Embed Size (px)
Citation preview

Lecture 4Lecture 4
Collective CommunicationsCollective Communications
Dr. Muhammad Hanif Durad
Department of Computer and Information Sciences
Pakistan Institute Engineering and Applied Sciences
Some slides have bee adapted with thanks from some other lectures available on Internet

Dr. Hanif Durad 2
Lecture Outline
Collective Communication First Program using Collective communication The Master- Slave Paradigm Multiplying a matrix with a vector
IntroMPI.ppt

Another Approach to Parallelism
Collective routines provide a higher-level way to organize a parallel program
Each process executes the same communication operations
MPI provides a rich set of collective operations…
Dr. Hanif Durad 3
IntroMPI.ppt

Collective Communication Involve all processes in the scope of communicator Three categories
synchronization (barrier()) data movement (broadcast, scatter, gather, alltoall) collective computation (reduce(), scan())
Limitations/differences from point-to-point blocking (no more true with MPI 2) does not take tag arguments works with MPI defined datatypes - not with derived types
Dr. Hanif Durad 4
Comm.ppt

Collective Communication Involves set of processes, defined by an intra-communicator. Message
tags not present. Principal collective operations:
MPI_Bcast() - Broadcast from root to all other processes MPI_Gather() - Gather values for group of processes MPI_Scatter() - Scatters buffer in parts to group of processes MPI_Alltoall() - Sends data from all processes to all processes MPI_Reduce()- Combine values on all processes to single value MPI_Reduce_scatter() - Combine values and scatter results MPI_Scan() - Compute prefix reductions of data on processes
Dr. Hanif Durad 5
slides2.ppt

One to Many
Basic primitives
• broadcast(data, source, group_id, …)
- group members
broadcast(data,…);
source
data
Comm.ppt

One to Many
Basic primitives
• scatter(data[], recvBuf, source, group_id, …)
•gather(sendBuf, recvBuf[], dest, group_id, …)
- group members
source data
scatter(data,…);
One-to-all personalized communication
Comm.ppt
gather(…)
dest
concatenationdual of scatter
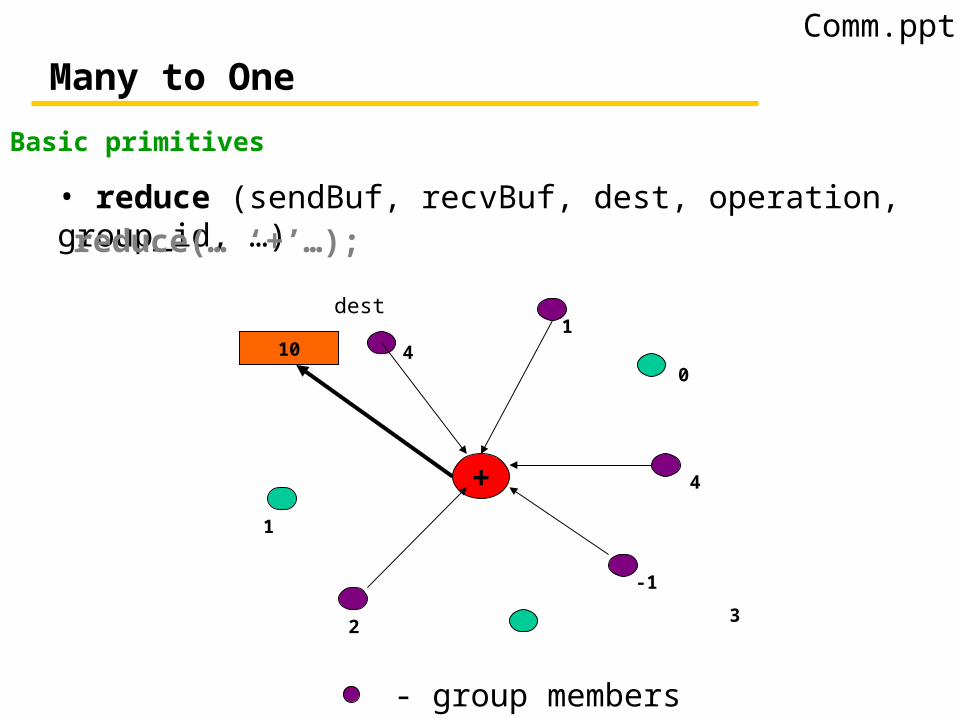
Many to One
Basic primitives
• reduce (sendBuf, recvBuf, dest, operation, group_id, …) reduce(… ‘+’…);
- group members
3
dest
10 41
0
4
-1
2
1
+
Comm.ppt

Many to One – scan()
Also called parallel prefix:
• scan(sendBuf, recvBuf, operation, group_id, …)
• performs reduce() on all predecessorsscan(sendBuf, recvBuf,‘*’, group_id, …);
- group members
sendBuf
4 104-1321
*
recvBuf
4 8 -8 -32 -32
* * * *
Prefix-Sum
Comm.ppt

MPI Names of various Operations
Dr. Hanif Durad 10
Slide from PC course Chapter 4

Calculating the value of π using mid point integration formula
Dr. Hanif Durad 11
First Program using Collective communication

Modeling the problem?
Dr. Hanif Durad 12
0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 12
2.2
2.4
2.6
2.8
3
3.2
3.4
3.6
3.8
4
1 1
20
0
1arctan
1 4dx x
x
>> x=0:.1:1>> y=1+x.^2>>plot(x,4./y)

Decomposition of a Problem
Dr. Hanif Durad 13

Different Ways to Partition Data
Dr. Hanif Durad 14

Example: PI in C (1/2)#include "mpi.h"
#include <math.h>
#include <stdio.h>
int main(int argc, char *argv[])
{
int done = 0, n, myid, numprocs, i, rc;
double PI25DT = 3.141592653589793238462643;
double mypi, pi, h, sum, x, a;
MPI_Init(&argc,&argv);
MPI_Comm_size(MPI_COMM_WORLD,&numprocs);
MPI_Comm_rank(MPI_COMM_WORLD,&myid);
while (!done) {
if (myid == 0) {
printf("Enter the number of intervals: (0 quits) ");
scanf("%d",&n);
}
15Dr. Hanif Durad
pi2.c

Example: PI in C (2/2)MPI_Bcast(&n, 1, MPI_INT, 0, MPI_COMM_WORLD);
if (n == 0) break;
h = 1.0 / (double) n;
sum = 0.0;
for (i = myid + 1; i <= n; i += numprocs) {
x = h * ((double)i - 0.5);
sum += 4.0 / (1.0 + x*x);
}
mypi = h * sum;
MPI_Reduce(&mypi, &pi, 1, MPI_DOUBLE, MPI_SUM, 0,
MPI_COMM_WORLD);
if (myid == 0)
printf("pi is approximately %.16f, Error is .16f\n",
pi, fabs(pi - PI25DT));
}
MPI_Finalize();
return 0;
}
16Dr. Hanif Durad

Example: PI in Fortran (1/2)program main
include "mpif.h"
integer done, n, myid, numprocs, i, rc
double pi25dt, mypi, pi, h, sum, x, z
data done /.false./
data PI25DT/3.141592653589793238462643/
call MPI_Init(ierr)
call MPI_Comm_size(MPI_COMM_WORLD,numprocs, ierr )
call MPI_Comm_rank(MPI_COMM_WORLD,myid, ierr)
do while (.not. done)
if (myid .eq. 0) then
print *,"Enter the number of intervals: (0 quits)"
read *, n
endif
call MPI_Bcast(n, 1, MPI_INTEGER, 0, MPI_COMM_WORLD, ierr )
if (n .eq. 0) goto 10 17Dr. Hanif Durad
pi.f90

Example: PI in Fortran (2/2)h =1.0/n
sum=0.0
do i=myid+1,n,numprocs
x=h*(i - 0.5)
sum+=4.0/(1.0+x*x)
enddo
mypi = h * sum
call MPI_Reduce(mypi, pi, 1, MPI_DOUBLE_PRECISION, MPI_SUM, 0, MPI_COMM_WORLD, ierr )
if (myid .eq. 0) then
print *, "pi is approximately ", pi, ", Error is ", abs(pi - PI25DT)
endif
10 continue
call MPI_Finalize( ierr )
end
18Dr. Hanif Durad

Example: PI in C++ (1/2)#include "mpi.h"
#include <math.h>
#include <iostream>
int main(int argc, char *argv[])
{
int done = 0, n, myid, numprocs, i, rc;
double PI25DT = 3.141592653589793238462643;
double mypi, pi, h, sum, x, a;
MPI::Init(argc, argv);
numprocs = MPI::COMM_WORLD.Get_size();
myid = MPI::COMM_WORLD.Get_rank();
while (!done) {
if (myid == 0) {
std::cout << "Enter the number of intervals: (0 quits) ";
std::cin >> n;;
}
19Dr. Hanif Durad
pi.cpp

Example: PI in C++ (2/2) MPI::COMM_WORLD.Bcast(&n, 1, MPI::INT, 0 );
if (n == 0) break;
h = 1.0 / (double) n;
sum = 0.0;
for (i = myid + 1; i <= n; i += numprocs) {
x = h * ((double)i - 0.5);
sum += 4.0 / (1.0 + x*x);
}
mypi = h * sum;
MPI::COMM_WORLD.Reduce(&mypi, &pi, 1, MPI::DOUBLE,
MPI::SUM, 0);
if (myid == 0)
std::cout << "pi is approximately " << pi <<
", Error is " << fabs(pi - PI25DT) << "\n";
}
MPI::Finalize();
return 0;
}
20Dr. Hanif Durad

Notes on C and Fortran C and Fortran bindings correspond closely In C:
mpi.h must be #included MPI functions return error codes or MPI_SUCCESS
In Fortran: mpif.h must be included, or use MPI module All MPI calls are to subroutines, with a place for the return code in the last
argument. C++ bindings, and Fortran-90 issues, are part of MPI-2.
Dr. Hanif Durad 21

Multiplying a matrix with a vector matvec.cpp & matvec1.cpp on virtue
Dr. Hanif Durad 22
2nd Program using Collective communication

The Master- Slave Paradigm
Dr. Hanif Durad 23
Morgan Kaufmann Publishers - Interconnection Networks. An Engineering Approach.pdf,

Dr. Hanif Durad 24

Dr. Hanif Durad 25

Multiplying a matrix with a matrix
Dr. Hanif Durad 26
3rd Program using Collective communication

The Collective Programming Model
One style of higher level programming is to use only collective routines
Provides a “data parallel” style of programming Easy to follow program flow
Dr. Hanif Durad 27

Not Covered Topologies: map a communicator onto, say, a 3D Cartesian
processor grid Implementation can provide ideal logical to physical mapping
Rich set of I/O functions: individual, collective, blocking and non-blocking Collective I/O can lead to many small requests being merged for more
efficient I/O One-sided communication: puts and gets with various
synchronization schemes Task creation and destruction: change number of tasks during a run
Few implementations available
28





























