Embed Size (px)
Citation preview

ルールベースから機械学習への道
2015-09-16サイボウズラボ西尾泰和
このスライドはサイボウズ社内の機械学習勉強会で話した内容から社内のデータなどのスライドを削除して再構成したものです。
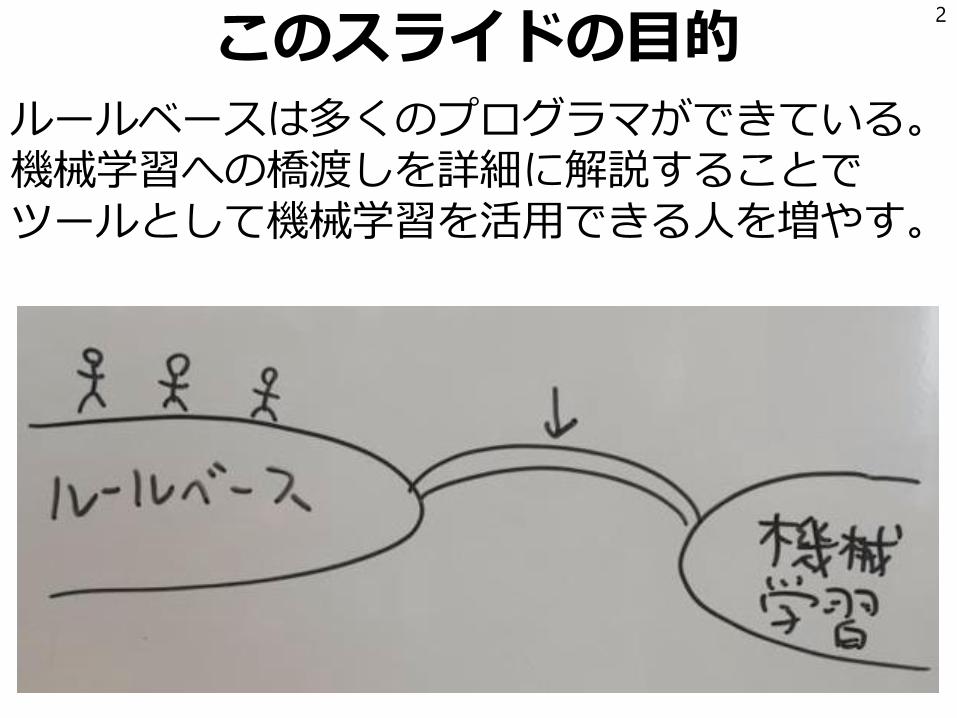
このスライドの目的
ルールベースは多くのプログラマができている。機械学習への橋渡しを詳細に解説することでツールとして機械学習を活用できる人を増やす。
2

「ルール」とは
将来的にいろいろな抽象化がされるが今のところは「TrueかFalseを返すコード」と思っていい。
3
if (これはルール) { … }
def foo(x):
… return True
return False# これもルール
*.py[cod]
*$py.class
*.so
env/
.eggs/
正規表現の羅列もルール

ルールはたくさんある
すでに皆さんの書いているコードの中にもルールはたくさんあるはず
「複雑な判断」が必要なケースではたくさんの細かいルールをまとめて大きな複雑な判断を行っているはず
「まとめる」とは何か?
4

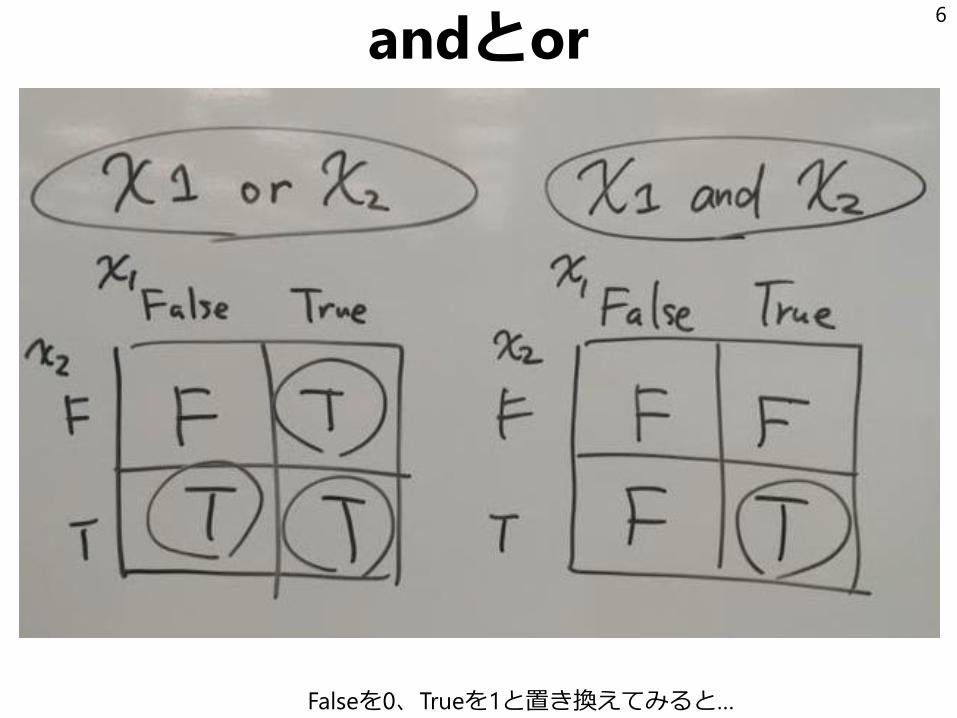
まとめかたの例(単純なもの)
「ルール1、ルール2、…ルールnのうちどれかがTrueの時にTrueを返す」
=全部をorでつなぐ
「ルール1、ルール2、…ルールnのすべてがTrueの時にTrueを返す」
=全部andでつなぐ
5
andとor6
Falseを0、Trueを1と置き換えてみると…

andとorの別表現7

論理式を数式に
「全部or/andでつなぐ」という論理式は「足して閾値と比較する」というコードに変換できる。
その書き換えに何のメリットが?
8

あいまいさの表現
「ルールx1, x2, x3…は時々誤爆するから単体ではあんまり信用出来ないけど、3個以上Trueになってる時はTrueを返したい」
= Σ(xi) > 2.5
これを論理式で書こうとするとめんどくさい。シンプルに表現できる表現方法を使うことで思考を節約する。
9

もっと複雑なケース10

例1一部信用出来ないルール
「ルールx1, x2, …は十分信用できるのでどれか一つがTrueならTrueを返していいけどルールx5, x6, …はn個以上Trueじゃないと信用出来ない」
これのシンプルな例としてx1 or (x2 and x3)を考える。x1は単体で信用できるが、x2とx3信頼出来ないので両方Trueの時だけにしたい。
11

x1を2倍する12

例1のまとめ
信用できるルールほど大きな「重み」が付く。
この表現方法のことを以下しばらく「重み付き和の方法」と呼ぶ。
13

例2例外があるルール
「ルールx1, x2…のどれかがTrueならTrueを返すただし例外としてルールx5がTrueの時を除く」
これのシンプルな形として(x1 or x2) and (not x3)
を考える。x3がTrueの場合を例外として、x1かx2
がTrueならTrueを返す。
14

x3が1の時Falseなので15
同じように右肩上がりで切りたい

x3を-2倍してみる16

例2のまとめ
否定には「負の重み」が付く。
17

例3もっと複雑なルール
Q:任意の論理式が重み付き和の方法で表現できる?
→YesともNoとも言える、ちょっと補足が必要。
例として
x1 xor x2 = (x1 or x2) and not (x1 and x2)を考えてみよう。
18
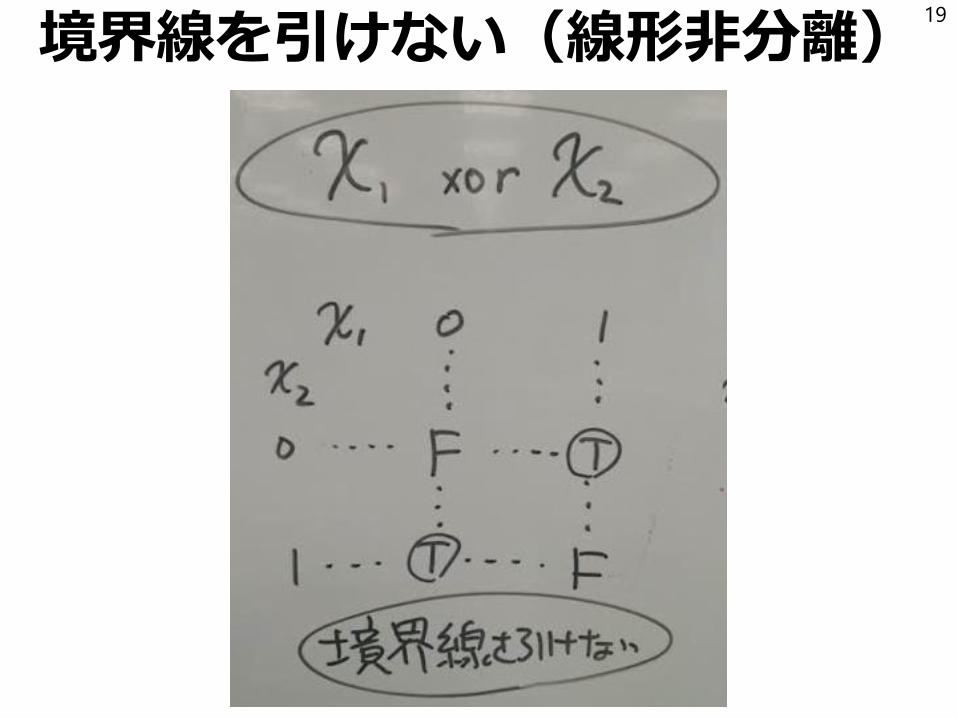
境界線を引けない(線形非分離)19

ルールを追加する
たとえば新しくx3というルールを追加する
x3 = x1 and x2
そうすると
x1 xor x2 = (x1 or x2) and not (x1 and x2)
= (x1 or x2) and (not x3)
これは例2と同じになる。
20

例3のまとめ
重み付き和の方法で表現できない論理式もある。
そんな時は「ルールの組み合わせ」を新しいルールとして追加すれば良い。
21

ここまでの流れ
複雑な判断が必要なケースでは細かいルールを「まとめ」て使っている。
その細かいルールのまとめかたにはandとorで論理的にまとめる方法の他に、重み付き和の方法がある。
後者のほうがあいまいな判断に使いやすい。
22

重みをどうやって決めるのか?
1. とりあえず全部1にする(今「全部and」や「全部or」なら良くはなっても悪くはならない)
2. 手で適当に指定する(このルールは誤爆多いから信用出来ないとか書いた人がわかっているケース)
3. 重みを機械的に決める
=機械学習
23

機械学習の(教師あり学習の)例24

予測
1. 入力に重みをかけて足しあわせ(Σ)
その結果が閾値θより大きいかどうかでTrueかFalseを出力する
25
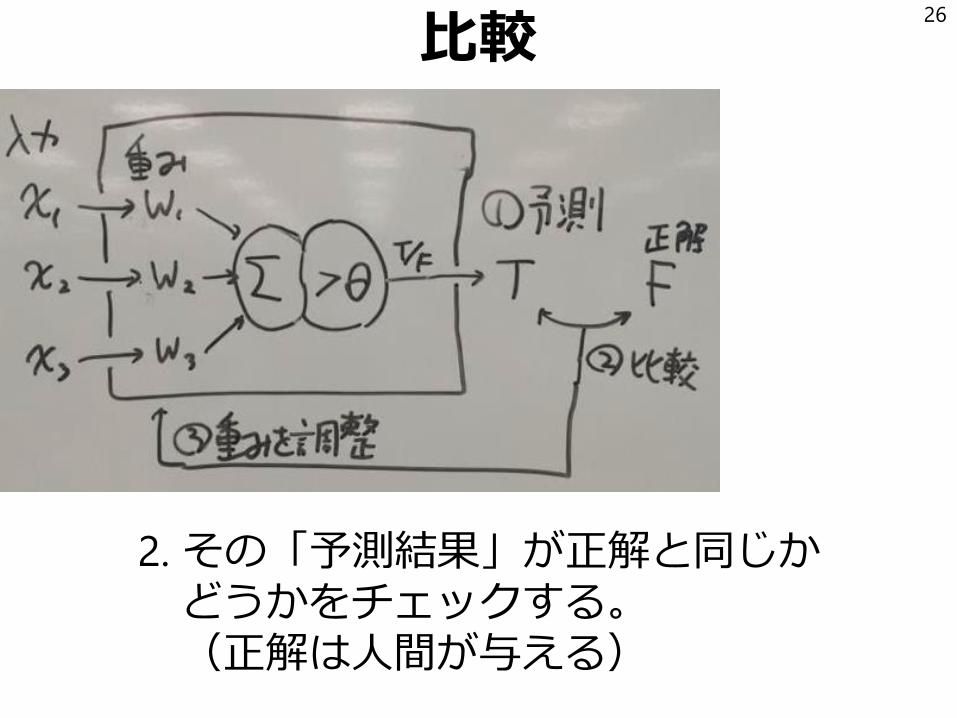
比較
2. その「予測結果」が正解と同じかどうかをチェックする。(正解は人間が与える)
26

重みを調整
3. 予測結果と正解が異なっていた場合正しくなる方向へと重みを調整する
27

重みの調整の例
1. 正解はFなのにTと予測した
2. つまりΣの結果が大きすぎる
3. wi * xi が大きいiについてwiをちょっと減らす
28
雑な方法だけどこれでもちゃんと学習する

元祖人工ニューロン
1943年、McCullochとPittsが神経細胞の振る舞いにヒントを得て論理計算が可能なモデルを提案*
それは「入力に重みを付けて足しあわせ、閾値を超えたら1の出力を出す」というものだった。
つまりここまで「重み付き和の方法」と呼んできたものは実は「McCulloch&Pitts型人工ニューロン」(MCP)だった。
29
* ‘A logical calculus of the ideas immanent in nervous activity’

大きく分けて2つの路線がある30
McCalloch-Pitts人工ニューロン

補足
細かいことを言えば機械学習の各手法はもっと複雑に枝分かれや合流をしているのだけど今回は「大きく分けて積み重ねていく系とそうでないのがあって、話題のDeepLearningは積み重ねる系だけど、今回は枯れた技術であるロジスティック回帰を使う」ぐらいの理解でOK
(細かいことの例:人工ニューロンを元に1958年にパーセプトロンが発表されるが、その当時のパーセプトロンは3層のものでも入力層と中間層の間はランダム結線で元祖と同じように線形非分離な問題が解けなかった。1969年にそれを指摘されて研究が下火になるが、1974年~1986年に誤差逆伝搬法のニューラルネットへの応用が発表され、多層のパーセプトロンがまともに学習できるようになった。一方、ロジスティック回帰は人工ニューロンとは無関係に1958年に発表されたが、後に2層の単純パーセプトロンと等価であることが示された)
31

ロジスティック回帰(LR)
・MCPはTrue/Falseを出力したがLRは確率値を出力する。
・MCPの入力は0/1だったが、LRは実数値で良い(けど今回は0/1で使う)
32

実際の流れ
「XXXするとよさそうなものがあったらYYY」というユーザストーリーを実現する方法を考える
1. 「XXXするとよさそうなものがあったら」に注目した
2.「XXXするとよさそう」を「判断」するコードが必要と考えた
33
以降伏字が多くなりますがご容赦を

実際の流れ
3. とりあえず適当にXXXっぽいキーワードで検索して眺めた
4. XXXっぽい発言がたくさんあるスレッドを発見したのでファイルに書き出した
5. それを眺めながら適当にルールを書いた
34

ルールの例
(削除されました)
35

重み
6. 「ルールの重みをどう決めるか?」→まずは全部の重みを1とした
7. 重みづけして足し合わせた値でソートしてどんな感じか観察した
36

スコアの高いもの
(削除されました)
37

スコアの低いもの
(削除されました)
38

適当に教師データを作る
8. さっきのランキングの上の方と下の方を見て正解がTになる例とFになる例を150件ほど別ファイルに転記
9. そのデータでロジスティック回帰
39

正解データを読んでLRを学習40
file_yes = codecs.open(‘XXX.txt', 'r', 'utf-8')
file_no = codecs.open('not_XXX.txt', 'r', 'utf-8')
xs = []
ys = []
for line in file_yes:
line = preprocess(line)
xs.append(make_feature_vector(line))
ys.append(1)
for line in file_no:
line = preprocess(line)
xs.append(make_feature_vector(line))
ys.append(0)
from sklearn.linear_model import LogisticRegression
model = LogisticRegression()
model.fit(xs, ys)

特徴ベクトルの作り方41
from rules import rules
def make_feature_vector(s):
fv = []
for f in rules:
rs = f(s)
if rs:
fv.append(1)
else:
fv.append(0)
return fv

能動学習
10. 正解を教えてないデータについて、ロジスティック回帰で予測をさせて、確率が0.5に近い順に表示させてみた(つまり現状の教師データではTかFか判断がつかないものを表示)
11. 0.5に近い順に1行ずつ表示して、僕が対話的にy/nを入力し、教師データに追加するようにした
12. 眺めながら、場合によってはルールのほうを追加した
42

例
(削除されました)
43

対話的に学習データを追加44
unknown = codecs.open(‘SOMETHING.txt', 'r', 'utf-8')
buf = []
for line in unknown:
s = preprocess(line)
v = make_feature_vector(s)
score = model.predict_proba(v)[0][1]
buf.append((abs(0.5 - score), score, s, line))
buf.sort()
for _dum, score, s, line in buf:
print u"{:.2f}".format(score),
print line.strip()
yn = raw_input('y/n?>')
if yn == 'y':
codecs.open(‘XXX.txt', 'a', 'utf-8').write(line)
elif yn == 'n':
codecs.open('not_XXX.txt', 'a', 'utf-8').write(line)
else:
print 'passed'

まとめ
ルールベースから機械学習への橋渡しのために
・ルールベースで書く・均等重みでランキング・ランキングを元に教師データを作成・その教師データでロジスティック回帰を学習・学習したロジスティック回帰を使って能動学習でテストデータを改善
という流れを解説した。
45





























