Embed Size (px)
Citation preview

Prof. Pier Luca Lanzi
Data Mining���Data Mining and Text Mining (UIC 583 @ Politecnico di Milano)

Prof. Pier Luca Lanzi
Why Data Mining? “Necessity is the mother of invention”
Explosive Growth of Data
Pressing need for the automated analysis of massive data
Emerged in the late 1980s Major developments in the mid 1990s

Prof. Pier Luca Lanzi http://consumer.media.seagate.com/2012/06/the-digital-den/how-much-data-is-generated-in-a-minute/

Prof. Pier Luca Lanzi
Some Data About Data���(http://wikibon.org/blog/big-data-statistics/)
• 2.7 Zetabytes of data exist in the digital universe today
• Facebook stores, accesses, and analyzes 30+ Petabytes of user generated data
• Walmart handles more than 1 million customer transactions every hour, stored into databases estimated to contain more than 2.5 petabytes of data
• More than 5 billion people are calling, texting, tweeting and browsing on mobile phones worldwide
• 100 terabytes of data uploaded daily to Facebook
• According to Twitter’s own research in early 2012, it sees roughly 175 million tweets every day, and has more than 465 million accounts
4

Prof. Pier Luca Lanzi
Evolution of Technology
• 1960s: data collection, database creation, & network DBMS
• 1970s: relational data model, relational DBMS implementation
• 1980s: RDBMS, advanced data models (extended-relational, OO, deductive, etc.); application-oriented DBMS ���(spatial, scientific, engineering, etc.)
• 1990s: data mining, data warehousing, multimedia databases, ���and Web databases
• 2000s: stream data management and mining, web technology (XML, data integration), global information systems
• 2010s: social networks, NoSQL, unstructured data, etc.
5

Prof. Pier Luca Lanzi http://launchhack.com/content/25-cartoons-give-current-big-data-hype-perspective/

Prof. Pier Luca Lanzi
What is the Commercial Viewpoint?
• Huge amounts of data is being collected ���and warehoused everyday § Web data, e-commerce § Purchases at department stores § Bank/Credit Card transactions
• Computers have become���cheaper and more powerful
• Competitive pressure is strong ���to provide better, customized services���(e.g., CRM or Customer Relationship Management)
• Poor data across businesses and the government costs ���the U.S. economy $3.1 trillion dollars a year ���(http://wikibon.org/blog/big-data-statistics/)
7

Prof. Pier Luca Lanzi
What is the Scientific Viewpoint?
• Data collected and stored at ���enormous speeds (GB/hour) § remote sensors on a satellite § telescopes scanning the skies § microarrays generating gene ���
expression data § scientific simulations ���
generating terabytes of data • Traditional techniques infeasible for raw data • Data mining may help scientists § in classifying and segmenting data § in Hypothesis Formation
8
Prof. Pier Luca Lanzi
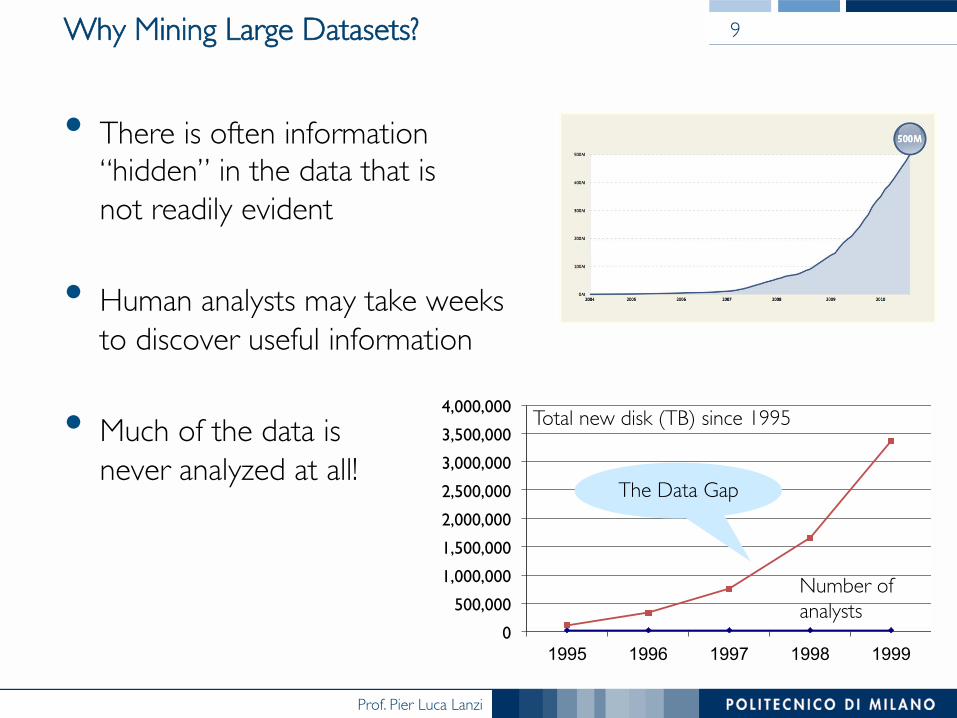
Why Mining Large Datasets?
• There is often information ���“hidden” in the data that is ���not readily evident
• Human analysts may take weeks ���to discover useful information
• Much of the data is���never analyzed at all!
0!
500,000!
1,000,000!
1,500,000!
2,000,000!
2,500,000!
3,000,000!
3,500,000!
4,000,000!
1995 1996 1997 1998 1999
The Data Gap
Total new disk (TB) since 1995
Number of analysts
9

Prof. Pier Luca Lanzi
10
Word cloud from Science “Dealing with Data” 11 February 2011 volume 331 issue 6018 pages 639-806

Prof. Pier Luca Lanzi
Science 11 February 2011 “Dealing with Data”
11

Prof. Pier Luca Lanzi
Examples

Prof. Pier Luca Lanzi
Examples
• Customer attrition § Given: customer information for the past months § Problem: predict who is likely to attrite next month, ���
or estimate customer value § Data: historical customer records
• Credit assessment § Given: a loan application § Problem: predict whether the bank should ���
approve the loan § Data: records from other loans
13

Prof. Pier Luca Lanzi http://wikibon.org/blog/role-of-the-data-scientist/
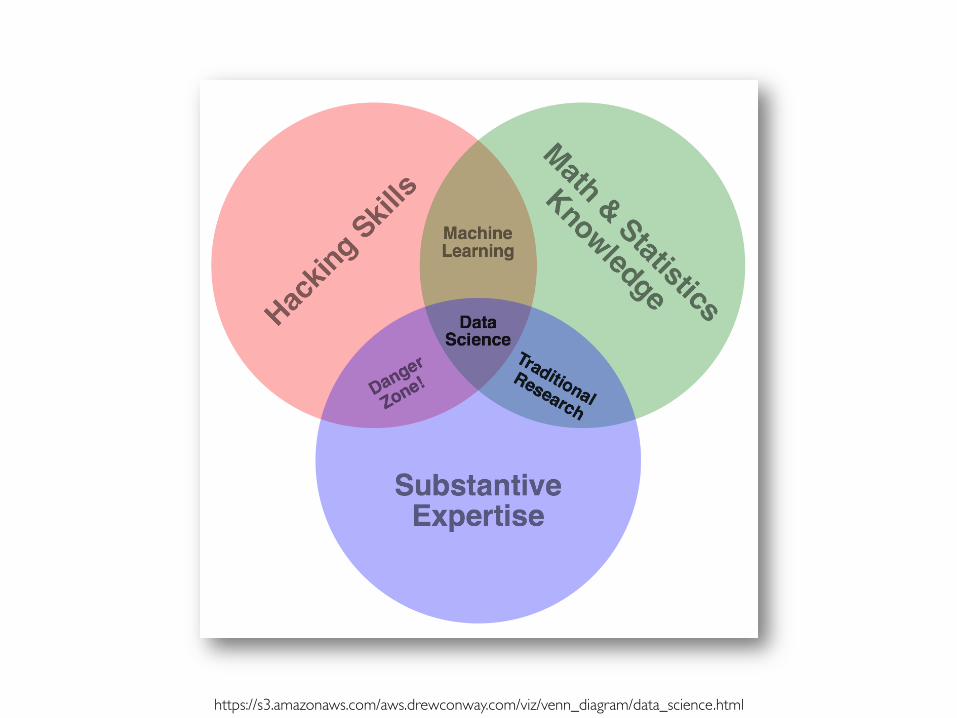
Prof. Pier Luca Lanzi https://s3.amazonaws.com/aws.drewconway.com/viz/venn_diagram/data_science.html

Prof. Pier Luca Lanzi
What is Data Mining?

Prof. Pier Luca Lanzi
What is Data Mining?
• The non-trivial process of identifying (1) valid, (2) novel, (3) potentially useful, and (4) understandable patterns in data.
• Alternative names, § Data Fishing, Data Dredging (1960-) § Data Mining (1990-), used by DB and business § Knowledge Discovery in Databases (1989-), used by AI § Business Intelligence, Information Harvesting, Information Discovery,
Knowledge Extraction, ... § Currently, Data Mining and Knowledge Discovery ���
are used interchangeably
• Data Mining is not looking up in the phone directory, it is not querying a Web search engine for information about “Amazon”
17
Prof. Pier Luca Lanzi
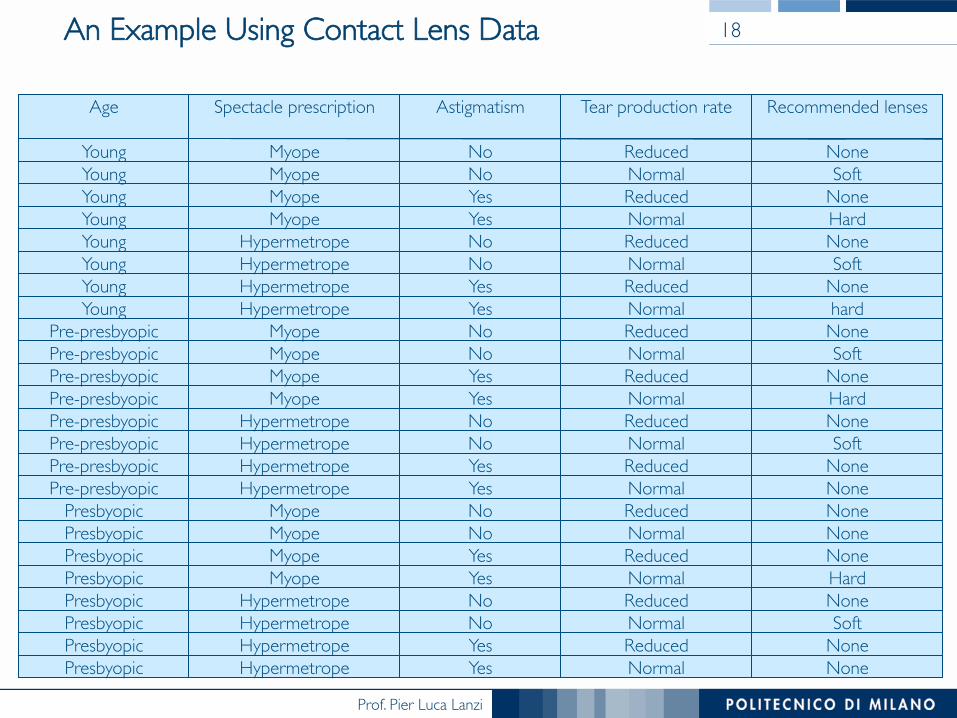
An Example Using Contact Lens Data 18
None Reduced Yes Hypermetrope Pre-presbyopic None Normal Yes Hypermetrope Pre-presbyopic None Reduced No Myope Presbyopic None Normal No Myope Presbyopic None Reduced Yes Myope Presbyopic Hard Normal Yes Myope Presbyopic None Reduced No Hypermetrope Presbyopic Soft Normal No Hypermetrope Presbyopic
None Reduced Yes Hypermetrope Presbyopic None Normal Yes Hypermetrope Presbyopic
Soft Normal No Hypermetrope Pre-presbyopic None Reduced No Hypermetrope Pre-presbyopic Hard Normal Yes Myope Pre-presbyopic None Reduced Yes Myope Pre-presbyopic Soft Normal No Myope Pre-presbyopic
None Reduced No Myope Pre-presbyopic hard Normal Yes Hypermetrope Young None Reduced Yes Hypermetrope Young Soft Normal No Hypermetrope Young
None Reduced No Hypermetrope Young Hard Normal Yes Myope Young None Reduced Yes Myope Young Soft Normal No Myope Young
None Reduced No Myope Young
Recommended lenses Tear production rate Astigmatism Spectacle prescription Age

Prof. Pier Luca Lanzi
An example of possible pattern if astigmatism = yes���
and tear production rate = normal���and spectacle prescription = myope���then recommendation = hard

Prof. Pier Luca Lanzi
is it a “good” pattern?
Prof. Pier Luca Lanzi
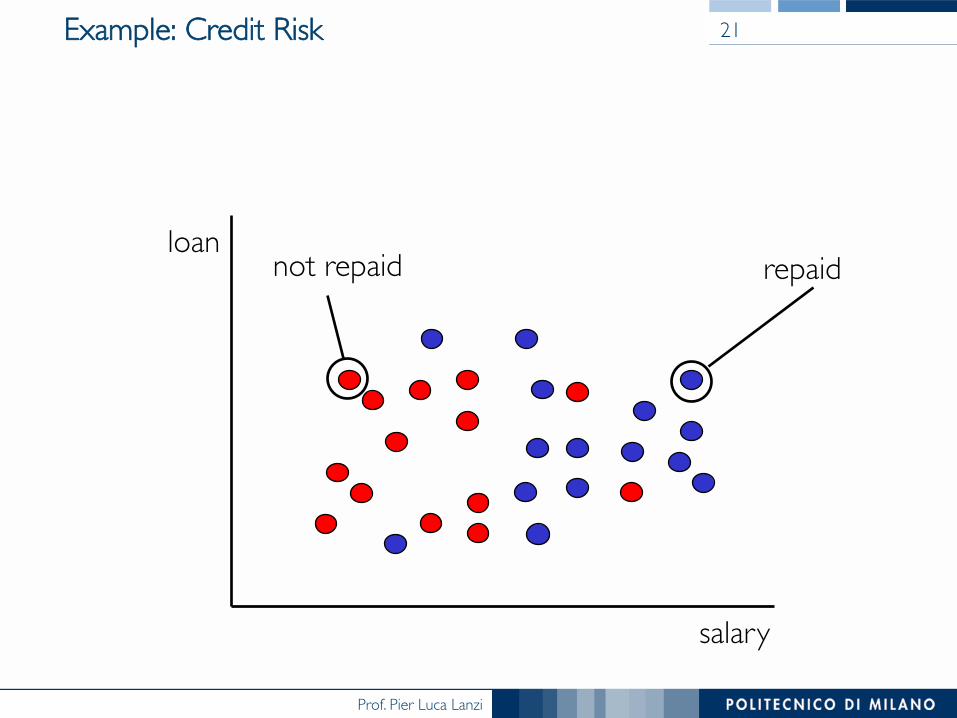
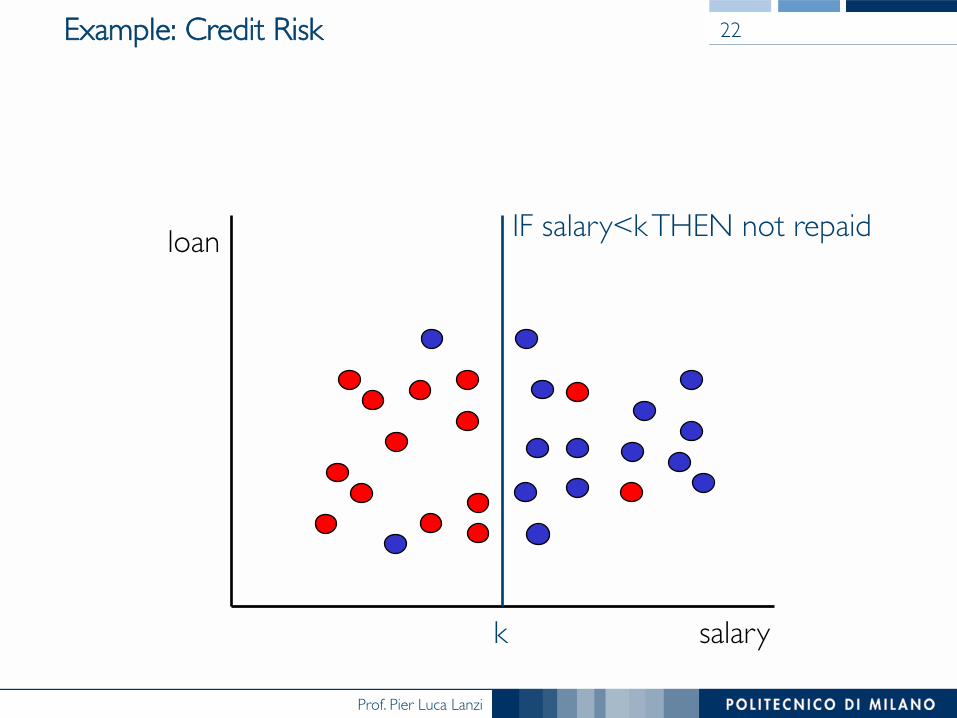
Example: Credit Risk 21
salary
loan not repaid repaid
Prof. Pier Luca Lanzi
Example: Credit Risk 22
salary
loan
k
IF salary<k THEN not repaid

Prof. Pier Luca Lanzi
How Can We Evaluate a Pattern?
• Is it valid? § The pattern has to be valid with respect ���
to a certainty level (rule true for the 86%) • Is it novel? § The value k should be previously ���
unknown or obvious • Is it useful? Is it actionable? § The pattern should provide information ���
useful to the bank for assessing credit risk • Is it understandable?
23

Prof. Pier Luca Lanzi
but there is another important question …
was it “worth” finding it? (I mean $ worth)
how much did the search cost?
how much value did it bring?

Prof. Pier Luca Lanzi
What is the General Idea?
• Build computer programs that navigate through databases automatically, seeking regularities or patterns
• There will be problems § Most patterns are banal and uninteresting § Most patterns are spurious, inexact, or contingent on
accidental coincidences in the particular dataset used § Real data is imperfect: Some parts will be garbled, ���
and some will be missing
• Algorithms need to be robust enough to cope with imperfect data and to extract regularities that are inexact but useful
25

Prof. Pier Luca Lanzi http://launchhack.com/content/25-cartoons-give-current-big-data-hype-perspective/
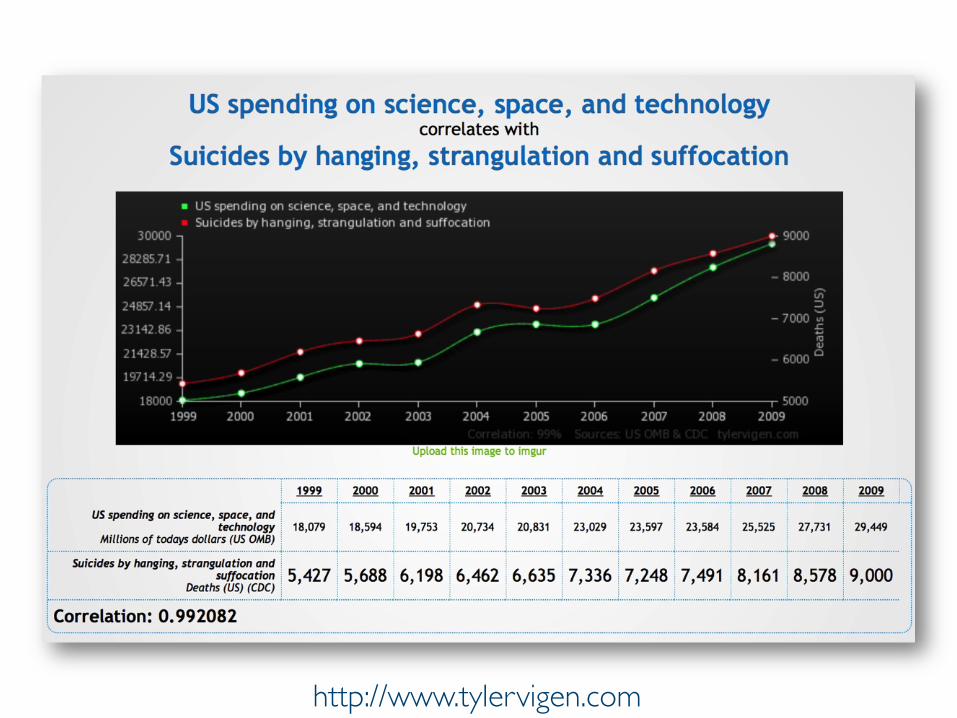
Prof. Pier Luca Lanzi http://www.tylervigen.com
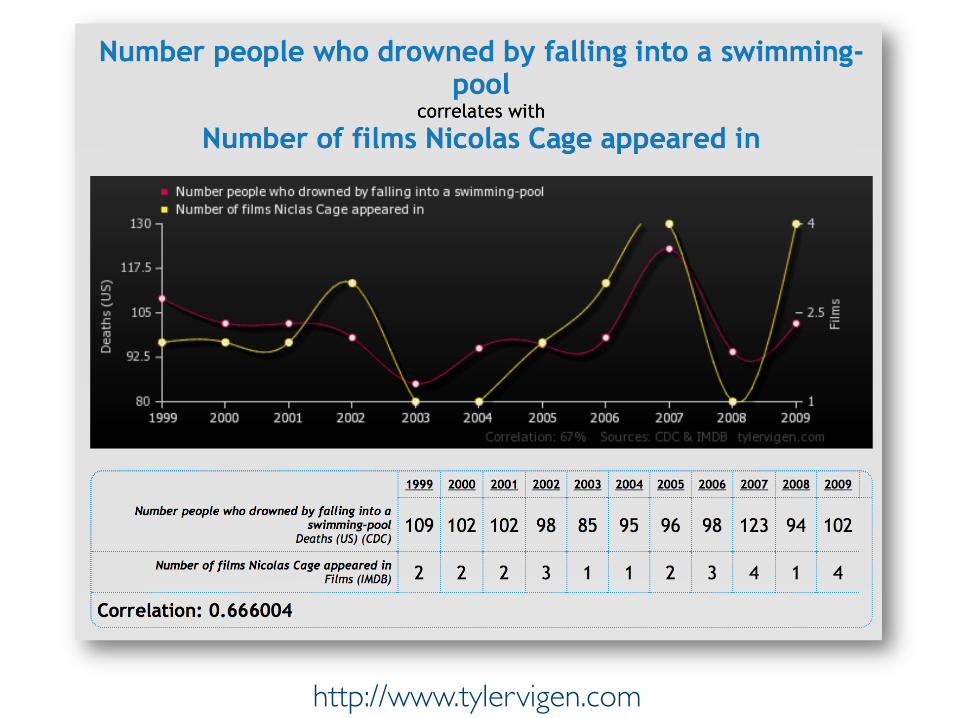
Prof. Pier Luca Lanzi http://www.tylervigen.com

Prof. Pier Luca Lanzi http://wikibon.org/blog/role-of-the-data-scientist/
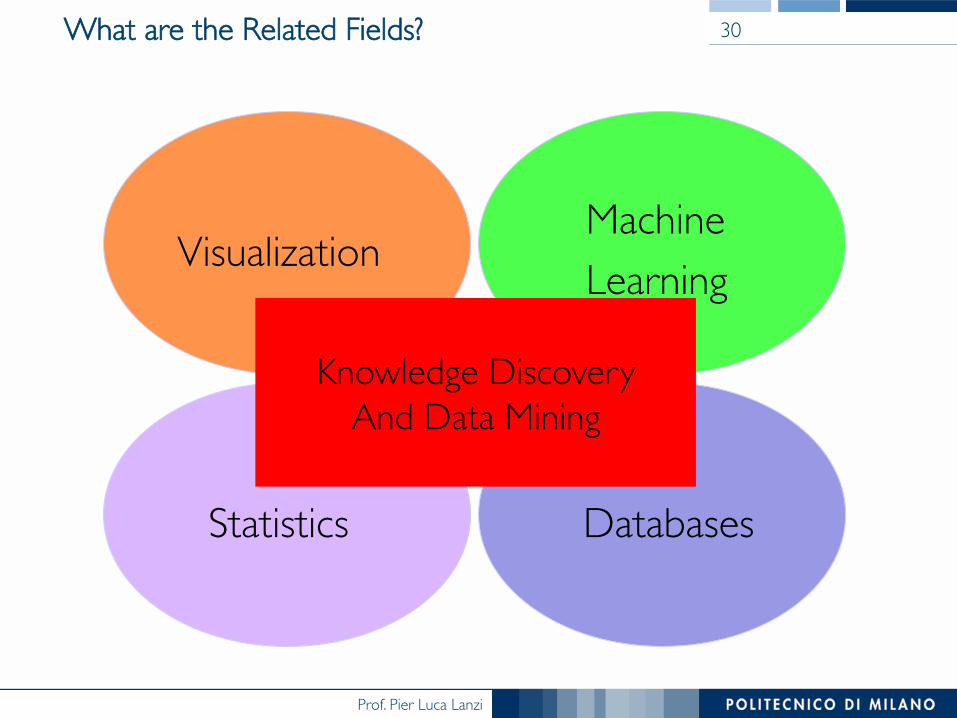
Prof. Pier Luca Lanzi
What are the Related Fields?
Databases Statistics
Machine Learning Visualization
Knowledge Discovery
And Data Mining
30

Prof. Pier Luca Lanzi
Statistics, Machine Learning, ���and Data Mining
• Statistics is more theory-based, focuses on testing hypotheses
• Machine learning is more based on heuristic, focuses on building program that learns, more general than Data Mining
• Knowledge Discovery § integrates theory and heuristics § focus on the entire process of discovery, including ���
data cleaning, learning, integration and visualization
Distinctions are blurred!
31

Prof. Pier Luca Lanzi
Why Is It Different?
• Tremendous amount of data § High scalability to handle terabytes of data
• High-dimensionality of data § Micro-array may have tens of thousands of dimensions
• High complexity of data § Data streams and sensor data § Time-series data, temporal data, sequence data § Structure data, graphs, social networks and multi-linked data § Heterogeneous databases and legacy databases § Spatial, spatiotemporal, multimedia, text and Web data § Software programs, scientific simulations
• New and sophisticated applications
32

Prof. Pier Luca Lanzi http://wikibon.org/blog/big-data-statistics/
Prof. Pier Luca Lanzi
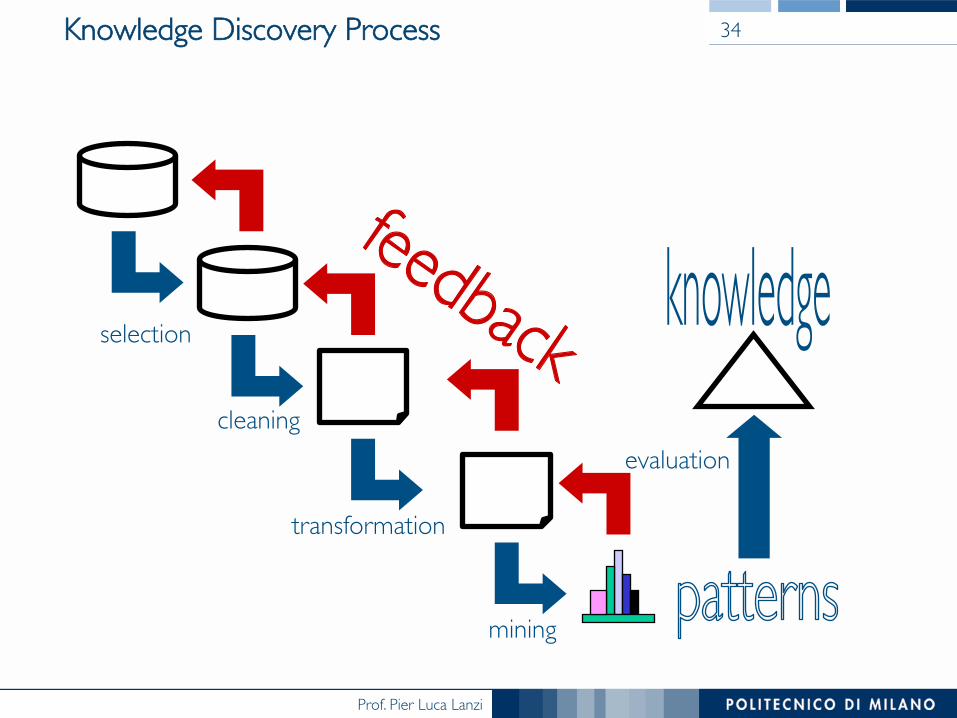
Knowledge Discovery Process 34
selection
cleaning
transformation
mining
evaluation

Prof. Pier Luca Lanzi
Knowledge Discovery Process ���What are the main steps?
• Learning the application domain to extract ���relevant prior knowledge and goals
• Data selection • Data cleaning • Data reduction and transformation • Mining
§ Select the mining approach: classification, ���regression, association, clustering, etc.
§ Choosing the mining algorithm(s) § Perform mining: search for patterns of interest
• Pattern evaluation and knowledge presentation § visualization, transformation, ���
removing redundant patterns, etc. • Use of discovered knowledge
35

Prof. Pier Luca Lanzi
What are the typical Data Mining tasks?

Prof. Pier Luca Lanzi http://wikibon.org/blog/big-data-statistics/

Prof. Pier Luca Lanzi
What are the Major Data Mining Tasks?
• Classification: predicting an item class • Clustering: finding clusters in data • Associations: frequent occurring events… • Visualization: to facilitate human discovery • Summarization: describing a group • Deviation Detection: finding changes • Estimation: predicting a continuous value • Link Analysis: finding relationship • “Sentiment” Analysis, “Opinion” Mining • But many appears as time goes by, opinion mining, ���
sentiment mining
38

Prof. Pier Luca Lanzi
Data Mining Tasks: classification 39
salary
loan
k
IF salary<k THEN not repaid
? ?

Prof. Pier Luca Lanzi
Data Mining Tasks: ���Classification & Prediction
• Finding models (functions) that describe ���and distinguish classes or concepts
• The goal is to describe the data or ���to make future prediction
• E.g., classify countries based on climate, ���or classify cars based on gas mileage
• Presentation: decision-tree, classification rule, neural network
• Prediction: Predict some unknown numerical values
40
Prof. Pier Luca Lanzi
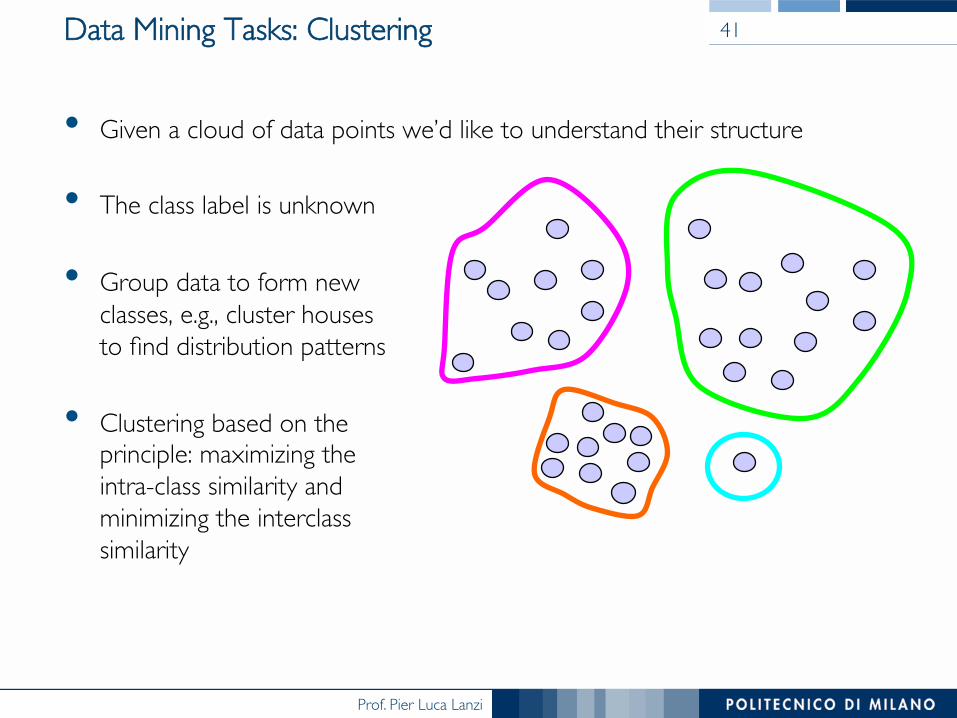
Data Mining Tasks: Clustering
• Given a cloud of data points we’d like to understand their structure
• The class label is unknown
• Group data to form new ���classes, e.g., cluster houses���to find distribution patterns
• Clustering based on the ���principle: maximizing the ���intra-class similarity and ���minimizing the interclass ���similarity
41

Prof. Pier Luca Lanzi
Data Mining Tasks: Associations
Bread Peanuts Milk Fruit Jam
Bread Jam Soda Chips Milk Fruit
Steak Jam Soda Chips Bread
Jam Soda Chips Milk Bread
Fruit Soda Chips Milk
Jam Soda Peanuts Milk Fruit
Fruit Soda Peanuts Milk
Fruit Peanuts Cheese Yogurt
Is there something interesting to be noted?
42

Prof. Pier Luca Lanzi
Data Mining Tasks: Associations
• Finds interesting associations and/or correlation relationships among large set of data items.
• E.g., 98% of people who purchase tires and auto accessories also get automotive services done
43

Prof. Pier Luca Lanzi
Data Mining Tasks: Other Tasks
• Outlier analysis § Outlier: a data object that does not comply���
with the general behavior of the data § It can be considered as noise or exception ���
but is quite useful in fraud detection, rare events analysis • Trend and evolution analysis
§ Trend and deviation: regression analysis § Sequential pattern mining, periodicity analysis § Similarity-based analysis
• Text Mining, Graph Mining, Data Streams • Sentiment Analysis, Opinion Mining, etc. • Other pattern-directed or statistical analyses
44

Prof. Pier Luca Lanzi
Relevant issues

Prof. Pier Luca Lanzi
Are all the “Discovered” Patterns Interesting?
• Data Mining may generate thousands of patterns, ���not all of them are interesting.
• Interestingness measures: a pattern is interesting if it is easily understood by humans, valid on new or test data with some degree of certainty, potentially useful, novel, or validates some hypothesis that a user seeks to confirm
• Objective vs. subjective interestingness measures:
• Objective: based on statistics and structures of patterns, e.g., support, confidence, etc.
• Subjective: based on user’s belief in the data, e.g., unexpectedness, novelty, etc.
46

Prof. Pier Luca Lanzi
Can We Find All and Only ���Interesting Patterns?
• Completeness § Find all the interesting patterns § Can a data mining system find all ���
the interesting patterns? § Association vs. classification vs. clustering
• Optimization § Search for only interesting patterns: § Can a data mining system find only ���
the interesting patterns? § Two approaches: (1) first general all the patterns and then
filter out the uninteresting ones; (2) generate only the interesting patterns—mining query optimization
47

Prof. Pier Luca Lanzi
What About Background Knowledge?
• A typical kind of background knowledge: Concept hierarchies
• Schema hierarchy § E.g., Street < City < ProvinceOrState < Country
• Set-grouping hierarchy § E.g., {20-39} = young, {40-59} = middle_aged
• Operation-derived hierarchy § email address: [email protected] § login-name < department < university < country
• Rule-based hierarchy § LowProfitMargin (X) <= Price(X, P1) and Cost (X, P2) ���
and (P1 - P2) < $50
48

Prof. Pier Luca Lanzi http://launchhack.com/content/25-cartoons-give-current-big-data-hype-perspective/

Prof. Pier Luca Lanzi
I noted that you did not mention …

Prof. Pier Luca Lanzi http://launchhack.com/content/25-cartoons-give-current-big-data-hype-perspective/
Prof. Pier Luca Lanzi

Prof. Pier Luca Lanzi http://gettingattention.org/2014/01/big-data-nonprofit-communications/

Prof. Pier Luca Lanzi
http://simplystatistics.org/2014/05/07/why-big-data-is-in-trouble-they-forgot-about-applied-statistics/
http://bits.blogs.nytimes.com/2014/03/28/google-flu-trends-the-limits-of-big-data/?_r=0
http://gking.harvard.edu/files/gking/files/0314policyforumff.pdf

Prof. Pier Luca Lanzi
https://www.youtube.com/watch?v=CO2mGny6fFs





























