(2012)
◯ ⼿法Ø ツイート情報からツイート・ユーザ・ハッシュタグ・URLをノード,RT・引⽤・作成をリンクとするグラフを構築
⾏動基準の特徴量
グラフ特徴量・ノード数・エッジ数・連結要素数
・ツイート数・ツイートしたユーザ数・RT数・RTしたユーザ数・ユーザに⾔及したツイート数・URLを引⽤したツイート数
Ø グラフ構造を表す指標と対象とする銘柄の翌⽇の価格の変化率や取引⾼との相関を分析
◯ 結果Ø グラフの連結要素数と取引⾼に正の相関関係
Ø 価格の変化率と相関のある指標は発⾒できず
どの銘柄の取引されやすいかは予測できるが,株価が上昇するか下落するかはわからない
実際は企業名をハッシュタグに⽤いているツイートを分析対象とする
+研究例:掲⽰板
丸⼭らの研究(2008)
Ø 各個別銘柄の掲⽰板から特徴量を抽出
◯ ⼿法
◯ 結果Ø 3つの指標とボラリティ・取引⾼には有意な相関関係が⾒られたが,変化率との相関はなし
・投稿数
・全投稿の強気⽐率
・⼀定期間内の強気 or 弱気投稿数の偏り
Ø 3つの指標と翌⽇の価格の変化率・ボラリティ(価格変動の標準偏差)・取引⾼の相関を分析
どの銘柄の取引されやすいかは予測できるが,株価が上昇するか下落するかはわからない

+研究例:ニュース
Schumakerらの研究(2010)
Ø Yahoo! Financeの記事から⽶国の個別銘柄の20分後の株価動向を予測
Ø あらかじめ株価関連⽤語の辞書を作成しておき,各記事に⽤語がどれだけ出現するかを⾒る
Ø 個別銘柄の株価の変化をサポートベクタ回帰を⽤いてモデル化
◯ ⼿法
◯ 結果Ø S&P 500 (⼤型株500銘柄から算出された株価指数)の構成銘柄で運⽤しているクオンツ・ファンドよりも運⽤成績が良い (8.5%のリターン)
Ø 20分後に1%以上の株価変動が起きると予測された銘柄の売買を⾏う
良い結果のように⾒えるが,実際は条件をかなり限定した⽐較を⾏っている

+研究例:経済レポート
和泉らの研究(2011)⾦融経済⽉報 (2015年12⽉)
Ø ⽇銀の発⾏する⾦融経済⽉報をテキストマイニング
◯ ⼿法
◯ 結果
Ø ⽂章から経済関連単語を抽出し,さらに主成分分析により30個の特徴量を抽出
Ø 重回帰分析で特徴量と国債市場の価格データの関係を表す回帰式を求める
Ø 価格の⼤幅な⾼騰や下落など,市場が⼤きく動く時の予兆を抽出できた
Ø 国債市場での運⽤テストでは数値データを使った回帰よりも⾼い運⽤益を得た





























