Embed Size (px)
Citation preview


I-LanguageAn Introduction to Linguistics as Cognitive Science

OXFORD CORE LINGUISTICSGENERAL EDITOR
David Adger, University of London
PUBLISHED
Core Syntax: A Minimalist Approach
David Adger
I-Language: An Introduction to Linguistics as Cognitive Science
Daniela Isac and Charles Reiss
IN PREPARATION
Core Semantics
Gillian Ramchand
Introduction to Theoretical Linguistics
Peter Svenonius

I-LanguageAn Introduction to Linguistics
as Cognitive Science
Daniela Isacand Charles Reiss
1

3Great Clarendon Street, Oxford OX2 6DP
Oxford University Press is a department of the University of Oxford.It furthers the University’s objective of excellence in research, scholarship,
and education by publishing worldwide in
Oxford New York
Auckland Cape Town Dar es Salaam Hong Kong KarachiKuala Lumpur Madrid Melbourne Mexico City Nairobi
New Delhi Shanghai Taipei Toronto
With offices in
Argentina Austria Brazil Chile Czech Republic France GreeceGuatemala Hungary Italy Japan Poland Portugal SingaporeSouth Korea Switzerland Thailand Turkey Ukraine Vietnam
Oxford is a registered trademark of Oxford University Pressin the UK and in certain other countries
Published in the United Statesby Oxford University Press Inc., New York
© Daniela Isac and Charles Reiss 2008
The moral rights of the authors have been assertedDatabase right Oxford University Press (maker)
First published 2008
All rights reserved. No part of this publication may be reproduced,stored in a retrieval system, or transmitted, in any form or by any means,
without the prior permission in writing of Oxford University Press,or as expressly permitted by law, or under terms agreed with the appropriate
reprographics rights organization. Enquiries concerning reproductionoutside the scope of the above should be sent to the Rights Department,
Oxford University Press, at the address above
You must not circulate this book in any other binding or coverand you must impose the same condition on any acquirer
British Library Cataloguing in Publication Data
Data available
Library of Congress Cataloging in Publication Data
Data available
Typeset by SPI Publisher Services, Pondicherry, IndiaPrinted in Spain by Cayfosa Quebecor
ISBN 978–0–19–953419–7 (Hbk.)ISBN 978–0–19–953420–3 (Pbk.)
1 3 5 7 9 10 8 6 4 2

Contents
Preface ixAcknowledgements xiList of Figures xiii
PART I The Object of Inquiry
1 What is I-language? 31.1 Jumping in 51.2 Equivalence classes 81.3 Partial reduplication in Samoan 91.4 Mentalism 121.5 I-language 131.6 Some implications of mentalism 141.7 Summing up 151.8 Exercises 17
2 I-everything: Triangles, streams, words 202.1 A triangle built by the mind 202.2 More visual construction 252.3 Auditory scene analysis 272.4 Words are built by the mind 302.5 Summing up 332.6 Exercises 33
3 Approaches to the study of language 363.1 Commonsense views of “language” 373.2 I-language 393.3 The kind of stuff we look at 433.4 Methodological dualism 483.5 Biolinguistics 513.6 And so? 523.7 Exercises 53

vi CONTENTS
4 I-/E-/P-Language 554.1 Computation in phonology 554.2 Extensional equivalence 614.3 Non-internalist approaches 674.4 How is communication possible? 724.5 Exercises 75
PART II Linguistic Representation and Computation
5 A syntactic theory that won’t work 795.1 General requirements on grammars 795.2 Finite state languages 875.3 Discussion 945.4 Power of grammars 975.5 Exercises 101
6 Abstract representations 1036.1 Abstractness 1036.2 Abstractness of sentence structure 1046.3 Allophony 1096.4 Turkish vowel harmony 1146.5 Words are not derived from words 1256.6 Think negative 1276.7 Summing up 1316.8 Exercises 132
7 Some details of sentence structure 1367.1 Basic syntactic categories 1367.2 Syntactic constituents 1397.3 Labels and phrasal categories 1447.4 Predicting syntactic patterns 1547.5 Using trees to predict reaction times 1647.6 To sum up 1677.7 Exercises 168
8 Binding 1708.1 Preliminaries 1718.2 Anaphors 173

CONTENTS vii
8.3 Pronouns and “referential expressions” 1818.4 Some implications 1818.5 Binding and wh-movement 1828.6 Non-structural factors in interpretation 1878.7 Exercises 189
9 Ergativity 1929.1 Preliminaries 1949.2 A nominative-accusative system 1979.3 An ergative-absolutive system 1989.4 A tense-split system 2019.5 A nominal-verbal mismatch 2029.6 A NP-split system 2039.7 Language, thought and culture 2069.8 Exercises 207
PART III Universal Grammar
10 Approaches to UG: Empirical evidence 21510.1 On the plausibility of innate knowledge 21610.2 More negative thoughts 22110.3 Exercises 233
11 Approaches to UG: Logic 23511.1 Let’s play cards 23811.2 Where does this leave us? 24511.3 Building blocks in other domains 24711.4 Exercises 248
PART IV Implications and Conclusions
12 Social implications 25312.1 Prescriptive vs. descriptive grammar 25312.2 Negation 25412.3 Change is constant 25612.4 Exercises 262

viii CONTENTS
13 Some philosophy 26513.1 Rationalism and empiricism 26513.2 Competence and performance 27113.3 Reference 27713.4 Essentialism 28213.5 Mind and body 28613.6 A view from neuroscience 29113.7 Exercises 298
14 Open questions and closing remarks 30014.1 You and your grammar 30014.2 Retracing the links among key -isms 30414.3 Bearing on philosophical questions 306
References 311Index 315

Preface
Our original goal was to write a popular book that would lead the readerthrough some fairly technical analyses of linguistic data. Instead of justreporting on the claims and results of modern linguistics, we wanted toshow the reader how to think like a linguist. In the end, we realized thata textbook format was more suitable, given the depth and breadth we areaiming at. We foresee the book serving as an introduction to linguistics forstudents planning to continue in the field, as well as for those with interestsin other branches of cognitive science. Throughout the book, linguisticissues are related to topics in vision, philosophy, ethology, and so on. Wehope that we can inspire our readers to continue the search for unifyingthemes among these fields.
All the material in this book has been presented to undergraduate stu-dents in large classes (often over one hundred students). Much of it hasalso been presented to middle school students, prison inmates, and non-academic audiences. In developing and teaching the materials, we have hadthe advantage of being a team of a syntactician and a phonologist, but wehope that any enthusiastic teacher will be able to understand the materialand help motivated students work through it. We think that the ideas areimportant, but, in fact, not very difficult when broken down. Additionalexercises and links to material related to the text can be found on the book’scompanion website: http://linguistics.concordia.ca/i_language/
As an introduction to linguistics the book is very narrow. There are nochapters on sociolinguistics or historical linguistics, for example. And yet,we strongly believe that the best results in these fields can be attained byincorporating the approach to the study of language we develop, basicallythe framework of generative grammar developed by Noam Chomsky andcollaborators since the 1950s. In some sense the book is an exegesis of theChomskyan program or, rather, our understanding of the program.
In the course of writing we often found each other to be frustratinglythick-headed about various topics. The resulting heated arguments havehelped us to achieve deeper understanding and greater intellectual humility

x PREFACE
and, we hope, to produce a better book. We expect that even sympatheticreaders will find much to object to in our presentation, but we think thatwe have succeeded in laying out a coherent position, sometimes by openlyattacking other positions, that can at least serve as the basis for fruitfuldebate. If any of our claims or arguments manage to get students’ “bloodpressure up to an appropriately high level” (to quote Morris Halle) wherethey seek to challenge our point of view, we will consider this to be asuccessful textbook.

Acknowledgements
There is probably nothing original in this book, and thus we are beholdento the community of linguists and other scholars from whom we haveliberally borrowed. In some cases we have acknowledged specific debts, butin general we have not. Most obviously, the book is inspired by and drawsheavily from the work of Noam Chomsky. We excuse our general failure atcareful attribution by adopting Chomsky’s own attitude that full attributionis not only impossible but also fairly unimportant. Our common goal as acommunity is to understand the object of study—the language faculty andthe human mind, in general.
That being said, we will point out that several authors have been mostinspiring in helping us to achieve our understanding of the place of linguis-tics in cognitive science. We mention these to encourage you to consult themon your own. We include their work in the readings for the course that thisbook grew out of, Language and Mind: The Chomskyan Program at Con-cordia University. Specific works by these cognitive scientists are listed inthe reading suggestions at the end of each chapter: Albert Bregman, MorrisHalle, Donald Hoffman, Ray Jackendoff, Zenon Pylyshyn. The course thatthis book grew out of was originally built around Jackendoff’s Patterns inthe Mind, and that book was so useful in developing our own understandingof the place of linguistics in cognitive science that it was actually a challengeto us as authors to move away from its excellent structure around threefundamental arguments.
Many of the articles in the four-volume Invitation to Cognitive Sci-ence, edited by Daniel Osherson, have also been instrumental as teachingresources, and we recommend them to students interested in making con-nections among the various branches of cognitive science.
We are also most grateful to our reviewers, Sam Epstein, Virginia Hill,and Ur Schlonsky, and the Core Linguistics Series Editor, David Adger,for useful feedback and for pushing us to not take the easy way out whendealing with technical linguistic topics. Their input has vastly improvedthe manuscript. It has been a pleasure to work with John Davey, our

xii AC KNOWLEDGEMENTS
Consultant Editor at Oxford, whose encouragement and flexibility aregreatly appreciated.
Two non-linguists read early drafts of the book. Harold Golubock pro-vided encouraging feedback—we originally wanted to write a popularbook for the intelligent lay reader and Harold was the perfect guineapig. Lesly Reiss managed to proofread the entire first draft, and she wasfascinated . . . fascinated that anyone would find this material interesting, asentiment she repeatedly shared with us. We are grateful to Chris Eldridgefor particularly helpful insight into the mind–body problem.
The hundreds of Concordia undergraduate students who took our courseand helped us develop the materials that have become this book mustbe acknowledged. Of all our students, Hisako Noguchi deserves specialmention. She not only took the class but she has served as a teachingassistant too many times to count. Her input has been crucial to thesuccess of the course and the development of teaching materials. MichaelGagnon and Alexis Wellwood provided excellent comments and SabinaMatyiku was very helpful with the graphics. Francis Murchison and KevinBrousseau contributed exercises on Kuna and Iyinu (Cree) based on theirown research. Michael Barkey’s work to develop the Concordia LinguisticsOutreach Project (CLOUT) was instrumental in getting us to think abouthow to introduce difficult material to diverse audiences. These audiences arealso to be thanked for their patience and feedback, especially the inmatesand teaching staff at Clinton County Correctional Facility in Dannemora,New York, where CLOUT presented several workshops.
Our friend and colleague Alan Bale has taught the Language and Mindcourse twice, and the book owes a lot to the influence of the materials hedeveloped and his own spin on topics we discuss.
It is impossible to say which examples, arguments or discussions con-tained herein were taken directly from Mark Hale—we have discussed everyissue in this book with him at some point over a very long period oftime. His influence on our thinking as reflected in these pages cannot beoverestimated.
Finally, we are grateful to our respective spouses who, despite the some-times cantankerous nature of much of our interaction, managed to deepentheir relationship with each other while we were engaged in this writingprocess.
We would like to dedicate the book to our parents and our children.

List of Figures
1.1 The equivalence class of nouns is itself an abstraction fromequivalence classes abstracted from sets of tokens ofindividual nouns. 10
2.1 Triangle constructed by visual system. 21
2.2 An illusory triskaidecagon. 23
2.3 Unnamed form constructed by visual system. 23
2.4 Rectangles constructed by visual system—of humans andbees, who can be trained to treat the two figures as membersof an equivalence class in terms of orientation. 24
2.5 The bees do not treat the illusory rectangle above as thesame as either of these two figures. 24
2.6 How many objects on the left? How many on the right? 25
2.7 Mouths, snouts, lips, eyes, and ears or Oonagh and Baby Z? 27
2.8 Spectrogram of a complex wave consisting of music andspeech. 28
2.9 The music (left) and the speech (right). 29
2.10 Waveform of a sentence. 30
2.11 Waveform of The spotted cat skidded by. 31
3.1 Which two of these look most alike? 48
6.1 The equivalence class of the phoneme /t/ is itself anabstraction from equivalence classes of allophonesabstracted from individual utterances. 113
6.2 A native speaker pronouncing the eight Turkish vowels. 117
10.1 Oonagh and Baby Z are raised in a very similar environment. 217
10.2 Instinct (Innate Knowledge) in goslings. 219
11.1 A non-“linguistic” card contrast. 244
13.1 Where does knowledge come from? 266

This page intentionally left blank

PART IThe Object of Inquiry

This page intentionally left blank

1What is I-language?
1.1 Jumping in 5
1.2 Equivalence classes 8
1.3 Partial reduplication in
Samoan 9
1.4 Mentalism 12
1.5 I-language 13
1.6 Some implications of
mentalism 14
1.7 Summing up 15
1.8 Exercises 17
In the summer of 1991 Charles lay in an Istanbul hotel room burning withfever, 15 percent lighter than his normal weight. In the other bed lay hisfriend Paul, who had just golfed his way to an MBA, also hot with fever,the inside of his mouth covered with blisters.1 Paul had paid for the room onhis credit card, so it was several steps above the dives they had been stayingin. He had gotten the name of a doctor in Istanbul from his mother back inKansas and was now on the phone with the hotel receptionist, who, giventhe price of the establishment, spoke excellent English. In vain, Paul wasasking her to find the number of Dr. Ozel—“That’s right, it’s o-z-e-l, Ozel.”It wasn’t happening.
From the depths of his delirium and intestinal distress, Charles finallyfound the strength to call out in a hoarse voice, “Tell her to try o with twodots,” referring to the Turkish letter ö, so Özel. Much to Paul’s surprise, shefound the number immediately. “Reiss, that’s amazing—how did you knowthat?” Paul asked, fully aware that Charles did not speak Turkish, and also
1 Charles had recommended that he rinse his mouth in the alkaline waters of LakeVan, but that hadn’t helped at all.

4 WHAT IS I-LANGUAGE?
annoyed with himself for having spoken to him civilly, since they were atone of the points in the trip when they wanted to strangle each other. “Ifyou had listened to me on the bus ride from Bucharest to Istanbul, insteadof obsessing about what pork products we would sample on the passagethrough Bulgaria, you would know,” Charles replied brightly, suddenlyenergized by his ability to gloat.
So, what had Charles tried to explain on that bus ride, in the thirtyseconds before Paul’s eyes glazed over? How did he know? The answer lies inCharles’s understanding of vowel patterns in Turkish, an example of a mostwonderful linguistic phenomenon called vowel harmony. Understanding ofTurkish vowel harmony happened to have a practical value in this situation,something neither of us has ever again experienced, but its real beautylies in the fact that it reflects some of the deepest workings of the humanmind.
Our goal in this book is to get you to accept this rather grandiose claimabout the vowel patterns in Turkish words. We will introduce many newideas, some of which will initially strike you as ridiculous. However, wewill try to convince you with logical arguments, data-based argumentsfrom both familiar and less familiar languages, and also appeal to generalscientific methodology.
Building on linguistic phenomena, our discussion will touch on someof the most longstanding and difficult issues in philosophy including thefollowing:
1.1 Big philosophical issues we will address� The Nature–Nurture debate: How much of what we are is innate and how
much depends on our experience?� What is knowledge? How is it acquired?� What is reality?� Whatever reality is, how can we get access to it?� Is there a principled distinction between mind and body?� How can our study of these issues bear on social questions and educa-
tional practice?
Given both the incomplete nature of all scientific inquiry and the limitedspace we have, we will not propose complete and final solutions to allthese problems, but we do hope to offer a real intellectual challenge ina fascinating domain. This should lead you to experience frustration . . .confusion . . . annoyance . . . and ultimately (we hope) . . . understanding andinsight and pleasure.

JUMPING IN 5
1.1 Jumping in
Not only the average person but also experts in fields like psychology, engi-neering, neuroscience, philosophy, and anthropology are willing to makeproclamations, sometimes in the pages of respected scholarly publications,about language—its evolution, its acquisition by children and adults, itsrelationship to thought, and so on. But there is a question that is prior toall of these issues, namely What is language? We aim in this book to provideyou with a deeper appreciation of the nature of language than that of theaverage academic in the fields listed above.
This book is not a catalogue of cool facts about language, nor is it a reporton the exciting findings of modern linguistics over the past fifty years—thereare several excellent books on the market for those purposes. Instead, ourstrategy is to get you to think about language the way linguists do. Withthis in mind, we’ll jump right in with some data (not Turkish—we’ll comeback to that later), before we even explain the somewhat obscure title of thebook. We won’t even tell you what “I-language” means yet. By the end ofthe chapter, we hope you will have an appreciation of the term that is muchdeeper than you would have if we just handed you a definition.
Let’s begin with a simple example, the relationship between singular andplural nouns in Warlpiri, an Australian Aboriginal language.
1.2 Warlpiri pluralsSINGULAR PLURAL
kurdu kurdukurdu child/childrenkamina kaminakamina girl/girls
In English, we form the plural of most nouns (but not all—look at children)by adding a suffix to the singular, as in girl-s. As you can see, it lookslike the plural of a noun in Warlpiri is formed by repeating the singular.This is a real plural—kurdukurdu does not just mean “two children,” itmeans “children” and is used to denote two or a hundred children—anynumber greater than one. You can probably guess the plural form of theword mardukuja “woman”—it is mardukujamardukuja.
Processes of word formation that involve repeating material from a basicform (all or just part of the basic form) to create a derived form are calledprocesses of reduplication. Reduplication processes are very common in thelanguages of the world with a variety of meanings, but are not productivein English.

6 WHAT IS I-LANGUAGE?
Even with this simple example, we can learn a lot about the nature oflanguage:
1.3 Some lessons about language based on Warlpiri pluralsa. Some aspects of language are simply memorized—it is necessary to
remember certain arbitrary links between sound and meaning, for exam-ple, that kurdu means “child” in Warlpiri but child means “child” inEnglish.
b. Some aspects of language involve rules or patterns. Your ability tocorrectly guess the Warlpiri form for “women” shows that the form canbe generated by a rule.
c. If there are rules, they have to apply to some kind of input and producesome kind of output. The Warlpiri plural formation rule highlights animportant aspect concerning the nature of rules of language—the unitsof language, the elements that rules affect, can be quite abstract. Wecannot give a definite answer to the question “What sound correspondsto the plural in Warlpiri?” because the answer varies depending oncontext. We will illustrate this point by discussing the rule in more detailbelow.
d. The rules apply to elements that are only definable in linguistic terms—for example, the Warlpiri plural rule applies to nouns, not verbs, and thenoun-verb distinction is a purely linguistic one.
The first item is fairly obvious, although the arbitrary nature of the sound-meaning links of human language was only really fully appreciated aboutone hundred years ago by the Swiss linguist Ferdinand de Saussure, theinventor of structuralism. The point is just that one of the requirements forlanguage is memory. A system, device, organism without memory cannotgenerate Warlpiri or English plural forms from singulars, since it has noway to store the singulars.
The second item will be dealt with again and again in this book. AWarlpiri speaker has to memorize that kurdu means “child”, but not how tosay “children,” since kurdukurdu is generated by a rule that repeats any nounin the singular form to make a plural. Of course the rule or pattern itselfmust be memorized, but this is an even more abstract kind of informationthan that required for memorizing words.
This discussion of reduplication illustrates a property of language centralto our approach: languages are computational systems. This term scaressome people, but all we mean by it is that language can be analyzed interms of explicit rules that apply to symbols. Given an input symbol anda rule that applies to that symbol, we can say what the output form willbe. The symbols and rules are different ones than those that are familiar in

JUMPING IN 7
math, but the goal of a computational approach is to make them as explicitas the formulas of math or the mathematical formulas used in sciences likephysics or chemistry.
To illustrate the third item, let’s compare Warlpiri to English, although wewill simplify greatly. In English, we can say that the rule for pluralization issomething like “If a noun is of the form x, then the plural of that noun is ofthe form x-s” as in girl-s. In Warlpiri, the rule must be something like “If anoun has the form x, then the plural of the noun is of the form xx.” Both theEnglish and the Warlpiri rules show that the rules of language must refer toVARIABLES. A variable is a kind of symbolic placeholder that can changein value each time a rule is applied. This is particularly clear for Warlpiri—the plural marker is not a constant “piece” of sound, as it apparently isin English regular forms, but rather a copy of the noun. Sometimes thevariable has the value kurdu, sometimes kamina, etc.
Variables in this sense are just like the variables of math—in a functionlike y = 2x + 3, we can plug in different values for the variable x and derivevalues for the dependent variable y. If x is set equal to 4 then y = 2 × 4 + 3,which is 11; if the variable x is set equal to 5, then y = 2 × 5 + 3, which is13; and so on.
In contrast to the Warlpiri rule that tells us to repeat the singular in orderto generate the plural, the English rule for regular plurals takes the variablecorresponding to a noun and adds a constant -s ending.2
If we really want to make the parallel to math explicit, we can think ofpluralization as a function mapping members of the set of singulars (thedomain of the function) to a set of plurals (the range of the function). InWarlpiri, the pluralization function is something like
1.4 f (x) = x�x
where the variable x is drawn from the set of singular nouns and the symbol� denotes CONCATENATION— a�b means “a followed by b.”
In English, the function would require a variable drawn from the set ofsingulars and a constant corresponding to the suffix:
1.5 f (x) = x�s
2 As we said above, we are oversimplifying, but probably only those readers who havetaken a linguistics course know what details we are glossing over. If you do not, you arebetter off, since you can concentrate on our point about variables and constants.

8 WHAT IS I-LANGUAGE?
Concatenation is not the same as mathematical addition or multiplication,but it may still be useful to draw a parallel in math. A function likef (x) = x + 3, where the output of the function, typically shown on they-axis of a graph, depends on the value assigned to the variable x added to aconstant, 3.
It is probably apparent that the notions of rules and variables are inti-mately related. By virtue of the fact that they refer to variables, rules applyto classes of entities. That is what makes the rules productive. The Warlpirirule that says “Repeat the singular x to make the plural xx” applies not justto kurdu, but to kamina, mardukuja, and in fact to all nouns.
With respect to item (1.3d.), note that nouns are just one of the cate-gories that linguistic rules operate on, but all linguistic categories are justthat—linguistic. They cannot be reduced to categories of physics, biology,psychology, or any other domain. The category noun cannot be defined as“a person, place, or thing”, despite what your English teacher told you.We’ll come back to this later.
1.2 Equivalence classes
Let’s elaborate on the notion of “variable” used above. The various nounsof Warlpiri have different pronunciations, and yet we are able to treat themall as members of a set or class of elements that are all subject to the samerule. In other words, any noun can stand in for the variable x in the Warlpirirule to give the output x�x. One way of understanding this is that the ruleignores the differences among various nouns and treats them all as membersof the abstract category or class “noun.”
However, there is another kind of abstraction that is necessary beforewe even can refer to the nouns in this class. If five Warlpiri speakers utterkurdu, the actual sound will be different coming from each speaker—thereare differences in the shapes and masses of their vocal apparatus, so thatan old man and a young child will produce tokens of kurdu with verydifferent physical characteristics. And yet someone hearing all five speakerscan perceive kurdu in each case.
Even more fundamentally, each pronunciation of kurdu by even a singlespeaker will be physically distinct with respect to the sound wave thatreaches a listener, due to differences in ambient noise, the moisture in thespeaker’s vocal tract, variability in muscle control of the speech organs, etc.

PARTIAL REDUPLICATION IN SAMOAN 9
We will come back to these issues in several subsequent chapters, but whatthey illustrate is a point made about eighty years ago by the great linguistand anthropologist Edward Sapir: “No entity in human experience can beadequately defined as the mechanical sum or product of its physical proper-ties.” In modern parlance, human perception and cognition depends uponequivalence classes—symbolic representations that may be derived fromexperience (tokens of a word heard) or somehow manifested in behavior(tokens of words uttered), but whose relationship with actual experience isquite complex. As Sapir noted “it is notorious how many of these physicalproperties are, or may be, overlooked as irrelevant” in a particular instance.In Chapter 2, we will illustrate these ideas with both linguistic examples andexamples from other cognitive domains.
Scientists, when they conduct experiments and build theories, also makeidealizations and consciously exclude certain observations from considera-tion. In describing equivalence classes, however, we are saying somethingdifferent. We are claiming that the human mind and cognitive systemsact as a filter on experience—they are built to collapse certain detectabledifferences when categorizing input.
Returning to Warlpiri, then, we see that we need to recognize that words,themselves, are just equivalence classes. The word kurdu is one such class,as is the word kamina. But then the category noun is also an equiva-lence class, an abstraction over the set of abstractions that correspond towords.
In Fig. 1.1 we see that individual nouns represent an abstraction fromvarious tokens of words that are spoken and perceived. The category nounis itself an abstraction over the set of individual nouns. The use of symbolsthat represent equivalence classes is one of the most important notions forunderstanding language.
There is much more philosophizing to be drawn out of the Warlpiriexample, but just for fun we will broaden our empirical base with anotherexample of reduplication before returning to big picture issues.
1.3 Partial reduplication in Samoan
In the case of Warlpiri, the input symbol corresponded to the singular formof a noun, call it x, and the output form could be denoted x�x. This patternis called “total reduplication” because the whole base form is repeated. In

10 WHAT IS I-LANGUAGE?
NounEQUIVALENCE CLASS
EQUIVALENCE
CLASSES
TOKENS OF BEHAVIOR/
PERCEPTION
kurdu
kurdu1
kurdu2etc.
kamina
kamina1
kamina2etc.
mardukuja
mardukuja1
mardukuja2etc.
etc.
Fig 1.1 The equivalence class of nouns is itself an abstraction from equivalenceclasses abstracted from sets of tokens of individual nouns.
the following discussion of Samoan, we will discover a pattern of partialreduplication, where only part of the base is repeated.
In Samoan, the singular of the verb “sit” is nofo “she sits” and the pluralis nonofo “they sit” as shown in (1.6).
1.6 Samoan verbs: sg-plnofo nonofo “sit”moe momoe “sleep”alofa alolofa “love”savali savavali “walk”maliu maliliu “die”
If you compare the singular with the plural, are you tempted to posit arule that adds a prefix no- to the singular to get the plural? We can rejectthis by considering some more data: the singular and plural for the verb“sleep” is moe/momoe—clearly there is no prefix no- here. So, maybe therule in Samoan involves reduplication, just as in Warlpiri, but in this casereduplication just repeats part of the base word, say the first syllable.3
Well, this idea fails when we get to another pair, the forms for the verbmeaning “love”: alofa/alolofa—the first syllable of the singular alofa is a-,and this is not repeated in the plural. Instead, the syllable lo is repeated in
3 We will assume that you have an intuitive notion of what a syllable is—it is atechnical term in linguistics.

PARTIAL REDUPLICATION IN SAMOAN 11
alolofa. Perhaps these forms show us that the correct rule involves startingat the beginning of the word, looking for the first consonant and the vowelfollowing that consonant, and then repeating the two of them. This wouldwork for the three verbs considered so far, but there is more data to consider:the last two verbs in example (1.6) show the forms savavali and maliliu,which shows that the correct rule involves copying the second to last syllableof the singular to make the plural.
We thus see that the Samoan rule requires a variable that constitutes apart of a root word. We won’t worry too much about how to representthis—it is an advanced topic, beyond the scope of this book, but here is oneapproach: suppose that we represent each verb as a sequence of numberedsyllables starting from the end of the word. So a two-syllable verb wouldcorrespond to (1.7a.) and a three-syllable word to (1.7b.), where the symbolÛ stands for a syllable.
1.7 Representing syllable sequencesa. Û2-Û1
b. Û3-Û2-Û1
c. Ûn-. . . -Û2-Û1
The representation in (1.7c.) corresponds to a word with an arbitrary num-ber of syllables, n. The rules for plural formation can now be stated byreferring to the variable Û2:
1.8 If Ûn-. . . -Û2-Û1 is a singular verb, then the plural is Ûn-. . . -Û2-Û2-Û1
We will revise our view of Samoan later, but for now we have an idea ofwhat is needed. The Samoan and Warlpiri both are instances of the sameprocess of reduplication. What differs is the nature of the variable that getsrepeated in each case: a full word in Warlpiri, a syllable in Samoan. It isexactly because we are able to abstract away from the different nature of thetwo variables that we can see that the two languages are in fact using thesame computational process, reduplication.
Our discussion of Samoan has also illustrated a crucial aspect of lin-guistic analysis—we examined pieces of data and made hypotheses that wehave then tested against more data, revising the hypotheses as necessary tomatch the full data set. This is a good example of how language data canbe subjected to the scientific method. The same methodology is used in allsciences. However, as we will discuss later, there is a deeper level of analysisthan just coming up with a rule that is consistent with the data.

12 WHAT IS I-LANGUAGE?
1.4 Mentalism
We have posited some rules to account for patterns of nouns in Warlpiriand verbs in Samoan. Let’s now ask what those rules are. Well, in somesense, they are our creation, hypotheses we made to account for data setson the page. However, unless we have some kind of mystical view of ourown creative powers, and assuming the data on the page is somehow relatedto what Warlpiri speakers and Samoans say, it seems reasonable to thinkthat these rules reflect something that existed prior to our analysis—in otherwords, we have discovered them, not invented them.
Even if the data we analyzed had never been written down, it seems thatthe rules describe a property of Warlpiri and Samoan speakers. In fact, thememorized singular forms needed to generate the plurals also describe aproperty of the speakers. Actually spoken words have a sound associatedwith them, but the rules and the variables they refer to do not—and, aswe have seen, even the constant parts do not, since each token is differentphysically. The rules, the variables, and also the memorized forms of thesingulars constitute properties of Warlpiri and Samoan speakers. Similarly,the information that cat is pronounced as it is, that it is subject to the regularplural formation rule, and that this rule adds -s to the end of the singularis a property of you. We will assume that these properties are a kind ofinformation somehow encoded in the brains of the speakers, and we willrefer to that kind of information as a kind of knowledge in the mind ofthe speakers. Linguistic analysis aims to discover what speakers know—wehave discovered, for example, that Samoan speakers know (that is, have asone of their properties) a rule that generates plural verbs by reduplicatingthe second to last syllable of the singular.
The preceding discussion falls under the mentalist approach to linguistics.It considers the information and rules and patterns that can be used to ana-lyze linguistic behavior to reflect mental properties, properties of the mindsof individuals—the mind consists of information and rules and patterns,some of which constitute knowledge of language. We will later argue thatwhat is mental is part of the biological world, and thus our approach is alsoknown as biolinguistics.
Neuroscientists who are trying to understand how cognition arises fromthe physical matter of the brain need linguists to tell them what kinds ofpowers inhere in the brains they are studying. If they cannot come up witha model of the brain that accounts for the ability to memorize words (like

I -LANGUAGE 13
Warlpiri singulars) and also store and apply rules that contain variables (thepluralization via reduplication rule of Warlpiri and Samoan, for instance)then their work is not done.
1.5 I-language
You now have all the pieces that are necessary to understand what I-language is. An I-language is a computational system that is encoded in,or a property of, an individual brain. It is a system of rules (a grammar)that computes over symbols that correspond to equivalence classes derivedeither from experience or other symbols. The mind contains (or perhapsis composed of) many such systems, for vision, language, etc., and an I-language is the name given to that one of these systems that generates thestructures associated with speaking and understanding speech.
The I-language approach to linguistics thus studies individual mentalgrammars, entities that are internal to each person. In addition to thesetwo words beginning with the letter I, there is a third relevant term implicitin the notion of a grammar as a system of rules or patterns. In mathematicsa set can be defined extensionally, by listing its members, or intensionally,by providing a formula or description that characterizes all and only themembers of the set. For example, {2, 4, 6, 8} extensionally defines the sameset as the intensional description “even numbers less than 10.” Notice thatan intensional definition is more practical for large sets, and required forinfinitely large ones like the set of all even numbers. A Warlpiri speakerneed not store the set of plurals as an extensionally defined list, since thereduplication rule defines this set intensionally as a function from the set ofsingulars.
1.9 Two characterizations of the set of Warlpiri plurals
Extensional: {kurdukurdu, kaminakamina, mardukujamar-dukuja, . . . }
Intensional: {x�x such that x is a singular noun}
The intensional characterization reflects the rule-governed nature of therelationship between singulars and plurals. I-language is meant to suggestall three of these notions—internal, individual, and intensional.
The study of the shared properties of all I-languages is thus the studyof what is sometimes called the human language faculty. This study is

14 WHAT IS I-LANGUAGE?
sometimes called Universal Grammar, the goal of which is to discover thecore of properties common to all I-languages.4 We will address implicationsof the I-language approach and also contrast it with other approachesthroughout the book.
1.6 Some implications of mentalism
This mentalistic, I-language approach to language has several implications.First of all, we need to recognize the difference between our consciousknowledge of Warlpiri and Samoan reduplication that we developed as ascientific analysis, and the unconscious knowledge that the speakers have.Samoans, for example, may have no idea what a syllable is, and thus couldnot tell us how the singular and plural verb forms they produce are related.They acquired these rules as pre-literate children without any direct instruc-tion from their parents—they were not given organized data sets as youwere.
Furthermore, if all speakers of Warlpiri were to die tomorrow, thennobody in the world would have the kind of knowledge that they have,and the language would cease to exist. We might have some writings thatdescribe our analysis of aspects of their language, but that is all. A language,for linguists, is a system of representations and rules in the mind of a person.If the person ceases to exist, that particular person’s language ceases to exist.In other words, we have been talking about the Samoan language and theWarlpiri language, but we have been doing so informally. From a linguisticperspective, each Warlpiri speaker and each Samoan speaker has his or herown set of symbols and rules, what we call his or her own mental grammar,his or her own I-language.
If this is so, that each Warlpiri speaker actually has his or her ownindividual mental grammar, then how can Warlpiri speakers communicatewith each other? Why do they seem to have the same grammar? The answeris simple—they have mental grammars that are quite similar because theyare all humans and they were exposed to similar linguistic experiences whenthey were acquiring their language as children.
4 Just as the terms physics and history refer both to objects of study (the physicalworld or the events of history) and the study itself (as in “He failed physics”), the termUniversal Grammar is also used sometimes to refer to the common core of the humanlanguage faculty.

SUMMING UP 15
Everything we have just said about Warlpiri and Samoan holds as well forEnglish. If we take the mentalistic approach seriously, then we have to admitthat there is no entity in the world that we can characterize as “English.”There is just a (large) bunch of people with fairly similar mental grammarsthat they can use to communicate in a way that is typically more efficientthan between what we call Japanese and English speakers, because the so-called English mental grammars are more similar to each other. We willcontinue to use terms like “the English language,” “Warlpiri plurals,” and“Samoan verbs,” but bear in mind that each name is a just practical labelfor a set of individual mental grammars that are identical with respect to agiven phenomenon under analysis.
1.7 Summing up
So, at this point, we hope you have an idea of the I-language approach. Theultimate goal is an understanding of the human language faculty, whichis instantiated in individual minds/brains, in the same way that we talk ofa human visual faculty. Each individual person, based on their particularexperience of language acquisition, ends up with a language faculty that isin a particular state.
We told you earlier that we would not review the major findings ofmodern linguistics, but we have changed our mind—here they are:
1.10 The fruits of linguistic research� Every language is different AND� Every language is the same.
Believe it or not, both of these claims have elicited virulent criticism. Obvi-ously, we have stated the claims like this for rhetorical effect, but we havesuggested that they can both, in fact, be true in some non-trivial way. Thetwo claims are complementary rather than contradictory.
We have illustrated the sense in which linguists say that each languageis different: each language corresponds to information in a particularmind. Since each person has at least slightly different experiences of lan-guage acquisition, it is not surprising that each ends up with differentgrammars, different bodies of information. When we say that two peoplespeak the same language, it is rather like saying that they are “near” eachother. This is a useful expression whose definition depends on numerous

16 WHAT IS I-LANGUAGE?
factors—Montreal is near Kingston, only three hours away; we work nearMary, only three blocks away; we are sitting near Mary, only three feetaway; Paul’s liver is near where his gall bladder used to be, only threeinches away (N.B. We know nothing about anatomy). What does near mean?There is no formal definition of the everyday word near, and there is noformal definition for the everyday term “English.” Linguistically, there areno dependable criteria for defining a speaker of English—some dialectsshare properties with Hungarian that others dialects do not share, forexample.
The situation becomes even clearer if we look at other languages (usingthe term in the everyday sense). Spanish and Italian are called differentlanguages, but speakers of the standards feel like they can communicatewith each other quite well. On the other hand, the various Italian dialectsare often mutually incomprehensible—they are called dialects of the samelanguage because they are spoken within the political boundaries of Italy,not for any linguistic reasons.
The second claim is just the hypothesis of Universal Grammar, an ideawe have already hinted at. We will try to show in later chapters that Uni-versal Grammar is more of a logical necessity than a hypothesis. However,in order to understand the claims, and to decide whether to accept orreject them, we propose to continue developing an understanding of whatlanguage is.
As promised, we have already argued for one apparently ridiculousnotion, the non-existence of English! As with any scientific endeavor, it is tobe expected that our results will surprise us from time to time, and that theywill be at odds with our everyday intuitions and common sense. In the sameway that modern science departs from our common sense, which tells usthat light should behave as either a particle or a wave, not both, or that ourbodies and our cars must be made of fundamentally different substances,we expect the scientific study of language to overturn some of our mostdearly held intuitions. This commitment to science and its ability to surpriseus is expressed well in the following quotation from Zenon Pylyshyn, apsychologist and computer scientist whose work inspired much of what youwill find in the following pages:
[I]f you believe P, and you believe that P entails Q, then even if Q seems more than alittle odd, you have some intellectual obligation to take seriously the possibility that Qmay be true, nonetheless. [Zenon Pylyshyn (1984), Computation and Cognition: xxii]

EXERCISES 17
Throughout the book, we intend to mind our Ps and Qs in accordance withPylyshyn’s dictum.
1.8 Exercises
Exercise 1.8.1. Ethnologue: Throughout the book we refer to languagesin the everyday sense of English, Warlpiri, Spanish, and so on. Findinformation about where languages are spoken, how many speakers theyhave and what family they belong to by consulting the Ethnologue athttp://www.ethnologue.com. Go to the website and write up a descrip-tion of the language that immediately follows your family name alpha-betically and the language that immediately follows your given name.(If your name is James Jameson, or something else that gives thesame language twice, use the language that precedes your family namealphabetically.)
Exercise 1.8.2. How do you express the meaning very in Pocomchí? Fillin the blanks.
adjective very + adjectivesaq white saqsaq very whiteraš green rašraš very greenq’eq black q’eqq’eq very blackq’an ripe very ripe, rottennim big very bigkaq red very red
Exercise 1.8.3. Can you see how to generate the set of definite nouns(like the bird) from the set of bare nouns (like bird) in Lyele? Note thatvowels in Lyele can bear one of three tones: a = mid tone; á = high tone;à = low tone. These tonal differences are distinctive—they can differentiatemeaning.
kúmí bird kúmíí the birdyálá millet yáláá the milletkùlí dog the dog

18 WHAT IS I-LANGUAGE?
Things may be a bit more complex than you thought:
nà foot nàá the footyijì church yijìí the churchya market yaá the marketcèlé parrot cèléé the parrot
To make the definite form (the + N) repeat but always usea tone.
What equivalence classes are relevant to a discussion of these Lyele nounforms?
Exercise 1.8.4. Is it English? Here are some sentences rendered in Stan-dard orthography that we have heard spoken in various places that arereferred to as English-speaking places. Identify differences from your ownvariety of English, if you can figure out the intended translation into yourown dialect. Are these sentences all English? How does the I-languageapproach bear on the issue?
1. We are allowed running here. (Montreal)2. We are allowed to run here. (Brooklyn)3. I did nothing today. (Brooklyn)4. I didn’t do nothing today. (Brooklyn)5. The government has decided to raise taxes. (Montreal)6. The government have decided to raise taxes. (London)7. I’m going to the dep to get some cigarettes and beer. (Montreal)8. That’s all the faster I can run. (Michigan)9. That’s as fast as I can run. (Brooklyn)
10. I might could go. (Alabama)11. I might be able to go. (Brooklyn)12. He been try make me mad. (Cajun English, Louisiana)13. I ate a egg. (Ypsilanti)14. I ate an egg. (Brooklyn)
Further Readings
� Chapters 1 and 2 of Patterns in the Mind by Ray Jackendoff (1994).This is an excellent book that inspired much of this book—we actuallyrecommend reading it all.

EXERCISES 19
� Recapturing the Mohawk Language by Marianne Mithun and WallaceChafe, in Timothy Shopen (1979) (ed.) Languages and their Status, (3–33). We have our students read this partly because Mohawk is spokenin the vicinity of Montreal where we teach, and partly because it givesinteresting illustrations of productive grammar in a language that isvery different from English. There are aspects of the article we disagreewith, but this can lead to useful discussion.

2I-everything: Triangles,
streams, words
2.1 A triangle built by the mind 20
2.2 More visual construction 25
2.3 Auditory scene analysis 27
2.4 Words are built by the mind 30
2.5 Summing up 33
2.6 Exercises 33
In the last chapter we introduced two important notions related toI-language: computation and equivalence classes. As we suggested, theseideas have quite broad relevance for an understanding of the human mind,and in this chapter we will provide demonstrations from various domainsin addition to linguistic ones. Abstracting away from physical propertiesand providing analyses in terms of equivalence classes is something that allscientists do, including linguists and other cognitive scientists. In the caseof cognitive science, this process of forming equivalence classes actuallyconstitutes the object of study. The human mind/brain automatically filtersincoming stimuli in such a way as to collapse even grossly distinct signalsand treat them identically. This kind of information processing is whatcognitive science studies.
2.1 A triangle built by the mind
Look at Fig. 2.1. If you are a normal human being you will see a whitetriangle with its vertices at the center of the three Pac-Man figures. Youcan see the edges of the triangle and trace them with your finger, but if youcover up the Pac-Men the edges seem to disappear. The area of the triangleis exactly the same shade of white as the background of the page, so it is not

A TRIANGLE BUILT BY THE MIND 21
Fig 2.1 Triangle constructed by visual system.
surprising that no edges remain visible. But why do you see a triangle in thefirst place—are you hallucinating? If so, why does every other human wholooks at such a page also see the triangle?
From the point of view of physics, which can measure things like thelight reflecting off the page, there is no distinction between the area insidethe triangle, its edges and the background. So is the triangle not real? Wecould decide to say that the triangle is not part of the real world and thusadopt a pure physicalist definition that accepts as real only that which canbe defined using the categories of physics, like mass, wavelength, velocity,etc. But that is not very satisfying—it leaves us with a big mystery: Whydoes everyone who looks at the page see the triangle? Isn’t that a real factabout real humans?
So, is there really a triangle on the page? The solution offered by cognitivescience to the triangle mystery is this. The human visual system interpretscertain stimuli in such a way as to construct a representation of a triangle.In other words, the triangle is not a physical property of the page buta result of how you process physical stimuli like this page under certaincircumstances—for example, when your head is oriented correctly, your eyesare open, and it is not pitch dark in the room. In other words, your mindimposes the triangle interpretation on the page. Now, one could just declarethat there is no triangle since its edges cannot be physically detected. Onecould decide that the only things that are real are those that can be describedin physical terms, and the edge of the triangle has no mass, or charge, orluminance, and so it is not a physical entity and thus not real. If the edgesaren’t real, the triangle itself cannot be real.
As we said, one can arbitrarily decide to use the term real in this way,but this puts us in an uncomfortable situation. On the one hand, we have toaccept that every single person who looks at the triangle figure sees the samething, a triangle, and so do certain animals, as can be shown by experiment,

22 I-EVERYTHING: TRIANGLES, STREAMS, WORDS
despite the fact that the thing they see is not real. Are we all deluded? Howcome we are all deluded in exactly the same way, then? On the other hand,if we want to study the human visual system scientifically, we have to acceptthe idea that science can study what is not real. Rather than arbitrarilydefining the real to include only that which has mass, charge, luminance,location, and so on, we can recognize that physics contains certain cate-gories and vision science others, but it is not the case that the categories ofone are necessarily more real than those of the other. In fact, the categoriesof modern physics are so remote from our everyday experience of what wecall the physical world, that they too must be considered abstractions. We’llelaborate on this later on.
People sometimes think that the fact that we see a triangle on the pagehas to do with the fact that we have the word triangle that we can apply tocertain experiences. There are at least two problems with this view. The firstproblem is that if we couldn’t recognize triangles in the first place, we wouldnot know what to apply the word to—it just doesn’t make sense to say thatthe word allows us to perceive the object.
The second problem is that our visual system constructs percepts ofedges and corners that compose objects even when we have no name forthem. Fig. 2.2 contains an illusory regular polygon with thirteen sides. Youexperience the illusion even if you do not know that such a figure is called atriskaidecagon by mathematicians.
We even see illusory shapes that nobody has a name for, as in the blob ofFig. 2.3.
We see the contours of a blob because of the way our visual systemprocesses the information received by our eyes. The triangle or blob weperceive is not part of the physical input to our eyes but is rather aninformation structure, or representation, constructed by the visual systembased on the input it receives and its own rules.
Note that we make no effort to see the triangle or the blob, and in fact wecan’t help but see the edges of these figures, even when it is pointed out thatthere is no difference in luminance between the figure and the background.Our visual system works the way it does despite contradictory consciousknowledge.
We mentioned that certain animals will also see shapes when presentedwith a display with illusory contours like Fig. 2.1. Nieder (2002) reviewsthe evidence for animal perception of such shapes: for example, bees havebeen trained in a Y-shaped tunnel to choose the correct branch to a sugar

A TRIANGLE BUILT BY THE MIND 23
Fig 2.2 An illusory triskaidecagon.
solution when that route is marked with stripes oriented in a particulardirection, say rising towards the right. The bees are then tested with therightward rising pattern replaced by various displays. If the display containsa solid rectangle or one with illusory edges as in Fig. 2.4, the bees treat itlike stripes with the same orientation.
However, if the display contains a solid triangle with the wrong ori-entation, or crucially with the Pac-Men oriented in a way that does notproduce illusory contours (even for us humans), the bees treat the displayas different from the rightward rising stripes. The two sides of Fig. 2.4 are
Fig 2.3 Unnamed form constructed by visual system.

24 I-EVERYTHING: TRIANGLES, STREAMS, WORDS
Fig 2.4 Rectangles constructed by visual system—of humans and bees,who can be trained to treat the two figures as members of an equivalence
class in terms of orientation.
processed as members of an equivalence class that excludes the two sides ofFig. 2.5. Clearly, from a purely physical perspective, one could argue thateach side of Fig. 2.4 is more like one of the members of Fig. 2.5 than likethe other member of Fig. 2.4. However, the well-defined contours of thesolid rectangle and the illusory contours of the other figure can be treatedas equivalent by a bee (and a human).
However, we can’t just say that the rectangle or triangle is “out in theworld.” If they were out in the world, then a computer vision system witha robotic eye that is way more sensitive than a human eye should be ableto detect these shapes at least as easily as a person can. However, it is, infact, very difficult to get an artificial system to recognize these displays asa rectangle or triangle. It is only a rectangle or triangle to a system thatprocesses information about incoming patterns of light in such a way asto construct the representation of such shapes. Nature has given us such asystem, but we haven’t yet figured out how to endow computers with such asystem. The rectangle or triangle is a symbolic representation, a memberof an equivalence class, that is internal to the entity (bee, cat, human,
Fig 2.5 The bees do not treat the illusory rectangle above as the sameas either of these two figures.

MORE VISUAL CONSTRUCTION 25
Fig 2.6 How many objects on the left? How many on the right?
whatever) that is constructing it. Since we assume that bees do not havewords for various shapes, we now have a third argument against relatingour perception of the triangle to our linguistic experience.
We now have a nice parallel to the discussion of the non-existence oflanguages from the previous chapter. There is no such thing as Warlpirior the Warlpiri word for “child” or the Warlpiri reduplication rule; thereare just a bunch of humans whose minds contain similar kinds of rules andsymbols that we informally group together as Warlpiri. Similarly, there isno triangle or rectangle on these pages, but humans (as well as membersof some other species), who all share the same kind of visual system, allconstruct the same percept upon exposure to this page. Our nervous systemsjust process information in this way. (As an aside, note that there are, infact, no triangles in the physical world—triangles are geometric figures withsides consisting of perfectly straight line segments meeting at vertices whoseangles add up to exactly 180◦. Perfectly straight line segments, for example,do not exist in the physical world.)
2.2 More visual construction
Our discussion of vision has already led us to some surprises, and furtherconsideration will, as you suspect, only show us greater complexity. Let’sassume a computational approach to vision that parallels in many waysthe approach we introduced for language in Chapter 1. On the topic ofrepresentation in perception Bregman (1990:3) makes the following point:
In using the word ‘representations’, we are implying the existence of a two-partsystem: one part forms the representations and another uses them to do such thingsas calculate . . .
Let’s now apply Bregman’s observation to Fig. 2.6.

26 I-EVERYTHING: TRIANGLES, STREAMS, WORDS
On the one hand, our visual system must clearly detect and representshading, textures, and edges. On the other hand, it must perform the cal-culations or inferences that lead us to see the left side of the figure asrepresenting an ellipse partly occluded by a rectangle, to group the twogray regions together. Note that our visual inference system cannot helpbut see things this way, and it does not matter that there is no right wayto experience the image—it may be a picture of a rectangle occluding anellipse, or it may be a picture of three distinct objects, as suggested by theright-hand side of the figure. In fact, it is just a pattern of ink on the page:we can specify its physical properties; and we can tell you what numbers weentered in the graphics program that we used to design it. But none of thismatters—we, as humans, cannot help but perform the computations thatlead to the perception of one object occluding another on the left-hand side.Note that the only difference between the two sides is the black perimeterof the rectangle on the left. The fill of the rectangle and the empty spaceperceived on the right-hand side are both just regions of the page withoutany ink.
The output of the visual system, representation of objects with colors,textures, shapes, and sizes feeds into other systems that also appear toinvolve computations and constructions.
Consider Figure 2.7. On the one hand, we see a nose, a snout, some ears,eyes, and lips, but, on the other hand, we see a picture of Oonagh andBaby Z. Is there any reason to even make such a part/whole distinction,or are we just being pedantic? Well, consider the following description ofthe condition prosopagnosia from the Preface of Hoffman’s (1998) VisualIntelligence:
After his stroke, Mr. P still had outstanding memory and intelligence. He could readand talk, and mixed well with the other patients on his ward. His vision was in mostrespects normal—with one notable exception: he couldn’t recognize the faces of peopleor animals. As he put it himself, “I can see the eyes, nose and mouth quite clearly,but they just don’t add up. They all seem chalked in, like on a blackboard . . . I haveto tell by the clothes or by the voice whether it is a man or a woman . . . The hairmay help a lot, or if there is a moustache . . . ” Even his own face, seen in a mirror,looked to him strange and unfamiliar. Mr. P had lost a critical aspect of his visualintelligence.
So, Mr. P appears to see normally in the sense of seeing objects like earsand noses and lips, but further computation by the face recognition sys-tem, involving the output of the visual system, is somehow impaired. We

AUDITORY SCENE ANALYSIS 27
Fig 2.7 Mouths, snouts, lips, eyes, and ears or Oonagh and Baby Z?
typically think of faces as objects in the world, but this case suggests thatface perception requires construction of a complex symbolic representationfrom the objects that themselves are constructed by the visual system. Theseprocesses of construction occur inside individual minds/brains according torules and principles (we might say grammars) of vision and face recognition.
2.3 Auditory scene analysis
Just as our mind actively constructs the objects of visual perception andface recognition, it also constructs the objects of auditory perception, whatwe hear. Imagine you are listening to the hum of an air conditioner andthen hear the footsteps of someone walking down the hall to your office.The hum is continuous, but the footsteps are a sequence of short sounds.From a physical point of view, each step is a separate event, yet youperceive the sound of footsteps as a single auditory “object.” Your mindintegrates the sequence of steps into what is called a single auditory stream.Notice that the continuous hum of the air conditioner constitutes anotherstream. Although this may seem obvious, in fact there is a tremendously

28 I-EVERYTHING: TRIANGLES, STREAMS, WORDS
Fig 2.8 Spectrogram of a complex wave consisting of music and speech.
complicated issue to explain. Every time a footstep occurs, the soundoriginating from the step combines with the sound of the hum, and thevibrations that reach your ears are a composite of these two sources andany others that may be present, such as a person talking on the phone atthe next desk. Yet your mind is somehow able to segregate the complexsound wave into two or more separate streams.
Auditory scene analysis is a framework for studying auditory perceptiondeveloped by Albert Bregman and his collaborators. Auditory scene analy-sis can be broken down into two main components. One problem, giventhe fact that sound waves from various sources are combined into a singlewave that reaches the eardrum, is that of simultaneous spectral integrationand segregation. The auditory system integrates into a single representationparts of the sound spectrum reaching the ear within a temporal window that“go together.” Of course, the decision that spectral regions “go together”is determined by properties of the auditory system, and in the case ofan illusion, the decision may lead to a non-veridical percept. An exampleof spectral integration is the perception of a played musical note and theovertones that give the instrument its unique timbre as emanating from thesame source. The process of assigning parts of the spectrum to differentperceptual sources is called spectral segregation: attending to speech whilea fan provides a high-frequency hum in the background requires spectralsegregation.
The other main component of auditory scene analysis is sequentialintegration—acoustic events occurring separated in time may be integratedinto a single auditory stream. Examples of streams include a sequence offootsteps or the continuous sound of falling rain. Individual sounds of afoot striking the ground are separated by silence or other sounds, yet thesteps are integrated into a single perceptual object, a stream.
The complexity of the task of auditory scene analysis can be appreciatedby considering the spectrogram in Fig. 2.8. This is the spectrogram of a

AUDITORY SCENE ANALYSIS 29
Fig 2.9 The music (left) and the speech (right).
wave created by mixing a sample of recorded speech and some music. Thespectrograms of the music and speech separately are shown in Fig. 2.9.In this example, we were able to display the music and speech separatelybecause we had the separate recordings. The mind has to extract suchinformation from a complex stimulus, like the mixed signal, to constructdistinct streams from a single physical signal.
The following quotation expresses the extent to which we construct ourauditory experience—just as the edges of the triangle above are constructedby our minds, so are the edges of auditory events:
The perceptual world is one of events with defined beginnings and endings . . . Anevent becomes defined by its temporal boundary. But this impression is not due tothe structure of the acoustic wave; the beginning and ending often are not physicallymarked by actual silent intervals. [Handel 1989]
This quotation suggests that our minds impose the structure of our audi-tory perception, just as with our visual perception, and it is pretty easy tofind parallels between the two domains. Suppose we remove the border ofthe rectangle on the left side of Fig. 2.6, giving the right side. It is less likelythat you perceive the two curved regions as belonging to a single ellipticalobject, since they appear separated by “empty space.” The presence of theborder on the white region on the left lets us perceive it as belonging to awhite object which can mask the non-visible part of a (continuous) ellipse.An exact parallel can be designed for audition.
If we take a tone and replace a portion of it with silence, we’ll hearthe resulting sound as having a gap in the tone. However, if we replacethe silence with broad-frequency white noise of a loudness that would besufficient to mask the tone, then we actually perceive the tone as continuingbehind the noise. Interestingly, we will be able to fill in a gap in a soundbehind a mask even if the surrounding portions are not constant. For

30 I-EVERYTHING: TRIANGLES, STREAMS, WORDS
Time (s)0 1.81882
−0.1562
0.2166
0
Fig 2.10 Waveform of a sentence.
example, a gap in a tone that rises in frequency can be restored by ourperceptual system if it is masked by noise.5
In vision and in audition the mind plays an active role in constructingour experience. In the next section we will discover that the perceptionof boundaries applies even to sound corresponding to speech—even wordboundaries are constructed by our minds.
2.4 Words are built by the mind
So, what is this discussion of vision and audition doing in a book onlinguistics? The point is that just as our visual and auditory percepts aredue to active mental processes, our linguistic cognition is also a function ofprocessing by our mental grammar. This is most easily demonstrated by ourperception of speech sounds and their organization into words.
Before we proceed, note that speech perception depends upon prior gen-eral auditory processing, since the words we hear are sounds. This relation-ship between audition and speech perception is somewhat like that betweenobject perception and face recognition discussed above: the output of onesystem is fed into another.
The display in Fig. 2.10 shows a waveform of a recorded utterance, Thespotted cat skidded by. The horizontal axis shows time and the vertical axisis basically a record of the loudness of the signal at each point. When thedisplay reaches up and down from the horizontal axis, the speaker’s voicewas most loud, and where the waveform is basically just a horizontal line,the speaker was silent. (Because of background noise there is never perfect
5 A demonstration and further discussion of this phenomenon can be foundhttp://ego.psych.mcgill.ca/labs/auditory/Demo29.html, which is accessible from the web-page of Al Bregman whose work inspired much of this discussion.

WORDS ARE BUILT BY THE MIND 31
The spotted cat skidded by
# s p # # s k #
Time (s)0 1.81882
Fig 2.11 Waveform of The spotted cat skidded by.
silence indicated.) Based on this information, try to figure out where eachword of this sentence begins and ends.
You were probably tempted to place your word boundaries whereverthe display indicates a silence. However, you will be surprised to see thetranscription we have provided of some of the sounds and the word bound-aries in Fig. 2.11. There are two particular aspects of the display to note.First, approximate word boundaries are indicated by the symbol #, butnote that there is not necessarily silence between words. Second, note thatthere is sometimes silence (apart from the slight noise in the signal) insideof words—this is normal when the utterance contains sounds like thosecorresponding to the letters p, t, k. In the words spotted and skidded thereis an s before a consonant in the same word, yet the waveform shows thatthere is silence between the two sounds.6
On the other hand, there is no silence between the words the and spotted.This situation is typical, and if we presented you with recorded speech froman unfamiliar language, you would not be able to find the word boundariesby either looking at the waveform or listening to the recordings. You need amental grammar of the language to impose word boundaries on the signal.
We learn from this example that, like the triangle we saw, the words weperceive in speech are the result of information processing. The sound wavethat reaches our ears does not inherently contain words. Our minds imposewords on signals we hear; the words are not part of the signal.
In the case of the perceived triangle, it turns out that any normal human(or bee) who can see will see the triangle, because we all have a visual systemthat processes information in the same way. In the case of language, there
6 This silence is there because of the way these consonants are articulated—a detailyou would learn more about in a phonetics course.

32 I-EVERYTHING: TRIANGLES, STREAMS, WORDS
is some learning involved—we perceive word boundaries in speech in waysthat depend on the languages we have learned. So linguistic informationprocessing appears to be more plastic, more influenced by experience, thanvisual information processing.
We will not go into further detail analyzing waveforms here, but wewill just mention that our perception of speech as consisting of discretesegments is also due to processing by our speech perception cognition—the actual signal does not consist of a well-defined sequence of segments,as you can perhaps tell by examining the waveform above. The portions ofthe waveform corresponding to each speech sound blend together, showingus that, like words, our perception of segments is due to the constructiveinformation processing carried out by our minds.
The point we have just made about triangles, auditory streams, faces, andwords turns out to be true of all categories of human experience—they arenot definable by their actual physical properties. For example, to again citeEdward Sapir, there is no way to define in physical terms, the differencebetween a club and a pole. An object is called a club if we use it as a club orbelieve that it was intended to be used as a club by the person who fashionedit—there are no necessary and sufficient physical criteria to make somethinga club as opposed to a pole.
Similarly, there are no necessary and sufficient physical criteria to deter-mine where word boundaries fall in a waveform. The perception of wordboundaries depends on which mental grammar is being used to processthe signal. The signal itself has no information about word boundaries,since words are not physically definable entities. We could even imagine asituation in which a given signal would be parsed into different words byspeakers of different languages.
Even closer to home, we have all had the experience of misparsing, ofassigning word boundaries in a fashion not intended by the speaker. Mis-assignment of word boundaries is one of the sources of “mishearing” thatleads to mondegreens7 like hearing Jimi Hendrix say ’Scuse me while I kissthis guy instead of the intended ’Scuse me while I kiss the sky. The [s] of skyis misparsed as belonging to the previous word. As we will see in Exercise2.6.2, [k] after [s], is usually indistinguishable from [g].
7 According to the Wikipedia, the term was coined by Sylvia Wright in Harper’sMagazine, November 1954, in a discussion of her understanding as a child of the poeticphrase And laid him on the green as And Lady Mondegreen.

EXERCISES 33
2.5 Summing up
So, to reiterate, the triangles and the words we perceive are related in a verycomplex and indirect fashion to the physical stimuli we receive. The factthat we can imagine words and triangles in our mind’s ear and eye, withoutany outside stimulus at all, further demonstrates that perception of theseentities is due to construction by the mind.
So why is this chapter called “I-Everything”? The “I” of I-language ischosen to suggest individual, internal, and intensional. It should be obviousthat the triangle you see, the auditory streams you hear, and the wordsyou identify in an utterance are all the output of “I”-systems. For exam-ple, each of us has our own individual visual system, and this system isclearly internal to us, part of our make-up as organisms. Moreover, it isnot the case that we can only perceive a limited number of objects whoseimages are stored in some kind of mental list. Like the productivity of ourlinguistic grammars, our visual computational systems are productive. Theyconstruct edges given an infinite range of stimuli. You do not see a triangleonly when looking at Fig. 2.1 from a single angle under one set of lightingconditions from a particular distance—try moving the page around or visithttp://www.cut-the-knot.org/Curriculum/Geometry/EdgeIllusion.shtml toexplore the visual grammar that lets you construct the edges of atriangle.
2.6 Exercises
Exercise 2.6.1. Word boundaries: The purpose of this exercise is to giveyou firsthand experience with the abstractness of linguistic representation.You will see that the word and segment boundaries we perceive are typicallynot present in the acoustic signal, but instead are imposed by our minds.This is a linguistic example of the construction of experience that we havediscussed in relation to vision and hearing.
You will work with a recorded sentence and try to find word boundaries.Using a sound editing program such as Praat (www.praat.org) examine thewaveform of the sound file ilang.wav available from the companion website.If you have trouble saving the file from your browser, then download the .zipfile containing all the materials you need and unzip it. You’ll end up with afolder containing the sound file.

34 I-EVERYTHING: TRIANGLES, STREAMS, WORDS
There is also an image of the waveform on the website, but you needa sound editing program to zoom in and play selections. You may find ituseful to print this waveform, or one from within Praat, to mark your wordboundaries on. In order to complete the exercise you need to be able to seethe waveform (a graph of intensity vs. time) and select and play portionsof the sound file. You also need to be able to find points in time in thewaveform window. This is pretty easy in Praat and most other phoneticsprograms.
You can also get a manual from the Praat homepage or get a manualwritten by our former student Tom Erik Stower from the companion page.(This manual contains more detail than you will need.) Write your answersdown on scrap paper as you proceed, so that you do not lose your work ifthe computer crashes or if your session is interrupted.
a. Provide an orthographic transcription of the sentence—that is, justwrite it in normal English writing.
b. For each word of the ten or so words in the sentence, write the endingtime of the word in milliseconds. (Count contractions like can’t as twowords, if there are any.) For example:End word 1 “the”: 136 msecEnd word 2 “cat”: 202 msecand so on.
c. Are there any cases of silence within a word? Give at least oneexample and say where the silence occurs—between which sounds?Example: The word “Casper” has silence between the s and the p.This can be heard and also seen because the waveform has almost noamplitude between those two sounds.
d. Is there generally silence or a pause between words? Give an exampleof two adjacent words where you had difficulty deciding on where toplace the boundary. Example: It was hard to decide on the boundarybetween “the” and “apple.”
e. Comment on any difficulties or interesting issues you encountered inany part of this exercise. (Say something coherent and relevant—ifyou found nothing interesting, fake it.)
Exercise 2.6.2. Take either a pre-recorded sentence or record your ownand mark the segment boundaries on the waveform. In other words, findthe division between adjacent sounds, like the s and the k of a word likesky. Comment on any problems you run into. See how your results compare

EXERCISES 35
to those of your classmates. Tom Erik’s manual will tell you how to markthe boundaries on a waveform in Praat and print out the results.
Exercise 2.6.3. More construction: Visit a website with optical illusionsand find examples of illusions that demonstrate your mind’s role in theconstruction of color, motion, and shape. Here is one excellent site:http://www.michaelbach.de/ot/index.html
Further Readings
These readings are all fantastic, and we have borrowed freely from them inthis book. Visual Intelligence is the most accessible.
� Chapters 1, 2, 7 of Visual Intelligence by Donald Hoffman (1998).� Chapter 1 of Auditory Scene Analysis by Albert Bregman (1990).� “The problem of reality” by Ray Jackendoff. Noûs, Vol. 25, No. 4.
Special Issue on Cognitive Science and Artificial Intelligence (Sep.,1991), pp. 411–33. Reprinted in Jackendoff’s Languages of the Mind:Essays on Mental Representation (1992).
� “Seeing more than meets the eye: Processing of illusory contours inanimals” by A. Nieder (2002). Journal of Comparative Physiology 188:249–60.

3Approaches to the study
of language
3.1 Commonsense views of
“language” 37
3.2 I-language 39
3.3 The kind of stuff we look at 43
3.4 Methodological dualism 48
3.5 Biolinguistics 51
3.6 And so? 52
3.7 Exercises 53
People have a lot of strong feelings about what language is. The termlanguage may bring to mind communication, literature, poetry, persuasion,and propaganda, among other things. On the other hand, for the linguist,or at least for the kind we are interested in telling you about, an inquiryinto human language involves examining patterns that reveal the existenceof rules, the rules of I-languages. The question we want to address in thischapter is why is it that linguists choose to focus on this notion of languageas opposed to others, say, language as a means of communication.
Before we answer this question, it is useful to notice that notions oflanguage as a system of communication, or as a conveyor of culture, arecommonsense notions of language, part of the intuitive and “untutoredideas people have about the world and how it works” (Nuti 2005:7). Incontrast, I-language seems to be a rather narrow term, with a technicaldefinition, one that does not seem to correspond in any direct way to ourcommonsense intuitions about language. This is not surprising, since thewords and concepts of everyday life appear to be insufficient for the task ofunderstanding in every other domain of scientific inquiry. The disconnectbetween normal experience and the scientific worldview appears to requirethe invention of a technical vocabulary in all fields of study.

COMMONSENSE VIEWS OF “LANGUAGE” 37
3.1 Commonsense views of “language”
This point about terminology can be easily illustrated with the term lan-guage. Let us take a look at some of the most common concepts of language.
3.1.1 Language is a form of expression
People may talk about the language of the body, the language of the hands,or even, like an artist we know, about the language of string balls thrown onthe floor. It is probably apparent that a concept of language that included allthese, as well as the kind of phenomena we have discussed, is way too vagueto constitute the object of scientific inquiry—pretty much any expressivething can be called a language in everyday discussion.
3.1.2 Language as an instrument/result of thought
Another commonly held belief is that language should be defined in itsrelation to thought and reasoning. Whether it is language that allows usto have (new) thoughts or whether it is thought that controls language is amatter of debate. Under one view, language shapes our perception of realityand predetermines what we see in the world around us. Thus, accordingto the so-called Sapir–Whorf hypothesis, we conceptualize nature alonglines laid down by our native languages. In contrast, under the other view,thoughts exist independently of language and language just matches (someof) the thoughts or concepts that exist independently in our mind. Whateverstand we take on this debate, we find out nothing about the nature oflanguage, and about why it has the properties it has. The “language shapesthought” position would amount to saying that language has the propertiesit has because it shapes thought. However, no real constraints on the prop-erties of language can be derived from this, since it is not very clear whatthe boundaries of our thoughts are and how to derive these boundaries.Similarly, the “thought controls language” position is just as unrevealing asto the properties of language. Under this view, one would have to say thatlanguage has the properties it has because it is predetermined by thought.This again leaves us with the task of identifying the limits of our thoughts,which are at least hard to define.

38 APPROACHES TO THE STUDY OF LANGUAGE
3.1.3 Language as a repository of culture
Another commonsense belief about language is that the language used by aculture primarily reflects that culture’s interests and concerns, and thus thatlanguage can be defined as a medium of culture.
As an illustration, consider the following quote from Mother Tongue byBill Bryson (1990):
Originally, thou was to you as in French tu is to vous. Thou signified either closefamiliarity or social inferiority, while you was the more impersonal and general term.In European languages to this day choosing between the two forms can present a veryreal social agony. As Jespersen, a Dane who appreciated these things, put it: “Englishhas thus attained the only manner of address worthy of a nation that respects theelementary rights of each individual.”
We won’t comment on the assumptions inherent in such a statement,but anyone who maintains illusions that there are interesting connectionsamong linguistic form and race and culture can look forward to enlight-enment by reading Franz Boas’s 1911 Introduction to the Handbook ofAmerican Indian Languages, reprinted in Boas et al. (1966). Boas showsthat basically every positive or negative correlation among race, language,and culture can be illustrated with cases from the American NorthwestCoast Native peoples. Geoffrey Pullum’s 1990 essay “The Great EskimoVocabulary Hoax”, about the notion that Eskimos have a lot of words forsnow, is also useful in this regard.
3.1.4 Language as a system of communication
Maybe the most widespread conception of language is that it is a com-munication system. While there is little doubt that language is used forcommunication purposes, keeping this in mind does not help at all to iden-tify the properties of this particular system of communication. Languageis not the only way people communicate; we also use gestures and facialexpressions, for example. At the same time, other species are also able tocommunicate and they do so by using a communication system as well.Saying that language is a system of communication leaves questions like thefollowing unanswered: Are all these systems alike? Or are they different?And if language is different, how is it different?
Morris Halle, the founder of generative phonology, argues that there aregood reasons not to think of language as a communication system:

I -LANGUAGE 39
Since language is not, in its essence, a means for transmitting [cognitive] information—though no one denies that we constantly use language for this very purpose—thenit is hardly surprising to find in languages much ambiguity and redundancy, as wellas other properties that are obviously undesirable in a good communication code.[Morris Halle 1975]
Halle, who spent ten years trying to apply engineering concepts from thestudy of information and communication to human language, came tobelieve that it is actually more productive to treat languages as arbitraryrule systems, like codes or games, in order to get insight into their structure.
3.2 I-language
The views sketched above try to elucidate our everyday thinking aboutlanguage and they are inappropriate for scientific accounts of languageitself. In a way, they presuppose that the concept language is already clearlydefined, and they address questions related to the relation between languageand other phenomena like socialization, or culture.
To give a concrete example, let’s consider briefly a view that languageacquisition and use is “just a matter of socialization.” This is a view thatis sometimes presented to students in branches of psychology like childdevelopment. Now, even if we had some idea what was meant by socializa-tion, we would still need a mentalist, computational theory, one based onI-language. It must be mentalist, since whatever it means to be “socialized”must at least include encoding in memory. If a child is socialized to covercertain body parts in public, then he or she must somehow remember todo so. Explicit rules against showing those body parts and implicit rulesof plural formation must all be encoded in memory if they are to have anyinfluence on behavior. No social interactionist theory can deny that what theWarlpiri child is “socialized” to do is reduplicate to make plurals, whereasthe English-speaking child is “socialized” to suffix. Each child ends up witha rule or pattern that can generate—be used to produce and understand—new forms. Thus, the “socialization” process must have led to a specificcomputational system. So, invoking the vague notion of socialization doesnothing to characterize or explain the human capacity for language.
At this point you might be thinking that all there is to it is a matterof taste: linguists are interested in I-language, and people who focus onthe relation between language and culture, language and thought, etc, just

40 APPROACHES TO THE STUDY OF LANGUAGE
aren’t! That is, of course, true. But the point is that the choice is notarbitrary. It’s not just a matter of taste. The choice is dictated by the aimof the pursuit. A scientific pursuit aims at discovering laws and principlesthat govern the way things are, and it does so by using logical reasoning andby making predictions that can be tested. In order to achieve such goals,scientists have to use terms in a narrow way. Just as physicists use energyand field in a special way, we will use language and grammar in a way thatappears to define a topic that is amenable to scientific study. We choose ascientific terminology that makes distinctions that we believe correspond toreal distinctions in the structure of the world.
Other uses of these terms are fine for ordinary discourse. In fact, thenon-scientific terms have priority—scientists borrow words from everydaylanguage and use them in a special way. People use the term water torefer to a vast range of solutions containing not only H2O, but also manyother substances, whereas chemists use water to refer only to H2O. Theeveryday word (or its linguistic ancestor) was in use before the developmentof chemistry, and it is an arbitrary fact that chemists borrowed this term torefer to a pure molecular substance. Chemistry did not do the same withthe other basic elements of ancient times: earth, air, and fire. It would nothave been inconceivable for chemistry to have applied the name air to whatit called instead oxygen. Chemistry did not discover the true meaning ofthe word water; rather chemistry borrowed the word for its own uses. Itis crucial to distinguish everyday and scientific language when talking notonly about chemistry but equally when talking about language itself.
The issue here is not whether the commonsense concepts of languagecan be used in deriving some kind of knowledge. Someone may believefor example that a certain degree of insight and reflective knowledge isachieved by the following passage from Jespersen’s Growth and Structureof the English Language (1911).
To bring out clearly one of these points I select at random, by way of contrast, apassage from the language of Hawaii: “I kona hiki ana aku ilaila ua hookipa ia mai laoia me ke aloha pumehana loa.” Thus it goes on, no single word ends in a consonant,and a group of two or more consonants is never found. Can anyone be in doubt thateven if such a language sound pleasantly and be full of music and harmony the totalimpression is childlike and effeminate? You do not expect much vigour or energy in apeople speaking such a language; it seems adapted only to inhabitants of sunny regionswhere the soil requires scarcely any labour on the part of man to yield him everythinghe wants, and where life therefore does not bear the stamp of a hard struggle againstnature and against fellow-creatures.

I -LANGUAGE 41
How much insight can be gained from this is debatable, but none of thestatements in these passages can be either proved or disproved objectivelyon the basis of logical reasoning. There is no indication as to why thelanguage of Hawaii should be considered childish and effeminate, exceptas a totally subjective opinion. Given this, no predictions can be formulatedas to what kind of “total impression” some random language would give.This is what makes such statements different from scientific statements.
3.2.1 Narrowness
Some people object to the narrow sense in which Chomsky and those influ-enced by him use the term language. Critics see this as a kind of linguisticimperialism. However, Zenon Pylyshyn (2003), in discussing his narrowuse of the term vision, basically in recognition of the many ways that theterms vision and seeing are used, as we discussed above, points out that“To use the term ‘vision’ to include all the organism’s intellectual activitythat originates with information at the eye and culminates in beliefs aboutthe world, or even actions is not very useful, since it runs together a lotof different processes.” The same arguments apply to our terminology forlanguage.
If we ask you to raise your right arm over your head, and you do so, wecan ask a physiologist for an account of your behavior that will be highlydetailed. He or she will be able to tell us about electrochemical events in yourbrain and the neurons leading to your arms; contraction and relaxationof various muscles; adjustments in systems responsible for balance andequilibrium; and the actions of proprioceptive systems that let you know,even with your eyes closed, that your arm is raised.
However, there are many, many, many things about which the physiologist(or neurologist or anatomist) will have to remain silent. He or she will notknow how it is that you understood the words addressed to you; or how youdecided to interpret them as a request; or how you decided to honor therequest; or how your intention actually set off the chain of events that canbe described in electrochemical and biomechanical detail alluded to above;or how you knew when your intention had been fulfilled. He or she mayalso not be aware of or care about the fact that you often raise your arm ina similar fashion to pick apples or to paint ceilings.
In other words, there are many mysteries connected with our arm-raisingevent. Yet, we do not decide that arm-raising as whole is a complete mystery

42 APPROACHES TO THE STUDY OF LANGUAGE
and that physiology should be abandoned as hopeless. We don’t give upscientific methodology for the areas where it seems to work, for examplein characterizing the chemical reactions in the synapses between neurons.Instead we try to identify areas in which some understanding is possible,and dissect our study of arm-raising accordingly—some things have to beput aside, other questions can be fruitfully explored. One could accusephysiologists of being narrow or unfair for excluding from their textbooksvast questions associated with arm-raising, but nobody does so.
We can also consider what vision scientists study. Their results may haverelevance to a wide range of issues, and perhaps give insight into a vast rangeof phenomena, but we do not expect vision scientists to explain and discusstrends in interior design, art history and the relative salaries of variousfashion models, despite the fact that all of these topics are somehow relatedto what people see.
Chomsky (2000:68) makes the same point with respect to linguists’“failure” to account for communication in general:
The proper conclusion is not that we must abandon concepts of language that canbe productively studied, but that the topic of successful communication in the actualworld of experience is far too complex and obscure to merit attention in empiricalinquiry, except as a guide to intuitions as we pursue research designed to lead to someunderstanding of the real world, communication included.
If Visinel tells Wang I love you, a linguist cannot figure out why he choseto communicate this particular idea; or whether he is lying; or whether heis not lying, but is trying to get a favor from Wang; or why he didn’t usesome other way of conveying his message, like I am quite attached to youand find you attractive and would do anything for you. But a linguist can tellyou that in the sentence that Visinel did say, I is the subject, love you is thepredicate, you is the object, and so on. Structures, rules, patterns—that’s thekind of stuff linguists talk about—not what we use language for; not whathaving language allows us to achieve; and not why we say particular thingson particular occasions.
A major premise of this book is that human language can be and shouldbe an object of scientific study, like other aspects of the natural world,including, say, chemical bonds and mammalian reproductive systems. Theidea that language can be studied scientifically is rejected by many people asridiculous. They claim that as an artifact of human invention language is tooflexible, too amorphous. It is not difficult to discern that people who hold

THE KIND OF STUFF W E LOOK AT 43
this opinion are just not willing to accept the kind of narrow delimitationthat is necessary in any scientific undertaking. Notice however, that thiskind of narrowness does not imply a claim that I-language is the only thingthat is worth investigating. In fact, Chomsky (2000:77) himself recognizesthat his approach is narrow:
Plainly, a naturalistic approach does not exclude other ways of trying to comprehendthe world. Someone committed to it can consistently believe (I do) that we learn muchmore of human interest about how people think and feel and act by reading novels orstudying history or the activities of ordinary life than from all naturalistic psychology,and perhaps always will; similarly, the arts may offer appreciation of the heavens towhich astrophysics does not aspire.
He sees the narrowness of focus as a necessity for naturalistic inquiry, theapproach of the natural sciences, but this narrowness has no bearing on therichness of all human experience or on the validity of other ways of thinkingabout the world.
Rather than arguing about the issue of whether language can or should bestudied scientifically, our attitude will be that the proof is in the pudding—if the explicit mathematical analysis of Warlpiri and Samoan reduplicationyield interesting results, then this suggests our approach is worthwhile. Ofcourse, we can’t demand that you find the results interesting—if redupli-cation turns you on, then scientific linguistics is for you. If you wonderhow reduplication reflects the Warlpiri and Samoan worldview and arenot satisfied with the answer “Not at all!,” then formal linguistics is notfor you.
3.3 The kind of stuff we look at
We have delimited the range of what we call language in a very narrowfashion. In order to give you a sense of what such narrowness can do forus, we now present some puzzles involving very simple patterns in English.Your interest may or may not be piqued by these examples—if it is not,read no further. If you are intrigued, then, as suggested by the followingquotation, you are ready to begin scientific inquiry into the nature of humanlanguage:
The beginning of science is the recognition that the simplest phenomena of ordinarylife raise quite serious problems: Why are they as they are, instead of some differentway? [Language and Problems of Knowledge Chomsky 1988:43]

44 APPROACHES TO THE STUDY OF LANGUAGE
The puzzles we present in the following section will resurface later in thebook. Here we present them just to illustrate the kind of things moderntheoretical linguistics takes as amenable to scientific inquiry, the kind ofpatterns that can give insight into our object of study, the human languagefaculty. As you will see, we do not need to go to the Australian outback tofind intriguing puzzles, the following are all drawn from English.
3.3.1 A puzzle concerning questions
Consider a sentence like the following:
3.1 The boy is singing.
To make a YES/NO question out of such a sentence you would probably saythe following:
3.2 Is the boy singing?
Now make a YES/NO question with this next sentence:
3.3 The boy who is dancing is very tall.
And with this one:
3.4 The boy is kissing the dog that is whining.
We are sure that you had no problem coming up with the following ques-tions:
3.5 Is the boy who is dancing very tall?
3.6 Is the boy kissing the dog that is whining?
But coming up with a general rule for how to form YES/NO questionsfrom declarative sentences is actually pretty hard to do. If you think it isnot so hard, consider additional sentences like the following:
3.7 The boy whose mother can sing well may chase the puppy that isrecovering from an injury that it received from a man who can bequite nasty.
We may have slowed you down a bit, but you can probably recognize thatthe corresponding question is this:
3.8 May the boy whose mother can sing well chase the puppy that isrecovering from an injury that it received from a man who can bequite nasty?

THE KIND OF STUFF W E LOOK AT 45
In other words, it is kind of hard to state the rule relating declarativesand the corresponding YES/NO question, but it is pretty easy to make therelevant sentences, at least until the sentences get quite long.
Compare this situation with the following. Here is a rule that is easy tostate:
3.9 Rule 1. Reverse order of words in a sentence A to form sequ-ence B.
Thus the following sequences of words are related by Rule 1:
3.10 The dog saw a cat.
3.11 Cat a saw dog the.
We are sure you will agree that Rule 1 is very easy to understand—you juststart at the right edge of A and read off words from right to left to get B.
Now consider the following sentence:
3.12 The tall man who is crying can drop the frog that is croaking.
Say the sentence to yourself a few times, then turn it into a question. Weassume this is easy to do. Now, look away from this page and apply Rule1—reverse the order of the words....
Now that you are looking back, we are willing to bet that you failed miser-ably at applying Rule 1 to the last example. Try with a shorter sentence likethis:
3.13 Three blind mice ran across the track.
We bet that you failed with this simple sentence too—or maybe you suc-ceeded, but you had to go really slowly.
Our first puzzle is the following: Why is the question formation rule,which is so hard to state, so easy to apply; and why is Rule 1, which seemseasy to state, so hard to apply.8 Obviously, we have not defined any explicitway to measure “hard” or “easy,” so we rely on intuition at this point.
8 One might suggest that the YES/NO rule involves displacing a single word, whereasRule 1 involves manipulating all the words in the sentence—to counter this replace Rule1 with a rule that just moves the fourth word of a sentence A to the front in order to formB—is this easy to apply?

46 APPROACHES TO THE STUDY OF LANGUAGE
3.3.2 Puzzles concerning relations among words
Consider the following:
3.14 a. Bill is perplexed. John kissed himself. (himself = John, himself cannotbe Bill)
b. Bill is perplexed. *Mary kissed himself. (himself cannot be Mary,himself cannot be Bill)
c. Bill is perplexed. John kissed him. (him cannot be John, him can beBill)
d. Bill is perplexed. *Himself kissed John. (himself cannot be John, andhimself cannot be Bill)
e. Bill is perplexed. He kissed John. (he cannot be John, but he can beBill)
In (3.14a.) himself must refer to the same person as John, and cannotrefer to a person mentioned outside the sentence that contains himself, suchas Bill. In (3.14b.) himself cannot refer to the same person as Mary, evenif Mary is in the same sentence, and it cannot refer to Bill either. In fact,there is no grammatical interpretation of this string, a status denoted by the‘*’. In (3.14c.), him cannot refer to the same person as John, which is in thesame sentence as him, and it has to refer to a person that is not mentioned inthe sentence, someone from outside of the sentence, say Bill, or some othermale. In (3.14d.) himself cannot refer to John, which is in the same sentenceas himself, and it cannot refer to Bill, which is in a different sentence, either.Like (3.14b.) there is no grammatical interpretation of this string. In the lastexample, (3.14e.) he cannot refer to John, which is in the same sentence, butit may refer to Bill, which is outside of the sentence where he occurs.
The form himself appears to be dependent for its interpretation onanother noun phrase.9 It appears that the relevant noun phrase must bein the same sentence as himself. But notice that this is not all. In exam-ple (3.14d.) there is a nominal expression in the same sentence as himselfthat the latter could potentially enter a dependency relation with, yet thesequence is ungrammatical, perhaps because himself precedes the otherexpression. In contrast, the form him appears not to be subject to theseconditions.
It turns out to be very difficult to explain the distribution of words likehim and himself with respect to other nominal expressions, despite the fact
9 We’ll clarify this notion later—examples of noun phrases are that tall man, the boywith the yellow hat, and Mary.

THE KIND OF STUFF W E LOOK AT 47
that they are very common words used even by small children. Thus, thedistribution of these words constitutes a puzzle on its own, and we will offera solution to this problem in a later chapter.
We now want to draw your attention to a deeper puzzle, one that relatesthe patterns we have just seen to other patterns. Consider the followingexamples:
3.15 a. Bill is perplexed. John didn’t kiss anybody.b. Bill is perplexed. John never kisses anybody.c. Bill is perplexed. ∗John kissed anybody.d. Bill is perplexed. ∗John always kissed anybody.e. Bill isn’t perplexed. ∗John kissed anybody.f. Bill isn’t perplexed. ∗John always kissed anybody.g. Bill is perplexed. ∗Anybody didn’t kiss John.
Examples (3.15a.–d.) suggest that anybody is somehow dependent on anegative word like the contracted n’t or never. Examples (3.15e.–f.) show thathaving a negative word in the immediate context of a preceding sentence isnot sufficient—such a negative cannot license the appearance of anybodyin these examples. Like himself, the interpretation of anybody appears toinvolve a relation or dependency among words within the sentence contain-ing anybody. The parallel between (3.15g.) and (3.14d.) is also striking—like himself, anybody seems to need to follow the word it is dependentupon.
The examples we looked at are short, simple strings with familiar Englishwords, and the judgments of what is and what is not grammatical are easyto make. For us, these phenomena present puzzles that are crying out for anexplanation in the same way as the proverbial apple that hit Newton on thehead. A sense of wonder about the complexity of everyday events is a nec-essary starting point. We will not tell you here what the detailed analysis ofthese examples is. At this point, all we want to do is illustrate the surprisingparallelism between the distribution of himself and anybody. We will showlater on that the accounts of these elements can be brought together: eachof them can be explained with the same basic notion—what we will callc-command.
Needless to say, questions like the ones we discussed above can easily ariseunder an I-language approach, but not under the other views of languagewe mentioned earlier. If language is viewed as a repository of culture or as avehicle for our thoughts, for example, questions like these couldn’t even be

48 APPROACHES TO THE STUDY OF LANGUAGE
Fig 3.1 Which two of these look most alike? Baboon image (left) usedby permission © Art Parts.
formulated, and even if they could, no insight could be gained regarding theobserved restrictions, since there is no cultural restriction against assuming,for example, that him in (3.14c.) can refer to the same person as John, andsince it is certainly possible to think about him as referring to the sameperson as John.
3.4 Methodological dualism
We have advocated an I-language approach on the basis of the fact thatthe narrowness of this concept allows for a scientific study of language.However, there is a lot of resistance to the idea that language can at allbe the object of scientific inquiry.
Suppose you see around campus a poster with a picture of a baboon,advertising a talk on the communication system of this primate species.Who do you expect to show up at the lecture? Probably a bunch ofcalculator- and backpack-toting science nerds. Same if the poster shows aphotograph of the Crab Nebula, an astronomical entity 7,000 light yearsaway from earth. However, if the poster advertises a lecture on languageor on the English language with a picture of a small human, you mightget people from the education department, the English department, thecommunications department, and very few science students. Why is this?Don’t the baby and the baboon look much more alike than the baboon andthe nebula in Fig. 3.1?

METHODOLOGICAL DUALISM 49
When discussion falls within the domain of the physical sciences,pretty much everyone agrees that everyday, commonsense conceptions orcategories do not map directly onto scientific ones. And a scientist hasno qualms about postulating unobservable entities and new theoreticalconcepts with limited application in everyday experience if these provide thebest solution to whatever problem is at stake—the physicist doesn’t worryif the layperson finds genes, valence or quarks unintuitive. In introducingthese concepts the scientist is not concerned if the solution he proposesbears little resemblance to pre-theoretic discourse or understanding.Humans do not have an immediate understanding or any intuitions aboutelectrons, protons, or neutrons, or the position of planets, and yet we areready to accept that scientific pursuits that rely on the postulation of theseentities are valid. Any scientific pursuit leads to this kind of gap betweenthe commonsense concepts and understanding and scientific concepts andunderstanding.
Since Newton posited gravitational fields to explain action at a distance,the effect of the moon on the tides of earth’s oceans, for example, oureveryday conception of how the world works and our scientific models havedrifted further and further apart:
At one time there was no very profound difference between the two versions. Thescientist accepted the familiar story [of the perceiving mind] in its main outline; onlyhe corrected a few facts here and there, and elaborated a few details. But latterlythe familiar story and the scientific story have diverged more and more widely—until it has become hard to recognise that they have anything in common. Notcontent with upsetting fundamentally our ideas of material substance, physics hasplayed strange pranks with our conceptions of space and time. Even causality hasundergone transformations. Physical science now deliberately aims at presenting anew version of the story of our experience from the very beginning, rejecting thefamiliar story as too erratic a foundation. [Sir Arthur Eddington, “Science andExperience.” 1934]
As the familiar story and the scientific story diverge it becomes impossibleto understand in any direct sense what the world is like according to thescientific view.
However, when it comes to language, or to any scientific theory of themind, there appears to be a double standard. Although many scholars invarious fields do not explicitly acknowledge their views, they are typicallynot willing to accept a gap between everyday and scientific notions inthe domain of mental phenomena. In the case of language, it seems that

50 APPROACHES TO THE STUDY OF LANGUAGE
philosophers are the main supporters of this double standard. As JerryFodor notes:
To a remarkable extent, and really out of thin air, philosophers have taken it uponthemselves to legislate conditions under which empirical inquiry into the mental mustproceed. [Fodor 2000, “It’s all in the mind,” Times Literary Supplement review ofChomsky 2000b]
The resistance is not necessarily due to assuming a dualist position, i.e. thatmental phenomena are to be kept apart from physical phenomena. Evensupporters of a monist position, who assume that the mind is somehowamenable to physical explanation, are usually skeptical about the possibilityof applying naturalistic scientific methodology accepted for the study of thephysical world to the study of the mind. This kind of double standard iscalled methodological dualism.
What methodological dualists propose instead as tools for the study ofmental phenomena is the use of intuitions about the mind provided bycommon sense, contrary to the practice used in other areas of naturalisticinquiry. Accounts are expected to be cast in terms of recognizable, familiarconcepts. For example, when it comes to language, philosophers tendto assume that the notion of language investigated should be one thatcorresponds to commonsense notions such as communication, and that theconcepts that will be instrumental in figuring out the properties of languageare concepts like truth, reference, belief, meaning, in their everyday intuitivesense.
The explanations that are cast in terms of such familiar concepts arepreferred to accounts that use specialized concepts that depart from com-monsense notions. Such latter attempts are dubbed as “dubious” and “out-rageous” on the grounds that they are counterintuitive, but nobody objectsto the theory of relativity or biological theories of cell reproduction on suchgrounds.
Explanatory theories of mind have been proposed, notably in the study of language.They have been seriously challenged, not for violating the canons of methodologicalnaturalism (which they seem to observe, reasonably well), but on other grounds:“philosophical grounds,” which are alleged to show that they are dubious, perhapsoutrageous, irrespective of success by the normal criteria of science; or perhaps thatthey are successful, but do not deal with “the mind” or “the mental” . . . [S]uch cri-tiques are commonly a form of methodological dualism, and . . . advocacy (or tacitacceptance) of that stance has been a leading theme of much of the most interestingwork in recent philosophy of language. [Chomsky 2000:77]

BIOLINGUISTICS 51
The stand we take in this book is a monist one, both from the point ofview of the object of study—mental phenomena are natural phenomenain the world, just as physical phenomena are; and from a methodologicalpoint of view—we expect our explanations of the mental to depart fromcommonsense intuitions in the same way that scientific explanations ofgravity, optics, thermodynamics, and genetics do.
3.5 Biolinguistics
The view we are adopting has more to it than just being a monist view inthe sense explained above. One could potentially believe that I-language isa legitimate object of scientific study, and that the methodology used toperform this study should be the usual scientific methodology employedby all sciences, but assume no necessary connection between I-languageand biological cognitive structures. Much work in cognitive science actuallyadopts this stance. The idea is that cognition should be studied as abstractcomputational-representational systems that, in principle, could be imple-mented in a wide variety of physical devices.
Under this view, the desire for a hamburger, the intention to pay forit on Tuesday, or the pain of a toothache each have computational-representational essence that is independent of their existence in the mindof a human desirer/intender/sufferer. Even more strongly, some researchersthink it is important to characterize cognition in such a way that it nec-essarily abstracts away from the physical system in which it happens to beinstantiated, so that we can accept the possibility that Martians, who mayhave very different physical structures from us, can be correctly said to havethe same desires/intentions/pains that we do. The arguments for Martiansapply equally to digital computers.
Under this view, the implementation of an I-language could be in ahuman brain, but also in a computer, for example, and whatever theoryone would come up with for accounting for the linguistic computationalproperties of the human mind will also apply to machines.
The view advocated in this book is that I-language is directly related toan organ of the human body, i.e. to some part or structure of the brain,and that I-language is the physiological function of such a structure in thebrain. Such an approach is only partly supported by the findings reportedby brain scientists—we know language is in there, but they have not made

52 APPROACHES TO THE STUDY OF LANGUAGE
much progress in identifying its neural correlates. In our view, the “purecomputation” approach to the study of language actually has a potentiallydeleterious effect on the search for understanding, an issue we will elaborateon in the next chapter.
We thus adopt the term biolinguistics in this book to emphasize the factthat we are studying a property of organisms, their language faculty. We aredoing this in the same vein as studies of dolphin communication systems, orthe navigational abilities of wasps—they all require complex computationalsystems that are constrained by the genetic endowment of the organismsthat engage in the relevant behaviors. In this sense, linguistics is just abranch of cognitive ethology, the study of the computational systems thatunderlie animal behavior.
3.6 And so?
Each one of us has a digestive system that releases enzymes, breaks downcomplex molecules and provides nourishment to the whole body. There are“digestologists” who try to understand the workings of this system, thedetails of which are inaccessible to the conscious knowledge of most of us.And this is in spite of the fact that we each have a more or less functionalhuman digestive system. Similarly, each of us who speaks “English” hasa mental grammar that is comprised of rules and patterns that relate tothe puzzles illustrated in Section 3.3. Our goal, as the digestologists of thelanguage faculty, is not to teach you how to speak or listen but rather tounveil these rules and patterns.
Again and again, we will return to the themes of computation and equiv-alence class within the framework of I-language. We do not aim for fairnessor completeness in our presentation of what language is and what linguis-tics is—the book represents our own biases and judgments about what iscrucial, as well as the shortcomings in our knowledge and understanding.However, we will present some phenomena of reasonable complexity, in away that we hope will render them accessible.
People tend to think of science as belonging to an elite few in our society.However, we suggest that the spirit and practice of science is accessible toanyone who can appreciate the following proclamation by Democritus, thefather of atomic theory:

EXERCISES 53
I would rather find a single causal law than be the king of Persia. [Democritus 5thcentury BC]
Part of the beauty of linguistics is that it is a fairly young field, andinteresting data is easily accessible for investigation. It is relatively easyfor a newcomer to enter the field and start making real discoveries andcontributions. We do not need complex measuring devices to start makinghypotheses and collecting further data that can bear on our two puzzles,for example. The devices and the source of data are readily available inour mind. In fact, several linguists have argued that when funding forscience education is scarce and when the general public is fairly ignorantabout the nature of science, the accessibility of linguistics makes it anideal vehicle for teaching skills of hypothesis formation and testing. In thisspirit the authors and their students have begun lecturing about linguisticsoutside of the university setting—in high schools, public libraries, and evenprisons.
If you decide to pursue the following discussion, if these puzzles intrigueyou, we promise an overview of linguistics, as grounded in cognitive science,that will stretch your mind and give you an appreciation derived from expe-rience that will be more broad and also more profound than that of manyacademics and professionals in fields that are concerned with some aspectof human language. With this experience-based knowledge, you will not beable to avoid the conclusion that many widely accepted views concerningthe nature of language are as misguided and empty as we now know theclaims of alchemy and astrology to be.
3.7 Exercises
Exercise 3.7.1. Ask three friends the following questions:
� What is language?� Can you characterize language without mentioning what we use it for?� Can language be studied scientifically, like biology or physics?
Discuss their responses in terms of the approaches introduced in thischapter.

54 APPROACHES TO THE STUDY OF LANGUAGE
Further Readings
Like most of Chomsky’s writings, these are difficult, but we hope the dis-cussion we have provided makes them more accessible.
� Chapter 1 of Knowledge of Language by Noam Chomsky (1986).� “Linguistics and brain science” by Noam Chomsky in A. Marantz, Y.
Miyashita, and W. O’Neil (eds), Image, Language, Brain, pp. 13–28.� “Language as a natural object” by Noam Chomsky (2000a). Chapter 5.

4I-/E-/P-Language
4.1 Computation in phonology 55
4.2 Extensional equivalence 61
4.3 Non-internalist approaches 67
4.4 How is communication
possible? 72
4.5 Exercises 75
By now, we hope that the internalist approach to linguistics, the approachthat takes the object of study to be the human language faculty and thestates it can attain, is clear. The computations and representations that wehave been discussing are always assumed to be computations and repre-sentations of specific human “computers” and “representers,” individualhumans whose linguistic experience has caused their language faculty toend up in a certain state.
In the first chapter we looked at the formation of complex words viareduplication in Warlpiri and Samoan. This kind of phenomenon falls inthe realm of morphology, the study of word formation from the morphemes,the minimal units of meaning that a speaker must have in memory. Inthis chapter we will look at an aspect of phonology, the sound patternsof language. In particular, we will focus on word stress. We will use thisdiscussion of word stress to gain further insight into the implications ofadopting the I-language perspective.
4.1 Computation in phonology
You probably have an idea of what stress is, and you probably know thatthe location of stress in English is unpredictable. For example, the character

56 I-/E- /P-LANGUAGE
in the non-Rocky film series starring Sylvester Stallone is Rambo, withstress (basically, extra loudness and duration, and higher pitch) on the firstsyllable. In contrast, the name of the poet played by Leonardo di Caprioin Total Eclipse is Rimbaud with stress on the second syllable. Aside fromthis difference in stress, which is not predictable from other aspects of thenames, such as what sounds they contain, the two names are identical inour dialects of English.
Some languages contrast with English in that the placement of stress ispredictable, and thus stress cannot be used to distinguish two names or twodifferent word meanings. Since our interest here is in computational aspectsof language, those that can be expressed by rules, we will focus now onlanguages with non-distinctive, rule-governed, predictable stress patterns.The discussion relies heavily on discussion by Bill Idsardi in his 1992 thesisfrom MIT, The Computation of Prosody.
In general, stress is realized on the vowels of a word, but it is traditionalto attribute stress to syllables. For our purposes, we will assume that eachvowel corresponds to a syllable. The symbols i,u,e,o,a represent vowels inthe following discussion, and so each one of these symbols will correspondto a single syllable. Finally, we note that words can have more than onestress, a primary stressed syllable, marked with an acute accent on the vowel,like á, and secondarily stressed syllables marked with a grave accent on thevowel, like à. We’ll assume that the stress system of I-languages is rule-based and that the input to the stress system is a string of syllables withno stress assigned, while the output is the same string with the correct stresspattern.
4.1.1 Two simple languages
Let’s look first at Weri, a language of Papua New Guinea. The followingdata is representative of words with an odd number of syllables (the (a.)cases) and those with an even number (like (b.)). We won’t even tell youwhat these words mean, so you can concentrate on the patterns of interest.
4.1 a. àkunèpetálb. ulùamít
Each of these forms represents the output of some phonological rule thatassigns stress in Weri. The input to this rule is the form without stress.

COMPUTATION IN PHONOLOGY 57
What we want to discover is the rule that takes these non-stressed formsand outputs the stressed forms.
4.2 a. akunepetal → àkunèpetálb. uluamit → ulùamít
Suppose the way stress is assigned to words in Weri is the following:
4.3 An algorithm for Weri stress� Syllables are grouped into pairs (each grouped pair is called a “foot”),
starting from the end of the word as follows:
a. a(kune)(petal)b. (ulu)(amit)
� Leftover syllables are grouped by themselves:
a. (a)(kune)(petal)b. (ulu)(amit)
� Stress is assigned to the syllable at the right edge of each foot:
a. (à)(kunè)(petàl)b. (ulù)(amìt)
� The rightmost stress in the word is made the primary stress:
a. (à)(kunè)(petál)b. (ulù)(amít)
We have thus generated the stress on the listed words, and it turns out thatthe algorithm will generate stress correctly on all Weri words.
Now consider data from another language called Maranungku, spokenin Northern Australia:
4.4 � tíralk� mérepèt� jángarmàta� lángkaràtefì� wélepèlemànta
Suppose we proposed the following algorithm to generate Maranungkustress.
4.5 An algorithm for Maranungku stress� Label the vowels of each syllables with an index from 1 to n, where n is
the number of syllables in the word, e.g.:� ti1ra2lk� me1re2pe3t� . . .
� Assign stress to each syllable whose vowel bears an odd-numbered index.� Assign primary stress to the syllable whose vowel bears the lowest index.

58 I-/E- /P-LANGUAGE
Just as we successfully generated Weri stress patterns above, we have nowdeveloped an algorithm to generate Maranungku stress patterns. Theseexamples illustrate once again the idea that languages are computationalsystems. However, you should be bothered at this point.
You may have noticed that the stress patterns of the two languages Weriand Maranungku are mirror images of each other. The former has primarystress on the last syllable and secondary stress on every other syllablecounting from the last. The latter has primary stress on the first syllable andsecondary stress on every other syllable counting from the first. Despite thisrelationship between the patterns, we have analyzed the two in completelydifferent terms. For Weri we needed to group syllables into feet of two andtarget the righthand syllable in each foot. For Maranungku we need to labelsyllables up to an arbitrarily high number, determine if a syllable is labeledwith an odd number, and, if it is, stress it.
You probably have figured out that we could have adopted the Werianalysis to Maranungku by just changing the starting point for groupingsyllables to the beginning of the word; stressing the leftmost member ofeach foot, and placing primary stress on the lefthand stressed syllable in theword.
Alternatively, we could have adapted the Maranungku analysis to Weriby assigning our indices from 1 to n starting at the end of the word andagain stressing the odd-numbered syllables.
There are three important issues to discuss at this point, and it is crucialto distinguish them:
a. Does it make sense to ask what the correct analysis is for each lan-guage?
b. Is it important to provide a unified analysis of the two languages?c. What is the correct unified analysis of the two languages?
We have developed two equivalent analyses for each language—a group-ing analysis and a counting analysis—and if we conceive of a languageas just a list of recorded utterances, there is no question of correctnessin choosing among equivalent analyses, analyses that will always map thesame input to the same output. But if we think of a particular grammaras actually characterizing a property of a particular human mind, thenthere is a correct grammar corresponding to the linguistic knowledge ofeach person. More than one grammar can simulate the output of a Weri orMaranungku speaker, but the goal of linguistics is to model the system of

COMPUTATION IN PHONOLOGY 59
knowledge that is actually in a person’s mind. So, the answer to our firstquestion is that it does make sense to ask what the correct analysis is.
If we believe that there is such a thing as the human language facultyor, indeed, such a thing as human language, then we are committed to theexistence of a unified analysis of stress systems of the two languages. If weanalyze them in completely different terms, then we are, in effect, sayingthat they are two different kinds of thing. Thus, it is important to providea unified analysis if we think we are faced with two instantiations of thehuman linguistic stress system.
The final question, the one that asks for the correct analysis, is a hot topicof research. We will postpone giving you an answer, but just to give you anindication of where we are heading, consider the following quotation fromChomsky’s Knowledge of Language (1986:38), where S0 refers to the initialstate of the language faculty, prior to any experience, and I-language refersto the mental grammar a speaker has.
Because evidence from Japanese can evidently bear on the correctness of a theory ofS0, it can have indirect—but very powerful—bearing on the choice of the grammarthat attempts to characterize the I-language attained by a speaker of English.
In other words, evidence from one language’s stress system, say that of Weri,should bear on the best analysis of the stress system in other languages,such as Maranungku, since each represents a development of the initial stateof the stress module of the human language faculty. Let us look at moredata that shows other ways in which languages may differ minimally in theirstress systems, while conforming to the same general pattern.
4.1.2 Some more data
The two languages we have just considered are sufficient to make the pointwe are interested in, but it will be useful to look at two more simple stresspatterns.
Here are two words from Warao, a language spoken in Venezuela:
4.6 a. yiwàranáeb. yàpurùkitàneháse
The general pattern in Warao is that stress falls on even-numbered vowelscounting from the end of the word, and main stress is on the secondto last vowel. So in the (a.) form, there is no stress on the first vowel,because the word has an odd number of vowels, but in the (b.) form the

60 I-/E- /P-LANGUAGE
initial vowel is stressed because the word has an even number of vowels.Here are the forms repeated with the vowels numbered and with syllablesgrouped in twos—we don’t want to bias our search for the right modeljust yet:
4.7 a. yi5wà4ra3ná2e1
yi(wàra)(náe)b. yà8pu7rù6ki5tà4ne3há2se1
(yàpu)(rùki)(tàne)(háse)
Like Weri, this language builds feet from the end of the word but it differs inthat it stresses the lefthand member of each foot and does not allow feet ofone syllable. Alternatively stated, Warao stresses even-numbered syllablescounting from the end of the word.
Finally consider Pintupi, an Australian language in which stress is againpredictable. See if you can extract the pattern based on the following forms:
4.8 Rules in phonology: Pintupi (Australian) stress
païa “earth”tjuúaya “many”maíawana “through from behind”puíiNkalatju “we (sat) on the hill”tjamulumpatjuNku “our relation”úıíirıNulampatju “the fire for our benefit flared up”
Now see if you can predict where the stress would fall on these Pintupiforms:
4.9 Where are the stressed syllables in the following words?
kuranjuluimpatjuõa “the first one who is our relation”yumaõiNkamaratjuõaka “because of mother-in-law”
You may have figured out that stress in Pintupi is exactly like in Mara-nungku, except that a final syllable is never stressed, even if it is odd-numbered. If we think about the grouping of syllables into pairs, we canthink of this condition as a failure to stress a syllable that is not part ofa pair. So this condition applies in Pintupi and Warao, but not in otherlanguages, like Maranungku or Weri. So this is one dimension along whichlanguages may differ minimally, while conforming to the same general typeof algorithm for assigning stress.
There are many, many languages like the four we have considered. Theyprovide us with good examples of computation within one small domain,

EXTENSIONAL EQUIVALENCE 61
as well as with the kind of (micro)variation that we can find within such adomain.
However, the simplicity of these patterns has allowed us to discuss threequestions that have been the subject of very important debates amongphilosophers and linguists over the past fifty years or so. In general, thephilosophical position (e.g. Quine’s) has been to deny the validity of tryingto choose a correct analysis for some linguistic data. All analyses that madethe right predictions were considered equally valid. We will see that thisview comes from failing to adopt the I-language perspective that languages(including stress systems) are components of actual individuals.
This is such an important point that we need to expound on it a bit.Recall the discussion of Samoan in Chapter 1. We forced you to makeand revise hypotheses as you received new data. Positing a prefix no- inthe form nonofo became less attractive when we expanded the set of datato include momoe, and the hypothesis that the first syllable is reduplicatedbecame untenable when we again expanded the empirical base to includealolofa. There is nothing surprising about this—a smaller set of data allowedfor a wider range of hypotheses concerning reduplication. As soon as weexpanded the corpus, however, some of the hypotheses had to be droppedor revised. Chomsky’s statement about Japanese and English, cited above,makes basically the same point: there is no good reason to consider only“English” data or “Weri” data—even when trying to figure out the natureof a Weri grammar, data from Maranungku, English, or Japanese could be,or rather should be, considered relevant. The empirical base of potentiallyrelevant data is all linguistic output of all human languages. This position isonly available to us once we adopt the I-language, biolinguistic approach. Infact this approach necessitates taking seriously the fact that Weri-type gram-mars, Maranungku-type grammars, Japanese-type grammars, and English-type grammars are built from the same primitives, primitives that can bepart of a computational system realized in a biological organism with theproperties of humans.
4.2 Extensional equivalence
Above we developed two competing analyses for the stress systems of eachof two languages, Weri and Maranungku. For each language we were able toconstruct a grouping algorithm and a counting algorithm for generating the

62 I-/E- /P-LANGUAGE
correct stress patterns. Two algorithms that produce the same outputs aresaid to be extensionally equivalent, so we can say that the two analyses thatwe proposed for, say, Weri correspond to extensionally equivalent grammarsfor Weri stress. Of course we are using the term grammar here not in thesense of “mental grammar” but to refer to the explicit rule systems, the algo-rithms, that we came up with as linguists. Our goal will be to understand theextent to which these algorithms we posit correspond to the actual mentalgrammars of Weri speakers.
Since the grammars of human languages are quite complex it may beuseful to illustrate this notion of extensional equivalence with a simplemathematical example. Suppose we wanted to devise a rule system to takesome input and generate as output a number that is a member of the setS = {1, 4, 7, 10, 13, 16, 19}. Well, there are actually an infinite number ofways of generating the set S—one way would be to just list the members ofthe set as inputs and map them to themselves as outputs, but there are otherways. For example, we could define a set of inputs I1 = {0, 1, 2, 3, 4, 5, 6}and a function f 1 = 3x + 1. Then for each element of I1 we could apply f 1
to it and generate a member of S. This system for generating S, along withtwo others, is given in (4.10)—you should check that they all work.
4.10 Extensional equivalence—three functions for generating a set ofnumbers:S = {1, 4, 7, 10, 13, 16, 19}.
a. 3x + 1, x ∈ {0, 1, 2, 3, 4, 5, 6}b. 3x − 2, x ∈ {1, 2, 3, 4, 5, 6, 7}c. (3x − 4)/2, x ∈ {2, 4, 6, 8, 10, 12, 14}
So all of these functions applied to their respective input sets are extension-ally equivalent—they all generate S.
Now, what if we asked what the correct function is for generating S. Doesthis question make any sense? We are just generating a set of numbers,a list of data, so there is no reason to say that any one is more correctthan any other. However, if you have a little device that always flashes anumber from S after you hit some button corresponding to a number fromanother set, then it does make sense to ask what is going on inside thedevice. There is no correct answer to the question “How is set S generated?”But there is a correct answer to the question “What is this device doingto generate members of S?” We may not be able to answer the question,or we may be able to only eliminate certain possibilities and claim that the

EXTENSIONAL EQUIVALENCE 63
correct answer is one of a certain class of answers. But a correct answer doesexist—we can be confident of its existence even if we do not know all of itsproperties.
Once we adopt the I-language perspective that language is best under-stood as individual grammars that are properties of individual minds, thenwe recognize that there is a correct answer concerning the true nature ofWeri stress.10 It may be hard to find out what it is, but there is a question oftruth of the matter. Our next step will be to see if there is any way to makeprogress on figuring out what that correct answer is—is it more likely thatthe correct answer relies on grouping syllables into pairs from right to leftand stressing the rightmost member of each group with primary stress inthe rightmost group, or on counting up the number of syllables in the word,finding that number n, assigning primary stress to syllable n and secondarystress to syllables n − 2, n − 4, n − 6, etc.?
The internalist I-language perspective will help us. Languages are prop-erties of individuals, and they take on their individual properties due to theeffects of experience on some initial state of the human language faculty.In other words, humans are born with the capacity to learn any humanstress system, but experience, the data a child is exposed to, determineswhich system is encoded in the learner’s mind as the stress grammar.Given this perspective, it is apparent that our goal as linguists should beto discover a single set of primitives of representation and computationthat can generate all the stress systems we observe. Since Weri speakersand Maranungku speakers are all humans, we assume that they start outwith the same cognitive apparatus for representing equivalence classes ofsyllables and words and computing stress. So, either both should use thesyllable-counting method or both should use the grouping method. If Weriuses the grouping method, then that tells us that the initial state of thelanguage faculty (referred to as S0 above) allows the learner to representwords by grouping syllables; similarly, if Weri uses the counting method,that has implications for the initial state. So, if we can get both Weri andMaranungku stress with only one kind of primitive (either counting orgrouping), then we should do so.
10 Just to be clear, nothing we have said implies that everyone referred to as a speakerof some particular “language” must have the same exact grammar even in cases wherethe outputs are apparently identical in a restricted domain, like stress. There is a correctanswer for each individual Weri speaker. The question of whether all extensionallyequivalent stress grammars are identical is an interesting one, but beyond our scope here.

64 I-/E- /P-LANGUAGE
To recapitulate, we have justified the view that there is a correct analysisfor the stress system for a language by appealing to the I-language per-spective. Since grammars are properties of individuals, there is a correctcharacterization of what those properties are. Second, since all humans areassumed to be capable of learning all languages from an initial state thathas the same basic resources, we have justified the idea that the same funda-mental notions should be used to model both Weri stress and Maranungkustress. If we reject internalism, the I-language perspective, then there is noreason to assume that one set of data labeled “Weri” and another set labeled“Maranungku” should be analyzed using the same representational andcomputational primitive elements. If our goal is to generate data sets or tosimulate the behavior of Weri speakers, then we don’t need to worry aboutwhat the correct analysis is.
So, cognitive biolinguistics is concerned with the correct characterizationof Weri stress as a step towards figuring out the nature of the languagefaculty of humans. People interested in generating sets of data, includingmany working linguists, are concerned with stating a set of rules that willgenerate a corpus of observed forms. Artificial intelligence, as opposedto cognitive science, is concerned with simulating human behavior, andsomeone working in this field may be happy to build a robot that simulatesWeri stress patterns but uses a grammar that is completely different in itsrepresentations and computations from that internal to a real Weri speaker.
Is there any hope of choosing between the counting and grouping analy-ses of Weri? We can at least make some suggestive observations. When weturn to syntax in subsequent chapters, we will see that the language facultynever has syntactic rules or structures that depend on counting words. Incontrast, the fundamental notion of syntax seems to be that certain wordsin a sentence are in closer relations than others. Appealing just to intuition,we hope you can agree that in a sentence like The man ate a fish there aregroups of words that “go together” in some sense: the man forms a group;a fish forms a group; but man ate and ate a do not form groups. If youaccept this intuition about English syntax, then we propose to attempt toapply this fundamental notion of grouping to analyze as much of language,all languages, as possible. And if we can use grouping, but never appeal tocounting, this may indicate that we have discovered a fundamental propertyof linguistic representations—they are structured.
Young children and many species of animals have been shown to be ableto distinguish small numbers of items, such as one versus three or two versus

EXTENSIONAL EQUIVALENCE 65
four. It is typically assumed that this is done by a process called subitizing,which is an almost immediate perception of number that even appears toutilize only a subset of the brain regions used for counting. Outside ofthe range of subitizing, animal and child performance on counting tasksdegrades immediately, so that even five and ten cannot be distinguished.Although the reports remain controversial, there have been claims that evenadults in the Amazonian Pirahã society (which has only about a hundredmembers) cannot count, but only subitize. In general, counting appearsto be a conscious activity that is not actually utilized by other cognitivesystems, something that appeared late in human evolution and appears latein development of the individual. It is thus attractive to not posit stress-generating algorithms that depend upon the language faculty counting toarbitrarily high numbers.
So, our conclusion is that English syntax and Weri and Maranungkustress are all best modeled using the notion of grouping—of syllables orwords, as relevant. By taking this strong stand we are forced to review ourdiscussion of Samoan reduplication in Chapter 1. We proposed a rule thatreduplicated syllable n − 1, and this appeared to be able to generate allthe data. However, an extensionally equivalent rule that groups syllablesfrom the end of the word into pairs and repeats the leftmost member of therightmost group is now preferable.
We repeat in (4.11) the Samoan forms with the grouping of the last twosyllables, which will make the parallel to stress systems more apparent.
4.11 Samoan verbs: sg-pl
(nofo) nonofo “sit”(moe) momoe “sleep”a(lofa) alolofa “love”sa(vali) savavali “walk”ma(liu) maliliu “die”
We are proposing that grouping of elements in a string into constituentsis a common operation in the construction of linguistic representations—itrecurs in syntax, in morphological reduplication, and in the phonology ofstress in various languages. The grouping process is part of an algorithmin each case for finding targets of specific processes—targeted syllables mayreceive stress, as in Weri, or they may be repeated, as in Samoan. We havediscovered a commonality, but there obviously must be room for variationas well: in some stress systems, like Weri and Warao, and in Samoan the

66 I-/E- /P-LANGUAGE
grouping of syllables must start at the end of the word; whereas in caseslike Maranungku and Pintupi the grouping starts at the beginning of theword. Another parameter of variation relates to which member of a groupis targeted for special treatment—the leftmost or the rightmost. Next, wehave seen that the treatment of syllables that are not part of a binary groupmust be considered—are they ignored or are they treated like the targetedsyllable of binary groups?
Here in (4.12) is the Pintupi data with the grouping of syllables (Û standsfor syllable). We can see that grouping starts at the beginning of the word;the leftmost member of each group is targeted; and a syllable that ends upas not part of a binary group gets ignored. This results in the fact that odd-numbered syllables are not stressed when they are final.
4.12 Pintupi stress (again)
(païa) (ÛÛ) “earth”(tjuúa)(ya) (ÛÛ)Û “many”(maía)(wana) (ÛÛ)(ÛÛ) “through from behind”(puíiN)(kala)(tju) (ÛÛ)(ÛÛ)Û “we (sat) on the hill”(tjamu)(lumpa)(tjuNku) (ÛÛ)(ÛÛ)(ÛÛ) “our relation”(úıíi)(rıNu)(lampa)(tju) (ÛÛ)(ÛÛ)(ÛÛ)Û “the fire for our benefit
flared up”
So, yes, Pintupi has a stress system that is different from that of Weri,Warao, and Maranungku, but it can be analyzed in terms of a set of primi-tive elements, equivalence classes (syllables, for example), and computations(grouping of two elements) that can be used to analyze not only the otherstress systems but a wide range of linguistic phenomena including Samoanreduplication.
This discussion of extensional equivalence and the internalist perspectivehas thus provided us with a framework for understanding how we canpursue a theory of Universal Grammar, a theory of S0, the intial state ofthe language faculty. Without the I-language, biolinguistics perspective, itis not even possible to pose the question of what is the correct rule in agiven case. The internalist perspective guarantees that there is a correctanswer, since grammars are actually instantiated in individual minds/brains.Since each I-language represents a development of the initial state of thelanguage faculty, we can gain insight into the correct characterization byexpanding our empirical base from a single language to all attested lan-guages. Finally, the biolinguistic approach encourages us to draw on what

NON-INTERNALIST APPROACHES 67
we know about other aspects of cognition, neuroscience, and evolutionto decide that a stress algorithm that groups syllables into feet is moreplausible than one that relies on counting arbitrarily high and referringto the notion of odd or even, a notion not part of any known naturalsystem.
Under the pure computation view that we discussed in Section 3.5, spe-cific evidence from the evolutionary and developmental biology of humans,as well as their general cognitive properties, is denied a part in character-izing the nature of language, since these are just the accidental propertiesof one kind of language computing-representing system. These biologi-cal properties might be absent from Martians who, let’s say, can performthe same input-output mappings. In other words, the pure computationapproach makes it impossible, and even undesirable, to choose amongextensionally equivalent grammars. The pure computation approach is astep backwards to Quine’s view that it is incoherent to ask what the bestgrammar is among ones that all generate the data.
4.3 Non-internalist approaches
While it is probably hard to find working linguists who would deny thathumans do store linguistic information in their minds or brains, it is notvery hard to find linguists and other scholars who insist that, in additionto the individual, internal “I-languages,” as Chomsky calls them, there isanother object of study for linguists, that has properties that differ fromI-languages.
We will briefly discuss three such examples, but we warn you to be on thelookout for more in your own reading in fields like philosophy, anthropol-ogy, psychology, and even linguistics, where both tacit and explicit rejectionsof the I-language approach are not as rare as one might expect.
Our first example comes from the work of Geoffrey Pullum, a linguistwho has actually done a lot of important work on the formal properties ofhuman language in general and on the analysis of particular languages. Togive a sense of his range of expertise, we just note that he has co-authoredan encyclopedic grammar of English and also done fieldwork and publishedon several endangered languages of Amazonia.
In an article comparing two approaches to syntactic modeling, Pullumand co-author Scholz (2001) made the following statements:

68 I-/E- /P-LANGUAGE
� millions of different people may be correctly described as speakers ofthe same language
� The Times in the UK, The New York Times in the USA, The SydneyMorning Herald in Australia, and other papers around the world allpublish in the same language
You can probably tell that, coming from a professional linguist, both ofthese statements reflect a rejection of the I-language approach advocated byChomsky and adopted in this book.
The second example is mentioned by Chomsky in a paper called “Lin-guistics and Brain Science” and comes from a very successful popular bookby Terence Deacon, a biological anthropologist formerly at Harvard andBoston University, and currently with appointments in both anthropologyand linguistics at the University of California at Berkeley. In a discussionof language acquisition in his 1997 book The Symbolic Species, Deaconcriticizes the view of “Chomsky and his followers” who
assert that the source for prior support for language acquisition must originate frominside the brain, on the unstated assumption that there is no other possible source.But there is another alternative: that the extra support for language learning is vestedneither in the brain of the child nor in the brains of parents or teachers, but outsidebrains, in language itself. [105]
The I-language perspective defines languages as mental grammars, encodedin individual brains, but Deacon explicitly refers to language (languages?)as “outside brains.” It is hard to imagine a clearer denial of the I-languageview.
Finally, we present a quotation from Michel Foucault, a French philoso-pher who has been most influential in the fields of literary criticism andcultural studies.
Language partakes in the world-wide dissemination of similitudes and signatures. Itmust therefore be studied itself as a thing in nature. Like animals, plants or stars,its elements have their laws of affinity and convenience, their necessary analogies.[Foucault 1973:35]
At first blush, this passage perhaps appears to support a scientific approachto language that should thus be consistent with the Chomskyan programwe have been developing. However, Foucault is not advocating the study ofthe human language faculty as an object of study of the same status as thehuman faculty of vision, but rather he is advocating recognition of some

NON-INTERNALIST APPROACHES 69
abstraction “language” that has an existence of its own, like animals andplants, not part of (human) animals.
Despite the very different approaches of Pullum, Deacon and Foucault,we find them equally incoherent in light of the discussion and discoveriesdiscussed thus far in this book. In the discussion that follows we will clarifywhy.
4.3.1 E-language
Chomsky makes a distinction in his book Knowledge of Language betweenthe I-language approach, that he advocates, and various other approachesto the study of language. It is possible, like Geoffrey Pullum, whom wecited above, to approach the study of language from a formal, compu-tational perspective and build very explicit mathematical models, but toconsider the object of study to be linguistic corpora, collections of data.These could be recorded utterances or text collections like a set of articlesfrom a single newspaper or various newspapers, as Pullum suggests in thequotation above. A corpus could also be a collection of utterances from“English” or “Italian,” or even the limited corpus of words from “Weri,”“Maranungku,” “Pintupi,” and “Warao” that we looked at earlier in thechapter. This approach is dubbed the E-language approach by Chomsky,where “E-”stands for “external,” in contrast to the “I-” of the internal, indi-vidual approach we have been developing. It is important to realize that E-language constitutes an attempt to come up with a formal characterizationof language, one that differs from everyday notions, and that the goal is tosubject E-languages to scientific study.
One problem, however, is that E-language is an incoherent notion—thecorpus is very often a collection of utterances produced by several speakers.Newspapers obviously represent the output of many individuals. Thus,there is no guarantee that a particular set of data can be modeled by a singlegrammar that corresponds to a possible humanly attainable language.
Furthermore, it is obvious that even a single individual can generateoutput that corresponds to mutiple grammars. Some people are clearly mul-tilingual, with grammars that we may refer to informally as “Japanese” and“English;” in other cases an individual may have grammars that correspondto what are called close dialects of a single language in everyday parlance.Again, even if one focuses on a collection of utterances produced by only

70 I-/E- /P-LANGUAGE
one speaker, there is no guarantee that this collection can be generated bya single mental grammar, a grammar that is a possible humanly attainablelanguage.
And, finally, even if one wishes to take into account data produced byonly one speaker, in only one language, say Quebec French, one still needsa way to define Quebec French. In fact, this is a more general problem forE-language approaches. How does one decide what constitutes the relevantcorpus? If one took all the newspapers published in Montreal, there wouldbe an incredible diversity of grammars represented, including some wewould call English or French, and many others. Any study of this corpusas a single system would lead to chaotic results—this would be a really badway to choose a corpus. On the other hand, someone might get reasonableresults by deciding to work on the corpus consisting of the last five yearsof French newpapers in Montreal. So, depending on the choice of thecorpus, one would get results that are more or less satisfactory. In orderto eliminate the choice that leads to unsatisfactory results, one has to rely(tacitly) on an everyday notion of language. In a sense, the E-languageperspective always tacitly relies upon the everyday notion of languagesand speech communities in order to define the corpus that is subject toanalysis.
For these reasons, the goal of I-linguistics is not to analyze corporaof data, or to analyze speech behavior, but rather to infer the nature ofthe human language faculty. E-language approaches are also interested inidentifying patterns underlying the corpora, but what differs is whetherthese patterns are assumed to be rooted in biology or not, whether theyare assumed to be dependent or independent of psychological states ofindividuals. Under an E-language perspective, the rules underlying the cor-pora are just that, rules that can correctly generate the data. On the otherhand, under an internalist perspective grammars are actually instantiatedin individual minds/brains. The rules of I-language grammars constituteknowledge, information encoded in the brain of a speaker at a certainpoint in time. The ultimate task of an I-linguist involves characterizing boththe initial state of the language faculty, before exposure to any experience,and the states the language faculty can attain after exposure to experience.As illustrated above, with examples from Weri, Maranungku, Pintupi, andWaori, an internalist view provides a filter for teasing apart rules that cangenerate a corpus but that are psychologically implausible from rules that

NON-INTERNALIST APPROACHES 71
both can underlie a corpus11 and are compatible with what we know aboutthe biology, including psychology, of humans.
4.3.2 P-language
Apart from E-language, there is yet another concept of language that seeslanguage as independent of any psychological states of individuals, as inde-pendent of speakers. Actually, such views are not incompatible with thebelief in what we have called I-language; the assumption is that in additionto individual I-languages, there exist entities, “languages,” independent ofthe existence of actual human speakers. Under such a view, English, forexample, is an idealization, or maybe an idea, like Plato’s ideal forms, thatis only imperfectly grasped or accessed by actual speakers of English, orrepresented in actual utterances—much like an ideal triangle cannot existin the physical world but is somehow manifest indirectly in triangles that wesee. This kind of perfect, ideal language is what Chomsky calls P-language(“P” for “Platonic”) and such a view is (typically implicitly) at the base ofmany philosophical discussions of language. It follows from such views thatthere are words out there in “English” that you might not know, that in factno speaker might know, but they are part of “English.” It also follows thatthere might be some patterns or rules of “English” that are not encoded inyour mind, or in anybody’s mind, that are also part of “English.” You canprobably see what the problem is. It is impossible to define the boundariesof P-English. How many words could there be that are part of “English” butwe, as mere mortal speakers, do not know? And how many patterns? Andhow can we tell whether these unknown words or patterns are really part ofP-English and not part of P-Romanian? There is no way to tell because we,as speakers that are only aspiring towards or grasping at the ideal “English,”do not have full access to it.
There are other questions that such an approach raises, namely do theseP-languages change? Well, if they are ideal, perfect entities, they probablydon’t change. But then did Shakespeare and Chaucer access the same P-English that we do? How about dialect variation? Do you participate in,
11 The choice of what constitutes the corpus is subject to the kind of idealizationscommon in all sciences, and also necessary for the E-language approach.

72 I-/E- /P-LANGUAGE
grasp, use, speak, aspire towards the same P-language as Bob Marley andGeorge W. Bush?
It is typically only a certain variety of philosopher that explicitly proposesthe existence of entities like P-languages. It is important to point out,however, that in everyday life we all implicitly act as if we believe that suchthings exist. When we play Scrabble or argue about whether somethingsomeone says “is an English word,” we implicity assume that there is anentity “English” that a word can be part of. When we ask if dog, snuck,or florb are English words, we do not mean something like “Is there anyindividual who we would call in everyday terms a ‘speaker of English’whose mental grammar contains a lexical item whose phonology is florb,”etc. We typically treat dictionaries as defining what languages, or at leastthe words of languages, “really” are. In everyday life we are people, notlinguists, and to speak like linguists in everyday life would make us aspopular as an astronomer who gave a discourse on the heliocentric solarsystem and the earth’s rotation every time he or she was invited to watcha gorgeous sunset—in everyday terms, the sun does set; in astronomicalterms, the earth rotates so that the sun is no longer visible to an observer onits surface. But talking constantly like an astronomer or linguist in everydaylife is annoying, perhaps even pathological. This is not a question of rightor wrong, but of choosing a way of speaking that is appropriate to thesituation—most of us do not find a discourse on the Copernican revolutionor Pintupi stress to be appropriate to a romantic picnic with an attractivemate (although we are aware that human perversity ranges quite widely).
4.4 How is communication possible?
If we want to deny the existence in the world of entities like “English”or “Japanese” that correspond to the everyday notions, and we also denythe coherence of the E-language conception implicit in the work of manylinguists, as well as the existence of the P-languages implicit in much philo-sophical work, we perhaps want to say something about why it appears tobe the case that two speakers of English or Japanese communicate with eachother, whereas speakers of two different languages, one English speaker andone Japanese speaker, say, have great difficulty in communicating.
Communication is a fairly vague notion. We assume that we can walkinto a noodle shop in Japan, lay some money down on the counter, point to

HOW IS COMMUNICATION POSSIBLE? 73
someone else’s bowl and get served the same dish. We may even be ableto imitate a pig or a fish to get some pork or a fish with our noodles.Communication can thus take place when people clearly do not have thesame grammar.
On the other hand, communication can fail even when the grammars aresimilar. We can walk into a shop in London and, in New York dialect, askfor some chips, and then become enraged when we are served french fries.What are called chips in New York are called crisps in London. Why can’twe communicate perfectly with other “English” speakers if we are speakingthe same language?
Given the I-language perspective, we just assume that some people have I-languages, grammars, that are very similar, based on similar experience andother people have grammars that are not very similar. Suppose we take twofootball teams trained to play by the rules of the Canadian Football League(CFL). They will play a game in which everyone is playing by the same setof rules. If we replace one team by a team playing with National FootballLeague (NFL) rules, we can imagine that the teams could continue to playwith each other, to interact, to compete, to communicate. If, instead of NFLrules, one team has the rules of rugby, things will get more chaotic, butsome interaction and play is still imaginable. And so on. Finally, imaginethat one team is playing by CFL rules and the other is playing by the rulesof Olympic synchronized swimming. Not much competitive interaction ispossible—we are in a situation like that in which a Japanese speaker and anEnglish speaker try to interact using their grammars—the rules are just toodifferent.
So, two people can talk to each other and communicate more or less whenthey have similar mental grammars, similar information and rules in theirbrains. This is the case because they are both human, so they have most ofthe same basic physical and cognitive resources, and because they must havehad enough experience that was similar in ways necessary to lead to similargrammars. There is no need to posit the existence of languages as entitiesthat exist apart from the existence of speakers, and there is no need to positconventions or public rules that constitute a language. Chomsky has madethis point in many places over the years:
It might be that when he listens to Mary speak, Peter proceeds by assuming that sheis identical to him, modulo M, some array of modifications that he must work out.Sometimes the task is easy, sometimes hard, sometimes hopeless. . . . Insofar as Petersucceeds in these tasks, he understands what Mary says as being what he means by

74 I-/E- /P-LANGUAGE
his comparable expression. The only (virtually) “shared structure” among humansgenerally is the initial state of the language faculty. Beyond that we expect to findno more than approximations, as in the case of other natural objects that grow anddevelop. [New Horizons 2000b:31]
Chomsky’s point is basically that if you start with two creatures that areidentical in relevant respects (they both have a human language faculty),and they have experiences that are similar enough during the process oflanguage acquisition, the ultimate states of their language faculties willbe similar to each other. When they interact, such individuals behave asif there is a set of regular correspondences between their languages, andthey try to discover and apply such correspondences, with more or lesssuccess.
Note that a Spaniard can go to Italy and communicate well, but he doesnot thus have an Italian grammar. Similarly, we, the authors, can go toJamaica and speak English and perhaps do worse than a Spaniard in Italy. Ifyou speak to a Portuguese person in Spanish, or a Dutch person in Germanthey might get offended, even if they understand you quite well on the basisof the similarity of their language to the one you use to address them.Speak to them in English and they probably won’t get offended, whetheror not they understand you. This is a reflection of how one’s linguistic self-consciousness is connected to ethnic and national identity, perhaps morestrongly than to communication.
A speaker of a Norwegian dialect as opposed to a Swedish dialect isrecognized as such if he grew up in Norway and not Sweden. His languagemay be extremely similar to that of someone who lives two kilometers awaybut is called a speaker of a Swedish dialect because she lives in Sweden.The language of these two people may be much closer by any measurewe want to apply than either is to the national standard of his or herrespective country. If the Swede goes to Norway to work or visit, she justspeaks Swedish and appears to be understood better than, say, someonewith a Glasgow Scottish accent coming to Brooklyn, New York. We tendto label languages and dialects on the basis of historical and politicalevents, or on the basis of labels that others have applied on those bases.Of course it would be an incredible coincidence if the way we referred tospeech behaviors—Brooklyn English and Glasgow English as opposed toNorwegian and Swedish—determined their properties. To believe this wouldreally be attributing magical powers to our naming practices!
We return to the issue of differences among dialects of “the same lan-guage” in Chapter 12. For now, note that the names of languages around

EXERCISES 75
the world, and the language-dialect distinction, are notions of everydaylanguage that cannot be the basis of scientific inquiry. If these labels turnedout to perfectly define natural divisions in the world, it would be as amazingan outcome as if terms like household pet defined a real biological category.Nobody expects genetics or evolution textbooks to have a chapter on house-hold pets and, similarly, there is no reason to think that what we refer to asEnglish or Norwegian or Chinese (which includes many mutually unintelli-gible dialects like Cantonese and Mandarin) should refer to a natural classof grammars.
The difference between Hindi and Urdu is a question of identity. A personwho speaks Hindi is typically Hindu and uses an alphabet derived from theSanskrit one; a person who speaks Urdu is typically Muslim and uses analphabet derived from the Arabic one. Similarly, a self-described speakerof Croatian is typically Catholic and uses the Latin alphabet, whereas aSerbian speaker is typically Orthodox and uses a version of the Cyrillicalphabet that Russian uses. In the former Yugoslavia, Serbian and Croatianspeakers lived in the same town and same houses even, and the schoolsalternated alphabets by week. There is no linguistic criterion distinguishingSerbs from Croats.
Our friend Bert Vaux has described a group living on the coast of theBlack Sea in Turkey who think that they speak a funny kind of Turk-ish. It turns out that they speak, according to the principles of historicallinguistics, a dialect of Armenian. Why do they call themselves Turkishspeakers?—because they are Muslim, and they identify with the TurkishMuslim world, and not the Armenian Christian world.
So, there are no necessary or sufficient linguistic conditions for identi-fying what we call in everyday speech a speaker of English or a speaker ofUrdu. This suggests that a scientific approach to the study of language willnot treat these terms as having any status in the theory. This is exactly thepractice in the I-language approach.
4.5 Exercises
Exercise 4.5.1. Stress rules: Consider the following two made-up words:
4.13 � pakulikamukitakamonisimu� musinimokatakimukaliku

76 I-/E- /P-LANGUAGE
Imagine that you are (a) a Weri speaker; (b) a Maranungku speaker; (c) aPintupi speaker; (d) a Waori speaker. What would be the output of yourstress assignment rule in each case?
Exercise 4.5.2. Kuna verbs: Concordia undergraduate student FrancisMurchison spent his last semester (Winter 2007) in Panama doing field-work on the Kuna language. Here is a basic morphology problem adaptedfrom his early fieldwork. Each word in Kuna corresponds to a sentence inEnglish. How much can you break up each Kuna word into morphemes,minimal units of meaning?
4.14 Kuna verbs
Kuna English
anuagunne I eat fishbeuagunne You eat fishweuagunne She/he eats fishanmaruagunne We eat fishbemaruagunne You all eat fishwemaruagunne They eat fishanogopgunne I eat coconutanuagunnsa I ate fish
Further Readings
� Chapter 2 of Chomsky’s Knowledge of Language (1986).

PART IILinguistic Representation and
Computation

This page intentionally left blank

5A syntactic theory that won’t
work
5.1 General requirements on
grammars 79
5.2 Finite state languages 87
5.3 Discussion 94
5.4 Power of grammars 97
5.5 Exercises 101
One of the most important documents of the so-called cognitive revolutionof the 1950s and 60s is Chomsky’s book Syntactic Structures, published in1957. The work presented in this small volume has had profound effectson linguistics, psychology, computer science, mathematics, and other fields.Surprisingly, the main ideas are relatively simple, and in this chapter ourdiscussion of issues that arise in the scientific study of language is inspiredby the first three chapters of Chomsky’s book, a mere ten pages of text.Many of the insights still stand, and so the book is of much more thanmerely historical interest.
5.1 General requirements on grammars
In Part I we presented the biolinguistic approach that focuses on the studyof I-language, language as knowledge that is encoded in the human mind,and not on a notion of language as a corpus of texts or as a set of observedbehaviors. The study of grammar is a matter of “individual psychology:”our minds contain an abstract system of rules that is one of the factors thatplay a role in our ability to produce and understand language. The aim of ascience of language is to reveal these rules.

80 A SYNTACTIC THEORY THAT WON’T WORK
Given that I-languages are encoded in people’s minds, it follows that theycannot be discovered in the sense in which we discover, say, archeologicalartifacts buried in the ground. Given the current state of the neurosciences,there is also no hope for the foreseeable future that we can learn about thenature of mental grammars by looking directly at brains—we have no ideahow, say, the Pintupi stress rule is encoded in neural tissue, which it mustsomehow be. Instead, we have to infer the properties of mental grammarson the basis of the kind of modeling and hypothesis formation and testingcommon to all scientific endeavors.
Our sources of evidence for these inferences come from variousdomains, including speaker judgments concerning the grammaticalityof utterances, as well as work done by psycholinguists and neurolin-guists involving measurements of blood flow and electrical activity inthe brain, eye movements during reading tasks, reaction times to var-ious stimuli, and others. The biolinguistic approach does not arbitrar-ily delimit our potential sources of information and insight but ratherwelcomes findings from any domain that may help in constructing acoherent and biologically plausible model of human language, includ-ing its acquisition by children. Our rejection of counting mechanisms instress systems illustrated an attempt to draw on general considerationsof biology and development in selecting among competing grammaticalmodels.
Whatever the details of the system of rules that is relevant for this orthat language, there are a number of requirements that all grammars mustcomply with. These are in part requirements that constrain any scientificundertaking, and partly requirements that spring from the fact that weview languages as a part of the natural, biological world. After sketchingsome of these requirements, we will examine a particular proposal for themathematical modeling of grammars and show how it can be demonstratedto be insufficient. Our arguments will rely on your intuitions about yourown English-type grammars.
5.1.1 Precise formulation
The following passage from the preface of Syntactic Structures (1957) is astraightforward description of Chomsky’s proposed methodology. Part ofits importance lies in the proposal, not completely novel at the time, yet still

GENERAL REQUIREMENTS ON GRAMMARS 81
controversial to this day, that normal scientific reasoning should be appliedto the study of language.
By pushing a precise but inadequate formulation to an unacceptable conclusion wecan often expose the exact source of this inadequacy and consequently gain a deeperunderstanding of the linguistic data. More positively a formalized theory may auto-matically provide solutions for many problems other than those for which it wasexplicitly designed. Obscure and intuition-bound notions can neither lead to absurdconclusions nor provide new and correct ones and hence they fail to be useful in twoimportant respects.
As you see, the passage accepts as a normal part of doing science theconstruction of models that inevitably turn out to be insufficiently powerfulfor the phenomenon under analysis. Chomsky points out that such models,when formulated precisely, can, by the very nature of their failings, provideinsight.
5.1.2 Universality
To some extent we expect that the grammar for each language will have itsown specific rules, but the ultimate goal of linguistic analysis “should bea theory in which the descriptive devices utilized in particular grammarsare presented and studied abstractly with no specific reference to particularlanguages” (p. 11). Looking back, we see that this is the idea of UniversalGrammar. Chomsky does not justify this statement of the ultimate goal oflinguistics, but it seems clear, especially when we are familiar with his laterwork, that he already saw the aim of his studies to be an understandingof the human language faculty. He refers to the study of Language, with acapital L, to distinguish it from the study of particular languages. In morecurrent writings Chomsky and his collaborators have taken the stand, atfirst blush “more than a little odd,” that all languages have the same rules,at least in the domain of syntax. We will return to this idea later in thebook.
5.1.3 Independence from meaning
In the preceding chapters we looked at rules relating the singular and pluralof Samoan verbs, rules relating the singular and plural of nouns in variouslanguages, and rules that provide the stress pattern of words. Clearly, those

82 A SYNTACTIC THEORY THAT WON’T WORK
rules applied to classes of words that were defined independently of mean-ing. The Warlpiri full reduplication rule, for instance, applies to all nouns,regardless of what the meaning of the noun is. Similarly, the Maranungkustress rule applies to all words, independent of their meaning.
Let us now consider yet other types of linguistic rules—the rules thatconcern the way in which sentences are constructed in various languages.Linguists call these syntactic rules. Syntactic rules differ from the stress rulesthat we illustrated earlier, which are examples of phonological rules, rulesgoverning sound patterns. Syntactic rules also differ from the rules of wordformation, prefixing, suffixing, and reduplication, for instance, that linguistscall morphological rules.
Even though in the case of morphology or phonology, people are readyto accept that the respective rules are divorced from meaning, for somereason, there is a tendency to believe that syntax, the arrangement ofwords in sentences, cannot be divorced from consideration of what thesentences mean. In other words, structure and meaning are assumed to beinseparable.
However, consider the following now famous example introduced byChomsky:
5.1 Colorless green ideas sleep furiously.
We don’t think of abstract nouns like ideas as being able to have a color,green, and being green seems to be incompatible with being colorless. Wealso don’t think of ideas as being able to sleep (although we can clearly saythis in some metaphorical sense). Finally, there seems to be something weirdin the juxtaposition of the verb sleep and the adverb furiously.
The point of this example is that despite all these incongruities and thefact that it is hard to imagine a situation in which the sentence wouldbe uttered, it feels intuitively like a well-formed sentence. Compare thesentence above with the following example:
5.2 Furiously sleep ideas green colorless.
This just does not feel like a sentence at all. It contains all the samewords as the previous example—in fact it just reverses their order—but itis difficult to even read it with normal sentence intonation, and it is evenhard to remember in comparison with the well-structured sentence. Without

GENERAL REQUIREMENTS ON GRAMMARS 83
looking back, try to repeat this example, then try to repeat the previous one,the famous sentence.12
This discussion suggests the independence of syntactic knowledge frommeaning by presenting an example that in some sense is meaningless and yetintuitively well formed, grammatical. It is hard to imagine a situation thatwould be accurately described by (5.1), and yet we react to it differently thanwe do to (5.2).
The same point can be made with examples that are easily interpretablebut ungrammatical.
5.3 Easily interpretable, yet ill-formed strings
a. *The child seems sleepingb. *John read the book that Mary bought it for him
The asterisk before these examples serves to indicate that they are not well-formed sentences.
However, it is trivially easy to assign an interpretation to both of thesesentences. When we hear (5.3a.), we automatically interpret it as meaningbasically the same thing as what The child seems to be sleeping means. Andyet, it intuitively feels like there is something wrong with the structureof the sentence. Similarly, even though (5.3b.) can easily be assigned aninterpretation—the same as John read the book that Mary bought for him, itis ungrammatical. Once again we see that structure and meaning appear tobe independent.
These examples are also helpful for developing a notion of grammatical-ity. A grammatical sentence or word or stress pattern is generated by thegrammar under consideration. Anything not generated by the grammar isungrammatical. In other words, grammaticality is not related to meaningand is not an absolute notion—a grammatical plural in Warlpiri is not agrammatical plural in Telugu.
At the time Chomsky wrote, and even today in certain approaches tocomputer processing of natural language, the notion of grammaticality iscorrelated with the probability a sentence has of being uttered: (more) gram-matical sentences are those that have a higher probability of being uttered.Chomsky provides the following strings in a discussion of this notion:
12 Many people who read these passages in Syntactic Structures do not even realizethat the string in (5.2) is the reversal of that in (5.1) until it is pointed out to them—wewere among those people.

84 A SYNTACTIC THEORY THAT WON’T WORK
5.4 Equally improbable utterances� I saw a fragile whale� I saw a fragile of
These two strings have basically zero probability of being uttered, and yetthe first seems well formed and the second does not. Just as syntactic well-formedness seems to be independent of semantic congruity, it also seems tobe independent of questions of probability.
Given the notion of grammaticality that we have developed, it followsthat there is no such thing as an ungrammatical sentence. Grammars gener-ate sentences, that, by definition, are grammatical; any string of words thatcannot be generated by a given grammar is, by definition, not a sentence—itis just a string of words. This distinction is not always made and it is com-mon, even in linguistics, to talk about ungrammatical sentences, althoughwe will try to avoid doing so in this book.
To sum up, the patterns of language can be studied independent of themeaning that the patterns happen to be associated with. The patterns arealso independent of the notion of probability. This applies to morphologicalrules, phonological rules, and syntactic rules alike.
5.1.4 Finiteness
Human life is finite in length. It follows from this brute fact both that thelongest sentence ever uttered by any person is finite in length, that is, itcontains a finite number of words; and it also follows that there can only bea finite number of sentences uttered by any person. These limits on sentencelength and the number of sentences a person can pronounce13 obviouslyhave nothing to do with the nature of grammar.
You probably share our intuition that any two well-formed sentences canbe strung together to make a well-formed sentence, like (5.5c.), formed from(5.5a.b.).
5.5 One way to make new sentencesa. The unexamined life is not worth living.b. I like cheese.c. I like cheese AND the unexamined life is not worth living.
13 Yeah, yeah—sentences are mental representations for a linguist, so you never pro-nounce a sentence in this technical sense. Bear with us in our mixing of technical andnon-technical language—we’ll be more careful later on.

GENERAL REQUIREMENTS ON GRAMMARS 85
The simple possibility of conjoining sentences with and allows us to iden-tify arbitrarily many new sentences with an arbitrarily high number ofwords.
We have the fact of mortality to explain the limits on observable sentencelength and the size of the output corpus of any individual person. Wealso have as an obvious fact the finite long-term memory and short-termprocessing and attentional resources of the human brain. This fact furtherlowers the ceiling on the length of the longest observable sentences. As weexplore approaches to syntactic modeling we will see that there is no reasonto build into the grammar itself a way to limit the length of sentences, and,in fact, that doing so would complicate our model without providing anybenefit or insight.
So, we will not require our models to account for the finite size ofobservable sentences and observable corpora, sets of recorded utterances.However, we must recognize the fact that grammars are encoded in the finitebrains that we have, and this does require that the grammars themselves befinite in size.
We have already introduced these ideas implicitly in the discussion ofstress: the stress algorithms we looked at were statable with a small numberof rules, and thus they were finite in size. However, despite the fact thatour list of data for each language was very limited, the algorithm couldbe applied to words of any length. Adding a restriction to the length of apossible word into our stress algorithm of, say, Pintupi may reflect a trueobservation about our corpus, or even about any possible corpus. However,such a restriction would be arbitrary and would complicate the model.
5.1.5 Output representations
The term grammar is used in linguistics with a certain ambiguity. In oneusage, a grammar is something in the mind of a speaker—the thing thatlinguists study. In the other usage, a grammar is the linguist’s model ofwhat is in the mind of a speaker—the product of a linguist’s analysis. Thisambiguity is common across disciplines in sciences, social sciences, andhumanities—the same term refers to the object of study and the theory ofthe object of study. The term physics, for example, refers to the propertiesof the physical world, what physicists study, and to the set of theories andhypotheses developed by physicists about the physical world. When we

86 A SYNTACTIC THEORY THAT WON’T WORK
explain an event by referring to the physics of the situation we are referringto hypothesized properties of the world; we are not referring to the studyof these properties. Physics, in the first sense, has been the same throughoutthe history of the universe; physics, in the second sense, was revolutionizedby Newton. (Note that the word history has the same ambiguity—whichsense is intended in the previous sentence?)
Almost all linguists use the term grammar in this ambiguous fashion.More recently, there has been an attempt to avoid this problem by usingthe term grammar to refer only to the linguist’s models. The object of study,what is being modeled, is referred to as the language. Thus, in more currentusage, the phrase mental grammar is avoided, and the term language isequated with I-language. This is a departure from earlier work, includingSyntactic Structures where Chomsky defines a language as a set of sen-tences, possibly with an infinite number of members.
These issues rarely cause confusion for the experienced scholar, but someterminological nightmares have become so entrenched that they are impos-sible to avoid at this point and are worth clarifying for the benefit of theuninitiated. Here is one of them: When we say that a string like John areleaving is ungrammatical, we mean that it is not generated by the I-languageunder consideration, call it L. Our job is to make a model, a grammar ofthis L. Now if we make a model M, and M generates John are leaving, thenby definition this sentence is grammatical with respect to M. Unfortunately,we will say things like “M is a bad model of L because M generates ungram-matical outputs.” But this is oxymoronic—grammatical means “generatedby a grammar.” What we intend is that M (the model of grammar weare currently considering) generates forms that are not grammatical withrespect to the object of inquiry (the mental grammar, I-language) L.
So, it should be clear from the preceding discussion that the model wepropose should generate all and only the sentences that the (I-)languagegenerates—the model grammar and the mental grammar should be a per-fect match. If there are sentences of the language that the model does notgenerate, then we say that the model undergenerates. If there are sentencesgenerated by the model that are not generated by the language, we say thatthe model overgenerates.
It is possible for a model to both under- and overgenerate with respect toa language. Suppose that we want to model Dana’s English-type I-languageand that the grammar we come up with generates only the following twosentences:

FINITE STATE LANGUAGES 87
5.6 a. I saw a frog dancing down Broadwayb. Three all kiss turtles one more
From the point of view of the model grammar, both of these strings aregrammatical, by hypothesis, since the grammar generates them. However,from the point of view of Dana’s mental grammar, of her I-language, onlythe first string is grammatical and the second one is ungrammatical, asindicated by the asterisk in (5.7b.), below.
5.7 a. I saw a frog dancing down Broadwayb. *Three all kiss turtles one more
Now, string (5.7a.) is grammatical both according to the model grammarand from the perspective of Dana’s mental grammar. However, Dana’s I-language actually generates an infinite number of other sentences in addi-tion to this one, so our model grammar undergenerates. String (5.7b.), onthe other hand, is grammatical according to the model grammar, but isnot generated by Dana’s I-language, which means that the model grammarovergenerates. You can probably imagine more subtle examples, but thepoint should be clear: the model grammar must generate ALL AND ONLY
the sentences generated by the mental grammar.
5.2 Finite state languages
With this background and set of requirements for our models, we cannow explore various classes of model grammars and their suitability forcapturing the syntax of human languages. Following Chomsky’s discussionwe adopt normal scientific methodology to first see if a mathematically verysimple grammar would be sufficient. The type of grammar he discusses firstis called a Finite State Grammar or fsg.
In Chapter 3 of Syntactic Structures, Chomsky’s approach is this: we canview sentences as finitely long strings of words in which certain orderingsare allowed and others are not, so let’s try to describe a language as somekind of simple string-generating mechanism.
One such device is called a Finite State Machine or Finite State Grammar(fsg). In the terminology of Syntactic Structures, a fsg generates a finite statelanguage.
A fsg has the following properties: the system can be in any one of a finitenumber of states, and moving from one state to another outputs a symbol.

88 A SYNTACTIC THEORY THAT WON’T WORK
There is at least one initial and one final state. The machine has no memory.Here is a fsg that generates a language consisting of just two sentences:
5.8 Simple Finite State Grammar
40 1The
2man
3
men
comes
come
This fsg generates the following two sentences:
5.9 � The man comes� The men come
In other words, there are exactly two paths through the machine from thestart state to the end state.
This fsg does indeed generate a set of sentences, and languages can beconceived of as sets of sentences, but this fsg lacks one of the most obviousproperties of human languages. It is true that each sentence is of finitelength, but there is no maximum length to the sentences in a language.Suppose you think that S1 is the longest sentence of English—well, we canalways precede S1 by I think that . . . to give I think that S1, as follows:
5.10 There is no longest sentence� S1 = Bill claims that Mary says that Tom claims that Alfred saw Claire bite
the frog.� S2 = I think that Bill claims that Mary says that Tom claims that Alfred
saw Claire bite the frog.
This new sentence S2 is longer than S1, and we can easily come up withanother sentence S3 of the form You suspect that S2:
5.11 You suspect that I think that Bill claims that Mary says that Tomclaims that Alfred saw Claire bite the frog.
There is no limit to how long a sentence can be.Similarly, there is no limit to the number of sentences a grammar can
generate, since if we have some finite set of sentences, we can always doublethe number of sentences by preceding each sentence in the original set byI think that . . . . So, our simple fsg fails to capture the fact that there is nolongest sentence and that a language cannot be said to consist of a finitenumber of sentences.

FINITE STATE LANGUAGES 89
Before we continue our study of fsgs, let’s be clear about the factthat there is a limit on the longest sentence a person can utter—forexample, it cannot be so long that it would take one hundred and fiftyyears to utter. Similarly, there is a finite number of sentences one canutter in a finite lifetime. However, in this paragraph we have slippedinto using the term sentence in a non-technical, everyday, intuitive sensethat corresponds only loosely to the sense of a string of symbols gen-erated by a grammar. A sentence in the technical sense of the wordhas no duration, no length in time, although it does have a length interms of a number of symbols (words). A given sentence may underliea particular utterance, but that utterance may involve speaking very fastor very slow, and thus utterance duration is not the same as sentencelength.
Similarly, there is no highest integer, but there is a highest integer that aperson can count to in a finite amount of time, and a highest number ofintegers that a person can name in a finite lifetime.
Let’s return to fsgs. It turns out that the challenge of generating aninfinitely large set of sentences can be met by fsgs by use of a simpledevice—looping. A loop in a fsg is a path that starts at a given node (state)and returns to that same node (state), either immediately or after passingthrough other nodes. Consider the following fsg with a loop that leaves anode and returns directly to the same node:
5.12 Finite State Grammar with a loop
40 1The
old2man
3
men
comes
come
Wow! This fsg now generates an infinite set of sentences:
5.13 � The man comes� The old man comes� The old, old man comes� etc.� The men come� The old men come� The old, old men come� etc.

90 A SYNTACTIC THEORY THAT WON’T WORK
This fsg can generate an infinite number of sentences because there are aninfinite number of paths from the start state to the end state. We can choosenot to follow the path that writes out old, we can choose to follow it once,or twice, etc.
So, while it is clear that fsgs are very simple, they does turn out to have thepower to capture one of the most salient aspects of language—“languagemakes infinite use of finite means” in the famous words of Wilhelm vonHumboldt (1767–1835). Despite having a finite number of words and rules,human languages have this property of infinity in two different ways: thereis no limit on the number of sentences a grammar can generate, and thereis no limit on the length of the sentences a grammar can generate. Bothof these properties follow from the fact that every language has a way toconnect sentences: if “A” is a sentence and “B” is a sentence, then “A andB” is a sentence. And “A and A and B” is also a sentence. All languagesalso have the means to embed a sentence inside another sentence, as we sawin (5.10), above. Conjoining and embedding are two ways of creating anarbitrary number of sentences, and sentences of arbitrary length.14
5.2.1 How do fsgs work?
In order to demonstrate how fsgs would model, or fail to model, humanlanguages, let’s first consider what are called toy languages. Toy languagesare sets of strings of symbols that are constructed to have the mathematicalproperties of real human languages, without a lot of distracting detail.Using toy languages, we can focus on the properties of human languageswe are interested in.
We can discuss a set of languages built out of just two “words,” thesymbols a and b. Each language is a set of strings (sequences) of a’s andb’s. For practice, here are two languages that Chomsky does not discuss:
5.14 Toy languages not from Syntactic Structures� L· {ab, aabb, aabbbbbbb . . . } = anbm
� L‚ {ab, abab, ababababab . . . } = (ab)n
The notation an means “the symbol a is repeated n times.” Similarly, bm
means “the symbol b is repeated m times.” The first language thus consists
14 Actually conjoining is a kind of embedding, but it is useful to distinguish the twohere for expository purposes.

FINITE STATE LANGUAGES 91
of strings that contain one or more a’s followed by one or more b’s. By usingdifferent symbols, n and m, we show that the number of times that a andb are repeated are independent of each other—they may be different. Ofcourse, they may be the same as well in a particular sentence.
Can you make a fsg to generate all and only these sentences—in otherwords, can you characterize L· using a fsg?
Your solution should be something like this:
5.15 A fsg for L·
2
b
0
a
1a b
The start state is labeled “0” and we mark the final state (or states) with adouble circle. The other numbers have no meaning and are just for reference.From the start state, one can proceed immediately to node 1 spelling out onea, or one can follow the loop from state 0 back to 0. Each time this path isfollowed, we get an a. The machine cannot stop until we reach state 2, andthe path from 1 to 2 will guarantee that we get at least one b. The stop state2 is a place where we can stop, but it is not necessary to stop; we can followthe b loop an arbitrary number of times before stopping.
As an exercise, you can make a fsg that allows the number of a’s and b’sto be zero.
Let’s move on to the second toy language, L‚. We are going to assumethat each transition can spell out at most a single symbol, and also thatthere are no null transitions, so that each transition spells out exactly onesymbol. With these constraints on possible machines, we can offer thefollowing solution for the language L‚ that generates arbitrarily long stringsof repetitions of ab.
5.16 A fsg for L‚
0 1a
b
In this fsg state 0 is also the termination state. You will notice that this fsgcan generate completely null strings (strings of zero length) because it is

92 A SYNTACTIC THEORY THAT WON’T WORK
possible to never leave state 0, to terminate without taking any transitions.How would you change the fsg to ensure that the shortest string it generatesis ab?
Now consider the following fsg:
5.17 An uninteresting fsg
0
ab
What strings consisting solely of a’s and b’s will this fsg in (5.17) generate?You can see that it will generate any such string. We can follow the a loopthirty-seven times, then the b loop twice, then go back to the a loop anotherthirty-seven times and then stop. Any string consisting of only these twosymbols can be generated by this fsg. This power is what makes this machinecompletely uninteresting even from the point of view of toy languages. It istrue that the fsg in (5.17) can generate all the sentences of L· (anbm) or L‚
((ab)n), but at the same time it will also generate strings that are membersof neither L· nor L‚.
The point of a grammar is to generate all the strings of a set and nothingelse. A proposed grammar should generate all and only the grammaticalsentences of the language we are modeling. Otherwise, it does not charac-terize the set of sentences in the language, since it does not distinguish themfrom non-sentences.
5.2.2 Why a fsg is not sufficient for English
In spite of its simplicity and its ability to generate an infinite number of sen-tences with finite means, Finite State Grammars have a serious drawback.There are whole classes of languages that fsgs cannot model. There are setsof sentences that human grammars generate that can only be generatedby a fsg that will necessarily generate lots of undesirable strings as well,strings that a human grammar cannot generate. In other words, if we makea fsg powerful enough to not undergenerate, then it will overgenerate—afsg cannot, by its very nature, match the power of languages with certain

FINITE STATE LANGUAGES 93
properties, properties that human languages have. Please be patient—thiswill become clear.
Here are some examples of languages that Chomsky presented in Syntac-tic Structures that cannot be modeled by a fsg.
5.18 Toy languages from Syntactic Structures� L1 = {ab, aabb, aaabbb, . . . } = anbn
� L2 = {aa, bb, abba, baab, aaaa, bbbb, aabaa, abbbba, . . . } = mirror image� L3 = {aa, bb, abab, baba, aaaa, bbbb, aabaab, abbabb, . . . } = XX
So, why can’t a Finite State Machine be made to generate these languages?The first consists of sentences containing some number of a’s followed bythe same number of b’s. The second consists of sentences containing anystring of a’s and b’s followed by the same string in reverse order (withperhaps a single “pivot” symbol between the two parts—in other words,each sentence in this language consists of a string and its mirror image).The third language consists of sentences that contain any string X of a’sand b’s repeated twice in a row. So, every sentence has the form XX. Thereis a common property shared by all these languages that makes it impossibleto devise a fsg that will generate them—they all require arbitrary amountsof memory, and, by design, a fsg does not have any memory.
They require memory because points in the string depend on previouspoints that can be arbitrarily far away. In the first language, for example, thenumber of b’s must exactly match the number of a’s. In the second language,the last symbol in a sentence must match the first symbol; the second to lastmust match the second; etc. In the third language, the whole second half ofa sentence must match the first half exactly.
The reason Chomsky gives these examples is that there are sentences inactual languages, including English, that have the same structure as that ofthe sentences in the toy grammars that cannot be generated by a fsg. Forexample, any sentence that involves the construction if . . . then . . . requireskeeping track of each if and matching it with a then. Similarly for theconstruction either . . . or . . . . So by creating sentences of English using suchconstructions we produce the logical structures seen in the languages thatcannot be generated by a fsg. We can show this in various ways, for exampleby labeling the first half of the relevant constructions with a and the secondhalf with b.
5.19 Some anbn structures in English� Ifa John is singing thenb it is raining

94 A SYNTACTIC THEORY THAT WON’T WORK
� Ifa eithera John is singing orb Bill hates Tony thenb it is raining� Ifa eithera John eithera loves Mary orb hates Tony orb Tom dances well
thenb it is raining
There has to be the same number of elements labeled a and b. We could alsolabel the relevant word pairs with their own indices to illustrate a mirror-image structure:
5.20 Labeling to show mirror-image structures in English� Ifa John is singing thena it is raining� Ifa eitherb John is singing orb Bill hates Tony thena it is raining� Ifa eitherb John eitherc loves Mary orc hates Tony orb Tom dances well
thena it is raining
We have first an if . . . then structure; then we embed an either . . . or structureinside of it; then we embed another either . . . or structure inside the firstone. These sentences become hard to understand as the embedding getsmore complex, but they conform to the rules of English-type grammars.Although Chomsky does not dwell on this point in Syntactic Structures, helater stresses this important distinction between grammaticality, conformitywith the patterns or rules or principles of the grammar, and processability.A very long sentence or one with lots of embedding may be hard to under-stand because of limits on memory and attention, yet it may conform to therules of a grammar.
5.3 Discussion
The previous demonstration of the insufficiency of fsgs may have gone by abit quickly, so we will now revisit some of the basic points using examplesbased on real English sentences. The two simple sentences of (5.21) showagreement in the form of the subject and the verb—the first has a singularsubject and a singular verb form, whereas the second has a plural subjectand a plural verb form. The fact that the subject of the first sentence issingular is encoded by the form man, as opposed to the plural subjectencoded by men in the second sentence.
5.21 A language with two sentences� The man here is leaving� The men here are leaving

DISCUSSION 95
If we want to generate these sentences using a fsg we run into a problemthat you may not have considered. We can surely generate the two sentencesusing a fsg like (5.22), but such a grammar will also generate sentences thatare ungrammatical in English.
5.22 Bad fsg
0 1The 2manmen
3here 4isare
5leaving
The grammar in (5.22) will generate only the two grammatical Englishsentences as long as we follow the two dotted transitions or the two dashedtransitions as we proceed from start to end state. However, by its verynature, a fsg does not have the capacity to guarantee this. When the gram-mar is in state 3, there is no memory of how it got there, whether via thedotted transition or the dashed transition between states 1 and 2. Such agrammar is said to overgenerate, since it generates sentences that are notgrammatical in the actual human grammar that we are trying to model. Thisfsg grammar, in addition to generating the two sentences we are interestedin, will also generate strings that are not grammatical in English such as thefollowing:
5.23 The grammar in (5.22) overgenerates
� *The man here are leaving� *The men here is leaving
If we want a fsg to generate all and only the sentences of the fragment ofEnglish we are considering, we need something like the following grammar,where the dashed and dotted pairs of lines need have no special status, sincethey lie on separate paths.
5.24 Good fsg
50 1The2man
6
men
3here
7here4
isleaving
are

96 A SYNTACTIC THEORY THAT WON’T WORK
This grammar in (5.24) will generate the two sentences we want and not gen-erate the two undesirable strings, but at a price—the grammar must encodethe word here twice, even though the two sentences intuitively appear tocontain the same word. It does not seem right to encode the word here twice,but the words the and leaving only once.
It may be apparent at this point that a fsg can be written that will generateall and only the sentences of any finite corpus—say all the strings thatappeared in The New York Times last year, or all of Shakespeare. Thesimplest way to achieve this is to have a distinct path from the start stateto an end state corresponding to each sentence in the corpus.
However, such grammars will need to contain massive amounts ofredundancy—words, and even identical strings of words, will have to berepeated numerous times. This point will be clearer if you try Exercise 5.5.7at the end of this chapter.
The examples raised by Chomsky involving mirror-image structures orrepeated sequences, as well as the examples we have given of subject verbagreement, all demonstrate the incapacity of fsgs to capture the fact thatpart of sentences involve so-called long distance dependencies. Parts of asentence that are dependent upon each other may be arbitrarily far fromeach other in terms of the number of words that intervene between them.Again, doing Exercise 5.5.7 will reinforce this idea better than any furtherdiscussion can.
5.3.1 Why did we go through it, then?
Why did we bother going through this long discussion of an approach tosyntax that clearly is not sufficiently powerful to capture the syntax of nat-ural language? Chomsky’s Syntactic Structures is of historical significanceas an early attempt to formalize the study of natural language—rememberthat most people still think of language as something to be studied inthe humanities, an amorphous, fluid, human construction. So one reasonis just to give you an idea of what it means to explore the question ofhow much computational power a mathematical model of language needs.It was revolutionary at the time even to ask such questions; the answeris still being vigorously pursued. Chomsky went on in his book to pro-pose a more complex theory, aspects of which we adopt in the followingchapters, but the book is a founding document of the cognitive revolution

POWER OF GRAMMARS 97
of the mid-twentieth century, and we hope to have shown that it is veryaccessible.
Second, our concern here is not to provide a final answer concerningthe nature of human language but rather to demonstrate a methodology,to show how one can explore the computational properties of humanlanguage. We are trying to model the computational properties of humanlanguage, so we start out with the simplest device that seems reasonable,something that can generate an infinite number of strings of unboundedlength. However, we then find that fsgs are not sufficiently powerful and weneed to try something with more computational power. Third, even failedattempts at modeling can be useful as we discussed in Section 5.1.1.
In our particular case, identifying the failings of fsgs gives us immediateunderstanding of the fact that a syntactic model should conform not only tothe list of general requirements mentioned above for possible grammars butalso to the need to account for long-distance dependencies, such as subject-verb agreement and if . . . then constructions, and so on.
5.4 Power of grammars
We mentioned that Syntactic Structures presents work that was influentialeven in formal language theory, a branch of theoretical computer science.As Chomsky attempted to understand human language, he presented moreand more powerful models. The set of grammar-types he defined fall alonga hierarchy of complexity now known as the Chomsky Hierarchy. To justgive you a taste of what it means to order languages in such a hierarchy,consider how one would solve the problem of generating structures of theform anbn.
One possibility is to provide the grammar with a counter: keep track ofthe a’s and match them with b’s. In other words, we can reject the constraintthat the language has no memory. However, if we want to maintain the ideathat there is no grammatical limit on the number or length of sentences, thenwe cannot choose the counter option. No actual counter in a real physicaldevice or organism can count arbitrarily high.
If we do not want to endow our grammars with a counter, then we canachieve the desired effect by allowing the grammar to introduce an a anda matching b together. Let’s illustrate. Suppose that a grammar consistedof rewrite rules that generated sentences by replacing symbols like S with

98 A SYNTACTIC THEORY THAT WON’T WORK
“words” like a or b. Let’s explore one such grammar, G1 with the followingproperties:
5.25 The grammar G1
� Symbols:� Non-terminal symbol: S� Terminal symbols: a, b
� Rewrite rules:
i. S → abii. S → aSb
Let’s assume that a sentence is generated by starting with S and applyingthe rules until only terminal symbols remain. Here, then, are some possiblesentences generated by G1.
5.26 Sentences of G1
� S → ab (by application of rule i.)� S → aSb → aabb (by application of rule ii. followed by application of
rule i.)� S → aSb → aaSbb → aaabbb (two applications of rule ii. followed by
application of rule i.)� S → aSb → aaSbb → aaaSbbb → . . . aaaaaaaSbbbbbbb →. . . aaaaaaaaaabbbbbbbbbb (nine applications of rule ii. followedby one application of rule i.)
Since the rewrite rules introduce matching a’s and b’s, it is unnecessary tohave a counter. By introducing an a and a b together, we get the same effectas a counter, but we can do so without setting an arbitrary limit on sentencelength.
Now, how does this kind of grammar, that uses rewrite rules, comparewith Finite State Grammars? Rewrite grammars can certainly do somethingthat Finite State Grammars cannot do, namely they can produce structuresof the form anbn. But can rewrite grammars deal with everything that FiniteState Grammars can? In other words, is it the case that rewrite grammarsare more powerful than Finite State Grammars? Chomsky shows that FiniteState Grammars have the same power as rewrite grammars, but only if anumber of restrictions are set on the rewrite grammars. We will not providethe details of the formal proof that Chomsky goes through, but here is thegeneral pattern of reasoning behind his proof. Since rewrite grammars withrestrictions are less powerful than rewrite grammars without restrictions,and given that rewrite grammars with restrictions have the same power as

POWER OF GRAMMARS 99
Finite State Grammars, it follows that rewrite grammars (without restric-tions) are more powerful than Finite State Grammars.
Here are the restrictions that, when added to rewrite grammars, willturn the latter into grammars of equal power to the power of Finite StateGrammars.
5.27 Some restrictions on a rewrite rule grammar� rewrite rules can only spell out a single terminal symbol OR� a single non-terminal symbol OR� a single terminal, followed by a non-terminal
It turns out that with such restrictions, we get a grammar that has thesame power as Finite State Grammars. In other words, by using thisrestricted rewrite grammar we can generate languages like our L· {ab aabbaabbbbbbb . . . } = anbm and L‚ {ab abab ababababab . . . } = (ab)n, just aswe can generate them with Finite State Grammars, and we cannot generatelanguages like L1= {ab, aabb, aaabbb, . . . } = anbn, L2 = {aa, bb, abba,baab, aaaa, bbbb, aabaa, abbbba, . . . } = mirror image or L3 = {aa, bb,abab, baba, aaaa, bbbb, aabaab, abbabb, . . . } = XX from Syntactic Struc-tures which require that matching elements be introduced together, just asFinite State Grammars cannot generate these. Here is one such restrictedgrammar, G2:
5.28 The grammar G2� Symbols:� Non-terminal symbols: S, T� Terminal symbols: a, b
� Rewrite rules:
i. S → aTii. T → b
iii. T → bS
This restricted grammar can generate L‚.If we let S be the start symbol, then we can generate the following
sentences:
5.29 Sentences of G2
� S → aT → ab (by application of rule i. and then rule ii.)� S → aT → abS → abaT → abab (by application of rule i. fol-
lowed by application of rule iii. followed by application of rule i.followed by application of rule ii.)

100 A SYNTACTIC THEORY THAT WON’T WORK
� S → aT → abS → abaT → . . . abababababababS →abababababababaT . . . abababababababababab (The sequencerule i.-rule iii. applies nine times, then rule i. applies followed byrule ii.)
This grammar generates all and only sequences of the form (ab)n, whichmeans that it characterizes or generates L‚ {ab, abab, ababababab . . . } =(ab)n.
We will not provide a formal proof, but we hope to suggest to you thata rewrite rule grammar with the kinds of restrictions we have placed onG2, the restrictions in (5.27), has exactly the power of a fsg, since it cannotintroduce matching elements that are separated by other elements. It can,however, achieve the effect of loops in the fsgs by having a rule that rewritesS as something that includes T, and a rule that rewrites T as something thatincludes S. If you accept (without proof) the claim that the restricted rewritegrammars are equivalent to fsgs, we can conclude that fsgs are less powerfulthan rewrite grammars in general, including grammars like G1.
If you are interested in such topics, you should find a book that dis-cusses formal language theory, such as Mathematical Methods in Lin-guistics by Partee et al. (1990). The Chomsky Hierarchy places fsgslower in the hierarchy of grammar formalisms than rewrite rule gram-mars that lack restrictions on how many terminals can be spelled outin one step, because any set of strings that can be generated with therestricted grammar can be generated with the unrestricted one, but not viceversa.
Chomsky’s demonstration, as presented here, shows that a restrictedrewrite rule grammar, or equivalently a fsg, is not sufficiently powerful togenerate the patterns we find in English. Since English (that is, the set ofgrammars of the type that we call English in everyday speech) is a humanlanguage, it can be concluded that fsgs are insufficient to model the humanlanguage faculty. Thus, we see how Chomsky’s approach licenses claimsabout Universal Grammar, even though the discussion looks at only a single(type of) human language.
Some linguists claim that we need more data before making proposalsabout Universal Grammar, and they criticize other linguists, like Chomsky,who have concentrated on a few languages, say Japanese, English, French,and German, and then proceeded to make universal claims. However,such criticism is invalid: Syntactic Structures demonstrates that Universal

EXERCISES 101
Grammar must be of at least a complexity greater than fsgs. No new datacan bear on this conclusion.
5.5 Exercises
In the following exercises, assume these conventions for Finite StateMachines:
� Start states are numbered 0� Other numbers are meaningless� End states use double circles� Each transition can only write out a single “word” a, b or c
Exercise 5.5.1. Make a Finite State Machine that will generate all andonly strings of the form (abc)n—that is abc repeated any number of timesgreater than or equal to 1: L = {abc, abcabc, abcabcabc, . . .}.Exercise 5.5.2. Can you make a Finite State Machine that generates a lan-guage whose sentences consist of any nonnull string of a’s and b’s followedby a single c followed by any string of a’s and b’s of the same length as thefirst such string? For example, baabacbabbb is a sentence in this languagebut baabacbbbb is not. Explain why there is no such machine or show themachine if you can.
Exercise 5.5.3. Can you make a Finite State Machine that generates a lan-guage whose sentences consist of any nonnull string of a’s and b’s followedby a single c followed by any nonnull string of a’s and b’s followed by threec’s? For example baabacbabbbccc is a sentence in this language and so isbaabacbbbbccc but cbabccc is not. Explain why there is no such machineor show the machine if you can.
Exercise 5.5.4. Can you make a Finite State Machine that generates alanguage whose sentences consist of any (possibly null) string of a’s and b’sfollowed by four c’s followed by any nonnull string of a’s and b’s? Explainwhy there is no such machine or show the machine if you can.
Exercise 5.5.5. Can you make a Finite State Machine that generates a lan-guage whose sentences consist of any nonnull string of a’s and b’s followedby between one and four c’s followed by any (possibly null) string of a’s andb’s? Explain why there is no such machine or show the machine if you can.

102 A SYNTACTIC THEORY THAT WON’T WORK
Exercise 5.5.6. Make a rewrite rule grammar that obeys the restrictionsin (5.27) that can generate L·. In other words, turn the fsg in (5.15) into arewrite rule grammar. (Hint: You need two non-terminal symbols.)
Exercise 5.5.7. Try to develop a fsg to generate all and only the sentencesin the following list. Ideally you should build up your grammar, for example,by making one for the first sentence, then the first two, then the first three,and so on.
a. The boy is washingb. The boy with blue eyes is washingc. The boys are washingd. The boys with blue eyes are washinge. The boy is washing himselff. The boys are washing themselvesg. The boy with blue eyes is washing himselfh. The boys with blue eyes are washing themselvesi. Both the boys with blue eyes are washing themselves
Further Readings
� Chapters 1, 2, 3 of Syntactic Structures by Noam Chomsky (1957).� Syntactic Structures Revisited by Lasnik et al. (2000).� Mathematical Methods in Linguistics by Partee et al. (1990).� “Chomsky Hierarchy” on Wikipedia is a useful overview for readers
with some technical training.

6Abstract representations
6.1 Abstractness 103
6.2 Abstractness of sentence
structure 104
6.3 Allophony 109
6.4 Turkish vowel harmony 114
6.5 Words are not derived from
words 125
6.6 Think negative 127
6.7 Summing up 131
6.8 Exercises 132
6.1 Abstractness
If linguistics studies grammars as properties of individual minds, then lin-guistics is part of psychology. Now, no book on psychology can do withoutsome anecdotes concerning experiments done on rats, so here we go.
According to results obtained by Seth Roberts, a psychologist at theUniversity of California at Berkeley, a rat can be trained to press a leverfor food after hearing a tone play for forty seconds.15 We found this tobe pretty surprising, but, once one accepts the validity of the result, it isperhaps not so shocking that the rats can also be trained to press a lever forfood after being exposed to forty seconds of a visual stimulus, like a lampbeing illuminated.
The really exciting result comes when the rats, after being trained to pressthe lever after forty seconds of sound, and also after forty seconds of light,are exposed to twenty seconds of sound and then the sound goes off andthe light goes on. What do they do? Do they wait for the full forty secondsof light? No! They press the lever after twenty seconds of light.
15 Obviously there is some pressing a bit early and some a bit late, but the rats aresurprisingly accurate.

104 ABSTRACT REPRESENTATIONS
This result only makes sense if the rats have not just learned to respond tocertain simple stimuli (like forty seconds of light or forty seconds of sound,which is what they have been trained on), but rather have learned somethingmore abstract like “Press the lever after forty seconds of stimulus.” In orderto learn this generalization, the rats must be able to cognize in terms ofan abstract category of duration, not sound duration or light duration, butduration pure and simple. Duration pure and simple cannot be observed, itcan only be abstracted from events that have duration. Rats (and humans,for that matter) use duration to construct equivalence classes of stimuli thatabstract away from the specific modality in which a stimulus is presented.
Of course, by now, this appeal to abstract categories should not botheryou—we have already discussed the fact that triangles we perceive and alsowords we perceive are constructions of our minds, and not just records ofphysical stimuli. The fascinating thing is that this abstractness seems to holdin all domains of human (and rodent) experience.
We would like you to keep this notion of abstractness in mind as weembark on a fairly sophisticated exploration of syntax, phonology, andmorphology, leaving behind the simple finite state models that we nowunderstand to be insufficient and turning instead to models that have manyof the crucial details used by linguists working today. Just as positing acategory DURATION appears to be necessary for making an intelligiblemodel of rat behavior, it appears to be necessary to model human linguisticbehavior by proposing categories of analysis that are not directly observ-able, that cannot be defined in terms of what we usually think of as thebuilding blocks of the physical world.
6.2 Abstractness of sentence structure
In this section we illustrate the idea that syntactic computation is structure-dependent. The phenomenon we are going to look at is the distribution ofthe contracted form of copula verbs in English. We will see that this elementis sensitive to a restriction that can only be stated in structural terms.
The examples in (6.1a.–d.) are all question-and-answer pairs.
6.1 a. Do you know if anyone is here yet?I know Mary is here.
b. Do you know if anyone is here yet?I know Mary’s here.
c. Do you know if anyone is here yet?I know Mary is.

ABSTRACTNESS OF SENTENCE STRUCTURE 105
d. Do you know if anyone is here yet?∗I know Mary’s.
The question is the same in all the instances, but the answers differ. Some ofthe question-answer pairs are well formed, as in (6.1a.–c.), whereas (6.1d.)is not. The answer in (6.1a.) contains the copula verb is followed by thelocational expression here. The answer in (6.1b.) is the same, except that itcontains the so-called “contracted” form of the copula, ’s. Sentence (6.1c.)is the same as (6.1a.) with the full copula form, but without here. So it seemspossible to either contract or not contract the copula, and to have or nothave here at the end of the sentence. However, for some reason, the answer in(6.1d.), that has both contraction and no here, is completely ungrammatical.This is odd. You may discard this by saying that (6.1d.) just doesn’t soundright, but the question is Why not? As noted in Chapter 3, when we stopto pay attention, even the “simplest phenomena of ordinary life raise quiteserious problems.”
Before working our way towards the generalization underlying thesefacts, let us point out that, whatever the generalization will turn out to be,we already know several things.
First of all, we know that the rule will have to be stated in abstractterms. Example (6.2) shows us that it is not the sound of (6.1d.) that makesit ungrammatical. If the string I know Mary’s occurs as an answer to adifferent question, as in Mary’s mother, then the string is well formed.
6.2 Do you know anyone’s mother?I know Mary’s.
No doubt you will have noticed that the difference between the answerin (6.2) and the answer in (6.1d.) is that ’s is the possessive ending ofMary in (6.2), and in (6.1d.) it is the copula verb. So, the account of theungrammaticality of (6.1d.) will have to be expressed in terms of abstractmorphemes like possessives, nouns, copulas.
Second, we know that the weirdness of (6.1d.) should be based on a ruleor pattern, not on a list of exceptions; the rule will have to explain whypossessive -s behaves differently from the so-called “contraction” of is, andwhy the contraction of is is sometimes fine, as in (6.1b.).16
16 We say “so-called” since calling the form ’s a contraction makes it sound like thisform is somehow derived from the “full” form is by the mental grammar of an Englishspeaker, but it is not at all apparent that this is the case.

106 ABSTRACT REPRESENTATIONS
Third, notice that most or all of us are unaware of such facts aboutour grammars. English speakers never produce these weird-sounding con-tractions like (6.1d.), and they know they are weird without knowingwhy.
So now let’s try to come up with a generalization that underlies thesesimple facts. One possibility that could come to mind is that the pattern in(6.1a.-d.) is due to some constraint that says: “the contracted copula can’tbe the last word before a pause.” However, sentence (6.3) shows this cannotbe the case, since in this sentence the word and follows the copula, and thesentence is still ungrammatical.
6.3 Do you know if anyone is here yet?∗I know Mary’s and Bill’s coming soon.
So on the one hand, when the contracted copula is followed by a wordlike here, as in (6.1b.), the result is grammatical, but when it is followed by aword like and, as in (6.3), the result is ungrammatical. Maybe it is the natureof the word that follows the contracted copula that matters, then. Let’s lookat more examples.
6.4 Do you know if anyone is here yet?∗I know Mary’s but she has to leave soon.
Example (6.4) shows that there is another word beside and that producesungrammaticality when it follows the contracted copula, namely but. Thisoffers a gleam of hope for our attempt to find a generalization, since andand but are both members of the same category—they are both connectors.We could now say that
6.5 The contracted form of the copula cannot bea. followed by a connector, orb. followed by a pause
We could stop here, and assume that this is the right generalization. If wedid, however, we would be missing a generalization—these two conditionsunder which is cannot be contracted can actually be captured by one singlestatement. This unification is possible because connectors and what we haveinformally called pauses have something in common. On the one hand,a pause occurs by definition at the end of particular types of strings, i.e.sentences. On the other hand, connectors link two strings that can be ofvarious types; it could be two nominal strings, or two verbal strings, or

ABSTRACTNESS OF SENTENCE STRUCTURE 107
two other types of strings, but, crucially, it could also be between twosentences.
6.6 Connectors
a. Mary and Peter are here.b. Mary opened the window and Peter closed it back again.
So it looks like connectors and pauses do share something, namely thatthey both can occur after sentences. The generalization in (6.5) could nowbe restated as in (6.7).
6.7 The contracted form of the copula must be followed by anotherword in the same sentence (inside the smallest S that contains thecopula).
So, the generalization does not refer to connectors and pauses, but we canuse the presence of these items to identify the end of a sentence. We will geta more detailed understanding of sentences in the next chapter.
It is interesting to note that English orthography appears to be very mis-leading with regard to the contracted copula. We write ’s for the contractedcopula and orthographically it attaches to the word to its left, the precedingword. However, it looks like the contracted form is actually dependent onthe word to its right, the following word. Since the connectors but and andin our examples are not inside of the first sentence, they are not able to“support” the contracted copula. A word like here, on the other hand, isinside of the first sentence, and thus it can be preceded by the contractedcopula.
Notice that the crucial distinction here is that between a string of wordsand a sentence. A string of words is merely a set of words arranged in somesequence. A sentence differs from a string in two ways. First, we assumethat SENTENCE is a category of grammatical computation, an equivalenceclass. Second, members of this equivalence class are structured—they con-sist of parts and subparts that ultimately reduce to words. We have notyet told you anything about this structure, we will come back to it andoffer more details in Chapter 7. For the time being, let us simply adopta notational convention: a string of words that shows up at the base of atriangle whose top vertex is notated with an S is a sentence, that is it hasa certain structure and is a member of an abstract equivalence class, theclass of sentences. With this convention we can represent the structure of anexample like Mary’s here but Bill is not as in (6.8). Notice that the contracted

108 ABSTRACT REPRESENTATIONS
copula is not the last word in its sentence, and hence the example isgrammatical.
6.8 S1
S3S2
Mary’s here but Bill is not
In contrast, if there is nothing following the contracted copula in its ownsentence, as in (6.9), the result is ungrammatical.
6.9 S1
S3S2
Mary’s but Bill is not
So why are we looking at this? One good reason is to just develop somehumility about the complexity of human language. When an educationalpsychologist or philosopher or anthropologist or neurologist makes a claimabout how language is learned or used, ask them to explain the copulareduction facts, to see if they actually have any idea what language is.
Another reason to look at this data is for further illustration of thenotions of computation and equivalence class. As we pointed out, there arevery precise rules governing where contracted forms can occur. It is not amatter of what “sounds good” in a particular case. And these rules haveto make reference to abstract equivalence classes like morphemes and thestructures that we represented by means of tree diagrams. These patterns donot inhere in the physical signal; they are pure mental constructs, examplesof how the mind processes information. When two words fall under thesame S node in one of our trees, that means that they are in a closer relation-ship than when they do not fall under the same node. These diagrams havepredictive power concerning grammaticality in the same way that models ofparticles have predictive power in physics. Thus, the examples support ourargument in favor of treating language from a scientific perspective and ourstance against methodological dualism.

ALLOPHONY 109
The generalization we discovered concerning the distribution of con-tracted forms is clearly specific to English; it reflects part of what it meansto have an English-type grammar, or what we usually refer to as to “knowEnglish.” However, the examples also have a relevance to Universal Gram-mar.
Recall that we rejected an account based merely on the linear ordering ofwords—it is not simply the case that the contraction needs to be followedby some word. Instead, a structural account was necessary—the contractedform and the following word have to be in a certain structural relationshipthat we can express using our tree diagrams. Well, it turns out that allsyntactic phenomena of all languages appear to rely on this notion ofstructure.
Rules of syntax never rely merely on linear order—they are structure-dependent. This appears to be a fundamental property of the human lan-guage faculty, and thus constitutes a fundamental property of the humanmind. Note that structure dependence is not a logical necessity—we caninvent rules that reverse the order of words in a sentence or move the thirdword to the front of the sentence, but no rules like this exist in humanlanguages, as far as we know.
Recall from Chapter 3 the puzzle concerning the difficulty of reversing thewords in a sentence as opposed to the ease of forming a Yes/No questionfrom a declarative. We pointed out that the question-formation rule wasdifficult to state, but we now can say a bit more—the rule will turn out tobe structure-dependent, like the rule for using the contracted form ’s, andunlike the string-reversing rule that is not a possible rule of human language.
6.3 Allophony
In this section we will once again consider some English data, but nowin the domain of phonology. In addition to the inherent interest of thephenomena, we can point out that this example illustrates the fact that“English” is not actually an entity in the world. The following discussionassumes a typical North American dialect, that of the second author, andthe exercises at the end of the chapter provide a chance to explore otherdialects of English.
Consider the following sentence spoken by a speaker of East Coast NorthAmerican English (a recording is available on the companion website).

110 ABSTRACT REPRESENTATIONS
6.10 That cat, Atom, didn’t want to stare at the two thin rats at easeatop the atomic pot.
How many t’s does it contain? Perhaps you paid attention to orthography,the writing system, and counted up the tokens of the letter t that appear inthe sentence and came up with the number 18 as your answer.
6.11 That cat, Atom, didn’t want to stare at the two thin rats at easeatop the atomic pot.
Now what is the sound corresponding to the letter t? Say it aloud afew times—ta ta ta. Well, most people will not be surprised to noticethat this sound is not pronounced for each written t, for example weknow that the spelling th does not correspond to the same sound in manydialects of English. If you are particularly sensitive to these issues, youmay notice that there are actually two sounds corresponding to the writ-ing th for most speakers of English that are different from the sound inta ta ta.
The sound of th in that and (both tokens of) the is called a voiced sound,involving vibration of the vocal folds, whereas the one in thin is called avoiceless sound, involving no vibration. You can make the difference moresalient by plugging your ears with your fingers while pronouncing the twosounds.
If you now consider the remaining 14 tokens of the letter t, you maybe in for a surprise. If you speak a typical North American dialect youwill find a distinct difference between the t of Atom and that of atomic.In fact, you will find that Atom and Adam are pronounced identical formost North American English speakers. If you pronounce the sentence in anatural fashion—not too carefully or formally—you will probably find thatthe sound in Atom is also found to correspond to the t in the phrase at ease,but that the sound in atomic is that found in atop.
Take a break, because things get worse. . . . Now say the word two whileholding your hand or a sheet of paper in front of your mouth. You willnotice that a puff of air makes the paper move, or is felt by your hand. Ifyou now say the word stare, no such puff is felt. Is this an idiosyncracy ofthese two words?—No, as we will see. But why do English speakers thinkof these words as both containing t? Your first reaction might be that weare guided by the orthography, that we think of the various pronunciationsof the letter t as versions of the same entity, just because we write them

ALLOPHONY 111
the same. We will try to show you that something more interesting is atplay.
Consider now the words cat and at. You should be able to tell that theseend in a sound that is very different from the ta ta ta sound, at least whenthe sentence is pronounced naturally. This sound is called a glottal stop. Itoccurs in the middle of what is written uh-uh to mean “no.”
Finally consider the part of the sentence written didn’t want to. In ournormal speech, the three written t’s have no pronunciation at all—you getsomething that might be written in a cartoon as dinnwanna or didnwanna.
So are there any regularities governing the distribution of these differentcorrelates of the letter t? Why are speakers so unaware of most of thesepatterns?
Let’s take a word like cat and put it in different contexts—compare thenatural pronunciation (at least for us) of the t in each context—again,recordings are on the companion website:
6.12 a. I saw a cat—a glottal stop [P], the sound in the middle of uh-uh “no.”b. The cat is on the mat—a flap, [R], the sound in the middle of butter and
ladder.c. I saw three cats—plain old t, [t], without a puff of air
And to complete our inventory compare the pronunciation of the letter inthe words below:
6.13 a. My tie is clean—an aspirated t, [th] followed by a puff of airb. My sty is clean—another plain old [t], although it actually sounds like a
d if you cut off the s, something you can do with a simple, free computerprogram like Praat, mentioned in Chapter 2.
The three forms in (6.12) show how alternations in the [t] of a givenmorpheme, cat, can be induced by placing it in various contexts. Whennothing follows in the sentence, or when there is a major syntactic breakfollowing, as in I saw a cat, and Sami did too, we get a glottal stop. Whenan unstressed vowel follows [t], whether within a word, as in atom, or in asyntactically close following word, as in 6.12b, we get a flap, as in The cat ison the mat. When an s follows within the word we get a plain [t], as in cats.
The examples (6.13) do not involve alternations within a morpheme butinstead are based on a distributional observation. At the beginning of aword, before a stressed syllable, we find the aspirated [th], whereas we getthe unaspirated [t] when there is a preceding s. You should confirm thatthese generalizations hold by coming up with other examples.

112 ABSTRACT REPRESENTATIONS
Now are these generalizations just a matter of how we have memorizedthe pronunciation of words like cat, tie, sty? Let’s test that idea. Imagine wetell you that we just bought two joots. You might ask us
6.14 What is a joot?
and we bet you would pronounce the t as a glottal stop (if your dialect islike ours). And we might answer “It’s like a banana,” to which you mightreply
6.15 Oh, a joot is a fruit?
And you would totally unconsciously pronounce the t of joot as a flapand the t of fruit as a glottal stop.17 Since, by assumption, you never heardanyone say joot before this exchange, and when you heard us say it, it had at, why did you say it with a flap or a glottal stop?
The answer is that your grammar, your I-language, the computationalsystem in your mind that underlies in a very abstract way your pronunci-ation, treats plain and aspirated [t], flap, and glottal stop as equivalenceclasses that are themselves realizations of a more abstract equivalence classcalled a phoneme. The traditional notation for this particular phoneme is/t/, which will do for our purposes. Our grammar then has a set of rulesthat determine the realization of /t/ in various contexts, in terms of the stillabstract elements, called allophones, plain and aspirated [t], glottal stop, andflap.
Phonemes are traditionally represented between backslash brackets, asin the top of Fig. 6.1. We somewhat arbitrarily have chosen the symbol/t/ to represent the phoneme in this case. The allophones, the conditionedvariant forms of the phoneme that show up in the output of the gram-mar, are represented in square brackets, [t]. Finally, Fig. 6.1 shows a rep-resentational format invented by Mark Hale—we have used little bodysymbols to represent actual tokens of speech. So, each allophone is anabstraction over tokens of speech or speech perception behavior, and eachphoneme is an abstraction over allophones. You should compare Fig. 6.1with Fig. 1.1 from Chapter 1, which represented nouns as equivalenceclasses.
17 With different intonation, you can produce joot with a glottal stop in this sentenceas well. This just shows how intonation interacts with other aspects of pronunciation, acomplication we don’t want to get into here.

ALLOPHONY 113
/t/EQUIVALENCE CLASS
Phoneme
EQUIVALENCE CLASSES
Allophones
TOKENS OF
BEHAVIOR/PERCEPTION
[t]
t1t2etc.
[th]
th1
th2etc.
[ ]
P1
P
P2
etc.
etc.
Fig 6.1 The equivalence class of the phoneme /t/ is itself an abstraction fromequivalence classes of allophones abstracted from individual utterances.
How did your grammar end up in this state? As you were learninglanguage you were unconsciously learning the patterns of alternation anddistribution that we just told you about. Based on these patterns, youconstructed equivalence classes, along with a computational system thatrelates equivalence classes to one another.
These examples are so simple, and if you speak the dialect we are describ-ing they are so hard to view objectively, that we think it is worthwhile tostress that they provide another very strong argument for the constructionof experience. Like the constructed edges of the triangle illusion, the identityof the sounds we hear is largely a product of the computations of our minds.Note that our perception of t sounds leads to us hearing signals that arephysically quite different as the same—we hear, in some sense, the plain andaspirated t, the glottal stop, the flap, and even silence (whatever it meansto hear silence) as tokens of the same type, the phoneme /t/. On the otherhand, we can point out that there are other flaps in our English that are notrelated to /t/ but to /d/—consider the pairs wed, wedding and feed, feedingthat have [d] in the first members and flap in the second.
6.16 Why does perception of t show construction of experience?� Things that are different physically perceived as the same� t/th/P/R/∅
� Things that are physically the same perceived as different:� wetting � [wERIN]� wedding � [wERIN]
So, in addition to leading us to experience phonetically distinct sounds(the various forms of /t/) as identical, our grammar also leads us toexperience two phonetically identical sounds as different, even when

114 ABSTRACT REPRESENTATIONS
they occur in exactly the same environment, as in wetting and wedding.Most speakers of dialects in which these words are complete homo-phones will insist that the words are pronounced differently. They are not,unless one produces a spelling pronunciation, a pronunciation that doesnot reflect the grammar, as in I said we[d]ing, not we[t]ing, but thisdoes not reflect what the grammar does with /t/ and /d/ inputs in thisenvironment.
We should note that it is perfectly possible to be a native speaker ofEnglish and treat flap and plain [t] as allophones of a single phoneme,and also be a native speaker of Japanese, in which [t] and flap repre-sent completely distinct phonemes. Or to be a speaker of both Englishand Thai, and thus treat plain and aspirated t as allophones in Englishbut as separate phonemes that can distinguish word meaning in Thai. Inother words, a bilingual person will process information and thus con-struct experience differently depending on which of the two I-languagesis used. The equivalence class is not in the signal but is a result of signalprocessing.
Before moving on, we reiterate that your own dialect of English may becompletely different from ours. For example, you may not have any flaps atall; and you may have glottal stops in places where we do not, as in wordslike writer, as opposed to a [d] in rider. We have a flap in the middle of bothof these words, and they only differ in terms of the vowels preceding the flap.This is typical of North American English, but it may be hard to convincespeakers that it is true. We have provided a recording on the companionwebsite.
6.4 Turkish vowel harmony
We are now ready to return to the analysis of Turkish vowel harmony, thephenomenon mentioned at the very beginning of the book. Consider thedata in (6.17) that shows the nominative singular, nominative plural, thegenitive singular and the genitive plural of eight Turkish nouns. Nominativeis the form used when the noun is subject of a sentence, so ipler would be theword for ropes in a sentence meaning “The ropes fell.” The genitive is usedto show possession, so ipin means “the rope’s, of the rope.” The genitiveplural combines the meanings genitive and plural, so iplerin means “of theropes.”

TURKISH VOWEL HARMONY 115
6.17 Turkish vowel harmony data18
nom. sg. nom. pl. gen. sg. gen. pl.a. ip ip-ler ip-in ip-ler-in “rope”b. kıl kıl-lar kıl-ın kıl-lar-ın “body hair”c. sap sap-lar sap-ın sap-lar-ın “stalk”d. uç uç-lar uç-un uç-lar-ın “tip”e. son son-lar son-un son-lar-ın “end”f. öç öç-ler öç-ün öç-ler-in “revenge”’g. gül gül-ler gül-ün gül-ler-in “rose”h. ek ek-ler ek-in ek-ler-in “joint”
As you look over the data you will notice that the plural suffix takes twodifferent forms -ler and -lar. In the genitive singular column, you noticefour different forms: -in, -ın, -un, -ün. In the genitive plural column we seethe same two forms of the plural, -ler, -lar, but only two forms of the genitivemarker.
Here are some questions about these forms:
� What determines the choice of vowel in each suffix?� How can we represent the suffix?� Do we have to say that the genitive suffix in the plural is different than
the genitive suffix in the singular, since the former has only two formsand the latter has four?
In order to begin to answer these questions, we need to understand a bitabout the phonetic correlates of Turkish vowels. We will need to describethem along three dimensions that we will illustrate using English vowels.First, pronounce the word beat slowly to yourself and try to pay attentionto the position of your tongue and jaw. For our purposes, what is importantis just to compare this vowel with that of bet. In the latter, you should feel(or see in a mirror) that your tongue and jaw are lower than in the former.We will refer to the vowel of beat, whose phonetic symbol is [i], as a HIGH
vowel, and to the vowel of bet, as a NON-HIGH vowel. For this vowel,we will use the symbol [e], since we will follow the Turkish writing systemin this discussion, although the symbol used in the International PhoneticAlphabet is [E].
Next, compare, by feeling and looking in a mirror, the vowel of beat withthat of boot, which we will write as [u]. You should notice that in beat your
18 The symbol ç represents the sound written ch in English. The vowel symbols willbe explained in the main text.

116 ABSTRACT REPRESENTATIONS
lips are spread rather wide, whereas in boot the lips are rounded. The vowelin boot is ROUND, that in beat is NON-ROUND.
The last parameter is a bit harder to notice, but it can also be illustratedusing beat and boot. Try to say the words slowly and silently, concentratingnot on the lips but on the difference in the position of the tongue. One wayto isolate what is happening with the tongue is to try to say a long version ofthe vowel in boot but forcing the lips to stay spread as for the vowel in beat.You won’t sound natural, and you will look funny, but you should noticethat the tongue is pulled further back in the mouth for the boot vowel thanfor the beat vowel. The latter is called a NON-BACK vowel and the formera BACK vowel.
The three binary choices NON-BACK vs. BACK, and so on, allow for2×2×2 combinations, each one corresponding to one of the eight Turkishvowels in the roots of the words in (6.17), as shown in the following table:
NON-BACK BACK
HIGH i ü ı uNON-HIGH e ö a o
NON-ROUND ROUND NON-ROUND ROUND
You can play with your speech articulators and figure out the approximatepronunciation of the other vowels in the table. For example, [ü] has thetongue forward and high like [i], but it has the lips rounded, like [u]. Thissound occurs in German, also written ü, and in French, where it is written u.If you are familiar with the International Phonetic Alphabet, you will knowthat the symbol for this vowel is [y].
The photographs in Fig. 6.2 will give you an idea of how these vowelsare articulated. You can hear sound files and see more photos on thecompanion website.
The descriptions in terms of the configurations of the vocal tract thatwe have provided correspond to equivalence classes of vowels. The labelof each class (for example HIGH) is typically called a distinctive featureor just feature in the linguistics literature. The features correspond to thelinguistically relevant distinctions among speech sounds in the languages ofthe world. Sets of segments that correspond to a feature description arecalled natural classes. For example, the set of HIGH vowels is a naturalclass (containing i, ü, ı, u), as is the set of HIGH, NON-ROUND vowels(containing i, ı). Note that the more features we list, the smaller the naturalclass is, because adding features makes the description more specific.

TURKISH VOWEL HARMONY 117
BACK
HIG
H
i ı uü
NO
N-H
IGH
oaöe
NON-BACK
NON-ROUND ROUND NON-ROUND ROUND
Fig 6.2 A native speaker pronouncing the eight Turkish vowels. See companionwebsite for side views and sound files. The photographer, Sabina Matyiku, and the
model, Ezgi Özdemir, are both Concordia undergraduate linguistics students.
For practice, list the members of the natural class of ROUND vowels inthe table. Now list the NON-HIGH, ROUND vowels. Now list the BACK
vowels.So we are now ready to analyze the Turkish forms—we have broken
down the data to make the presentation clearer. We begin with just someof the nominative singular and plural forms you saw above, as well as somenew forms that will make the patterns more apparent. Try to answer thequestions before you read the discussion that follows.
6.18 Turkish singular/plural pairs
singular plural meaning
dev devler “giant”kek kekler “cake”can canlar “soul”cep cepler “pocket”tarz tarzlar “type”kap kaplar “recipient”çek çekler “check”saç saçlar “hair”

118 ABSTRACT REPRESENTATIONS
sey seyler “thing”ters tersler “contrary”ask asklar “love”
a. What are the two forms of the plural suffix? 1. 2.b. What determines where you find each suffix?
� Suffix (1.) occurs . . .� Suffix (2.) occurs . . .
Notice that the plural of sap is saplar and the plural of ek is ekler. It turnsout that this is a general pattern—if the root has just an a, then the plural is-lar; if the root has just an e, then the plural is -ler.
What about the other roots that take -lar in the plural? They are uç, kıl,son. What do you notice about the four vowels a, o, u, ı? . . . Right, they areall BACK. And the four vowels that take the suffix -ler are all NON-BACK:e, ö, i, ü.
6.19 More Turkish singular/plural pairs
singular plural meaning
ip ipler “rope”kıl kıllar “body hair”sap saplar “stalk”uç uçlar “edge”son sonlar “end”öç öçler “vengeance”gül güller “rose”ek ekler “junction”
a. What are the two forms of the plural suffix? 1. 2.b. What determines where you find each suffix?
� Suffix (1.) occurs . . .� Suffix (2.) occurs . . .
So to compute which vowel occurs in the plural, we read the NON-BACK/BACK value of the vowel on the bare singular root form and choosethe version of the plural whose value agrees with it.
Let’s be explicit—what does this show us about equivalence classes? Well,the vowels that are, say, NON-BACK, are not all pronounced with thetongue in exactly the same place—for the purposes of phonology, lots ofphysical detail is ignored, and these vowels can be treated as identical insome respect.

TURKISH VOWEL HARMONY 119
Why does this illustrate computation? Well, we can formulate an explicitalgorithm referring to symbols that corresponds to the patterns we see inthe data. Something like this algorithm seems to underlie the behavior ofTurkish speakers.
Before we proceed, we should note that Turkish speakers are not physi-cally constrained to obey the patterns of vowel harmony. For instance, theymay be bilingual in Turkish and English, so as people their behavior is notalways vowel-harmonic. Also, we can ask a Turkish speaker to pronounce,say, sap-ler, and he or she will be able to do so—but this does not reflect thecomputations of the grammar. Grammars do not directly model behavior,and behavior is just one of the sources of evidence for understanding thecomputations of the grammar.
So what is the plural suffix in Turkish? How is it stored in the mind ofa speaker? Is its vowel encoded as NON-BACK or BACK? Let’s ask someeasier questions. What does the plural suffix start with? It seems reasonableto assume that it starts with an l, since there is no evidence that it isanything else. We won’t worry here about how to express l using features(we would need many new ones). It also seems reasonable that it ends withr. So the form is something like -lVr, where V is the vowel we need tofigure out.
The V in the middle of the plural suffix appears never in a rounded form,and it appears never as a HIGH vowel, so it seems reasonable to assumethat the stored form is a member of the equivalence classes NON-HIGH
and NON-ROUND. What about the value for NON-BACK/BACK? Well, wecould assume that it is NON-BACK, basically that the vowel is stored inmemory as e, and then change it into a when it follows a BACK vowel. Butwe could also assume it is basically BACK and have a rule that changes it toe when it follows a NON-BACK vowel.
These two options seem equally valid, and there is no principled way tochoose among them. If all we wanted to do was write a computer programto mimic Turkish output, then it would not matter which one we use.However, the cognitive biolinguistic approach assumes that there is sometruth to the matter concerning what computations characterize a Turkishgrammar.19 We have a third option, in addition to choosing between aand e.
19 Obviously, different speakers could have different versions of the rule, even if theirgrammatical output is the same.

120 ABSTRACT REPRESENTATIONS
First, let’s recognize that a child learning Turkish would find him- orherself in a situation like that of us, the linguists—there is no principled wayto decide between basic e or a. If part of the goal of grammatical theory isto explain how children learn language, then leaving them to make randomchoices is not much of a solution. A second point to appreciate is that, oncewe have features, the symbols e, a, and so on become unnecessary. Thesesymbols are just abbreviations for highly specific equivalence classes: e isjust an abbreviation for the intersection of the sets denoted by NON-BACK,NON-HIGH, and NON-ROUND. This realization liberates us to proposethat the equivalence class in memory that corresponds to the vowel in theplural suffix is just characterized as NON-HIGH, NON-ROUND—with novalue for the third contrast NON-BACK/BACK. In other words, the vowel inthe suffix has no value along this dimension and the computational system,the phonological grammar, provides it with one. The stored form of thevowel is thus something like this:
VNON-ROUND
NON-HIGH
The plural suffix then contains this vowel preceded by an l and followed byr. As noted above, we will not provide featural representations for l and r,and thus we represent the suffix thus:
l
V
NON-ROUND
NON-HIGH
r
This conclusion not only frees us from being forced to make an arbitrarychoice but also leads to an elegant analysis of the rest of the data, as we willnow see.
We turn now to an analysis of the genitive singular forms. We need tofirst identify what forms occur, then determine the environment in whicheach variant occurs, and finally posit a form that is stored in memory thatcan be used to compute the output forms.
6.20 Turkish nominative and genitive singular pairs
nom. singular genitive singular meaning
ip ipin “rope”kıl kılın “body hair”

TURKISH VOWEL HARMONY 121
sap sapın “stalk”uç uçun “edge”son sonun “end”öç öçün “vengeance”gül gülün “rose”ek ekin “junction”
a. What are the four forms of the genitive suffix?1. 2. 3. 4.
b. What determines where you find each suffix?� Suffix (1.) occurs . . .� Suffix (2.) occurs . . .� Suffix (3.) occurs . . .� Suffix (4.) occurs . . .
Here are the four vowels that occur in the suffix: i, ü, ı, u. What do theyhave in common? They are all HIGH, so it seems reasonable to suppose thatthis suffix is stored in memory with a vowel encoded as HIGH.
Now, where does the form -in occur? It occurs in the forms ipin and ekin.These are the forms with root vowels that are NON-BACK, NON-ROUND,which agrees with the vowel i of the suffix. Where does the suffix -ün occur?It occurs in the forms öçün and gülün, which have vowels that agree withthe suffix vowel in being NON-BACK, ROUND. We get the same patternwith the other two forms of the suffix: -ın occurs with sapın and kılın, whichboth have BACK, NON-ROUND vowels; and -un occurs in uçun and sonun,where the vowels are BACK, ROUND.
We now see that we don’t have to choose a particular vowel to representthe genitive suffix. It is stored in memory as containing a vowel that isspecified as just HIGH, and that’s it:[
VHIGH
]n
The other features are filled in by the computational system to matchthose of the vowel that precedes.
The genitive suffix is thus encoded in memory as an abstract entity thatstarts with a vowel specified as HIGH followed by an n. The other featuresof the vowel get filled in depending on the context by the grammar. Notethat the stored forms of the vowels of the plural and the genitive are bothlacking specification for some features, but the two vowels are distinct fromeach other.

122 ABSTRACT REPRESENTATIONS
We are now ready to tackle the genitive plurals.
6.21 Turkish nominative singular/genitive plural pairs
nom. singular genitive plural meaning
ip iplerin “rope”kıl kılların “body hair”sap sapların “stalk”uç uçların “edge”son sonların “end”öç öçlerin “vengeance”gül güllerin “rose”ek eklerin “junction”
a. What are the two forms of the genitive suffix in this data?1. 2.
b. What determines where you find each suffix?� Suffix (1.) occurs . . .� Suffix (2.) occurs . . .
Recall that we wondered if the genitive marker in the genitive pluralneeded to be encoded differently from that in the singular, since the formershows up in only two forms, whereas the latter has the four combinationsof NON-BACK/BACK and ROUND/NON-ROUND discussed above. Thegenitive marker in the plural has only the NON-ROUND variants. Whatdo you think—are there two genitive markers, one for singular and one forplural, or can the two patterns, a four-way contrast and a two-way contrast,all be derived from a single underlying form?
We propose that there is a single genitive suffix underlyingly. To seehow this works, consider the system of morphology and phonology thatwe are proposing. The morphology takes roots and suffixes as they arestored in memory and puts them together. That will give us structures likethe following for a form that exits the grammar as öçler, with the vowelsexpressed in terms of features. We use phonetic symbols for the consonantsfor ease of presentation.
6.22 Input to the phonology for öçler
INPUT:
VNON-BACK
ROUND
NON-HIGH
ç-l
V
NON-ROUND
NON-HIGH
r

TURKISH VOWEL HARMONY 123
Since the suffix vowel is lacking a specification for NON-BACK/BACK, itlooks to its left and copies the first one it finds—in this case the NON-BACK
of the vowel ö.
6.23 Output of the phonology for öçler
OUTPUT:
VNON-BACK
ROUND
NON-HIGH
çl
VNON-BACK
NON-ROUND
NON-HIGH
r
A mapping from the combination of stored forms to the output generatedby the phonology is called a derivation. For the genitive of the same root wehave the following derivation, again with missing values copied from theleft:
6.24 Derivation of öçün
INPUT:
VNON-BACK
ROUND
NON-HIGH
ç-
[V
HIGH
]n
OUTPUT:
VNON-BACK
ROUND
NON-HIGH
ç
VNON-BACK
ROUND
HIGH
n
Now, let’s see what happens when we add both suffixes to the sameroot. Now we have two vowels in a row that are missing values for somefeatures.
6.25 Input representation of öçlerin
INPUT:
VNON-BACK
ROUND
NON-HIGH
ç-l
V
NON-ROUND
NON-HIGH
r
[V
HIGH
]n
We assume that a vowel that is missing values for any feature pairlike ROUND/NON-ROUND looks to its left and copies the first valueit finds. Both suffixes have to look all the way to the root vowel toget a value for NON-BACK/BACK. This is the only feature missing forthe plural marker. The genitive marker, however, also needs a value forROUND/NON-ROUND. In the genitive singular, the first such value tothe left was on the root, but, in this case, the plural marker has a rele-vant feature, and the genitive suffix copies it. Thus, we end up with thefollowing:

124 ABSTRACT REPRESENTATIONS
6.26 Output representation of öçlerin with features for the vowels
OUTPUT:
VNON-BACK
ROUND
NON-HIGH
çl
VNON-BACK
NON-ROUND
NON-HIGH
r
VNON-BACK
NON-ROUND
HIGH
n
We now see that we can derive the genitive alternations in the singular andplural from the same abstract stored form. There are fewer surface formsof the genitive suffix in the plural because the genitive suffix always getsits ROUND/NON-ROUND value from the plural suffix. The latter is alwaysNON-ROUND since it is underlyingly specified as such. We also see thatthe form of the suffixes is determined phonologically—the computationsdepend on the preceding vowel, not on what root the suffix is attachedto. This is clear, because different forms of the genitive surface with agiven root, depending on what intervenes. The root öç- takes a genitivesuffix -ün if the suffix follows the root directly, but it takes the form -in if aNON-ROUND vowel like that of the plural comes between the root and thegenitive.
Now, we have just illustrated the computational nature of vowel harmonyin Turkish. Getting back to our story, it turns out that the vowels of Turkishroots tend to be harmonic as well, especially with regard to the featuresNON-BACK/BACK. Here are some examples:
6.27 Harmonic Turkish roots
BACK boru “pipe”arı “bee”oda “room”
NON-BACK inek “cow”dere “river”güzel “beautiful”
There are some exceptions, especially in recent borrowings like pilot“pilot,” but for the most part all the vowels in a root will be eitherNON-BACK or BACK. This is how Charles knew that Ozel was a veryunlikely name, and that Özel would conform to the general pattern of thelanguage.20
20 Paul did manage to visit our venerable doctor, who inadvertently squirted someanesthetic into his eye, and then diagnosed him as having a case of trenchmouth thateventually cleared up on its own. This story is not meant to denigrate the Turkish medicalprofession—after all, Dr. Özel worked at the American hospital in Istanbul.

WORDS ARE NOT DERIVED FROM WORDS 125
So, like our analyses of syntactic structure and the allophones of /t/, weonce again end up positing very abstract symbols—this time the partiallyspecified vowels of Turkish—to account for complex sets of linguistic data.We turn in the next section to yet one more analysis, from the domain ofmorphology, that demonstrates just how abstract the equivalence classesare over which grammatical computations apply.
6.5 Words are not derived from words
Recall the discussion of Warlpiri and Samoan from Chapter 1. In thoseexamples, we assumed that the plurals were built from the singulars. Simi-larly, we saw that the Turkish nominative plural, genitive singular, and gen-itive plural seem to be formed from the nominative singular form by addingsuffixes and providing them with the appropriate values for missing features.So far, it always appeared to be the case that complex words are built out ofsimple words. However, in some languages, even for simple categories likesingular and plural, it is necessary to recognize a complication—it may bethe case that both singular and plural need to be expressed as a functionof some unit that, by itself, is neither singular or plural. In fact, this unitcannot ever appear as a word on its own. An example will help to clarify.
Here are some singular/plural pairs from the language Swahili, spoken inTanzania and other countries in eastern Africa (the letter š is pronouncedlike sh). Swahili is the native language of about one million people, but isused as a second language by about 30 million.
6.28 Swahili singular/plural pairs
singular plural meaning
mtoto watoto “child/children”mtu watu “person/people”mpiši wapiši “cook/cooks”mgeni wageni “stranger/strangers”
Note that each singular/plural pair shares something—for “child/children”it is toto; for “person/people” it is tu, and so on.
If we want to revive our mathematical analogies from Chapter 1, wherewe expressed the plural in Warlpiri as a function of the singular, then wecan treat the Swahili singular and plural forms as being generated by twodifferent functions of the same independent variable. If we refer to the

126 ABSTRACT REPRESENTATIONS
shared part of each pair as the ROOT, then the functions can be expressedas follows:
6.29 � SINGULAR = m�ROOT� PLURAL = wa�ROOT
The singular is a function of the root computed by placing m before theroot. The plural is a function of the root computed by placing wa before theroot.
In order to highlight the fact that we are dealing with the computationof two dependent variables, SINGULAR and PLURAL, from the same inde-pendent variable ROOT, we can rewrite this as follows.
6.30 � One function of ROOT = m�ROOT� Another function of ROOT = wa�ROOT
These examples introduce a convention commonly used in math. An equiv-alent notation to, for example, y = 2x + 3 is f (x) = 2x + 3. This just means“There is some function of the independent variable x, computed by 2x + 3,and we will call this function f (x). This is read as “f of x.”
If we want to distinguish this function of x from another one, we can justassign it another letter. For example, we can refer to f (x) and g(x), twofunctions of the same variable, just as the Swahili singular and plural aretwo functions applied to the same set of roots. An alternative notation isto use always f , but with indexes that distinguish functions: f 1(x) is onefunction and f 2(x) is another.
Using our Swahili example, we could express the two functions by assum-ing that x is a variable standing for the members of the set of roots. Thenwe would have, say, the following:
6.31 a. f (x) = m�xb. g(x) = wa�x
Similarly in math, we can have two functions of a variable like, say, thefollowing:
6.32 a. f (x) = 2x − 3b. g(x) = 4x
What’s the point? Well, there are two. First, we want to remind you onceagain why we focus on the theme of computation. The application ofmathematical notions like variables and functions, if it gives us insight,

THINK NEGATIVE 127
supports our contention that language, at least some aspects of language,are amenable to scientific inquiry.
The second point is to illustrate, once again, the abstract nature of thesymbolic elements over which grammatical computations occur. As we haveseen, words are highly abstract entities, but now we have found evidence thatwords actually have to be analyzed in terms of even more abstract elements.These elements, roots, and prefixes and suffixes cannot be used on their ownwithout occurring in combination with other elements—for example, toto,without a prefix, is not a Swahili word.
6.6 Think negative
In the preceding sections we have given you a sample of linguistic topicsthat we find useful for illustrating notions like computation and equivalenceclass. Our examples thus far have been drawn from phonology, morphology,and syntax. In this section we introduce you to some semantic patterns,patterns related to meaning, drawing on very simple English data relatedto one of the puzzles introduced in Chapter 3. We expect that you will besurprised at the regularities that emerge.
Before we delve into the data, we would like you to ask yourselfhow much you know about basic set theory. Many people will say thatthey know almost nothing. If you do know some basic set theory, thenthink about when you learned it. We assume that, unless you havedeviant parents, it was sometime after the age of six. Now hold thosethoughts. . . .
Consider the following sentences:
6.33 � Sami wasn’t wearing clothes� Sami wasn’t wearing footwear� Sami wasn’t wearing socks� Sami wasn’t wearing white socks
Notice that we can insert a word like any in these sentences as indicatedbelow and the result is grammatical:
6.34 � Sami wasn’t wearing any clothes� Sami wasn’t wearing any footwear� Sami wasn’t wearing any socks� Sami wasn’t wearing any white socks

128 ABSTRACT REPRESENTATIONS
However, the examples become ungrammatical if we remove the negation:
6.35 � ∗Sami was wearing any clothes� ∗Sami was wearing any footwear� ∗Sami was wearing any socks� ∗Sami was wearing any white socks
The generalization seems to be that there is some relationship betweennegation and the presence of any. This is confirmed by the fact that, ifwe remove any from the ungrammatical strings above, the result becomesgrammatical.
6.36 � Sami was wearing clothes� Sami was wearing footwear� Sami was wearing socks� Sami was wearing white socks
What’s interesting is that there are other lexical items, apart from any,that are sensitive to whether the sentence in which they occur is affirmativeor negative, in other words to the polarity of the sentence in which theyoccur. Such items include ever, yet, at all, anything, and others. Just likeany, such items are grammatical in negative sentences but ungrammaticalin affirmative ones.
6.37 a. Sami wasn’t ever wearing clothesb. Sami wasn’t wearing clothes yetc. Sami wasn’t wearing clothes at alld. Sami wasn’t wearing anything
6.38 a. ∗Sami was ever wearing clothesb. ∗Sami was wearing clothes yetc. ∗Sami was wearing clothes at alld. ∗Sami was wearing anything
The technical name for such words is negative polarity items (NPIs). NPIsthus form an equivalence class of semantic computation, a class of itemsthat share the property of being sensitive to the (negative) polarity of thesentence in which they occur. These observations would be enough to makeyou aware of the fact that linguistic computation operates on equivalenceclasses at all levels, including the semantic one. However, it turns out thatnot only are items like any, ever, yet, or at all members of a class that can beconsistently defined in a semantic way but the negative environment in whichthese items occur grammatically is itself a member of a larger equivalence

THINK NEGATIVE 129
class which can be defined semantically. In order to see that, consider againthe negative sentences in (6.33):
6.39 � Sami wasn’t wearing clothes ⇒� Sami wasn’t wearing footwear ⇒� Sami wasn’t wearing socks ⇒� Sami wasn’t wearing white socks
Observe that the meanings, the propositions expressed by these sentences,have certain entailment relations among them, as shown by the arrows. Inparticular, the meaning of the higher elements in the list entails the meaningof the lower ones. If we know that a higher one is true, we know that theones below it are true as well. It is impossible that a higher one be true anda lower one false. For example, if Sami wasn’t wearing footwear, then it isnecessarily the case that he was not wearing socks, including white socks. In(6.39), the objects are in a downward-entailing environment.
In contrast to the sentences we just examined, those in (6.36), which donot constitute a proper environment for the occurrence of any, have theentailment relations reversed, as indicated below. The lower sentences entailthe higher ones—if Sami was wearing white socks, then it is necessarily thecase that he was wearing socks, footwear, clothing.
6.40 � Sami was wearing clothes ⇐� Sami was wearing footwear ⇐� Sami was wearing socks ⇐� Sami was wearing white socks
In (6.40), the objects are in an upward-entailing environment.Now think about what these entailment relations mean. Every white sock
is a sock. And every sock is a piece of footwear. And every piece of footwearis an article of clothing. The terms we have used refer to nested sets: the setof clothes is a superset of the set of footwear, or, equivalently, the set offootwear is a subset of the set of clothes. The claim we want to make is thatNPIs are not actually sensitive to the polarity of the sentence in which theyoccur but to the directionality of the entailment relations that the respectivesentences license. More specifically, NPIs are a class of lexical items thatoccur in downward-entailing environments like (6.39). Such environmentsinclude negative contexts, but are not reduced to the latter. In other words,negative contexts are just one member of a larger equivalence class—thatof downward-entailing contexts. That this is the right generalization issupported by the following data showing various contexts in which NPIslike any can occur.

130 ABSTRACT REPRESENTATIONS
6.41 More entailment switches∗any any∗Sami always wears any socks Sami never wears any socks∗Sami often wears any socks Sami hardly wears any socks∗Sami left with any socks Sami left without any socks∗Many cats wear any socks Few cats wear any socks∗Sami smiles after Sami smiles before
he puts on any socks he puts on any socks
You can confirm that never behaves just like the negative marker n’t withrespect to entailment: if Sami never wears socks, then we know that he neverwears white socks. This is perhaps unsurprising since never so transparentlycontains negation. The same is true about hardly and without. However, youmay be surprised to see that few and before also create downward-entailingenvironments, in spite of the fact that it is hard to maintain that they containnegation in any way. For example, if Sami smiles before he puts on socks,he clearly smiles before he puts on white socks; and if it is the case that fewcats wear socks, it is also the case that few cats wear white socks.
You may have already thought of some difficulties with what we havepresented so far. First of all, you may be thinking about uses of NPIs thatclearly do not appear in downward-entailing environments. For example,the word anything seems to be an NPI, as shown above, yet sentences like(6.42) are perfectly grammatical.
6.42 He’ll eat anything
This is a so-called “free-choice” usage, and we will assume that it is actuallya different item from the NPIs we have been looking at. We cannot providefull justification here, but we just note that the two types of sentences aretranslated with very different elements in many languages, for example,French.
6.43 English French
Negation: He won’t eat anything Il ne mange rienFree Choice: He’ll eat anything Il mange n’importe quoi
Since there are languages that do not treat free-choice meanings and NPIsidentically, we will assume that they correspond to distinct representations,even in English where they are homophonous. In other words, simplifyinga bit, we assume that English actually has two different words pronouncedanything, one corresponding to French rien and one to n’importe quoi.

SUMMING UP 131
A second issue that you may have noticed is that NPIs also occur inYes/No questions:
6.44 NPIs in questions� Did you kick anyone?� Have you ever been to Timbuktu?� Has anybody seen my girl?
It is hard to say what a question means, and thus it is hard to say what aquestion entails—it is not clear that it even makes sense to ask if Does Samiwear socks? entails Does Sami wear white socks? Informally, we just notethat if the answer to the first question is “no,” this entails that the answer tothe second is the same, so perhaps this is the way to interpret entailment inquestions. This is a topic of current research that we leave aside.
Recall our question about your knowledge of set theory in the beginningof this discussion. Not only English but all languages make use of NPIs;they all require analysis in terms of entailments, implications that canbe understood as set theoretic relations. Thus, in a sense, everybody whospeaks a language has knowledge of set theory. Every human languagemakes implicit use of notions like subset and superset well before formalschooling begins. Downward-entailing environments make up an equiva-lence class that turns out to be defining for a class of lexical items—theclass of NPIs. These two equivalence classes do not have correlates outsideof the semantics—they are pure semantic categories. Notice in this sensethat the syntactic correlates of NPIs do not make up a coherent syntacticcategory—NPIs like any are determiners, ever is an adverb, while at all is aprepositional phrase. We will come back to NPIs in later chapters to studytheir syntax, and also to discuss some differences in NPI patterns acrossdialects of English.
6.7 Summing up
In this chapter, we first saw that it is necessary to appeal to a very abstractnotion of syntactic structure—we can’t understand the patterns of possiblesentences by just considering sequences of sounds or words. We then arguedfor the abstract notion phoneme in order to account for the patterns of dis-tribution and alternation of speech sounds like plain and aspirated [t], flap,and glottal stop. In the next section, we showed that a reasonable analysis

132 ABSTRACT REPRESENTATIONS
of Turkish vowel harmony leads us to posit forms stored in memory that arenot even pronounceable since some of the features that determine pronunci-ation are filled in by the computational system. Then we argued that, at leastin some cases like Swahili nouns, the building blocks of words are abstractroots, elements that cannot be used in isolation. It is not always possible toanalyze complex words as consisting of simple words. Finally, we examinedthe set theoretic conditions on the distribution of certain words and phrases.
In each phenomenon we looked at, contracted copula, allophones of /t/,Turkish vowel harmony, Swahili nouns, and English NPIs, we saw that wecould make an explicit formulation of the relevant pattern. We saw thatthe output of the grammar can be computed by explicit rules. These rulesapply to equivalence classes of abstract symbols, or complex structures ofsymbols, that are related to the physical manifestations of speech in onlyvery indirect ways.
6.8 Exercises
Exercise 6.8.1. Do grammars avoid ambiguity? When we present theMary’s data in class, we have found that there are always some studentswho insist that the unacceptability of ∗I know Mary’s in the sense intendedin (6.1d.) must be somehow connected to the fact that the string has another,acceptable reading. In other words, these students suggest that we, or ourgrammars, somehow refuse to allow strings that are ambiguous.
There are several problems with such a view, the most obvious beingthat it is trivial to find examples of ambiguity, of all types. The string Isaw the man with a telescope has two obvious readings, one in which theman who was seen had a telescope and one in which the device used forseeing was a telescope. Of course, there is also another pair of readingsthat can be paraphrased as I regularly use a telescope to cut (to saw) theman and I regularly cut the man who has a telescope. The second problemwith the explanation that appeals to ambiguity is that grammars, which arejust computational systems, have no way to avoid generating ambiguousstructures—they just produce outputs from inputs mechanically, and,furthermore, grammars have no reason to care about ambiguity. Peoplecommunicate, grammars do not.
In any case, it is still useful to come up with examples where the issueof ambiguity does not arise. We can find such cases by making our subject

EXERCISES 133
plural as in (6.45a.). In spoken English, there is also a reduced or contractedform of the plural copula, although there is no standard orthographicconvention for writing this—we have used ’er. We see that the patterns ofgrammaticality are exactly the same as in the previous sentences.
6.45 Do you know if anyone is here yet?a. I know Sami and Bill are here.b. I know Sami and Bill ’er here.c. I know Sami and Bill are.d. ∗I know Sami and Bill ’er.e. ∗I know Sami and Bill ’er, but Mary’s not.
Explain how these examples help to show that avoidance of ambiguity isirrelevant to an explanation of the distribution of the contracted copulaforms that we developed in this chapter.
Exercise 6.8.2. English allophones: Using Praat record the following setsof words, making a separate file for each set. The Praat manual or our mini-manual will tell you how to do this.
� leaf, feel� bead, bean� pit, spit, bit
a. Using the symbols of the International Phonetic Alphabet, one mighttranscribe the first set as [lif] and [fi]. In Praat, open (using READ) thefirst file, select it in the object list, and then choose EDIT. Play thefile. Then select the file in your Praat object list and choose Modify >
Reverse. Play the waveform again. Based on the transcription, one wouldexpect the reverse of leaf, feel to sound like the original. Does it? Recordother examples of words that begin with l and words that end with l.Try to select the part corresponding to l in the waveforms. Is there aconsistent difference between the initial and final pronunciation of thisletter?
b. Open the file containing bead, bean. One might expect the two wordscontain the same vowel since one might transcribe the words [bid] and[bin]. Isolate the vowel part of each word in the waveform and play it.Do they sound the same? Try to find other examples of each of thesetwo types of vowel. Try to find other vowel pairs that differ in the sameway, such as those in these words: lode, loam, lone, lobe. Does Englishhave twice as many vowels as you thought? Hint: It depends on whatyou mean by “a vowel.” Think of equivalence classes.

134 ABSTRACT REPRESENTATIONS
c. Like /t/, the phoneme /p/ has a plain and aspirated variant. Open andplay the file containing pit, spit, bit, then select and play the aspiratedand unaspirated allophones of /p/ by selecting parts of the waveform.Then select all of spit except the /s/. Play what remains—how does itsound?
Exercise 6.8.3. Guaymí: This language is spoken in Panama and CostaRica by about 128,000 people. Use the notation we developed for Swahili toexpress Guaymí verbs as a function of two variables, based on the followingtable:
present past meaning
kuge kugaba burns/burnedblite blitaba speaks/spokekite kitaba throws/threwmete metaba hits/hit
Exercise 6.8.4. Nahuatl: An expression like z = 5w − 2x + 3y − 6 rep-resents z as a function of three independent variables. Come up with afunction of three variables to generate the form of possessed nouns inNahuatl, spoken by about 1.5 million people in Mexico. List the full setof possibilities for each variable.
nokali my house nokalimes my housesmokali your house mokalimes your housesikali his house ikalimes his housesnopelo my dog nopelomes my dogsmopelo your dog mopelomes your dogsipelo his dog ipelomes his dogsnokwahmili my cornfield nokwahmilimes my cornfieldsmokwahmili your cornfield mokwahmilimes your cornfieldsikwahmili his cornfield ikwahmilimes his cornfields
Further Readings
The first of these readings is not only very funny in places but is also afoundational document of the cognitive revolution. The second is a classicof psychology, and is also very entertaining. As you read these articlesthink about how they illustrate the necessity of positing abstract represen-tations in order to understand human and rat behavior. The third selection

EXERCISES 135
is Roberts’s discussion of the sense of time in rats—it is fairly long anddifficult, but definitely a worthwhile read. The author publishes widely, bothin academic journals and in popular media such as Spy magazine.
� Review of Skinner’s Verbal Behavior by Noam Chomsky (1959).� “Cognitive maps in rats and man” by E. C. Tolman (1948).� “The mental representation of time: Uncovering a biological clock” by
Seth Roberts (1998).

7Some details of sentence
structure
7.1 Basic syntactic categories 136
7.2 Syntactic constituents 139
7.3 Labels and phrasal
categories 144
7.4 Predicting syntactic
patterns 154
7.5 Using trees to predict
reaction times 164
7.6 To sum up 167
7.7 Exercises 168
In previous chapters we argued that the input to operations involved inlinguistic computation must be abstract entities, i.e. classes of words, orroots, or sounds, in other words, equivalence classes. In Chapter 1 we hintedat the existence of some abstract syntactic categories, such as noun and verb,and in Chapter 6 we illustrated another equivalence class that is relevantfor syntactic computation, namely the class SENTENCE. In this chapter weoffer more details on equivalence classes in syntax and the computationsinvolving them.
7.1 Basic syntactic categories
Consider the following examples:
7.1 a. This fat cat is red with white spotsb. This fat chicken is red with white spotsc. This fat pencil is red with white spotsd. ∗This fat goes is red with white spots
In (7.1a.), the word cat can be substituted by certain other words,say, chicken or pencil, and grammaticality is preserved, as in (7.1b.c.).

BASIC SYNTACTIC CATEGORIES 137
However, if a word like goes is substituted for cat, as in (7.1d.), the result isungrammatical. Crucially, when we substituted cat for chicken or pencil, weleft the rest unchanged and the result was still a grammatical sentence. Thissuggests that cat, chicken and pencil share some property that goes does notshare, and thus that they are members of a syntactic equivalence class. Asmembers of the same equivalence class they have the same syntactic distri-bution. The syntactic distribution of the equivalence class that includes cat,chicken, and pencil but excludes goes can be identified by the (immediate)contexts in which these words can occur, as in (7.2):
7.2 This fat . . . is
We will take the fact that certain words, cat, chicken, and pencil, can occurin this context to be an indication that they share a property to the exclusionof other words. We will refer to the class of words that have this property asnouns, Ns. Since goes cannot occur in this context, it does not have the samesyntactic distribution, and thus it appears not to belong to the category, theequivalence class, N.
Now, just as we replaced cat by chicken and pencil in (7.1) to discoverthe class N, we can replace other words in the same sentence to discoverother syntactic categories. For example, we can replace the first word, this,with that, the, or a, as illustrated in (7.3b.–d.). Each of these replacementsyields a grammatical sentence, which suggests that this, that, the, and aare all members of the same syntactic category. We call this the categoryof determiners, D. However, replacement of the same word, this, with aword like away, as in (7.3e.), is ungrammatical, which suggests that awayis not part of the same class as that, the, or a, and thus that it is not adeterminer.
7.3 a. This fat cat is red with white spotsb. That fat cat is red with white spotsc. The fat cat is red with white spotsd. A fat cat is red with white spotse. ∗Away fat cat is red with white spots
The category of determiners, then, is defined by the context given in (7.4)below.
7.4 . . . fat chicken
The same substitution test can be applied not only for cat and this butfor all words in (7.1a.). Each of the words in (7.1a.) belongs to a certainsyntactic category that can be defined by a minimal context in the manner

138 SOME DETAILS OF SENTENCE STRUCTURE
illustrated in (7.2) and (7.4). Apart from the category determiner and noun,(7.1a.) also contains words belonging to categories like verb (V), preposition(P), and adjective (A).
7.5 ThisD fatA catN isV redA withP whiteA spotsN.
Given that (7.1b.c.) are identical to (7.1a.), with the exception of the factthat a different noun is substituted for cat, (7.1b.c.) contain words thatbelong to exactly the same syntactic categories as (7.1a.).
7.6 ThisD fatA chickenN isV redA withP whiteA spotsN.
7.7 ThisD fatA pencilN isV redA withP whiteA spotsN.
In other words, (7.1a.-c.) can be seen as particular instantiations of thesame string of syntactic categories and, conversely, one and the same stringof syntactic categories can be instantiated by different words. To furtherillustrate this latter point, consider the following sentence.
7.8 That blue fish got skinny despite strong warnings.
Even though (7.8) obviously means a different thing than (7.1a.-c.), at acertain level they are all the same, they are all definable by the same stringof syntactic categories.
7.9 ThatD blueA fishN gotV skinnyA despiteP strongA warningsN.
Just as in (7.1a.) we replaced cat by other nouns, such as chicken andpencil, in (7.8) we replaced each of the words in (7.1a.) with other wordsin the same syntactic categories. What is crucial is that the words thatwe substitute for our initial words should keep the sentence grammatical.Grammaticality is preserved whenever the word we substitute belongs tothe same category as the one we replace.
We can now go back to the minimal distributional contexts we pro-vided for nouns and determiners. It should be obvious by now that wecould express these contexts at a higher level of generality, by usingsyntactic categories instead of just words. So, the distributional contextfor nouns is [D A . . . V], rather than just [This fat . . . is], and for deter-miners is [. . . A N], rather than [ . . . fat cat]. This captures the fact thata noun, for instance, can occur not only in the context [This fat . . . is]but also in a context like [that blue . . . grows], [a redundant . . . gets],or any other context that represents an instantiation of [D A . . . V].Similarly, expressing the distributional context in terms of categoriesrather than words captures the fact that a determiner would be any

SYNTAC TIC CONSTITUENTS 139
word that occurs in the context [ . . . fat cat], or [ . . . smiling face], or[ . . . implausible excuse], in fact in any context that contains words repre-senting instantiations of the A and N categories that are part of [. . . A N].Last, but not least, expressing the distributional context in terms of cat-egories also allows us to treat all members of a particular category alike.For example, the distributional context [D A . . . V] can accommodate anynoun, irrespective of whether it is singular or plural, masculine or feminine,third person or first or second. This is closely related to the fact that theD, A and V, which are part of the distributional context, can themselvespotentially be instantiated by any D, A, and V, regardless of whether theyare singular or plural, masculine or feminine, third person or first or second.Clearly, expressing the distributional context in terms of lexical items orwords would fail to capture that singular and plural nouns, for instance,share the same distribution at some level. To see that, notice that pluralnouns cannot be inserted into the context [a fat . . . is], since in English, thenoun has to agree with the form of the D (this as opposed to these, forexample) and of the V (is as opposed to are). In contrast, plural nouns caneasily be inserted in a context like [D A . . . V], as for instance in “these fatcats are,” or “some tall students left.”
The careful reader will surely have noticed that the substitution methodswe have suggested are not formal proofs of, or even foolproof tests for,category membership. They are heuristics, tests that build on our intuitionsand seem to help us develop formal models, but strictly speaking they arenot themselves part of the theory of grammar. They are techniques forbuilding a model that have proven to be useful.
7.2 Syntactic constituents
Let us now consider a string like (7.10).
7.10 I spotted that rodent with a telescope.
There are two meanings associated with such a string.21 One interpre-tation is that the rodent in question was spotted, in some unspecifiedmanner, but that the rodent is specified as having a telescope—in thiscase, with a telescope tells us something about the rodent, not about theevent of spotting. The second meaning could be paraphrased as “Using
21 Actually, there are more: we are taking the verb spot in the sense of “see” andleaving aside the meaning “to put spots on.”

140 SOME DETAILS OF SENTENCE STRUCTURE
a telescope, I spotted that rodent.” In other words with a telescope may beunderstood as specifying something about the verb that describes the actioninvolved.
Clearly, these two interpretations cannot be distinguished from eachother just by using categories like noun, verb, etc., since both interpretationscorrespond to the same string of such categories, the string in (7.10). Thetwo interpretations can, however, be distinguished by grouping togetherthe categories in this string in two different ways. One crucial differenceis indicated in (7.11a.b.).
7.11 a. IN [spottedV [thatD rodentN withP aD telescopeN ]]b. IN [[spottedV thatD rodentN ] withP aD telescopeN ]
The difference between the two consists in whether with a telescope isgrouped together with that rodent (to the exclusion of spotted) or not. If itis, as in (7.11a.), then we will say that the string that rodent with a telescopemakes up a phrasal category. Otherwise, if the grouping is as in (7.11b.),then that rodent and with a telescope are part of separate phrasal categories.Each of the two groupings of the atomic categories N, D, A, and so on,gives rise to a distinct organization into phrasal categories.
The general term that covers both simple and phrasal categories is con-stituents, since categories constitute the structure of the sentence. In (7.11a.)above, the sequence of simple syntactic categories D, N, P, D, N make upa constituent instantiated by thatD rodentN withP aD telescopeN, whereas in(7.11b.) the sequence thatD rodentN makes up a constituent with spottedV,rather than with withP aD telescopeN.
A question that might come to mind is “How do we come up with thegrouping in (7.11a.b.)?” One answer is that our native speaker intuitionssupport the grouping of the simple categories involved in the way indicatedin (7.11a.b.). Our intuition tells us that the string thatD rodentN withP aD
telescopeN in (7.11a.) has a certain cohesion, acts as group. In additionto this intuition, we can test this cohesion of syntactic constituents invarious ways. One test consists of replacing a string of words with certainsimple lexical items. If the replacement yields a grammatical result, thenthe string of words that was replaced is a constituent; if not, it is not aconstituent. Under the interpretation in (7.11a.), shown again in (7.12),for example, that rodent with a telescope can be replaced by a pronounlike it.

SYNTAC TIC CONSTITUENTS 141
7.12 I spotted [that rodent with a telescope], and Mary spotted [it], too.([it]=[that rodent with a telescope])
The pronoun it can also replace a sequence of words in (7.11b.), but,crucially, it cannot replace the whole string that rodent with a telescope butonly part of it, namely that rodent.
7.13 I spotted [that rodent] with a telescope and Mary spotted [it] witha magnifying glass. ([it]=[that rodent])
Another way of showing the same thing is to look at it from the other end.If a pronoun like it shows up in an example like (7.12), where it replaces thesequence that rodent with a telescope, then the only possible interpretationfor the string I spotted that rodent with a telescope is the one in which therodent had the telescope. If, on the other hand, it replaces that rodent,to the exclusion of with a telescope, as in (7.13), then the only possibleinterpretation is the one in which the telescope was used as an instrumentto spot the rodent.
Turning now to (7.11b.), we can apply the same kind of substitution testto show that spotted that rodent makes up a constituent, to the exclusion ofwith a telescope.
7.14 I [spotted that rodent] with a telescope and Mary [did] with amagnifying glass. ([did]=[spotted that rodent])
The pro-verb did can also replace a sequence of words in (7.11a.), but,crucially, it cannot replace just the string spotted that rodent, but only thelarger string spotted that rodent with a telescope.
7.15 I [spotted [that rodent with a telescope]] and Mary [did], too.([did]=[spotted that rodent with a telescope])
Now let’s try to work our way to providing the complete constituencyof (7.11a.b.). In order to do that, notice that the phrasal categories thatwe have identified so far, such as that rodent with a telescope and spottedthat rodent with a telescope in (7.11a.), and that rodent and spotted thatrodent in (7.11b.), are complex not only in the sense that they contain asequence of simple syntactic categories. Each of these phrasal categoriescan be broken down into subconstituents that are themselves complex. Forexample, the constituent that rodent with a telescope in (7.11a.) contains asubconstituent rodent with a telescope that is itself complex, that is made

142 SOME DETAILS OF SENTENCE STRUCTURE
up of several simple syntactic categories. That rodent with a telescope doesmake up a (sub)constituent can be shown by the fact that this sequence canbe replaced by a pronoun like one.
7.16 � [that [rodent with a telescope]]� [that [one]]
Moreover, even this subconstituent, rodent with a telescope, can be furtherbroken down into its own subconstituents. One such example is the stringwith a telescope, which can be replaced by some other modifying word, suchas there:
7.17 � [that [rodent [with a telescope]]]� [that [rodent [there]]]
Finally, the phrase a telescope can also be identified as a (sub)constituent,as shown by the fact that it can be replaced by the pronoun it:
7.18 � [that [rodent [with a telescope]]]� [that [rodent [with [ it ]]]]
So, in (7.11a.), a telescope is a phrasal category; with a telescope is aphrasal category; rodent with a telescope is a phrasal category; and thatrodent with a telescope is a phrasal category.
A sentence is thus made up of simple syntactic categories that con-tain a single word of the types we have seen, N, V, and so on, andof phrasal categories that are successively embedded within each other.The arrangement of these categories constitutes the structure of the sen-tence. This structure can be illustrated either by using brackets, as wehave been doing, or else by using tree diagrams, as in (7.19) and (7.20).We give you the complete constituency of both sentences (7.11a.b.). Thefirst exercise at the end of the chapter will provide you with more teststhat you can use in order to check the constituency of sentences. Youcan go through this exercise and convince yourself that the grouping weindicate below corresponds to the actual syntactic constituents of ourstring.

SYNTAC TIC CONSTITUENTS 143
7.19 Tree structure for (7.11a.):[I [spotted [that [rodent [with [a telescope]]]]]]
•
N
I
•
V
spotted
•
D
that
•
N
rodent
•
P
with
•
D
a
N
telescope
7.20 Tree structure for (7.11b.):[I [spotted [that rodent]] [with [a telescope]]]
•
N
I
•
•
V
spotted
•
D
that
N
rodent
•
P
with
•
D
a
N
telescope
Nodes that are combined to form a higher-level node are called sisters.Notice that each of the nodes in these trees above the level of the word is

144 SOME DETAILS OF SENTENCE STRUCTURE
the result of joining together exactly two constituents. In other words, eachnode above the word-level terminal nodes is binary branching. We assumethat this is the case for all trees in all languages. We will not provide afull justification for this position, and we acknowledge that many linguistsdisagree with it. However, since we suppose the basic operation of syntaxto be grouping of two elements to form a constituent, binarity followsautomatically.22
7.3 Labels and phrasal categories
Now, the nodes in these trees could be labeled. The labeling of each non-terminal node is not random—it inherits the label of one of its components.We call the component that provides the label to the resulting node a head.For example, the label of the category resulting from syntactically merginga nominal element like books and an adjectival one like interesting will haveto be either nominal or adjectival, since the two components are a nominalelement and an adjectival one. Now let us take a look at the meaning ofthe phrase interesting books—it denotes a type of books and not a type ofinteresting, so it is reasonable to assume that the head is the nominal elementbooks. The semantic relationship between the head books and the non-head interesting is one of modification: we say that interesting is a modifierof books. Semantically, the modification relation in our example is a set-intersection relation: if we assume that books denotes the set of all booksand interesting denotes the set of all interesting entities, we may say that thedenotation of interesting books is the intersection of the set of books and theset of interesting entities. In other words, interesting books denotes a subsetof the set of books, namely the subset of books that also have the propertyof being interesting.23
22 Trees are binary, not because there is a rule of Universal Grammar that says theymust be, but because of the nature of the basic operation that constructs trees, knownas Merge in current syntactic theory. In many cases, there is clear evidence that treesare binary-branching; in other cases, there is not clear evidence for say, binarity versusternary (three-way) branching. We assume that the more elegant model adopts theposition that all trees are consistently binary, since the number of branches is actuallya consequence of how they are constructed.
23 The modification relation between an adjective and a noun is not always set inter-section. An example of a non-intersective adjective is fake as in fake gun.

LABELS AND PHRASAL CATEGORIES 145
Categories other than adjectives can also serve as modifiers. Some mod-ifiers are prepositional, for example, as in books on the table. On the otherhand, not all modified categories are nouns. Verbal expressions can also bemodified, as in run with a duck, or run fast.
Apart from its semantics, there are other ways of identifying the headof a construction. Morphologically, the features of the phrase are inheritedfrom the head. For instance, the phrase books on the table is plural, just asits head noun books, and unlike table. Syntactically, a phrase always has thesame distribution as its head. In our example, interesting books has the samedistribution as books, not as interesting.
7.21 � He has many [interesting books].� He has many [books].� ∗He has many [interesting].
The modification relation is not the only relation that a head might havewith the non-head. Another possible relation is a selection relation: apartfrom being modified by a phrase, the head can select for a certain phrase.A verb like gather, for instance, must be accompanied by a noun, as ingather peanuts. If this noun is missing, the result is ungrammatical, as in*Peter gathered.24 When an element, like gather, requires another element,like peanuts, we say that the former selects for the latter. So, it appears thatthe verb gather selects for the noun peanuts. Notice that this is completelydifferent from the semantic relation between a head and a modifier; themodifier can be missing, and the phrase without the modifier would still bewell formed.
Now, as they stand, the two phrases—interesting books and gatherpeanuts—seem to be built out of simple lexical, word-like categories, asin the following diagrams. These diagrams indicate not only the internalconstituency of our phrases, but also the fact that interesting books is syntac-tically more complex than the simple noun books, and that gather peanutsis syntactically more complex than gather. This is captured by assigning aphrasal label to the resulting node: XP, rather than a simple terminal nodeX (with P for “Phrase”). The term X here is a variable ranging over the setof primitive categories, so there are NPs, VPs, and so on.
24 We set aside the so-called “collective” use of gather, as in The family gathered inNew York each winter.

146 SOME DETAILS OF SENTENCE STRUCTURE
7.22 PN
A
interesting
N
books
7.23 PV
V
gather
N
peanuts
These diagrams are not entirely accurate, however. Notice that the simplenoun peanuts in gather peanuts could be replaced with a more complexsyntactic object, like blue peanuts, and the replacement would not disturbthe relation with the verbal head gather—gather would still be the head andblue peanuts would be the selected syntactic phrase. Crucially, blue peanuts isof the same nature as peanuts—they are both nominal. In order to captureboth possibilities, we might say that the head gather always takes a nounphrase as a complement, and that this noun phrase could be instantiatedeither by a complex phrase, like blue peanuts or by a simple lexical item likepeanuts. In other words, the simple noun peanuts is just a particular case ofa more general pattern, which is indicated in the diagram below.
7.24 VP
V
gather
NP
N
peanuts
Likewise, in interesting books, interesting could be replaced with a morecomplex phrase like very interesting, and the simple noun books could bereplaced with a more complex phrase, like books on linguistics. The relationbetween the two components would still be one of modification: very inter-esting would still be a modifier of books on linguistics. In order to captureboth possibilities, we might say, as in the case of gather peanuts above, that

LABELS AND PHRASAL CATEGORIES 147
interesting books is just a particular case of a more general pattern, the onegiven below.
7.25 NP
AP
A
interesting
NP
N
books
With this in mind, let us now look again at the trees above for the twointerpretations of our rodent example, but this time let’s label the nodesthat show up in the tree. Let’s begin with the first interpretation, that is, theone under which the rodent has the telescope.
7.26 S
NP
N
I
VP
V
spotted
NP
D
that
NP
NP
N
rodent
PP
P
with
NP
D
a
NP
N
telescope
A first observation is that the labels we used are somewhat simplified. Forinstance, we assumed that the result of merging together a determiner anda noun is a nominal phrasal category—a NP, and therefore that the head isthe noun rather than the D. In this, we glossed over an important distinctionbetween functional categories, like determiners, and lexical categories, like

148 SOME DETAILS OF SENTENCE STRUCTURE
nouns and verbs. Our aim here is not to provide you with the latest syntacticmodel for analyzing the structure of sentences but to convince you thatsentences do have a structure, and that the building blocks of this structureare syntactic constituents.
Let us go through the labeling in this tree from the bottom up. The labelof the node immediately dominating the P with and the NP a telescope is aPP. In other words, we assumed that the head is the preposition with. Therelevant subtree is given below.
7.27 PP
P
with
NP
D
a N
NP
telescope
A preposition expresses a relation—in our rodent example a relation eitherbetween the N rodent and the NP a telescope or between the V spotted andthe NP a telescope. By choosing the P as the head, rather than the NP, wecapture the fact that it is the P that establishes the relation in question. Thearguments of the relation depend on the P head.
Going on with the labels we used in (7.26), notice first that we groupedtogether the noun rodent and the PP with a telescope, and only then didwe put together the resulting constituent with the determiner that. This issupported by the fact that we can replace the whole string rodent with atelescope with a word like one. This indicates that rodent with a telescopemakes up a phrasal category to the exclusion of that. Moreover, our rep-resentation assigns to rodent the label NP. In fact, what (7.26) says is thatrodent is a N, which in turn is a possible way in which NPs can be analyzed.In order to see why we analyze rodent as a NP, compare the following twostrings:
7.28 a. that rodent with a telescopeb. that inquisitive rodent with a telescope
It is clear from these examples that the simple noun rodent could bereplaced with a phrase, something like inquisitive rodent. This points to thefact that the simple noun rodent is just one of the possible instantiations of

LABELS AND PHRASAL CATEGORIES 149
a noun phrase. This is why the structure we proposed in (7.26) contains aNP label that dominates an N label.
7.29 •
D
that
•
NP
N
rodent
PP
P
with
NP
D
a N
NP
telescope
Now, we indicated in (7.26) that the label of the constituent formed byjoining together the NP rodent and the PP with a telescope is nominal—aNP. This is because our familiar semantic and distributional tests clearlypoint to this conclusion. Semantically, rodent with a telescope is a typeof rodent and not a type of telescope or a type of with-ness, and, dis-tributionally, rodent with a telescope occurs in the same environments asrodent.
7.30 a. [A rodent with a telescope] is all we need in this house.b. [A rodent] is all we need in this house.
Moving on upwards to higher nodes in (7.26), the NP that rodent witha telescope is joined together with the verb spotted. We assumed that theverb is the head that selects a NP as a complement. To show that it isthe verb that is the head of the newly created phrase spotted that rodentwith a telescope, consider the fact that this whole phrase can be replacedby a simple verb like did in (7.15), and therefore that it has the samedistribution as a verb. The phrase that results from joining together the verbspotted and the NP that rodent with a telescope is thus a VP, as indicated in(7.31).

150 SOME DETAILS OF SENTENCE STRUCTURE
7.31 PV
V
spotted
NP
D
that
NP
NP
N
rodent
PP
P
with
NP
D
a N
NP
telescope
Finally, the highest node is the sentential node S, which is the result ofjoining together the VP spotted that rodent with a telescope and the NP I.Regardless of whether the relation between the two phrases that combine isone of modification or of selection, the principle we have adopted so faris that the resulting node should inherit the category of one of the twosubconstituents: either N or V. However, labeling the resulting node as Sis obviously inconsistent with this principle. This inconsistency is unavoid-able given the incompleteness of our presentation and its resolution wouldrequire a discussion of so-called functional categories, something that wewill not address in this book. For our purposes it is sufficient to note that asentence S has two immediate syntactic constituents: a NP—the subject ofthe sentence, and a VP—the predicate. You should bear in mind, though,that the example under discussion illustrates only one possible instantiationof the two major constituents of a sentence. It turns out that the subjectof a sentence can be any phrasal category, not just a NP. It is true thatin most cases the subject of a sentence is a NP, just as in our example.However, the subject of a sentence can also be a prepositional phrase, asin (7.32a.), an adjectival phrase, as in (7.32b.), or even another sentence,as in (7.32c.).
7.32 a. [Under the table] is Oonagh’s favorite place.b. [Fortunate] is what we consider ourselves to be.c. [That Davey always talks about Sami] is something we all got used to.

LABELS AND PHRASAL CATEGORIES 151
Likewise, the predicate can be something more complex than a VP, suchas an auxiliary phrase. We’ll come back with more details about auxiliaryphrases in the next section.
Both readings of (7.10) correspond to a simple sentence. Sometimes,however, one can put two or more sentences together as in (7.33) and build acomplex sentence. One example is in (7.32c.). Other examples are providedbelow:
7.33 a. Mary thought [I spotted that rodent with a telescope].b. I believe [Mary thought [I spotted that rodent with a telescope]].c. I scorn the man [who thought [I spotted that rodent with a telescope]].
In (7.33a.) our initial sentence I spotted that rodent with a telescope isselected as a complement by the verb thought. The verb thought togetherwith I spotted that rodent with a telescope make up a VP which in turncombines with a subject NP Mary.
Furthermore, in (7.33b.) this resulting sentence—Mary thought I spotteda rodent with a telescope—is itself selected as a complement by the verbbelieve. The resulting VP—believe Mary thought I spotted that rodent witha telescope—combines with the NP I, and a new sentence is formed. Thus,(7.33b.) contains three sentences: the all-encompassing one—I believe Marythought I spotted that rodent with a telescope; another one which is a sub-component of it—Mary thought I spotted that rodent with a telescope; and athird one which is a subcomponent of the latter, namely I spotted that rodentwith a telescope.
Example (7.33c.) contains again the sentence I spotted that rodent witha telescope which is selected by the verb think, but it also contains asentence—who thought I spotted that rodent with a telescope, that is notselected by any head. This sentence is immediately related to the noun man,and its relation to the latter is one of modification. The meaning of (7.33c.)is that the object of my scorn is an individual who has both the property ofbeing a man and the property of being someone who thought I spotted thatrodent with a telescope.
We will call sentences like I spotted that rodent with a telescope,and who thought I spotted that rodent with a telescope, that occur aspart of a larger sentence, as in (7.33), embedded sentences or embed-ded clauses. Non-embedded sentences are called main sentences or mainclauses. We will return to the notion of embedded clause in the nextchapter.

152 SOME DETAILS OF SENTENCE STRUCTURE
Let us now focus on the tree of (7.11b.), which represents the reading inwhich with a telescope indicates the instrument of spotting.
7.34 S
NP
N
I
VP
VP
V
spotted
NP
D
that
N
rodent
PP
P
with
NP
D
a N
NP
telescope
We labeled the constituent resulting from merging the verb spotted andthe nominal constituent that rodent as VP. In other words, we assumed thatthe head is the verb.
7.35 PV
V
spotted
NP
D NP
that N
rodent
This assumption can be justified both on semantic grounds and with dis-tributional arguments. Semantically, spotted that rodent denotes a particulartype of event that is a subclass of the event denoted by the verb spotted. Inother words, spotting a rodent is a type of spotting event, rather than atype of rodent. Distributionally, spotted that rodent can be substitued witha simple verb like did, for instance.
7.36 I [spotted that rodent] with a telescope, and Mary [did] with a magnifyingglass.

LABELS AND PHRASAL CATEGORIES 153
Moving on, we assumed that the result of joining together the VP spottedthat rodent and the PP with a telescope is a verbal constituent.
7.37 VP
VP
V
spotted
NP
D NP
that N
rodent
PP
P
with
NP
D
a N
NP
telescope
Semantically, spotting a rodent with a telescope is a specific type of spottinga rodent event. Distributionally, spotted that rodent with a telescope occursin the same contexts as spotted that rodent.
7.38 a. I spotted that rodent with a telescope.b. I spotted that rodent.
The highest label in (7.34) should make sense by now, as we have alreadyjustified it for (7.26). See the exercise at the end of the chapter for morepractice.
Let us wrap up this discussion. Sentences are not just strings of words.What is crucial for a string of words to be a sentence is structure. Thestructure is actually a reflection of how words are grouped together intoconstituents. One way of representing a sentence is in the form of the treediagram. Each node in the tree is a constituent. The identity of a nodeis provided not only by its label, since there can be several VPs or NPsin the same sentence, for instance. Clearly, the two instances of VPs orNPs are different from each other. Apart from the label, which providesinformation about the nature of that node, the hierarchical position of therespective node is also important for identifying a particular constituent.The constituent a telescope, for example, is the NP which is sister to thepreposition with, whereas that rodent with a telescope is the NP which issister to the verb spotted. The hierarchical position of nodes will turn out tobe crucial in the next chapter.

154 SOME DETAILS OF SENTENCE STRUCTURE
Given our new understanding of what a sentence is, it is now clear thatin everyday speech, we might say “The sentence I spotted that rodent with atelescope is ambiguous,” but, as linguists, we would say the following: “Thestring I spotted that rodent with a telescope corresponds to two sentences”since a sentence is a string of words with a particular arrangement ofelements, a structure among the words.
7.4 Predicting syntactic patterns
You are probably still skeptical about the utility of drawing these trees, theutility of thinking of sentences as structures. You might just be saying toyourself “What’s the big deal? Strings of words like I spotted that rodentwith a telescope have two meanings, and I just figure them out because theyboth make sense. Why do I need all this complicated syntactic structure tounderstand something about meaning?”
Even with these simple examples, we can demonstrate the usefulness ofsyntactic structure—we’ll give more complex applications later. One moti-vation for positing structure as part of the representation of a sentence isthat, as we saw in the previous chapter, a notion of structure is required tomake predictions about the grammaticality or ungrammaticality of strings.Remember that we needed to refer to a unit of structure—the sentence—inorder to understand when the contracted form of the copula could appear.In order to further illustrate this point, consider the string The fish will hitthe chicken with the belt. This string is made up of several simple syntacticcategories, like D, N, V, P, some of which occur several times. This stringalso contains a category that we haven’t yet introduced: the auxiliary (Aux).Auxiliary verbs like might, will, can, have, be precede lexical verbs like hit orsmile.
7.39 TheD fishN willAux hitV theD chickenN withP theD beltN
In fact, the relation between the auxiliary and the lexical verb is more thanjust simple precedence; the auxiliary selects a lexical verb of a particularform. To convince yourself of this, think of examples like Peter has brokenthe ice or Peter will break the ice, where it is clear that the morphologicalform of the lexical verb—broken versus break—is dictated by the choiceof the auxiliary. An auxiliary like has selects a past participle form likebroken, whereas will selects the short infinitive form break. Given that the

PREDICTING SYNTACTIC PATTERNS 155
auxiliary is the item that selects and that the lexical verb is selected, wewill assume that the auxiliary is a head and that the verb is part of the VPcomplement selected by the auxiliary.25 In other words, our string containsa verb phrase hit the chicken with the belt headed by the lexical verb hitand an auxiliary phrase will hit the chicken with the belt headed by theauxiliary will. This is represented in (7.40), with the triangle representingstructure that we are not yet specifying, apart from the claim there isa node that contains exactly everything under the triangle—the VP is aconstituent.
7.40 S
NP
D
the
NP
N
fish
AuxP
Aux
will
VP
hitV the chicken with the belt
There are, of course, several other phrasal categories in this string, such asthe noun phrases the fish, and the chicken with the belt, and the belt, and theprepositional phrase with the belt.
Let’s focus on this PP with the belt. The head of the PP is the prepositionwith, while the belt is its (non-head) sister. The relation between the two isone of selection: the P head with selects a NP that in this case is instan-tiated by the belt. What this means is that if there is no NP following thepreposition with the result is ungrammatical, as in (7.41).
7.41 ∗The fish will hit the chicken with.
You might have noticed that the string The fish will hit the chicken withthe belt can have two interpretations: one in which the belt is an instrumentwith which the fish hit the chicken and one in which the belt is a fashionaccessory of the chicken.26 Crucially, the prepositional phrase with the belt
25 These assumptions can be justified, but it would take us too far afield to do so here.26 The two readings are exactly parallel to those of the rodent sentences in the previous
section—we just want to give you some practice in abstracting away from particularlexical items.

156 SOME DETAILS OF SENTENCE STRUCTURE
is a constituent under both interpretations. In fact, the difference betweenthe two is whether the prepositional phrase with a belt is grouped togetherin a larger constituent with the chicken or not. The two ways of groupingthe simple syntactic categories into phrasal categories that correspond tothe two interpretations are given below:
7.42 a. TheD fishN [willAux[hitV [theD chickenN [withP theD beltN]]]]b. TheD fishN [willAux [[hitV theD chickenN ] [withP theD beltN]]]
Now suppose we ask the following question:
7.43 What will the fish hit the chicken with?
Note that this can only be a question about what hitting utensil wasused, not about what was holding up the pants of the chicken who gothit. In other words, this question can only correspond to the grouping in(7.42b.), and not to the one in (7.42a.). Notice there is nothing wrong withthe other meaning—we can express it by saying something like one of thefollowing:
7.44 Asking about the chickena. The fish will hit the chicken with what?b. What was the chicken that the fish will hit wearing?c. For what x is it the case that the fish will hit the chicken and the chicken
was with x?
The problem is just that the question in (7.43) cannot be interpreted asparalleling any of these questions in (7.44). One striking difference betweenquestions (7.43) and (7.44a.) is the position of what. In (7.43) it is at thebeginning of the sentence, whereas in (7.44a.) it is at the end. However,in both instances, what is interpreted as the noun phrase selected by thepreposition with. In both cases, what replaces a NP constituent—a belt in(7.42a.b.), which is a sister of the preposition with. Clearly, the prepositionwith is the same in both (7.43) and (7.44a.). More specifically, in both (7.43)and (7.44a.) the preposition with selects a noun phrase that must followthe preposition. In (7.44a.) this noun phrase is where we expect it to be—itfollows the preposition. However, in (7.43), the noun phrase selected by thepreposition with does not show up in the expected place but at the beginningof the sentence.
How can we relate these two facts? On the one hand, what is selectedby the preposition with and thus should be next to the preposition, and

PREDICTING SYNTACTIC PATTERNS 157
on the other hand, what occurs at the beginning of the sentence in spite ofthe fact that it is interpreted as the noun phrase selected by the prepositionwith.
We will assume that what in (7.43) occupies both positions at the sametime, that there is a copy of what in each position. We will refer to thesetwo positions as the base position and the derived position. We will assumethat the base position of what is the position where we would expect what tobe by virtue of the fact that it is selected by the preposition with—namelyright next to the preposition. The other position—the one at the front ofthe sentence—will be assumed to be a derived position, in the sense thatwe will consider that the copy that shows up there is the result of whatis called a movement or dislocation operation. Thus, what originates inits base position, as a sister to the preposition and then it “moves” to aderived position, at the left edge of the sentence. This particular process ofputting question words in the front of the sentence is called wh-movementsince it affects words like who, what, when, where, why. The process is alsocalled wh-movement when referring to questions beginning with how, andlinguists even refer to the process as wh-movement when talking about otherlanguages where the question words do not begin with wh. Wh-movement isa very common process in the languages of the world, maybe even commonto all languages in some sense.
There are processes that move other constituents in addition to wh-words.For example, you might have noticed that in order to ask a wh-questionin English, there are two constituents that must move: the wh and theauxiliary. We will come back to auxiliary movement at the end of thissection.
Let us now go back to (7.43). Remember that (7.43) can only be aquestion about what hitting utensil was used, not about what was holdingup the pants of the chicken who got hit.
Why should this be? One way of describing these facts is to say thatmovement of what correlates with a particular interpretation. Alternatively,we may say that movement is impossible if what we want is the secondinterpretation.
Notice that, in general, there is no restriction on how far a word like whatcan be displaced to get to the beginning of the sentence. We have added anindex on the what and inserted a copy of what in the base position to showwhere the what must be interpreted, as the object of the preposition with.The strikethrough indicates that this copy is not pronounced.

158 SOME DETAILS OF SENTENCE STRUCTURE
7.45 Whati will the fish who kissed the rat who bit the kitty who lickedthe turtle who scratched the pony’s eyes out hit the chicken withwhati ?
So why can the what in (7.45) move so far to the front of the sentence, but itcannot do so to form a question from (7.43) corresponding to the meaningsexpressed in (7.44)?
Instead of answering this question, we’ll give you another case of theimpossibility of asking a question by putting what or who at the beginningof a sentence.
7.46 Two simple sentencesa. You will see John.b. You will see Bill and John.
Note that a wh-question in which the wh-item corresponds to John is gram-matical only for (7.46a.), but not (7.46b).
7.47 Only one wh-question possiblea. Who will you see?b. *Who will you see Bill and?
Despite the fact that we find it trivial to assign an interpretation to (7.47b.),we have clear judgments that it is ill formed. (In fact, this example againillustrates Chomsky’s point from Syntactic Structures about the indepen-dence of meaning and syntax.) Why should this be? Since the meaning isfairly easy, the reason for the ungrammaticality cannot have anything to dowith the fact that we use language for communication.
More surprising, perhaps, is the fact that this conclusion about wh-questions does not appear to be a fact only about English—it seems tobe a fact about all languages, and, thus, it appears to reflect in some waya fundamental property of the human language faculty. We won’t worryabout how to formalize this in more general terms, but note that we need torefer to our abstract structures and equivalence classes just to formulate theissue.
How does this relate to our previous sentences about a fish hitting achicken? Well, recall that we could not front a wh-element that was insidea PP that modified the object noun, in other words something like thefollowing structure does not allow wh-elements to be fronted:

PREDICTING SYNTACTIC PATTERNS 159
7.48 NP
D
the
NP1
NP2
N
chicken
PP
P
with
NP3
N
what
The tree in (7.48) shows the case where the PP with what is inside of NP1
headed by chicken. We can ask a so-called echo question with this structure,like (7.44a.), leaving what in place, but we cannot move it to the front.
At this point, the generalization can be stated in fairly simple terms. Itappears to be the case that wh-words like what and who cannot be moved tothe front of the sentence when the position where they are interpreted fallsinside of another noun phrase. In (7.48), we see that what is NP3, which isinside the PP, which is inside of NP1. NP3 thus is inside of NP1.
A phrase like Bill and John or Bill and who is a NP that itself contains twoNPs—one is Bill and the other is John or who.27 For reasons not relevant toour point here, we do not want to present the internal structure of the toplevel NPs, and so we adopt again the standard convention of abbreviatingstructure with a triangle. In other words, everything under the trianglebelongs to the same constituent, but we are not making any claims aboutthe internal structure and subconstituents, other than the fact that Bill andJohn and who are also NPs.
7.49 NP1
BillNP2 and JohnNP3
BillNP2 and whoNP3
NP1
27 The reason why we assume that Bill and John are NPs, rather than Ns should beobvious by now. It is true that Bill and John are simple nouns, but clearly each of themcould be replaced, in the same construction, by a more complex nominal phrase, as forinstance in the teacher and the student.

160 SOME DETAILS OF SENTENCE STRUCTURE
Again we see that the wh-element is a NP inside another NP, and that seemsto make it impossible to place it at the front of the sentence. It appears tobe the case this kind of constraint on wh-questions holds in all languages.This appears to be a constraint on the kind of computations that the humanlanguage faculty is capable of. People can pronounce strings like *Who didyou see Bill and?, but grammars do not generate structures corresponding tothese strings—they are not sentences.
The most important point that we want to make, however, is only partlyrelated to the universality of such constraints. The other part is that suchconstraints can only be understood—in fact they can only be stated—inrelation to the structure that we assign to strings. This dependency on thestructure transcends meaning and interpretation: it is not simply the casethat we assign two interpretations to a string and that those two interpreta-tions can be related to two different structures. Even though it is clear thatthe two interpretations of a string like I spotted that rodent with a telescopeor The fish hit the chicken with the belt can each be related to two differentstructures, one can make the claim that this relation between meaning andstructure is not a necessary one. After all, we haven’t shown that the mean-ing and structure must be related, but we have made only the weaker point,that they can be related. On the other hand, the discussion above about therestrictions on wh-movement makes a stronger point: certain patterns canonly be understood by appeal to models of syntactic structure.
We have discussed the movement possibilities for the equivalence classof wh-elements, a category that appears to be present in all languages.However, English wh-questions involve an additional instance of movement,apart from the movement of the wh-constituent. There is also movementof the auxiliary—copies appear in two positions. The auxiliary occupies aposition immediately preceding the verb in The fish will hit the chicken withthe belt, and we assume that this is the base position. However, in What willthe fish hit the chicken with?, the auxiliary is separated from the verb by thesubject the fish, and we will assume that the auxiliary undergoes movement.Its base position is in between the subject and the lexical verb, as in (7.40),whereas its derived position is in front of the subject the fish. So, both theauxiliary and the wh-element are pronounced in a derived position beforethe subject. Furthermore, the relative position of the auxiliary with respectto the wh-constituent is also important. Thus, (7.50a.), in which the wh-constituent precedes the auxiliary, is grammatical, but (7.50b.), in which thewh-constituent follows the auxiliary, is ungrammatical.

PREDICTING SYNTACTIC PATTERNS 161
7.50 a. What will the fish will hit the chicken with what?b. ∗Will what the fish will hit the chicken with what?
This suggests that the derived positions for both wh- and auxiliary-movement are not just “anywhere in front of the subject,” but such thatthe dislocated wh-constituent precedes the dislocated auxiliary. We won’tprovide the arguments here, but it turns out that what is relevant is notsimply precedence but a hierarchical relation called c-command, defined inSection 8.2—the dislocated wh-constituent must c-command the dislocatedauxiliary. The structure we propose is that in (7.51). We have labeled thenode resulting from joining together the moved copy of the auxiliary withthe S node as S′ in order to capture the fact that the resulting phrase is stillsentential, but nevertheless different from the S node that does not containany fronted constituents.
7.51 S′
NP
N
what
S′
Aux
will
S
NP
D
the
NP
N
fish
AuxP
Aux
will
VP
VP
V
hit
NP
D
the
NP
N
chicken
PP
P
with
NP
N
what

162 SOME DETAILS OF SENTENCE STRUCTURE
Looking at the tree in (7.51), you may have the intuition that the wh-wordends up in a higher position than the Aux. Similarly, the derived position ofeach moved item seems to be higher than its base position. The definition ofc-command developed in the next chapter formalizes this notion of “higherin the tree,” a fundamental component of structure dependence in syntax.
There is a third structure-dependent aspect to these examples, this onerelevant to the properties of the base position of a moved item. We havealready seen that there are certain restrictions on the kind of environmentfrom which a wh-constituent can be moved. We have shown that a wh-constituent like what cannot be moved from inside a NP like the chickenwith what or Bill and who. Before we proceed to show a similar constrainton the base position of Aux movement, we need to demonstrate that thisprocess is independent of wh-movement. The examples in (7.52) show this:
7.52 a. The fish will hit the chicken with the belt.b. What will the fish will hit the chicken with what?c. Will the fish will hit the chicken with the belt?d. I wonder who the chicken will hit who.
Example (7.52b.) has both kinds of movement, but you can get Auxmovement without wh-movement, as in (7.52c.); and you can also get wh-movement without Aux movement, as in (7.52d.).
We can now return to the structural constraint on the base position ofAux movement. It turns out that only the Aux of the highest level S isfronted in questions. Movement of an auxiliary to the front of a main S isimpossible if that Aux is embedded under another S. Consider the following:
7.53 The boy who can dance will kiss the dog that should whine.
What Yes/No sentence corresponds to this sentence? Which of the threeauxiliaries gets copied to the front of the sentence? Here are the options.
7.54 Which Aux gets fronted?
a. ∗Can the boy who can dance will kiss the dog that should whine?b. Will the boy who can dance will kiss the dog that should whine?c. ∗Should the boy who can dance will kiss the dog that should whine.
Only (7.54b.) is grammatical. The reason is apparent if we look at the(abbreviated) tree for (7.53), which shows the base positions of all theauxiliaries in (7.54b.).

PREDICTING SYNTACTIC PATTERNS 163
7.55 Tree for (7.53)S
NP
The boy
S
who can dance
AuxP
Aux
will
VP
V
kiss
NP
the dog
S
that should whine
Of the three auxiliaries, only will is not contained in an additional S, otherthan the main S. So, will can move to form a question.
7.56 Tree for (7.54b.)
S′
Aux
Will
S
NP
the boy
S
who can dance
AuxP
Aux
will
VP
V
kiss
NP
the dog
S
that should whine
You can confirm for yourself that this result generalizes—it is always theAux of the main S that is fronted to make a question. In this case, it happensto be the second Aux in declarative sentences, but linear position is notrelevant. You will be asked to demonstrate this in an exercise.

164 SOME DETAILS OF SENTENCE STRUCTURE
To sum up, there are restrictions both on the base position and on thederived position for the movement of the auxiliary. These restrictions con-cern the hierarchical position of these elements—movement of the auxiliaryis structure-dependent.
We are now in a position to further discuss one of the puzzles wementioned in Chapter 3—the one concerning Yes/No questions. When weintroduced this puzzle, we pointed out that in spite of the fact that Englishspeakers have no problem generating grammatical Yes/No questions whengiven a declarative, they typically cannot formulate the rule for doing so.Without having any conscious knowledge of what an Aux is or what a syn-tactic tree looks like, every English speaker can quickly generate a questionwhen prompted with a declarative sentence.
In contrast, it is trivially simple to state a rule for reversing the orderof words in terms that the average person will understand, and, yet, whenprompted with a sentence, it is impossible for people to quickly reply withthe string of words in reverse order—they need time, and perhaps a penciland paper. Why is there such a discrepancy in performance of these tasks?
The grammar itself does not form questions from declarative sentences,but it appears that people can use their grammar to construct sentences thatmeet certain explicitly provided criteria, like “Give the question correspond-ing to this statement.” We can harness the computations of the grammar,which are fast and inaccessible to consciousness, to perform this task. Wedo not have any such system for reversing words, and so we have to performthe string reversal task consciously and methodically, thus slowly.
7.5 Using trees to predict reaction times
If you like laboratory procedures and statistics, you will be pleased to learnthat the syntactic structures we have been positing can also be used to maketestable predictions in a laboratory setting. If sentences were just strings ofwords, then we would expect that the time it takes to recognize a writtensentence would be a function of its length and the words it contains—ittakes longer to process more words than fewer, and common words aretypically recognized faster than less common words.
It turns out, however, that sentence structure, as modeled by our trees, isan important factor in the time it takes speakers to recognize a sentence as
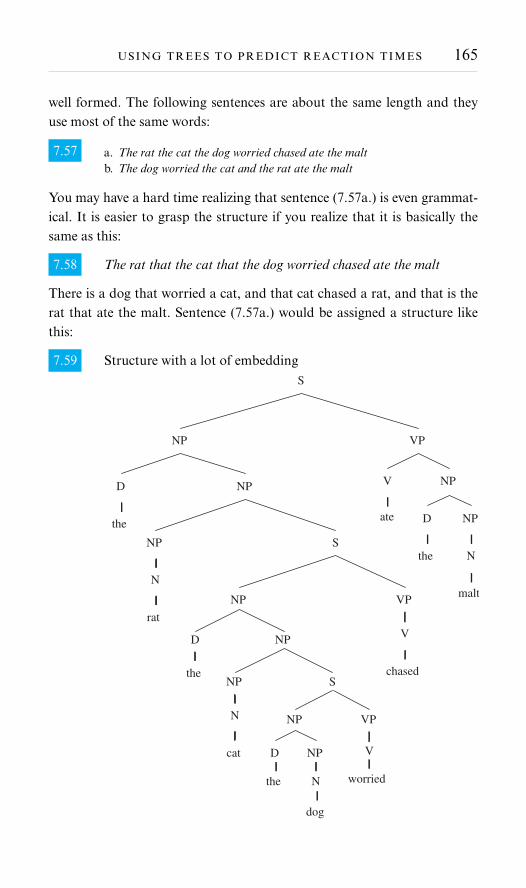
USING TREES TO PREDICT REACTION TIMES 165
well formed. The following sentences are about the same length and theyuse most of the same words:
7.57 a. The rat the cat the dog worried chased ate the maltb. The dog worried the cat and the rat ate the malt
You may have a hard time realizing that sentence (7.57a.) is even grammat-ical. It is easier to grasp the structure if you realize that it is basically thesame as this:
7.58 The rat that the cat that the dog worried chased ate the malt
There is a dog that worried a cat, and that cat chased a rat, and that is therat that ate the malt. Sentence (7.57a.) would be assigned a structure likethis:
7.59 Structure with a lot of embeddingS
NP
D
the
NP
NP
N
rat
S
NP
D
the
NP
NP
N
cat
S
NP
D
the
NP
N
dog
VP
V
worried
VP
V
chased
VP
V
ate
NP
D
the
NP
N
malt

166 SOME DETAILS OF SENTENCE STRUCTURE
What this structure shows is first of all that the main VP of the sentence isate the malt. This is captured by the fact that the top S node splits into aNP, the subject of the sentence, and a VP.28 This VP ate the malt which issister of the subject NP is called the main predicate of the sentence. Now,the subject is rather complex syntactically. First, the NP subject node splitsinto a determiner and a NP. This NP contains two nodes: a NP and a S.One of them must be the head and the other one the non-head. Given thatit is the NP rat that provides its label to the higher node, it must be that theNP rat is the head. The sister of this NP node is obviously a modifier ofthe NP rat. In other words, the subject of this sentence is not just any ratbut one that has the property expressed by this modifier—the property ofhaving been chased by some entity. Notice now that this latter entity itselfis expressed by a rather complex syntactic phrase. The NP denoting thisentity again expresses a modification relation—the head is a NP—cat—thathas the property expressed by the S modifier, namely the property of havingbeen worried by the dog. In contrast, sentence (7.57b.) has less complexstructure:29
7.60 Structure with less embeddingS
S
NP
D
the
NP
N
dog
VP
V
worried
NP
D
the
NP
N
cat
S
Sand
NP
D
the
NP
N
rat
VP
V
ate
NP
D
the
NP
N
malt
28 We will be forced to complicate this below with the introduction of auxiliary verbsin Chapter 10.
29 We are not going to justify this structure for conjoined sentences here.

TO SUM UP 167
You can tell that sentence (7.57a.) has a much deeper level of embeddingthan sentence (7.57b.). Sentence (7.57a.) has a NP subject that containstwo successively embedded modifiers. Both of these modifiers are expressedsyntactically by a S node. The most deeply embedded S is a modifier of thenoun cat, whereas the next, higher embedded S is a modifier of the nounrat. Moreover the S modifying cat is embedded within the S modifying rat,which is itself embedded under the main sentence. When we ask subjectsto read strings of words and press a button if the string corresponds to agrammatical sentence, we find that sentences with more embedding requirea longer response time than those with less embedding. So a sentencelike (7.57a.) would require more time than a sentence like (7.57b.) in sucha task.
Thus, the syntactic structures that we represent in tree diagrams havethe same status as any other scientific models—they give us insight intophenomena and can be used to make experimental predictions that can bereplicated.
7.6 To sum up
If you remain skeptical about the “reality” of these trees, the validity ofpositing them, consider the following points:
� These abstract derivations can only be stated in terms of abstracttrees, which in turn are abstract structures described in termsof relations among words. However, as we saw, even the notionof word is an abstraction, one that has no consistent physicalcorrelates.
� If we reject derivations we fail to account for very strong intuitions andpatterns such as the fact that the verbs in Pat broke the door and Whatdid Pat break? are the same verb. In one sentence the verb is followed byan object and in the other it is not, yet it seems extremely uninsightfulto consider them as two different verbs.
� Like the components of any scientific model, trees and derivationsgive us insight into observed data and allow us to make predictionsin replicable experiments. One can be a methodological dualist bystipulation—deny the reality of cognitive phenomena—but there doesnot seem to be any good reason to do so, since the models of physics

168 SOME DETAILS OF SENTENCE STRUCTURE
and chemistry, say, have exactly the same status as those of linguistics—they afford us an understanding of phenomena in ways that can bemade mathematically explicit.
� There are no competing explanations of wh-movement or the distri-bution of the reduced copula that even come close to the accountprovided using syntactic structure. Many questions remain, but sci-entific explanations are always incomplete and open to improve-ment.
In the following chapters, one of our goals will be to apply our modelof syntactic structure to explain some very puzzling patterns of Englishsyntax.
7.7 Exercises
Exercise 7.7.1. Tree Practice: For more practice of how words aregrouped together into constituents, and for the labeling of these con-stituents, consider the following string.
7.61 The fish with the hat hit the chicken with the belt.
Draw the tree for the meaning in which the chicken’s pants won’t fall down.What is with a belt modifying? What does this PP attach to? What does witha hat modify? What does this PP attach to?
Now draw the tree for the reading in which the fish uses a fashionaccessory as a chicken-hitting implement. How does this tree differ fromthe previous one?
Exercise 7.7.2. Aux movement: In the tree in (7.55) there are three distinctauxiliaries, and it is the one whose base position is second that is fronted.
i. Give a Yes/No question which also contains three auxiliaries, but inwhich the Aux whose base position is first undergoes Aux movement.Draw the tree showing base and derived positions.
ii. Give another Yes/No question in which the Aux whose base positionis last of the three is fronted. Draw the tree showing base and derivedpositions.
iii. Without drawing a tree, give a Yes/No question in which there arenine auxiliaries (you can reuse them—for example, you can use should

EXERCISES 169
more than once) and the one that is moved is the seventh in baseposition.
iv. What do these examples tell us about linear order and structure?
Further Reading
� The chapters on syntax by H. Lasnik (The Forms of Sentences) andsentence processing by J. D. Fodor (Comprehending Sentence Struc-ture) in Osherson (1995) complement the discussion in this chapter.

8Binding
8.1 Preliminaries 171
8.2 Anaphors 173
8.3 Pronouns and “referential
expressions” 181
8.4 Some implications 181
8.5 Binding and wh-movement 182
8.6 Non-structural factors in
interpretation 187
8.7 Exercises 189
This chapter is concerned with one of the puzzles introduced in Chapter 3concerning the distribution of reflexives, also called anaphors, like himselfand herself, as opposed to regular pronouns like he, him, she, and her. Wewill be studying a fairly narrow range of data and ignoring some difficultissues,30 but the analysis will be challenging, nonetheless. One point thatwill hopefully come through by the end of the chapter is an old one—the distribution of these items is structure-dependent. In other words, thegeneralizations concerning the distribution of reflexives or of regular pro-nouns can only be expressed by referring to the structure of the clausethat contains these items. In addition, we hope that you will be once moreintrigued by the complexity of the phenomena underlying the grammar ofnatural languages, and implicitly by the complexity of your knowledge—your knowledge of language, that is. In a way, what follows, and in fact allof the rules we have described so far, are things you already know. You may
30 For example, we are not interested here in the form that is used for emphasis, as inMary, herself, killed the snake—this is probably a different herself from the one we areinterested in, since in other languages it is expressed as a completely different word fromthe reflexive.

PRELIMINARIES 171
be not aware of them, but you know them, since you have absolutely noproblem producing and understanding sentences that represent the outputof these rules. So let us now tell you what you know about words like herselfor himself, and about words like her or him.
8.1 Preliminaries
Before we begin, we need to introduce some notational conventions. Ifwe asked you if the string Mary saw her corresponds to a grammati-cal sentence in your dialect of English, you would probably say that itdoes. However, when you make this decision you clearly have in minda certain interpretation of the individual words and their relations. Forexample, if you interpret saw not as the past tense of see but as a formof the verb to saw, then the string cannot be said to correspond toa grammatical sentence. The grammatical string in this case would beMary sawed her, and it would contain the past tense form of the verbto saw.
Another condition on your acceptance of Mary saw her as grammatical isthat you must not interpret her as referring to the same individual as Mary.One notation for expressing the distinctions we are interested in is the useof indices on nominal expressions. Informally, we will say that two NPsthat have the same index “refer to the same individual” and two nominalexpressions that bear different indices “refer to different individuals.” So thegrammatical reading of Mary saw her corresponds to something like (8.1).
8.1 Maryi saw her j
Mary bears the index i and her bears the index j , so the two refer todifferent individuals. In contrast, the ungrammatical reading correspondsto something like (8.2).
8.2 ∗Maryi saw heri
This string is marked with an asterisk, which means that the string isungrammatical under the reading in which Mary and her refer to the sameindividual.
For ease of presentation, and in order to save space, it is customary to usean abbreviatory convention to present the contrast between (8.1) and (8.2),as shown in (8.3).

172 BINDING
8.3 Maryi saw her∗i/j
This means that the string Mary saw her corresponds to an ungrammaticalsentence if her is indexed identically to Mary, but it corresponds to agrammatical one if they are indexed differently. Of course, the values ofthe indices are arbitrary, and what is important are the labeling relationsamong nominal constituents, NPs. Thus, (8.4) has the same interpretationas (8.3):
8.4 Mary j saw heri/∗ j
Finally, note that the labeling relations that correspond to grammaticalsentences change when we substitute reflexives for regular pronouns:
8.5 Maryi saw herselfi/∗ j
In this case, the string corresponds to a grammatical sentence only if Maryand herself have the same index.
We hedged a bit above when we said that indices informally are under-stood to relate to the individuals or entities that nominal expressions referto. The reason for this is that we want to avoid a slew of issues that arisein situations like the following. Suppose that you and Bob Dylan went intoa wax museum on different days and each saw a wax statue labeled “BobDylan.” Our judgment is that the following strings would both correspondto grammatical sentences expressing true propositions if uttered after thesemuseum visits:
8.6 a. You saw Bob Dylan at the wax museum.b. Bob Dylani saw himselfi at the wax museum.
Clearly Bob Dylan, the museum guest, and the wax statue of Bob Dylan aredifferent entities in the world—one has a digestive system and one does not,for example. So, the indices clearly cannot be denoting identity of objectsin the world. For now, all we will say is that the relation between words andthings in the world is not simple, and we will avoid dealing with it at thispoint by devising a theory of pronoun and reflexive distribution that refersjust to the indices on nominal expressions. How these relate to objects inthe world is not a matter of syntax, although we will have something to sayabout the issue in a later chapter.

ANAPHORS 173
8.2 Anaphors
What we want to do now is to account for the distribution and interpreta-tion of anaphoric (reflexive) pronouns like herself. We will then relate ourfindings to aspects of the model of syntax that we have been developingin previous chapters. The first important requirement that we should keepin mind is that the model we develop should not overgenerate—it shouldnot predict the grammaticality of structures that are clearly ungrammaticalaccording to our native speaker judgments. It is equally important that themodel also should not undergenerate—it should not treat as ungrammatical,or fail to generate, structures that our judgment tells us are perfectly wellformed. We don’t want our model to be too lax or too strict—we want it togenerate all and only the grammatical forms.
Consider first the following strings.
8.7 a. ∗Maryi sees herself j .b. Maryi sees herselfi .c. ∗Herselfi sees Maryi .
Comparing (8.7a.) and (8.7b.) we might conclude that the right generaliza-tion is something like (8.8).
8.8 Hypothesis I: herself must appear in a sentence that contains acoindexed nominal expression, a phrase bearing the same indexas herself.
This condition is not satisfied in (8.7a.) because herself is indexed j, butMary is labeled i. This explains why (8.7a.) is ungrammatical. In (8.7b.) thetwo nominal expressions are both indexed i, and therefore the conditionfor the occurrence of herself is met, and the sentence is grammatical, asexpected. Sentence (8.7c.) however suggests that mere co-occurrence with acoindexed nominal expression is not sufficient—apparently the coindexedexpression must precede the reflexive. Such a simple data set may lead youto modify our initial hypothesis concerning the distribution of herself inEnglish sentences, along the lines of Hypothesis II.
8.9 Hypothesis II: herself must be preceded by a coindexed nominalexpression, a phrase bearing the same index as herself.
You might already suspect that it is unlikely that Hypothesis II wouldbe correct. In previous chapters we have seen a number of syntactic

174 BINDING
phenomena that are sensitive to the structure of a sentence and neither mereco-occurrence nor linear precedence rely on structural notions.
In order to check the validity of Hypothesis II, we should look at moredata and see whether Hypothesis II can account for it. Consider (8.10):
8.10 a. ∗Maryi knows that Jane j loves herselfi .b. Maryi knows that Jane j loves herself j .
Example (8.10a.) is ungrammatical even though, as required by HypothesisII, herself is preceded by a coindexed NP, namely Mary. Thus, HypothesisII overgenerates—it wrongly predicts the grammaticality of (8.10a.).
Example (8.10b.) is consistent with Hypothesis II, since herself is pre-ceded by coindexed Jane and the example is a grammatical sentence. Butwe need a hypothesis that works for all and only the grammatical sentences.In other words, even if Hypothesis II is successful in generating (8.7b.), aswell as (8.10b.), therefore for all the grammatical strings in our sample, itdoes not generate only the grammatical strings, since it would also generate(8.10a.).
Let’s try something else then:
8.11 Hypothesis III: herself must be preceded by a coindexed nomi-nal expression, and no other nominal expression may intervenebetween herself and the coindexed preceding nominal expression.
The first thing to do is to check whether this new Hypothesis actuallyworks for the examples that we have already looked at, (8.7a.-c.) and(8.10a.-b.). This is something that you can do by yourself at this point. Onceyou have convinced yourself of this, consider the following.
8.12 a. ∗A friend j of Mary’si flogs herselfi .b. A friend j of Mary’si flogs herself j .c. ∗I flog herselfi .d. ∗Maryi knows that I/we/they/you flog herselfi .
Examples (8.12a.) and (8.12b.) are doubly problematic for Hypothe-sis III. First, it looks like (8.12a.) should be grammatical, since no nominalconstituent intervenes between herself and the coindexed Mary. But theexample is ungrammatical according to our native speaker judgments. ThusHypothesis III overgenerates: it generates strings that are not grammaticalfor the mental grammar being modeled.
Hypothesis III also fails when we look at example (8.12b.). We judge it tobe grammatical from the point of view of our mental grammar. However,

ANAPHORS 175
it is not generated by Hypothesis III since Mary intervenes between herselfand coindexed friend. This means that Hypothesis III also undergenerates:it fails to generate sentences that are grammatical in the mental grammarbeing modeled.
Hypothesis III has to be rejected because it both undergenerates—doesnot generate all—and overgenerates—does not generate only—the sen-tences of the language being modeled.
Example (8.12c.) suggests that herself definitely needs to occur with somepreceding coindexed nominal expression and that this expression needs toagree with respect to properties like person, gender, and number. Sentence(8.12d.) shows us that we cannot appeal to the need for clarity to explainthe distribution of herself—this anaphor denotes an individual that is thirdperson singular and female, and the only thing in the sentence it agreeswith for these features is Mary. Yet, the anaphor cannot be licensed in thissentence. This suggests that avoidance of ambiguity has no bearing on theanalysis of anaphor distribution, since there is only one plausible antecedentfor herself, and yet the string is ungrammatical.
Anyway, we know that many sentences are ambiguous. Let’s considersome sentences with a regular pronoun like her rather than a reflexive.
8.13 Maryi told Sue j that Janek likes heri, j,∗k,l .
The indexing in (8.13) indicates that we get a grammatical sentence fromthis string if her is coindexed with Mary, Sue, or some other nominalexpression referring to a human female, but not Jane. Some ambiguitiesare possible and others are not.
So, here is the final Hypothesis we will make:
8.14 Hypothesis IV: an anaphor, like herself, must be bound in itsminimal clause.
You should not yet be able to understand this—we need some definitionsfirst.
8.15 Some definitions:� Clause: this is a notion we have already introduced in the previous
chapter. We defined a clause as a syntactic phrase that contains twoconstituents: an XP functioning as the subject of the clause and a VPor AuxP. We also mentioned that some clauses may be complex andmay include several embedded clauses that are dependent on variousconstituents in the main clause. For example, John thinks Mary left Mon-treal yesterday is a complex clause that contains a main clause and one

176 BINDING
embedded clause. The embedded clause contains the VP left Montrealyesterday and its subject Mary, and is dependent on the verb thinks, whichselects this clause as a complement. The main clause contains its subjectNP John and its VP thinks Mary left Montreal yesterday.
� Binding: A constituent · of a sentence binds another constituent ‚ just incase · and ‚ are coindexed and · c-commands ‚.
� C-command: · c-commands ‚ just in case · does not contain ‚, but everycategory that contains · contains ‚. (This is most easily seen if we drawtrees for our sentences and translate contain to dominate.)
To get a feel for c-command consider the following tree:
8.16 What are the c-command relations in this tree?
A
B
C
E
D
F
M
N
G
H
I
J
K
L
You should be able to see that node C c-commands nodes D and F, andnothing else. Node A doesn’t c-command anything, since it contains ordominates all the other nodes. Node K c-commands nodes N, G, I, Hand J.
If we call two nodes immediately dominated by the same node “sisters”then each node c-commands its sister and all nodes dominated by its sister.The relationship of c-command is not relevant only to binding phenom-ena. It is a relationship that pervades syntax, as we will see in subsequentchapters.
Now that we have the definition of c-command, let’s go back to Hypoth-esis IV which says that herself must be bound in its minimal clause. In thesentence John thinks Mary left Montreal yesterday, both clauses containMary, but the embedded clause is the minimal clause containing Mary. Onthe other hand, the minimal clause of John is the main clause.
Let’s check that Hypothesis IV actually works. We need to check threeconditions on the relationship between herself and a potential antecedent.
8.17 Three conditions in Hypothesis IV� Is there a nominal constituent that is coindexed with herself ?� Does that nominal constituent c-command herself ?

ANAPHORS 177
Those two conditions constitute binding—herself is bound if thoseconditions hold.
� Is that nominal constituent in the same minimal clause as herself ?
This is referred to as a locality condition—the binder must be local tothe bindee.
Let’s apply Hypothesis IV to examples (8.7a.b.). Examine the followingtree that represents the structure that would be assigned to these strings byour grammar.
8.18 Trees for (8.7a.b.)
1. ∗S
NP
N
Maryi
VP
V
sees
NP
N
herself j
2. S
NP
N
Maryi
VP
V
sees
NP
N
herselfi
These trees have the same structure and the same lexical items, but theindexing on herself differs. If we select the index j for herself the form isungrammatical; if we select the index i for herself, we have a grammaticalsentence.
Actually, we now have to admit to having purposely led you astray. Thusfar we have indexed the examples in a misleading way. First, we need topoint out that indices are part of the abstract representation that we assignto a string and not part of the string itself. Thus, the index should notshow up on the lexical item herself in the diagrams above, but on one ofthe syntactic nodes which are part of the tree.
Second, whatever theory of reference one ultimately adopts, it seems clearthat Ns themselves are not referential. Bare nouns, nouns that are notpreceded by any determiner, do not in fact refer to individuals but ratherto sets of individuals.31 Thus, a bare noun like car, for example, does notrefer to a particular individual car but to any car, to the set of all cars. On
31 Just to be clear, we are not referring to individuals out in the world but ratherto mental representations. We remind you that a theory of reference will probably notcorrespond in a straightforward way to commonsense notions, and for present purposesyou will have to accept some of our stipulations concerning indexation.

178 BINDING
the other hand, if a noun like car is preceded by a determiner like this, thenthe whole NP this car refers to a single individual car, in contrast to thebare noun car. It appears, then, that (some) NPs can refer to individuals,but Ns cannot, and thus we propose that indices are a feature that can onlybelong to NPs, but not to Ns. Let us return now to our trees, and fix ourindices.
8.19 Revised trees for (8.7a.b.)
a. ∗S
NPi
N
Mary
VP
V
sees
NP j
N
herself
b. S
NPi
N
Mary
VP
V
sees
NPi
N
herself
Now we can confirm that Hypothesis IV works for these examples. Exam-ple (8.7a.), in which herself j is not coindexed with Maryi obviously doesnot satisfy Hypothesis IV. The tree in (8.19a.) shows that the two NPsthat dominate herself and Mary are in the same minimal clause, and thatNPi , which dominates Mary, does c-command NP j , which dominates her-self, but the two are not coindexed so binding fails. Thus (8.7a.) is pre-dicted to be ungrammatical by Hypothesis IV. This is consistent with ourintuitions.
The labeling that makes herself coindexed with Mary leads to a gram-matical sentence corresponding to (8.7b.) above. This is consistent withHypothesis IV:
� There is a nominal constituent, NPi Mary, that is coindexed with NPi
herself.� NPi Mary c-commands NPi herself.� Given that the two conditions above are met, NPi herself is bound.� Since there is only one clause in this example, it is clear that NPi herself
and NPi Mary are in the same minimal clause.
The string in (8.7c.) clearly is ungrammatical since the NPi herselfappears in subject position, and the coindexed NPi Mary cannot c-command it, and thus cannot bind it.

ANAPHORS 179
So, (8.7a.) is ungrammatical because of a failure of the coindexationrequirement and (8.7c.) is ungrammatical because of a failure of the c-command requirement. To see an example of the failure of locality, therequirement that binding of a reflexive should hold within the minimalclause containing the reflexive, we need to examine structures with morethan one clause, such as examples (8.10a.b.). We have labeled each S in atree with a distinct subscript so that we can refer to it.
8.20 Trees of (8.10a.b.) with correct labeling
a. *S1
NPi
N
Mary
VP
V
knows
S2
NP j
N
Jane
VP
V
loves
NPi
N
herself
b. S1
NPi
N
Mary
VP
V
knows
S2
NP j
N
Jane
VP
V
loves
NP j
N
herself
In (8.20a.) the NP anaphor herself is c-commanded by both the NP Maryand the NP Jane, but only the NP Mary is coindexed with the NP herself.Thus, only the NP Mary binds the NP herself. So, the NP herself is bound,but the minimal clause containing the NP herself is S2, and the NP Maryis not contained in S2. Therefore the locality condition for binding ofreflexives is not satisfied and (8.20a.) is ungrammatical.
In (8.20b.), on the other hand, the NP Jane is coindexed with the NPherself ; and at the same time it c-commands the same NP herself. Moreover,the NP Jane is in the same minimal clause with the NP herself. All theconditions necessary for Hypothesis IV to apply are met, so we have agrammatical sentence.
We now turn to the more complex cases, the ones that Hypothesis IIIcould not handle. At this point we will start making use of our abbreviatoryconvention for indexation by presenting a single tree with both indexeslisted, one of which will be marked with an asterisk to show that this choicerepresents an ungrammatical structure.

180 BINDING
Examples (8.12a.b.) involve the embedding of one NP inside another, asthe following tree makes clear.
8.21 Trees for (8.12a.b.) NP within NP
S
NP j
D
a
NP
N
friend
PP
P
of
NPi
N
Mary’s
VP
V
flogs
NP∗i/j
N
herself
For (8.12a.) the NP Mary’s is indexed i , and it is contained in the NPa friend of Mary’s, which itself is indexed j . Since the NP Mary’s cannotc-command the NP herself, it cannot bind the latter, and so (8.12a.) isungrammatical.
You can see that the NP a friend of Mary’s is the sister of the VP, andthus c-commands everything in the VP, including the NP herself. If theNP a friend of Mary’s is also coindexed with the NP herself, it will bind it,and since there is only one clause, it will bind it in the minimal clause thatcontains the NP herself. All the conditions that are necessary for HypothesisIII to apply are met, and thus example (8.12b.) is a grammatical sentence.
The reasons for the ungrammaticality of (8.12c.d.) should now be obvi-ous. The first person pronoun I has incompatible features with the thirdperson female herself, so we will assume that the two NPs that dominatethem cannot be coindexed.
In (8.12d.) the NP Mary is the only nominal expression that is featurallycompatible with the NP herself, and yet, because the NP Mary does notbind the NP herself locally, the conditions for Hypothesis IV to applycannot be met, and all the listed options are ungrammatical.
Hypothesis IV will thus account for a wide range of data. There are afew cases, however, where it appears to fail, and it is a question of currentresearch how to deal with such cases. We are not going to discuss such caseshere, but see if you can come up with any data that poses a problem for

SOME IMPLICATIONS 181
Hypothesis IV on your own. In any case, take a moment to ponder howdifficult it has been to study even the very simple English data examinedthus far. Of course, the solution itself is not difficult to understand—coindexation, c-command, and locality are all simple notions.
8.3 Pronouns and “referential expressions”
We have come up with an analysis for the distribution of anaphors likeherself, themselves, and so on. Anaphors have turned out to be nominalexpressions with a deficient referential potential, in the sense that they needanother (coindexed) NP in order to acquire the ability to refer to an individ-ual. Crucially, this other NP must occupy a position that is subject to well-defined structural conditions. Apart from anaphors, nominal expressionscan also be of two other types from the point of view of their referentialpotential: pronouns and referential or R-expressions. Both of these typesof expressions are subject to their own “binding” conditions. We will notprovide the details of these conditions here. You will be asked to try tofind the conditions for the distribution of regular pronouns like her, him,as well as for R-expressions like Mary, the cat, or those three blind mice inthe exercises at the end of the chapter.
8.4 Some implications
We argued earlier that a sentence is not just a string of words but ratherhas a structure that relates certain words to each other to form constituents.If our approach to binding phenomena is valid, it suggests that sentences,which are members of an equivalence class used by the syntax, are not onlystructured but also must encode indexing on NPs. Even a well-structuredrepresentation will be ungrammatical if the coindexation relations amongparts are not licit.
Just like sentence structure, binding relations (c-command and index-ation) have no physical correlates in the speech signal; thus, they mustbe constructed, or computed, by the language faculty. Since, as we haveargued, syntactic relations are always structure-dependent, it appears to bethe case that the human language faculty can only construct patterns thatare sensitive to structure, and not, for example, linear order notions like“x intervenes between y and z.” Notions like binding and the differencesbetween pronouns, R-expressions and anaphors also appear to recur over

182 BINDING
and over again in the languages of the world, thus suggesting that they arepart of the primitive resources that constitute the language faculty.
8.5 Binding and wh-movement
In this section we want to consider one apparent counterexample to ourhypothesis about the distribution of anaphors, namely the hypothesis thatanaphors must be bound in their minimal clause. The relevant example isgiven below:
8.22 I wonder whoi John j thinks squashed himselfi,∗ j,∗k
This example initally appears problematic. Our intuition tells us that theanaphor himself must be interpreted as referring to the same individual aswho. However, the position of who seems to be outside of the minimal clausecontaining himself. Notice that who is outside of the clause containing theverb think, since it precedes the verb think, as well as its subject John. If thisis so, then who is clearly outside of the embedded sentence containing theverb squashed to which himself is related. Now, if our hypothesis about thedistribution of anaphors is correct, then himself must be coindexed with alocal c-commanding NP. However, the problem is that who does not seem tosatisfy the locality condition, since it is out of the minimal clause containingthe anaphor.
In order to solve this problem, notice that squashed seems to be missing asubject. An English clause containing a transitive verb like squashed alsocontains an object and a subject, in the order subject-verb-object, as in(8.23).
8.23 a. [Peter]SU [squashed]V [the squirrel]OBJ .b. [Peter]SU [squashed]V [himself]OBJ .
In (8.22), the object of squashed occurs in the expected position, that isafter the verb, but the category immediately preceding the verb squashedis another verb—the verb think, which clearly cannot be the subject ofsquashed. Notice at the same time that we do interpret one of the NPs in(8.22) as being the subject of squashed. This NP is precisely the NP who,which is coindexed with our anaphor. To convince yourself of this, compare(8.22) with (8.24) below.
8.24 a. John thinks Peter squashed the squirrelb. I wonder who John thinks squashed the squirrel?

BINDING AND wh-MOVEMENT 183
In (8.24b.), it should be obvious that the subject of squashed is who.The answer to the question in (8.24b.) is Peter and Peter is the subject ofsquashed in (8.24a.). Yet, the only difference between (8.22) and (8.24) is theanaphoric vs. non-anaphoric nature of the object of the verb squashed. Therelation of who to the verb squashed is the same in both instances: who is thesubject of squashed. If this is so, the clause that contains the anaphor himselfin (8.22) seems to contain all the constituents that normally occur witha transitive verb like squashed, but one of these constituents, the subject,occurs in a dislocated position relative to the verb squashed. Why is that?The answer lies in the somehow special properties of constituents like who,which were briefly described in the previous chapter.
There are several ways to formalize this property of wh-expressions. Theanalysis we have adopted in this book is to assume that sentences that con-tain wh-expressions like who, what, what student, which, which student, why,for what reason, etc., can be assigned a tree-like representation that indi-cates both the base position and the derived position of the wh-expression.Continuing an older terminology, we will say that the wh-constituent movesfrom the base to the derived position, and that as a result of movement acopy of the wh-constituent appears in a dislocated position.
The appearance of wh-phrases in two positions occurs not only in com-plex strings like (8.22), which contain a main clause and two embeddedclauses, but also in simple clauses like (8.25).
8.25 a. John squashed Mike.b. Who did John squash?
Let’s assume that the order subject-verb-object corresponds to the basepositions of the subject and object of a clause. Sentence (8.25a.) transpar-ently reflects this order. In other words, the subject John and the object Mikeoccupy their base positions. In (8.25b.), however, the subject John is in itsbase position, but the object of the verb is not. The object of squash in(8.25b.) is who, and who does not follow the verb, as expected under thesubject-verb-object order, but precedes it. In other words, the object of theverb squash in (8.25b.) is pronounced in its derived position.
The representation that we assign to (8.22) and that includes both thebase and the derived positions of who is given in (8.26). There are three Snodes in this representation: the higher one corresponds to the main clause,the middle one to the clause immediately selected by the verb wonder ofthe main clause, and the lowest one to the most deeply embedded clause,

184 BINDING
the clause selected by the verb think of the middle clause. In addition, themiddle clause is dominated not only by an S node, but also by an S′ node,which actually contains the S and the NP who. We will not offer any detailsabout the S′ node. For our purposes, S′ should be seen as an extension ofthe S node. Each of the three S nodes is analyzed as containing a subjectNP and a VP, the verbal predicate.
8.26 S
NP
N
I
VP
V
wonder
S′
NP
N
who
S
NP
N
John
VP
V
thinks
S
NP
N
who
VP
V
squashed
NP
N
himself
Given that who is the subject of the verb squashed, the base position ofwho is to the left of the verb squashed. Structurally, this corresponds to theNP position in the embedded clause that is sister to the VP that containsthe verb squashed and the object himself. The derived position of who, onthe other hand, is higher than the S node whose subject is John.
At this point you might wonder how all this can help with the problemwe pointed out at the beginning of this section related to the distributionof himself. Remember that the problem posed by (8.22) was that himself iscoindexed with who in spite of the fact that our theory predicts that (8.22)should be ungrammatical, since himself and who do not seem to be in thesame minimal clause—the locality condition appears not to be satisfied.

BINDING AND wh-MOVEMENT 185
However, (8.22) is grammatical and coindexation between himself and whois possible. How can this be?
Given what we now know about wh-expressions, it is easy to account forexamples like (8.22). In order to see this, let us first point out that the twocopies of who in (8.26) must be coindexed by virtue of their being copiesof the same lexical item. The representation in (8.26) that also contains theindexes on who is shown below.
8.27 S
NP
N
I
VP
V
wonder
S′
NPi
N
who
S
NP
N
John
VP
V
thinks
S
NPi
N
who
VP
V
squashed
NP
N
himself
Now, even if the copy of who that occupies a derived position is not inthe same minimal clause as himself, the base copy of who clearly is. The treerepresentation in (8.26) shows that the base copy of who and himself aredominated by the same S node. Notice that a sentence like Who squashedhimself? is grammatical and the interpretation that we assign to it is one inwhich himself and who are coindexed. This shows that a wh-expression likewho can be a binder for an anaphor. So, on the one hand, the two copies ofwho must be coindexed, as discussed above, and, on the other hand, himselfmust be coindexed with the base copy of who. The only way in which both

186 BINDING
these coindexation conditions can hold simultaneously is if all three of theseNPs bear the same index, as in the representation below.
8.28 S
NP
N
I
VP
V
wonder
S′
NPi
N
who
S
NP
N
John
VP
V
thinks
S
NPi
N
who
VP
V
squashed
NPi
N
himself
This representation now accounts both for the fact that (8.22) is gram-matical in spite of the fact that himself does not have a pronounced localbinder, and for the fact that himself is interpreted as being coindexed witha distant NP, namely with the higher copy of who. The grammaticality of(8.22) can be explained by the presence of the lower copy of who, the one inthe base position, which acts as a local binder for himself. The coindexationbetween himself and the higher copy of who is simply a side effect of thecoindexation between the local binder for himself and the higher copy ofwho. This latter coindexation follows in turn from the fact that the lower whoand the higher who are copies of the same NP constituent—one that corre-sponds to its base position and one that corresponds to its derived position.
We hope you find this example as impressive as we do—it allows us tobring together the notions of wh-movement and binding, which we arguedfor independently, in an elegant manner. This is an example of the benefitsof precise formulation mentioned in the quotation from the Preface of

NON-STRUCTURAL FACTORS IN INTERPRETATION 187
Syntactic Structures in Section 5.1.1—our model of wh-movement was not“explicitly designed” to make our account of binding work out right, and,yet, the model of wh-movement “automatically provides” a solution for anapparent counterexample to the binding generalizations.
Once again, we need to step back and appreciate what this teaches usabout basic issues like the nature of sentences. A sentence is not just a stringof words but rather a string of words with a structure—we posited structuralrelations in part to account for ambiguous strings. However, in addition tostructure, we need to assume that indexation is also part of a sentence’srepresentation. Furthermore, a sentence is not just an indexed structuralarrangement of words but rather a representation that contains the deriva-tional history of constituents that are subject to syntactic movement—itcontains both the base position of constituents that move, and their derivedposition, where they are pronounced.32 We now appreciate that the compu-tations involved in evaluating the binding conditions appear to refer to thebase position of the binder.
Once again, we see that linguistic computation involves construction bythe mind of very abstract structures involving equivalence classes with nogrounding in the categories of physics. Just as our minds construct trianglesand words and auditory streams and phonemes, it constructs syntacticrepresentations and derivations over which c-command relations andindexations can be evaluated. All of this computation and representationgoes on in our minds and thus can only be considered under the I–languageapproach.
8.6 Non-structural factors in interpretation
We have tried to maintain a distinction between the output of the grammarand the production and comprehension behavior of speakers. Our bind-ing conditions involve precise formal models, but when looking at actualbehavior, whether speech, comprehension, or even the behavior of providinggrammaticality judgments, “there are all those other ways in which thewinsome mess of what we call real life encroaches on the austere simplicityof a mathematical abstraction” (to quote mathematician Vašek Chvàtal). In
32 Remember that movement is one of the possible metaphors used to describe therelationship among the relevant positions in a tree.

188 BINDING
some cases the issue is obvious, for example, it is easy to understand why aspeaker will have difficulty with judgments about the grammaticality of asentence that takes three minutes to utter. However, other cases are not sosimple and warrant further discussion.
Let’s now consider the interpretation of the possessive form her in (8.29).Example (8.29a.) has at least the two interpretations shown by the indexing.The bicycle could belong to either the asker, Janie, or the askee, Loretta. Thesame holds for sentence (8.29b.)—we get the two readings, one in which it isthe asker’s bicycle and one in which it is the askee’s. (We can also interprether in each sentence as neither the asker nor the askee, but this possibilitydoes not concern us here.)
8.29 Parallelism in interpretationa. Janiei asked Loretta j to fix heri, j bicycle—at least two readings.b. Rayettek asked Evel to fix herk,l bicycle—at least two readings.c. Janiei asked Loretta j to fix heri, j bicycle and Rayettek asked Evel to fix
herk,l bicycle—how many of the following readings are possible: i & k; i& l; j & k; j & l?
Given the two possibilities under consideration for each sentence, onewould expect the conjunction of the two sentences to have four possibleinterpretations, since there are four combinations provided by the two sim-ple sentences—her is the asker in both cases; her is the askee in both cases;her is the asker in the first case and the askee in the second case; and heris the askee in the first case and the asker in the second. However, speakersof English report that only the first two options are possible readings ofthe sentence—either her is the asker in both cases or it is the askee inboth.
Although it is not entirely clear what the explanation is for why theother two readings are not acceptable to speakers, linguists have decidedthat the necessity of interpreting both instances of her in parallel reflectsa property of how we process sentences in real time, and not a fact aboutthe interpretations of pronouns made available by the grammar. In otherwords, we recognize that many factors other than binding theory enter intopeople’s speech comprehension and production behavior.
Many people initially judge the following string to be ill formed:
8.30 The pilot called the flight attendant into the cabin because sheneeded his help.

EXERCISES 189
However, as soon as it is pointed out that the pilot can be a woman and theflight attendant a man, those who judged the sentence ill formed revise theiropinions. It appears that when a person interprets pronoun reference, he orshe calls on many diverse aspects of cognition, including (possibly false)presuppositions about the gender of individuals in certain professions. Wewould never make any progress in linguistics, or any other science, if wedid not recognize that various factors can interact to produce an observedbehavior.
So, binding theory determines a range of possibilities for pronoun inter-pretation that may be further constrained by other factors, such as a biasto interpret parallel strings in parallel fashion when they occur in sequence,or general knowledge or suppositions about the nature of the world. Justlike the hypothetical physiologist from Chapter 3 who limits study to a verynarrow range of human behavior related to arm raising, the linguist mustlimit study to those aspects of pronoun interpretation that seem to offer thepromise of being formalizable. We further discuss this issue of isolability ofthe grammar in Chapter 14.
8.7 Exercises
Exercise 8.7.1. Show with trees that the following examples a. and b.show exactly the same problems for Hypothesis II as (8.12a.) and (8.12b.),respectively.
a. ∗The teacher j who Maryi likes flogs herselfi .b. The teacher j who Maryi likes flogs herself j .
Exercise 8.7.2. R-expressions and binding theory: Consider the followingdata and confirm that these examples are compatible with the claim thatR-expressions cannot be bound at all, even at a distance. The opposite ofbound is “free,” so we can say “R-expressions must be free.”
a. Shei loves Mary∗i/j .b. Shei says that John loves Mary∗i/j .c. John says that Jim thinks that shei promises to tell Bill to beg Sam to
force Mary∗i/j to eat better.d. The womani who loves her j/k told Mary j to leave immediately.
Draw a tree for each example and explain why each indexed R-expressionis or is not bound by other indexed NPs.

190 BINDING
Exercise 8.7.3. Pronouns and binding theory: The point of this exercise isto reinforce the idea that syntactic phenomena are structure-dependent. Inthe text we examined the conditions on the appearance of anaphors (likehimself and herself ) and in the exercise (8.7.2) the conditions on regularreferring expressions. You will now go through similar steps of reasoning todiscover conditions on the distribution of non-reflexive pronouns like himand her.
Some data:
a. Tomi sees him j .b. ∗Tomi sees himi .
1. Propose a Hypothesis I that relies exclusively on linear order to accountfor the grammatical vs. ungrammatical indexing of him and Tom in (a.)and (b.):
More data:
c. Tomi knows that Fred j loves himi .d. ∗Tomi knows that Fred j loves him j .
Explain:
2. Why is (c.) a problem for Hypothesis I?3. Is (d.) a problem for Hypothesis I? Explain.4. Propose another linear order Hypothesis II using the notion of interven-
tion (x comes between between a and b) to account for just (a.b.c.d.):
More data:
e. The aromatherapist j Tomi likes flogs himi .f. ∗The aromatherapist j Tomi likes flogs him j .g. A friend j of Tom’si flogs himi .h. ∗A friend j of Tom’si flogs him j .i. Hei flogs him j .
Explain:
5. Why is (e.) a problem for Hypothesis II?6. Why is (f.) a problem for Hypothesis II?7. Why is (g.) a problem for Hypothesis II?8. Why is (h.) a problem for Hypothesis II?9. Is (i.) a problem for Hypothesis II?
Draw trees and show indexing on the noun phrases for sentences p.-t. Usethe trees in the chapter to help you.

EXERCISES 191
10. e:f:g:h:i:
A constituent · of a sentence binds another constituent ‚ just in case thesetwo conditions are satisfied:
11. i.ii.
Give the letter of an example from the sentences above in which:
12. him is bound, and the sentence is grammatical:13. him is not bound, and the sentence is grammatical:14. Formulate a Hypothesis III for the distribution of him that uses binding
and accounts for all of (a.-i.):
Consider the grammaticality of the three sentences represented by the fol-lowing string and indexation: Whoi does Annie j think loves her∗i/j/k.
15. Explain only the reason why the following reading is ungrammatical.Your answer should include a tree (tell us what it is a tree of) and onesentence.
Whoi does Annie j think loves her∗i .

9Ergativity
9.1 Preliminaries 194
9.2 A nominative-accusative
system 197
9.3 An ergative-absolutive
system 198
9.4 A tense-split system 201
9.5 A nominal-verbal mismatch 202
9.6 A NP-split system 203
9.7 Language, thought and
culture 206
9.8 Exercises 207
As we indicated in Chapter 1, experts in all sorts of fields are willing tomake proclamations about the acquisition, use, and evolution of languagewithout anything like the depth of knowledge about what language is thatyou now have from reading this book. In this chapter we survey some lessfamiliar language data—partly just for the fun of it; partly to reinforce asense of humility about the complexity of language, a sense that we wishwas more widely shared by non-linguists; and partly to further illustrate thefollowing:
� how linguists reason about data patterns;� the tension that arises from the complementary goals of developing a
theory of Universal Grammar and accounting for the diversity of theworld’s languages; and
� once again, the idea that our minds construct linguisticrepresentations—the analysis is not “in the signal.”
To construct these representations, a grammar needs a set of symbolicequivalence classes. A theory of Universal Grammar must specify a set ofprimitives—the fundamental representational primitives that constitute the

ERGATIVITY 193
equivalence classes of all grammars, and the computational primitives thatconstitute the computations of possible individual grammars. Linguistics isstill a long way from this goal, and in this chapter we will content ourselveswith a fairly superficial description of some complex phenomena. There doexist several well-articulated analyses of the data we present, but our aim isnot to bring you to the cutting edge of linguistic research in this area butrather to attain the goals sketched above, especially the goal of increasing asense of humility.
We will examine a phenomenon called ergativity found in many languagesspread all over the world, but not present in obvious form in the major lan-guages of science and culture such as English, German, French, Japanese,Chinese, Arabic, or Spanish. The “exoticness” of the phenomena we discussis just a reflection of our particular point of view given the languages wehappen to speak—there is nothing inherently strange about these patternsand, in fact, modern linguistics has been able to abstract away from muchof the superficial differences among languages to find some underlyingunity.
We have already applied similar reasoning in the domain of phonology.In our discussion of English allophones in Chapter 6, we saw that Englishintegrates the mental representations plain [t] and aspirated [th] into a singleequivalence class, the phoneme /t/. In contrast, a language like Thai treatsthe two kinds of t as belonging to separate phonemes. So, the phonemeequivalence classes of English phonology differ from those of Thai. Wewill see in Chapter 11 that the two languages must construct their equiv-alence classes from a universal set of innate, atomic building blocks, butthe languages differ in the combinations that are made from these atoms.The atomic building blocks are entities like the vowel features we used toaccount for Turkish vowel harmony in Chapter 6—the features themselvescorrespond to equivalence classes. In the course of language acquisitioneach language treats certain bundles of features as higher-order equivalenceclasses. The human language faculty thus has some plasticity with respectto which equivalence classes can enter into computations. In English thelearner abstracts away from the difference between [t] and [th], whereasin Thai the learner does not. What better illustration could one want forSapir’s statement quoted in Chapter 1 that “no entity in human experiencecan be adequately defined as the mechanical sum or product of its physicalproperties”? Both English and Thai have aspirated and unaspirated conso-nants, but they pattern completely differently in the two types of grammar.

194 ERGATIVITY
In the following sections, we will illustrate a similar kind of plasticity,not in the domain of phonology but in morphosyntax, the interface ofmorphology and syntax, of a variety of languages.
9.1 Preliminaries
As we proceed, we will make use of three distinct sets of terminology torefer to syntactic phrases, and it will become apparent that we need all three.Consider a sentence like (9.1):
9.1 He kicked the frog.
The element he can be described in several ways:
9.2 Describing a constituent like he� it is a PRONOUN, which is a kind of NP� it is the SUBJECT of the sentence� it is in the NOMINATIVE CASE, as opposed to a form like him
In this chapter we will be examining the relationships among these threeways of describing constituents of a sentence.
The first categorization we used was NP. NPs, VPs, and so on are phrasesbuilt from elements called lexical categories like N and V. A more traditionalterm for “lexical category” is part of speech.
The second categorization includes categories like subject and object. Inthe model of syntax we developed earlier, these labels were just names forpositions in a syntactic tree—the subject is the NP that is the direct daughterof the sentence node and c-commands the rest of the sentence. The objectis just the name of the NP that is the daughter of the VP and sister ofthe V.
Notions like subject and object are called grammatical functions or gram-matical relations. In some syntactic theories, grammatical functions areactual theoretical primitives, not just names for positions in the tree. Inthis book, we use the terms only in a descriptive way to indicate syntacticpositions. You will soon see that the status of these notions is more complexthan you may have realized. There are many difficult issues that arise whenstudying these topics, some of them not yet resolved. For our purposeswe will assume that every sentence in every language has a subject, whichmeans that every sentence has an NP as a direct daughter of S.

PRELIMINARIES 195
If there is only one argument of a verb, we assume it is the subject andsay that the sentence is intransitive.33 If the verb has both a subject and anobject, we will say that it is transitive. A ditransitive has a subject as well astwo arguments within the VP.
9.3 Transitivity� Mary yawned (no arguments within the VP) = Intransitive� Mary kicked him (one argument within the VP) = Transitive� Mary gave him the cold shoulder (two arguments within the VP) =
Ditransitive
In the following discussion, we won’t worry about ditransitives, or aboutwhich NP is the object of the verb give, but we mention them just to makeit clear that our sketch is far from complete.
In English the subject and verb sometimes show agreement:
9.4 Agreement in English
PRESENT PAST
SINGULAR He sees John He saw JohnPLURAL They see John They saw John
The verb marker -s occurs only on present tense verbs with a third personsingular subject like he. Thus sees is said to agree with he, and see agreeswith they. In the past tense, however, there is no overt marking of agreement.
Some languages show much richer agreement systems, with differentforms for each person and number of the subject, with the differencesmarked in all tenses. Latin is such a language, as shown by the followingforms for the verb amare “to love”:
9.5 Subject-verb agreement in two Latin tenses
PRESENT FUTURE
SG PL SG PL
1st amo amamus amabo amabimus2nd amas amatis amabis amabitis3rd amat amant amabit amabunt
Each of the three persons in the singular and plural has its own endingsin both the present and future tenses. Aside from a failure to distinguish
33 More sophisticated readers will see that we are glossing over the subcategories ofintransitive verbs, unergatives and unaccusatives, and assuming that all intransitives endup with a NP in subject position, although the base position of this NP may differ fromits derived position.

196 ERGATIVITY
singular and plural in the second person form you, English pronounsmark the same person and number distinctions as do the Latin verbsuffixes.
Many languages mark categories that English does not mark at all. Forexample, the English form we write corresponds to four distinct forms inMohawk, an Iroquoian language, and also in Tok Pisin, an English-basedCreole, one of the official languages of Papua New Guinea. Mohawk marksthe differences with verbal morphology, whereas Tok Pisin does it withpronoun morphology. The four-way contrast corresponding to English weis shown in (9.6).
9.6 First person, non-singular forms in three languages
Mohawk Tok Pisin English1, DU, EXC iakenihiá:tons mitupela raitim we write1, PL, EXC iakwahiá:tons mipela raitim we write1, DU, INC tenihiá:tons yumitupela raitim we write1, PL, INC tewahiá:tons yumipela raitim we write
First of all, these two languages differentiate plural from dual, which isused for subjects that have exactly two members. Second, these languagesdistinguish forms that are inclusive of the person addressed (“me andyou”), from forms that are exclusive of the addressee (“me and her, butnot you”).
Note that these languages make more distinctions than English in personand number categories, but, like French and German, they do not distin-guish what is rendered in English as we write and we are writing. So, it is notthe case that we can say that either English or Mohawk is more complexthan the other. We can find a contrast that is overt in the morphology ofeach language but not the other. The notion of complexity appears to beirrelevant to the comparison of languages.
In addition to the subject-verb agreement patterns we have looked at,some languages show agreement of a verb with its object as well. Hungarianhas very rich subject-verb agreement, but as the following forms show, thereis also some agreement with objects.
9.7 Hungarian has some nice suffixes on verbs:
Verb I V an X I V the X I V yousend küldök küldöm küldelekwatch lesek lesem leslekawait várok várom várlak

A NOMINATIVE-ACCUSATIVE SYSTEM 197
Having read the discussion of Turkish in Chapter 6, you surely recognizethat there is some kind of vowel harmony in Hungarian as well—we won’tanalyze it here. Focus instead on the difference in endings between a verbwith an indefinite third person object (such as a boy), a definite third personobject (such as the boy), and a second person (singular or plural) object(you). The verb suffixes thus encode features of both the subject and objectin Hungarian—a different form of the verb is used for I send a boy, I sendthe boy and I send you.
We have already introduced lexical categories like N, V, and their phrasalcounterparts, NP, VP, and so on. These are assumed to be based on proper-ties or features that define equivalence classes in the mental dictionary, thelexicon of a grammar. We have also seen grammatical function terms likesubject and object that are defined, at least in some approaches, as namesfor positions in syntactic trees. The last categorization we discuss is notlexical or syntactic but rather morphological. Terms like nominative caserefer to the form taken by the elements in NPs, especially their head nouns.Case is very limited in English, only showing up in the pronoun system indistinctions like I / me, which are both first person singular pronouns, orwe / us which are both first person plural pronouns, or she / her which areboth third person singular female pronouns. In other languages, case maybe marked on all nouns, and sometimes on the determiners and adjectivesthat modify them. We will see an example below from Latin. The remainderof this chapter is about verbal agreement patterns and case systems—themarkers on verbs and nouns (or NPs) that show their relationship to eachother.
9.2 A nominative-accusative system
We are now ready to examine some data following a very useful surveypresented by Payne (1997). Consider the Latin sentences in (9.8). Sentence(9.8a.) is intransitive since it has a subject, dominus “master,” but no object.Sentence (9.8b.) has exactly the same structure, but with a different subject,servus “slave.” Notice that dominus and servus both end in -s—that is not anaccident. Note that in the transitive sentences (9.8c.) and (9.8d.) we also getforms ending in -s serving as subjects, as the translations show. In additionto the subject dominus in (9.8c.) we also get a form of the word for slave,but with the ending -m instead of -s, that is servum. This NP is the object of

198 ERGATIVITY
sentence (9.8c.). Likewise, in (9.8d.) servus is the subject and dominum is theobject.
9.8 Latin nominative-accusative system
a. dominus venit “the master is coming”b. servus venit “the slave is coming”c. dominus servum audit “the master hears the slave”d. servus dominum audit “the slave hears the master”
The traditional name for a morphological case form in a language likeLatin, one that treats subjects of transitives and subjects of intransitivesalike, is nominative. So, in our examples, -s is the nominative ending, andwe say that dominus and servus are “in the nominative case.” The suffix-m that appears on the objects of transitive verbs marks the accusative, sodominum and servum are in the accusative case.
Note that English uses the same pattern, at least for pronouns:
9.9 English pronoun case
a. I am comingb. She is comingc. I hear herd. She hears me
The forms I and she are used for subjects, whereas me and her are forobjects.34 A language that uses the Latin or English case pattern is called anominative-accusative language. Of course, it is not the names of the casesthat make a nominative-accusative language but rather the pattern of havingsubjects all sharing the same form in opposition to the form of objects.
9.3 An ergative-absolutive system
At this point you may be wondering how else a case system could beorganized. Some languages do not show any overt morphological case at all.Aside from the pronouns, English NPs have no case35 and the grammatical
34 Of course things are actually more complex if you consider real colloquial Englishof many dialects. Like many speakers of English, we use me as a subject form in sentenceslike Me and John left early.
35 That is, no nominative/accusative distinction. The possessive form, as in John’sbook, is sometimes treated as a case called genitive, which we met in the Turkish dis-cussion of Chapter 6.

AN ERGATIVE-ABSOLUTIVE SYSTEM 199
functions correspond only to positions in the sentence. Even among Englishpronouns the second person form you does not distinguish nominative fromaccusative.
A very different kind of case system is manifested in the Yup’ik Eskimolanguage of Alaska. Find the subjects of sentences (9.10a.-d.). You will notethat there are two sets of suffixes. In (9.10a.) and (9.10c.) the subject ismarked with -aq, but in (9.10b.) and (9.10d.) the subject is marked with -am. What is the difference between the sentences? Note that (9.10a.) and(9.10c.) are intransitives, there is a subject but no object, whereas (9.10b.)and (9.10d.) are transitive, there is a subject and an object of the verb.
9.10 Ergative-absolutive system
Yup’ik Eskimo (Alaska)a. Doris-aq ayallruuq “Doris traveled”b. Tom-am Doris-aq cingallura “Tom greeted Doris”c. Tom-aq ayallruuq “Tom traveled”d. Doris-am Tom-aq cingallura “Doris greeted Tom”e. Ayallruu-nga “I traveled”f. Ayallruu-q “He traveled”g. Cingallru-a-nga “He greeted me”
If we look at the markings on the objects in (9.10b.) and (9.10d.), we seethat the suffix is -aq, the same as the subjects in (9.10a.) and (9.10c.). Here isa summary of the patterns in (9.10a.-d.) for Yup’ik and (9.8a.-d.) for Latin:
9.11 Two case-marking patterns
Yup’ik LatinSubject of transitive (ST) -am -sSubject of intransitive (SI) -aq -sObject (O) -aq -m
A case form that is used to mark objects (O) and subjects of intransitives(SI), as opposed to subjects of transitives (ST) is called an absolutive case.The form used to mark transitive subjects in such a system is called the erga-tive case. Yup’ik is called an ergative-absolutive (or sometimes just ergative)system.
The table in (9.12) shows us that a nominative-accusative system treats allsubjects the same with respect to morphological case, whereas an ergative-absolutive system treats objects the same as subjects of intransitives. Thethree-way distinction of grammatical relations is divided up in two differentways:

200 ERGATIVITY
9.12 Two case-marking patterns
Yup’ik Latin
ERGATIVE STNOMINATIVE
ABSOLUTIVESIO ACCUSATIVE
As you can see, we have chosen the abbreviations O, SI and ST for object,subject of intransitive and subject of transitive. It is worth pointing out thata more standard set of abbreviations is O (for “object”), S (for “subject”)and A (originally for “agent”), respectively—these labels exemplify a poten-tially confusing mixing of categories (grammatical functions and semanticnotions).
Thus far, we have discussed ergative-absolutive and nominative-accusative patterns solely as a property of NPs. Now examine sentences(9.10e.f.g.). In particular, look at the suffixes on the verbs. Unlike Englishverbs which can only mark agreement with the subject, Yup’ik verbs aresomewhat like Hungarian in that they can mark both subject and objectagreement. We have a limited data set, but you can see that the first personagreement marker -nga in (9.10e.) corresponds to an intransitive subject(which need not be expressed by an independent NP), and in (9.10g.) itcorresponds to the object of a transitive verb.
You can also see that the third person subject agreement markers in(9.10f.) and (9.10g.) are different. Perhaps at this point you are not surprisedby this—after all, the -q in (9.10f.) marks the fact that the subject is subjectof an intransitive verb, whereas the -a- in (9.10g.) marks agreement with asubject of a transitive verb.
To summarize, the marking on both nouns and verbs in Yup’ik treats thesubject of an intransitive and the object of a transitive alike, in contrast withthe subject of a transitive. The marking on nouns parallels that on verbs.Keep this in mind as we proceed.
For some reason, it typically takes students a while to be able to keepstraight the ergative-absolutive vs. nominative-accusative contrast. Here isan informal example to help you. Consider the following sentences involv-ing transitive and intransitive uses of the verb grow.
9.13 English transitive alternation
TRANSITIVE INTRANSITIVE
a. Davey and Sami grow pansies there Pansies grow thereb. They grow them there They grow there

A TENSE-SPLIT SYSTEM 201
English uses different pronoun forms to correspond to the word pansies inthe two (9.13b.) sentences—they as opposed to them. However, from thepoint of view of meaning, it is clear that both sentences describe a situa-tion in which pansies blossom. So you can imagine a language, English′,which marks the argument that has the same relationship to the verb in aconsistent fashion, as in (9.14).
9.14 Hypothetical English′ transitive alternation
TRANSITIVE INTRANSITIVE
a. Davey and Sami grow pansies there Pansies grow thereb. They grow them there Them grow there
This hypothetical English′ shows an ergative-absolutive pattern, since theform they is only used for subject of transitive, and them is used for bothobjects and intransitive subjects.
9.4 A tense-split system
The next language we examine is Georgian, spoken in the Republic ofGeorgia, in the Caucasus region. You can see from sentences (9.15a.b.) thatGeorgian seems to have a nominative case marker -i that shows up on thesubject in both sentences, both SI and ST, and an accusative case marker -son the O in (9.15b.). However, examination of (9.15c.) and (9.15d.) showsa patterning of the SI in (9.15c.) and the O in (9.15d.), both marked by-i, as opposed to the ST in (9.15d.) marked by -ma. The other differencebetween the sentences is their tense—Georgian is an example of a tense-split language. It has the nominative-accusative pattern in the present, andthe ergative-absolutive pattern in the past tense.
9.15 Tense-split system in Georgian
a. student-i midis “The student goes”student-NOM goes
b. student-i ceril-s cers “The student writes the letter”student-NOM letter-ACC writes
c. student-i mivida “The student went”student-ABS went
d. student-ma ceril-i dacera “The student wrote the letter”student-ERG letter-ABS wrote
There is a potentially disturbing aspect of this analysis. The subjects of(9.15a.) and (9.15c.) look exactly the same—studenti, and they are both

202 ERGATIVITY
subject of a form of the verb that we translate by “go.” However, in (9.15a.)the suffix -i must be analyzed as nominative, due to its occurrence on thesubject in (9.15b.); and in (9.15c.), the -i must be analyzed as absolutive,given its occurrence on the object in (9.15d.). Recall, however, that cases arecategorized by virtue of patterns of relations, not, for example, on the basisof their phonological content. The NPs in Georgian show one pattern inthe present tense and another in the past.
This example once again illustrates the necessity for abstract symbolicequivalence classes in linguistic analysis, since the patterns force us to posittwo distinct case markers of the form -i. The form studenti is a subject inall of our sentences above, but it can also be an object. Can you give anEnglish sentence that you think would be rendered into Georgian with theword studenti as an object?
9.5 A nominal-verbal mismatch
Recall from the discussion of Yup’ik that the ergative-absolutive pattern onNPs was echoed in the verb agreement markers. For example, the sentencestranslated “I traveled” and “He greeted me,” with a first person singularSI and O, respectively, both had verbs marked with -nga. Similarly, thereare languages with nominative-accusative case marking on NPs and subjectand object agreement on the verb following the same pattern of groupingtogether SI and O in contrast to ST.
With these patterns in mind, look at the Managalasi data in (9.16). Thefirst two sentences are intransitive, and so you can see that the SI forms of“you” and “I” are a and na, respectively. Sentence (9.16c.) shows that the Oform of “you,” a, is the same as the SI form in (9.16a.); and (9.16d.) showsthat the O form for “me” is the same as the SI form in (9.16b.). Thus, thepronouns show the ergative-absolutive pattern.
9.16 NP vs. V marking split in Managalasi (Papua New Guinea)
a. a vaP-ena “you will go”2SG go-FUT:2SG
b. na vaP-ejo “I will go”1SG go-FUT:1SG
c. nara a an-aP-ejo “I will hit you”1SG 2SG hit-2SG-FUT:1SG

A NP-SPLIT SYSTEM 203
d. ara na an-iP-ena “you will hit me”2SG 1SG hit-1SG-FUT:2SG
Compare this system of pronouns with the so-called agreement markers onthe verbs in Managalasi. We see that the verb root meaning “go” is vaP andthe one meaning “hit” is an. There are suffixes on these roots that agreewith the subject and object pronouns. The suffix ena in (9.16a.) marks asecond person singular subject (in the future tense), and the suffix ejo in(9.16b.) marks a first person singular subject (again in the future tense).These sentences are intransitive, so the subjects are both SI. However, wesee in sentences (9.16c.d.) that transitive subjects are marked the same asintransitive ones. In (9.16c.) the subject is “I” and the verb again is markedwith ejo, as in (9.16b.). There is a second person singular marker aP agreeingwith the object that differs from the ena SI marker in (9.16a.). Sentence(9.16d.) does have ena but as a ST, and it has an object marker iP.
9.17 Two patterns in a single language—Managalasi first singular
Pronouns Verb Markersnara ST
ejona
SIO iP
The first exercise at the end of this chapter asks you to make a similar tableto show that the same pattern holds for the second person singular forms.
Managalasi provides another example of why it is not useful to classifylanguages as nominative-accusative or ergative-absolutive. In Georgian, thecase system of NPs depended on the tense of the verb. In Managalasi, thepronouns pattern one way and the verb agreement markers pattern theother way. This suggests that the distinction between these systems cannotbe stated at the level of the language (the grammar) as a whole. In Georgianit depends on tense; in Managalasi it depends on the pronoun-verb contrast.Think about the implications of these findings for a theory of UniversalGrammar.
9.6 A NP-split system
We now consider data from an Australian language called Dyirbal thatillustrates yet another kind of split between a nominative-accusative andan ergative-absolutive system.

204 ERGATIVITY
First, examine the Dyirbal sentences below. We have provided both anEnglish paraphrase with pronouns in order to show case distinctions thatare not present on other English NPs and a translation of the Dyirbalwords. The typeface coding (bold and italics) both highlights the correspon-dences in words in Dyirbal and English and corresponds to consistent caseforms across the three Dyirbal sentences.
9.18 Some simple Dyirbal sentences
English Dyirbal glossa. he saw her yabu ñumaNgu buran “father saw mother”b. she returned yabu banaganyu “mother returned”c. she saw him ñuma yabuNgu buran “mother saw father”
We see that the meaning “mother” is expressed consistently by yabu. Whenthis form occurs as the object of a transitive in (9.18a.), the form isjust yabu. When it is the subject of an intransitive in (9.18b.), the formis again yabu. When it is the subject of a transitive verb in (9.18c.) it occurswith the suffix -Ngu. We can call this the ergative marker; the absolutive formsare unsuffixed.
9.19 Ergative-absolutive case pattern
ñuma yabuNgu buran “mother saw father”father mother sawABSOLUTIVE ERGATIVE
yabu banagan “mother returned”mother returnedABSOLUTIVE
The same pattern applies to the words for father—so how do you say inDyirbal “Father returned”?
Here is a table showing the case forms for the Dyirbal word for “mother”in contrast to the pattern shown by the English third singular female pro-noun:
9.20 Case patterns for English pronoun and Dyirbal noun
English DyirbalTransitive subject she yabuNguIntransitive subject she yabuObject her yabu
So far, Dyirbal just looks like Yup’ik, or Georgian in the past tense, orthe pronouns of Managalasi. Now look at sentences that contain first andsecond person plural pronouns corresponding to we / us and you.

A NP-SPLIT SYSTEM 205
9.21 Dyirbal pronouns
a. Nana banaganyu “we returned”we-all returned.NON-FUT
b. nyurra banagany “you returned”you-all returned.NON-FUT
c. nyurra Nanana buran “you saw us”you-all we-all see.NON-FUT
d. Nana nyurrana buran “we saw you”we-all you-all see.NON-FUT
If we arrange these forms in a table we see that the pronouns behaveaccording to a nominative-accusative pattern.
9.22 Lexical NPs vs. pronouns in Dyirbal
ROOT “mother” “father” “we all” “you all”ST yabuNgu ñumaNgu
SINana nyurra
yabu ñumaO Nanana nyurrana
It thus appears that NPs with a lexical head like the word for “mother”or “father” follow the ergative-absolutive pattern, whereas the pronouns wehave seen follow the nominative-accusative pattern. In Dyirbal the equiva-lence class of NPs has two subcategories that differ in terms of their case-marking properties.
Once again, we see that we cannot characterize grammars as ergative-absolutive or nominative-accusative. In Yup’ik, all nominals follow theergative-absolutive pattern. In Dyirbal, there is a split between nouns andpronouns. In Georgian, the pattern depends on the tense of the verb. InManagalasi, there is a different patterning on NPs and verb agreementmarkers. In order to characterize these languages we would have to “lookinside,” below the level of the whole grammar to the behavior of individualmorphemes. For example, the cases assigned by Georgian verbs appearto depend on the morpheme that marks tense. In Dyirbal, case patternsdepend on the NPs that are involved.
At first blush, such patterns make the search for Universal Grammarappear to be a hopeless enterprise—it seems that almost anything goes. Butthis is far from true. In fact, some current approaches to syntax, especiallythe so-called Minimalist Program initiated by Chomsky, go so far as tosuggest that all languages have the same syntax, including the mechanismsfor case assignment. The different syntactic phenomena we observe arethen attributed to differences in the properties of individual lexical items,

206 ERGATIVITY
including so-called functional items that express grammatical notions liketense and person.
Under this view, there is a single universal mechanism for treating theNPs that occur in various structural positions in syntactic trees. In Geor-gian, the tense morphemes differ in how they affect case marking. InYup’ik, all tenses behave like the Georgian past. There are many detailsto be worked out and many controversial aspects of this approach, butthe general idea is this: we know that languages differ with respect tothe content of their lexicons—the English word owl covers both chouetteand hibou of French. English, on the other hand, has a distinction inaspect in the present tense that is lacking in French: I sleep and I amsleeping would both be translated as je dors in French. We can character-ize these differences as differences in the morphemes available in the twolanguages, a difference between the lexicons. Once we do this, the idea thatall languages follow the same rules, at some abstract level, becomes moreplausible.
9.7 Language, thought and culture
At this point you have certainly come to appreciate somewhat the com-plexity of human language. We actually suspect that you are less sure thatyou understand what language really is now that we have gotten you toaccept that nothing about it corresponds to our pre-theoretical, everydaynotions. With your new appreciation of ergativity and related phenomena,ask yourself what the implications would be for someone who wants to finda link between linguistic structures and the worldview, thought processes,or culture of a particular group. A tremendous problem immediately loomsup—what are the elements of a worldview, thought, or culture that can beput into correlation with linguistic elements? Another question is: Is it evenplausible to think that, say, all speakers of Dyirbal, Basque, Georgian, andother languages with ergative-absolutive systems share aspects of thought,worldview, or culture that are not shared by speakers of other languagesthat have no apparent ergativity? Finally, suppose that we could correlateaspects of culture with particular case-marking systems: What do we doabout split systems? Do Georgians think and act like English speakers whenthey use the present tense, but think and act like Dyirbal speakers (using

EXERCISES 207
lexical nouns, not pronouns) when they (the Georgians) use the past tense?This all seems rather implausible, and in fact there appears to be no evidencefor a correlation between aspects of linguistic structure and any cultural orcognitive property.
9.8 Exercises
Exercise 9.8.1. Managalasi second person: Go back to the discussion ofManagalasi and create a table like that in (9.11) for the second personsingular forms from the data in (9.16).
Exercise 9.8.2. Iyinû-Aimûn verbs: This exercise was prepared by ourstudent Kevin Brousseau who is a speaker of this Algonquian language,a dialect of Cree spoken in Quebec, Canada.
Consider the following sentences:
i. nicîI-PAST
tahcishkuwâukick
atimwdog
“I kicked the dog”ii. nicî
I-PAST
tahcishkenkick
tehtapûnchair
“I kicked the chair”iii. cî
PAST
pahcishinfall
anthat
atimwdog
“That dog fell”iv. cî
PAST
pahchihtinfall
anthat
tehtapûnchair
“That chair fell”
What seems to condition the form of the verb in the two transitive sentences(i.) and (ii.)? What seems to condition the form of the verb in the twointransitive sentences (iii.) and (iv.)? What do these facts together remindyou of?
The words for “girl, woman, man, boy, moose” can all replace the wordfor “dog” in the sentences above; and the words for “sock, shoe, canoe” canall replace the word for “chair,” but if we replace, say, “dog” with “canoe”or “chair” with “man,” the sequences become ungrammatical. Note that

208 ERGATIVITY
the form mishtikw can mean both “tree” and “stick,” but it is clear in eachof the following which meaning is intended:
i. nicîI-PAST
tahcishkuwâukick
mishtikwtree/stick
“I kicked the tree”ii. nicî
I-PAST
tahcishkenkick
mishtikwtree/stick
“I kicked the stick”iii. cî
PAST
pahcishinfall
anthat
mishtikwtree/stick
“That tree fell”iv. cî
PAST
pahchihtinfall
anthat
mishtikwtree/stick
“That stick fell”
Do the nouns in Iyinû-Aimûn appear to fall into different groups? Howmight you label those groups? Do you think it is plausible that a mentalgrammar, which we have been characterizing as a symbol-processing com-putational system, is sensitive to the kind of information you appealed toin characterizing the noun classes? How does the following bear on thisissue?
i. nicîI-PAST
muwâueat
âihkunâubread
“I ate the bread”ii. nicî
I-PAST
mîchameat
mîcimfood
“I ate the food”iii. cî
PAST
pahcishinfall
anthat
asinîstone
“That stone fell”
What determines the nature of Iyinû-Aimûn noun equivalence classes—what the nouns mean or an abstract and arbitrary feature?
Exercise 9.8.3. Guugu Yimidhirr cases: Assume that you in a translationalways refers to second person singular. Assume that word order is com-pletely free in this language. Ignore any variation between long (double)and short (single) vowels.

EXERCISES 209
1. Nyundu ganaa? Are you well?2. Nyulu galmba ganaa. She is also fine.
� What is the word for well, fine? a.⇒ The first two sentences have no verb—it need not be expressed in
such sentences. You can also think of the adjective as serving as averb.
� What is the word for you? b.� For she? c.
3. Nyundu dhadaa? Are you going to go?� What is the verb in this sentence (in Guugu Yimidhirr)?
d.4. Yuu, ngayu dhadaa. Yes, I am going to go.5. Ngayu galmba dhadaa. I too am going to go.
� What is the word for also, too? e.� For yes? f.� For I? g.� For she? h.
6. Ngali dhadaa gulbuuygu. You and I will go together.� If gulbuuygu means together, what does ngali mean?
i.7. Nyundu ganaa. You are OK.
⇒ Note that a question does not have different word order from astatement—sentences 7. and 1. are the same in Guugu Yimidhirr.
8. Nyundu Billy nhaadhi. You saw Billy.� What is the word for Billy? j.� For saw? k.
9. Ngayu Billy nhaadhi. I saw Billy.10. Nyundu nganhi nhaadhi. You saw me.
� What does nganhi mean? l.11. Ngayu nhina nhaadhi. I saw you.
� What does nhina mean? m.� Using only the sentences above, find a transitive sentence (one with
a subject and an object) with you (sg.) as the subject. n.#� Then find an intransitive sentence (no object) with you as the sub-
ject. o.#� Then find one with you as an object. p.#
This gives us you as an ST, an SI, and an O.

210 ERGATIVITY
� Fill in the following table:
2 sg.ST q.SI r.O s.
� Based on the entries in your table, does the 2 sg. pronoun follow thenominative-accusative pattern, the ergative-absolutive pattern, orsome other pattern?t.
12. Nyulu nganhi nhaadhi. He saw me.13. Ngayu nhangu daamay. I speared him.14. Nyundu nhangu nhaadhi. You saw him.15. Nyulu nhina nhaadhi. He saw you.
� How do you think you say She saw you?u.
� Now fill in the table below:
1sg. 2sg. 3sg.STSIO
� Do the first and third person forms show the same pattern as thesecond person form?Consider the further data below.
16. Billy ngayu nhaadhi. I saw Billy.17. Nhina nhaadhi ngayu. I saw you.18. Nhaadhi nhangu nyundu. You saw him.19. Ngayu ganaa. I am well.20. Wanhu dhadaara? Who is going?21. Wanhdhu Billy nhaadhi? Who saw Billy?22. Nyundu wanhu nhaadhi? Who did you see?23. Nyundu buli? Did you fall down?24. Wanhdhu nhina dhuurrngay? Who pushed you?25. Billy-ngun nganhi dhuurrngay. Billy pushed me.26. Nganhi dhuurrngay. I was pushed./Someone pushed me.27. Billy dhadaa. Billy is going to go.28. Ngayu Billy nhaadhi. I saw Billy.29. Billy-ngun nganhi nhadhi. Billy saw me.30. Yarrga-ngun nganhi gunday. The boy hit me.

EXERCISES 211
31. Yugu-ngun bayan dumbi. The tree crushed the house.32. Yarraman-ngun nhina dhuurrngay. The horse pushed you.33. Yugu buli. The tree fell.34. Ngayu yugu bulii-mani. I made the tree fall.35. Nambal duday. The rock rolled away.
� Complete the table:
PERSONAL PRONOUNS wh-PRONOUN Name Common NP1sg. 2sg. 3sg. who Billy the boy etc.
ST w. z. cc.SI x. aa. dd.O y. bb. ee.
� How do names pattern? Ergative/absolutive or nomina-tive/accusative?ff.
� How do regular noun phrases pattern?gg.
� How does the Guugu Yimidhirr word for who pattern?hh.
� How do you think you say The boy rolled the rock away?ii.
� How do you think you say The boy got pushed?jj.
� Which sentence best shows that a ST need not be a volitional, con-scious agent but rather just be the subject of a transitive sentence?kk.#
Exercise 9.8.4. Lakhota: Do the agreement markers on the Lakhota verbsin the following data show a nominative-accusative pattern, an ergative-absolutive pattern, or something else? What seems to determine the formsof a marker agreeing with an intransitive subject? What categories do weneed to refer to to predict the forms of a SI? Do you think it is consistentwith our discussion thus far that the grammar should be sensitive to suchissues? Can you propose any alternative accounts based only on structure?
a-ma-ya-phe “you hit me”DIR-1SG-2SG-hit
wa-0-ktékte “I kill him”1SG-3SG-kill

212 ERGATIVITY
0-ma-ktékte “He kills me”3SG-1SG-kill
ma-hîxpaye “I fall”1SG-fall
ma-t’e’ “I die”1SG-die
ma-caca “I shiver”1SG-shiver
wa-škate “I play”1SG-play
wa-nûwe “I swim”1SG-swim
wa-lowa “I sing”1SG-sing
Further Readings
Pullum’s essay is not only entertaining but also very useful for preparing youfor the inevitable moment when someone finds out that you have studied lin-guistics and asks about the massive number of words for “snow” in Eskimo.Mark Baker’s highly accessible book provides an excellent overview oflanguage variation in the context of a theory of Universal Grammar.
� The Great Eskimo Vocabulary Hoax by Pullum (1991).� The Atoms of Language by Mark Baker (2001).

PART IIIUniversal Grammar

This page intentionally left blank

10Approaches to UG: Empirical
evidence
10.1 On the plausibility of
innate knowledge 216
10.2 More negative thoughts 221
10.3 Exercises 233
In previous chapters our main goal was to develop an understanding ofwhat language is. The way we did that was by discussing many issuerelated to the concept of I-language, by drawing on examples from variousindividual I-languages. As mentioned in Chapter 1, however, even thoughelucidating aspects of individual languages is certainly an important task,one that should precede any other task, this is by no means the ultimateaim of linguistics. Linguistic theory has a goal that goes beyond the study ofparticular I-languages, namely to develop an understanding of the humanlanguage faculty itself. I-languages are fairly different from each other,sometimes in unexpected ways, but ultimately they are all human languagesthat can be equally well acquired by any human. This means that theremust be something that all human languages share. The set of the sharedproperties of all I-languages and the study of this topic are both calledUniversal Grammar (UG). Universal Grammar is understood not only asa characterization of the core properties of all languages but also as theinitial state of the language faculty. This latter view of Universal Grammaris intimately related to the way in which language acquisition is accountedfor. Given that any human can acquire any human language, many lin-guists have concluded that there is an initial capacity for learning humanlanguages, some innate knowledge, that all humans share.
In this chapter we provide an example of apparent innate knowledgeoutside of linguistics, in fact from another species, to help make the idea of

216 APPROACHES TO UG: EMPIRICAL EVIDENCE
domain-specific innate knowledge plausible. We then provide another dataanalysis as an indirect argument for specific content of an innate languagefaculty, a Universal Grammar. Here, as elsewhere in the book, we are lessconcerned with the details of specific analyses and specific claims in theliterature concerning both linguistic facts and other phenomena than weare with demonstrating how linguists think and the kinds of evidence thatthey look for. We encourage you to remain skeptical concerning the claimswe present, but we hope to convince you that the overall program is headedin the right direction.
10.1 On the plausibility of innate knowledge
As we pointed out in an earlier chapter, the notion of innate linguisticknowledge, or Universal Grammar, has generated a lot of controversy.Some of this controversy, we hold, arises from a failure to appreciate theI-language perspective. The example of Terry Deacon’s work, discussedin Chapter 4, represents this problem: he has no reason to accept innatelinguistic knowledge or Universal Grammar, since he appears to conceiveof language as existing outside of the minds of speakers. However, thereare also scholars who accept a fundamentally psychological approach tolanguage yet are resistant to the idea that humans have innate knowledgespecific to language. Their position is basically that we are able to learn anduse language because of our general intelligence. Just as we can learn toread, play chess, dance the tango, or interact in social situations, we learnlanguage using cognitive skills that are not specific to a single domain. Itis unlikely that we evolved a tango faculty or a chess faculty, the argumentgoes, and it is equally improbable that we have a specific faculty dedicatedto language.
There are two aspects to this view that we want to address in this section.First, we want to argue that general intelligence is not enough to learn justany skill. Second, we want to show that domain-specific innate knowledgedoes appear to exist elsewhere, and thus is at least plausible.
10.1.1 Is it enough to be very smart?
Humans have large brains and we like to think of ourselves as very smart.In general, though, we know that a larger machine or tool cannot always

ON THE PLAUSIBILITY OF INNATE KNOWLEDGE 217
Fig 10.1 Oonagh and Baby Z are raised in a very similar environment.
perform the functions of a smaller one—a large hammer cannot do whata small screwdriver can and most steamrollers do not allow you to sendtext messages as well as a compact cellphone does. If you want differentfunctions, you need more than size, you need built-in specialized properties.Now the question becomes whether having and using a language is a funda-mentally different type of function from dancing a tango—we’ll explore thistopic in the next chapter. For now we will make some suggestive remarksconcerning domain-specific knowledge.
Consider the two organisms in Fig. 10.1. Baby Z (left) was about twoyears old when this picture was taken and Oonagh was about nine. Therewere many similarities in how they were treated:
� Baby Z and Oonagh often shared the same food.� Baby Z and Oonagh went out on the mountain every day.� Baby Z and Oonagh received a lot of physical attention, including hugs,
caresses, and grooming.� Baby Z and Oonagh both have heard people speaking to them and
around them.
Of course, Oonagh had this wonderful upbringing for a lot longer than Zhas—nine years as compared with two years. Perhaps this explains whyOonagh has certain skills that Z does not have. For example, when wetake her onto the mountain, she knows where to find groundhogs and how

218 APPROACHES TO UG: EMPIRICAL EVIDENCE
to sneak up on them and catch them. However, when we think back, werealize that Oonagh already knew how to hunt when she was Z’s age. Onepossibility is that Z is a slow learner; another is that he lacks Oonagh’sinnate knowledge that turned her into an expert hunter with no instruction.
On the other hand, at the time this picture was taken, after nine years ofexposure to language, Oonagh appeared to understand and sometimes obeyabout five words in one language. Z, in contrast, appeared to understandseveral hundred words in three languages, and also to produce many stringsof words in orders consistent with the language from which they weredrawn.36
In the following year, Oonagh seemed not to progress at all, whereas Z’svocabulary expanded and his sentence structures become complex enoughthat we could make remarks like “Notice that he inverts subject and aux-iliary verb in wh-questions like Who did Sissy call? but he doesn’t invertin Yes/No questions, but rather begins with if as in If Sissy can give mea cookie? to mean ‘Can Sissy give me a cookie?’.” We also noticed thathe started using negative polarity items in the way that we use them—Idon’t want any, instead of I don’t want some—at around two years and ninemonths old. We have no evidence that Oonagh is sensitive to the differencebetween some and any.
Note that Oonagh has much better hearing than Z, including sensitivityto a wider frequency range. It seems to us that externalist perspectives onlanguage, something like Deacon’s view that posits that language is “outthere” in the world, would lead us to expect that Oonagh’s better hearingand longer experience would have given her better access to language. It hasnot. We can attribute her linguistic failure to a lack of intelligence, but thenwe should do the same with respect to Z’s hunting failure. They are bothwell fed and coddled, so neither has any obvious survival motivation toeither talk or hunt. They just seem to be endowed with different propertiesthat develop as they grow up, one as a dog and one as a kid. One of thekid-properties seems to be a language faculty.
10.1.2 Bird brains
We will now move on to other animals, geese, in order to demonstrate theplausibility of innate knowledge in other species. If you cut out a cardboard
36 In spite of his much more extensive linguistic knowledge, his obedience levelsmatched Oonagh’s.

ON THE PLAUSIBILITY OF INNATE KNOWLEDGE 219
−→ hawk
←− goose
Fig 10.2 Instinct (Innate Knowledge) in goslings.
shape like that in Fig. 10.2 and move it right to left over a cage of newlyhatched goslings, the baby birds do not react. However, if you move itleft to right, the goslings appear to panic and run for cover. It just sohappens that such a shape moving left to right resembles the silhouette of ahawk, a bird of prey that hunts goslings, whereas moving in the other direc-tion, the shape resembles the silhouette of a goose or other non-predatorybirds.
It is a commonplace to ascribe such reactions to “instinct.” Clearly, themother birds while sitting on the eggs (if they were indeed present in thelaboratory where these birds were raised) did not tap a message on the shellof the egg in some kind of bird version of Morse code explaining to theunhatched gosling “If you see a shape like this, moving towards the longend, run like crazy, but if it moves the other way, you can relax.” Somehow,God or evolution has arranged things so that the goslings have some kind ofknowledge of shape and motion that underlies their behavior—it’s not thatthey think “Hey, that looks like a hawk, I better find cover,” but it seemsreasonable to say that they know something about that shape, or rather anequivalence class of perceived shapes, and that their knowledge leads themto act in a certain way.
This knowledge is not learned, and thus is innate, and it is very domain-specific—it has to do with shapes and motion perceived visually. If we arewilling to attribute this complex quality of domain-specific innate knowl-edge to bird-brained goslings, it seems unjustified to deny the possibil-ity that humans, too, have innate domain-specific knowledge, perhaps forlanguage.

220 APPROACHES TO UG: EMPIRICAL EVIDENCE
10.1.3 An experiment of nature
If we want to claim that it is the structure of the human brain that allowsthe development of language and not just its size, then it is interesting to askwhat would happen if an organism had a brain with human structure, butin miniature. Unfortunately, nature has performed this experiment in thegenetic defect of Seckel syndrome, also called nanocephalic or bird-headeddwarfism.
Most cases of dwarfism result in a body that is disproportionate with thehead. The head and brain are normal in size and intelligence is unaffected.Seckel syndrome, in contrast, results in a head that is proportionate insize to the body and thus is much smaller than that of normal humans.Subjects with Seckel syndrome suffer from severe mental retardation, butare reported to acquire language relatively normally—there is some delayin reaching developmental milestones, but the language acquired has nor-mal syntax, morphology, and phonology. This suggests that the structureof the brain, not its absolute size, is what allows for the acquisition ofhuman language. Perhaps it is more clear to say that a human brainwill have a human language faculty, thus focusing on what is presentfrom birth, rather than on the details of particular languages that may beacquired.
One implicit assumption of the preceding discussion is that knowledge iscorrelated with the physical properties of the brain. Given this assumption,our discussion thus far is meant to suggest the following:
� the existence of innate knowledge is plausible� the existence of domain-specific knowledge is plausible� the structure of the human brain results in or is correlated with human
cognitive capacities including innate linguistic knowledge.
For some reason, such a claim tends to evoke much less controversy if wereplace human with canine and linguistic with hunting knowledge. However,there seem to be no good reasons for this difference, aside from an emo-tional attachment to maintaining for humans a unique place in the world.For real understanding of what we are, we find it almost trivially obviousthat we need to consider the human mind and brain as objects of the naturalworld.

MORE NEGATIVE THOUGHTS 221
10.2 More negative thoughts
In the previous sections we argued for the plausibility of innate knowl-edge arising from the structure of a normal human brain. In this section,we invoke a very different kind of argument for innate knowledge, butone that is also based on empirical considerations. Bear with us as wework through yet another data set—we return to the discussion of neg-ative polarity items, a category introduced in Chapter 6. Our goal is tomake explicit in syntactic terms what it means for a NPI to “be in” adownward-entailing environment. We will show you that the distributionof NPIs like ever or anything, as opposed to sometimes or something, canbe accounted for by using the same kinds of primitives as the ones weneed for describing the distribution of anaphors like himself or herself.The existence of such primitives, that turn out to be crucial for analyzinga number of apparently unrelated phenomena not only in English butin all languages, constitutes empirical evidence for the existence of Uni-versal Grammar. Keep in mind that, although we may get mired in thedetails of analyzing specific English words, we are doing so with a muchloftier goal—we are trying to discover some of the content of UniversalGrammar.
Let’s start with what we already know about the distribution of NPIs:their occurrence can be correlated with downward-entailing environments,that is, with environments that license an inference from supersets to sub-sets, like the following:
10.1 � If Davey is wearing (any) footwear, he is in trouble. ⇒� If Davey is wearing (any) socks, he is in trouble.
The question we are asking now is whether this licensing relation hasany syntactic correlates? In other words, is there any particular syntac-tic element that determines the downward-entailing properties of a par-ticular sentence? And, correlatively, if downward entailment is relatedto such an element, what exactly does it mean to say that NPIs arelicensed by this element? As usual, we will simplify the discussion—inthis case by focusing on only one NPI—the adverb ever, and only onedownward-entailing context—negative sentences. However, at the end ofour demonstration based on negative sentences we will discuss ways of

222 APPROACHES TO UG: EMPIRICAL EVIDENCE
generalizing the conclusions to the other downward-entailing contexts aswell.
You should now be an expert in the process of hypothesis formation andtesting, so what we will do is to show you the relevant data and just providesome guidance. Consider the sentences in (10.2).
10.2 a. Nobody ever saw Davey.b. Sami didn’t ever see Davey.c. Sami didn’t see Davey ever.d. *Sami ever saw Davey.e. *Sami saw Davey ever.
Make a co-occurrence hypothesis about the distribution of ever. In otherwords, the grammatical sentences (10.2a.-c.) contain a certain kind ofelement lacking in the ungrammatical strings (10.2d.e.). Make an initialhypothesis:
10.3 Hypothesis I: ever can occur only if the sentence contains . . .
Here’s another string that should be grammatical by Hypothesis I but isnot.
10.4 f. *Davey ever sees nobody.
Propose an alternative to Hypothesis I that accounts for all the examplesconsidered thus far. Refer to linear order in formulating this second hypoth-esis.
10.5 Hypothesis II: ever can occur only if . . .
Here again are some more examples.
10.6 g. *Mary claims that Sami ever sings.h. Mary claims that Sami doesn’t ever sing.i. Mary doesn’t claim that Sami ever sings. [= She does not claim “Sami
sometimes sings.”]
Is this data consistent with Hypothesis II? Explain how Hypothesis IIapplies to each of these examples.
Now consider the following:

MORE NEGATIVE THOUGHTS 223
10.7 j. *A man I don’t know claims that Sami ever sings.k. I never said that Sami ever sings.l. *A man who never did anything nice said that Sami ever sings.
Is this data consistent with Hypothesis II? Explain how Hypothesis IIapplies to each of these examples.
Here are some more examples.
10.8 m. Davey does not believe Sami ever sings.n. Davey agrees that Fred does not know that Trevor insists that Mary
believes that Sami ever sings.
By now you should see that we need a new hypothesis. FormulateHypothesis III that will account for all the examples seen so far. It must tellus why grammatical sentences are grammatical as well as why the ungram-maticals are ungrammatical. You will need to make a proposal concerningthe position in the tree for negative words like not and n’t—let’s assume thatthey are in a position that c-commands the main VP. Here is the tree forsentence (m):
10.9 Position of negationS
NP
N
Davey
AuxP
Aux
does
VP
NegP
Neg
not
VP
V
believe
S
NP
N
Sami
VP
AdvP
Adv
ever
VP
V
sings

224 APPROACHES TO UG: EMPIRICAL EVIDENCE
And here is another sentence with negation expressed by the NP nobody:
10.10 Nobody ever said Sami ever accepted the offer.S
NP·
N
Nobody
VP
AdvP
Adv
ever2
VP
V
said
S
NP
N
Sami
VP
AdvP
Adv
ever1
VP
V
accepted
NP
Det
the
NP
N
offer
10.11 Hypothesis III: ever can occur only if . . .
First, confirm that your Hypothesis III works for the earlier cases as well(i.e. 10.2–10.8). Then use Hypothesis III to explain why each instance of everin (10.10) is grammatical. You can see that the negative expression nobodythat is NPa c-commands both ever1 and ever2.
Now use Hypothesis III to explain why each instance of ever in thefollowing sentence is ungrammatical:
10.12 *A man who loves nobody ever said Sami ever accepted theoffer.
Here is the tree:

MORE NEGATIVE THOUGHTS 225
10.13 No c-command∗S
NP
Det
A
NP
N
man
S
who loves nobody
VP
AdvP
Adv
ever
VP
V
said
S
NP
N
Sami
VP
AdvP
Adv
ever
VP
V
accepted
NP
Det
the
NP
N
offer
If you formulate Hypothesis III correctly you can now combine this resultwith our discoveries in Chapter 8 to construct a 2 × 2 table as in (10.14).
10.14 � her—must not be in a local c-command relation (may be c-commanded,but not locally)
� herself —must be in a local c-command relation� the girl—must not be c-commanded� ever—must be c-commanded
Locality crucial Locality irrelevantMust be c-commanded herself everMust NOT be c-commanded her the girl
Some expressions, anaphors like herself, need to be in a local c-commandrelation with a coindexed antecedent; regular pronouns like her cannotbe locally c-commanded by a coindexed antecedent; referring expressionslike the girl must not be c-commanded at any distance by a coindexedantecedent; and we now have found that negative polarity items like evermust be c-commanded by a negative element, but that locality does notmatter.
The conditions on the appearance of the word ever actually apply to thewhole set (the equivalence class) of words known as negative polarity items

226 APPROACHES TO UG: EMPIRICAL EVIDENCE
(NPIs). As we saw in Chapter 6, other NPIs include any, anybody, anything,yet, at all, etc. For now, we can assume that Hypothesis III generalizes asfollows:
10.15 NPIs like ever must be c-commanded by a NEGATIVE word.
Before we conclude on NPIs, we want to address one more point.Hypothesis III takes care of NPIs occurring in negative contexts, but whatabout the other contexts that license NPIs? We know already that theright semantic generalization is that NPIs are licensed by contexts thatare downward-entailing. Negative contexts are just a particular exampleof downward-entailing environments, but the latter are not reduced to theformer. There are other downward-entailing contexts, such as the onesbelow, that also license NPIs.
10.16 a. Davey left without ever saying goodbye.b. Few people ever impressed Davey as much as Sami.c. Davey thinks before he ever says anything.d. If Sami ever calls, Davey dances gracefully.
How can we generalize Hypothesis III to these contexts? There are twocrucial parts to consider: (1) each sentence has an item that triggers adownward-entailment context; and (2) in each case NPIs can only occurin the domain c-commanded by the trigger.
We can tease apart these two aspects by first replacing the trigger with anelement that does not trigger downward entailment, as in (10.17). Compareeach sentence to its correspondent in (10.16):
10.17 a. *Davey left by ever saying goodbye.b. *Many people ever impressed Davey as much as Sami.c. *Davey thinks after he ever says anything.d. *Sami ever calls, if Davey dances gracefully.
In (10.16a.) the relevant item that renders the context downward-entailing is without; in (10.16b.) it is few; in (10.16c.) it is before; andin (10.16d.) it is if. The effect that these items have on the sentence inwhich they occur is the same as the effect that a negative element has. Wecall such items downward-entailing operators. In the corresponding exam-ples in (10.17) we have replaced these items with ones that do not trig-ger downward entailments (10.17a.-c.), or we have moved the downward-entailing operator to the other clause (10.17d.). In each case the result isungrammatical.

MORE NEGATIVE THOUGHTS 227
So, we need a downward-entailing operator to be present, but at this pointyou will not be surprised to know that the operator has to be in a particularposition with respect to the NPI—it must c-command the NPI. Withoutgoing into all the details, you can probably see that the downward-entailingoperator in the following examples clearly does not c-command the NPI,and thus the results are ungrammatical.
10.18 a. *Davey ever left without saying goodbye.b. *Davey ever impressed few people as much as Sami.c. *Davey ever thinks before he says anything.d. *Sami ever calls, if Davey dances gracefully.
Let’s review by concentrating on the (c.) sentences of (10.16, 10.17,10.18). In (10.17c.), after is not a downward-entailing operator andthis cannot license the presence of ever, so the string is ungrammat-ical. In (10.18c.) we have a downward-entailing operator, before, butit does not c-command ever—(10.19) is the tree structure we propose,with before occupying what is called a complementizer (Comp) posi-tion at the beginning of an S′, similar to the position of the connec-tors introduced in Chapter 6. The NPI c-commands before, but not viceversa.
10.19 Potential tree for (10.18c.)∗S
NP
N
Davey
VP
AdvP
Adv
ever
VP
V
thinks
S′
COMP
before
S
NP
N
he
VP
V
says
NP
N
anything

228 APPROACHES TO UG: EMPIRICAL EVIDENCE
In contrast, the tree for the grammatical (10.16c.) has the NPIs ever andanything c-commanded by the downward-entailing operator before.
10.20 Tree for (10.16c.)S
NP
N
Davey
VP
V
thinks
S′
COMP
before
S
NP
N
he
VP
AdvP
Adv
ever
VP
V
says
NP
N
anything
In this sentence, and the rest of the examples in (10.16), there is adownward-entailing operator present and it c-commands the NPI. We thushave found the general version of Hypothesis III:
10.21 NPIs must be c-commanded by a downward-entailing operator.
Note that a single operator can license more than one NPI, as shown by theoccurrence of both ever and anything in this example.
To review, we have identified two equivalence classes, downward-entailingoperators and NPIs, as well as the c-command relation, which is relevant tothe relation between members of these two categories.
Imagine someone had asked you, before you studied any linguistics, ifyou thought there could be any significant generalization that governedthe distribution of a pronoun like anybody, adverbs like ever or yet, and

MORE NEGATIVE THOUGHTS 229
prepositional phrases like at all. Not only have we discovered that theyare subject to the same condition—c-command by a downward-entailingoperator, but we have also shown that their distribution can be capturedby using the same primitives that are needed to explain the distribution ofexpressions like her, herself, and the girl.
At this point, you might be convinced that c-command is a primitivethat is needed for the analysis of several phenomena, such as the distri-bution of anaphors and pronouns, or the distribution of NPIs, but youmight still be skeptical about the actual universality of these categoriesand the c-command relation. After all, we have only shown you Englishexamples.
Consider now the following examples from Modern Greek.
10.22 a. *I Ilektra enekrine kanena sxedhio.the Electra approved any plan
b. I Ilektra dhen enekrine kanena sxedhio.the Electra not approved any plan“Electra didn’t approve any plan.”
c. O papus pethane xoris na dhi kanena apo ta egonia tuthe grandfather died without subj. see any from the grandchildren his“My grandfather died without seeing any of his grandchildren.”
d. O papus pethane prin na dhi kanena apo ta egonia tuthe grandfather died before subj. see any from the grandchildren his“My grandfather died before seeing any of his grandchildren.”
e. An his tin Ilectra puthena, na tis pis na me perimeniif see the Electra anywhere, subj her tell subj me wait“If you see Electra anywhere, tell her to wait for me.”
f. Elaxisti fitites idhan tipota.very-few students saw anything“Very few students saw anything.”
Just as in English, Greek NPIs must be c-commanded by a downward-entailing operator. In (10.22a.), the example includes no downward-entailing operator at all, and this explains why the occurrence of kanenain this context leads to ungrammaticality. In (10.22b.), kanena “any” isc-commanded by the downward-entailing operator dhen “not;” in (10.22c.)by xoris “without;” and in (10.22d.) by prin “before.” The NPI illustratedin (10.22e.) is puthena “anywhere,” and the latter is c-commanded by thedownward-entailing operator an “if,” while in (10.22f.), the NPI tipota“anything” is c-commanded by the downward-entailing operator elaxisti“very few.”

230 APPROACHES TO UG: EMPIRICAL EVIDENCE
We have not provided a proof that Greek works in exactly the sameway as English with respect to NPIs, and, as usual, there are complicatingfactors as we look at NPIs cross-linguistically. Nonetheless it is striking thatdownward entailment and c-command should recur as necessary compo-nents of the explanations. It is at least plausible that this recurrence reflectsa deep fact about the kinds of generalizations that the language facultyencodes.
So, c-command is clearly not restricted to English. We now show twonew non-English phenomena which require appeal to c-command: nounincorporation and phonological “liaison.”
Noun incorporation is a phenomenon in which a noun root appearsinside of a complex verb form. Although we have presented word for-mation within the domain of morphology, in many cases, the distinctionbetween morphology and syntax is still being explored in current research.In simplified terms, the generalization, due to Mark Baker (2001:90ff.),is
10.23 Noun incorporation: Incorporated nouns are copies ofnouns that meet the following conditions:� they are bare nouns, nouns that occur without modifiers� their base position is that of the nearest NP to the verb which is c-
commanded by the verb.
Consider the following Mohawk examples, where the slightly varyingboldface form means “meat”:
10.24 a. Owiraa wahrake ne owahru.Baby ate the meat
b. Owiraa wahawahrake.Baby meat-ate
c. *Wahawirake ne owahru.Baby-ate the meat
In (10.24a.) the noun is not a bare noun, since there is an article presentin the NP, so incorporation cannot apply. In (10.24b.) the base positionof “meat” would be the object position, which is c-commanded by theverb. Since the c-command condition is met, and since this is a bare noun,incorporation occurs. The subject noun cannot be incorporated, in (10.24c),since the subject NP c-commands the verb and is not c-commanded by it.

MORE NEGATIVE THOUGHTS 231
As a final dramatic example of the universality of c-command, considerthe phenomenon of liaison in French. Liaison refers to the presence ofcertain consonants that are pronounced at the end of a word when thefollowing word begins with a vowel. Before a consonant-initial word theconsonant is not pronounced. The string le marchand de draps anglais cor-responds to two meanings in French.
10.25 lethe
marchandmerchant
deof
drapscloth
anglaisEnglish
This can mean “the English merchant of cloth” or “the merchant of Englishcloth.” When it has the first meaning, the s at the end of draps is notpronounced, but when it has the second meaning, the s is pronounced(as z).
Now examine the trees that correspond to these two meanings. If themeaning is “English merchant of cloth” then anglais modifies the NP marc-hand de draps and thus they are sisters in the tree, as in (10.26).
10.26 � [Le [[marchand [de draps]] anglais]]� the English cloth seller
NP
D
le
NP
NP
N
marchand
PP
P
de
NP
N
draps
AP
A
anglais
However, if anglais modifies draps then these two words must be sisters, asin (10.27).

232 APPROACHES TO UG: EMPIRICAL EVIDENCE
10.27 � [Le [marchand [de [draps anglais]]]]� the seller of English cloth
NP
D
le
NP
N
marchand
PP
P
de
NP
NP
N
draps
AP
A
anglais
We are not going to attempt to prove that we have the correct analy-sis, but just note that in (10.27), the NP draps c-commands the adjec-tive, and that is where we get the liaison consonant z. We suggestthat the c-command relation is a necessary condition for liaison tooccur. In (10.26) draps does not c-command anglais and liaison cannotoccur.
If our suggestion is correct concerning c-command as a condition onliaison, then it now appears that this structural relation is found acrossconstructions and across languages—it is a good candidate as a basiccomponent of Universal Grammar. There is no logical reason why c-command should recur in construction after construction and in languageafter language. There is also no reason that relates the recurrence of c-command to the fact that we sometimes use language for communica-tion. It just appears to be an arbitrary property of the language fac-ulty that linguists have discovered—its very arbitrariness makes it mostinteresting.
Appealing to c-command really does allow us “to abstract from the welterof descriptive complexity certain general principles governing computationthat would allow the rules of a particular language to be given in very

EXERCISES 233
simple forms” (Chomsky 2000b:122), which is the ultimate goal of linguistictheory. In addition, we must recognize that the relation of c-command isnot present in the acoustic signal—it is a very abstract relation definedover the abstract tree structures that the mind constructs. The fact that c-command is not detectable in the signal and the fact that it is not taughtto kids by their parents make it a good candidate for an aspect of innateknowledge.
In conclusion, we have provided two kinds of empirical evidencefor the plausibility of innate knowledge. First, we have argued thatinnate knoweldge is found in animals, for example in the differentialreactions shown to various shapes without any prior experience. Sec-ond, we argued that the recurrence of patterns like c-command rela-tions across languages and across syntactic constructions suggests theuse of a toolkit of primitives from which the patterns of language areconstructed.
10.3 Exercises
Exercise 10.3.1. Complex syntax of NPIs: Consider the following exam-ple. Draw a tree with as much detail of structure as you can argue for.Explain why each instance of ever is well formed in accordance with thefinal hypothesis developed in the chapter. Discuss any complications thatthis example presents.
10.28 Nobody who ever did anything nice ever said Sami sings.
Exercise 10.3.2. “Mixed” languages: Mark Baker, author of Atoms ofLanguage, proposes that Universal Grammar determines that languagesshould be either head-initial (with prepositions and verbs before theirobjects etc.) or head-final (with postpositions and verbs after their objectsetc.). Amharic, however, shows properties of both types. To explain suchmixed cases Baker says
Amharic, for example, is a Semitic language, related to pure head-initial lan-guages like Arabic and Hebrew but spoken in Africa, in the environmentof head-final Cushitic and Nilo-Saharan languages. The conflict of histori-cal and geographic influences could partially explain why Amharic is a mixedcase.

234 APPROACHES TO UG: EMPIRICAL EVIDENCE
What do you think of Baker’s proposal in the context of the I-languageapproach?
Further Readings
� Canty and Gould (1995) discusses the original goose/hawk findingsfrom 1939 and 1948, as well as problems with attempts to reproducethe effect.

11Approaches to UG: Logic
11.1 Let’s play cards 238
11.2 Where does this leave us? 245
11.3 Building blocks in other
domains 247
11.4 Exercises 248
In Chapter 10 we argued that evaluation of c-command relations is a fun-damental component of the human language faculty, on the basis of itsrecurrence in accounting for a wide range of phenomena in various lan-guages. We did not actually address the issue of how individual languagesare acquired, but instead implicitly adopted the approach that we haveto first get an understanding of what language is before we ask how it isacquired or used.
It is common in discussions of Universal Grammar and innateness torefer to the speed and ease with which children learn language or the factthat the ability to learn languages appears to deteriorate as adulthoodapproaches. We have not based any arguments on such notions, since theyseem to us to be imprecise—kids learn language fast compared to what? Ifit took twice as long as it does, would that be an argument against innate-ness? Also, it appears that much of what we impressionistically think of aslanguage acquisition is really just maturation of the performance systemsand acquisition of lexical items—young infants do not know any wordsand they spend a lot of time, as Melancholy Jacques says, mewling andpuking, so it is hard to get much evidence about their underlying linguisticcompetence.

236 APPROACHES TO UG: LO GI C
In this chapter we take a very different approach to arguing for the exis-tence of Universal Grammar—we try to argue that it is a logical necessitythat there exist some substantive knowledge specific to language prior towhat we call language acquisition.
The idea that it is possible to develop a non-trivial Universal Grammar isnot necessarily tied to the notion of innateness. Under non-internalist viewsof language, views that reject the I-language perspective we developed inPart I, there could potentially be universal aspects of language accordingto some other definition. For example, if one adopted the view of lan-guages as Platonic ideals existing apart from speakers, then, presumably,it would be possible that all these P-languages could have some commonproperties, whatever it is that makes them languages, that nothing else has.However, the notion of Universal Grammar in the context of the I-languageperspective seems to us to necessarily lead to what is sometimes called theInnateness (or Nativist) Hypothesis for language, the idea that (non-trivial)aspects of the linguistic competence of every human are derived from thegenetic endowment that makes us human, just as aspects of our visualsystems and our digestive systems are dependent on the human genome.
Basically, the Innateness Hypothesis for language states that a plausi-ble source for those aspects of mental grammars that are universal andunlearnable is genetic inheritance. Human languages are constrained andpartially determined by our genes. The same is true for the communicationsystems, visual systems, and digestive systems of whales, dogs, birds, andcockroaches, too.
It is hard to imagine how anyone could object to the Innateness Hypoth-esis, thus described. In some sense it could be taken as a description ofa research topic, rather than a hypothesis: it is clear that there is such athing as a human language faculty and it must have some initial state beforethe effects of individual experience; Universal Grammar attempts to under-stand that initial state. However, we want to take an even stronger position.We want to argue that it is a logical necessity that there be a body of innateknowledge that is specific to language (obviously not particular languages).We will demonstrate this by explicating a position we refer to as the Innate-ness of Primitives Principle (IofPP). One formulation of IofPP comes fromRay Jackendoff (1990:40): “In any computational theory, ‘learning’ canconsist only of creating novel combinations of primitives already innatelyavailable.”

APPROACHES TO UG: LOGIC 237
We will demonstrate the logical necessity of IofPP with a set of model lan-guages. The chain of reasoning we will pursue in explicating the IofPP canbe summarized as follows. Intelligence (by which we mean merely cognition)consists of the construction and manipulation of symbolic representations.Interacting intelligently with the world requires the ability to parse input(assign it a representation). Learning is a form of intelligent interactionwith the world, thus learning requires parsing inputs into representations.Without an innate set of representational primitives, learning cannot begin.
As you surely appreciate by now, actual human languages are quitecomplex, so we will discuss IofPP in light of a set of toy languages. Incharacterizing these languages we need to keep in mind the notion ofequivalence classes corresponding to features like those we discussed inour characterization of vowels when we analyzed Turkish vowel harmonyin Chapter 6. Linguists are far from agreeing on what the proper set oflinguistic features are, and there are many kinds of feature systems proposedin the literature, for both syntax and phonology. In addition to our mainpoint concerning innateness, we hope that the following discussion willalso provide you with some insight into the various possibilities for featuresystems that you may encounter as you learn more about linguistics.
In our discussion of vowels we introduced paired features like ROUND
and NON-ROUND. More typically such pairs are described as valuationsof a single binary feature [± ROUND]—vowels can be [+ROUND] or[−ROUND]. Another way to describe a symbol like [+ROUND] is as anattribute-value pair: ROUND is an attribute and it can have the value “+”or “−”. Features can be binary or have more values, for example, somesystems assign vowels any one of three values for height, as opposed tothe HIGH vs. NON-HIGH contrast we set up in our discussion of Turkish.But our discussion also hinted at the possibility of privative features thatare either present or absent, attributes that cannot take different values. Inthe following discussion you will see some of the implications of choosingone or another feature system. Finally, our discussion of Turkish implicitlymade use of another tool of feature theory, underspecification. We allowedsegments to be either fully specified for all attributes, for example a HIGH,FRONT, ROUND vowel in a word root; or partially underspecified, forexample, the NON-HIGH, NON-ROUND vowel of the plural suffix thatonly received its valuation for FRONT or NON-FRONT by copying it froma vowel to its left.

238 APPROACHES TO UG: LO GI C
11.1 Let’s play cards
In this section we illustrate the logic the Innateness of Primitives Principlestatement by using model languages consisting of sets of playing cards froma normal deck. In our analogy, cards correspond to strings of words ofnatural languages. From our point of view as observers, a card c will begrammatical, ungrammatical, or neither to a “speaker” of a card grammarG. The reason for the third possibility (‘neither’) will become clear below.We further assume that learners of these “card languages” are endowedwith an innate card language faculty. We will explore the effect of tin-kering with “card UG” below. In general, UG will consist of types ofsymbols and logical operators for symbols. Our assumptions are sketchedin (11.1).
11.1 General Principles:� Each card is grammatical, ungrammatical, or neither.� A grammar is a set of conditions on cards.� UG is a set of primitives, including:� types of symbols (features)� logical operators defined over these symbols
� A card c is “grammatical” with respect to a grammar G iff c satisfies theconditions imposed by G. In such a case we will say, informally, that c is“in G.”
We will now explore how the nature of “card UG” limits the set of possiblelanguages available to a learner.
11.1.1 UG1
Assume first that UG makes available to the learner the (privative) fea-ture NUMBERCARD which characterizes cards that bear the numbers twothrough ten. Further assume that UG makes available the four suits: clubs,diamonds, hearts, spades (♣,♦, ♥, ♠). These also function as privativefeatures.37 Finally, assume that UG makes available the logical operatorAND, which allows for the conjunction of features in structural descriptions.We call this version of universal grammar UG1.
37 Note that only one of these suit features can characterize any given card. Wecould equivalently propose an attribute SUIT that can be paired with one of fourvalues, ♣, ♦,♥, ♠.

LET’S PLAY CARDS 239
11.2 UG1� Features:
NUMBERCARD
♣, ♦, ♥, ♠� Operators: AND
11.1.1.1 Possible grammars given UG1 Now consider some possible gram-mars, given the definition of UG1. Our first grammar is G1, which ischaracterized as follows: G1 = [NUMBERCARD]. This is to be read as “Asentence/card is in G1 if and only if it is a numbercard.” So, the king ofdiamonds is ungrammatical in G1. This is because a king is not a number-card. On the other hand the six of diamonds and the three of clubs are bothgrammatical in G1.
Consider a second possible grammar G2, characterized as follows: G2 =[NUMBERCARD AND ♦]. This is to be read as “A sentence/card is in G2
if and only if it is a diamond numbercard.” In this grammar the king ofdiamonds is still ungrammatical, but so is the three of clubs. The six ofdiamonds is obviously grammatical.
Now consider G3, defined as follows: G3 = [♠]. That is,“A sentence/cardis in G3 if and only if it is a spade.” It is obvious what the grammaticalsentences of this grammar are, but we now ask: What is the representationof 5♠? K♠? 5♣? The answers are [NUMBERCARD AND ♠], [♠] and *[NUM-BERCARD AND ♣],38 respectively. Only the third is ungrammatical, since itis not a spade.
Finally, consider G4, which is characterized by no features at all. Inother words, it places no restrictions on which cards are grammatical:G4 = [ ]. That is to say “Every sentence/card is in G4.” But now, is thiscompletely true? The answer is that it is true of all the cards character-izable by UG1, say the fifty-two cards that can be assigned a represen-tation given UG1. However, a tarot card or even a joker would not begrammatical in G4, given UG1. (Thinking ahead a bit, what would theirrepresentation be?)
38 We are assuming that the learner retains access to the UG-given features, even ifthese features are not used in the acquired language. Rejecting this assumption would notsubstantively affect the argument, but would unnecessarily complicate the exposition. Weare indebted to Afton Lewis for discussions on this point.

240 APPROACHES TO UG: LO GI C
11.1.1.2 Impossible grammars given UG1 Since any given UG delimits theset of possible grammars, it is also instructive to consider a few impossiblegrammars, under the assumption of UG1. Consider first (non-)grammarF1 described as follows: F1 = [PICTURECARD]. In other words, “A sen-tence/card is in F1 if and only if it is a picturecard.” Clearly this is animpossible grammar, since UG1 does not provide for a class of all andonly picturecards. (Recall that NUMBERCARD is privative by hypothesis.)Similarly, consider F2 = [NUMBERCARD OR ♦]: “A sentence/card is inF2 if and only if it is a numbercard or a diamond (or both).” This isan impossible grammar since UG1 does not provide the logical operatorOR. Next consider a potential grammar with severely limited expressivecapacity: F3 = [6 AND ♠], that is “A sentence/card is in F3 if and only ifit is the six of spades.” This grammar is impossible given UG1 since UG1does not provide the means to represent a six as different from any othernumber.
11.1.2 UG2
Now imagine another species endowed with a different universal grammarcalled UG2, characterized by the following features: [±PICTURE], which isequivalent to having the mutually exclusive privative features [NUMBER-CARD, PICTURECARD], and [±RED], which is equivalent to having themutually exclusive features [RED, BLACK]. UG2, like UG1, provides theoperator AND.
11.3 UG2� Features:
[±PICTURE][±RED]
� Operators: AND
11.1.2.1 Some possible grammars given UG2 A possible grammar givenUG2 is G5 = [+RED AND −PICTURE]: “A sentence/card is in G5 if and onlyif it is a red numbercard.” What is the representation of 7♦ in this gram-mar? What about 7♥? And 7♠? The answers are [+RED AND −PICTURE],[+RED AND −PICTURE] and ∗[−RED AND −PICTURE], respectively. Sincethe suits are not distinguishable given UG2, the learner parses the two redcards as [+RED]. Since the numbers are indistinguishable given UG2 (as

LET’S PLAY CARDS 241
was the case with UG1) the fact that the three cards in question are allsevens is lost to the learner. They are all just [−PICTURE]. Now considerG6 = [+RED]:“A sentence/card is in G6 if and only if it is a red card.” Thisgrammar will include all the red cards, hearts and diamonds, number andpicturecards, though of course these distinctions are not made by creaturesendowed with UG2—they are only made by beings like us whose geneticendowment equips them to represent such contrasts.
11.1.2.2 Some impossible grammars given UG2 It should be easy now tosee that the following two potential grammars are impossible given UG2.
� F4 = [♠]“A sentence/card is in F4 if and only if it is a spade.”
� F5 = [+PICTURE OR −RED]“A sentence/card is in F5 if and only if it is a picturecard or a black card (orboth).”
The first is impossible since UG2 does not distinguish the suits; the second,because UG2 does not provide OR. Note, however, that although F4 isimpossible assuming UG2, its specification is identical to the grammar G3
which is allowed by UG1. So, again, the nature of UG determines the set ofpossible grammars.
11.1.3 UG3
We leave it to the reader to confirm that the following characterization of athird UG, UG3, allows for G7, G8, and G9, but excludes F6, F7, and F8.
11.4 Description of UG3� Features:
[PICTURECARD][2,3,4,5,6,7,8,9,10][±RED]
� Operators: AND, OR
11.5 Some possible grammars given UG3:� G7 = [+RED AND 9]
“A sentence/card is in G7 if and only if it is a red nine.”� G8 = [−RED AND PICTURECARD]
“A sentence/card is in G8 if and only if it is a black picturecard.”� G9 = [PICTURECARD OR +RED]. “A sentence/card is in G9 if and only if
it is a red card or a picturecard (or both).”

242 APPROACHES TO UG: LO GI C
11.6 Some impossible grammars given UG3:� F6 = [♠]
“A sentence/card is in F6 if and only if it is a spade.”� F7 = [NUMBER]
“A sentence/card is in F7 if and only if it is a numbercard.”� F8 = [−RED AND Q]
“A sentence/card is in F8 if and only if it is a black queen.”
It is worth pointing out that, given UG3, it is possible to acquire agrammar that is extensionally equivalent to F7, call it G10: “A sentence/cardis grammatical if it is [2 OR 3 OR 4 OR 5 OR 6 OR 7 OR 8 OR 9 OR 10].” Ofcourse, as we discussed in Chapter 4, the I-language perspective allows us toset as our goal the discovery of the “correct” model of a speaker’s grammar,one that is, for example, compatible with a theory of UG that underliesall human languages. Thus if a creature endowed with UG3 appeared tohave a grammar extensionally equivalent to F7 and G10, we would knowthat the correct characterization of this grammar would be the latter andnot the former. We have accessible the term “numbercard” but the speciesendowed with UG3 does not. So, we have demonstrated how the nature ofUG limits the set of possible grammars—the set of achievable final states ofthe language faculty is partially determined by what is present at the initialstate.
11.1.4 An impoverished UG4
Now imagine that UG4 provides only a single privative feature: [♦]. Whathappens if we expose a learner to 5♦? The learner parses (constructs a rep-resentation for) [♦]. The “5” is unparsable. It is not linguistic information.Now, expose the learner to “6♥.” The learner parses nothing! There is nolinguistic information in the input. (A linguistic parallel would be the parseof a belch by a human phonological system.) In fact only two grammarscan be defined given UG4. G11 = [♦] allows all and only diamond cardsas grammatical utterances. G12 = [ ] defines, actually, a grammar that isextensionally equivalent to G11, that is the two contain the same sentencesbut these sentences are generated by different grammars. The reason is that,given G12, cards can either be assigned the representation ♦, or they arenot parsed at all. So the only cards that will count as linguistic entities arethe diamonds. (What happens if we instead use a binary feature [±♦]? Hint:

LET’S PLAY CARDS 243
In addition to languages with no restrictions, like G12, we can define twolanguages that contain non-overlapping sets of cards.)
11.1.5 A really impoverished UG5
What if UG provides nothing at all—no features and no operators? Then,no matter what we expose the learner to, nothing will be parsed. Thestarting point for the grammar we ultimately construct cannot be an emptyslate since, to quote Jackendoff again, “Without Mental Grammar, there’sno language perception—just noise” (1994:164). To reiterate: The set ofprimitives supplied by UG determines the set of possible grammars thatcan be described. Without any primitives, no grammar can be described. Sothe card language faculty of a creature endowed with UG5 will parse anygiven card in the same way as it will parse a tarot card, the Mona Lisa, orthe smell of pepperoni. Any innate system that parses such entities distinctlymust be endowed with a mechanism for distinguishing between them. Thismechanism, obviously, must be innate.
Before we move on, consider the contrast between a really large 2♠(like a prop for a magician) and a really small one (like a card from atravel deck), as depicted in Fig. 11.1. Obviously these two cards differphysically—one is big and one is small. They may even have differentpatterns on their backs and differ in many other ways. But the two cardsare linguistically identical. They differ in the same way that whisperingand shouting a given word differ, that is, they differ only paralinguistically.From the linguistic perspective they are members of the same equivalenceclass.
Crucially, our claim is not that the contrast in card size will be imper-ceptible to an acquirer—merely that no size information will be used in theconstruction of the representations relevant to the “linguistic” module. Thatis, given a particular card UG, the relevance of specific contrasts that fallwithin the perceptual capabilities of the learner for card-grammar learningcan be made explicit. The set of possible card grammars consists preciselyof those that are UG-consistent. The fact that a learner can perceive the dif-ference between large cards and small ones, or between a card on the ceilingand a card on the floor, will not be relevant to the grammatical learningtask. For a learner for whom these contrasts are perceptible, any theorythat fails to recognize innate primitives within the card-grammar domain

244 APPROACHES TO UG: LO GI C
♠
♠
2♠
2♠
♠
♠
2♠
2♠
Fig 11.1 A non-“linguistic” card contrast.
will fail to account for the construction of grammars—i.e. the primitivesof grammar construction cannot arise from the primitives of perception.
We have been forced to the logical conclusion that there must be some-thing at the initial state of the grammar in order to allow learning tooccur. However, one might object: “Maybe the primitives at the initialstate are even more basic than what we have posited. For example, if weare sensitive to the difference between straight and curved lines we coulddiscover the distinction between ♦ and ♥.” This is perfectly reasonable.It just means that, say, “straight” vs. “curved” are the innate primitives.But YA GOTTA START WITH SOMETHING! That something is UniversalGrammar.
It should now be obvious that we are heading towards the conclu-sion that children must “know” (that is have innate access to) the setof linguistic features used in all of the languages of the world. Ofcourse, they must also have innate access to a set of logical operators orfunctions—the AND and OR of card grammars or the operators of realhuman grammars that make phenomena like reduplication and c-commandpossible.
Obviously, we are not claiming that the set of primitives of phonologycorresponds exactly to the set of distinctive features referred to in theliterature. There is no question that some of the features have yet to beidentified or properly distinguished from others. In some cases a currentlyassumed feature may represent a conglomeration of the actual primitivesof phonological representation. However, by definition, UG, the innate

WHERE DOES THIS LEAVE US? 245
component of the language faculty, consists of the elements of linguisticrepresentation that cannot be derived from anything else.
Consider a proposal that X is necessary for the acquisition of humanlanguage and that X is innate. Critics of the proposed innateness of X mustformulate their criticism in one of two ways. Either they must provide alearning path that is not dependent on X—i.e. they must challenge theclaim that X is necessary for the acquisition of human language, or theymust derive X from some other, more basic entities and processes (suchas Y), themselves available to the acquirer innately. In the absence of suchalternatives, the criticism is invalid. The second alternative is the favorite ofso-called constructivist theories of cognitive development. However, notethat the appeal to “general learning mechanisms,” without specifying indetail what the set of actual primitives involved in any such mechanismsare, is not a responsible critique of the nativist stance.
11.2 Where does this leave us?
It seems to be immensely difficult for many people to come to grips withthe idea that in order to learn, the learner must possess the relevant rep-resentational primitives within the learning domain. We have been forcedto conclude that children are born knowing the set of features used inthe languages of the world. Is this logical conclusion even remotely plau-sible? Well, recall our quotations from Zenon Pylyshyn at the end ofChapter 1:
[I]f you believe P, and you believe that P entails Q, then even if Q seems more thana little odd, you have some intellectual obligation to take seriously the possibility thatQ may be true, nonetheless.
It is more than a little odd to think that infants have this knowledge.However, researchers who have taken the possibility seriously have foundempirical support for this conclusion. For just about every possible contrastin the language of the world that has been tested, experiments indicatethat newborn infants are sensitive to the contrast. Well-known and well-replicated results by Janet Werker and her colleagues indicate that languageacquisition involves the loss of the ability to make distinctions. We are“deafened” by our experience, in some sense, since by around ten monthschildren appear to respond differently to contrasts to which they were

246 APPROACHES TO UG: LO GI C
sensitive just after birth.39 This is an exciting topic that has been studiedusing ingenious techniques showing children’s sensitivity to various con-trasts, but we will not present the details here.
Werker’s results on children’s abilities to distinguish adult categories ofspeech sounds, and thus to represent them as members of different cate-gories, suggest that children’s speech output does not provide direct evi-dence of their underlying representational system. As we will discuss inChapter 13, the same is true for adults—speech behavior does not providedirect access to the grammar, since many systems, the so-called performancesystems, intervene between the grammar and the speech output. As in anyother domain of behavior,40 babies’ immature cognitive and physiologicalperformance systems make their speech output sound messier than that ofadults, thus obscuring their underlying systems even more.
We can distill this presentation of the IofPP with what is superficially aparadox: the fact that languages are learned proves that there is an innatebasis for language. This is valid, not paradoxical, since in order to learnany aspects of linguistic knowledge, there must necessarily be some bodyof innate knowledge that allows for the parsing of input into representa-tions from which generalizations can be extracted. Without the innate basisnothing can be parsed, so nothing can be learned.
Before we conclude this discussion of the logical necessity of innate fea-tures, we should make it clear that there are many scholars in phonetics,phonology, and psychology who would not accept our conclusions in thischapter. Instead, they believe that by statistical analysis of ambient speech,categories can be constructed without any innate structure. For example,consider the announcement of a recent conference workshop (NELS 38,the 38th meeting of the North East Linguistic Society):
Some of the founding assumptions of Generative Phonology involve abstract unitssuch as distinctive features, timing units, syllables, and constraints. The innatenessof these units has been seen as an important part of their nature. Recent work hassought to undermine the claim that innate primitives are necessary for phonological
39 They do not lose the capacity to hear distinctions of sound but only to hear themas linguistic distinctions. However, even this loss appears to be reversible, at least to acertain age, when a new language is learned—something apparently gets the languagefaculty to “turn on” access to the innately available linguistic contrasts in order to learna new grammar.
40 Any domain other than learning, which perhaps should not be considered abehavior—see discussion in Chapter 13. Our position here is controversial—see Haleand Reiss (1998) for detailed arguments.

BUILDING BLOCKS IN OTHER DOMAINS 247
theory, often drawing more directly upon more concrete factors such as phonetics andlanguage change as sources of explanation.
In our opinion, no empirical evidence by itself can undermine our logicalargument for the innateness of primitives. Our conclusions may be false, butthis must be shown by a critique of either our premises or our reasoning.This debate relates to a fundamental difference between the rationalist viewswe represent and a more data-oriented empiricist perspective. We cannotprovide a full presentation of all the relevant issues in these debates, but wewill revisit some of them in Chapter 13.
11.3 Building blocks in other domains
The notion that all languages are constructed from the same “raw mate-rials,” the same innate set of primitive features and operators, what issometimes called the human language faculty or Universal Grammar,continues to encounter resistance. In this chapter and the previous one,we have provided several arguments to address this resistance. We men-tioned the instinct or innate knowledge in birds concerning the visualrepresentation of potential predators. This example suggested the plausi-bility of innate knowledge in a non-linguistic capacity of a non-humanspecies. It does not prove the existence of UG, but turns the skeptic’sdoubts around—why should we attribute innate knowledge to a speciesand a capacity that we tend to think of as less complex than humansand their language, but resist the notion of UG, innate knowledge spe-cific to language? We then presented empirical evidence for the recur-rence of the c-command relation across constructions and languages asan illustration of the kind of abstract properties that characterize UG.In this chapter we have presented a logical argument that no learningcan occur without an innate set of representational primitives. Beforewe close, we offer another conceptual argument to counter skepticismabout UG.
Start with your own body—run your hands across your face, poke your-self in the eye, floss your teeth until you bleed, fatten your liver with amartini, think about how beautiful life is. Every single part of your body ismade up of cells—skin cells, eyeball cells, blood cells, liver cells, brain cells,etc. And it turns out that every single one of these cells contains the exact

248 APPROACHES TO UG: LO GI C
same genetic material; the diversity of the cells in your body arises from asingle set of building blocks (aside from gametes which are missing half ofyour genetic material). Now let’s expand our focus, from your own body toall living things. All genetic material, all DNA, is built out of an alphabet (afeature set) of four, yes, four units called nucleotides. Combinations of thesefour nucleotides are different enough to provide the code to build a fruitfly,a shark, and you.
Now consider the inanimate world in addition to the biological world:your mother, the sun, the fenders on the passing bus, silk underwear, yourcat, the chocolate pudding you ate for breakfast, and every other materialobject you know about consist of protons, neutrons, and electrons orga-nized in different ways. That is just three, yes, three basic atomic particlesthat can be combined to make the physical world we experience in all itsdiversity.
Now let’s consider human languages and their diversity: Chinese, French,Greek, Hungarian, to name just a few. They are hugely different from eachother. But then again, isn’t a shark different from a human? Or chocolatepudding from the sun? And yet, one of the findings of modern science isthat sharks, pudding, humans, and the sun are all alike at some level; theyare all made of the same basic atomic particles and the differences resultfrom the way in which these atoms are combined. In light of these findingsof modern science in other domains, findings that perhaps violate commonsense, the possibility that Mohawk, Japanese, English, Greek, and so on,might be modeled by various combinations of some basic elements (locality,c-command, and the like) becomes perhaps more palatable.
11.4 Exercises
Exercise 11.4.1. Defining the initial state: Your task in this exercise is todemonstrate how UG (the initial state of the language faculty) determinesthe set of grammars that a learner can possibly acquire. You are to create aparallel to the card languages we talked about in the chapter.
Instead of using playing cards your grammars will be based on Canadiancoins of the following denominations: 1¢, 5¢, 10¢, 25¢, $1, $2. (Feel free touse some other set of things, for example, another currency or the pizzatopping combinations on a menu—mushrooms and pepperoni, pepperoni,anchovies, and extra cheese, etc.)

EXERCISES 249
You should make up some feature systems based on these coins (or piz-zas), as well as some operators—please use at least one operator other thanAND and OR, and use one privative feature and one binary feature. Onepossibility for an operator is NOT, a negation operator, but we encourageyou to find or invent others—just explain carefully. For this exercise, thinkof a language as a set of coins (parallel to the sets of cards)—for a givencoin, a grammar has to treat it as grammatical or ungrammatical.
Before you begin your answer, read through all the questions. Your earlierchoices will affect later ones.
UG1: Define a coin Universal Grammar, UG1, in terms of someoperators and symbols (features) that can describe the coins.
a. Operators:b. Features:� Define two grammars that can be stated in terms of UG1
c. G1.1:d. G1.2:� Now define two grammars that cannot be stated in terms of UG1
and explain why each is not possible
e. F1.1:f. F1.2:
UG2: Define another coin Universal Grammar, UG2, in terms of someoperators and symbols (features) that can describe the coins. Beforeyou proceed with defining UG2, read the rest of this question.
g. Operators:h. Features:� Define two grammars that can be stated in terms of UG2
i. G2.1—a language that generates a set of sentences equivalent tothat described by one of the impossible languages, item F1.1 or F1.2:
j. G2.2—a language that is extensionally equivalent to G1.1 or G1.2
(generates the same set of sentences), but does so using differentsymbols or operators:
� Now define two grammars that cannot be stated in terms of UG2
and explain why each is not possible
k. F2.1:l. F2.2:

250 APPROACHES TO UG: LO GI C
Further Readings
In the Meno there is a demonstration of innate knowledge that is worththinking about. Socrates leads an uneducated slave boy through a geometricproof and claims to demonstrate that all he is doing is drawing out know-ledge that the boy already had. The paper on the subset principle containsthe card language demonstration with more detail on phonological acquisi-tion. Carroll’s book is an excellent overview of recent ideas in evolutionaryand developmental genetics which shows how diversity can arise out ofinteractions of a few basic primitives.
� Selection from the Plato’s Meno—link from course page.� “The subset principle in phonology: Why the tabula can’t be rasa” by
Hale and Reiss (2003).� Endless Forms Most Beautiful: The New Science of Evo Devo and the
Making of the Animal Kingdom by Sean Carroll (2005).

PART IVImplications and Conclusions

This page intentionally left blank

12Social implications
12.1 Prescriptive vs. descriptive
grammar 253
12.2 Negation 254
12.3 Change is constant 256
12.4 Exercises 262
12.1 Prescriptive vs. descriptive grammar
At this point it should be apparent that linguistics is not concerned with so-called proper grammar. For a variety of historical and social reasons, certainlinguistic forms are associated with a level of prestige that actually has nobasis in their linguistic properties—Standard English is not more preciseor logical than other dialect forms. We take the position that no languageor dialect is more precise or logical than any other, but even applying thesame (ultimately misguided) criteria used to argue for the superiority of,say, Standard English, it is trivial to demonstrate that this dialect is oftenless precise and less logical than less prestigious ones.
In this book we have introduced the terms grammar and rule as ele-ments of a scientific theory. Scientific grammar is concerned with describingand classifying linguistic data with the ultimate goal of understanding theproperties of the human language faculty. This enterprise is sometimescalled descriptive grammar in contrast to the prescriptive grammar thatwe are taught in school, the main purpose of which is to prescribe “cor-rect” linguistic forms. The notion of correctness has no place in scientificgrammar—a particular grammar G generates a form f as an output or itdoes not. The rules of scientific grammar are thus statements characterizingnatural objects—they are either universal rules that are properties of all

254 SOCIAL IMPLICATIONS
human languages or particular rules of individual I-languages. Of course,we may sometimes posit the existence of a rule but later revise our view, justas conjectures in any scientific domain are subject to revision.
Focusing on the taxonomic and descriptive work that accompaniesattempts at explanation, we can compare the distinction between scien-tific grammar and prescriptive grammar to that between an anthropolog-ical sketch of a society and an etiquette manual. An anthropologist maydescribe the wedding rites of some community, but will not say that thebride should have worn white and the forks should have been placed onthe left of the plate at the reception. While the distinction between scientificgrammar and prescriptive grammar should be obvious to you at this point,given how much you now know about linguistics, we still find that even, orrather, especially, educated people have a hard time overcoming linguisticprejudices and believing that there is no basis for viewing some linguisticsystems as better or worse than others, either in general or for specific tasks.In the following paragraphs we provide further arguments against linguisticprejudice. If you discuss linguistics with “educated” people you may find itconvenient to have some of these arguments on hand.
12.2 Negation
How do you react if you hear someone say something like (12.1a.b.)?
12.1 a. Non-Standard Dialect: He didn’t eat no cake.� Standard: He didn’t eat any cake.
b. Non-Standard Dialect: He didn’t give nothing to nobody.� Standard: He didn’t give anything to anybody.
People educated in Standard English, people who use forms more like theglosses given below the non-Standard forms in (12.1), will often react tosuch utterances as reflecting not only a lack of education but also a lackof precision in thought, since the speaker appears to be unaware of thesimple logical principle that “two negatives make a positive.” Accordingto everyday conceptions, the negative word no in (12.1a.) “cancels out”the negation of the negated verb didn’t. For sentence (12.1b.) everydayconceptions are not as clear—do nothing and nobody both cancel outthe negation on the verb, or do we have three negatives, which computesto a negative—two cancel out and one remains? In fact, as expected,everyday thoughts about such things do not form part of a coherent

NEGATION 255
theory, and, like most commonsense notions about language, they are justwrong.
While there is no hesitation to condemn the use of multiple nega-tion in modern speakers whose social and educational background differsfrom one’s own, few people are ready to propose that Geoffrey Chaucer,the fourteenth-century poet, philosopher, and diplomat, was lazy, stupid,or incapable of clear thinking because he wrote lines like (12.2) in theCanterbury Tales:
12.2 he nevere yet no villeyneye ne saydein al his lyf unto no manner wight
A quasi-etymological, word-for-word translation would be “He never didnot say no evil to no kind of person.” However, an accurate translationfrom the Middle English would be “He didn’t ever say any evil, in allhis life, to any kind of person.” The form and pattern of negative words,including the negative polarity items we discussed in Chapters 6 and 10,differ in Chaucer’s English from our Modern Standard dialect. However,both grammars follow principles of meaning and form that depend uponstructural notions like c-command and entailment relations expressible interms of set theory that we introduced in earlier chapters. These represen-tational and computational primitives are the building blocks of all humanlanguages.
Since speakers who produce utterances like those in (12.1) are humans,the output of their grammars, too, reflects c-command and set theoreticrelations. Simply put, our (the authors’) mental grammars output NPIs pro-nounced any in the same context that the mental grammars of Chaucer anda speaker who produces the dialect forms in (12.1) output NPIs pronouncedno. All three dialects are equally “logical” and equally capable of expressingprecise thoughts.
We now see that there is some contribution to be made to society fromlinguistic analysis. The crucial step we hope you can make is to go fromformal analysis of linguistic differences to an appreciation of the complexityof all languages and the incoherence of claims of superiority, inferiority,or greater or lesser richness for any particular system. In an educationalcontext, the social and economic benefit of teaching standard languagesis best achieved via cold but respectful scientific analysis and explanation.Imagine the effect on teacher and student alike of learning that saying Ididn’t see nobody is not an indicator of stupidity but rather shows that

256 SOCIAL IMPLICATIONS
one’s mental grammar parallels that of Chaucer or an Italian speaker!We ourselves have done such demonstrations to high school students andteachers, and even to high school equivalency students in a maximum secu-rity prison. Just as the facts of genetics demonstrate the groundlessness ofracial prejudice, linguistic science should serve society by undermining thewidespread linguistic misconceptions that affect all social and educationalinstitutions.
12.3 Change is constant
We have records from ancient times of writers complaining about the sloppyspeech of the masses and the decay of the language. We even have evidencefrom graffiti written by less-educated Romans that illustrate the forms crit-icized by the grammarians.
In addition to the rants of the prescriptive grammarians, we also havewritings that criticize their pedantry, such as this passage by St. Augus-tine (4th–5th century) about solecisms (constructions that do not corre-spond to prescriptive grammar) and barbarisms (non-standard pronuncia-tions).
What is called a solecism is simply what results when words are not combined accord-ing to the rules by which our predecessors, who spoke with some authority, combinedthem. Whether you say inter homines or inter hominibus [to mean among men] doesnot matter to a student intent upon things. Likewise, what is a barbarism but a wordarticulated with letters or sounds that are not the same as those with which it wasnormally articulated by those who spoke Latin before us? Whether one says ignoscerewith a long or short third syllable is of little concern to someone beseeching God toforgive his sins. [De Doctrina Christiana 2.13.9 (Augustine 1995)]
Augustine sensibly recognizes that language change occurs but that newsystems are as good as old ones for the purposes to which we putlanguage.
The linguistic descendants of the average Roman’s Latin are the Romancelanguages French, Spanish, Italian, Romanian, Sardinian, and so on. Theselanguages, of course, are the result of the “decay” bemoaned by the ancients,but this fact does not stop the French Academy and the Office de la LangueFrançaise in Quebec from bemoaning the currently ongoing decay of thelanguage of Molière. Word borrowings from other languages and changesin syntax, morphology, and phonology occur constantly in the course

CHANGE IS CONSTANT 257
of language transmission from generation to generation—nobody has thesame exact I-language as anyone else, so nobody can have the same exactI-language as their parents.
Ironically, the prescriptive grammarians are so confused that they some-times complain about innovative forms and sometimes archaic forms.Quebec French has retained vowel distinctions from Old French that arelost in Standard French, such as a distinction in the vowels of the wordsla as in la fille “the girl” and là as in cette fille-là “that girl there.”Schoolchildren in Quebec are taught that the two words are homophones,pronounced the same, by teachers who only pronounce them the samewhen teaching that they are homophones, when doing grammar, andnever when speaking normally. It is no wonder that the students areconfused.
Our daughter, who attends French school in Quebec has even been taughtthat the order of pronouns in Quebec French differs from that of StandardFrench because it reflects the fact that the settlers in Quebec were hardwork-ing, unsophisticated rustics who were so busy trapping fur-bearing animalsand cultivating the earth that they had no time to cultivate themselves.One teacher at our daughter’s elite private school explained that StandardFrench dis-le-moi “tell it to me” is rendered in Quebec French as dis-moi-lebecause the latter is shorter, faster, and easier to say than the former, andthus more suitable for the hardworking, uncultured Québecois. This viewseems to reflect a different notion of shortness than what we are familiarwith, since the two forms contain the same three units. These personalanecdotes of ours report generally held opinions that even make it intothe pages of our local newspapers in opinion pieces signed by universityprofessors.
For a particularly clear case of how silly it is to worry about the fact oflanguage change consider the formation of the future tense in the historyof French. Classical Latin had what is called a synthetic future, the futureform of a verb was a single word: amo “I love” has the future form amabo“I will love.” Late Latin expressed the future periphrastically by the useof an auxiliary verb identical in form to the verb “to have”: amare habeo,literally “to love I have” expressed the future tense. The modern Romancelanguages, like Latin, have a synthetic form, for example French j’aimerai.Modern French also has developed a periphrastic form using the verb “togo”: je vais aimer “I am going to love.” Since we are making a binarydistinction between synthetic and periphrastic forms it follows that any

258 SOCIAL IMPLICATIONS
two future tense forms from the “same language”41 will both be syntheticfutures, both be periphrastic futures, or they will differ along this dimen-sion.42 As we see from the history of French, the change can go in bothdirections. So, the “decay” from Classical Latin resulted in the periphrasticfuture of Late Latin; but the “decay” from Late Latin to what is (arbitrarily)called, say, French, led to a new synthetic future. If change can both elim-inate and introduce synthetic tense forms, then it is clearly silly to view itas “decay” or “degeneration.” Yet this is typically how language changeis viewed in almost every culture where opinions are expressed on thematter.
Since language is partially learned and since children are not telepathic,they have no direct access to what is in the minds of people around them.Transmission of grammar is imperfect and so-called language change isinevitable. An approach to historical linguistics that takes seriously theI-language perspective can be found in Mark Hale’s (2007) HistoricalLinguistics: Theory and Method.
Not only is it the case that change in the rules and meanings vary fromspeaker to speaker and generation to generation but those who worry aboutsuch things cannot possibly be aware of the nature of most of the actualrules and structures of human languages that concern them. The work ofmodern linguistics over the past fifty years has uncovered patterns that arejust now being recognized—explanations are still being sought. It is unlikelythat the members of the French Academy or William Safire, who writes onlanguage for The New York Times, have an understanding of binding theorythat comes anywhere near the sophistication of yours. Excellent discussionof the fact that many of the rules of prescriptive grammar do not even workfor the forms they are meant to apply to can be found in “The LanguageMavens,” Chapter 9 of Steven Pinker’s entertaining bestseller The LanguageInstinct.
An old joke about prescriptive grammar illustrates its naiveté with respectto actual linguistic structure: A farmer is touring Harvard Yard and stops
41 Remember, we are using this term in an informal, non-I-language sense in whichClassical Latin, Late Latin, Modern Standard French, and Quebec French are the “samelanguage.”
42 Of course, a language can have more than one form that is used to denote future,like Modern French, and it can also have no form—many languages have only a pastand a non-past, and specifically future time is denoted by using adverbial expressionslike “tomorrow” or “next year.”

CHANGE IS CONSTANT 259
a passing student to ask “Where’s the library at?” The pedantic studentreplies “At Harvard, we never end a sentence with a preposition,” to whichthe farmer responds “Where’s the library at, $*!&@%#©^‡¿” (fill in yourfavorite epithet). Although we, the authors, do not use this particular con-struction, we do say things like Where the heck did that come from?, endingwith a preposition. So, the Harvard student is condemning a structure thatis widespread in the speech of people at least as educated as we are (Ph.D.linguists). More interestingly, it is clear that the Harvard student does notunderstand that linguistic generalizations are structure-dependent, and notformulatable in terms of just linear order—recall the discussion of Mary’sfrom Chapter 6. The farmer solves the problem of having a sentence-finalpreposition, but probably not in a way that would satisfy the student whoprobably is aware at some level that the farmer’s revised utterance does notsatisfy the principle he is trying to articulate.
Despite the fact that this so-called preposition stranding is frowned uponin written Standard English, it is widespread in the speech of just aboutall speakers, regardless of the prestige of their dialect. It turns out that thisdangerous phenomenon of preposition stranding is not only threateningEnglish but insidiously endangering the health of French as well. We livein Montreal, Quebec where many people are concerned not only for thesurvival of French but also with protecting the language from the malignanteffects of English. Quebec French allows sentences like the following: Çac’est la fille que je parlais avec, literally “That is the girl that I was speakingwith,” with the preposition avec “stranded” at the end of the sentence. Suchforms, which are not accepted by French prescriptive grammars, are oftencited as anglicisms, English-influenced forms that should be avoided tomaintain the purity of the language. However, it appears to be the case thatpreposition stranding in Quebec French is very different from the pattern inEnglish. There appears to be a lot of dialect variation but, at least amongour students, only certain prepositions can be stranded. The monosyllabicprepositions à “to” and de “of,” for example, appear to be “unstrandable”:The string *Ça c’est la fille que je parlais à, literally “That is the girl that Iwas speaking to” appears to be ill formed, despite its apparent structuralidentity with the sentence containing the preposition avec. Our goal hereis not to analyze these facts but merely to point out that, as usual, theyare more complex than they appear at first glance, and that the rules ofprescriptive grammarians reflect tremendous ignorance about the nature oflanguage.

260 SOCIAL IMPLICATIONS
As we have pointed out, in addition to the incoherence of their pre-scriptions and their ignorance, prescriptive grammarians fail to recognizethat they are fighting a losing battle. Change is a constant and there hasnever been a linguistic golden age from which today’s youth is straying evenfurther than their parents. If archaic forms are somehow taken to be betterthan innovative forms, then prescriptivists should be telling us to use the(b.) form instead of the (a.) form in the following pairs:
12.3 Are archaic forms more acceptable?Modern Standard forms Unacceptable archaic forms
i. a. You are losers. b. *Ye are losers.ii. a. You (sg.) are a loser. b. *Thou art a loser.
iii. a. The table stands on its legs. b. *The table stands on his legs.iv. a. Both of my brothers are losers. b. *Both of my brethren are losers.
In (12.3i.), the form you is derived from what used to be the form used forobjects. The nominative, subject form was ye, as in the song Come all yefaithful. . . . In the second person plural, Modern English does not make thedistinction made, for example, between we and us in the first person. Noprescriptivists tell us to use ye anymore.
In (12.3ii.) we see just how “sloppy” Standard English is—not onlyhas it lost a case distinction but the pronoun system does not distin-guish between singular and plural anymore. Older varieties of the lan-guage used thou for the singular nominative form, as in Wherefore art thouRomeo? “Why are you Romeo?”, but no prescriptivists bemoan this “loss ofprecision”.
In (12.3iii.) we see not the loss of an older distinction but an innovativeform. The form its as a possessive of it is only a few hundred years old.Earlier, the form his served as possessive of both he and it. No prescriptivistsbemoan this neologism, probably because it has been around for too longby now.
Finally, in (12.3iv.) we see the form brethren, which earlier was the normalplural form for brother but is now restricted to members of a religiousorder. Prescriptivists would be outraged by anyone who said My footshurt, yet such a form would have the same status as the now acceptablebrothers once had. There is no rhyme or reason to prescriptivist proclama-tions.
What do we do with people who say Me and John went to the store?A prescriptivist may point out that such people (including your humble

CHANGE IS CONSTANT 261
authors) never would say ∗Me went to the store. So, the prescriptivist wouldargue, these speakers are not internally consistent—sometimes they useI for the nominative singular form and sometimes they use me, whereasprescriptive grammar demands consistent use of the nominative I wheneverthere is a first person subject.
The correct response to this view is that I =/ I—given our recognition thateveryone has his or her own mental grammar, that languages are individualand internal, it is a mistake to equate the I and me of dialects that generate Iwent to the store, John and I went to the store, and You saw me with the I andme of dialects that generate I went to the store, Me and John went to the storeand You saw me. The I and me of the non-Standard dialect cannot simply beanalyzed as a case difference, nominative vs. accusative. After going throughthe discussion of ergativity in Chapter 9, we hope you appreciate that casesystems can be fairly complex.
This discussion brings us back to the discussions in Chapters 1 and 4where we established that English does not exist as a coherent, scientificallydefinable entity. Different speakers of so-called English have different pro-noun systems, as we have just seen. There are lots of other ways in whichthey can differ. For example, many speakers of Canadian English say thingslike the sentences in (12.4a.), which are ungrammatical to us, the authors—our grammar does not generate them.
12.4 Some Canadianismsa. Canadian
� You’re allowed playing ball here.� I’m done my homework.
b. Standard� You’re allowed to play ball here.� I’m done with my homework or I’ve done my homework.
We have labeled the forms that correspond to our forms as “Standard,” butit is probably the case that prescriptive grammars typically do not discussthe argument structure of the verb allow—in our dialect it takes an infini-tival complement like to play, whereas in the relevant Canadian dialects ittakes an -ing form like playing. As far as we know, the structural differencereflected in the sentences with done is also not discussed in prescriptivegrammars.
Once again, we have been talking as if there is a word correspondingto Canadian allow and our allow. But we have already seen that the twodiffer in the syntactic configurations in which they occur. They also differ

262 SOCIAL IMPLICATIONS
slightly in pronunciation. The question then arises of what the word allowcould be. The answer, from the I-language perspective, is that each of us hasdifferent verbs in our mental dictionaries, and that these verbs may be moreor less alike in their phonology, their syntax, and their meaning, but each isa mental representation in an individual mental grammar.43
Viewed from this perspective of systems of symbolic representations inindividual minds, it becomes hard to justify any kind of linguistic prejudice.How could one abstract computational system built upon the resources ofthe innate human language faculty be better than another?
12.4 Exercises
Exercise 12.4.1. Reflexives in two dialects: Consider the following formsof the reflexive pronoun from both Standard English and a non-Standarddialect.
Standard Non-Standardmyself ourselves myself ourselvesyourself yourselves yourself yourselvesherself themselves herself theirselveshimself hisself
Assume that these forms are all composed of two parts, a personal pronounand -self / -selves. Is there any basis for claiming that the set of Standardforms is more logical than the set of dialect forms? Less logical?
Exercise 12.4.2. Second person pronouns: In Brooklyn some people saythings like I’ll see yous later (we have adopted Standard orthography.) Oneof the features of this dialect seen in this sentence is the form of the pluralsecond person pronoun yous which is distinct from the singular you. Manypeople argue that speakers of Brooklyn English are clearly more carefuland less lazy than speakers of Standard English who do not distinguish asecond person singular from a second person plural pronoun. How couldyou convince such snobs that Standard English speakers are not necessarily
43 Sometimes the grammar refers to the computational system, without the lexicon,and sometimes it refers to both. Here we speak of the lexicon as part of the grammar,but the issue is of no import for our point.

EXERCISES 263
illogical and sloppy people who cannot express basic distinctions of numberlike that expressed by the Brooklynites? (Can the SE speakers tell if they aretalking to more than one person?) Can you suggest a way to help the poorStandard English speakers learn the (superficially, at least) more logicalBrooklyn system? (Can you somehow show the SE speakers data from theirown dialects that suggests a singular-plural distinction in second person?)You can also relate your answer to other linguistic prejudices you knowabout.
Exercise 12.4.3. Two dialects of polarity items: Consider the followingsentences of Standard English and a non-Standard dialect. Assume thatthe paired sentences have the same meaning.
STANDARD DIALECT
a. Free choice He’ll eat anything He’ll eat anythingb. Positive polarity He ate something nasty He ate something nastyc. Negative object 1 He won’t eat anything He won’t eat nothingd. Negative object 2 He will eat nothing He won’t eat nothinge. Negative subject Nothing happened Ain’t nothing happened
The two dialects appear to agree in Free choice contexts like (a.) where theyboth use anything. They also agree in Positive polarity contexts where theyuse something. What can you say about the last three sentences? How wouldyou characterize the forms used in each dialect? It may help to know thatthe form nothing in the Standard is sometimes called a negative quantifier.We’ll assume that ∗Nothing happened is ungrammatical in the non-Standarddialect in question.
How does this dialect difference support the perspective of I-language?Can you incorporate into your response the fact that, like the otherforms, nothing varies widely in its pronunciation among dialects, with arange including such diverse forms as the following [n@Tn
", n@TIN, n@fn
",
n@Pn"]?
Further Readings
Labov’s article is frightening in showing just how wrong-headed thinkingabout language can be among many highly educated professionals. Rick-ford’s webpage lists several sources related to the Ebonics controversy in theUnited States. Hyman’s paper surveys traditions of prescriptive grammar in

264 SOCIAL IMPLICATIONS
the Greek, Roman, Christian, Muslim and Sanskrit traditions and ties thediscussion to religious issues. Pinker’s chapter, like the whole book, is a funread.
� “Academic ignorance and black intelligence” by William Labov (1972).� Various articles by John Rickford on the Ebonics Controversy. Avail-
able at http://www.stanford.edu/ rickford/ebonics/.� “Bad Grammar in Context” by Malcolm Hyman (2002).� “The Language Mavens,” Chapter 9 of The Language Instinct by Steven
Pinker (1994).

13Some philosophy
13.1 Rationalism and
empiricism 265
13.2 Competence and
performance 271
13.3 Reference 277
13.4 Essentialism 282
13.5 Mind and body 286
13.6 A view from neuroscience 291
13.7 Exercises 298
In this chapter we will discuss various topics in philosophy, some of whichtraditionally fall into the domain of philosophy of language, such as thenature of reference and meaning, but also others that go beyond the connec-tions between linguistics and philosophy. Broader issues include the mind-body problem and the contrast of rationalism and empiricism. We are notphilosophers, yet we will try to convince you that the cognitive biolinguisticI-language perspective we have presented can provide insight into a widerange of philosophical questions that have stumped more traditional phi-losophy. Our survey will be brief and dogmatic, and our conclusions mayseem outrageous, but we encourage you both to take them seriously and toseek out contrasting points of view.
13.1 Rationalism and empiricism
Many philosophers and cognitive scientists are concerned with the questionof the sources of knowledge—where does knowledge come from? Broadlyspeaking, a distinction is often made between rationalism and empiricism.Rationalism is the view that knowledge is acquired through reason, for

266 SOME PHILOSOPHY
Fig 13.1 Where does knowledge come from?
example, by logical inference. Empiricism is the view that knowledge arisesfrom our sensory experience, what we see, hear, smell, touch, and taste. Thetwo views are not mutually exclusive, but they are typically discussed ascontrasting approaches to the question of the source of knowledge.
The distinction between rationalism and empiricism is relevant to twoseparate issues in linguistics and cognitive science. On the one hand, thereis the question of scientific knowledge—where do theories and hypothesesand intuitions come from? This concern is shared with any philosopher ofscience interested in the activity of scientists. A focus on rationalism wouldfavor the view in which scientists come up with ideas, make inferences anddeductions, and only then appeal to observation to confirm or refute predic-tions. A focus on empiricism would favor a view in which generalizations,theories, and laws arise out of a large body of observation.
On the other hand, the rationalism–empiricism debate in cognitive sci-ence is also related to the sources of the kind of knowledge that is the

RATIONALISM AND EMPIRICISM 267
object of study. For example, does the acquisition of knowledge of a specificlanguage by children involve imposing innately determined categories onobserved experience, a view in line with a rationalist perspective, or doesit arise from observing linguistic output in one’s environment and thenextracting regularities from this data, a view favored by an empiricist per-spective?
The rationalism–empiricism debate at both of these levels is a tremendoustopic with a long history, and we cannot even attempt a thorough discus-sion. In terms of scientific discovery, it is probably the case that the averageperson is primarily an empiricist, and this corresponds to the popular viewthat the primary activity of a scientist is to do experiments and makeobservations from which generalizations will emerge. It is pretty clear thatthis everyday view cannot be correct, since there are an infinite number ofhypotheses compatible with any body of data. It is also the case that thereare an infinite number of observations that can be made, an infinite numberof experiments to perform. If scientists were not guided by ideas, they wouldjust perform experiments (if that would even be the appropriate term forsuch activity) at random, with no sense of what they were looking for.
In the domain of human knowledge, especially in linguistics, therationalism–empiricism debate often revolves around what is called theargument from the poverty of the stimulus. The argument is basically thatchildren end up knowing much more about language than, say, an unbiasedpattern recognizer could learn from the same input. Paralleling the discus-sion above, there are an infinite number of grammars compatible with anycorpus that a child will be exposed to, and, yet, children generalize beyondthe forms they have encountered. Perhaps they have heard sentences inwhich wh-words are pronounced in a derived position that is up to thirteenwords away from the base position, and, yet, they do not end up with rulesthat limit the linear distance between base and derived positions to thirteenwords. Consider this case:
13.1 What did the tall guy with bright green dreadlocks and a friendlypregnant German shepherd really want the fat bald guy in abright pink tutu to hear what?
Twenty-seven words intervene between the derived position copy of whatat the beginning of the sentence and the base position copy at the end.Perhaps you have never heard an example of wh-movement with exactlytwenty-seven words between base and derived position, yet you recognize

268 SOME PHILOSOPHY
this example as grammatical. And, unless you hang out in some very inter-esting places, you probably never heard this exact set of words put togetherin any sentence. Yet, somehow, you recognize the sentence in (13.1) as amember of an equivalence class that includes (13.2a.b.), but not (13.2c.).
13.2 More wh-movementa. What did the bad dog eat what?b. Who did the tall guy with bright green dreadlocks and a friendly preg-
nant German shepherd really want the fat bald guy in a bright pink tututo hear who?
c. *The boy did the tall guy with bright green dreadlocks and a friendlypregnant German shepherd really want the fat bald guy in a bright pinktutu to hear the boy?
The string in (13.2c.) is of course superficially more similar to (13.2b.) and(13.1) than (13.2a.) is. However, this kind of similarity is not relevant to thegeneralizations that human language learners make. Children’s grammarsalways end up with structure-dependent rules that do generalize beyondwhat they hear, but they only generalize in some ways and not others—onlysome analogies to what they have heard work. Children do not generalizeabout numbers of intervening words, and they do generalize in ways thatmake reference to subcategories of NPs. Those that belong to the equiva-lence class of wh-items are treated differently from others.
Much ink continues to be spilt on this issue of what can be learnedfrom the observed data, and it has even been claimed that linguists whoadopt the argument from poverty of the stimulus are guilty of poverty ofimagination about how learning proceeds. However, as Howard Lasnik haspointed out, and as you will appreciate if you did the segmentation exercisein Chapter 2, the poverty of the stimulus exists right at the word level. Thereare no words in the input signal, words are constructions of the mind.Without an innate category WORD there would be no reason for kids tosegment the acoustic signal they receive. In fact, there must already be aninnate system to separate speech signal input from other input, just as otherspecies recognize the communication sounds of their conspecifics against abackground of other noises.
In an underappreciated paper written in 1976, Robert Hammarberg dis-cussed empiricism in linguistics, specifically with regard to the phonetic andphonological analysis of speech segments. Hammarberg contrasts the thencurrent standard view in phonetics, the field that studies the acoustic and

RATIONALISM AND EMPIRICISM 269
physiological aspects of speech sounds, with the emerging approaches underdevelopment by Chomsky and his collaborators.
Chomskian linguistics is explicitly anti-empiricist, and all indications are that currentphilosophy of science is moving toward a rejection of the empiricist programme(Fodor, (1968), pp. xiv ff ). A key feature of the new programme is exactly a reeval-uation of the concept of observation. Observations are now held to be judgments,and these judgments are made in terms of the criteria provided by the paradigm.Thus the taxonomy of a discipline is to be regarded as imposed from above, ratherthan emerging from below, i.e., rather than emerging in the form of brute facts beforethe unprejudiced eyes or ears of the researcher. The relevance of this to the study ofphonetics and phonology should be obvious: the concept of the segment, which isindispensable to phonetics and phonology, is a creature of the paradigm, not of theraw data. [Hammarberg 1976:354]
Hammarberg here is mainly concerned with empiricism and rationalismin the domain of scientific inquiry, but it follows that he is also a rationalistwhen it comes to understanding the sources of linguistic knowledge inspeakers’ minds, since the learner, like the analyst, cannot discover segmentsin the signal. Hammarberg is very clearly a mentalist:
[I]t should be perfectly obvious by now that segments do not exist outside the humanmind. [354]
But it is also clear that this mentalist position is not at all at odds with takingnotions like “segment” as objects of serious scientific inquiry. He addressesthe position of phoneticians who treat the segment as merely a convenientfiction for description and categorization, but he responds that
there would be little value in such an approach. Science aims for a theory of the real,and to base one’s descriptions and generalizations on a fictional taxonomy could onlylead to one’s theories being fictional as well. [355]
This point, that theories should be assumed to model real aspects of theworld, has also been made by Chomsky in various places (for example, in“Language as a natural object,” 2000a:111) where he mentions that therehave been periods in the history of chemistry when the formulas and modelswere assumed to be merely calculating devices. This contrast in attitude con-cerning theories is sometimes referred to as the difference between “realist”and “instrumentalist” positions.

270 SOME PHILOSOPHY
Unfortunately, Hammarberg appears to have been overly optimisticabout the downfall of empiricism.44 Radical empiricism refuses to die inlinguistics and cognitive science, and it even appears to be on the riserecently, a development perhaps tied to the accessibility of data collectionand analysis equipment—if such powerful tools are available and one canget large grants to buy them, it is mighty tempting to use them, even if theydistract us from what is actually interesting and important. People workingin areas of statistical or probabilistic linguistics would scoff at arguments forfeatures and innate categories, such as those we presented in Chapter 11.They would argue that children can extract equivalence classes based onstatistical analysis of the input they receive without any innate categories.
Note that dogs, who have very good hearing, do not end up with thephonological categories that a child ends up with upon exposure to thesame input, so the categories cannot literally be present in the signal. Evenif some kind of statistical analysis is part of acquisition, there has to beinnate knowledge (or whatever you want to call it) of what categories to dothe statistics over. Statistics about loudness and distance from the speakerand the ambient air temperature appear to be ignored in acquiring linguisticrepresentations. In fact, statistics about context and many acoustic detailsare clearly completely irrelevant to the construction of linguistic represen-tations at some point: a word you learn in a single noon encounter with askinny, distant screaming woman on the tundra can be whispered at dawnin the ear of a soft-spoken plump man on a tropical island. Any theory oflanguage acquisition that even approaches strict empiricism has a hard timeaccounting for such facts. And since empiricists claim to like facts, this getsthem into trouble.
Lila Gleitman and Elissa Newport (1995) discuss rationalist- andempiricist-oriented approaches to language acquisition in terms of a con-trast that we can summarize as follows.
� Empiricist focus: Children’s speech at a particular age directly reflectsthe amount of input they have heard and the forms that they haveheard—basically they just imitate what they hear, and the more theyhear, the better they imitate.
� Rationalist focus: Children’s speech at a particular age tends to be cor-related with other developmental milestones, including non-linguistic
44 Hammarberg himself, who was trained as a phonetician, was scorned by the fieldfor his anti-empiricism and never managed to get an academic position [p.c.].

COMPETENCE AND PERFORMANCE 271
aspects of cognitive and physical development; they also produce formsthat they have never heard and no adult ever would use.
The empiricist focuses on the stimuli the child receives, what is outside,granting minimal responsibility to any domain-specific cognitive apparatus,any innate language faculty, for example. In contrast, the rationalist focuseson what comes from within the learner, and downplays the role of massiveamounts of data in attaining a grammar. Gleitman and Newport make avery simple argument in favor of the rationalist position. A child raised ina fully bilingual environment can be assumed to get about half as muchinput in each language as a child raised in a monolingual environment. Iflanguage acquisition was primarily data-driven, then we would expect largedelays in the development of bilingual children as measured by variousmilestones in linguistic performance. It turns out, however, that no suchmassive delays are observed. Children in bilingual environments tend to beat about the same level of production and comprehension in both languagesas children in monolingual environments, despite receiving about half asmuch data on average.
In our reference to the sense of time in rats (and humans) in Chapter 6we mentioned that pure duration cannot be observed—events and processeshave a duration, but the category itself is an abstraction imposed by therodent or human mind. We can build a computer that measures duration ofsound signals and light signals and treats the results the same, regardless ofthe input channel of the signal, but we have to make sure that we programthe computer to do this—we have to use a single clock or merge the resultsof a sound clock and a light clock. Duration pure and simple is not in thesignal. We already know that the same is true for the sound segments andwords we hear, as well as the syntactic structure that is imposed on speechby our minds. A strict empiricist approach to language acquisition failsbecause without the necessary pre-existing mental apparatus that humanshave, but that snakes, fish, and dogs do not have, there are no categoriesover which to generalize.
13.2 Competence and performance
We have been assuming to this point that it is fairly obvious what a languageacquirer has to do and what a linguist has to account for—generalizationsand patterns have to be imposed on the data in the form of equivalence

272 SOME PHILOSOPHY
classes and computations involving these classes. Throughout this book,however, we have ignored a crucial fact: It is far from clear what the data isover which the generalizations and patterns must apply.
The subject matter of linguistics cannot actually be what people say, if“what people say” is understood to refer to the sounds they make whenspeaking. Many people speak more than one language and it would be ahopeless task to follow a person around and model in a consistent way(develop a grammar of) their speech output if they sometimes said dog,sometimes chien (French for “dog”) and sometimes perro (the Spanishword). Even when we decide that a given utterance provides evidence fora particular grammar, we have to recognize that the output of a personand the output of a grammar are two very different things. By definition,the grammar outputs representations, abstract mental entities that cannotbe seen or heard directly. These representations can be fed to other sys-tems, ultimately leading to the sounds of speech emanating from a person’smouth, but many other factors contribute to such sounds:
� did the grammar in fact generate a complete sentence or was it inter-rupted in its computations?
� did the processors receive into memory buffers an intact representationor were multiple grammar outputs mingled?
� did the processes of attention allocation dedicate enough resources topassing this representation on to other systems?
� was the nervous system functioning “normally” or was it compromisedby alcohol or fatigue or drugs?
� were the biomechanical features of the vocal tract and respiratory tractthat enter into speaking functioning properly?
� was the oral tract clear of peanut butter and pretzels when articulatingspeech?
. . . and so on.In the linguistics literature the constant knowledge that constitutes an
I-language is sometimes referred to as a speaker’s competence. This termis contrasted with what is called performance. Linguistic performance isnot a well-defined notion—basically all aspects of speech production andcomprehension, and perhaps even the making of grammaticality judgments,that do not reflect the grammar are called performance.
In the literature, discussions of performance typically are concerned onlywith so-called performance errors, situations in which the performance

COMPETENCE AND PERFORMANCE 273
systems appear to obscure the grammatical output. For example, when aperson pronounces a tongue twister like She sells sea shells by the seashoreand switches some of the s and sh sounds, we assume that the representationof the words in memory has not changed, but rather the switch is dueto something going wrong in one of the performance systems interveningbetween grammatical output and the speech signal.
The subject matter of linguistics thus is not speech. It is the knowledgesystem underlying speech. We must use speech as one source of data,because the knowledge is not directly observable, and the indirect data isall we have. Other forms of indirect data are the judgments people providewhen asked if a string is grammatical and the reaction time experimentsmentioned in Chapter 7, where structural complexity correlates with thetime it takes to judge that a string corresponds to a well-formed sentence.
This situation is not unique to linguistics. In fact, any time a scientistuses meter readings to draw inferences about the nature of the world, thesame method is at work—observations must be interpreted in light of sometheoretical framework in order to draw inferences about phenomena thatare not directly observable. For example, nobody has ever observed anelectron with the naked eye, and yet scientists build theories about electrons.In drawing inferences about the underlying linguistic system, we have to becareful to distinguish the underlying knowledge, or competence, from theeffects of the various performance systems that lead to observable output.
Thus, we need to constantly be aware of a distinction between the objectof study in linguistics and the sources of evidence available to us. All speechoutput that we observe has to be evaluated to determine how well it reflectsthe output of the grammar and to what extent various performance factorshave influenced the observed speech output. We obviously do not want ourtheory of Universal Grammar to be modeling aspects of speech output thatreflect the effects of performance systems, whether these effects are sporadicand irregular, or systematic.45
The distinction between competence and performance and the fact thatmental grammars, I-languages, are properties of individual minds arebehind the following famous quotation from Chomsky’s Aspects of theTheory of Syntax (1965:3):
Linguistic theory is concerned primarily with an ideal speaker listener, in a completelyhomogeneous speech community, who knows its language perfectly and is unaffected
45 See Hale and Reiss (2008) for discussion of what UG should be modeling.

274 SOME PHILOSOPHY
by such grammatically irrelevant conditions as memory limitations, shifts of atten-tion and interest, and errors (random or characteristic) in applying his knowledge oflanguage in actual performance. This seems to me to have been the position of thefounders of modern general linguistics, and no cogent reason for modifying it hasbeen offered. To study actual linguistic performance, we must consider the interactionof a variety of factors, of which the underlying competence of the speaker-hearer isonly one. In this respect, study of language is no different from empirical investigationof other complex phenomena. [emphasis added]
Chomsky is basically pointing out the distinction between our everydayuse of terms like speaking English and the kinds of categories we mustconsider when undertaking a scientific analysis. Yet, this passage has evokedincredibly virulent reactions both from within and from outside the linguis-tics community. You will have no trouble finding examples if you searchthe phrase “homogeneous speech community” on the internet. The generalcomplaint can be paraphrased like this:
Chomsky proposes to study language by modeling an ideal speaker-hearer in a com-pletely homogenous speech community, but there are no languages like this—thereis always intra- and interspeaker variation correlated with temporary or more per-manent social circumstances, and no speech community is completely homogenous.Therefore, Chomsky’s idealizations are so radical as to be uninteresting and uselessfor an understanding of how language really works.
At the time Chomsky wrote the passage in Aspects of the Theory of Syntaxhe had not introduced the term I-language, and perhaps his expression ofthe goals of linguistics, as he conceived them, could have been clearer. Weare not concerned with such issues, but instead with providing you withan understanding of where the objections represented above are misguided,even if our terminology is anachronistic.
There are two issues to clarify, neither of which is particularly difficult.First of all, interpret the term language when Chomsky uses it to mean I-language. This is clearly not the same as the everyday word that we usewhen we talk about the English language and its variants around the globe.So, it is simply the case that Chomsky is speaking of a completely differententity from that referred to in expressions like “the language of Jamaica isEnglish.”
The second issue is that Chomsky would be the first to agree that gen-erative linguistics is basically useless for providing insight into how speechcommunities work (whatever that means), or for explaining all aspects oflanguage behavior. These topics, if they are coherent at all, are clearly far

COMPETENCE AND PERFORMANCE 275
too complex for scientific inquiry. Science makes progress only when narrowissues are examined, not vague, all-encompassing questions like “How doesthe world work?”
Chomsky’s idealizations allow us to study I-language, and to view thecomplexity of observed linguistic behavior as arising from the performancefactors we have mentioned, including physiological and cognitive factors, aswell as the interaction of individuals with grammars that differ to varyingdegrees, the presence of multiple grammars underlying the speech behaviorof a single individual, the arbitrary boundaries on speech communities,and so on. A model of I-language will surely be simpler than a modelof the use and interaction of multiple I-languages. And, surely, nobodycan deny that the individual members of a speech community each havesome kind of cognitive system, so it seems unreasonable for those interestedin speech communities to complain about an effort to understand thesesimpler systems that are components of speech communities.
Now that we have clarified the competence–performance distinction, itshould be apparent that Universal Grammar must be a theory of the uni-versal aspects of linguistic competence, since performance factors are notpart of grammar by definition.
There are some linguists and other scholars who suggest that the mod-eling of Universal Grammar must wait until we have more data, untilmore languages have been observed. We pointed out in Chapter 5 that thedemonstration of the insufficiency of Finite State Grammar for a modelof the human language faculty is a result that is not subject to revision onthe basis of more data: Finite State Grammars cannot model English-typegrammars, so they cannot be powerful enough for Universal Grammar.
The preceding discussion of the competence–performance distinctionprovides yet more grist for the anti-empiricist mill of generative linguistics.There is no reason to wait to observe more languages before building atheory of Universal Grammar, because we have not yet observed a singlelanguage! Remember, we are interested in I-languages, mental grammars,and these are not available to direct inspection any more than quarks are—their existence and their nature must be inferred.
Chomsky and others have long advocated the necessity of focusing oncompetence theories:
In my opinion, many psychologists have a curious definition of their discipline. Adefinition that is destructive, suicidal. A dead end. They want to confine themselvessolely to the study of performance—behavior—yet, as I’ve said, it makes no sense to

276 SOME PHILOSOPHY
construct a discipline that studies the manner in which a system is acquired or utilized,but refuses to consider the nature of this system. [Chomsky 1977:49]
[I]f we confine ourselves to the scientific and intellectual goals of understandingpsychological phenomena [as opposed to predicting observed behavior] one could cer-tainly make a good case for the claim that there is a need to direct our attention awayfrom superficial “data fitting” models toward deeper structural theories. [Pylyshyn1973:48]
One reason for this position is that, despite empiricist claims to the contrary,even performance or behavior is difficult to define. Empiricists also face thedifficult problem of defining what the data points are if they want to extractgeneralizations from them.
In Species of Mind, their 1997 book on cognitive ethology, the cognitivescience of (non-human) animals, Colin Allen and Marc Bekoff discussthe difficulty of defining behavior. Does behavior imply movement? Aren’tfreezing or playing dead behaviors? Is secreting a hormone or a noxiousodor a behavior? Does movement imply behavior? Allen and Bekoff pointout that “One would not, for instance, expect an ethological explanationfor the motion of an armadillo dragged fifty meters along a highway bya speeding pickup truck” (p. 42), but what about blinking, breathing, andhaving a pulse? There is movement involved, but is there behavior? Perhapsbehavior is just as abstract a notion as grammar, or even more so, despitethe empiricist’s insistence that our theories must be grounded in observabledata.
Grammars are not directly observable and observable language behavioris clearly the result of many interacting systems—motor planning, atten-tion, learning systems, physical properties of the vocal tract, and so on.This means that it is difficult to build theories, since we are never surewhen patterns we see reflect somewhat directly underlying competence. Itis difficult, but c’est la vie.
It has been suggested that Chomsky invoked the competence–performance distinction to explain away some difficult facts, but we thinkthis represents a misunderstanding of a crucial point that is typically onlyimplicit. Like our discussion of rationalism vs. empiricism, the competence–performance distinction is not only relevant to the linguist’s theorizingbut it is also relevant to a characterization of the acquiring child. The“data” that children get, the speech behavior they are exposed to, con-tains numerous mis-starts, mis-pronunciations, switches between grammar,doors closed in the middle of sentences from the next room, and so on. If

REFERENCE 277
children attempted to build a grammar based directly on the spoken soundsthey heard, the result would definitely not be a possible human language.Children somehow come to the language-learning situation with a learningsystem that knows that the data will be messy, and that much of what isheard will have to be discarded. Exactly how they sort and discard remainslargely a mystery, but a mystery that the theory of Universal Grammarattempts to help solve.
13.3 Reference
One aspect of language that seems to involve learning in a relativelystraightforward way is the arbitrary connection between phonological rep-resentations and meanings. The everyday notion of meaning is typicallyrelated to the idea of “picking out things in the world.” We will see thatthings are not so simple—once again, it is not very clear what the “data”actually is.
Most sane people believe that languages contain words and phrases thatrefer to things in the world—the phrase the sun means “the sun” becauseit refers to the sun; the phrase George W. Bush means “George W. Bush”because it refers to George W. Bush; and so on. Sometimes the situationis a bit more complex—for example, dogs apparently refers to the set ofall dogs in the world and a dog needs to be interpreted as referring to onemember of the set of dogs in the world. A phrase like the dog seems to haveseveral ways of referring: it can refer to a particular dog that is relevant toa particular discourse—I have a dog and a cat, but I like the dog more—orit can function as a generic term referring to the whole set—The dog is afaithful beast—or it can refer to a particular dog which is present when thesentence is uttered—Does the dog bite?—perhaps said while pointing to aparticular dog.
Despite the apparent obviousness of the view that linguistic expressionsrefer to the world, we will argue that, in fact, such a position is unten-able. As in just about every other domain that has been investigated sci-entifically, the beliefs of most sane people just do not stand up underscrutiny.
The commonsense view can be paraphrased as positing a relation, calledreference, between words or phrases, which, according to the I-languageapproach we have developed, are in the heads or minds of individuals, and

278 SOME PHILOSOPHY
things in the world outside of individual minds. There are at least two waysto undermine the commonsense, apparently obvious view of language andreference.
First, for a good many words and phrases, everyone is in agreement thatno corresponding entities exist “out in the world.” We talk about unicorns,universal peace, the ether, and the United Federation of Planets, withoutbelieving that any of these entities actually exist in the world outside ourheads. These examples do not show that no words or phrases refer tothings in the world, but only that some fail to refer in this simple-mindedway. However, these examples do show that this reference relation is not anecessary component of what a word is or does, since many words do nothave this component.
Other examples consistent with the idea that phrases need not refer to theworld are conditional statements like If John arrives early, we’ll take him todinner or If I could afford it, I’d have you iced. These sentences clearly have ameaning, and yet they are built upon descriptions of situations that do notyet or may never exist.
A more radical attack on the simple view of reference comes from theidea that the words or phrases that we use reflect the way in which ourminds divide up the world, but the latter does not correspond in any directmanner with the properties of the physical world as characterized by thephysical sciences. The claim is not to be confused with some kind of idealistphilosophy that denies the existence of the physical world. Physicists canspecify regions of space-time with great accuracy, and also characterize theregions with respect to their mass or average molecular kinetic energy or thewavelength of light that they reflect. However, these characterizations can-not be directly correlated with the words and phrases of everyday languageand the objects of everyday thought.
There are many examples that can be used to demonstrate that ourconcepts of things do not correspond to physically definable entities in theworld and that the terms of our language correspond to our concepts ratherthan physically definable entities. Obvious examples are the illusory triangle,rectangle, and blob from Chapter 2. There is ink on the page, but your mindinterprets the input to your eyes as a triangle, rectangle, or blob. It is notreally useful to ask if there is really a triangle on the page, although it isinteresting to explore under what conditions we see a triangle. And, to floga dead horse, the phonemes, words, c-command relations, and so on, arealso constructions of your interpreting, constructing mind. Hammarberg

REFERENCE 279
said it, too: “[I]t should be perfectly obvious by now that segments do notexist outside the human mind”.
Here is one of those odd conclusions that Pylyshyn warned us about:everything we experience is like the triangle. Your home, your beloved, yournose, your dreams and aspirations, your high school diploma and highschool degree, the /t/-s in cat, cats, atomic, atom, want a—everything. Yourmind carves up the world in certain ways, or rather, constructs a certainkind of world, because it is built to process information in certain ways.
Actually, each component of your mind has, or rather, is a set of world-construction rules. Your visual system creates visual objects and scenes,the components of the visual world; your auditory system creates auditoryscenes consisting of auditory streams that in turn consist of auditory events,the components of the auditory world;46 your language faculty createssentences, structures that consist of phrases, which in turn consist of mor-phemes, which in turn consist of symbols that we correlate to variables (asin our reduplication examples) or the speech segments that we describedas sets of features (as in our Turkish vowel harmony example); and so onfor all our other faculties. Some scholars have even posited components, ormodules, of mind that construct the categories in domains such as moralreasoning (Mikhail (2007), and Jackendoff’s contribution to Macnamara,Jackendoff, Bloom, and Wynn (1999)). In domains like moral reasoning itis easy to accept that the categories are mental constructs. In vision andlanguage, we have spent a lot of energy trying to convince you that theentities involved are mental constructs, too. Words we perceive, for example,do not correspond to “pieces” of sound separated by silence.
The hard step to take is to accept that our everyday understanding ofspace and objects is also the product of construction, that the objectsthat we think of as populating the physical world do not correspond ina straightforward manner to the objects that physics recognizes. In otherwords, the “physical world” of human experience and the “physical world”of the science of physics are two very different worlds, or, rather, two dif-ferent structures imposed on the one and only world. We are not headingtowards an idealist philosophy and we will even adduce the authority of aphysicist later in the chapter on a closely related point, so bear with us.
Maybe you will take us more seriously if we introduce an example fromantiquity—the philosophical puzzle of the Ship of Theseus. If we replace a
46 These are technical terms, used in work such as Bregman (1990).

280 SOME PHILOSOPHY
plank from this ship, is it the same ship—does the ship continue to exist?Our intuition is that it does. What if we replace two planks? Or ten? Notethat the ship can even be conceived as persisting if we replace every singleplank, every single physical part, over time. How can this be if the ship is aphysical object? Things get even worse when we consider that the removedplanks can be collected and set up in exactly their original configurationand yet the ship thus constructed does not correspond to the original ship,or at least not obviously so.
To update the issue, consider that we typically think of our cars asphysical objects, yet if we put on winter tires, replace the windshield, the gastank, and even the engine, re-upholster the interior, putty, paint and addfins to the body, the law does not require us to get a new license plate. Thelegal identity of the car seems to transcend its physical composition in a waythat is not well understood. In fact, the identity of the car as the same entityappears to depend on our own internal construction of a concept that per-sists through time. There are no necessary or sufficient physical (in the senseof physics) correlates to the triangles we perceive—they can be black or blueor red or defined by regions of small x’s on a background of o’s. Similarly,there are no necessary or sufficient correlates to the concept CAR or evento the concept of a particular car—BILL’S CAR—no set of molecules, nospace-time continuum can define a car. This lack of necessary and sufficientconditions is characteristic of equivalence classes as discussed by Pylyshyn(1984), and we suggest that both CAR and BILL’S CAR are not labelsof objects recognized by the science of physics but rather of objects ofhuman experience of the world, equivalence classes of our faculty of objectcognition.
Each of us constructs CAR concepts that relate to aspects in the physicalworld much like the relation between our triangle percept and ink on thepage in Chapter 2. We humans impose “car-ness” on aspects of experience.We tend to appear to agree about what cars are out in the world because wehave very similar apparatus for imposing structure on our experience of theworld and very similar input systems with which we transduce incomingstimuli, convert them to mental representations. Note that we also canconstruct CAR concepts without any external stimulus—in visual imageryor other kinds of thought. These concepts, these cars, have no physicalcorrelates whatsoever, despite the fact that we may conceive of them asobjects in our world of human physical experience.
Similar considerations apply to living beings, and the argument is perhapseasier to accept in this domain, given notions like self and soul that are part

REFERENCE 281
of our everyday concepts. Chomsky mentions the stories of the Frog Princeof the fairy tale and Sylvester the Donkey of the children’s story—when theformer undergoes the transformation from man to frog and the latter fromdonkey to rock, children, like adults, have no trouble conceiving of the frogor rock as the same entity as the man or donkey, respectively. The rock hasno hair and no ears, the dogs detect no donkey smell on it, and it does nottalk or bray. Yet it remains Sylvester the Donkey because our concepts andwords refer to a continuity that transcends physical continuity.
Perhaps a good way to think about it is that the names and conceptshave been associated with an index. The physical properties associated withthe index may change, but the identity remains merely by virtue of beingassociated with an index.
Chomsky discusses many examples of words whose apparent referent isnot simply some physical object. We refer to doors and windows as thingsthat can be installed and painted, but we also refer to the possibility ofpassing through a door or window, focusing on the space bounded by theframe. The frame and the space have very different properties, but we donot think of the words as being ambiguous. For example, we do not thinkof a room as having four windows in one sense (frames) and four in theother sense (spaces)—the word refers to a complex concept that cannot bereduced to a consistent physical characterization.
Similar considerations hold for the word house. We can make an arbitrarydecision that our house ends two meters below the center of the doorknobof the front entrance, but such a decision is exactly that—arbitrary and withno basis in how we conceive of what a house is. Our house can burn downand be rebuilt slightly to the south—its physical properties are completelydifferent and yet we can conceive of it as the same house. Similarly, a citycan be destroyed and rebuilt in a different location. An institution suchas a university is at the same time a collection of buildings, associationsamong individuals, legal and social conventions, and so on. So, clearly,words referring to such an institution cannot be referring just to things inthe physical world.
The observation that the identity even of simple objects transcends theirphysical characterization was made in the 1930s by the linguist and anthro-pologist Edward Sapir in the paper mentioned in Chapter 1. Sapir pointsout that a given physical object can be described from the point of view ofphysics as having a certain length, mass, color, and chemical composition,but that a physical description can never tell us if the object is a club or apole. Two poles may differ greatly in their physical attributes, and a given

282 SOME PHILOSOPHY
pole may be identical to a given club from this perspective. What makes uscall one a club and the other a pole depends on how we use them or intendto use them, and perhaps our beliefs about the intent of the person whomade each object. If we see you take a certain object, plant it in a hole linedup with other similar objects and string barbed wire between these objects,we will refer to them as “poles.” If, instead, we see you use the same objectto bang someone on the head, we call it a club.
We began this chapter by presenting two ways in which the rationalism vs.empiricism debate relates to language. The first one concerns the source ofour theories: do we start with observations and then make generalizationsand provide hypotheses, or do we make inferences and deductions, and onlythen appeal to observation? The position we have argued for is a rationalistone. The second way in which the rationalist vs. empiricist debate appliesto language concerns the source of our knowledge of language as speakers.Here, too, we have sided with rationalists, who admit innate knowledge as apossibility, as opposed to empiricists, who advocate that knowledge is pri-marily derived from experience. Our discussion about reference suggests yetfurther problems for the empiricist perspective, since the very objects thatare part of our experience and observations are actually mental constructs.Acquiring knowledge of language partly consists of constructing “sound-meaning” correspondences for words.47 And yet, the meanings of words donot directly map to the physical world of science but rather to the worldof human experience, the world as perceived by us humans, including boththose aspects we consider to be physical, material objects, and other aspectsto which we do not attribute these properties. So, there is no sense in whichword meaning, as a component of knowledge of language, can be conceivedof as being derived from experience and observation, unless what we meanis that it is derived from our own perception of experience and from theway in which we carve or categorize our observations. But, of course, thatamounts to actually taking a mentalist, rationalist stand.
13.4 Essentialism
One of the immediate consequences of accepting that language is not aboutthe “real” world is that an essentialist position becomes untenable. Let usexplain.
47 Of course, we mean phonological representations, not actual sound.

ESSENTIALISM 283
Our teenaged daughter speaks both English and French, but her firstlanguage was Romanian. Once, while crossing the street a few years ago, shejokingly said to Charles: “I hope that car does not step on me.” She thenexplained that this was a literal translation of how you say in Romanian “Ihope that car does not hit me.” We explained, much to her astonishment,that upon learning this fact about Romanian, some philosophers mightactually engage in a discussion of whether cars really step on you.
You probably think we are being unfair to the community of philoso-phers, but you should consider the kinds of questions that philosophershave been asking for millennia. The Platonic dialogues portray Socratesengaged in discussion of such questions as What is beauty/justice/virtue?More recently, retired Princeton philosophy professor Harry Frankfurtengaged in what might be best characterized as meta-bullshit when heexplored the question What is bullshit? in a book published in 2005 byPrinceton University Press entitled On Bullshit. These questions are actuallyno different in kind from questions like Can a machine think?, Can animalsdo evil?, or Can a car step on you? All these questions presuppose that thereis a matter of truth at stake, and the truth depends crucially on what thewords in question really mean. If we figure out the real meaning of thinking,or stepping on, or beauty, or justice, or bullshit, then we will be able toanswer the questions correctly. This idea is directly related to the idea thatunderstanding the world involves understanding the essence, or real nature,of the things that words refer to. However, as pointed out in the precedingchapter, we each use words in certain ways, and we have developed similarways of using words with similar sounds if we acquire our languages undersimilar circumstances. But there is no truth to the matter, no question of thereal, that is, correct, meaning of a word.
We have (perhaps unfairly) caricatured philosophers as overly prone toessentialist discourse, and we must point out that, in fact, the most promi-nent critic of the view that science should attempt to define the essence ofnamed entities was the twentieth-century philosopher Karl Popper. He con-trasted such methodological essentialism with methodological nominalism.The essentialist tries to answer questions like What is movement? or What isan atom? The nominalist in contrast asks questions like How do the planetsmove? or Under what conditions will an atom radiate light?
And to those philosophers who tell [the nominalist] that before having answered the“what is” question he cannot hope to give exact answers to any of the “how” questions,he will reply, if at all, by pointing out that he much prefers that modest degree of

284 SOME PHILOSOPHY
exactness which he can achieve by his methods to the pretentious muddle which theyhave achieved by theirs.
. . . methodological nominalism is nowadays fairly generally accepted in the naturalsciences. The problems of the social sciences, on the other hand, are still for the mostpart treated by essentialist methods. This is in my opinion, one of the main reasons fortheir backwardness. But many who have noticed this situation judge it differently. Theybelieve that the difference in method is necessary, and that it reflects an “essential”difference between the “natures” of these two fields of research. [Popper 1945:33.Popper’s footnote deleted]
Popper goes on to discuss why the social sciences (and humanities) acceptessentialism, and it is interesting, but beyond the scope of this book to com-pare Popper’s discussion with that of methodological dualism in Chapter 3of this book.
In order to impress upon you how seriously Popper took the issue ofessentialism among his fellow philosophers, we provide the following quo-tation from volume 2 of the same work cited above:
The problem of definitions and of the “meaning of terms” is the most importantsource of Aristotle’s regrettably still prevailing intellectual influence, of all that verbaland empty scholasticism that haunts not only the Middle Ages, but our own contem-porary philosophy; for even a philosophy as recent as that of L. Wittgenstein suffers, aswe shall see, from this influence. The development of thought since Aristotle could, Ithink, be summed up by saying that every discipline, as long as it used the Aristotelianmethod of definition, has remained arrested in a state of empty verbiage and barrenscholasticism, and that the degree to which the various sciences have been able to makeany progress depended on the degree to which they have been able to get rid of thisessentialist method. (This is why so much of our “social science” still belongs to theMiddle Ages.) The discussion of this method will have to be a little abstract, owingto the fact that the problem has been so thoroughly muddled by Plato and Aristotle,whose influence has given rise to such deep-rooted prejudices that the prospect ofdispelling them does not seem very bright. In spite of all that, it is perhaps not withoutinterest to analyse the source of so much confusion and verbiage. [Popper 1945, Vol. II]
Popper’s refusal to mince words made it very difficult for him to find apublisher for what ended up becoming one of the century’s most influen-tial philosophical works. The book was rejected by American publishersbecause of its criticism of Plato and Aristotle and finally published inLondon in 1945. We have neither the space nor the competence to defendPopper here, but we will just point out that the problem of essentialist think-ing appears to lie behind many of the enduring “puzzles” of philosophy oflanguage and mind. We now turn to one such “puzzle.”

ESSENTIALISM 285
The great mathematician Alan Turing asked the question Can a machinethink? in a famous paper in 1951, but sensibly enough immediately providedthe following response to his own question:
The original question “Can machines think?” I believe to be too meaningless todeserve discussion. Nevertheless I believe that at the end of the century the use ofwords and general educated opinion will have altered so much that one will be able tospeak of machines thinking without expecting to be contradicted.
Turing explains that whatever we call what machines are doing has nobearing on what they are actually doing. It may or may not be useful toapply the label thinking to what digital computers do, but Turing predictedthat the label would be used by educated people at some point.
The amount of ink that has been spilt on Turing’s question, all thewhile ignoring his dismissal a few paragraphs later, is mind-boggling. Con-tributors include philosophers, computer scientists, artifical intelligenceresearchers, psychologists, theologians, and more. A quick web search turnsup this example from the kurzweilai.net website in an article “Can amachine think?” by Clinton Kelly from 2001:
Why do we think computers may have the “right stuff ?” The reasons are among someof the most significant philosophical concepts of the late 20th century.
In one variant or another, the question “can a machine think” has occupied theattention of philosophers and others for centuries, stimulated from time-to-time bythe emergence of ingenious mechanisms which suggested at least the possibility of anaffirmative answer. In our own times, we have seen the creation of machines that areautonomous—robots, for example, that can perform tasks without constant humansupervision. Does this mean that the device thinks? Thinking about what it meansfor a machine to think means thinking, as well, about ourselves. Indeed, what does itmean to think? Does thinking define humanity? Do animals think?
Chomsky has pointed out that the meaninglessness of these questions fol-lows from the I-language perspective in which we use words to refer andto mean things, but do not attribute reference and meanings to the wordsthemselves:
[I]t is not a question of fact, but a matter of decision as to whether to adopt a certainmetaphorical usage, as when we say (in English) that airplanes fly, but comets do not—and as for space shuttles, choices differ. Similarly, submarines set sail, but do not swim.There can be no sensible debate about such topics; or about machine intelligence, withthe many familiar variants. [Chomsky 2000a:114]
Whatever we call what computers do or what gorillas do, it may or maynot be useful to compare them to what we think humans do when we say

286 SOME PHILOSOPHY
they are thinking. As we have seen in our discussions of the verb see inChapter 2 and in our discussions of the word language, everyday terms usedto describe human behavior and cognition tend to cover a wide range ofdifferent phenomena when we begin to subject them to scientific inquiry.The question of whether machines “really” think is no more useful than thequestion of whether cars “really” step on people.
You can probably see how the discussion of reference and essentialismties in with the Platonic, P-language conception of language introduced inChapter 4. If the words of languages exist outside of human minds, as idealforms, then they have true meanings—the ones they actually have. It follows,then, that one can judge usages that do not conform to these true meaningsas “wrong” or “false.” This chain of reasoning helps to explain why thereexists a strong prescriptivist strain among philosophers. (We won’t try tosubstantiate this characterization—all you need to do to convince yourselfis try explaining the positions on I-language and prescriptive grammarwe have presented to a philosophically “sophisticated” friend. They willassume that you are being crazy, stupid, or both.)
13.5 Mind and body
In this section we will briefly discuss one of the most enduring topics ofphilosophical discussion, the so-called “mind-body” problem. This issue issometimes referred to as the “ontological problem” since ontology is thestudy of what exists, and the issues we are concerned with are whether“mind” and “body” both exist and whether or not the distinction betweenthem is a principled one. A related question, of course, is why the two canapparently interact if they are completely distinct—we know that a vodkamartini with three olives or a good workout (physical things) can make usfeel happy (a mental thing), for example.
We use the term “mind” in the context of the ontological problem, torefer to what throughout history has been called mind, thought, spirit,and soul, and various roughly equivalent terms in other languages. Evenrestricting ourselves to thought, we find that discussion is further confusedby a failure to distinguish cognition of the kind we have been discussing,visual, auditory, and linguistic computation for example, from conscious(self-)awareness and conscious thought.

MIND AND BODY 287
This is not the place to review the history of the ontological problem,but we can briefly mention some of the major themes and positions thathave been proposed and defended. The view that mind stuff and bodystuff are both real but fundamentally distinct is referred to as dualism. Themost famous advocate of dualism is the great seventeenth-century Frenchmathematician and philosopher René Descartes, from whose name derivesa view of the ontological problem known as Cartesian dualism. Descartes isfamous for his skepticism—he began his investigations into the ontologicalproblem by doubting everything. You are probably familiar with his famousstatement I think, therefore I am, which was the first conclusion he accepted:the fact that he thinks shows that he must exist. So, Descartes accepted firstthe existence of thought and thus mind. It took some further argumentationfor him to accept that his body was real.
Idealism, whose most famous representative was Bishop Berkeley writingin the eighteenth century, is the position that only mental stuff exists. Theuniverse is just thought, and things exist just by virtue of being thoughtabout or perceived. Since everything is always in the mind of God, thingsthat we think of as physical objects do not go in and out of existence accord-ing to our thoughts about them—God has a lot more attentional resourcesthan we do (probably infinitely more) and so He can keep everything inmind, thus ensuring the permanence of the so-called physical world.
In our everyday lives, most of us are probably dualists. Whether webelieve in the soul in accordance with some religious tradition or because weexperience our minds as independent of our bodies in so many ways, we tendto talk and act like dualists of one sort or another. These everyday beliefsshow many incoherent and inconsistent properties upon examination. Forexample, Descartes defined the physical as that which has location andextension in space, and most people would readily agree that the soul orthe spirit or the mind lacks this property. However, at the same time, wetend to think of the mind/soul/spirit as somehow inhabiting or being insidethe body and departing upon death of the body. How can something bothnot have location and extension and be located inside our head or hearts?
When thinking about these issues as scientists or philosophers, manymodern thinkers reject dualism for a form of materialism—the idea thatonly physical stuff exists. Thus the body is real, but the mind is not real inthe same way. There are many varieties of materialism and an excellent sur-vey is provided in Paul Churchland’s 1984 Matter and Consciousness. Twopopular versions of materialism are reductive materialism and eliminative

288 SOME PHILOSOPHY
materialism. Reductive materialism takes the position that the phenomenaof mental life, thoughts and consciousness, will be reducible to categories ofthe natural sciences. For example, thinking about cockroaches in the jungleis ultimately reducible to, or describable as, a certain electrochemical stateof the brain. Eliminative materialists go even further. They do not wantto reduce the mentalistic talk to physical neurological terms, but rathereliminate the mentalistic talk altogether.
In the history of science there have been many proposals for entities thatare no longer thought to exist. The whole universe was assumed, until theearly twentieth century, to be full of “the ether” that served as a medium ofelectromagnetic radiation. Sound and water waves require a medium, so thesame was assumed for light and other waves emitted from distant stars. Wenow know that electromagnetic radiation does not require a medium, andthus the ether has been eliminated from physics. Eliminative materialists,including Churchland, who wrote an excellent review of the philosopherJohn Searle’s views on these matters called “Betty Crocker’s theory of con-sciousness” (Churchland 1988), propose that mentalistic terms like thought,knowledge, and belief should be eliminated from the science of the mind.From a scientific perspective, the eliminativists argue, thought is as unnec-essary an element for an understanding of cognition as the ether is for anundertanding of the physical universe.
In our opinion, Chomsky has cut the Gordian knot of the mind/bodyproblem by arguing that the issue is incoherent, not because of the dif-ficulty of identifying what the mental is, but because of the incoherenceof the notion “body”—the physical world cannot be defined or identifiedin any coherent fashion. Eddington, in the quotation repeated below fromChapter 3, had in mind the divergence of everyday experience of space andtime from what we know about the scales of particle physics and cosmology.Cognitive science has gone further in showing that even on the middle scaleof everyday life, perception of time, space, motion, etc. can be greatly atodds with what physical measurements record.
At one time there was no very profound difference between the two versions. Thescientist accepted the familiar story [of the perceiving mind] in its main outline; onlyhe corrected a few facts here and there, and elaborated a few details. But latterly thefamiliar story and the scientific story have diverged more and more widely—untilit has become hard to recognise that they have anything in common. Not contentwith upsetting fundamentally our ideas of material substance, physics has playedstrange pranks with our conceptions of space and time. Even causality has undergone

MIND AND BODY 289
transformations. Physical science now deliberately aims at presenting a new version ofthe story of our experience from the very beginning, rejecting the familiar story as tooerratic a foundation.
Chomsky’s insight about the vast gulf between everyday experience andscientific understanding is not new, but his application of this idea to themind/body problem apparently is new, and almost universally ignored orrejected by the philosophical community.
As the familiar story and the scientific story diverge it becomes impossibleto understand in any direct sense what the world is like according to thescientific view. As Chomsky puts it, science no longer aims to make theworld intelligible but only to construct intelligible theories that appear togive us some insight into phenomena in very narrow domains, far removedfrom everyday experience.
So what Chomsky (2000:106) proposes is to use the term “mental”informally, “with no metaphysical import” as pre-theoretically defining adomain of inquiry in the same way that terms like “optical,” “chemical,”or “biological” are used. Nobody wastes their time trying to determinethe essence of the optical. But there are certain interfacing explanatorytheories that have been constructed that we group together for the purposesof writing textbooks or organizing departments in universities. Because of afairly informal naming practice we should not assume to have discovereda coherent, distinct aspect of reality. The mind-body “problem” is justanother essentialist fallacy under this view.
Instead of asking whether the triangle of Chapter 2 exists, or whetherMaranungku foot structure exists, or NPs exist, the cognitive scienceapproach to the study of the mind asks questions like What are the bindingconditions on NPs in English? Positing NPs and their c-command relationsallows us to build an explicit explanatory theory that appears to give insightinto some aspect of the world (in this case one that we happen to calllinguistic, part of the mental world). Questions about whether NPs reallyexist, just like similar questions about gravitational fields or electrons, donot provide any insight. According to Chomsky (1997:132) in Johnson andErneling (1997) such “[o]ntological questions are generally beside the point,hardly more than a form of harrassment.”
The fairly arbitrary labeling of domains is made apparent in a passagefrom The Computer and the Brain (2000) by the mathematician John vonNeumann describing a nerve impulse propagated along an axon:

290 SOME PHILOSOPHY
One of its characteristics is certainly that it is an electrical disturbance; in fact, it ismost frequently described as being just that. This disturbance is usually an electri-cal potential of something like 50 millivolts and of about a millisecond’s duration.Concurrently with this electrical disturbance there also occur chemical changes alongthe axon. Thus, in the area of the axon over which the pulse-potential is passing, theionic constitution of the intracellular fluid changes, and so do the electrical-chemicalproperties (conductivity, permeability) of the wall of the axon, the membrane. At theendings of the axon the chemical character of the change is even more obvious; there,specific and characteristic substances make their appearance when the pulse arrives.Finally, there are probably mechanical changes as well. Indeed, it is very likely that thechanges of the various ionic permeabilities of the cell membrane (cf. above) can comeabout only by reorientation of its molecules, i.e. by mechanical changes involving therelative positions of these constituents. [40–41]
So is the neural impulse an electrical, chemical, or mechanical phenom-enon? Nothing depends on the answer and so the question is probably not auseful one. The names of these domains roughly delineate topics of study inwhich some progress has been made developing explanatory theories, andthe same is true of linguistics, vision and quantum mechanics. There is nochemical world or mechanical world or optical world or linguistic world.There is just the world, and more or less explanatory theories that we canmake about aspects of the world. The world itself will not be intelligibleto what Eddington calls the “storyteller” of the perceiving mind, but ourscientific theories can be intelligible.
Chomsky argues, and much of this book has attempted to support thisview, that under a certain perspective of what language is, we can developexplanatory formal models that give us some insight into phenomena underthe same kinds of idealizations made in all pure sciences. The decisionto treat human language as a natural object is vindicated by the insightachieved. The same can be said for the study of vision and other mentalfaculties.
So, Chomsky solves the mind-body problem by denying a principled dis-tinction between what is mental and what is physical. Not only is the worldof physics remote from our own pre-scientific notions and understanding,but physics changes to include whatever physicists posit. Before Newtonthere were no gravitational fields in physics. Rather than reducing mental-istic notions, including linguistic ones like word, c-command, or phonemeto materialist definitions in terms of neurons and chemicals or quarksand ions, Chomsky proposes that various domains in which intelligibletheories have been constructed may perhaps one day be unified. Just as

A VIEW FROM NEUROSCIENCE 291
the unification of chemistry and physics in the twentieth century requiredchanges in the theories of both fields, the unification of linguistics withneuroscience, if it is ever possible, will require the positing of neural prop-erties that are currently not known. Why would we want to try to reducelinguistics to a neuroscience that we know to be incomplete? In fact, by pay-ing attention to what computational properties human language exhibits(such as recursion and c-command) neuroscientists can design researchprograms that will lead to the discovery of the necessary computationalapparatus.
13.6 A view from neuroscience
In order to convey what a bad job linguists have done at communicatingtheir ideas it will be useful to compare the views we have developed with thediscussion of language and cognition presented recently in a popular bookby a prominent neuroscientist. Gerald Edelman won a Nobel Prize for hiswork on antibodies, but he is also director of the Neurosciences Instituteand president of the Neurosciences Research Foundation. In his 2004 bookWider Than the Sky: The Phenomenal Gift of Consciousness, Edelman takesa very skeptical view of mental representations which he defines as
a term used by some cognitive psychologists who have a computational view of themind. The term is applied to precise symbolic constructs or codes corresponding toobjects and, by their computation, putatively explaining behavior. [167]
Not surprisingly, topics like Warlpiri reduplication or conditions onanaphor binding are not handled in Edelman’s discussions of language.Instead, Edelman muses on the origins of language in evolution, not onlyvia the development of the vocal tract and the auditory system but also withregard to our upright posture which he assumes is a necessary precursor oflanguage:
In freeing the upper extremities from brachiation (climbing or hanging) or walking, awhole precursor set involving the interpretation of gestures by the self and by othersmay have been opened up for early hominines. [102]
Edelman continues by suggesting that this evolutionary history may berepeated in child development:
Whether infants who have learned to walk, and have their upper limbs free, developsimilar capabilities before the exercise of extensive speech acts is a question that

292 SOME PHILOSOPHY
remains. The acquisition of language may be enormously facilitated by the develop-ment of conscious imagery related to movements and motor control. Almost certainly,concepts of objects, events, and succession must exist in a child’s mind before theexercise of language. According to these ideas, the sequences of actions of the freeupper extremities may prepare the basal ganglion–cortical loops for the emergence ofsyntactical sequences, establishing what might be called a protosyntax.
Clearly, one of the largest steps towards the acquisition of true language is therealization that an arbitrary token—a gesture or a word—stands for a thing or anevent. When a sufficiently large lexicon of such tokens is accumulated, higher-orderconsciousness can greatly expand in range. Association can be made by metaphor,and with ongoing activity, early metaphor can be transformed into more precisecategorization of intrapersonal and interpersonal experience. The gift of narrative andan expanded sense of temporal succession then follow. [102–3]
Where do we start? Edelman is certainly hedging with all these mays andmights, but let’s assume that he wants us to take these ideas seriously.Basically, he seems to be suggesting that upright posture freed the hands touse gesture, which in turn led to conscious imagery related to movements,which in turn led to (proto-)syntax. Combined with the “realization” thatarbitrary signs or tokens stand for a thing or event and a bit of metaphor;this all leads to the “gift of narrative.” If Edelman were not such an impor-tant figure, this just-so story would hardly warrant a response. However, ananalysis of the factual and conceptual errors reflected in this passage shouldprove instructive.
We start with some points about children’s capacities at birth. Let’s firstnote that a vast body of research suggests that children have “concepts ofobjects, events, and succession” as soon as they can be tested, basicallyfrom birth. Elizabeth Spelke (1994), for example, has some very concreteproposals concerning children’s initial concepts about the physical world. Ifthis research is valid, then making such concepts a prerequisite for languageis an empty requirement, since the concepts are there from the beginningand so “language” can be as well.
Second, the idea that cognitive development must be preceded by motorand spatial experience and learning is an obsolete notion associated moststrongly with the great developmental psychologist Jean Piaget. A concreteexample of such ideas would be that children should have to be able to lineup sticks in size order (a task involving motor skills and spatial perception)before they could correctly use comparatives, like Pat is taller than Kim (alinguistic construction). As Annette Karmiloff-Smith, a student of Piaget’s,

A VIEW FROM NEUROSCIENCE 293
has shown, children with Williams Syndrome, a severe form of mentalretardation, are able to use comparatives in speech, but they are completelyincapable of lining up sticks in size order.
Third, some linguistic knowledge, or knowledge that ends up being usedby the language faculty, can be shown to be present in newborns. Based onthe low frequency signals that make it into the uterus through the mother’sbelly, newborns can distinguish the rhythmic properties of their mother’slanguage from that of a wide range of other languages. As mentioned inChapter 11, newborns also appear to be sensitive to any phonetic contrastthat can appear in a language of the world, while at the same time theyignore contrasts that are not used linguistically.
It is clear from the passage that Edelman is ignoring the competence–performance distinction presented above. As just mentioned, very younginfants have speech perception capacities that are completely out of linewith their lousy abilities at articulating sounds. Later, it is clear that theircomprehension of complex syntactic constructions far outstrips the com-plexity of their produced sentences. Like aphasics, or even people with para-lyzed vocal apparatus, children’s syntactic knowledge cannot be determinedby just observing their behavior.
Notice that Edelman is after big game—consciousness. He is not satisfiedto investigate the neuroscience of, say, how the brain computes Warlpirireduplication or subject–verb agreement in English or how you recognizeyour mother’s face from the side, topics about which nothing at all is knownat the level of neurons. One would think that normal scientific practicewould entail the preliminary investigation of simpler aspects of cognitionbefore proposing a solution for what is perhaps the greatest mystery of themind, consciousness. Not only is there little evidence that consciousness isactually amenable to scientific study but Edelman bizarrely suggests thatit is clear that language itself involves conscious thought—he refers toconscious imagery and the realization of the arbitrariness of linguistic signs.So, he not only tackles the most difficult problem, the basis of conscious-ness, but he also assumes that the evolution and acquisition of languagenecessarily involve consciousness. Recall the analyses of phonology, mor-phology, syntax, and semantics in Chapters 6–9 which proceeded withoutany reference to consciousness. We are certain that no reader of this bookwho was not already trained as a linguist had conscious knowledge of thebinding conditions, for example. In fact, even after reading Chapter 8, the

294 SOME PHILOSOPHY
workings of your grammar with respect to binding remain as inaccessibleto consciousness as his own enzyme secretion remains to a gastrologist.
Edelman continues the passage above to discuss “past recollections andfuture imaginations,” which relate to one of the most wondrous propertiesof human language. We use language to refer not only to objects we see nowbut also to things we saw yesterday or last year, events we hope to witness,situations that did not arise and could never arise, and so on. The term dis-placed reference is commonly applied to a subset of these uses of language,those that do not refer specifically to things in the immediate environment.Despite Edelman’s willingness to sketch a plausible evolutionary scenariofor the development of language, and given his latitude in discussing thenature of language, it is striking that he does not mention that the onlywell-established case of displaced reference in a communication system is inthe waggle dance of honey bees, which, performed in the hive, conveys thedistance, direction, and abundance of a food source. Presumably, Edelmandoes not attribute to bees and humans the same evolutionary path todisplaced reference.
Finally, let’s comment on Edelman’s appeal to metaphor. The discussionis so vague that it is hard to criticize, yet it is reminiscent of a recurrentanti-nativist appeal to analogy as the basis of language acquisition. Theproblem is that the child acquiring language has no way of knowing whichmetaphors or analogies will work and which will not. Since we have at leastsome idea of how to formalize the notion of analogy, we will continue thediscussion in that vein.
Here is a simple example, borrowed from Ivan Sag and Tom Wasow,of how analogy fails the learner. Fill in your favorite profane verb in thefollowing contexts:
13.3 A failure of analogya. @#$&*% yourself!b. Go @#$&*% yourself!c. @#$&*% you!
Reasoning by analogy, we ask “Sentence 1 is to sentence 2 as sentence 3is to x. What is x?” Clearly x should be the following:
13.4 *Go @#$&*% you!
But (13.4) is clearly ungrammatical, as any native speaker can attest. Anal-ogy fails.

A VIEW FROM NEUROSCIENCE 295
Here is another example. Consider the difference between the sentencesthat end in an NP and those that do not.
13.5 Another failure of analogya. John is too tough to eat tofub. John is too tough to eatc. John is too tough to talk to Billd. John is too tough to talk to
In (13.5a.) the object of eat is tofu. Example (13.5b.) is ambiguous: it canmean that John is so tough that he won’t engage in eating of anything, orthat John is so tough that we can’t eat him. We might expect, reasoning byanalogy, that leaving the NP Bill off of (13.5c.) would yield an ambiguousstring, but (13.5d.) is not ambiguous. Example (13.5d.) can only meanthat John is so tough that we can’t talk to him, and not that he is sotough that he won’t engage in talking to anyone at all. Simple analogy failsagain.
If analogy or metaphor sometimes work and sometimes do not, then wecannot claim that they provide an explanation in just those cases wherethey work. This would constitute opportunistic appeal to analogy—kind oflike the way people invoke astrology. Typically, linguists say that analogyis irrelevant to language learning. Another way to think about it is thatUniversal Grammar is the theory of just which analogies are entertainedby children in the course of language acquisition. The language facultyspecifies certain analogies that play a role in learning, but not others.
Let’s consider one more, fairly complex example where analogy fails.One might expect that, by analogy, a string of words would contribute aconsistent meaning to any string it is embedded in. Consider a possibleand an impossible reading of the following string, as indicated by theindexation:
13.6 The menm expected to see them∗m/n
The pronoun them cannot be coindexed with the men as you now under-stand from our discussion in Chapter 8. However, them can be indexed withany index distinct from that borne by the men. Now consider the same stringembedded in a larger context.
13.7 I wonder whoi the men j expected to see them∗i/j/k

296 SOME PHILOSOPHY
Here we see that them can indeed be coindexed with the men (or withanything else other than who). Why should this be? Why does the analogybetween (13.6) and (13.7) fail?48
You actually already have almost all the tools to answer this question.Like the base- and derived-position copies of NPs that we introduced forwh–movement, we will assume that there are base- and derived-positioncopies of NPs in a sentence like John expects to go. The abstract structurewill be assumed to have two copies of John:
13.8 � John expects to go� John expects John to go
We can now apply this to the sentences above. Here is the tree for (13.6):
13.9 S
NPm
D
the
NP
VP
V
expected
S
NPm
D NP
the N
men
VP
V
to see
NP
N
them∗m/n
N
men
You can see that them is locally c-commanded by the base-position copy ofthe men, and thus, they must not be coindexed—pronouns like him cannotoccur in such an environment.
Now look at the tree for (13.7):
48 If you have trouble getting the two readings consider the following:� The men are dressed up for Halloween; they expect to be seen by someone. I
wonder whoi the men j expected to see them j .� The women are dressed up for Halloween; the men expect that someone will see
the women. I wonder whoi the men j expected to see themk.

A VIEW FROM NEUROSCIENCE 297
13.10 S
NP
N
I
VP
V
wonder
S′
NP
N
whoi
S
NPj
D NP
the N
men
VP
V
expected
S
NP
N
whoi
VP
V
to see
NP
N
them∗i/j/k
Once again there is an instance of the men (the only instance, in this case)which can bind them. However, this is not local binding, since the men is notin the minimal clause that contains them.
There is no need to appeal to consciousness in this discussion, and infact it is pretty clear that the binding conditions are not accessible toconsciousness or related to consciousness in any other way, except thathumans have both. Furthermore, we have already learned that the sentencestructure, and even the words, do not have invariant physical correlates—there is no sense in which “the actions of the free upper extremities” lead toa “proto-syntax,” if proto-syntax has anything to do with the actual syntaxof c-command and the like.
Edelman appears to scorn an approach to cognition (well, he keeps refer-ring to consciousness, but it looks like he means any cognition complexenough to be specific to human language) based on symbolic equivalence

298 SOME PHILOSOPHY
classes and “programs and algorithms” (p. 33) such as we have presented,which he refers to (repeating a common and misleading characterization) as“computer models” of the mind (see his Chapter 4, especially). He rightlyinsists (p. 33) that
it is important to construct a brain theory that is principled and compatible withevolution and development. By principled, I mean a theory that describes the prin-ciples governing the major mechanisms by which the brain deals with informationand novelty.
There is nothing to argue with here, but Edelman continues: “One suchtheory or model is the idea that the brain is like a computer . . . ”, a view herejects in no uncertain terms: “Once more with feeling: the brain is not acomputer and the world is not a piece of tape” (p. 39).
But isn’t it also right to insist on a brain theory that can handle redu-plication, vowel harmony, binding, negative polarity items, and whateverelse we need to model human language? If neuroscience has no insight tooffer into these issues, then that is a problem for neuroscience, given therobustness of the linguistic accounts. Neuroscience is clearly not ready forunification with linguistic theory, but that is no bad reflection on linguistics,which has enough problems of its own, to be sure, but also has offered intel-ligible explanations with predictive power for a wide range of observablephenomena.
13.7 Exercises
Exercise 13.7.1. We began this book claiming that we would relate Turk-ish vowel harmony to important philosophical questions. Have we suc-ceeded? Can you trace a line of thought from vowel harmony to the mind-body problem, for example?
Exercise 13.7.2. Chomsky (2000b:12) says that
it is a rare philosopher who would scoff at [the] weird and counterintuitive principles[of physics] as contrary to right thinking and therefore untenable. But this standpointis commonly regarded as inapplicable to cognitive science, linguistics in particular . . .This seems to be nothing more than a kind of “methodological dualism,” far morepernicious than the traditional metaphysical dualism, which was a scientific hypoth-esis, naturalistic in spirit. Abandoning this dualist stance, we pursue inquiry where itleads.

EXERCISES 299
In a page or so, unpack this quotation, and explain the distinction betweenthe two kinds of dualism that Chomsky is describing.
Exercise 13.7.3. At some point children are able to play a game in whichthey name an “opposite” for words you provide to them, even for new pairs.For example, given hot–cold and up–down, a child will provide dry whenprompted with wet, small when prompted with big, and so on. Sketch twotheories for how children can come to be able to do this, a more empiricisttheory and a more rationalist theory. What observations could lead childrento develop the concept of “opposite”? What challenges are faced by arationalist, nativist approach?
Further Readings
� “Initial knowledge: six suggestions” by Elizabeth Spelke (1994).� “The problem of reality” by Ray Jackendoff (1992).� “Review of Skinner’s Verbal Behavior” by Noam Chomsky (1959).� “The metaphysics of coarticulation” by R. Hammarberg (1976).

14Open questions and closing
remarks
14.1 You and your grammar 300
14.2 Retracing the links among
key -isms 304
14.3 Bearing on philosophical
questions 306
14.1 You and your grammar
Two of our primary concerns in this book can be stated in such a way asto seem contradictory. On the one hand, we wanted you to accept a narrowconception of what language is—we wanted to abstract away from issueslike communication and other purposes to which we apply language. Onthe other hand, we want you to appreciate the complexity of linguistic phe-nomena, even when we restrict ourselves to looking at the vowel patterns ofTurkish or the “contracted” verb ’s in English. Paradoxically, by narrowingour focus, we are able to make discoveries that have broad implications forour understanding of the rich complexity of the human mind.
People are complex, a sentiment expressed in the rant against superficial-ity and narrowness in the song containing lines from the movie Fight Club:
You are not your bank account.You are not the clothes you wear.You are not the contents of your wallet.You are not your bowel cancer.You are not your grande latte.You are not the car you drive.You are not your $*!&@%#^‡¿ © khakis.
. . . and you are not your grammar.

YOU AND YOUR GRAMMAR 301
You speak and assign interpretations to utterances you hear or imagine,but these tasks are not the result of the deaf, dumb, and blind grammar.Your grammar is just one component of a complex individual with mem-ories of the past and predictions about the future (which may or may notbe consistent with those held by others). Using language to communicate,lie, seduce, inform, and pray is something people do, not grammars. Butscience demands that we be narrow in our investigations, that we try tofind evidence concerning individual phenomena that enter into our com-plex behavior. Studying what somebody will say on a given occasion orwhether someone will raise his arm overhead when asked will not lead tointeresting results. Studying somebody’s binding conditions or the nature ofimpulse transmission in motor neurons has led to scientifically interestingresults.
Abstracting away from the massive complexity of human behavior is verydifficult, but is probably a necessary component of a naturalistic approachto the study of the mind. Even among certain linguists we find resistance tothe idea that binding or vowel harmony can be studied as isolable systems.Such linguists advocate blurring the line between phonetics and phonologyor between syntax and semantics. For example, there is a current trend ofassuming that phonetic facts about articulation and acoustics of speechsounds are directly available to the phonological grammar.49
Our views concerning isolability of grammatical components followsthose of philosophers of science such as Lawrence Sklar (2000:54–5), whohas even made the point that without such isolability, science itself wouldprobably be impossible:
. . . without a sufficient degree of isolability of systems we could never arrive at anylawlike regularities for describing the world at all. For unless systems were sufficientlyindependent of one another in their behavior, the understanding of the evolution ofeven the smallest part of the universe would mean keeping track of the behavior ofall of its constituents. It is hard to see how the means for prediction and explanationcould ever be found in such a world . . . it can be argued that unless such idealizationof isolability were sufficiently legitimate in a sufficiently dominant domain of cases, wecould not have any science at all.
If we take Sklar seriously, then to the extent we have gained scientificinsight into the nature of vowel harmony, binding, negative polarity, and
49 See Hale and Reiss (2008) for discussion of these issues under the rubric of“markedness” theory.

302 OPEN QUESTIONS AND CLOSING REMARKS
the like, it must be that our “idealizations of isolability were sufficientlylegitimate.”50
As people, not scientists, other approaches to language are more suit-able for getting insight into what is important to us emotionally, socially,esthetically. Despite stereotypes to the contrary, it is not the case that takingan appropriately narrow scientific view within a domain, such as language,prevents one from taking a broader view in everyday life. Just as biologistsdo not lose their capacity to enjoy the beauty of a flower, linguists are ableto enjoy all the uses to which language is put, literature, song, rhetoric,and so on. Repeating a quotation we have already used, we see that hisscientific approach does not prevent Chomsky (2000:77) from appreciatingart, literature, or any other aspect of life.
Plainly, a naturalistic approach does not exclude other ways of trying to comprehendthe world. Someone committed to it can consistently believe (I do) that we learnmuch more of human interest about how people think and feel and act by readingnovels or studying history or the activities of ordinary life than from all of naturalisticpsychology, and perhaps always will; similarly, the arts may offer appreciation of theheavens to which astrophysics does not aspire.
Your grammar is only one aspect of you that determines what you say andhow you interpret sentences. As an illustration of other aspects, apart fromgrammar, that influence the interpretation and acceptability of what we say,consider the following sentences.
14.1 What influences acceptability?a. John told Bill to kiss himself.b. John told Bill to kiss him.c. Bill kissed himself.d. Bill outlived himself.e. The pilot called the flight attendant into the cabin because she needed
his help.
In interpreting (14.1a.), binding conditions determine that himself canonly be interpreted as referring to Bill. In (14.1b.) binding conditions donot uniquely determine the interpretation of him, but they do rule out Billas a possible interpretation. Examples (14.1c.) and (14.1d.) have the sameform, but the second seems odd. This has nothing to do with binding, butrather with the nature of mortality. This sentence is odd to us, but it is notthe grammar’s business to take mortality into account. Many people judge
50 We are indebted to Mark Hale for this quotation. Further discussion of isolabilityand language can be found in Hale (2007) and Hale and Reiss (2008).

YOU AND YOUR GRAMMAR 303
sentence (14.1e.) to be ungrammatical when they first hear it, but if it ispointed out that the sentence makes perfect sense if the pilot is a womanand the flight attendant a man, they immediately change their judgment.The judgment of the string as unacceptable has to do with preconceptionsabout typical matches between gender and profession, surely something wedo not want to build into the grammar. The grammar had better be isolablefrom such factors, or else studying it is a hopeless enterprise.
Grammars are symbolic computational systems, and as such they can-not care whether the sentences they generate result in utterances that areambiguous, contain sequences that sound like taboo words, or fail to com-municate. Your legs cannot go for a walk, since going for a walk involvesintentions, goals, beliefs—things that legs do not have. People have inten-tions, goals and beliefs, and people go for walks. In the same way, you, notyour grammar, can decide to disambiguate your utterances. The view weare opposing is part of what is sometimes called a functionalist approach tolanguage, an approach that aims to explain aspects of language structurefrom the perspective of language as a communication system. We have notaddressed this issue directly in this book, but have rather assumed whatis sometimes called the formalist position that attempts to merely under-stand the computational properties of language. Our examples from syntax,semantics, morphology, and phonology lead us to accept the sentimentexpressed by Morris Halle (1975), already quoted in Chapter 3:
Since language is not, in its essence, a means for transmitting [cognitive] information—though no one denies that we constantly use language for this very purpose—then itis hardly surprising to find in languages much ambiguity and redundancy, as well asother properties that are obviously undesirable in a good communication code
Halle prefers to look at language as an abstract code, like a pointless game,rather than as a form of purposeful behavior, and we think that this is auseful perspective—whatever we use it for, a language, a mental grammar,has certain properties. Linguists want to find out what those properties are.Obviously those properties must allow us to use language for the things weuse it for, but there is no reason to believe that the accidental and arbitraryproperties we observe in language make it particularly bad (or good) atwhat we use it for. We don’t have any choice but to use what we have, so thequestion of the goodness of language is empty.
There is no obvious way in which wh-movement or the generation ofallophones are good for communication, for example. In a sentence like

304 OPEN QUESTIONS AND CLOSING REMARKS
What did Bill eat? a speaker has to generate a tree with what as the object ofeat but pronounce a copy in a different position; a listener hears the copyin sentence-initial position, but has to reconstruct a meaning with what asthe object of eat, basically undoing the speaker’s derivation. Why did thespeaker apply wh-movement (notated by us as a copy) at all? It can’t be forreasons of communication, since the listener just undoes the movement forinterpretation. If we note that even when we engage in an internal mono-logue, “thinking in words,” we apply wh-movement, it becomes apparentthat such syntactic processes have no communicative function. In fact, inthe context of internal monologue, the whole notion of communicationbecomes strange—who is communicating with whom?—and its irrelevanceto understanding grammar becomes apparent.
Similarly, a speaker generates a word like Tom from a stored repre-sentation that begins with the phoneme /t/, then applies a phonologicalderivation that turns /t/ into the allophone [th]. A listener has to strip offthe aspiration in order to search his or her own mental lexicon for an itemthat begins with the phoneme /t/. Why doesn’t the speaker just pronouncean unaspirated initial [t]? There is no physiological reason for aspirating—Spanish speakers don’t aspirate their initial voiceless stops.
One might even argue, as Chomsky (1971:44) has, that the non-functionalaspects of language are most interesting.
Where properties of language can be explained on such “functional” grounds, theyprovide no revealing insight into the nature of mind. Precisely because the expla-nations proposed here are “formal explanations,” precisely because the proposedprinciples are not essential or even natural properties of any imaginable language, theyprovide a revealing mirror of the mind (if correct).
It is hard to imagine how the adding and deleting of aspiration or theconstruction and interpretation of wh-movement in a conversation aids incommunication—it does seem like a pointless game, but a game whose ruleslinguists rejoice in discovering.
14.2 Retracing the links among key -isms
By treating language as a code or a symbol-manipulating process, by adopt-ing computationalism, we were able to focus on its formal properties—what kinds of rules manipulate the symbols? Once we posited such symbol-manipulation processes, we were able to ask what these processes are, and

RETRACING THE LINKS AMONG KEY -isms 305
we were led to conclude that they must be contained in or constitutiveof individual minds: we adopted mentalism; and since minds are assumedto be an aspect of brains, which are inside of us, this leads in turn tointernalism. We called the information encoded as one component of ourmind “linguistic knowledge.” This led to the further question of asking howthis knowledge comes to be part of individual minds. Since the categoriesover which the computations apply are not directly contained in the signal,we adopted the position of constructivism, the idea that input is organizedby the mind by the imposition of structure on stimuli.
However, not all linguistic knowledge can be constructed on the basisof merely making generalizations about the physical signals we receiveas children, so we rejected constructivism in a stronger sense, sometimesassociated with the psychologist Jean Piaget. This sense of constructivism isclosely related to empiricism in that it posits that categories of, say, linguisticknowledge can somehow be discovered or induced by analogy to patternsexperienced through the senses and motor activity. We rejected this viewof the origins of the fundamental categories, the fundamental equivalenceclasses, of cognition.
The recurrence of equivalence classes and of highly specific patterns,like c-command, across languages, as well as the logical argument thatno learning can occur without an initial representational system led us toposit nativism, the idea that a certain amount of linguistic knowledge isdetermined by the human genome.51 Nativism refers to knowledge prior toexperience, and thus is tied to rationalism, in the sense that we can haveknowledge in the absence of experience. The innate endowment is whatwe use to process input, to construct representations. Because we treatlanguage as a property of biological entities, we allow ourselves to studyit as a property of the natural world, subject to the normal principles usedin the natural sciences. This position of naturalism also allows us to justifybringing data from one language (say, Weri) to bear on our analysis ofanother language (say, Maranungku)—both represent possible states of anatural system, the human language faculty.
51 Some of what we call linguistic knowledge is potentially also determined by thegenome of other species—innateness in humans does not rule out innateness in otherspecies any more than the claim that our genes determine production of certain proteinsthat make us develop into humans implies that we do not share those genes and proteinswith other species.

306 OPEN QUESTIONS AND CLOSING REMARKS
This naturalistic approach also allows us to bring non-linguistic datato bear on our analyses—we should not attribute to the human languagefaculty any property that is inconsistent with the fact of language being atrait of individual biological organisms. This constraint on our hypothesisspace cannot be exploited if we reject internalism for externalism, treatinglanguages as sets of sentences “out in the world.”
Inquiry into language can be broken down into (at least) the followingfour questions:
14.2 Questions about languagea. What constitutes knowledge of language?b. How is knowledge of language acquired?c. How is knowledge of language put to use?d. What are the physical mechanisms that serve as the material basis for
this system of knowledge and for the use of this knowledge?
We pointed out in Chapter 1 that question (14.2a.) is logically prior to theothers—for example, we need to understand what is being acquired beforewe study language acquisition. As obvious as this should be, it is probablythe case that most scholars working on language acquisition, whether inpsychology, linguistics, or education departments, have a much less sophis-ticated understanding of what language (mental grammar) is than you doafter working through this book. Given what you now know about thenature of language, you are better prepared to attack the other questions.For example, as a neuroscientist you would have a better idea of whatkinds of properties you should be looking for. Your theory of the nervoussystem has to be compatible with some linguistic theory that can accountfor Turkish vowel harmony and Warlpiri reduplication, for example.
The phenomenon of language is particularly useful for understandingthe links among the -isms we have adopted: computationalism, mentalism,internalism, constructivism, rationalism, nativism, and naturalism. Giventhe relevance of these themes to a wide variety of disciplines, a betterunderstanding of the nature of language will have broad implications.
14.3 Bearing on philosophical questions
In Chapter 1 we promised that we would relate Turkish vowel harmony tosome of the most ancient and challenging philosophical questions, repeatedhere.

BEARING ON PHILOSOPHICAL QUESTIONS 307
14.3 Big philosophical issues we addressed� The Nature–Nurture debate: How much of what we are is innate and how
much depends on our experience?� What is knowledge? How is it acquired?� What is reality?� Is there a distinction between mind and body?� How can our study of these issues bear on social questions and educa-
tional practice?
We raised the Nature–Nurture debate in our discussions of UniversalGrammar, which also relates to the questions about knowledge. In thedomain of language, knowledge has to include a computational system thatcan use variables in order to account for reduplication, for example. Somelinguistic knowledge is acquired, since languages differ, but we argued thatsome must be built into the system—there is a human language faculty. Weillustrated the mind’s construction of visual percepts, such as the edges ofthe illusory triangle, and of linguistic objects such as words and syntacticstructures. The words we hear seem to be real to us, so it seems like a goodidea to consider more of the world as real than just what belongs to thedomain of physics. We need to recognize words as constructs of our mind,but real at the same time, since our minds are real parts of the natural world.We now see that our discussion had bearing on yet another set of -isms,those relating to the mind/body problem: dualism, idealism, and a wholeslew of variations on materialism.
We have tried to convince you that by accepting language as a validobject of scientific inquiry, we can ask questions that make no sense underother approaches, and that we can even find some answers. In all fieldsscience posits theoretical entities that are far removed from everyday expe-rience in the world—this is as true in particle physics and syntactic the-ory, and thus we see that the study of the mental and the study of thephysical proceed in the same manner. The physical world is just whateveris posited by current physics, but this has no actually intelligible corre-spondence to how we experience the world. So, the mind-body problemdisappears—the two terms are just loose denominations for aspects of theworld that one can study. As in the other natural sciences, naturalism inlinguistics leads to realism—we assume that our theories are not aboutfictions, but about aspects of the world, since they give unforeseen insight,allow us to make predictions, and so on, just like the theories in otherdomains.

308 OPEN QUESTIONS AND CLOSING REMARKS
We have pointed out in several places that experts in a variety of fieldsmake claims about language that are either completely unsupported oractually even refuted by available evidence. In the realm of academic dis-course such ignorance is fairly innocuous, but there are cases where misun-derstanding of the nature of language is harmful. One example is the case ofmedical doctors and educators who advise parents of deaf children to notexpose their child to a signed language, or who advise immigrant parents tonot speak their native language to their children. There is no evidence thatlearning multiple languages in childhood is difficult or leads to confusionor problems in language development.
Despite the fairly widespread (but not universal) acceptance of formalapproaches to language as a valid research program within the academiccommunity, there is still tremendous ignorance about and resistance tosuch perspectives in society at large. Two examples familiar to us are thereactions to the Ebonics controversy in the United States over the lastten years, as well as the constant stream of outright nonsense concern-ing the nature of local French dialects in the mainstream media and inschool curricula in Quebec. These cases demonstrate that linguists, as acommunity, have failed to effectively communicate their findings to thepublic. Such communication is crucial since ignorance about the nature oflanguage is not only unacceptable in a scientifically advanced society butalso generates discrimination and misguided educational policy. Crucially,some of the most ignorant statements about non-Standard languages oftencome from members of the ethnic group that is associated with the language.Many African-American leaders fail to understand the fact that the dialectsloosely referred to as Ebonics or “Black English” are not impoverishedor illogical just because their negative polarity items look like Chaucer’s.Similarly in Quebec, even many people with strong separatist political lean-ings decry the use of words and patterns of Quebec French that differ fromInternational Standard French in some arbitrary way. Imagine children inNew York being ridiculed and punished in school for referring to elevators(the normal American form) instead of lifts (the British term). Yet, this isdirectly analogous to what goes on in French schools in Quebec.
As an extreme case of the ignorance of “experts” consider the caseof an indigenous community in Alaska, reported to have incredibly highrates of Fetal Alcohol Syndrome leading to language disorders. Lily WongFillmore, a linguist who studied the community, was able to ascertain thatthe “problem” turned out to be that the community speaks a language

BEARING ON PHILOSOPHICAL QUESTIONS 309
known as “Village English,” an English-based Creole whose divergencesfrom Standard English obviously do not reflect any kind of pathology.Under the biolinguistic approach, “English” does not exist—the object ofstudy is the set of internal, individual I-languages instantiated in humanminds/brains. One would hope that better understanding of the nature oflanguage by the academic and public sectors would make misdiagnosis ofdialect differences as mental retardation less likely.
We must stress that it is the responsibility of linguists to better educatethe public and members of other professions, many of whom are quite inter-ested in learning more about language. Recently, we received an invitationfrom a doctor friend to speak to medical personnel in the infectious diseasesunit of a hospital in New York City. One requested topic for us to addresswas whether the Creoles spoken by many of the hospital’s Caribbeanpatients are as good as “real” languages like English and Spanish at describ-ing symptoms! Any budding linguist who reads this should be heartened bythe opportunities you will have to contribute to society as a scientist—thereis so much work for us to do.
A prerequisite for undertaking the dissemination of ideas to fight igno-rance and social ills and to improve education is to understand the natureof human language. Answering, at least partially, What is knowledge oflanguage? is the logical first step. We hope we have helped you to take thisstep.
Further Readings
� New Horizons in the Study of Language and Mind by Noam Chomsky(2000b).
� Article on Lily Wong Fillmore’s work in Alaska: follow the link fromthe companion website.

This page intentionally left blank

References
ALLEN, COLIN and BEKOFF, MARC (1997). Species of Mind: The Philosophy andBiology of Cognitive Ethology. Cambridge, MA: MIT Press.
AUGUSTINE SAINT, BISHOP OF HIPPO (1995). De Doctrina Christiana. Oxford:Clarendon Press.
BAKER, MARK C. (2001). The Atoms of Language. New York: Basic Books.BOAS, FRANZ, POWELL, JOHN WESLEY, and HOLDER, PRESTON (1966). Intro-
duction to the Handbook of American Indian languages. A Bison book, BB301.Lincoln: University of Nebraska Press.
BREGMAN, ALBERT S. (1990). Auditory Scene Analysis: The Perceptual Organiza-tion of Sound. Cambridge, MA: MIT Press.
BRYSON, BILL (1990). The Mother Tongue: English & How It Got That Way (1stedn). New York: W. Morrow.
CANTY, NORA and GOULD, JAMES L. (1995). ‘The hawk/goose experiment:sources of variability’. Animal Behaviour 50(4), 1091–1095.
CARROLL, SEAN B. (2005). Endless Forms Most Beautiful: The New Science of EvoDevo and The Making of the Animal Kingdom. New York: Norton.
CHOMSKY, NOAM (1957). Syntactic Structures. The Hague: Mouton.CHOMSKY, NOAM (1959). ‘Review of Verbal Behavior by B. F. Skinner’. Language
35(1), 26–58.CHOMSKY, NOAM (1965). Aspects of the Theory of Syntax. Cambridge, MA: MIT
Press.CHOMSKY, NOAM (1971). ‘Deep structure, surface structure and semantic inter-
pretation’, in Semantics, an Interdisciplinary Reader in Linguistics, Philosophy andPsychology (ed. D. Steinberg and L. Jakobovits). Cambridge, MA: CambridgeUniversity Press, pp. 183–216.
CHOMSKY, NOAM (1986). Knowledge of Language: Its Nature, Origin, and Use.New York: Praeger.
CHOMSKY, NOAM (1988). Language and Problems of Knowledge: The ManaguaLectures. Cambridge, MA: MIT Press.
CHOMSKY, NOAM (2000a). ‘Language as a natural object’. See Chomsky (2000b),pp. 106–33.
CHOMSKY, NOAM (2000b). New Horizons in the Study of Language and Mind.Cambridge, MA: Cambridge University Press.
CHURCHLAND, PAUL M. (1984). Matter and Consciousness: A Contem-porary Introduction to the Philosophy of Mind. Cambridge, MA: MITPress.

312 REFERENCES
CHURCHLAND, PAUL M. (1998). ‘Betty Crocker’s theory of consciousness’, inOn the contrary: Critical Essays, 1987–1997 (ed. P. M. Churchland and P. S.Churchland). Cambridge, MA: MIT Press, pp. 113–22.
DEACON, TERRENCE WILLIAM (1997). The Symbolic Species: The Co-evolutionof Language and the Brain. New York: W. W. Norton.
EDDINGTON, ARTHUR STANLEY (1934). ‘Science and experience,’ in New Path-ways in Science. Messenger lectures. New York: The Macmillan Company,pp. 1–26.
EDELMAN, GERALD M. (2004). Wider Than the Sky: The Phenomenal Gift ofConsciousness. New Haven: Yale University Press.
FODOR, JERRY A. (1968). Psychological Explanation: An Introduction to the Phi-losophy of Psychology. A Random House study in problems of philosophy. NewYork: Random House.
FODOR, JERRY A. (2000). ‘It’s all in the mind’. Review of Chomsky’s New Hori-zons. Times Literary Supplement.
FOUCAULT, MICHEL (1966, 1973). The Order of Things: An Archaeology of theHuman Sciences. New York: Vintage Book.
FRANKFURT, HARRY G. (2005). On Bullshit. Princeton, NJ: Princeton UniversityPress.
GLEITMAN, LILA R. and NEWPORT, ELISSA (1995). ‘The invention of languageby children: Environmental and biological influences on the acquisition of lan-guage’. See Osherson and Gleitman (1995), pp. 1–24.
HALE, MARK (2007). Historical Linguistics: Theory and Method. Blackwell text-books in linguistics. Malden, MA: Blackwell.
HALE, MARK and REISS, CHARLES (1998). ‘Formal and empirical argu-ments concerning phonological acquisition’. Linguistic Inquiry 29, 656–83.
HALE, MARK and REISS, CHARLES (2003). ‘The subset principle in phonology:Why the tabula can’t be rasa’. Journal of Linguistics 39, 219–44.
HALE, MARK and REISS, CHARLES (2008). The Phonological Enterprise. Oxford:Oxford University Press.
HALLE, MORRIS (1975). ‘Confessio grammatici’. Language 51, 525–35.HAMMARBERG, R. (1976). ‘The metaphysics of coarticulation’. Journal of Phonet-
ics 4, 353–63.HANDEL, STEPHEN (1989). Listening: An Introduction to the Perception of Audi-
tory Events. Cambridge, MA: MIT Press.HOFFMAN, DONALD D. (1998). Visual Intelligence: How We Create What We See.
New York: W. W. Norton.HYMAN, MALCOLM (2002). ‘Bad grammar in context’. New England Classical
Journal 29(2), 94–101. Also at http://archimedes.fas.harvard.edu/mdh/.IDSARDI, WILLIAM JAMES (1992). The Computation of Prosody. Ph.D. thesis.
Cambridge, MA: MIT Press.JACKENDOFF, RAY (1990). Semantic Structures. Cambridge, MA: MIT Press.

REFERENCES 313
JACKENDOFF, RAY (1992). ‘The problem of reality’, in Languages of the Mind:Essays on Mental Representation. Cambridge, MA: MIT Press, pp. 157–76.
JACKENDOFF, RAY (1994). Patterns in the Mind: Language and Human Nature.New York: Basic Books.
JACKENDOFF, RAY, BLOOM, PAUL, and WYNN, KAREN (1999). Language,Logic, and Concepts: Essays in Memory of John Macnamara. Cambridge, MA:MIT Press.
JOHNSON, DAVID MARTEL and ERNELING, CHRISTINA E. (1997). The Futureof the Congnitive Revolution. New York: Oxford University Press.
LABOV, W. (1972). ‘Academic ignorance and black intelligence’. The AtlanticMonthly, 59–67.
LASNIK, HOWARD, DEPIANTE, MARCELA A., and STEPANOV, ARTHUR
(2000). Syntactic Structures Revisited: Contemporary Lectures on Classic Trans-formational Theory. Current studies in linguistics. Cambridge, MA: MITPress.
MARANTZ, ALEC, MIYASHITA, Y., and O’NEIL, WAYNE A. (2000). Image,Language, Brain: Papers from the First Mind Articulation Project Symposium.Cambridge, MA: MIT Press.
MIKHAIL, JOHN (2007). ‘Universal moral grammar: theory, evidence and thefuture’. Trends in Cognitive Sciences 11(4), 143–52.
NIEDER, A. (2002). ‘Seeing more than meets the eye: Processing of illusory con-tours in animals’. Journal of Comparative Physiology 188, 249–60.
NUTI, MILENA (2005). Ethnoscience: Examining Common Sense. Ph.D. thesis.University College London.
OSHERSON, DANIEL N. and GLEITMAN, LILA R. (1995). An Invitation to Cog-nitive Science (2nd edn). Cambridge, MA: MIT Press.
PARTEE, BARBARA HALL, MEULEN, ALICE G. B. TER, and WALL, ROBERT
EUGENE (1990). Mathematical Methods in Linguistics. Dordrecht: KluwerAcademic.
PAYNE, THOMAS EDWARD (1997). Describing Morphosyntax: A Guide for FieldLinguists. Cambridge, U.K.: Cambridge University Press.
PINKER, STEVEN (1994). The Language Instinct (1st edn). New York: W. Morrowand Co.
POPPER, KARL RAIMUND (1952). The Open Society and Its Enemies. London:Routledge & Kegan Paul.
PULLUM, GEOFFREY K. (1991). The Great Eskimo Vocabulary Hoax, and OtherIrreverent Essays on the Study of Language. Chicago: University of ChicagoPress.
PULLUM, GEOFFREY K. and SCHOLZ, BARBARA C. (2001). ‘On the distinctionbetween model-theoretic and generative-enumerative syntactic frameworks’, inLogical Aspects of Computational Linguistics (ed. G. M. Philippe de Grootand C. Retoré). Lecture Notes in Artificial Intelligence. Berlin: Springer Verlag,pp. 17–43.

314 REFERENCES
PYLYSHYN, ZENON W. (1973). ‘The role of competence theories in cognitive psy-chology’. Journal of Psycholinguistic Research, 11, 21–50.
PYLYSHYN, ZENON W. (1984). Computation and Cognition: Toward a Foundationfor Cognitive Science. Cambridge, MA: MIT Press.
PYLYSHYN, ZENON W. (2003). Seeing and Visualizing: It’s Not What You Think.Cambridge, MA: MIT Press.
SHOPEN, TIMOTHY (ed.) (1979). Languages and Their Status. Cambridge, MA:Winthrop Publishers.
SKLAR, LAWRENCE (2000). Theory and Truth: Philosophical Critique within Foun-dational Science. Oxford: Oxford University Press.
SPELKE, ELIZABETH (1994). ‘Initial knowledge: six suggestions’. Cognition, 50,431–45.
VON HUMBOLDT, WILHELM (1836). Über die Verschiedenheit des menschlichenSprachbaues und ihren Einfluss auf die geistige Entwickelung des Men-schengeschlechts. Berlin: Royal Academy of Sciences of Berlin.
VON NEUMANN, JOHN (2000). The Computer and the Brain (2nd edn). New Haven,CT: Yale University Press.
WERKER, JANET (1995). ‘Exploring developmental changes in cross-languagespeech perception’. See Osherson and Gleitman (1995), pp. 87–106.
WONG FILLMORE, LILY. http://gse.berkeley.edu/admin/publications/termpaper/spring00/fillmore_alaska.html.

Index
acceptability 302acquisition 235, 245allophones 112, 132ambiguity 132, 175anaphors 170Arabic 75Armenian 75aspirated 193auditory perception 27–9auditory scene analysis 28auditory stream 27
baboon 48base position 157, 296bee 31behavior 119Berkeley, George Bishop 287bilingual, phonology of 114binary branching 144binding 176, 177, 297biolinguistics 12, 64, 66, 80Boas, Franz 38Bob Dylan 172Bregman, Albert 30Bryson, Bill 38bullshit 283
c-command 176, 179Canterbury Tales 255card language and grammars 238categories 32Chaucer, Geoffrey 255, 308child
language acquisition 120Chinese 75Chomsky Hierarchy 100
Chomsky, Noam 41–3, 50, 59, 67, 68,71, 73, 79–81, 285, 302
Churchland, Paul 287, 288club and pole analogy 32co-occurrence 173cognitive revolution 96coindexation 179Colorless green ideas sleep furiously 82commonsense 16, 36, 49, 177, 255communication 15, 36, 38, 42, 48,
72–4competence 272computation 39, 60, 96, 108, 112, 119,
132computational 6, 25, 56computations 26, 66concatenation 8connector 106construction of experience 113copula 132Crab Nebula 48Croatian 75culture 36, 39
de Saussure, Ferdinand 6Deacon, Terence 68, 216Democritus 52derivation 123derived position 157, 296Descartes, René 287descriptive grammar 253Determiners 137digestive system 52discovered
vs. invented 12diversity, linguistic 192

316 INDEX
dualism 50, 287duration, as an abstract category 104,
271
E-language 69–72Ebonics 308Eddington, Sir Arthur 49Edelman, Gerald 291effeminate language 41embedding 94empiricism 265, 266English 38, 44, 48, 56, 109, 110, 132,
283Canadian 261copula 104Middle 255non-existence of 16orthography 107possessive ending 105
entailment 129in questions 131
equivalence class 9, 13, 20, 24, 52,66, 108, 112, 114, 116, 118, 120,136
essentialism 283ether 288ethology, cognitive 52extensional equivalence 61, 66
face recognition 26feature, distinctive 116, 237Fetal Alcohol Syndrome 308Fight Club 300Fillmore, Lily Wong 308finite length of sentences 84finite number of sentences 84Finite State Grammar 87, 100flap 111Fodor, Jerry 50football, CFL vs. NFL 73Foucault 68Frankfurt, Harry 283free-choice 130French, Québec 38, 259, 308
Frog Prince 281function 7, 126functional categories 147
Gleitman, Lila 270glottal stop 111grammar
ambiguity of the term 85grammaticality 84
Hale, Mark 258, 302Halle, Morris 38, 303Hammarberg, Robert 268Handel, Stephen 29Harvard 258Hawaiian 40head 144Hendrix, Jimi 32Hindi 75homogeneous speech community 274Human Language Faculty 15, 55, 100,
305Humboldt, Wilhelm von 90
I-language 13, 33, 36, 43, 51, 55, 63, 64,67, 68, 71, 73, 80, 86, 112
idealism 287idealization 9Idsardi, Bill 56index 171individuals 178information processing 20, 31, 32innate knowledge 216Innateness of Primitives Principle 236intensional 13internalism 64, 66, 70International Phonetic Alphabet 115,
116, 133intervene 174isolability 189, 301
Jackendoff, Ray 236, 238Jespersen, Otto 40joot, nonsense word 112

INDEX 317
Karmiloff-Smith, Annette 292Kelly, Clinton 285knowledge
conscious vs. unconscious 14Kuna 76
languageand culture 38, 205ffand thought 37, 205ff
language acquisition 15, 294language faculty, see human language
facultyLasnik, Howard 268lexical categories 147linear order 109locality 177, 179logical operator 238loop, in a fsg 89
Maranungku 57Martians 51masking, auditory and visual 29materialism 287meaning 82, 265mental representations 177mentalist 12metaphor and analogy 294methodological dualism 50mind-body problem 265modification 144mondegreens 32monist 50, 51morpheme 55, 108
alternations 111morphology 55, 122
natural class 116naturalistic 43Nature–Nurture debate 307negation
multiple 255negative polarity items 128, 255neurolinguistics 80neuroscientists 12
Newport, Elissa 270Newton 49nominalism 284non-veridical 28Norwegian 75noun 8Nuti, Milena 36
ontological problem 286orthography 107, 110overgenerate 86, 173, 175
P-language 71, 72Payne, Thomas 197perception
and linguistic experience 25perceptual object 28performance 272philosophy of language 265phoneme 112, 131, 193phonology 55, 109, 118, 122physical stimuli 33physiology 41, 42Piaget, Jean 292Pinker, Steven 258Pintupi 60Plato 71Popper, Karl 283Poverty of the Stimulus 267Praat 33, 133precedence 174prejudice
linguistic 254preposition 148preposition stranding 259prescriptive grammar 253privative feature 238probability 83pronouns 170proprioception 41psycholinguistics 80Pullum, Geoffrey 67Pylyshyn, Zenon 16, 41, 245, 279

318 INDEX
questionwh- 157yes/no 44
Rambo 56rat 103rationalism 265reaction time 273reduplication 5, 10, 39, 43, 55, 66, 82reference 177, 265reflexives 170representation 14, 25, 26rewrite rules 97Rimbaud 56Roberts, Seth 103Romanian 283root 127, 132
Safire, William 258Sag, Ivan 294Samoan 10, 43Sankskrit 75Sapir, Edward 9, 32Sapir–Whorf 37scientific grammar 254scientific methodology 11, 42, 50, 51,
80selection 145semantics 127, 131sequential integration 28Serbian 75set theory 127, 131, 177Ship of Theseus 279sisters 143, 176Sklar, Lawrence 301socialization 39spectral integration 28spectral segregation 28spectrogram 28Spelke, Elizabeth 292stress 55
counting analysis 58counting vs. grouping analyses 64grouping analysis 58unified analysis 59
structure dependent 82, 104, 109Swahili 125, 132Sylvester the Donkey 281syntactic structure 131Syntactic Structures 79, 187syntax
syntactic rules 82
Tanzania 125terminal symbol 99transcription 31tree diagram 108triangles 20, 33Turing, Alan 285Turkish 75
genitive 114nominative 114vowel harmony 4, 114, 132, 237vowels 115
undergenerate 86, 173, 175underspecification 237ungrammatical sentence, non-existence
of 84Universal Grammar 14, 16, 66, 81,
100, 109, 236Urdu 75
variable 7Vaux, Bert 75vision 26, 31, 41von Neumann, John 289
Warao 59Warlpiri 5, 9, 25, 39, 43Wasow, Tom 294waveform 30, 32wax museum 172Weri 56Werker, Janet 245wh-movement 157Williams Syndrome 293word boundaries 31–3Wright, Sylvia 32